
Submitted:
06 May 2025
Posted:
09 May 2025
You are already at the latest version
Abstract
Sparse reward environments pose significant challenges in reinforcement learning, especially within multi-agent systems (MAS) where feedback is delayed and shared across agents, leading to suboptimal learning. We propose Collaborative Multi-dimensional Course Learning (CCL), a novel curriculum learning framework that addresses this by (1) refining intermediate tasks for individual agents, (2) using a variational evolutionary algorithm to generate informative subtasks, and (3) co-evolving agents with their environment to enhance training stability. Experiments on five cooperative tasks in the MPE and Hide-and-Seek environments show that CCL outperforms existing methods in sparse reward settings.
Keywords:
Multi-Agent Reinforcement Learning (MARL)
; Sparse Reward Environments
; Curriculum Learning
; Co-evolutionary Algorithms
; Task Generation
; Evolutionary Reinforcement Learning
; Cooperative Problem Solving
1. Introduction
Deep Reinforcement Learning (DRL) has shown substantial success in Multi-Agent Systems (MAS), with notable applications in robotics [1,2], gaming [3], and autonomous driving [4]. Despite this progress, sparse reward environments continue to hinder learning efficiency, as agents often receive feedback only after completing complex tasks. This delayed reward signal limits exploration and makes policy optimization difficult.
To improve exploration under sparse rewards, several strategies have been proposed, including reward shaping [5,6], imitation learning [7], policy transfer [8], and curriculum learning [9,10]. These methods aim to strengthen the reward signal and guide agents toward effective behaviors. While effective in single-agent environments, their performance often degrades in MAS, where multiple interacting agents exacerbate environmental dynamics and expand the joint state-action space [11,12,13].
In response, we propose Collaborative Multi-dimensional Course Learning (CCL), a co-evolutionary curriculum learning framework tailored for sparse-reward cooperative MAS. CCL introduces three core innovations:
- (1)
- It generates agent-specific intermediate tasks using a variational evolutionary algorithm, enabling balanced strategy development.
- (2)
- It models co-evolution between agents and their environment [14], aligning task complexity with agents’ learning progress.
- (3)
- It improves training stability by dynamically adapting task difficulty to match agent skill levels.
Through extensive experiments across five tasks in the MPE and Hide-and-Seek (HnS) environments, CCL consistently outperforms existing baselines, demonstrating enhanced learning efficiency and robustness in sparse-reward multi-agent scenarios.
Figure 1.
MPE is validated with three different collaborative task scenarios.
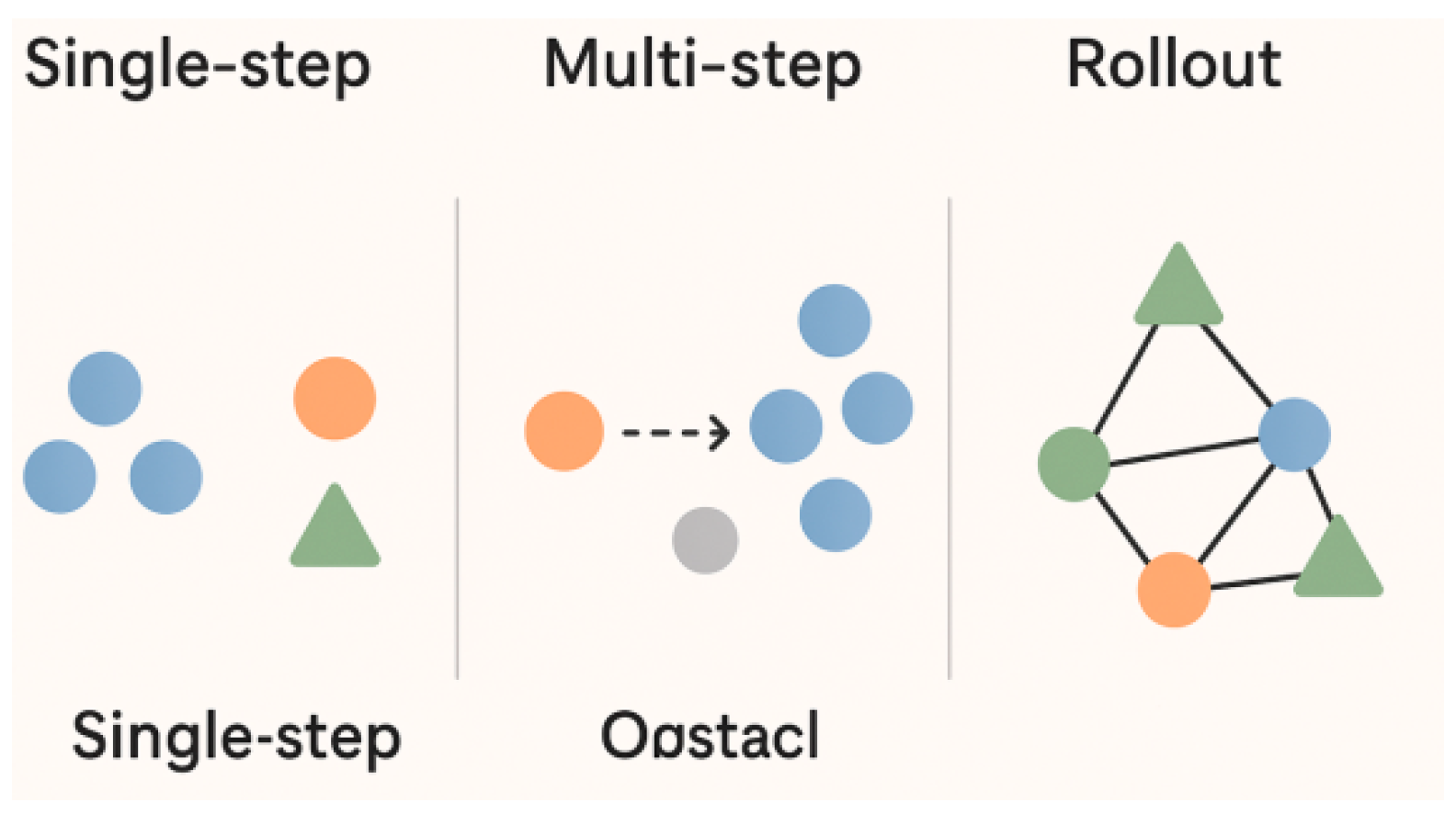
2. Problem Statement
In reinforcement learning, the reward signal is a critical feedback mechanism guiding agents to assess their actions and learn optimal policies via the Bellman equation [15]. While a well-designed reward function defines the task objective and measures agent behavior, agents may still pursue suboptimal strategies. Nonetheless, carefully crafted rewards greatly enhance learning efficiency and policy convergence [16].
Figure 2.
Intermediate task generation in MAS is more complex than in single-agent settings due to the need to account for agent-specific subtasks. In sparse reward environments where rewards are shared, incorporating an individual perspective mechanism becomes essential to ensure effective task decomposition and learning.
Figure 2.
Intermediate task generation in MAS is more complex than in single-agent settings due to the need to account for agent-specific subtasks. In sparse reward environments where rewards are shared, incorporating an individual perspective mechanism becomes essential to ensure effective task decomposition and learning.
Designing dense rewards in complex MAS is challenging due to reliance on prior knowledge, which often fails to capture all interaction dynamics. Sparse rewards offer a more flexible alternative by providing feedback only upon reaching a critical goal state [17], reducing dependence on manual reward design and improving generalization.
In non-sparse reward settings, at each time step t, the agent observes its current state 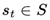 and selects an action
and selects an action 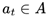 based on its policy
based on its policy 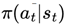 . The chosen action results in a transition to a new state st+1, determined by the environment’s transition dynamics
. The chosen action results in a transition to a new state st+1, determined by the environment’s transition dynamics 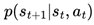 , and an associated reward rt is obtained from the reward function
, and an associated reward rt is obtained from the reward function 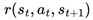 . The sequence of states, actions, following states, and rewards over an episode of T time steps form the trajectory
. The sequence of states, actions, following states, and rewards over an episode of T time steps form the trajectory 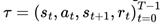 , where T is either determined by the maximum episode length or specific task termination conditions. This outlines the process of reinforcement learning for a single agent.
, where T is either determined by the maximum episode length or specific task termination conditions. This outlines the process of reinforcement learning for a single agent.
and selects an action based on its policy . The chosen action results in a transition to a new state st+1, determined by the environment’s transition dynamics , and an associated reward rt is obtained from the reward function . The sequence of states, actions, following states, and rewards over an episode of T time steps form the trajectory , where T is either determined by the maximum episode length or specific task termination conditions. This outlines the process of reinforcement learning for a single agent.The goal of this individual agent is to learn and maximize its expected cumulative rewarded policy:
where γ is the discount factor, representing future rewards’ diminishing value refinement degree of the optimization process is carried out by each time step inside the trajectory, that is, the optimization granularity is accurate to each time step.
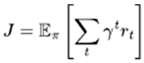 |
(1) |
However, the system dynamics significantly intensify when extending this general framework to MAS under sparse reward conditions. In this system, there are N decision-making agents, where each agent i takes an action ai at time step t based on the observed state information and following its dedicated policy 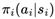 . The global state st of the system is composed of the joint states of all individual agents, denoted as
. The global state st of the system is composed of the joint states of all individual agents, denoted as 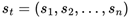 . Correspondingly, the joint action at at each time step is also formed by the combination of actions from all agents, i.e.,
. Correspondingly, the joint action at at each time step is also formed by the combination of actions from all agents, i.e., 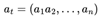 . In the sparse reward environment, reward signals only emerge when the system achieves specific predefined goal states, posing more significant challenges for agent collaboration and strategy optimization.
. In the sparse reward environment, reward signals only emerge when the system achieves specific predefined goal states, posing more significant challenges for agent collaboration and strategy optimization.
. The global state st of the system is composed of the joint states of all individual agents, denoted as . Correspondingly, the joint action at at each time step is also formed by the combination of actions from all agents, i.e., . In the sparse reward environment, reward signals only emerge when the system achieves specific predefined goal states, posing more significant challenges for agent collaboration and strategy optimization.In cooperative multi-agent tasks, the goal of each agent is no longer focused on maximizing its reward but instead shifts toward optimizing the cumulative reward of the entire system. This requires agents to collaborate effectively, coordinating their actions to achieve the shared objective, thereby improving the overall performance of the multi-agent system. Consequently, the objective function J for each agent i is transformed into 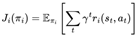 , where
, where 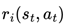 represents the reward received by agent i at time step t given the state st and joint action at. The overall goal of the multi-agent system (MAS) then becomes the sum of the individual objectives, denoted as
represents the reward received by agent i at time step t given the state st and joint action at. The overall goal of the multi-agent system (MAS) then becomes the sum of the individual objectives, denoted as 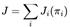 .
.
, where represents the reward received by agent i at time step t given the state st and joint action at. The overall goal of the multi-agent system (MAS) then becomes the sum of the individual objectives, denoted as .At this point, it becomes evident that the essence of a multi-agent reinforcement learning algorithm lies in utilizing the rewards earned by all agents to optimize the overall collaborative strategy. However, this challenge is significantly heightened in a sparse reward environment, where agents receive limited feedback, making it difficult to effectively guide their actions and improve coordination toward the collective goal. In the case that there are only very few 0-1 reward signals, the total reward of the system can be simplified to a binary function:
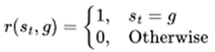 |
(2) |
As the number of agents increases, training variance in MAS grows exponentially. In sparse reward settings, agents must achieve sub-goals aligned with a shared objective, yet often receive little to no feedback, making learning difficult. This lack of guidance hampers exploration and destabilizes training, rendering many single-agent methods ineffective. To address these challenges, we propose Collaborative Multi-dimensional Course Learning (CCL) for more stable and efficient multi-agent training.
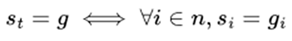 |
(3) |
3. Related Work
3.1. Curriculum Learning
Sparse reward environments have driven the development of various exploration strategies in reinforcement learning, including reward shaping [18], intrinsic motivation [19], and curriculum learning [20]. While the first two enhance learning by densifying rewards, curriculum learning adopts a divide-and-conquer approach—decomposing complex tasks into simpler subtasks arranged in increasing difficulty [1,21,22].
In reinforcement learning, curriculum learning involves three main components: task generation, task ranking, and transfer learning [23]. These can be guided by automated methods [9] or expert knowledge, though the latter often introduces biases [24,25]. Adaptive Automatic Curriculum Learning (ACL) addresses this by dynamically tailoring task sequences to agent progress, without manual intervention.
3.2. Evolutionary Reinforcement Learning
Evolutionary Algorithms (EAs) optimize policies through selection, mutation, and recombination of candidate solutions based on fitness scores [31]. Their integration with reinforcement learning aims to address issues like sparse rewards and limited policy diversity [29,30,34].
Though promising [32,33], combining EAs with RL introduces challenges, notably the computational overhead from large populations [24] and the difficulty of retaining informative environmental features during evolutionary encoding. Effective integration requires balancing exploration benefits with computational feasibility[44,45,46,47,48,49,50,51].
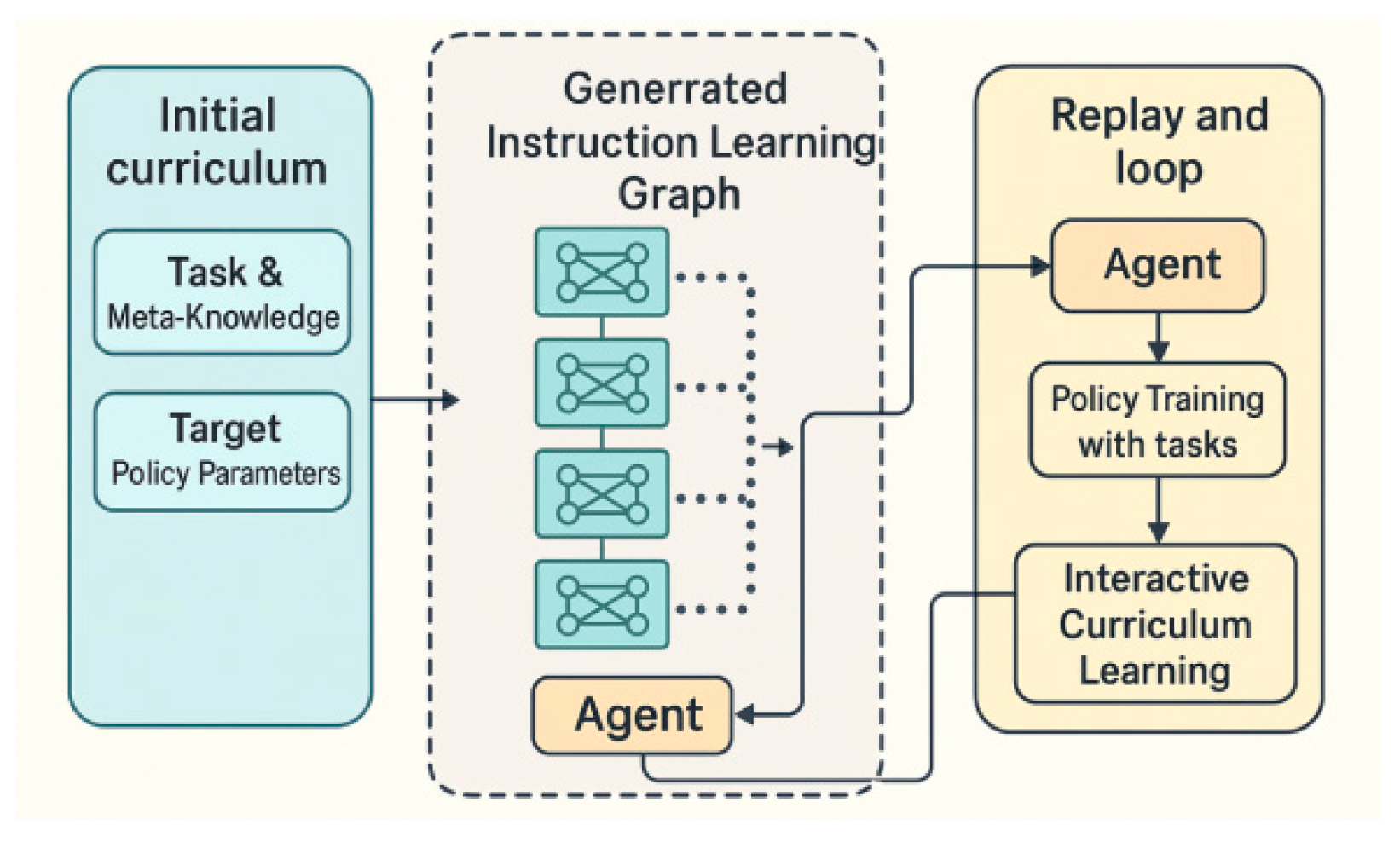
4. Methodology
4.1. The Variational Individual-Perspective Evolutionary Operator
In this section, we provide a detailed explanation of all the components of CMCL. As a coevolutionary system with two primary parts, the agents are trained using the existing Multi-Agent Proximal Policy Optimization (MAPPO) algorithm[35], which will not be elaborated on here. The complete workflow of the CMCL algorithm is outlined in Algorithm 1.
Evolutionary Curriculum Initialization Due to the low initial policy performance of a MAS at the start of training, agents struggle to accomplish complex tasks. Therefore, minimizing the norm of task individuals within the initial population is essential. Assuming the initial task domain is Ω0, the randomly initialized task population should meet the following conditions, where d represents the initial Euclidean norm between the agent and the task, and δ is a robust hyperparameter, typically set to be about one percent of the total task space size.
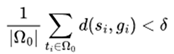 |
(4) |
 |
Task Fitness Definition: Previous methods often assessed intermediate tasks using agent performance metrics [24,30,36] or simple binary filters [37], which fail to capture the non-linear nature of task difficulty. Tasks with success rates near 0 or 1 offer little training value, while those closer to the midpoint present a more suitable challenge. To address this, we model fitness as a non-linear function, favoring tasks of moderate difficulty that best support learning progression. To capture this non-linear relationship, we establish a sigmoid-shaped fitness function to describe the adaptability of tasks to the current level of agent performance, where r represents the average success rate of the agents on task t.
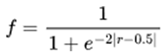 |
(5) |
Variational Individual-perspective Crossover In a MAS, the single reward signal is distributed across multiple dimensions, especially from the perspective of different agents, leading to imbalances in the progression of individual strategies. Therefore, based on the encoding method mentioned earlier, operating on intermediate tasks at the individual level within the MAS is necessary. Assuming that in a particular round of intermediate task generation, N individuals from the previous task generation 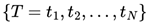 are randomly divided into two groups TA and TB. Then, we take N/2task pairs
are randomly divided into two groups TA and TB. Then, we take N/2task pairs 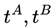 from and to produce new children in the population.
from and to produce new children in the population.
are randomly divided into two groups TA and TB. Then, we take N/2task pairs from and to produce new children in the population.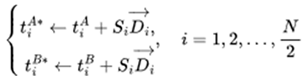 |
(6) |
In the above formula, si represents the crossover step size for pair i, and 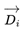 represents the crossover direction for pair i. The calculations of si and are shown below:
represents the crossover direction for pair i. The calculations of si and are shown below:
represents the crossover direction for pair i. The calculations of si and are shown below: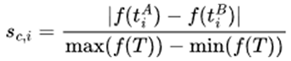 |
(7) |
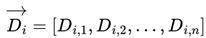 |
Di,j denotes the direction of the j-th agent in pair i, obtained by uniform random sampling.
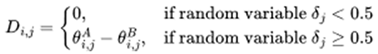 |
(8) |
The proposed variational individual-perspective crossover ensures each agent's subtask direction contributes equally to curriculum evolution, enabling broader exploration compared to traditional methods. In a MAS with nnn entities, this results in 2n2^n2n possible direction combinations, enhancing diversity in intermediate task generation.
To address catastrophic forgetting [38,39], we adopt a soft selection strategy. Rather than discarding low-fitness individuals, the entire population is retained, and a fraction (α\alphaα, typically 0.2–0.4) of historical individuals is reintroduced each iteration. This maintains task diversity, preserves challenging tasks for future stages, and helps avoid local optima.
4.2. Elite Prototype Fitness Evaluation
Evolutionary algorithms often require maintaining a sufficiently large population to ensure diversity and prevent being trapped in local optima or influenced by randomness. However, evaluating the fitness of intermediate tasks in a large curriculum population significantly increases computational cost. To mitigate this issue, we propose a prototype-based fitness estimation method.
First, we uniformly sample tasks in each iteration and measure their success rate r and fitness f . These sampled tasks, called prototypes, are used in actual training. Next, we employ a K-Nearest Neighbor (KNN) approach to estimate the fitness of tasks not directly used in training.
Assume there are m individuals in the prototype task set P, with fitness values fi for each i, and individuals in the query task set Q, represented as vectors qj for each j. For any individual qj in the query set Q, its fitness value fj can be calculated as shown below
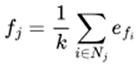 |
(9) |
In the formula, Nj represents the set of indices of the k-closest individuals in the prototype task set P to the vector qj , based on the Euclidean distance. This can be expressed as follows:
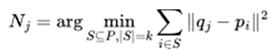 |
(10) |
5. Experiment
5.1. Main Result
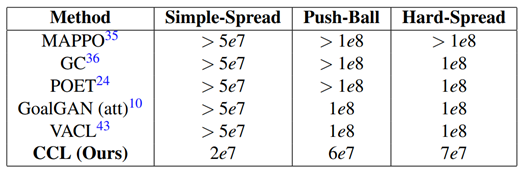
We evaluate CCL on five cooperative tasks across two environments: simple/complex propagation and Push-ball from the MPE benchmark [40], and ramp-passing and lock-back from the MuJoCo-based HnS environment [41]. All tasks use a binary (0-1) sparse reward structure, with results averaged over three random seeds. Training is conducted using MAPPO [35] on a system with an Nvidia RTX 3090 GPU and a 14-core CPU. Attention mechanisms [42] are also integrated to improve agent coordination.
We compare CCL with five baselines:
- Vanilla MAPPO [35] – Direct training on the target task without intermediate tasks.
- POET [24] – Uses task evolution; implemented with the same setup as CCL for fairness.
- GC [36] – An improved version of POET with enhanced task generation.
- GoalGAN [10] – Combines curriculum learning with attention-based enhancements.
- VACL [43] – Applies variational methods to create robust intermediate tasks.
5.2. Ablation Studies
Adaptive Mutation Step: Ablation studies show that using an adaptive mutation step size enhances flexibility and performance in sparse reward environments compared to fixed or no mutation. While mutation promotes strategy diversity, improper step sizes can degrade learning. Notably, adaptive mutation proves as effective as crossover and individual-perspective variation in improving CCL’s performance (see Figure 3).
Non-linear Factor in Fitness Function: As shown in Figure 4, the sigmoid fitness function delivers better performance than the linear form 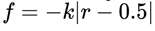 . This improvement stems from the sigmoid function’s properties: as the agent’s success rate approaches 0 or 1, the task’s suitability to the agent’s abilities decreases exponentially. Specifically, when the success rate is exactly 0.5, the fitness value remains consistently at 0.5. This approach effectively integrates nonlinear elements into the success rate distribution, enabling the fitness function to more accurately represent the relationship between task difficulty and the agent’s skill level.
. This improvement stems from the sigmoid function’s properties: as the agent’s success rate approaches 0 or 1, the task’s suitability to the agent’s abilities decreases exponentially. Specifically, when the success rate is exactly 0.5, the fitness value remains consistently at 0.5. This approach effectively integrates nonlinear elements into the success rate distribution, enabling the fitness function to more accurately represent the relationship between task difficulty and the agent’s skill level.
. This improvement stems from the sigmoid function’s properties: as the agent’s success rate approaches 0 or 1, the task’s suitability to the agent’s abilities decreases exponentially. Specifically, when the success rate is exactly 0.5, the fitness value remains consistently at 0.5. This approach effectively integrates nonlinear elements into the success rate distribution, enabling the fitness function to more accurately represent the relationship between task difficulty and the agent’s skill level.6. Conclusion
This paper presents CCL, a co-evolutionary curriculum learning framework designed to improve training stability and performance in sparse-reward multi-agent systems (MAS). By generating a population of intermediate tasks, using a variational individual-perspective crossover, and employing elite prototype-based fitness evaluation, CCL enhances exploration and coordination. Experiments in MPE and HnS environments show that CCL consistently outperforms existing baselines. Ablation studies further validate the importance of each component.
Despite its strengths, CCL’s current design is focused on cooperative MAS. Future work should explore its applicability in competitive or mixed-behavior settings, where coordination and conflict coexist. Moreover, the storage of historical tasks for soft selection increases memory usage; optimizing this via compression or selective retention is a promising direction for reducing overhead.
References
- Abbass, H.; Petraki, E.; Hussein, A.; McCall, F.; Elsawah, S. A model of symbiomemesis: machine education and communication as pillars for human-autonomy symbiosis. Philos. Transactions Royal Soc. A 2021, 379, 20200364. [Google Scholar] [CrossRef] [PubMed]
- Perrusquía, A.; Yu, W.; Li, X. Multi-agent reinforcement learning for redundant robot control in task-space. Int. J. Mach. Learn. Cybern. 2021, 12, 231–241. [Google Scholar] [CrossRef]
- Rashid, T.; et al. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 1–51. [Google Scholar]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv:1610.03295 (2016).
- Ng, A. Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Icml, vol. 1999, 99, 278–287. [Google Scholar]
- Hu, Y.; et al. Learning to utilize shaping rewards: A new approach of reward shaping. Adv. Neural Inf. Process. Syst. 2020, 33, 15931–15941. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, 2011)., 627–635 (JMLR Workshop and Conference Proceedings.
- Duan, Y.; et al. One-shot imitation learning. Adv. neural information processing systems 30 ( 2017.
- Florensa, C.; Held, D.; Wulfmeier, M.; Zhang, M.; Abbeel, P. Reverse curriculum generation for reinforcement learning. In Conference on robot learning, 482–495 (PMLR, 2017).
- Florensa, C.; Held, D.; Geng, X.; Abbeel, P. Automatic goal generation for reinforcement learning agents. In International conference on machine learning, 1515–1528 (PMLR, 2018).
- Bloembergen, D.; Tuyls, K.; Hennes, D.; Kaisers, M. Evolutionary dynamics of multi-agent learning: A survey. J. Artif. Intell. Res. 2015, 53, 659–697. [Google Scholar] [CrossRef]
- Bu¸soniu, L.; Babuška, R.; De Schutter, B. Multi-agent reinforcement learning: An overview. Innov. multi-agent systems applications-1 183–221 (2010).
- Hernandez-Leal, P.; Kartal, B.; Taylor, M. E. A survey and critique of multiagent deep reinforcement learning. Auton. Agents Multi-Agent Syst. 2019, 33, 750–797. [Google Scholar] [CrossRef]
- Antonio, L. M.; Coello, C. A. C. Coevolutionary multiobjective evolutionary algorithms: Survey of the state-of-the-art. IEEE Transactions on Evol. Comput. 2017, 22, 851–865. [Google Scholar] [CrossRef]
- Kaelbling, L. P.; Littman, M. L.; Moore, A. W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Dewey, D. Reinforcement learning and the reward engineering principle. In 2014 AAAI Spring Symposium Series (2014). 9/11.
- Booth, S.; et al. The perils of trial-and-error reward design: misdesign through overfitting and invalid task specifications. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 2023, 37, 5920–5929. [Google Scholar] [CrossRef]
- Laud, A. D. Theory and application of reward shaping in reinforcement learning (University of Illinois at UrbanaChampaign, 2004).
- Barto, A. G. Intrinsic motivation and reinforcement learning. Intrinsically motivated learning natural artificial systems 17–47 (2013).
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning; 41–48 (2009). [Google Scholar]
- Rohde, D. L.; Plaut, D. C. Language acquisition in the absence of explicit negative evidence: How important is starting small? Cognition 1999, 72, 67–109. [Google Scholar] [CrossRef] [PubMed]
- Elman, J. L. Learning and development in neural networks: The importance of starting small. Cognition 1993, 48, 71–99. [Google Scholar] [CrossRef] [PubMed]
- Narvekar, S.; Sinapov, J.; Stone, P. Autonomous task sequencing for customized curriculum design in reinforcement learning. In IJCAI, 2536–2542 (2017).
- Wang, R.; Lehman, J.; Clune, J.; Stanley, K. O. Paired open-ended trailblazer (poet): Endlessly generating increasingly complex and diverse learning environments and their solutions. arXiv:1901.01753 (2019).
- Cobbe, K.; Klimov, O.; Hesse, C.; Kim, T.; Schulman, J. Quantifying generalization in reinforcement learning. In International conference on machine learning, 1282–1289 (PMLR, 2019).
- Ren, Z.; Dong, D.; Li, H.; Chen, C. Self-paced prioritized curriculum learning with coverage penalty in deep reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2216–2226. [Google Scholar] [CrossRef]
- Wu, J.; et al. Portal: Automatic curricula generation for multiagent reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 2024, 38, 15934–15942. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, X.; Guo, Z.; Hu, T.; Ma, H. Csce: Boosting llm reasoning by simultaneous enhancing of casual significance and consistency. arXiv:2409.17174 (2024).
- Samvelyan, M.; et al. Maestro: Open-ended environment design for multi-agent reinforcement learning. arXiv:2303.03376 (2023).
- Parker-Holder, J.; et al. Evolving curricula with regret-based environment design. In International Conference on Machine Learning, 17473–17498 (PMLR, 2022).
- Beyer, H.-G.; Schwefel, H.-P. Evolution strategies–a comprehensive introduction. Nat. computing 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Miconi, T.; Rawal, A.; Clune, J.; Stanley, K. O. Backpropamine: training self-modifying neural networks with differentiable neuromodulated plasticity. arXiv:2002.10585 (2020).
- Pagliuca, P.; Milano, N.; Nolfi, S. Efficacy of modern neuro-evolutionary strategies for continuous control optimization. Front. Robotics AI 2020, 7, 98. [Google Scholar] [CrossRef]
- Long, Q.; et al. Evolutionary population curriculum for scaling multi-agent reinforcement learning. arXiv:2003.10423 (2020).
- Yu, C.; et al. The surprising effectiveness of ppo in cooperative multi-agent games. Adv. Neural Inf. Process. Syst. 2022, 35, 24611–24624. [Google Scholar]
- Song, Y.; Schneider, J. Robust reinforcement learning via genetic curriculum. In 2022 International Conference on Robotics and Automation (ICRA), 5560–5566 (IEEE, 2022).
- Racaniere, S.; et al. Automated curricula through setter-solver interactions. arXiv:1909.12892 (2019).
- Cahill, A. Catastrophic forgetting in reinforcement-learning environments. Ph.D. thesis, Citeseer (2011).
- French, R. M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef]
- Lowe, R.; et al. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. neural information processing systems 30 ( 2017.
- Baker, B.; et al. Emergent tool use from multi-agent autocurricula. arXiv:1909.07528 (2019).
- Vaswani, A.; et al. Attention is all you need [j]. Adv. neural information processing systems 2017, 30, 261–272. [Google Scholar]
- Chen, J.; et al. Variational automatic curriculum learning for sparse-reward cooperative multi-agent problems. Adv. Neural Inf. Process. Syst. 2021, 34, 9681–9693. [Google Scholar]
- Qi, X.; Zhang, Z.; Zheng, H.; et al.: MedConv: Convolutions Beat Transformers on Long-Tailed Bone Density Prediction. arXiv preprint arXiv:2502.00631 (2025).
- Wang, K.; Zhang, X.; Guo, Z.; et al.: CSCE: Boosting LLM Reasoning by Simultaneous Enhancing of Causal Significance and Consistency. arXiv preprint arXiv:2409.17174 (2024).
- Liu, S.; Wang, K.: Comprehensive Review: Advancing Cognitive Computing through Theory of Mind Integration and Deep Learning in Artificial Intelligence. In: Proc. 8th Int. Conf. on Computer Science and Application Engineering, pp. 31–35 (2024).
- Zhang, X.; Wang, K.; Hu, T.; et al.: Enhancing Autonomous Driving through Dual-Process Learning with Behavior and Reflection Integration. In: ICASSP 2025 – IEEE Int. Conf. on Acoustics, Speech and Signal Processing, pp. 1–5. IEEE, Seoul (2025).
- Zou, B.; Guo, Z.; Qin, W.; et al.: Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition. In: ICASSP 2025 – IEEE Int. Conf. on Acoustics, Speech and Signal Processing, pp. 1–5. IEEE, Seoul (2025).
- Hu, T.; Zhang, X.; Ma, H.; et al.: Autonomous Driving System Based on Dual Process Theory and Deliberate Practice Theory. Manuscript (2025).
- Zhang, X.; Wang, K.; Hu, T.; et al.: Efficient Knowledge Transfer in Multi-Task Learning through Task-Adaptive Low-Rank Representation. arXiv preprint arXiv:2505.00009 (2025).
- Wang, K.; Ye, C.; Zhang, H.; et al.: Graph-Driven Multimodal Feature Learning Framework for Apparent Personality Assessment. arXiv preprint arXiv:2504.11515 (2025).
Figure 3.
The adaptive step usage ablation experiments which shows its effect.
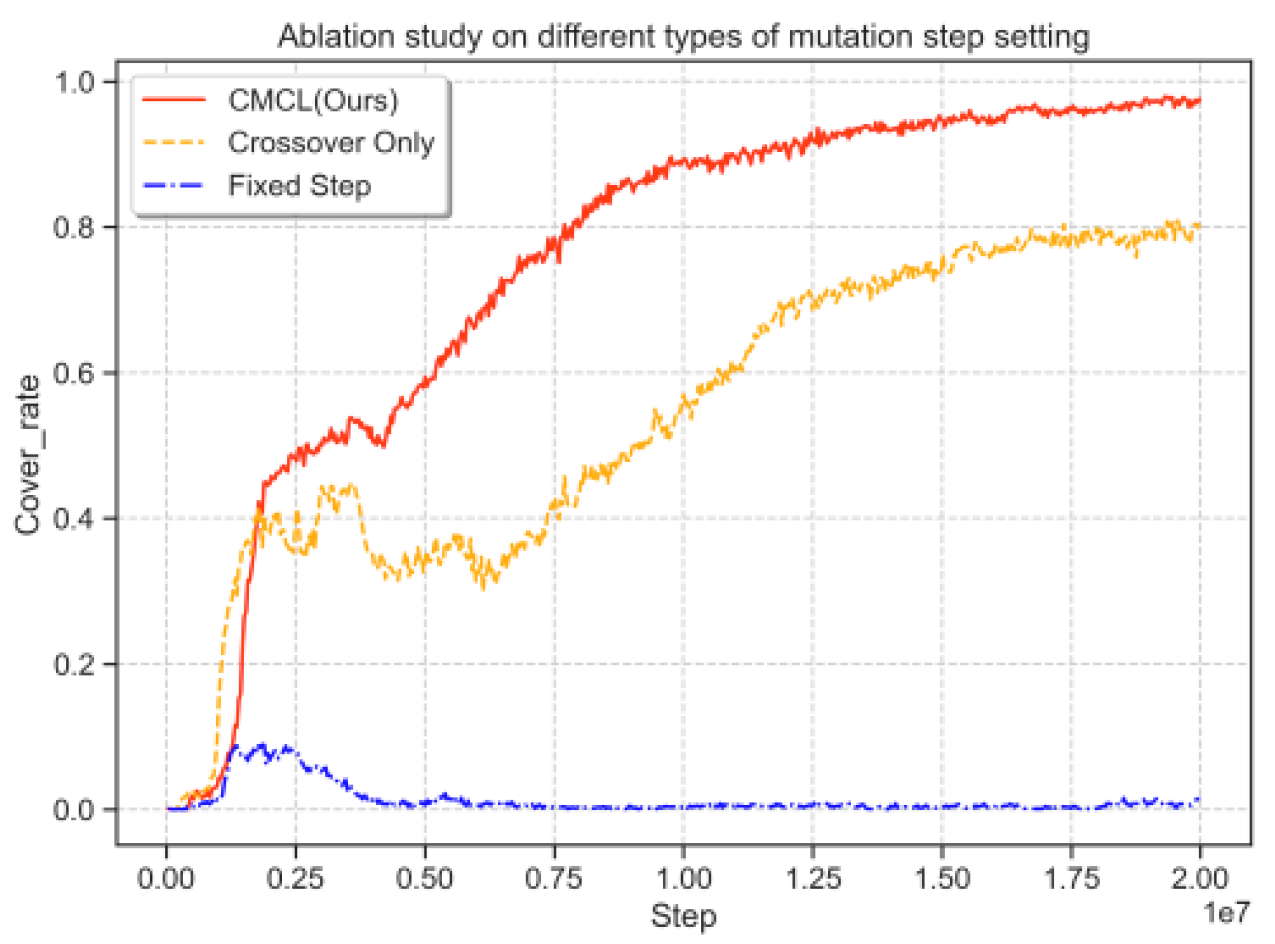
Figure 4.
The comparison of using absolute value and sigmoid-shaped fitness function.
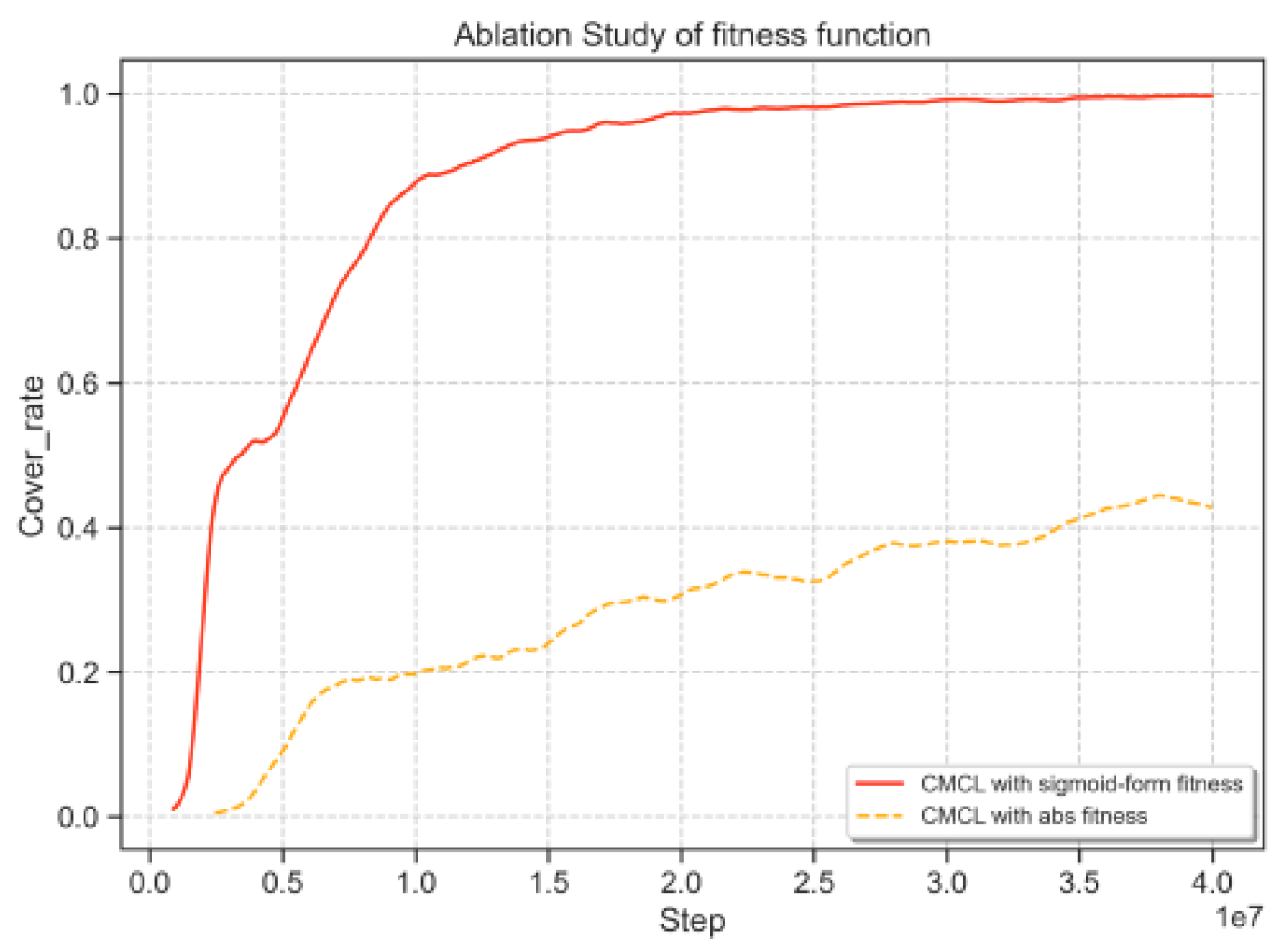

Table 1.
The Performance Comparison of CCL and Other Baselines on Simulated Environments.
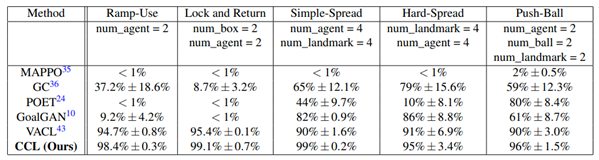 |
Table 2.
Performance Metrics for Various Methods across Different Tasks.
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



