Submitted:
28 March 2025
Posted:
31 March 2025
You are already at the latest version
Abstract
We use the data of three papers “Statistical Inference on the Shape Parameter of Inverse Generalized Weibull Distribution” (Zhuang et al.), “Sequential Confidence Intervals for Comparing Two Proportions with Applications in A/B Testing” (Hu et al.) and “On Designing of Bayesian Shewhart-Type Control Charts for Maxwell Distributed Processes with Application of Boring Machine” (Alshahrani et al.) to compare the above authors findings with ours. From the analysis we get different results: the cause is that they use the Probability Limits of the PI (Probability Interval) as they were the Confidence Limits (Control Limits of the Control Charts, CCs). The Control Limits in the Shewhart CCs are based on the Normal Distribution (Central Limit Theorem, CLT) and are not valid for non-normal distributed data: consequently, the decisions about the “In Control” (IC) and “Out Of Control” (OOC) states of the process are wrong. The Control Limits of the CCs are wrongly computed, due to unsound knowledge of the fundamental concept of Confidence Interval. Minitab and other software (e.g. JMP, SAS) use the “T Charts”, claimed to be a good method for dealing with “rare events”, but their computed Control Limits of the CCs are wrong. The same happens for the Confidence Limits of the parameters of the distribution involved in the papers (Weibull, Inverse Weibull, Gamma, Binomial, Maxwell). We will show that the Reliability Integral Theory (RIT) is able to solve these problems and the Sequential way of dealing with data.
Keywords:
Control Charts
; exponential distribution
; TBE
; T Charts
; Minitab
; JMP
; Reliability Integral Theory
MSC:
1. Introduction
Since 1989, the author (FG) tried to inform the Scientific Community about the flaws in the use of (“wrong”) quality methods for making Quality [1] and in 1999 about the GIQA (Golden Integral Quality Approach) showing how to manage Quality during all the activities of the Product and Process Development in a Company [2], including the Process Management and Control Charts (CC) for Process Control. Control Charts (CC) use sequentially the collected data to assess if a Production or Service process output is to be considered In Control (IC) or Out Of Control (OOC); the decision is very important for taking Corrective Actions (CA), if needed.
But before that we mention the very interesting the statements in the Excerpt 1:
Excerpt 1. From the paper “Misguided Statistical Process Monitoring Approaches”
In the recent paper “Misguided Statistical Process Monitoring Approaches” by W. Woodall, N. Saleh, M. Mahmoud, V. Tercero-Gómez, and S.
Knoth, published in Advanced Statistical Methods in Process Monitoring, Finance,
and Environmental Science, 2023, We read in the Abstract: Hundreds of
papers on flawed statistical process monitoring (SPM) methods have appeared in
the literature over the past decade or so. The presence of so many ill-advised
methods, and so much incorrect theory, adversely affects the SPM research
field. Critiques of some of the various misguided, and/or misrepresented,
approaches have been published in the past 2 years in an effort to stem this
tide. These critiques are briefly reviewed here. References…
We agree with the authors in the excerpt 1, but, nevertheless, they did not realise the problem that we are giving here: wrong Control Limits in CCs for Rare Events, with data exponentially or Weibull or Maxwell distributed. Several papers compute “a-scientific” control limits… See References…
We will show that the Test of Hypotheses and the Confidence Intervals (CI) are intimately related and so equivalent for decision making. Using the data in [3,4,5] with good statistical methods [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33] we give our “reflections on Sequential Methods and Control Charts (CCs)”.
We will try to state that several papers (that are not cited here, but you can find in the “Garden of flowers” [24] and some in the Appendix C) compute in an a-scientific way (see the formulae in the Appendix C) the Control Limits of CCs for “Individual Measures or Exponential, Weibull, Maxwell and Gamma distributed data”, indicated as I-CC (Individual Control Charts); we dare to show, to the Scientific Community, how to compute the True Control Limits (True Confidence Limits). If the author is right, then all the decisions, taken up today, have been very costly to the Companies using those Control Limits; therefore, “Corrective Actions” are needed, according to the Quality Principles, because NO “Preventive Actions” were taken [1,2,27,28,29,30,31,32,33,34,35,36]: this is shown through the suggested published papers. Humbly, given our strong commitment to Quality [34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57], we would dare to provide the “truth”: Truth makes you free [hen (“hic et nunc”=here and now)].
On 22nd of February 2024, we found the paper “Publishing an applied statistics paper: Guidance and advice from editors” published in Quality and Reliability Engineering International (QREI-2024, 1-17) [by C. M. Anderson-Cook, Lu, R. B. Gramacy, L. A. Jones-Farmer, D. C. Montgomery, W. H. Woodall; the authors have important qualifications and Awards]; since I-CC is a part of “applied statistics” we think that their hints will help: the authors’ sentence “Like all decisions made in the face of uncertainty, Type I (good papers rejected) and Type II (flawed papers accepted) errors happen since the peer review process is not infallible.” is very important for this paper: the interested readers can see [34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57] and the Appendix B.
To let the reader follow our way of approaching the problem of estimation we will use various Figures and data: this is caused by the fact that there are wrong ideas in the literature.
By reading [24] and other papers, the readers are confronted with this type of practical problem: we have a warehouse with two departments
- a)
- in the 1st of them, we have a sample (the “The Garden of flowers… in [24]”) of “products (papers)” produced by various production lines (authors)
- b)
- while, in the other, we have some few products produced by the same production line (same author)
- c)
- several inspectors (Peer Reviewers, PRs) analyse the “quality of the products” in the two departments; the PRs can be the same (but we do not know) for both the departments
- d)
- The final result, according to the judgment of the inspectors (PRs), is the following: the products stored in the 1st dept. are good, while the products in the 2nd dept. are defective. It is a very clear situation, as one can guess by the following statement of a PR: “Our limits [in the 1st dept.] are calculated using standard mathematical statistical results/methods as is typical in the vast literature of similar papers [24].” See the standard mathematical statistical results/methods in the Appendix C and meditate (see the formulae there)!
Hence, the problem becomes “…the standard … methods as is typical …”: are those standards typical methods (in the “The Garden … in [24]” and in the Appendix C) scientific?
If θ denotes the population parameter, the general form of the null hypothesis is H0: {θ∈Θ0} versus the alternative hypothesis H1: {θ∈Θ1}, where Θ0 is a subset of the parameter space Θ and Θ1 a subset disjoint from Θ0.; Θ0∪Θ1= Θ and Θ0∩Θ1=∅; before collecting any data, with H0 we accept a probability of wrong decision , while with H1 we accept a probability of wrong decision . We will use in the following discussion. After the data analysis, we can compute the Confidence Interval, LCL-------UCL, of the estimated value, with Confidence Level .
Using the Table 1 data (remission time of 128 bladder cancer patients) we will see that the practical problem becomes hence a Theoretical one [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57] (all references and Figure 1). Since those data are well “exponentially distributed” we anticipate here, immediately, the wrong formulae (either using the parameter or its estimate , with ) in the formula (1) (as you can find in [24])
The readers should understand clearly the Theoretical and Practical Difference between L------U (the Probability Interval) and LCL------UCL (the Confidence Interval), pictorially shown in the Figure 1: the two lines L and U depends on the parameter θ (to be estimated) and on the two probabilities α and β, while the two points L and U depends on the assumed value θ0 of the parameter and on the two chosen probabilities α and β; after the data analysis, we compute the estimate of the parameter θ and from that the Confidence Interval LCL------UCL, with Confidence Level . It is clear now the wrong ideas in the formukae (1).
In the formulae (1), for the interval LCL------UCL (named Control Interval, for the authors [24]), the LCL actually must be L and the UCL actually must be U, vertical interval L------U (Figure 1); the actual interval LCL------UCL is the horizontal one in the Figure 1, which is not that of the formulae (1). Since the errors have been continuing for at least 25 years, we dare to say that this paper is an Education Advance for all the Scholars, for the software sellers and the users: they should study the books and papers in [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57].
The readers could think that the I-CCs are well known and well dealt in the scientific literature about Quality. We have some doubt about that: we will show that, at least in one field, the I-CC_TBE (with TBE, Time Between Event data) usage, it is not so: there are several published papers, in “scientific magazines and Journals (well appreciated by the Scholars)” with wrong Control Limits; a sample of the involved papers (from 1994 to January 2024) can be found in [23,24]”. Therefore, those authors do not extract the maximum information from the data in the Process Control. “The Garden…” [24] and the excerpts 1, with the Deming’s statements, constitute the Literature Review.
Excerpt 2. Some statements of Deming about Knowledge and Theory (Deming 1986, 1997)
“Management need to grow-up their knowledge because experience alone, without theory, teaches nothing what to do to make Quality” “Experience alone, without theory, teaches management nothing about what to do to improve quality and competitive position, nor how to do it.), ... understanding of quality requires education. There is no substitute for knowledge. It is a hazard to copy. It is necessary to understand the theory of what one wishes to do or to make..... hundreds of people are learning what is wrong. .... I make this statement on the basis of experience, seeing every day the devastating effects of incompetent teaching and faulty applications. Again, teaching of beginners should be doneby a master, not by a hack”.
We hope that the Deming statements about knowledge will interest the Readers (Excerpt 2).
A preliminary case is shown in Appendix A.
The statistical concepts in section 2 are very important for our purpose.
2. Materials and Methods
2.1. A reduced Background of Statistical Concepts
This section is essential to understand the “problems related to I-CC and sequential estimation” as we found in the literature. We suggest it for the formulae given and for the difference between the concepts of PI (Probability Interval) and CI (Confidence Interval): this is overlooked in “The Garden … [24]” (a sample is in the Appendix C).
See a first case in the appendix A. Therefore, we humbly ask the reader to carefully meditate on the content.
Engineering Analysis is related to the investigation of phenomena underlying products and processes; the analyst can communicate with the phenomena only through the observed data, collected with sound experiments (designed for the purpose): any phenomenon, in an experiment, can be considered as a measurement-generating process [MGP, a black box that we do not know] that provides us with information about its behaviour through a measurement process [MP, known and managed by the experimenter], giving us the observed data (the “message”).
It is a law of nature that the data are variable, even in conditions considered fixed, due to many unknown causes.
MGP and MP form the Communication Channel from the phenomenon to the experimenter.
The information, necessarily incomplete, contained in the data, has to be extracted using sound statistical methods (the best possible, if we can). To do that, we consider a statistical model F(x|θ) associated with a random variable (RV) X giving rise to the measurements, the “determinations” {x1, x2, …, xn}=D of the RV, constituting the “observed sample” D; n is the sample size. Notice the function F(x|θ) [a function of real numbers, whose form we assume we know] with the symbol θ accounting for an unknown quantity (or some unknown quantities) that we want to estimate (assess) by suitably analysing the sample D.
We indicate by the pdf (probability density function) and by the Cumulative Function, where is the set of the parameters of the functions.
We state in the Table 1 a sample of models where θ is a set of parameters:
Two important models are the Normal and the Exponential, but we consider also the others for comparison. When we have the Normal model, written as (x|), with (parameters) mean E[X]=μ and variance Var[X]=σ2 with pdf
When we have Exponential model, with (the single parameter) mean E[X]= (variance Var[X]=2), whose pdf is written in two equivalent ways .
When we have the observed sample D={x1, x2, …, xn}, our general problem is to estimate the value of the parameters of the model (representing the parent population) from the information given by the sample. We define some criteria which we require a "good" estimate to satisfy and see whether there exist any "best" estimates. We assume that the parent population is distributed in a form, the model, which is completely determinate but for the value θ0 of some parameter, e.g. unidimensional, θ, or bidimensional θ={μ, σ2}; we consider only one or two parameters, for easiness.
We seek some function of θ, say τ(θ), named inference function, and we see if we can find a RV T which can have the following properties: unbiasedness, sufficiency, efficiency. Statistical Theory allows us the analysis of these properties of the estimators (RVs).
We use the symbols and for the unbiased estimators T1 and T2 of the mean and the variance.
Luckily, we have that T1, in the Exponential model , is efficient [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33], and it extracts the total available information from any random sample, while the couple T1 and T2, in the Normal model, are jointly sufficient statistics for the inference function τ(θ)=(μ, σ2), so extracting the maximum possible of the total available information from any random sample. The estimators (which are RVs) have their own “distribution” depending on the parent model F(x|θ) and on the sample D: we use the symbol for that “distribution”. It is used to assess their properties. For a given (collected) sample D the estimator provides a value t (real number) named the estimate of τ(θ), unidimensional.
A way of finding the estimate is to compute the Likelihood Function [LF] and to maximise it: the solution of the equation =0 is termed Maximum Likelihood Estimate [MLE]. Both are used for sequential tests.
The LF is important because it allows us finding the MVB (Minimum Variance Bound, Cramer-Rao theorem) [1,2,6,7,8,9,10,11,12,13,14,15,16,26,27,28,29,30,31,32,33,34,35,36] of an unbiased RV T [related to the inference function τ(θ)], such that
The inverse of the MVB(T) provides a measure of the total available amount of information in D, relevant to the inference function τ(θ) and to the statistical model F(x|θ).
Naming IT(T) the information extracted by the RV T we have that [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,26,27,28,29,30,31,32,33,34,35,36]
IT(T)=1/MVB(T) ⇔ T is an Efficient Estimator.
If T is an Efficient Estimator there is no better estimator able to extract more information from D.
The estimates considered before were “point estimates” with their properties, looking for the “best” single value of the inference function τ(θ).
We must now introduce the concept of Confidence Interval (CI) and Confidence Level (CL) [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,26,27,28,29,30,31,32,33,34,35,36].
The “interval estimates” comprise all the values between τL (Lower confidence limit) and τU (Upper confidence limit); the CI is defined by the numerical interval CI={τL-----τU}, where τL and τU are two quantities computed from the observed sample D: when we make the statement that τ(θ)∈CI, we accept, before any computation, that, doing that, we can be right, in a long run of applications, (1-α)%=CL of the applications, BUT we cannot know IF we are right in the single application (CL=Confidence Level).
We know, before any computation, that we can be wrong α% of the times but we do not know when it happens.
The reader must be very careful to distinguish between the Probability Interval PI={L-----U}, where the endpoints L and U depends on the distribution of the estimator T (that we decide to use, which does not depend on the “observed sample” D) and, on the probability π=1-α (that we fix before any computation), as follows by the probabilistic statement (4) [se the Figure 1 for the exponential density, when n=1]
and Confidence Interval CI={τL-----τU} which depends on the “observed sample” D.
Notice that the Probability Interval PI={L-----U}, given in the formula (4), does not depend on the data D, as you can pictorially see in Figure 1: L and U are the Probability Limits. Notice that, on the contrary, the Confidence Interval CI={τL-----τU} does depend on the data D, pictorially seen in Figure 1. This point is essential for all the papers in the References.
Shewhart identified this approach, L and U, on page 275 of [19] where he states:

The Tchebycheff Inequality: IF the RV X is arbitrary with density f(x) and finite variance THEN we have the probability , where . This is a “Probabilistic Theorem”.
It can be transferred into Statistics. Let’s suppose that we want to determine experimentally the unknown mean within a “stated error ε”. From the above (Probabilistic) Inequality we have ; IF THEN the event is “very probable” in an experiment: this means that the observed value of the RV X can be written as and hence . In other words, using as an estimate of we commit an error that “most likely” does not exceed . IF, on the contrary, , we need n data in order to write , where is the RV “mean”; hence we can derive ., where is the “empirical mean” computed from the data. In other words, using as an estimate of we commit an error that “most likely” does not exceed . See the excerpts 3, 3a, 3b.
Notice that, when we write , we consider the Confidence Interval CI [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33], and no longer the Probability Interval PI [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33].
These statistical concepts are very important for our purpose when we consider the Sequential tests and the Control Charts, especially with Individual data.
Notice that the error made by several authors [4,5,24] is generated by lack of knowledge of the difference between PI and CI [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33]: they think wrongly that CI=PI, a diffused disease [4,5,24]! They should study some of the books/papers [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33] and remember the Deming statements (excerpt 2).
The Deming statements are important for Quality. Managers, scholars; the professors must learn Logic, Design of Experiments and Statistical Thinking to draw good decisions. The authors must, as well. Quality must be their number one objective: they must learn Quality methods as well, using Intellectual Honesty [1,2,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33]. Using (4), those authors do not extract the maximum information from the data in the Process Control. To extract the maximum information from the data one needs statistical valid Methods [1,2,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33].
As you can find in any good book or paper [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33] there is a strict relationship between CI and Test Of Hypothesis, known also as Null Hypothesis Significance Testing Procedure (NHSTP). In Hypothesis Testing (see the Appendix B), the experimenter wants to assess if a “thought” value of a parameter of a distribution is confirmed (or rejected) by the collected data: for example, for the mean μ (parameter) of the Normal (x|) density, he sets the “null hypothesis” H0={μ=μ0} and the probability P=α of being wrong if he decides that the “null hypothesis” H0 is true, when actually it is opposite: H0 is wrong. When we analyse, at once, the observed sample D={x1, x2, …, xn} and we compute the empirical (observed) mean and the empirical (observed) standard deviation , we define the Acceptance interval, which is the CI
Notice that the interval (for the Normal model, assumed) [see the Appendix B]
is the Probability Interval such that .
A fundamental reflection is in order: the formulae (5) and (6) tempt the unwise guy to think that he can get the Acceptance interval, which is the CI [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23], by substituting the assumed values of the parameters with the empirical (observed) mean and standard deviation . This trick is valid only for the Normal distribution.
The formulae (5) can be used sequentially to test H0={μ=μ0} versus H1={μ=μ1<μ0}; for any value 2<k≤n; we obtain n-2 CIs, decreasing in length; we can continue until either μ1<LCL or UCL<μ0, or both (verify) μ1<LCL and UCL<μ0.
More ideas about these points can be found in [34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57].
In the field of Control Charts, with Shewhart, instead of the formula (5), we use (7)
where the t distribution value is replaced by the value of the Normal distribution, actually =3, and a coefficient is used to make “unbiased” the estimate of the standard deviation, computed from the information given by the sample.
Actually, Shewhart does not use the coefficient is as you can see from page 294 of Shewhart book (1931), where is the “Grand Mean”, computed from D [named here empirical (observed) mean ], is “estimated standard of each sample” (named here s, with sample size n=20, in excerpt 3)
Excerpt 3. From Shewhart book (1931), on page 294
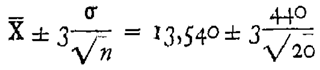
The application of these ideas in the Individual CCs can be seen in the Appendix A, in the Figure A1: the standard deviation is derived from the Mobile Range (which is exponentially distributed as the original UTI data). The formula in the excerpt 3 tells us that the process is OOC (Out Of Control).
2.2. Control Charts for Process Management
Statistical Process Management (SPM) entails Statistical Theory and tools used for monitoring any type of processes, industrial or not. The Control Charts (CCs) are the tool used for monitoring a process, to assess its two states: the first, when the process, named IC (In Control), operates under the common causes of variation (variation is always naturally present in any phenomenon) and the second, named OOC (Out Of Control), when the process operates under some assignable causes of variation. The CCs, using the observed data, allow us to decide if the process is IC or OOC. CCs are a statistical test of hypothesis for the process null hypothesis H0={IC} versus the alternative hypothesis H1={OOC}. Control Charts were very considered by Deming [9,10] and Juran [12] after Shewhart invention [19,20].
We start with Shewhart ideas (see the excerpts 3, 3a and 3b).
In the excerpts, is the (experimental) “Grand Mean”, computed from D (we, on the contrary, use the symbol ), is the (experimental) “estimated standard of each sample” (we, on the contrary, use the symbol s, with sample size n=20, in excerpts 3a, 3b), is the “estimated mean standard deviation of all the samples” (we, on the contrary, use the symbol ).
Excerpt 3a. From Shewhart book (1931), on page 89

On page 95, he also states that
Excerpt 3b. From Shewhart book (1931), on page 294


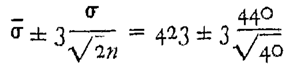
So, we clearly see that Shewhart, the inventor of the CCs, used the data to compute the Control Limits, LCL (Lower Control Limit, which is the Lower Confidence Limit) and UCL (Upper Control Limit, the Upper Confidence Limit) both for the mean (1st parameter of the Normal pdf) and for (2nd parameter of the Normal pdf). They are considered the limits comprising 0.9973n of the observed data. Similar ideas can be found in [5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42] (with Rozanov, 1975, we see the idea that CCs can be viewed as a Stochastic Process).
We invite the readers to consider that if one assumes that the process is In Control (IC) and if he knows the parameters of the distribution he can test if the assumed known values of the parameters are confirmed or disproved by the data, then he does not need the Control Charts; it is sufficient to use NHSTP! (see App. B)
Remember the ideas in the previous section and compare Excerpts 3, 3a, 3b (where LCL, UCL depend on the data) with the following Excerpt 4 (where LCL, UCL depend on the Random Variables) and appreciate the profound “logic” difference: this is the cause of the many errors in the CCs for TBE [Time Between Events (see [4,5,24]).
Excerpt 4. From a paper in the “Garden… [24]”. Notice that one of the authors wrote several papers…

The formulae, in the excerpt 4, LCL1 and UCL1 are actually the Probability Limits (L and U) of the Probability Interval PI in the formula (4), when is the pdf of the Estimator T, related to the Normal model F(x; μ, σ2). Using (4), those authors do not extract the maximum information from the data in the Process Control. From the Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36] we derive that the interval L=μY-3σY------μY+3σY=U is the PI such that the RV Y=
and it is not the CI of the mean μ=μY [as wrongly said in the Excerpt 4, where actually (LCL1-----UCL1)=PI].
The same error is in other books and papers (not shown here but the reader can see in [21,22,23,24]).
The data plotted in the CCs [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33,34,35,36] (see the Figure 2) are the means , determinations of the RVs , i=1, 2, ..., n (n=number of the samples) computed from the sequentially collected data of the i-th sample Di={xij, j=1, 2, ..., k} (k=sample size)}, determinations of the RVs at very close instants tij, j=1, 2, ..., k. In other applications I-CC (see the Figure 3), the data plotted are the Individual Data , determinations of the Individual Random Variables , i=1, 2, ..., n (n=number of the collected data), modelling the measurement process (MP) of the “Quality Characteristic” of the product: this model is very general because it is able to consider every distribution of the Random Process , as we can see in the next section. From the excerpts 3, 3a, 3b and formula (5) it is clear that Shewhart was using the Normal distribution, as a consequence of the Central Limit Theorem (CLT) [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,26,27,28,29,30,31,32,33,34,35,36]. In fact, he wrote on page 289 of his book (1931) “… we saw that, no matter what the nature of the distribution function of the quality is, the distribution of the arithmetic mean approaches normality rapidly with increase in n (his n is our k), and in all cases the expected value of means of samples of n (our k) is the same as the expected value of the universe” (CLT in Excerpt 3, 3a, 3b).
Let k be the sample size; the RVs are assumed to follow a normal distribution and uncorrelated; [ith rational subgroup] is the mean of RVs IID j=1, 2, ..., k, (k data sampled, at very near times tij).
To show our way of dealing with CCs we consider the process as a “stand-by system whose transition times from a state to the subsequent one” are the collected data. The lifetime of “stand-by system” is the sum of the lifetimes of each unit. The process (modelled by a “stand-by …”) behaves as a Stochastic Process [25,26,27,28,29,30,31,32,33], that we can manage by the Reliability Integral Theory (RIT): see the next section; this method is very general because it is able to consider every distribution of .
If we assume that is distributed as f(x) [probability density function (pdf) of “transitions from a state to the subsequent state” of a stand-by subsystem] the pdf of the (RV) mean is, due the CLT (page 289 of 1931 Shewhart book), [experimental mean ] with mean and variance . is the “grand” mean and is the “grand” variance: the pdf of the (RV) grand mean [experimental “grand” mean ]. In Figure 2 we show the determinations of the RVs and of .
When the process is Out Of Control (OOC, assignable causes of variation, some of the means , estimated by the experimental means , are “statistically different)” from the others [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33,34,35,36]. We can assess the OOC state of the process via the Confidence Intervals (provided by the Control Limits) with CL=0.9973; see the Appendix B. Remember the trick valid only for the Normal Distribution ….; consider the PI, L=μY-3σY------μY+3σY=U; putting in place of and in place of we get the CI of when the sample size k is considered for each , with CL=0.9973. The quantity is the mean of the standard deviations of each sample. This allows us to compare each (subsystem) mean , q=1,2, …, n, to any other (subsystem) mean r=1,2, …, n, and to the (Stand-by system) grand mean . If two of them are different, the process is classified as OOC. The quantities and are the Control Limits of the CC, which are the Confidence Limits. When the Ranges Ri=max(xij)-min(xij) are considered for each sample we have , and , U, where is the “mean range” and the coefficients A2, D3, D4 are tabulated and depend on the sample size k [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,25,26,27,28,29,30,31,32,33,34,35,36].
See the Appendix B: it is important for understanding our ideas.
We stress that the interval LCLX-------UCLX is the “Confidence Interval” with “Confidence Level” CL=1-α=0.9973 for the unknown mean of the Stochastic Process X(t) [25,26,27,28,29,30,31,32,33,34,35,36]. The interval LCLR----------UCLR is the “Confidence Interval” with “Confidence Level” CL=1-α=0.9973 for the unknown Range of the Stochastic Process X(t) [25,26,27,28,29,30,31,32,33,34,35,36].
Notice that, ONLY for normally distributed data, the length of the Control Interval (UCLX-LCLX, which is the Confidence Interval) equals the length of the Probability Interval, PI (U-L): UCLX-LCLX=U-L.
The error highlighted, i.e. the confusion between the Probability Interval and the Control Limits (Confidence Interval!) has no consequences for decisions when the data are Normally distributed, as considered by Shewhart. On the contrary, it has BIG consequences for decisions WHEN the data are Non-Normally distributed [4,5,24].
We think that the paper “Quality of Methods for Quality is important”, [1] appreciated and mentioned by J. Juran at the plenary session of the EOQC (European Organization for Quality Control) Conference (1989), should be considered and meditated.
2.3. Statistics and RIT
We are going to present the fundamental concepts about RIT (Reliability Integral Theory) that we use for computing the Control Limits (Confidence Limits) of CCs. RIT is the natural way for Sequential Tests, because the transitions happen sequentially; to provide the ideas, we use a “4 units Stand-by system”, depicted by 5 states (Figure 4): 0 is the state with all units not-failed; 1 is the state with the first unit failed; 2 is the state with the second unit failed; and so on, until the system enters the state 5 where all the 4 units are failed (down state, in yellow): any transition provides a datum to be used for the computations. RIT can be found in the author’s books…
RIT can be used for parameters estimation and Confidence Intervals (CI), (Galetto 1981, 1982, 1995, 2010, 2015, 2016), in particular for Control Charts (Deming, 1986, 1997, Shewhart 1931, 1936, Galetto 2004, 2006, 2015). In fact, any Statistical or Reliability Test can be depicted by an “Associated Stand-by System” [25,26,27,28,29,30,31,32,33,34,35,36] whose transitions are ruled by the kernels bk,j(s); we write the fundamental system of integral equations for the reliability tests, whose duration t is related to interval 0-----t; the collected data tj can be viewed as the times of the various failures (of the units comprising the System) [t0=0 is the start of the test, t is the end of the test and g is the number of the data (4 in the Figure 4)]
Firstly, we assume that the kernel is the pdf of the exponential distribution (|), where is the failure rate of each unit and : is the MTTF of each unit. We state that is the probability that the stand-by system does not enter the state g (5 in Figure 4), at time t, when it starts in the state j (0, 1, …, 4) at time tj, is the probability that the system does not leave the state j, is the probability that the system makes the transition j→j+1, in the interval s-----s+ds.
The system reliability is the solution of the mathematical system of the Integral Equations (8)
With we obtain the solution (see Figure 5, putting the Mean Time To Failure MTTF of each unit=θ, ) (see the Figure 5)
The reliability system (8) can be written in matrix form,
At the end of the reliability test, at time t, we know the data (the times of the transitions tj) and the “observed” empirical sample D={x1, x2, …, xg}, where xj=tj – tj-1 is the length between the transitions; the transition instants are tj = tj-1 + xj giving the “observed” transition sample D*={t1, t2, …, tg-1, tg, t=end of the test} (times of the transitions tj).
We consider now that we want to estimate the unknown MTTF=θ=1/λ of each item comprising the “associated” stand-by system [24,25,26,27,28,29,30]: each datum is a measurement from the exponential pdf; we compute the determinant of the integral system (9), where is the “Total Time on Test” [ in the Figure 5]: the “Associated Stand-by System” [25,26,27,28,29,30,31,32,33] in the Statistics books provides the pdf of the sum of the RV Xi of the “observed” empirical sample D={x1, x2, …, xg}. At the end time t of the test, the integral equations, constrained by the constraint D*, provide the equation
It is important to notice that, in the case of exponential distribution [11,12,13,14,15,16,25,26,27,28,29,30,31,32,33,34,35,36], it is exactly the same result as the one provided by the MLM Maximum Likelihood Method.
If the kernel is the pdf (|) the data are normally distributed, , with sample size n, then we get the usual estimator such that .
The same happens with any other distribution (e.g. see the Table 1) provided that we write the kernel .
The reliability function , [formula (8)], with the parameter , of the “Associated Stand-by System” provides the Operating Characteristic Curve (OC Curve, reliability of the system) [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36] and allows to find the Confidence Limits ( Lower and Upper) of the “unknown” mean , to be estimated, for any type of distribution (Exponential, Weibull, Rayleigh, Normal, Gamma, Inverted Weibull, General Inverted Weibull, …); by solving, with (a general) unknown (indicated as) , the two equations (|); we get the two values (, ) such that
where is the (computed) “total of the length of the transitions xi=tj - tj-1 data of the empirical sample D” and CL= is the Confidence Level. CI=-------- is the Confidence Interval: and .
For example, with Figure 5, we can derive and , with CL=0.8. It is quite interesting that the book [14] Meeker et al., “Statistical Intervals: A Guide for Practitioners and Researchers”, John Wiley & Sons (2017) use the same ideas of FG (shown in the formula 11) for computing the CI; the only difference is that the author FG defined the procedure in 1982 [26], 35 years before Meeker et al.
As said before, we can use RIT for the Sequential Tests; we have only to consider the various transitions and the Total Time on Test to the last transition we want to consider.
2.4. Control Charts for TBE Data. Some Ideas for Phase I Analysis
Let’s consider now TBE (Time Between Event, time between transitions) data, exponentially or Weibull distributed. Quite a lot of authors (in the “Garden … [24]”) compute wrongly the Control Limits (which are the Confidence Limits) of these CCs.
The formulae, shown in the section “Control Charts for Process Management”, are based on the Normal distribution (thanks to the CLT; see the excerpts 3, 3a and 3b); unfortunately, they are used also for NON_normal data (e.g. see formulae (1)): for that, sometimes, the NON_normal data are transformed “with suitable transformations” in order to “produce Normal data” and to apply those formulae (above) [e.g. Montgomery in his book].
Sometimes we have few data and then we use the so called “Individual Control Charts” I-CC. The I-CCs are very much used for exponentially (or Weibull) distributed data: they are also named “rare events Control Charts for TBE (Time Between Events) data”, I-CC_TBE.
In the previous section, we computed the CI=-------- of the parameter , using the (subsample) “transition times durations”: =“total of the transition times durations (length of the transitions xi=tj - tj-1 data) in the empirical sample (subsample with n=4 only, as an example)” and Confidence Level CL=.
When we deal with a I-CC_TBE we compute the LCL and UCL of the mean θ through the empirical mean of each transition, for the… ; we solve the two following equations (12) for the two unknown values LCL and UCL, for of each item in the sample, similar to (11)
where now /n is the “mean, to be attributed, to the single lengths of the single transitions xi=tj-tj-1 data in the empirical sample D with the Confidence Level CL=: and .
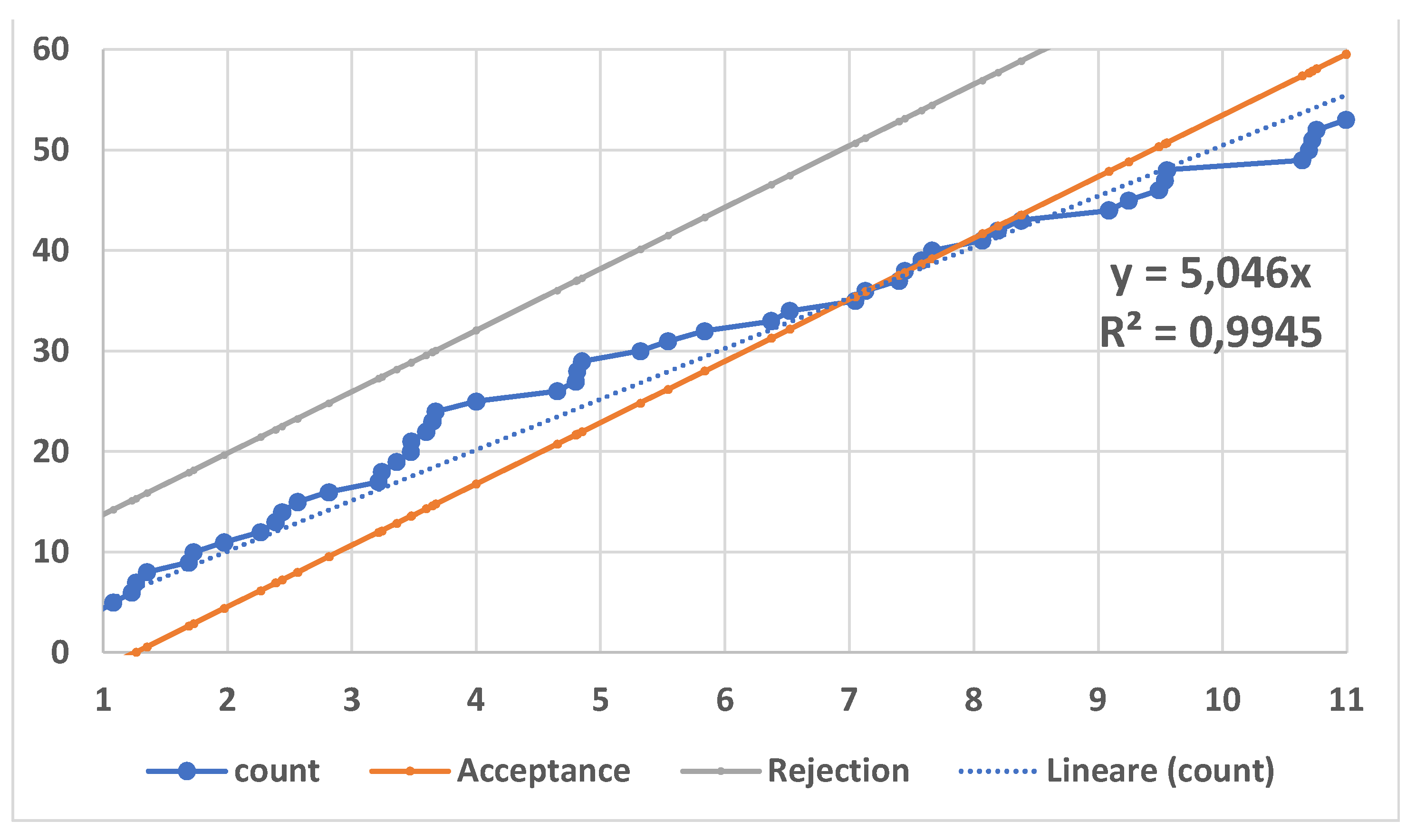
In the next sections we can see the Scientific Results found by a Scientific Theory (we anticipate them: the Control Limits are LCL=18.0 days and UCL=88039.3 days).
3. Results
In this section we provide the scientific analysis of the “remission time” data [3] and compare our result with those of the authors: the findings are completely different and the decisions, consequently, should be different, with different costs of wrong decisions.
3.1. Control Charts for TBE Data. Phase I Analysis
The “remission time of 128 bladder cancer patients” data are in the Table 2.
Using all the 128 Cancer data the authors write:
Excerpt 5. Zhuang et al., Statistical Inference on … Generalized Weibull Distribution. 2024
It is reasonable to assume that the remission times of
bladder cancer patients follow an GIW distribution. Based on the given data for
the 128 patients, as well as the information from …, we further assume the
distribution is GIW(=61.38, =0.51, =8.19).
They add also:
Excerpt 6. Zhuang et al., Statistical Inference on … Generalized Weibull Distribution. 2024
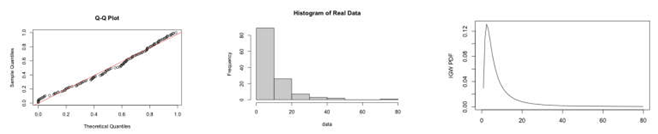
Figure 3 (our Excerpt 7) displays the Q-Q plot for the observed data versus the theoretical IGW distribution, given that =61.38, =0.51, =8.19, which confirms that this data set would be suitable for the proposed methodologies. We have also included the histogram of the observed data, and the density curve, to provide further insight.
So, the authors decided to “assume” (use) the GIW(x|β, η, ω): to analyse all the 128 data in Table 2; their estimates are in Excerpts 5 ,6. Looking at Q-Q Plot and Histogram (in Excerpt 7) the readers can have some doubts about the use. of GIW.
Excerpt 7. QQ plot of remission time of 128 bladder cancer patients with IGW histogram of the real data and probability density GIW (estimates of the parameters ω ̂=61.38, β ̂=0.51, η ̂=8.19), from [3]
As a matter of fact, we can draw the Figure 6, TTOT (of the data xi) versus i/n (n=128); from the graph it is evident that the exponential distribution is suitable for the data analysis. Therefore, we will compare the models Exponential, Inverted W and GIW.
We divide the data in two sets: the first based on the first 32 data and the second considering the others.
Fitting the Weibull distribution, one finds β=1.17 and η=8.88, with -2lnL=198.58; since the 1∈CI of β, with CL=80% we are allowed to use the exponential distribution (as given in Figure 6).
Seeing the Figure 7 we find that the data show an OOC.
The Figure 8 shows that the first 32 data do not allow to assess if the “null hypothesis” H0={θ=10}, with α=0.025 is to be accepted or rejected in favour of the H1={θ=5.75} with β=0.025. The Sequential Test (Wald) is inefficient for the first 32 data. Compare with Figure 9.
The last CI={6.08, 12.23}, Figure 9, shows that the first 32 data allows to assess that the “null hypothesis” H0={θ=10}, with α=0.025 is to be accepted but H1={θ=5.75} rejected with β>0.025: {5.75<6.08<10<12.23}. The Sequential CIs are not more efficient than Wald Test.
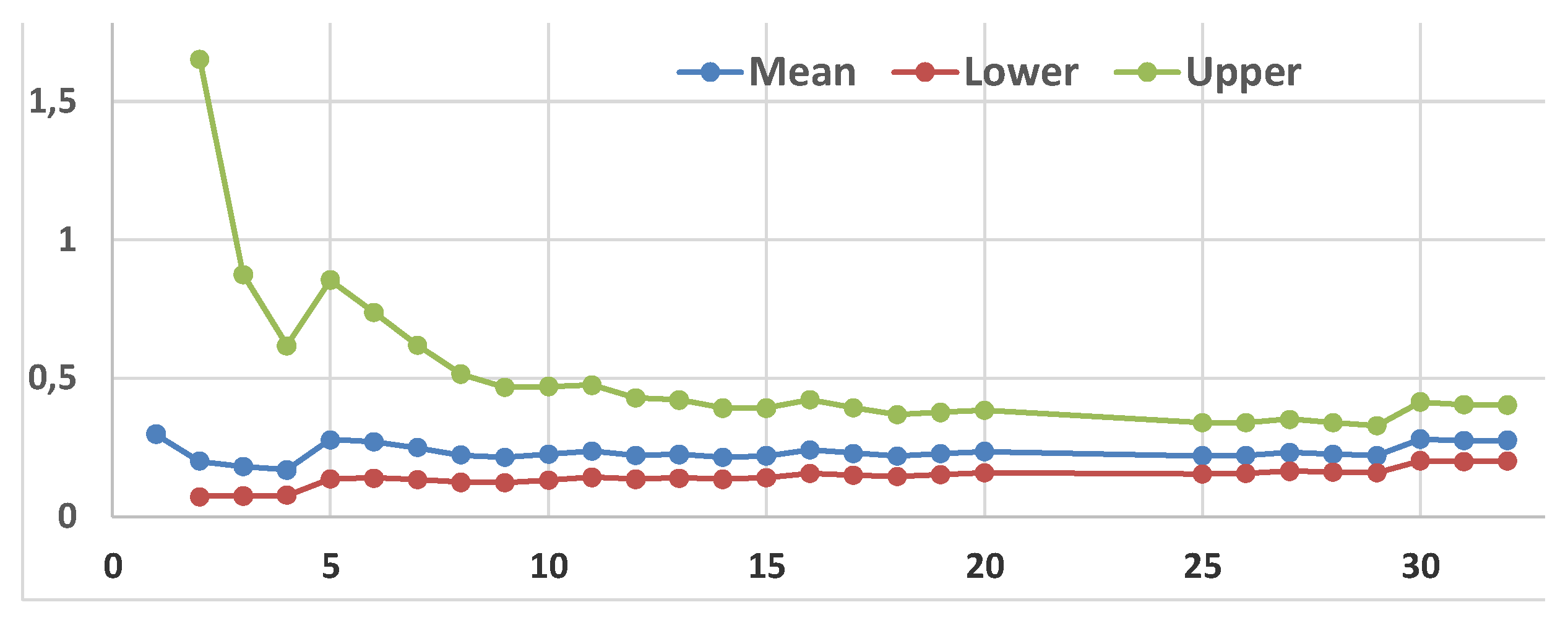
Fitting the Inverse Weibull distribution, on the first 32 data (1/xi), one finds β=1.0422 and η=0.281, with -2lnL=18.59; since the 1∈CI of β, with CL=80% we are allowed to use the exponential distribution, as we could do for the data xi. The conclusion, the first 32 data (1/xi), about the sequential CIs would be the same as for the data xi.
Figure 10.
Sequential Confidence Intervals (α=β=0.025) for the Inverse Weibull distribution
In the next session we consider all the 128 data and compare our results with the authors of [3].
For exponentially distributed data (12) becomes (13) [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33], k=1, with CL=
The endpoints of the CI=--------are the Control Limits of the I-CC_TBE.
This is the right method to extract the “true” complete information contained in the sample (see the figs. 7, 8, 9). The Figures are justified by the Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33] and are related to the formulae [(12), (13) for k=1], for the I-CC_TBE charts.
Remember the book Meeker et al., “Statistical Intervals: A Guide for Practitioners and Researchers”, John Wiley & Sons (2017): the authors use the same ideas of FG; the only difference is that FG invented 30 years before, at least.
Compare the formulae [(13), for k=1], theoretically derived with a sound Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33], with the ones in the Excerpt [in the Appendix C (a small sample from the “Garden … [24]”)] and notice that the two Minitab authors (Santiago&Smith) use the “empirical mean ” in place of the in the Figure 1: it is the same trick of replacing to the mean μ which is valid for the Normal distributed data only; e.g., see the formulae (1)!
3.2. Control Charts for TBE Data. Phase II Analysis
We saw in the previous section what usually it is done during the Phase I of the application of CCs: estimation of the mean and standard deviation; later, their values are assumed as “true known” parameters of the data distribution, in view of the Phase II.
We considered the first 32 (out of 128 remission times of bladder) Cancer data; using all the 128 data the authors found (Excerpts 5, 6) the distribution GIW(x|β, η, ω): with estimated parameters =0.51, =8.19, =61.38; on the contrary we found that the exponential distribution (after fitting the Weibull and the Inverse Weibull) was suitable: that allowed us to make many considerations about the use of sequential sampling.
Now we consider all the 128 data and see new considerations.
In particular, for TBE individual data the exponential distribution is assumed with a known parameter λ0 or θ0.
We consider now what it is done during the Phase II of the application of CCs for TBE data individual exponentially distributed.
As previously we find that the Exponential distribution is well fitting the data, Figure 11, opposite to the distribution GIW(x|β, η, ω): .
The last CI={9.36, 11.22}, Figure 12, shows that the 128 data allows to assess that the “null hypothesis” H0={θ=10}, with α=0.025 is to be accepted but H1={θ=5.75} rejected with β>0.025: {5.75<9.36<10<11.22}. The Sequential CIs are less efficient than Wald Test.
Figure 12.
Sequential Confidence Intervals (α=β=0.025) of the 128 Cancer data with hypotheses H0={θ=10} versus H1={θ=5.75}. Exponential distribution is suitable
Figure 12.
Sequential Confidence Intervals (α=β=0.025) of the 128 Cancer data with hypotheses H0={θ=10} versus H1={θ=5.75}. Exponential distribution is suitable
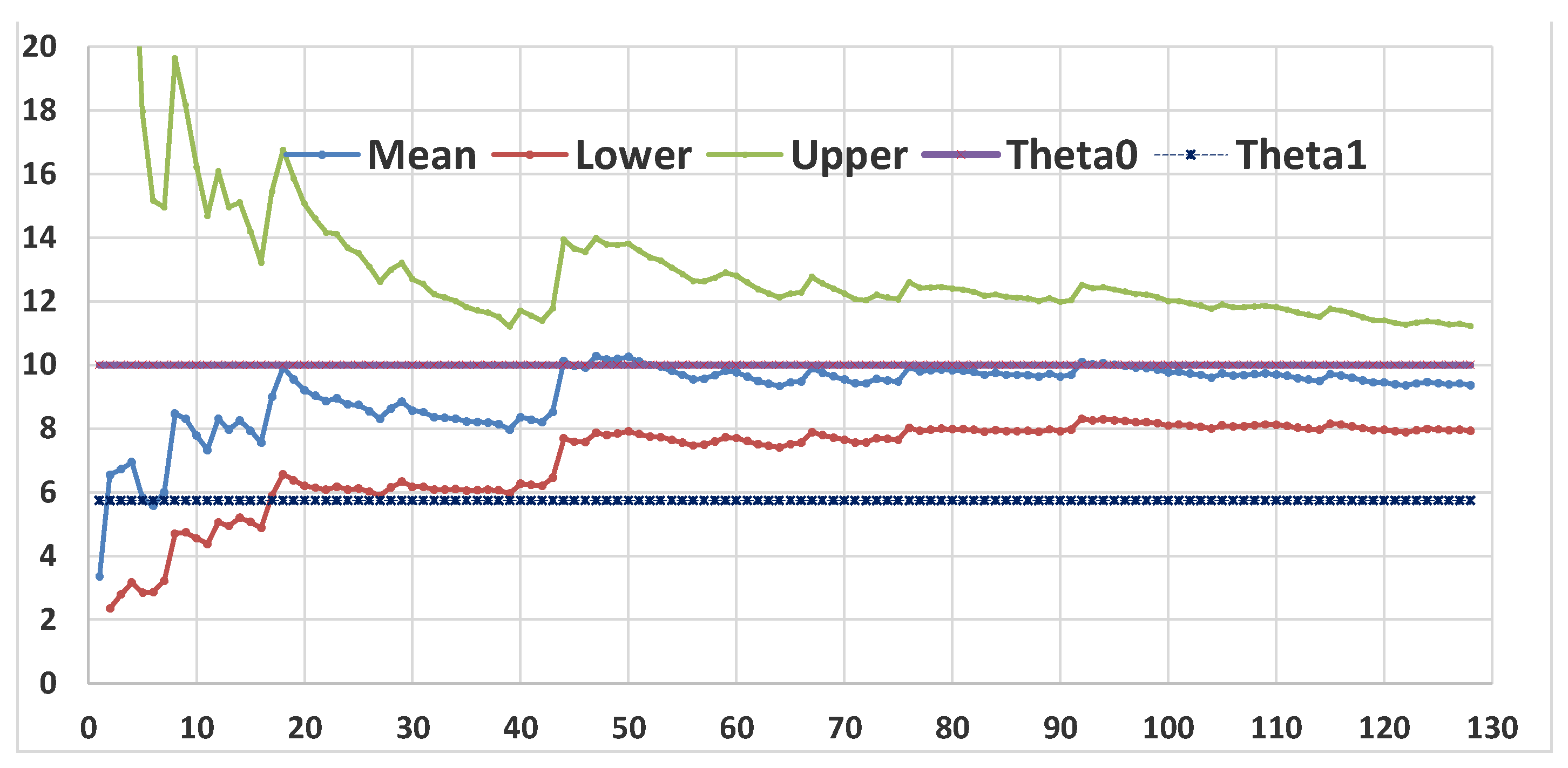
Figure 13.
Sequential Test (Wald) of the 128 Cancer data; the decision to Accept H0={θ=10} happens at the 42nd point
Figure 13.
Sequential Test (Wald) of the 128 Cancer data; the decision to Accept H0={θ=10} happens at the 42nd point
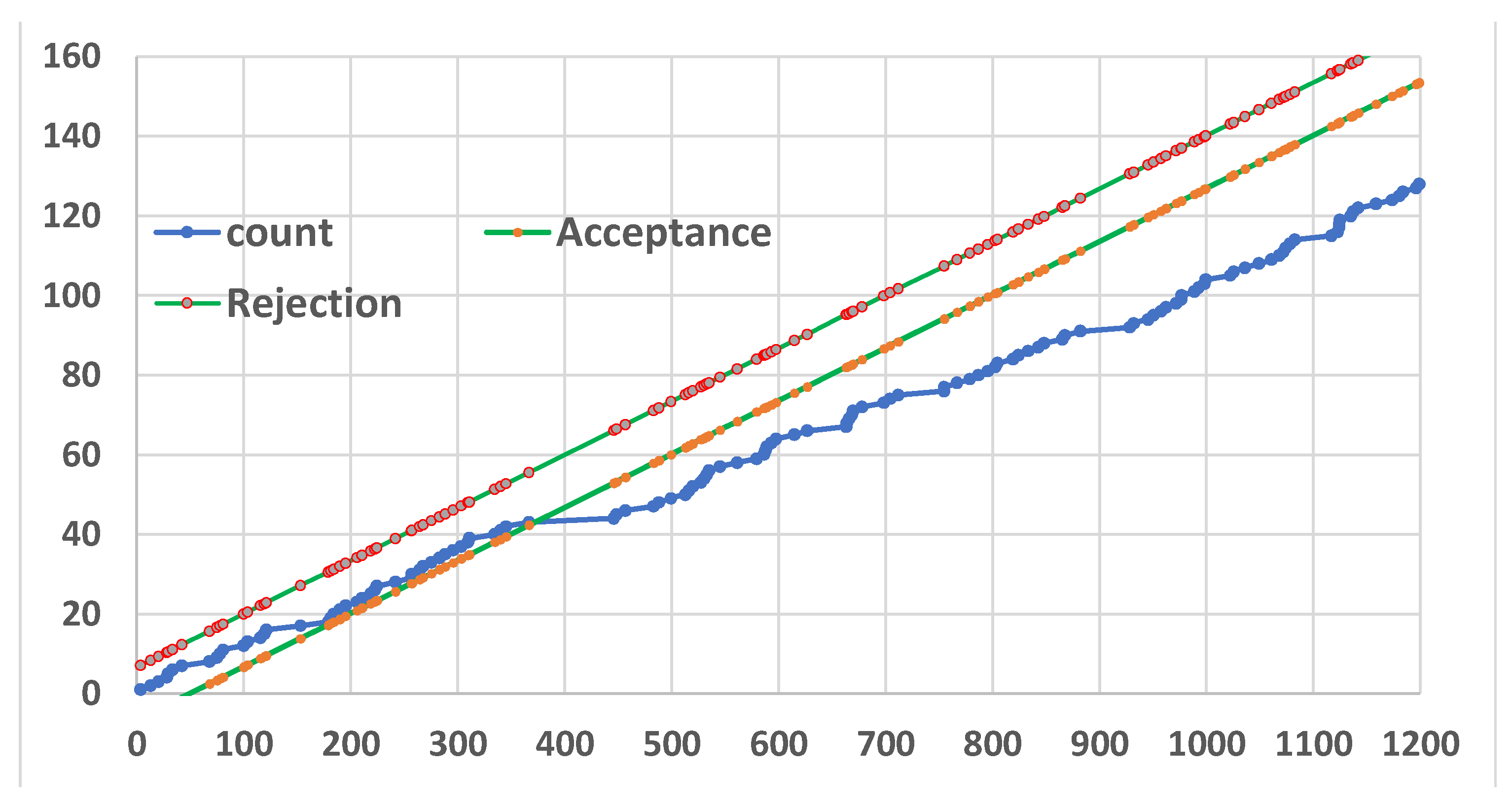
Figure 14.
Control Chart of the 128 Cancer data: the process is OOC
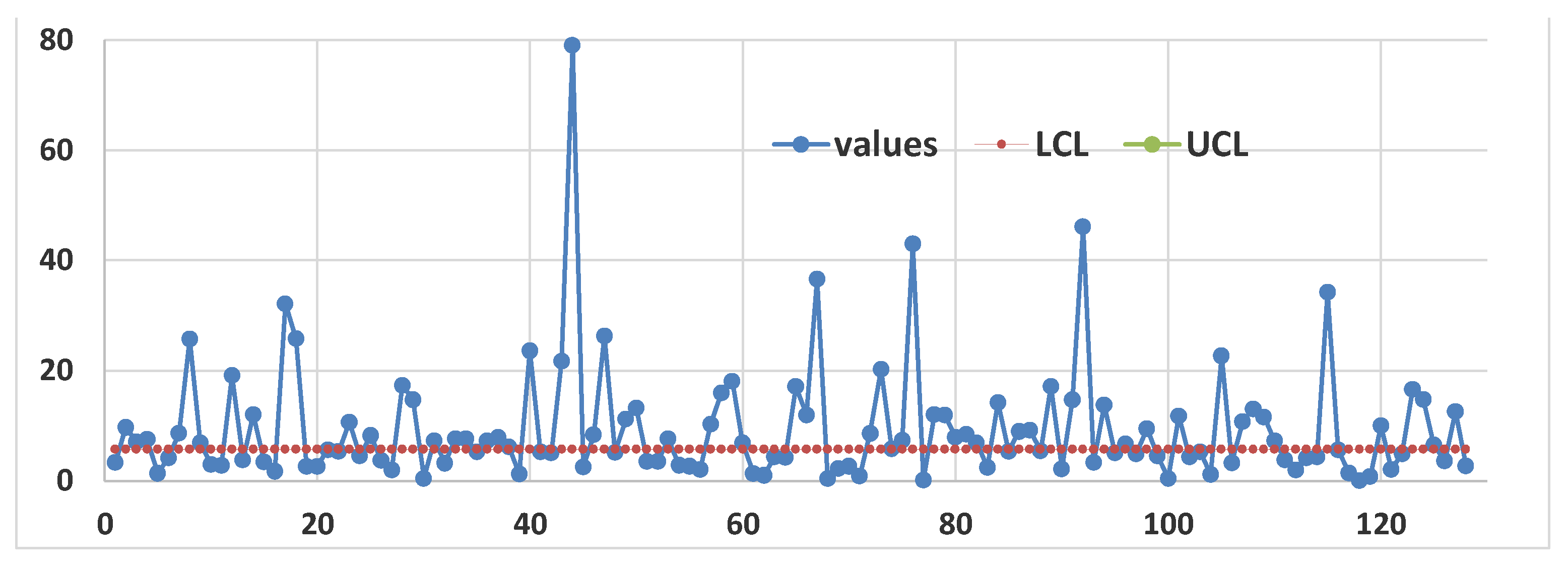
As it happened previously, we find that the CC provides much more information to the Manager to allow him to take sound decisions.
Since the CCs are “sequential tests” we think that it is wise to use them.
3.3. Sequential Test by the Authors of [3]
Now we see what the authors of [3] did about their distribution GIW(x|β, η, ω): (in the paper they use α in place of our ω; we introduced ω because α is the type I probability risk, associated to H0).
They found the MLE (Maximum Likelihood Estimate and Estimator ) of the parameter ω, with n the number of the data considered, H and B estimators of η and β
and computed ; from that they computed the 95% Confidence Interval as (59.82, 63.07), which is defined as , where d is the “accuracy” of the CI. They proved a very interesting result: the distribution GIW(x|β, η, ω) depends only on n, the number of data considered, and not on the parameters of GIW(x|β, η, ω) of the Random Variable .
Notice that the Confidence Interval (59.82, 63.07) is actually a Probability Interval, showing the same error mentioned in [24].
The authors state (in Excerpt 8)
Excerpt 8. Zhuang et al., Statistical Inference on … Generalized Weibull Distribution. 2024
Now, using this real data set (our Table 2), we illustrate the procedures we discussed for constructing a fixed-accuracy confidence interval for ω (our symbol for the one of the authors). Suppose a group of researchers has decided to create a 95% confidence interval for α with d = 1.2. According to …, we search for the sample size that is needed under such requirements. The smallest sample size that is needed turns out to be 73. Figure 4 (our Excerpt 7) shows the relationship between the coverage probability and the required sample size. It is clear that, as we increase the sample size N, the coverage probability goes up for fixed values of d and ω. Thus, sample size 73 is the minimum number of observations that we need to achieve the targeted level, 95%
We tried to draw a “TTOT (Total Time On Test transform) of the 128 Cancer data” (similar to Figure 11) with GIW(x|0.51, 8.19, 61.38): ; it is impossible to draw such a graph with data in Table 2. To understand the reader can see the Figure 15:
It is evident from Table 2 that only the smallest nine data 0.08, 0.20, 0.40, 0.50, 0.51 0.81, 0.90, 1.05, 1,19 could be shown in the Figure 15; the other 119 data are all near the ordinate 1 (in the Figure 15).
How could GIW(x|0.51, 8.19, 61.38) fit suitably the 128 Cancer data?
So, the Excerpt 8 is quite doubtful.
To understand we created the Figure 16 where we have shown, versus the number of data, the Inverse data (of those in Table 2), the sum of the inverse of the collected data named “Tot_inverse” and the “Tot_inverse_B” from the Distribution GIW(x|0.51, 8.19, 61.38), with their interpolating formulae (where x “actually” is the number of counts, 1, 2, 3 ,…, n-2, n-1, n).
We see that the “Tot_inverse_B” , from the Distribution GIW(x|0.51, 8.19, 61.38), does not fit well the successive sums of the Inverse data (of those in Table 2).
What is the consequence? We leave it to the readers…
Computing the quantity “Tot_inverse_B”=, we find the estimate , that is different from the estimate of the authors ; so getting the Distribution GIW(x|0.51, 8.19, 61.38). Their 95% Confidence Interval, , where d is the “accuracy” of the CI, was (59.82, 63.07): notice that the “named” CI_Zhuang=(59.82, 63.07) is actually a Probability Interval, showing the same error mentioned in [24].
It is important to notice that (the upper limit of the “named” CI_Zhuang=(59.82, 63.07). We leave to the readers to say what that means!
Let’s indicate as T the Random Variable ; we have that , with density where is the scale parameter and is the shape parameter ().
We can write the Probability statement, for any value chosen g,
where L------U is the interval that comprises the RV T with probability 1-α and G is the Cumulative Gamma Distribution.
From (14) can derive the “equivalent” Probability statement, for any value chosen g,
where L ------U is the random interval that comprises the parameter ω with probability 1-α.
After the estimation of we have the Confidence Interval, surely different from the “named” CI=(59.82, 63.07).
By taking advantage of the fact [3] that , follows a Gamma distribution with parameters n and 1/ω, we can compute directly the CI by computing the OC Curve (Operating Characteristic Curve) OC(%)=1 - Gamma(1.956|128, 1/ω); we show it in Figure 17:
It is clear that the intersections of the OC Curve (Figure 17) with the two horizontal lines y=0.025 and y=0.975, provide the limits of the CI, which are different from the “named” CI_Zhuang=(59.82, 63.07).
The Confidence limits are the values of the “unknown” variable ω satisfying next two equations, with D= Tot_inverse_B, computed with all the 128 data
Putting Dg= computed with g data, we can get the successive Confidence Intervals CIg; two of them can be seen in the Figure 18 with their OC Curves, for g=128and g=73.
Our CI73 (Figure 18) is CI73≈(83, 131); notice the big difference with the one given in the Excerpt 9. Notice that the value 61.38, estimated by all the 128 data, is named as “true value” (which is unknown).
Excerpt 9. Zhuang et al., Statistical Inference on … Generalized Weibull Distribution. 2024
Now, using the data that we setup from Table 5, we just take the first 73 observations and construct the confidence interval for 𝜔. These observations give us a 95% confidence interval as (59.84, 63.07). This interval covers the true value of 𝜔, which is 61.38, by only utilizing 73 observations.
Notice that ω128=64.24 while ω73=104.07, quite a big difference with the “true value” 61.38, as in the Excerpt 9.
Obviously the CIs are different from the ones in [3].
3.4. Other Cases
Now we consider the paper [4] by Hu et al. “Sequential Confidence Intervals for Comparing Two Proportions with Applications in A/B Testing. Mathematics 2025, 13, 161.”
The authors say:
Excerpt 10. Hu et al. “Sequential Confidence Intervals for … A/B Testing. Mathematics 2025”
Suppose we are interested in some common characteristic, referred to as success, possessed by two independent dichotomous populations, say X and Y. The success probabilities are denoted by p1 and p2, respectively, where 0 < pi < 1, i = 1,2. Our goal is to compare their magnitudes and determine whether one is significantly greater than the other. Assume that we have collected random samples X1,...,Xn1 and Y1,...,Yn2 from X and Y, respectively, where the sample sizes n1 and n2 are not necessarily the same. Then, the Xi’s are independent and identically distributed (i.i.d.) Bernoulli (p1) random variables, … Omissis … To compare the magnitudes of p1 and p2, we construct a confidence interval for the ratio p1/p2 … As p1/p2 is always positive, we apply the log transformation on it and the resulting quantity log(p1/p2) takes values on (−∞,∞). According to the central limit theorem and the delta method, we find that for i = 1,2, as ni → ∞, where represents convergence in distribution and . For sufficiently large n1 and n2, we have the approximate normality of the difference in …
Everything is based on the CLT (Central Limit Theorem) and “simulation studies”…
The authors consider two real cases:
Excerpt 11. Hu et al. “Sequential Confidence Intervals for … A/B Testing. Mathematics 2025”
a) To illustrate the application, we analyse a dataset
collected from the Kaggle platform accessed on 3 March 2024
(https://www.kaggle.com/code/yufengsui/datacamp-project-mobile-games-a-b-testing/notebook),
referred to as the Cookie Cats data. The dataset contains information on
over90,000 users of the mobile puzzle game Cookie Cats, developed by Tactile
Entertainment.
b) a large company seeks to increase sales through
advertisements and has substantial user base plans. To assess the effectiveness
of advertisements in boosting sales, an A/B testing experiment was conducted
using a dataset collected from the Kaggle platform accessed on 11 May 2024
(https://www.kaggle.com/datasets/
farhadzeynalli/online-advertising-effectiveness-study-ab-testing/data), referred
to as the Online Advertising data.
We did not consider the datasets in Excerpt 11.
Here we want to say that there is no need to consider asymptotic results, because we can apply the Theory we provided before: it is enough to consider the that the logarithm transformation satisfy the relation .
Another case we want to consider is in the paper [5] by Alshahrani et al., “On Designing of Bayesian Shewhart-Type Control Charts for Maxwell Distributed Processes with Application of Boring Machine. Mathematics 2023, 11, 1126”
The authors say:
Excerpt 12. Alshahrani et al., “On Designing … of Boring Machine. Mathematics 2023”
The assumptions of normality for the quality characteristic may not be achieved in practice… Therefore, using the normal distribution for non-normal data may result in a false alarm in process monitoring or may allow for the later detection of changes. In the literature, several researchers suggested control charts for quality characteristic which follows a skewed distribution. … The Maxwell (or Maxwell–Boltzmann) distribution is a familiar positively skewed distribution. The Maxwell distribution has a smoothly increasing hazard risk; therefore, it is commonly used in life-testing experiments and reliability analysis where the assumption of constant hazard risk, such as in exponential distribution, is not practical. The Maxwell distribution is widely used in statistical machines, physics, chemistry, and life testing experiment, but it is recently has been applied in the SPC techniques.
If X is a RV having the Maxwell distribution with scale parameter , then its pdf is as follows: .
The ML Estimator (which is a RV) of the parameter is ; the transformation shows that , the Gamma distribution, and . It is interesting to note that if x is interpreted as the velocity of a particle of unit mass (m=1), the quantity is the energy of the particle and the two components X1 and X2 can be considered as independent RVs normally distributed with mean E[X]=0 and variance Var[X]=.
The authors consider correctly the Probability Limits, But, unfortunately, they wrote “Practically, the parameter may be known or unknown then the probability control limits of the control chart are defined as follows:….”.
Notice that in Control Charts (CCs) we use the Control Limits, LCL and UCL, NOT the “probability control limits of the control chart”!.
The authors made a lot of simulation and eventually applied their ideas to
Excerpt 13. Alshahrani et al., “On Designing … of Boring Machine. Mathematics 2023”
Real Data Analysis. A boring machine is a tool used for making a wide hole in a fixed workpiece. These machines make use of a single steel cutting edge, carbide or diamond, or a small grinding wheel to make the hole cleaner, more accurate, and more specific. Boring machines
with multiple spindles are typically used in a manufacturing plant where
production is on a large scale. This study uses a real dataset by Hossain et
al. that addressed the failure rate of the vertical boring machine. This data
set was also considered … to review the optimum maintenance approach for the
vertical boring machine. Subsequently, … conducted a detailed statistical
investigation to evaluate the distributions, which best fit this data set. They
examined models such as exponential, gamma, Maxwell, lognormal, Weibull, and
estimated the parameters of these models with the maximum likelihood method. In
addition, various information criteria such as Akaike, second-order, Bayesian,
and the Kolmogorov–Smirnov test have shown that the Maxwell distribution is the
best fitted to this data set: the data set followed the Maxwell distribution
(p-value 0.4775) with=1777.86. The failure time data for a vertical boring
machine are specified as follows: 2802, 2937, 2136, 4359, 4020, 1781, 2816,
2655, 3886, 2296, 3158, 3695, 4155, 3811, 2380, 376, 2172, 3705, 2848, 4339,
2076, 2672, 3632, 1976, 1700, 1596, 1701, 3575, 3802, 4351, 4291, and 808.
Using JMP for the Individual Control Chart on x2 data we found Figure 19
This can be compared to Figure 20
To understand the difference between the Control Limits (LCL and UCL) and the Probability Limits (L and U) you have to analyse the Figure 21.
The application of the Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57] to the Boring data (Excerpt 13) is in the Figure 22.
The “scientific” Control Chart for the Boring data (Excerpt 13) is in the Figure 23: the process is OOC, contrary to the findings in the Figure 20; the cause is the use of the Probability Limits (LPL, UPL) instead of the Control Limits (LCL, UCL).
The Figure 24 shows the sequential Confidence Intervals for the Boring data (Excerpt 13); 13 data are necessary for a Confidence Interval=(2333350, 5733177)
The Figure 25 shows the Sequential (Wald) Test Confidence for the Boring data (Excerpt 13); one sees that at the 13rd datum the “step-line” number of failures versus the total of squared times, intersects the Acceptance line; the competing Hypotheses are versus .
It is important to remember that the CI=(2427479, 4286847) is computed from all the data with CL=0.95.
4. Discussion
We got different results from those authors: the cause is that they use the Probability Limits of the PI (Probability Interval) as they were the Confidence Limits (Control Limits of the Control Charts).
The proof of the confusion between the intervals L-------U (Probability Interval) and LCL-------UCL (Confidence Interval) in the domain of Control Charts (for Process Management) highlight the importance and novelty of these ideas in the Statistical Theory and in the applications.
For the “location” parameter in the CCs, from the Theory, we know that two mean (parameter), q=1,2, …, n, and any other mean (parameter), r=1,2, …, n, are different, with risk α, if their estimates are not both included in their common Confidence Interval as the CI of the grand mean (parameter) is.
Let’s consider the formula (4) and apply it to a “Normal model” (due to CLT, and assuming known variance), sequentially we can write the “real” fixed interval L----U comprising the RV (vertical interval) and the Random Interval comprising the unknown mean (horizontal interval) (Figure 14)
When the RV assume its determination (numerical value) (grand mean) the Random Interval becomes the Confidence Interval for the parameter μ, with CL=1-α: risk α that the horizontal line does not comprise the “mean” μ.
This is particularly important for the Individual Control Charts for Exponential, Weibull, Inverted Weibull, General Inverted Weibull, Maxwell and Gamma distributed data: this is what Deming calls “Profound Knowledge (understanding variation)” [9,10]. In this case, the Figure 21, Figure 22, Figure 26 look like the Figure 1, where you see the Confidence Interval, the realisation of the horizontal Random Interval.
The case we considered shows clearly that the analyses, in the Process Management, taken so far have been wrong and the decisions have been misleading, when the collected data follow a Non-Normal distribution [24].
Since a lot of papers (related to Exponential, Weibull, Inverted Weibull, General Inverted Weibull, Maxwell and Gamma distributions), with the same problem as that of “The garden of flowers” [24], are published in reputed Journals we think that the “alternative” title “History is written by the winners. Reflections on Control Charts for Process Control” is suitable for this paper: the authors of the wrong papers [24] are the winners.
Further studies should consider other distributions which cannot be transformed into the above distributions considered before.
5. Conclusions
With our Figures (and the Appendix C, that is a short extract from the “Garden … [24]”) we humbly ask the readers to look at the references [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57] and find how much the author has been fond of Quality and Scientificness in the Quality (Statistics, Mathematics, Thermodynamics, …) Fields.
The errors, in the “Garden … [24]”, are caused by the lack of knowledge of sound statistical concepts about the properties of the parameters of the parent distribution generating the data, and the related Confidence Intervals. For the I-CC_TBE the computed Control Limits (which are actually the Confidence Intervals), in the literature are wrong due to lack of knowledge of the difference between Probability Intervals (PI) and Confidence Intervals (CI); see the Figures 22, 23, 26 and 1). Therefore, the consequent decisions about Process IC and OOC are wrong.
We saw that RIT is able to solve various problems in the estimation (and Confidence Interval evaluation) of the parameters of distributions. The basics of RIT have been given.
We could have shown many other cases (from papers not mentioned here, that you can find in [22,23,24]) where errors were present due to the lack of knowledge of RIT and sound statistical ideas.
Following the scientific ideas of Galileo Galilei, the author many times tried to compel several scholars to be scientific (Galetto 1981-2025). Only Juran appreciated the author’s ideas when he mentioned the paper “Quality of methods for quality is important” at the plenary session of EOQC Conference, Vienna. [1]
For the control charts, it came out that RIT proved that the T Charts, for rare events and TBE (Time Between Events), used in the software Minitab, SixPack, JMP or SAS are wrong [56,57]. So doing the author increased the h-index of the mentioned authors who published wrong papers.
RIT allows the scholars (managers, students, professors) to find sound methods also for the ideas shown by Wheeler in Quality Digest documents.
We informed the authors and the Journals who published wrong papers by writing various letters to the Editors…: no “Corrective Action”, a basic activity for Quality has been carried out by them so far. The same happened for Minitab Management. We attended a JMP forum in the JMP User Community and informed them that their “Control Charts for Rare Events” were wrong: they preferred to stop the discussion, instead to acknowledge the JMP faults [56,57].
So, dis-quality continues to be diffused people and people continue taking wrong decisions…
Deficiencies in products and methods generate huge cost of Dis-quality (poor quality) as highlighted by Deming and Juran. Any book and paper are products (providing methods): their wrong ideas and methods generate huge cost for the Companies using them. The methods given here provide the way to avoid such costs, especially when RIT gives the right way to deal with Preventive Maintenance (risks and costs), Spare Parts Management (cost of unavailability of systems and production losses), Inventory Management, cost of wrong analyses and decisions.
Figure 27.
Probability Intervals L-----U versus Confidence Intervals LCL-----UCL in Control Charts
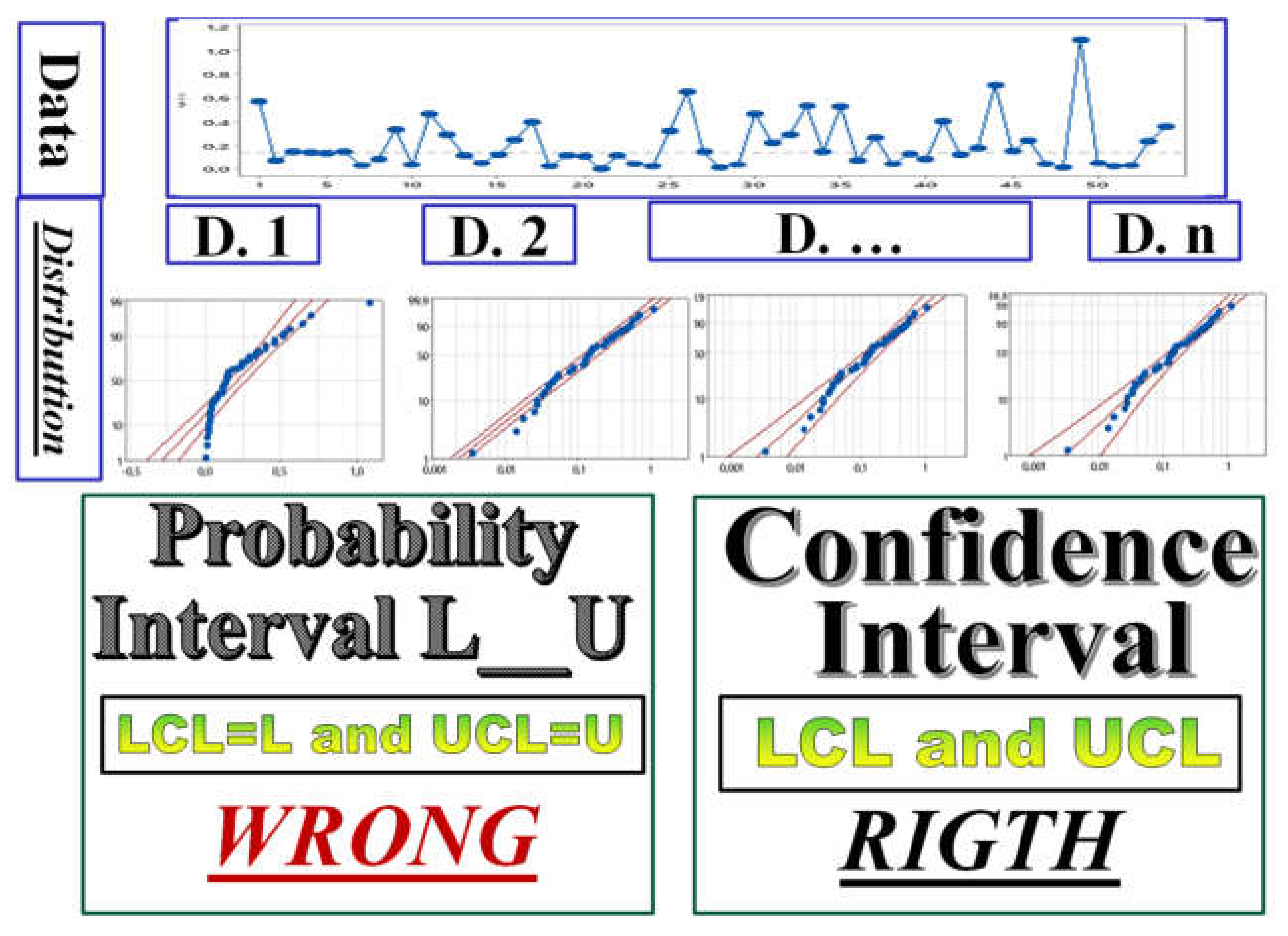
We think that we provided the readers with the belief that Quality of Methods for Quality is important.
The reader should remember the Deming’s statements and the ideas in [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57].
Unfortunately, many authors do not know Scientifically the role (concept) of Confidence Intervals (Appendix B) for Hypothesis Testing.
Therefore, they do not extract the maximum information form the data in the Process Control.
Control Charts are a means to test the hypothesis about the process states, H0={Process In Control} versus H1={Process Out Of Control}, with stated risk α=0.0027.
We have a big problem about Knowledge: sound Education is needed.
We think that the Figure 28 conveys the fundamental ideas about the need of Theory for devising sound Methods, to be used in real applications in order to avoid the Dis-quality Vicious Circle.
Humbly, given our commitment to Quality and our long-life love for it [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57], we would venture to quote Voltaire:
“It is dangerous to be right in matters on which the established men are wrong.” because “Many are destined to reason wrongly; others, not to reason at all; and others, to persecute those who do reason.” So, “The more often a stupidity is repeated, the more it gets the appearance of wisdom.” and “It is difficult to free fools from the chains they revere.”
Let’s hope that Logic and Truth prevail and allow our message to be understood (figs. 27, 28).
The objective of collecting and analysing data is to take the right action. The computations are merely a means to characterize the process behaviour. However, it is important to use the right Control Limits take the right action about the process states, i.e., In Control versus Out Of Control.
On July-December 2024 we again verified (through several new downloaded papers, not shown here) that the Pandemic Disease about the (wrong) Control Limits, that are actually the Probability Limits of the PI is still present …
There will be any chance that the Pandemic Disease ends? See the Excerpt 14: notice the (ignorant) words “plugging into …”. The only way out is Knowledge… (Figure 28): Deming’s [7,8] Profound Knowledge, Metanoia, Theory.
Excerpt 14. From “Conditional analysis of Phase II exponential chart… an event”, Q. Tech. & Quantitative Mgt, ’19

We think that we provided the readers with several ideas and methods to be meditated in view of the applications, generating wealth for the companies using them.
There is no “free lunch”: metanoia and study are needed and necessary.
Funding
“This research received no external funding”
Data Availability Statement
“MDPI Research Data Policies” at https://www.mdpi.com/ethics.
Acknowledgments
In this section, you can acknowledge any support given which is not covered by the author contribution or funding sections. This may include administrative and technical support, or donations in kind (e.g., materials used for experiments).
Conflicts of Interest
“The author declares no conflicts of interest.”
Abbreviations
The following abbreviations are used in this manuscript:
| LCL, UCL | Control Limits of the Control Charts (CCs) |
| L, U | Probability Limits related to a probability 1-α |
| θ | Parameter of the Exponential Distribution |
| θL-----θU | Confidence Interval of the parameter θ |
| RIT | Reliability Integral Theory |
Appendix A
A very illuminating case
We consider a case found in the paper (with 148 mentions) “Control Charts based on the Exponential distribution”, Quality Engineering, March 2013, of Santiago&Smith, two experts of Minitab Inc. at that time. You find it mentioned in the “Garden…” [24] and in the Appendix C.
This is important because we analysed the data with Minitab software and JMP software and we found astonishing results: the cause are the formulae
The author knew that Minitab computes wrongly the Control Limits of the Individual Control Chart. He wanted to assess how the JMP Student Version would deal with them using the following 54 data analysed by Santiago&Smith in their paper; they are “Urinary Tract Infection (UTI) data collected in a hospital”; the distribution of the data is the Exponential.

Table A1.
UTI data (“Control Charts based on the Exponential distribution”)
| UTI | UTI | UTI | UTI | UTI | UTI | ||||||
| 1 | 0.57014 | 11 | 0.46530 | 21 | 0.00347 | 31 | 0.22222 | 41 | 0.40347 | 51 | 0.02778 |
| 2 | 0.07431 | 12 | 0.29514 | 22 | 0.12014 | 32 | 0.29514 | 42 | 0.12639 | 52 | 0.03472 |
| 3 | 0.15278 | 13 | 0.11944 | 23 | 0.04861 | 33 | 0.53472 | 43 | 0.18403 | 53 | 0.23611 |
| 4 | 0.14583 | 14 | 0.05208 | 24 | 0.02778 | 34 | 0.15139 | 44 | 0.70833 | 54 | 0.35972 |
| 5 | 0.13889 | 15 | 0.12500 | 25 | 0.32639 | 35 | 0.52569 | 45 | 0.15625 | ||
| 6 | 0.14931 | 16 | 0.25000 | 26 | 0.64931 | 36 | 0.07986 | 46 | 0.24653 | ||
| 7 | 0.03333 | 17 | 0.40069 | 27 | 0.14931 | 37 | 0.27083 | 47 | 0.04514 | ||
| 8 | 0.08681 | 18 | 0.02500 | 28 | 0.01389 | 38 | 0.04514 | 48 | 0.01736 | ||
| 9 | 0.33681 | 19 | 0.12014 | 29 | 0.03819 | 39 | 0.13542 | 49 | 1.08889 | ||
| 10 | 0.03819 | 20 | 0.11458 | 30 | 0.46806 | 40 | 0.08681 | 50 | 0.05208 |
The analysis with JMP software, using the Rare Events Profiler, is in the Figure A1.
NOTICE that JMP, for Rare Events, Exponentially distributed, in the Figure A1, uses the Normal distribution! NONSENSE
It finds the UTI process OOC: both the charts, Individuals and Mobile Range are OOC.
The author informed the JMP User Community.
After various discussions, a member of the Staff (using the Exponential Distribution) provided the Figure A2.
You see that, now (Figure A2), the UTI process is IC: both the charts, Individuals and Mobile Range are IC; opposite decision than before (Figure A1), by the same JMP software (but with two different methods: the first is the standard method, while the second was devised by a JMP Staff member).
Figure A1.
First Control Chart by JMP.
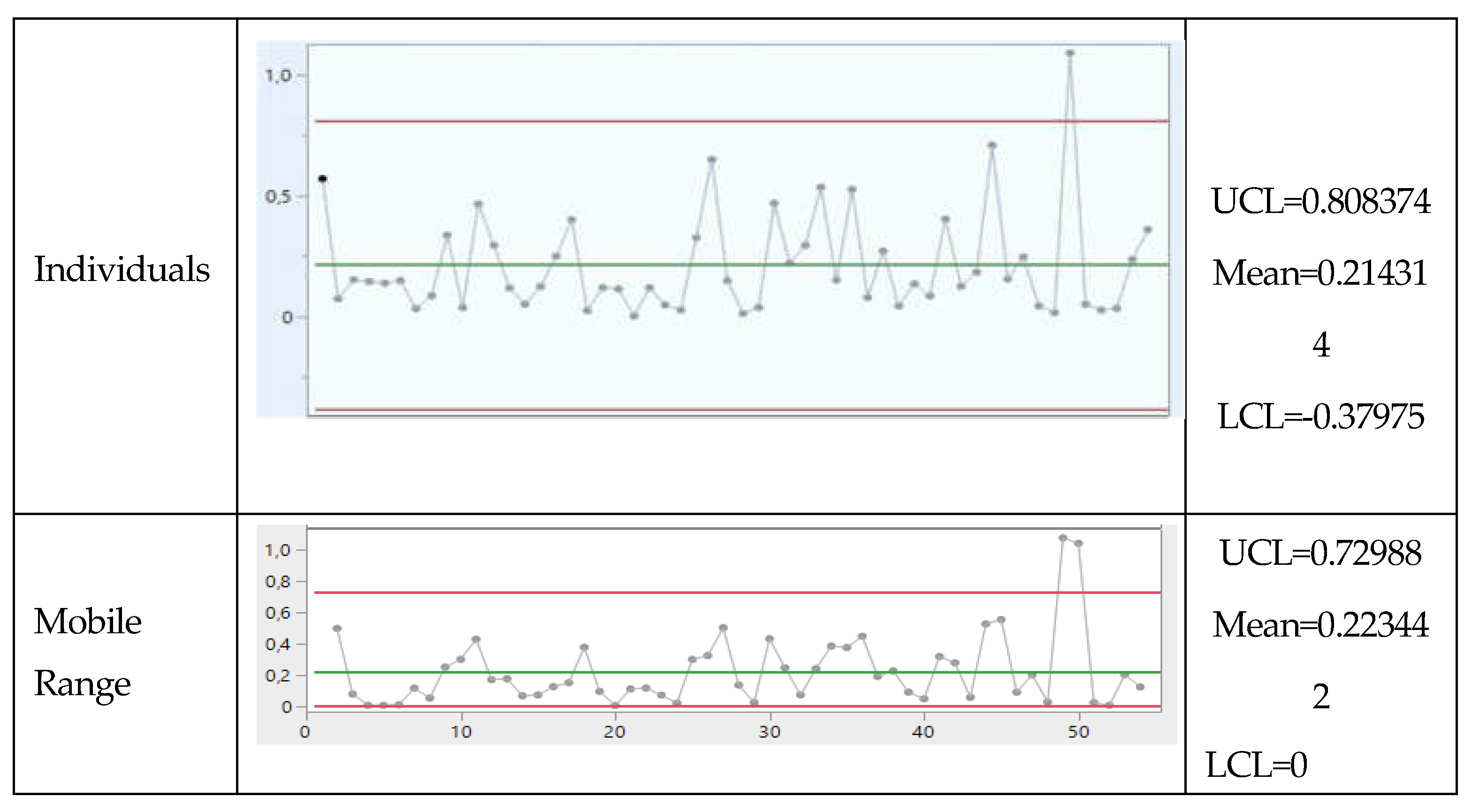
Figure A2.
Second Control Chart by a member of the Staff of JMP. Notice the numbers (LCL and UCL)!
Notice the LCL, the Mean and the UCL of both charts.
Compute the mean of all the data and you find a different value: therefore, the mean in the charts is not the mean of the process!
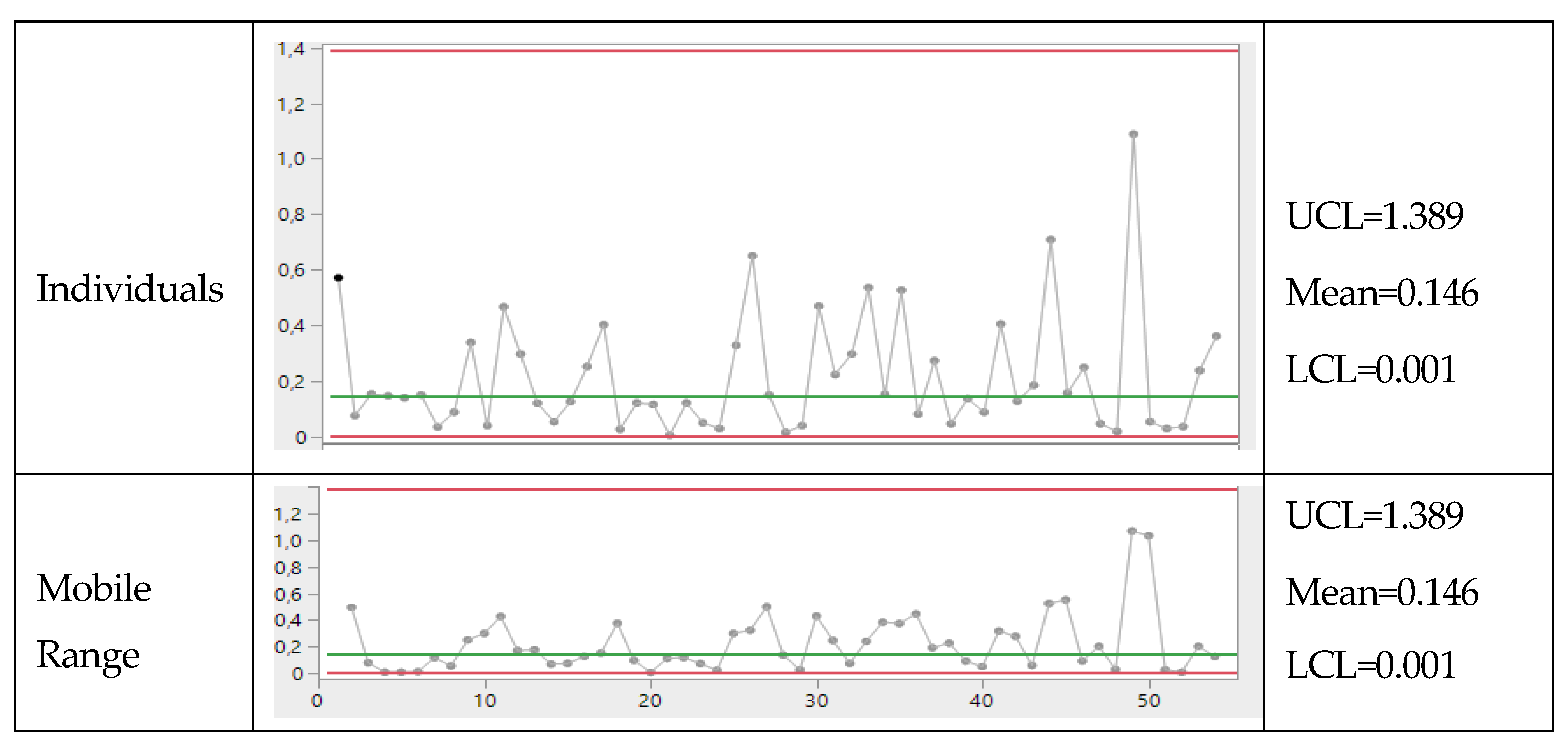
If one analyses the data with Minitab, he finds the Figure A3.
You see that now the UTI process is IC: notice the LCL, Mean and UCL.
A natural question arises: which of the three Figures is correct?
Actually, they all are wrong, as you can see from the Figure A4:
The Figure A5 confirms that the data are exponentially distributed; TTOT is the Total Time On Test and i/n is the proportion of counts data.
We see that the Sequential Test cannot asses in any way if a process is IC or OOC.
Figure A3.
Individual Control Chart by Minitab.

Figure A4.
Individual Control Chart by FG, using RIT: UTI process OOC.
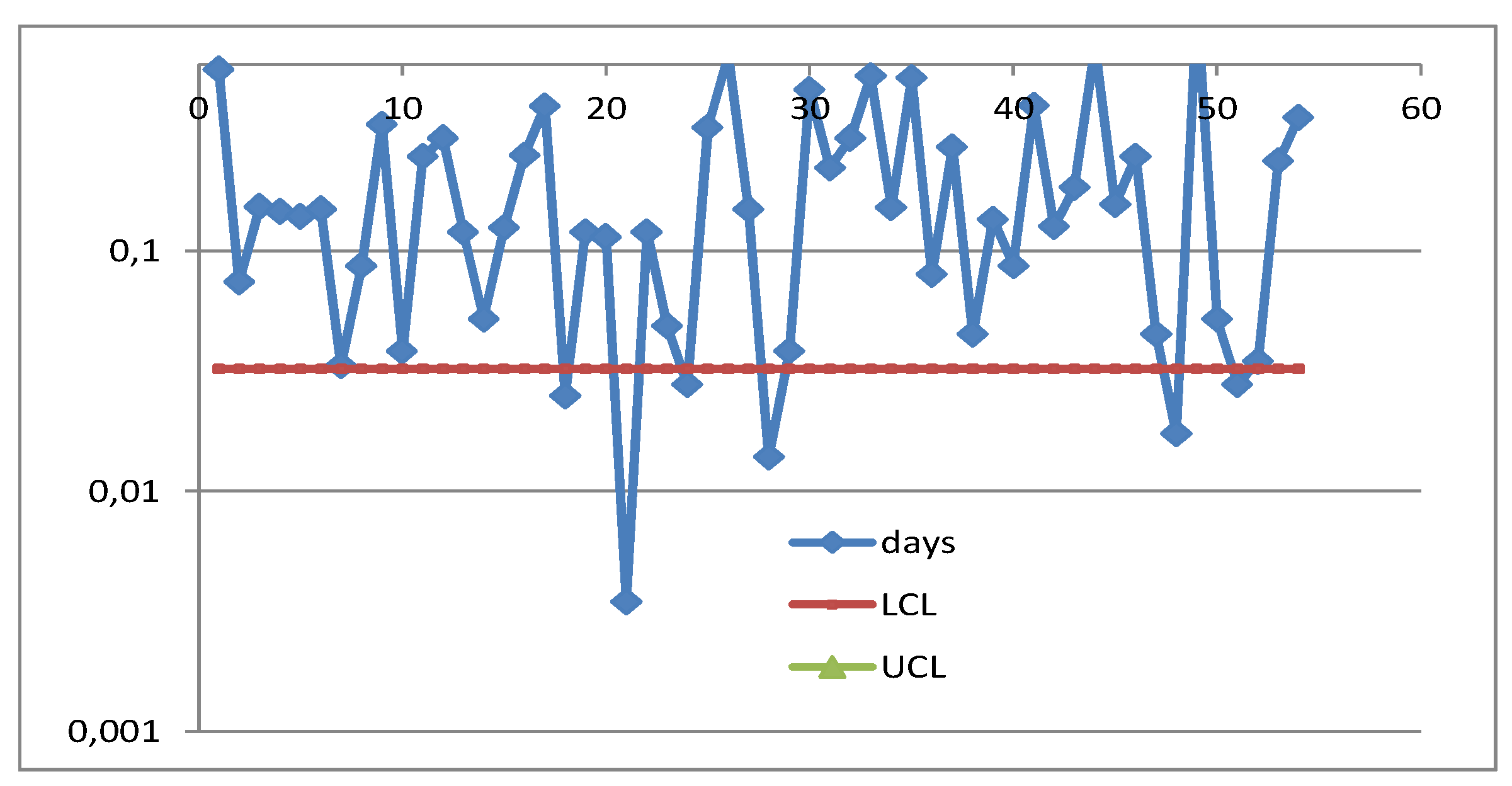
Figure A5.
TTOT (Total Time On Test) versus the proportion of counts data: UTI process.
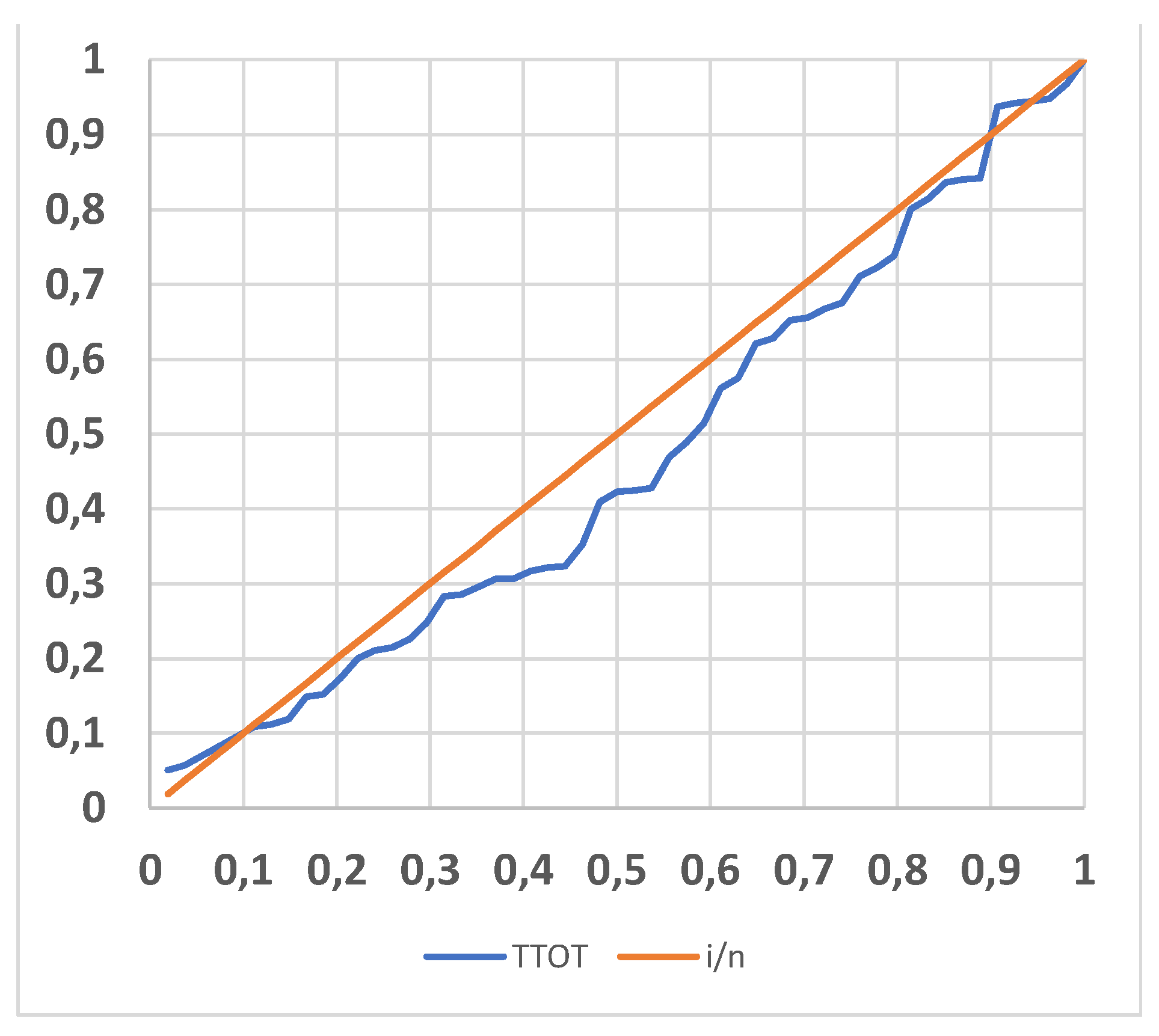
Figure A6.
UTI data. Sequential Test of Hypothesis: with α=0.025 versus with β=0.025.
The author offered JMP to become a better statistical software provider by solving the flaw according to JMP advertising:

No reaction … and therefore NO Corrective Action.
Appendix B
The Statistical Hypotheses and the related risks
We define as statistical hypothesis a statement about a population parameter (e.g. the ′′true′′ mean, the ′′true′′ shape, the ′′true′′ variance, the ′′true′′ reliability, the ′′true′′ failure rate, …n that we assume to exists and has a value even though it is unknown to us). The set of all the possible values of the parameter is called the parameter space Θ. The goal of a hypothesis test is to decide, based on a sample drawn from the population, which value hypothesized for the population parameter of the parameter space Θ can be accepted as true. Remember: nobody knows the truth…
Generally, two competitive hypotheses are defined, the null hypothesis H0 and the alternative hypothesis H1.
If θ denotes the population parameter, the general form of the null hypothesis is H0: {θ∈Θ0} versus the alternative hypothesis H1: {θ∈Θ1}, where Θ0 is a subset of the parameter space Θ and Θ1 a subset disjoint from Θ0.; Θ0∪Θ1= Θ and Θ0∩Θ1=∅. If the set Θ0={θ0, a single value} the null hypothesis H0 is called simple; on the contrary, the null hypothesis H0 is called composite. If the set Θ1={θ1, a single value} the alternative hypothesis H1 is called simple; on the contrary, the alternative hypothesis H1 is called composite.
In a hypothesis testing problem, after observing the sample (and getting the empirical sample of the data D) the experimenter (the Manager, the Researcher, the Scholar) must decide either to «accept» H0 as true or to reject H0 as false and then decide, on the opposite, that H1 is true.
Let’s make an example: let the reliability goal be [θ being the MTTF]; we ask the data D, from the reliability test to confirm the goal we set. Nobody knows the reality; otherwise, there would be no need of any test.
The test data D are the determinations of the random variables related to the items under test; it can happen then that the data, after their elaboration, provide us with an estimate far from (and therefore they induce us to decide that the goal has not been achieved).
Generally, in the case of reliability test, the reliability goal to be achieved is called null hypothesis .
The hypotheses are classified in various manners, such as (and some suitable combinations)
- Simple Hypothesis: it specifies completely the distribution (probabilistic model) and the values of the parameters of the distribution of the Random Variable under consideration
- Composite Hypothesis: it specifies completely the distribution (probabilistic model) BUT NOT the values of the parameters of the distribution of the Random Variable under consideration
- a. Parametric Hypothesis: it specifies completely the distribution (probabilistic model) and the values (some or all) of the parameters of the distribution of the Random Variable under consideration
- b. Non-parametric Hypothesis: it does not specify the distribution (probabilistic model) of the Random Variable under consideration
A hypothesis testing procedure (or simply a hypothesis test) is a rule (decision criterion) that specifies
- for which sample values the decision is made to «accept» H0 as true,
- for which sample values H0 is rejected and then H1 is accepted as true.
based on managerial/Statistics which defines
- the test statistic (a formula to analyse the data)
- the critical region R (rejection region)
to be used for decisions, with the stated risks: decision criterion.
The subset of the sample space for which H0 will be rejected is called rejection region (or critical region). The complement of the rejection region is called the acceptance region.
A hypothesis test of H0: {θ∈Θ0} versus the alternative hypothesis H1: {θ∈Θ1}, (Θ0∩Θ1=∅) might make one of two types of errors, traditionally named Type I Error and Type II Error; their probabilities are indicated as α and β.
Table B1.
Statistical Hypotheses and risks.
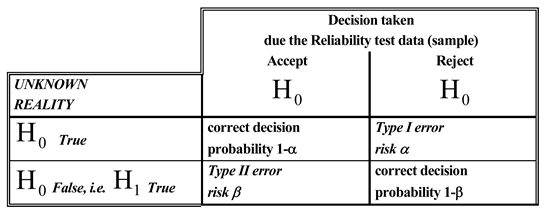 |
If «actually» H0: {θ∈Θ0} is true and the hypothesis test (the rule), due to the collected data, incorrectly decides to reject H0 then the test (and the Experimenter, the Manager, the Researcher, the Scholar who follow the rule) makes a Type I Error, whose probability is α. If, on the other hand, «actually» θ∈Θ1 but the test (the rule), due to the collected data, incorrectly decides to accept H0 then the test (and the Experimenter, the Manager, the Researcher, the Scholar who follow the rule) makes a Type II Error, whose probability is β.
These two different situations are depicted in the Table B1 (for simple parametric hypotheses).
Notice that when we decide to “accept the null hypothesis” in reality we use a short-hand statement saying that we do not have enough elements to state the contrary.
It is evident that
Suppose R is the rejection region for a test, based on a «statistic s(D)» (the formula to elaborate the sampled data D).
Then for H0: {θ∈Θ0}, the test makes a mistake if «s(D)∈R», so that the probability of a Type I Error is α=P(S(D)∈R) [S(D) is the random variable giving the result s(D)].
It is important the power of the test 1-β, which is the probability of rejecting H0 when in reality H0 is false
Therefore, the power function of a hypothesis test with rejection region R is the function of θ defined by β(θ)=P(S(D)∈R). The function 1-β(θ), power function, is often named the Operating Characteristic curve [OC curve].
A good test has power function near 1 for most θ∉Θ0 and, on the other hand, near 0 and for most θ∈Θ0.
From a managerial point of view, it is sound using powerful tests: a powerful test (finds the reality and) rejects what must be rejected.
It is obvious that we want that the test is the most powerful and therefore one must seek for the statistics which have the maximum power; it’s absolutely analogous to the search of efficient estimators.
We know that the competition of simple hypotheses can have a good property: the most powerful critical region [i.e. the rejection region found has the highest power 1-β(θ)=P(S(D)∉R) of H1 against H0, for any α (α sometimes is called size of the critical region)]; a theorem regarding the likelihood ratio proves that.
Let’s define the likelihood ratio tests; let Θ denote the entire parameter space; the likelihood ratio test statistic for testing H0: {θ∈Θ0} versus θ∈Θ1 is the ratio [which uses the Likelihood function L(θ|D)]
A likelihood ratio test is any test that has a rejection region that has the form {s(D): λ(D)≤c}, where c is any number satisfying 0≤c≤1 and s(D) is the “statistic” by which we elaborate the data of the empirical sample D. This test is a measure of how much the evidence, provided by the data D, supports H0.
The previous criterion is very simple if the two competing hypotheses are both simple: H0: {θ=θ0} versus H1: {θ=θ1}.
Let L0 be the Likelihood function L(θ0|D) and L1 be the Likelihood function L(θ1|D): the most powerful test is the one that has the most powerful critical region C={s(D): L1/L0≥kα}, where the quantity kα is chosen in such a way that the Type I Error has a risk (probability) α. The most powerful critical region C has the highest power 1-β(θ).
Usually when an efficient estimator exists, this provides then a powerful statistic, giving the most powerful test.
For the Normal model
the test about H0: {θ∈Θ0} where is a given number, we get
where has the t distribution with n-1 degrees of freedom when H0 is true.
After some algebra, the test of H0 may be performed as follows: we compute the quantity and if
H0 is accepted; otherwise H0 is rejected.
It is worthwhile to observe that the Confidence Interval for is
Hence, the test of H0 is equivalent to the following points, for any distribution of the data:
- 1)
- Construct a confidence interval for the population parameter (e.g. mean) we are interested in
- 2)
- IF the hypothesised THEN Accept H0; otherwise H0 is rejected.
Remember that 1) and 2) are suitable for any distribution of the data:
This has great importance for Control Charts, as you can see in the Figure B1
Figure B1.
LCL and UCL of Control Charts with their risks.
The good Managers, Researchers, Scholars do not forget that the two risks always are present and therefore they must take care of the power of the test 1-β, they use for the decision (as per the principles F1 and F2) [24,25,26,27,28,29,30].
Such Managers, Researchers, Scholars use the Scientific Method.
It is important to state immediately and in an explicit way that
- ⇒ the risks must be stated,
- ⇒ together with the goals (the hypotheses),
- ⇒ BEFORE any statistical (reliability) test is carried out.
For demonstration of reliability characteristics, with reliability tests, Managers, Students, Researchers and Scholars must take into account, according the F1 principle, the very great importance of W. E. Deming statements
- A Figure without a theory tells nothing.
- There is no substitute for knowledge.
- There is widespread resistance of knowledge.
- Knowledge is a scarce national resource.
- Why waste Knowledge?
- Management need to grow-up their knowledge because experience alone, without theory, teaches nothing what to do to make Quality
- Anyone that engages teaching by hacks deserves to be rooked.
From these, unfortunately for Quality, for the Customers, for the Users and for the Society, this devastating result
- The result is that hundreds of people are learning what is wrong. I make this statement on the basis of experience, seeing every day the devastating effects of incompetent teaching and faulty applications.
In many occasions and several Conferences on Total Quality Management for Higher Education Institutions, [Toulon (1998), Verona (1999), Derby (2000), Mons (2001), Lisbon (2002), Oviedo (2003), Palermo (2005), Paisley (2006), Florence (2008), Verona (2009)] the author (FG) showed many real cases, found in books and magazines specialized on Quality related to concepts, methods and applications wrong, linked to Quality [21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57]. All the very many documents published (more than 250) by F. Galetto show the profound truth that
facts and Figures are useless, if not dangerous, without a sound theory (F. Galetto, 2000),
Brain is the most important asset: let's not forget it. (F. Galetto, 2003),
All that is particularly important for the analysis of any type of data (quality or reliability).
Sequential sampling
Sequential sampling refers to a routine in which each unit is “measured” about a kind of quantity of interest (length, weight, defectiveness, duration, reliability, failure rate, …) and the “cumulated” quantity is employed in decision taking about the acceptance of the null hypothesis H0, with 1-α as the risk of Accepting H0, when it is true. At any “measurement” 1, 2, …, k, decision rules are required to provide for a) Acceptance of H0, b) Rejection of H0, or c) continuation of sampling (by taking a new unit); this process continues until a decision a) or b) is taken; the number of items then drawn defines the sample size: sequential sampling, in general, leads to an expected sample size smaller than other sampling methods.
As seen before, the likelihood ratio test is used; the likelihood ratio test statistic for testing H0 versus H1 is the ratio q(k)=L1(k)/L0(k), where k is the present sample size, with the rules (after Whild, 1945), a) if then retain H0, b) if then choose H1 and reject H0, if then continue sampling. These rules, under a suitable transformation of scale, lead to two Decision parallel lines, the Acceptance line and the Rejection line: the successive points of the “transformed value of q(k)” generate a random walk path; when the path reaches a decision line inspection ceases, while when the path is contained within the two lines, sampling is continued.
Appendix C. (related to [24])

In a subsequent paper “Improved Shewhart-Type Charts for Monitoring Times Between Events”, Journal of Quality Technology,
2016 (found online, 2024, March), we find again the same error [formula (2)]:
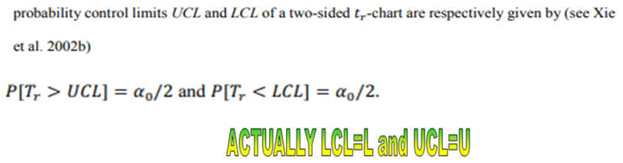
In another paper we found

Many other cases, with the same errors, can be found in the “Garden …[24], and the Conclusions” where the authors name LCL and UCL what actually are the Probability Limits L and U.
There is no “free lunch”: metanoia and study are needed and necessary.
References
- Galetto, F., Quality of methods for quality is important. European Organisation for Quality Control Conference, Vienna. 1989.
- Galetto, F., GIQA, the Golden Integral Quality Approach: from Management of Quality to Quality of Management. Total Quality Management (TQM), Vol. 10, No. 1; 1999.
- Zhuang, Y., Bapat, S.R.; Wang, W. Statistical Inference on the Shape Parameter of Inverse Generalized Weibull Distribution. Mathematics 2024, 12, 3906. [CrossRef]
- Hu, J., Zheng, L.; Alanazi, I. Sequential Confidence Intervals for Comparing Two Proportions with Applications in A/B Testing. Mathematics 2025, 13, 161. [CrossRef]
- Alshahrani, F., Almanjahie, I.M.; Khan, M.; Anwar, S.M.; Rasheed, Z.; Cheema, A.N. On Designing of Bayesian Shewhart-Type Control Charts for Maxwell Distributed Processes with Application of Boring Machine. Mathematics 2023, 11, 1126. [CrossRef]
- Belz, M. Statistical Methods in the Process Industry: McMillan; 1973.
- Casella, Berger, Statistical Inference, 2nd edition: Duxbury Advanced Series; 2002.
- Cramer, H. Mathematical Methods of Statistics: Princeton University Press; 1961.
- Deming W. E., Out of the Crisis, Cambridge University Press; 1986.
- Deming W. E., The new economics for industry, government, education: Cambridge University Press; 1997.
- Dore, P., Introduzione al Calcolo delle Probabilità e alle sue applicazioni ingegneristiche, Casa Editrice Pàtron, Bologna; 1962.
- Juran, J., Quality Control Handbook, 4th, 5th ed.: McGraw-Hill, New York: 1988-98.
- Kendall, Stuart, (1961) The advanced Theory of Statistics, Volume 2, Inference and Relationship:, Hafner Publishing Company; 1961.
- Meeker, W. Q., Hahn, G. J., Escobar, L. A. Statistical Intervals: A Guide for Practitioners and Researchers. John Wiley & Sons. 2017.
- Mood, Graybill, Introduction to the Theory of Statistics, 2nd ed.: McGraw Hill; 1963.
- Rao, C. R., Linear Statistical Inference and its Applications: Wiley & Sons; 1965.
- Rozanov, Y., Processus Aleatoire, Editions MIR: Moscow, (traduit du russe); 1975.
- Ryan, T. P., Statistical Methods for Quality Improvement: Wiley & Sons; 1989.
- Shewhart W. A., Economic Control of Quality of Manufactured Products: D. Van Nostrand Company; 1931.
- Shewhart W.A., Statistical Method from the Viewpoint of Quality Control: Graduate School, Washington; 1936.
- D. J. Wheeler, Various posts, Online available from Quality Digest.
- Galetto, F., (2014), Papers, and Documents of FG, Research Gate.
- Galetto, F., (2015-2024), Papers, and Documents of FG, Academia.edu.
- Galetto, F., (2024), The garden of flowers, Academia.edu.
- Galetto, F., Affidabilità Teoria e Metodi di calcolo: CLEUP editore, Padova (Italy); 1981-94.
- Galetto, F., Affidabilità Prove di affidabilità: distribuzione incognita, distribuzione esponenziale: CLEUP editore, Padova (Italy); 1982, 85, 94.
- Galetto, F., Qualità. Alcuni metodi statistici da Manager: CUSL, Torino (Italy; 1995-99).
- Galetto, F., Gestione Manageriale della Affidabilità: CLUT, Torino (Italy); 2010.
- Galetto, F., Manutenzione e Affidabilità: CLUT, Torino (Italy); 2015.
- Galetto, F., Reliability and Maintenance, Scientific Methods, Practical Approach, Vol-1: www.morebooks.de.; 2016.
- Galetto, F., Reliability and Maintenance, Scientific Methods, Practical Approach, Vol-2: www.morebooks.de.; 2016.
- Galetto, F., Statistical Process Management, ELIVA press ISBN 9781636482897; 2019.
- Galetto F., Affidabilità per la manutenzione, Manutenzione per la disponibilità: tab edizioni, Roma (Italy), ISBN 978-88-92-95-435-9, www.tabedizioni.it; 2022.
- Galetto, F., (2015) Hope for the Future: Overcoming the DEEP Ignorance on the CI (Confidence Intervals) and on the DOE (Design of Experiments), Science J. Applied Mathematics and Statistics, Vol. 3, No. 3, pp. 99-123. [CrossRef]
- Galetto, F., (2015) Management Versus Science: Peer-Reviewers do not Know the Subject They Have to Analyse, Journal of Investment and Management. Vol. 4, No. 6, pp. 319-329. [CrossRef]
- Galetto, F., (2015) The first step to Science Innovation: Down to the Basics., Journal of Investment and Management. Vol. 4, No. 6, pp. 319-329. [CrossRef]
- Galetto F., (2021) Minitab T charts and quality decisions, Journal of Statistics and Management Systems. [CrossRef]
- Galetto, F., (2012) Six Sigma: help or hoax for Quality?, 11th Conference on TQM for HEI, Israel.
- Galetto, F., (2020) Six Sigma_Hoax against Quality_Professionals Ignorance and MINITAB WRONG T Charts, HAL Archives Ouvert, 2020.
- Galetto, F., (2021) Control Charts for TBE and Quality Decisions, Academia.edu.
- Galetto F. (2021) ASSURE: Adopting Statistical Significance for Understanding Research and Engineering, Journal of Engineering and Applied Sciences Technology, ISSN: 2634 – 8853, 2021 SRC/JEAST-128. [CrossRef]
- Galetto F. (2023) Control Charts, Scientific Derivation of Control Limits and Average Run Length, International Journal of Latest Engineering Research and Applications (IJLERA) ISSN: 2455-7137 Volume – 08, Issue – 01, January 2023, PP – 11-45.
- Galetto, F., (2006) Quality Education and quality papers, IPSI, Marbella (Spain).
- Galetto, F., (2006) Quality Education versus Peer Review, IPSI, Montenegro.
- Galetto, F., (2006) Does Peer Review assure Quality of papers and Education? 8th Conference on TQM for HEI, Paisley (Scotland).
- Galetto, F., (1998), Quality Education on Quality for Future Managers, 1st Conference on TQM for HEI (Higher Education Institutions), Toulon (France).
- Galetto, F., (2000), Quality Education for Professors teaching Quality to Future Managers, 3rd Conference on TQM for HEI, Derby (UK).
- Galetto, F., (2001), Looking for Quality in "quality books", 4th Conference on TQM for HEI, Mons (Belgium).
- Galetto, F., (2001), Quality and Control Carts: Managerial assessment during Product Development and Production Process, AT&T (Society of Automotive Engineers), Barcelona (Spain).
- Galetto, F., (2001), Quality QFD and control charts, Conference ATA, Florence (Italy).
- Galetto, F., (2002), Business excellence Quality and Control Charts”, 7th TQM Conference, Verona (Italy).
- Galetto, F., (2002), Fuzzy Logic and Control Charts, 3rd ICME Conference, Ischia (Italy).
- Galetto, F., (2002), Analysis of "new" control charts for Quality assessment, 5th Conference on TQM for HEI, Lisbon (Portugal).
- Galetto, F., (2009), The Pentalogy, VIPSI, Belgrade (Serbia).
- Galetto, F., (2010),The Pentalogy Beyond, 9th Conference on TQM for HEI, Verona (Italy).
- Galetto, F., (2024), News on Control Charts for JMP, Academia.edu.
- Galetto, F., (2024), JMP and Minitab betray Quality, Academia.edu.
Figure 1.
Theoretical and Practical Difference between L------U and LCL------UCL.
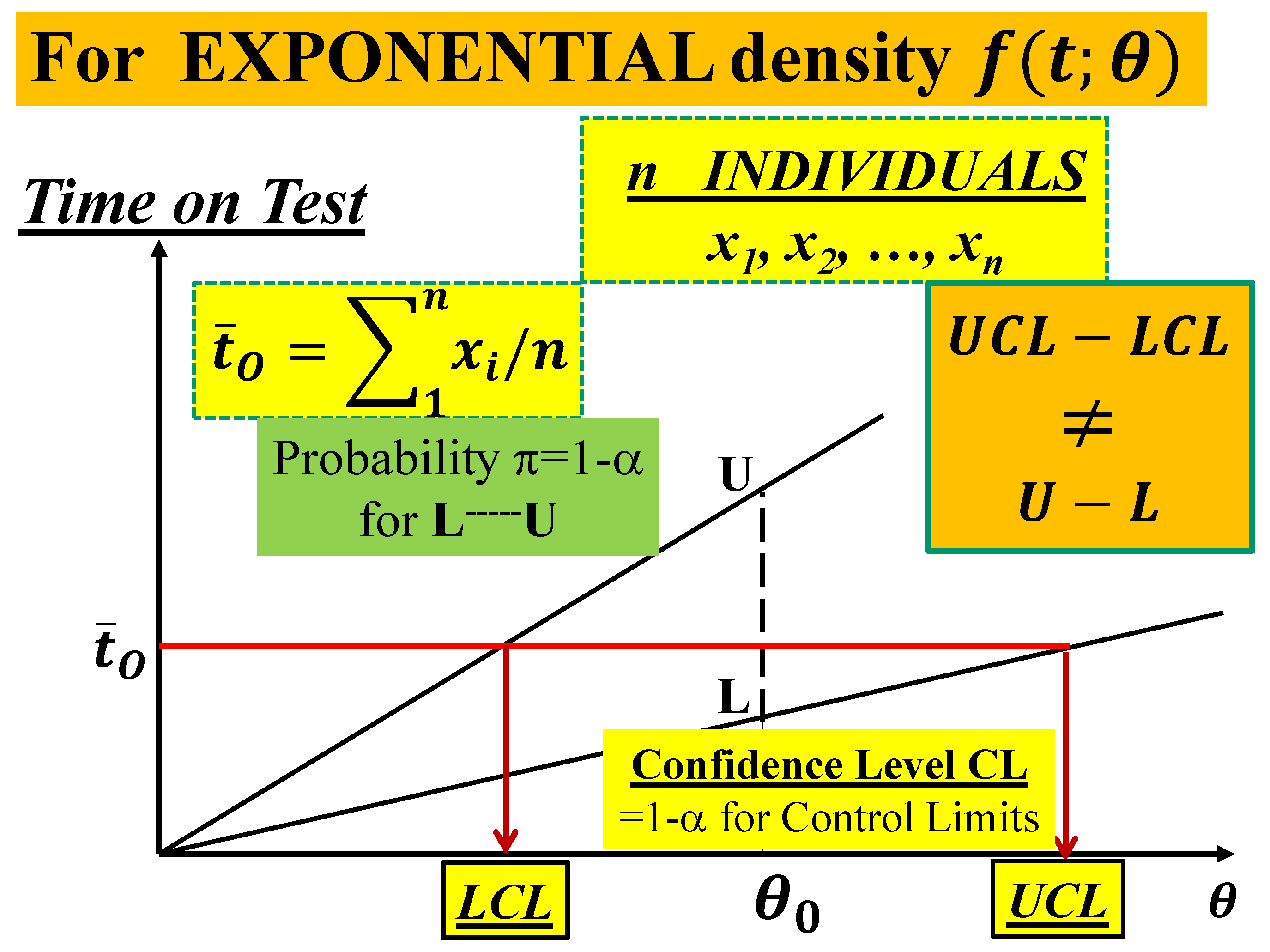
Figure 2.
Control Limits LCLX----UCLX=L----U (Probability interval), for Normal data (Individuals xij, sample size k) “sample means”
Figure 2.
Control Limits LCLX----UCLX=L----U (Probability interval), for Normal data (Individuals xij, sample size k) “sample means”
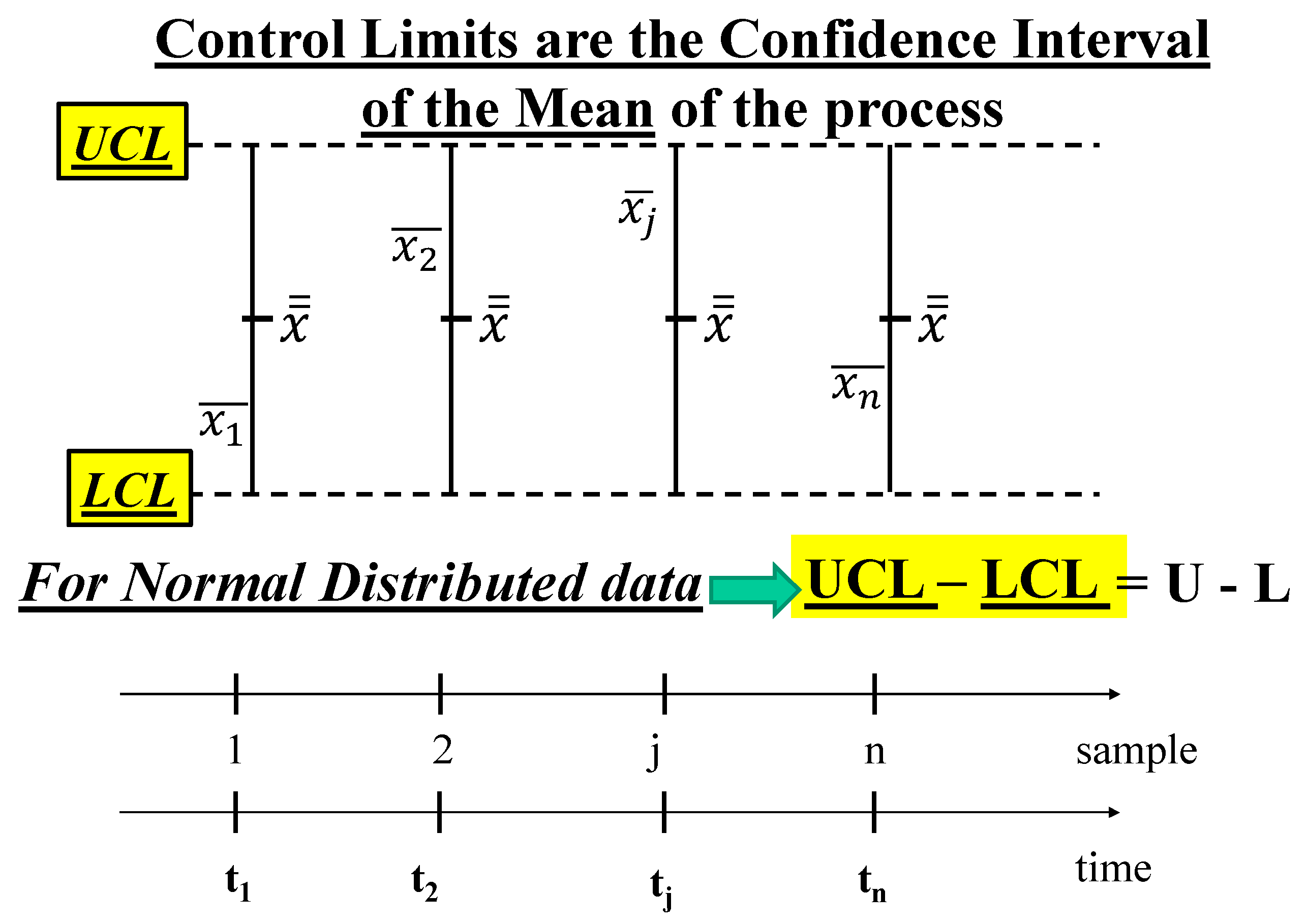
Figure 3.
Individual Control Chart (sample size k=1). Control Limits LCL----UCL=L----U (Probability interval), for Normal data (Individuals xi) and “grand mean” .
Figure 3.
Individual Control Chart (sample size k=1). Control Limits LCL----UCL=L----U (Probability interval), for Normal data (Individuals xi) and “grand mean” .
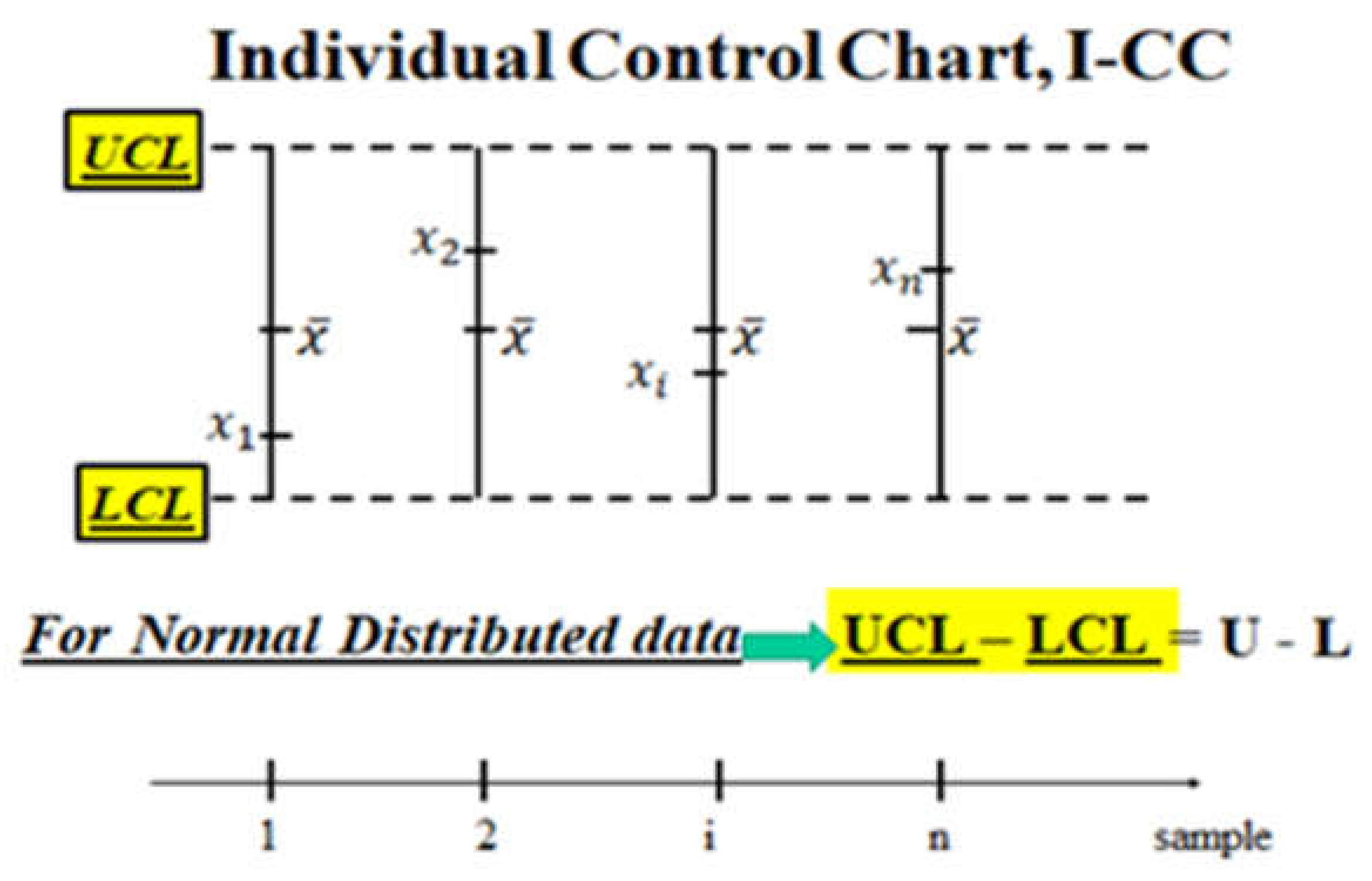
Figure 4.
A “4 units Stand-by system” and its states
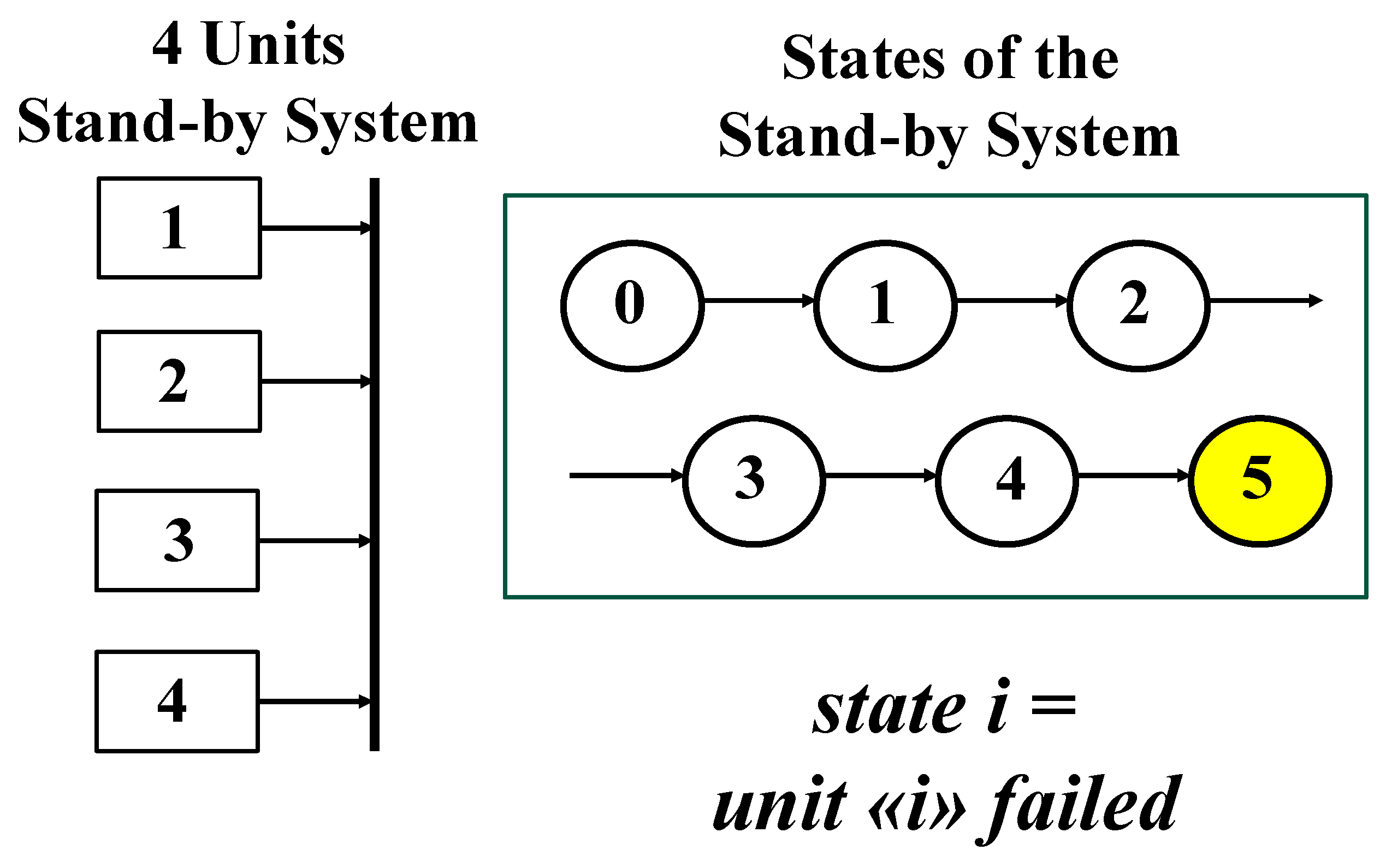
Figure 5.
Example of Reliability of a “4 units
Stand-by system” with MTTF=θ=123 days;
is the total time on
test of the 4 units. To compute the CI (with CL=0.8), find the abscissas of the
intersections at
and
…
Figure 5.
Example of Reliability of a “4 units
Stand-by system” with MTTF=θ=123 days;
is the total time on
test of the 4 units. To compute the CI (with CL=0.8), find the abscissas of the
intersections at
and
…
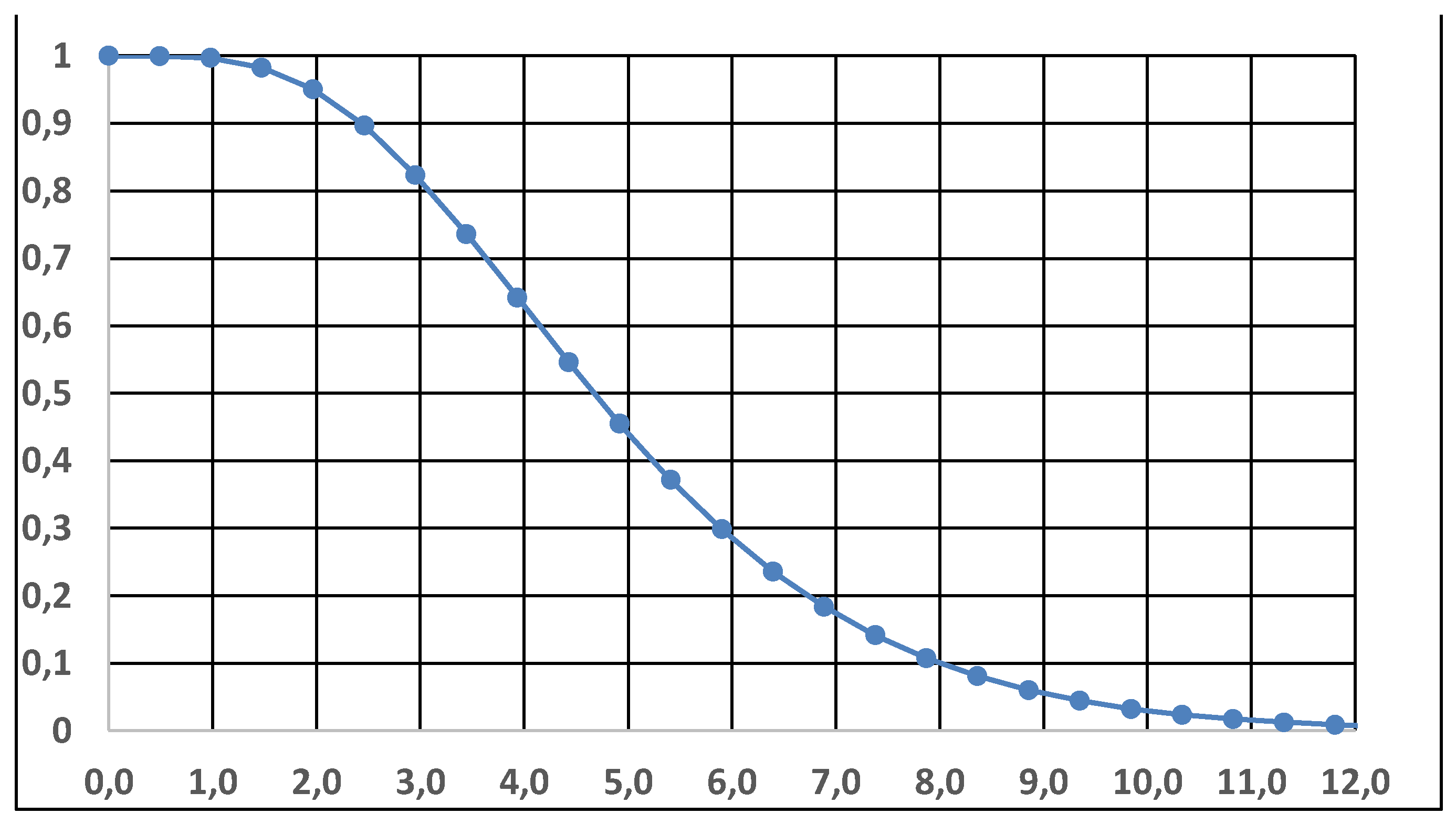
Figure 6.
TTOT (Total Time On Test transform) of the Cancer data. Exponential distribution is suitable
Figure 6.
TTOT (Total Time On Test transform) of the Cancer data. Exponential distribution is suitable
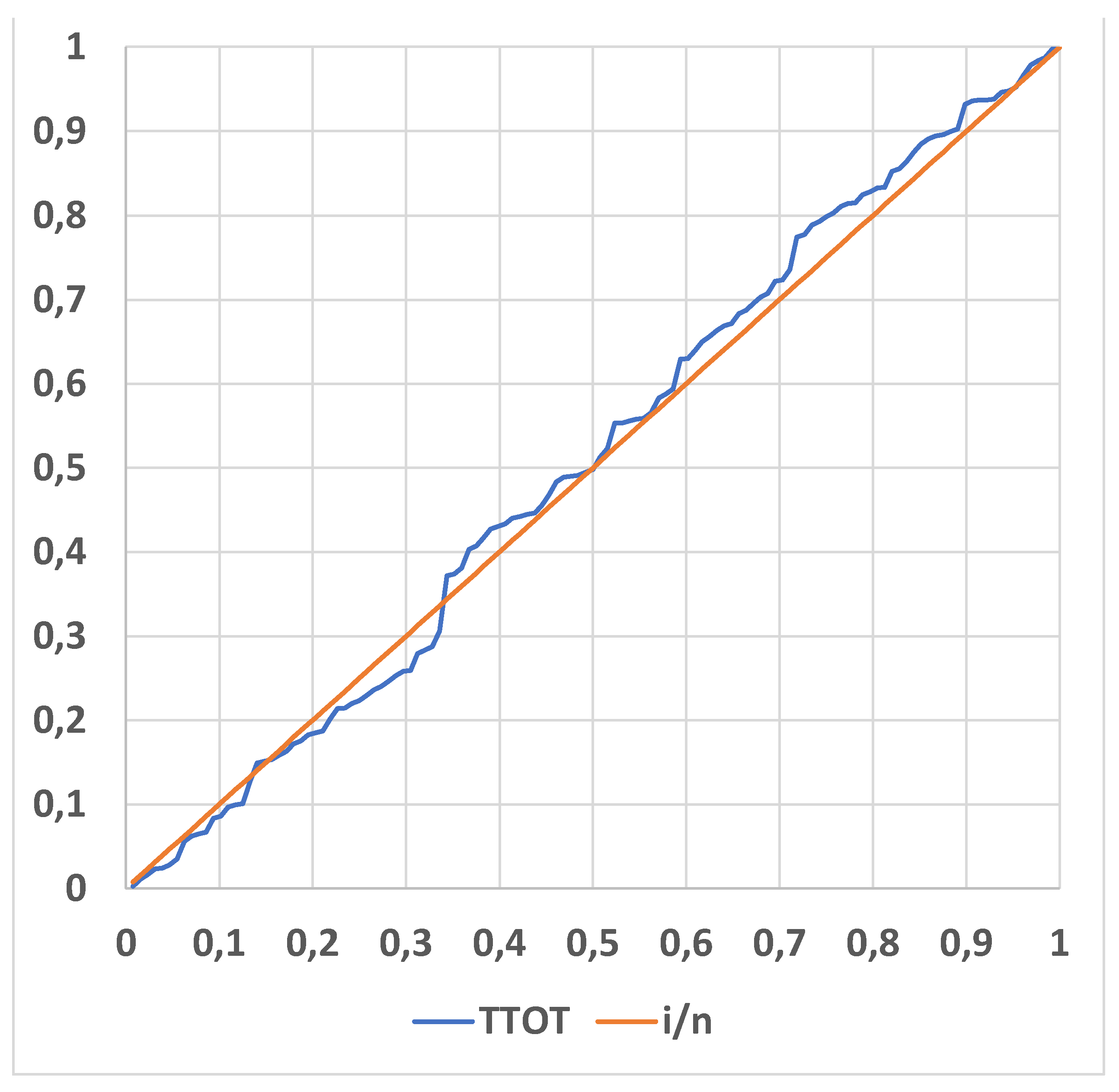
Figure 7.
CC of the first 32 Cancer data (Exponential distribution): process OOC (1 point)
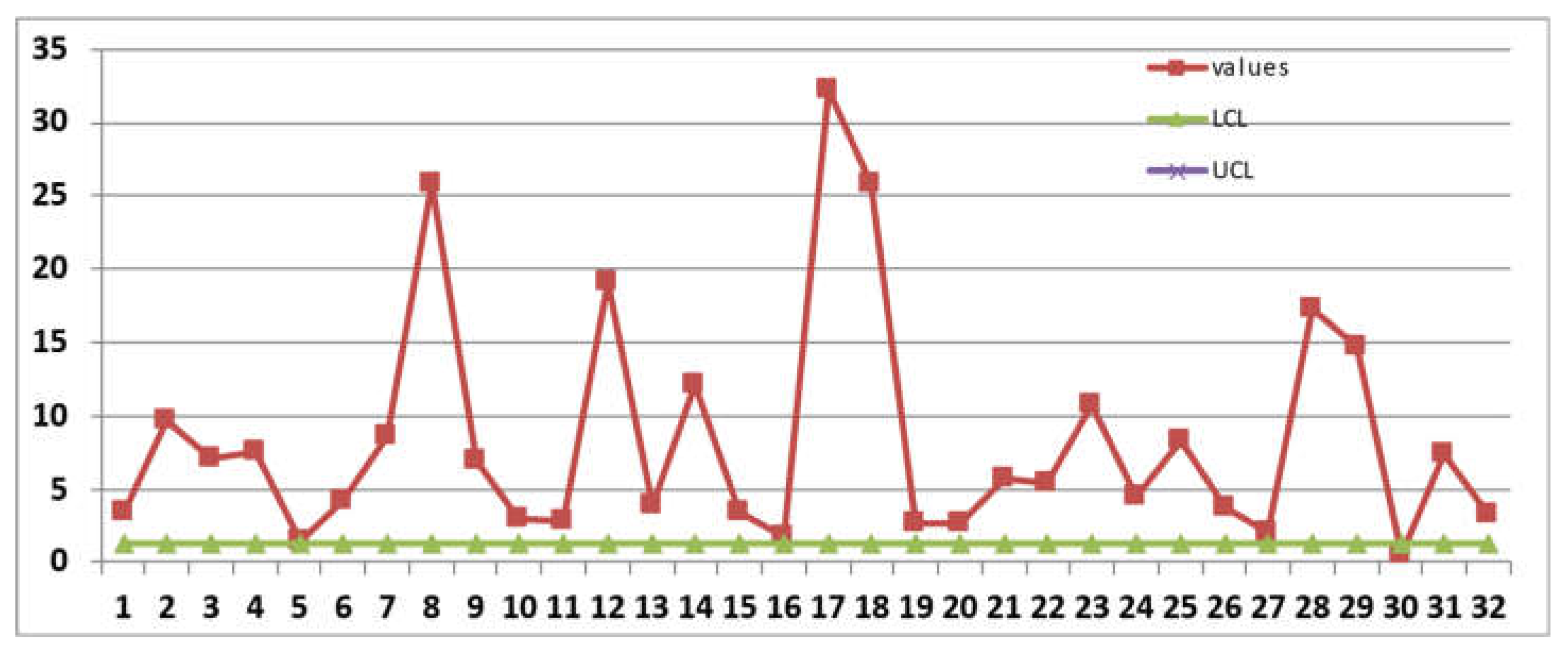
Figure 8.
Sequential Test (Wald) of the 32 first data
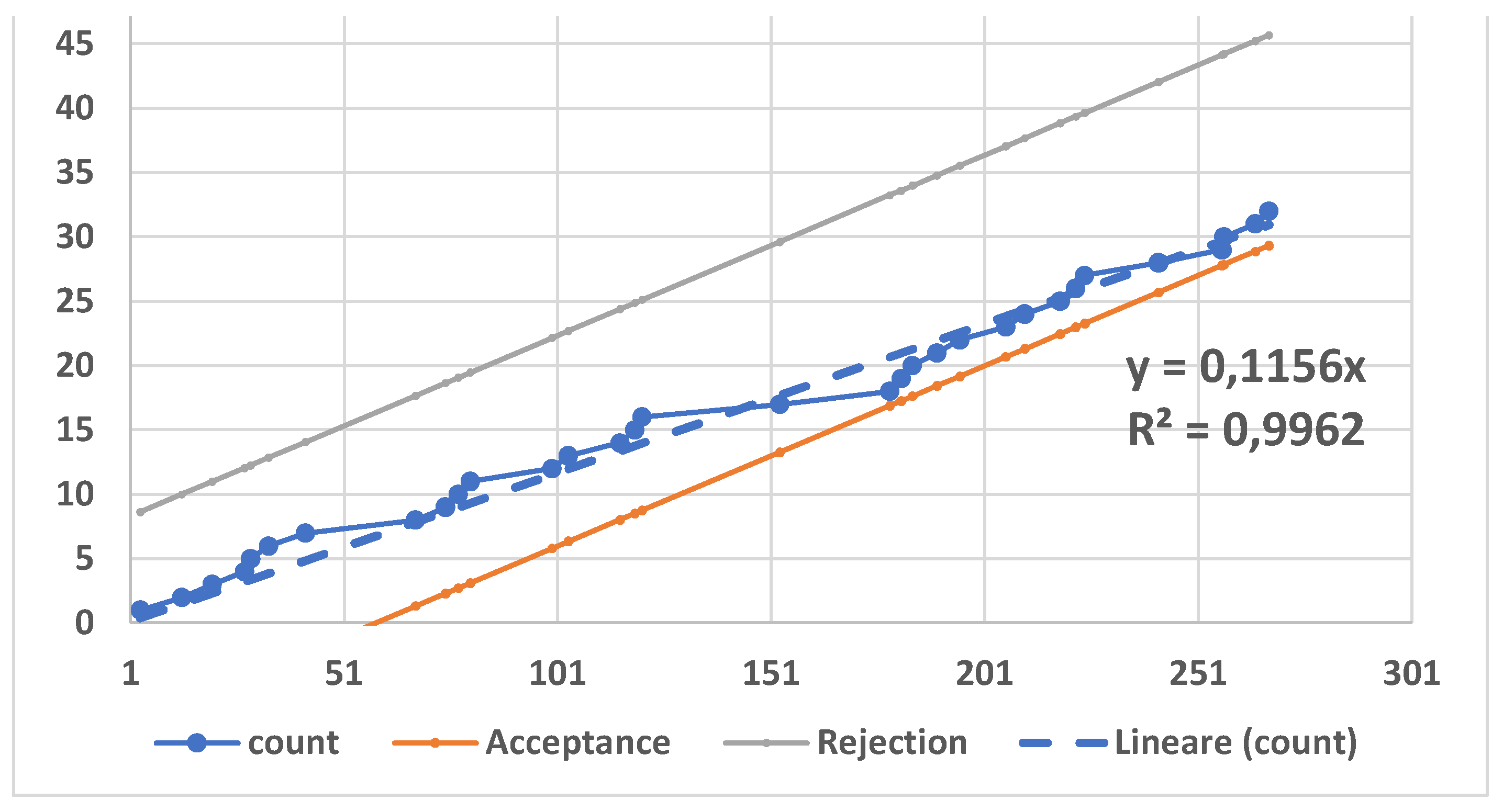
Figure 9.
Sequential Confidence Intervals (α=β=0.025) for the Exponential distribution
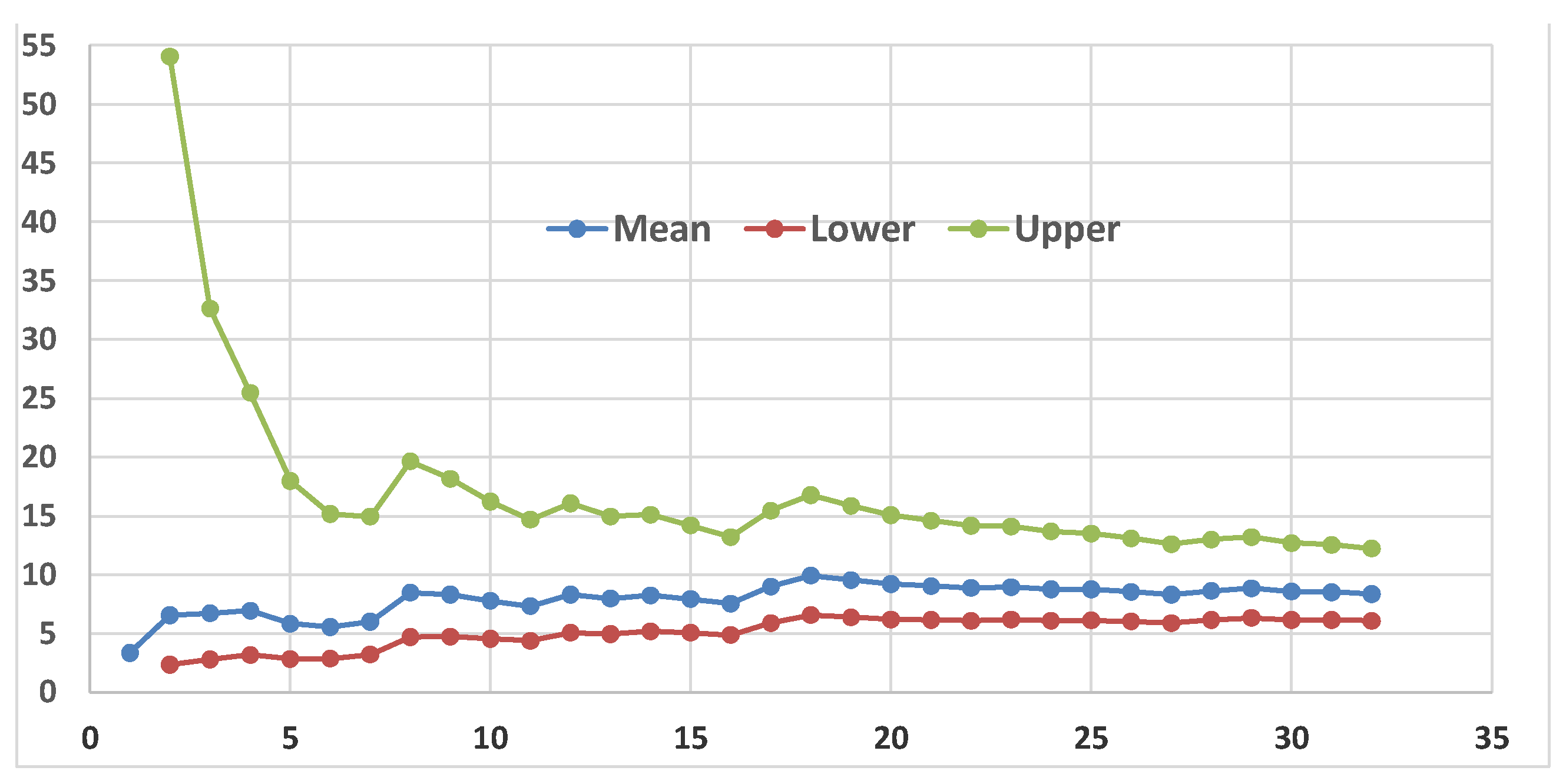
Figure 11.
TTOT (Total Time On Test transform) of the 128 Cancer data. Exponential distribution is suitable
Figure 11.
TTOT (Total Time On Test transform) of the 128 Cancer data. Exponential distribution is suitable
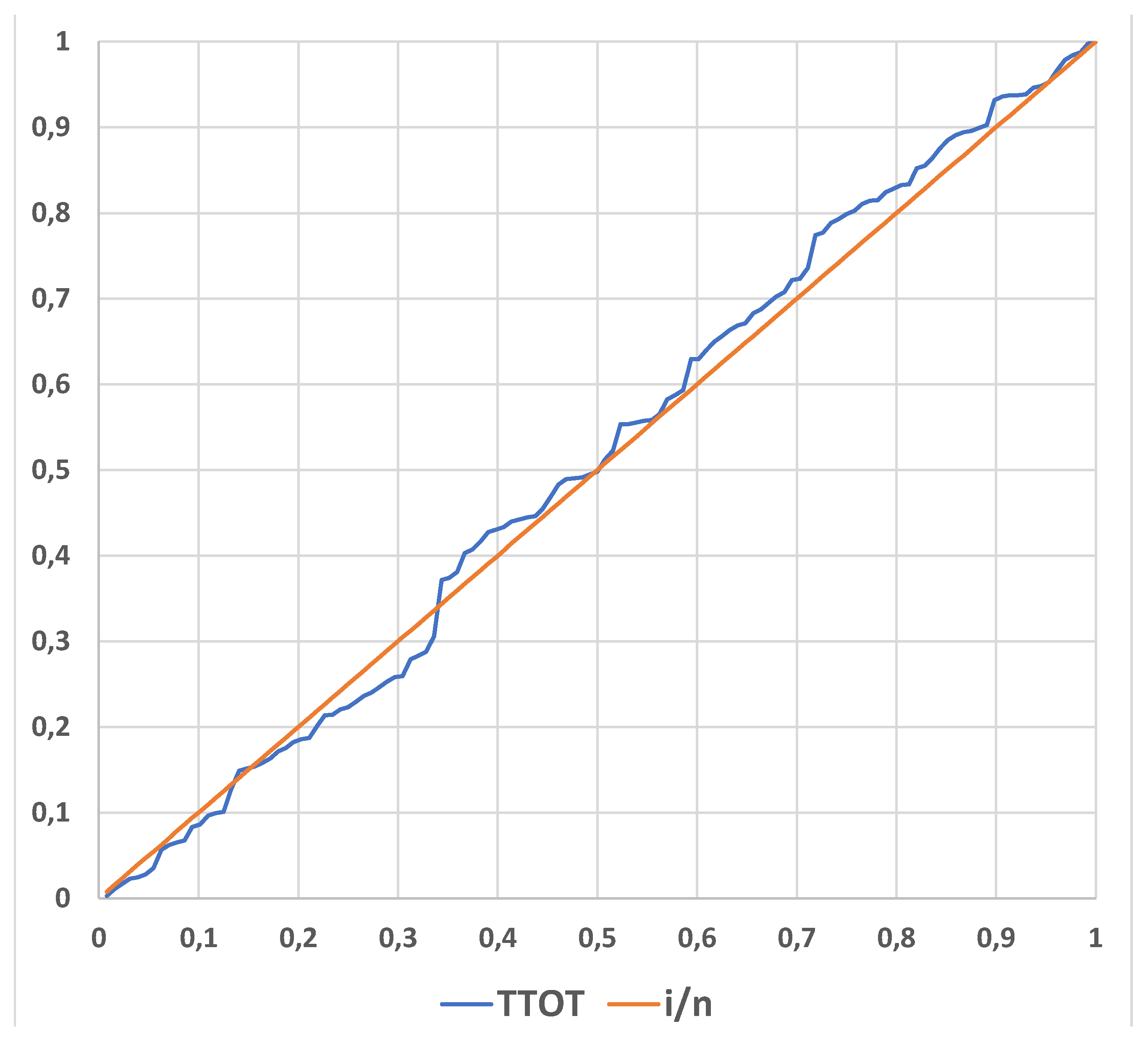
Figure 15.
Distribution GIW(x|0.51, 8.19, 61.38) for values from 0 to 1.2
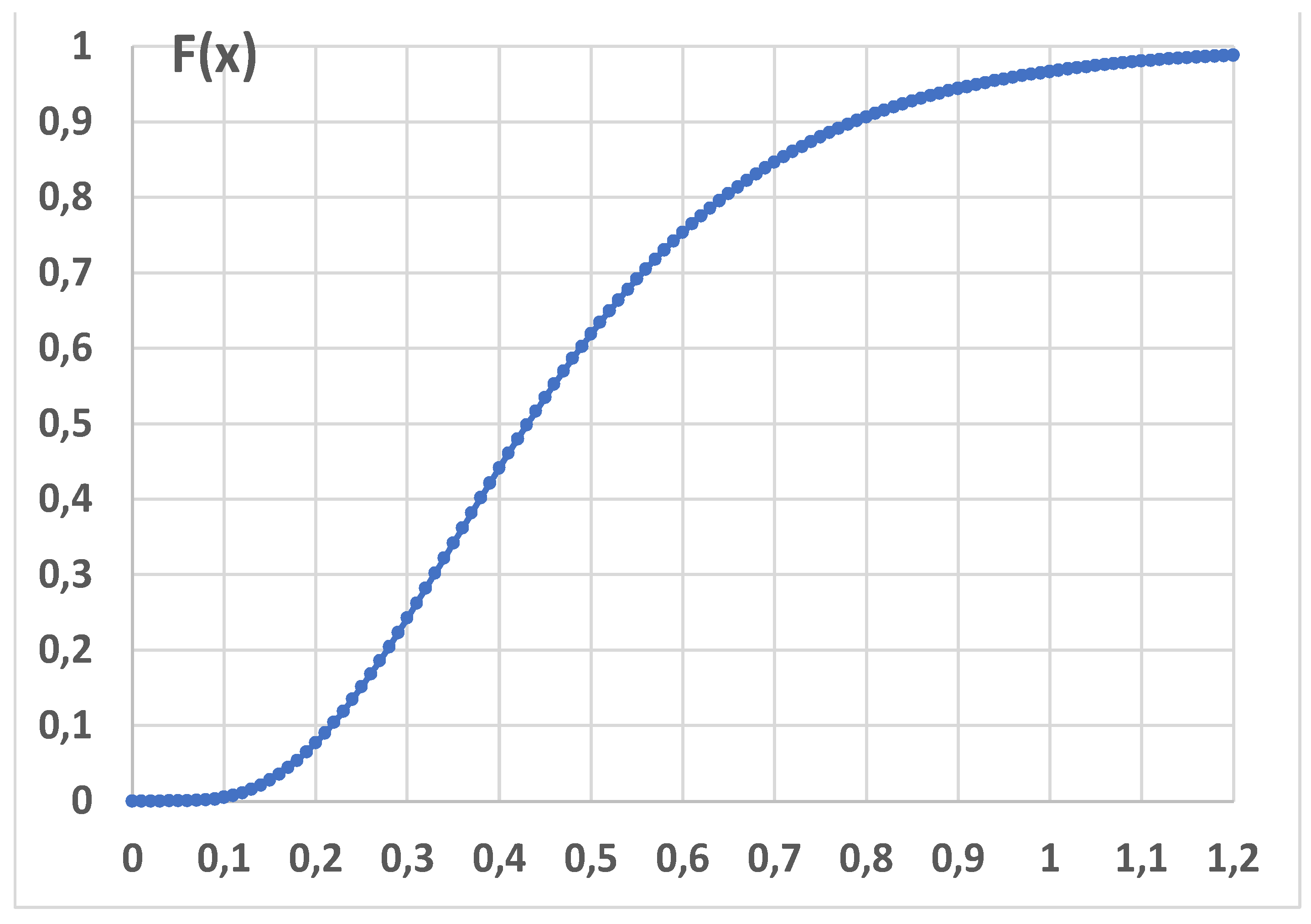
Figure 16.
Inverse data (of those in Table 2), sum of the inverse of collected data named “Tot_inverse” and “Tot_inverse_B” from the Distribution GIW(x|0.51, 8.19, 61.38). x in the interpolating formulae is the number of counts, not the collected data.
Figure 16.
Inverse data (of those in Table 2), sum of the inverse of collected data named “Tot_inverse” and “Tot_inverse_B” from the Distribution GIW(x|0.51, 8.19, 61.38). x in the interpolating formulae is the number of counts, not the collected data.
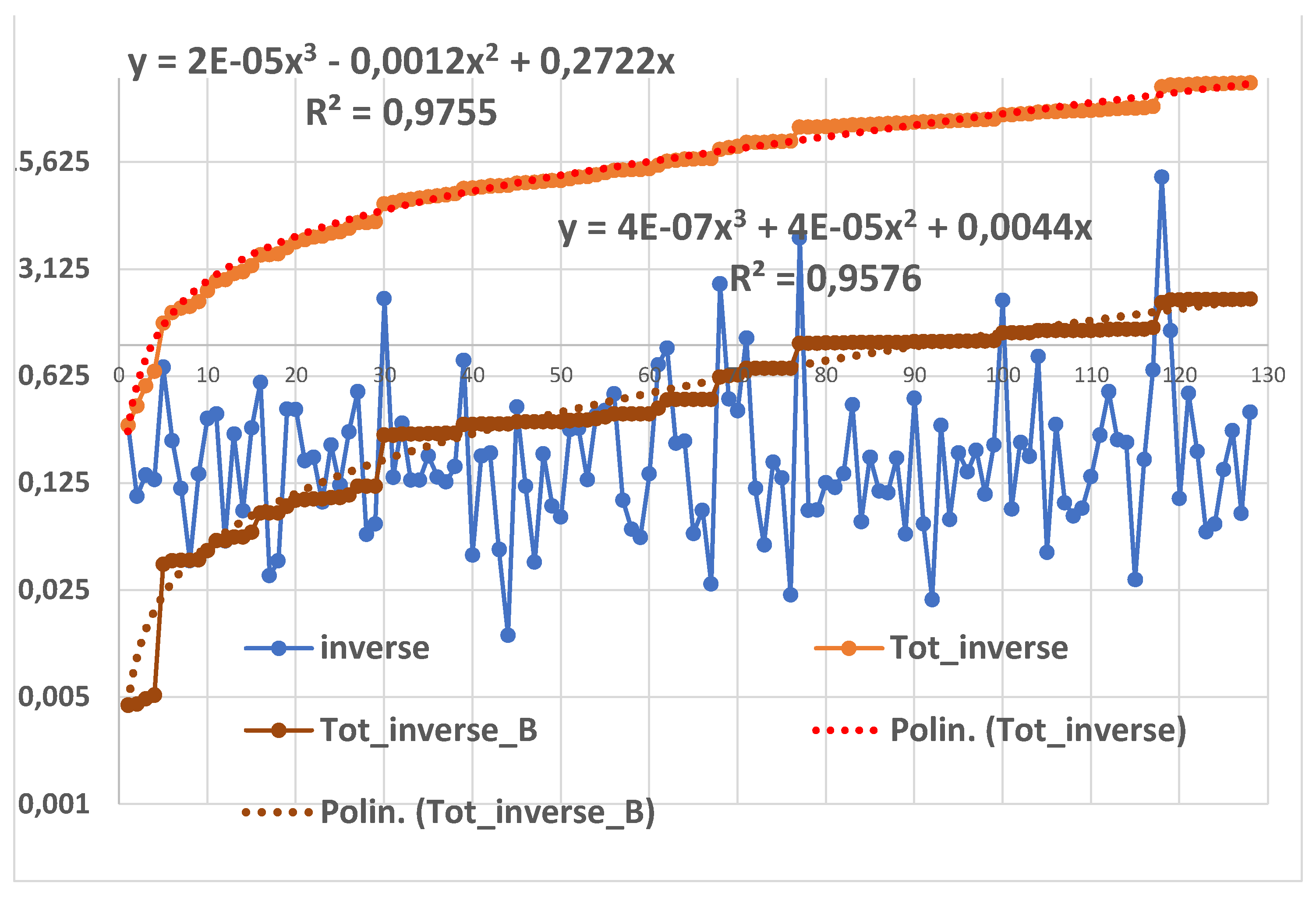
Figure 17.
OC Curve and pdf (multiplied by 40) versus ω (omega), given “Tot_inverse_B” from the Distribution GIW(x|0.51, 8.19, 61.38). The intersections of the OC with the two horizontal lines y=0.025 and y=0.975, provide the limits of the CI.
Figure 17.
OC Curve and pdf (multiplied by 40) versus ω (omega), given “Tot_inverse_B” from the Distribution GIW(x|0.51, 8.19, 61.38). The intersections of the OC with the two horizontal lines y=0.025 and y=0.975, provide the limits of the CI.
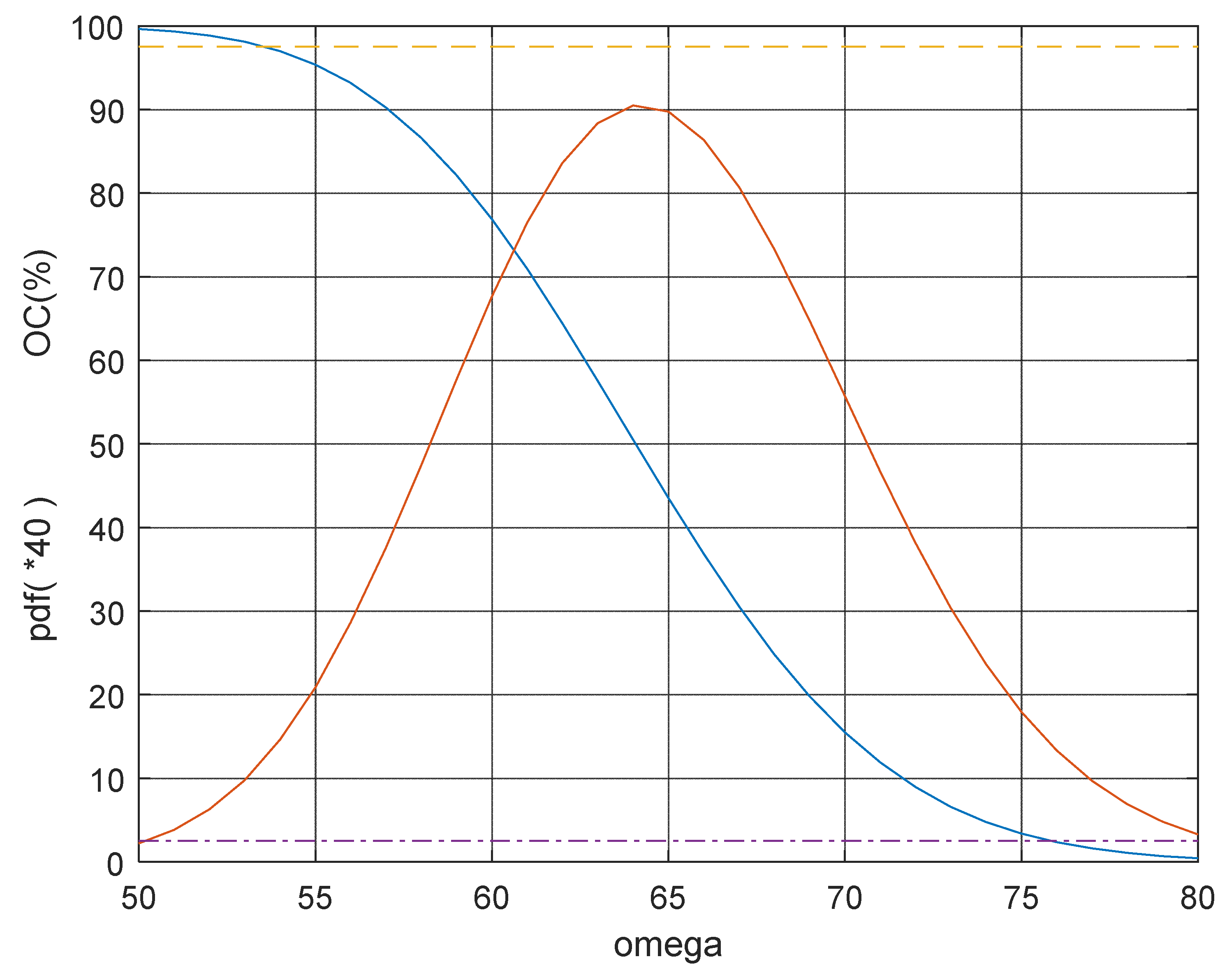
Figure 18.
Two OC Curves versus ω (omega). The intersections of each OC with the two horizontal lines y=0.025 and y=0.975, provide the limits of the CIs. The curve “on the right” is for g=73 (the sample size “optimum” for decision, according to Excerpt 9); the other is for g=128.
Figure 18.
Two OC Curves versus ω (omega). The intersections of each OC with the two horizontal lines y=0.025 and y=0.975, provide the limits of the CIs. The curve “on the right” is for g=73 (the sample size “optimum” for decision, according to Excerpt 9); the other is for g=128.
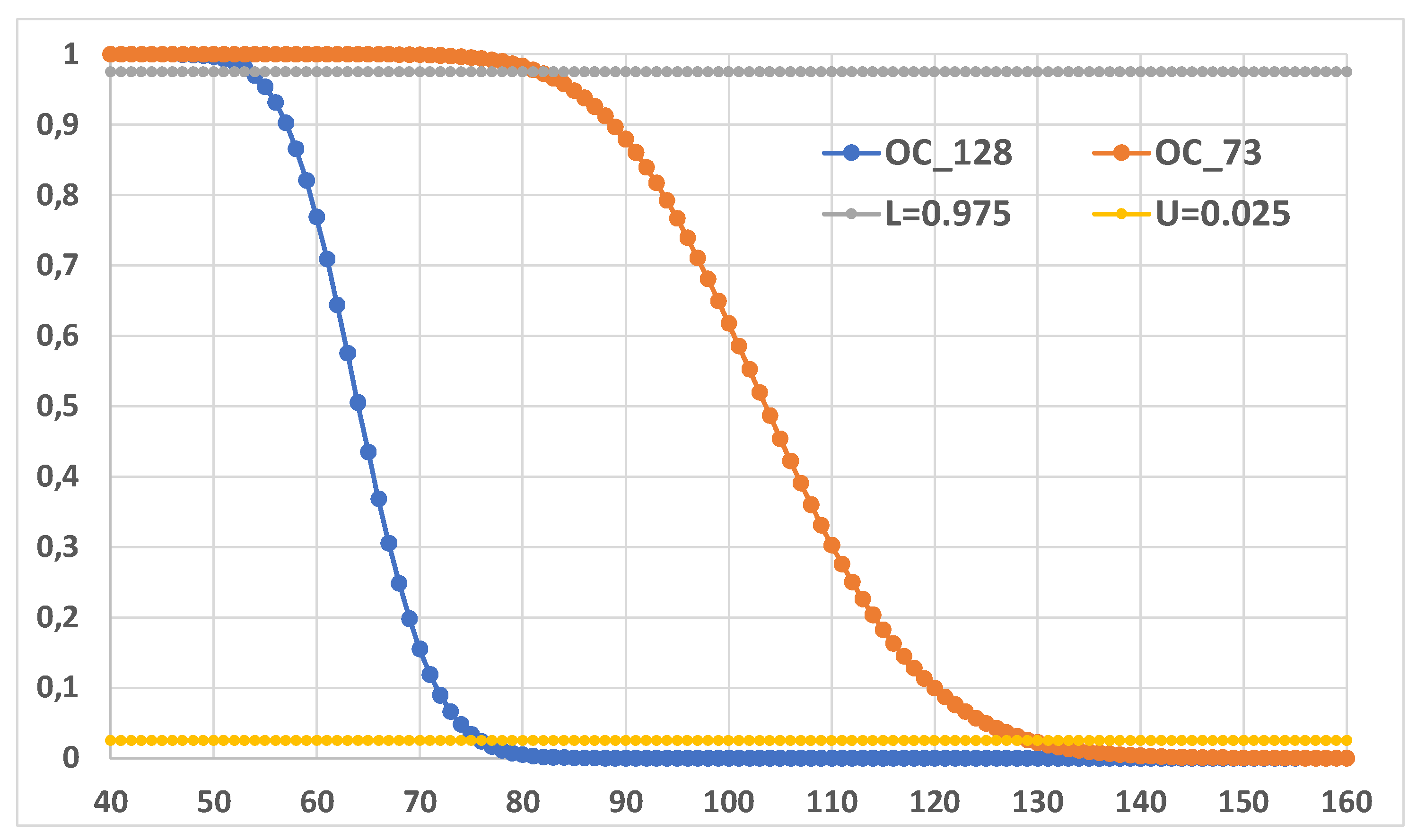
Figure 19.
ICC by JMP on x2 data; the LCL and UCL are not the Control Limits but the Probability Limits
Figure 19.
ICC by JMP on x2 data; the LCL and UCL are not the Control Limits but the Probability Limits
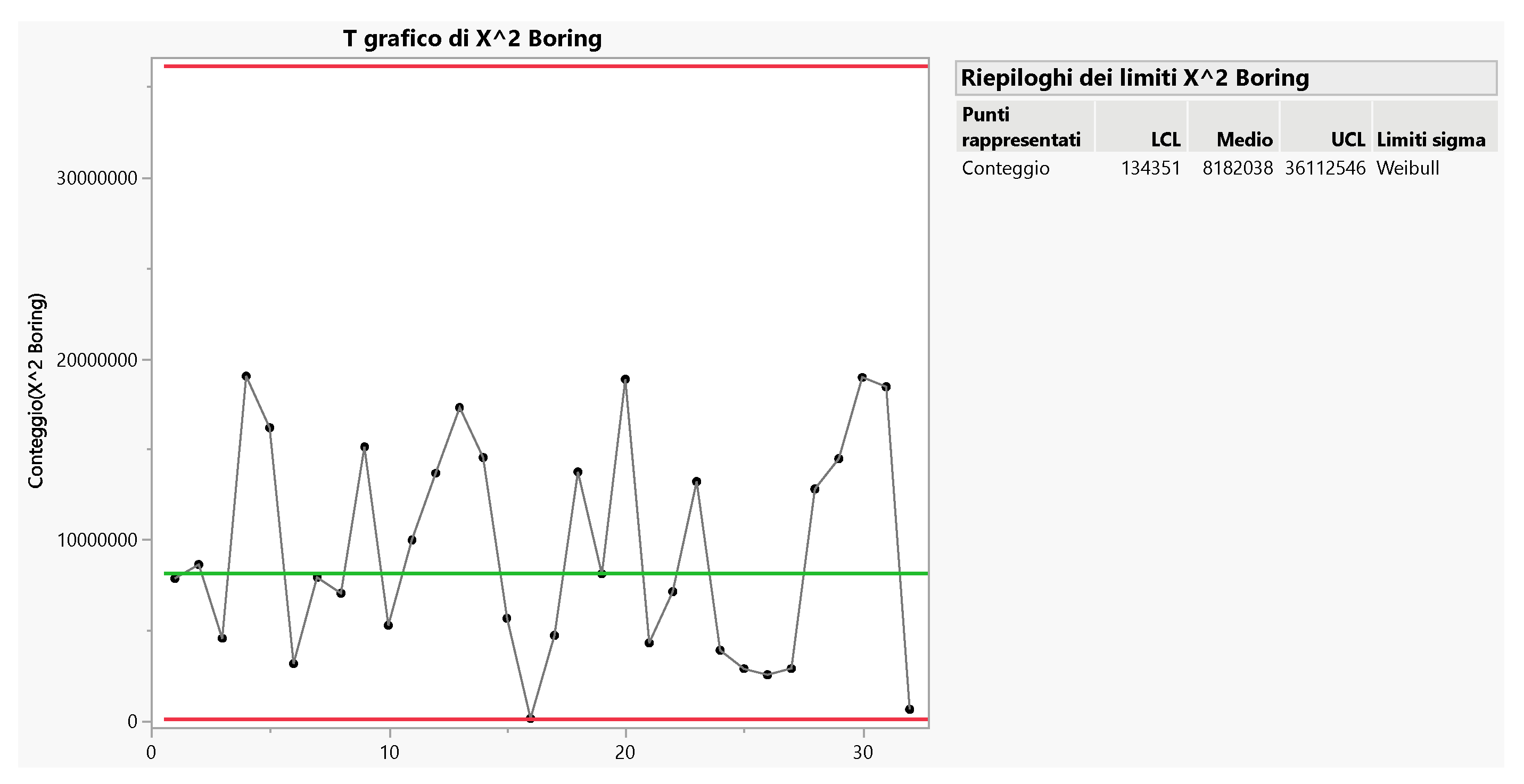
Figure 20.
ICC by Alshahrani et al., “On Designing … of Boring Machine. Mathematics 2023”; you see the Probability Limits (LPL, UPL) …
Figure 20.
ICC by Alshahrani et al., “On Designing … of Boring Machine. Mathematics 2023”; you see the Probability Limits (LPL, UPL) …
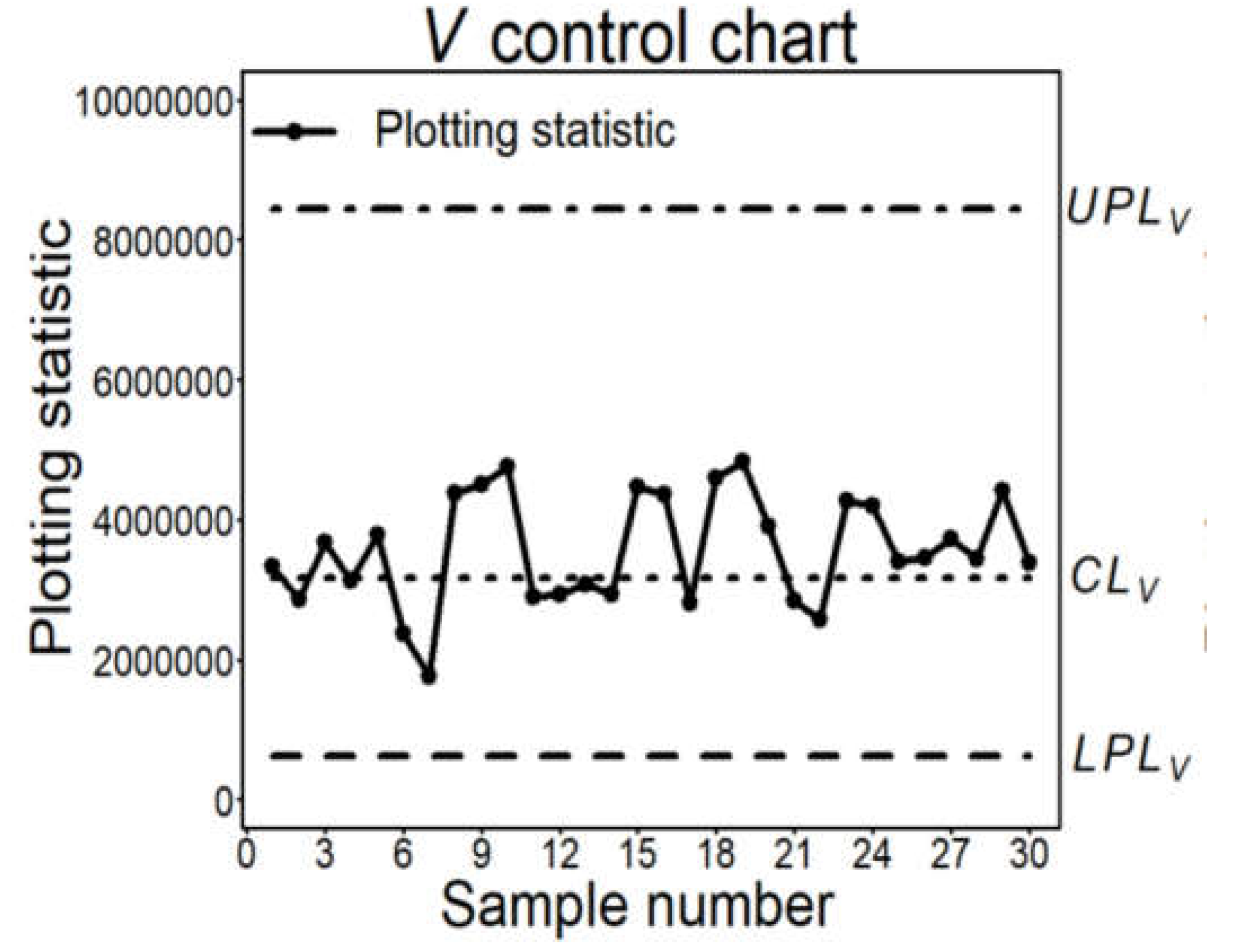
Figure 21.
Difference between the Control Limits (LCL and UCL) and the Probability Limits (L and U) by the Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57]
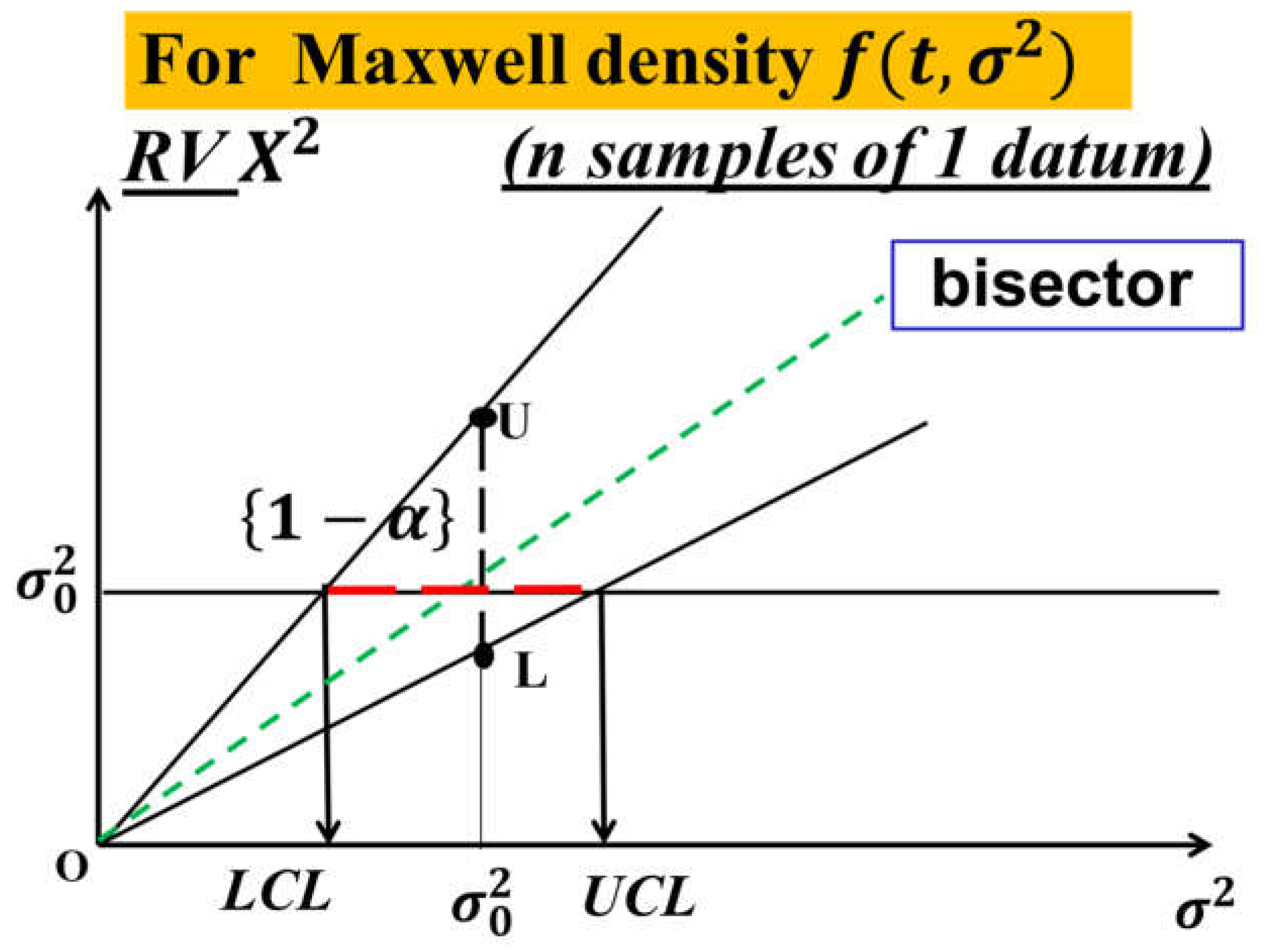
Figure 22.
Difference between the Control Limits (LCL and UCL) and the Probability Limits (L and U) of the Boring data, according to the Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57], with CL=0.95; the vertical lines (red, green) intersect the horizontal line at the points LCL and UCL
Figure 22.
Difference between the Control Limits (LCL and UCL) and the Probability Limits (L and U) of the Boring data, according to the Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57], with CL=0.95; the vertical lines (red, green) intersect the horizontal line at the points LCL and UCL
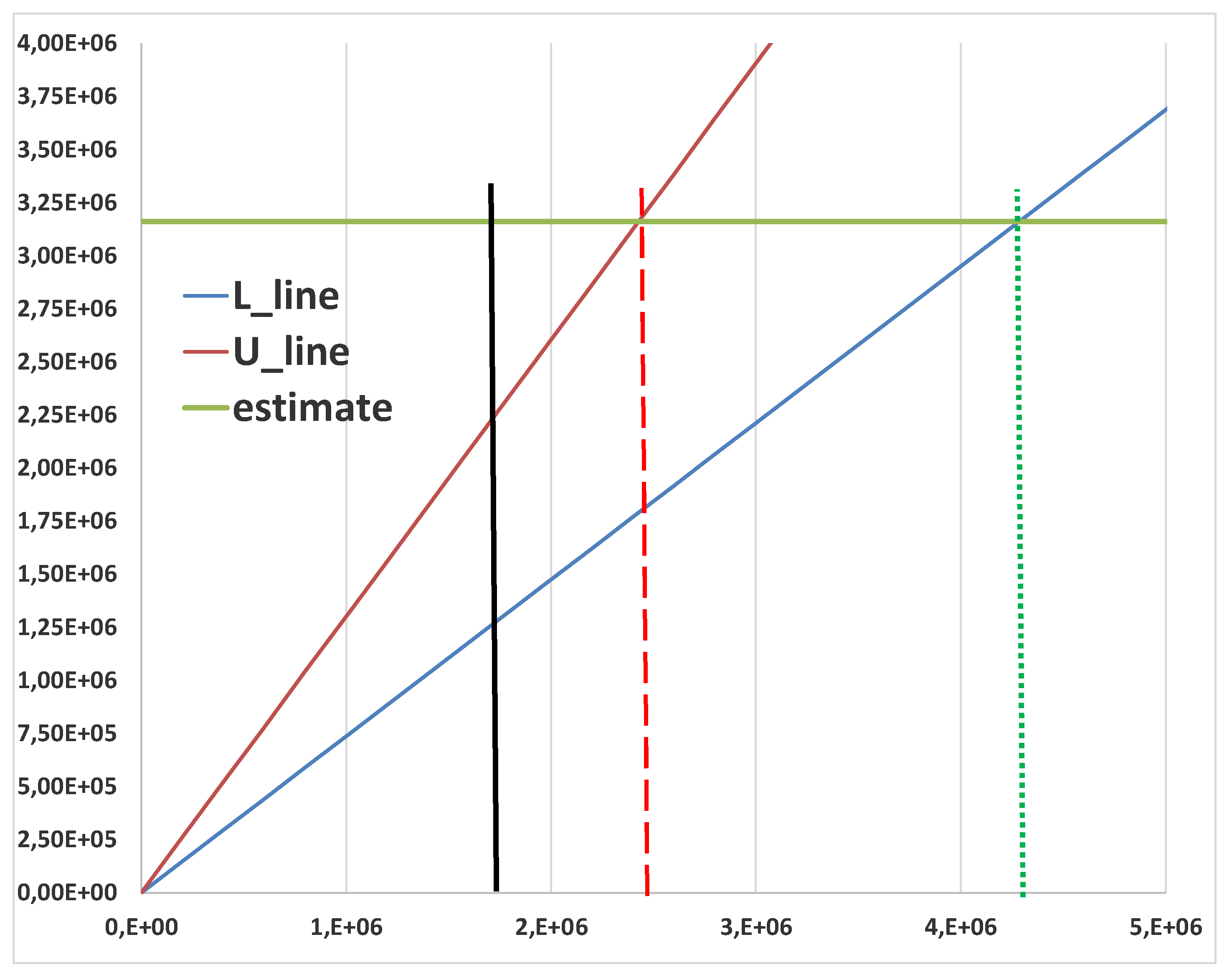
Figure 23.
The “scientific” Control Limits (LCL and UCL) of the Boring data, according to the Theory [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57], with CL=0.9973
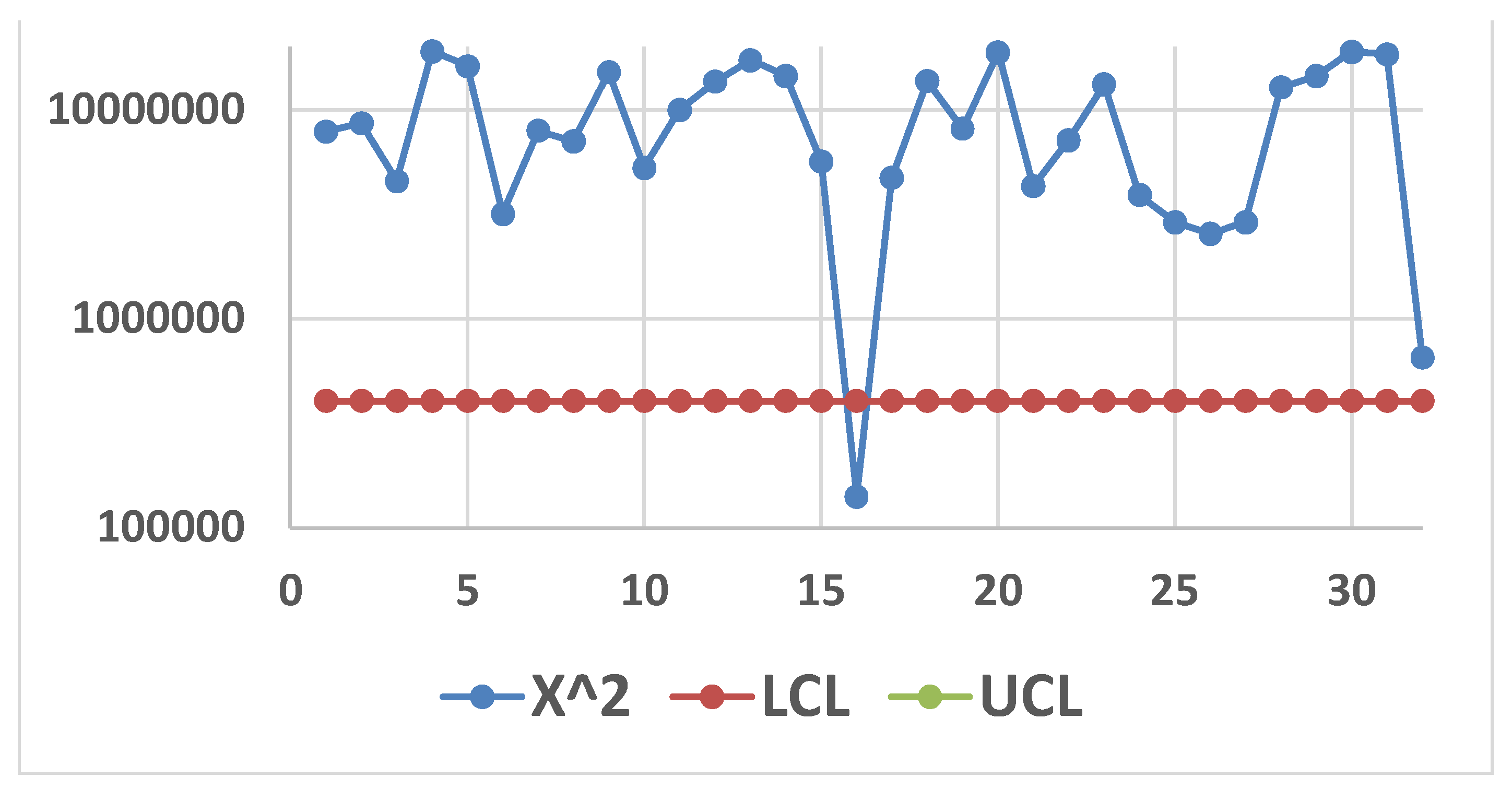
Figure 24.
The sequential Confidence Limits of the Boring data, with CL=0.95
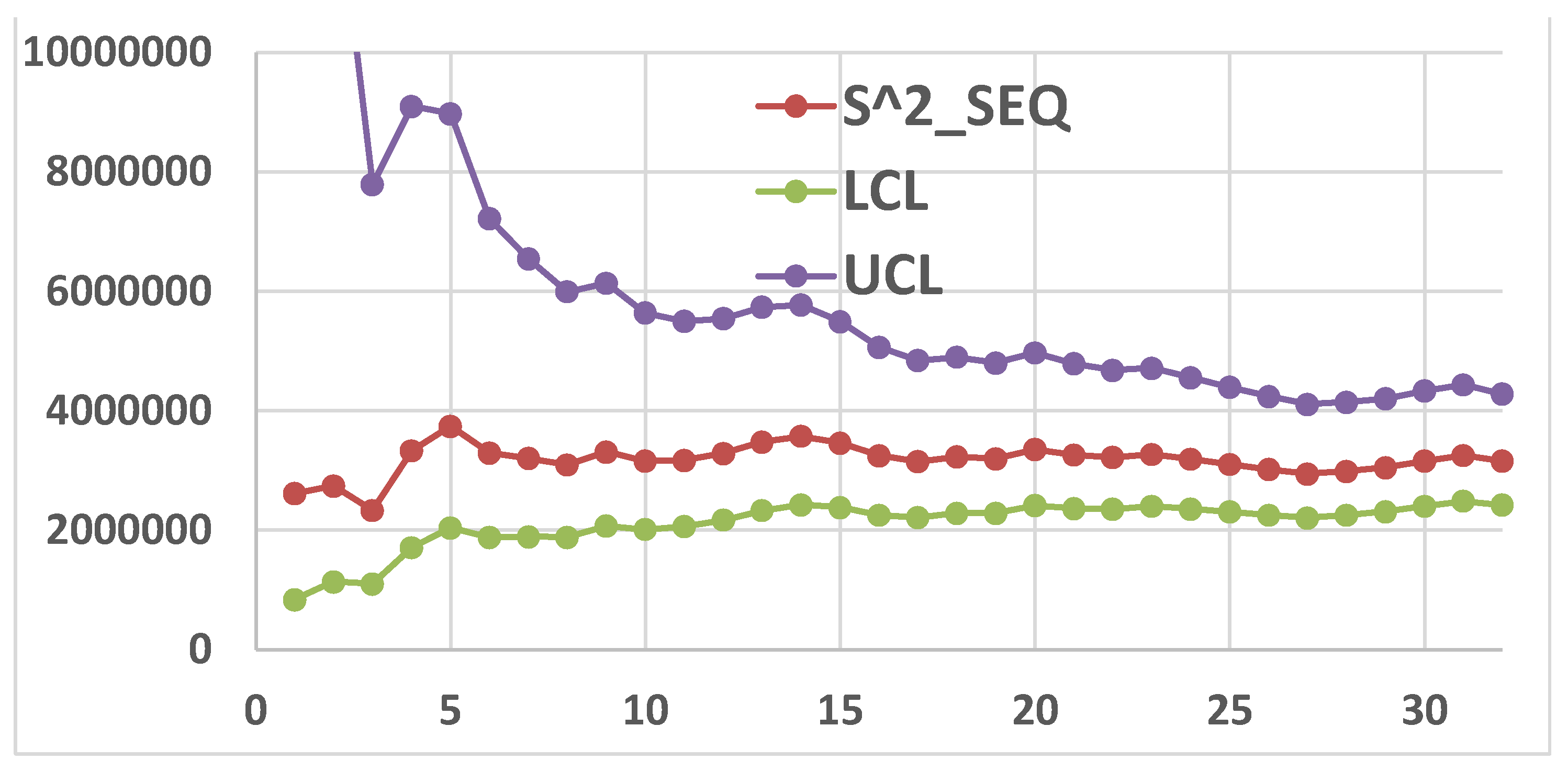
Figure 25.
Sequential Test (Wald) for the Boring data, with α=0.025 and β=0.025
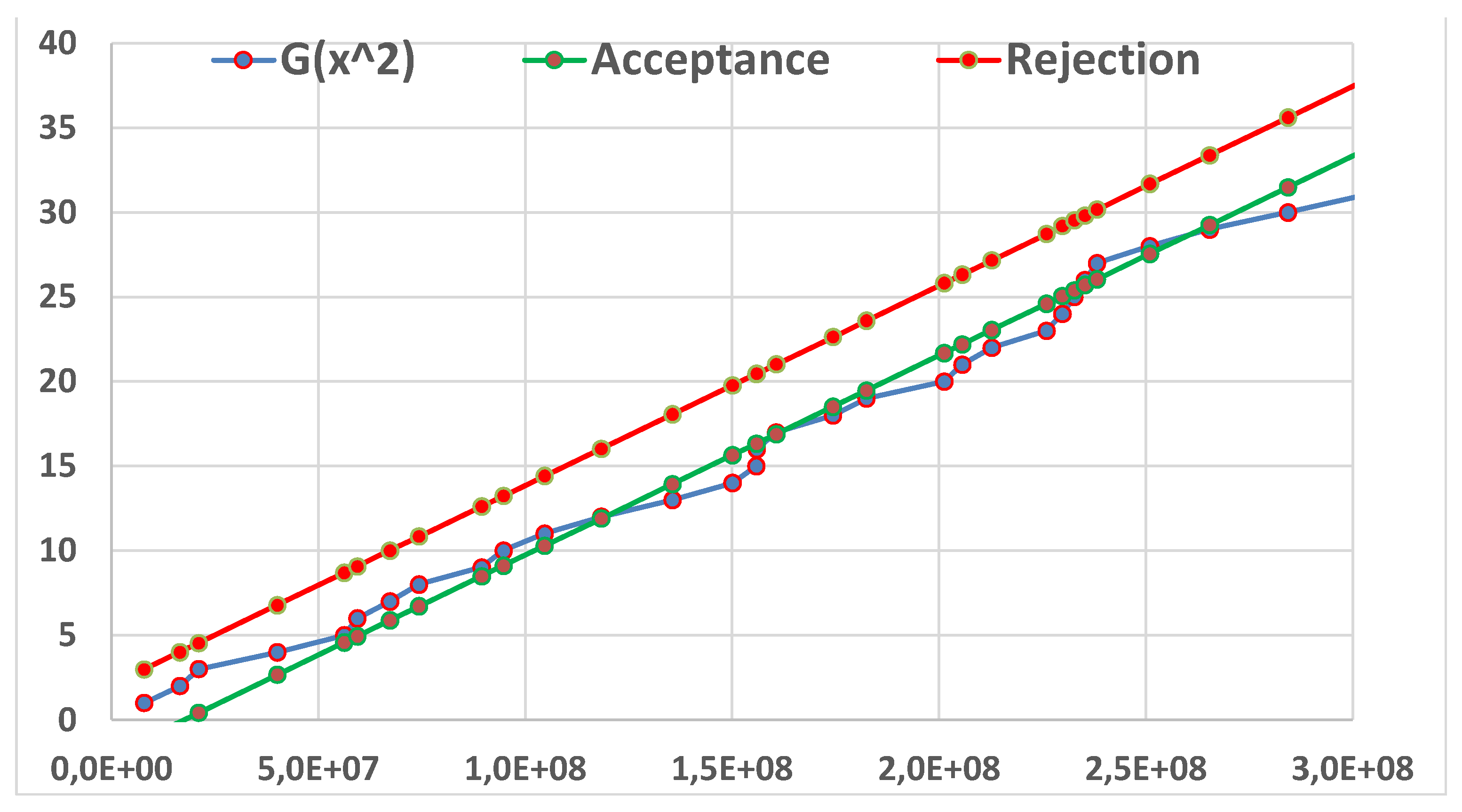
Figure 26.
Probability Interval L---U (vertical line) versus Random Intervals comprising the “mean” μ (horizontal random variable lines), for Normally distributed RVs .
Figure 26.
Probability Interval L---U (vertical line) versus Random Intervals comprising the “mean” μ (horizontal random variable lines), for Normally distributed RVs .
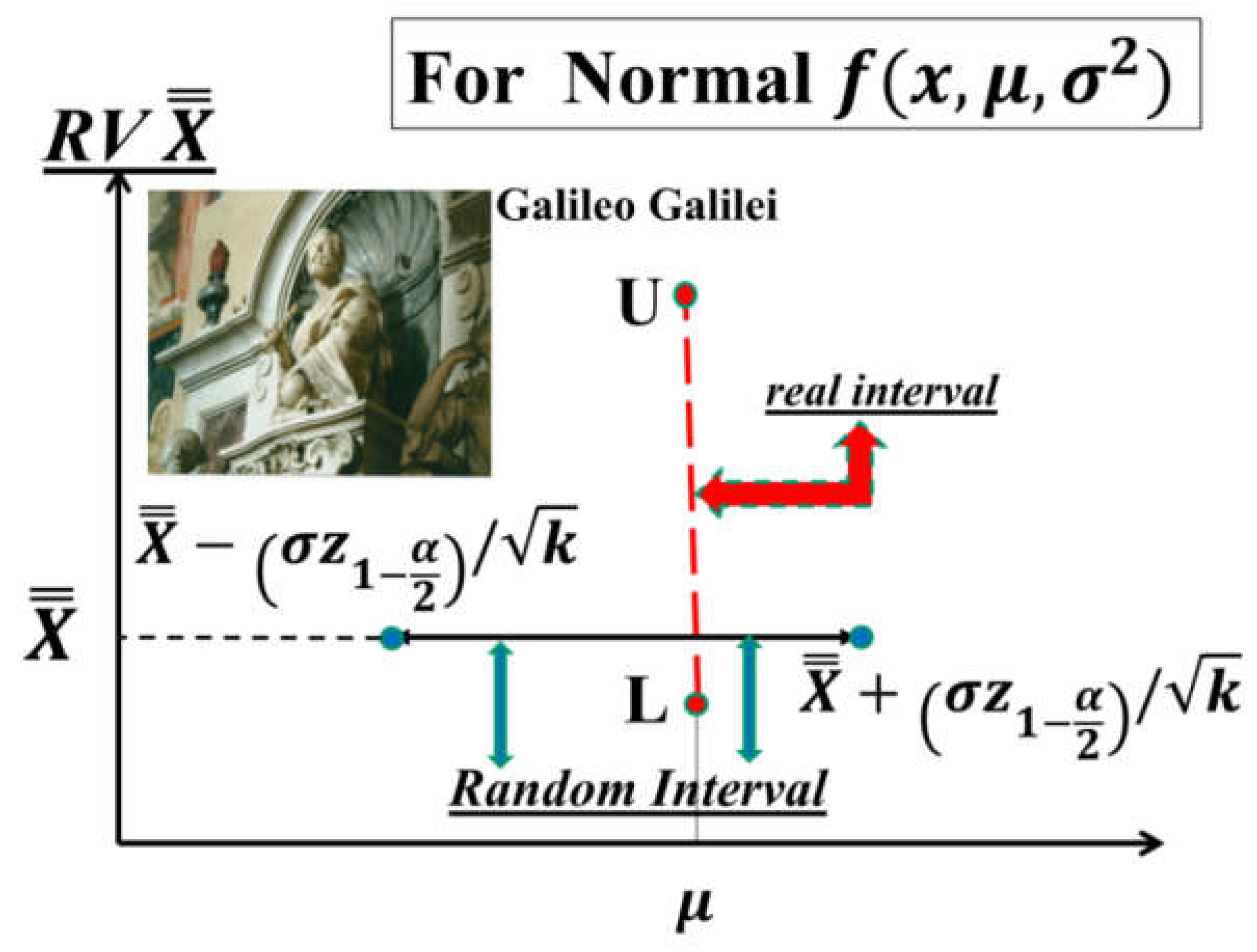
Figure 28.
Knowledge versus Ignorance, in Tools and Methods.

Table 1.
Some probability models for data analysis
| Name | parameters | Symbol | |||
| Exponential | E(x|θ) | ||||
| Weibull | W(x|β,η) | ||||
| Inverted Weibull | IW(x|β,η) | ||||
| General Inverted W | GIW(x|β,η,ω) | ||||
| Maxwell | σ2 | MW(x|σ) | |||
| Normal | μ | σ2 | N(x|μ, σ2) | ||
Table 2.
Data “of remission time of 128 bladder cancer patients” from “Statistical Inference on the Shape Parameter of Inverse Generalized Weibull Distribution”, Mathematics (2024) [3].
Table 2.
Data “of remission time of 128 bladder cancer patients” from “Statistical Inference on the Shape Parameter of Inverse Generalized Weibull Distribution”, Mathematics (2024) [3].
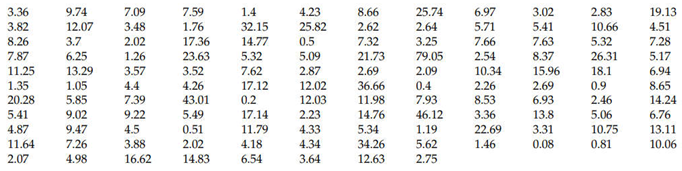 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



