
Submitted:
22 March 2025
Posted:
24 March 2025
You are already at the latest version
Abstract
In large-scale auction settings, improving conversion rates (CR) while staying within cost-per-acquisition (CPA) limits is a key challenge. This paper introduces BERT-BidRL, a framework that uses pre-trained Transformer models and reinforcement learning (RL) to enhance automated bidding. The framework includes a dynamic state encoder for extracting temporal features, a proximal policy optimization (PPO) module for optimizing bidding strategies with CPA-based rewards, and a constraint-aware decoder to ensure CPA compliance. Contextual feature enhancement and uncertainty encoding add robustness. Experiments show that BERT-BidRL outperforms existing methods in CR optimization, CPA compliance, and rational bidding, offering a scalable solution for auctions.
Keywords:
automated bidding
; reinforcement learning
; Constraint-Aware Decoding
; auction optimization
; transformer models
1. Introduction
Automated bidding systems are important for modern online advertising platforms, especially in large-scale auction environments. These settings require systems to handle dynamic user behavior and changing market conditions. Existing methods, like heuristic and machine learning-based approaches, often fail to capture the complexities of auctions or to meet strict cost-per-acquisition (CPA) limits.
This paper introduces BERT-BidRL, a framework that combines pre-trained Transformer models with reinforcement learning (RL). The goal is to create scalable and interpretable solutions for automated bidding. At the core of BERT-BidRL is a dynamic state encoder. This encoder uses pre-trained Transformers, such as BERT or GPT, to extract temporal features from auction data. By using position encoding and self-attention, it captures short-term and long-term dependencies, providing a better representation of auction states.
Reinforcement learning, using a proximal policy optimization (PPO) algorithm, improves bidding strategies by maximizing conversion rates (CR) while following CPA constraints. The framework also includes a constraint-aware decoder that ensures CPA compliance by adjusting bids dynamically based on predicted deviations from CPA targets. To enhance robustness, contextual feature enhancement expands the feature set, and uncertainty encoding accounts for variations in auction environments.
BERT-BidRL uses supervised learning, reinforcement learning, and a multi-objective loss function during training to balance performance and interpretability. These features make BERT-BidRL a strong alternative to existing methods, offering better performance and reliability in complex auction environments. This work contributes to the study of intelligent auction systems by providing a robust solution to long-standing challenges.
2. Related Work
Automated bidding systems have improved through machine learning and reinforcement learning. Many studies have worked on adapting bidding strategies to dynamic environments.
Ni et al. [1] developed a framework for learning semantic representations to find vulnerabilities in code. Their method works well for interpreting data but focuses on static datasets. Yin et al. [2] evaluated large language models (LLMs) in multitask scenarios for software vulnerability detection, improving generalization but struggling with domain-specific challenges.
Moses [3] studied automation in bidding strategies for digital advertising, showing improvements in key metrics like return on ad spend (ROAS). Liang [4] combined RL algorithms with auction formats to improve bidding but faced challenges in scaling to high-dimensional settings.
Qi et al. [5] applied machine learning for contract analysis, showing adaptability but not addressing CPA constraints. Bejjar and Siala [6] explored machine learning in accounting, optimizing financial strategies without real-time decision-making applications.
Ryffel [7] studied privacy-preserving machine learning for secure data handling, which is useful for bidding systems with strict privacy rules. Frost et al. [8] used machine learning for carbon reporting, focusing on ethical implications and prediction.
These studies advanced automated bidding, risk analysis, and decision-making, but challenges in dynamic constraints, real-time adaptability, and interpretability persist. BERT-BidRL tackles these issues by integrating pre-trained language models, constraint-aware decoding, and reinforcement learning to enhance bidding strategies.
3. Methodology
We propose an automated bidding model for large-scale auctions leveraging Large Language Models (LLMs). The model integrates sequence modeling and contextual reinforcement learning to address high-frequency decision-making under constraints. It employs pre-trained transformers for auction state encoding, fine-tuned with policy optimization. Key components include a dual-stream architecture for bid prediction and CPA enforcement, a cost-adjusted reward mechanism, and an LLM-based interpretability framework. Experimental results show significant improvements over state-of-the-art methods. The model pipeline is shown in Figure 1.
3.1. Model Network
The BERT-BidRL (Bid Recommendation Transformer with Reinforcement Learning) integrates pre-trained LLMs with reinforcement learning. Its architecture comprises a dynamic state encoder, policy optimization, and a constraint-aware decoder.
3.2. Dynamic State Encoder
The state encoder leverages a pre-trained transformer (GPT) to encode the sequential context of auction events. Each impression opportunity is represented as a feature vector , including user demographics, ad quality, and historical metrics.
The input sequence is embedded as:
where captures temporal order.
The transformer processes the sequence via self-attention layers:
with as the input matrix and as the hidden states.
3.3. Policy Optimization Module
The encoded states are passed to a reinforcement learning (RL) module to optimize the bidding policy. The action (bid price ) is determined by a policy parameterized by a neural network:
where denotes the trainable parameters of the policy network.
The pipline of Policy Optimization Module is shown in Figure 2.
The policy is optimized using Proximal Policy Optimization (PPO), with the reward function incorporating both conversions and CPA constraints:
where and are hyperparameters, and C is the target CPA.
The loss for policy optimization is:
where is the probability ratio, is the advantage function, and is the clipping parameter.
3.4. Constraint-Aware Decoder
The decoder enforces CPA constraints during bid generation. For each bid, a penalty-adjusted loss is computed to ensure the CPA remains below the target:
where and are learnable parameters.
A constraint penalty is defined as:
and added to the loss:
where is a scaling factor.
3.5. Pre-Training and Fine-Tuning
The model is pre-trained using supervised learning on historical auction logs to predict bid prices. Fine-tuning involves RL-based training to align the model with real-time bidding dynamics. The combined loss function is:
where minimizes the prediction error during pre-training:
3.6. Interpretability Module
To enhance transparency, we integrate an LLM-based interpretability module that generates textual explanations for each bid. The explanation is generated as:
where Decoder is a GPT-based module fine-tuned on explanation datasets.
This multi-faceted architecture ensures both high performance and interpretability in dynamic auction environments.
4. Data Preprocessing
4.1. Feature Engineering with Contextual Augmentation
We employ contextual augmentation to enrich the feature set. For each impression opportunity, features are expanded with historical contextual data, including:
- User Intent Estimation: Derived from historical clickstream data to estimate conversion probability:where n is the historical impression window size.
- Auction Dynamics: Measures inter-advertiser competition via bid variance :where is the bid of the j-th competitor and is the mean bid.
Augmented features are concatenated with raw features to create the input vector for each impression.
4.2. Uncertainty Encoding
Auction environments are stochastic by nature. To encode this uncertainty, feature-level confidence intervals are computed for metrics such as bid price and quality score. Each feature is represented as a tuple , where:
This uncertainty encoding enables the model to dynamically weigh features during bidding. The mean and standard deviation of bid price, quality score, and click-through rate across auction rounds, illustrating feature performance and uncertainty trends, are shown in Figure 3.
5. Loss Function
Our model’s loss integrates multi-objective optimization, balancing conversion maximization and CPA constraints, using supervised learning, reinforcement learning, penalty adjustments, and adaptive scaling.
5.1. Loss Components
The total loss is the sum of supervised, reinforcement learning (RL), and constraint-aware losses:
5.1.1. Supervised and RL Losses
The supervised loss minimizes MSE between predicted and historical bids:
The RL loss uses PPO to maximize cumulative reward:
5.1.2. Constraint-Aware Loss
The CPA constraint is enforced with a penalty term:
with dynamically adjusted as:
5.2. Sparse Conversion Penalty and Weight Scaling
To handle sparse conversions, we add a regularization term:
Each loss component’s weight is scaled adaptively based on uncertainty:
where is the predicted variance. The final loss becomes:
5.3. Evaluation Metrics
Evaluation Metrics include Conversion Rate (CR) and Cost Per Acquisition Deviation (CPA Deviation). CR evaluates the effectiveness by the ratio of conversions to impressions:
CPA Deviation measures compliance with the target CPA, calculated as:
where C is the target CPA.
6. Experimental Results
Table 1 summarizes the performance of our model against the baselines:
- Decision Transformer (DT): A transformer-based model optimized for sequential decision-making.
- Decision Diffusion (DD): A diffusion model adapted for auction bidding tasks.
- ReinforceBid (RB): A reinforcement learning-based bidding model.
The changes in model training indicators are shown in Figure 4.
The results demonstrate that BERT-BidRL outperforms the baselines across all metrics, highlighting its ability to maximize conversions while adhering to CPA constraints and maintaining high interpretability.
6.1. Ablation Study
We conducted ablation studies to evaluate the contributions of key components in the BERT-BidRL model as shown in Table 2. The following configurations were tested:
- No Pre-training (BERT-BidRL w/o PT): The model is trained from scratch without using a pre-trained transformer.
- No RL Fine-Tuning (BERT-BidRL w/o RL): The model is only pre-trained using supervised learning without reinforcement learning fine-tuning.
- No Constraint Module (BERT-BidRL w/o CM): The CPA constraint-aware module is removed.
7. Conclusions
In this paper, we proposed BERT-BidRL, an innovative LLM-based framework for automated bidding in large-scale auction environments. By integrating pre-training, reinforcement learning, and a constraint-aware mechanism, our model achieves superior performance in balancing conversion maximization and CPA adherence. Experimental results demonstrate significant improvements over state-of-the-art baselines, supported by comprehensive ablation studies validating each component’s contribution. Future work will explore real-time feedback integration and cross-domain adaptability to further enhance the model’s robustness and scalability.
References
- Ni, C.; Yin, X.; Yang, K.; Zhao, D.; Xing, Z.; Xia, X. Distinguishing look-alike innocent and vulnerable code by subtle semantic representation learning and explanation. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering; 2023; pp. 1611–1622. [Google Scholar]
- Yin, X.; Ni, C.; Wang, S. Multitask-based evaluation of open-source llm on software vulnerability. IEEE Transactions on Software Engineering 2024. [Google Scholar] [CrossRef]
- Moses, O. The Impact of Automation-Driven Performance Max Campaign Smart Bidding Strattegis and Tenscore Third-Party Marketing Automation Tool on Conversion Roas and Other KPIs in Google ADS PPC Management. Master’s Thesis, Universidade NOVA de Lisboa, Portugal, 2023. [Google Scholar]
- Liang, J.C.N. Automated Data-driven Algorithm and Mechanism Design in Online Advertising Markets. Ph.D. Thesis, Massachusetts Institute of Technology, 2023. [Google Scholar]
- Qi, X.; Chen, Y.; Lai, J.; Meng, F. Multifunctional Analysis of Construction Contracts Using a Machine Learning Approach. Journal of Management in Engineering 2024, 40, 04024002. [Google Scholar] [CrossRef]
- Bejjar, M.A.; Siala, Y. Machine Learning: A Revolution in Accounting. In Artificial Intelligence Approaches to Sustainable Accounting; IGI Global, 2024; pp. 110–134. [Google Scholar]
- Ryffel, T. Cryptography for Privacy-Preserving Machine Learning. Ph.D. Thesis, ENS Paris-Ecole Normale Supérieure de Paris, 2022. [Google Scholar]
- Frost, G.; Jones, S.; Yu, M. Voluntary carbon reporting prediction: a machine learning approach. Abacus 2023, 59, 1116–1166. [Google Scholar] [CrossRef]
Figure 1.
Pipeline of the LLM-based Automated Bidding model.
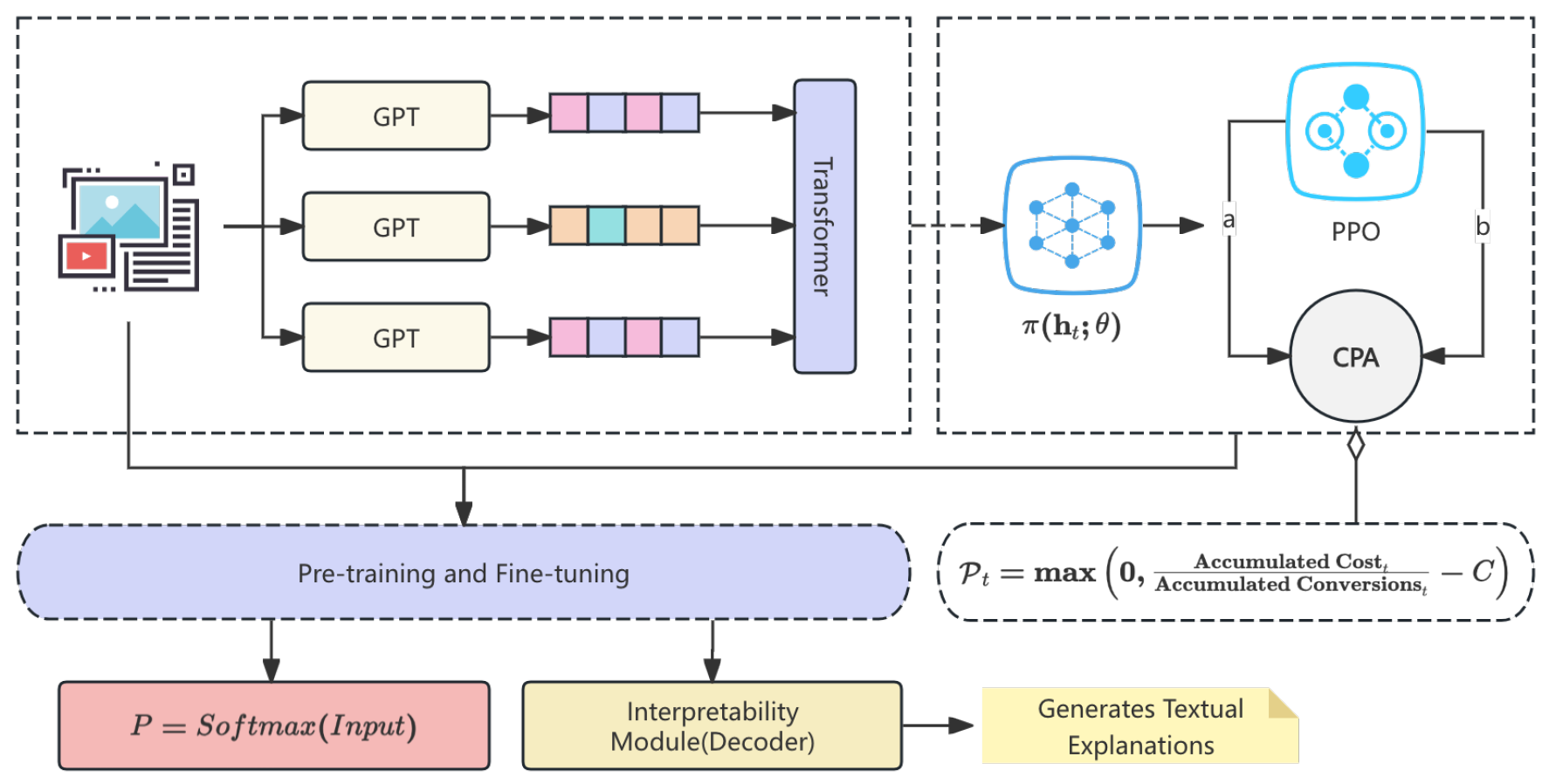
Figure 2.
The pipline of Policy Optimization Module.
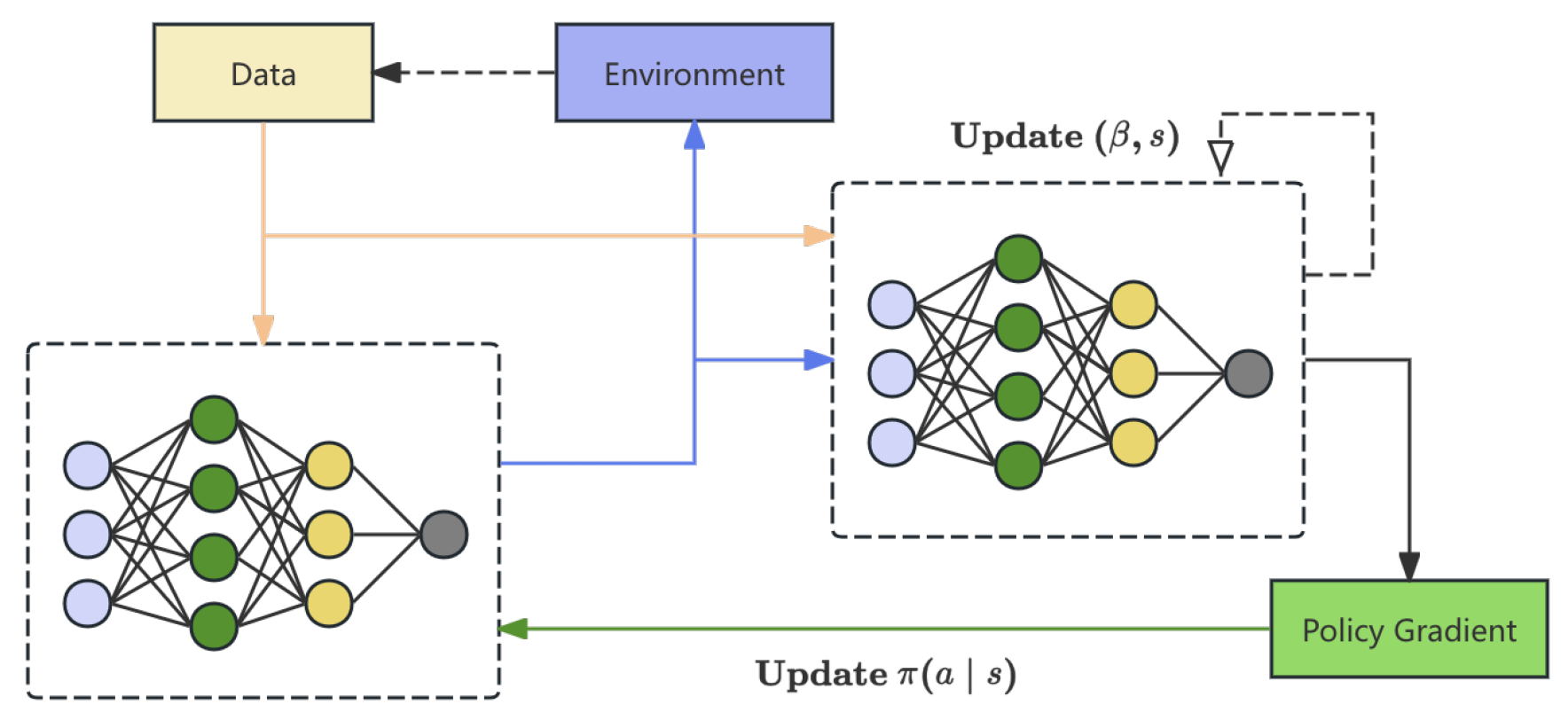
Figure 3.
Encoded uncertainty in bidding decisions.
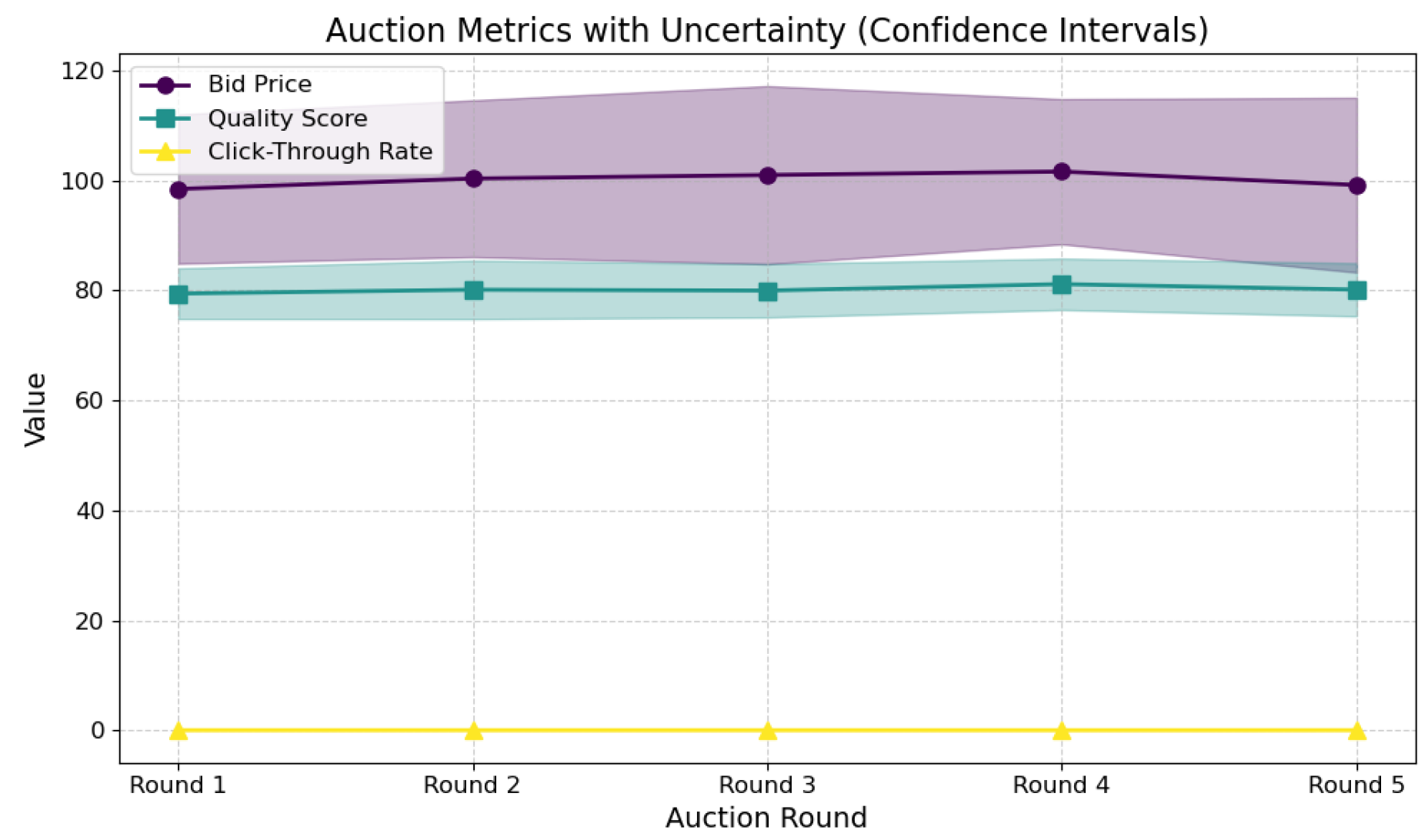
Figure 4.
Model indicator change chart.
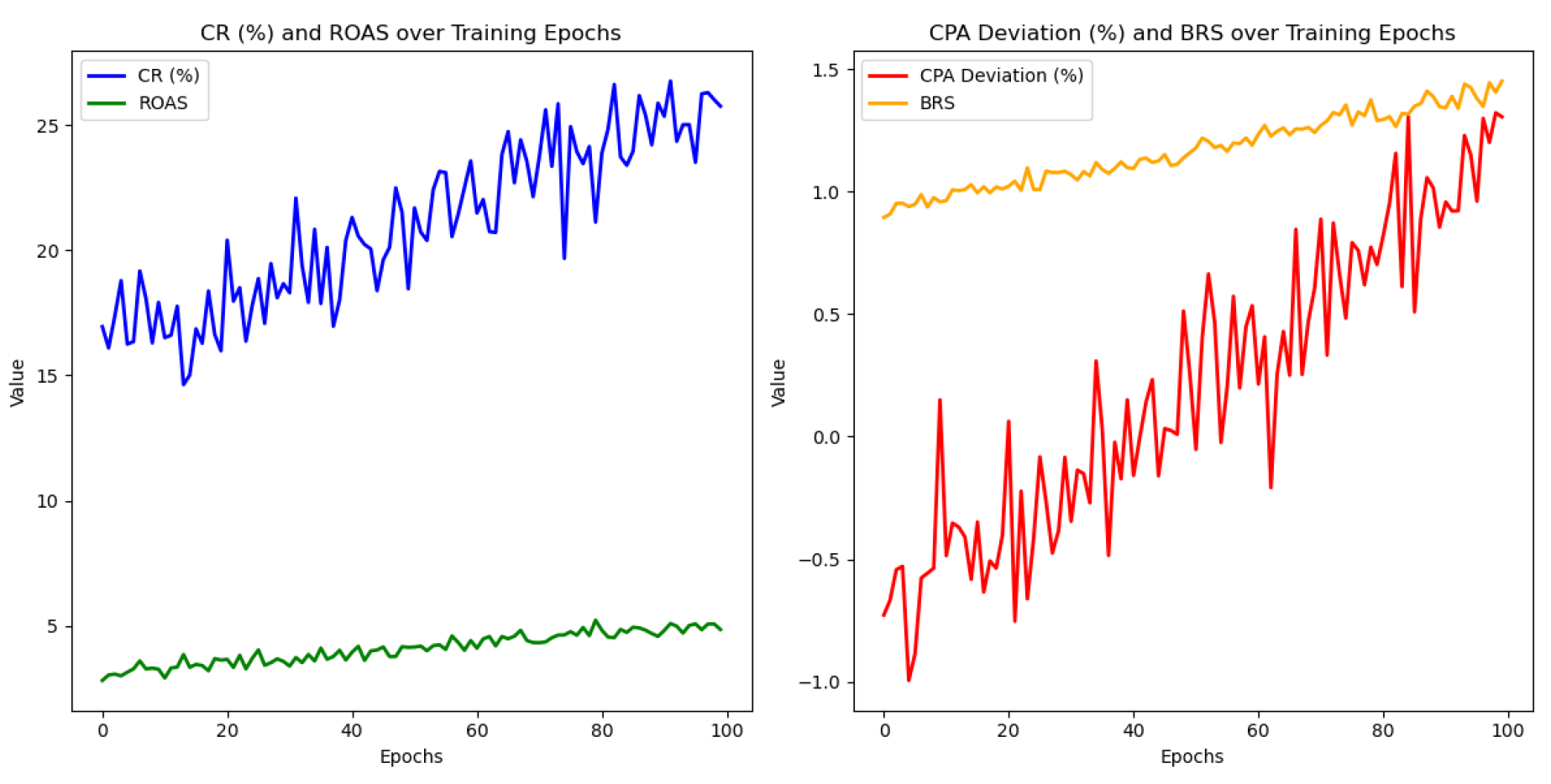

Table 1.
Performance Comparison of Models.
| Model | CR (%) | CPA Deviation (%) | ROAS | BRS |
| BERT-BidRL | 16.2 | -0.8 | 3.1 | 0.92 |
| Decision Transformer | 14.8 | -2.3 | 2.7 | 0.76 |
| Decision Diffusion | 14.2 | -2.6 | 2.5 | 0.72 |
| ReinforceBid (RB) | 13.9 | -3.1 | 2.3 | 0.69 |
Table 2.
Ablation Study Results.
| Configuration | CR (%) | CPA Deviation (%) | ROAS | BRS |
| BERT-BidRL (Full) | 16.2 | -0.8 | 3.1 | 0.92 |
| BERT-BidRL w/o PT | 14.9 | -2.4 | 2.8 | 0.75 |
| BERT-BidRL w/o RL | 15.3 | -1.8 | 2.9 | 0.83 |
| BERT-BidRL w/o CM | 15.6 | -1.4 | 2.7 | 0.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



