The exploration of LLMs and their interaction with Application Programming Interfaces (APIs) such as the Google Places API for providing recommendations is an emerging area of interest in natural language processing (NLP) and artificial intelligence (AI). This literature review synthesizes recent studies to outline current methodologies and challenges in how LLMs communicate with the Google Places API to provide dynamic and personalized recommendations.
The study conducted by Silva and Tesfagiorgis in 2023 [
6] examined various prompt designs generated by GPT4 to enhance the effectiveness of LLMs when interacting with APIs. The authors conducted experiments to identify the most efficient prompt structures, finding that finetuned prompted LLMs performed significantly better than no fine tuned systems in terms of accuracy and response times. The research outlined the importance of optimizing prompt designs being inputted into LLMs. The research by Patil et al. [
7] highlights the benefits of finetuning LLMs, demonstrating that models tailored to specific tasks consistently outperform general purpose models like ChatGPT4 and Llama3 in API interactions. The study tested and revealed results of improved performance metrics, such as precision and speed, when the LLMs were finetuned. Similarly, Luo et al. [
8] investigated various finetuning techniques and their impact on LLM performance. By testing various methods, their study identified the most effective strategies for optimizing response times and ensuring relevance in API generated results. The findings confirmed that specific finetuning approaches enhance efficiency and accuracy, making LLMs more viable for real time applications requiring rapid data retrieval. Roumeliotis et al. [
9] investigated the integration of LLMs with unsupervised learning techniques such as K-Means clustering and content based filtering to refine product recommendation systems. Their study demonstrated that incorporating GPT4’s advanced natural language understanding significantly improved the precision and relevance of recommendations. Spinelli [
10] examined the importance of robust language models in processing intricate queries efficiently, emphasizing that advanced linguistic comprehension is essential for accurate API interactions. This research supports the use of ChatGPT4, an LLM already capable of processing com plex language structures, to communicate effectively with the Google Places API. The research by Mao et al. [
11] proposes that larger LLMs can handle diverse data inputs efficiently but may be subdued to potential stability risks due to adaptive learning techniques. The paper discusses how scalable approaches might lead to instability in the models, suggesting that while scalability is essential, it must be balanced with measures to maintain system stability and reliability. Lin et al. [
12] provided an in-depth analysis of LLMs in recommender systems, outlining their roles in different stages of the recommendation pipeline, such as feature engineering and user interaction. Their study also addressed key challenges, including efficiency, effectiveness, and ethical concerns when using LLMs in recommendation tasks. Hu et al. [
13] indicates that scalable training strategies may compromise the overall efficiency of LLMs, similar to what was said in the research paper by Mao et al. [
11]. The study discusses the balance between adaptability and stability, suggesting careful consideration of training strategies to ensure that scalability does not come at the cost of efficiency and performance. Nathan et al. [
14] in his work presented a framework that was able to integrate LLMs with traditional reinforcement learners. He experimented with this integration both in the context of movies and book recommendation settings. In [
15], the authors have reviewed latest LLMs and their integration with existing recommendation systems along with the fine-tuning techniques. The author has discussed whether finetuning of whole LLM can be done. However, fine tuning of the prompt can perform the same task to avoid the pain. The main focus of the research was to work on prompt design effectively to leverage the effectiveness of the large language models. The reviewed literature revealed gaps in understanding the long-term learning capabilities of LLMs and their adaptation to dynamic, real time data. Most studies focused on specific API tasks such as email automation or weather forecasting, where static or minimally changing data was used. However, limited research has explored how LLMs handle real time, dynamic data interactions—particularly in the con text of recommendation systems. Furthermore, there were no peer reviewed research papers on LLMs specifically interacting with the Google Places API to provide recommendations based on user input.
Table 1.
Comparison Among Existing Works.
| Author(s) |
Key Findings. |
| Silva & Tesfagiorgis (2023) [6] |
Effective prompt designs & finetuning methods. |
| Patil et al. (2023) [7] |
Finetuned LLMs outperform GPT4 in API inter actions. |
| Luo et al. (2024) [8] |
Finetuning improves LLM performance w.r.t. response times. |
| Roumeliotis et al. (2024) [9] |
LLMbased unsupervised clustering enhances recommendation precision. |
| Spinellis (2024) [10] |
Linguistic structures are crucial for precise API |
| calls. Mao et al. (2024) [11] |
LLMs handle diverse inputs efficiently but risk stability. |
| Lin et al. (2023) [12] |
Examined LLMs in recommendation pipelines, focusing on efficiency and ethical considerations. |
| Hu et al. (2024) [13] |
Scalable training strategies might compromise LLM efficiency. |
Nathan et al. &
Giorgio et al. (2024) [14] |
Integrated LLMs to improve RLbased recommendations. |
| Fan et al. (2023) [15] |
Emphasized the finetuning of prompt design to leverage the effectiveness of the LLMs for context aware recommendations. |
Currently, ChatGPT’s recommendations are constrained by its inability to access live data while recommending contextually aware restaurant rec ommendations such as operating hours, reviews, and business status. This research project aims to address this limitation by integrating the Google Places API with ChatGPT4o to provide contextaware recommendations based on user queries and realtime data.
In this research, we have developed a framework that enables the seam less integration of LLMs with existing recommendation systems to provide context sensitive and personalized recommendations. The development of such a framework paves the way for future advancements in recommendation systems by leveraging real time data to address existing research gaps. To achieve this, we have designed and developed the restaurant recommendations system utilizing ChatGPT4.o and Google API. The proposed system offers recommendations based on user defined criteria, including dietary preferences, desired ambiance, budget constraints, and location.
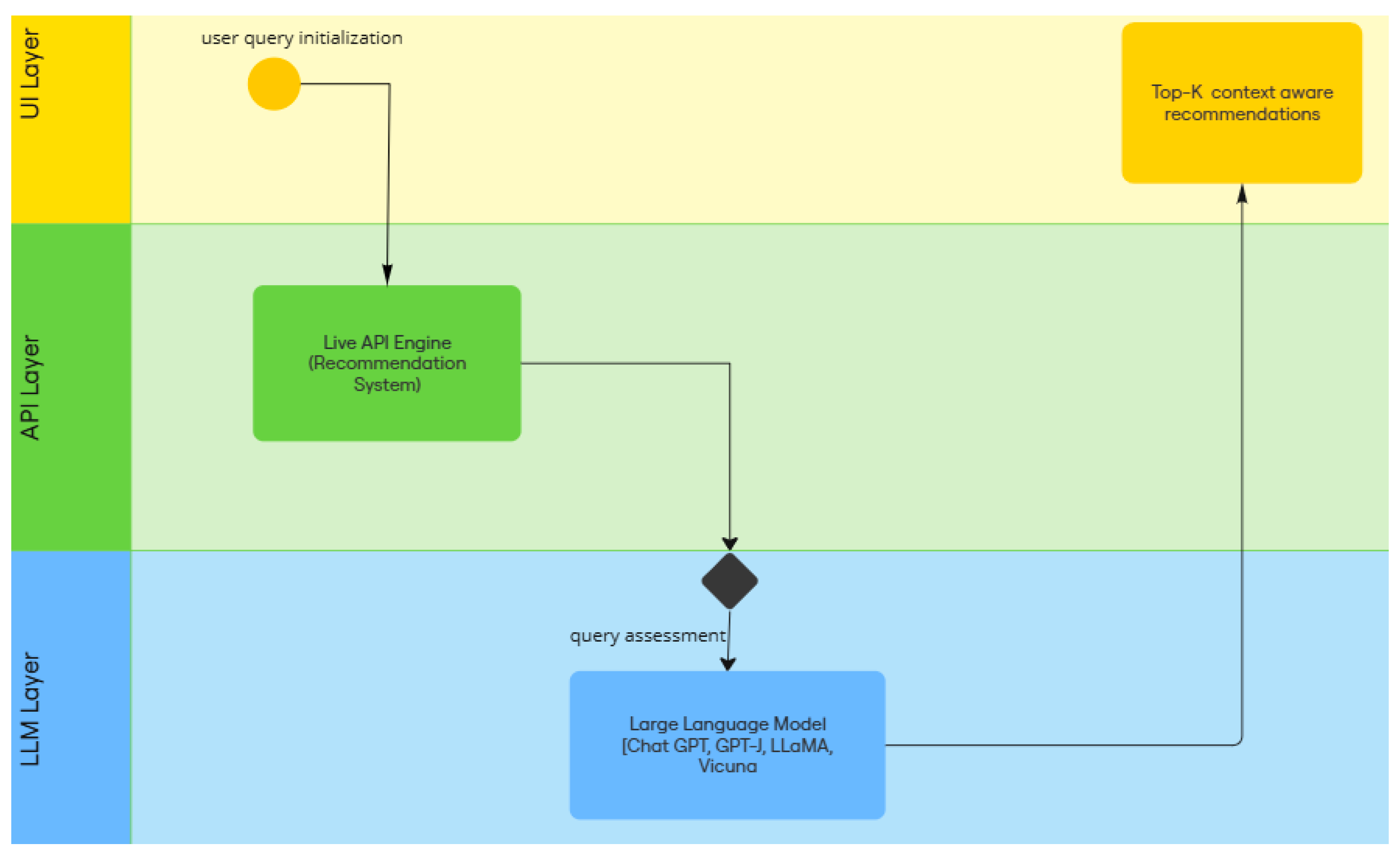
1.1. Framework Design
The designed framework consists of three layers as shown in
Figure 1. The first layer is UI layer. This layer allows user to interact with the system and submit query. The same layer is responsible for sending context tualized recommendations back to the user. This layer has been developed using ShadcnUI components [
16], chosen for their flexibility and ability to deliver a clean, responsive user experience. The Google Maps Embed feature via ext.js [
17] provides users with an interactive map view of recommended restaurants. The intermediate layer is available to processing query and pro vide recommendations while accessing the live data which is then passed to the third layer for further optimization using LLMs. Once the LLM processes the query’s context, it sends the recommendations back to the UI layer. The backend is implemented using Next.js, which provides API routes to manage requests and data flow between the user interface, Google Places API, and OpenAI API [
18]. The aisdk/Open AI library enables direct interaction with OpenAI’s ChatGPT4o model. The AI Client class in the backend manages the recommendation generation, using the custom prompt schema to provide ChatGPT with structured data.
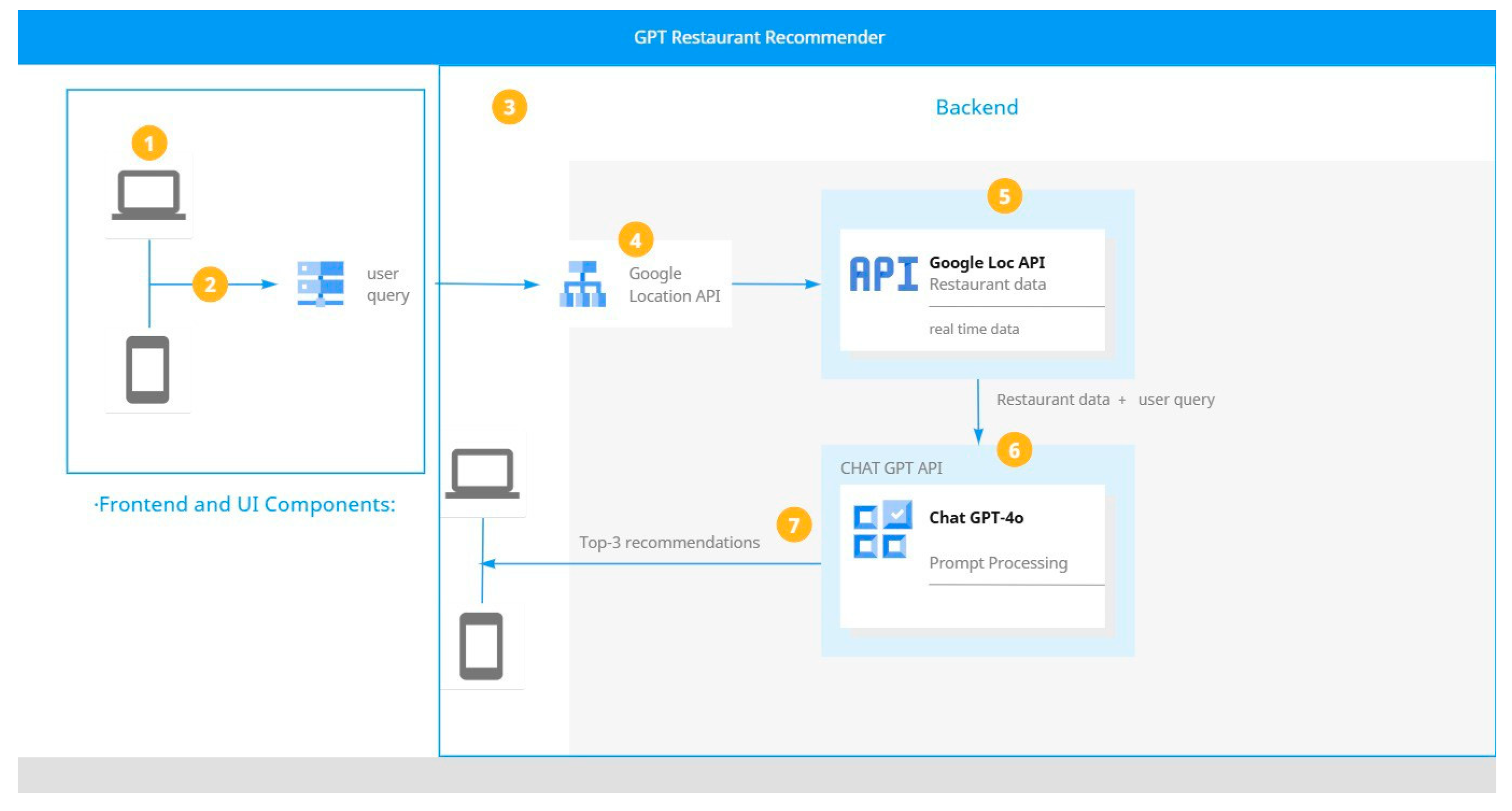
To materialize the effectiveness of the proposed framework, a web application named “GPT restaurant recommender” is developed. The technology stack adopted for this development includes Next.js [
19] deployed on Ver cel [
20], a modern deployment platform optimized for serverless web applications. The architecture integrates several components to deliver recommendations.
Figure 2 shows the system architecture diagram.
The user initiates the process by entering their inquiry such as location, dietary requirements, and any other additional context to the web application. The system makes an API call to Google Places to collect initial restaurant data based on user preferences. The Google Places API returns a list of restaurants that match the initial query parameters, providing information such as restaurant name, location, rating, and other relevant attributes. ChatGPT processes the restaurant data retrieved from Google Places alongside the user’s specific criteria. ChatGPT evaluates each restaurant to determine the top recommendations based on the relevance of the user’s query. Once the evaluation is complete, ChatGPT selects the top three relevant restaurants from the list, by filtering based on user preferences and embedded ethical constraints.
The selected restaurants are then sent to users via the web interface, each accompanied by details such as location, contact information, and ratings. The user views the final recommendations, allowing them to choose a restaurant based on the personalized suggestions provided. This structured flow ensures that the system meet user requirements for personalized, location based, and relevant restaurant recommendations while maintaining quick response times.
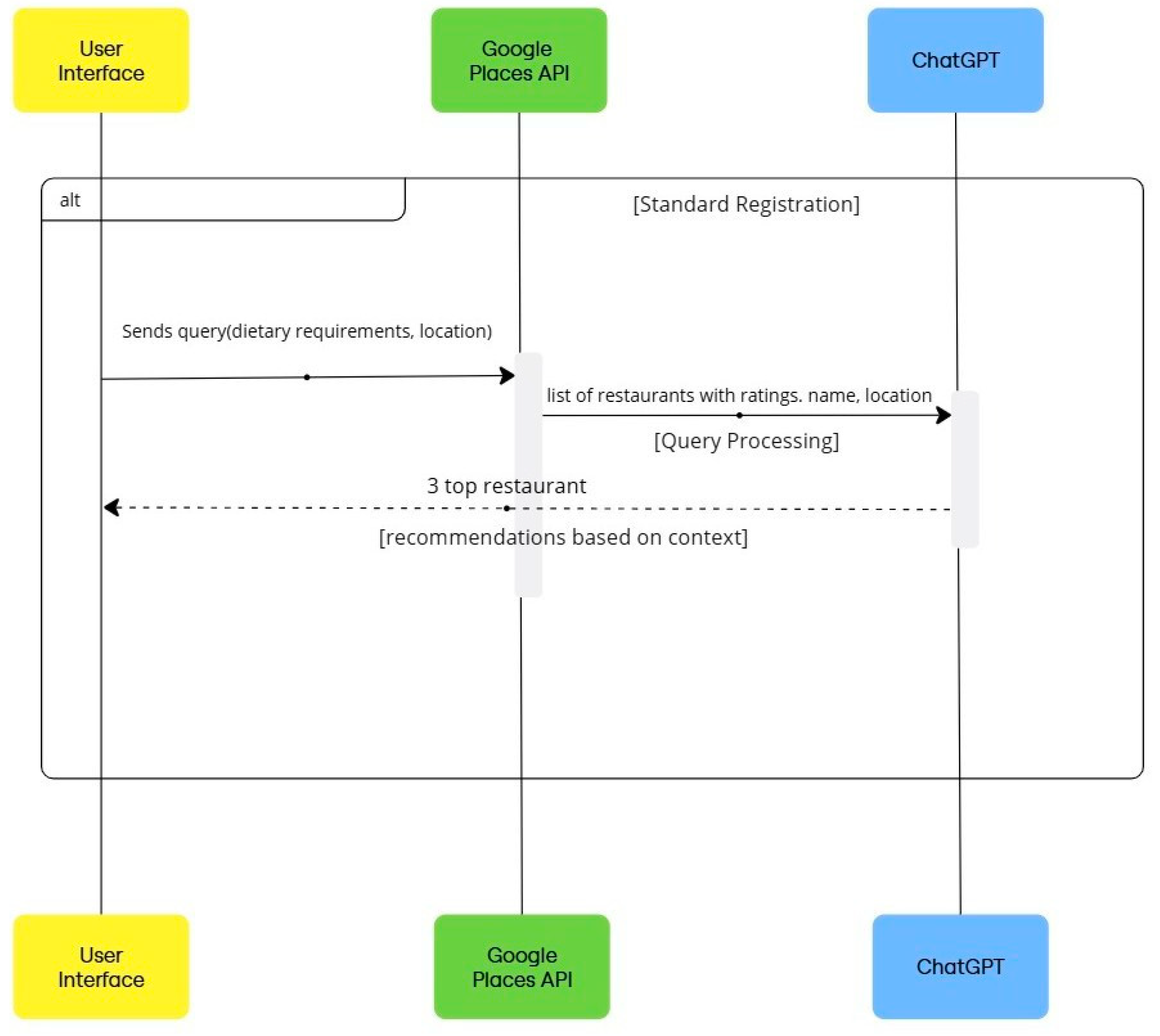
Figure 3 illustrates the system process for the diagram. The screen grabs of the web application to realize the research idea are shown in
Figure 4,
Figure 5 and
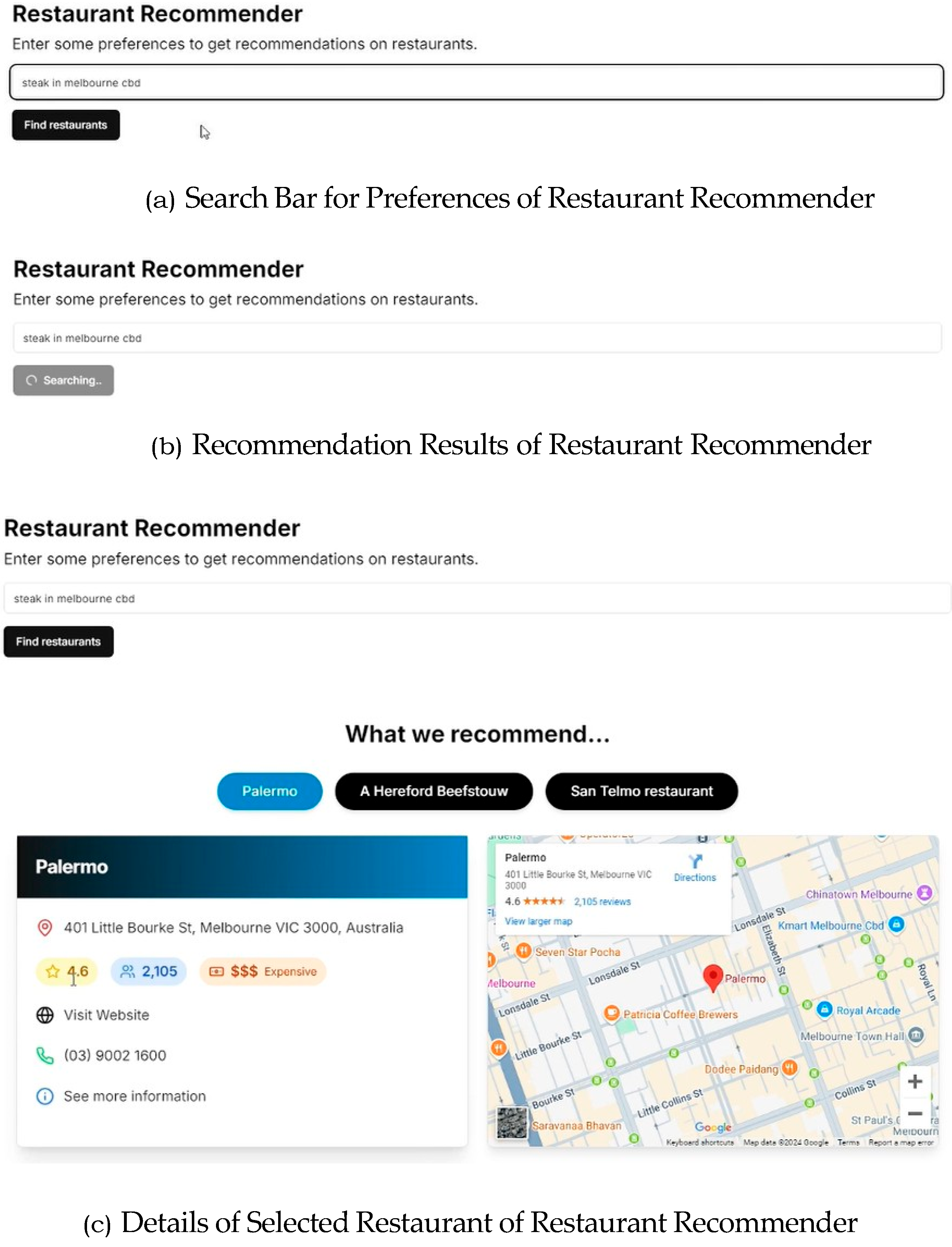
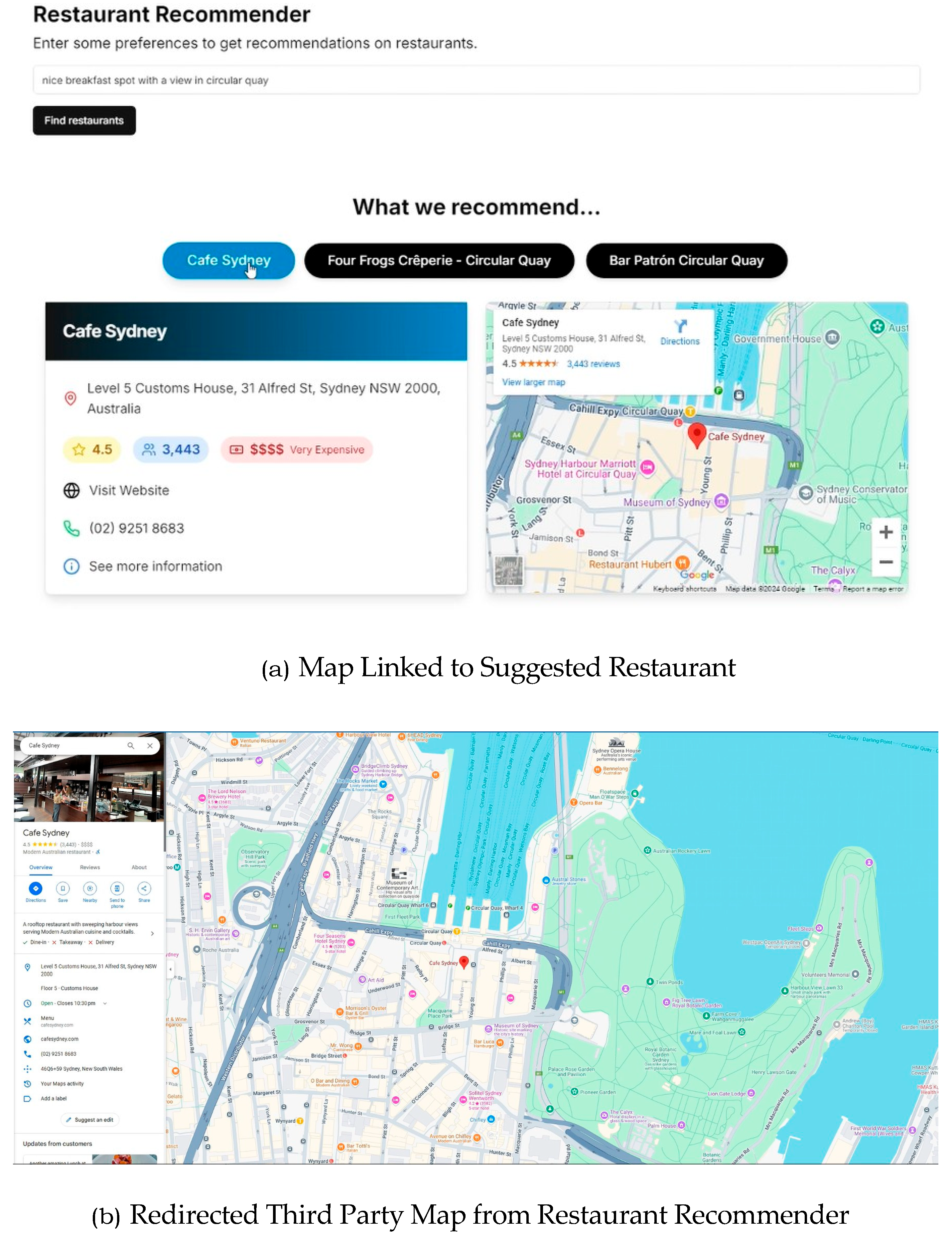
Figure 6 respectively. The web application begins by prompting the user to enter their preferences to receive personalized restaurant recommendations, as shown in
Figure 4a. Upon clicking “Find restaurants” button, the system initiates a searching process (
Figure 4b), retrieving and ranking relevant restaurant options. The top three recommendations are then displayed to the user. When a restaurant is selected, additional details such as rating, budget indication and an interactive map are proved to the user for convenience as shown in
Figure 4c.
Figure 5a demonstrates a search performed for the Sydney region. Clicking on the map feature allows users to view the restaurant’s precise location on Google Maps, offering seamless navigation assistance as shown in
Figure 5b.
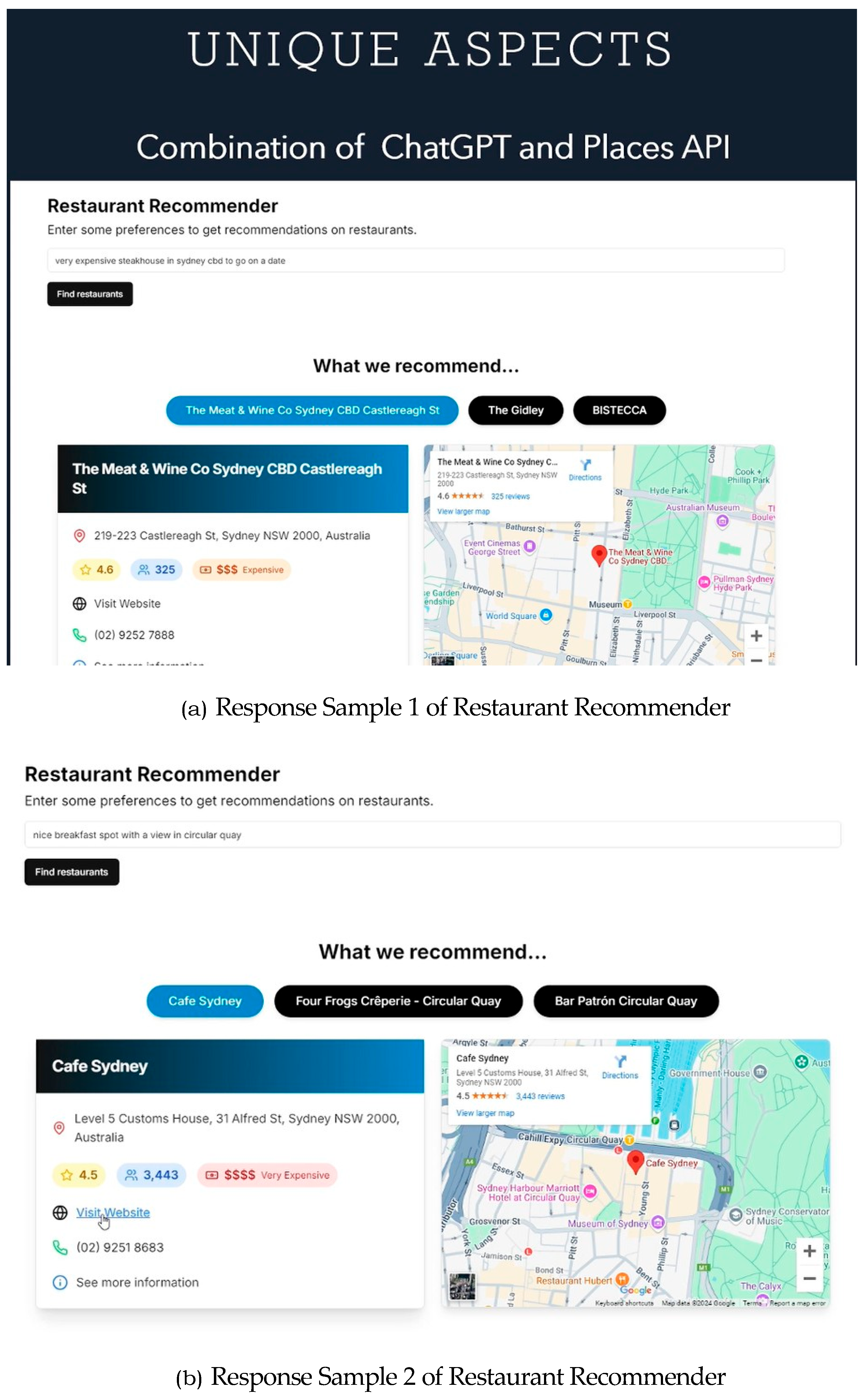
Figure 6a,b below illustrate the web application’s responses when user preferences are modified. By adjusting criteria such as budget constraints and dining preferences, the system generates distinct recommendations, showcasing its ability to adapt dynamically to varying user inputs. This demonstrates the effectiveness of the proposed framework and the robustness of its design principles in delivering personalized and context-aware recommendations.
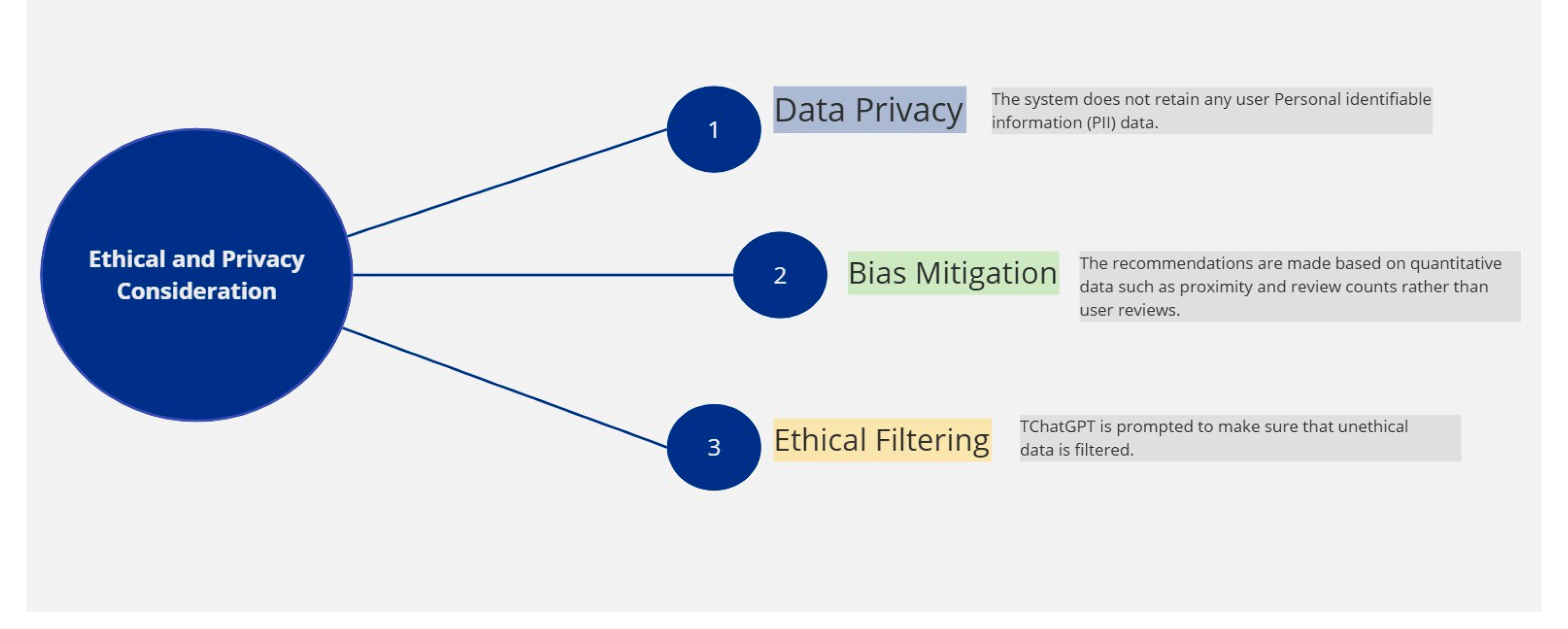
1.2. Ethical and Privacy Consideration
To ensure that ethical AI principles and user privacy are followed, careful design considerations are adopted as shown in
Figure 7 below. These ethical and privacy considerations ensure that the recommendation system is secure, transparent, and reliable, aligning with best practices in the deployment of responsible AI.
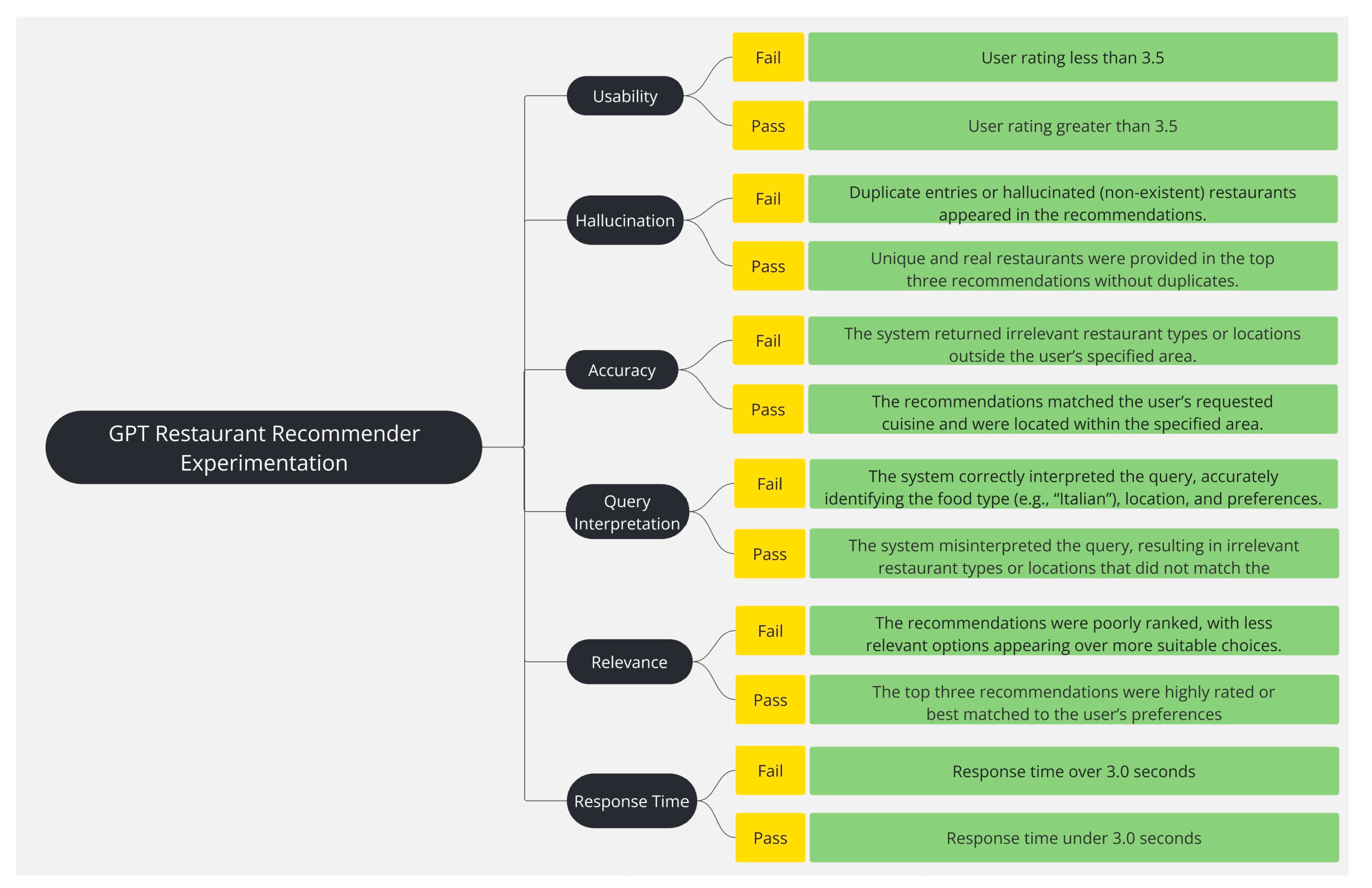
Experimentation and Evaluation
The primary objective of this experiment is to evaluate the application of LLMs (specifically ChatGPT4o) in enhancing existing recommendation systems, such as Google, for restaurant recommendations. To evaluate the performance improvement by integrating LLMs with the existing recommendation systems a set of metrics has been defined. These include the management of complex queries, contextual accuracy, user satisfaction, and system response time, as presented in
Table 2.
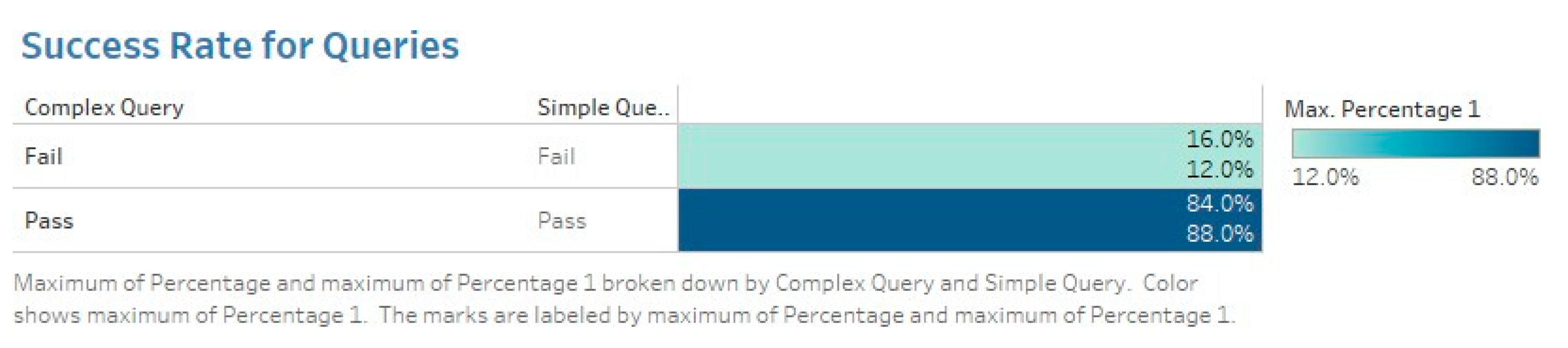
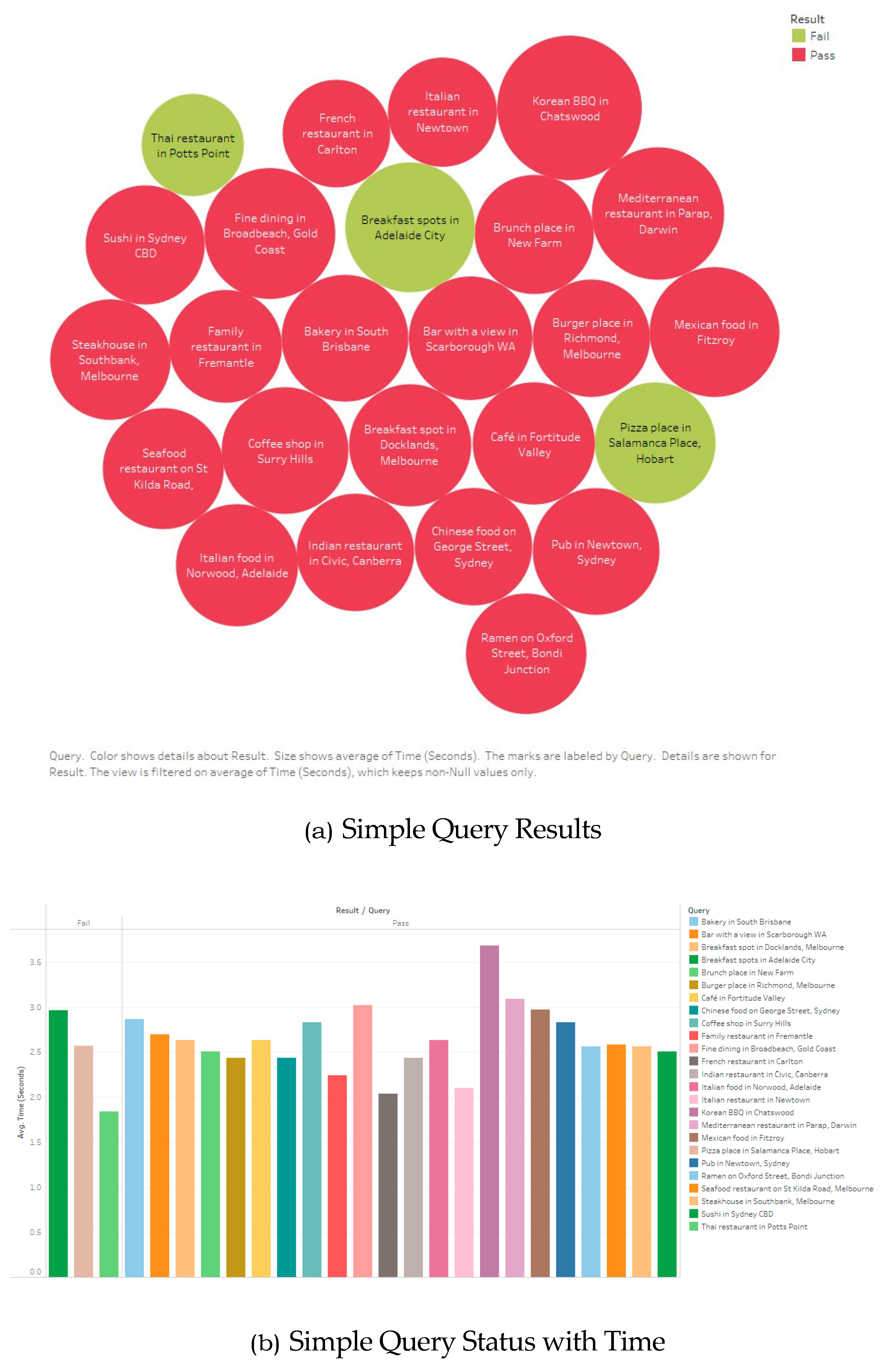
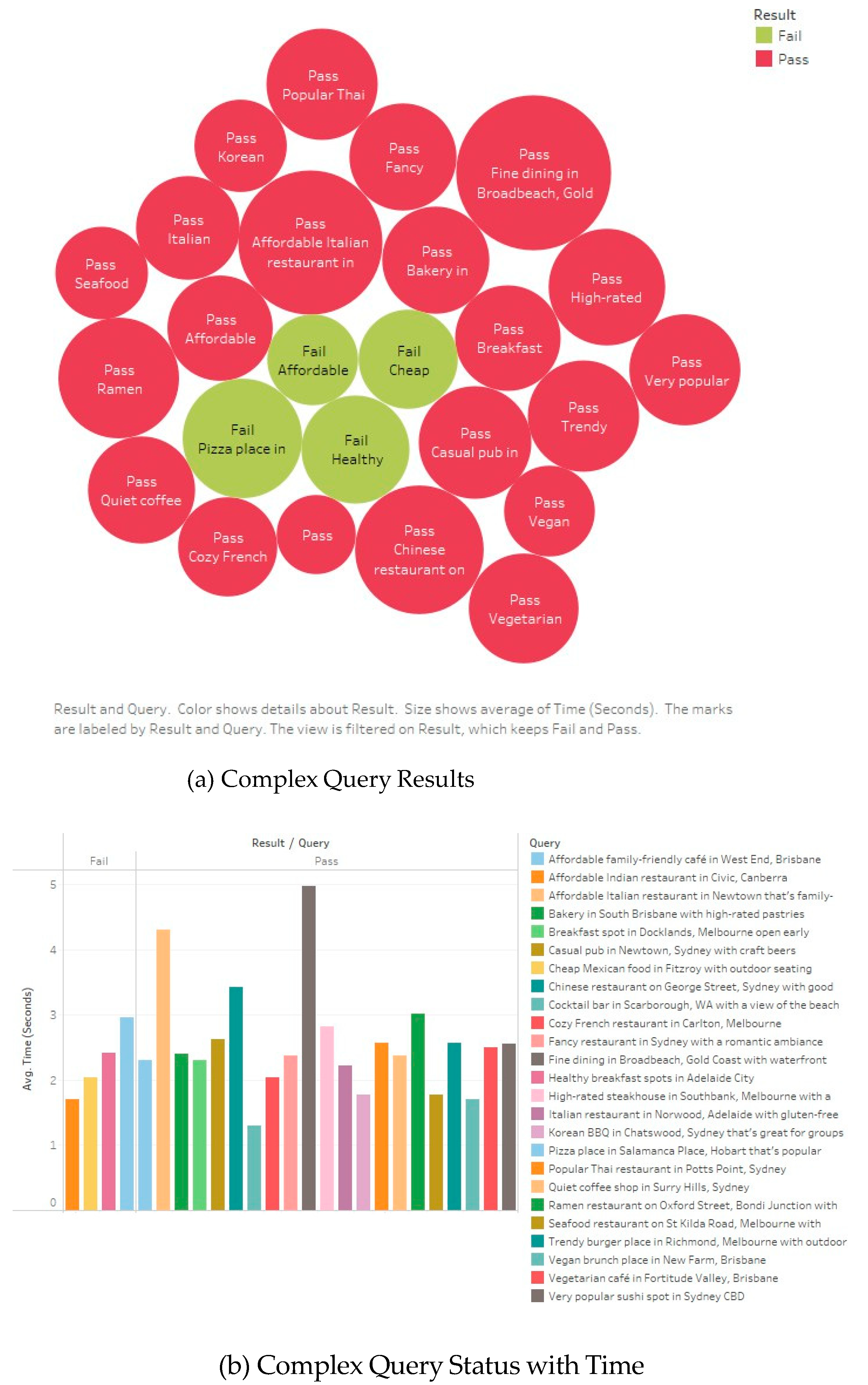
Management of complex queries demonstrated the ability of the system to process and interpret complex queries. It also reflects the system’s capacity to understand multifaceted user requests. This criteria was measured by the system’s ability to correctly interpret and apply specified constraints while maintaining the accuracy and relevance of recommendations. The pass rate for basic queries was 88%, whereas complex queries achieved an 84% success rate, indicating that while the system effectively managed standard requests, nuanced multicriteria filtering introduced additional challenges.
Contextual (location based) results ensure that recommendations align with the user’s specified geographical constraints, such as suburb, city, or street level details. The system leveraged the Google Places API to retrieve real time restaurant data and applied further filtering to rank results based on location relevance. High accuracy of contextual recommendations indicates if the system effectively adhered to spatial constraints.
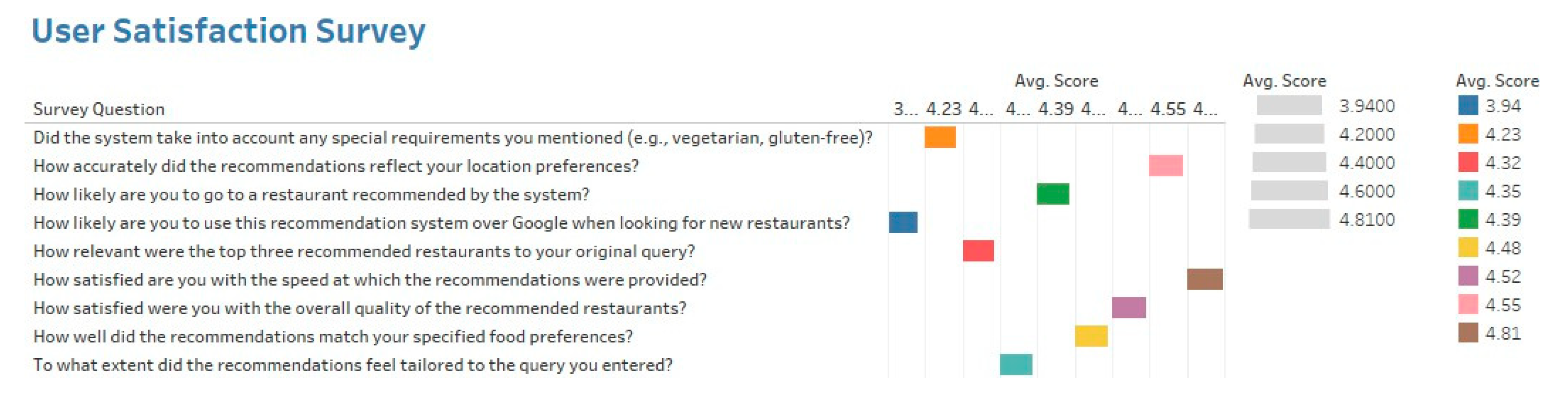
User satisfaction assessment ensures that the system is user friendly and helps in the quantification of user requirement satisfaction. It was assessed through a structured survey where participants evaluated key aspects of the system, including recommendation relevance, personalization, handling of special requirements, and overall usability. The aspects included the system response time, food preference accuracy, overall recommendation quality, and customization capability.
System response time was measured across all test case user inquiries to determine whether the recommendation system could deliver results within the predefined 3.0second threshold. The slightly faster response time for complex queries can be attributed to the smaller dataset retrieved from the API. A small number of test cases exceeded the 3.0second threshold, particularly those involving high complexity requests, but these instances rep resented outliers rather than systemic inefficiencies.
For system experimentation, two sets of user requests were formulated. Each is for complex and simple requests, respectively. Successful query testing requires that each query satisfy all the criteria outlined in
Table 2. Failure to meet any criterion resulted in an overall failure of the query.
Figure 8 shows the failure and passing rate of queries.