Submitted:
07 February 2025
Posted:
10 February 2025
You are already at the latest version
Abstract
Abstract Large language models (LLMs) can process and produce text with high accuracy by utilizing advanced architectures based on deep neural networks, especially transformers. Using self-supervised learning and massive datasets, these models can extract complex semantic relationships and perform tasks such as machine translation, text summarization, question answering, and multimodal learning. However, current language models still face challenges such as limitations in deep reasoning, inability to perform multi-step inference, high computational costs, algorithmic bias, and security issues. In this article, HyperLLM is introduced as an evolved and multimodal model that can simultaneously analyze image, audio, and video data in addition to language processing. This model utilizes advanced neural architectures, adaptive learning algorithms, quantum processing, and federated learning to perform complex inferences without retraining. The essential features of HyperLLM include integrating quantum computing, optimizing processing resources, increasing processing speed, reducing operating costs, and improving energy sustainability. Also, this model will be able to preserve user privacy and increase data security by using advanced cryptographic mechanisms and decentralized learning. HyperLLM can be considered a bridge between existing language models and artificial general intelligence (AGI), which can reason beyond statistical patterns and create a fundamental transformation in information processing, human-centered interactions, and intelligent decision-making systems.
Keywords:
large language model
; HyperLLM
; artificial general intelligence
; LLM advanced
; multimodal learning
1. Introduction
Large Language Models (LLMs) are deep neural network-based artificial intelligence systems that use advanced architectures, especially Transformers, to process and generate text. Using self-supervised learning and large datasets, these models can model the statistical distribution of natural language, extract complex semantic relationships, and perform tasks such as machine translation, text summarization, question answering, and multimodal learning [1,2]. Using vector embeddings in high-dimensional spaces, these models can preserve long-term dependencies in text data and establish more accurate conceptual relationships between words and phrases. From a structural and architectural perspective, large language models rely on multi-head self-attention layers that enable the extraction of nonlinear dependency relationships in long sequences. In these models, the pretraining process is performed on a large amount of data and optimized for specific tasks through fine-tuning or transfer learning [3,4]. Some of the most famous models include GPT-4 (from OpenAI), PaLM-2 (from Google DeepMind), Llama (from Meta AI), and T5 (from Google), each of which is optimized for a specific field. Despite the high performance of these models, there are fundamental challenges in scalability, computational efficiency, bias mitigation, and data security and privacy [5,6]. Today's models require potent processors such as GPUs and TPUs, and due to the high training costs, their large-scale use is limited. Also, issues such as "linguistic hallucination" in text generation, model controllability, and dependence on training data quality are serious challenges in developing advanced LLMs [7,8]. In the future, combining these models with quantum computing, more efficient architectures such as sparse models, and new approaches in adaptive learning could lead to a new generation of LLMs, which can be imagined as HyperLLM.Despite significant advances in natural language processing, current large language models such as GPT-4, Gemini, and Llama still face fundamental limitations that affect their performance in complex and specialized applications. One of the basic challenges of these models is their limitations in deep reasoning and multi-step logical inference, such that their ability to analyze and process incomplete or ambiguous information still needs to be improved. In addition, the lack of dynamic learning is another key shortcoming of these models, meaning that the models above require re-training sessions to update their knowledge, which is extremely expensive in terms of both computational cost and energy consumption. On the other hand, controlling bias and algorithmic inequalities remains a serious challenge, as these models are implicitly influenced by their training data and may produce outputs with racial, gender, or cultural biases. Security and privacy limitations are also a concern, as current models lack strong cryptographic mechanisms to process sensitive user data. Finally, the challenge of computational efficiency and the dependence of these models on extensive hardware infrastructures such as graphics processing units (GPUs) and computational accelerators (TPUs) have prevented their widespread and efficient deployment in industrial and enterprise environments. With the significant progress of large language models (LLM) and their integration into various scientific and industrial fields, the need to develop a new generation of these models with capabilities beyond traditional natural language processing frameworks is increasingly felt. HyperLLM can be considered an evolved and multimodal model that, in addition to text processing, can simultaneously analyze multimodal data such as images, audio, and video. This model can perform complex inference processes dynamically without retraining by utilizing advanced neural network architectures and adaptive learning algorithms. One of the outstanding features of HyperLLM is the integration of quantum computing capabilities and architectures optimized in terms of computing resource consumption, which will lead to increased processing speed, reduced operating costs, and improved energy sustainability on a large scale. On the other hand, this model can fully protect users' privacy by using advanced cryptographic techniques and federated learning. HyperLLM can be considered as a bridge between current large language models and artificial general intelligence (AGI), which is capable of reasoning beyond purely statistical patterns and paves the way for a fundamental transformation in information processing, human-centered interactions, and intelligent decision-making systems.
2. Key Features of HyperLLM
Large language models (LLMs) have made significant progress in natural language understanding and processing complex data in recent years [9]. However, one of the fundamental challenges in developing these models is the ability to process multimodally, such that the model can simultaneously analyze and interpret text, image, audio, and video data. In this regard, HyperLLM, a more advanced generation of language models, must utilize sophisticated architectures that enable multimodal processing and understand the deep connections between these data. Existing models such as GPT-4, Gemini, and Flamingo have advanced in multimodal processing but still face limitations such as poor convergence of information from different sources and high dependence on preprocessed data. HyperLLM must overcome these limitations by using cross-modal attention mechanisms. These mechanisms allow the model to discover deep semantic relationships between text and image, identify temporal correlations between audio and video, and simultaneously have high adaptability to multimodal inputs. Implementing a Unified Multimodal Encoder based on Self-Supervised Learning at the computational architecture level can improve the model's heterogeneous data processing. In addition, the development of standard multimodal embeddings, in which abstract features of text, image, and audio data are mapped into a homogeneous vector space, is essential for synchronizing information from different sources. Other challenges should also be considered in the HyperLLM design. In this regard, using Sparse Activation Models, Edge AI Mechanisms, and computational optimization through pruning and quantization techniques can enhance the model's performance to a higher level. Overall, HyperLLM can optimally process multimodal data ext,ract complex semantic dependencies between different modalities, and effectively apply them in its decision-making process. This capability will make it a powerful medical tool, multimodal media analysis, and human-machine interactions.
2.1. Multimodal Capabilities in HyperLLM
One of the fundamental challenges in developing large language models (LLM) is to improve the multimodal data processing capability so that the model can simultaneously and optimally analyze and interpret text, image, audio, and video information [10]. As a more advanced generation of language models, HyperLLM must utilize complex architectures that process multimodal data and deeply understand the relationships between these data. In this regard, the integration of specialized neural networks such as Transformers for natural language processing (NLP), convolutional neural networks (CNNs) for image analysis, and recurrent neural networks (RNNs) or Wav2Vec for audio processing is essential. HyperLLM must be able to integrate these models into a unified framework to achieve a comprehensive understanding of multimodal inputs. In addition, current models such as GPT-4, Gemini, and Flamingo have progressed in this area. However, they still face limitations, including poor convergence of information from different sources and dependence on pre-processed data. HyperLLM should address this deficiency by utilizing cross-modal attention mechanisms [11,12]. These mechanisms allow the model to discover deep semantic connections between text and image, identify temporal correlations between audio and video, and simultaneously have high adaptability to input data. Implementing a Unified Multimodal Encoder based on Self-Supervised Learning at the computational architecture level can improve heterogeneous data processing. Hence, this requires the development of standard multimodal embeddings in which abstract features of text, image, and audio data are mapped into a homogeneous vector space [13,14,15]. Other challenging issues like increasing the scalability of multimodal data processing, optimizing computational resources, and minimizing the latency of model inference should also be considered in the HyperLLM design. To this end, using Sparse Activation Models, Edge AI mechanisms, and computational optimization through Pruning and Quantization techniques can enhance the model's performance to a higher level. In summary, HyperLLM can extract complex semantic dependencies between different modalities in addition to processing multimodal data and efficiently applying them in its decision-making. This feature will not only enhance the reasoning capabilities of the model but also make it a powerful tool for fields such as medicine, multimodal media analysis, and human-machine interaction.
2.2. Advanced Reasoning and Adaptive Logic in HyperLLM
One of the key features expected in HyperLLM is the ability to perform Advanced Reasoning and utilize Adaptive Logic to process and infer information in complex and unstable conditions. This feature allows the model to go beyond simple statistical pattern matching and to perform multi-step inference, solve complex problems, and interpret ambiguous data with high accuracy and efficiency.
2.2.1. Advanced Reasoning
Advanced Reasoning in language models refers to the ability to process data hierarchically, analyze relationships between concepts, and extract new knowledge from existing information. In HyperLLM, this type of Reasoning is taken to higher levels, including combining Transformer-based architectures with graph neural networks (GNNs) and symbolic reasoning models. This approach allows for more complex processing and interpretation in different reasoning frameworks. Deductive Reasoning in HyperLLM enables the model to draw logical and accurate inferences from known principles. Inductive Reasoning will allow it to generalize general patterns from sample data and predict new information using probabilities. Analogical Reasoning, with the help of graph processing capabilities, allows the model to identify structural similarities between seemingly unrelated concepts and use them to solve new problems. Also, by analyzing dependencies between variables, Causal Reasoning enables us to understand causal relationships and provide logical explanations for observed events. Combining these methods in HyperLLM enhances the reasoning power of the model and its ability to process linguistic concepts more deeply and make adaptive decisions when faced with complex problems.
2.2.2. Adaptive Logic
One of the fundamental limitations of current language models is the inability to change Reasoning and adaptive logic based on environmental conditions and data changes. Using Adaptive Logic, HyperLLM can dynamically change the inference process based on new evidence and provide probabilistic and adaptive answers in situations of uncertainty. This model can revise and update the knowledge structure without extensive retraining, improving continuous learning and adapting to dynamic environments. HyperLLM combines reinforcement learning models with fuzzy logic and probabilistic Reasoning to create a flexible and dynamic reasoning structure that achieves this capability. From an implementation perspective, this model leverages the integration of machine learning with symbolic logic, which combines Transformer-based models with Semantic Knowledge Graphs to improve semantic inference. Bayesian Inference also enables dynamic decision-making under uncertainty, while Abstract Learning enables generalizing rules and concepts to unrelated domains. Furthermore, integrating First-Order Logic (FOL) into the HyperLLM architecture increases the accuracy in understanding complex concepts and provides more profound reasoning results.
2.2.3. Implementing Advanced Reasoning and Adaptive Logic in HyperLLM
In implementing advanced reasoning and adaptive logic in HyperLLM, it is essential to use a combination of symbolic reasoning and machine learning methods. Symbolic reasoning is based on First-Order Logic (FOL), Semantic Knowledge Graphs, and deductive inference, which allows the model to understand structured reasoning rules. On the other hand, machine learning and deep neural network-based models can process large data sets and infer statistical patterns. Still, they are weak in causal and logical reasoning. HyperLLM can facilitate deep learning and symbolic reasoning by using Neuro-Symbolic AI techniques. For example, Markov Logic Networks (MLN) can combine fuzzy logic and probabilistic models, and Bayesian Neural Networks (BNNs) can be used for inference under uncertainty. In addition, Differentiable Logic Programming methods allow the model to derive logical rules from raw data. At the same time, Probabilistic Soft Logic (PSL) can process uncertain relationships and noisy data. Using Graph Neural Networks (GNNs) also allows the extraction of complex semantic relationships in HyperLLM knowledge bases, which can help the model understand indirect relationships and analyze hierarchical concepts. Despite the high potential of HyperLLM, the development of this system faces several technical challenges. One of the most significant obstacles is the need for massive processing power and optimized hardware architectures to process models with trillions of parameters. Hence, this requires supercomputers, special processors such as NVIDIA H100 GPUs, and new-generation TPUs. In addition, bias control and model transparency are key challenges in large language models, which in HyperLLM, due to symbolic reasoning, can propagate systematic biases existing in knowledge bases. Solutions such as automatic bias control through Adversarial Reinforcement Learning or Human-in-the-loop Adaptive Feedback can help mitigate these problems. Also, cybersecurity and privacy, especially in multi-modal data processing, require the design of high-level cryptographic protocols, federated learning-based processing, and differential privacy methods to enable the secure use of the model in sensitive applications such as medicine and financial data analysis. Finally, energy sustainability is also a key challenge in developing large-scale models, which requires energy optimization through Sparse Models, Edge AI, and quantum computing-based processing architectures.
2.3. Dynamic Learning & Continuous Adaptation In HyperLLM
In HyperLLM, the concept of dynamic learning and continuous adaptation is one of its key features. Unlike conventional language models that rely on batch training processes and require retraining on new data sets to update information, HyperLLM can benefit from a continuous adaptive learning architecture. By combining Adaptive Memory Networks and Sequential Meta-Optimization Algorithms, this architecture can process and embed knowledge changes in real-time without the need for complete retraining. In addition, sparse models and fine-tuned reinforcement learning allow HyperLLM to absorb and process new information with minimal computational cost. This capability increases processing and energy efficiency and enables the development of autonomous models with the ability to adapt to environmental data in real time. As a result, HyperLLM can continuously update its knowledge and learn from conceptual and linguistic changes in interaction with users and the environment automatically and without human intervention. Hence, this is an essential step towards developing language models beyond current generations.
2.4. Deep Personalization in HyperLLM
Using self-adaptive AI architectures and multi-layered semantic representation models, HyperLLM offers a new level of deep personalization that is not only dependent on surface parameters such as user preferences but also uses distributed dynamic learning matrices, interactive feedback models and neural long-term memory to adapt to complex cognitive, emotional, and functional contexts. In HyperLLM, personalization does not only rely on static profiling and default settings but also uses transfer learning, adaptive fine-tuning, and multi-source data fusion mechanisms to extract and model each user’s specific linguistic features, speech style, communication intent, and behavioral patterns. Hence, this allows the model to dynamically adjust neural weightings to user-dependent parameters over repeated interactions, resulting in linguistically and semantically accurate responses that are cognitively and emotionally optimized. A key advantage of this level of personalization in HyperLLM is the use of advanced neural long-term memory models and semantic encoding, which enable the system to analyze long-term sequences of interactions and identify user cognitive and behavioral trends over extended time scales. This process is enhanced by hierarchical neural networks and reinforcement memory models so that the model can account for complex reasoning contexts and tailor its production decisions to the individual needs of users. Regarding security, HyperLLM uses federated encryption, privacy-preserving learning, and distributed data exchange protocols to achieve deep personalization while preserving privacy. This combination ensures that personalization occurs in a secure and decentralized environment without the risk of exposing or misusing sensitive user information. Overall, deep personalization in HyperLLM optimizes user interactions and adds a layer of cognitive inference to the model’s responses through neural self-optimization mechanisms and adaptive behavior analysis, resulting in more accurate, relevant, and natural content in terms of human perception.
2.5. Computational Efficiency and Energy Efficiency in HyperLLM
Large Language Models (LLMs) are one of the fundamental challenges of modern AI due to their high computational complexity, huge processing resource requirements, and significant energy consumption. As an advanced architecture, HyperLLM uses Adaptive Load Balancing Algorithms and Dynamically Sparse Neural Networks to reduce unnecessary computation and achieve energy efficiency beyond existing models. One of the key approaches in this model is the use of Hybrid Multi-Tier Architectures, which combine advanced Transformer Neural Networks, Adaptive Quantum-Assisted Models, and Tensor Decomposition for Parameter Pruning. This combination reduces the dependency on linear and traditional processing, enabling deep learning operations with minimal computational power. Hybrid Quantum-Classical Computation also plays a vital role in energy optimization; this technique increases efficiency at the architectural level by accelerating heavy matrix operations, such as tensor multiplication and tensor-kernel calculations, and reduces the need for conventional hardware. In addition, HyperLLM uses Precision Reduction Algorithms that minimize processing costs and energy consumption in training and inference operations by intelligently adjusting the precision of variables and reducing processing bits at specific levels. The use of low-power processing units optimized for vector operations (Low-Power Vectorized Processing Units) in the hardware architecture allows for a reduction of more than 40% in energy consumption compared to traditional Transformer models. On the other hand, Edge AI and Decentralized AI Processing in HyperLLM intelligently organize the distribution of computations between the cloud, edge servers, and end devices. This solution reduces the need to send large amounts of data to data centers, thereby reducing network latency, optimizing communication traffic, and increasing energy efficiency at the infrastructure level. Implementing Dynamic Computational Engines with Adaptive Activation Control allows HyperLLM to keep only the necessary parts of the neural network active at any given time, thereby reducing the need to run unnecessary processing and increasing overall efficiency. Finally, Chip-Level Optimization in HyperLLM optimizes energy performance through integrated Quantum Processing Units (QPUs) and Application-Specific AI Accelerators for neural models, paving the way for creating highly efficient and scalable models. These innovations enable faster and more energy-efficient processing and significantly reduce the carbon emissions of AI processing compared to classical models, paving the way for the sustainable development of intelligent language models at scale.
3. Proposed Architecture of HyperLLM
The proposed HyperLLM architecture is designed as an advanced generation of large language models (LLMs) to provide higher performance and optimize multi-dimensional data. This architecture uses modern technologies and advanced algorithms to address complex processing challenges and reduce computational and energy costs. Four key elements used in this architecture are Sparse Models to optimize the number of parameters, the combination of advanced neural networks including Transformers, CNNs, and RNNs to process multi-dimensional data, the use of quantum computing to reduce computational complexity, and the use of Edge AI for faster processing and reduced dependence on cloud infrastructure. This combination of technologies allows HyperLLM to operate effectively and efficiently in complex, large-scale environments.
3.1. Extremely High Parameters and Sparse Models in HyperLLM
One of the biggest challenges in designing and developing large language models (LLMs) is managing the extremely high volume of parameters and optimizing the computational processes to reduce energy and time costs. In classical LLM models, the number of parameters is usually so large that high computational costs simultaneously accompany the training and inference processes. Therefore, sparse models in the HyperLLM architecture have been proposed as a key solution to these challenges. Sparse models are mainly based on the selective activation of neurons and parameters in neural networks. In other words, in this approach, only a part of the model parameters that are relevant to a specific input and task are activated. In contrast, other parts that do not affect the results remain inactive. This process is particularly useful in models such as Sparse Transformer Architectures, which can use only the parts of the network that are relevant to processing specific inputs without having to activate all parameters. Hence, the HyperLLM architecture uses advanced techniques such as Mixture of Experts (MoE) to achieve this optimal performance. In MoE, the network is divided into expert groups, each of which can process data in a specific domain. In this model, only one or more expert groups are activated for each input, while the other groups remain inactive. Hence, this allows the model to selectively use different network parts during processing, thus making optimal use of computing power. In this context, Sparse Transformers are particularly useful for reducing the computational complexity of natural language processing. In this architecture, only a portion of each processing layer's parameters are activated, resulting in reduced processing time and reduced memory and energy consumption. Since these models selectively activate neurons and layers, faster processing and better scalability are possible. This approach allows the HyperLLM model to utilize much higher processing power without processing all the model parameters at each stage. As a result, the model can scale when faced with large and complex inputs without requiring abundant computational resources and high energy consumption. In addition, these techniques allow HyperLLM to operate effectively in situations where optimizing energy consumption and reducing processing latency are of great importance. Overall, using sparse models in the HyperLLM architecture helps reduce the need for computational resources and increases scalability, energy costs, and model accuracy in processing complex data. Figure 1 illustrates of using sparse models and Mixture of Experts (MoE) in HyperLLM to optimize computational efficiency.
3.2. Combining Advanced Neural Networks (Transformers + CNNs + RNNs) in HyperLLM
In HyperLLM architecture, multimodal data processing requires advanced neural networks, each capable of analyzing a specific data type with different characteristics. Three consequential types of neural networks are used to achieve this goal: Transformers, Convolutional Neural Networks (CNNs), and Recurrent Neural Networks (RNNs). Each of these networks has specializations in processing different data modalities, and combining them in a single architecture allows HyperLLM to effectively process complex and multimodal data and understand the semantic and temporal relationships between them.
- Transformers: Transformer networks are one of the most advanced and widely used Natural Language Processing (NLP) architectures. These networks are specifically designed to process sequential data such as text. Transformers can model long-term and complex dependencies between words and phrases in a sentence or paragraph, especially by using a self-attention mechanism that allows the model to examine the semantic relationships between all input words simultaneously. These features make HyperLLM capable of processing complex and lengthy texts with higher accuracy and efficiency. In HyperLLM, Transformers are used to understand and analyze text data. These networks can effectively discover the semantic structure and how different text sentences are related, producing more accurate and meaningful text.
- Convolutional Neural Networks (CNNs): CNNs are traditionally used to process image data. These networks extract essential features from images using convolution filters and various dimensionality reduction techniques. CNNs are particularly good at recognizing complex spatial patterns and structures, which is critical in image data processing. In HyperLLM, CNNs analyze image data or data with spatial features (such as medical images or video-based data). CNNs allow the model to extract essential features such as edges, textures, and shapes from images and pass them to other networks (such as Transformers) for further analysis.
- Recurrent Neural Networks (RNNs): RNNs are designed to process sequential and temporal data. They are instrumental in audio data processing, video analysis, and temporal predictions. By learning from temporal sequences and preserving previous states in subsequent processing, RNNs can understand temporal patterns and audio sequences or continuous signals. In HyperLLM, RNNs process audio, speech, and other sequential data. The model can effectively analyze spoken language and understand an audio conversation's temporal and semantic relationships. Also, using more advanced LSTM and GRU models, which avoid the short-term memory problems of traditional RNNs, provides higher accuracy and efficiency in processing more complex data.
Combining these three types of neural networks in HyperLLM allows the model to understand and process different data with diverse characteristics. Transformers are used for natural language processing and semantic analysis, CNNs for image and spatial data processing, and RNNs allow the model to process sequential and temporal data. This combined architecture helps the model analyze text, photo, and audio data and discover semantic, spatial, and temporal relationships between them. Ultimately, this combination makes HyperLLM capable of processing multimodal data with high accuracy and speed and can effectively perform in various applications such as text understanding, image analysis, speech processing, and temporal data analysis. Figure 2 represents how HyperLLM processes text, image, and sequential data using Transformers, CNNs, and RNNs to achieve high accuracy and efficiency.
3.3. Quantum Computing in AI Models
Quantum computing is one of the fundamental innovations in science and technology that has great potential to revolutionize various fields, including artificial intelligence (AI). While traditional AI models are designed based on classical computing, quantum computing can make a huge difference, especially in complex deep learning processes and large language models (LLMs). In this context, using quantum computing, especially in deep learning models, can significantly increase calculations' performance, processing speed, and optimization.
- Basic principles of quantum computing: Quantum computing is based on the principles of quantum physics and takes advantage of the properties of quantum particles, such as superposition and entanglement. Unlike classical computing, where information is stored and processed in binary form (zero and one), in quantum computing, quantum bits or qubits can be in different states at the same time. These features allow quantum computing to perform calculations in parallel and significantly increase processing speed.
- The role of quantum computing in AI models: In AI models, especially in complex and large-scale data processing, classical computing usually faces problems such as high energy consumption and long processing time. In particular, deep learning models and neural networks require complex calculations that are time-consuming and costly. Quantum computing using quantum algorithms can exponentially increase processing speed and reduce energy consumption, especially in parts of deep learning models that require complex matrix operations.
-
Quantum algorithms for optimization in AI: One of the biggest challenges of artificial intelligence models is optimizing model parameters and reducing computational complexity. In this context, quantum algorithms can play a prominent role:
- ✓
- Quantum Approximate Optimization Algorithm (QAOA): This algorithm is particularly useful in solving complex optimization problems in machine learning. QAOA can more efficiently search the ample search space of machine learning model parameters and help find more optimal solutions.
- ✓
- Variational Quantum Circuits (VQC): VQC algorithms solve optimization problems in complex data processing and deep learning models. These algorithms use a combined quantum structure for optimization, which can significantly reduce the time and cost of data processing.
- ✓
- Quantum Neural Networks (QNNs): Using quantum neural networks (QNNs) is an essential innovation in deep learning. QNNs specifically use quantum computing power to train and predict train and predict complex data. These networks can harness quantum computing power to perform complex calculations faster and more accurately.
- Advantages of Using Quantum Computing in AI: Quantum computing in artificial intelligence models brings several benefits that can significantly improve the performance and efficiency of AI systems. One of the main advantages is the increased processing speed; quantum computing, using superposition and entanglement capabilities, can perform complex calculations in parallel and in a shorter time, much faster than classical methods. Also, reducing computational complexity is another prominent advantage; quantum computing can help improve processing performance and find more optimal solutions, especially in optimization problems with a large and complex search space. On the other hand, reducing energy consumption compared to classical methods is another key feature of quantum computing, which makes this technology very suitable for use in large-scale and complex artificial intelligence models. Ultimately, quantum computing will allow AI systems to analyze more complicated and multifaceted data with greater accuracy, which has significant implications for applications such as natural language processing, computer vision, and advanced simulations. Figure 3 represents the role of quantum computing in AI models, illustrating its basic principles, optimization algorithms, and how it enhances deep learning models by improving processing speed and reducing energy consumption.
3.4. Using Edge AI for Faster Processing
In the advanced HyperLLM architecture, Edge AI (Edge Artificial Intelligence) is one of the key technologies to increase processing speed and reduce dependence on cloud infrastructure. Edge AI means transferring complex processing to local devices such as smartphones, sensors, edge processors, and other industrial equipment that process information locally. This method transfers heavy computing load from central servers to devices closer to the data source, significantly reducing processing latency. In traditional cloud-based systems, data is sent from user devices to central servers, where complex processing is performed, and then the results are returned to the device. This process increases response time, especially in environments requiring real-time processing. However, Edge AI processes data directly without being transferred to cloud centers, leading to reduced latency and accelerated results. This feature is essential for audio and video processing and complex simulations requiring high speed. On the other hand, Edge AI also significantly increases user security and privacy. Transferring sensitive data to central servers can pose security risks in cloud systems. However, in Edge AI, data is processed locally, and only the final results are sent to the server, which brings significant privacy benefits. Another important aspect of using Edge AI is optimizing energy consumption. In cloud-based systems, heavy processing and computing depend on energy-intensive data centers. With Edge AI, processing is moved to local devices with lower power consumption, which helps optimize power consumption at scale. As a result, HyperLLM with Edge AI can perform faster and more efficiently in various environments without relying on heavy computing resources and high power consumption. Finally, to achieve the best results in this architecture, HyperLLM uses techniques such as Federated Learning and Model Compression to reduce processing requirements at the Edge level. These techniques enable HyperLLM models to run efficiently without heavy processing resources and in decentralized environments while maintaining model adaptability and scalability. This comprehensive approach makes HyperLLM stand out in processing speed and improves scalability, security, and energy efficiency in advanced and complex computing processes. Figure 4 represents how HyperLLM utilizes Edge AI to enhance processing speed, security, and energy efficiency by transferring processing tasks to local devices, reducing latency, and optimizing power consumption.
4. Comparison with Existing Models
The HyperLLM model is one of the most advanced machine learning models. It was designed by combining modern technologies such as Sparse Models, Quantum Computing, and Edge AI to optimally meet the needs of processing complex and multi-modal data. This model is very efficient in processing various data simultaneously, including text, image, and voice, and it has unique features that distinguish it from other similar models.
- Ability to process multi-modal data: One of the prominent features of HyperLLM is its ability to process multi-modal data. This model can process various data such as text, voice, and image simultaneously and accurately. Unlike models such as GPT-4, specifically designed to process text data, HyperLLM can simultaneously create complex relationships between different data and analyze them in a coordinated manner. This feature makes it very suitable for applications that require processing multiple data sets and their interaction, such as augmented reality (AR), virtual reality (VR), and complex analytics in medicine and engineering.
- Scalability and large-scale processing: HyperLLM can effectively provide high scalability in processing large data sets due to sparse models and quantum computing. Sparse models, especially compared to traditional models, can focus only on specific data parts, reducing computational complexity and improving model performance at large scales. In contrast, models such as DeepSeek, mainly designed for specific or limited data, have lower performance at larger scales. This high scalability feature of HyperLLM allows it to work effectively on massive projects with large data volumes, such as global predictions and large-scale models in data science.
- Computational optimization using quantum computing: One of HyperLLM's unique features is quantum computing. This model uses quantum algorithms such as QAOA and VQC to optimize processing operations, which makes HyperLLM significantly more efficient than other models such as GPT-4 and T5, which rely on substantial processing resources. Quantum computing can perform heavy processing with incredible speed and accuracy, allowing HyperLLM to perform much better in processing complex and diverse data. This feature is essential in advanced data analytics and scientific predictions that require high-speed and accurate calculations.
- Energy consumption and local processing with Edge AI: By leveraging Edge AI, HyperLLM has become one of the models that can perform processing locally. Hence, this means there is no need to send data to data centers, and the information is processed on local devices such as smartphones, Internet of Things (IoT) devices, or smart sensors. This approach makes HyperLLM consume less energy and significantly increases processing speed compared to models such as GPT-3, which rely on data centers for processing. This feature can dramatically help improve performance, especially in applications like machine learning models in the cloud or real-time medical diagnosis systems.
- Security and Privacy: One of the main challenges in machine learning models, especially in sensitive fields such as medicine and finance, is the issue of data security and privacy. HyperLLM uses local processing and federated learning to allow data to be processed locally without sending it to central servers. This feature is a great advantage, especially against concerns about privacy and unauthorized access to data. In contrast, models such as GPT-3, which send data to data centers, may pose additional security concerns, especially when sensitive data with private information becomes available.
- Processing Speed: HyperLLM uses Edge AI and distributed models to process data at very high speeds. This model performs exceptionally well in fields that require fast data processing, such as real-time medical diagnosis or instant financial analysis. Unlike models like GPT-4, which requires a lot of resources for heavy processing and processing large amounts of data, HyperLLM can significantly increase processing speed by using local processing and quantum optimizations.
- Compatibility with emerging technologies: Due to quantum computing and Edge AI, HyperLLM can coordinate and integrate with emerging technologies such as the Internet of Things (IoT), 5G, and augmented reality (AR). This feature is a great advantage, especially in advanced industries and in large-scale projects, such as smart cities or the development of innovative medical systems. In contrast, models like DeepSeek and BERT, which mainly focus on processing textual and structured data, may not be as efficient as HyperLLM in newer, more complex fields.
Therefore, HyperLLM can perform much better than other models as a new model with unique features such as multi-modal data processing, high scalability, quantum computing, Edge AI, and local processing. This model has wide applications, especially in advanced industries, medical systems, and complex data analytics, and can be considered a superior option compared to other models, such as GPT-4 and DeepSeek, which are designed for specific data processing. This comparison is shown in Table 1.
5. Challenges and Considerations in Developing HyperLLM
The development of the HyperLLM model is accompanied by several challenges that directly affect its performance, scalability, and adoption in real-world applications. One of the most critical challenges is the need for very heavy computations, leading to high processing resource consumption and increased infrastructure costs. In addition, large language models often face the issue of bias and ethical considerations, which can produce unbalanced and unfair outputs. In addition, protecting user privacy and information security has become vital due to the enormous volume of data to be processed. Finally, the energy sustainability and high costs of these models' training and inference process pose severe limitations to their development and widespread application. These challenges require advanced solutions and continuous optimizations in HyperLLM's architectural design and processing methods.
5.1. HyperLLM Development Requires Massive Computation
Large language models (LLMs) such as HyperLLM consist of billions of parameters that require massive computational resources for learning, tuning, and inference. The vast amount of processing data, the high complexity of the neural network architecture, and the need for extensive matrix calculations are the most critical factors that significantly increase the computation required for this model. This requirement creates challenges regarding energy consumption, hardware costs, and model training time, as discussed below.
- Data volume and computational complexity: Large language models require massive datasets for deep learning and understanding language complexities, including multilingual texts, scientific texts, research papers, and extensive conversational data. Processing this data requires performing millions of mathematical operations on large numerical vectors and employing optimization algorithms such as AdamW to adjust weights and improve model convergence. This process requires highly high processing power and heavily burdens processing units.
- Large matrix operations and high processing load: Transformer models, which form the core of the HyperLLM architecture, rely on the Self-Attention mechanism to analyze dependencies between words on a large scale. This operation depends on high-dimensional matrix multiplication and integration, which has a computational cost of Ο(n2)d Here n is the number of tokens, and d is the embedded vector dimension). Huge models with billions of parameters require high-power GPU and TPU processing resources, increasing hardware costs and energy consumption.
- Energy consumption and infrastructure costs: Processing large models requires data centers with thousands of graphics processing units (GPUs) and tensor processors (TPUs). These data centers consume a significant amount of electrical energy annually, which, in addition to heavy financial costs, also has severe environmental impacts. Training a large language model like GPT-4 reportedly consumes hundreds of thousands of kilowatt-hours of energy, equivalent to several years of electricity consumption for a small city.
- Inference latency and slow response times: Even after training the model, inference is computationally intensive, mainly in real-time applications such as intelligent assistants, translation systems, or medical chatbots. This challenge leads to increased latency and reduced operational efficiency of the model, especially in scenarios that require fast processing and high scalability.
Several key solutions can be implemented to optimize HyperLLM processing and reduce computational costs. Using sparse models and a Mixture of Expert (MoE) architectures can eliminate unnecessary processing and increase efficiency. Using Efficient Transformers such as Longformer and Linformer helps reduce the complexity of Self-Attention. Using advanced processing units such as TPU, FPGA, and ASIC and combining them with hybrid quantum computing can improve model performance. Also, Edge AI reduces response time and optimizes energy consumption by processing data locally. Methods such as Model Pruning and Quantization allow lighter models to be run on low-power hardware. Finally, Federated Learning reduces the need to send raw data to processing centers by processing data locally and improves information security.
5.2. Bias Control and Ethical Issues in HyperLLM
With the proliferation of large-scale language models (LLMs) such as HyperLLM, which are trained on large amounts of text data, one of the fundamental challenges in developing and using these models is controlling bias and respecting ethical considerations. Bias in language models can manifest itself in the form of racial, gender, cultural, linguistic, and even ideological biases, which in many cases are unintentional and result from biases in the training data or the learning structure of the model. Hence, this affects the accuracy and validity of the model and can lead to negative social consequences, inequality in automated decision-making, and even violations of ethical principles and users' rights. In this regard, one of the key concerns in developing HyperLLM is to design mechanisms to identify, evaluate, and reduce bias so that the model can present its outputs fairly, impartially, and within the framework of ethical values. This challenge is accompanied by complexities such as large amounts of heterogeneous data, cultural differences in text interpretation, and limitations of deep learning algorithms, which require advanced and multi-layered solutions to manage this problem. In the following, we will examine the origin of bias in HyperLLM, its consequences, and methods for reducing bias by improving training data, modifying model architecture, and developing transparent AI monitoring tools.
- The impact of training data on model bias: Bias in language models such as HyperLLM usually stems from the training data's quality and diversity. Large language models are trained using vast amounts of text data collected from various sources, but this data may have historical, cultural, or social biases. For example, if the model is trained on texts in which gender roles are stereotypically defined, it may reproduce those biases in its responses. Also, imbalances in the training data can cause the model to favor particular groups, languages, or perspectives while underrepresenting others. Therefore, one of the essential steps in controlling bias is to diversify the training dataset, remove or reduce biased data, and create a reasonable balance between different perspectives.
- The role of model architecture in creating or reducing bias: In addition to the training data, the architecture of the model and how it learns can also create or exacerbate bias. Due to their reliance on statistical patterns and superficial correlations in the data, many deep learning models may misunderstand relationships as general rules. For example, the model may unconsciously generalize these patterns if the training data shows more negative sentiment expressions about particular groups. One key approach to this problem is employing weight adjustment and normalization techniques during model training. Also, using hybrid architectures that allow for active filtering of model outputs can help reduce bias.
- Ethical challenges and implications of bias in AI systems: Bias in language models goes beyond a technical issue and broadly impacts social justice, automated decision-making, and public trust in AI technologies. Models such as HyperLLM, which are used in medical, legal, economic, and social fields, if they are biased, can lead to unfair decisions, reproduce inequalities, and undermine the rights of affected groups. For example, if the model is trained on biased data in employment applications, it may unfairly deprive people of job opportunities. Also, when processing less widely used languages or specific cultural groups, the model may not be able to produce accurate information and, as a result, marginalize these groups.
Technical and non-technical solutions are proposed to reduce bias in HyperLLM. Technically, using fairness-aware training techniques, data re-distribution, and bias correction methods during model training are among the effective solutions. Additionally, bias detection metrics and testing models on diverse datasets can help identify and control bias. From a non-technical perspective, establishing ethical standards, increasing transparency in how models are trained, and human oversight of the outputs produced can play an essential role in reducing bias and building public trust. Controlling bias requires a multi-layered approach that includes data optimization, model architecture, and active performance monitoring of AI systems.
5.3. Energy Sustainability and High Costs
Large language models such as HyperLLM face serious challenges regarding energy sustainability and operational costs due to their complex architecture, huge parameter volume, and extensive processing requirements. Training and running these models require vast computational resources, which leads to high energy consumption, increased hardware and maintenance costs, and exacerbated environmental impacts. Hence, this raises concerns from an environmental sustainability perspective and poses severe economic constraints for organizations, research institutes, and technology companies. The key challenge sections related to this issue are reviewed and optimized, and onions are presented.
- High energy consumption and environmental impact: Large language models like HyperLLM require massive processing power for training and inference. This process involves billions of matrix operations and parameter optimizations executed on GPUs, TPUs, and high-end servers. This amount of processing leads to significant power consumption and increased heat generation in data centers, creating challenges from an energy resource management perspective. Studies have shown that training a large language model can require several megawatt-hours of energy, equivalent to emitting several tons of carbon dioxide (CO₂) into the atmosphere. In addition, the increasing demand for simultaneous inference and providing fast responses at large scales also significantly increases energy consumption in the operational phase, placing significant constraints on the sustainability of these models in terms of the use of renewable energy sources.
- High infrastructure and computing costs: Implementing and running large models like HyperLLM requires advanced and costly computing infrastructure. These costs include high-power processing hardware such as advanced GPUs such as NVIDIA A100 and new generation TPUs, which have high operating costs due to the high processing power required. In addition, high energy consumption increases the need for advanced cooling systems and the costs of maintaining and operating data centers. Continuous model updates are another financial challenge in this area, as processing large volumes of new data and training complex models requires extensive and expensive computing infrastructure. These issues make developing and using advanced language models challenging and economically unviable for many small organizations and even some research institutions.
Several optimization strategies can be implemented to address the challenges associated with energy consumption and high costs. One of these strategies is the use of Sparse and Mixture of Experts (MoE) models, which activate only parts of the model at each stage and, as a result, significantly reduce energy consumption. Using energy-efficient processors such as Google TPUv5 or quantum processors (QPUs) also increases computational efficiency without increasing energy consumption. Distributed learning and Edge AI are other optimization methods that reduce the processing load on data centers and optimize operational costs by transferring part of the processing to edge devices. In addition, the use of model compression techniques such as Quantization, Knowledge Distillation, and Low-Rank Factorization helps reduce model complexity and, as a result, reduce energy consumption. Finally, renewable energy, such as solar, wind systems, and green data centers, can reduce dependence on fossil energy sources and optimize operating costs.
6. Future Perspectives and Research Directions
The development of the HyperLLM model requires the exploration of advanced research paths that can address the challenges of scalability, computational optimization, and reasoning. One key area is the integration of classical and quantum computing so that the processing power of the model in complex matrix operations can be exponentially increased by using quantum algorithms such as QAOA and VQC. In addition, improving bias control mechanisms and enhancing model interpretability by developing causal learning and self-explainable AI techniques can play an essential role in reducing ethical problems and enhancing system reliability. Other critical research paths are energy optimization and reducing processing costs, which will be possible through sparse architectures, model compression, and special-purpose hardware such as neural processing units (NPUs) and Edge AI accelerators. Also, due to the increasing need for data security and privacy, the use of federated learning mechanisms, homomorphic encryption, and differential privacy are key solutions. Finally, combining multimodal architectures for processing text, image, and audio data by integrating multimodal transformer models with CNN and RNN architectures can create a more robust model that can deeply understand real-world data. Developing HyperLLM in these directions will improve performance, reduce current limitations, and open new horizons in using intelligent language models in advanced applications.
6.1. The Role of Quantum Computing and New Algorithms in the Future of HyperLLM
As the dimensions of large language models (LLMs) and their processing complexity increase, classical computing gradually encounters fundamental limitations in scalability, processing time, and energy consumption. Models like HyperLLM, designed for multi-modal processing, complex reasoning, and interaction with large and heterogeneous data, require new computational approaches to increase processing efficiency and reduce computational costs. In the meantime, quantum computing has been proposed as one of the most promising research directions for optimizing deep learning and processing future language models. One of the most critical challenges of large language models is the large matrix computations in the layers of deep neural networks, which in classical systems require very high processing power. In this regard, quantum algorithms such as Quantum Approximate Optimization Algorithm (QAOA) and Variational Quantum Circuits (VQC) can exponentially speed up the processing of feature vectors and matrix operations by using quantum superposition and entanglement. Hence, this reduces the learning and inference time and optimizes the costs related to energy consumption and maintenance of hardware infrastructure. Another important research direction in this area is the development of quantum neural networks (QNNs), which can implement learning layers directly at the quantum level and create new structures of language models. Combining these networks with hybrid quantum-classical learning algorithms can reduce the processing requirements of HyperLLM and turn it into a low-power, high-speed, and scalable model. Another key challenge for large language models is maintaining a balance between accuracy and speed in processing multi-dimensional data. In this regard, using quantum natural language processing (Quantum NLP) as an emerging field can revolutionize language models. Quantum Word Embeddings and Quantum Sentence Representations can extract semantic relationships between words and sentences with higher accuracy and faster processing than classical models. Hence, this can enable HyperLLM to discover deeper understanding and more complex dependencies between linguistic data. On the other hand, new algorithms such as Quantum Reinforcement Learning (QRL) can optimize decision-making mechanisms and model interaction with complex environments. These algorithms can simultaneously examine different learning paths and select the best possible decision using the quantum ensemble principle. Such a capability could make HyperLLM a brighter, more adaptable, and more effective model for interacting with new and dynamic data. From an infrastructure perspective, one of the main challenges in implementing large-scale language models is the limited hardware resources and costs associated with data processing in supercomputers and data centers. Quantum computing, especially hybrid quantum-classical systems, can maximize efficiency by distributing processing tasks between classical and quantum processors. Developing these systems and optimizing the interaction between quantum computing and classical architectures will be key directions for the future of HyperLLM. Finally, the future research direction of HyperLLM should move towards integrating quantum computing with other advanced technologies, such as neuromorphic computing and distributed artificial intelligence. This combination can solve the challenges related to scalability, processing speed, energy consumption, and autonomous learning, making HyperLLM an extremely advanced, scalable, and efficient model for multi-modal data processing and advanced reasoning in the future.
6.2. HyperLLM in the Fields of Medicine, Education, Big Data Analytics and Industry
As an advanced architecture in large language models (LLMs), the HyperLLM model has broad potential in interdisciplinary applications. By utilizing hybrid neural networks (Transformers, CNNs, and RNNs), sparse models, quantum computing, and edge processing (Edge AI), this model not only enhances the natural language processing capability to a new level but also enables multi-modal processing of complex data. In this regard, the research paths of HyperLLM in medicine, education, big data analytics, and industry are four key areas that require in-depth studies and future technological developments.
- Medicine: One of the most critical applications of HyperLLM in modern medicine is to increase the accuracy and speed of disease diagnosis systems and suggest treatment methods based on multimodal data analysis. Given the ability to process text data (medical texts, scientific articles, and patient records), image data (medical imaging such as MRI, CT-Scan, and X-ray), and signal data (ECG, EEG, and genomic data), the HyperLLM model can perform clinical diagnoses with very high accuracy. Using Sparse Models and a Mixture of Expert (MoE) architectures optimizes model processing and reduces computational costs in complex medical analyses. In addition, using quantum computing (Quantum AI) to solve complex problems, such as molecular dynamics in the discovery of new drugs and modeling of protein interactions, allows for accelerating research processes in biotechnology. In personalized medicine, HyperLLM, by utilizing federated learning models and real-time processing in Edge AI, can provide treatment recommendations specifically for each patient without sending sensitive data to cloud processing centers, increasing patient data security and protecting their privacy.
- Education: HyperLLM will be key in developing intelligent and personalized learning systems. The use of multimodal natural language models (MLMs) allows for detailed analysis of how each individual learns and provides educational content tailored to the learner's knowledge and abilities. For example, by using Transformer-CNN-RNN networks, this model will improve voice and text interactions and enhance augmented and virtual reality (AR/VR)-based learning systems. In addition, in language and conversation training systems, HyperLLM can adjust training to the linguistic characteristics of each individual by understanding linguistic and dialect differences in depth. In more advanced sectors, developing Edge AI and Federated Learning-based models will enable the implementation of these educational systems without dependence on the Internet or cloud servers, reducing processing latency and increasing equitable access to innovative education in underserved areas.
- Big Data Analytics: HyperLLM can play a key role in predictive modeling, business trend analysis, and discovering hidden patterns in data. Sparse Models and distributed processing structures allow the model to process a massive amount of structured and unstructured data without experiencing scalability problems in traditional processing systems. For example, the Mixture of Experts (MoE) and Attention Mechanisms models in HyperLLM can analyze real-time streaming data and extract hidden patterns in data. In addition, using quantum algorithms such as QAOA and VQC can increase model performance in complex analyses such as social network analysis, fraud detection in financial systems, and search algorithm optimization. Also, developing decentralized processing systems using Edge AI and federated computing will enable big data analysis without dependence on expensive cloud data centers, leading to reduced processing costs and optimized energy consumption.
- Industry: In industry, HyperLLM applications can include supply chain management, predicting industrial equipment failures, and optimizing production processes. Distributed AI and Edge AI models enable industrial devices to process sensor data and make real-time decisions autonomously. In this regard, using Hybrid Quantum-Classical Learning can increase the efficiency of control systems and facilitate troubleshooting of complex equipment through deep learning-based modeling and IoT data processing. In the supply chain, HyperLLM can use Transformer models to analyze demand trends, predict resource shortages, and optimize logistics, which will increase productivity and reduce operating costs. On the other hand, transfer learning and edge computing enable the implementation of these models in industrial environments without heavy computing infrastructure, which will be of great importance in the automotive, semiconductor manufacturing, and energy management industries.
7. Conclusions
As an advanced generation of large language models, HyperLLM has overcome common limitations in natural language processing by using quantum computing, multi-modal architectures, and computational optimization. This model can process text, image, and audio data simultaneously, and by using Sparse Models and adaptive learning, it performs reasoning processes without retraining. One of the key features of HyperLLM is increasing processing speed, reducing operating costs, and improving energy sustainability, which is made possible by using Edge AI and federated learning. In addition, user security and privacy are fully guaranteed by using advanced cryptography and decentralized processing. HyperLLM bridges today's large language models and Artificial General Intelligence (AGI), which can reason beyond statistical patterns and create a new path in information processing, human-centered interactions, and intelligent decision-making systems.
References
- Gallifant, J., Afshar, M., Ameen, S., Aphinyanaphongs, Y., Chen, S., Cacciamani, G., Demner-Fushman, D., Dligach, D., Daneshjou, R., Fernandes, C. and Hansen, L.H., 2025. The TRIPOD-LLM reporting guideline for studies using large language models. Nature Medicine, pp.1-10. [CrossRef]
- Zhu, X., Zhou, W., Han, Q.L., Ma, W., Wen, S. and Xiang, Y., 2025. When Software Security Meets Large Language Models: A Survey. IEEE/CAA Journal of Automatica Sinica, 12(2), pp.317-334. [CrossRef]
- Alber, D.A., Yang, Z., Alyakin, A., Yang, E., Rai, S., Valliani, A.A., Zhang, J., Rosenbaum, G.R., Amend-Thomas, A.K., Kurland, D.B. and Kremer, C.M., 2025. Medical large language models are vulnerable to data-poisoning attacks. Nature Medicine, pp.1-9. [CrossRef]
- Johri, S., Jeong, J., Tran, B.A., Schlessinger, D.I., Wongvibulsin, S., Barnes, L.A., Zhou, H.Y., Cai, Z.R., Van Allen, E.M., Kim, D. and Daneshjou, R., 2025. An evaluation framework for clinical use of large language models in patient interaction tasks. Nature Medicine, pp.1-10. [CrossRef]
- Wang, J., Shi, R., Le, Q., Shan, K., Chen, Z., Zhou, X., He, Y. and Hong, J., 2025. Evaluating the effectiveness of large language models in patient education for conjunctivitis. British Journal of Ophthalmology, 109(2), pp.185-191. [CrossRef]
- Ntinopoulos, V., Biefer, H.R.C., Tudorache, I., Papadopoulos, N., Odavic, D., Risteski, P., Haeussler, A. and Dzemali, O., 2025. Large language models for data extraction from unstructured and semi-structured electronic health records: a multiple model performance evaluation. BMJ Health & Care Informatics, 32(1), p.e101139. [CrossRef]
- Kachris, C., 2025. A survey on hardware accelerators for large language models. Applied Sciences, 15(2), p.586. [CrossRef]
- Long, S., Tan, J., Mao, B., Tang, F., Li, Y., Zhao, M. and Kato, N., 2025. A Survey on Intelligent Network Operations and Performance Optimization Based on Large Language Models. IEEE Communications Surveys & Tutorials. [CrossRef]
- Chandran, R. and Tan, M.L., 2025. Efficiently Scaling LLMs Challenges and Solutions in Distributed Architectures. Baltic Multidisciplinary Research Letters Journal, 2(1), pp.57-66.
- Zhang, C., Xu, Q., Yu, Y., Zhou, G., Zeng, K., Chang, F. and Ding, K., 2025. A survey on potentials, pathways, and challenges of large language models in new-generation intelligent manufacturing. Robotics and Computer-Integrated Manufacturing, 92, p.102883. [CrossRef]
- Wang, P., Lu, W., Lu, C., Zhou, R., Li, M. and Qin, L., 2025. Large Language Model for Medical Images: A Survey of Taxonomy, Systematic Review, and Future Trends. Big Data Mining and Analytics, 8(2), pp.496-517. [CrossRef]
- Song, S., Li, X., Li, S., Zhao, S., Yu, J., Ma, J., Mao, X., Zhang, W. and Wang, M., 2025. How to Bridge the Gap between Modalities: Survey on Multimodal Large Language Model. IEEE Transactions on Knowledge and Data Engineering. [CrossRef]
- Sun, Y., Li, X. and Sha, Z., 2025. Large Language Models for Computer-Aided Design (LLM4CAD) Fine-Tuned: Dataset and Experiments. Journal of Mechanical Design, pp.1-19. [CrossRef]
- Qi, C., Xu, H., Zheng, L., Chen, P. and Gu, X., 2025, January. TMATH A Dataset for Evaluating Large Language Models in Generating Educational Hints for Math Word Problems. In Proceedings of the 31st International Conference on Computational Linguistics (pp. 5082-5093).
- Memduhoğlu, A., 2025. Towards AI-Assisted Mapmaking: Assessing the Capabilities of GPT-4o in Cartographic Design. ISPRS International Journal of Geo-Information, 14(1), p.35. [CrossRef]
Figure 1.
Sparse Models and Optimization in HyperLLM.
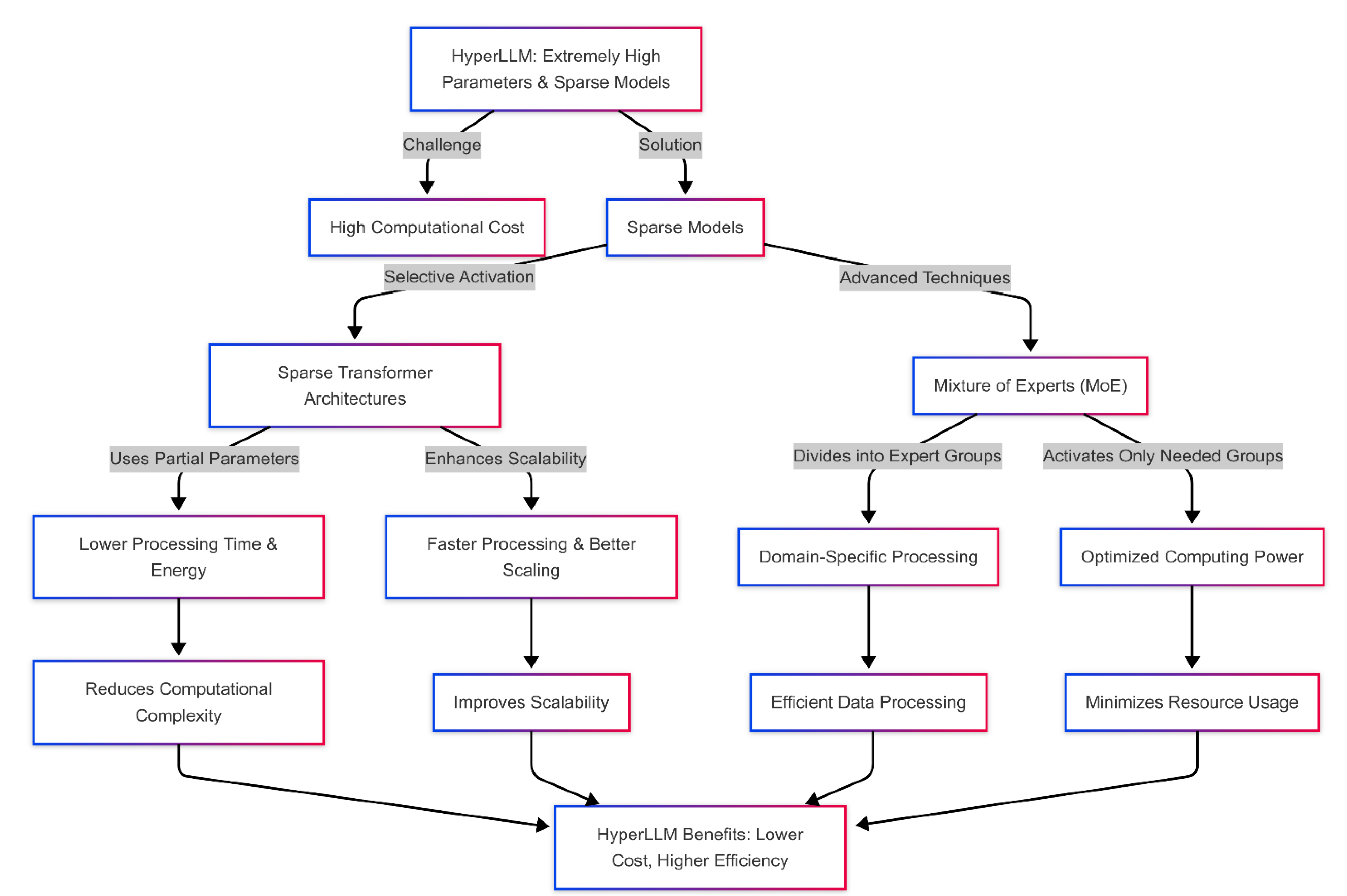
Figure 2.
Multimodal Data Processing in HyperLLM.
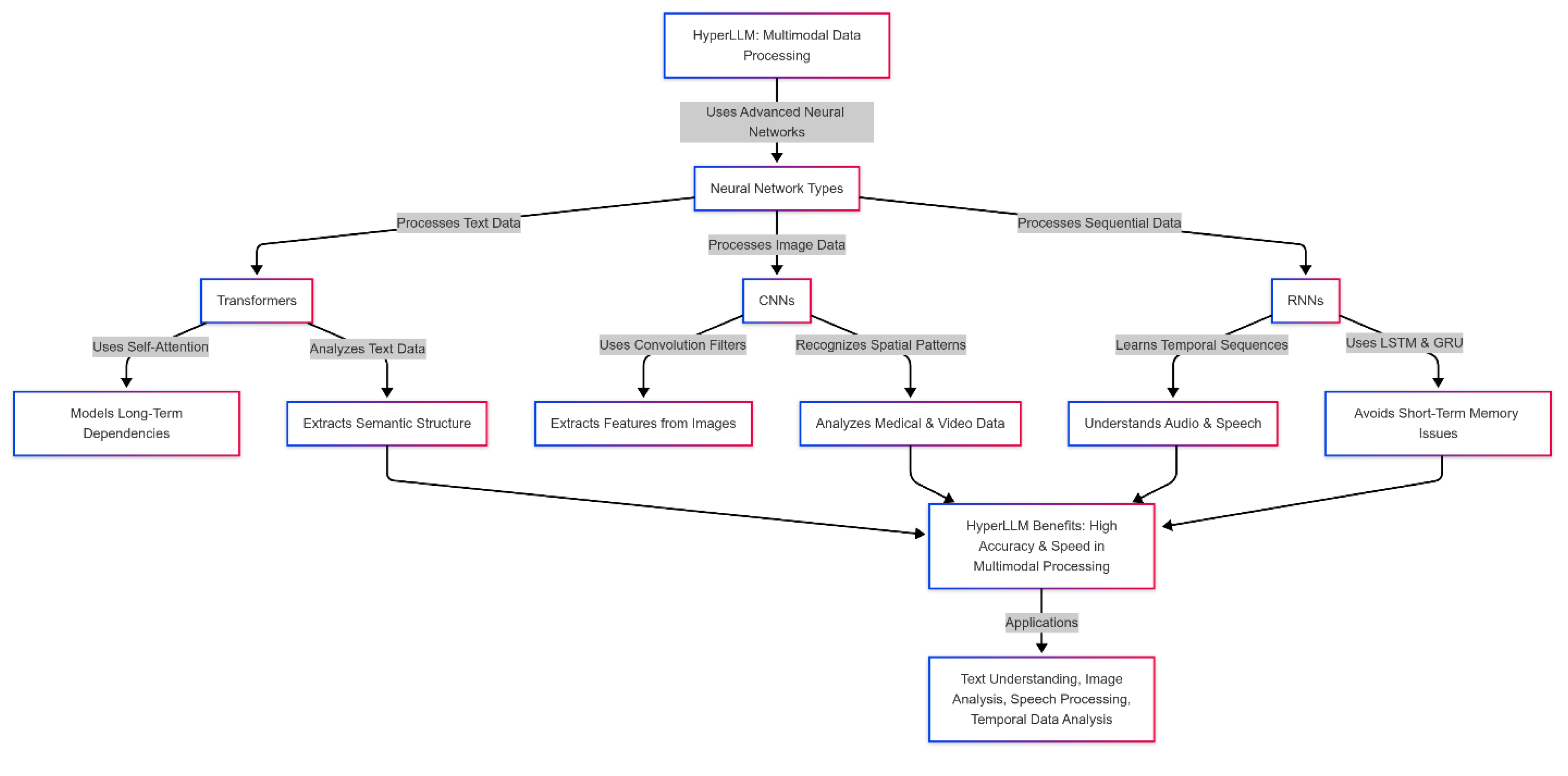
Figure 3.
Quantum Computing in AI Models: Principles, Role, and Optimization Algorithms.
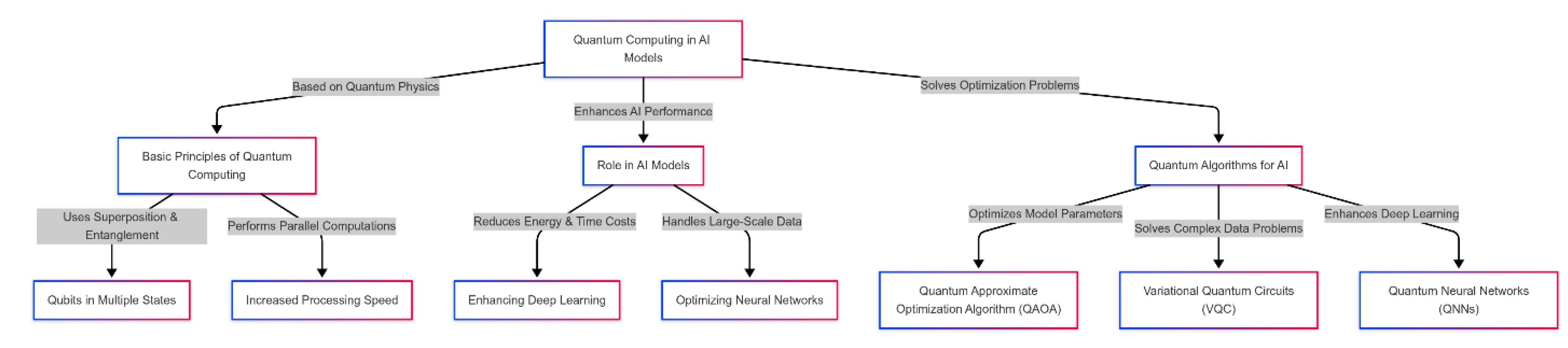
Figure 4.
HyperLLM Architecture with Edge AI: Enhancing Processing Speed, Security, and Energy Efficiency.
Figure 4.
HyperLLM Architecture with Edge AI: Enhancing Processing Speed, Security, and Energy Efficiency.
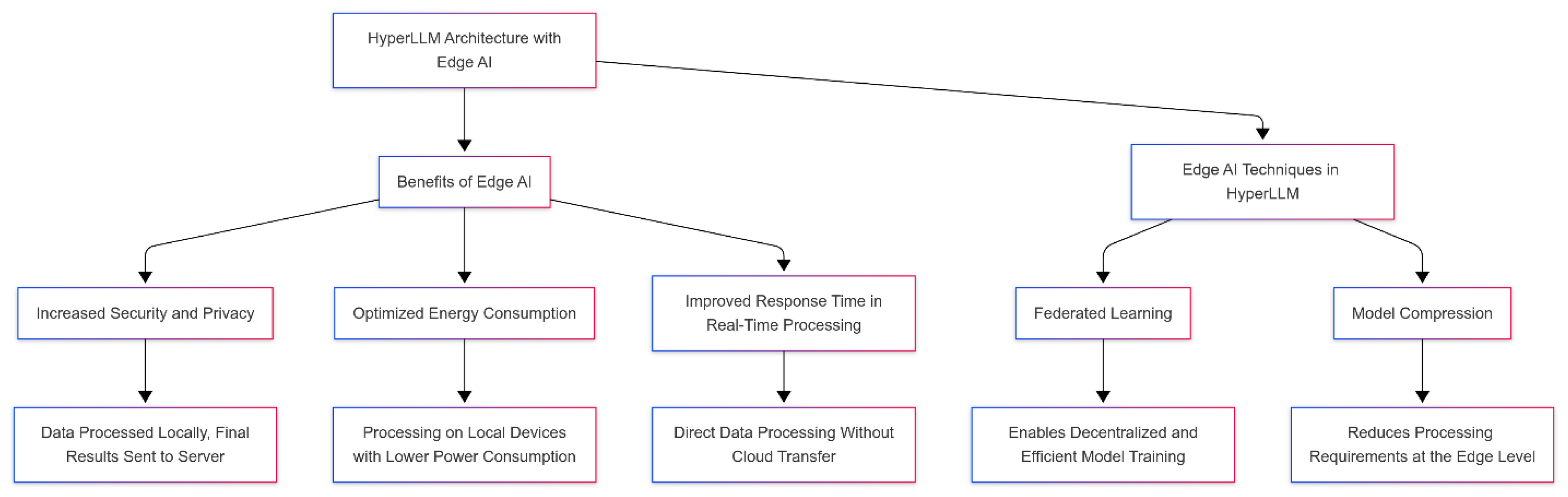

Table 1.
Comparison of HyperLLM with 7 Popular LLM Models.
| Parameter | HyperLLM | GPT-4 | DeepSeek | BERT | T5 | XLNet | GPT-3 | LaMDA |
| Multimodal Data Processing Ability | Very High (combines text, audio, and visual data) | High (focused on text processing) | Moderate (best for text data) | Moderate (text processing) | High (text and structured data) | High (multimodal models) | Moderate (best for text) | Very High (focused on conversational and text data) |
| Scalability | Excellent (high scalability with Sparse Models) | Very Good | Suitable (best for specific data types) | Good (moderate scalability) | Very Good | Sound (structured data processing) | Very Good | Good (focused on conversational tasks) |
| Computational Optimization | Excellent (Quantum computing & Sparse Models) | Good (advanced techniques) | Moderate (limited optimization) | Good (optimization for text) | Excellent (high optimization for structures) | Good (complex computations) | Moderate (heavy computations) | Good (optimized for conversational processing) |
| Energy Consumption | Very Low (Edge AI and Sparse Models) | Moderate (high computational needs) | Moderate (limited optimization) | Moderate (computationally intensive) | Low (specific optimizations) | Moderate (high energy consumption) | High (requires robust infrastructure) | Low (local processing and optimization) |
| Processing Speed | Very Fast (local processing with Edge AI) | Fast (with advanced processing) | Moderate (limited processing speed) | Moderate (delayed processing) | Fast (for diverse data types) | Moderate (complex computations) | Fast (quick processing) | Very Fast (real-time conversational processing) |
| Security and Privacy | Very High (local processing & Federated Learning) | Good (data protection) | Moderate (sensitive data processed) | Good (high security in text processing) | Suitable (optimized privacy measures) | Good (data protection) | Moderate (privacy concerns) | Very Good (focus on privacy in conversation) |
| Compatibility with Emerging Technologies | Excellent (Quantum Computing & Edge AI) | Good (utilizes emerging technologies) | Moderate (limited compatibility) | Suitable (compatible with algorithms) | Very Good (integration with new technologies) | Good (can integrate with technologies) | Suitable (uses emerging technologies) | Excellent (advanced in conversational language) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



