
Submitted:
01 February 2025
Posted:
03 February 2025
You are already at the latest version
Abstract
This paper presents a comparative analysis of OpenAI's GPT-4 and its optimized variant, GPT-4o, focusing on their architectural differences, performance, and real-world applications. GPT-4, built upon the Transformer architecture, has set new standards in natural language processing (NLP) with its capacity to generate coherent and contextually relevant text across a wide range of tasks. However, its computational demands, requiring substantial hardware resources, make it less accessible for smaller organizations and real-time applications. In contrast, GPT-4o addresses these challenges by incorporating optimizations such as model compression, parameter pruning, and memory-efficient computation, allowing it to deliver similar performance with significantly lower computational requirements. This paper examines the trade-offs between raw performance and computational efficiency, evaluating both models on standard NLP benchmarks and across diverse sectors such as healthcare, education, and customer service. Our analysis aims to provide insights into the practical deployment of these models, particularly in resource-constrained environments.
Keywords:
1. Introduction
2. Overview of ChatGPT-4
2.1. Architecture
2.2. Training and Fine-Tuning
2.3. Performance
3. Overview of ChatGPT-4o
3.1. Architectural Enhancements
3.2. Optimization Techniques
3.2.1. Model Compression
3.2.2. Memory-Efficient Layers
3.2.3. Dynamic Batching
3.3. Performance
4. Comparative Analysis
4.1. Accuracy and Efficiency
4.2. Cost of Deployment
4.3. Real-World Applications
4.3.1. Education
4.3.2. Healthcare
4.3.3. Customer Service
5. Limitations and Future Directions
6. Conclusions
References
- Brown, T.B. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research 2020, 21, 1–67. [Google Scholar]
- Shahriar, S.; Lund, B.D.; Mannuru, N.R.; Arshad, M.A.; Hayawi, K.; Bevara, R.V.K.; Mannuru, A.; Batool, L. Putting gpt-4o to the sword: A comprehensive evaluation of language, vision, speech, and multimodal proficiency. Applied Sciences 2024, 14, 7782. [Google Scholar] [CrossRef]
- Kipp, M. From GPT-3.5 to GPT-4. o: A Leap in AI’s Medical Exam Performance. Information 2024, 15, 543. [Google Scholar] [CrossRef]
- Liu, C.L.; Ho, C.T.; Wu, T.C. Custom GPTs Enhancing Performance and Evidence Compared with GPT-3.5, GPT-4, and GPT-4o? A Study on the Emergency Medicine Specialist Examination. Healthcare 2024, 12, 1726. [Google Scholar] [CrossRef]
- Temsah, M.H.; Jamal, A.; Alhasan, K.; Temsah, A.A.; Malki, K.H. OpenAI o1-Preview vs. ChatGPT in Healthcare: A New Frontier in Medical AI Reasoning. Cureus 2024, 16. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, K.; Jagadeesh, A.; Falakaflaki, P.; Kayayan, E.; Tao, G.; Haghighat Ghahfarokhi, M.; Gupta, D.; Gupta, A.; Gupta, V.; et al. The potential and pitfalls of using a large language model such as ChatGPT, GPT-4, or LLaMA as a clinical assistant. Journal of the American Medical Informatics Association 2024, 31, 1884–1891. [Google Scholar] [CrossRef] [PubMed]
- Günay, S.; Öztürk, A.; Yiğit, Y. The accuracy of Gemini, GPT-4, and GPT-4o in ECG analysis: A comparison with cardiologists and emergency medicine specialists. The American journal of emergency medicine 2024, 84, 68–73. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. Advances in Neural Information Processing Systems 2017. [Google Scholar]
- Radford, A. Improving language understanding by generative pre-training 2018.
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Lei Ba, J.; Kiros, J.R.; Hinton, G.E. Layer normalization. ArXiv e-prints 2016, pp. arXiv–1607.
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I.; et al. Language models are unsupervised multitask learners. OpenAI blog 2019, 1, 9. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning language models from human preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Gite, S.; Rawat, U.; Kumar, S.; Saini, B.; Bhatt, A.; Kotecha, K.; Naik, N. Unfolding Conversational Artificial Intelligence: A Systematic Review of Datasets, Techniques and Challenges in Developments. Engineered Science 2024. [Google Scholar] [CrossRef]
- Casheekar, A.; Lahiri, A.; Rath, K.; Prabhakar, K.S.; Srinivasan, K. A contemporary review on chatbots, AI-powered virtual conversational agents, ChatGPT: Applications, open challenges and future research directions. Computer Science Review 2024, 52, 100632. [Google Scholar] [CrossRef]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P.F. Learning to summarize with human feedback. Advances in Neural Information Processing Systems 2020, 33, 3008–3021. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, 2021, pp. 610–623.
- Frankenreiter, J.; Nyarko, J. Natural language processing in legal tech. Legal Tech and the Future of Civil Justice (David Engstrom ed.) Forthcoming 2022.
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green ai. Communications of the ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Patterson, D.; Gonzalez, J.; Le, Q.; Liang, C.; Munguia, L.; Rothchild, D.; So, D.; Texier, M.; Dean, J. Carbon emissions and large neural network training. arXiv 2021. arXiv 2014, arXiv:2104.10350. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16. Springer, 2020, pp. 121–137.
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems 2019, 32. [Google Scholar]
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. Advances in neural information processing systems 1989, 2. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized neural networks: Training neural networks with low precision weights and activations. Journal of Machine Learning Research 2018, 18, 1–30. [Google Scholar]
- Chen, T.; Xu, B.; Zhang, C.; Guestrin, C. Training Deep Nets with Sublinear Memory Cost. CoRR 2016, arXiv:1604.06174. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Advances in neural information processing systems 2015, 28. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Kitaev, N.; Kaiser, .; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Chen, T.; Xu, B.; Zhang, C.; Guestrin, C. Training deep nets with sublinear memory cost. arXiv 2016, arXiv:1604.06174. [Google Scholar]
- Mittal, V.; Bhushan, B. Accelerated computer vision inference with AI on the edge. Proceedings of the 2020 IEEE 9th International Conference on Communication Systems and Network Technologies (CSNT). IEEE, 2020; 55–60. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- OpenAI. Hello GPT-4o, 2025. [Accessed 31-01-2025].
- Hurst, A.; Lerer, A.; Goucher, A.P.; Perelman, A.; Ramesh, A.; Clark, A.; Ostrow, A.; Welihinda, A.; Hayes, A.; Radford, A.; et al. Gpt-4o system card. arXiv 2024, arXiv:2410.21276. [Google Scholar]
- Topol, E. Deep medicine: how artificial intelligence can make healthcare human again; Hachette UK, 2019.
- Gale, T.; Elsen, E.; Hooker, S. The state of sparsity in deep neural networks. arXiv 2019, arXiv:1902.09574. [Google Scholar]
- Mehta, S.; Rangwala, H.; Ramakrishnan, N. Low rank factorization for compact multi-head self-attention. arXiv 2019, arXiv:1912.00835. [Google Scholar]
- Sutton, R.S. Reinforcement learning: An introduction. A Bradford Book 2018.
- Besold, T.R.; d’Avila Garcez, A.; Bader, S.; Bowman, H.; Domingos, P.; Hitzler, P.; Kühnberger, K.U.; Lamb, L.C.; Lima, P.M.V.; de Penning, L.; et al. Neural-symbolic learning and reasoning: A survey and interpretation 1. In Neuro-Symbolic Artificial Intelligence: The State of the Art; IOS press, 2021; pp. 1–51.
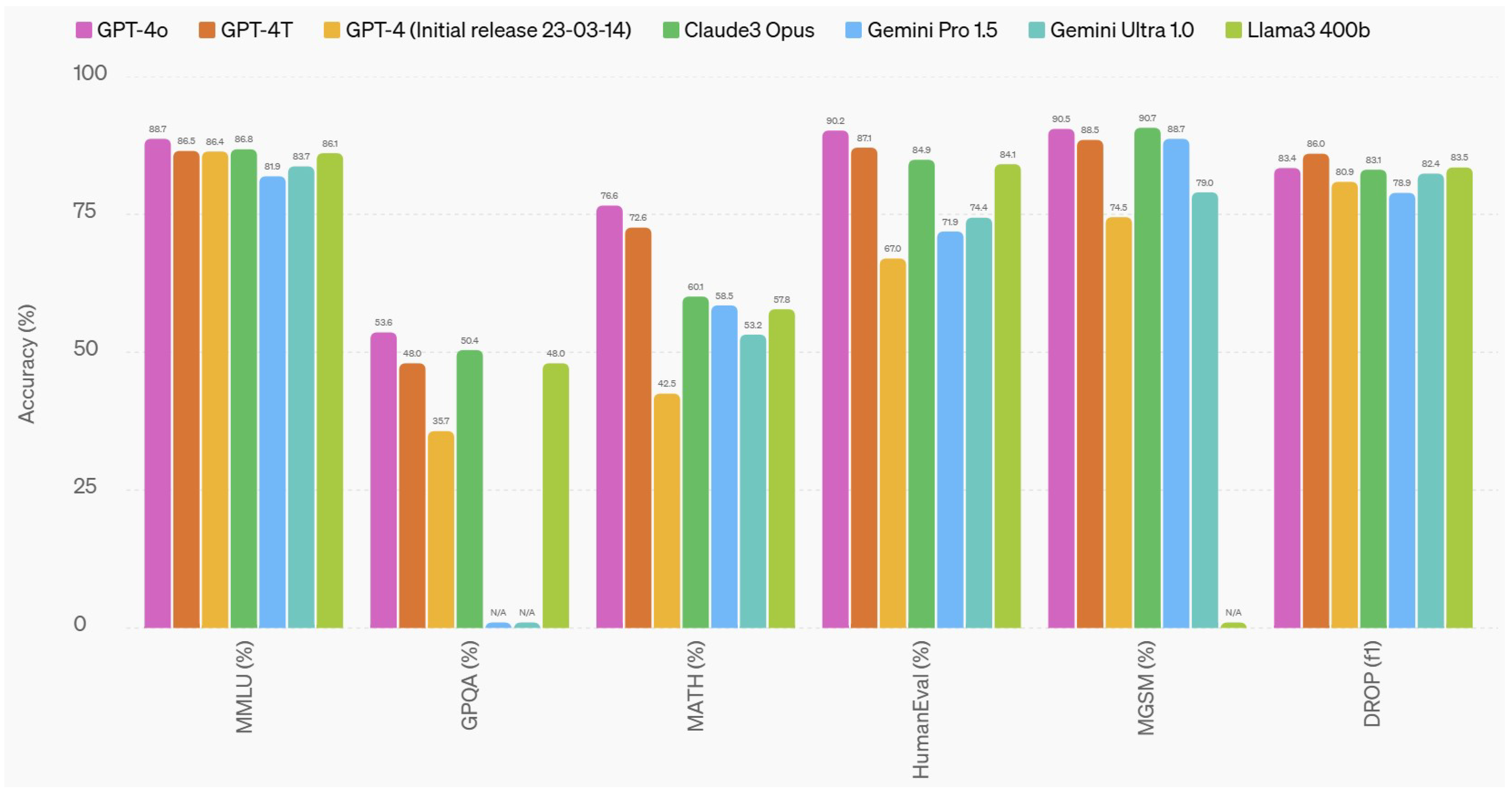
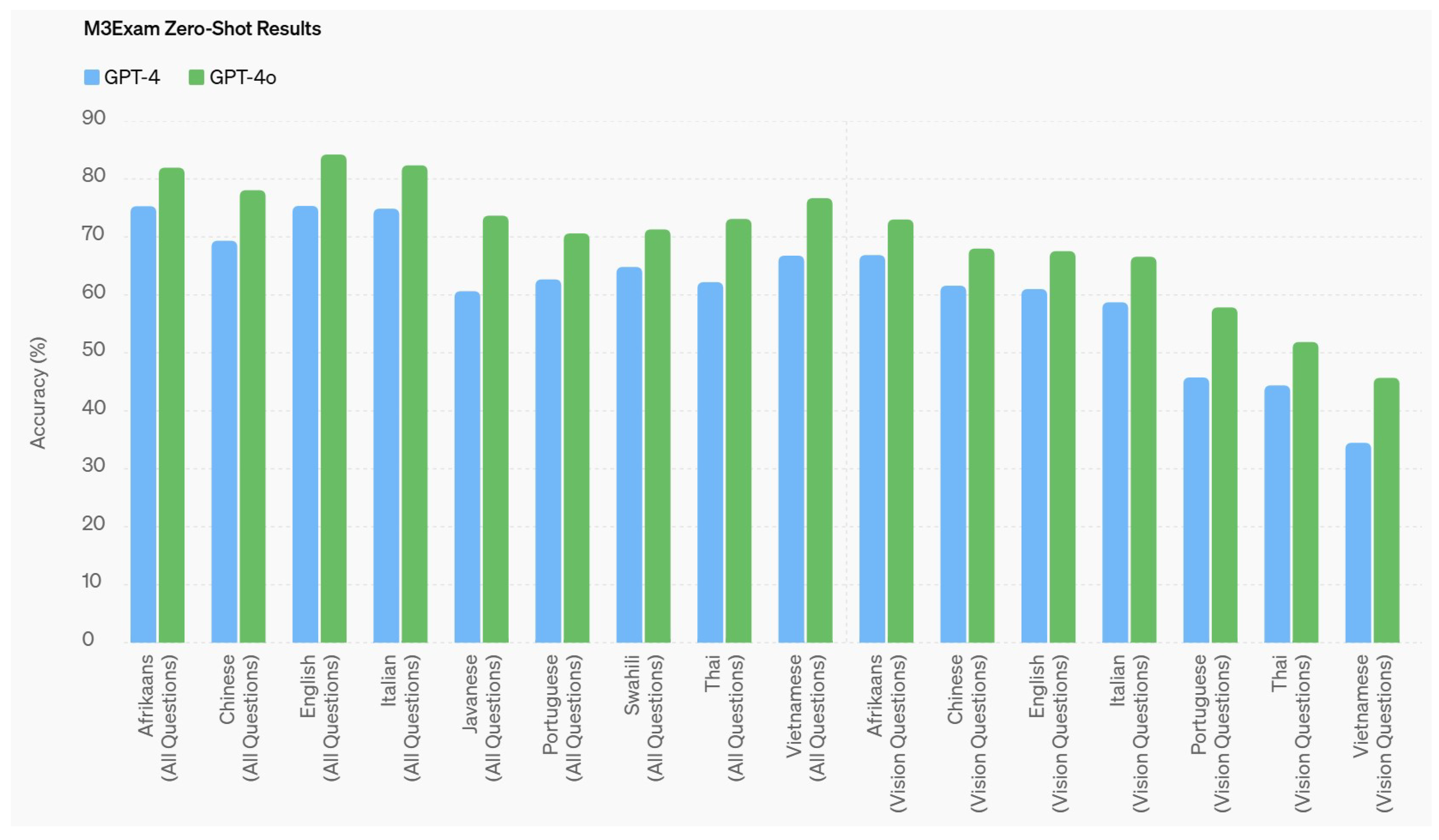
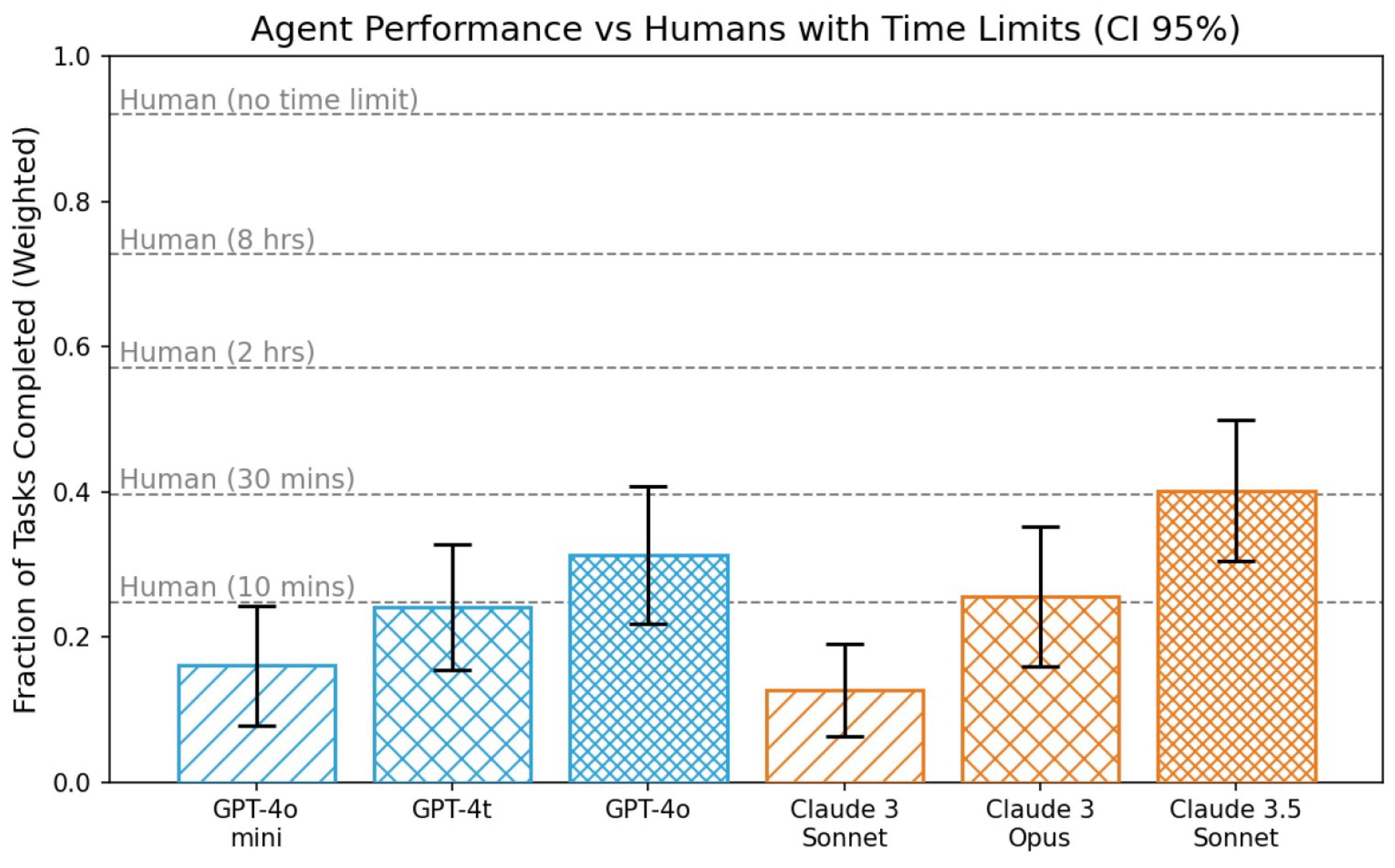
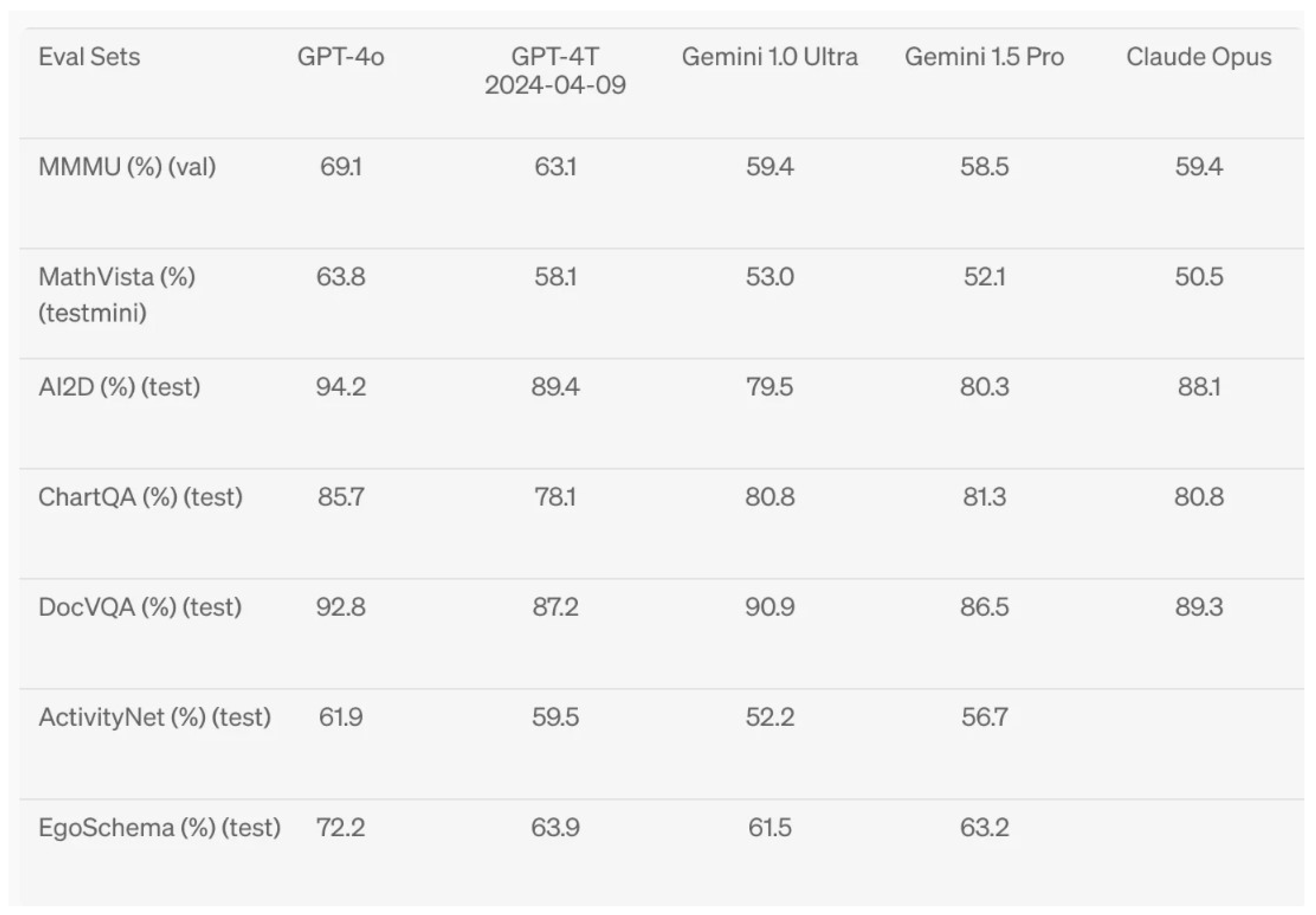

| Medical Knowledge Task | GPT-4T (May 2024) | GPT-4o |
|---|---|---|
| MedQA USMLE 4 Options (0-shot) | 0.78 | 0.89 |
| MedQA USMLE 4 Options (5-shot) | 0.81 | 0.89 |
| MedQA USMLE 5 Options (0-shot) | 0.75 | 0.86 |
| MedQA USMLE 5 Options (5-shot) | 0.78 | 0.87 |
| MedQA Taiwan (0-shot) | 0.82 | 0.91 |
| MedQA Taiwan (5-shot) | 0.86 | 0.91 |
| MedQA Mainland China (0-shot) | 0.72 | 0.84 |
| MedQA Mainland China (5-shot) | 0.78 | 0.86 |
| MMLU Clinical Knowledge (0-shot) | 0.85 | 0.92 |
| MMLU Clinical Knowledge (5-shot) | 0.87 | 0.92 |
| MMLU Medical Genetics (0-shot) | 0.93 | 0.96 |
| MMLU Medical Genetics (5-shot) | 0.95 | 0.95 |
| MMLU Anatomy (0-shot) | 0.79 | 0.89 |
| MMLU Anatomy (5-shot) | 0.85 | 0.89 |
| MMLU Professional Medicine (0-shot) | 0.92 | 0.94 |
| MMLU Professional Medicine (5-shot) | 0.92 | 0.94 |
| MMLU College Biology (0-shot) | 0.93 | 0.95 |
| MMLU College Biology (5-shot) | 0.95 | 0.95 |
| MMLU College Medicine (0-shot) | 0.74 | 0.84 |
| MMLU College Medicine (5-shot) | 0.80 | 0.89 |
| MedMCQA Dev (0-shot) | 0.70 | 0.77 |
| MedMCQA Dev (5-shot) | 0.72 | 0.79 |
| Model | English | Amharic | Hausa | Northern Sotho | Swahili | Yoruba |
|---|---|---|---|---|---|---|
| (n=523) | (n=518) | (n=475) | (Sepedi, n=520) | (n=520) | (n=520) | |
| GPT 3.5 Turbo | 80.3 | 6.1 | 26.1 | 26.9 | 62.1 | 27.3 |
| GPT-4o mini | 93.9 | 42.7 | 58.5 | 37.4 | 76.9 | 43.8 |
| GPT-4 | 89.7 | 27.4 | 28.8 | 30 | 83.5 | 31.7 |
| GPT-4o | 94.8 | 71.4 | 75.4 | 70 | 86.5 | 65.8 |
| Model | English | Amharic | Hausa | Northern Sotho | Swahili | Yoruba |
|---|---|---|---|---|---|---|
| (n=809) | (n=808) | (n=808) | (Sepedi, n=809) | (n=808) | (n=809) | |
| GPT 3.5 Turbo | 53.6 | 26.1 | 29.1 | 29.3 | 40 | 28.3 |
| GPT-4o mini | 66.5 | 33.9 | 42.1 | 36.1 | 48.4 | 35.8 |
| GPT-4 | 81.3 | 42.6 | 37.6 | 42.9 | 62 | 41.3 |
| GPT-4o | 81.4 | 55.4 | 59.2 | 59.1 | 64.4 | 51.1 |
| Model | Amharic | Hausa | Yoruba |
|---|---|---|---|
| (n=77) | (n=155) | (n=258) | |
| GPT 3.5 Turbo | 22.1 | 32.3 | 28.3 |
| GPT-4o mini | 33.8 | 43.2 | 44.2 |
| GPT-4 | 41.6 | 41.9 | 41.9 |
| GPT-4o | 44.2 | 59.4 | 60.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



