Submitted:
31 January 2025
Posted:
31 January 2025
You are already at the latest version
Abstract
The mushroom farming industry struggles to automate harvesting due to limited large-scale annotated datasets and the complex growth patterns of mushrooms, which complicate detection, segmentation, and pose estimation. To address this, we introduce a synthetic dataset with 40,000 unique scenes of white Agaricus bisporus and brown baby bella mushrooms, capturing realistic variations in quantity, position, orientation, and growth stages. Our two-stage pose estimation pipeline combines 2D object detection and instance segmentation with a 3D point cloud-based pose estimation network using a Point Transformer. By employing a continuous 6D rotation representation and a geodesic loss, our method ensures precise rotation predictions. Experiments show that processing point clouds with 1,024 points and the 6D Gram-Schmidt rotation representation yields optimal results, achieving an average rotational error of 1.67∘ on synthetic data, surpassing current state-of-the-art methods in mushroom pose estimation. The model further generalizes well to real-world data, attaining a mean angle difference of 3.68∘ on a subset of the M18K dataset with ground-truth annotations. This approach aims to drive automation in harvesting, growth monitoring, and quality assessment in the mushroom industry.
Keywords:
Synthetic Dataset
; Mushroom Detection
; Mushroom Pose Estimation
; Point Cloud
; Deep Learning
; Computer Vision
; Mushroom Harvesting Automation
; Object Detection
; Instance Segmentation
1. Introduction
The mushroom industry has a vital role in global agriculture, providing nutritious food and driving economic growth. With growing consumer demand, innovative cultivation practices are essential to improve productivity, efficiency, and product quality. Automation technologies, especially those using computer vision, have the potential to transform mushroom farming by enabling precise monitoring of growth and controlled harvesting throughout the cultivation process.
Implementing computer vision models for automated mushroom harvesting presents unique challenges. Mushrooms have subtle texture variations, and often grow in dense clusters within controlled environments. Accurate detection, segmentation, and pose estimation of mushrooms can be further complicated by occlusions, changing light conditions, and similar-looking background elements. Additionally, development of robust machine learning models requires extensive annotated data, which is limited due to the labor-intensive data collection and annotation required in industrial settings. Current datasets for mushroom detection and classification are limited in scale and realism. While recent publications provide 3D mushroom datasets [1,2]; these datasets fall short in capturing the natural appearance, dense clustering, and realistic environmental backgrounds typical of mushroom farms. Moreover, they often impose a minimum spacing between mushrooms, which fails to mimic the close proximity and clustering commonly seen in actual cultivation environments.
To bridge these gaps, we present a comprehensive and fully customizable pipeline to generate synthetic scenes designed for training and evaluating computer vision models in the mushroom industry. Our pipeline includes two widely cultivated mushroom species, white Agaricus bisporus and brown baby bella. We also generated 20,000 unique scenes per species, totaling 40,000 scenes which will be publicly available. This number of images was chosen to ensure comprehensive coverage of orientations, sizes, locations, and backgrounds, which is vital for robust detection and pose estimation. To justify this choice, we conducted an experiment measuring the average pairwise distance in feature space as we increased the sample size from a small subset up to 20,000 images (see Figure 1). In this experiment, we randomly sampled incremental subsets of the dataset and computed the mean Euclidean distance between every pair of object-level feature vectors (centers, dimensions, and orientations). The resulting curve shows that this distance grows quickly at first but begins to plateau, indicating diminishing returns beyond roughly 20,000 images.
However, by generating more than 20,000 images, one can still achieve higher coverage of the distribution. Due to storage and hardware limitations, we settled on 20,000 per species, which remains sufficiently large for training modern neural networks. Since deep learning benefits from as much data as possible, having a large, diverse set of synthetic images—without redundancy, given the vast configuration space—substantially strengthens a model’s ability to generalize. Moreover, the dataset remains scalable: researchers can easily generate additional scenes, further improving training effectiveness and performance. Each scene features a random number of mushrooms ranging from 1 to 100 in varied locations, orientations, and scales, simulating diverse growth stages and arrangements. This dataset greatly exceeds prior datasets in size, the largest of which contains only 150 scenes [1].
Our synthetic dataset is generated from 3D scans of mushrooms and high-resolution soil images to closely replicate the appearance of real-world mushroom farms. For each species of both white and brown mushrooms, we used seven detailed 3D models to capture natural variations in mushroom appearance, as shown in Figure 2. By integrating realistic models and textures, as well as images having a mixture of different mushroom sizes, this dataset is designed for training models applicable to industrial applications.
Our dataset can be utilized in a variety of applications, including 2D and 3D mushroom detection and pose estimation (which we focus on in this paper), monocular depth estimation of RGB images, growth monitoring, and automatic harvesting. While we only demonstrate the first application here, the data can also be used to obtain depth information from single RGB images, track mushroom development stages over time, and assist robotic systems in efficiently harvesting mushrooms.
Our data generation pipeline incorporates controlled variability in mushroom appearance, arrangement, and environmental factors to closely replicate industrial cultivation conditions. By allowing mushrooms to grow in dense clusters without enforcing minimum spacing, we tried to provide a more realistic dataset compared to previous similar studies. Figure 3 presents sample 3D scenes from our dataset for both white and brown mushrooms. The synthetic nature of our data provides precise annotations for each image, including segmentation masks, bounding boxes, depth maps, and 3D pose information. This comprehensive dataset enables the training of robust computer vision models suited for industrial applications.
The key contributions of our work are:
- We introduce a novel synthetic dataset generation pipeline tailored for the mushroom industry, providing detailed annotations for various computer vision tasks.
- Our data generation pipeline uses real 3D-scanned mushroom models and high-resolution soil images, enhancing dataset relevance.
- We validate our dataset through quantitative and qualitative analysis, benchmarking machine learning models on relevant tasks to demonstrate its potential for advancing automation in the mushroom industry.
- We propose a state-of-the-art 3D object detection and pose estimation pipeline for use in robotic mushroom harvesting applications.
2. Related Work
3D synthetic datasets will play a key role in enabling mushroom detection and segmentation, pose estimation using point cloud, developing and testing deep learning models for point cloud processing and applying them in pose estimation using RGB-D data in a robotic system for mushroom harvesting systems. This section reviews the key advancements in these areas with a focus on their relevance to mushroom harvesting automation.
2.1. Mushroom Detection and Segmentation in Agriculture
Accurate detection and segmentation of mushrooms is critical for automating tasks like harvesting, growth monitoring, and quality assessment in the mushroom industry. Several studies have developed models to address the challenges in agricultural settings.
Yang et al. [3] proposed PR-SOLOv2, an enhanced segmentation algorithm based on SOLOv2 with the addition of the PointRend module. Their model achieves a 93.04% segmentation accuracy and a 98.13% successful segmentation rate in dense clusters of mushrooms, effectively handling occlusions and deformations. Similarly, Shi et al. [4] introduced an improved RTMDet-Ins model with global attention mechanisms for segmenting Agaricus bisporus in RGB-D panoramic images, enabling precise segmentation and localization crucial for harvesting. The authors achieve an overall precision of 98.64%.
In our previous work, M18K [5], we introduced a comprehensive RGB-D dataset of real mushrooms for detection and instance segmentation to address the scarcity of public datasets in this field. Benchmarking with models like Mask R-CNN and YOLO showed strong performance, establishing M18K as a valuable resource for advancing automation in mushroom agriculture.
2.2. Synthetic Datasets for Agricultural Applications
Creating synthetic datasets has become an effective solution to address the scarcity of annotated real-world data in agriculture. Anagnostopoulou et al. [1] developed a synthetic mushroom scenes dataset using a three-stage pipeline, enhancing image realism with ControlNet transformations. Their dataset enabled high-accuracy detection and segmentation models fine-tuned on synthetic data.
Károly and Galambos [6] developed a synthetic dataset generation method in Blender for mushroom growth monitoring, automating the production of photorealistic images and precise segmentation masks to aid deep learning models in object segmentation. Similarly, Cieslak et al. [7] created a diverse synthetic dataset of soybean crops with weeds, supporting machine learning for vision-based farming. Their pipeline simulated various agricultural scenarios, and models trained on this synthetic data showed improved segmentation, underscoring the value of synthetic datasets in enhancing real-world applications.
2.3. 3D Pose Estimation Using Point Clouds
Estimating 6D object poses is essential for robotic manipulation and automated harvesting. Gao et al. [8] used a deep learning model based on PointNet [9] for 6D pose estimation with point clouds, applying separate networks for rotation and translation to achieve high accuracy on the YCB-Video dataset using only depth data. Dang et al. [10] tackled 6D pose estimation challenges in real-world data by introducing Match Normalization and a negative log-likelihood loss function, enhancing training stability and robustness and outperforming traditional methods on datasets like TUD-L and LINEMOD. Chen et al. [11] introduced PointPoseNet, a model for 6D object pose estimation that processes point clouds from RGB-D images. By regressing point-wise unit vectors toward object keypoints, the model achieved an average pose estimation accuracies of 98.4% and 79.5% on LINEMOD and Occlusion LINEMOD datasets and demonstrated robustness in occluded and cluttered environments.
2.4. Deep Learning Models for Point Cloud Processing
Deep learning models for point cloud data have greatly advanced 3D object recognition and segmentation. PointNet [12] introduced a novel architecture that processes raw point clouds directly, using symmetric functions to achieve invariance to input permutation. PointNet++ [9] extended this framework by capturing local geometric structures through a hierarchical approach, addressing limitations in handling complex scenes and varying point densities. Zhao et al. [13] developed the Point Transformer, incorporating self-attention mechanisms to capture both local and global dependencies in 3D spatial structures. Using vector attention and positional encoding, the Point Transformer achieved state-of-the-art results in semantic segmentation and object classification on large-scale datasets. They achieved mIoU of 70.4% on Area 5 of S3DIS dataset, outperforming the strongest prior model by 3.3 absolute percentage points and crossing the 70% mIoU threshold for the first time
2.5. Pose Estimation with RGB-D Data
Integrating RGB-D data for object detection and pose estimation has been widely studied. Soltan et al. [14] developed a pipeline that combines point cloud processing and deep learning for object classification and position estimation, achieving 95% correct robot positioning with both RGB and depth data while remaining computationally efficient. Baisa and Al-Diri [15] proposed a method for mushroom detection, localization, and 3D pose estimation using an RGB-D sensor, employing segmentation and the Circular Hough Transform for detection, followed by global registration for pose estimation. Their approach achieved 99.14% F1-score, demonstrating its suitability for robotic harvesting applications.
2.6. Robotic Systems for Mushroom Harvesting
Recent advancements in robotic harvesting systems emphasize integrated detection, localization, and manipulation. Mavridis et al. [16] developed an affordable robotic harvesting system tailored for existing mushroom farms, combining a scanning vision setup with a gantry robot. Using YOLOv5 for detection and a two-step model-fitting technique for pose estimation, their system achieved accurate harvesting with minimal orientation error. Lin et al. [17] presented a mushroom detection and positioning method based on an improved YOLOv2 algorithm. By incorporating a Kalman filter and LSTM network for tracking and prediction, their system provided real-time performance suitable for automated sorting in industrial applications. Koirala et al. have contributed significantly to the development of robotic grippers and harvesting systems tailored for button mushrooms [18,19,20]. In [19], Koirala et al. introduced a compact hybrid three-finger gripper for automated harvesting in densely spaced, multi-layered growing environments. The gripper combines rigid and soft components, with textured soft pads on the fingertips to enhance grip while minimizing mushroom damage. Force-resistive sensors regulate pressure, ensuring optimal gripping force. The gripper achieved a 100% success rate for single mushrooms and 64% for clusters, demonstrating its potential for efficient, damage-free harvesting in commercial mushroom farms.
In a comprehensive review [20], Koirala et al. analyzed recent advancements in robotic systems for button mushroom harvesting, focusing on components like manipulators, end-effectors, collection mechanisms, mobile platforms, and computer vision systems. They discussed challenges faced by commercial systems, including high initial costs, energy requirements, and moderate success rates in complex farm settings. The review emphasized the need for precise detection and handling to prevent damage and improve efficiency, suggesting future directions such as enhancing vision algorithms for clustered mushrooms and optimizing end-effectors for gentle handling.
This work underscores the importance of specialized gripper designs and integrated systems in advancing automated mushroom harvesting. While progress has been made, challenges remain in achieving high success rates in clustered environments and minimizing impact on neighboring mushrooms. Our work complements these efforts by providing accurate 3D pose estimation, supplying robotic manipulators and grippers with precise orientation data for each mushroom, enhancing harvesting efficiency and reducing damage.
2.7. Limitations of Existing Works and Our Contributions
Despite advancements in mushroom detection, segmentation, and pose estimation, current datasets and models often lack the realism and variability required to generalize to complex agricultural settings. Current synthetic datasets [1,6] fail to capture patterns, such as dense clustering and varied orientations. Additionally, pose estimation methods using point clouds have mainly focused on general objects [8,11] with limited application to mushrooms. Continuous rotation representations, like the 6D approach by Zhou et al. [21], show promise but need further exploration for agricultural products.
Our work addresses these gaps by introducing a comprehensive synthetic dataset generation pipeline, using real 3D-scanned models and high-definition soil images. We developed a novel two-stage pose estimation model based on the Point Transformer network [13] and a 6D rotation representation with geodesic loss, tailored to the unique challenges of the mushroom industry. By integrating 2D object detection with 3D pose estimation, our approach effectively manages dense clusters and complex orientations, advancing automation in mushroom cultivation.
3. Methodology
3.1. Synthetic Scene Generation
To generate a realistic and diverse dataset for training computer vision models in the mushroom industry, we developed a synthetic scene generation pipeline with two key components: (1) ground plane generation using Perlin noise [22] to simulate natural terrain, and (2) random mushroom placement with transformations and collision detection to replicate cluttered environments with occlusions.
3.1.1. Ground Plane Generation
The ground plane represents the soil surface where mushrooms grow. To mimic the natural, uneven appearance of soil in cultivation environments, we create a ground plane mesh and apply Perlin noise for height variation. Defined as a grid of points with dimensions and resolutions and along the x and y axes, respectively. The Perlin noise function is calculated at each grid point to determine the elevation :
where:
- A is the amplitude controlling the height variation.
- s is the scaling factor affecting the frequency of the noise.
- is the base elevation (set to zero in our case).
-
is the Perlin noise function defined as:where:
- -
- O is the number of octaves controlling the level of detail.
- -
- p is the persistence determining the amplitude reduction at each octave.
- -
- is a smooth noise function.
Adjusting parameters such as amplitude A, scaling factor s, number of octaves O, and persistence p, we control the roughness and appearance of the ground surface. Figure 4 illustrates an example of the generated Perlin noise applied to the ground plane. High-definition soil textures are then mapped onto this surface to enhance realism, using texture tiling to cover the entire plane seamlessly.
3.1.2. Mushroom Placement
Mushrooms are placed on the ground plane with random transformations and collision detection to emulate natural growth patterns, including clustering and varied orientations. Each mushroom is assigned a random position within a specified range , ensuring even distribution. The z-coordinate coordinate is set to zero and adjusted based on the ground elevation at . Random rotations are applied to simulate natural variations in mushroom orientation. The rotations around the x (roll), y (pitch), and z (yaw) axes are defined by the angles , , and , respectively. These angles are sampled as follows:
- Roll (): Sampled from a Gaussian distribution .
- Pitch (): Sampled from a Gaussian distribution .
- Yaw (): Uniformly sampled from .
The standard deviations and control the extent of variation in roll and pitch. Distribution plots for each rotation angle are provided in Figure 5.
The combined rotation matrix R is computed by multiplying the individual rotation matrices:
where , , and are the rotation matrices around the x, y, and z axes, respectively.
To represent different mushroom sizes, mushrooms are scaled uniformly. The scaling factor s is randomly sampled from a uniform distribution . Additionally, random stretching factors , , and are applied along each axis to introduce variability in mushroom shapes:
where is sampled from . A placeholder figure showing the size distribution is provided in Figure 6.
To realistically model mushroom clusters, we allow mushrooms to be placed in proximity, sometimes with minimal overlap. Collision detection is performed using mesh intersection tests rather than simple bounding box checks, capturing the actual geometry of the mushrooms for a more accurate representation of natural clustering. For each new mushroom, intersections are checked with the k nearest previously placed mushrooms based on Euclidean distance. If the intersection volume exceeds a set threshold, the placement is deemed invalid, and a new position is sampled, with the process repeated up to a maximum number of attempts, set to 100. This value is a hyperparameter of the generation pipeline. Increasing it allows for denser and more realistic mushroom clusters but slows down the generation process. After applying random rotation and scaling transformations, the same affine transformations are applied to the mushroom’s oriented bounding box (OBB) to ensure consistent annotations. To ensure mushrooms are properly positioned on uneven terrain, we adjust their vertical placement based on the ground elevation at their coordinates derived from the Perlin noise function. Each mushroom is translated along the z-axis so that the base of its stem aligns with the ground surface, avoiding visual artifacts like floating or submerged mushrooms.
3.1.3. Mushroom Placement Algorithm
Algorithm 1 summarizes the mushroom placement process, outlining the key steps to ensure realism and diversity in the generated scenes.
| Algorithm 1 Mushroom Placement Process |
Require: Ground plane mesh, list of mushroom models, maximum attempts M, overlap threshold
|
In the algorithm:
- M is the maximum placement attempts (set to 100) to balance computational cost and placement success.
- is the overlap threshold (5% IoU), ensuring minimal collisions. Larger can yield unrealistic overlaps; stricter thresholds reduce feasibility.
- Transformations (position, orientation, size) ensure unique, realistic mushroom instances.
- Collision detection uses mesh intersection volumes, checked against .
By following this process, we generate scenes with varying numbers of mushrooms, realistic clustering, and diverse appearances, closely mimicking conditions in actual mushroom cultivation environments.
3.2. Pose Estimation Model Training
Our pose estimation pipeline, depicted in Figure 8, leverages two neural networks to estimate the 3D orientation (pose) of mushrooms in the generated scenes. The first network performs object detection and instance segmentation on RGB images, locating individual mushrooms and generating segmentation masks. The second network estimates each mushroom’s 3D pose by processing its corresponding point cloud, extracted using the segmentation masks. Initially, we attempted to predict rotation matrices directly from the complete scene’s point cloud, but this approach yielded suboptimal results due to overlapping mushrooms and environmental clutter. By isolating each mushroom with 2D detection and segmentation, pose estimation accuracy improved significantly. Figure 7 shows examples of extracted mushroom cap point clouds.
The pose estimation pipeline starts with a 2D object detection and segmentation network. We use an RGB-based convolutional neural network, such as Mask R-CNN [23], to detect mushrooms in the scene and generate instance segmentation masks, producing bounding boxes and pixel-wise masks for each detected mushroom. These instance masks allow us to extract individual mushroom point clouds from the complete scene’s point cloud, which are then processed by the 3D pose estimation network to predict the rotation matrix representing each mushroom’s 3D orientation.
To evaluate the effectiveness of different point cloud feature extractors, we compared PointNet [12], PointNet++ [9], and the Point Transformer [13], using the as the pose accuracy metric. Results were (PointNet), (PointNet++), and (Point Transformer), with the Point Transformer performing best. We thus adopt the Point Transformer backbone, which processes point clouds directly, is permutation-invariant, and effectively captures local and global features through self-attention.
The network takes a point cloud as input, where N is the number of points, each with 3D coordinates . Local aggregation layers perform feature extraction by capturing local geometric structures, using sampling and grouping to form neighborhoods, followed by multi-layer perceptron’s (MLPs) for feature extraction. Self-attention layers model long-range dependencies and global context within the point cloud. Point-wise features are aggregated into a global feature vector via max pooling, and fully connected layers map this vector to a 6D rotation representation, with a normalization layer ensuring valid rotation outputs.
Predicting 3D rotations is challenging due to the non-Euclidean nature of rotation groups and discontinuities in conventional representations like Euler angles. To overcome these issues, we use the continuous 6D rotation representation proposed by Zhou et al. [21] and train with a geodesic loss function. A rotation matrix can be uniquely represented by its first two columns, concatenated into a 6D vector . To reconstruct the full rotation matrix from , we apply the Gram-Schmidt orthogonalization process:
where are the first and second components of , and × denotes the cross product.
The geodesic loss measures the rotational distance between two rotation matrices on the manifold [24]. Given the predicted rotation matrix and the ground truth rotation matrix , the geodesic loss is defined as:
To ensure numerical stability, we clamp the input to the arccos function within , where is a small constant (e.g., ).
The training process involves generating training samples consisting of point clouds of individual mushrooms and their corresponding ground truth rotation matrices. Data augmentation techniques, such as random jittering and scaling, are applied to improve generalization. During the forward pass, the point cloud is input to the pose estimation network, which outputs a normalized 6D rotation vector . This vector is converted to a rotation matrix using the Gram-Schmidt process. The geodesic loss is computed between and the ground truth rotation matrix . Gradients are computed with respect to the network parameters, and the weights are updated using the Adam optimizer with a learning rate of . The model’s performance is evaluated on a separate validation set to monitor overfitting and adjust hyperparameters as needed.
The pose estimation network is implemented using PyTorch and PyTorch Lightning for efficient training and scalability. We trained the network with a batch size of 32 for 200 epochs. The Adam optimizer is used with an initial learning rate of , and learning rate scheduling is applied to reduce the learning rate upon plateau. Input point clouds are normalized to fit within a unit sphere to ensure scale invariance. Data augmentation techniques, including random permutations, and Gaussian noise, are applied to the input point clouds during training to improve the network’s robustness. To handle the discontinuities in rotation space, we ensure that the geodesic loss is computed within a stable numerical range by clamping the input to the arccos function.
By combining 2D object detection with 3D pose estimation, we decomposed the complex task of estimating mushroom poses in cluttered scenes into manageable sub-tasks. This approach allows the pose estimation network to focus on individual mushrooms, reducing interference from overlapping objects and background noise. The use of the 6D rotation representation and the geodesic loss was essential for stable training and accurate rotation predictions. Alternative rotation representations, such as Euler angles or quaternions, can suffer from discontinuities or ambiguities, which hinder the learning process.
Figure 8.
Complete two-stage pose estimation pipeline. Dotted boxes and lines are used for backward pass during training, and solid lines and boxes are used during forward pass (inference). The dataset provides Ground Truth (GT) annotations.
Figure 8.
Complete two-stage pose estimation pipeline. Dotted boxes and lines are used for backward pass during training, and solid lines and boxes are used during forward pass (inference). The dataset provides Ground Truth (GT) annotations.
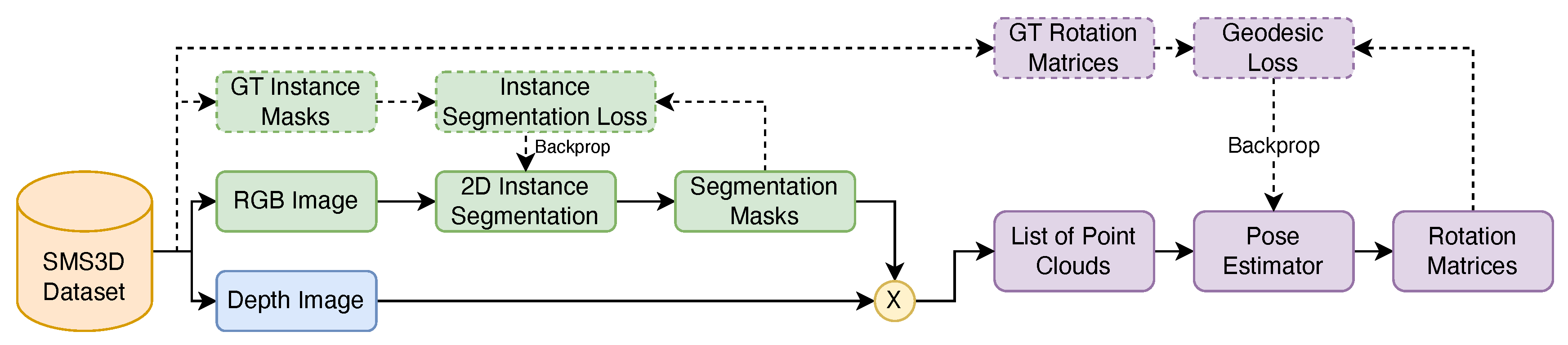
To effectively capture intricate geometric relationships within the point cloud data, we chose the Point Transformer model as the backbone for the pose estimation network. The self-attention mechanism of the Point Transformer enables modeling of both local and global dependencies, which is crucial for accurate pose estimation in complex scenes.
4. Results
In this section, we present the experimental results of our pose estimation model and associated ablation studies. We evaluate the impact of various factors on the model’s performance, including the number of sampled points, rotation representation methods, and the inclusion of RGB information. Additionally, we report the performance of the 2D object detection and instance segmentation component and demonstrate the applicability of our model to real-world data.
4.1. Evaluation of Pose Estimation
We conducted extensive experiments to assess the performance of our 3D pose estimation network. All ablation studies were conducted over 10 epochs to quickly evaluate the effects of different settings. After identifying the optimal configuration, we trained the model for a longer duration of 200 epochs to achieve the best possible performance.
4.1.1. Effect of Number of Points
To determine the impact of the number of sampled points from each mushroom point cloud, we experimented with three different settings: 64, 256, and 1,024 points. In all cases, we excluded the RGB information and used the 6D rotation representation with the Gram-Schmidt process.
Table 1 summarizes the results of these experiments. As the number of points increases, the model’s performance improves, indicating that a higher point density provides more geometric information for accurate pose estimation. However, increasing the number of points also affects the inference time.
4.1.2. Effect of Rotation Representation
We investigated the influence of different rotation representations on the model’s accuracy. Using 1,024 points without RGB information, we compared the following rotation representations: 6D Gram-Schmidt, 9D rotation matrix, quaternion, and Euler angles. The 6D Gram-Schmidt method achieved the best results, likely due to its continuity and avoidance of singularities or ambiguities present in other representations. Euler angles can suffer from discontinuities and gimbal lock, while quaternions have ambiguity between and representing the same rotation.
Table 2 shows the performance of each rotation representation.
4.1.3. Effect of Including RGB Information
We explored whether incorporating RGB color information into the point cloud would enhance the model’s performance. Using 1,024 points and the 6D Gram-Schmidt rotation representation, we trained models with and without RGB features. The inclusion of RGB information did not lead to significant improvements in rotation estimation accuracy, suggesting that the geometric structure captured by the point cloud is the primary contributor to accurate pose estimation in our scenario.
Table 3 presents the results of this experiment.
4.1.4. Model Performance and Inference Time
The experiments revealed a trade-off between model accuracy and inference time. Increasing the number of points improves performance but also increases computational load. Similarly, more complex rotation representations can affect inference speed. These factors must be balanced to achieve practical real-time performance in industrial applications.
4.1.5. Final Model Performance
Using the optimal configuration identified from the ablation studies—1,024 points, 6D Gram-Schmidt rotation representation, and excluding RGB information—we trained the model for 200 epochs. This extended training allowed the model to converge fully and achieve its best performance at a geodesic loss value of 0.059 for the validation set.
Figure 9 shows the error distribution for roll, pitch, and yaw components separately. The model demonstrates consistent accuracy across all rotation axes, indicating its robustness in estimating the complete orientation of mushrooms.
Additionally, we analyzed the rotation errors versus the size of the mushrooms and observed slightly higher errors for smaller mushrooms due to being partially occluded by taller mushrooms. The results demonstrating the errors in roll, pitch, and yaw prediction are depicted in Figure 10.
We also provide a visual comparison between the ground truth and predicted oriented bounding boxes in Figure 11. The predicted bounding boxes closely align with the ground truth, visually confirming the model’s accuracy.
4.1.6. Comparison with State-of-the-Art Methods
To evaluate the effectiveness of our proposed pose estimation method, we compare its performance against several state-of-the-art approaches in object pose estimation, particularly those applied to mushrooms. The primary metric for comparison is the average rotational error, denoted as , which quantifies the mean angular difference between the predicted and ground truth orientations.
On our synthetic validation set, our approach achieves an average rotational error of , outperforming other methods by a substantial margin. Table 4 presents these comparative results, including the synthetic dataset (This Work (Synthetic)) and the evaluation on 10 real images including 330 mushroom instances (This Work (Real, 10 Images)) from the M18K dataset, for which we labeled ground-truth 3D OBB rotations.
Our method’s superior performance (particularly on synthetic data) can be attributed to several key factors:
- The use of the 6D rotation representation with the Gram-Schmidt process ensures continuity and avoids ambiguities inherent in other representations, facilitating more accurate rotation predictions.
- The adoption of the Point Transformer network [13] allows for effective capture of both local and global geometric features within the point cloud data through self-attention mechanisms.
- The combination of 2D object detection and instance segmentation with 3D pose estimation isolates individual mushrooms, reducing the complexity introduced by overlapping objects and background clutter.
- Extensive training on a comprehensive synthetic dataset that closely mimics real-world conditions enhances the model’s generalization capabilities.
4.2. 2D Object Detection and Instance Segmentation Results
The performance of the 2D object detection and instance segmentation component is crucial for accurately isolating individual mushrooms for pose estimation. We evaluated this component using standard metrics such as Average Precision (AP) for detection and segmentation tasks. We also evaluated the 2D object detection and instance segmentation performance on the real-world dataset. Table 5 shows the detection results including Average Precision (AP), Average Recall (AR), and F1 score across all IoU thresholds. The model maintains high accuracy, suggesting that the synthetic data effectively supplemented the real-world training data. Especially in the case of pre-training the 2D detection and instance segmentation model on the synthetic data and fine-tuning the pre-trained model on the real-world images of the M18K dataset, we observed a significant improvement in both detection and instance segmentation results.
4.3. Application to Real-World Data
To assess the applicability of our model in real-world scenarios, we applied the trained system to real-world RGB-D images from our previous dataset, M18K. We used the M18K dataset to train the 2D object detection and instance segmentation component, ensuring it is adapted to real-world visual characteristics. For the 3D pose estimation component, we employed the model trained on the synthetic dataset.
4.3.1. Quantitative Evaluation on Real M18K Images
We additionally labeled 10 images (330 mushroom instances) from the M18K dataset with ground-truth 3D oriented bounding box rotations using the CVAT tool. Running inference on this newly annotated set shows a mean angle difference of 3.68 degrees between our predicted rotations and the ground truth. This quantitative result demonstrates that our model, trained entirely on synthetic data for pose estimation, generalizes effectively to real mushroom images.
4.3.2. Qualitative Results
Figure 12 provides a visual comparison of ground-truth versus predicted oriented bounding boxes on one of these newly annotated real images. The predictions closely match the ground-truth orientations, suggesting that, despite the domain gap between synthetic and real data, the model successfully captures the poses of mushrooms in real-world scenes.
These results underscore the value of our synthetic dataset in enhancing model performance and facilitating the development of computer vision applications in the mushroom industry. They also demonstrate that the pose estimation component, though trained on synthetic data, achieves compelling performance on real mushroom images, both qualitatively and quantitatively (3.68 degrees of average rotational error).
5. Discussion
The experimental results demonstrate the effectiveness of our proposed synthetic dataset and pose estimation model for applications in the mushroom industry. By achieving an average rotational error of on our synthetic dataset, our method significantly outperforms state-of-the-art approaches, which reported errors ranging from to [2,15,25]. This substantial improvement highlights the robustness and precision of our model in estimating mushroom poses.
The ablation studies provide valuable insights into the factors influencing model performance and guide the selection of optimal configurations. The investigation into the number of sampled points revealed that increasing the point cloud density enhances the model’s ability to capture geometric details essential for accurate pose estimation. Using 1,024 points strikes a balance between performance and computational efficiency, offering sufficient detail without incurring excessive processing time.
The comparison of rotation representations highlighted the superiority of the 6D Gram-Schmidt method. Its continuity and avoidance of singularities make it well-suited for neural network training. The limitations of Euler angles, such as discontinuities and gimbal lock, and the ambiguity inherent in quaternions between and adversely affect model convergence and accuracy. The 6D representation addresses these issues, leading to more stable and precise rotation predictions, which contributed to outperforming existing methods.
Including RGB information in the point cloud did not significantly improve the model’s performance. This outcome suggests that the geometric structure of the mushrooms, as captured by the spatial coordinates, is the primary determinant of pose estimation accuracy in our context. The color information may not provide additional discriminative features necessary for orientation estimation, or the network may require a different architecture to leverage such data effectively.
To evaluate our model in real-world conditions, we tested it on a set of 10 images (330 mushrooms) from the M18K dataset, where we labeled the 3D oriented bounding box rotations. On this real subset, the model achieved a mean angle difference of , indicating that the pose estimation component, trained entirely on synthetic data, generalizes well to real mushroom images. Nonetheless, a gap remains between the model’s performance on synthetic data (1.67°) and real data (3.68°), underscoring the potential benefits of acquiring additional real-world annotations or improving domain adaptation techniques.
While our synthetic dataset closely approximates real-world conditions, it may not capture all variations present in diverse mushroom cultivation environments. Factors such as lighting differences, extreme occlusions, and diverse sensor noise characteristics in real-world data can still impact performance. Expanding the annotated real dataset beyond the current subset of 10 images would enable a more comprehensive quantitative assessment and potentially guide further improvements.
Future work should focus on bridging the domain gap further by incorporating domain adaptation techniques or generating synthetic data that more closely mimics real-world sensor characteristics. Acquiring a larger set of annotated real-world data for fine-tuning could also enhance model performance. Expanding the dataset to include more mushroom species and varying environmental conditions would improve the model’s robustness and applicability across different cultivation setups. Additionally, implementing the pose estimation algorithm in a robotic system and evaluating its impact on automated harvesting performance will shed light on how accurate the orientation estimates need to be to meet industrial requirements.
6. Conclusion
In this paper, we presented a comprehensive synthetic dataset generation pipeline and a two-stage pose estimation pipeline tailored for the mushroom industry. By leveraging high-definition 3D scans of mushrooms and realistic soil textures, we generated 40,000 unique scenes that accurately reflect real-world cultivation environments. Our data generation process accounts for natural growth patterns, including clustering and variability in size and orientation.
The proposed pose estimation model combines 2D object detection and instance segmentation with a point cloud-based orientation estimation network. Through extensive experiments, we demonstrated that using a 6D rotation representation with the Gram-Schmidt process and processing 1,024 points without RGB information yields the best performance. The Point Transformer backbone effectively captures both local and global geometric features, enabling accurate pose estimation even in complex scenes.
Our method achieved an average rotational error of on synthetic data, significantly outperforming state-of-the-art methods in mushroom 3D pose estimation. When evaluated on 10 labeled real images from the M18K dataset, the model achieved a mean angle difference of , showcasing its ability to generalize to real-world conditions despite being trained on synthetic data alone. This level of precision is crucial for applications such as automated harvesting, where accurate orientation information directly impacts the effectiveness of robotic manipulators.
Applying the model to these real-world images further underscores its potential for practical applications such as automated harvesting, growth monitoring, and quality assessment. The results indicate that our synthetic dataset serves as a valuable resource for training models in scenarios where real-world annotated data is limited.
Our work addresses key challenges in developing computer vision systems for the mushroom industry and contributes a significant dataset and methodology for future research. By continuing to refine the models and dataset, we aim to facilitate the adoption of automation technologies that enhance productivity, efficiency, and product quality in mushroom cultivation. Future efforts will focus on expanding the dataset to encompass more varieties and conditions, as well as integrating domain adaptation techniques to further bridge the gap between synthetic and real-world data. Additionally, evaluating the algorithm’s performance in a real robotic harvesting setup will provide insights into how to meet operational requirements in industrial mushroom production.
Funding
The work was partially supported by the United States Department of Agriculture grants #2021-67022-34889, 2022-67022-37867, and 2023-51300-40853, as well as the University of Houston Infrastructure Grant.
Acknowledgments
We would like to acknowledge Kenneth Wood, Armando Juarez, and Bruce Knobeloch from Monterey Mushroom Inc. for allowing us to visit and obtain the necessary information from the mushroom farm in Madisonville, TX, USA.
References
- Anagnostopoulou, D.; Retsinas, G.; Efthymiou, N.; Filntisis, P.; Maragos, P. A Realistic Synthetic Mushroom Scenes Dataset. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2023. [Google Scholar] [CrossRef]
- Retsinas, G.; Efthymiou, N.; Maragos, P. Mushroom Segmentation and 3D Pose Estimation From Point Clouds Using Fully Convolutional Geometric Features and Implicit Pose Encoding. 2023. [Google Scholar] [CrossRef]
- Yang, S.; Zhang, J.; Yuan, J. A High-Accuracy Contour Segmentation and Reconstruction of a Dense Cluster of Mushrooms Based on Improved SOLOv2. Agriculture 2024, 14, 1646. [Google Scholar] [CrossRef]
- Shi, C.; Mo, Y.; Ren, X.; Nie, J.; Zhang, C.; Yuan, J.; Zhu, C. Improved Real-Time Models for Object Detection and Instance Segmentation for Agaricus bisporus Segmentation and Localization System Using RGB-D Panoramic Stitching Images. Agriculture 2024, 14, 735. [Google Scholar] [CrossRef]
- Zakeri, A.; Fawakherji, M.; Kang, J.; Koirala, B.; Balan, V.; Zhu, W.; Benhaddou, D.; Merchant, F.A. M18K: A Comprehensive RGB-D Dataset and Benchmark for Mushroom Detection and Instance Segmentation. arXiv 2024. [Google Scholar] [CrossRef]
- Károly, A.I.; Galambos, P. Automated Dataset Generation with Blender for Deep Learning-based Object Segmentation. In Proceedings of the 2022 IEEE 20th Jubilee World Symposium on Applied Machine Intelligence and Informatics (SAMI); 2022. [Google Scholar] [CrossRef]
- Cieslak, M.; Govindarajan, U.; Garcia, A.; Chandrashekar, A.; Hädrich, T.; Mendoza-Drosik, A.; Michels, D.L.; Pirk, S.; Fu, C.C.; Pałubicki, W. Generating Diverse Agricultural Data for Vision-Based Farming Applications. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2024. [Google Scholar] [CrossRef]
- Gao, G.; Lauri, M.; Wang, Y.; Hu, X.; Zhang, J.; Frintrop, S. 6D Object Pose Regression via Supervised Learning on Point Clouds. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA); 2020. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17. Red Hook, NY, USA; 2017. [Google Scholar] [CrossRef]
- Dang, Z.; Wang, L.; Guo, Y.; Salzmann, M. Learning-Based Point Cloud Registration for 6D Object Pose Estimation in the Real World. In Proceedings of the Computer Vision – ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Cham, 2022. [Google Scholar] [CrossRef]
- Chen, W.; Duan, J.; Basevi, H.; Chang, H.J.; Leonardis, A. PointPoseNet: Point Pose Network for Robust 6D Object Pose Estimation. 2020. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. 2017. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point Transformer. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021; pp. 16259–16268. [Google Scholar] [CrossRef]
- Soltan, S.; Oleinikov, A.; Demirci, M.F.; Shintemirov, A. Deep Learning-Based Object Classification and Position Estimation Pipeline for Potential Use in Robotized Pick-and-Place Operations. Robotics 2020, 9, 63. [Google Scholar] [CrossRef]
- Baisa, N.L.; Al-Diri, B. Mushrooms Detection, Localization and 3D Pose Estimation using RGB-D Sensor for Robotic-picking Applications. 2022. [Google Scholar] [CrossRef]
- Mavridis, P.; Mavrikis, N.; Mastrogeorgiou, A.; Chatzakos, P. Low-cost, accurate robotic harvesting system for existing mushroom farms. In Proceedings of the 2023 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM); 2023. [Google Scholar] [CrossRef]
- Lin, A.; Liu, Y.; Zhang, L. Mushroom Detection and Positioning Method Based on Neural Network. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC); 2021; Vol. 5, pp. 1174–1178. [Google Scholar] [CrossRef]
- Development of a Compact Hybrid Gripper for Automated Harvesting of White Button Mushroom. In Proceedings of the ASME 2024 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Washington, DC, USA, 25–28 August 2024; Volume 7. Available online: https://asmedigitalcollection.asme.org/IDETC-CIE/proceedings-pdf/IDETC-CIE2024/88414/V007T07A036/7403466/v007t07a036-detc2024-143056.pdf. [CrossRef]
- Koirala, B.; Kafle, A.; Nguyen, H.C.; Kang, J.; Zakeri, A.; Balan, V.; Merchant, F.; Benhaddou, D.; Zhu, W. A Hybrid Three-Finger Gripper for Automated Harvesting of Button Mushrooms. Actuators 2024, 13, 287. [Google Scholar] [CrossRef]
- Koirala, B.; Zakeri, A.; Kang, J.; Kafle, A.; Balan, V.; Merchant, F.A.; Benhaddou, D.; Zhu, W. Robotic Button Mushroom Harvesting Systems: A Review of Design, Mechanism, and Future Directions. Applied Sciences 2024, 14, 9229. [Google Scholar] [CrossRef]
- Zhou, Y.; Barnes, C.; Lu, J.; Yang, J.; Li, H. On the Continuity of Rotation Representations in Neural Networks. 2019. [Google Scholar] [CrossRef]
- Perlin, K. An image synthesizer. SIGGRAPH’85. New York, NY, USA; 1985; pp. 287–296. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. 2017. [Google Scholar] [CrossRef]
- Huynh, D.Q. Metrics for 3D Rotations: Comparison and Analysis. Journal of Mathematical Imaging and Vision 2009, 35, 155–164. [Google Scholar] [CrossRef]
- Retsinas, G.; Efthymiou, N.; Anagnostopoulou, D.; Maragos, P. Mushroom Detection and Three Dimensional Pose Estimation from Multi-View Point Clouds. Sensors 2023, 23, 3576. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Average pairwise distance in feature space as the sample size increases.
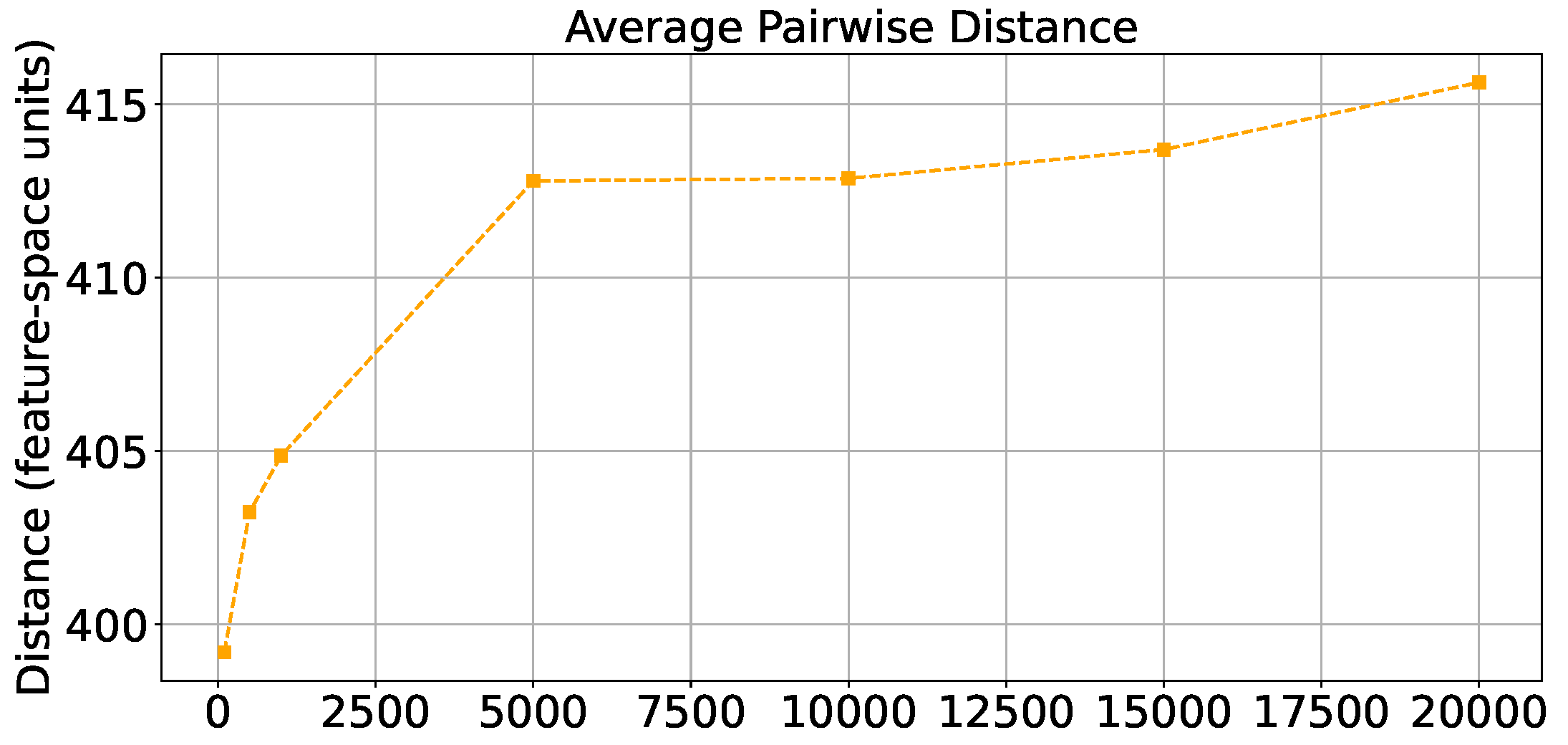
Figure 2.
High-definition 3D models of mushrooms used in the dataset. Top row: White Agaricus bisporus; Bottom row: Brown baby bella.
Figure 2.
High-definition 3D models of mushrooms used in the dataset. Top row: White Agaricus bisporus; Bottom row: Brown baby bella.

Figure 3.
Sample 3D scenes with oriented bounding boxes from the dataset. Left: White mushrooms; Right: Brown mushrooms.
Figure 3.
Sample 3D scenes with oriented bounding boxes from the dataset. Left: White mushrooms; Right: Brown mushrooms.

Figure 4.
Visualization of Perlin noise applied to the ground plane to simulate natural terrain variations.
Figure 4.
Visualization of Perlin noise applied to the ground plane to simulate natural terrain variations.

Figure 5.
Distributions of rotation angles applied to mushrooms: (a) Roll (), (b) Pitch (), (c) Yaw ().
Figure 5.
Distributions of rotation angles applied to mushrooms: (a) Roll (), (b) Pitch (), (c) Yaw ().
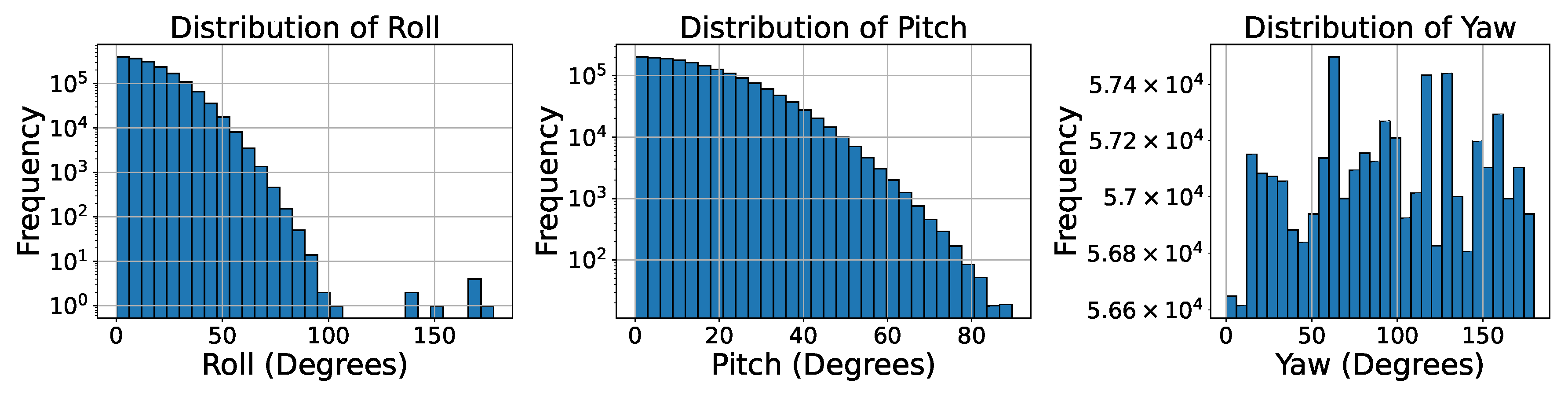
Figure 6.
Distribution of scaling factors applied to mushrooms to simulate different growth stages.
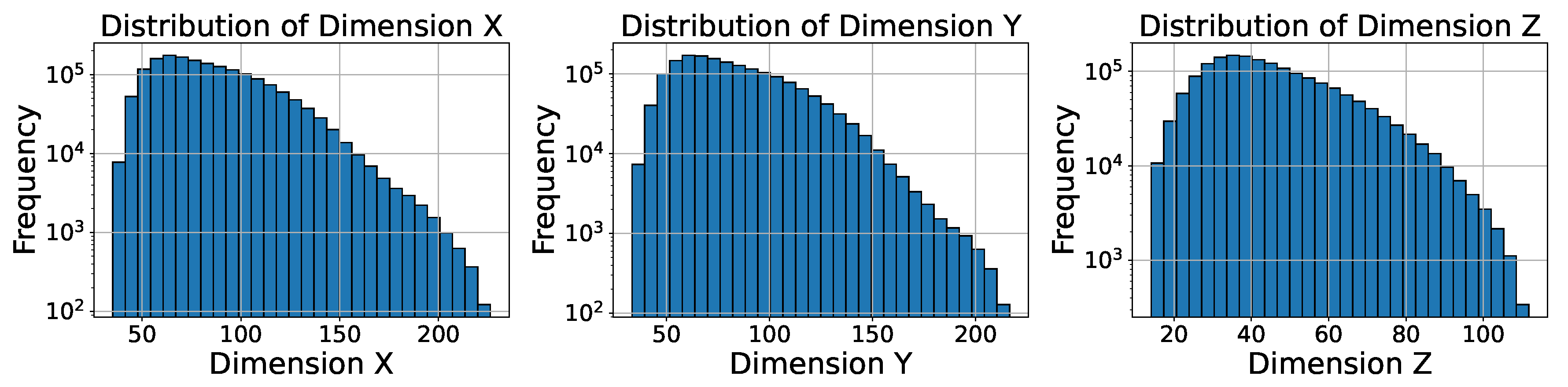
Figure 7.
Sample mushroom cap 3D point cloud.

Figure 9.
Error distribution of rotation estimation for roll, pitch, and yaw angles.
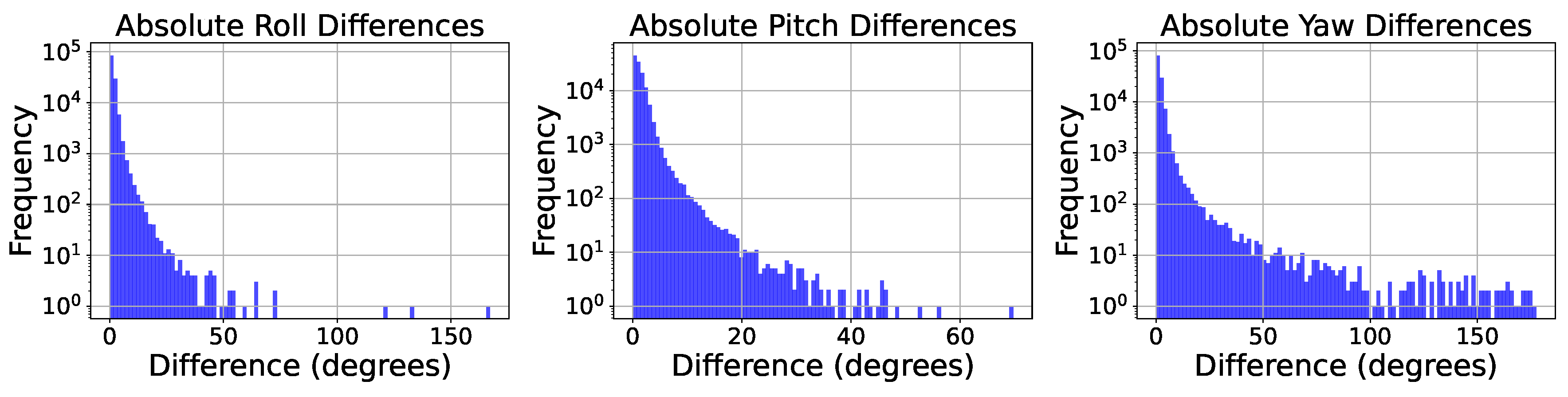
Figure 10.
Error distribution of rotation estimation vs the size of the mushroom for roll, pitch, and yaw angles.
Figure 10.
Error distribution of rotation estimation vs the size of the mushroom for roll, pitch, and yaw angles.

Figure 11.
Comparison of ground truth and predicted oriented bounding boxes for sample mushrooms.
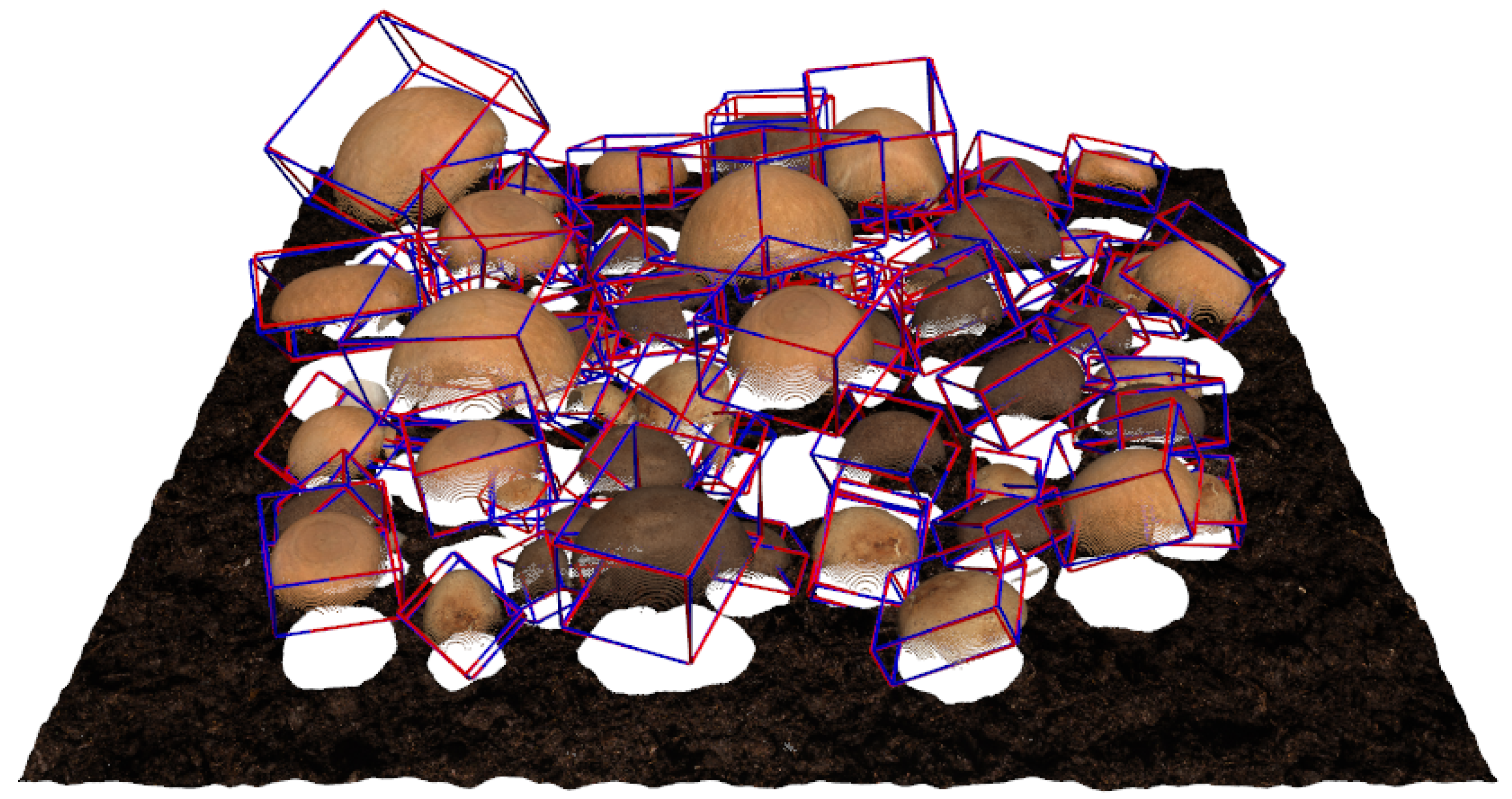
Figure 12.
Visualization of ground truth (blue) vs. predicted (red) oriented bounding boxes on real-world point clouds from the M18K dataset (10 labeled images).
Figure 12.
Visualization of ground truth (blue) vs. predicted (red) oriented bounding boxes on real-world point clouds from the M18K dataset (10 labeled images).


Table 1.
Effect of the number of sampled points on pose estimation performance. All models use the 6D rotation representation without RGB information.
Table 1.
Effect of the number of sampled points on pose estimation performance. All models use the 6D rotation representation without RGB information.
| Number of Points | Geodesic Loss Value | Inference Time (ms) |
|---|---|---|
| 64 | 0.628 | 2.561 |
| 256 | 0.505 | 3.481 |
| 1,024 | 0.421 | 5.536 |
Table 2.
Comparison of different rotation representations on pose estimation performance. All models use 1,024 points without RGB information.
Table 2.
Comparison of different rotation representations on pose estimation performance. All models use 1,024 points without RGB information.
| Rotation Representation | Geodesic Loss Value |
|---|---|
| 6D Gram-Schmidt | 0.421 |
| 9D Rotation Matrix | 1.595 |
| Quaternion | 0.622 |
| Euler Angles | 1.169 |
Table 3.
Effect of including RGB information on pose estimation performance. All models use 1,024 points and the 6D Gram-Schmidt rotation representation.
Table 3.
Effect of including RGB information on pose estimation performance. All models use 1,024 points and the 6D Gram-Schmidt rotation representation.
| Model Configuration | Geodesic Loss Value |
|---|---|
| Without RGB | 0.421 |
| With RGB | 1.610 |
Table 4.
Comparison of our method with state-of-the-art methods in terms of average rotational error . Our method achieves the lowest error on synthetic data and shows strong performance on the real subset (10 images) of the M18K dataset.
Table 4.
Comparison of our method with state-of-the-art methods in terms of average rotational error . Our method achieves the lowest error on synthetic data and shows strong performance on the real subset (10 images) of the M18K dataset.
| Method | IoU Threshold | (degrees) |
|---|---|---|
| Retsinas et al. [2] | 25% | 4.22 |
| Baisa & Al-Diri [15] | - | 13.5 |
| Retsinas et al. [25] | 25% | 8.70 |
| Retsinas et al. [25] | 50% | 7.27 |
| This Work (Synthetic) | - | 1.67 |
| This Work (Real, 10 Images) | - | 3.68 |
Table 5.
Performance metrics for 2D detection and segmentation on SMS3D dataset and M18K dataset. M18K’s results are improved after pre-training the model on SMS3D.
Table 5.
Performance metrics for 2D detection and segmentation on SMS3D dataset and M18K dataset. M18K’s results are improved after pre-training the model on SMS3D.
| Dataset | Detection | Segmentation | ||||
|---|---|---|---|---|---|---|
| F1 | AP | AR | F1 | AP | AR | |
| SMS3D | 0.927 | 0.901 | 0.955 | 0.919 | 0.907 | 0.933 |
| M18K | 0.891 | 0.876 | 0.905 | 0.881 | 0.866 | 0.896 |
| M18K (Pre-Trained on SMS3D) | 0.905 | 0.889 | 0.922 | 0.915 | 0.901 | 0.931 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



