1. Introduction
Sports betting, traditionally seen as a recreational activity, has become a significant financial sector driven by technological advancements and the proliferation of online betting platforms [
1]. The industry allows bettors to place wagers on the outcomes of sporting events with odds that reflect the likelihood of various scenarios. As this market has grown, it has evolved from traditional betting shops to sophisticated online platforms that offer a wide range of betting options, including real-time and in-play bets. The accessibility and convenience of online betting have significantly contributed to the sector’s rapid expansion, attracting a global audience and generating billions in revenue annually [
2,
3].
The growth of sports betting has been paralleled by an explosion of data generation, making it one of the most data-intensive industries [
4]. This sector mirrors traditional financial markets, where odds and betting strategies are akin to stock market predictions. Bookmakers collect a large amount of data from various sources, including player statistics, team performance, live game data, and even social media sentiment [
5]. This data-driven environment provides fertile ground for the application of machine learning (ML) techniques, which have become essential to managing the complexities of odds setting, risk assessment, and optimization of betting strategy. Machine learning models, particularly those that incorporate real-time data, are crucial to maintaining competitive odds that attract bettors while ensuring profitability for bookmakers.
Machine learning has significantly impacted the sports betting landscape by improving both the accuracy of predictions and the efficiency of betting strategies. For bookmakers, ML models enable dynamic odds setting and sophisticated risk management, adjusting for new information as events unfold [
6]. For bettors, ML provides the tools to develop data-driven strategies that improve the chances of success by identifying value bets and exploiting market inefficiencies [
7,
8]. As a result, the sports betting industry increasingly resembles a financial sector, with both bettors and bookmakers leveraging advanced predictive analytics to maximize returns. This growing reliance on ML underscores the need for ongoing research on new techniques and emphasizes the importance of ethical considerations, such as transparency and fairness, in the implementation of ML in sports betting. Machine learning, a subset of artificial intelligence, involves the use of algorithms and statistical models to identify patterns and make predictions from data. In the context of sports betting, machine learning techniques can be applied to vast amounts of historical data, including team statistics, player performance metrics, injuries, weather conditions, and even odds movements of bookmakers [
9]. By analyzing these diverse data sources, machine learning models can uncover intricate relationships and trends that may not be apparent to human analysts. This leads to the research question (
RQ1):
how can machine learning algorithms be leveraged to predict match outcomes and maximize profitability in sports betting?
The application of machine learning in sports betting has garnered significant attention from researchers and industry professionals alike. Numerous studies have explored the use of various machine learning algorithms, such as support vector machines, random forests, neural networks, Bayesian and ensemble methods, to predict the outcomes of sporting events with greater accuracy [
10]. These predictive models have the potential to outperform traditional analytical methods and provide valuable insights to bettors, enabling them to make more informed decisions and potentially increasing their profitability.
In addition, machine learning techniques have been employed to identify mispriced odds offered by bookmakers, presenting opportunities for savvy bettors to capitalize on these inefficiencies [
11,
12]. By developing models that can accurately predict match outcomes and compare them with the odds offered by bookmakers, bettors can identify instances where the odds are mispriced, allowing them to place bets with a positive expected value. Recently, anomaly detection models have been developed to identify suspicious betting patterns that may indicate match-fixing [
11,
13,
14]. These models analyze a range of variables including sports results, team rankings, player data, and betting odds to detect abnormal behaviors that deviate from the expected. Classifying matches as normal, caution, danger, or abnormal based on ensemble model predictions, the system aims to ensure fairness and integrity in sports competitions [
15,
16].
Despite the promising potential of machine learning in sports betting, there are several challenges and limitations. Data availability and quality can be a significant hurdle, as some sports may have limited historical data or incomplete records. Furthermore, the dynamic nature of sports, with factors such as injuries and team dynamics, can introduce uncertainties that may not be fully captured by predictive models [
17]. This raises another critical research question (
RQ2):
what are the challenges and limitations associated with the application of machine learning in sports betting, and how can novel multimodal approaches be developed to address these issues and improve predictive performance?
Building on this, a more holistic approach to risk management can be found by drawing parallels to financial portfolio management, where investments are balanced to maximize returns while minimizing risk. Similarly, adaptive betting portfolios could be developed using ML techniques to optimize returns for bettors. This introduces the third research question (
RQ3):
How can machine learning be applied to create adaptive betting portfolios that optimize returns while minimizing risk, similar to financial portfolio management? (
Table 1).
This systematic review aims to synthesize the current state of research on the application of machine learning techniques in sports betting. By examining the existing literature, we seek to provide a comprehensive overview of the methodologies used, the challenges encountered, and the potential benefits and limitations of using machine learning in this domain. Furthermore, we explore future directions and opportunities for further research, as the field of machine learning continues to evolve and offers new avenues for innovation in sports betting.
In this review, we limit our scope to soccer. The remainder of the paper is organized as follows.
Section 2 presents the methodology employed in this study;
Section 3 reviews the related work in the field of machine learning in sports betting;
Section 4 delves into the various machine learning techniques applied to sports betting;
Section 5 provides a detailed discussion of the findings;
Section 6 evaluates the datasets and features used in the studies;
Section 7 explores the machine learning platforms for betting tips;
Section 8 outlines the challenges and limitations encountered; and finally,
Section 9 presents future directions for research in this area.
2. Methodology
The primary objective of this systematic review is to explore the current challenges and advances in applying machine learning techniques to sports betting. The insights derived from this review will serve as a basis for future research in this rapidly evolving field. The research questions and objectives addressed in this study are described in
Table 1. This systematic review follows the PRISMA guidelines (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) to ensure a rigorous and transparent review process (
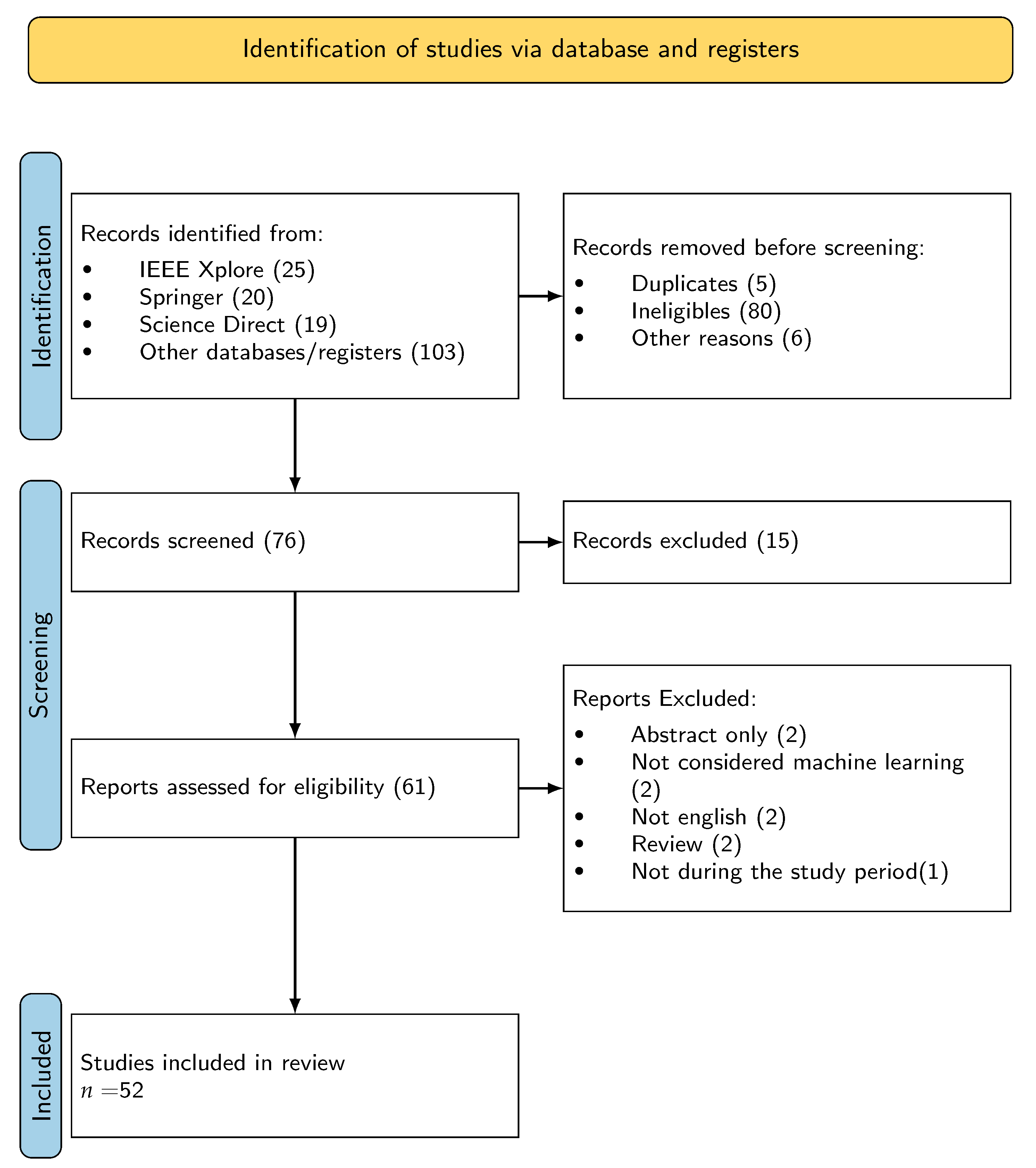
Figure 1). PRISMA was used to structure the review process, including the formulation of research questions, the identification of relevant studies, the evaluation of the quality of the study, the extraction of data, and the synthesis of the findings.
2.1. Data Selection
A comprehensive search was conducted in multiple electronic databases, including IEEE Xplore, Springer, Science Direct, MDPI, arXiv, and Google Scholar. The search terms were carefully selected to capture all relevant studies and included combinations of keywords such as "machine learning", "sports betting", "predictive analytics", "odds estimation", "value betting", and "soccer".
2.2. Inclusion and Exclusion Criteria
The inclusion criteria for this review include studies published between January 2010 and July 2024 that apply machine learning techniques to predict outcomes in soccer betting. These studies consist of peer-reviewed articles, conference papers, and preprints that evaluate the effectiveness of predictive models. A total of 167 articles were initially identified through the search. After applying the inclusion criteria, 49 articles remained for further analysis (
Table 2,
Figure 2). Exclusion criteria include non-English publications, studies focusing on machine learning methods, and articles that do not contain empirical data, such as purely theoretical or opinion papers.
2.3. Data Extraction
Data were extracted from each included study, focusing on several key aspects: study details (including author, year, title and journal), the machine learning algorithms used, the characteristics of the dataset (such as size, type and characteristics), performance metrics (including accuracy, precision, recall and Ranked Probability Score), and key findings and limitations.
3. Related Work
The application of machine learning techniques to sports betting has gained significant attention in recent years, and researchers have explored various approaches to leverage data and predictive models to identify profitable betting opportunities.
Outcome prediction. A substantial portion of the literature focuses on the development of predictive models to accurately forecast the results of sporting events. Bunker and Thabtah [
18] proposed a machine learning framework for the prediction of sports results, evaluating the performance of several algorithms, including support vector machines (SVMs), decision trees and neural networks, on various sports datasets. Their findings suggest that advanced feature engineering, incorporating factors such as team form, head-to-head records, and home advantage, can improve predictive performance compared to using basic box-score statistics.
Miljković et al. [
19] explored the use of data mining techniques, such as decision trees and neural networks, to predict the outcomes of basketball matches. Their results demonstrated the potential of these methods to outperform traditional statistical models, particularly when incorporating diverse features such as team rankings, player statistics, and betting odds. Horvat and Job [
7] conducted an initial review of machine learning techniques in the literature on sports betting, examining more than 100 studies on predicting outcomes. They identified neural networks and SVMs as the most common models and highlighted the importance of feature extraction and selection to enhance prediction accuracy. The review also pointed out the lack of standardized datasets and the need to include contextual factors such as player injuries and psychological states.
Kollár [
20] discussed the use of Artificial Neural Networks (ANN), Markov chains, and SVMs to handle complex patterns and enormous data sets to forecast sports results. They emphasized the dynamic nature of sports events, which poses challenges such as inconsistent data and the need for frequent model retraining. Feature selection and extraction were found to be crucial in improving model performance and accuracy.
Odds estimation and value betting. Another line of research investigates the use of machine learning models to estimate the true probability of outcomes, which can then be compared to bookmakers’ odds to identify value bets–examples where the model’s predicted probability differs significantly from the implied odds. Franck et al. [
21] examined inter-market arbitrage opportunities in betting markets, highlighting the potential to exploit inefficiencies and biases in bookmakers’ odds-setting processes.
Betting strategies and risk management. Walsh and Joshi [
10] conducted a comprehensive study on the importance of model calibration in sports betting. They showed that optimizing predictive models for calibration, rather than accuracy, leads to significantly higher betting profits, with a calibration-optimized model generating 69.86% higher average returns compared to an accuracy-optimized model. Building on this idea of model optimization in the sports betting market, Arscott [
22] showed that illegal bookmakers engage in risk management activities 6.5 times more frequently than legal bookmakers. Offshore bookmakers employ pricing policies to balance their books, reducing cash flow variance but also decreasing profits, with illegal bookmakers adjusting commissions on 39% of their prices, compared to 6% for legal bookmakers. This distinction highlights the differing priorities between illegal and legal bookmakers, where illegal firms prioritize risk management due to their limited access to external financing.
Continuing the examination of sports betting strategies, Matej et al. [
23] conducted an experimental review of the most popular betting approaches using modern portfolio theory and the Kelly criterion. They demonstrated that formal investment strategies, when applied with risk control modifications, significantly enhance profitability. Their adaptive fractional Kelly method was especially effective in different sports, highlighting the practical importance of mitigating the unrealistic assumptions inherent in pure mathematical strategies. Testing in horse racing, basketball, and soccer confirmed the necessity of these risk control methods to achieve optimal results.
Technological advancements in sports analytics. Keys et al. [
24] conducted a systematic review investigating innovative techniques to monitor training loads for the prediction of injury and performance. They highlighted the use of Global Positioning System (GPS), accelerometers, and Rated Perceived Exertion (RPE) to track and predict athlete performance and injury risk. Machine learning was noted for its potential to identify important predictive features, though standardized methods and more research are needed to optimize its application in sports.
Naik et al. [
25] conducted an extensive investigation into computer vision in sports, concluding with significant improvements in video analysis. This review included recognition of sports players and balls, tracking, trajectory prediction, and event classification. It emphasized how AI and machine learning improve accuracy and efficiency while tackling challenges such as occlusions, low-resolution video, and real-time analysis. For sports video analysis, the review suggested the use of complex algorithms, standard datasets, and GPU-based workstations and embedded platforms.
4. Machine Learning in Soccer
Machine learning techniques have been extensively applied in various sports betting scenarios, demonstrating their potential to improve prediction accuracy and profitability. Research has demonstrated the effectiveness of models, including artificial neural networks, support vector machines, and ensemble methods in sports (soccer, basketball, tennis, cricket, American football, baseball, horse racing, rugby, golf, and hockey). These models leverage vast datasets, including historical match data, player statistics, and betting odds, to uncover patterns and trends that inform betting strategies. For instance, in soccer, methods such as the Rank Probability Score (RPS) and Principal Component Analysis (PCA) are utilized to identify betting inefficiencies and predict the outcomes of matches (
Table 3).
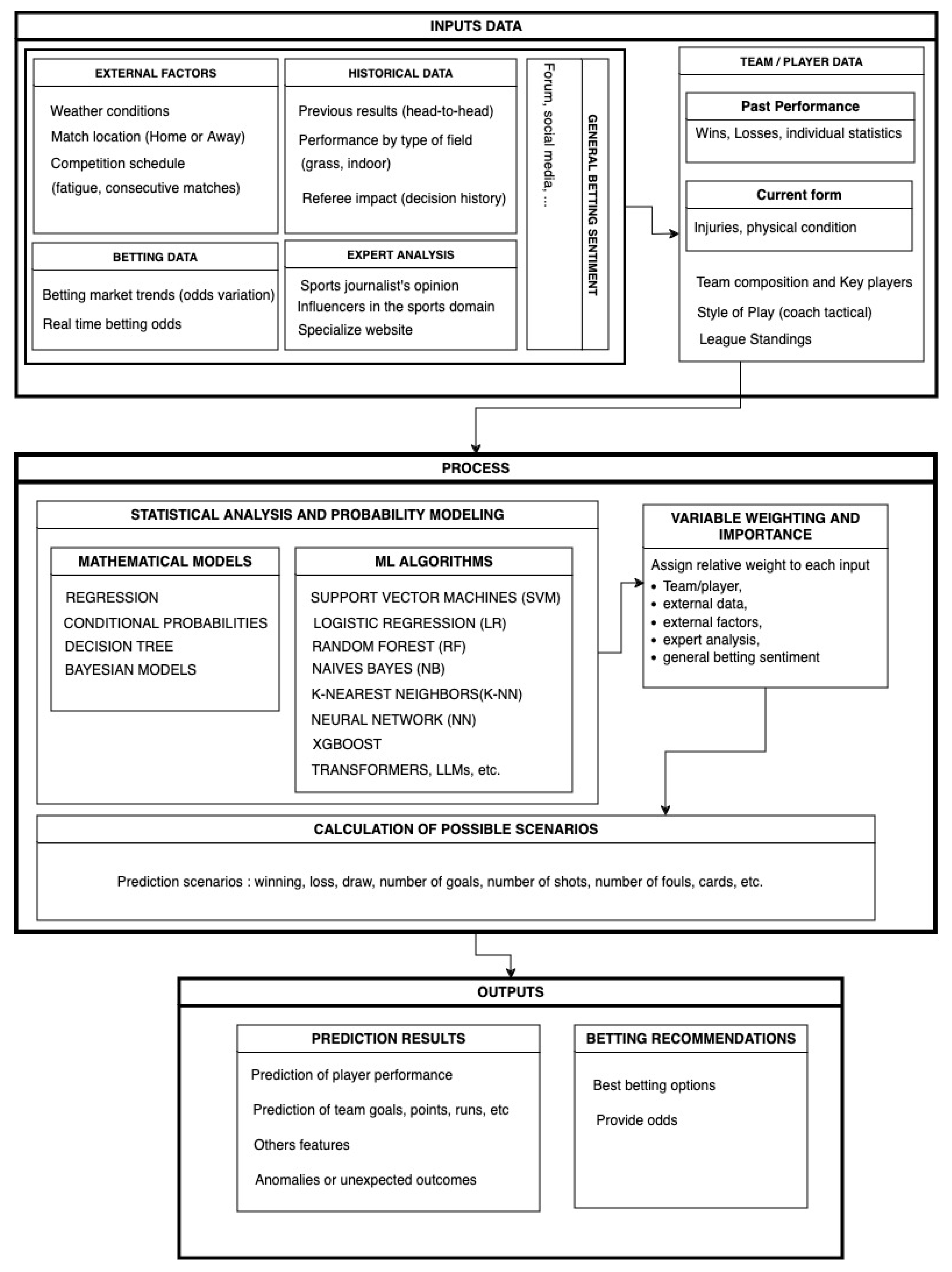
Figure 3 illustrates a comprehensive system for predicting sports betting outcomes using machine learning. The construction of such machine learning models includes multiple data sources, including external factors (for example, weather and match location), historical performance data, real-time betting odds, expert analysis, and general public sentiment from social media.
The system generates outputs such as probability-based predictions for match outcomes (e.g., win, loss, or draw), detailed performance metrics like goals scored, shots taken, and cards received, and betting recommendations including Bet Boosts. By integrating historical data, real-time statistics, expert insights, and betting market trends, the model enhances prediction accuracy and offers bettors and stakeholders informed betting options and odds. This progression aligns with the broader advancements in soccer analytics, where numerous studies have explored methodologies for predicting match outcomes, player performance, and tactical strategies. The following sections review key contributions in the field, focusing on methodologies, datasets, and results, as summarized in
Table 3 and illustrated in
Figure 2 and
Figure 4.
4.1. Analyzing Inefficiencies and Predictive Models in Football Betting Markets
Research on inefficiencies in the online European football gambling market, as conducted by Constantinou and Fenton [
41], spanned seven seasons (2005/06 to 2011/12) and examined data from 14 European leagues to identify arbitrage opportunities and biases in bookmakers’ odds. By analyzing profit margins and assessing bookmakers’ accuracy using the Rank Probability Score (RPS), the study uncovered significant arbitrage opportunities arising from discrepancies in profit margins across bookmakers. Notably, no improvement in the accuracy of odds was observed over time, suggesting persistent inefficiencies. The dataset for this analysis was sourced from
www.football-data.co.uk.
In the domain of match outcome prediction, Tax and Joustra [
26] investigated results in the Dutch Eredivisie across thirteen seasons (2000–2013). Employing dimensionality reduction techniques like PCA and classification algorithms such as Naïve Bayes, Multilayer Perceptron, and LogitBoost, the study achieved a maximum prediction accuracy of 56.054% using a hybrid model that combined public data with betting odds. Similarly, Hervert-Escobar et al. [
27] utilized a Bayesian framework enriched with historical match data and triangular distributions to predict match outcomes, including the 2018 FIFA World Cup group stage. The model, trained on over 200,000 match results, achieved an RPS of 0.2620, showcasing high accuracy. Both studies utilized diverse datasets, including
www.football-data.co.uk,
www.elfvoetbal.nl,
www.transfermarkt.co.uk, and
www.fcupdate.nl.
4.2. ML for Soccer Tactics and Event Prediction
Recent advancements in AI have significantly contributed to optimizing soccer tactics and predicting key match events. For instance, TacticAI, developed by Wang et al. [
36], leverages geometric deep learning on spatio-temporal player tracking data to enhance football tactics, particularly corner kick strategies. This tool was validated on 7,176 corner kicks from the 2020–2021 Premier League seasons, demonstrating high prediction accuracy and garnering expert approval in 90
Similarly, Goka et al. [
37] introduced a novel method for predicting shooting events based on players’ spatial-temporal relations modeled through complete bipartite graphs. By combining Mask R-CNN for player detection with a graph convolutional recurring neural network (GCRNN), their approach yielded an impressive AP of 0.967 and an F1 score of 0.914. The study relied on 400 video clips from the 2019 and 2020 Japan J1 League seasons. In a different domain, Anzer and Bauer [
42] advanced expected goals (xG) modeling using an extreme gradient boosting algorithm to analyze 105,627 shots from the German Bundesliga. The model excelled with an RPS of 0.197, utilizing data from ChyronHego’s TRACAB system alongside Bundesliga event data.
4.3. ML Applications in Player Valuation and Match Outcome Predictions
Machine learning also plays a crucial role in player valuation and match outcome predictions. Li et al. [
28] employed machine learning techniques to assess football players’ market value using data from FBREF and CAPOLOGY. Comparing multiple linear regression and random forest models, the latter stood out with an R² value of 0.948, supported by metrics like AIC, BIC, RMSE, and R² values. Additionally, Peters and Pacheco [
43] investigated the impact of player lineups on football score predictions using machine learning models, including SVR, which outperformed other techniques in predicting final scores. Their dataset encompassed 680 English Premier League matches (2020–2022), sourced from online repositories like FixtureDownload and FBRef.
In another example, Deng and Zhong [
38] analyzed soccer match data from 11 European countries spanning 2008 to 2016. By applying logistic regression, decision trees, random forests, and deep neural networks (DNN), they achieved a peak accuracy of 99% with DNN models. Similarly, Ćwiklinski et al. [
44] used machine learning algorithms like Random Forest, Naïve Bayes, and AdaBoost to support team-building and player transfer decisions. Their work, based on Sofascore data covering 4,700 players across four seasons, achieved an accuracy of 0.82 and an F1 score of 0.83. Extending these applications to betting strategies, Stübinger et al. [
45] employed ensemble machine learning techniques to predict match outcomes for 47,856 matches in Europe’s top five leagues, resulting in a 1.58
4.4. Predictive Modeling Across Leagues and Contexts
Predictive models have been applied across various soccer leagues and contexts, yielding valuable insights. Ganesan and Harini [
46] explored the English Premier League (EPL), using SVM, XGBoost, and logistic regression, with XGBoost showing superior performance. Similarly, Andrews et al. [
29] leveraged the CRISP-DM framework to predict EPL match outcomes, finding that logistic regression yielded the best F1 score of 0.6119. The use of advanced data sources has also been pivotal; Hubáček et al. [
32] evaluated statistical models and rating systems for soccer matches, with Berrar ratings and Double Weibull models excelling in predictions based on 218,916 match results from 52 leagues.
Expanding to international contexts, Mattera [
47] employed score-driven models, including the generalized autoregressive score model (GAS), to predict binary outcomes in soccer matches from the EPL and Serie A, analyzing 13 seasons of data. Meanwhile, Malamatinos et al. [
35] applied CatBoost to predict outcomes in the Greek Super League, achieving 67.73% accuracy with data spanning six seasons (2014–2020). Finally, Geurkink et al. [
48] focused on Belgian professional soccer, where Extreme Gradient Boosting identified critical match outcome variables with 89.6% accuracy using a SportVU-tracked dataset.
7. Machine Learning Platforms for Betting Tips
Machine learning platforms specializing in the commercialization of predictive analytics and insights offer bettors valuable tools to build their bet slips and parlays.
Sports AI presents itself as a comprehensive AI-driven solution for sports bettors, leveraging machine learning to identify value bets and potentially profitable betting opportunities in various sports and bookmakers (
https://www.sports-ai.dev/). Similarly,
DeepBetting, a French startup, sells betting tips based on machine learning and deep learning algorithms trained on historical sports data, covering major football leagues (
https://deepbetting.io/).
BetIdeas analyzes statistics from more than 500 leagues around the world to provide free AI betting tips, exact score predictions, both teams to score tips, and a "bet of the day" feature (
https://betideas.com/). Another notable platform,
1x2AI, quantifies the confidence level of the predictions, allowing users to filter the tips based on how certain the algorithms are of the outcome (
https://1x2.ai/tips/).
Leans.ai covers multiple sports such as soccer, tennis, basketball, and esports, offering a free trial and a 60-day money-back guarantee (
https://leans.ai/).
FindYourBettingTips focuses on AI sports betting predictions for football matches and publishes articles explaining the rationale behind each tip, supported by a Telegram community of over 5,000 members (
https://findyourbettingtips.com/).
PredictBet provides AI betting tips for matches up to two weeks in advance, together with a blog on sports news and betting insights (
https://predictbet.ai/).
BetQL offers detailed match predictions, expected value calculations, smart money tracking, and more using AI models (
https://betql.co/).
WinnerOdds employs AI algorithms to estimate real probabilities of match outcomes and find value bets, including tools like odds comparison and variable staking plans (
https://winnerodds.com/).
BettorView offers an AI betting tips free trial and boasts AI models that have achieved a 60% ROI for NFL picks since 2016 (
https://www.bettorview.com/). Lastly,
Scaleo is an affiliate marketing platform that provides machine learning solutions for user segmentation, predictions of betting behavior, risk management and compliance checks in the gambling industry (
https://www.scaleo.io/).
8. Challenges and Limitations
The application of machine learning in sports betting presents several challenges and limitations that researchers and practitioners must navigate to enhance predictive accuracy and operational effectiveness. This section discusses key issues, including data availability, the dynamic nature of sports, model overfitting, feature selection, ethical concerns, computational resources, and regulatory challenges (RQ2).
8.1. Data Availability and Quality
Data availability and quality represent a significant challenge in soccer analytics. Despite the increasing accessibility of publicly available datasets, many studies rely on proprietary data sources such as player tracking systems and event data providers (e.g., ChyronHego’s TRACAB system, SportVU, and Wyscout). Public datasets often lack granularity and completeness, hindering the development of highly accurate models. Furthermore, inconsistencies in data collection methods and annotation standards can lead to noisy or biased datasets, as seen in Hubáček et al. [
32], who highlighted variations in dataset quality across leagues. Addressing these challenges requires collaboration between data providers, clubs, and researchers to establish standardized data collection protocols.
In addition, the dynamic nature of data generation in soccer further complicates these issues. Player performance, team dynamics, and even environmental factors like weather are recorded differently across leagues and seasons, creating disparities that challenge the reproducibility of research findings. Several studies have noted that the proprietary nature of high-quality datasets often excludes researchers from smaller institutions or regions with limited resources, thus limiting innovation and diversity in research approaches. Comprehensive, accessible, and standardized datasets are imperative to fostering progress in soccer analytics.
8.2. Dynamic Nature of Sports
The dynamic and unpredictable nature of soccer poses inherent challenges for modeling and prediction. Soccer involves numerous factors such as tactical adjustments, player injuries, and referee decisions that are difficult to capture in static datasets. Models like TacticAI [
36], which incorporate spatio-temporal tracking, attempt to address these complexities, but the high variability in match outcomes and player behavior remains a limitation. As highlighted by Goka et al. [
37], even advanced methods struggle to account for rare events such as penalties or last-minute goals, which significantly influence match results.
Moreover, the temporal evolution of tactics and player roles adds another layer of complexity to predictive modeling. For example, the increasing use of high-press strategies in modern soccer has shifted traditional metrics of success, such as ball possession, to include more nuanced indicators like pressing efficiency. Models need to evolve continuously to capture these tactical shifts accurately. Without real-time data integration and adaptability, models risk becoming outdated, thus diminishing their predictive reliability.
8.3. Model Overfitting and Generalization
Overfitting is a common issue in machine learning models, particularly when training on small or homogeneous datasets. Models like deep neural networks [
38], which achieve high accuracy on training data, often fail to generalize to new or unseen matches. Ensemble methods [
32] and regularization techniques have been employed to mitigate overfitting, but the trade-off between model complexity and generalization remains an open research question. Cross-validation and the use of diverse datasets spanning multiple leagues and seasons are essential to improve generalizability.
Despite these efforts, the challenge of generalization persists, particularly when applying models across leagues with varying play styles and data quality. For instance, a model trained on the English Premier League may underperform when applied to the Japanese J1 League due to differences in tactical preferences and player characteristics. Addressing these discrepancies requires not only diverse datasets but also the integration of transfer learning techniques to enable cross-league adaptability. This ensures models are robust and applicable in varied contexts.
8.4. Feature Selection and Engineering
Feature selection and engineering are critical for developing robust soccer analytics models. Many studies, such as Berrar et al. [
52] and Rico-González et al. [
50], emphasize the importance of domain knowledge in identifying relevant features. However, the inclusion of redundant or irrelevant features can lead to overfitting and reduced model performance. Methods like dimensionality reduction [
26] and feature importance analysis [
42] are commonly used to address this challenge. The dynamic nature of soccer also necessitates adaptive feature engineering to account for evolving tactics and player roles.
A deeper challenge lies in the interpretability of engineered features, especially when using complex methods like neural networks. Black-box models often make predictions based on intricate feature interactions that are difficult to explain, which may hinder their acceptance among coaches and analysts. Transparent feature selection processes and explainable AI techniques are crucial to bridge the gap between advanced analytics and actionable insights, ensuring models are not only accurate but also interpretable and trustworthy.
8.5. Ethical and Integrity Concerns
The application of machine learning in soccer raises ethical and integrity concerns, particularly regarding data privacy and the potential misuse of predictive models. For instance, player performance analytics may lead to biased scouting or contract decisions if not transparently implemented. Additionally, models predicting match outcomes [
53] could be exploited for gambling purposes, raising questions about their impact on the integrity of the sport. Researchers must ensure ethical data usage and consider the broader implications of their work.
Furthermore, the increasing reliance on machine learning could exacerbate inequalities in access to technology and resources among teams and leagues. Wealthier organizations with access to advanced analytics may gain a disproportionate advantage, potentially widening the competitive gap in soccer. Ethical frameworks and regulatory oversight are needed to ensure fair play, protect player rights, and prevent the misuse of analytical tools, fostering a more equitable application of technology in the sport.
8.6. Computational Resources
Advanced machine learning models, such as geometric deep learning [
36] and extreme gradient boosting [
48], often require substantial computational resources. These requirements pose barriers for smaller research teams and organizations with limited budgets. Cloud-based platforms and collaborative initiatives can help address these limitations by providing access to high-performance computing resources. However, the computational cost of processing large-scale datasets and training complex models remains a significant challenge.
In addition to hardware limitations, the energy consumption associated with training large models raises environmental concerns. As machine learning becomes increasingly central to soccer analytics, researchers must explore energy-efficient algorithms and computational frameworks. Initiatives that balance model performance with sustainability are critical to ensuring the long-term viability of analytics-driven approaches in soccer.
8.7. Regulatory and Legal Challenges
The use of machine learning in soccer is subject to various regulatory and legal challenges, particularly concerning data ownership and intellectual property rights. Many datasets used in research, such as those from Li et al. [
28] and Hubáček et al. [
32], are sourced from proprietary platforms, raising questions about licensing and data sharing. Furthermore, the development of predictive models for gambling purposes may conflict with regulations in certain jurisdictions. Addressing these challenges requires clear legal frameworks and ethical guidelines to govern the use of machine learning in soccer analytics.
Moreover, cross-border collaborations in soccer analytics often encounter legal discrepancies, as data privacy regulations such as GDPR in Europe differ significantly from laws in other regions. Researchers and organizations must navigate these complexities to ensure compliance while fostering international partnerships. Establishing global standards for data usage and model deployment can facilitate collaboration and innovation while addressing legal uncertainties.
9. Future Directions
In traditional financial markets, portfolio optimization is a well-established strategy in which investors allocate assets in a way that balances risk and return, with the aim of maximizing profitability. This concept, rooted in Modern Portfolio Theory [
54], involves the selection of a mix of stocks, bonds, or other financial instruments that together provide the best possible return for a given level of risk. Portfolio management relies heavily on data analysis, predictive modeling, and optimization techniques to dynamically adjust asset allocations based on market conditions and investor goals. ML has further revolutionized this field by improving predictive capabilities and enabling real-time adjustments to portfolios that significantly improve decision-making in finance [
55].
When we make a parallel with sports betting, the concept of a ’betting portfolio’ is similar to financial portfolio management, aiming to optimize bet combinations to maximize returns and minimize risk. In such a context, ML can play a key role by analyzing vast datasets, including game results, player statistics, odds, and external factors like weather and team morale. Hence, ML models can be exploited to design diversified betting portfolios that adapt dynamically to game conditions, much like financial portfolios adjust to market changes (
RQ3). Beyond win-loss predictions, ML could also be designed to enable sophisticated portfolio management, treating bets as assets that affect overall risk and return [
56].
As the use of ML in betting grows, there is also a critical need for transparency in the models being deployed. In the financial world, transparent models are increasingly valued for their ability to provide interpretable insights into how investment decisions are made, which is essential to maintain investor trust and regulatory compliance. Similarly, in sports betting, the adoption of Explainable AI techniques, such as SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations), can demystify complex ML predictions and provide bettors and stakeholders with clear, understandable explanations of why certain bets are favored or why odds are set in a particular way [
57]. This transparency is not only vital for ethical considerations, but also helps bettors make more informed decisions, ultimately contributing to a more fair and accountable betting environment [
58].
10. Conclusions
We have explored the impact of machine learning on soccer and have highlighted its potential to be leveraged as a key component of a financial portfolio. The integration of ML into sports betting marks a major shift, transforming the industry into a data-driven sector with strong parallels to traditional financial markets. With machine learning, diverse datasets can be analyzed, such as historical game data, real-time player statistics, and social media sentiment. This capability improves predictive accuracy and optimizes betting strategies. By treating bets as assets within a ’betting portfolio’, similar to financial portfolio management, machine learning enables dynamic adjustment of strategies, improving overall risk and return for bettors and bookmakers as conditions evolve.
As machine learning models such as deep learning and reinforcement learning advance, they offer opportunities to elevate sports betting into a sophisticated investment strategy similar to stock trading. These models facilitate the creation of adaptive betting portfolios that optimize returns and manage risks, driving profitability in a competitive market. The emphasis on transparency and explainability will be essential for maintaining ethical standards and regulatory compliance. By fully embracing these technologies, sports betting can evolve from a game of chance into a strategic financial activity, unlocking new growth opportunities and positioning itself alongside traditional financial sectors.