Submitted:
26 January 2025
Posted:
26 January 2025
You are already at the latest version
Abstract
This work presents the implementation of Deep Deterministic Policy Gradient (DDPG) algorithm to enhance target reaching capability of the seven Degree-of-Freedom (7-DoF) Franka Panda robot arm. A simulated environment is established by employing OpenAI Gym, PyBullet, and Panda Gym. Upon completion of 100,000 training time steps, the DDPG algorithm attains a success rate of 100% and an average reward of -1.8. The actor loss and critic loss values are 0.0846 and 0.00486, respectively, indicating improved decision-making and accurate value function estimations. The simulation results demonstrate the efficiency of DDPG in improving robotic arm performance, highlighting its potential for application to improve robot arm manipulation.
Keywords:
1. Introduction
2. Modeling of Robotic Arm
2.1. Direct Kinematic Model of Robot Arm
- The rotation matrix () represents the orientation of the i-th frame relative to the -th frame.
- represents the center of the link frame with components (, , and ).
2.1.1. DH Axis Representation
- d: a distance between the current frame and the previous frame along the Z-axis,
- (): an angle between the X-axis of the previous frame and the X-axis of the current frame about the previous z-axis,
- a: a distance between the Z-axes of the current and previous frames.
- : an offset of the previous frame from the current frame along the Z-axis of the current frame.
2.2. Incremental Inverse Kinematics of Robot Arm
- represents the change in end-effector position around a reference point and
- represents the change in joint angles around a reference point .
- where represents the partial derivative of the component of the end-effector position with respect to the joint angle.
2.2.1. Steps of Incremental Inverse Kinematics
- Define the starting pose and set up the Incremental inverse kinematics from (3.29)
- Determine the deviation relative to the target pose; e.g.
- Check for termination; e.g..
- Solve
- Calculate new joint angles
3. Deep Reinforcement Learning Algorithm Design
3.1. Policy Gradient Algorithm
- Objective function(): Represents the expected cumulative reward obtained by following the policy in the given environment. The objective function is optimized by adjusting the parameter to maximize the expected cumulative reward.
- Discounted state distribution(): Represents the probability of being in a particular state s under the policy . Mathematically,where when starting from and following policy for t time steps.
- Action-value function (( ): Represents the expected cumulative reward obtained by taking action a in state s and following the policy thereafter.
- Policy function(): Represents the probability of taking action a in state s under the parameterized policy .
3.1.1. Derivation of Policy Gradient Theorem
- When
- When , consider every action that might be taken and add up the probabilities of reaching the desired state:
- The goal is to move from s to x after steps, by following .The agent can first move from s to intermediate state going to final state x in the last steps after the k stages. This allows to recursively update the visitation probability.
3.1.2. Off-Policy Policy Gradient
3.2. Deterministic Policy Gradient (DPG)
- The initial distribution over states
- : Starting from state s, the visitation probability density at state after moving k steps by policy .
-
: Discounted state distribution, defined as
3.3. Deep Deterministic Policy Gradient (DDPG)
3.4. Working of DDPG Algorithm
| Algorithm 1: Deep Deterministic Policy Gradient |
 |
4. Results And Discussions
4.1. Software Configuration
4.2. Hyper Parameter Selection and Initial Search
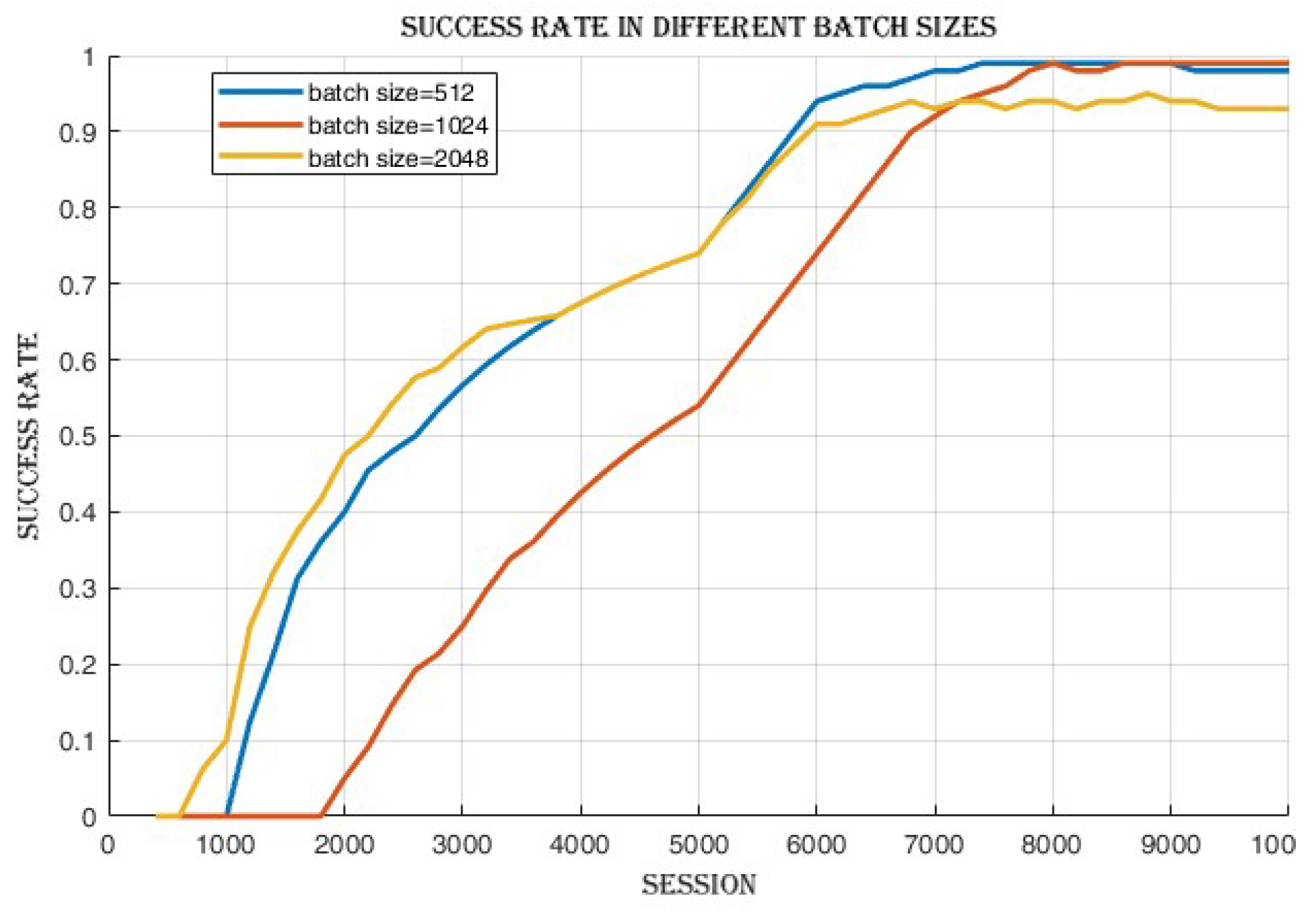
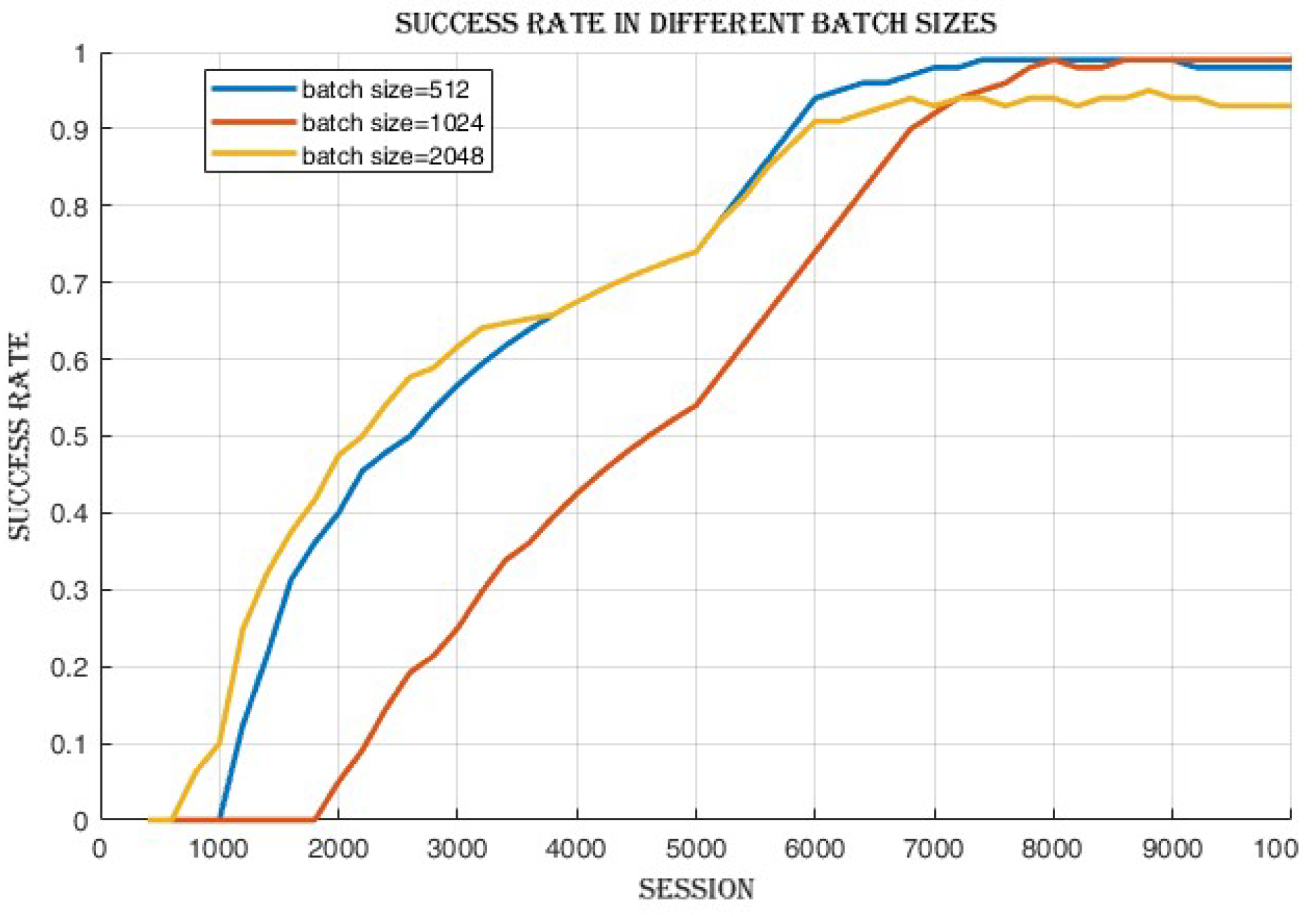
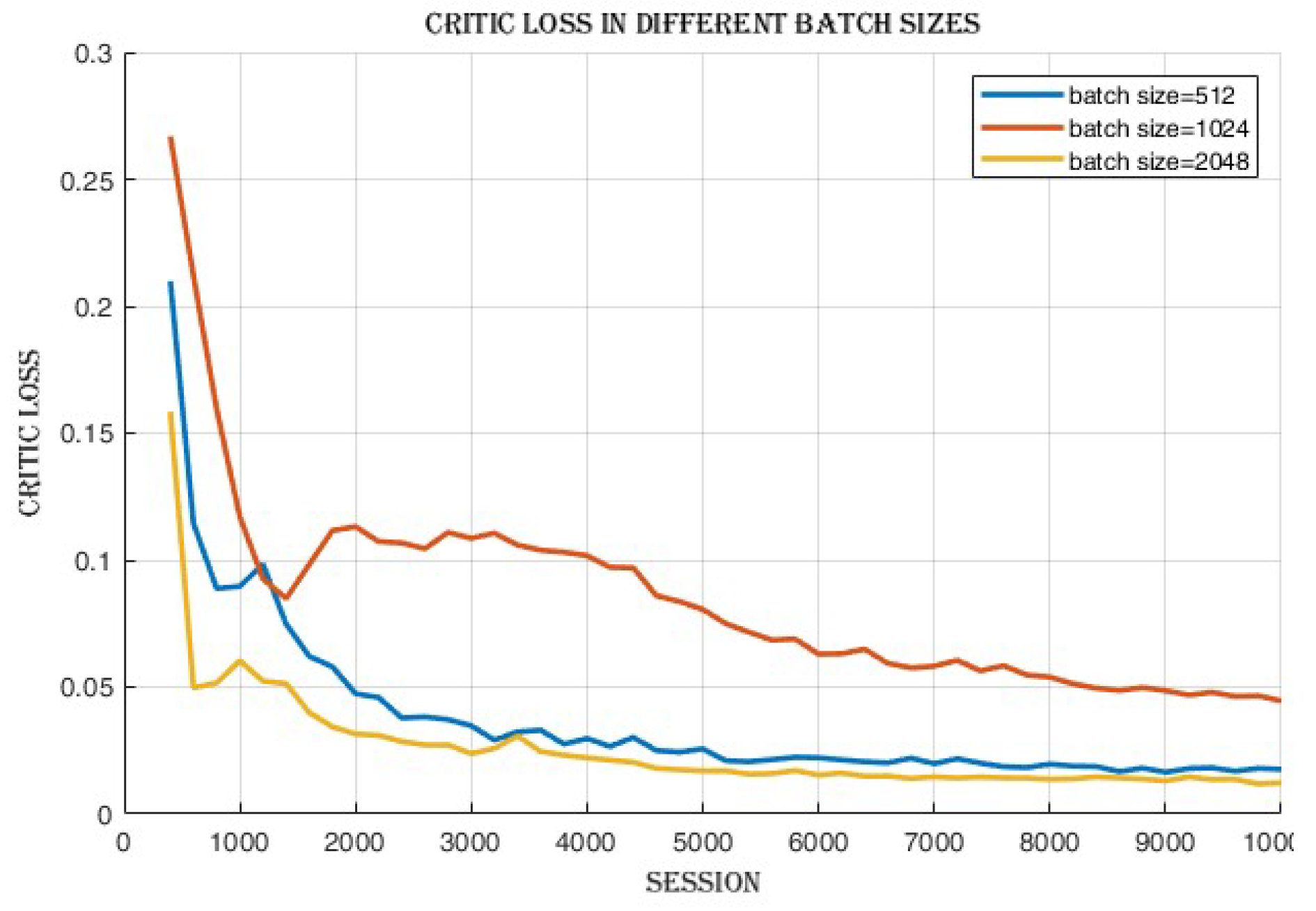
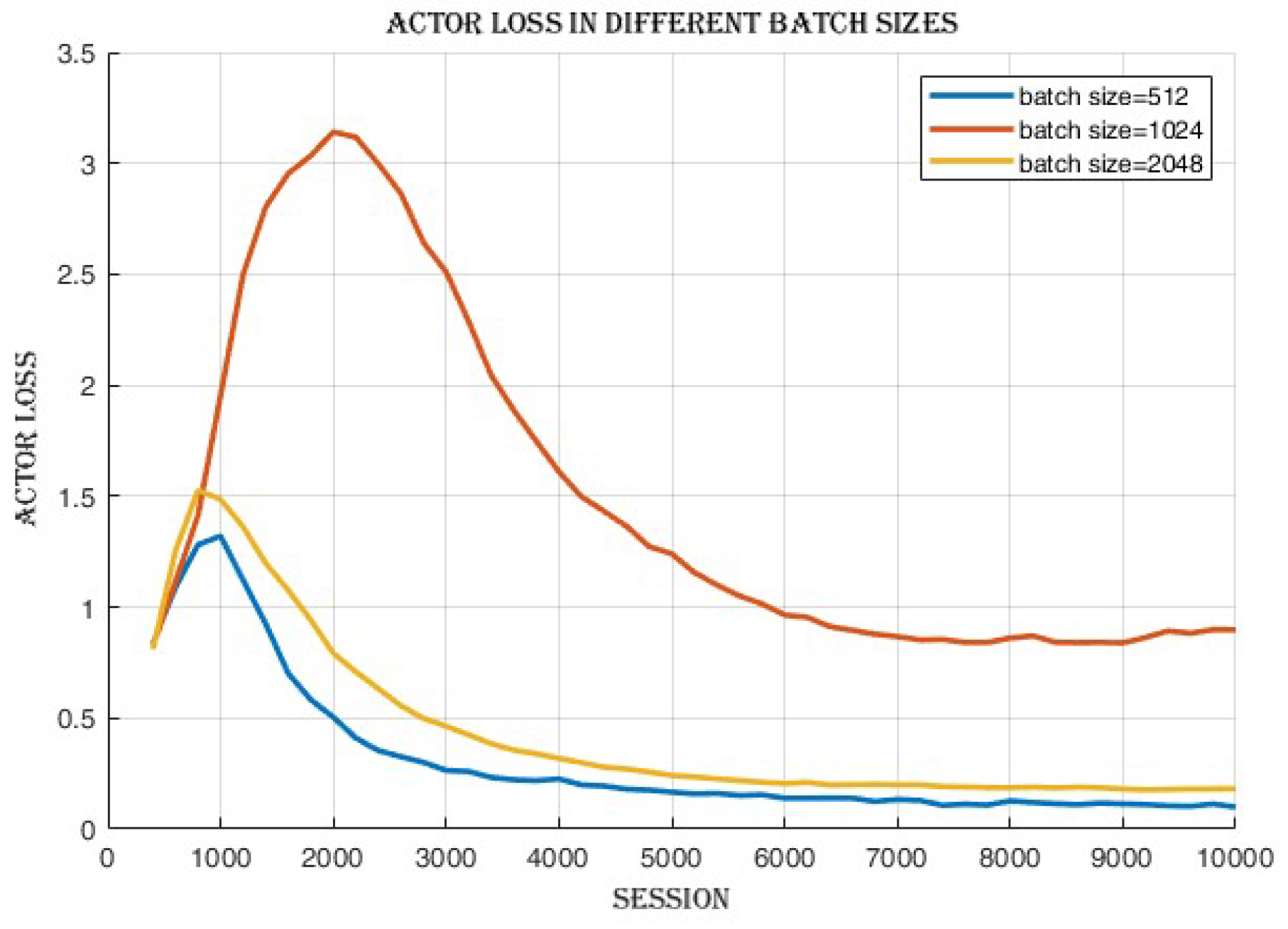
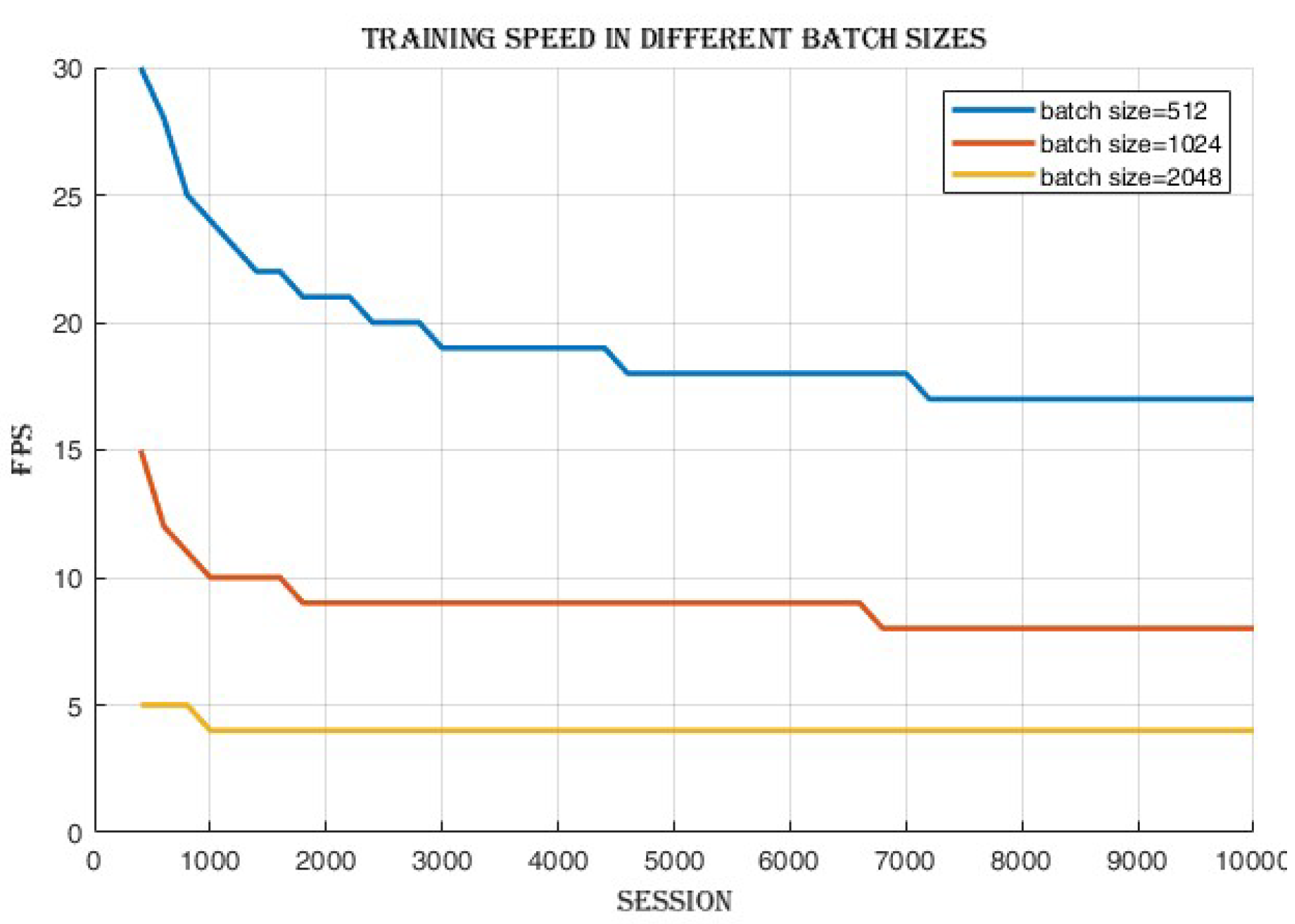
4.2.1. Batch Size Comparison
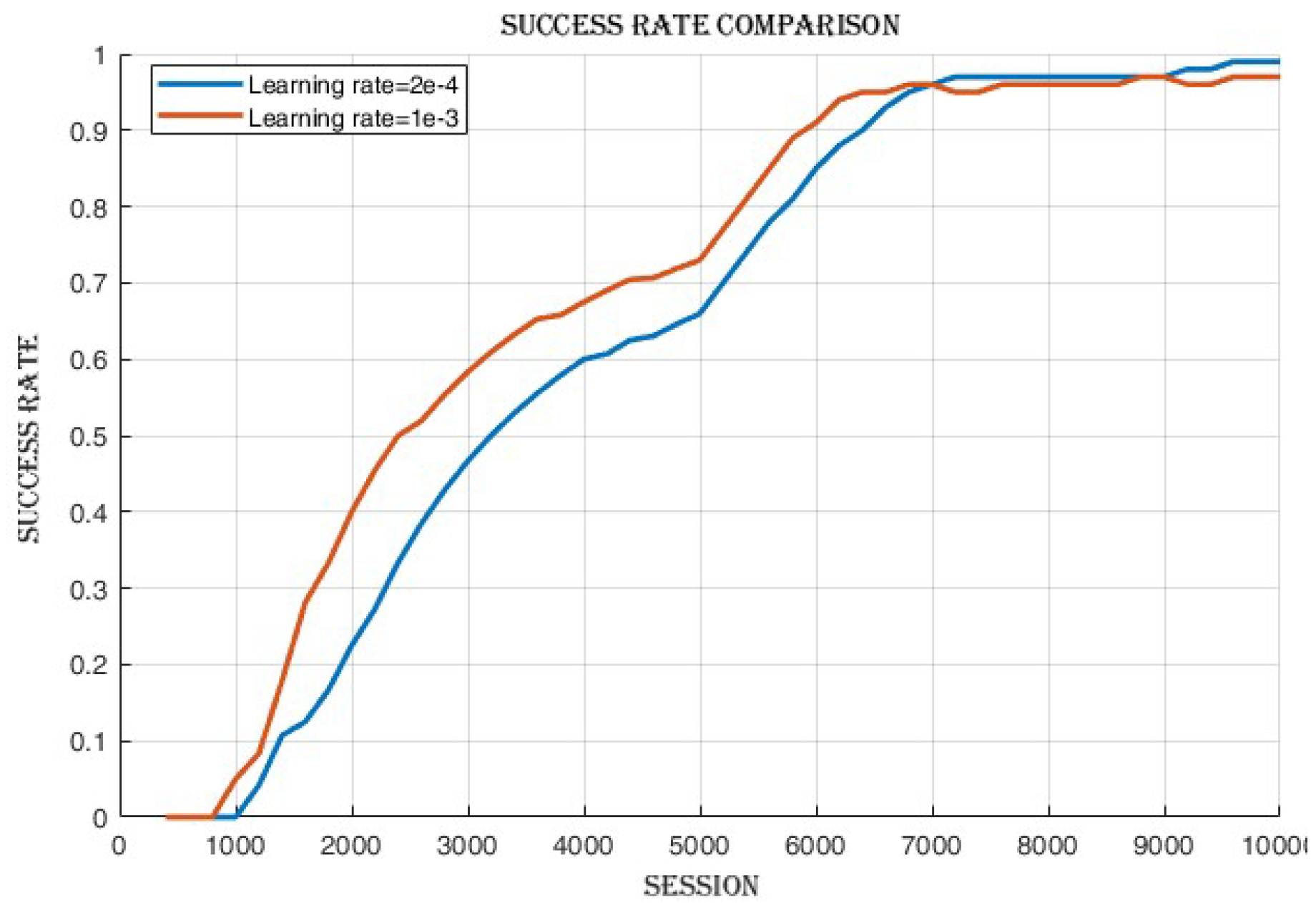
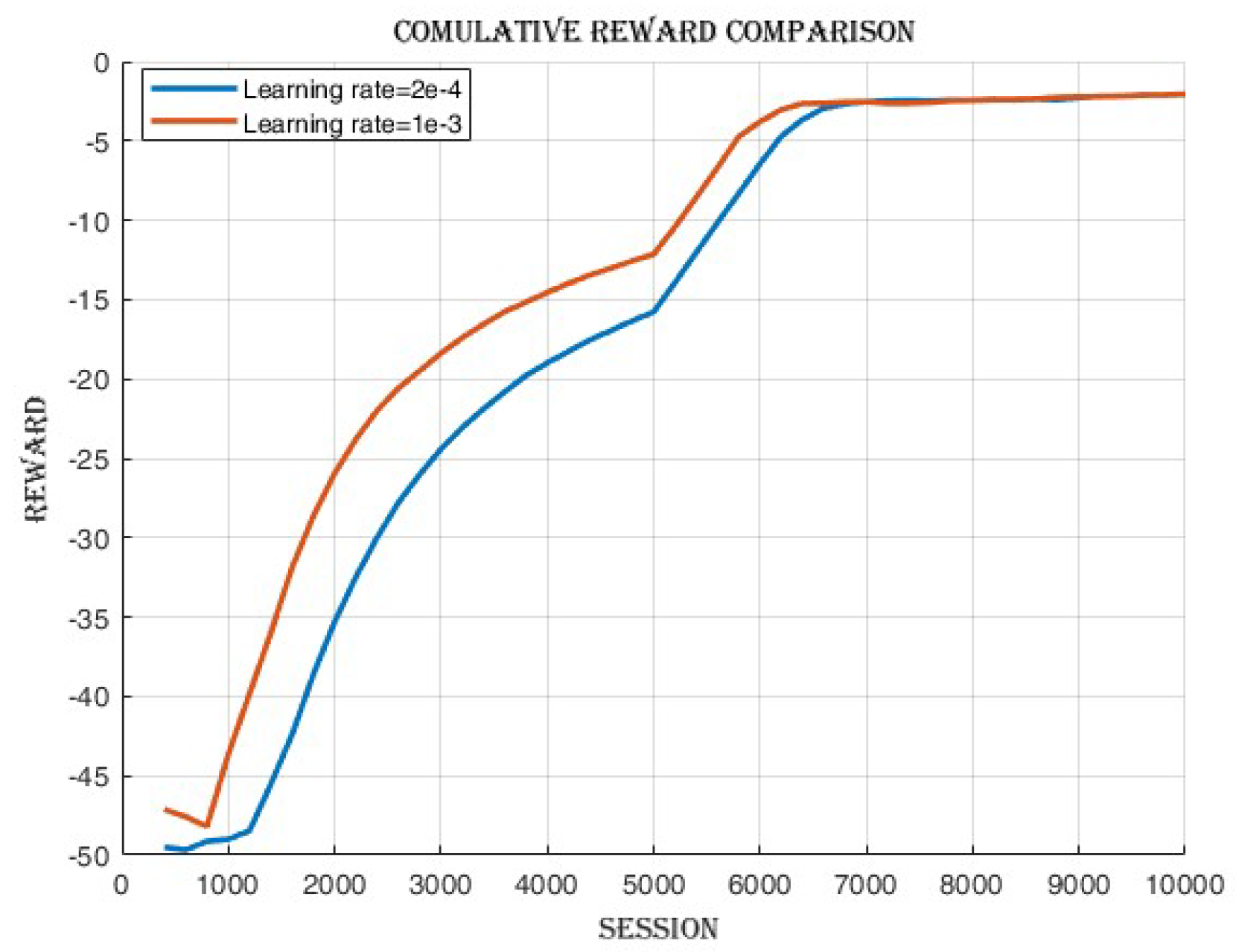
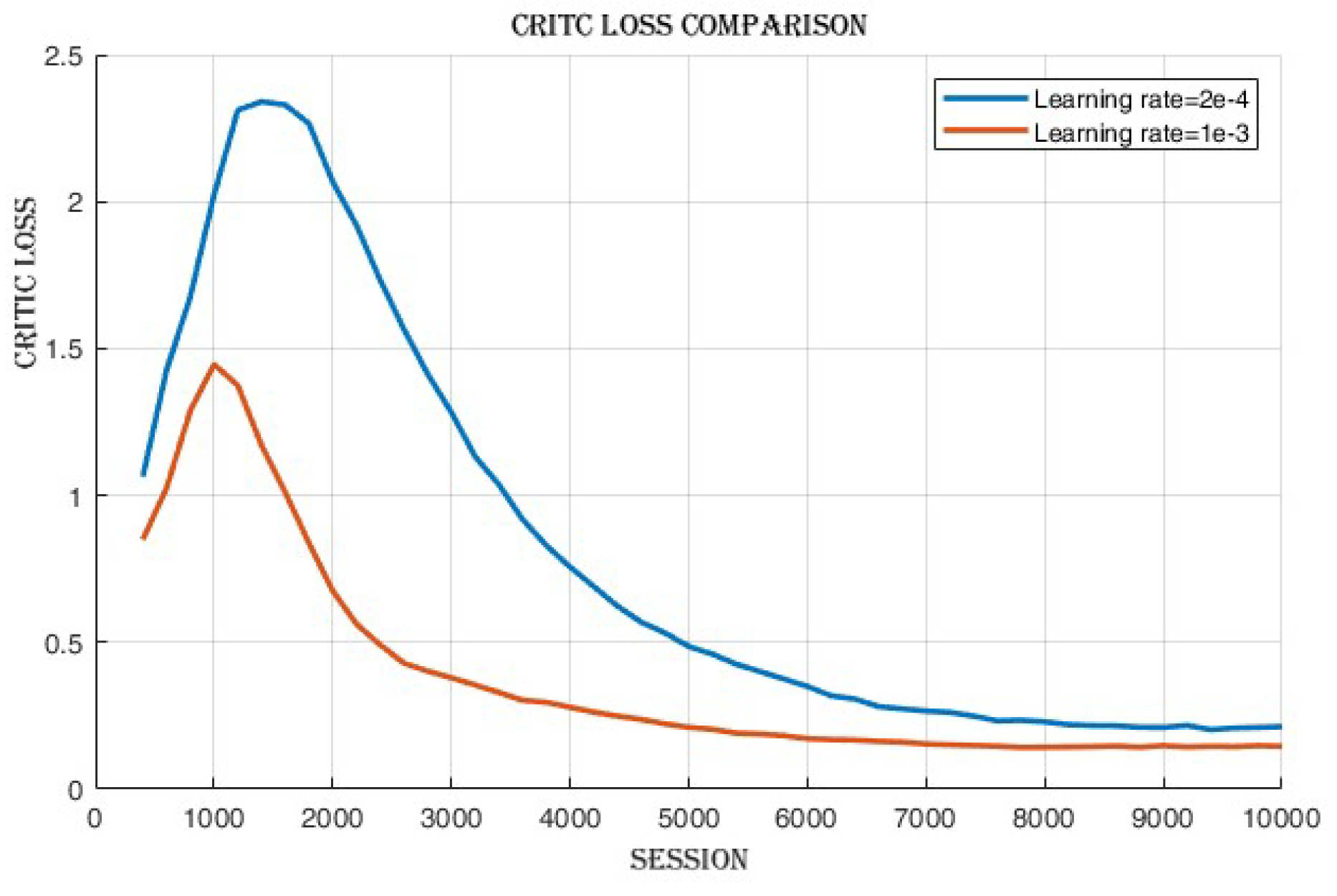
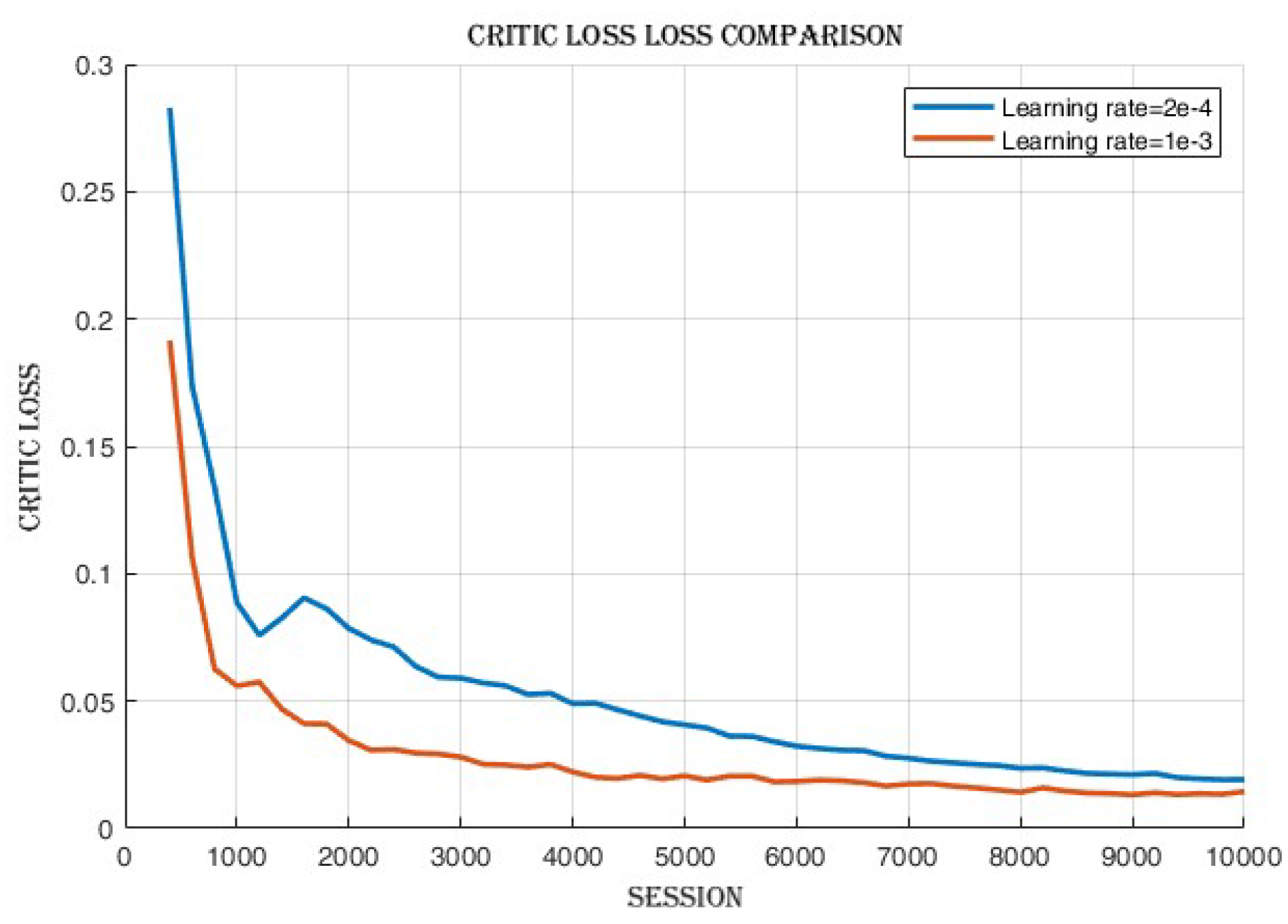
4.2.2. Learning Rate Comparison
4.3. Selection of Optimal Hyperparameters and Extended Training of DDPG Agent

| Parameter | Value |
|---|---|
| Policy | MultiInputPolicy |
| Replay buffer class | HerReplayBuffer |
| Verbose | 1 |
| Gamma | 0.95 |
| Tau () | 0.005 |
| Batch size | 2048 |
| Buffer size | 100000 |
| Replay buffer kwargs | rb kwargs |
| Learning rate | 1e-3 |
| Action noise | Normal action noise |
| Policy kwargs | Policy kwargs |
| Tensorboard log | Log path |
| Category | Value | Category | Value |
|---|---|---|---|
| rollout/ | rollout/ | ||
| Episode length | 50 | Episode length | 50 |
| Episode mean reward | -49.2 | Episode mean reward | -1.8 |
| Success rate | 0 | Success rate | 1 |
| time/ | time/ | ||
| Episodes | 4 | Episodes | 2000 |
| FPS | 18 | FPS | 5 |
| Time elapsed | 10 | Time elapsed | 19505 |
| Total timesteps | 200 | Total time steps | 100000 |
| train/ | train/ | ||
| Actor loss | 0.625 | Actor loss | 0.0846 |
| Critic loss | 0.401 | Critic loss | 0.00486 |
| Learning rate | 0.001 | Learning rate | 0.001 |
| Number of updates | 50 | Number of updates | 99850 |
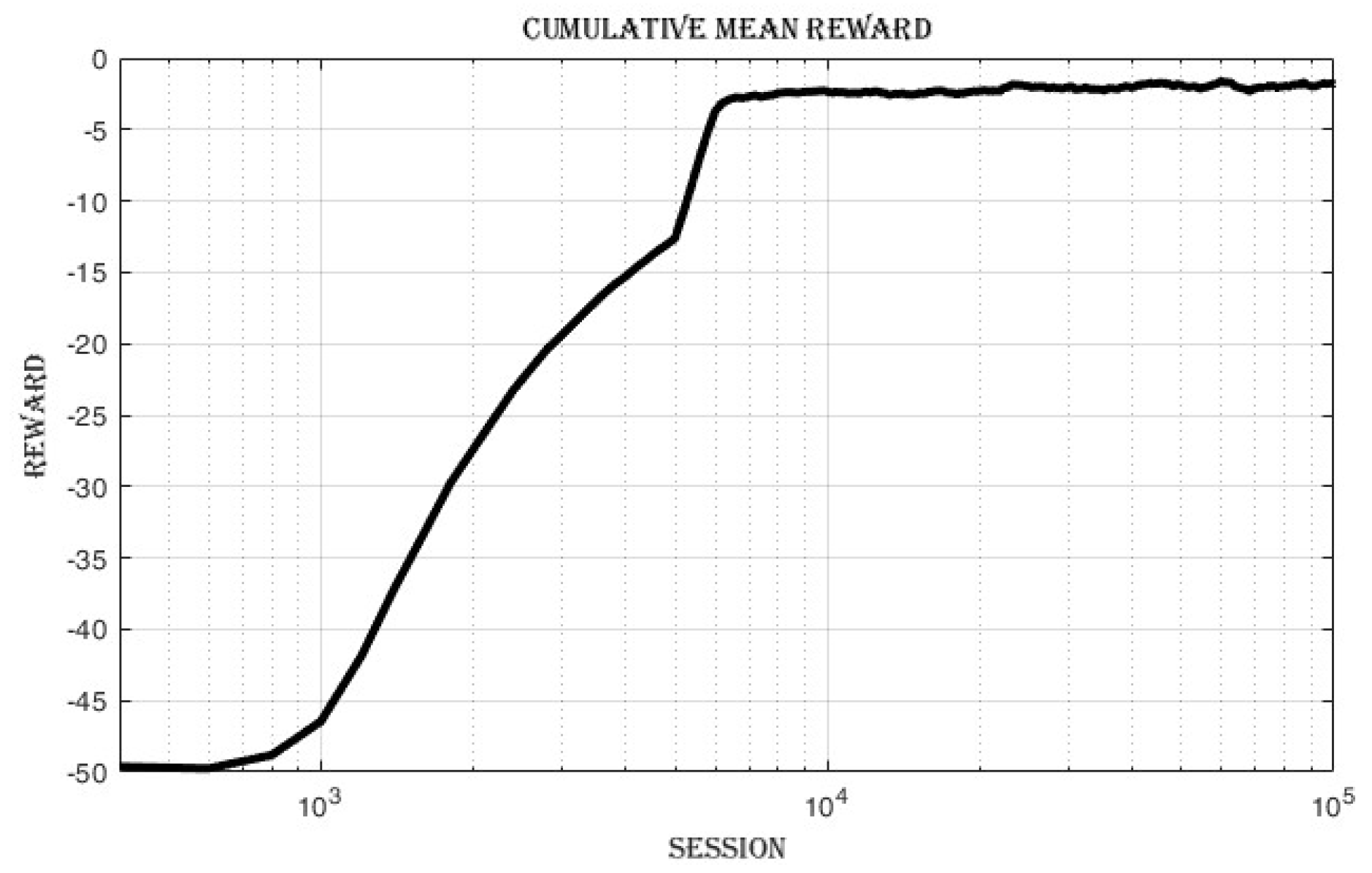
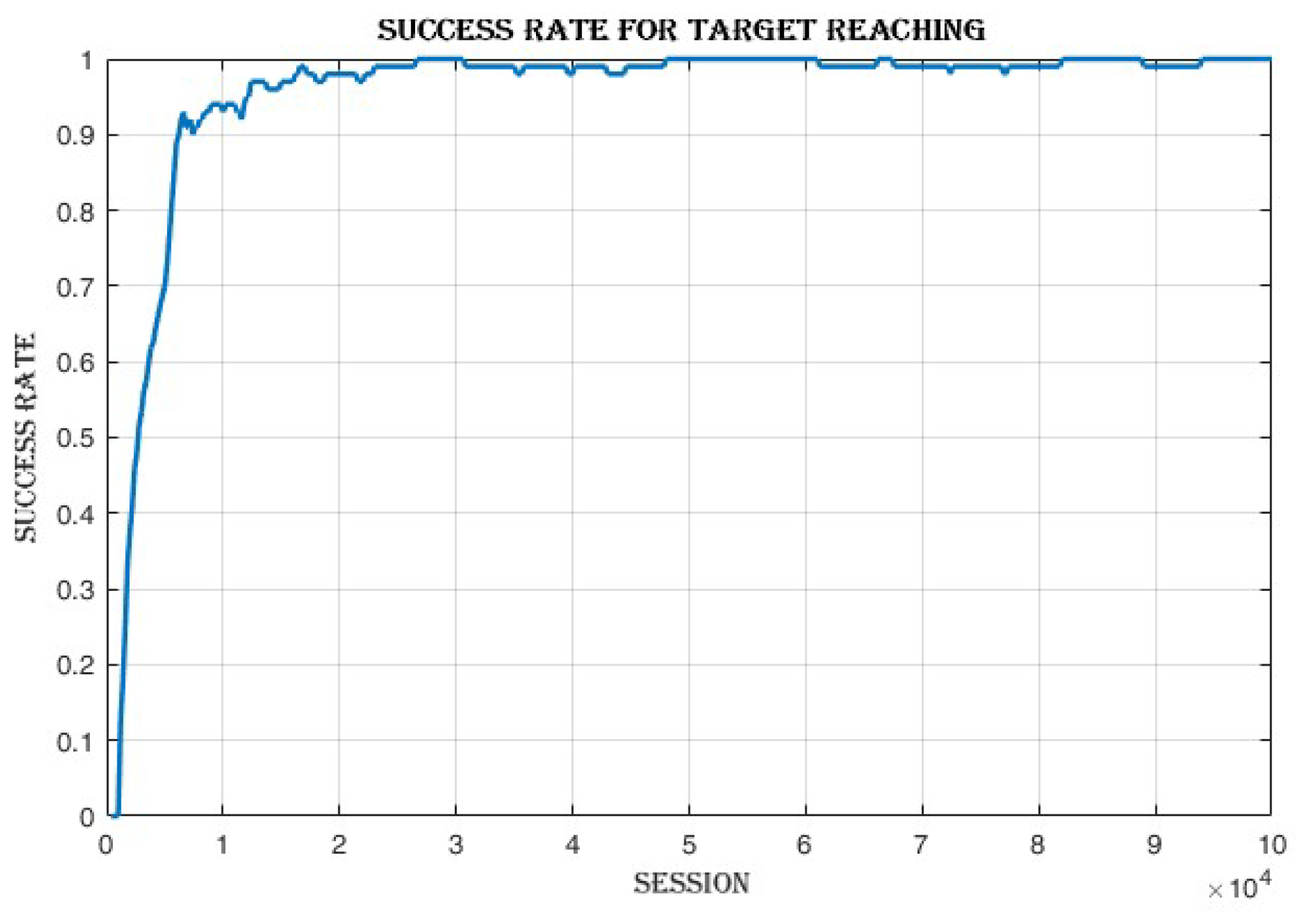
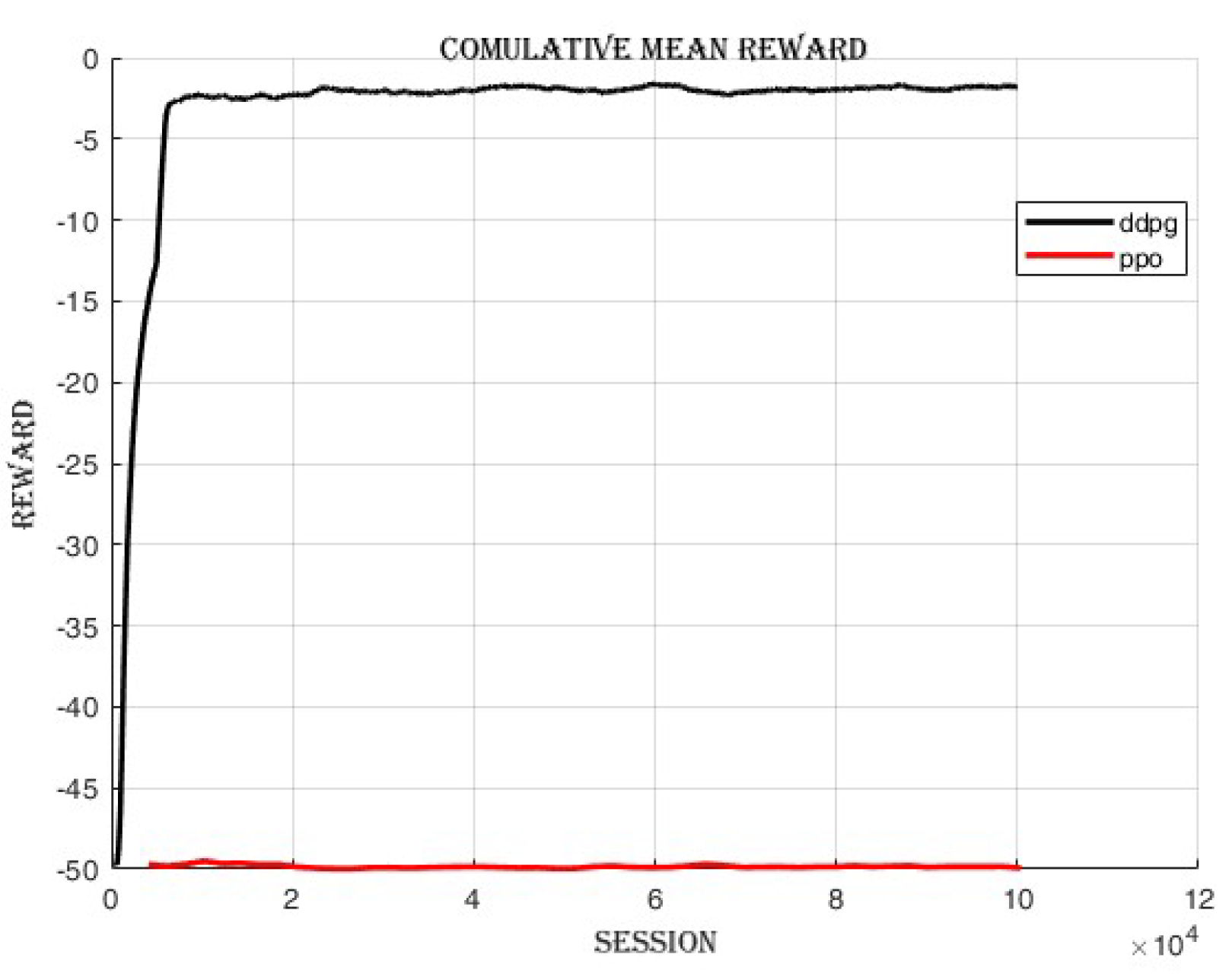
4.3.1. Improvement in Cumulative Reward and Success Rate
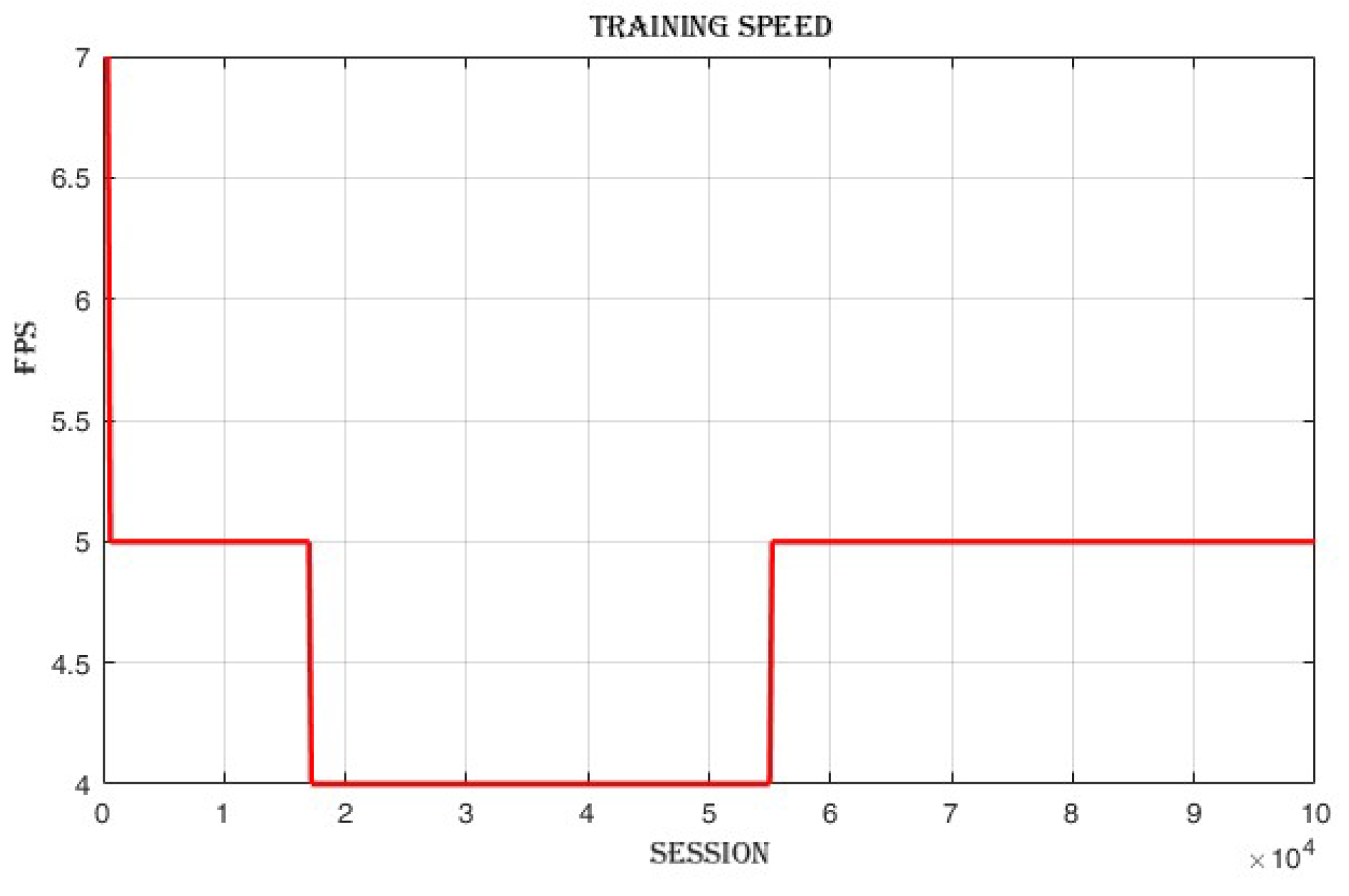
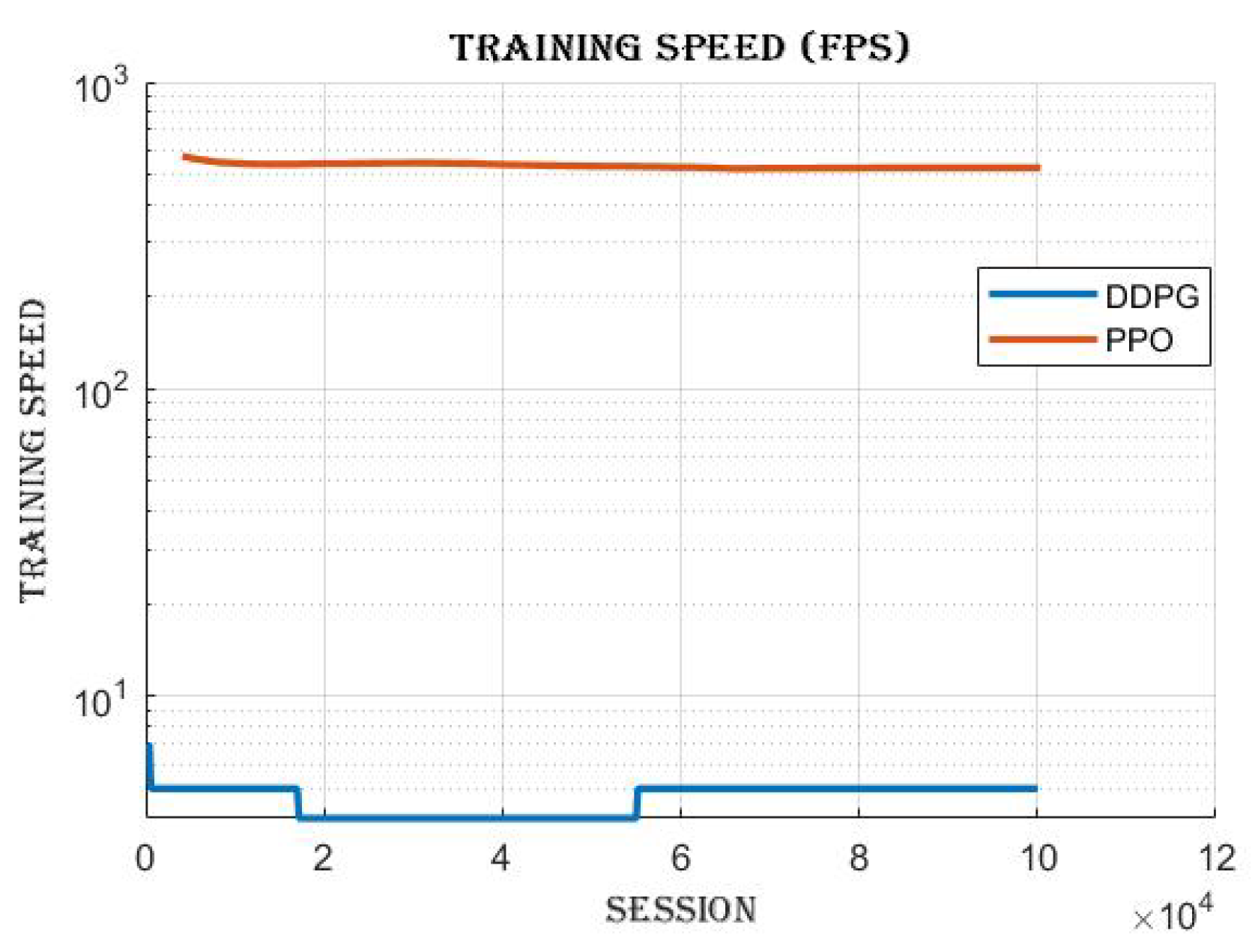
4.3.2. Frames per Second (FPS)
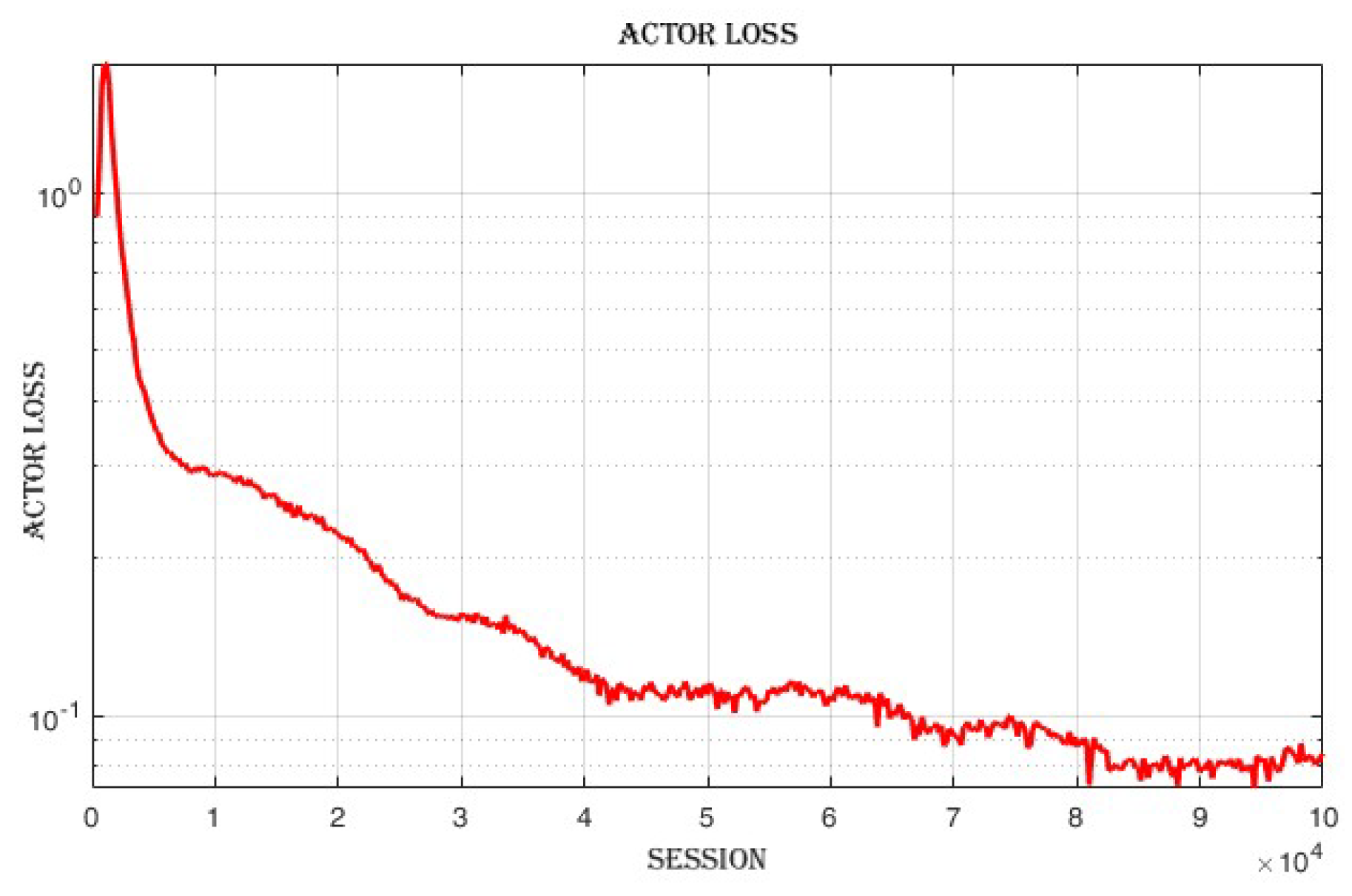
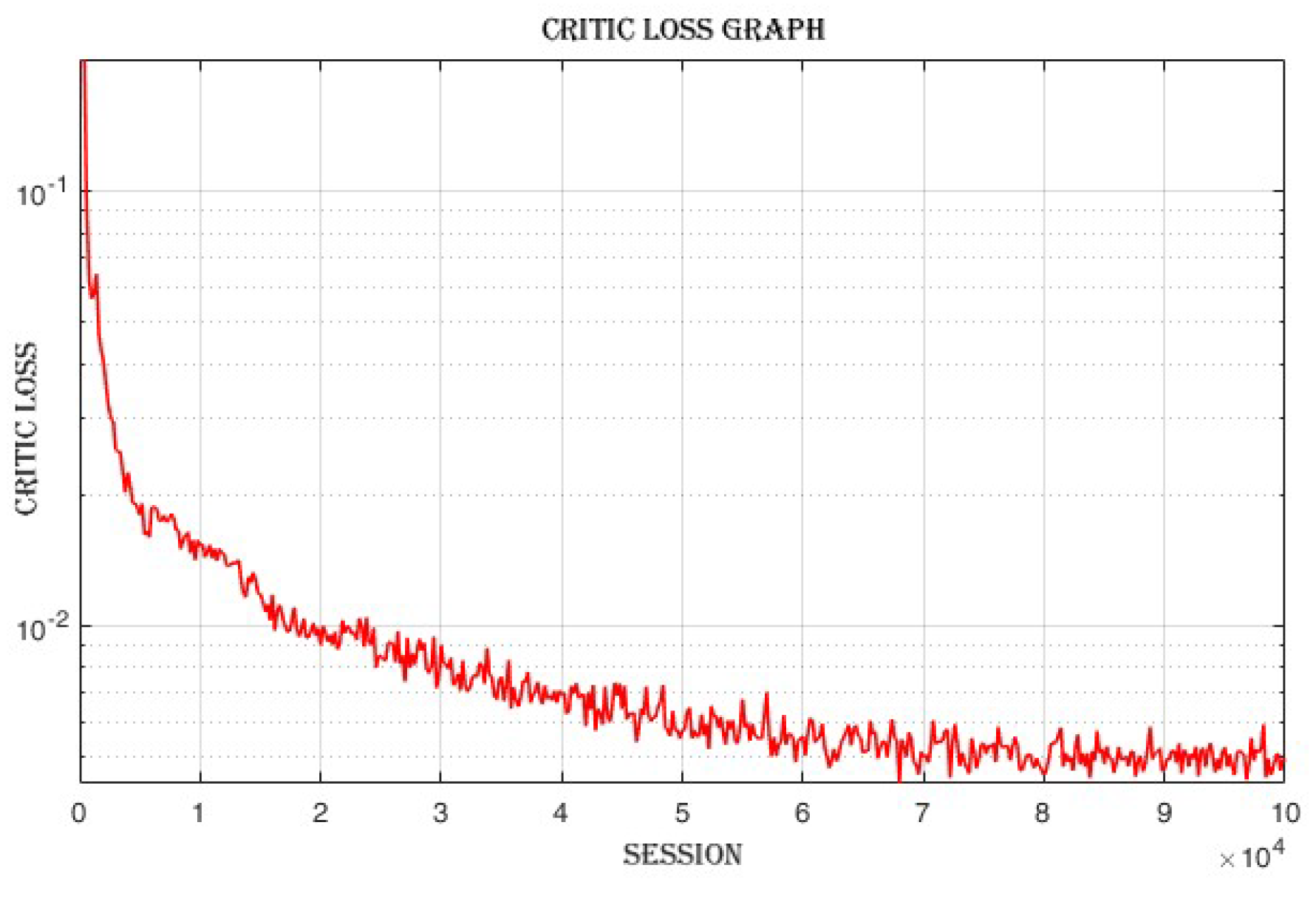
4.3.3. Improvement in Actor and Critic Losses
4.4. Comparing DDPG and PPO: Off-Policy vs. On-Policy Reinforcement Learning Algorithms
5. Conclusion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohsen, S.; Behrooz, A.; Roza, D. Artificial intelligence, machine learning and deep learning in advanced robotics, a review. Cognitive Robotics 2023, 3, 54–70. [Google Scholar]
- Sridharan, M.; Stone, P. Color Learning on a Mobile Robot: Towards Full Autonomy under Changing Illumination. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI); 2007; pp. 2212–2217. [Google Scholar]
- Xinle, Y.; Minghe, Sh.; Lingling, Sh. Adaptive and intelligent control of a dual-arm space robot for target manipulation during the post-capture phase. Aerospace Science and Technology 2023, 142, 108688. [Google Scholar]
- Abayasiri, R. A. M.; Jayasekara, A. G. B. P.; Gopura, R. A. R. C.; Kazuo, K. Intelligent Object Manipulation for a Wheelchair-Mounted Robotic Arm. Journal of Robotics, 2024. [Google Scholar]
- Mohammed, M. A.; Hui, L.; Norbert, St.; Kerstin, Th. Intelligent arm manipulation system in life science labs using H20 mobile robot and Kinect sensor. 2016 IEEE 8th International Conference on Intelligent Systems (IS), Sofia, Bulgaria, 2016. [Google Scholar]
- Yoshiyuki Ohmura and Yasuo Kuniyoshi. Humanoid robot which can lift a 30kg box by whole body contact and tactile feedback. 007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 2007; pp. 1136–1141. [Google Scholar]
- Li, Z.; Ming, J.; Dewan, F.; Hossain, M.A. Intelligent facial emotion recognition and semantic-based topic detection for a humanoid robot. Expert Systems with Applications 2013, 40, 5160–5168. [Google Scholar]
- Martin, J. G. Muros, F. J., Maestre, J. M., and Camacho, E. F. Multi-robot task allocation clustering based on game theory. Robotics and Autonomous Systems. Robotics and Autonomous Systems 2023, 161, 104314. [Google Scholar] [CrossRef]
- Nguyen, M. N. T. Ba, D. X. A neural flexible PID controller for task-space control of robotic manipulators. Frontiers in Robotics and AI 2023, 9, 975850. [Google Scholar]
- Laurenzi, A. Antonucci, D., Tsagarakis, N. G., and Muratore, L. The XBot2 real-time middleware for robotics. Robotics and Autonomous Systems. Robotics and Autonomous Systems 2023, 163, 104379. [Google Scholar] [CrossRef]
- Zhang, L. Jiang, M., Farid, D., and Hossain, M. A. Intelligent Facial Emotion Recognition and Semantic-Based Topic Detection for a Humanoid Robot. Expert Systems with Applications 2013, 40, 5160–5168. [Google Scholar] [CrossRef]
- Floreano, D. Wood, R. J. Science, Technology, and the Future of Small Autonomous Drones. Nature 2015, 521, 460–466. [Google Scholar] [CrossRef] [PubMed]
- Chen, T. D. , Kockelman, K. M., and Hanna, J. P. Operations of a Shared, Autonomous, Electric Vehicle Fleet: Implications of Vehicle & Charging Infrastructure Decisions. Transportation Research Part A: Policy and Practice, 2016. [Google Scholar]
- Chen, Z. Jia, X., Riedel, A., and Zhang, M. A Bio-Inspired Swimming Robot. 2014 IEEE International Conference on Robotics and Automation (ICRA), 2014; pp. 2564–2564. [Google Scholar]
- Ohmura, Y. and Kuniyoshi, Y. Humanoid Robot Which Can Lift a 30kg Box by Whole Body Contact and Tactile Feedback. 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems; 2007; pp. 1136–1141. [Google Scholar]
- Kappassov, Z. Corrales, J.-A., and Perdereau, V. Tactile Sensing in Dexterous Robot Hands. Robotics and Autonomous Systems 2015, 74, 195–-220. [Google Scholar] [CrossRef]
- Arisumi, H. Miossec, S., Chardonnet, J.-R., and Yokoi, K Dynamic Lifting by Whole Body Motion of Humanoid Robots. 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems; 2008; pp. 668–675. [Google Scholar]
- Aryslan, M. Yevgeniy, L., Troy, H., Richard, P. A deep reinforcement-learning approach for inverse kinematics solution of a high degree of freedom robotic manipulator. Robotics 2022, 11, 44. [Google Scholar] [CrossRef]
- Serhat, O. Enver T., Erkan Z. Adaptive Cartesian space control of robotic manipulators: A concurrent learning based approach. Journal of the Franklin Institute 2024, 361, 106701. [Google Scholar]
- Kaelbling, L. P. Littman, M. L., and Moore, A. Reinforcement Learning: A Survey. Journal of Artificial Intelligence Research 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Fadi, Al. , Katarina Gr. Reinforcement learning algorithms: An overview and classification. 2021 IEEE Canadian Conference on Elec-trical and Computer Engineering (CCECE); 2021; pp. 1–7. [Google Scholar]
- Thrun, S.; and Littman, M. L. Reinforcement Learning: An Introduction. AI Magazine 2000, 21, 103-. [Google Scholar]
- Smruti Amarjyoti. Deep reinforcement learning for robotic manipulation-the state of the art. arXiv:1701.08878, 2017.
- Jens, K., Bagnell. Reinforcement learning in robotics: A survey. The International Journal of Robotics Research 2013, 32, 1238–1274. [Google Scholar]
- Tianci, G. Optimizing robotic arm control using deep Q-learning and artificial neural networks through demonstration-based methodologies: A case study of dynamic and static conditions. Robotics and Autonomous Systems 2024, 104771. [Google Scholar]
- Andrea, Fr., Elisa. Robotic Arm Control and Task Training through Deep Reinforcement Learning. 2020, arXiv:2005.02632v1. [Google Scholar]
- Jonaid, Sh., Michael. Optimizing Deep Reinforcement Learning for Adaptive Robotic Arm Control. 2024, arXiv:2407.02503v1. [Google Scholar]
- Roman, P. , Jakub, K. Computation 2024, 12(6), 116. [Google Scholar]
- Wanqing, X., Yuqian. Deep reinforcement learning based proactive dynamic obstacle avoidance for safe human-robot collaboration. Manufacturing Letters 2024, 1246–1256. [Google Scholar]
- Franka Emika Documentation. Control Parameters Documentation, 2024. Available at: CrossRef.
- Weng, L. Policy Gradient Algorithms. Lil’Log, 2018. 2024. Available online: https://lilianweng.github.io/posts/2018-04-08-policy-gradient.
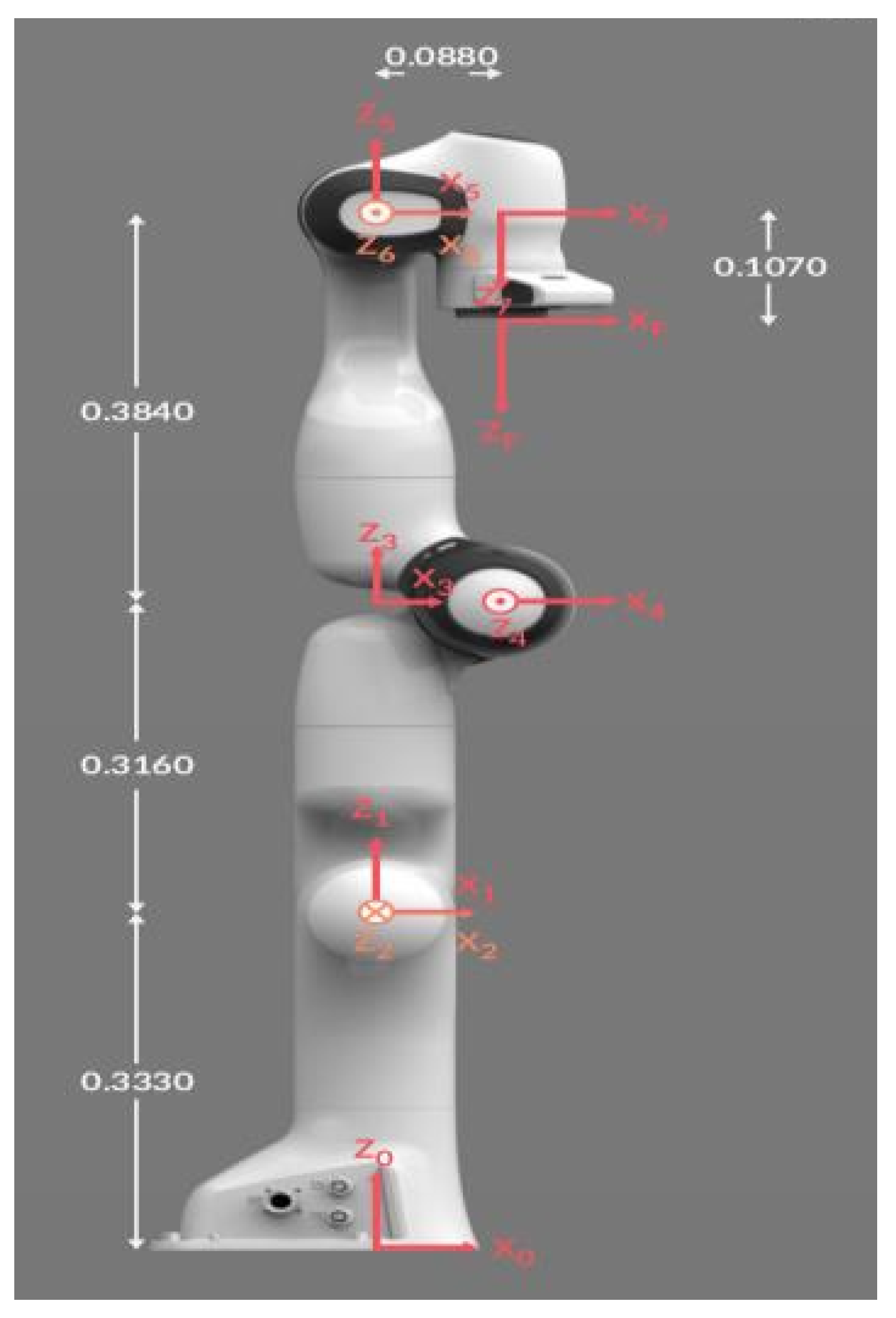
| Joint | a(m) | d(m) | (m) | (rad) |
|---|---|---|---|---|
| 1 | 0 | 0.333 | 0 | |
| 2 | 0 | 0 | -90 | |
| 3 | 0 | 0.316 | 90 | |
| 4 | 0.0825 | 0 | 90 | |
| 5 | -0.0825 | 0.384 | -90 | |
| 6 | 0 | 0 | 90 | |
| 7 | 0.088 | 0 | 90 | |
| Flange | 0 | 0.107 | 0 | 0 |
| Parameter | Value |
|---|---|
| Policy | MultiInputPolicy |
| Replay buffer class | HerReplayBuffer |
| Verbose | 1 |
| Gamma | 0.95 |
| Tau () | 0.005 |
| Batch size | 512,1024,2048 |
| Buffer size | 100000 |
| Replay buffer kwargs | rb kwargs |
| Learning rate | 1e-3 , 2e-4 |
| Action noise | Normal action noise |
| Policy kwargs | Policy kwargs |
| Tensorboard log | Log path |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



