1. Introduction
Credit card fraud continues to cast a formidable shadow over individuals and financial institutions worldwide, exacting significant financial tolls and causing immeasurable harm to unsuspecting victims [
1]. The devious nature of credit card fraud entails the unauthorised and fraudulent use of credit card data by malicious third parties, which has serious negative effects on the economy and causes psychological pain [
2]. The significant global extent of this issue is emphasized by the striking statistics disclosed in the Nilson Report. It disclosed that in 2018, losses attributed to card fraud surged beyond an astounding
$27.85 billion, highlighting the urgent necessity for formidable and efficient fraud detection systems [
3]. The global financial losses due to credit card fraud reached 32.34 billion in 2021, with the US accounting for 11.9 billion or 37% of worldwide losses. Credit card fraud is projected to cost the global card industry 397 billion over the next 10 years, with 165 billion in losses coming from the US [
4].
Credit card fraud can have severe financial, emotional, and psychological impacts on victims. 12% of US identity theft victims experienced out-of-pocket costs averaging
$690, and 32% reported moderate to severe emotional distress [
5,
6]. To mitigate the impact of credit card fraud, fraud detection systems play a pivotal role by identifying and thwarting fraudulent transactions in real-time [
7]. These systems harness advanced data mining techniques to analyse vast volumes of transactional data, facilitating early detection of anomalous patterns and enabling timely interventions to minimize financial losses [
8].
In the realm of credit card fraud detection, conventional data mining techniques such as decision trees, neural networks, logistic regression, and rule-based algorithms have been widely employed [
9]. Despite some successes, these methods grapple with inherent limitations that hinder their efficacy in this context. One primary constraint is the challenge posed by highly imbalanced datasets, where instances of fraud are markedly rare. This imbalance can lead to suboptimal accuracy as models tend to be biased toward the majority class [
10]. The skewed nature of the data can result in the misclassification of fraudulent transactions, contributing to elevated false positive rates, thereby diminishing the overall reliability of the fraud detection system [
11].
Moreover, the inadequacy of conventional techniques in capturing intricate fraud patterns is evident. Credit card fraud often involves sophisticated and dynamic patterns that conventional models struggle to discern due to their limitations in handling non-linearity and complex interdependencies [
10]. Fraudsters constantly adapt their tactics, necessitating models with a higher degree of flexibility. This limitation underscores the need for more sophisticated approaches in credit card fraud detection.
Introducing convolutional techniques into this domain introduces additional challenges. One significant hurdle is the sequential nature of credit card transactions, where temporal dependencies play a crucial role [
12]. Convolutional Neural Networks (CNNs), designed originally for grid-like data such as images, may not inherently capture the sequential dependencies present in transaction sequences [
10]. The sequential nature of transactions, with varying time intervals and orders, poses a unique challenge for CNNs, which are not explicitly tailored for processing such temporal data.
Furthermore, the high dimensionality and variable sequence lengths inherent in credit card transactions present obstacles for traditional CNN architectures [
12]. Transactions vary widely in terms of amounts, locations, and frequencies, resulting in datasets with diverse characteristics. Conventional CNNs may face difficulties efficiently handling such variable-length sequential data [
10].
A critical concern is the limited interpretability of CNNs, often regarded as black-box models [
13]. While CNNs excel in predictive capabilities, their opacity in revealing the decision-making process poses challenges, particularly in scenarios where interpretability is crucial, such as in fraud detection [
10]. Understanding the rationale behind a model’s prediction is essential for building trust among stakeholders and complying with regulatory requirements [
14].
In response to these challenges, researchers have turned to hybrid data mining techniques, which amalgamate diverse algorithms and approaches to leverage their collective strengths while mitigating individual weaknesses [
15]. One notable example is the integration of decision trees and ensemble methods, as demonstrated in the work by [
16]. In their study, the authors proposed a hybrid approach that combined the interpretability of decision trees with the robustness of ensemble methods, specifically a random forest. The decision tree component provided a clear and interpretable model, allowing for a straightforward understanding of the features contributing to fraud detection. Simultaneously, the ensemble method addressed issues related to overfitting and enhanced predictive accuracy by aggregating the outputs of multiple decision trees. This amalgamation of techniques leverages the interpretability of decision trees and the predictive power of ensemble methods, showcasing the potential of hybrid approaches in credit card fraud detection [
17]. The emergence of hybrid methods holds the promise of enhancing credit card fraud detection by reducing false positives, improving accuracy, and providing more resilient protection to individuals and financial institutions [
18].
In this study we investigate and assess the usefulness of hybrid methods of data mining for identifying credit card fraud in light of the present constraints and the urgent need for more reliable fraud detection systems. By delving into the intricacies of these hybrid approaches, the study endeavours to unravel new possibilities in fraud detection technology, forging a path towards more secure financial transactions and bolstering confidence in electronic payment systems.
2. Related Works
Credit card fraud has emerged as a significant concern for individuals and financial institutions worldwide, leading to substantial financial losses and causing severe repercussions for victims. [
19] highlights the pressing need for robust fraud detection systems to counter the ever-evolving tactics employed by fraudulent actors. Various studies have underscored the global impact of credit card fraud and the urgency to implement effective preventive measures [
2]. The Nilson Report’s alarming statistics revealed that bank fraud losses surpassed
$27.85 billion in 2018, reinforcing the urgency to develop advanced fraud detection technologies [
3]. This section comprehensively evaluates existing research in credit card fraud detection, emphasizing traditional data mining methods and the emerging trend toward hybrid techniques.
Traditional data mining techniques including decision trees, neural networks, logistic regression, and rule-based algorithms have been employed diversely to credit card fraud detection. [
20] showcased the effectiveness of decision trees, underscoring their utility in capturing decision boundaries within the intricate landscape of credit card transactions. The transparency of decision trees has made them valuable not only for identifying potentially fraudulent activities but also for offering insights into the reasoning behind each classification.
[
21] investigated the effect of imbalanced data on decision trees performance when they employed decision trees to credit card fraud detection, and highlighted a significant challenge posed by imbalanced datasets. In fraud detection scenarios, legitimate transactions often far outnumber fraudulent ones, creating an inherent imbalance. [
21] emphasized that this imbalance can lead to biased models, with decision trees potentially favouring the majority class and resulting in suboptimal accuracy. The study pinpointed a critical limitation that decision tree models must contend with, urging a closer examination of their adaptability to imbalanced datasets in the context of credit card fraud detection. [
22] provided further insights into the specific attributes of decision trees that contribute to their effectiveness in fraud detection. Their research delved into the optimization of decision tree parameters to enhance model performance, offering practical guidance on parameter tuning for credit card fraud detection scenarios. Furthermore, [
23] conducted a comparative analysis of decision trees against other machine learning models, shedding light on the relative strengths and weaknesses of decision trees in the context of credit card fraud detection. Their findings contributed to the ongoing dialogue regarding the optimal selection of models in different fraud detection scenarios. Moreover, [
24] explored the application of ensemble methods involving decision trees for improved fraud detection accuracy. Their research demonstrated the advantages of combining decision trees into ensembles, leveraging the diversity of individual trees to enhance overall model robustness.
Artificial neural network is another data mining model explored for credit card fraud detection, marked by its profound recognition of its prowess in modelling nonlinear relationships within intricate transactional data. [
25] conducted an in-depth analysis of the challenges inherent in deploying neural networks for fraud detection, particularly in the context of the dynamic nature of fraudulent patterns. Their research emphasized the necessity for continuous refinement in the application of neural networks to ensure adaptability to evolving tactics employed by fraudsters. [
26] delved into the importance of feature engineering in enhancing the performance of neural networks for fraud detection. Their research highlighted the significance of selecting and transforming input features to maximize the effectiveness of neural networks in discerning fraudulent activities. The study by [
25] shed light on the delicate balance between the flexibility of neural networks and the evolving landscape of credit card fraud. Building upon this foundation, [
27] provided insights into the optimization of neural network architectures for enhanced fraud detection accuracy. Their research focused on the fine-tuning of hyperparameters and model architectures to achieve better performance in identifying fraudulent transactions. However, [
28] critically evaluated the limitations of neural networks in capturing subtle and evolving fraud patterns. Their research emphasized scenarios where the sheer complexity of neural network models might hinder interpretability, posing challenges in understanding and validating the decision-making processes. This critical viewpoint contributed to a more nuanced understanding of the trade-offs associated with the application of neural networks in the specific context of credit card fraud detection.
In exploring the landscape of logistic regression in fraud detection, [
29] demonstrated its viability as a baseline method, leveraging its simplicity and interpretability for initial analyses. [
30] investigated the impact of ensemble methods involving logistic regression in enhancing fraud detection accuracy. Their research showcased the advantages of combining logistic regression into ensembles, leveraging the diversity of individual models to bolster overall system robustness. Furthermore, [
31] delved into the improvement of logistic regression algorithms for credit card fraud detection. Their research focused on enhancing the algorithm’s capacity to handle intricate fraud patterns, providing insights into the nuanced tuning of logistic regression models for improved performance. Logistic regression is not effective in capturing subtle and evolving fraud patterns, this limitation is associated with its simplicity, which denied its application to complex fraudulent tactics detection [
32].
Rule-based algorithms have been a cornerstone in the landscape of credit card fraud detection, offering transparent decision-making processes and interpretability [
33]. In a practical application, [
34] implemented rule-based algorithms in real-world credit card transaction data, providing empirical insights into their effectiveness. Their research highlighted the adaptability of rule-based models to different types of fraud scenarios, offering a tangible demonstration of their applicability in authentic settings. [
35] combined optimized rule-based algorithms and machine learning techniques to the evolving landscape of fraud patterns, showcasing the potential for rule-based algorithms to align with machine learning advancements. [
36] explored the integration of rule-based algorithms with explainability techniques, aiming to bridge the gap between transparency and complexity. Rule-based model is deterministic in nature hence, struggle to capture the nuanced relationships within transactional data, underscoring the need for adaptive and learning-based approaches [
37].
According to [
15], there is a growing interest in hybrid data mining techniques as a promising solution to address the limitations of conventional methods. Hybrid methods combine diverse algorithms or approaches, leveraging the strengths of individual techniques while compensating for their weaknesses [
38]. These hybrid approaches offer the potential to improve credit card fraud detection accuracy and reduce false positives, thus providing more resilient protection to individuals and financial institutions [
18]. [
18] further emphasized the significance of integrating multiple data mining techniques to advance fraud detection systems.
[
39] proposed a hybrid model that combined linear regression (LR) and support vector machine (SVM). Leveraging on the interpretability prowess of LR, and SVM strength of capturing nonlinear patterns. The hybrid model achieved an accuracy of 94.5%, outperforming individual models. The model of [
40] is a hybrid of Random Forest and neural network, leveraging on the efficiency of Random Forest to detect normal instances and neural network strength to detect frudulent transaction patterns. addressed the critical challenge of timely detecting fraudulent credit card transactions in the financial industry, emphasizing the highly skewed nature of the dataset with a small ratio of fraud to normal transactions. This hybrid approach, as per their findings, demonstrated high accuracy and confidence in predicting the label of new samples. [
41] introduced hybrid approaches involving AdaBoost and majority voting methods. Their evaluation, initially using a publicly available credit card dataset and subsequently with real-world financial institution data, showed the robustness of hybrid models. The hybrid model with majority voting demonstrated superior accuracy, achieving an Matthew Correlation Coefficient score of 0.823. Furthermore, when applied to real financial institution data, the hybrid models attained a perfect MCC score of 1. The introduction of noise in data samples, ranging from 10% to 30%, validated the robustness of the majority voting method, with an impressive MCC score of 0.942 under 30% noise. This study underscores the efficacy of hybrid methods, particularly majority voting, in enhancing credit card fraud detection accuracy, even in the presence of noise. [
42] addressed the escalating issue of credit card fraud in the digital era by proposing a framework that amalgamates three distinct techniques: Decision Trees, Neural Network, and K-Nearest Neighbour. In the quest for effective fraud detection, the researchers assigned labels to new transactions by considering the majority output from these methodologies. The study emphasized the adaptability of the model, asserting its competence across varied dataset sizes and types due to the synergistic benefits derived from the individual techniques.
Despite the successes recorded in addressing credit card fraud detection, there are still unresolved challenges that researchers in the field are working relentlessly to resolve. the challenges include:
Ever evolving nature of fraud pattern.
Interpretability of models, which is of great concerns especially in industries where regulatory compliance and transparency are paramount.
Imbalanced datasets.
Developing scalable models that ensure timely detection without compromising accuracy.
Hybrid models show promise in enhancing accuracy, there is a lack of consensus on the optimal combination of algorithms for specific contexts.
To address these gaps we propose a hybrid data mining approach that leverages the strengths of diverse algorithms to enhance adaptability, interpretability, and scalability. By systematically evaluating the performance of different algorithmic combinations, This research aims to contribute insights into the design and implementation of more effective credit card fraud detection systems. Additionally, this study will explore innovative techniques for handling imbalanced datasets and enhancing the interpretability of the models, ensuring that the approach aligns with industry needs. By focusing on these gaps, this research seeks to advance the field of credit card fraud detection, providing practical solutions that can be implemented in real-world scenarios. The outcomes of this research have the potential to significantly improve the accuracy and efficiency of fraud detection systems, ultimately reducing financial losses for individuals and institutions.
4. Experimentation
This section contains discussion of data exploration, data preparation and preprocessing, system setup and experiments, and results presentation and discussion.
4.1. Data Exploration
The dataset utilized in this research is a simulated credit card transaction dataset spanning the duration from January 1, 2019, to December 31, 2020. The simulation process was carried out using the Sparkov Data Generation tool created by [
46]. This dataset is intentionally designed to encompass both legitimate and fraudulent transactions, providing a diverse and comprehensive foundation for training and testing the credit card fraud detection model. The dataset comprises transactions involving credit cards issued to 1000 customers engaging in transactions with a pool of 800 merchants.
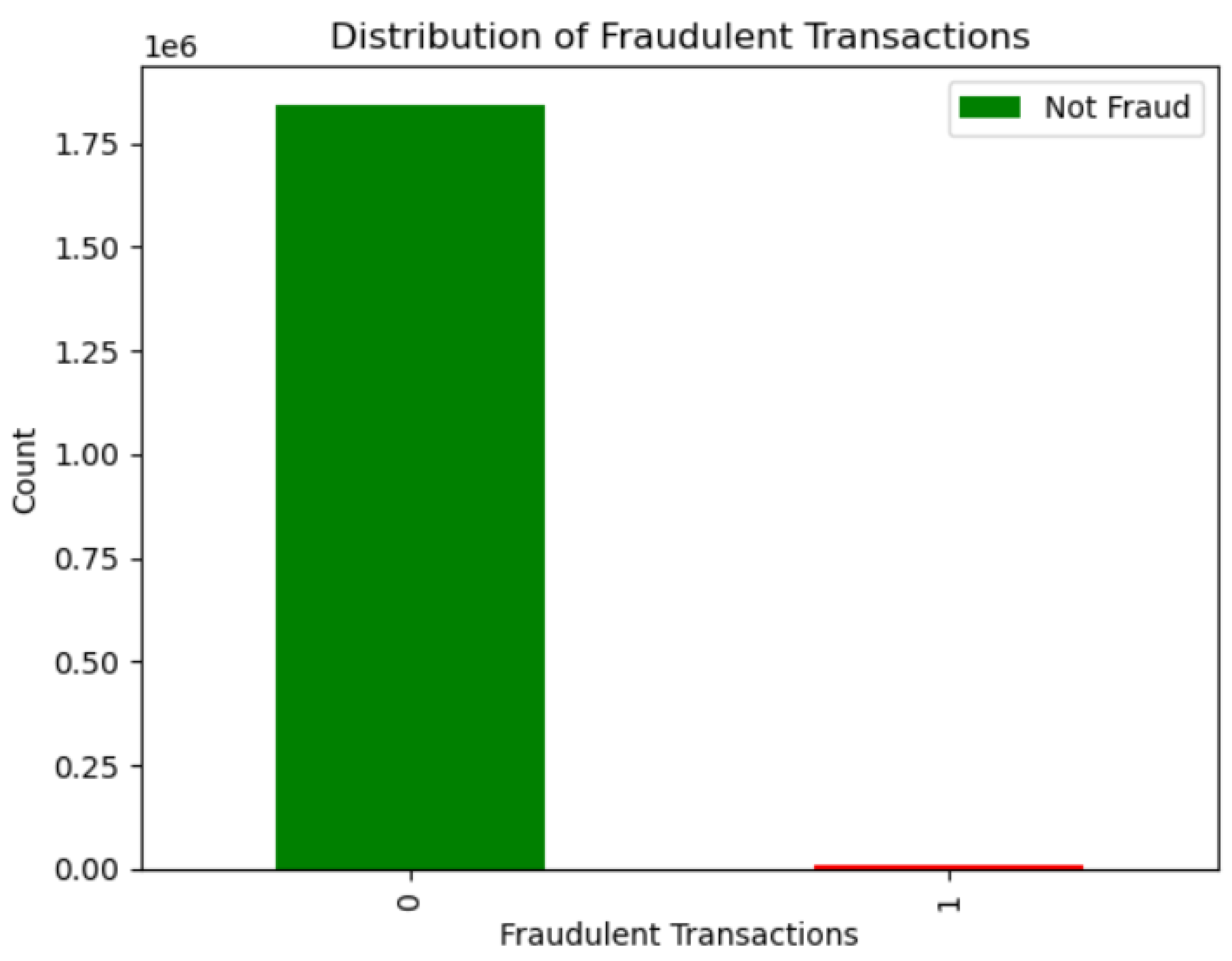
The dataset exhibits a significant class imbalance, with approximately 1.84 million instances of legitimate transactions and about 10 thousand instances of fraudulent transactions. The initial dataset contained a vast number of transactions. However, to circumvent computational challenges and potential delays in model training, a smaller random subset sample, termed the Proof of Concept (POC) dataset, was created from the original dataset having 109,651 records and 23 features. It is important to note that the POC dataset maintains the same imbalance ratio as the original dataset.
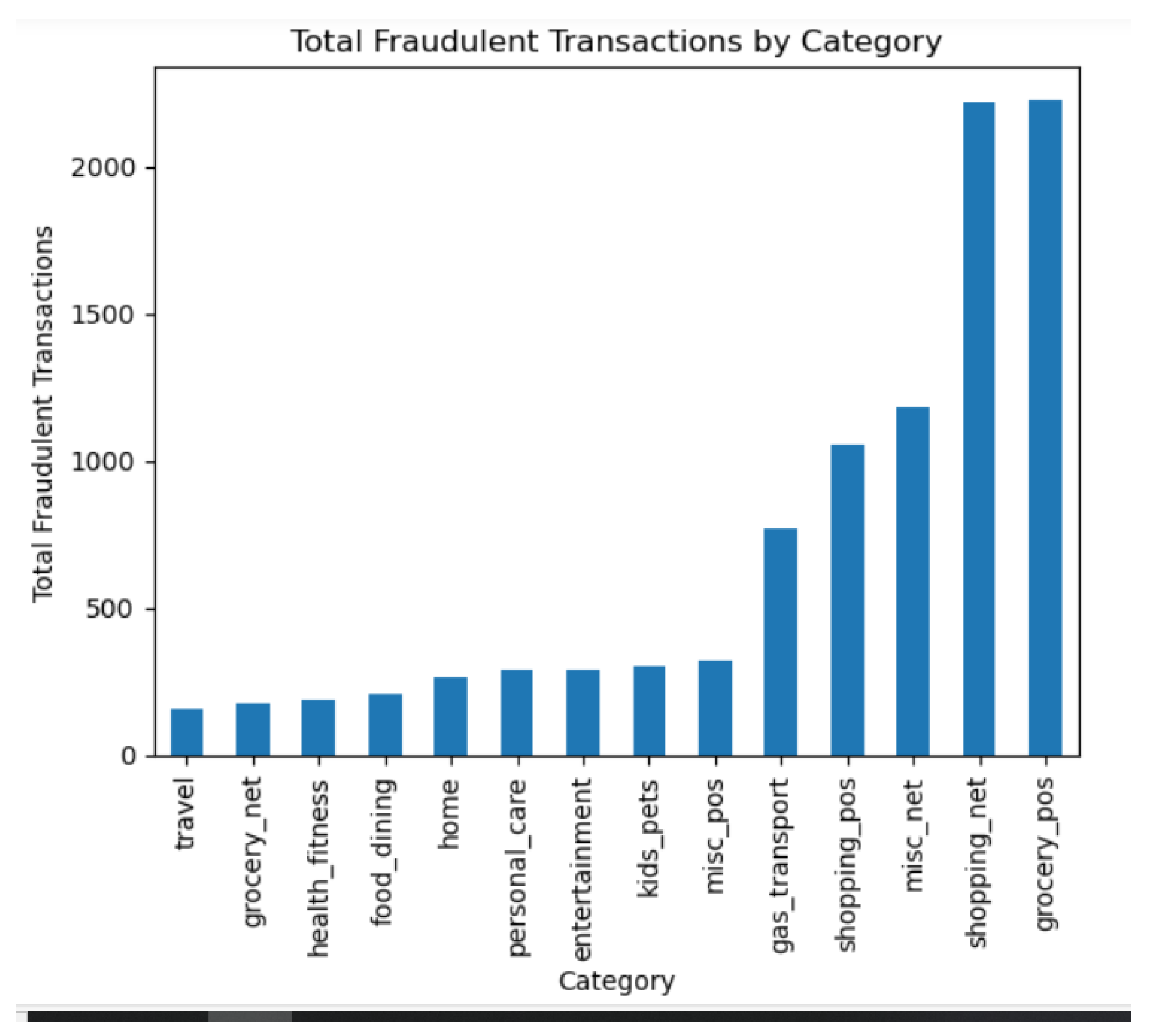
Figure 3 provides valuable insights into the patterns and preferences targeted by potentially fraudulent activities. Among the categories, "shopping_net" and "grocery_pos" stand out with notably higher counts of fraudulent transactions, indicating that these areas are more susceptible to fraudulent activities. On the other hand, categories such as "travel" and "grocery_net" exhibit lower counts, suggesting a comparatively lower incidence of fraudulent transactions in these domains. This granular analysis of category-wise fraudulent transactions contributes to a nuanced understanding of the specific sectors within which credit card fraud is more prevalent, offering valuable guidance for the development of a targeted and effective credit card fraud detection model.
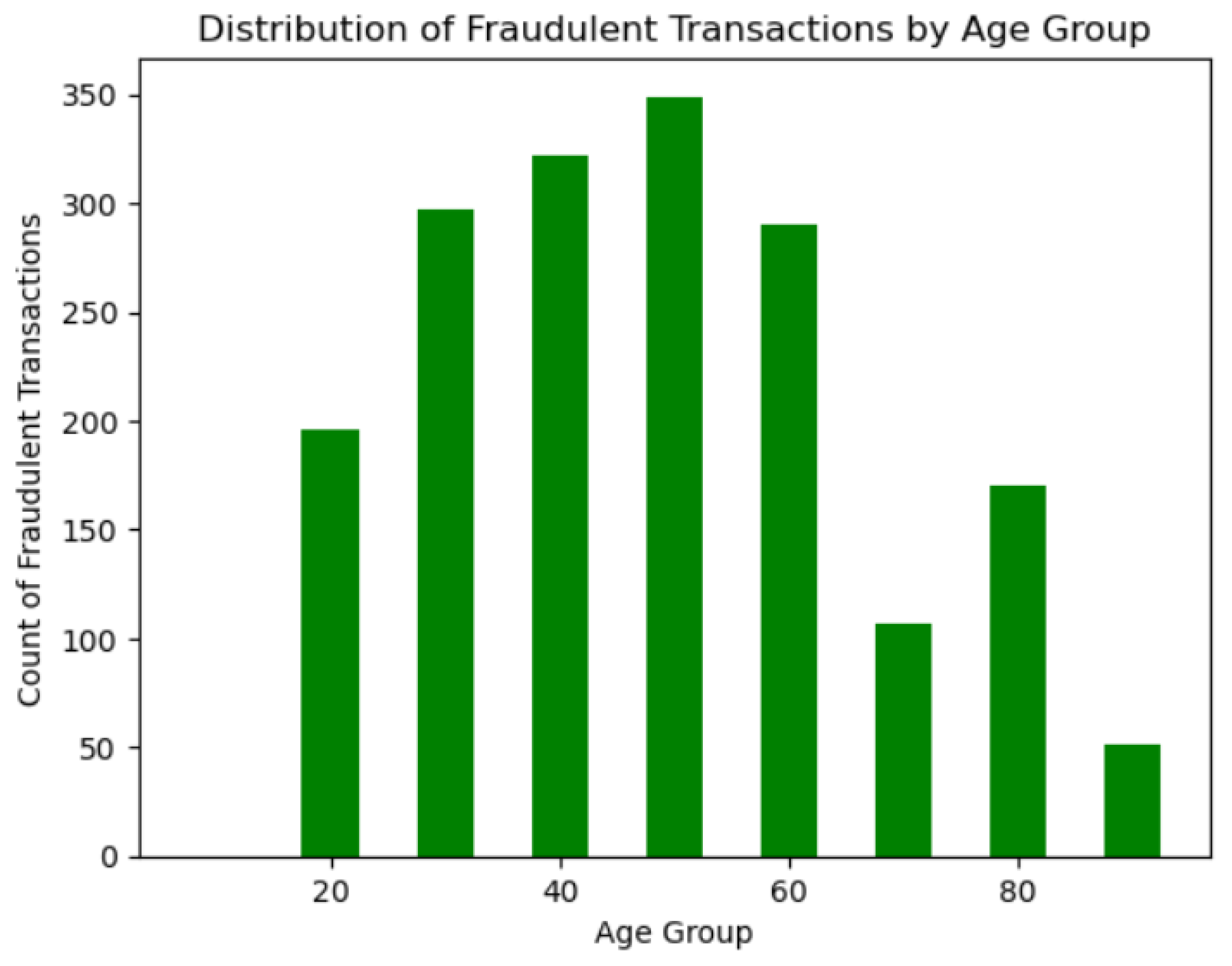
Figure 4 give the distribution of credit card fraud counts across age groups which challenges the conventional notion that older customers are inherently more susceptible to such fraudulent activities. Contrary to expectations, the data presents a nuanced picture, as reflected in the histogram. Notably, individuals between the ages of 30 and 60 emerge as more likely victims of credit card fraud, debunking the stereotype that older age groups are disproportionately affected. This finding underscores the necessity of leveraging data-driven insights rather than relying on preconceived notions, emphasizing the importance of tailoring fraud detection models to consider specific age demographics. By understanding the age-related patterns in credit card fraud, the model can better adapt its predictive capabilities to the actual distribution of fraudulent activities within different age groups, enhancing its accuracy and relevance in real-world scenarios.
4.2. Data Preparation and Preprocessing
The data preparation phase is integral to ensuring the dataset is suitable for model training and evaluation. The procedure consider in this study include the transformation of categorical feature to numerical equivalent to ensure model compatibility. Next to data transformation is data scaling and normalization, which ensure uniformity in the range and distribution of data values. Min-Max scaling is employed in this research as the feature scaling technique. Min-Max scaling transforms features to a specific range, usually [0, 1], preserving the relationships between data points while preventing outliers from unduly affecting the model.
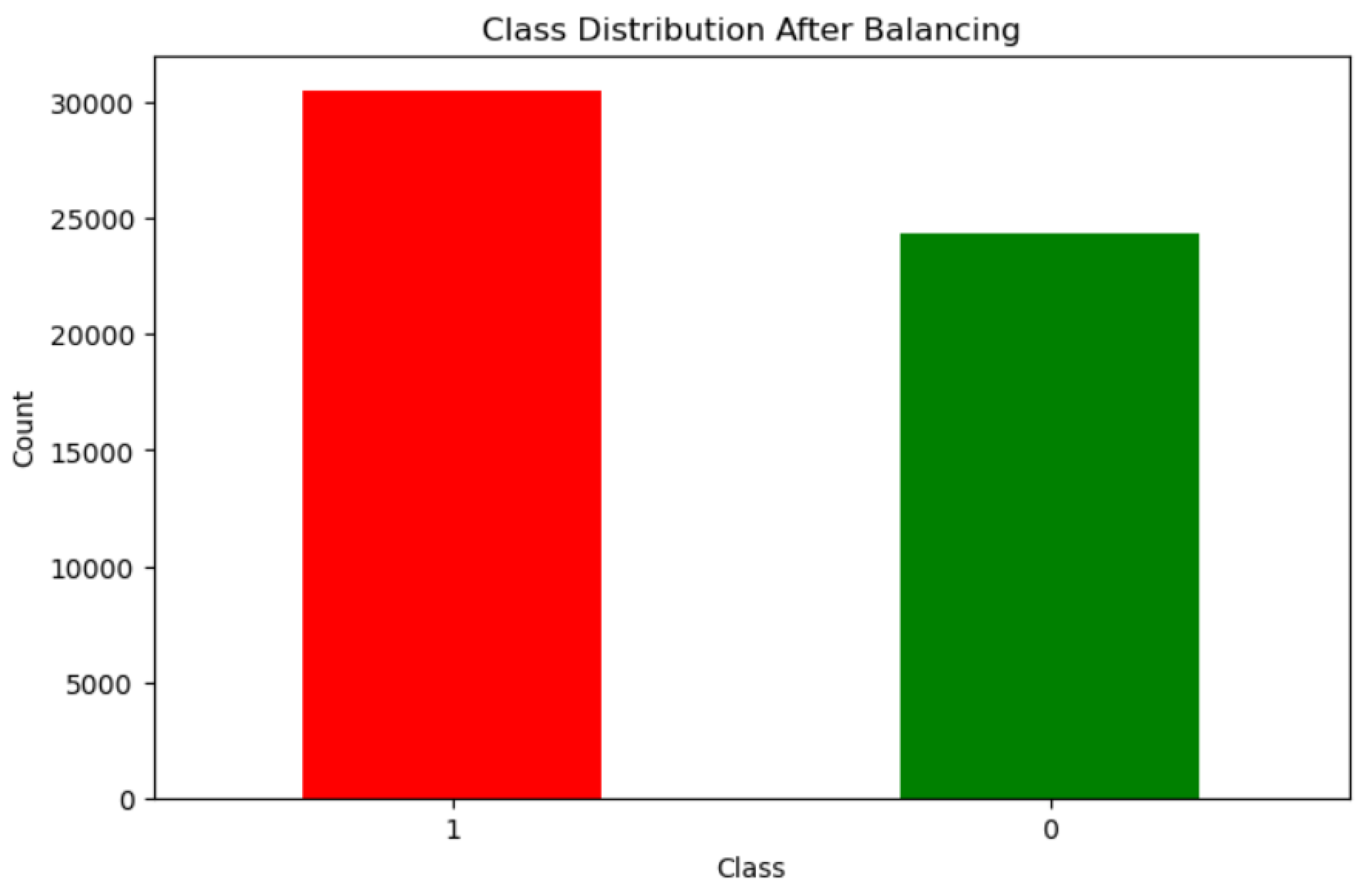
Data imbalance is then handled using the SMOTE-ENN (Synthetic Minority Over-Sampling Technique with Edited Nearest Neighbours) techniques proposed in [
47]. This approach involves oversampling the minority class using SMOTE and then applying ENN to eliminate overlapping between classes, thereby producing well-defined class clusters. This preprocessing step is crucial for creating a more balanced and representative dataset for training the machine learning model, ultimately enhancing its ability to discern patterns associated with credit card fraud.
Figure 5 and
Figure 6 show the effect of SMOTE-ENN on the dataset before and after its application, respectively.
Lastly, the dataset is split into training and testing sets in the ratio of 80:20 respectively. The goal of this section is to create a robust and representative dataset that facilitates the development of an accurate and generalizable credit card fraud detection model.
4.3. System setup and Experiments
The experiments are carried out in two stages: The initial stage of model training involved a comprehensive process using popular machine learning libraries and classifiers. The process was implemented using the scikit-learn library in Python, which provides a consistent interface for various machine learning algorithms. The dataset was split into training (80%) and testing (20%) sets using the train_test_split function from scikit-learn, a crucial step in ensuring the model’s generalizability to unseen data. The models selected for training in the first stage were the eXtreme Gradient Boosting (XGBOOST), Light Gradient Boosting Machine (LGBM), Decision Trees, Neural Networks, Random Forests, Support Vector Machines (SVM), and AdaBoost. Distinct hyperparameters were carefully chosen for each classifier to optimize their individual performances. The XGBoost model was configured with a maximum tree depth of 3, a learning rate of 0.1, and 100 estimators. The LGBM model utilized 31 leaves, a learning rate of 0.05, and 100 estimators. Decision Trees were constructed without a specified maximum depth and with minimum samples split of 2. Neural Networks consisted of a single hidden layer with 100 neurons, using the rectified linear unit (ReLU) activation function and the Adam solver. Random Forests incorporated 100 estimators without a maximum depth restriction and minimum samples split of 2. The Support Vector Machines (SVM) model was configured with a regularization parameter (C) of 1.0, using a radial basis function (RBF) kernel, and enabling probability estimation. Lastly, the AdaBoost model included 50 weak learners with a learning rate of 1.0. These tailored hyperparameters were designed to strike a balance between computational efficiency and model accuracy across various algorithms. Each classifier was trained on the training set, and performance metrics such as accuracy, precision, recall, F1 score, and area under the ROC curve (ROC AUC) were calculated using scikit-learn metrics. The models were then evaluated on the test set to assess their generalization capabilities.
In the second stage of the experiments for hybrid model development, the Light Gradient Boosting Machine (LGBM) with the highest Area Under the Receiver Operating Characteristic (AUROC) in the first stage served as the base model. Ensemble models were created by combining the LGBM with each of the following classifiers: eXtreme Gradient Boosting (XGBOOST), Decision Trees, Neural Networks, Random Forests, Support Vector Machines (SVM), and AdaBoost. This ensemble approach aligns with the concept of model stacking or blending, where multiple models are combined to improve overall predictive performance. Each hybrid model underwent training using the same dataset split used in the initial stage. The performance of each ensemble model is then evaluated on the test set using key metrics such as accuracy, precision, recall, F1 score, and ROC AUC. These metrics provide a comprehensive understanding of the model’s ability to correctly classify instances of fraud and non-fraud transactions. The final evaluation of these ensemble models will provide insights into the potential synergies achieved by combining LGBM with different algorithms and guide the selection of the most effective hybrid model for credit card fraud detection.
4.4. Result Presentation and Discussion
The result and discussion section provides a detailed evaluation of the model performance, comparing the proposed hybrid models with established machine learning algorithms. Initially, the single algorithms (XGBoost, LGBM, Decision Trees, Neural Networks, Random Forests, SVM, and AdaBoost) were individually assessed based on Accuracy scores. Notably, all single models exhibited relatively similar performance values, ranging from 0.62 to 0.84 reflecting their competence in credit card fraud detection.
The first stage of model development yields diverse results across various classifiers, highlighting the nuanced performance of each algorithm in credit card fraud detection. Among the classifiers, the XGBoost performed reasonably well with a 78% accuracy and 89% AUROC but the Light Gradient Boosting Machine (LGBM) stood out as a top performer, demonstrating notable accuracy (0.84), precision (0.76), recall (0.81), and an impressive Area Under the Receiver Operating Characteristic (AUROC) score of 0.82. LGBM’s robust performance, particularly in correctly identifying fraudulent transactions, positions it as a strong candidate for the second stage of hybrid model development. On the other hand, some classifiers, such as Decision Trees and Neural Networks, exhibit comparatively lower performance metrics. Decision Trees, with an accuracy of 0.62 and a modest AUROC of 0.63, show limitations in capturing the complexity of the credit card fraud detection task. Neural Networks, while achieving a balanced accuracy (0.71) and recall (0.72), indicate challenges in precision (0.68), suggesting a propensity for false positives. The robust performance of LGBM positions it as a strong base model and combining it with other algorithms in the ensemble models aims to create a more comprehensive and effective fraud detection system.
Table 1 contains summary of the classifiers.
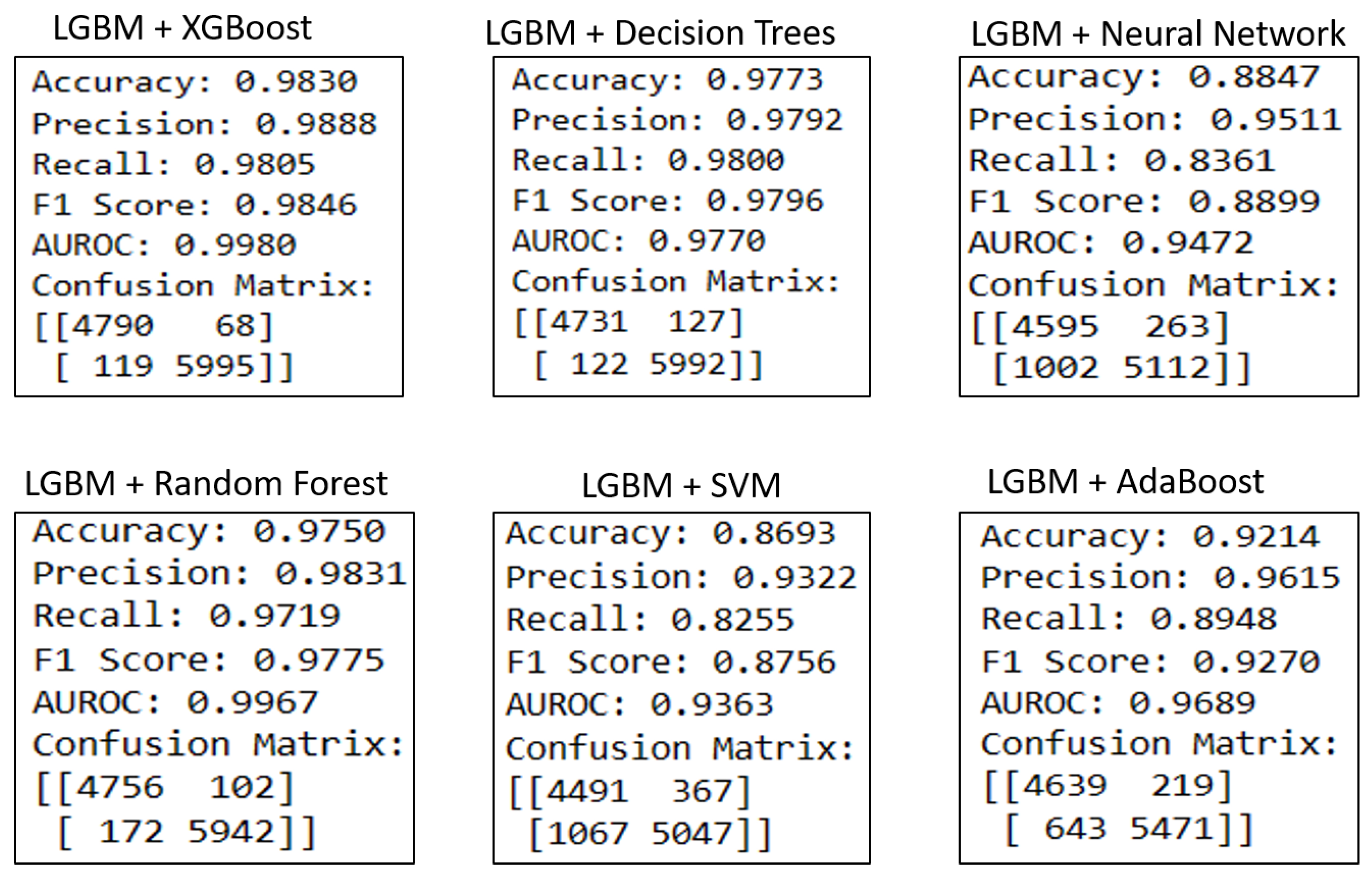
Details of hybrid models using LGBM as base model is presented in
Table 2 and
Figure 7. , the first hybrid model, LGBM + XGBoost, demonstrates superior accuracy (98.30%), precision (98.88%), and AUROC (99.80%) than XGBoost. The recall (98.05%) and F1 score (98.46%) indicate a balanced performance. The confusion matrix shows fewer false positives (68) and false negatives (119) compared to XGBoost, suggesting LGBM’s ability to minimize both Type I and Type II errors. The hybridization of LGBM and Decision Trees shows commending results, the confusion matrix shows that 5992 fraud cases were correctly identified with 127 false positives and 122 false negatives. This implies that the hybrid model, while effective, may slightly misclassify certain transactions as fraudulent. Hybrid of LGBM and Neural Networks exhibit comparatively low recall performance implying a challenge in capturing all fraud instances. In the confusion matrix, the hybrid model shows a higher number of false negatives (1002), indicating a potential limitation in identifying all fraudulent transactions. The hybrid of LGBM and Random Forests shows good performance, it effectively minimizes false alarms but has the tendency to overlook some fraudulent transactions. The performance of the hybrid of LGBM + SVM is moderate, its confusion matrix reveals a higher number of false negatives (1067), indicating potential challenges in identifying all fraud cases. LGBM and AdaBoost hybrid presents a balanced performance and its confusion matrix reveals the model’s effectiveness in fraud prediction.