Submitted:
14 January 2025
Posted:
14 January 2025
You are already at the latest version
Abstract
We deal with two-dimensional copulas from the perspective of their entropy. We formulate a problem of finding a copula with maximum entropy when some values of the copula are given. As expected, the solution is a copula with a piecewise constant density (a checkerboard copula). This allows to simplify the optimisation of the continuous objective function, entropy, to optimisation of finitely many density values. We present several ideas simplifying this problem. It has a feasible numerical solution. We present several instances which admit also closed-form solutions.
Keywords:
maximum entropy estimator
; copula
; density
; convex optimization
1. Formulation of the task
1.1. Motivation
Copulas are a successful tool for the description of any dependence of continuous random variables. Based on empirical data, we may try to find a copula best describing the underlying distribution.
The standard approach to fitting the parametric copula classes is widely used across various copula applications. The hidden assumption behind this is the knowledge of the dependence model for which we try to estimate the parameters. However, there are many applications where this approach is not desirable because of the lack of knowledge, insufficient sample size, or a high dimension of the task. Then we want to find a model based on general copulas. When there is no other information than the sample, the empirical or discrete copulas and their continuous extensions can be used. Because of the incomplete information of copula values in between the known values, the maximum entropy principle can also be applied.
We study the problem of finding a joint probability distribution from partial information, when we are given
- (I1)
- the marginals,
- (I2)
- the values of the joint cumulative distribution function (joint cdf) at finitely many points.
This refers to the situation when we have (or assume to have) complete information about the marginals, but we do not know their dependence. The sample is discrete and it can possibly be discretised to a coarser scale. Thus we know the desired values of the copula only on a 2D rectangular grid of points resulting from the discretization. This task has a standard solution (a checkerboard copula, see below). However, some of these constraints may be missing for various reasons. In particular, we may have too few elements of the sample (possibly none) in some 2D intervals, so we do not consider it a reliable support for modelling the whole copula. We investigate this case.
1.2. Criteria of Optimality
Suppose that we have two continuous random variables, , with known cumulative distribution functions, . They need not be independent and their dependence can be specified, e.g., by their joint cdf, . According to Sklar’s theorem (see [1,2]), it can be determined also by the respective copula, . This is the joint cumulative distribution function of transformed random variables , , which have the uniform distribution on the interval ,1
where are such that , . The copula gives “pure” information of the dependence of , independently of the marginal distributions. It allows the expression of an arbitrary dependence between two continuous random variables.2
Definition 1.
If there is a function such that the copula can be expressed as its integral,
it is called a density of the copula . The differential entropy of the copula is the (Shannon) entropy [3] of its density, given by
where
Remark 1.
The differential entropy of a copula does not exist if the copula is not absolutely continuous, i.e., it does not have a density. Our proposed solution avoids this problem.
1.3. Related Work and History of the Problem
One of the earliest pioneers in studying multivariate distributions was Claude E. Shannon, who introduced his groundbreaking work on information theory in [3]. Later, in 1959, Abe Sklar introduced copulas in his seminal work, which laid the foundation for the study of dependency structures in multivariate distributions [2].
The principle of maximum entropy in the choice of a distribution was well defended by Jaynes [4]. Several approaches to this aim have been proposed.
The study of copulas in relation to entropy began to gain attention around 2010, with foundational work by Pougaza et al. [5,6]. They give a nice overview and motivation of the maximum entropy principle.3 They maximize the differential entropy of the original joint cdf, while we propose to maximize the differential entropy of the corresponding copula.
The early contributions were primarily theoretical. Later on, Ma and Sun [7] introduced the use of the maximum entropy principle to estimate mutual information via copulas. Subsequently, Singh and Zhang [8] expanded the application of copulas connected to entropy for multivariate stochastic modeling in water engineering.
Piantadosi et al [9] (resp. [10]) found bivariate (resp. multivariate) copulas with maximal differential entropy under the knowledge of
- (I1)
- the marginals,
- (I3)
- the grade correlation coefficients.
Their solutions are checkerboard copulas.
Recently Lin et al. [11] applied the principle of maximum entropy and found checkerboard copulas as solutions. Their approach differs in the aspect that they start from distributions whose marginals are not continuous; the discontinuities determine the checkerboard structure. The difficulties of extension of the copula approach to distributions with discontinuous marginals are presented by Genest et al. [12].
While the literature on this topic remains relatively limited, this leaves considerable room for further theoretical advancements and potential new applications.
None of the preceding approaches restricts solutions by prescribed values at some points (I2). Sometimes the values of the joint cdf (and hence also of the copula) at some points are known. Such constraints can originate, e.g., from a discretization of a continuous scale. We want to choose a distribution fitting to these constraints.
Let us choose the distribution whose copula has maximal differential entropy (among those fitting to the constraints). The principle of maximal entropy was successfully used in many other tasks. It expresses our intention “not to include more information than that contained in the constraints.” Choosing this option, we try not to introduce any other dependence than that which follows from the given restrictions. This seems to be a natural criterion for the choice of the model fitting to constraints.
The result can be equivalently described by the joint cdf or by the copula. The differential entropy of the joint cdf suffers some drawbacks, e.g., it is not invariant to the change of scale; the entropies of random variables X and , , are different. In contrast to it, the copula remains the same even if the random variables are transformed by arbitrary increasing functions ,
Thus the differential entropy of a copula is a well-defined notion which can be a criterion for the choice of the model.4
In this paper, we formulate the task of finding a copula with maximal differential entropy fitting the constraints. We convert it to a finite-dimensional optimization problem. As one of the main contributions, we prove that the result is independent of some inputs. This further simplifies the task. It leads to a system of higher-order polynomial equations which allows for a numerical solution using convex optimization. We show that in the simplest cases, an analytical solution is also feasible.
1.4. Notation and Formulation of the Problem
Before the formulation of the task solved in this paper, let us introduce our notation. We restrict attention to 2-copulas, i.e., binary functions describing the dependence of two random variables. We are trying to find a copula, . As we shall not deal with another copula in the sequel, we shall denote it briefly by C. For the readers not familiar with the notion of a copula, it can be any joint cdf with marginals uniformly distributed on .5 They are characterized by the following necessary and sufficient conditions:
Inequality (4) means that the probability
is non-negative.
The constraints are finitely many points in where the value of the copula is given. Their first (resp. second) coordinates can be organized in an increasing sequence , resp. . These values determine a rectangular grid. At some of the grid points, , the values are given,
We denote by the set of all indices for which the values of the copula are given by (6). To simplify the notation, we define additionally , . The corresponding new grid points are at the boundary of the domain of the copula and form the set
The values of the copula at the boundary are given by (2), (3), so we may define for all by
In total, (6) is required for all from the set
and can be expressed as
In figures, we use a filled disk to denote a grid point at which the value is given (an element of G) and an empty circle to denote a grid point where the value is not restricted. Figure 1 and Figure 2 demonstrate our notation.
Problem 1.
Let , , and let there be given values for all in some set G such that . Find a copula C satisfying (6) for all . Moreover, among all such copulas, we want to find one with maximum differential entropy.
The necessary and sufficient conditions for a copula, in particular (4), imply necessary conditions for solvability of Problem 1 which later will appear also sufficient.
Proposition 1.
A necessary condition for the existence of a solution to Problem 1 is the conjunction of (7), (8), and
- (N)
- If , , , then
In the sequel, we assume that the constraints satisfy these conditions.
2. General Results
2.1. Reformulation to a Finite-Dimensional Optimization
As formulated, Problem 1 looks like a task from variational calculus. We shall transform it into a finite-dimensional optimization problem.
It is well-known that among all absolutely continuous distributions on a bounded set, the uniform distribution has the highest differential entropy (if the integral of the density over the whole domain is fixed). We shall derive a consequence of this principle. To simplify its formulation, we denote the lengths of intervals between neighboring grid points:
for all , (see Figure 1).
Proposition 2.
Let , . The restriction of the copula C to the two-dimensional open interval contributes to the copula differential entropy by
Among all copulas with a given value
the contribution (9) is maximal iff its density is constant,
almost everywhere on . Without loss of generality, we may choose the copula with density (11) for all .
Proposition 2 determines the solution to Problem 1 (almost everywhere) when all values
are given, i.e., , , , . Even when this is not the case, there are some optimal values , , and the copula density on can be chosen according to (11) because there are no other restrictions on its values. This observation allows us to restrict attention to copulas with piecewise constant densities, so-called checkerboard copulas. Lin et al. [11] also found checkerboard copulas by maximization of the differential entropy, although they solved a different task.
It remains to find the optimal values of finitely many densities on intervals (rectangles) for . Equivalently, we look for the values defined by (10). From them, the values of the copula at grid points can be computed as sums
In particular, for , resp. , we obtain
These formulas can be equivalently expressed using row and column sums:
Remark 2.
We do not deal with the values of density on the boundaries of these intervals. The boundaries are of measure zero, so they do not influence the results. In fact, the densities at these boundaries are not uniquely defined.
Copulas that do not have densities or entropies (see Remark 1) do not seem to be good candidates for approximation and cannot compete with our proposed solution.
The differential entropy of the checkerboard copula is
provided that all (otherwise, the corresponding summand of the differential entropy is 0, i.e., minimal). We shall deal with the following reformulation:
Problem 2.
Let , , and let there be given values for all in some set G such that . Suppose that values , , satisfy the necessary conditions from Proposition 1. Find values , , satisfying
and such that the differential entropy
is maximal.
2.2. Decomposition of the Problem
We concentrate on rectangles with the following property:
- (B)
- The values of the copula at all grid points at the boundary of the rectangle are given, i.e.,
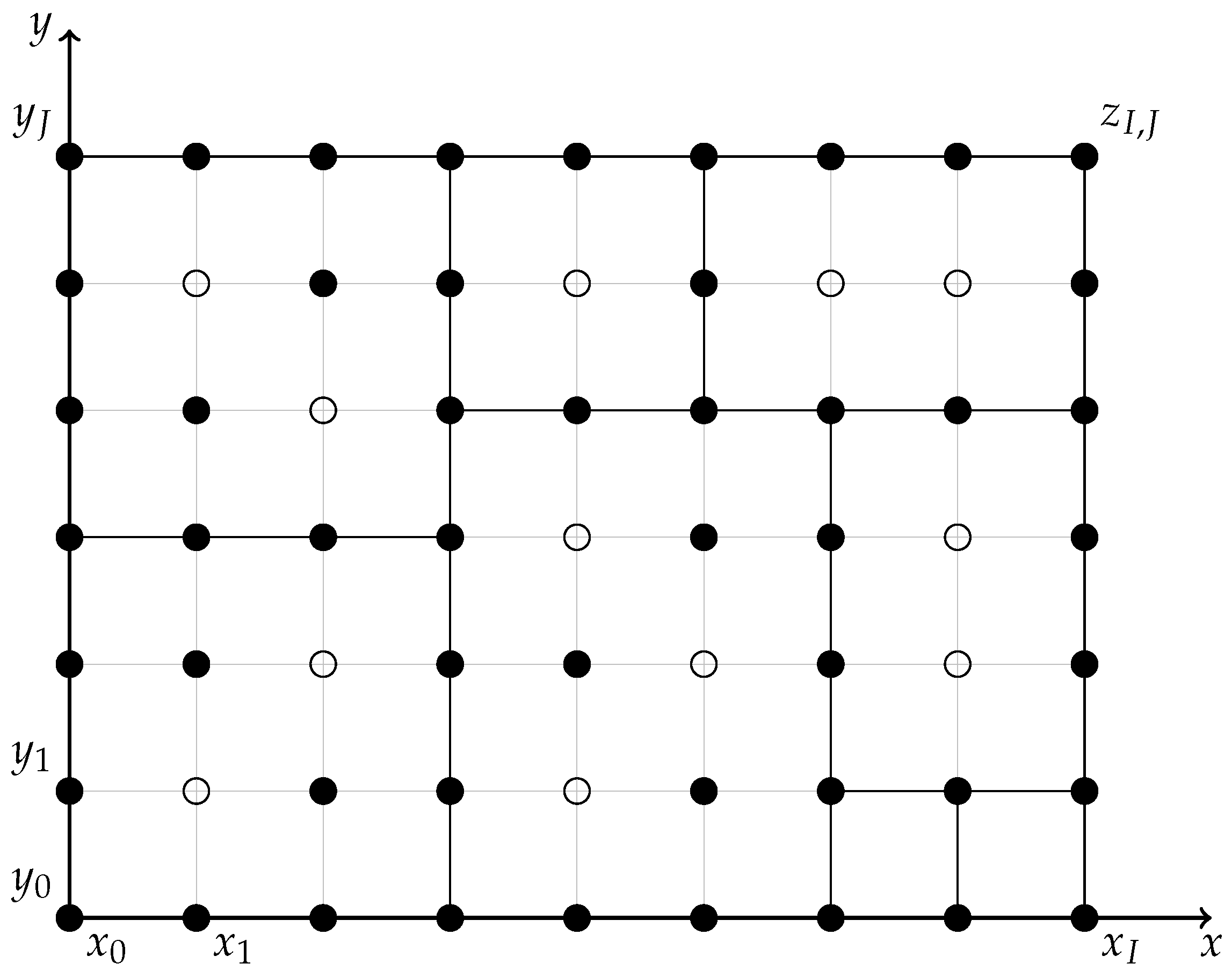
Let us consider a rectangle satisfying (B). If all its grid points in some row or column (not at the boundary) are in G, then we can split it into two disjoint rectangles satisfying (B). (The choice need not be unique.) If this is not the case (i.e., there is a missing value in each row and each column6), we call the rectangle irreducible. Irreducible rectangles can be equivalently characterized as minimal rectangles satisfying (B). The whole domain can be covered by disjoint irreducible rectangles. This may allow us to decompose the problem into simpler ones, dealing with each irreducible rectangle separately. Figure 2 shows eight irreducible rectangles. Each component of the decomposed task has the following formulation. The active restrictions refer to grid points with indices from the set . Notice that the monotonicity of the values needs to be formulated explicitly, while in Problem 2 it followed from (7).
Problem 3.
Let , , and let be a set such that
Suppose that values are given for all so that sequences , are nondecreasing and(N)is satisfied. Find values , , satisfying
for all and such that the contribution to the differential entropy
is maximal.
In the sequel, we analyze special cases of irreducible rectangles. Before that, we simplify indexing by shifting the rectangle to the origin.
2.3. Shifted Indexing
If a rectangle satisfies (B), the corresponding values ,
, are bounded only by the row and column sums
which are non-negative values satisfying the equality
The same task is obtained if we take a rectangle of the same size with the lower left vertex at the origin and impose the same requirements on the row and column sums. We shall apply this simplification, and instead of the original task for a general rectangle, we shall, without loss of generality, solve the case when in the above notation (with the new upper bounds still denoted by ; the above general indexing will not be used anymore). The boundary grid points form the set
The situation simplifies not only in indexing (starting from 0, resp. 1), but also the values at the bottom and left edge become zero. The values at the top and right bound must be modified to general values , , which are not determined by , like they were in (8). The modified task is as follows.
Problem 4.
As in [11], this is an optimization of a concave function that has a maximum that can be found numerically (applying standard convex optimization with the opposite sign). For numerical solutions of convex tasks, standard references are, e.g., [15,16,17,18]. We shall show that analytical solutions exist in some cases and we demonstrate them to support the intuition about the task.
3. Less General Tasks
In this section, we collect results related to Problem 4. Throughout this section, we consider an irreducible rectangle .
3.1. Rectangle with no Given Values Inside
Suppose that the set has an empty intersection with the interior of the rectangle . This is an instance of Problem 4; equations (22) reduce to monotonicity.
Problem 5.
Let , , and let
Suppose that values are given for all so that (7) is satisfied for all and and sequences , are nondecreasing. Find values , , satisfying
and such that the contribution to the differential entropy
is maximal.
The solution need not be a copula with a constant density at because we must keep the correct row and column sums.
We use Lagrange multipliers , ; the Lagrange function is
We put all partial derivatives equal to zero and obtain a system of equations
where , . Equivalently,
Subtracting the last ones, we obtain
and express using or as
We see that all rows (resp. columns) are multiples of the last one and the matrix composed of all is a dyad (a product of two vectors),
where are the row sums, the column sums, and the constant c can be determined from the known total sum
This is an expected result that says that the probability density of a result in an elementary rectangle is the product of the probability densities of the marginal distributions.
3.2. Methodology of Solving Particular Cases
Here we collect ideas used to solve particular cases described in the appendices. We consider Problem 4. This leads to a system of linear equations; after the Gauss–Jordan elimination, it could look like
where are some constants computed from the values . Until we consider the maximized differential entropy, some variables can be chosen and the rest can be computed from them. This describes all possible solutions to the system of linear equations (ignoring their bounds). To maximize the differential entropy, we compute the partial derivatives of the contribution to the differential entropy and put them equal to zero. We obtain
equations, where is the number of given values inside the rectangle.
Theorem 1.
The optimal solution to Problem 4 is independent of the values , .
Proof.
Recall that
This leads to an optimization in those variables where the copula values are not given ().
In the criterion, each variable , , occurs in four equations; for and with coeefficient 1 and for and with coeefficient .
We solve this task by computing the partial derivatives w.r.t. unknown values and putting them zero,
This can be expressed as
Multiplying this by , we obtain an equation independent of , , , and . This holds for all and , . Due to (28), also the values are independent of , . □
Besides the independence of the result on interval lengths , , we proved that each equation in the system describing entropy maximization is of the form
where is the set of indices for which occurs with the positive sign and is the set of indices for which occurs with the negative sign. Apparently, , therefore the units in (29) cancelled.
The only problem is that may depend also on other variables. Thus the summands contain not only constants , but also other independent variables.
In the appendices, we present explicit solutions to some specific instances of Problem 4. They lead to higher-order algebraic equations.
4. Conclusion
We formulated the task of fitting a continuous copula to finitely many given values in such a way that the entropy of the copula density is maximal. This is motivated by situations when some of the values are prescribed and the rest of the copula should be “as independent as possible”, with the intention not to include any other dependence than that contained in the constraints. We simplified the task with several hints, showed that it has a unique solution (because it is equivalent to a convex optimization problem), and demonstrated that a closed-form solution can be found analytically in some simple cases, although it may require solving higher-order polynomials. We propose this concept as an alternative to current approaches, which also maximize the entropy, but use different restrictions of the admitted copulas.
Author Contributions
Writing – original draft, Milan Bubák and Mirko Navara. All authors will be updated at each stage of manuscript processing, including submission, revision, and revision reminder, via emails from our system or the assigned Assistant Editor.
Funding
This research was supported by the CTU institutional support (Future Fund).
Data Availability Statement
This research is not accompanied by any additional data.
Acknowledgments
The authors are grateful to Michal Dibala who inspired and initiated this research. They thank the anonymous reviewers for their comments which helped to improve the original manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
In Problem 4, we put , (see Figure A1).
Figure A1.
Example 1
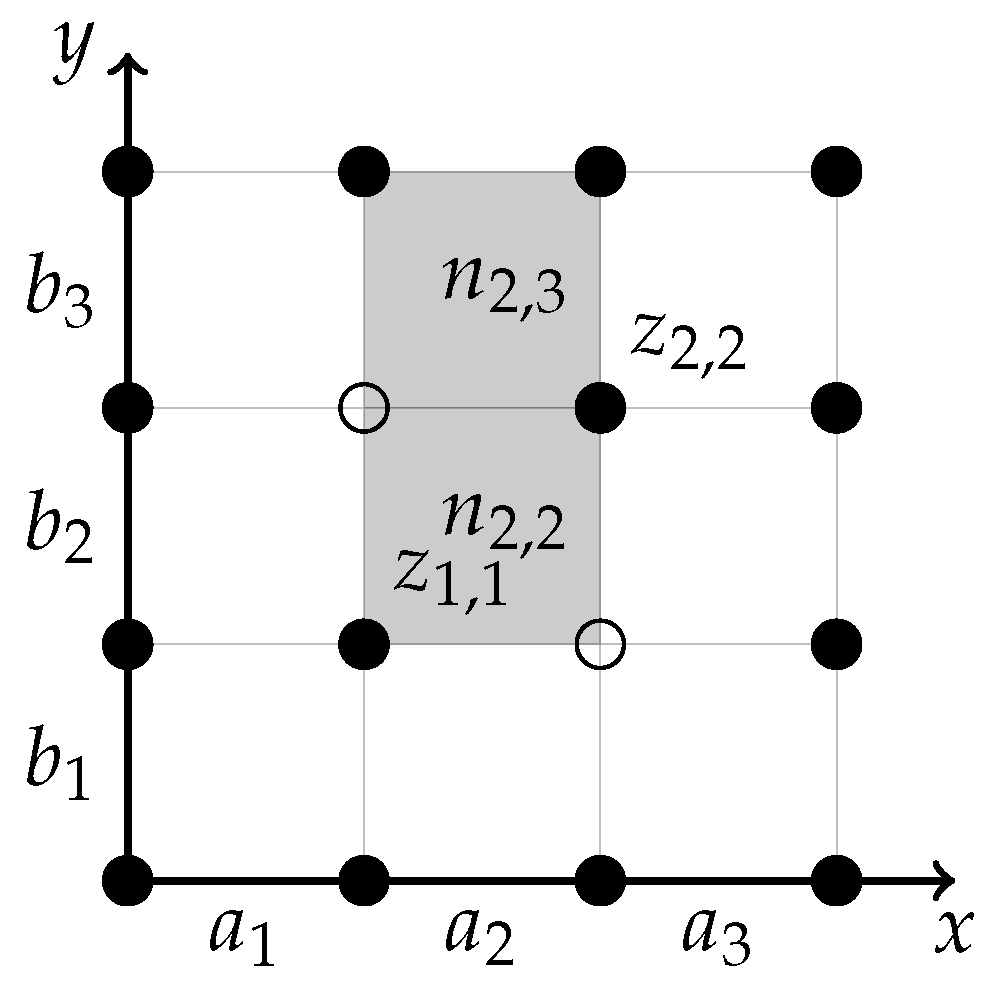
The task can be formulated as follows.
We take , as variables allowing us to express the general solution of the system of linear equations; we introduce new constants as abbreviations.
Substituting this in the optimality criterion and putting its partial derivatives equal to zero, we obtain
These equations can be simplified to
The divisors are equal and thus cancel out, as shown in the proof of Theorem 1, and this leads to the expression
We divide the second equation by the first,
and can be expressed as
Substituting to (A1) and expanding, we obtain an equation for ,
This is an algebraic equation of order three. It can be solved analytically using Cardano formulas. A problem remains that it can have up to three roots; we want one that is real. The cubic coefficient is
If it is nonzero, there is at least one real root. Moreover, we need it in the interval . Substituting to (A2), we obtain , which should be also in the interval , as well as all other unknowns. However, we know (from the convexity of the task, resp. concavity of the maximized criterion) that a solution with this property exists.
Appendix B
In Problem 4, we put , , (see Figure A2).
Figure A2.
Example 3
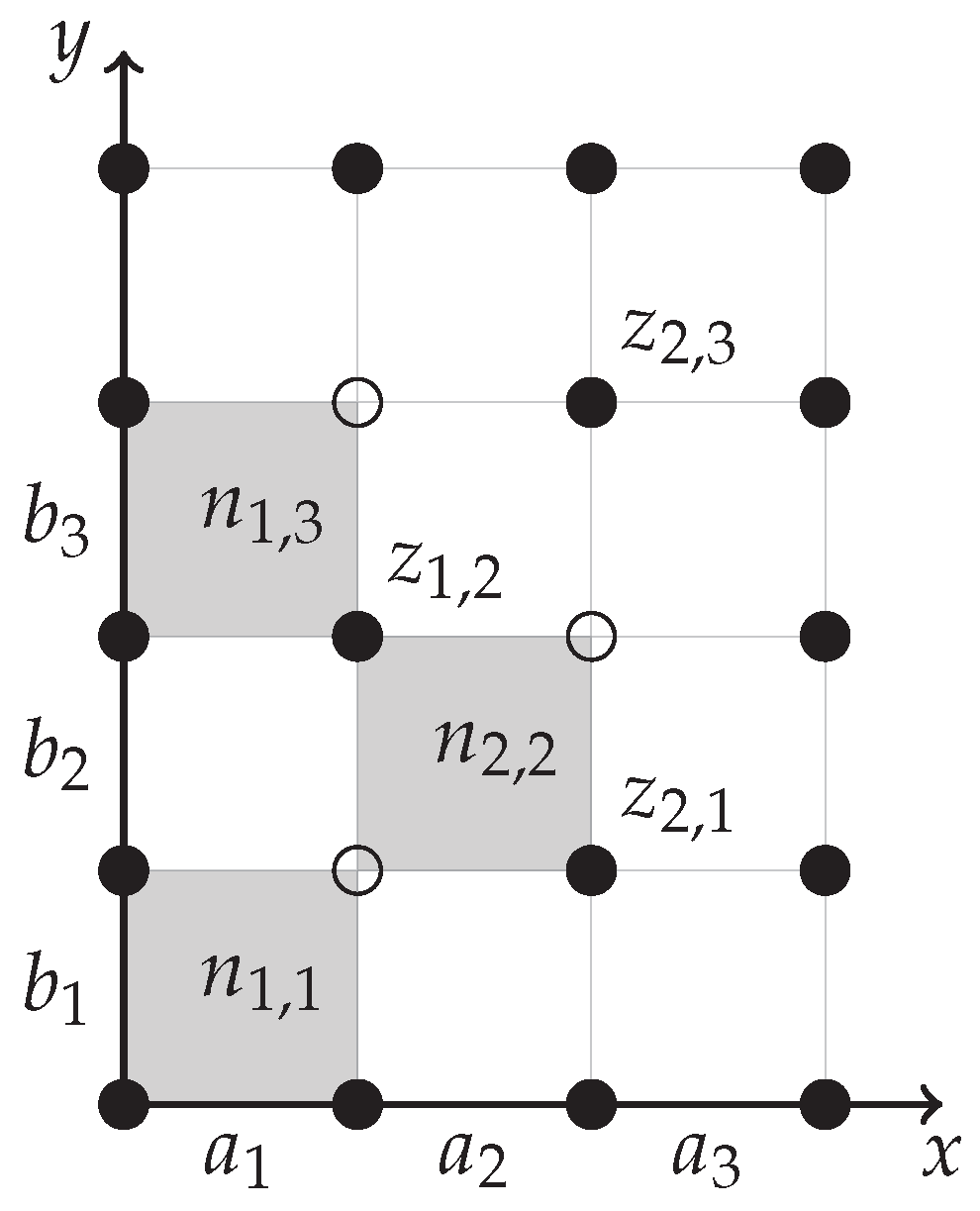
The task can be formulated as follows.
where the constants are some sums of as in the previous example. We take , , as variables allowing us to express the general solution of the system of linear equations.
We put the partial derivatives equal to zero and eliminate the logarithms. We obtain products of factors in the form of a sum of some and a constant . We also know that the result is independent of the values , . In particular, we obtain
From (A3) we separate the factors containing only the variable ,
The second equation in (A3) can be written as
We substitute (A4) to the left-hand side and express as
The third equation in (A3) can be rewritten as
In the last equation of (A7), we substitute from (A6) and obtain :
We have both in (A6) and in (A8) expressed as functions of . This can be substituted to the first equation in (A3), which yields
where L (resp. R) denotes the left-hand (resp. right-hand) side of the equation. We modify this expression to discuss its analytical solvability:
Multiplication by a common divisor or both sides gives
After expansion, the left-hand side is a polynomial of order 4 and the right-hand side is a polynomial of order 3. Their difference is a polynomial of order 4, which is solvable analytically.
| 1 | The bounds, 0 and 1, are omitted for simplification of formulas. |
| 2 | More generally, an n-copula describes the dependence of n random variables. Here we deal only with 2-copulas. |
| 3 | The paper [5] deals equally with several definitions of entropy, here we consider only the original Shannon entropy, as the best-motivated notion. |
| 4 | |
| 5 | Strictly speaking, the joint cdf is defined on the whole plane, but its restriction to the unit square, even to its interior, , determines the copula uniquely. |
| 6 | The boundary rows and columns are not considered. |
| 7 | From now on, we denote this set again by G, although this was used for all given values from before. |
References
- Nelsen, R.B. An Introduction to Copulas, 2nd ed.; Vol. 139, Lecture Notes in Statistics, Springer, New York, NY, 2006.
- Sklar, A. Fonctions de répartition à n dimensions et leurs marges; Vol. 8, Publ. Inst. Statist. Univ. Paris, 1959; pp. 229–231.
- Shannon, C.E. A Mathematical Theory of Communication. The Bell System Technical Journal 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. Physical Review 1957, 106, 620–628. [Google Scholar] [CrossRef]
- Pougaza, D.B.; Mohammad-Djafari, A. Maximum Entropies Copulas. In Proceedings of the 30th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering, France, 2010; pp. 329–336, [https://pubs.aip.org/aip/acp/article-pdf/1305/1/329/11567694/329_1_online.pdf]. [CrossRef]
- Pougaza, D.B.; Mohammad-Djafari, A.; cois Bercher, J.F. Link between copula and tomography. Pattern Recognition Letters 2010, 31, 2258–2264. [Google Scholar] [CrossRef]
- Ma, J.; Sun, Z. Mutual information is copula entropy. Tsinghua Science & Technology 2011, 16, 51–54. [Google Scholar] [CrossRef]
- Singh, V.P.; Zhang, L. Copula–entropy theory for multivariate stochastic modeling in water engineering. Geoscience Letters 2018, 5. [Google Scholar] [CrossRef]
- Piantadosi, J.; Howlett, P.; Boland, J.W. Matching the grade correlation coefficient using a copula with maximum disorder. Journal of Industrial and Management Optimization 2007, 3, 305–312. [Google Scholar] [CrossRef]
- Piantadosi, J.; Howlett, P.; Borwein, J. Copulas with Maximum Entropy. Optimization Letters 2012, 6, 99–125. [Google Scholar] [CrossRef]
- Lin, L.; Wang, R.; Zhang, R.; Zhao, C. The checkerboard copula and dependence concepts. ArXiv e-prints, [arXiv:2404.15023].
- Genest, C.; Nešlehová, J.G.; Rémillard, B. Asymptotic behavior of the empirical multilinear copula process under broad conditions. Journal of Multivariate Analysis 2017, 159, 82–110. [Google Scholar] [CrossRef]
- Dibala, M.; Navara, M. Discrete Copulas and Maximal Entropy Principle. In Proceedings of the Copulas and Their Applications, Almeria, Spain; 2017; p. 24. [Google Scholar]
- Bubák, M. Copulas with Maximal Entropy (in Czech). [http://hdl.handle.net/10467/115430]. BSc. Thesis, Czech Technical University in Prague, 2024.
- Bertsekas, D.P.; Nedić, A.; Ozdaglar, A.E. Convex Analysis and Optimization; Athena Scientific, 2003.
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press, 2004.
- Hiriart-Urruty, J.; Lemaréchal, C. Fundamentals of Convex Analysis; Grundlehren Text Editions, Springer, 2004.
- Rockafellar, R.T. Convex Analysis; Princeton Mathematical Series, Princeton University Press, 1970.
Figure 1.
Sample of our notation
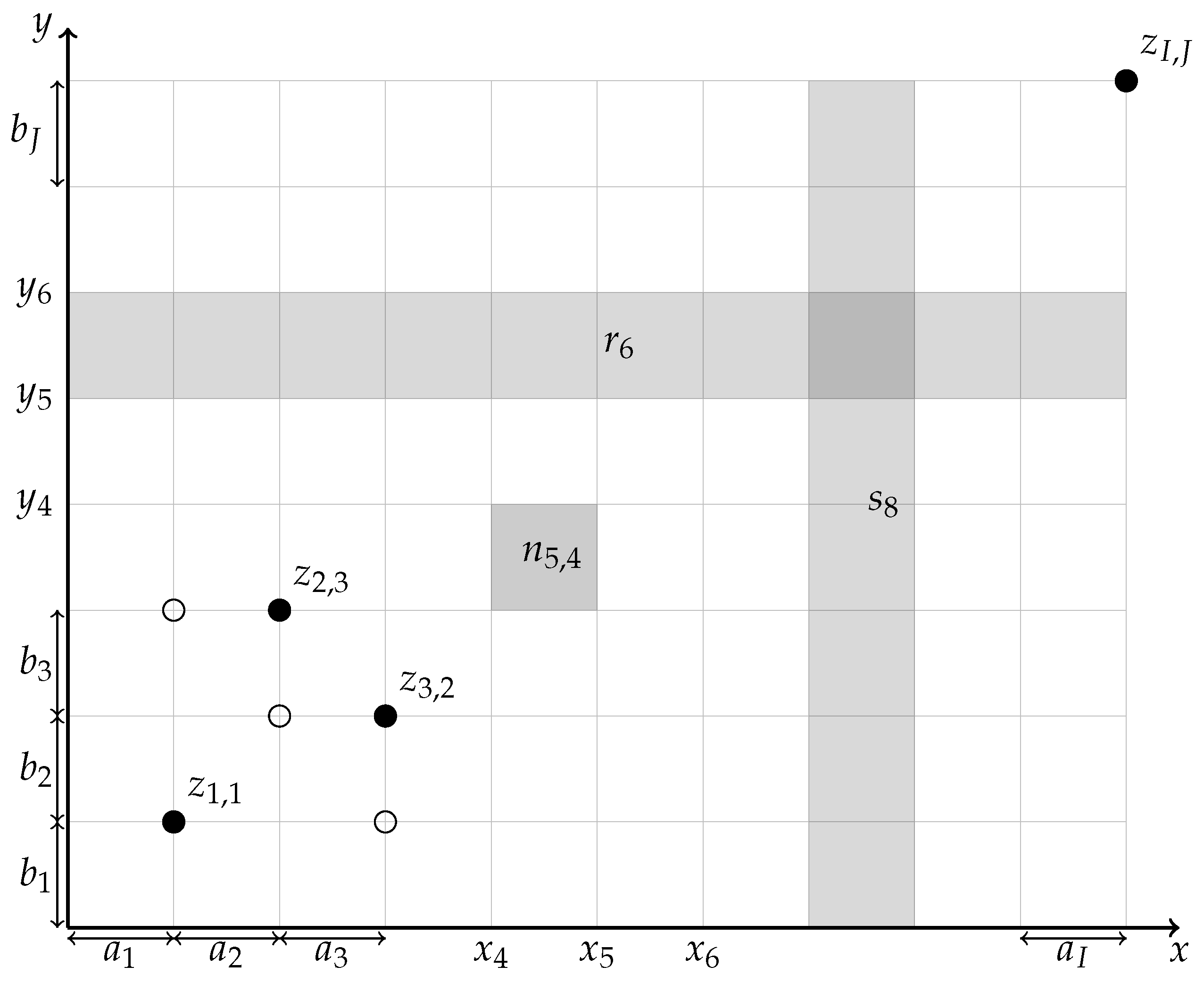
Figure 2.
Possible set G of points in which the values of a copula are given and a covering of the grid by disjoint irreducible rectangles (bold lines)
Figure 2.
Possible set G of points in which the values of a copula are given and a covering of the grid by disjoint irreducible rectangles (bold lines)
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



