
Submitted:
24 December 2024
Posted:
26 December 2024
You are already at the latest version
Abstract
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multimodal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field.
Keywords:
| Contents | |
| 1. Introduction……………………………………………………………………………………… | 3 |
| 2. Fundamental of OS Agents…………………………………………………………………… | 5 |
| 2.1. Key Component…………………………………………………………………………… | 5 |
| 2.2. Capability………………………………………………………………………………… | 5 |
| 3. Construction of OS Agents…………………………………………………………………… | 6 |
| 3.1. Foundation Model……………………………………………………………………… | 6 |
| 3.1.1. Architecture……………………………………………………………………… | 7 |
| 3.1.2. Pre-Training……………………………………………………………………… | 8 |
| 3.1.3. Supervised Finetuning………………………………………………………… | 9 |
| 3.1.4. Reinforcement Learning………………………………………………………… | 10 |
| 3.2. Agent Framework……………………………………………………………………… | 10 |
| 3.2.1. Perception……………………………………………………………………… | 12 |
| 3.2.2. Planning………………………………………………………………………… | 12 |
| 3.2.3. Memory………………………………………………………………………… | 13 |
| 3.2.4. Action…………………………………………………………………………… | 16 |
| 4. Evaluation of OS Agents……………………………………………………………………… | 16 |
| 4.1. Evaluation Protocol……………………………………………………………………… | 17 |
| 4.1.1. Evaluation Principle……………………………………………………………… | 17 |
| 4.1.2. Evaluation Metric………………………………………………………………… | 18 |
| 4.2. Evaluation Benchmark…………………………………………………………………… | 19 |
| 4.2.1. Evaluation Platform……………………………………………………………… | 19 |
| 4.2.2. Benchmark Setting………………………………………………………………… | 19 |
| 4.2.3. Task……………………………………………………………………………… | 20 |
| 5. Challenge & Future…………………………………………………………………………… | 21 |
| 5.1. Safety & Privacy…………………………………………………………………………… | 21 |
| 5.1.1. Attack……………………………………………………………………………… | 21 |
| 5.1.2. Defense…………………………………………………………………………… | 21 |
| 5.1.3. Benchmark……………………………………………………………………… | 22 |
| 5.2. Personalization & Self-Evolution……………………………………………………… | 22 |
| 6. Related Work……………………………………………………………………………… | 22 |
| 7. Conclusion………………………………………………………………………………… | 23 |
| 8. References………………………………………………………………………………… | 23 |
1. Introduction
2. Fundamental of OS Agents
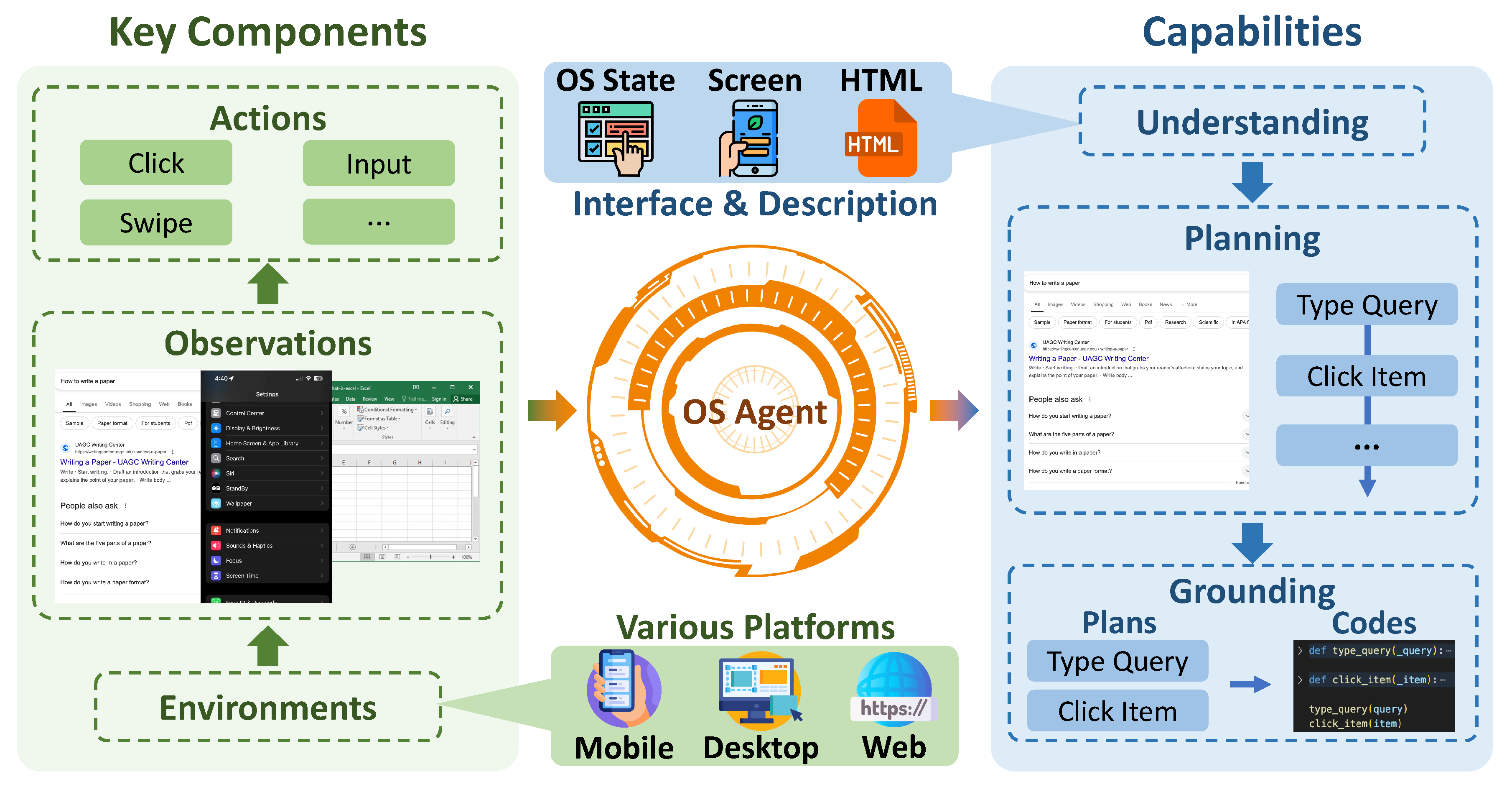
2.1. Key Component
2.2. Capability
3. Construction of OS Agents
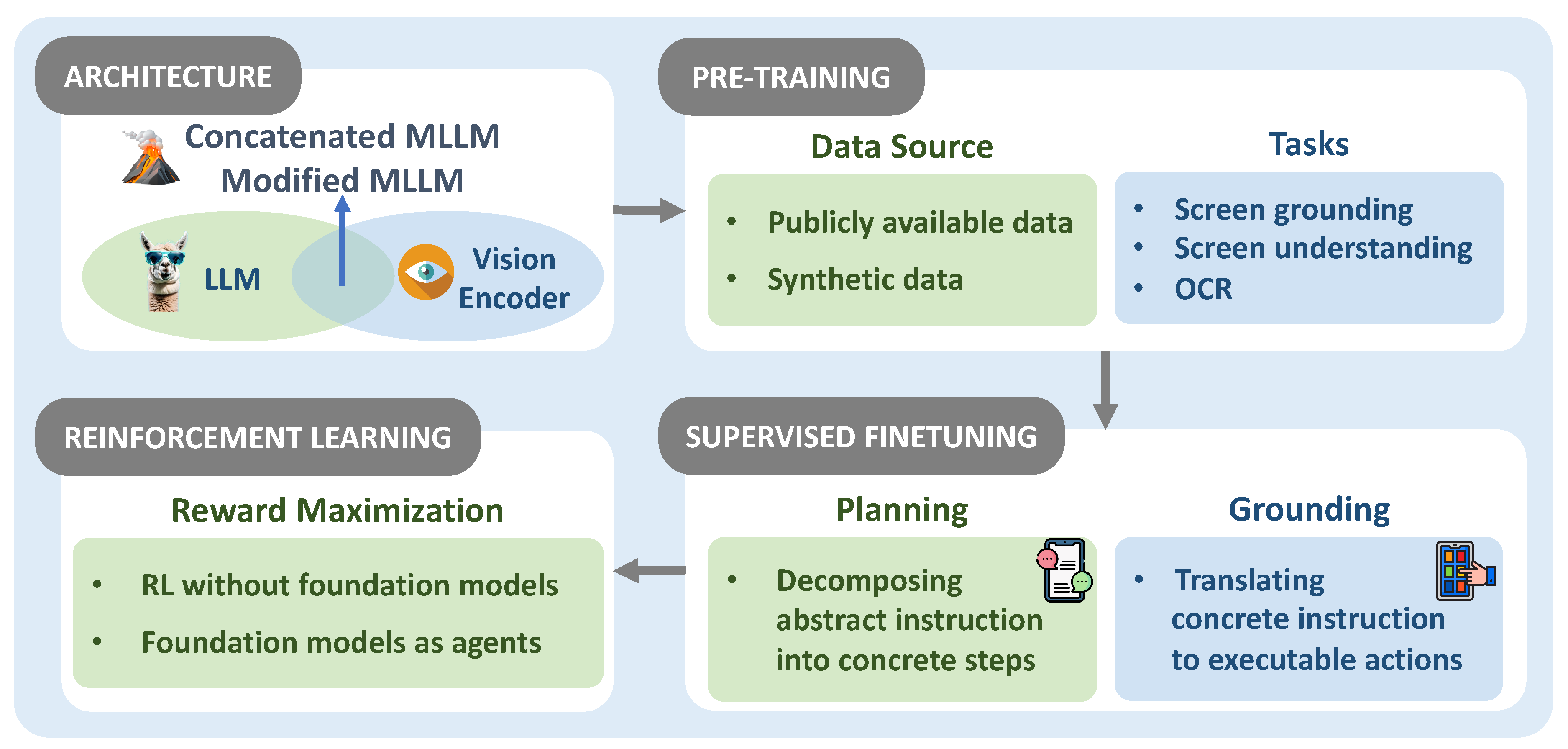
3.1. Foundation Model
3.1.1. Architecture
3.1.2. Pre-Training
3.1.3. Supervised Finetuning
3.1.4. Reinforcement Learning
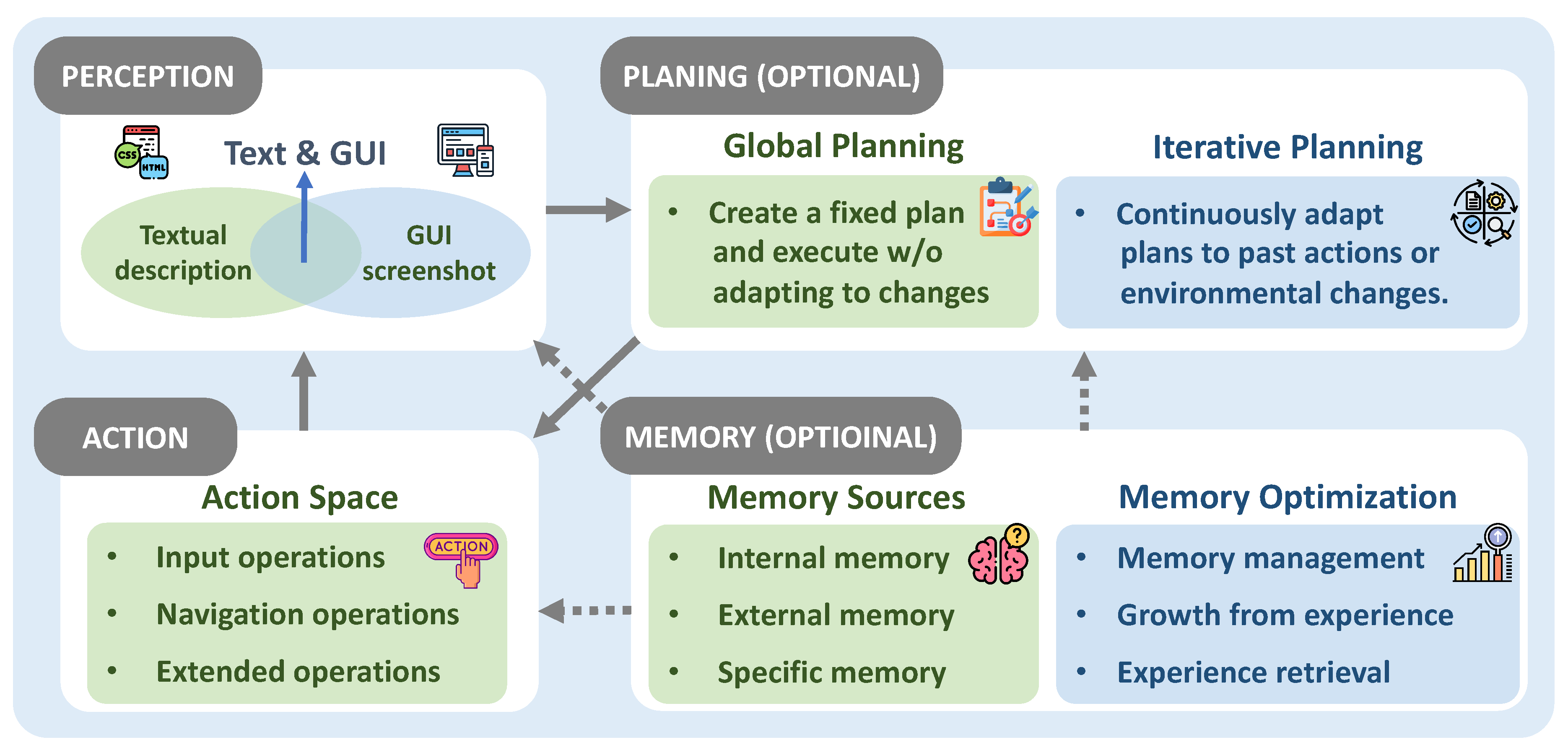
3.2. Agent Framework
3.2.1. Perception
3.2.2. Planning
3.2.3. Memory
-
Internal Memory. In the following, we introduce several components of Internal Memory. (1) Action History. By recording each step of operations, the action history helps OS Agents track task paths and optimize decisions. For instance, Auto-GUI [44] integrates historical and future action plans through the chain of previous action histories. (2) Screenshots. The storage of screenshots supports visual reasoning and the recognition of GUI components. For example, CoAT [26] semantically processes screenshots to extract interface information, enabling better understanding of the task scene. Wang and Liu [28], Rawles et al. [136] utilize screenshots annotated with Set-of-Mark (SoM) to support visual reasoning, accurately identify GUI components, and perform precise operations, while also aiding in task planning and validation. ToL [137] uses GUI screenshots as input to construct a Hierarchical Layout Tree and combines visual reasoning to generate descriptions of content and layout. (3) State Data. Dynamic information from the environment, such as page positions and window states, are stored to help OS Agents quickly locate task objectives and maintain high task execution accuracy in changing environments. Specifically, CoCo-Agent [138] records layouts and dynamic states through Comprehensive Environment Perception (CEP), while Abuelsaad et al. [113], Tao et al. [119] employ Document Object Model denoising techniques to dynamically store page information. In the following, we present the two forms of internal memory.Short-term Memory stores immediate information about the current task, including the action history of the agent, state information, and the execution trajectory of the task. It supports decision optimization and task tracking, providing contextual support for the ongoing task. Recent advances focus on improving the memory capabilities of OS Agents. For example, understanding the layout of objects in a scene through visual information enables multimodal agents to possess more comprehensive cognitive abilities when handling complex tasks.Long-term Memory stores historical tasks and interaction records, such as the execution paths of previous tasks, providing references and reasoning support for future tasks. For example, OS-Copilot [29] stores user preferences and the agent’s historical knowledge, such as semantic knowledge and task history, as declarative memory. This is used to make personalized decisions and execute tasks, while dynamically generating new tools or storing task-related skill codes during task execution [114].
- External Memory. External memory provides long-term knowledge support, primarily enriching an agent’s memory capabilities through knowledge bases, external documents, and online information. For instance, agents can retrieve domain-specific background information from external knowledge bases to make more informed judgments in tasks requiring domain expertise. Additionally, some agents dynamically acquire external knowledge by invoking tools such as Application Programming Interfaces (APIs) [49,139], integrating this knowledge into their memory to assist with task execution and decision optimization.
-
Specific Memory. Specific memory focuses on storing information directly related to specific tasks and user needs while incorporating extensive task knowledge and optimized application functions, which can be stored internally or extended through external data sources [140]. Specific Memory can store task execution rules, subtask decomposition methods, and domain knowledge [116]. It provides agents with prior knowledge to assist in handling complex tasks. For instance, MobileGPT [118] adopts a three-tier hierarchical memory structure (task, sub-task, action) and organizes memory in the form of a transition graph, breaking tasks down into sub-tasks represented as function calls for quick access and efficient invocation, while CoCo-Agent [138] employs task decomposition and Conditional Action Prediction (CAP) to store execution rules and methods. In terms of interface element recognition and interaction, Wang and Liu [28], He et al. [50], Agashe et al. [109] enhance task understanding by parsing the Accessibility Tree to obtain information about all UI elements on the screen.Additionally, Specific Memory can also be used to record user profiles, preferences, and interaction histories to support personalized recommendations, demand prediction, and inference of implicit information. For example, OS-Copilot [29] records user preferences through user profiles, such as tool usage habits and music or video preferences, enabling personalized solutions and recommendation services. Moreover, Specific Memory also supports recording application function descriptions and page access history to facilitate cross-application operation optimization and historical task tracking. For instance, AppAgent [23] learns application functionality by recording operation histories and state changes, storing this information as documentation. Similarly, ClickAgent [45] improves understanding and operational efficiency in application environments by using GUI localization models to identify and locate GUI elements within applications, while also recording functionality descriptions and historical task information.
- Management. For humans, memory information is constantly processed and abstracted in the brain. Similarly, the memory of OS Agents can be effectively managed to generate higher-level information, consolidate redundant content, and remove irrelevant or outdated information. Effective memory management enhances overall performance and prevents efficiency loss caused by information overload. In specific, Yan et al. [24], Tan et al. 114] introduce a multimodal self-summarization mechanism, generating concise historical records in natural language to replace directly storing complete screens or action sequences. WebAgent [17] understands and summarizes long HTML documents through local and global attention mechanisms, as well as long-span denoising objectives. On the other hand, WebVoyager [27] employs a Context Clipping method, retaining the most recent three observations while keeping a complete record of thoughts and actions from the history. However, for longer tasks, this approach may lead to the loss of important information, potentially affecting task completion. Additionally, Agent-E [113] optimizes webpage representations by filtering task-relevant content, compressing DOM structure hierarchies, and retaining key parent-child relationships, thereby reducing redundancy. AGENTOCCAM [108] optimizes the agent’s workflow memory through a planning tree, treating each new plan as an independent goal and removing historical step information related to previous plans.
- Growth Experience. By revisiting each step of a task, the agent can analyze successes and failures, identify opportunities for improvement, and avoid repeating mistakes in similar scenarios [58]. For instance, MobA [140] introduces dual reflection, evaluating task feasibility before execution and reviewing completion status afterward. Additionally, In [120], the agent analyzes the sequence of actions after a task failure, identifies the earliest critical missteps, and generates structured recommendations for alternative actions. OS Agents can return to a previous state and choose an alternative path when the current task path proves infeasible or the results do not meet expectations, which is akin to classic search algorithms, enabling the agent to explore multiple potential solutions and find the optimal path. For example, LASER [25] uses a Memory Buffer mechanism to store intermediate results that were not selected during exploration, allowing the agent to backtrack flexibly within the state space. After taking an incorrect action, the agent can return to a previous state and retry. SheetCopilot [122] utilizes a state machine mechanism to guide the model in re-planning actions by providing error feedback and spreadsheet state feedback, while MobA [140] uses a tree-like task structure to record the complete path, ensuring an efficient backtracking process.
- Experience Retrieval. OS Agents can efficiently plan and execute by retrieving experiences similar to the current task from long-term memory, which helps to reduce redundant operations [115,121]. For instance, AWM [133] extracts similar task workflows from past tasks and reuses them in new tasks, minimizing the need for repetitive learning. Additionally, PeriGuru [46] uses the K-Nearest Neighbors algorithm to retrieve similar task cases from a task database and combines them with Historical Actions to enhance decision-making through prompts.
3.2.4. Action
4. Evaluation of OS Agents
4.1. Evaluation Protocol
4.1.1. Evaluation Principle
4.1.2. Evaluation Metric
- Task Completion Metrics. Task Completion Metrics measure the effectiveness of OS Agents in successfully accomplishing assigned tasks. These metrics cover several key aspects. Overall Success Rate (SR) [38,40,42,44] provides a straightforward measure of the proportion of tasks that are fully completed. Accuracy [156,157,168] assesses the precision of the agent’s responses or actions, ensuring outputs closely match with the expected outcomes. Additionally, Reward function [32,39,40,169] is another critical metric, which assigns numerical values to guide agents toward specific objectives in reinforcement learning.
- Efficiency Metrics. Efficiency Metrics evaluate how efficiently the agent completes assigned tasks, considering factors such as step cost, hardware expenses, and time expenditure. Specifically, Step Ratio [43,159,170] compares the number of steps taken by the agent to the optimal one (often defined by human performance). A lower step ratio indicates a more efficient and optimized task execution, while higher ratios highlight redundant or unnecessary actions. API Cost [168,171,172] evaluates the financial costs associated with API calls, which is particularly relevant for agents that use external language models or cloud services. Furthermore, Execution Time [173] measures the time required for the agent to complete a task, and Peak Memory Allocation [151] shows the maximum GPU memory usage during computation. These efficiency metrics are critical for evaluating the real-time performance of agents, especially in resource-constrained environments.
4.2. Evaluation Benchmark
4.2.1. Evaluation Platform
4.2.2. Benchmark Setting
4.2.3. Task
- GUI Grounding. GUI grounding tasks aim to evaluate agent’s abilities to transform instructions to various actionable elements. Grounding is fundamental for interacting with operation systems that OS Agents must possess. Early works, such as PIXELHELP [147], provide a benchmark that pairs English instructions with actions performed by users on a mobile emulator.
- Information Processing. In the context of interactive agents, the ability to effectively handle information is a critical component for addressing complex tasks. This encompasses not only retrieving relevant data from various sources but also summarizing and distilling information to meet specific user needs. Such capabilities are particularly essential in dynamic and diverse environments, where agents must process large volumes of information, and deliver accurate results. To explore these competencies, Information Processing Tasks can be further categorized into two main types: (1) Information Retrieval Tasks [42,150,151] examine agent’s ability to process complex and dynamic information by understanding instructions and GUI interfaces, extracting the desired information or data. Browsers (either web-based or local applications) are ideal platforms for information retrieval tasks due to their vast repositories of information. Additionally, applications with integrated data services also serve as retrieval platforms. For instance, AndroidWorld [34] requires OS Agents to retrieve scheduled events from Simple Calendar Pro. (2) Information Summarizing Tasks are designed to summarize specified information from a GUI interface, testing agent’s ability to comprehend and process information. For example, certain tasks in WebLinx [41] focus on summarizing web-based news articles or user reviews.
- Agentic Tasks. Agentic tasks are designed to evaluate an agent’s core abilities (as mentioned in §2.2) and represent a key focus in current research. In these tasks, OS Agents are provided with an instruction or goal and tasked with identifying the required steps, planning actions, and executing them until the target state is reached, without relying on any explicit navigation guidance. For instance, WebLINX [41] offers both low-level and high-level instructions, challenging agents to complete single-step or multi-step tasks, thereby testing their planning capabilities. Similarly, MMInA [151] emphasizes multi-hop tasks, requiring agents to navigate across multiple websites to fulfill the given instruction.
5. Challenge & Future
5.1. Safety & Privacy
5.1.1. Attack
5.1.2. Defense
5.1.3. Benchmark
5.2. Personalization & Self-Evolution
6. Related Work
7. Conclusion
References
- Apple Inc. Siri - apple, 2024. URL https://www.apple.com/siri/. Accessed: 2024-12-04.
- Microsoft Research. Cortana research - microsoft research, 2024. URL https://www.microsoft.com/en-us/research/group/cortana-research/. Accessed: 2024-12-04.
- Google. Google assistant, 2024. URL https://assistant.google.com/. Accessed: 2024-12-04.
- Amazon. Alexa - amazon, 2024. URL https://alexa.amazon.com/. Accessed: 2024-12-04.
- Amrita S Tulshan and Sudhir Namdeorao Dhage. Survey on virtual assistant: Google assistant, siri, cortana, alexa. In Advances in Signal Processing and Intelligent Recognition Systems: 4th International Symposium SIRS 2018, Bangalore, India, September 19–22, 2018, Revised Selected Papers 4, pages 190–201. Springer, 2019.
- Google. Gemini - google. URL https://gemini.google.com/. Accessed: 2024-12-12.
- OpenAI. Home - openai. URL https://openai.com/. Accessed: 2024-12-12.
- xAI. x.ai. URL https://x.ai/. Accessed: 2024-12-12.
- 01.AI. 01.ai. URL https://www.lingyiwanwu.com/. Accessed: 2024-12-12.
- Anthropic. Anthropic. URL https://www.anthropic.com/. Accessed: 2024-12-12.
- Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating llms by human preference, 2024.
- Anthropic. 3.5 models and computer use - anthropic, 2024a. URL https://www.anthropic.com/news/3-5-models-and-computer-use. Accessed: 2024-12-04.
- Apple. Apple intelligence, 2024. URL https://www.apple.com/apple-intelligence/. Accessed: 2024-12-04.
- Xiao Liu, Bo Qin, Dongzhu Liang, Guang Dong, Hanyu Lai, Hanchen Zhang, Hanlin Zhao, Iat Long Iong, Jiadai Sun, Jiaqi Wang, et al. Autoglm: Autonomous foundation agents for guis. arXiv preprint arXiv:2411.00820, 2024a.
- Google DeepMind. Project mariner, 2024. URL https://deepmind.google/technologies/project-mariner/. Accessed: 2024-12-04.
- Anthropic. Claude model - anthropic, 2024b. URL https://www.anthropic.com/claude. Accessed: 2024-12-04.
- Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis. arXiv preprint arXiv:2307.12856, 2023.
- Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, and Zhe Gan. Ferret-ui: Grounded mobile ui understanding with multimodal llms. In European Conference on Computer Vision, pages 240–255. Springer, 2025.
- Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents. arXiv preprint arXiv:2410.05243, 2024.
- Ziyang Meng, Yu Dai, Zezheng Gong, Shaoxiong Guo, Minglong Tang, and Tongquan Wei. Vga: Vision gui assistant–minimizing hallucinations through image-centric fine-tuning. arXiv preprint arXiv:2406.14056, 2024.
- Xuetian Chen, Hangcheng Li, Jiaqing Liang, Sihang Jiang, and Deqing Yang. Edge: Enhanced grounded gui understanding with enriched multi-granularity synthetic data. arXiv preprint arXiv:2410.19461, 2024a.
- Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents. arXiv preprint arXiv:2410.23218, 2024a.
- Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users. arXiv preprint arXiv:2312.13771, 2023a.
- An Yan, Zhengyuan Yang, Wanrong Zhu, Kevin Lin, Linjie Li, Jianfeng Wang, Jianwei Yang, Yiwu Zhong, Julian McAuley, Jianfeng Gao, et al. Gpt-4v in wonderland: Large multimodal models for zero-shot smartphone gui navigation. arXiv preprint arXiv:2311.07562, 2023.
- Kaixin Ma, Hongming Zhang, Hongwei Wang, Xiaoman Pan, Wenhao Yu, and Dong Yu. Laser: Llm agent with state-space exploration for web navigation. arXiv preprint arXiv:2309.08172, 2023.
- Jiwen Zhang, Jihao Wu, Yihua Teng, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, and Duyu Tang. Android in the zoo: Chain-of-action-thought for gui agents. arXiv preprint arXiv:2403.02713, 2024a.
- Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. arXiv preprint arXiv:2401.13919, 2024a.
- Xiaoqiang Wang and Bang Liu. Oscar: Operating system control via state-aware reasoning and re-planning. arXiv preprint arXiv:2410.18963, 2024.
- Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumianze Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. Os-copilot: Towards generalist computer agents with self-improvement. arXiv preprint arXiv:2402.07456, 2024b.
- Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, et al. Assistgui: Task-oriented desktop graphical user interface automation. arXiv preprint arXiv:2312.13108, 2023.
- Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. Windows agent arena: Evaluating multi-modal os agents at scale. arXiv preprint arXiv:2409.08264, 2024.
- Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem Alshikh, and Ruslan Salakhutdinov. Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web. arXiv preprint arXiv:2402.17553, 2024.
- Sagar Gubbi Venkatesh, Partha Talukdar, and Srini Narayanan. Ugif: Ui grounded instruction following. arXiv preprint arXiv:2211.07615, 2022.
- Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573, 2024a.
- Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on computer control agents. arXiv preprint arXiv:2406.03679, 2024a.
- William E Bishop, Alice Li, Christopher Rawles, and Oriana Riva. Latent state estimation helps ui agents to reason. arXiv preprint arXiv:2405.11120, 2024.
- Mingzhe Xing, Rongkai Zhang, Hui Xue, Qi Chen, Fan Yang, and Zhen Xiao. Understanding the weakness of large language model agents within a complex android environment. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6061–6072, 2024.
- Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang. World of bits: An open-domain platform for web-based agents. In International Conference on Machine Learning, pages 3135–3144. PMLR, 2017.
- Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems, 35::0 20744–20757, 2022.
- Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. arXiv preprint arXiv:2401.13649, 2024a.
- Xing Han Lù, Zdeněk Kasner, and Siva Reddy. Weblinx: Real-world website navigation with multi-turn dialogue. arXiv preprint arXiv:2402.05930, 2024.
- Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks? arXiv preprint arXiv:2403.07718, 2024.
- Juyong Lee, Taywon Min, Minyong An, Dongyoon Hahm, Haeone Lee, Changyeon Kim, and Kimin Lee. Benchmarking mobile device control agents across diverse configurations. arXiv preprint arXiv:2404.16660, 2024a.
- Zhuosheng Zhang and Aston Zhang. You only look at screens: Multimodal chain-of-action agents. arXiv preprint arXiv:2309.11436, 2023.
- Jakub Hoscilowicz, Bartosz Maj, Bartosz Kozakiewicz, Oleksii Tymoshchuk, and Artur Janicki. Clickagent: Enhancing ui location capabilities of autonomous agents. arXiv preprint arXiv:2410.11872, 2024.
- Kelin Fu, Yang Tian, and Kaigui Bian. Periguru: A peripheral robotic mobile app operation assistant based on gui image understanding and prompting with llm. arXiv preprint arXiv:2409.09354, 2024.
- Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v (ision) is a generalist web agent, if grounded. arXiv preprint arXiv:2401.01614, 2024a.
- Liangtai Sun, Xingyu Chen, Lu Chen, Tianle Dai, Zichen Zhu, and Kai Yu. Meta-gui: Towards multi-modal conversational agents on mobile gui. arXiv preprint arXiv:2205.11029, 2022.
- Yueqi Song, Frank Xu, Shuyan Zhou, and Graham Neubig. Beyond browsing: Api-based web agents. arXiv preprint arXiv:2410.16464, 2024.
- Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Hongming Zhang, Tianqing Fang, Zhenzhong Lan, and Dong Yu. Openwebvoyager: Building multimodal web agents via iterative real-world exploration, feedback and optimization. arXiv preprint arXiv:2410.19609, 2024b.
- Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. Aios: Llm agent operating system. arXiv e-prints, pp. arXiv–2403, 2024.
- Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, et al. Autowebglm: A large language model-based web navigating agent. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5295–5306, 2024.
- Songqin Nong, Jiali Zhu, Rui Wu, Jiongchao Jin, Shuo Shan, Xiutian Huang, and Wenhao Xu. Mobileflow: A multimodal llm for mobile gui agent. arXiv preprint arXiv:2407.04346, 2024.
- Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14281–14290, 2024a.
- Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey, 2023. URL https://arxiv.org/abs/2212.10403.
- Yadong Zhang, Shaoguang Mao, Tao Ge, Xun Wang, Adrian de Wynter, Yan Xia, Wenshan Wu, Ting Song, Man Lan, and Furu Wei. Llm as a mastermind: A survey of strategic reasoning with large language models, 2024b. URL https://arxiv.org/abs/2404.01230.
- Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey. arXiv preprint arXiv:2402.02716, 2024a.
- Geunwoo Kim, Pierre Baldi, and Stephen McAleer. Language models can solve computer tasks. Advances in Neural Information Processing Systems, 36, 2024a.
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https://arxiv.org/abs/2210.03629.
- Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2023.
- Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023.
- Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, et al. Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617, 2023. [CrossRef]
- Chaojun Xiao, Xueyu Hu, Zhiyuan Liu, Cunchao Tu, and Maosong Sun. Lawformer: A pre-trained language model for chinese legal long documents. AI Open, 2::0 79–84, 2021. [CrossRef]
- Harrison Chase. LangChain, October 2022. URL https://github.com/langchain-ai/langchain.
- Significant Gravitas. AutoGPT. URL https://github.com/Significant-Gravitas/AutoGPT.
- Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework, 2024b. URL https://arxiv.org/abs/2308.00352.
- Xueyu Hu, Ziyu Zhao, Shuang Wei, Ziwei Chai, Qianli Ma, Guoyin Wang, Xuwu Wang, Jing Su, Jingjing Xu, Ming Zhu, et al. Infiagent-dabench: Evaluating agents on data analysis tasks. arXiv preprint arXiv:2401.05507, 2024a.
- Zhangsheng Li, Keen You, Haotian Zhang, Di Feng, Harsh Agrawal, Xiujun Li, Mohana Prasad Sathya Moorthy, Jeff Nichols, Yinfei Yang, and Zhe Gan. Ferret-ui 2: Mastering universal user interface understanding across platforms. arXiv preprint arXiv:2410.18967, 2024b.
- Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Zechen Bai, Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for generalist gui agent. In NeurIPS 2024 Workshop on Open-World Agents, 2024.
- Junpeng Liu, Tianyue Ou, Yifan Song, Yuxiao Qu, Wai Lam, Chenyan Xiong, Wenhu Chen, Graham Neubig, and Xiang Yue. Harnessing webpage uis for text-rich visual understanding. arXiv preprint arXiv:2410.13824, 2024b.
- Pawel Pawlowski, Krystian Zawistowski, Wojciech Lapacz, Marcin Skorupa, Adam Wiacek, Sebastien Postansque, and Jakub Hoscilowicz. Tinyclick: Single-turn agent for empowering gui automation. arXiv preprint arXiv:2410.11871, 2024.
- Shikhar Murty, Dzmitry Bahdanau, and Christopher D Manning. Nnetscape navigator: Complex demonstrations for web agents without a demonstrator. arXiv preprint arXiv:2410.02907, 2024.
- Tianyue Ou, Frank F Xu, Aman Madaan, Jiarui Liu, Robert Lo, Abishek Sridhar, Sudipta Sengupta, Dan Roth, Graham Neubig, and Shuyan Zhou. Synatra: Turning indirect knowledge into direct demonstrations for digital agents at scale. arXiv preprint arXiv:2409.15637, 2024.
- Qinzhuo Wu, Weikai Xu, Wei Liu, Tao Tan, Jianfeng Liu, Ang Li, Jian Luan, Bin Wang, and Shuo Shang. Mobilevlm: A vision-language model for better intra-and inter-ui understanding. arXiv preprint arXiv:2409.14818, 2024c.
- Jiwen Zhang, Yaqi Yu, Minghui Liao, Wentao Li, Jihao Wu, and Zhongyu Wei. Ui-hawk: Unleashing the screen stream understanding for gui agents. Preprints, 2024c.
- Qinchen Wu, Difei Gao, Kevin Qinghong Lin, Zhuoyu Wu, Xiangwu Guo, Peiran Li, Weichen Zhang, Hengxu Wang, and Mike Zheng Shou. Gui action narrator: Where and when did that action take place? arXiv preprint arXiv:2406.13719, 2024d.
- Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, and Ping Luo. Gui odyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. arXiv preprint arXiv:2406.08451, 2024a.
- Andrea Burns, Kate Saenko, and Bryan A Plummer. Tell me what’s next: Textual foresight for generic ui representations. arXiv preprint arXiv:2406.07822, 2024.
- Lucas-Andrei Thil, Mirela Popa, and Gerasimos Spanakis. Navigating webai: Training agents to complete web tasks with large language models and reinforcement learning. In Proceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, pages 866–874, 2024.
- Moghis Fereidouni et al. Search beyond queries: Training smaller language models for web interactions via reinforcement learning. arXiv preprint arXiv:2404.10887, 2024.
- Ajay Patel, Markus Hofmarcher, Claudiu Leoveanu-Condrei, Marius-Constantin Dinu, Chris Callison-Burch, and Sepp Hochreiter. Large language models can self-improve at web agent tasks. arXiv preprint arXiv:2405.20309, 2024.
- Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Cărbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. Screenai: A vision-language model for ui and infographics understanding. arXiv preprint arXiv:2402.04615, 2024.
- Jihyung Kil, Chan Hee Song, Boyuan Zheng, Xiang Deng, Yu Su, and Wei-Lun Chao. Dual-view visual contextualization for web navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14445–14454, 2024.
- Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935, 2024a.
- Yue Jiang, Eldon Schoop, Amanda Swearngin, and Jeffrey Nichols. Iluvui: Instruction-tuned language-vision modeling of uis from machine conversations. arXiv preprint arXiv:2310.04869, 2023.
- Zhizheng Zhang, Wenxuan Xie, Xiaoyi Zhang, and Yan Lu. Reinforced ui instruction grounding: Towards a generic ui task automation api. arXiv preprint arXiv:2310.04716, 2023b.
- Iat Long Iong, Xiao Liu, Yuxuan Chen, Hanyu Lai, Shuntian Yao, Pengbo Shen, Hao Yu, Yuxiao Dong, and Jie Tang. Openwebagent: An open toolkit to enable web agents on large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 72–81, 2024.
- Hiroki Furuta, Kuang-Huei Lee, Ofir Nachum, Yutaka Matsuo, Aleksandra Faust, Shixiang Shane Gu, and Izzeddin Gur. Multimodal web navigation with instruction-finetuned foundation models. arXiv preprint arXiv:2305.11854, 2023.
- Hiroki Furuta, Yutaka Matsuo, Aleksandra Faust, and Izzeddin Gur. Exposing limitations of language model agents in sequential-task compositions on the web. In ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024.
- Longxi Gao, Li Zhang, Shihe Wang, Shangguang Wang, Yuanchun Li, and Mengwei Xu. Mobileviews: A large-scale mobile gui dataset. arXiv preprint arXiv:2409.14337, 2024a.
- Yifan Xu, Xiao Liu, Xueqiao Sun, Siyi Cheng, Hao Yu, Hanyu Lai, Shudan Zhang, Dan Zhang, Jie Tang, and Yuxiao Dong. Androidlab: Training and systematic benchmarking of android autonomous agents. arXiv preprint arXiv:2410.24024, 2024a.
- Jacob Devlin. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Tom B Brown. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, et al. Guicourse: From general vision language models to versatile gui agents. arXiv preprint arXiv:2406.11317, 2024b.
- Qi Chen, Dileepa Pitawela, Chongyang Zhao, Gengze Zhou, Hsiang-Ting Chen, and Qi Wu. Webvln: Vision-and-language navigation on websites. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1165–1173, 2024c.
- Richard S Sutton. Reinforcement learning: An introduction. A Bradford Book, 2018.
- Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, and Percy Liang. Reinforcement learning on web interfaces using workflow-guided exploration. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=ryTp3f-0-.
- Izzeddin Gur, Ulrich Rueckert, Aleksandra Faust, and Dilek Hakkani-Tur. Learning to navigate the web. arXiv preprint arXiv:1812.09195, 2018.
- Sheng Jia, Jamie Kiros, and Jimmy Ba. Dom-q-net: Grounded rl on structured language. arXiv preprint arXiv:1902.07257, 2019.
- Maayan Shvo, Zhiming Hu, Rodrigo Toro Icarte, Iqbal Mohomed, Allan D Jepson, and Sheila A McIlraith. Appbuddy: Learning to accomplish tasks in mobile apps via reinforcement learning. In Canadian AI, 2021. [CrossRef]
- Peter C Humphreys, David Raposo, Tobias Pohlen, Gregory Thornton, Rachita Chhaparia, Alistair Muldal, Josh Abramson, Petko Georgiev, Adam Santoro, and Timothy Lillicrap. A data-driven approach for learning to control computers. In International Conference on Machine Learning, pages 9466–9482. PMLR, 2022.
- FengPeiyuan, Yichen He, Guanhua Huang, Yuan Lin, Hanchong Zhang, Yuchen Zhang, and Hang Li. AGILE: A novel reinforcement learning framework of LLM agents. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=Ul3lDYo3XQ.
- Peter Shaw, Mandar Joshi, James Cohan, Jonathan Berant, Panupong Pasupat, Hexiang Hu, Urvashi Khandelwal, Kenton Lee, and Kristina N Toutanova. From pixels to ui actions: Learning to follow instructions via graphical user interfaces. Advances in Neural Information Processing Systems, 36::0 34354–34370, 2023.
- Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Kumar. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning. arXiv preprint arXiv:2406.11896, 2024.
- Taiyi Wang, Zhihao Wu, Jianheng Liu, Jianye Hao, Jun Wang, and Kun Shao. Distrl: An asynchronous distributed reinforcement learning framework for on-device control agents. arXiv preprint arXiv:2410.14803, 2024a.
- Hongru Cai, Yongqi Li, Wenjie Wang, Fengbin Zhu, Xiaoyu Shen, Wenjie Li, and Tat-Seng Chua. Large language models empowered personalized web agents. arXiv preprint arXiv:2410.17236, 2024.
- Ke Yang, Yao Liu, Sapana Chaudhary, Rasool Fakoor, Pratik Chaudhari, George Karypis, and Huzefa Rangwala. Agentoccam: A simple yet strong baseline for llm-based web agents. arXiv preprint arXiv:2410.13825, 2024a.
- Saaket Agashe, Jiuzhou Han, Shuyu Gan, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s: An open agentic framework that uses computers like a human. arXiv preprint arXiv:2410.08164, 2024.
- Zeru Shi, Kai Mei, Mingyu Jin, Yongye Su, Chaoji Zuo, Wenyue Hua, Wujiang Xu, Yujie Ren, Zirui Liu, Mengnan Du, et al. From commands to prompts: Llm-based semantic file system for aios. arXiv preprint arXiv:2410.11843, 2024.
- Mobina Shahbandeh, Parsa Alian, Noor Nashid, and Ali Mesbah. Naviqate: Functionality-guided web application navigation, 2024. URL https://arxiv.org/abs/2409.10741.
- Husam Barham and Mohammed Fasha. Towards llmci-multimodal ai for llm-vision ui operation. 2024.
- Tamer Abuelsaad, Deepak Akkil, Prasenjit Dey, Ashish Jagmohan, Aditya Vempaty, and Ravi Kokku. Agent-e: From autonomous web navigation to foundational design principles in agentic systems. arXiv preprint arXiv:2407.13032, 2024.
- Weihao Tan, Wentao Zhang, Xinrun Xu, Haochong Xia, Gang Ding, Boyu Li, Bohan Zhou, Junpeng Yue, Jiechuan Jiang, Yewen Li, et al. Cradle: Empowering foundation agents towards general computer control. In NeurIPS 2024 Workshop on Open-World Agents.
- Yang Deng, Xuan Zhang, Wenxuan Zhang, Yifei Yuan, See-Kiong Ng, and Tat-Seng Chua. On the multi-turn instruction following for conversational web agents. arXiv preprint arXiv:2402.15057, 2024a.
- Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024b.
- Tinghe Ding. Mobileagent: enhancing mobile control via human-machine interaction and sop integration. arXiv preprint arXiv:2401.04124, 2024.
- Sunjae Lee, Junyoung Choi, Jungjae Lee, Munim Hasan Wasi, Hojun Choi, Steven Y Ko, Sangeun Oh, and Insik Shin. Explore, select, derive, and recall: Augmenting llm with human-like memory for mobile task automation. arXiv preprint arXiv:2312.03003, 2023a.
- Heyi Tao, Sethuraman TV, Michal Shlapentokh-Rothman, and Derek Hoiem. Webwise: Web interface control and sequential exploration with large language models. arXiv preprint arXiv:2310.16042, 2023.
- Tao Li, Gang Li, Zhiwei Deng, Bryan Wang, and Yang Li. A zero-shot language agent for computer control with structured reflection. arXiv preprint arXiv:2310.08740, 2023.
- Longtao Zheng, Rundong Wang, Xinrun Wang, and Bo An. Synapse: Trajectory-as-exemplar prompting with memory for computer control. In The Twelfth International Conference on Learning Representations, 2023a.
- Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and ZHAO-XIANG ZHANG. Sheetcopilot: Bringing software productivity to the next level through large language models. Advances in Neural Information Processing Systems, 36, 2024c.
- Bryan Wang, Gang Li, and Yang Li. Enabling conversational interaction with mobile ui using large language models. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–17, 2023a.
- Junting Lu, Zhiyang Zhang, Fangkai Yang, Jue Zhang, Lu Wang, Chao Du, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Qi Zhang. Turn every application into an agent: Towards efficient human-agent-computer interaction with api-first llm-based agents. arXiv preprint arXiv:2409.17140, 2024b.
- Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v, 2023. URL https://arxiv.org/abs/2310.11441.
- Srinivas Sunkara, Maria Wang, Lijuan Liu, Gilles Baechler, Yu-Chung Hsiao, Abhanshu Sharma, James Stout, et al. Towards better semantic understanding of mobile interfaces. arXiv preprint arXiv:2210.02663, 2022.
- Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2024c. URL https://arxiv.org/abs/2303.05499.
- Kenton Lee, Mandar Joshi, Iulia Raluca Turc, Hexiang Hu, Fangyu Liu, Julian Martin Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding. In International Conference on Machine Learning, pages 18893–18912. PMLR, 2023b.
- Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems, 36, 2024b.
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URL https://arxiv.org/abs/2201.11903.
- Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366.
- Wangchunshu Zhou, Yuchen Eleanor Jiang, Peng Cui, Tiannan Wang, Zhenxin Xiao, Yifan Hou, Ryan Cotterell, and Mrinmaya Sachan. Recurrentgpt: Interactive generation of (arbitrarily) long text, 2023a. URL https://arxiv.org/abs/2305.13304.
- Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024c.
- Tian Huang, Chun Yu, Weinan Shi, Zijian Peng, David Yang, Weiqi Sun, and Yuanchun Shi. Promptrpa: Generating robotic process automation on smartphones from textual prompts. arXiv preprint arXiv:2404.02475, 2024b.
- Jaekyeom Kim, Dong-Ki Kim, Lajanugen Logeswaran, Sungryull Sohn, and Honglak Lee. Auto-intent: Automated intent discovery and self-exploration for large language model web agents. arXiv preprint arXiv:2410.22552, 2024b.
- Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems, 36, 2024b.
- Read Anywhere Pointed. Layout-aware gui screen reading with tree-of-lens grounding.
- Xinbei Ma, Zhuosheng Zhang, and Hai Zhao. Coco-agent: A comprehensive cognitive mllm agent for smartphone gui automation. In Findings of the Association for Computational Linguistics ACL 2024, pages 9097–9110, 2024a.
- Revanth Gangi Reddy, Sagnik Mukherjee, Jeonghwan Kim, Zhenhailong Wang, Dilek Hakkani-Tur, and Heng Ji. Infogent: An agent-based framework for web information aggregation. arXiv preprint arXiv:2410.19054, 2024.
- Zichen Zhu, Hao Tang, Yansi Li, Kunyao Lan, Yixuan Jiang, Hao Zhou, Yixiao Wang, Situo Zhang, Liangtai Sun, Lu Chen, et al. Moba: A two-level agent system for efficient mobile task automation. arXiv preprint arXiv:2410.13757, 2024.
- Runliang Niu, Jindong Li, Shiqi Wang, Yali Fu, Xiyu Hu, Xueyuan Leng, He Kong, Yi Chang, and Qi Wang. Screenagent: A vision language model-driven computer control agent. arXiv preprint arXiv:2402.07945, 2024.
- Junhee Cho, Jihoon Kim, Daseul Bae, Jinho Choo, Youngjune Gwon, and Yeong-Dae Kwon. Caap: Context-aware action planning prompting to solve computer tasks with front-end ui only. arXiv preprint arXiv:2406.06947, 2024.
- Jing Yu Koh, Stephen McAleer, Daniel Fried, and Ruslan Salakhutdinov. Tree search for language model agents. arXiv preprint arXiv:2407.01476, 2024b.
- Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Li Zhang, Shihe Wang, Xianqing Jia, Zhihan Zheng, Yunhe Yan, Longxi Gao, Yuanchun Li, and Mengwei Xu. Llamatouch: A faithful and scalable testbed for mobile ui task automation. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, pages 1–13, 2024d.
- Andrea Burns, Deniz Arsan, Sanjna Agrawal, Ranjitha Kumar, Kate Saenko, and Bryan A Plummer. A dataset for interactive vision-language navigation with unknown command feasibility. In European Conference on Computer Vision, pages 312–328. Springer, 2022.
- Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, and Jason Baldridge. Mapping natural language instructions to mobile ui action sequences. arXiv preprint arXiv:2005.03776, 2020.
- Zilong Wang, Yuedong Cui, Li Zhong, Zimin Zhang, Da Yin, Bill Yuchen Lin, and Jingbo Shang. Officebench: Benchmarking language agents across multiple applications for office automation. arXiv preprint arXiv:2407.19056, 2024d.
- Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. arXiv preprint arXiv:2404.07972, 2024.
- Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, et al. Webcanvas: Benchmarking web agents in online environments. arXiv preprint arXiv:2406.12373, 2024.
- Ziniu Zhang, Shulin Tian, Liangyu Chen, and Ziwei Liu. Mmina: Benchmarking multihop multimodal internet agents. arXiv preprint arXiv:2404.09992, 2024e.
- Longtao Zheng, Zhiyuan Huang, Zhenghai Xue, Xinrun Wang, Bo An, and Shuicheng Yan. Agentstudio: A toolkit for building general virtual agents. arXiv preprint arXiv:2403.17918, 2024b.
- Kevin Xu, Yeganeh Kordi, Tanay Nayak, Ado Asija, Yizhong Wang, Kate Sanders, Adam Byerly, Jingyu Zhang, Benjamin Van Durme, and Daniel Khashabi. Tur [k] ingbench: A challenge benchmark for web agents. arXiv preprint arXiv:2403.11905, 2024b.
- Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023b.
- Panupong Pasupat, Tian-Shun Jiang, Evan Zheran Liu, Kelvin Guu, and Percy Liang. Mapping natural language commands to web elements. arXiv preprint arXiv:1808.09132, 2018.
- Maria Wang, Srinivas Sunkara, Gilles Baechler, Jason Lin, Yun Zhu, Fedir Zubach, Lei Shu, and Jindong Chen. Webquest: A benchmark for multimodal qa on web page sequences. arXiv preprint arXiv:2409.13711, 2024e.
- Kaining Ying, Fanqing Meng, Jin Wang, Zhiqian Li, Han Lin, Yue Yang, Hao Zhang, Wenbo Zhang, Yuqi Lin, Shuo Liu, et al. Mmt-bench: A comprehensive multimodal benchmark for evaluating large vision-language models towards multitask agi. arXiv preprint arXiv:2404.16006, 2024.
- Yilun Jin, Zheng Li, Chenwei Zhang, Tianyu Cao, Yifan Gao, Pratik Jayarao, Mao Li, Xin Liu, Ritesh Sarkhel, Xianfeng Tang, et al. Shopping mmlu: A massive multi-task online shopping benchmark for large language models. arXiv preprint arXiv:2410.20745, 2024.
- Luyuan Wang, Yongyu Deng, Yiwei Zha, Guodong Mao, Qinmin Wang, Tianchen Min, Wei Chen, and Shoufa Chen. Mobileagentbench: An efficient and user-friendly benchmark for mobile llm agents. arXiv preprint arXiv:2406.08184, 2024f.
- Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In NeurIPS, 2023b.
- Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688, 2023.
- Tu Vu, Kalpesh Krishna, Salaheddin Alzubi, Chris Tar, Manaal Faruqui, and Yun-Hsuan Sung. Foundational autoraters: Taming large language models for better automatic evaluation, 2024. URL https://arxiv.org/abs/2407.10817.
- Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo. A survey on llm-as-a-judge, 2024. URL https://arxiv.org/abs/2411.15594.
- Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models, 2024c. URL https://arxiv.org/abs/2310.08491.
- Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source language model specialized in evaluating other language models, 2024d. URL https://arxiv.org/abs/2405.01535.
- Tassnim Dardouri, Laura Minkova, Jessica López Espejel, Walid Dahhane, and El Hassane Ettifouri. Visual grounding for desktop graphical user interfaces. arXiv preprint arXiv:2407.01558, 2024.
- Irene Weber. Large language models as software components: A taxonomy for llm-integrated applications. CoRR, abs/2406.10300, 2024.
- Zekai Zhang, Yiduo Guo, Yaobo Liang, Dongyan Zhao, and Nan Duan. Pptc-r benchmark: Towards evaluating the robustness of large language models for powerpoint task completion. arXiv preprint arXiv:2403.03788, 2024f.
- Danyang Zhang, Lu Chen, and Kai Yu. Mobile-env: A universal platform for training and evaluation of mobile interaction. arXiv preprint arXiv:2305.08144, 2023c.
- Jingxuan Chen, Derek Yuen, Bin Xie, Yuhao Yang, Gongwei Chen, Zhihao Wu, Li Yixing, Xurui Zhou, Weiwen Liu, Shuai Wang, et al. Spa-bench: A comprehensive benchmark for smartphone agent evaluation. In NeurIPS 2024 Workshop on Open-World Agents, 2024d.
- Yiduo Guo, Zekai Zhang, Yaobo Liang, Dongyan Zhao, and Nan Duan. Pptc benchmark: Evaluating large language models for powerpoint task completion. arXiv preprint arXiv:2311.01767, 2023.
- Shihan Deng, Weikai Xu, Hongda Sun, Wei Liu, Tao Tan, Jianfeng Liu, Ang Li, Jian Luan, Bin Wang, Rui Yan, et al. Mobile-bench: An evaluation benchmark for llm-based mobile agents. arXiv preprint arXiv:2407.00993, 2024c.
- Tianqi Xu, Linyao Chen, Dai-Jie Wu, Yanjun Chen, Zecheng Zhang, Xiang Yao, Zhiqiang Xie, Yongchao Chen, Shilong Liu, Bochen Qian, et al. Crab: Cross-environment agent benchmark for multimodal language model agents. arXiv preprint arXiv:2407.01511, 2024c.
- Danny Park. Human player outwits freysa ai agent in $47,000 crypto challenge, 2024. URL https://www.theblock.co/amp/post/328747/human-player-outwits-freysa-ai-agent-in-47000-crypto-challenge. Accessed: 2024-11-30.
- Zehang Deng, Yongjian Guo, Changzhou Han, Wanlun Ma, Junwu Xiong, Sheng Wen, and Yang Xiang. Ai agents under threat: A survey of key security challenges and future pathways, 2024d. URL https://arxiv.org/abs/2406.02630.
- Yuyou Gan, Yong Yang, Zhe Ma, Ping He, Rui Zeng, Yiming Wang, Qingming Li, Chunyi Zhou, Songze Li, Ting Wang, Yunjun Gao, Yingcai Wu, and Shouling Ji. Navigating the risks: A survey of security, privacy, and ethics threats in llm-based agents, 2024a. URL https://arxiv.org/abs/2411.09523.
- Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High-Confidence Computing, 4:0 (2)::0 100211, June 2024. ISSN 2667-2952. 10.1016/j.hcc.2024.100211. [CrossRef]
- Erfan Shayegani, Md Abdullah Al Mamun, Yu Fu, Pedram Zaree, Yue Dong, and Nael Abu-Ghazaleh. Survey of vulnerabilities in large language models revealed by adversarial attacks, 2023. URL https://arxiv.org/abs/2310.10844.
- Tianyu Cui, Yanling Wang, Chuanpu Fu, Yong Xiao, Sijia Li, Xinhao Deng, Yunpeng Liu, Qinglin Zhang, Ziyi Qiu, Peiyang Li, Zhixing Tan, Junwu Xiong, Xinyu Kong, Zujie Wen, Ke Xu, and Qi Li. Risk taxonomy, mitigation, and assessment benchmarks of large language model systems, 2024. URL https://arxiv.org/abs/2401.05778.
- Shenzhi Wang, Chang Liu, Zilong Zheng, Siyuan Qi, Shuo Chen, Qisen Yang, Andrew Zhao, Chaofei Wang, Shiji Song, and Gao Huang. Boosting llm agents with recursive contemplation for effective deception handling. In Findings of the Association for Computational Linguistics ACL 2024, pages 9909–9953, 2024g.
- Seth Neel and Peter Chang. Privacy issues in large language models: A survey, 2024. URL https://arxiv.org/abs/2312.06717.
- Fangzhou Wu, Shutong Wu, Yulong Cao, and Chaowei Xiao. Wipi: A new web threat for llm-driven web agents, 2024e. URL https://arxiv.org/abs/2402.16965.
- Chen Henry Wu, Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried, and Aditi Raghunathan. Adversarial attacks on multimodal agents, 2024f. URL https://arxiv.org/abs/2406.12814.
- Xinbei Ma, Yiting Wang, Yao Yao, Tongxin Yuan, Aston Zhang, Zhuosheng Zhang, and Hai Zhao. Caution for the environment: Multimodal agents are susceptible to environmental distractions, 2024b. URL https://arxiv.org/abs/2408.02544.
- Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. Eia: Environmental injection attack on generalist web agents for privacy leakage, 2024. URL https://arxiv.org/abs/2409.11295.
- Chejian Xu, Mintong Kang, Jiawei Zhang, Zeyi Liao, Lingbo Mo, Mengqi Yuan, Huan Sun, and Bo Li. Advweb: Controllable black-box attacks on vlm-powered web agents, 2024d. URL https://arxiv.org/abs/2410.17401.
- Yanzhe Zhang, Tao Yu, and Diyi Yang. Attacking vision-language computer agents via pop-ups, 2024g. URL https://arxiv.org/abs/2411.02391.
- Priyanshu Kumar, Elaine Lau, Saranya Vijayakumar, Tu Trinh, Scale Red Team, Elaine Chang, Vaughn Robinson, Sean Hendryx, Shuyan Zhou, Matt Fredrikson, Summer Yue, and Zifan Wang. Refusal-trained llms are easily jailbroken as browser agents, 2024. URL https://arxiv.org/abs/2410.13886.
- Yulong Yang, Xinshan Yang, Shuaidong Li, Chenhao Lin, Zhengyu Zhao, Chao Shen, and Tianwei Zhang. Security matrix for multimodal agents on mobile devices: A systematic and proof of concept study, 2024b. URL https://arxiv.org/abs/2407.09295.
- Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox, 2024. URL https://arxiv.org/abs/2309.15817.
- Wenyue Hua, Xianjun Yang, Mingyu Jin, Zelong Li, Wei Cheng, Ruixiang Tang, and Yongfeng Zhang. Trustagent: Towards safe and trustworthy llm-based agents, 2024. URL https://arxiv.org/abs/2402.01586.
- Haishuo Fang, Xiaodan Zhu, and Iryna Gurevych. Inferact: Inferring safe actions for llm-based agents through preemptive evaluation and human feedback, 2024. URL https://arxiv.org/abs/2407.11843.
- Zhen Xiang, Linzhi Zheng, Yanjie Li, Junyuan Hong, Qinbin Li, Han Xie, Jiawei Zhang, Zidi Xiong, Chulin Xie, Carl Yang, Dawn Song, and Bo Li. Guardagent: Safeguard llm agents by a guard agent via knowledge-enabled reasoning, 2024. URL https://arxiv.org/abs/2406.09187.
- Md Shamsujjoha, Qinghua Lu, Dehai Zhao, and Liming Zhu. Designing multi-layered runtime guardrails for foundation model based agents: Swiss cheese model for ai safety by design, 2024. URL https://arxiv.org/abs/2408.02205.
- Rodrigo Pedro, Daniel Castro, Paulo Carreira, and Nuno Santos. From prompt injections to sql injection attacks: How protected is your llm-integrated web application?, 2023. URL https://arxiv.org/abs/2308.01990.
- Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov. St-webagentbench: A benchmark for evaluating safety and trustworthiness in web agents, 2024. URL https://arxiv.org/abs/2410.06703.
- Juyong Lee, Dongyoon Hahm, June Suk Choi, W. Bradley Knox, and Kimin Lee. Mobilesafetybench: Evaluating safety of autonomous agents in mobile device control, 2024b. URL https://arxiv.org/abs/2410.17520.
- Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023b.
- Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory. arXiv preprint arXiv:2305.17144, 2023.
- Wangchunshu Zhou, Yixin Ou, Shengwei Ding, Long Li, Jialong Wu, Tiannan Wang, Jiamin Chen, Shuai Wang, Xiaohua Xu, Ningyu Zhang, Huajun Chen, and Yuchen Eleanor Jiang. Symbolic learning enables self-evolving agents, 2024. URL https://arxiv.org/abs/2406.18532.
- Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, and Yunchao Wei. Appagent v2: Advanced agent for flexible mobile interactions. arXiv preprint arXiv:2408.11824, 2024d.
- Alan Wake, Albert Wang, Bei Chen, CX Lv, Chao Li, Chengen Huang, Chenglin Cai, Chujie Zheng, Daniel Cooper, Ethan Dai, et al. Yi-lightning technical report. arXiv preprint arXiv:2412.01253, 2024.
- Dongxu Li, Yudong Liu, Haoning Wu, Yue Wang, Zhiqi Shen, Bowen Qu, Xinyao Niu, Guoyin Wang, Bei Chen, and Junnan Li. Aria: An open multimodal native mixture-of-experts model, 2024e. URL https://arxiv.org/abs/2410.05993.
- Kaizhi Zheng, Xuehai He, and Xin Eric Wang. Minigpt-5: Interleaved vision-and-language generation via generative vokens, 2024c. URL https://arxiv.org/abs/2310.02239.
- Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023. URL https://arxiv.org/abs/2308.12966.
- Yong Dai, Duyu Tang, Liangxin Liu, Minghuan Tan, Cong Zhou, Jingquan Wang, Zhangyin Feng, Fan Zhang, Xueyu Hu, and Shuming Shi. One model, multiple modalities: A sparsely activated approach for text, sound, image, video and code, 2022. URL https://arxiv.org/abs/2205.06126.
- Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. National Science Review, page nwae403, 2024. [CrossRef]
- Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, and Dong Yu. Mm-llms: Recent advances in multimodal large language models. arXiv preprint arXiv:2401.13601, 2024h.
- Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. On llms-driven synthetic data generation, curation, and evaluation: A survey. arXiv preprint arXiv:2406.15126, 2024.
- Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792, 2023d.
- Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18:0 (6)::0 186345, 2024h. [CrossRef]
- Yuheng Cheng, Ceyao Zhang, Zhengwen Zhang, Xiangrui Meng, Sirui Hong, Wenhao Li, Zihao Wang, Zekai Wang, Feng Yin, Junhua Zhao, et al. Exploring large language model based intelligent agents: Definitions, methods, and prospects. arXiv preprint arXiv:2401.03428, 2024b.
- Yuyou Gan, Yong Yang, Zhe Ma, Ping He, Rui Zeng, Yiming Wang, Qingming Li, Chunyi Zhou, Songze Li, Ting Wang, et al. Navigating the risks: A survey of security, privacy, and ethics threats in llm-based agents. arXiv preprint arXiv:2411.09523, 2024b.
- Wangchunshu Zhou, Yuchen Eleanor Jiang, Long Li, Jialong Wu, Tiannan Wang, Shi Qiu, Jintian Zhang, Jing Chen, Ruipu Wu, Shuai Wang, Shiding Zhu, Jiyu Chen, Wentao Zhang, Xiangru Tang, Ningyu Zhang, Huajun Chen, Peng Cui, and Mrinmaya Sachan. Agents: An open-source framework for autonomous language agents, 2023c. URL https://arxiv.org/abs/2309.07870.
- Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model based agents. arXiv preprint arXiv:2404.13501, 2024i.
- Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges. Vicinagearth, 1:0 (1)::0 9, 2024f. [CrossRef]
- Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, and Huajun Chen. Reasoning with language model prompting: A survey. arXiv preprint arXiv:2212.09597, 2022.
- Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large language models for software engineering: A systematic literature review. ACM Transactions on Software Engineering and Methodology, 2023. [CrossRef]
- Sihao Hu, Tiansheng Huang, Fatih Ilhan, Selim Tekin, Gaowen Liu, Ramana Kompella, and Ling Liu. A survey on large language model-based game agents. arXiv preprint arXiv:2404.02039, 2024b.
- Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, et al. Personal llm agents: Insights and survey about the capability, efficiency and security. arXiv preprint arXiv:2401.05459, 2024g.
- Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, Rui Kong, Yile Wang, Hanfei Geng, Jian Luan, Xuefeng Jin, Zilong Ye, Guanjing Xiong, Fan Zhang, Xiang Li, Mengwei Xu, Zhijun Li, Peng Li, Yang Liu, Ya-Qin Zhang, and Yunxin Liu. Personal llm agents: Insights and survey about the capability, efficiency and security, 2024h. URL https://arxiv.org/abs/2401.05459.
- Biao Wu, Yanda Li, Meng Fang, Zirui Song, Zhiwei Zhang, Yunchao Wei, and Ling Chen. Foundations and recent trends in multimodal mobile agents: A survey, 2024g. URL https://arxiv.org/abs/2411.02006.
- Shuai Wang, Weiwen Liu, Jingxuan Chen, Weinan Gan, Xingshan Zeng, Shuai Yu, Xinlong Hao, Kun Shao, Yasheng Wang, and Ruiming Tang. Gui agents with foundation models: A comprehensive survey, 2024i. URL https://arxiv.org/abs/2411.04890.
- Minghe Gao, Wendong Bu, Bingchen Miao, Yang Wu, Yunfei Li, Juncheng Li, Siliang Tang, Qi Wu, Yueting Zhuang, and Meng Wang. Generalist virtual agents: A survey on autonomous agents across digital platforms, 2024b. URL https://arxiv.org/abs/2411.10943.
- Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Qingwei Lin, Saravan Rajmohan, et al. Large language model-brained gui agents: A survey. arXiv preprint arXiv:2411.18279, 2024j.
| 1 | J.A.R.V.I.S. stands for “Just A Rather Very Intelligent System”, a fictional AI assistant character from the Marvel Cinematic Universe. It appears in Iron Man (2008), The Avengers (2012), and other films, serving as Tony Stark’s (Iron Man’s) personal assistant and interface for his technology. |
| 2 | Rankings were determined using the Chatbot Arena LLM Leaderboard [11] as of December 22, 2024. For models originating from the same producer, rankings were assigned based on the performance of the highest-ranking model. |
| 3 | Given the varying interpretations of ’grounding’ across different domains, in this subsubsection, the term ’grounding’ specifically refers to visual grounding, which is the process of locating objects or regions in an image based on a natural language query. This definition differs from the one used in §2.2. |
| 4 |
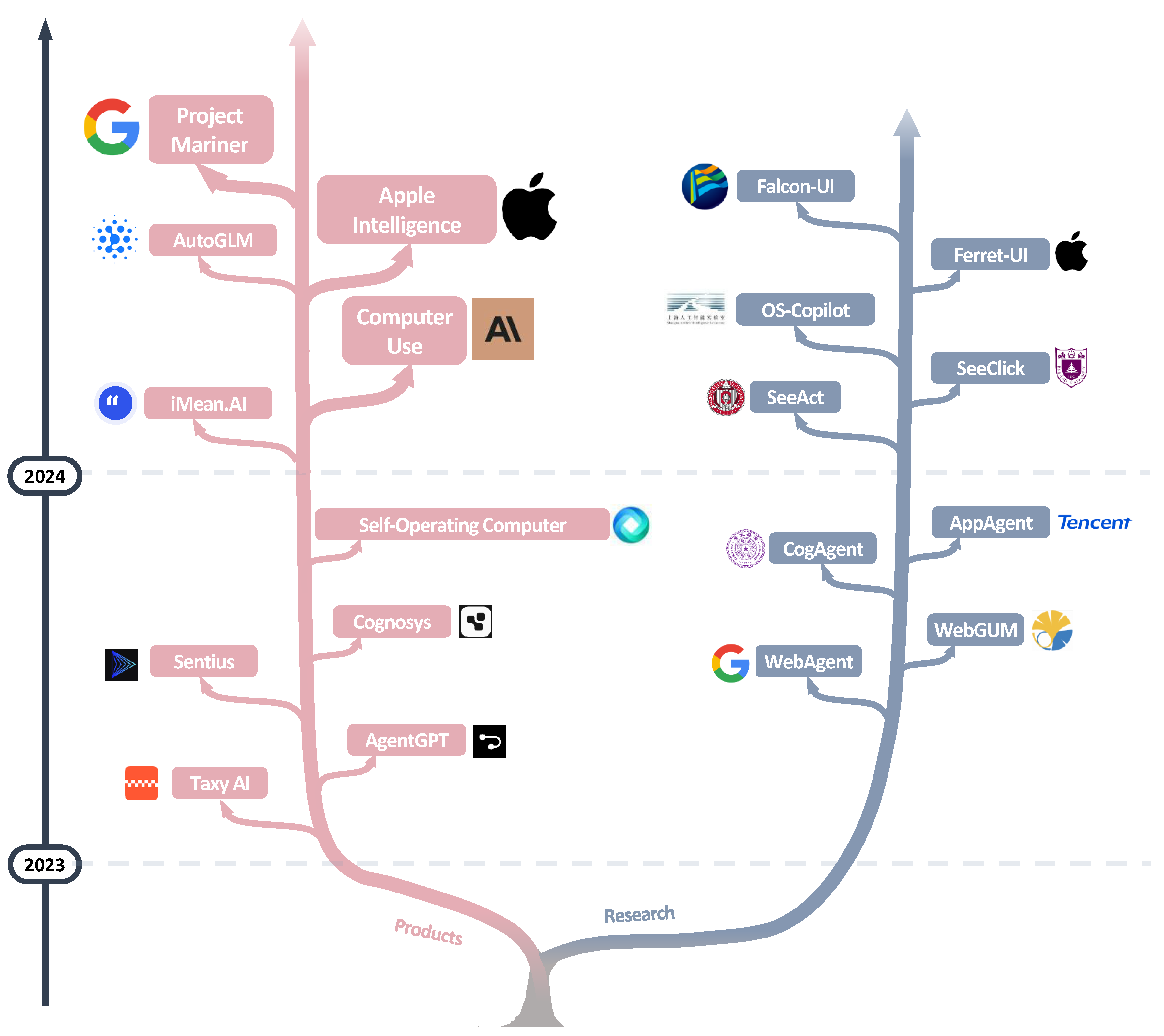

| Model | Arch. | PT | SFT | RL | Date |
|---|---|---|---|---|---|
| OS-Atlas [22] | Exist. MLLMs | ✓ | ✓ | - | 10/2024 |
| AutoGLM [14] | Exist. LLMs | ✓ | ✓ | ✓ | 10/2024 |
| EDGE [21] | Exist. MLLMs | - | ✓ | - | 10/2024 |
| Ferret-UI 2 [68] | Exist. MLLMs | - | ✓ | - | 10/2024 |
| ShowUI [69] | Exist. MLLMs | ✓ | ✓ | - | 10/2024 |
| UIX [70] | Exist. MLLMs | - | ✓ | - | 10/2024 |
| TinyClick [71] | Exist. MLLMs | ✓ | - | - | 10/2024 |
| UGround [19] | Exist. MLLMs | - | ✓ | - | 10/2024 |
| NNetNav [72] | Exist. LLMs | - | ✓ | - | 10/2024 |
| Synatra [73] | Exist. LLMs | - | ✓ | - | 09/2024 |
| MobileVLM [74] | Exist. MLLMs | ✓ | ✓ | - | 09/2024 |
| UI-Hawk [75] | Mod. MLLMs | ✓ | ✓ | - | 08/2024 |
| GUI Action Narrator [76] | Exist. MLLMs | - | ✓ | - | 07/2024 |
| MobileFlow [53] | Mod. MLLMs | ✓ | ✓ | - | 07/2024 |
| VGA [20] | Exist. MLLMs | - | ✓ | - | 06/2024 |
| OdysseyAgent [77] | Exist. MLLMs | - | ✓ | - | 06/2024 |
| Textual Foresight [78] | Concat. MLLMs | ✓ | ✓ | - | 06/2024 |
| WebAI [79] | Concat. MLLMs | - | ✓ | ✓ | 05/2024 |
| GLAINTEL [80] | Exist. MLLMs | - | - | ✓ | 04/2024 |
| Ferret-UI [18] | Exist. MLLMs | - | ✓ | - | 04/2024 |
| AutoWebGLM [52] | Exist. LLMs | - | ✓ | ✓ | 04/2024 |
| Patel et al. [81] | Exist. LLMs | - | ✓ | - | 03/2024 |
| ScreenAI [82] | Exist. MLLMs | ✓ | ✓ | - | 02/2024 |
| Dual-VCR [83] | Concat. MLLMs | - | ✓ | - | 02/2024 |
| SeeClick [84] | Exist. MLLMs | ✓ | ✓ | - | 01/2024 |
| CogAgent [54] | Mod. MLLMs | ✓ | ✓ | - | 12/2023 |
| ILuvUI [85] | Mod. MLLMs | - | ✓ | - | 10/2023 |
| RUIG [86] | Concat. MLLMs | - | - | ✓ | 10/2023 |
| WebAgent [87] | Concat. LLMs | ✓ | ✓ | - | 07/2023 |
| WebGUM [88] | Concat. MLLMs | - | ✓ | - | 05/2023 |
| Agent | Perception | Planning | Memory | Action | Date |
|---|---|---|---|---|---|
| OpenWebVoyager [50] | GS, SG | - | - | IO, NO | 10/2024 |
| OSCAR [28] | GS, DG | IT | AE | EO | 10/2024 |
| PUMA [107] | TD | - | - | IO, NO, EO | 10/2024 |
| AgentOccam [108] | TD | IT | MA | IO, NO | 10/2024 |
| Agent S [109] | GS, SG | GL | EA, AE, MA | IO, NO | 10/2024 |
| ClickAgent [45] | GS | IT | AE | IO, NO | 10/2024 |
| LSFS [110] | GS, SG | - | - | EO | 09/2024 |
| NaviQAte [111] | GS, SG | - | - | IO | 09/2024 |
| PeriGuru [46] | GS, DG | IT | EA, AE | IO, NO | 09/2024 |
| OpenWebAgent [87] | GS, DG | - | - | IO | 08/2024 |
| LLMCI [112] | GS, SG | - | - | EO | 07/2024 |
| Agent-E [113] | TD | IT | AE, MA | IO, NO | 07/2024 |
| Cradle [114] | GS | IT | EA, AE, MA | EO | 03/2024 |
| CoAT [26] | GS | IT | - | IO, NO | 03/2024 |
| Self-MAP [115] | - | IT | EA | IO | 02/2024 |
| OS-Copilot [29] | TD | GL | EA, AE | IO, EO | 02/2024 |
| Mobile-Agent [116] | GS, SG | IT | AE | IO, NO | 01/2024 |
| WebVoyager [27] | GS, VG | IT | MA | IO, NO | 01/2024 |
| AIA [117] | GS, VG | GL | - | IO, NO | 01/2024 |
| SeeAct [47] | GS, SG | - | AE | IO | 01/2024 |
| AppAgent [23] | GS, DG | IT | AE | IO, NO | 12/2023 |
| ACE [30] | TD | GL | AE | IO, NO | 12/2023 |
| MobileGPT [118] | TD | GL | MA | IO, NO | 12/2023 |
| MM-Navigator [24] | GS, VG | - | MA | IO, NO | 11/2023 |
| WebWise [119] | TD | - | MA | IO, NO | 10/2023 |
| Li et al. [120] | TD | IT | AE | IO, NO | 10/2023 |
| Laser [25] | TD | IT | AE | IO, NO | 09/2023 |
| Synapse [121] | - | - | MA | IO | 06/2023 |
| SheetCopilot [122] | TD | IT | AE | EO | 05/2023 |
| RCI [58] | - | IT | AE | IO, NO | 03/2023 |
| Wang et al. [123] | TD | - | - | IO | 09/2022 |
| Benchmark | Platform | BS | OET | Task | Date |
|---|---|---|---|---|---|
| AndroidControl [144] | M/P | ST | - | AT | 06/2024 |
| AndroidWorld [34] | M/P | IT | RW | AT | 05/2024 |
| Android-50 [36] | M/P | IT | RW | AT | 05/2024 |
| B-MoCA [43] | M/P | IT | RW | AT | 04/2024 |
| LlamaTouch [145] | M/P | IT | RW | AT | 04/2024 |
| AndroidArena [33] | M/P | IT | RW | AT | 02/2024 |
| AITW [136] | M/P | ST | - | AT | 07/2023 |
| UGIF-DataSet [33] | M/P | ST | - | AT | 11/2022 |
| MoTIF [146] | M/P | ST | - | AT | 02/2022 |
| PIXELHELP [147] | M/P | IT | RW | GG | 05/2020 |
| WindowsAgentArena [31] | PC | IT | RW | AT | 09/2024 |
| OfficeBench [148] | PC | IT | RW | AT | 07/2024 |
| OSWorld [149] | PC | IT | RW | AT | 04/2024 |
| OmniACT [32] | PC | ST | - | CG | 02/2024 |
| ASSISTGUI [30] | PC | IT | RW | AT | 12/2023 |
| Mind2Web-Live [150] | Web | IT | RW | IF, AT | 06/2024 |
| MMInA [151] | Web | IT | RW | IF, AT | 04/2024 |
| GroundUI [152] | Web | ST | - | GG | 03/2024 |
| TurkingBench [153] | Web | IT | RW | AT | 03/2024 |
| WorkArena [42] | Web | IT | RW | IF, AT | 03/2024 |
| WebLINX [41] | Web | ST | - | IF, AT | 02/2024 |
| Visualwebarena [40] | Web | IT | RW | GG, AT | 01/2024 |
| WebVLN-v1 [96] | Web | IT | RW | IF, AT | 12/2023 |
| WebArena [154] | Web | IT | RW | AT | 07/2023 |
| Mind2Web [129] | Web | ST | - | IF, AT | 06/2023 |
| WebShop [39] | Web | ST | - | AT | 07/2022 |
| PhraseNode [155] | Web | ST | - | GG | 08/2018 |
| MiniWoB [38] | Web | ST | - | AT | 08/2017 |
| FormWoB [38] | Web | IT | SM | AT | 08/2017 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



