Submitted:
22 December 2024
Posted:
24 December 2024
Read the latest preprint version here
Abstract
This paper presents an efficient Grey Wolf Optimizer (EGWO) designed to address the limitations of the standard Grey Wolf Optimizer (GWO), focusing on reducing memory usage and accelerating convergence. The proposed method integrates Sinusoidal Mapping for enhanced population diversity and a Transverse- Longitudinal Crossover strategy to balance global explo- ration and local exploitation. These innovations improve search efficiency and optimization precision while main- taining a lightweight computational footprint. Experi- mental evaluations on 10 benchmark functions demon- strate EGWO’s superior performance in convergence speed, solution accuracy, and robustness. Its application to hyperparameter tuning of a Random Forest model for a housing price dataset confirms its practical utility, fur- ther supported by SHAP-based interpretability analysis.
Keywords:
Grey Wolf Optimizer
; Lightweight Optimization
; Sinusoidal Mapping
; Crossover Strategy
; Random Forest
; SHAP Analysis
1. Introduction
With the development of intelligent optimization algorithms [32], some memory efficient and scalable models have been rising to a favor [29,30]. Among these, bio-inspired optimization methods have proven to be highly effective in solving complex global opti- mization problems [33]. These algorithms simulate the behaviors and collaborative mechanisms of biological groups in nature, enabling efficient exploration of large search spaces to find near-optimal solutions [2,31]. Among these methods, the Grey Wolf Optimizer (GWO), proposed by Mirjalili et al. in 2014, has gained significant attention due to its simplicity and efficiency. GWO has been successfully applied in various fields such as engineering design, data mining, and machine learning [22].
GWO mimics the hunting behavior of grey wolves in nature, leveraging the collaborative efforts of four different roles: α, β, δ, and ω wolves. The α wolf leads the group, guiding the hunting process; the β and δ wolves assist in exploration and adjust the search direction; while the ω wolves follow and maintain the diversity of the population, preventing premature convergence to local optima. The process involves strategies of encircling, tracking, and capturing prey, progressively narrowing the search space to approach the optimal solution [7].
Despite its success in various applications, GWO has limitations that restrict its performance. Firstly, the random initialization of the population can result in uneven distribution, which affects early-stage search efficiency [1]. Secondly, GWO tends to get trapped in local optima when dealing with complex, high- dimensional, or multimodal optimization problems, due to its insufficient global exploration capability. Additionally, as iterations proceed, the diversity of the population decreases, leading to slow convergence in the later stages [3].
To address these challenges, this paper proposes an Enhanced Grey Wolf Optimizer (EGWO), which in- corporates advanced strategies to improve both global exploration and local exploitation capabilities. Specif- ically, EGWO employs a hybrid initialization strategy that combines geometric uniform distribution with ran- dom sampling, ensuring better initial diversity of the population. This approach enhances early-stage search efficiency by overcoming the limitations of traditional random initialization [35]. Furthermore, a dynamic weight adjustment mechanism is introduced, enabling adaptive balancing between global exploration and local exploitation throughout the optimization process [38]. An adaptive step size strategy is also applied, allowing for fine-tuned search capabilities based on solution quality, thus facilitating more precise explo- ration.
The performance of SCGWO is evaluated through extensive experiments on multiple complex benchmark functions and compared with the classic GWO. The results demonstrate that SCGWO achieves faster con- vergence and higher accuracy, particularly in high- dimensional, nonlinear, and multimodal optimization problems. Additionally, SCGWO shows greater robust- ness across multiple independent runs, highlighting its stability.
To further demonstrate its effectiveness in practical applications, SCGWO is applied to the hyperparameter optimization of random forest models using the Boston housing price dataset [9]. The results indicate that SCGWO outperforms traditional optimization meth- ods, achieving superior convergence and performance in model tuning.
Main Contributions
The key contributions of this paper are summarized as follows:
- Proposed an Enhanced Grey Wolf Opti- mizer (SCGWO): A novel improvement of the GWO algorithm is presented, integrating Sinu- soidal Mapping for population initialization and a Transverse-Longitudinal Crossover strategy, sig- nificantly enhancing both global exploration and local exploitation capabilities.
- Introduced Dynamic Weight Adjustment Mechanism: A dynamic weight adjustment mechanism is developed to adaptively balance the roles of α, β, and δ wolves, ensuring better exploration in early stages and faster convergence in later stages.
- Evaluated on Comprehensive Benchmark Functions: The proposed SCGWO is rigor- ously tested on 10 complex benchmark functions, demonstrating superior performance in terms of convergence speed, solution accuracy, and robust- ness when compared to the classic GWO.
- Validated through Real-World Application: The effectiveness of SCGWO is further validated through its application to the hyperparameter op- timization of a random forest model, achieving better tuning results than conventional optimiza- tion methods.
and the prey, and the update of the wolves’ position, respectively. The parameters A and C are defined as:
where r1 and r2 are random vectors in [0, 1], and a is a parameter that decreases linearly from 2 to 0 over the course of iterations.
A = 2a · r1 − a
C = 2 · r2
2) Hunting Prey: The candidate wolves’ positions are updated by tracking the positions of the three leading wolves: α, β, and δ, as shown by the following equations:
Dα= |C1 · Xα− X|
Dβ= |C2 · Xβ− X|
Dδ= |C3 · Xδ− X|
The updated positions of the three leading wolves are:
X1 = Xα− A1 · Dα
X2 = Xβ− A2 · Dβ
X3 = Xδ− A3 · Dδ
The final position of the candidate wolf is deter- mined by averaging the positions influenced by α, β, and δ:
X1 + X2 + X3
2. Related Work
X(t + 1) = 3
2.1. Grey Wolf Optimizer (GWO)
The Grey Wolf Optimizer (GWO) is a nature- inspired optimization algorithm that models the be- havior of grey wolves in their natural hunting process. It was introduced by Seyedali Mirjalili et al. in 2014 [22]. The core idea of the algorithm is to convert the optimization problem into a process where a group of grey wolves search for prey. Within the wolf pack, there are four different roles: α, β, δ, and candidate wolves, representing the current best solution, the second-best solution, the third-best solution, and other candidate solutions, respectively. The hunting process of grey wolves is simulated through the following three phases: encircling prey, hunting prey, and attacking prey.
1) Encircling Prey: During the hunting process, grey wolves encircle the prey using the following equations:
where Xp represents the position of the prey, and X is the position of the grey wolf. X(t + 1) is the updated position of the grey wolf at time t + 1. Equations (1) and (2) model the distance between the grey wolves
D = |C · Xp(t) − X(t)|
X(t + 1) = Xp(t) − A · D
3) Attacking Prey: As the grey wolves iteratively update their positions, they adjust the roles of the lead- ing wolves and continue the process until a termination condition is met, such as reaching a maximum number of iterations or achieving a desired fitness level.
2.2. Improvements to GWO
Since the introduction of GWO, numerous improve- ments have been proposed to enhance its performance. Emary et al. (2016) proposed a binary version of GWO for feature selection, which outperformed traditional methods such as particle swarm optimization (PSO) and genetic algorithms (GA) in various datasets [7]. Other studies, such as those by Abdollahzadeh et al. (2020), have incorporated chaos theory into GWO to increase population diversity and prevent prema- ture convergence [1]. Hybrid approaches combining GWO with differential evolution (DE) and simulated annealing (SA) have also demonstrated improved per- formance in complex optimization tasks [6], [35].
However, most of these studies focus on either global exploration or local exploitation, failing to address both aspects simultaneously. To bridge this gap, this paper proposes a novel strategy that integrates Sinusoidal Mapping for initial population diversity and a Transverse-Longitudinal Crossover mechanism, aim- ing to balance global search capabilities with refined local optimization [38].
3. Enhanced Grey Wolf Optimizer
where MSxt
and MSxt
represent the new (SCGWO)
offspring generated from individuals xt
and xt
3.1. Sinusoidal Chaos Mapping for Population Initial- Ization
In traditional GWO, the initial population is gener- ated through random sampling, which often results in uneven distribution across the search space, negatively impacting convergence efficiency and accuracy. To address this, we adopt a Sinusoidal Chaos Mapping method, which generates a more uniformly distributed set of sample points, thereby enhancing the diversity of the initial population. The Sinusoidal Chaos Mapping is a typical form of chaotic mapping with a simple mathematical structure. Its expression is as follows:
where the parameter a = 2.3 and the initial value
xk+1 = a · x2 sin(π · xk),
x(0) = 0.7. By using this mapping, the diversity of the initial population is significantly improved, allowing for a more effective exploration of the search space and enhancing the algorithm’s convergence speed and accuracy [1].
3.2. Transverse-Longitudinal Crossover Strategy
The Transverse-Longitudinal Crossover Strategy is a key method for significantly improving the perfor- mance of the SCGWO. Traditional GWO often faces challenges with population individuals clustering in local regions of the search space, leading to prema- ture convergence. To overcome this limitation, the transverse-longitudinal crossover strategy introduces crossover operations that encourage individuals to ex-through transverse crossover, r1 and r2 are random numbers in the range [0, 1], and c1 and c2 are constants in the range [−1, 1]. After the transverse crossover operation, individuals can generate offspring with a higher probability within their respective hypercube spaces and edges, thus expanding the search space and improving global exploration. The offspring generated through this crossover must compete with their par- ents, and the individual with higher fitness is retained, ensuring a balance between exploration and exploita- tion.
2) Longitudinal Crossover Operation: The longitu- dinal crossover operation addresses the tendency of GWO to get stuck in local optima in later stages of the optimization process. This occurs when some individuals in the population reach local optima too early, causing the convergence speed to increase while the ability to explore the global optimum diminishes. The lack of a mutation mechanism in GWO restricts its ability to continue approaching the global optimum. Therefore, after performing transverse crossover, it is necessary to apply longitudinal crossover to further enhance the algorithm’s ability to escape local optima.
Longitudinal crossover operates on all dimensions of newly generated offspring, with a lower probability than transverse crossover, similar to mutation in ge- netic algorithms. If a newly generated individual xt undergoes longitudinal crossover between dimensions d1 and d2, the calculation is as follows:
plore a wider range of the solution space. Specifically, the transverse crossover enhances the global explo-
ration capability, enabling the population to escape from local optima, while the longitudinal crossover refines the solution in local regions, ensuring that no promising areas are overlooked near the optimal solution. This combined strategy not only increases the diversity of the algorithm but also accelerates the convergence process.
MSxi,d1 t i,d = r1 · xti,d + (1 − r1) · xti,d2
1) Transverse Crossover Operation: The transverse crossover operation in SCGWO is similar to the crossover operation in genetic algorithms, focusing on exchanging information between different individ- uals across the same dimension. This approach is designed to improve the global search capability of the population. By randomly arranging the individuals in the population and performing crossover on the d-th dimension, the positions of the individuals are updated as follows:
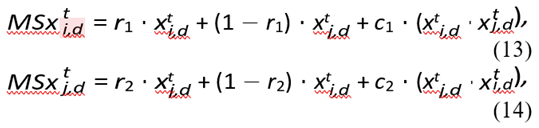
where MSxt is the offspring generated from di- mensions d1 and d2 of individual xt through lon- gitudinal crossover, and r1 ∈ [0, 1]. Similar to the transverse crossover operation, the offspring gener- ated through longitudinal crossover competes with its parent, and the individual with higher fitness is preserved. This selection mechanism allows crossover participants to retain their superior dimensional in- formation while improving population diversity and solution quality.
By combining transverse and longitudinal crossover operations, SCGWO effectively balances the ability to explore and exploit, resulting in a more efficient con- vergence to the global optimum. As the algorithm iter- ates, if an individual escapes a local optimum through longitudinal crossover in one dimension, this improve- ment is rapidly spread through transverse crossover, reinforcing the quality of the new solution throughout the population. This combined approach significantly enhances the algorithm’s ability to overcome local op-tima and improve both convergence speed and solution
4. Simulations and Results
4.1. Experiment Setup
4.2. Results and Discussion
Figure 1a show the convergence curves for four representative functions. As shown, SCGWO signifi- cantly outperforms the traditional GWO in terms of convergence speed and solution accuracy [3].

Table 2.
Comparison of GWO and SCGWO on 10 Benchmark Functions.
| Function | Algorithm | Best Value | Mean Value |
|---|---|---|---|
| F1 | GWO SCGWO |
2.15 × 10−4 1.36 × 10−5 |
1.67 × 10−3 7.35 × 10−4 |
| F2 | GWO SCGWO |
3.01 × 10−4 4.61 × 10−6 |
1.94 × 10−3 5.21 × 10−4 |
| F3 | GWO SCGWO |
2.61 × 10−5 1.11 × 10−6 |
6.32 × 10−5 4.31 × 10−6 |
| F4 | GWO SCGWO |
6.01 × 10−5 2.01 × 10−6 |
9.18 × 10−5 5.11 × 10−6 |
| F5 | GWO SCGWO |
5.82 × 10−3 3.07 × 10−3 |
9.21 × 10−1 1.08 × 10−2 |
| F6 | GWO SCGWO |
1.11 × 10−5 6.13 × 10−8 |
1.17 × 10−4 1.23 × 10−7 |
| F7 | GWO SCGWO |
1.21 × 10−4 2.26 × 10−5 |
1.81 × 10−2 4.38 × 10−3 |
| F8 | GWO SCGWO |
6.48 × 10−4 5.31 × 10−6 |
1.84 × 10−3 2.28 × 10−5 |
| F9 | GWO SCGWO |
8.30 × 10−3 4.06 × 10−5 |
1.68 × 10−2 2.22 × 10−4 |
| F10 | GWO SCGWO |
6.06 × 10−3 6.56 × 10−5 |
4.02 × 10−2 5.12 × 10−4 |
5. Random Forest Hyperparameter Optimization
SCGWO was applied to optimize the hyperparam- eters of a random forest regression model using the Boston housing price dataset from Kaggle [9]. The results are summarized in Table 3, showing that SCGWO outperformed traditional methods.
Figure 1.
Convergence Curves of SCGWO and GWO on Different Benchmark Functions.
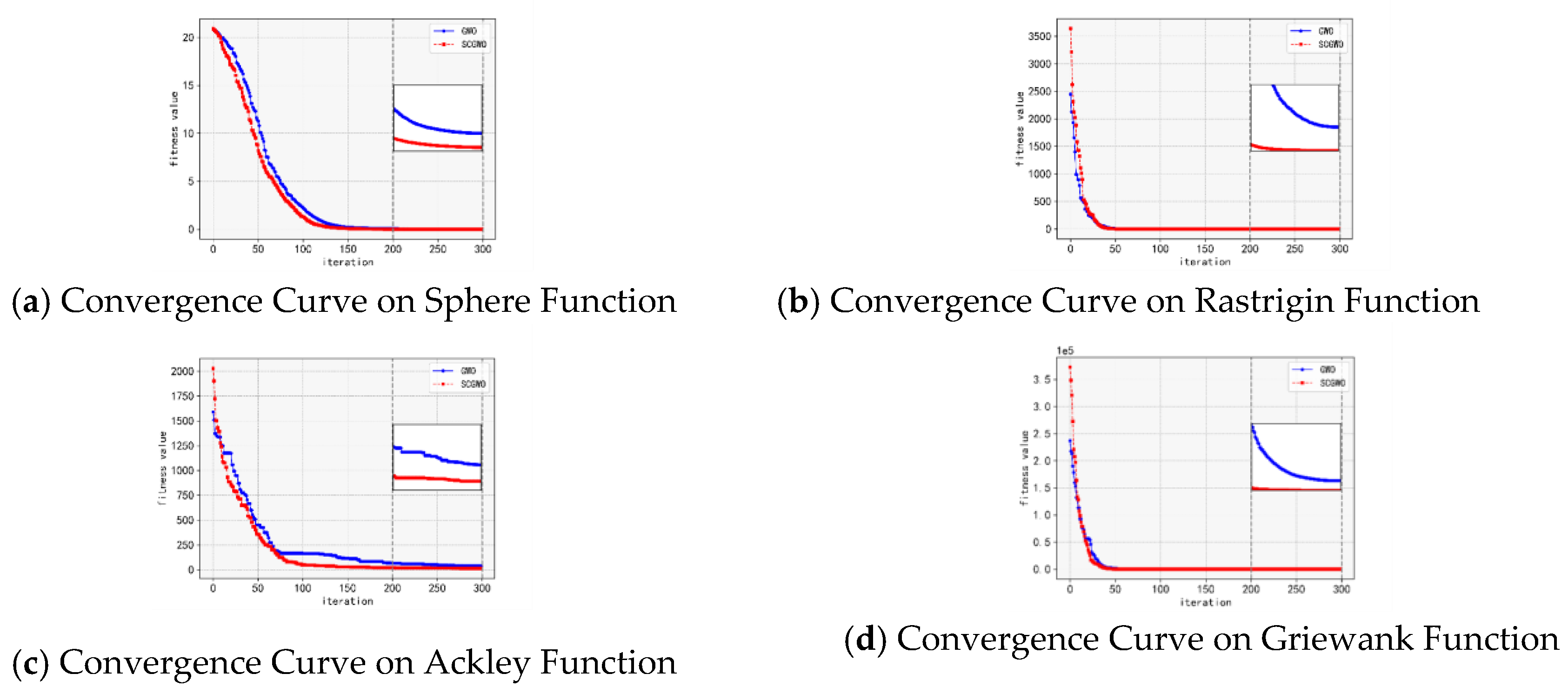
Table 3.
Performance Comparison on Random For- est Hyperparameter Optimization.
| Method | MAE (train) | RMSE (train) | R2 (train) | MAE (test) | RMSE (test) |
|---|---|---|---|---|---|
| Default | 285109 | 398584 | 0.9494 | 957916 | 1357261 |
| GWO | 413922 | 547712 | 0.9045 | 922632 | 1262471 |
| SCGWO | 448753 | 616299 | 0.8791 | 917518 | 1238437 |
6. Shap Analysis
SHAP (SHapley Additive exPlanations) analysis was used to interpret the SCGWO-optimized random forest model’s predictions. The SHAP summary plot, shown in Figure 2, highlights the key features con- tributing to the model’s predictions.
To ensure a more convincing evaluation, 30 compar- ative experiments were conducted on 10 benchmark functions. For each experiment, the best value, mean, and standard deviation were recorded. The average of the results from 30 experiments was calculated as the final result for comparison, as shown in the table below.
7. Future Work
In future work, we aim to explore the potential of SCGWO in addressing more challenging machine learning applications. For instance, optimizing deep neural network architectures, as demonstrated by Gao et al. [8], could benefit from SCGWO’s capacity to handle complex high-dimensional optimization tasks. Additionally, combining SCGWO with other optimiza- tion techniques, such as particle swarm optimization (PSO), may improve performance in real-time systems, particularly in dynamic environments like warehouse robotics [12,14].
One promising direction for SCGWO is its applica- tion to multitask learning systems. Techniques like the MT2ST framework, which transitions from multitask to single-task learning [19], could leverage SCGWO for fine-tuning task-specific performance. Similarly, SCGWO can enhance the robustness of representation learning in symmetric positive definite manifolds, as explored by Bu et al. [4].
In healthcare, SCGWO has the potential to optimize ensemble learning techniques in medical diagnostics. For example, ensemble models have been used to improve skin lesion diagnosis [20], and SCGWO could further refine the weighting of model components to enhance diagnostic accuracy. Likewise, SCGWO could improve performance in stroke treatment outcome pre- diction [21] and biomedical imaging tasks [10].
Real-time 3D imaging tasks, such as crack detection [36], could also benefit from SCGWO by improving the computational efficiency of multi-sensor fusion models. Furthermore, SCGWO could be applied to optimize reinforcement learning algorithms for robot navigation in complex warehouse layouts [13], enhanc- ing adaptability and efficiency.
In content moderation, SCGWO could optimize machine learning models to integrate community rules for better transparency, as proposed by Xin et al. [34]. Similarly, it holds promise in mitigating knowledge conflicts in large language models for model compres- sion [17], and for question answering [5], which could advance human-computer interaction technologies.
For cloud computing and networking, SCGWO can optimize resource allocation dynamically, building on prior research into distributed systems [39]. Addi- tionally, in cybersecurity, SCGWO may contribute to defending against sequential query-based blackbox attacks [26] or enhancing meta-learning enabled ad- versarial defenses [27].
Recent advancements in deep learning optimizers, such as those enhancing stability with sigmoid and tanh functions [37], suggest that SCGWO could im- prove learning efficiency in large-scale models. More- over, SCGWO’s potential applications in large-scale object detection [25] indicate its versatility for real- world tasks.
In time series modeling, SCGWO could optimize advanced models, such as Transformers and LSTMs,for applications in healthcare like heart rate prediction [24]. Furthermore, integrating SCGWO with quantized low-rank adaptation (QLoRA) methods for stock mar- ket prediction [23] could enhance adaptability and decision-making in financial forecasting.
In recommendation systems, SCGWO could im- prove optimization strategies based on graph neural networks [28,18], yielding better predictive perfor- mance in dynamic environments. SCGWO could also play a vital role in optimizing intelligent vehicle classi- fication models in traffic systems [15,16], enhancing multi-sensor fusion and reducing computation time.
Finally, SCGWO holds promise in enhancing large language models for detecting AI-generated content. By optimizing adaptive ensembles of fine-tuned trans- formers [11], SCGWO could improve detection sys- tems’ speed and accuracy.
Overall, SCGWO exhibits significant potential across diverse domains, including healthcare, au- tonomous systems, financial technology, and intel- ligent transportation. Its adaptability and efficiency make it a valuable tool for addressing complex, high- dimensional problems, paving the way for broader applications in theoretical and practical research.
8. Conclusions
This paper proposes an improved Grey Wolf Op- timizer, SCGWO, which integrates Sinusoidal Map- ping and a Transverse-Longitudinal Crossover strategy. SCGWO was tested on several benchmark functions and applied to hyperparameter optimization in a ran- dom forest regression model. The results demonstrate that SCGWO outperforms traditional GWO in both convergence speed and solution accuracy. Future work will explore its application in more complex optimiza- tion problems and real-time systems.
Appendix
Modeling and Optimization
A random forest regression model was built using the Boston housing price dataset. The dataset was split into a 70:30 ratio for training and testing, respectively. The model was trained on the training set and tested for its generalization ability on the test set. Three configurations were evaluated: default hyperparame- ters, GWO-optimized hyperparameters, and SCGWO- optimized hyperparameters.
The performance of each model configuration was measured using evaluation metrics such as Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and the coefficient of determination (R2). The results for the three methods are presented in Table 3.
The results demonstrate that the SCGWO-optimized random forest model achieved the best performance, not only on the training set but also on the test set, effectively reducing overfitting compared to the default and GWO-optimized models.
Figure 3.
Comparison of Model Fitting for Default, GWO, and SCGWO Optimizations.
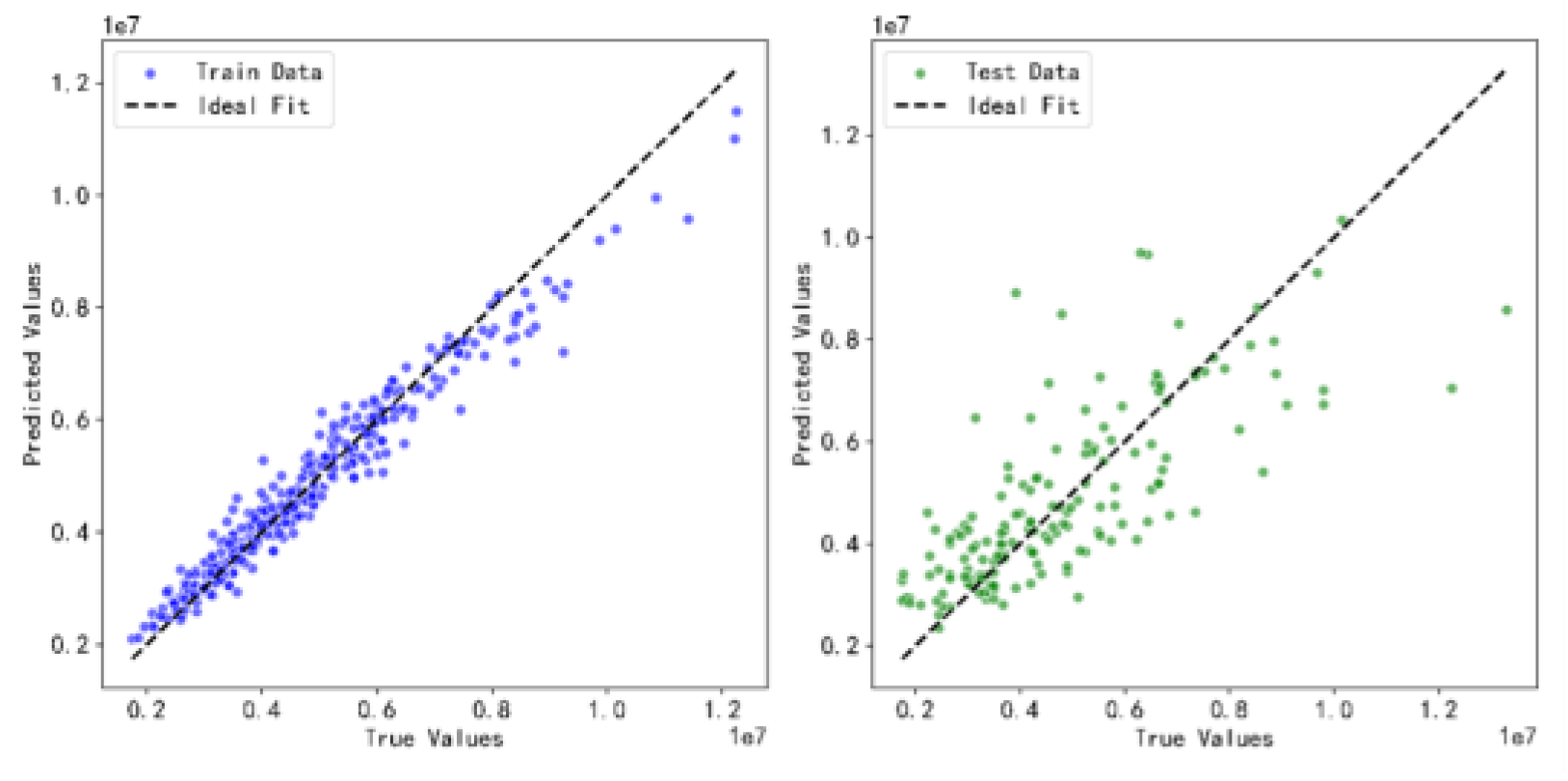
From Figure 3, it is evident that the SCGWO- optimized model has the lowest error margins and pro- vides better overall predictions. This result highlights the efficiency of the SCGWO method in hyperparam- eter tuning of complex models.
References
- Behnam Abdollahzadeh, Reza Ebrahimi, and Saeed Arani Arani. Improved grey wolf optimization algorithm based on chaos theory for optimization problems. Applied Soft Computing 2020, 90, 106187. [Google Scholar]
- Sanjay Arora and Satvir Singh. A review on nature-inspired optimization algorithms. International Journal of Industrial Engineering Computations 2019, 10, 681–709. [Google Scholar]
- Jagdish Bansal and Himanshu Sharma. Enhanced grey wolf optimizer with levy flight for engineering design optimization. Journal of Computational Design and Engineering 2022, 9, 23–38. [Google Scholar]
- Xingyuan Bu, Yuwei Wu, Zhi Gao, and Yunde Jia. Deep convolutional network with locality and sparsity constraints for texture classification. Pattern Recognition 2019, 91, 34–46. [Google Scholar] [CrossRef]
- Han Cao, Zhaoyang Zhang, Xiangtian Li, Chufan Wu, Han- song Zhang, and Wenqing Zhang. Mitigating knowledge conflicts in language model-driven question answering, 2024.
- Gaurav Dhiman and Vijay Kumar. Hybrid optimization strate- gies combining grey wolf optimizer with differential evolution and simulated annealing. Expert Systems with Applications 2021, 159, 113584. [Google Scholar]
- Ebrahim Emary, Hossam M Zawbaa, and Aboul Ella Has- sanien. Binary grey wolf optimization approaches for feature selection. Neurocomputing 2016, 172, 371–381. [Google Scholar] [CrossRef]
- Zhi Gao, Yuwei Wu, Xingyuan Bu, Tan Yu, Junsong Yuan, and Yunde Jia. Learning a robust representation via a deep network on symmetric positive definite manifolds. Pattern Recognition 2019, 92, 1–12. [Google Scholar] [CrossRef]
- Soliman Khalil. Machine learning model for hous- ing dataset. 2021. Kaggle. Available online: https://www.kaggle.com/code/solimankhalil/ ml-model-linear-regression-housing-dataset.
- Zhixin Lai, Jing Wu, Suiyao Chen, Yucheng Zhou, and Naira Hovakimyan. Residual-based language models are free boosters for biomedical imaging tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 5086–5096, June 2024.
- Zhixin Lai, Xuesheng Zhang, and Suiyao Chen. Adaptive ensembles of fine-tuned transformers for llm-generated text detection. 2024.
- Keqin Li, Jiajing Chen, Denzhi Yu, Tao Dajun, Xinyu Qiu, Lian Jieting, Sun Baiwei, Zhang Shengyuan, Zhenyu Wan, Ran Ji, et al. Deep reinforcement learning-based obstacle avoidance for robot movement in warehouse environments. arXiv preprint arXiv:2409.14972, 2024.
- Keqin Li, Lipeng Liu, Jiajing Chen, Dezhi Yu, Xiaofan Zhou, Ming Li, Congyu Wang, and Zhao Li. Research on reinforce- ment learning based warehouse robot navigation algorithm in complex warehouse layout. arXiv preprint arXiv:2411.06128, 2024.
- Keqin Li, Jin Wang, Xubo Wu, Xirui Peng, Runmian Chang, Xiaoyu Deng, Yiwen Kang, Yue Yang, Fanghao Ni, and Bo Hong. Optimizing automated picking systems in warehouse robots using machine learning. arXiv preprint arXiv:2408.16633, 2024.
- Xinjin Li, Jinghao Chang, Tiexin Li, Wenhan Fan, Yu Ma, and Haowei Ni. A vehicle classification method based on machine learning. Preprints, July 2024.
- Xinjin Li, Yuanzhe Yang, Yixiao Yuan, Yu Ma, Yangchen Huang, and Haowei Ni. Intelligent vehicle classification sys- tem based on deep learning and multi-sensor fusion. Preprints, July 2024.
- Dong Liu, Zhixin Lai, Yite Wang, Jing Wu, Yanxuan Yu, Zhongwei Wan, Benjamin Lengerich, and Ying Nian Wu. Efficient large foundation model inference: A perspective from model and system co-design. 2024.
- Dong Liu, Roger Waleffe, Meng Jiang, and Shivaram Venkataraman. Graphsnapshot: Graph machine learning ac- celeration with fast storage and retrieval. 2024.
- Dong Liu and Yanxuan, Yu. Mt2st: Adaptive multi-task to single-task learning. 2024.
- Xiaoyi Liu, Zhou Yu, Lianghao Tan, Yafeng Yan, and Ge Shi. Enhancing skin lesion diagnosis with ensemble learning. 2024.
- Danqing Ma, Meng Wang, Ao Xiang, Zongqing Qi, and Qin Yang. Transformer-based classification outcome prediction for multimodal stroke treatment. 2024.
- Seyedali Mirjalili, Seyed Mohammad Mirjalili, and Andrew Lewis. Grey wolf optimizer. Advances in Engineering Software 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Haowei Ni, Shuchen Meng, Xupeng Chen, Ziqing Zhao, Andi Chen, Panfeng Li, Shiyao Zhang, Qifu Yin, Yuanqing Wang, and Yuxi Chan. Harnessing earnings reports for stock predictions: A qlora-enhanced llm approach. arXiv preprint arXiv:2408.06634, 2024.
- Haowei Ni, Shuchen Meng, Xieming Geng, Panfeng Li, Zhuoying Li, Xupeng Chen, Xiaotong Wang, and Shiyao Zhang. Time series modeling for heart rate prediction: From arima to transformers. arXiv preprint arXiv:2406.12199, 2024.
- Junran Peng, Xingyuan Bu, Ming Sun, Zhaoxiang Zhang, Tieniu Tan, and Junjie Yan. Large-scale object detection in the wild from imbalanced multi-labels. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9709–9718, 2020.
- Yiyi Tao. Sqba: sequential query-based blackbox attack. In Fifth International Conference on Artificial Intelligence and Computer Science (AICS 2023), volume 12803, page 128032Q. International Society for Optics and Photonics, SPIE, 2017.
- Yiyi Tao. Meta learning enabled adversarial defense. In 2023 IEEE International Conference on Sensors, Electronics and Computer Engineering (ICSECE), pages 1326–1330, 2023.
- Zeyu Wang, Yue Zhu, Zichao Li, Zhuoyue Wang, Hao Qin, and Xinqi Liu. Graph neural network recommendation system for football formation. Applied Science and Biotechnology Journal for Advanced Research, 2024; 3, 33–39.
- Yijie Weng, Yongnian Cao, Meng Li, and Xuechun Yang. The application of big data and ai in risk control models: Safeguarding user security. International Journal of Frontiers in Engineering Technology, 2024; 6.
- Yijie Weng and Jianhao, Wu. Big data and machine learning in defence. International Journal of Computer Science and Information Technology 2024, 16. [Google Scholar]
- Yijie Weng and Jianhao, Wu. Fortifying the global data fortress: a multidimensional examination of cyber security indexes and data protection measures across 193 nations. International Journal of Frontiers in Engineering Technology 2024, 6. [Google Scholar]
- Yijie Weng and Jianhao, Wu. Leveraging artificial intelligence to enhance data security and combat cyber attacks. Journal of Artificial Intelligence General science (JAIGS), 2024; 5, 392–399ISSN 3006- 4023. [Google Scholar]
- Yijie Weng, Jianhao Wu, Tara Kelly, and William Johnson. Comprehensive overview of artificial intelligence applications in modern industries. arXiv preprint arXiv:2409.13059, 2024.
- Wangjiaxuan Xin, Kanlun Wang, Zhe Fu, and Lina Zhou. Let community rules be reflected in online content moderation. 2024.
- Xiaofei Yang and Jinsong Guo. A novel hybrid algorithm of ant colony optimization and grey wolf optimizer for continuous optimization problems. Expert Systems with Applications 2020, 150, 113282. [Google Scholar]
- Haowei Zhang, Kang Gao, Huiying Huang, Shitong Hou, Jun Li, and Gang Wu. Fully decouple convolutional network for damage detection of rebars in rc beams. Engineering Structures 2023, 285, 116023. [Google Scholar] [CrossRef]
- Hongye Zheng, Bingxing Wang, Minheng Xiao, Honglin Qin, Zhizhong Wu, and Lianghao Tan. Adaptive friction in deep learning: Enhancing optimizers with sigmoid and tanh func- tion. arXiv preprint arXiv:2408.11839, 2024.
- Hua Zhu, Yi Wang, and Jian Zhang. An adaptive multi- population differential evolution with cooperative co-evolution for high-dimensional optimization. Swarm and Evolutionary Computation 2019, 44, 226–239. [Google Scholar]
- Wenbo Zhu. Optimizing distributed networking with big data scheduling and cloud computing. In International Conference on Cloud Computing, Internet of Things, and Computer Ap- plications (CICA 2022), volume 12303, pages 23–28. SPIE, 2022.
Figure 2.
SHAP Summary Plot for Random Forest Model.
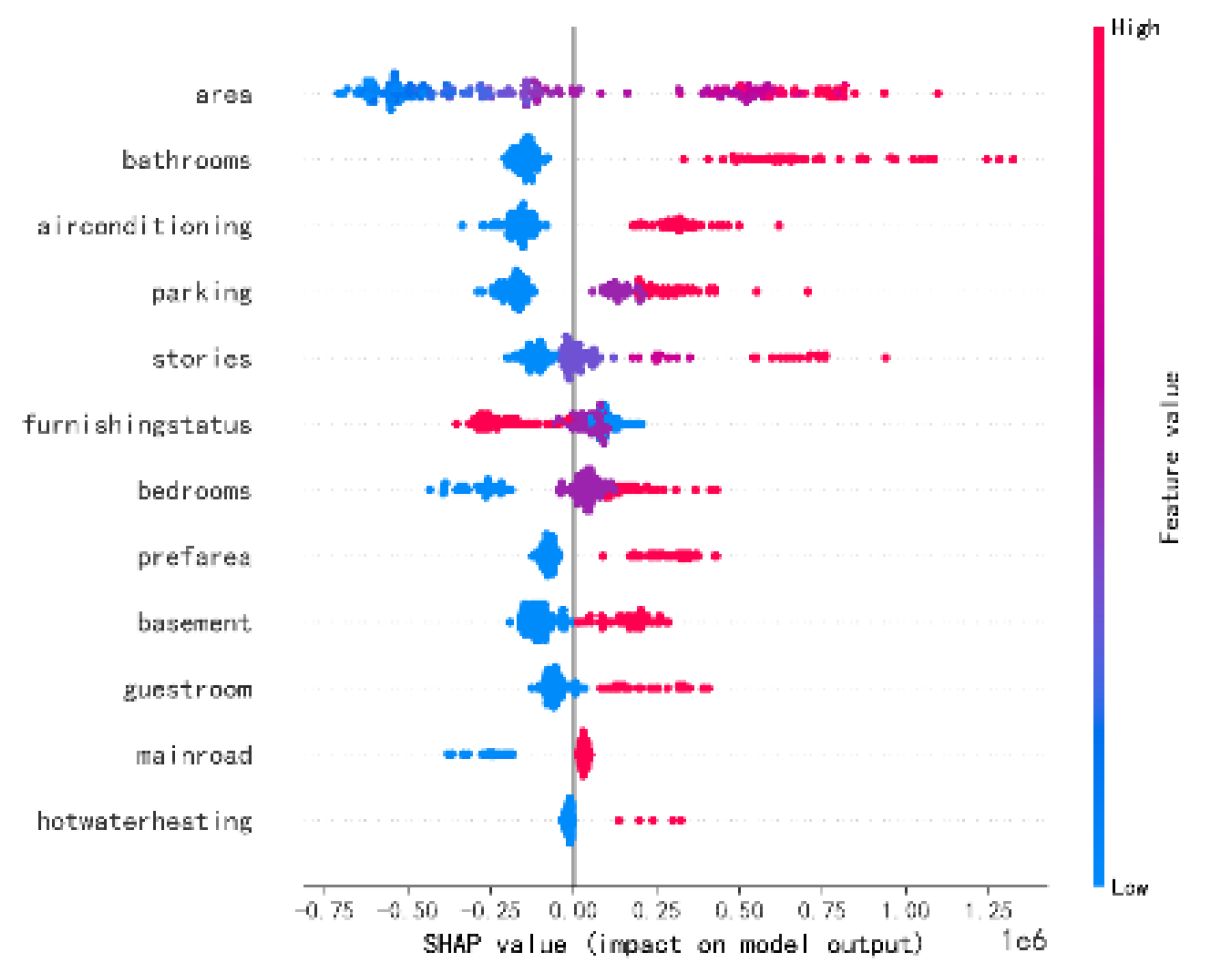
Table 1.
Benchmark Functions for SCGWO Perfor- mance Testing.
| Function | Name | Search Range | DIM | OPT Value |
|---|---|---|---|---|
| F1 | Sphere | [-100, 100] | 30 | 0 |
| F2 | Schwefel2.22 | [-10, 10] | 30 | 0 |
| F3 | Schwefel1.2 | [-100, 100] | 30 | 0 |
| F4 | Schwefel2.21 | [-100, 100] | 30 | 0 |
| F5 | Rosenbrock | [-30, 30] | 30 | 0 |
| F6 | Step | [-100, 100] | 30 | 0 |
| F7 | Rastrigin | [-5.12, 5.12] | 30 | 0 |
| F8 | Ackley | [-32, 32] | 30 | 0 |
| F9 | Griewank | [-600, 600] | 30 | 0 |
| F10 | Penalized | [-50, 50] | 30 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



