Submitted:
22 December 2024
Posted:
23 December 2024
Read the latest preprint version here
Abstract
This paper introduces "SeamCarver," a LLM-enhanced method that redefines image resizing . SeamCarver addresses the limitations of traditional seam carving with static pre-defined parameters, it uses LLM to achieve dynamic and user-controlled AI-resizing of images. We also evaluate the performance of SeamCarver on different datasets.The inclusion of LLMs in this research facilitates dynamic optimization of parameter tuning and adaptive energy function adjustments, enhancing overall robustness and efficiency of image resizing. SeamCarver emerges as a transformative tool, offering versatile, high-quality resized images.
Keywords:
efficient machine learning
; LLMs in vision
I. Introduction
SeamCarver is an image resizing method de- signed to maintain important image details during resizing. By integrating large language models (LLMs), SeamCarver goes beyond tra- ditional methods, enabling a smarter, context- aware resizing process. LLMs enhance tasks such as region prioritization, interpolation, edge detection, and energy calculation by an- alyzing image context or textual inputs. This allows SeamCarver to preserve crucial image features like faces and text while optimizing resizing for different scenarios.
This paper explores how LLMs improve the accuracy and efficiency of image resizing.
II. Background
i. LLM-Enhanced Image Resizing: The SeamCarver Approach
SeamCarver enhances the traditional seam carv- ing method by incorporating LLMs. The in- tegration of LLMs allows for dynamic resiz- ing of images based on real-time context and user input, rather than relying on fixed pa- rameters. The LLM dynamically optimizes the energy functions that determine how seams are selected and removed, making the resizing process adaptive and context-sensitive. This approach allows for superior preservation of image details and better quality when resizing for specific tasks, such as creating thumbnails or preparing images for various screen sizes.
LLMs contribute by adjusting the parame-ters based on the content of the image and the desired effect, improving the quality of re- sized images while providing flexibility. The dynamic optimization of the resizing process using LLMs represents a major leap in the flex- ibility and efficiency of image resizing tech- niques.
ii. LLM-Related Work
Recent research in Large Language Models (LLMs) has demonstrated their potential in a variety of domains, including image process- ing. LLMs, originally designed for natural lan- guage understanding, have been adapted to enhance image processing workflows through advanced model architectures and optimiza- tion techniques.
For instance, Li et al. (2024) demonstrated how LLMs can optimize convolutional neural network (CNN) layers for feature extraction in image processing tasks, improving the per- formance of deep learning models in image classification and segmentation [16]. Zhang et al. (2024) explored the use of LLMs in multi-modal fusion networks, enabling the integration of both visual and textual infor- mation, which enhances image analysis tasks [11,13,25,27].
Additionally, efficient algorithm design [1,5,8,12,14,25,28,30] and efficient LLMs [19,20] have shown promise in model compression. Through dynamic optimization, LLMs allow for more context-aware resizing by adjusting energy functions during the process. This flexi- bility ensures that fine-grained details are pre- served, which is especially crucial for tasks like content-aware resizing, as seen in techniques such as SeamCarver. Studies on text-to-image models have demonstrated how LLMs can modify images based on contextual prompts [2,9,15,16,17,18,29], providing further ad- vancements in content-aware image resizing.
These advancements highlight the increas- ing role of LLMs in enhancing traditional im- age processing tasks and their ability to con-tribute significantly to content-aware resizing techniques like SeamCarver.
iii. Image and Vision Generation Work
The application of deep learning techniques in image and vision generation has also seen signifi- cant advancements [3,4,5,7,10,23,26,27]. Deep convolutional networks, for instance, have been used for texture classification (Bu et al., 2019), which is directly relevant to tasks like energy function optimization in SeamCarver [1]. These methods help improve the detail preservation during image resizing by ensur- ing that textures and edges are maintained throughout the process.
Furthermore, multi-modal fusion networks and techniques for image-driven predictions (as demonstrated by Dan et al., 2024) offer im- portant insights into how AI can be used to process and modify images in real-time [4,5]. Besides, model compression currently becom- ing a favor from both model and system design perspective [21,22]. These innovations align closely with SeamCarver’s goal of dynamic, user-controlled image resizing, making them valuable for future developments in image re- sizing technology.
iv. Image Resizing and Seam Carving Research
SeamCarver builds upon earlier work in im- age resizing techniques. In addition to the foun- dational work by Avidan and Shamir (2007), other studies have contributed to enhancing seam carving methods. Kiess (2014) introduced improved edge preservation methods within seam carving [?], which is crucial for ensuring that resized images do not suffer from visi- ble distortions along object boundaries. Zhang (2015) compared classic image resizing meth- ods and found that seam carving provided superior results when compared to simpler resizing techniques, particularly in terms of detail preservation [?].
Frankovich (2011) further advanced seam carving by integrating energy gradient func- tionals to enhance the carving process, provid- ing even more control over the resizing opera- tion [?]. These improvements are incorporated into SeamCarver, which leverages LLMs to fur- ther optimize the parameter tuning and energy functions during resizing.
v. Impact of SeamCarver and Future Directions
The development of SeamCarver represents a significant step forward in content-aware im- age resizing. By leveraging the power of LLMs, this approach enables adaptive resizing, main- taining high-quality images across a variety of use cases. As machine learning and AI continue to evolve, future versions of Seam- Carver could integrate even more advanced techniques, such as generative models for even higher-quality resizing and multi-task learning to tailor resizing for specific contexts.
Moreover, SeamCarver provides an excellent example of how LLMs can be used to enhance traditional image processing tasks, enabling more intelligent and user-driven modifications to images. This work will likely spur further research into dynamic image resizing and con- tribute to more versatile, AI-enhanced image editing tools in the future.
III. Functionality
SeamCarver leverages LLM-Augmented meth- ods to ensure adaptive, high-quality image re- sizing while preserving both structural and semantic integrity. The key functionalities are:
- LLM-Augmented Region Prioritization: LLMs analyze semantics or textual inputs to prioritize key regions, ensuring critical areas (e.g., faces, text) are preserved.
- LLM-Augmented Bicubic Interpolation: LLMs optimize bicubic interpolation for high-quality enlargements, adjusting pa- rameters based on context or user input.
- LLM-Augmented LC Algorithm: LLMs adapt the LC algorithm by adjusting weights, ensuring the preservation of im- portant image features during resizing.
- LLM-Augmented Canny Edge Detection: LLMs guide Canny edge detection to re- fine boundaries, enhancing clarity and ac- curacy based on contextual analysis.
- LLM-Augmented Hough Transformation: LLMs strengthen the Hough transforma- tion, detecting structural lines and ensur- ing the preservation of geometric features.
- LLM-Augmented Absolute Energy Func- tion: LLMs dynamically adjust energy maps to improve seam selection for more precise resizing.
- LLM-Augmented Dual Energy Model: LLMs refine energy functions, enhanc- ing flexibility and ensuring effective seam carving across various use cases.
- LLM-Augmented Performance Evalua- tion: CNN-based classification experi- ments on CIFAR-10 are enhanced with LLM feedback to fine-tune resizing results.
IV. LLM-Guided Region Prioritization
To enhance the seam carving process, we in- tegrate Large Language Models (LLMs) to guide region prioritization during image re- sizing. Traditional seam carving typically re- moves seams based on an energy map derived from pixel-level intensity or gradient differ- ences. However, this method may struggle to preserve regions with semantic significance, such as faces, text, or objects, which require more context-aware resizing. Our approach in- troduces LLMs to assign semantic importance to different regions of the image, modifying the energy map to prioritize the preservation of these crucial regions.
i. Method Overview
Given an image I, the initial energy map E(x, y) is computed using standard seam carving tech-niques, typically relying on pixel-based fea- tures such as intensity gradients and contrast:

where ∇Ix(x, y) and ∇Iy(x, y) represent the gradient values of the image I at pixel (x, y) in the x- and y-directions, respectively.
Next, a Large Language Model (LLM) is employed to analyze either the image content directly or a user-provided textual description of the regions to prioritize. For example, a user might specify that "faces should be preserved" or "text should remain readable." This descrip- tion is processed by the LLM, which assigns an importance score S(x, y) to each pixel based on its semantic relevance. The function that generates these scores is denoted as:
where fLLM represents the output of the LLM processing both the image I and a descrip- tion D. The LLM interprets the description D through its internal knowledge of language and context, identifying which parts of the im- age correspond to higher-priority regions (e.g., faces, text, objects).
S(x, y) = fLLM(I, D)
The LLM’s understanding of the image is derived using advanced techniques like **trans- former architectures** [24] and **contextual embedding** [6], which allow the model to cap- ture both local and global relationships within the image, ensuring that important features are accurately recognized and prioritized. For example, the LLM might recognize that a re- gion containing a face is more important than a background area when performing resizing.
ii. Energy Map Adjustment
To modify the energy map, the semantic im- portance scores S(x, y) are combined with the original energy map E(x, y). This modified energy map E′(x, y) is calculated as follows:
where α is a scalar weight that determines the influence of the LLM-based importance scores on the energy map. By incorporating S(x, y), the energy map becomes content-aware, en- suring that the regions with higher semantic importance (e.g., faces, text) have lower energy values, making them less likely to be removed during the seam carving process.
E′(x, y) = E(x, y) + α ·S(x, y)
iii. Energy Map Adjustment
The modified energy map E′(x, y) is calculated as:
where: - E(x, y) is the original energy map.
E′(x, y) = E(x, y) + αS(x, y)
- S(x, y) is the semantic importance score de- rived from the LLM. - α is a weight factor con- trolling the influence of semantic importance.
iv. Pseudocode
| Algorithm 1 LLM-Guided Region Prioritiza- tion for Seam Carving |
|
Initialize: Compute the initial energy map E(x, y) for the image I; Obtain semantic importance scores S(x, y) from LLM based on image content or user description; Normalize the importance scores S(x, y) to a suitable range. Adjustment: 1. For each pixel (x, y), compute the adjusted energy map: E′(x, y) = E(x, y) + α · S(x, y) 2. Set α to control the influence of semantic importance on the energy map. 3. Repeat for all pixels to generate the adjusted energy map E′. Output: The adjusted energy map E′ for guiding seam carving. |
V. LLM-Augmented Bicubic Interpolation
SeamCarver integrate a LLM-Augmented bicubic interpolation method for image resizing. This method uses a bicubic policy to smooth pixel values, with LLMs improving the visual quality of enlarged images. However, traditional bicubic interpolation does not account for the semantic importance of image regions. To address this limitation, we augment the standard interpolation with semantic guidance from LLMs, ensuring that regions of high importance—such as faces, text, and objects—are preserved more effectively during enlargement.
The traditional bicubic interpolation algo- rithm operates by using a 4x4 pixel grid sur- rounding the target pixel to calculate the new pixel value. This method typically focuses on the rate of change between neighboring pixel intensities. In contrast, our approach leverages LLMs to assign semantic importance scores S(x, y) to each pixel, reflecting its con- textual significance. These importance scores are derived from the image content or a user- provided description, and they adjust the inter- polation weights, effectively guiding the resiz-ing process to preserve critical regions.
The bicubic interpolation formula for a pixel at position (x, y) is based on calculating the weighted sum of the 4x4 neighborhood of sur- rounding pixels. Traditionally, the interpola- tion weights w(x) and w(y) are determined based on the relative distance between the tar- get pixel and its neighbors. These weights can be defined as:

Then, the new pixel value at position (X, Y) is computed by summing the contributions of the surrounding 16 pixels:
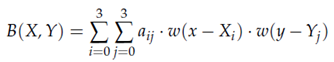
For a floating-point pixel coordinate (x, y), the interpolation involves considering the 4x4 neighborhood (xi, yj), where i, j = 0, 1, 2, 3, and calculating the new pixel value as follows:

In the augmented version, the weights w(x) and w(y) are modified based on the impor- tance scores S(x, y) derived from the LLM. For each pixel, we compute the adjusted interpola- tion weight w′(x) as:
where β is a scalar factor that controls the influence of the semantic importance score. By incorporating these adjusted weights into the interpolation process, regions deemed impor- tant by the LLM receive greater priority during the resizing process, resulting in higher-quality enlargements that better preserve semantic con- tent.
w′(x) = w(x) · (1 + β ·S(x, y))
The incorporation of LLMs significantly improves the ability of bicubic interpolation to perform content-aware resizing, ensuring that important regions, such as faces, text, or other key objects, are preserved with higher fidelity. The LLM’s ability to interpret the image context or a user’s textual description enables a more adaptive resizing strategy, where the image can be enlarged in a way that prioritizes and preserves the most semantically relevant regions.
In conclusion, this approach not only enhances the visual quality of enlarged images by preserving important areas but also allows for a more flexible and context-aware image resizing process. The integration of LLMs elevates bicubic interpolation from a purely geometric operation to a more intelligent, contextsensitive method, improving overall resizing performance.
VI. LLM-Augmented LC (Loyalty-Clarity) Policy
SeamCarver also used LLM-Augmented LC (Loyalty-Clarity) Policy to resize images. Tra- ditionally, the LC policy evaluates each pixel’s contrast relative to the entire image, focusing on maintaining the most visually significant el- ements. However, by incorporating **LLMs**, we enhance this method with semantic under- standing, allowing the system to prioritize im- age regions based not only on visual contrast but also on their semantic importance, as un- derstood from contextual descriptions or image content analysis.
i. Global Contrast Calculation with LLM Influence
The traditional LC policy computes the global contrast of a pixel by summing the distance between the pixel in question and all other pix- els in the image. This measure indicates the pixel’s relative importance in terms of visual contrast. In our **LLM-augmented** approach, the global contrast is modified by considering semantic relevance, as dictated by the LLM’s analysis of the image or user-provided descrip- tion.
For instance, if a user inputs that the image contains important "faces" or "text," the LLM assigns higher weights to these regions, increasing their importance in the contrast calculation. The LLM’s guidance is mathematically integrated into the contrast calculation as follows:
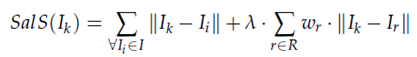
In this formulation: - Ik represents the intensity of the pixel being analyzed, while Ii represents the intensity of all other pixels. - wr is the weight assigned to a region r by the LLM, which is based on its semantic importance, such as prioritizing faces or text. - λ is a scaling factor that controls the influence of the **LLM**’s weighting on the global contrast calculation.
By adjusting wr based on the LLM-driven understanding of important regions, the algo- rithm effectively prioritizes preservation of the semantically significant areas.
ii. Frequency-Based Refinement with LLM Augmentation
To further refine the contrast measure, we incor- porate the frequency distribution of intensity values in the image. The traditional frequency- based contrast is enhanced with the LLM’s semantic input, which guides how regions of different intensities should be prioritized.
In the standard approach, the global contrast for a pixel Ik is computed as:

Where: - fn is the frequency of the intensity value an. - am represents the intensity of the pixel Ik, and an are the intensity values of all other pixels.
In the LLM-augmented approach, the LLM provides additional weighting for specific re- gions, emphasizing the importance of certain intensities based on semantic input. The modi- fied calculation is:

Here, wr adjusts the weight of the frequency term for pixels in semantically significant regions, as determined by the LLM. This allows for a more refined and context-aware adjustment of the image’s contrast, ensuring that the most relevant image areas are preserved during the resizing process.
iii. Application in Image Resizing
By incorporating LLM-guided adjustments into the LC Policy, SeamCarver becomes signif- icantly more content-aware. The LLM allows the software to prioritize critical regions—such as human faces, text, or objects—based on user input or semantic analysis of the image. This semantic understanding of the image ensures that, even during resizing, key features remain sharp and well-defined, while less important regions are more freely adjusted.
For example, if a user specifies that "faces" should be preserved, the LLM ensures that these areas have a higher weight during the resizing process, while the surrounding less important areas can be resized with minimal distortion. This LLM-augmented LC Policy thus improves the visual integrity of resized images, making the process more adaptable to both user needs and semantic context.
Figure 1.
Outlier detected by the LC algorithm.

VII. LLM-Augmented Canny Line Detection
In SeamCarver, the LLM-augmented Canny Line Detection algorithm enhances edge and structural feature preservation during image resizing. By incorporating Large Language Models (LLMs), the edge detection process is guided semantically to prioritize regions that are critical to image content, such as faces and text.
i. Algorithm Overview
The Canny Edge Detection algorithm detects edges by analyzing intensity gradients. The standard method detects edges using the first derivative of the image’s intensity, but the LLM-augmented approach incorporates semantic information, adjusting the edge detection for important regions identified by the LLM.
ii. Gaussian Filter Application
The image is first smoothed using a Gaussian filter to reduce noise. The filter is represented as:

This step prepares the image for the gradi- ent calculation while minimizing false edges. In the LLM-augmented process, the filter may be adapted based on the semantic regions de- tected by the LLM, ensuring more precise edge detection in critical areas.
iii. Gradient Calculation with LLM Augmentation
After Gaussian filtering, the gradient at each pixel (i, j) is calculated using the Sobel opera- tor:


Where Gx(i, j) and Gy(i, j) are the deriva- tives in the horizontal and vertical directions, respectively.
In the LLM-augmented method, the gradi- ents are modified by the semantic importance S(i, j) of each region, as identified by the LLM. The semantic importance adjusts the gradient magnitude, giving higher weight to edges in critical areas:
Gaug(i, j) = G(i, j) ·S(i, j)
Here, S(i, j) is the semantic score assigned by the LLM, where higher values correspond to regions that are semantically more important (e.g., faces, text).
iv. Edge Enhancement
The Canny algorithm applies non-maximum suppression and hysteresis thresholding to refine the detected edges. In the LLM- augmented process, the suppression threshold is adapted based on the importance scores:

By incorporating the LLM, edges in semanti- cally significant regions (e.g., faces or objects) are preserved with greater accuracy, while less important areas are suppressed more aggres- sively.
v. Significance in Image Resizing
The LLM-augmented Canny Line Detection improves the image resizing process by ensur- ing that the edges and features critical to the image’s content are better preserved. This is es- pecially important when resizing images with significant content like faces or text, where tra- ditional methods might fail to preserve impor- tant details.
Figure 2.
Original Image.

Figure 3.
Edges Detected by the Canny Detector (with LLM Augmentation).

VIII. LLM-Augmented Hough Transformation
The SeamCarver software integrates the LLM- Augmented Hough Transformation to en- hance line detection during image resizing. This method incorporates semantic guidance from Large Language Models (LLMs) to en- sure the preservation of key structural features, such as text or faces, during resizing. The LLM augments the traditional Hough Transforma- tion by adjusting the accumulator based on the semantic importance of regions within the image.
i. Algorithm Overview
The Hough Transformation detects lines by mapping points from the image domain to the Hough space. In the traditional approach, collinear points converge to peaks in Hough space, indicating the presence of a line. The LLM-Augmented Hough Transformation in- troduces semantic weighting to this process, en- suring that semantically significant lines (e.g., those in text or faces) are prioritized during line detection.
ii. Mathematical Formulation
In the standard Hough Transformation, the ac- cumulator is updated by incrementing for each detected edge pixel. However, in the LLM- Augmented Hough Transformation, the up- date to the accumulator is influenced by a se- mantic importance score S(x, y) derived from the LLM. This adjustment ensures that seman- tically important regions of the image have a greater influence on the detection of lines.
The basic equation for updating the accumu- lator with the semantic weight S(x, y) is:
Accumulator(r, θ) ← Accumulator(r, θ) + S(x, y)
Where: - r = x cos(θ) + y sin(θ) is the radial distance in Hough space. - θ is the angle of the line in Hough space. - S(x, y) is the se- mantic importance score of the pixel (x, y), as determined by the LLM.
This formulation adjusts the weight of each edge pixel based on the semantic relevance of its location in the image. Higher S(x, y) values are assigned to pixels in semantically important regions, such as those in faces or text.
iii. LLM-Augmented Hough Transfor- mation Algorithm
The implementation of the LLM-Augmented Hough Transformation in SeamCarver is out- lined as follows:
| Algorithm 2 LLM-Augmented Hough Transformation for Line Detection |
|
Require: Image: input digital image; Ensure: Lines detected in the image, with se- mantic guidance from the LLM. 1: Apply edge detection (e.g., Canny edge detector) to the image. 2: Initialize Hough space and accumulator: Accumulator(r, θ) = 0 3: for each edge pixel (x, y) in the image do 4: for each angle θ do 5: Compute radial distance r = x cos(θ) + y sin(θ) 6: Retrieve the semantic score S(x, y) from the LLM for pixel (x, y) 7: Update accumulator: Accumulator(r, θ) ← Accumulator(r, θ) + S(x, y) 8: end for 9: end for 10: Detect peaks in the accumulator. 11: Convert infinite lines to finite lines. |
iv. Significance of LLM-Augmented Hough Transformation in Image Resiz- ing
The LLM-Augmented Hough Transformation allows SeamCarver to preserve important lin- ear structures during resizing. By integrating semantic scores from the LLM, the algorithm ensures that critical features, such as text or faces, are prioritized in the resizing process, making the output more content-aware and maintaining the visual integrity of the resized image.
Figure 4.
Original Image.

Figure 5.
Lines Detected by LLM-Augmented Hough Transformation with Background.

Figure 6.
Prominent Lines Detected by LLM- Augmented Hough Transformation.

IX. LLM-Augmented Absolute Energy Equation
In SeamCarver, the LLM-Augmented Absolute Energy Equation is employed to enhance the dynamic programming approach for image re- sizing, particularly when handling high-detail images. This method leverages semantic in- sights provided by Large Language Models (LLMs) to refine the energy gradient calcu- lations, thus improving seam carving perfor- mance in complex images.
i. Conceptual Overview
The LLM-Augmented Absolute Energy Equa- tion introduces a new dimension to the energy gradient computation by integrating semantic feedback from the LLM. This feedback adjusts the energy gradient of the image in regions that are semantically significant, ensuring that the resizing process preserves critical structural features such as text, faces, and important ob- jects. The LLM’s semantic understanding aids in determining areas that should not be re- sized aggressively, even if they are energetically weak.
ii. Mathematical Formulation
The energy gradient update process is adjusted to incorporate the semantic weighting derived from the LLM. In the original energy equation, the energy of the image e(I) is calculated as the sum of the absolute gradients in both x and y directions

The LLM-Augmented Absolute Energy Equation modifies this by introducing a se- mantic weight function S(x, y), which adjusts the energy gradient based on the semantic im- portance of the pixel:

Here, S(x, y) is the semantic importance score of pixel (x, y), which is provided by the LLM. This score reflects the pixel’s relevance in the context of the image, such as text or fa- cial features, and alters the traditional energy calculation to preserve these features more ef- fectively.
iii. Cumulative Energy Update
The cumulative energy matrix is updated with the additional LLM-semantic weighting, where the energy gradient is further refined for se- mantically significant areas. The cost compo- nents CL, CR, and CU are modified as follows to include the semantic weight:

The updated cost function now takes into account the semantic relevance of the pixels as modified by the LLM. This ensures that the resizing process preserves important features, even in low-energy regions.
iv. Comparative Energy Functions
The original energy function is updated using the minimum of the cost components as fol- lows:

In contrast, the LLM-Augmented Absolute Energy Equation incorporates the semantic weighting in the energy update process:

This update now accounts for the semantic weight of each pixel, making the seam carving process more aware of the image’s content, en- suring that important features are preserved even when they might otherwise be considered low-energy regions.
v. Impact on Image Processing
The LLM-Augmented Absolute Energy Equa- tion improves the seam carving process by integrating semantic understanding into the energy gradient calculations. The LLM helps identify and preserve critical areas in the im- age, such as text, faces, and other meaningful structures. This refined approach ensures that important visual content is retained during the resizing process, even in highly detailed im- ages. As a result, the resized image maintains its visual and structural integrity, making the process more content-aware and efficient.
X. LLM-Augmented Dual Gradient Energy Equation
In SeamCarver, the LLM-Augmented Dual Gradient Energy Equation advances edge de- tection by incorporating LLMs to enhance nu- merical differentiation and gradient computa- tion. The LLM-modified method dynamically adapts the gradient calculation based on local image structure, improving energy mapping and seam carving in images with complex textures.
i. LLM-Enhanced Numerical Differ- entiation
To improve gradient calculation, the LLM algo- rithm adapts the traditional Taylor expansion for numerical differentiation. The forward and backward Taylor expansions are modified to reflect the dynamic adjustments provided by LLMs based on the local context:

Similarly, for the backward expansion:

where ξ1, ξ2 ∈ (x, x + ∆x). The LLM adapts the step size dynamically based on local image features, improving gradient accuracy.
ii. LLM-Modified Gradient Approxi- mation
For gradient calculation, the forward difference approximation is modified with LLM to adjust the step size dynamically based on the image structure. This ensures that the method ac- curately captures fine details and changes in gradient direction:


Here, ∆ fx(x, y) and ∆ fy(x, y) represent the additional corrections provided by the LLM, which fine-tune the gradient approximation based on contextual understanding of the im- age.
iii. LLM-Refined Energy Calculation
The energy for each pixel is computed using the squared sum of the LLM-modified gradient components for the RGB channels in both x and y directions:


The total energy is the square root of the sum of these squared gradients:

LLMs enhance the gradient calculations by providing dynamic adjustments that improve the detection of subtle edges and structures, ensuring that important image features are pre- served during the resizing process.
iv. Application of LLM-Augmented Dual Gradient Energy
The LLM-Augmented Dual Gradient Energy Equation improves seam carving by enabling SeamCarver to detect and preserve important image edges more effectively. LLMs help dy- namically adapt the energy and gradient calcu- lations based on image context, ensuring that complex textures and fine details are preserved during resizing, leading to improved image quality and structural integrity.
XI. Result Evaluation
To evaluate the effectiveness of the image resiz- ing methods in SeamCarver, we conducted an experiment using Convolutional Neural Net- works (CNNs) for image classification. The goal was to compare how different resiz- ing techniques impact classification accuracy. Additionally, we explored the role of LLM- augmented approaches in enhancing image feature preservation and improving classifica- tion outcomes after resizing.
i. Experimental Setup
In the experiment, images were resized us- ing various methods implemented in Seam- Carver, including traditional methods and LLM-augmented approaches. The resized im- ages were then fed into a CNN model to assess how well each resizing method preserved im- age features essential for accurate classification. The CIFAR-10 dataset, a well-known bench- mark in image classification, was used for this experiment.
ii. Methodology
The workflow of the experiment is as follows:
Figure 7.
Workflow of the experiment, including LLM- augmented methods for image resizing.

The CNN model was first trained on the orig- inal CIFAR-10 images, and subsequently, the same model was used to classify images that had been resized using different methods in SeamCarver. This allowed us to evaluate how each resizing method influenced the model’s ability to recognize key features. Additionally, LLM-augmented methods were used to im- prove the preservation of important image de- tails during resizing, enhancing classification accuracy.
iii. Results and Discussion
The results, including accuracy metrics and error rates for each sub-experiment, are pro- vided below. The experiment revealed that LLM-augmented resizing methods led to supe- rior performance in image classification, partic- ularly in cases where maintaining fine image details was critical.
Figure 8.
Error and accuracy of a sub-experiment show- ing the improvements from LLM-augmented methods.
Figure 8.
Error and accuracy of a sub-experiment show- ing the improvements from LLM-augmented methods.

Illustrative examples of images processed by different methods, including LLM-augmented techniques, are shown below, highlighting the visual differences in the resized images and how LLM-augmented methods contribute to better feature preservation.
Figure 9.
Image processed by the Bicubic Method.

Figure 10.
Image processed by the Absolute Energy Method.

Figure 11.
Image processed by the Canny Edge Detec- tion Method.

Figure 12.
Image processed by the Dual Gradient Energy Method.

Figure 13.
Image processed by the Hough Transforma- tion Method.

Figure 14.
Image processed by the LC Method.

iv. Conclusion
This experiment highlights the significant im- provements brought by LLM-augmented meth- ods in image resizing. By integrating LLM- augmented techniques, SeamCarver can pre- serve finer image details, resulting in im- proved performance for image classification tasks. These findings emphasize the impor- tance of selecting the right resizing method in applications where image recognition accuracy is crucial.
References
- Xingyuan Bu, Yuwei Wu, Zhi Gao, and Yunde Jia. Deep convolutional network with locality and sparsity constraints for texture classification. Pattern Recognition, 91:34–46, 2019.
- Han Cao, Zhaoyang Zhang, Xiangtian Li, Chufan Wu, Hansong Zhang, and Wenqing Zhang. Mitigating knowledge conflicts in language model-driven question answering. 2024. URL: https://arxiv.org/abs/2411.11344, arXiv:2411.11344.
- Yu Cheng, Qin Yang, Liyang Wang, Ao Xi- ang, and Jingyu Zhang. Research on credit risk early warning model of com- mercial banks based on neural network al- gorithm. 2024. URL: https://arxiv.org/abs/2405.10762, arXiv:2405.10762.
- Han-Cheng Dan, Zhetao Huang, Bingjie Lu, and Mengyu Li. Image-driven predic- tion system: Automatic extraction of ag- gregate gradation of pavement core sam- ples integrating deep learning and inter- active image processing framework. Con- struction and Building Materials, 453:139056, 2024.
- Han-Cheng Dan, Bingjie Lu, and Mengyu Li. Evaluation of asphalt pavement tex- ture using multiview stereo reconstruc- tion based on deep learning. Construction and Building Materials, 412:134837, 2024.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre- training of deep bidirectional transform- ers for language understanding. In Pro- ceedings of NAACL-HLT, 2019.
- Xiu Fang, Suxin Si, Guohao Sun, Quan Z Sheng, Wenjun Wu, Kang Wang, and Hang Lv. Selecting workers wisely for crowdsourcing when copiers and domain experts co-exist. Future Internet, 14(2):37, 2022.
- Fusen Guo, Huadong Mo, Jianzhang Wu, Lei Pan, Hailing Zhou, Zhibo Zhang, Lin Li, and Fengling Huang. A hybrid stack- ing model for enhanced short-term load forecasting. Electronics, 13(14):2719, 2024.
- Yue Guo, Shiqi Chen, Ronghui Zhan, Wei Wang, and Jun Zhang. Lmsd-yolo: A lightweight yolo algorithm for multi- scale sar ship detection. Remote Sensing, 14(19):4801, 2022.
- Yuting Hu, Han Cao, Zhongliang Yang, and Yongfeng Huang. Improving text- image matching with adversarial learning and circle loss for multi-modal steganog- raphy. In International Workshop on Digital Watermarking, pages 41–52. Springer, 2020.
- Zhuohuan Hu, Fu Lei, Yuxin Fan, Zong Ke, Ge Shi, and Zichao Li. Research on financial multi-asset portfolio risk predic- tion model based on convolutional neural networks and image processing. arXiv preprint arXiv:2412.03618, 2024.
- Zong Ke, Jingyu Xu, Zizhou Zhang, Yu Cheng, and Wenjun Wu. A consoli- dated volatility prediction with back prop- agation neural network and genetic al- gorithm. arXiv preprint arXiv:2412.07223, 2024.
- Zong Ke and Yuchen Yin. Tail risk alert based on conditional autoregressive var by regression quantiles and machine learn- ing algorithms. arXiv.org, 2024. URL: https://arxiv.org/abs/2412.06193.
- Zong Ke and Yuchen Yin. Tail risk alert based on conditional autoregres- sive var by regression quantiles and ma- chine learning algorithms. arXiv preprint arXiv:2412.06193, 2024.
- Zhixin Lai, Jing Wu, Suiyao Chen, Yucheng Zhou, and Naira Hovakimyan. Residual-based language models are free boosters for biomedical imaging. 2024. URL: https://arxiv.org/abs/2403.17343, arXiv:2403.17343.
- Keqin Li, Lipeng Liu, Jiajing Chen, Dezhi Yu, Xiaofan Zhou, Ming Li, Congyu Wang, and Zhao Li. Research on reinforcement learning based warehouse robot naviga- tion algorithm in complex warehouse lay- out. arXiv preprint arXiv:2411.06128, 2024.
- Keqin Li, Jin Wang, Xubo Wu, Xirui Peng, Runmian Chang, Xiaoyu Deng, Yi- wen Kang, Yue Yang, Fanghao Ni, and Bo Hong. Optimizing automated pick- ing systems in warehouse robots us- ing machine learning. arXiv preprint arXiv:2408.16633, 2024.
- Sicheng Li, Keqiang Sun, Zhixin Lai, Xiaoshi Wu, Feng Qiu, Haoran Xie, Kazunori Miyata, and Hongsheng Li. Ecnet: Effective controllable text-to- image diffusion models. 2024. URL: https://arxiv.org/abs/2403.18417, arXiv:2403.18417.
- Dong Liu, Zhixin Lai, Yite Wang, Jing Wu, Yanxuan Yu, Zhongwei Wan, Ben- jamin Lengerich, and Ying Nian Wu. Ef- ficient large foundation model inference: A perspective from model and system co- design. 2024. URL: https://arxiv.org/ abs/2409.01990, arXiv:2409.01990.
- Dong Liu and Kaiser Pister. Llmeasyquant – an easy to use toolkit for llm quantiza- tion. 2024. URL: https://arxiv.org/abs/2406.19657, arXiv:2406.19657.
- Dong Liu, Roger Waleffe, Meng Jiang, and Shivaram Venkataraman. Graph-.
- snapshot: Graph machine learning ac- celeration with fast storage and retrieval. 2024. URL: https://arxiv.org/abs/2406.17918, arXiv:2406.17918.
- Dong Liu and Yanxuan Yu. Mt2st: Adap- tive multi-task to single-task learning. 2024. URL: https://arxiv.org/abs/2406.18038, arXiv:2406.18038.
- Junran Peng, Xingyuan Bu, Ming Sun, Zhaoxiang Zhang, Tieniu Tan, and Jun- jie Yan. Large-scale object detection in the wild from imbalanced multi-labels. In Pro- ceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 9709–9718, 2020.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Il- lia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
- Chunya Wu, Zhuoyu Yu, and Dexuan Song. Window views psychological effects on indoor thermal perception: A compari- son experiment based on virtual reality environments. E3S Web of Conferences, 546:02003, 2024. URL:. https://doi.org/10.1051/e3sconf/202454602003. [CrossRef]
- Wenjun Wu. Alphanetv4: Alpha mining model. arXiv preprint arXiv:2411.04409, 2024.
- Ao Xiang, Zongqing Qi, Han Wang, Qin Yang, and Danqing Ma. A multimodal fusion network for student emotion recog- nition based on transformer and tensor product. 2024. URL: https://arxiv.org/abs/2403.08511, arXiv:2403.08511.
- Jun Xiang, Jun Chen, and Yanchao Liu. Hybrid multiscale search for dynamic planning of multi-agent drone traffic. Jour- nal of Guidance, Control, and Dynamics, 46(10):1963–1974, 2023.
- Wangjiaxuan Xin, Kanlun Wang, Zhe Fu, and Lina Zhou. Let community rules be reflected in online content modera- tion. 2024. URL: https://arxiv.org/ abs/2408.12035, arXiv:2408.12035.
- Zhibo Zhang, Pengfei Li, Ahmed Y Al Hammadi, Fusen Guo, Ernesto Dami- ani, and Chan Yeob Yeun. Reputation- based federated learning defense to miti- gate threats in eeg signal classification. In 2024 16th International Conference on Com- puter and Automation Engineering (ICCAE), pages 173–180. IEEE, 2024.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



