Submitted:
20 December 2024
Posted:
23 December 2024
You are already at the latest version
Abstract
We examine the Rosencrantz coin that can "stick" in states for extended periods. Non-ergodic dynamics is highlighted by logarithmically growing block lengths in sequences. Traditional entropy decomposition into predictable and unpredictable components fails due to the absence of stationary distributions. Instead, sequence structure is characterized by block probabilities and Stirling numbers of the second kind, peaking at block size n/logn. For large n, combinatorial growth dominates probability decay, creating a deterministic-like structure. This approach shifts the focus from predicting states to predicting temporal horizons, providing insights into systems beyond traditional equilibrium frameworks.
Keywords:
Entropy decomposition
; Characteristic times
; Non-ergodic dynamics
1. Introduction
Predicting the future state of a system is a fundamental challenge across various fields, from physics and information theory to economics and cognitive science [1]. Simple systems, such as a biased coin, can encapsulate profound insights into uncertainty, entropy, and information dynamics. In traditional ergodic systems, where the dynamics ensure that time averages converge to ensemble averages, predictability is often assessed using entropy and its decomposition into predictable and unpredictable components [2]. These components are characterized by measures such as recurrence time, residence time, and repetition time, which capture the structure of state sequences and quantify the degree of uncertainty (see Section 2).
However, many real-world systems exhibit non-ergodic behavior, where the assumption of visiting all possible states uniformly over time breaks down. In such systems, conventional entropy-based methods become inadequate because there is no stationary distribution to describe long-term behavior. Instead, non-ergodic systems are marked by prolonged persistence in certain states, leading to sequences dominated by blocks of repeated outcomes. A striking example of such a system can be found in Tom Stoppard’s play Rosencrantz and Guildenstern Are Dead, where Rosencrantz experiences an improbable streak of 92 consecutive heads [3] that challenge traditional probabilistic frameworks. This anomaly prompts deeper exploration into non-ergodic dynamics, where long-term correlations lead to prolonged persistence in specific states. The Rosencrantz coin model (Section 3) provides a useful abstraction for studying systems with long-term correlations and memory effects. In this model, the barrier to switching states may remain constant or change intermittently, governed by a stochastic threshold. This behavior results in block-like structures within the sequences, where the lengths of these blocks increase logarithmically over time, leading to sequences dominated by blocks of persistent states. The model offers insights into the interplay between randomness and determinism, highlighting how predictable patterns emerge even in fundamentally stochastic processes (see Section 4).
To analyze these patterns, we explore the combinatorial structures governing the emerging block sequences, particularly focusing on the Stirling numbers of the second kind, which count the ways to partition sequences into non-empty blocks. The Stirling numbers reveal that for sufficiently long sequences, the most probable partitioning involves blocks of length approximately , where n is the sequence length. This combinatorial insight compensates for the lack of a stationary distribution and enables meaningful predictions of the system’s temporal behavior (Section 4).
Our analysis shows that in a non-ergodic system, the balance between combinatorial growth and the exponential decay of block probabilities results in a deterministic-like structure within a fundamentally random process. Instead of predicting individual outcomes, the focus shifts to predicting the length of sequences based on the observed block size. The concept of a temporal horizon — the characteristic length of time over which predictable patterns emerge — becomes central in non-ergodic systems. Instead of predicting the next state, the focus shifts to predicting the duration of structured behavior based on observed block sizes (Section 4). The logarithmic utility of time for prediction the future, which reflects diminishing "returns" on prediction, further connects these ideas to hyperbolic time discounting models often found in human and animal decision-making (Section 5). This novel approach offers a deeper understanding of the dynamics of non-ergodic systems, bridging concepts from information theory, combinatorics, and stochastic processes.
The paper is organized as follows: Section 2 discusses entropy decomposition in stationary Markov chains, highlighting predictable and unpredictable components and introducing the notions of characteristic times. Section 3 introduces the Rosencrantz coin model and explores its stochastic dynamics. Section 4 delves into the structure and dynamics of sequences in the non-ergodic Rosencrantz coin model, focusing on the combinatorial properties of block partitions. Section 5 presents a detailed discussion of the findings, and Section 6 concludes the paper by summarizing the key insights and implications for non-ergodic systems.
2. Decomposition of Entropy in Stationary Markov Chains – Predictable and Unpredictable Information
An outcome of each coin flip, governed by the transition matrix encapsulates a single bit of information. The probability of state repetition, determines how this information is divided into predictable and unpredictable components [2]. When , the sequence becomes perfectly predictable, locking outcomes into stationary patterns like (heads) or (tails). Similarly, when , the sequence alternates deterministically: . In contrast, corresponds to complete randomness, making future outcomes wholly unpredictable.
For long sequences () generated by an N-state, irreducible, and recurrent Markov chain with a stationary transition matrix , the relative frequency of visits to state k converges to the stationary distribution , such that for all s. The probability of each specific sequence becomes extremely small for large decreasing as . Consequently, the number of distinct sequences consistent with the stationary distribution decreases exponentially with n, viz.,
where is the decay rate at which the number of different sequences constrained by the stationary distribution decreases with sequence length n. Up to a factor of , the decay rate , corresponds to the Boltzmann-Gibbs-Shannon entropy quantifying the uncertainty of a Markov chain’s state in equilibrium:
The inverse frequency in (2) is the expected recurrence time of sequence returns to state Thus, can be termed the utility function of recurrence time, quantifying the reduction in diversity of state sequences caused by the repetition of state k in the most likely sequence patterns corresponding to the stationary distribution .
The entropy (2) serves as a foundation for decomposing the system’s total uncertainty into predictable and unpredictable components [2,4,5]. To analyze the information dynamics, we add and subtract the following conditional entropy quantities to , grouping the resulting terms into distinct informational quantities:
The excess entropy quantifies the influence of past states on the present and future states, capturing the system’s structural correlations and predictive potential. The conditional mutual information represents the information shared between the current state and the future state , independent of past history. It vanishes for both fully deterministic and completely random systems, reflecting the absence of predictive utility in these extremes. The sum of the excess entropy and the conditional mutual information shown in the second line of (3) represents the predictable information in the system [2,4]. This component quantifies the portion of the total uncertainty in the future state that can be resolved using information about the current state and the past states within the system’s dynamics. In contrast, the unpredictable component given in the third line of (3), quantifies the intrinsic randomness in the system that remains unresolved even with full knowledge of its history. The entropy decomposition in (3) is closed, meaning it completely partitions the total entropy into predictable and the unpredictable components. For a fully deterministic system (e.g., or ), the unpredictable component vanishes, , making the entire entropy predictable, . Conversely, for a completely random system (), the predictable components disappear. In this case, as observations of the prior sequence provide no information for predicting future states (). Similarly, attempts to predict the next state by repeating or alternating the current state fail, as .
In a finite-state, irreducible Markov chain, the entropy rate quantifies the uncertainty associated with transitions from one state to the next. It is formally given by:
where the second formulation highlights the connection to the geometric mean of transition probabilities. The term can be interpreted as the geometric mean time-averaged transition probability rate (per step) from the state k over an infinitely long observation period:
where is the observed frequency of transitions from k to s over the most likely sequence of length n. The frequency converges to the transition probability as . The inverse of the geometric mean transition probability rate, , represents the average residence time in state k. The excess entropy takes a form similar to the entropy (2):
where the ratio of average recurrence and residence times, measures the transience of state k in a sequence consistent with the stationary distribution . Low transience implies that typical sequences are more predictable. Conversely, in the case of maximally random sequences where , states are visited regularly, and the excess entropy (6) does not enhance predictability. The formula for excess entropy remains valid only for non-deterministic processes where all states can be visited and exited with non-zero probability. If the system remains indefinitely in a single state, the excess entropy becomes undefined because the system’s behavior carries no uncertainty.
Similarly, the conditional entropy,
quantifies the uncertainty associated with the statistics of trigrams involving two transitions. The transition probability rate,
represents the asymptotic frequency of trigrams starting with state k. The relative frequency converges to the corresponding elements of the squared transition matrix , over long, most likely sequences conforming the stationary distribution . The conditional mutual information,
measures the amount of information shared between the current state and the future state , independently of the historical context provided by . In the context of coin tossing, the mutual information (9) emerges from uncertainty in choosing between alternating the present coin side () or repeating the current side () when predicting the coin’s future state. The mutual information vanishes for the fair coin (), where transitions are completely random and independent. It also vanishes for a fully deterministic coin ( or ), where past states provide no additional information for predicting future behavior.
When the past and present states of the chain are known, the predictable information about the future state can be expressed as:
The conditional probability represents the likelihood that, in a two-step transition starting from k, both steps remain in k. The inverse conditional probability, can be interpreted as the average state repetition time — the expected time between instances where state k appears consecutively twice. Predictable information, therefore, reflects the balance between recurrences (returns to states) and state repetitions (remaining in the same state). Systems with frequent recurrences and repetitions exhibit high predictability, indicating more organized and regular behavior. In contrast, systems with infrequent recurrences and frequent state changes exhibit low predictability, suggesting a more random and chaotic behavior. According to (3), unpredictable information is then defined as:
The logarithm of the state repetition time which can also be interpreted as the utility of state repetition, emphasizes the exponential growth of unpredictability when repetition times increase. Conversely, lower values of indicate reduced uncertainty and predictable behavior.
Figure 1 provides a detailed visualization of the entropy decomposition (3) for a biased coin modeled as a Markov chain with transition matrix
where p and q are the probabilities of repeating the current state.
In Figure 1.a, the three surfaces illustrate different information quantities as functions of p and q. The top surface represents the total entropy capturing the overall uncertainty in the system’s state. For a symmetric chain (), the uncertainty reaches its maximum of 1 bit. The entropy decreases when as one state becomes more probable than another, reducing overall uncertainty. The middle surface shows the entropy rate , measuring the uncertainty in predicting the next state given the past states. When , this surface coincides with the top one, indicating that the system behaves like a fair coin with no memory of past states. The bottom surface illustrates the conditional mutual information , measures the predictive power of the current state for the next state, independent of past history. When , the bottom surface highlights the tension between two simple prediction strategies — repeating or alternating the current state — reflecting the inherent randomness of a fair coin. The gaps between these surfaces reveal how the total uncertainty is partitioned. The gap between the top and middle surfaces corresponds to the excess entropy , capturing the structured, predictable correlations in the system. Together with the space below the bottom surface, these gaps represent the amount of predictable information . The gap between the middle and bottom surfaces represents the unpredictable component of the system, which diminishes as p and q approach deterministic values (0 or 1), reflecting minimal randomness.
In Figure 1.b, the decomposition of entropy is presented more intuitively. The top, convex surface shows the unpredictable component, peaking at 1 bit for a fair coin () and dropping to zero for deterministic scenarios (). The bottom, concave surface represents the predictable component, which grows as the system becomes more deterministic. This figure highlights the delicate balance between randomness and structure, emphasizing how the predictability of the system depends on the interplay between state repetition probabilities.
3. Stochastic Dynamics of Rosencrantz’s Coin
In Tom Stoppard’s play "Rosencrantz and Guildenstern Are Dead" [3], Rosencrantz improbably wins 92 consecutive coin flips, prompting Guildenstern to speculate that their situation may be influenced by supernatural forces. Indeed, he is correct—for their lives are no longer governed by chance but by the will of the king. Here, we present a simple probabilistic model in which such an improbable sequence can naturally arise, where long-term correlations effectively “freeze” the coin in one of its states. Our model builds on previous approaches using stochastic thresholds to study ecological subsistence dynamics and systems near critical instability points [6,7].
In this model, each "coin flip" corresponds to a step in a stochastic process. At each step, a random variable X, representing the energy or capability to transition, is drawn from a probability distribution . Similarly, the barrier height Y is also a random variable with its own distribution . The process updates X at every step, reflecting the inherent randomness in the transition capability. However, the barrier height Y updates intermittently: with probability , a new Y is drawn from ; otherwise, Y retains its current value. The process remains in the current state at step t if , but transitions to another state if (see Figure 2).
The total number of consecutive successful coin flips, , represents the duration of Rosencrantz’s improbable streak — the time the process remains in the state where . This framework provides a simple probabilistic explanation for how extraordinary sequences of successes can arise.
The analysis of this model (see [6,7] for details) depends on the specific distributions and , as well as on the value of the barrier update probability . When the barrier is maximally volatile (), Y is updated at every step. In this regime, the probability of observing successful flips is given by
which decays exponentially with , regardless of the specific form of and . The expected duration of state in such a sequence is always finite,
For uniform distributions over , the coin behaves like a fair coin, and the probability of consecutive successes simplifies to:
and the expected duration of state equals
When , the barrier Y remains constant throughout the process. In this case, the probability of successful flips is:
For uniform distributions over , the probability (16) reduces to the Beta function . Thus, for large , the probability of state decays as:
The power-law decay in (17) implies that Rosencrantz’s coin appears biased toward producing extended streaks of success, as the expected duration of state diverges, , indicating that blocks of any length can appear in sufficiently long sequences.
For intermediate values of with uniform distributions over , the barrier Y alternates between stability and variability. This dynamic creates a mixture of exponential and power-law decay for the probability of successful flips [6,7]:
where the coefficients are defined by:
and represents all integer partitions of k, viz., .
If , , the barrier height Y is typically close to one, making transitions rare and sharp. When X remains uniformly distributed, the probability of successful flips follows a Zipf-like behavior [7]:
where is the Riemann Zeta function. This result reflects the dominance of rare, extended streaks of success, evoking a sense of order emerging from randomness. The Rosencrantz coin can also be described by an integral row-stochastic matrix, viz.,
which captures the transition probabilities over a finite interval t. Unlike the stationary Markov chain (12), which describes instantaneous transitions, reflects the cumulative effect of all probabilities up to time t.
In the absence of correlations (), when the height of the energy barrier Y changes at every time step and all transitions are statistically independent, the stationary chain , corresponding to a fair coin, can be related to the Markov process generator for the integral transition matrix , where I is the identity matrix. In this case, the integral matrix is the solution of the differential equation with the initial condition However, when correlated transitions occur (), the integral matrix no longer has a straightforward relationship with the instantaneous transition matrix .
In the Rosencrantz coin model, the long-time behavior of recurrence times, which describe how long it takes, on average, for the system to return to a given state, depends significantly on the parameter (see Figure 3). When , the barrier height changes dynamically with each step.In this case, the probabilities of coin’s states decay as , and the recurrence time quickly converges to 2:
This behavior corresponds to a fair coin with a stationary distribution of states . Here, the ergodic hypothesis holds, meaning the system visits all allowable states with equal frequency over a long enough time. Consequently, time averages and ensemble averages become equivalent.
In contrast, when , the barrier height remains fixed, and the recurrence time increases logarithmically. This growth is described by:
where is the digamma function, and is Euler’s constant. In this scenario, the ergodic hypothesis does not hold because the recurrence times are not constant. The system’s behavior becomes non-ergodic, meaning it does not visit all states with the same frequency, and ensemble averages lose their equivalence to time averages.
When correlations are present, the Rosencrantz coin shows increasingly prolonged intervals before returning to a given state, rendering the concept of a stationary distribution invalid. The recurrence time grows without settling into a steady pattern, indicating that time averages diverge from ensemble averages and the system’s dynamics are non-ergodic.
4. Structure and Dynamics of Sequences in the Non-Ergodic Rosencrantz Coin Model
To study the sequences generated by the non-ergodic Rosencrantz coin, entropy and its decomposition into predictable and unpredictable components are inapplicable because there is no stationary distribution. Figuratively speaking, the coin "sticks" in each of its states, meaning the structure of observed sequences is characterized by blocks of varying length where the coin remains in the same state for an extended period of time. As we have seen from the analysis of recurrence times (Section 3), the length of such blocks gradually increases, so that increasingly extended streaks of success would be observed in sufficiently long sequences. Because the expected recurrence times grow logarithmically, the system’s dynamics become increasingly non-stationary, and the typical assumptions of equilibrium and steady-state distributions no longer apply. The probability to observe such a sequence, consisting of m consecutive blocks of lengths , is characterized by the product , where is a partition of n into m terms.
The number of ways to partition a sequence of n elements into m blocks is given by the Stirling numbers of the second kind [8], which satisfy the recurrence relation:
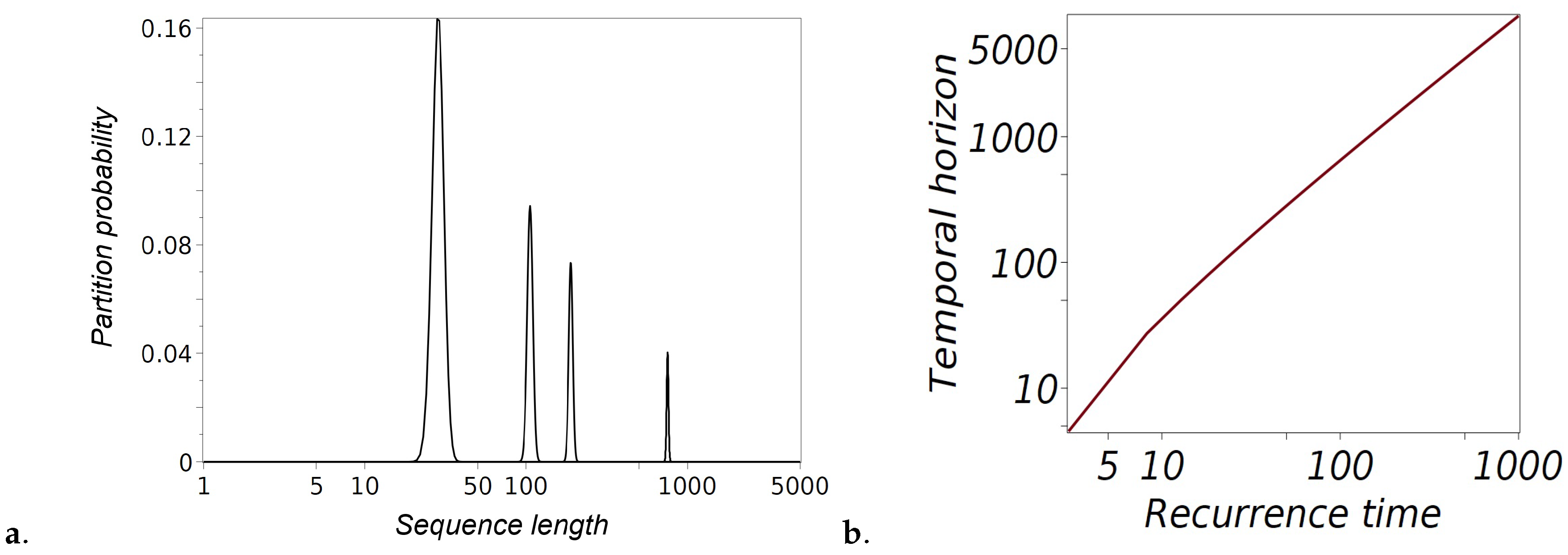
The values of are not uniformly distributed across all possible block sizes but exhibit a maximum for specific values of m. Figure 4.a shows the normalized Stirling numbers of the second kind, representing the probability of partitioning a sequence of length n into m non-empty blocks. The normalization uses corresponding Bell numbers, , which count the total number of partitions of an n-set. This normalization scales large combinatorial values into probabilities, enabling clear graphical representation. The horizontal axis uses a logarithmic scale to depict sequence lengths of 100, 500, 1000, and 5000, while the vertical axis shows the corresponding partition probabilities. The sharp peaks in the distributions highlight the most probable partition configurations for each sequence length.
As n increases, certain partition configurations become increasingly dominant due to the combinatorial growth of the Stirling numbers. These configurations correspond to partitions where the block sizes are roughly balanced, maximizing the number of ways the sequence can be divided.
Taking the natural logarithm of , we get:
By differentiating and setting , we find the position of the maximum probability to be . A detailed analysis conducted in [9] provides a more accurate estimate:
Substituting this value of back into the asymptotic expression for the logarithm of the maximum Stirling number, we have:
The above estimate suggests that the system’s temporal horizon n is most likely partitioned into blocks of size representing the typical duration spent in a state before switching. The combinatorial advantage that favors specific block sizes reflects the intrinsic structure determined by the Stirling numbers of the second kind for large n.The estimates in (27) become increasingly accurate as n grows; however, for smaller n, correction terms can significantly influence the approximation (see Figure 4).
According to Rennie and Dobson [9], as n increases, the most likely partition of the sequence into blocks approaches the configuration described by (27). The deviation between the maximum Stirling number and the actual Stirling number for this partition is given by:
The rate of convergence to the most likely partition structure in (28) can be interpreted as an entropy-like function - a measure of block related entropy for the non-ergodic system. The value varies only slightly over a wide range of n. Asymptotically, a sequence of length n will most likely be divided into blocks, each of length , which is the characteristic recurrence time for the Rosencrantz coin remaining in a particular state. Consequently, the probability of observing a sequence consistent with the configuration of maximum likelihood equals to
being compensated by the last correction term in the asymptotic approximation for the maximum Stirling number (27) – for blocks of the most probable size, the power-law decay over time is offset by the combinatorial growth of partitions. The term in (29) corresponds to the entropy of a stationary coin, as discussed earlier in (2). It captures the balance between the combinatorial growth of the predominant partitions and the algebraic decay of block probabilities (17), which stabilizes the characteristic block size at . For sufficiently large n, the combinatorial increase in the number of predominant partitions compensates for the decay in block probabilities, ultimately dominating the system’s behavior. Consequently, the structure of generated sequences resembles a deterministic schedule rather than a purely random process. The deterministic-like pattern emerges because the recurrence time aligns with the residence and repetition times, making the sequence’s structure predictable. This conclusion fully aligns with the case of a biased coin , where the probabilities p and q of repeating a state are close to one. Under these conditions, the coin’s behavior becomes almost entirely predictable (see Figure 1).
For such a non-ergodic system, the relevant question is not whether the next state of the coin can be predicted, but whether the temporal horizon — the length of the sequence of flips that can be predicted based on the observed characteristic block size . Solving the equation gives:
where refers to the -th branch of the Lambert function, defined as the inverse of This branch is real-valued for and decreases monotonically towards negative infinity as () along the negative real axis, which forms the branch cut [10]. Figure 4.b illustrates the relationship between the recurrence time and the temporal horizon as given by (30). The curve demonstrates that as the recurrence time, derived from the optimal block size determined by combinatorial analysis, increases, the temporal horizon grows super-linearly. This relationship implies that the longer the system remains in a state before switching, the further into the future one can predict its behavior. Solving via the Lambert function (30) also provides a quantitative prediction of how long structured behavior will persist.
5. Discussion - Temporal Horizons and the Predictive Economy of Non-Ergodic Systems
In the study of non-ergodic systems like the Rosencrantz coin model, the temporal horizon refers to the characteristic duration over which predictable patterns and structures emerge within the system’s evolution. Unlike ergodic systems, where time averages converge to ensemble averages, non-ergodic systems fail to visit all possible states uniformly. Consequently, the system’s long-term behavior cannot be fully captured by stationary probability distributions.
This limitation shifts the analytical focus to understanding the durations between key events, such as state switches or recurrences. In such cases, combinatorial insights compensate for the absence of a stationary distribution, enabling meaningful temporal predictions in systems governed by deterministic-like patterns amidst randomness. The interplay between the recurrence time and the temporal horizon provides a robust framework for predicting the extent of structured behavior in non-ergodic processes.
Partitioning these sequences into blocks of persistent states reveals a deep connection to combinatorial structures, particularly the Stirling numbers of the second kind. These numbers exhibit a sharp maximum for partitions of size . For sufficiently large n, the combinatorial growth in the number of partitions compensates for the decay in block probabilities for the most likely partitions . This balance between increasing block lengths and decreasing block probabilities results in a deterministic-like structure within an inherently stochastic system.
The temporal horizon, defined by the duration over which predictable patterns emerge, offers a new perspective for analyzing non-ergodic processes. The logarithmic recurrence time can be interpreted as the prediction utility of time within a conceptual prediction economy. The logarithmic utility of time implies that predictable patterns arise over increasingly longer horizons. Although the first derivative , indicating that additional time enhances prediction, the second derivative reflects diminishing returns: each subsequent unit of time (or coin flip) adds less predictive value than the previous one. The concave nature of the logarithmic utility highlights this diminishing predictive benefit.
This logarithmic structure seamlessly leads to hyperbolic time discounting in prediction. Hyperbolic discounting prioritizes short-term forecasts with higher certainty over long-term, uncertain ones. The Arrow-Pratt measure of risk aversion [11,12] and the Leland measure of prudence [13] formalize this idea:
These measures describe how knowledge of a block’s length improves the ability to predict the temporal horizon. This relationship aligns with the hyperbolic time discounting model, a well-established framework in human [14] and animal [15] intertemporal choice, where immediate rewards are weighted more heavily than future gains. In the Rosencrantz coin model, this perspective underscores the preference for short-term, reliable predictions over long-term, uncertain ones.
6. Conclusion
In this paper, we explored the dynamics of both ergodic and non-ergodic systems through the lens of a coin-flipping model, specifically focusing on the Rosencrantz coin that can "freeze" in one of its states. We compared the behavior of a conventional biased coin, characterized by predictable and unpredictable entropy components, to the non-ergodic Rosencrantz coin, where the absence of a stationary distribution alters the predictability framework.
In the ergodic case, entropy decomposition into predictable and unpredictable components relies on characteristic times such as recurrence, residence, and repetition times. These measures provide insights into the structure and behavior of state sequences generated by stationary Markov chains. However, in the non-ergodic Rosencrantz coin model, where the system can persist in a state for extended periods, traditional entropy decomposition becomes inapplicable.
Our analysis demonstrated that the Rosencrantz coin’s non-ergodic dynamics lead to logarithmically increasing block lengths in sequences of persistent states. By leveraging the Stirling numbers of the second kind, we identified the most probable partition size of and showed that combinatorial growth in the number of partitions compensates for the algebraic decay of block probabilities. This balance results in deterministic-like structures emerging from fundamentally stochastic processes.
The concept of a temporal horizon , defined by the recurrence time , provides a framework for predicting the duration of structured behavior in non-ergodic systems. The logarithmic utility of time implies diminishing predictive returns as the temporal horizon extends, aligning with hyperbolic time discounting models seen in human and animal decision-making.
In conclusion, the Rosencrantz coin model reveals that in non-ergodic systems, predictability is less about individual outcomes and more about understanding the length of sequences governed by persistent state blocks. This study bridges information theory, combinatorics, and stochastic processes, offering a deeper perspective on the dynamics and predictability of systems where conventional equilibrium frameworks fail.
Funding
This research received no external funding.
Acknowledgments
We thank Texas Tech University for the administrative and technical support.
References
- Álvar Daza, Alexandre Wagemakers, Miguel A. F. Sanjuán; Multistability and unpredictability. Physics Today 1 November 2024; 77 (11): 44–50. [CrossRef]
- Volchenkov, D. Memories of the Future. Predictable and Unpredictable Information in Fractional Flipping a Biased Coin. Entropy 2019, 21, 807. [CrossRef]
- Stoppard, Tom. Rosencrantz and Guildenstern Are Dead. Page 23. Grove Press, 1967.
- James, R.G., Ellison, Ch.J. and Crutchfield, J.P., "Anatomy of a Bit: Information in a Time Series Measurement", CHAOS 21:3 (2011) 037109.
- Volchenkov, D., Infinite Ergodic Walks in Finite Connected Undirected Graphs. Entropy 2021, 23 (2), 205. [CrossRef]
- Floriani, E., Volchenkov, D., Lima, R., “A System close to a threshold of instability”, J. of Physics A: Math. General 36, 4771-4783 (2003).
- Volchenkov, D., "Survival under Uncertainty an Introduction to Probability Models of Social Structure and Evolution", Springer Series: Understanding Complex Systems, 240 pages, ISBN 978-3-319-39419-0, Berlin / Heidelberg 2016.
- Graham, R.L., Knuth, D.E., Patashnik, O. Concrete Mathematics, Addison–Wesley, Reading MA. ISBN 0-201-14236-8, p. 244 1988.
- Rennie, B.C., Dobson, A.J., On stirling numbers of the second kind, Journal of Combinatorial Theory, Volume 7, Issue 2, Pages 116-121, 1969.
- Corless, R. M., Gonnet, G. H., Hare, D. E. G., Jeffrey, D. J., & Knuth, D. E. On the Lambert W Function. Advances in Computational Mathematics, 5(1), 329–359 (1996). [CrossRef]
- Pratt, J.W., Risk Aversion in the Small and in the Large. Econometrica, 32(1/2), 122–136 (1964). [CrossRef]
- Arrow, K.J., Essays in the Theory of Risk-Bearing. Markham Publishing Co. 1971.
- Leland, H.E., Saving and uncertainty: the precautionary demand for saving. Q. J. Econ. 82, 465–473 (1968).
- Laibson, D., "Golden Eggs and Hyperbolic Discounting." Quarterly Journal of Economics, 112(2), 443–477 (1997). [CrossRef]
- Mazur, J.E., "An Adjusting Procedure for Studying Delayed Reinforcement." In The Effect of Delay and of Intervening Events on Reinforcement Value (Eds. Michael L. Commons, James E. Mazur, John A. Nevin, and Howard Rachlin), Series: Quantitative Analyses of Behavior, Volume 5, Lawrence Erlbaum Associates (pp. 55-73)(1987).
Figure 1.
Decomposition of entropy into its components (3) for a biased coin modeled as a Markov chain . a). The top surface shows the total entropy , the middle surface shows the entropy rate (7), and the bottom surface shows the conditional mutual information (9). The gap between the top and middle surfaces illustrate the excess entropy (6). The gap between the middle and the bottom surfaces corresponds to the unpredictable information component (11) of the system. b.) The top, convex surface shows the unpredictable component of information, reaching a maximum of 1 bit for a fair coin (), but reducing to zero for a deterministic coin ().
Figure 1.
Decomposition of entropy into its components (3) for a biased coin modeled as a Markov chain . a). The top surface shows the total entropy , the middle surface shows the entropy rate (7), and the bottom surface shows the conditional mutual information (9). The gap between the top and middle surfaces illustrate the excess entropy (6). The gap between the middle and the bottom surfaces corresponds to the unpredictable information component (11) of the system. b.) The top, convex surface shows the unpredictable component of information, reaching a maximum of 1 bit for a fair coin (), but reducing to zero for a deterministic coin ().
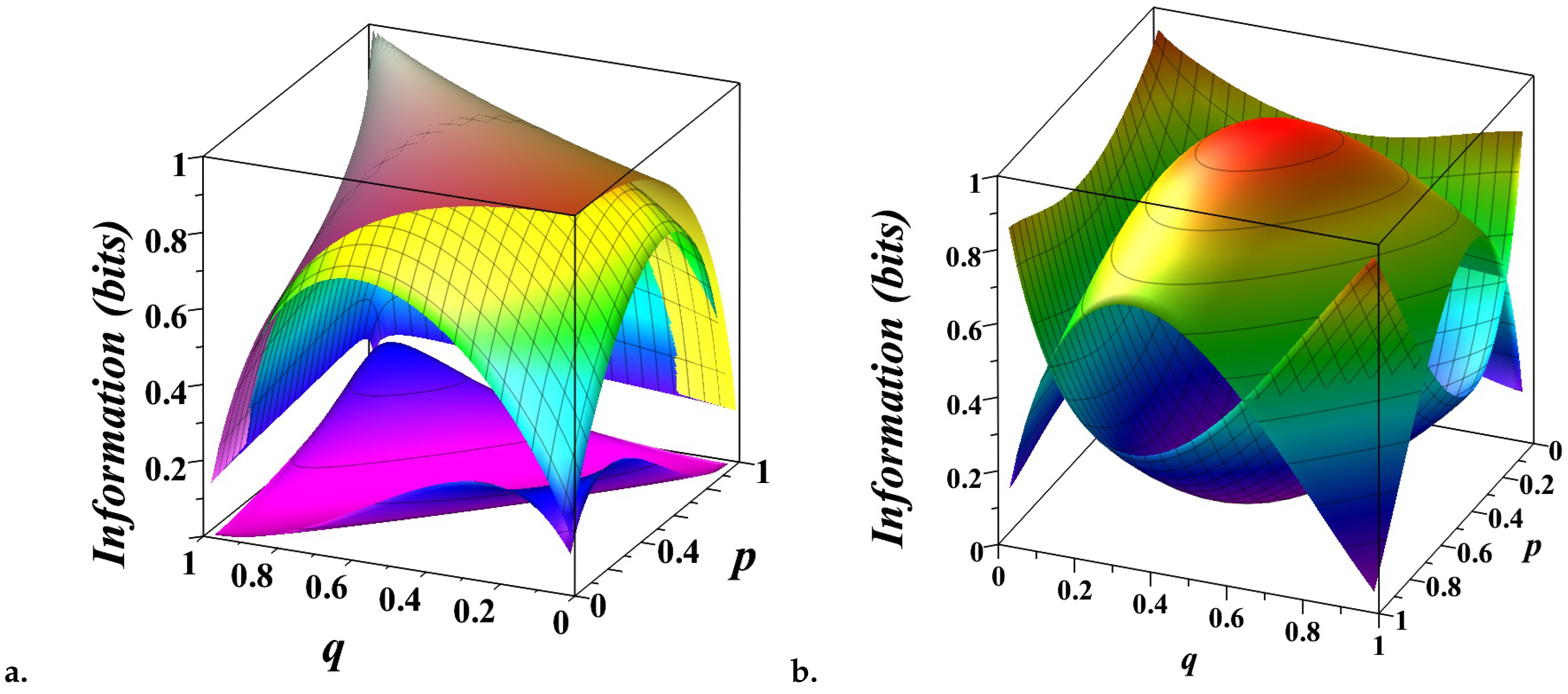
Figure 2.
Illustration of a stochastic process where a dynamic barrier Y and random "energy" X determine state transitions (Rosencrantz’s coin).
Figure 2.
Illustration of a stochastic process where a dynamic barrier Y and random "energy" X determine state transitions (Rosencrantz’s coin).

Figure 3.
Recurrence times for the Rosencrantz coin model. The curves represent different and : when (solid line), shows a stable recurrence time of 2, consistent with a fair coin and the ergodic hypothesis; (dotted line) shows gradually increasing recurrence times; when (dashed line) shows significantly increasing recurrence times.
Figure 3.
Recurrence times for the Rosencrantz coin model. The curves represent different and : when (solid line), shows a stable recurrence time of 2, consistent with a fair coin and the ergodic hypothesis; (dotted line) shows gradually increasing recurrence times; when (dashed line) shows significantly increasing recurrence times.
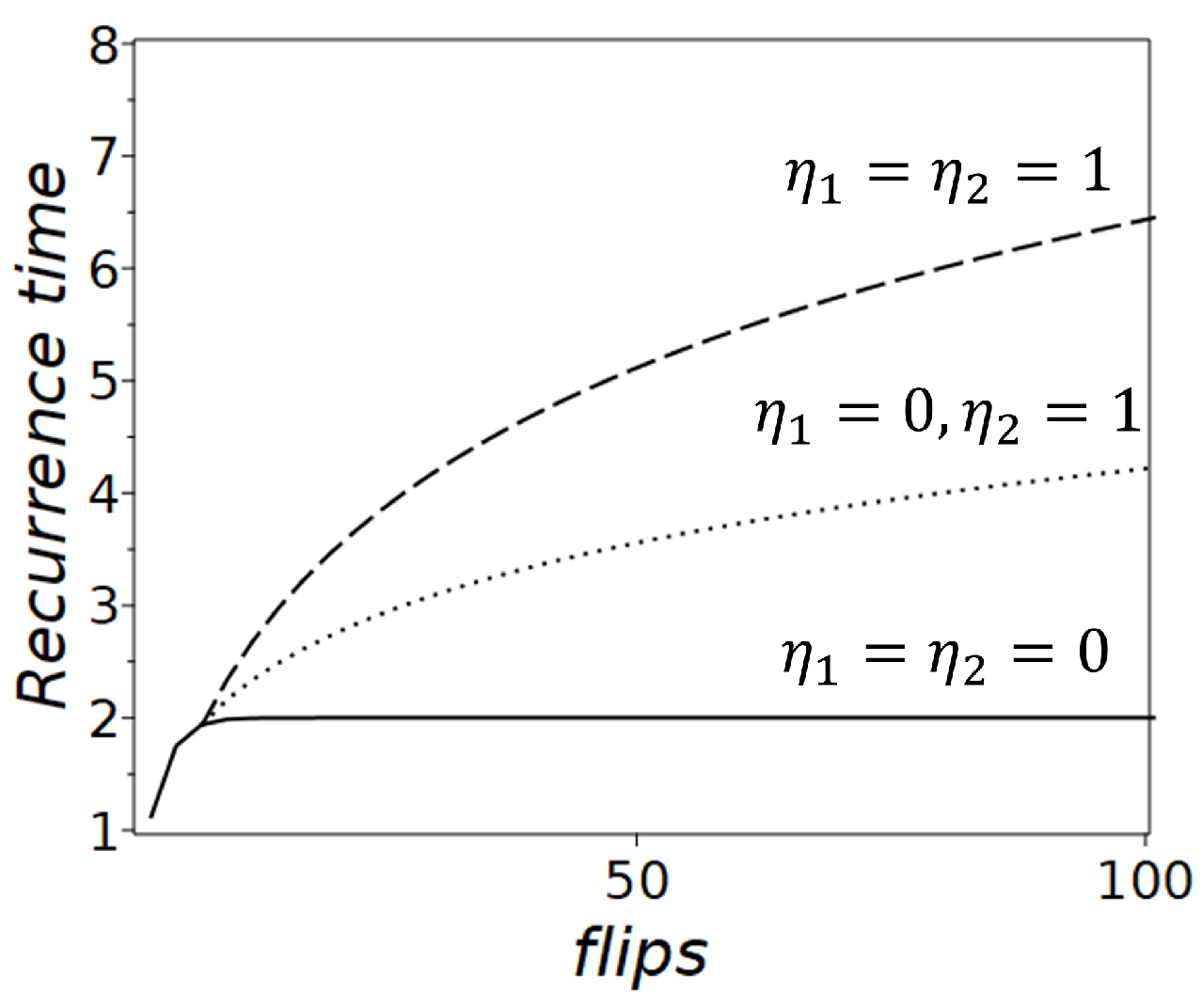
Figure 4.
a). Partition probabilities for sequences of lengths 100, 500, 1000, and 5000. The graph displays the Stirling numbers of the second kind, normalized by the corresponding Bell numbers, representing the probability of partitioning a sequence of length n into m non-empty subsets. The sharp peaks, located at , indicate the maxima of the Stirling numbers, highlighting the most probable partition configurations. The horizontal axis uses a logarithmic scale to effectively capture the wide range of sequence lengths. b..) Temporal horizon as a function of recurrence time for a non-ergodic Rosencrantz coin
Figure 4.
a). Partition probabilities for sequences of lengths 100, 500, 1000, and 5000. The graph displays the Stirling numbers of the second kind, normalized by the corresponding Bell numbers, representing the probability of partitioning a sequence of length n into m non-empty subsets. The sharp peaks, located at , indicate the maxima of the Stirling numbers, highlighting the most probable partition configurations. The horizontal axis uses a logarithmic scale to effectively capture the wide range of sequence lengths. b..) Temporal horizon as a function of recurrence time for a non-ergodic Rosencrantz coin
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



