Submitted:
18 December 2024
Posted:
19 December 2024
Read the latest preprint version here
Abstract
Conditional Value-at-Risk (CVaR) is one of the most popular risk measures in finance, used in risk management as a complementary measure to Value-at-Risk (VaR). VaR estimates potential losses within a given confidence level, such as 95% or 99%, but does not account for tail risks. CVaR addresses this gap by calculating the expected losses exceeding the VaR threshold, providing a more comprehensive risk assessment for extreme events. This research explores the application of Denoising Diffusion Probabilistic Models (DDPM) to enhance CVaR calculations. Traditional CVaR methods often fail to capture tail events accurately, whereas DDPMs generate a wider range of market scenarios, improving the estimation of extreme risks. However, these models require significant computational resources and may present interpretability challenges.
Keywords:
Introduction
Definition of VaR and CVaR
- VaR on 95% of confidence level = 50.000$
- CVaR on 95% of confidence level = 70.000$

| Aspect | Value-at-Risk(VaR) | Conditional-Value-at-Risk(CVaR) |
| Definition | Maximum loss at a specific confidence level. | Average loss when VaR exceeding. |
| InformationalValue | General understanding of risk, but without what is happening beyond VaR. | Helps to understand how serious could be rare and extremal losses. |
Traditional Method of CVAR Assessment
- Historical modelling: using data for previous profit for example for year or other period. Firstly calculating VaR, then only cases where losses exceed the VaR value are considered. CVaR is the average value that losses. For example: If the worst 5% of losses 10.000$, 12.000$, 15.000$ etc., so CVaR is average of that values.
- Variance-Covariance Method is easy to use and assume that returns follow a normal distribution. After calculating VaR need to average exceeded losses. This method is simple, but its have some limits like poor perform in extreme values in the data.
- Monte Carlo Simulation: simulating thousands of random scenarios for returns using mathematical models. This method more precise because it can account for non-standard return distributions
Definition of Denoising Diffusion Probabilistic Models
Advantage of Using Denoising Diffusion Probabilistic Models
-
Accuracy of modelling complex distributions.
- To evaluate CVaR critical important consider rare, extremal events, that creates “tails” of distributions of losses.
- DDPM gradually add some noise to the data, that change it to random noise, then learn to delete it and restore the data. It helps to models better learn complex data dependencies.
- 2.
-
Generating different market scenarios.
- For calculating CVaR need create a purge number of possible scenarios, also rare events, that can not be introduced in historical data.
- After learning DDPM can generate synthetic data, that did not presented in historical data.
- 3.
-
Stable of the learning.
- Generative models as GANs can be non-stable while learning, which leads to problems such as “model collapse”. DDPM uses a sequential learning process that makes learning more stable and less prone to failure.
- 4.
-
Interpretability of the Data Structure.
- Understanding risk requires that the model provides realistic scenarios based on known characteristics of the data. Process of adding and removing noise in DDPM is closely linked to real data, allowing the model to generate plausible market scenarios.
- 5.
-
Difference between other models.
- Unlike other models as GAN and VAE, DDPM better modelling tails of the distributions and less prone to learning problems.
- DDPM generate high quality data, because it does not simplify the structure of hidden factors within the model.
- DDPM is easier to scale for complex data, such as time series.
- 6.
-
Using DDPM in CVaR calculating
- CVaR need goof understanding of tail risks, which meet not often in real data.
- Model can better modeling tail events, improving calculate average loss in the most extreme events.
Disadvantages of Using Denoising Diffusion Probabilistic Models
-
Requires significant computational resources:
- DDPM is resource-intensive due to its multi-step process. This issue can be mitigated by optimizing the model and utilizing advanced hardware.
- 2.
-
Challenges in interpreting outcomes:
- Understanding the results of generative models can be difficult. However, visualizing the scenarios produced by DDPM helps make the analysis more intuitive.
Methodology
-
Data Preprocessing:
- ○
- The dataset used comprises daily returns of financial instruments from the S&P 500 index. The data includes timestamps, asset names, and their respective returns.
- ○
- Missing data points are handled using imputation techniques, and returns are calculated from adjusted closing prices.
- ○
- Data normalization is performed to ensure that all inputs lie within a consistent scale, aiding the stability of the model during training.
- 2.
-
Model Architecture:
- ○
- The DDPM consists of a neural network that learns to model the noise distribution applied to the data during the forward diffusion process. The network architecture includes multiple convolutional layers to capture both temporal dependencies and high-dimensional features.
- ○
-
Key components include:
- ■
- Encoder-Decoder Framework: Encodes input data into a compressed latent representation and decodes it during the reverse process.
- ■
- Attention Mechanisms: Incorporated to focus on key temporal patterns in the data.
- ■
- Noise Scheduler: Determines the magnitude of noise added at each timestep.
- 3.
-
Training Process:
- ○
- The forward diffusion process involves adding Gaussian noise to the data iteratively, controlled by the noise schedule.
- ○
- The reverse diffusion process learns to denoise the data by predicting the added noise at each timestep.
- ○
- A loss function, typically Mean Squared Error (MSE), measures the difference between the predicted and actual noise at each step.
- ○
- The model is trained over multiple epochs using the Adam optimizer, with learning rate decay to stabilize convergence.
- 4.
-
CVaR Calculation:
- ○
- Synthetic return scenarios are generated using the trained DDPM. These scenarios include rare and extreme events that traditional methods often miss.
- ○
- VaR is calculated at the desired confidence level (e.g., 95%).
- ○
- CVaR is derived by averaging the losses that exceed the VaR threshold across the generated scenarios.
- 5.
-
Model Evaluation:
- ○
- The DDPM's performance is compared against traditional methods such as Historical Simulation and Monte Carlo Simulation.
- ○
-
Evaluation metrics include:
- ■
- Accuracy: Ability to replicate historical tail risks.
- ■
- Robustness: Performance under volatile market conditions.
- ■
- Computational Efficiency: Time and resources required for training and inference.
Application of Denoising Diffusion Probabilistic Models (DDPMs)
- Forward Process: In this phase, noise is gradually added to the data over several timesteps. This transforms the original data into a completely noisy representation. The forward process is defined by a noise schedule that determines how noise is incrementally added. This phase ensures that the data becomes independent of its original distribution, preparing it for unbiased generation during the reverse process.
- Reverse Process: Once the model learns the noise patterns from the forward process, it begins the reverse process, gradually denoising the data to reconstruct the original distribution. The reverse process is guided by a trained neural network that predicts the noise at each timestep. This step requires sophisticated optimization techniques to ensure accurate reconstruction and meaningful data generation.
The Role of Hyperparameters in DDPMs
Comparison with Traditional Models
- Accurate Tail Risk Modeling: DDPMs effectively capture rare and extreme events, enhancing the accuracy of CVaR calculations.
- Synthetic Scenario Generation: By generating diverse market scenarios, DDPMs improve risk assessment under extreme conditions.
- Stability: Unlike GANs, DDPMs offer a more stable training process, reducing the risk of model collapse.
- Time-Series Adaptability: DDPMs are well-suited for financial data, incorporating temporal dynamics into risk modeling.
- High Resolution: The iterative process enables DDPMs to generate detailed and realistic scenarios, critical for tail risk analysis.
- Challenges of DDPMs:
- Computational Resources: The iterative process of DDPMs requires significant computational power, as it involves multiple forward and reverse steps for each data sample.
- Interpretability: Understanding the outcomes of generative models can be complex, although visualizing generated scenarios aids analysis.
- Hyperparameter Sensitivity: Achieving optimal performance requires careful tuning of noise schedules and model architecture.
- Daily Returns During COVID-19
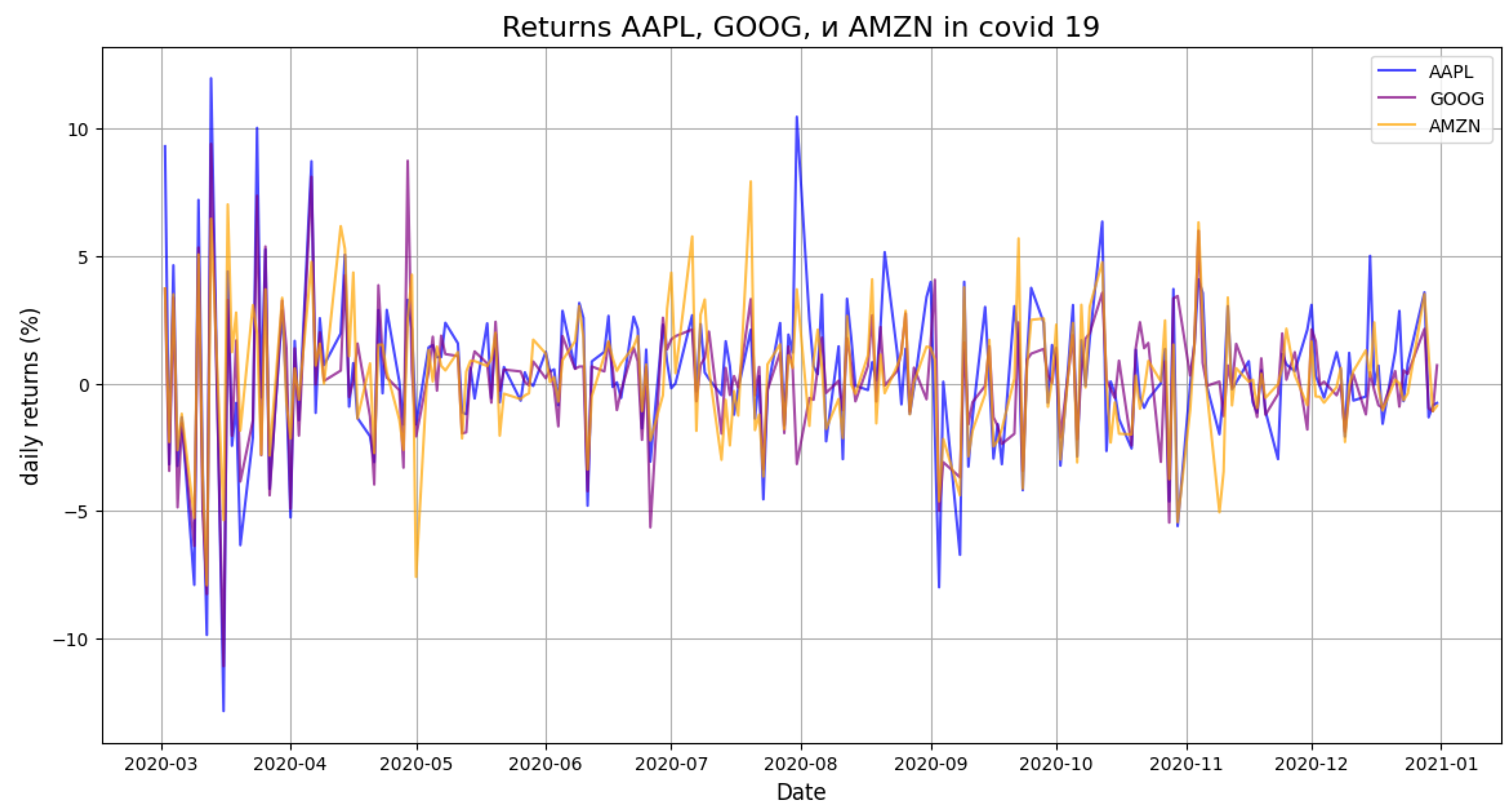
- 2.
- Correlation Heatmaps Across Periods
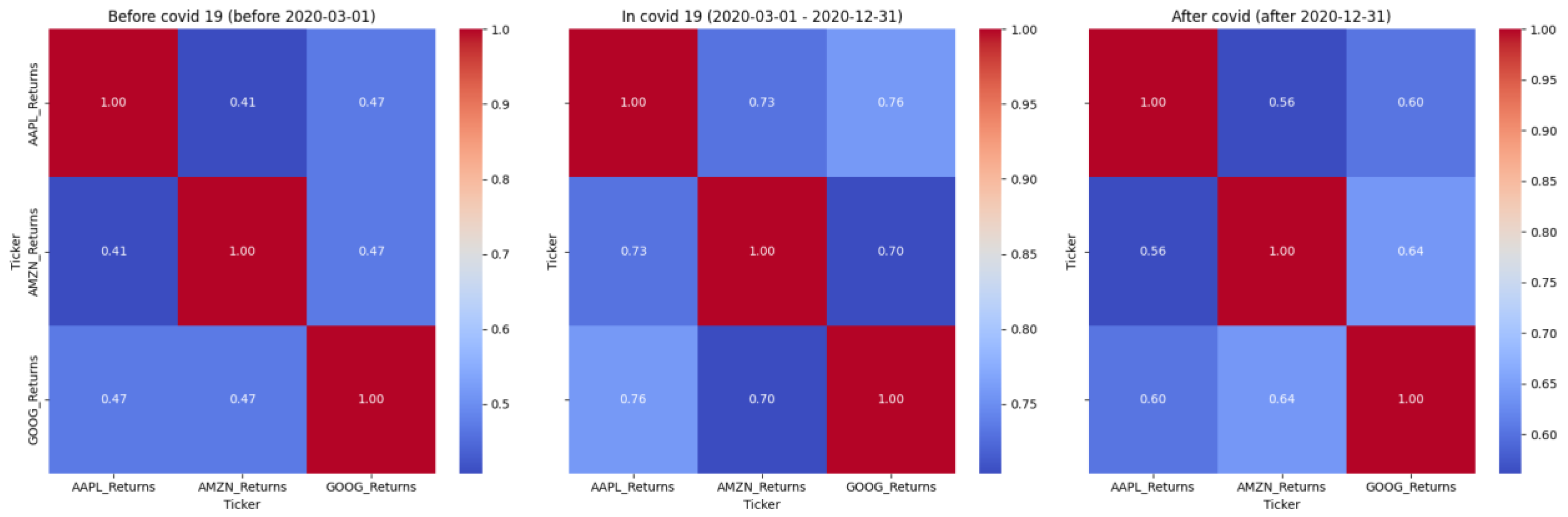
- 3.
- Prediction vs. Actual Values
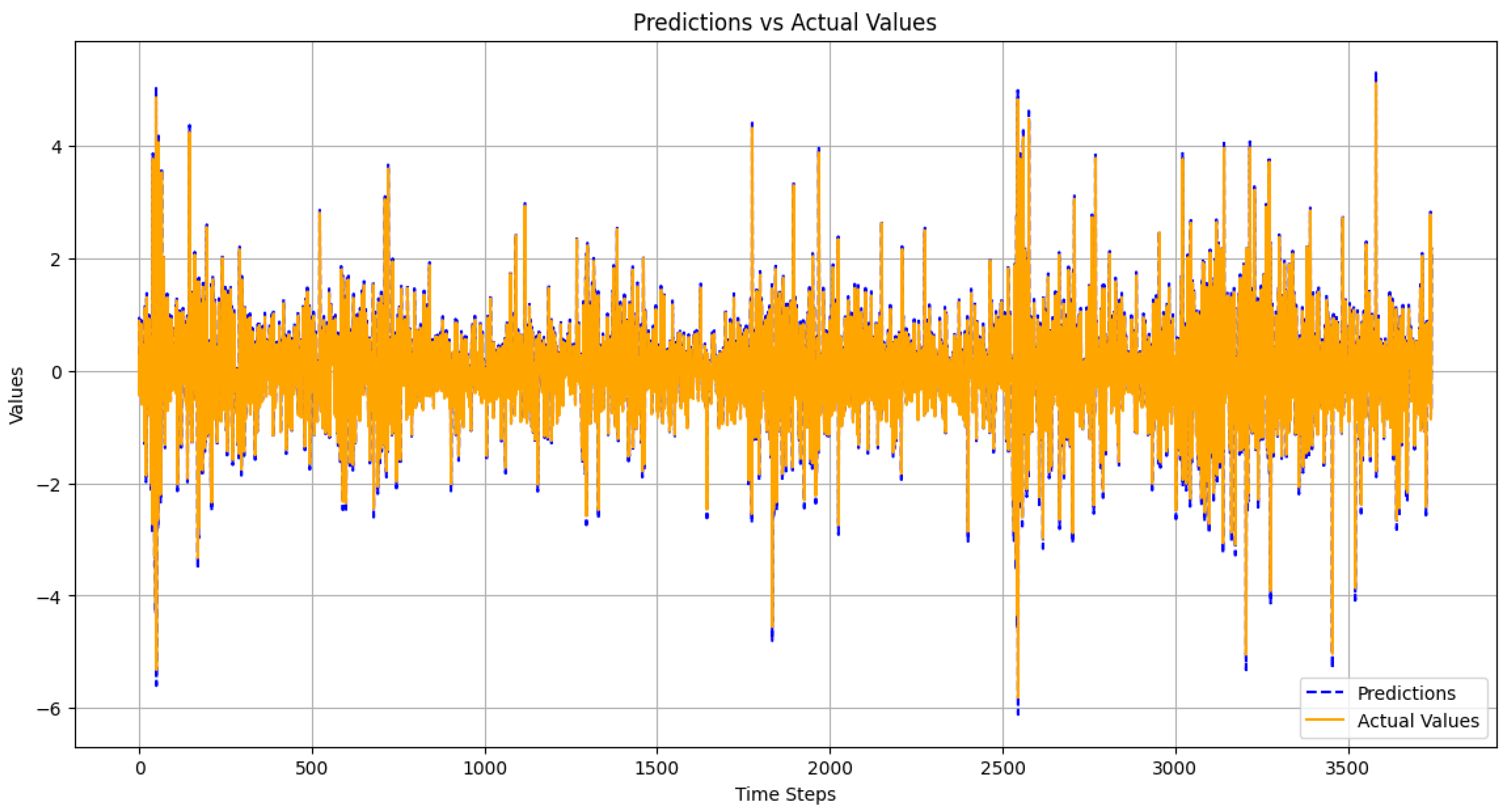
- 4.
- Error Distribution Histogram
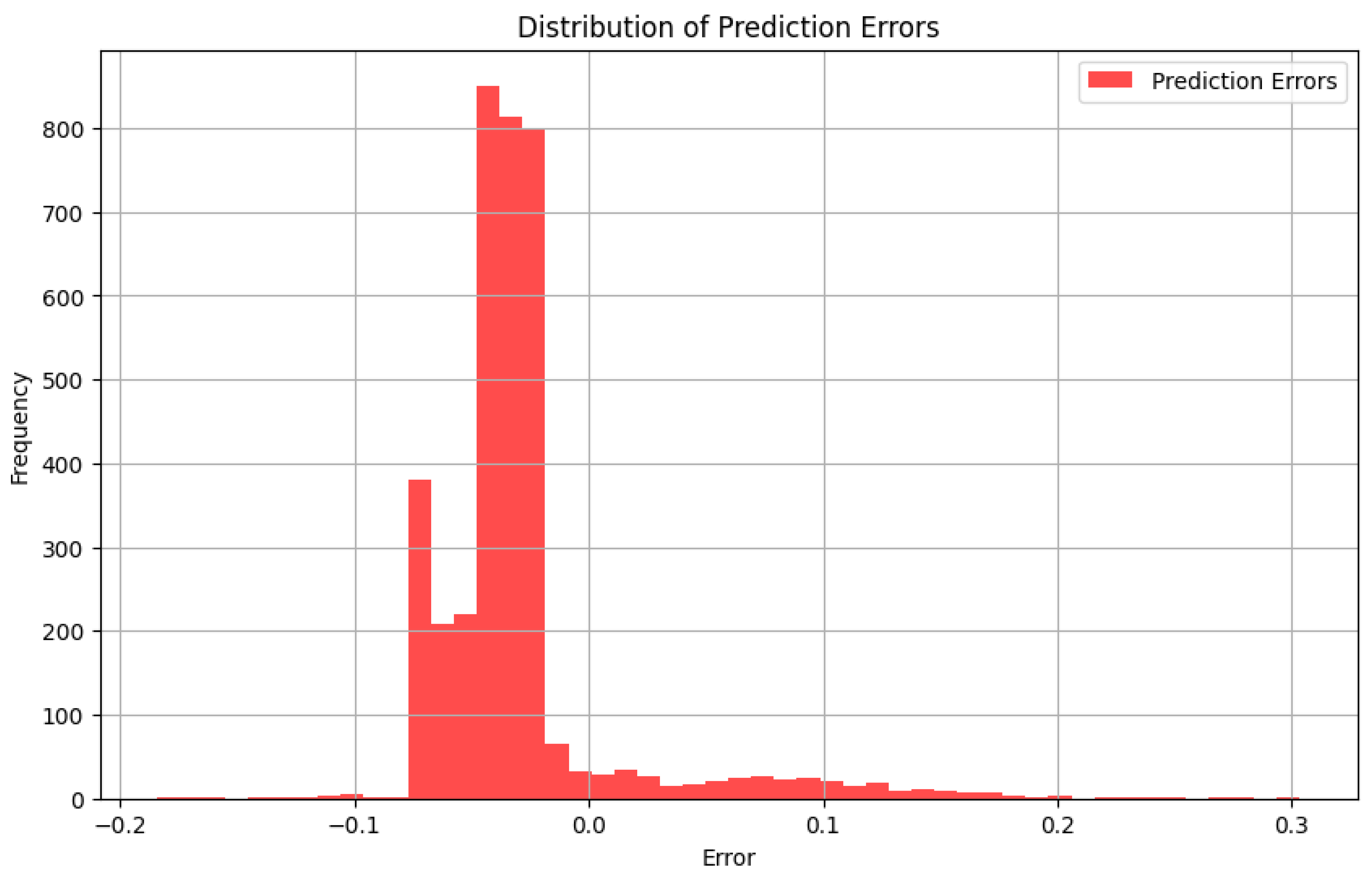
Conclusion
References
- Yamai, Y.; Yoshiba, T. Value-at-Risk versus Expected Shortfall: A Practical Perspective. Journal of Banking & Finance 2005, 29, 997–1015. [Google Scholar]
- Rockafellar, R.T.; Uryasev, S. Optimization of Conditional Value-at-Risk. Journal of Risk 2000, 2, 21–41. [Google Scholar] [CrossRef]
- Goodfellow, I.; et al. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Ho, J.; et al. Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems 2020, 33, 6840–6851. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



