1. Introduction
With the advancement of three-dimensional (3D) vision technology, Light Detection and Ranging (LiDAR) has become an indispensable data format in 3D scene understanding tasks due to its ability to provide high-precision measurements and preserve the original geometric information of objects in 3D space. These tasks encompass object classification, object detection, and object segmentation, making LiDAR point cloud data one of the research hotspots in the field of 3D vision [
1]. However, in practical applications, the collected point cloud data is often sparse or incomplete due to factors such as object occlusion, surface reflection, and sensor resolution, which severely affects the accuracy and efficiency of subsequent 3D understanding tasks. Therefore, shape completion of incomplete point cloud data to enhance the efficient use of point cloud data has become a crucial foundational work.
Despite certain progress in point cloud completion techniques, existing algorithms still suffer from significant information loss and suboptimal fusion effects in multimodal feature extraction and integration. These issues make it difficult for point cloud feature information to simultaneously consider local and global features, and the structural information of images is severely lost. To address these problems, this paper proposes a LiDAR point cloud multi-scale completion algorithm based on image rotation attention mechanism. The algorithm aims to improve the accuracy and efficiency of point cloud completion through innovative methods to meet the growing demand for 3D data processing.
The core contributions of this study are twofold: First, a Rotating Channel Attention (RCA) module is proposed, which significantly enhances the extraction capability of image features by adding a rotating channel attention mechanism to the existing image feature extractor. Second, the point cloud feature extractor is optimized by adopting a multi-scale method that extracts features through local and global hierarchical methods, effectively enhancing the capability of point cloud feature extraction. These improvements enable the network to better extract image structural information, allowing the extraction of incomplete point cloud features to consider both global and local information. Furthermore, through multi-level progressive feature fusion, the algorithm enhances the complementary capability of information between different modalities, thereby making the point cloud completion results more accurate.
The scope of this study mainly focuses on the development and optimization of multi-scale completion algorithms for LiDAR point clouds, as well as the innovation of multimodal feature extraction and fusion techniques. Through these methods, we hope to promote the development of the field of 3D vision, especially in terms of improving the accuracy and efficiency of point cloud data processing. In terms of background, this paper is based on the current importance of LiDAR point cloud data in 3D scene understanding and the challenges faced by existing technologies in handling incomplete data, proposing a new solution to provide a new perspective and tools for research and application in related fields.
2. Related Works
Currently, point cloud completion methods can be categorized into traditional approaches and deep learning methods. In traditional methods, geometry-based prior regularization [
2] and template-based feature matching [
3] are the two mainstream strategies, but they yield suboptimal completion results. Deep learning methods can be further divided into single-modal and multi-modal point cloud completion approaches. Single-modal point cloud completion methods utilize only object point cloud data for shape completion. Qi Charles et al.’s PointNet [
4], as a multilayer perceptron (MLP) method for points, directly inspired the network design of many subsequent scholars. PointNet++ [
5] and TopNet [
6] incorporate hierarchical architectures to consider the local structural features of point clouds. To mitigate the structural loss brought by MLP, AtlasNet [
7] and MSN [
8] reconstruct complete outputs by evaluating a set of surface parameters, from which a complete point cloud can be generated. The encoder-decoder architecture pioneered by PCN [
9] requires no structural assumptions or annotation information about the underlying shape. PoinTr [
10] adapts the Transformer module for 3D completion tasks by creating a geometry-aware module to model local geometric relationships. Additionally, SnowflakeNet [
11] generates child points by learning the transition of specific regions to gradually split parent points, enabling the network to predict highly detailed shape geometries.
In single-modal point cloud completion works, the limited available geometric cues result in high uncertainty in inferring missing regions of point clouds. Furthermore, the low scanning resolution of 3D data typically leads to sparsely captured data, making it difficult to determine whether the missing regions in the point cloud are due to incompleteness or inherent sparsity. Therefore, leveraging the complementary information between multi-modalities to enhance point cloud completion effects is essential. The Cross-modal multi-scale point cloud feature fusion shape completion network (CMFN) utilizes different data information fusion methods to achieve the enhancement of point cloud data information. The unordered and unstructured nature of point clouds prevents them from directly extracting features using structural characteristics like images, so using image information to represent point cloud information during the point cloud completion process can improve the completion accuracy. In image-guided point cloud shape completion methods, extracting dual-modality information and effectively fusing it is key to point cloud completion work, which this paper focuses on in terms of feature extraction for both modalities.
Zhang et al. [
12] proposed the ViPC network, which inputs incomplete point clouds and object images into the network, generating a coarse point cloud based on the object image information before fusing it with the incomplete point cloud. Building on this, Zhu et al. [
13] proposed the CSDN network, which differs from the ViPC network in that it uses an encoder-decoder structure to first recover the overall but coarse shape of the point cloud before refining local details. Emanuele et al. [
14] proposed XMFnet, which outperforms its predecessors in point cloud completion performance, characterized by the introduction of cross-attention mechanisms and self-attention mechanisms to supervise the structural generation of point clouds. Although the aforementioned methods have achieved better completion results using multi-modal information in point cloud completion tasks, they also have some issues in implementation: the ViPC network consumes a significant amount of memory and computational resources to generate coarse point clouds from image information, with suboptimal results; the CSDN network has excessive computational demands, and the underutilization of multi-modal information leads to imprecise completion details; the XMFnet network’s insufficient feature extraction capabilities for point cloud and image data result in non-refined local structures in the decoded point cloud.
Addressing the shortcomings of current multi-modal point cloud completion algorithms, this paper proposes a LiDAR point cloud multi-scale completion algorithm based on the image rotation attention mechanism. The specific contributions are: 1) The introduction of the Rotating Channel Attention (RCA) module, which enhances the extraction capability of image features by adding a rotating channel attention mechanism to existing image feature extractors. 2) The optimization of the point cloud feature extractor, which employs a multi-scale method for hierarchical feature extraction, both locally and globally, to enhance the capability of point cloud feature extraction.
3. Methodology
3.1. Overall Framework of Network
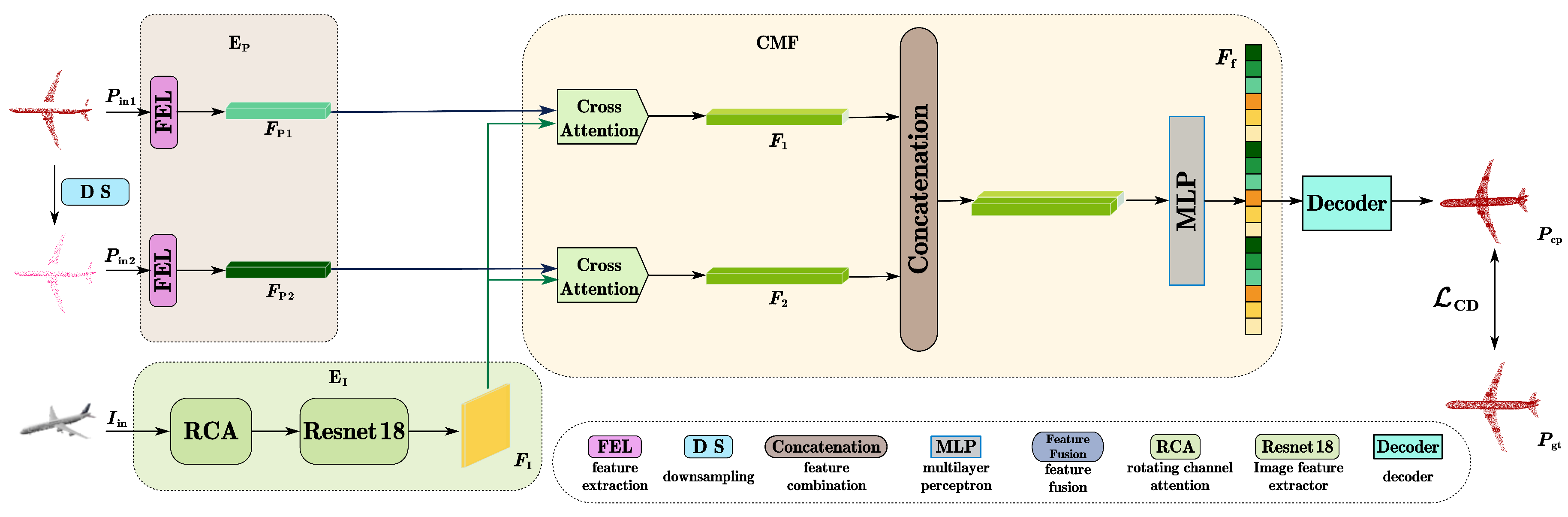
As shown in
Figure 1, the overall framework of the cross-modal multi-scale feature fusion network. The network employs an encoder-decoder architecture, divided into four parts: point cloud multi-scale feature extractor, image feature extractor, cross-modal feature fusion (CMF), and decoder. The input to the point cloud feature extractor is two point clouds of different scales (
and
), which are then fed into their respective feature extractors to obtain multi-scale feature vectors (
and
). The image feature extractor extracts features from image data, resulting in the feature vector
. The following two subsections of this paper will focus on the image feature extractor and the point cloud multi-scale feature extractor.
The cross-modal feature fusion (CMF) utilizes cross-attention and self-attention mechanisms [
15] to integrate feature information from both modalities. As shown in
Figure 1, the image features
are fused with the point cloud features
to obtain the fused features
. The features
are then concatenated with
in parallel and fed into a multilayer perceptron (MLP) layer to obtain the final fused features
. This paper employs multi-head attention mechanisms, first distinguishing between the two different modality features. The paper uses
and
as the query matrix
Q and the key matrix
K respectively, with
V representing the value matrix for each. The paper applies three rounds of cross-attention and self-attention mechanisms, allowing the image features and point cloud features to be gradually fused into the feature vector
, which is then fed into the decoder.
The decoder (D) is an important component of the network, aimed at accurately estimating the specific locations of the missing parts of the point cloud while maintaining both local and global structures. The paper employs a joint feature embedding method to complete the full point cloud. First, the original input data
undergoes a second round of farthest point sampling to obtain the sampling result
). The decoder uses
k branches to generate the point cloud, with each branch using multiple MLP layers to generate points, which are then combined into a new point cloud and finally concatenated with the farthest point sampling point cloud to form the final completed point cloud. The CMFN network proposed in this paper uses the Chamfer distance (CD) loss function [
16] to evaluate the similarity between the completed point cloud
and the real point cloud
, guiding the network training.
Figure 1.
Overall frame diagram of cross-modal multi-scale feature fusion
Figure 1.
Overall frame diagram of cross-modal multi-scale feature fusion
3.2. Point Cloud Multi-Scale Extractor
The Point Cloud Multi-Scale Feature Extractor (PCMSFE) takes as input two point clouds of different scales (
and
), with the number of points being
, where
N is the number of points in the original point cloud, and the second scale point cloud
is obtained by Farthest Point Sampling (FPS) [
6] from the original point cloud. The input data of different scales are processed through the Feature Embedding Layer (FEL), resulting in point cloud feature vectors
and
of the same dimensionality.
The Feature Embedding Layer (FEL) employs Dynamic Graph Convolution [
17] (DGCNN) to extract features from point cloud data. The idea behind dynamic graph convolution is to use the relationships between points (i.e., edges) to perform convolution operations, thereby extracting features from point cloud data. The input point cloud data in this paper is given by:
,
. For any point
, we use the K-Nearest Neighbors (KNN) algorithm to find the K nearest points around it and connect them to form edges, represented by the vector
. The specific calculation is as follows:
where, represents the concatenation of local feature information with global feature information, doubling the feature dimension. The function denotes the convolution operation, and indicates the max pooling operation. After mapping through the aforementioned functions, the point generates a feature point with K-point neighborhood features.
3.3. Image Feature Extractor
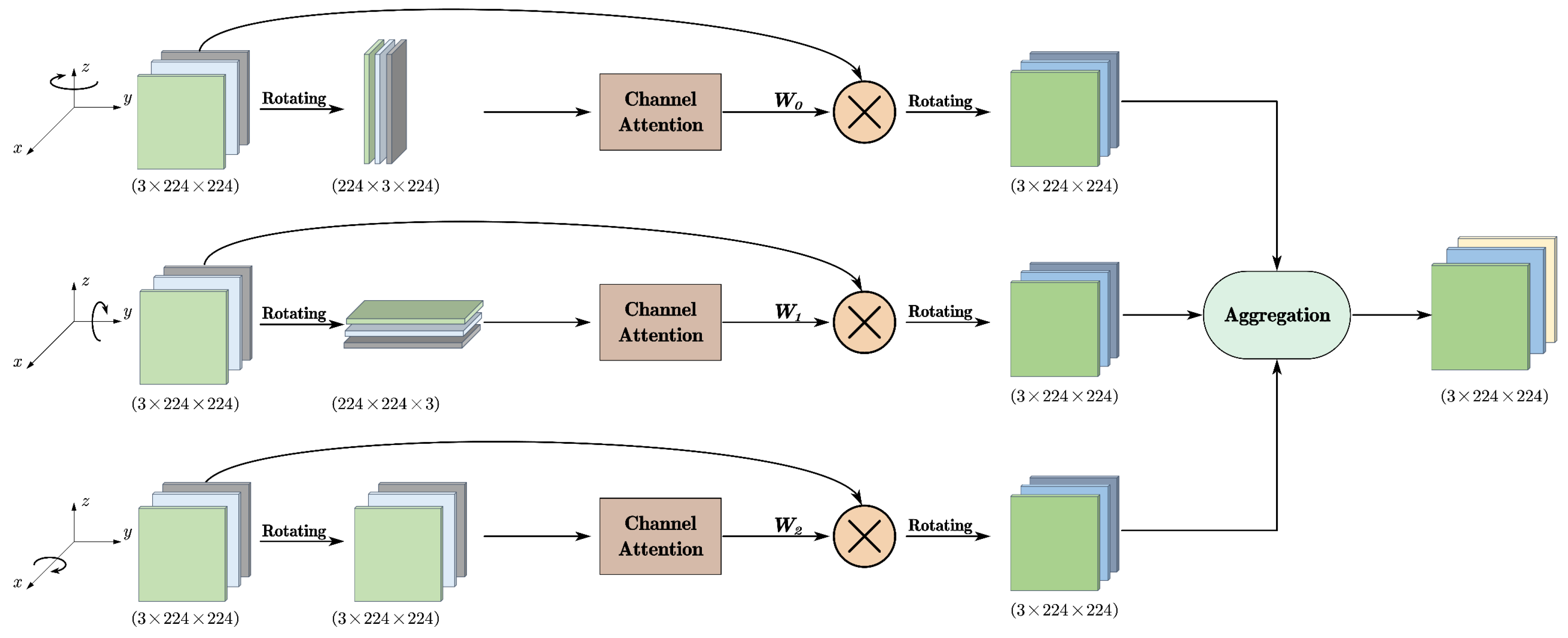
To better utilize the texture and structural information of images to assist in the completion of incomplete point clouds with higher accuracy, this paper proposes an image feature extractor based on the Rotating Channel Attention (RCA) mechanism.
As shown in
Figure 2 the Rotating Channel Attention (RCA) consists of three parallel branches. The first and second branches involve rotation and interaction between the channel dimension
C and the spatial dimensions
H and
W (rotating 90° clockwise around the z-axis and y-axis, respectively), achieving information exchange between different dimensions. The last branch constructs spatial attention using the spatial dimensions
H and
W (rotating 90° clockwise around the x-axis), focusing on local information. The outputs of the three branches are then aggregated using an averaging method to produce the final output.
The calculation process is as follows:
where , , represent the rotation operations around the x-axis, y-axis, and z-axis, respectively, and denotes the convolution operation. The resulting coefficient matrices after rotation and convolution are represented by , , and . The operation denotes the aggregation of these matrices to generate the final result y.
The image input
is processed through the RCA operation before being fed into the Resnet18 [
18] network, ultimately yielding the image feature
. The RCA module shares information between different channels of the image, enriching the image information in each channel and further enhancing the cross-modal feature fusion effect.
3.4. Point Cloud Similarity Evaluation Metrics
The network model evaluation metrics employed in this study are the Chamfer Distance (CD) and the F-Score. The CD loss function is utilized within the text to guide the network training. The similarity evaluation criterion between the completed point cloud and the real point cloud is based on the Chamfer Distance, which is defined as follows:
where represents the real point cloud, represents a point in the real point cloud, represents the completed point cloud, represents a point in the completed point cloud, and N represents the number of points in the point cloud. When training with the CD loss function, the goal of the optimization algorithm is to minimize the CD loss, thereby allowing the completed point cloud to better match the real point cloud.
The F-Score is a shape-matching based point cloud similarity evaluation metric used to detect any shape deviations between two point clouds. The calculation steps for the F-Score are as follows: 1) For each point
in the real point cloud, find the closest point
in the completed point cloud; 2) If the Euclidean distance between
and its closest point
is less than a threshold (in experiments, the threshold is set to 0.001 times the diameter of the point cloud), then point
is considered to be successfully matched; otherwise, it is considered a false match; 3) Calculate the number of true matches (TP), false matches (FP), and the number of points not successfully matched (FN); 4) Based on the definitions of precision and recall, compute the F-Score:
where the precision rate represents the proportion of correctly matched points, and the recall rate represents the proportion of points that are correctly matched. The F-Score takes into account both the precision and recall rates, providing a comprehensive measure of the similarity between two point clouds.
4. Result and Discussion
To test the effectiveness of the network algorithm, all experiments in this paper are conducted on the public dataset ShapeNet-ViPC. Additionally, this paper’s algorithm is compared with recent relevant deep learning methods for point cloud completion, and the effectiveness of each module within the network is verified through ablation experiments.
4.1. Datasets and Experimental Configuration
The network algorithm proposed in this paper is trained and tested on the public dataset ShapeNet-ViPC to evaluate its effectiveness. The ShapeNet-ViPC dataset comprises 13 object categories with a total of 38,328 objects, each featuring 24 incomplete point clouds with different occlusion perspectives and 24 corresponding real point clouds. For the 24 incomplete point cloud perspectives, there are 24 images in PNG format. The real point clouds contain 3,500 points each, the incomplete point clouds contain 2,048 points each, and the image pixel size is 24x24. Following convention, 80% of the data is used for training and 20% for testing.
Experimental Conditions: The experiments in this paper are conducted on the Ubuntu operating system using the PyTorch platform with the corresponding version of CUDA, and the GPU device used is the NVIDIA V100.
Experimental Parameter Settings: The optimizer used in the experiments is Adam (Adaptive Moment Estimation) [
19], with an initial learning rate of 0.001, which is subsequently reduced by a factor of
after 25 and 125 epochs. The batch size is set to 128, and the number of epochs is set to 200.
The input point cloud data is given by . After passing through the point cloud multi-scale feature extractor, the features are extracted with dimensions of . The image feature extractor uses a ResNet18 network embedded with the RCA module, with image input , and the output is . In the cross-modal feature fusion module (CMF), the multi-head is set to 4, with inputs and , producing fused features and at different scales, both with dimensions of . In the decoder, the original point cloud undergoes farthest point sampling to obtain the sampled points . The decoder has k branches, each producing 128 points, and the final completed point cloud is formed by combining the points from all branches with the sampled points.
4.2. Expriment Result Analysis
This paper utilizes the Chamfer Distance (CD) loss to guide the network training and test the effectiveness of the network. As previously mentioned, the principle of calculating the CD loss function is such that a smaller CD distance indicates greater similarity between two point clouds.
Table 1 presents a comparison of the completion results between our CMFN algorithm and other completion algorithms. The bolded numbers indicate the best completion results for that category.
From
Table 1, it can be observed that on the ShapeNet-ViPC dataset, multi-modal point cloud completion methods outperform single-modal point cloud completion methods, and our proposed CMFN network has achieved state-of-the-art (SOTA) performance among both single-modal and multi-modal algorithms. The completion effects for objects in 8 categories show a certain improvement over the latest multi-modal completion algorithm, XMFnet, especially in the category of lamps where the CD evaluation metric decreased by 41.38%, and the average metric across the 8 categories decreased by 11.71%.
Table 1.
Using CD evaluation index to compare the effect on ShapeNet-VIPC dataset
Table 1.
Using CD evaluation index to compare the effect on ShapeNet-VIPC dataset
| |
Methods |
Avg |
Airplane |
Cabinet |
Car |
Chair |
Lamp |
Sofa |
Table |
Watercraft |
| Single modal |
AtlasNet [7] |
6.062 |
5.032 |
6.414 |
4.868 |
8.161 |
7.182 |
6.023 |
6.561 |
4.261 |
| FoldingNet [20] |
6.271 |
5.242 |
6.958 |
5.307 |
8.823 |
6.504 |
6.368 |
7.080 |
3.882 |
| PCN [9] |
5.619 |
4.246 |
6.409 |
4.840 |
7.441 |
6.331 |
5.668 |
6.508 |
3.510 |
| TopNet [6] |
4.976 |
3.710 |
5.629 |
4.530 |
6.391 |
5.547 |
5.281 |
5.381 |
3.350 |
| ECG [21] |
4.957 |
2.952 |
6.721 |
5.243 |
5.867 |
4.602 |
6.813 |
4.332 |
3.127 |
| VRC-Net [22] |
4.598 |
2.813 |
6.108 |
4.932 |
5.342 |
4.103 |
6.614 |
3.953 |
2.925 |
| Multi-modal |
ViPC [12] |
3.308 |
1.760 |
4.558 |
3.183 |
2.476 |
2.867 |
4.481 |
4.990 |
2.197 |
| XMFnet [14] |
1.443 |
0.572 |
1.980 |
1.754 |
1.403 |
1.810 |
1.702 |
1.386 |
0.945 |
| Ours |
1.274 |
0.561 |
1.796 |
1.686 |
1.376 |
1.061 |
1.582 |
1.342 |
0.788 |
Table 2 presents a comparison of the results from nine point cloud completion algorithms on the ShapeNet-ViPC dataset, using the F-Score as the evaluation metric. The bolded numbers indicate the best completion results for each category.
It can be observed from
Table 2 that the CMFN network proposed in this paper achieved optimal performance in seven categories according to the F-Score metric, with an average improvement of 3.1% over the XMFnet network, and a significant enhancement of 10.98% in the category of lamps. It is noteworthy that the performance of our algorithm in terms of the F-Score metric is slightly inferior to that of the CD metric, since our network is trained and tested using the CD loss function, which tends to perform poorly in point cloud uniformity distribution. Consequently, networks trained with the CD loss function may exhibit a decline in the evaluation of point cloud completion effectiveness when assessed with the shape-matching similarity metric of F-Score. Nonetheless, our algorithm still demonstrates an improvement in this metric.
Table 2.
Using CD evaluation index to compare the effect on ShapeNet-VIPC dataset
Table 2.
Using CD evaluation index to compare the effect on ShapeNet-VIPC dataset
| |
Methods |
Avg |
Airplane |
Cabinet |
Car |
Chair |
Lamp |
Sofa |
Table |
Watercraft |
| Single modal |
AtlasNet [7] |
0.410 |
0.509 |
0.304 |
0.379 |
0.326 |
0.426 |
0.318 |
0.469 |
0.551 |
| FoldingNet [20] |
0.331 |
0.432 |
0.237 |
0.300 |
0.204 |
0.360 |
0.249 |
0.351 |
0.518 |
| PCN [9] |
0.407 |
0.578 |
0.270 |
0.331 |
0.323 |
0.456 |
0.293 |
0.431 |
0.577 |
| TopNet [6] |
0.467 |
0.593 |
0.358 |
0.405 |
0.388 |
0.491 |
0.361 |
0.528 |
0.615 |
| ECG [21] |
0.704 |
0.880 |
0.542 |
0.713 |
0.671 |
0.689 |
0.534 |
0.792 |
0.810 |
| VRC-Net [22] |
0.764 |
0.902 |
0.621 |
0.753 |
0.722 |
0.823 |
0.654 |
0.810 |
0.832 |
| Multi-modal |
ViPC [12] |
0.591 |
0.803 |
0.451 |
0.512 |
0.529 |
0.706 |
0.434 |
0.594 |
0.730 |
| XMFnet [14] |
0.796 |
0.961 |
0.662 |
0.691 |
0.809 |
0.792 |
0.723 |
0.830 |
0.901 |
| Ours |
0.822 |
0.968 |
0.696 |
0.710 |
0.812 |
0.879 |
0.748 |
0.835 |
0.929 |
4.3. Visualization
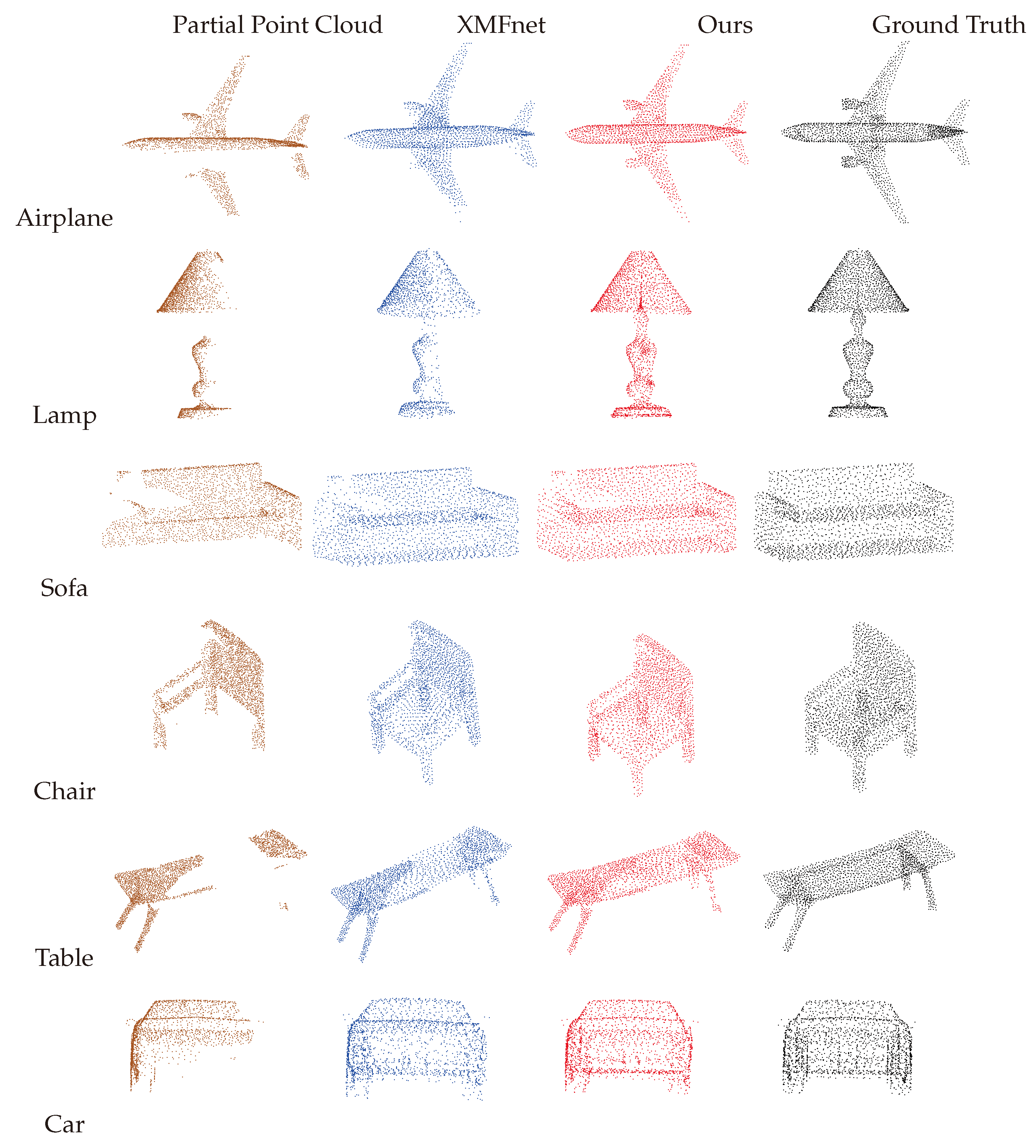
The visual comparison between the network algorithm proposed in this paper, CMFN, and the benchmark algorithm XMFnet is shown in
Figure 3. The figure presents the incomplete point clouds for six categories, the completion results from the XMFnet network, the completion results from the CMFN network, and the visualization of the real point clouds. By comparing the visual results from both networks with the real point clouds, it can be observed that the completion effect of the CMFN network is generally superior to that of the XMFnet network, with fewer outliers, more distinct structural details, and a more uniform density distribution in the point clouds. In the airplane category completion, the CMFN network provides more precise details compared to XMFnet, with the lower engine contour details being more similar to the real point cloud. The XMFnet network failed to complete the shape of the lower wing of the airplane, while the CMFN network captured the details of the lower wing, and the comparison of the nose and tail completion also reflects the advantages of the network proposed in this paper. In the table lamp category, the CMFN network’s completion result is closer to the real point cloud, whereas the XMFnet network’s completion result has more outliers in the lampshade and fails to complete the details of the lamp column and base contour. The CMFN network not only completes the structural details of the missing parts but also outperforms the former in terms of uniform point cloud density distribution. Additionally, in the table category, it can be observed that the network proposed in this paper significantly outperforms the XMFnet network in completing the contour of the missing tabletop area, which is more similar to the real point cloud contour, and the point cloud density distribution on the tabletop is more uniform.
4.4. Ablation
To validate the effectiveness of the multi-scale module and the Rotating Channel Attention (RCA) module in the CMFN network, this paper conducted multiple ablation studies on the ShapeNet-ViPC dataset. The network models were configured as the complete CMFN model, a model using only the RCA module, and a model using only the multi-scale module. The experimental results were compared with those of the benchmark network XMFnet, as shown in
Table 3. It is worth noting that while validating the effectiveness of the multi-scale module, this paper also verified the impact of different point cloud numbers at the second scale on the experimental results.
In the ablation experiments, three categories—lamps, ships, and cabinets—were used as reference data. From
Table 3, it can be observed that each module in the algorithm proposed in this paper is effective. The RCA module enhances the capability of image feature extraction by sharing information between channels. The multi-scale module uses DGCNN to extract point cloud features, where DGCNN repeatedly employs the K-Nearest Neighbors (KNN) clustering algorithm to improve the extraction of local and global feature information. The first scale of the point cloud input is set to the original data of 2048, which preserves the structural information of the original point cloud during the feature extraction process. The second scale of the point cloud input is set to 512, allowing for the extraction of global features after multiple graph convolutions. The ablation study indicates that setting the second scale point cloud input to 512 yields better results than 1024, confirming that a second scale point cloud of 512 can extract higher global feature information.
5. Conclusions
This paper presents a novel point cloud shape completion network that enhances data feature extraction capabilities by employing a multi-modal feature fusion approach within an encoder-decoder structure. An RCA (Rotating Channel Attention) module is integrated into the image feature extraction process to improve the extraction of image features, leveraging the textural and structural information of images to assist in the extraction of point cloud features. In the point cloud feature extraction process, a multi-scale method is utilized to enhance the extraction capabilities, not only increasing the inter-point relatedness within each sample’s point cloud but also integrating the correlation between local and global feature information, thereby generating point clouds with more accurate structural information.
The paper employs a multi-layer cross-attention mechanism to gradually fuse image features and point cloud features, achieving a multi-modal information feature-level fusion effect. The proposed algorithm compares favorably with both single-modal and multi-modal point cloud completion algorithms, achieving the best results. Specifically, when compared with the most recent multi-modal point cloud completion algorithm XMFnet, the average CD value was reduced by 11.71%, with a 41.38% reduction in the CD value for the lamp category. It is noteworthy that the proposed algorithm exhibited issues of local point cloud density inconsistency and a higher number of outliers during point cloud completion. Analysis indicates that the inconsistency in completion point cloud density is due to the use of the CD loss function to guide network training, while the excess of outliers may be attributed to insufficient local structural detail constraints during the point cloud generation process. Therefore, designing a more effective point cloud similarity evaluation method and a decoder with multi-modal feature constraints will be one of the future research directions in point cloud completion.
Author Contributions
Conceptualization, Gu S. and Wan J.; methodology, Gu S. and Xu K.; software, Gu S. and Hou B.; validation, Hou B. and Ma Y.; writing—review and editing, Gu S., Hou B. and Ma Y.; visualization, Hou B.; supervision, Wan J.; funding acquisition, Xu K.
Funding
This research was funded by the National Natural Science Foundation of China, Project Name:Research on High-Quality Perception of Targets in Dynamically Complex Scenes; Grant Number: U24B20138.
Conflicts of Interest
The authors declare no conflicts of interest.The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Mitra, N.J.; Pauly, M.; Wand, M.; Ceylan, D. Symmetry in 3D Geometry: Extraction and Applications. Comput. Graph. Forum 2013, 32, 1–23. [Google Scholar] [CrossRef]
- Li, Y.; Dai, A.; Guibas, L.J.; Nießner, M. Database-Assisted Object Retrieval for Real-Time 3D Reconstruction. Comput. Graph. Forum 2015, 34, 435–446. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society, 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; 2017; pp. 5099–5108. [Google Scholar]
- Tchapmi, L.P.; Kosaraju, V.; Rezatofighi, H.; Reid, I.D.; Savarese, S. TopNet: Structural Point Cloud Decoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation / IEEE, 2019; pp. 383–392. [Google Scholar] [CrossRef]
- Schnabel, R.; Degener, P.; Klein, R. Completion and Reconstruction with Primitive Shapes. Comput. Graph. Forum 2009, 28, 503–512. [Google Scholar] [CrossRef]
- Liu, M.; Sheng, L.; Yang, S.; Shao, J.; Hu, S. Morphing and Sampling Network for Dense Point Cloud Completion. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press, 2020; pp. 11596–11603. [Google Scholar] [CrossRef]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. PCN: Point Completion Network. In Proceedings of the 2018 International Conference on 3D Vision, 3DV 2018, Verona, Italy, 5–8 September 2018; IEEE Computer Society, 2018; pp. 728–737. [Google Scholar] [CrossRef]
- Yu, X.; Rao, Y.; Wang, Z.; Liu, Z.; Lu, J.; Zhou, J. PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE, 2021; pp. 12478–12487. [Google Scholar] [CrossRef]
- Xiang, P.; Wen, X.; Liu, Y.; Cao, Y.; Wan, P.; Zheng, W.; Han, Z. SnowflakeNet: Point Cloud Completion by Snowflake Point Deconvolution with Skip-Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE, 2021; pp. 5479–5489. [Google Scholar] [CrossRef]
- Zhang, X.; Feng, Y.; Li, S.; Zou, C.; Wan, H.; Zhao, X.; Guo, Y.; Gao, Y. View-Guided Point Cloud Completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, 19–25 June 2021; Computer Vision Foundation / IEEE, 2021; pp. 15890–15899. [Google Scholar] [CrossRef]
- Zhu, Z.; Nan, L.; Xie, H.; Chen, H.; Wang, J.; Wei, M.; Qin, J. CSDN: Cross-Modal Shape-Transfer Dual-Refinement Network for Point Cloud Completion. IEEE Trans. Vis. Comput. Graph. 2024, 30, 3545–3563. [Google Scholar] [CrossRef] [PubMed]
- Aiello, E.; Valsesia, D.; Magli, E. Cross-modal Learning for Image-Guided Point Cloud Shape Completion. In Proceedings of the Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, 28 November–9 December 2022; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; 2022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; 2017; pp. 5998–6008. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society, 2017; pp. 2463–2471. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 146–1. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer, 2016; Vol. 9908, Lecture Notes in Computer Science. pp. 630–645. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; 2015. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation / IEEE Computer Society, 2018; pp. 206–215. [Google Scholar] [CrossRef]
- Pan, L. ECG: Edge-aware Point Cloud Completion with Graph Convolution. IEEE Robotics Autom. Lett. 2020, 5, 4392–4398. [Google Scholar] [CrossRef]
- Pan, L.; Chen, X.; Cai, Z.; Zhang, J.; Zhao, H.; Yi, S.; Liu, Z. Variational Relational Point Completion Network for Robust 3D Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11340–11351. [Google Scholar] [CrossRef] [PubMed]
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).