
Submitted:
07 December 2024
Posted:
09 December 2024
You are already at the latest version
Abstract
In this paper, we consider the application of brute force computational techniques (BFCT) for solving computational problems in mathematical analysis and matrix algebra in floating-point computing environment. These techniques include, among others, simple matrix computations and analysis of graphs of functions. Since BFCT are based on matrix calculations the program system MATLAB® is suitable for their computer realization. The computations in this paper are done in double precision floating-point arithmetic obeying the 2019 IEEE Standard for binary floating-point calculations. One of the aims of the paper is to analyze cases when popular algorithms and software fail to produce correct answers without warning for the user. In real time control applications this may have catastrophic consequences with heavy material damage and human casualties. It is known, or suspected, that a number of man-made catastrophes such as Dharhan accident (1991), Ariane 5 launch failure (1996), Boeing 737 Max tragedies (2018, 2019) and others are due to errors in the computer software and hardware. Another application of BFCT is finding good initial guesses for known computational algorithms. Sometimes simple and fast BFCT are useful tools in solving computational problems correctly and in real time. Among particular problems considered are genuine addition of machine numbers, numerically stable computations, finding minimums of arrays, minimization of functions, solving finite equations, integration and differentiation, computing condensed and canonical forms of matrices and clarifying the concepts of least squares method in the light of the conflict Remainders vs. Errors. Usually BFCT are applied under user’s supervision which is not be possible in automatic implementation of computational methods. To implement BFCT automatically is a challenging problem in the area of artificial intelligence (AI) and of mathematical artificial intelligence (MAI) in particular. BFCT allow to reveal the underlying arithmetic (FPA, VPA, etc.) in the performance of computational algorithms. Last but not least this paper may have some tutorial value since at certain places computational algorithms and mathematical software are still taught without taking into account the properties of computational algorithms and machine arithmetic.
Keywords:
computational algorithms
; brute force computations
; reference solutions
; machine arithmetic
; failure of computer codes
MSC: 65-04; 65Y04
1. Introduction and Notation
1.1. Preliminaries
Sophisticated computational algorithms have been developed during the last 300 years for solving a large variety of problems in mathematical and engineering sciences [1,2,3,4,5]. When digital computers become available since the middle of 20th century it became clear that some computational algorithms of the past are not suitable for computer implementation at least without significant modifications. Other algorithms (albeit very clever) became obsolete. Thus paradigms of scientific computations had been changed and new types of modern computational algorithms were developed and implemented as computer codes.
When implemented as computer codes in floating-point computer environment such as MATLAB® [6,7] and Maple [8], however, some of these computational algorithms may produce wrong results without warning. Other systems as Mathematica [9,10] use variable precision arithmetic (VPA) and may avoid such pitfalls at the price of certain increase of the time necessary for performance of the algorithms. In such cases BFCT and a detailed analysis of computational problems with reference solution (CPRS) may be useful.
BFCT may also be used to obtain initial guesses for computational algorithms intended to solve finite equations and minimize functions of one or several scalar arguments. We stress finally that Monte Carlo algorithms [11] are also a form BFCT. As a perspective, a combination of mathematical AI [12,13] with BFCT is yet to be developed.
The computations in this paper are done in double precision binary floating-point arithmetic (FPA) obeying the IEEE Standard [14]. Some of the matrix notations used are inspired by the language of MATLAB®. The codes for the numerical experiments are given so the results may be checked independently. BFCT allow to reveal the underlying machine arithmetic.
1.2. General Notations
Next we use the following general notations.
- – set of integers
- – set of integers , where
- – set of integers
- – set of real (complex) numbers
- – imaginary unit, where
- – sum of the scalar quantities
- – definite integral of the function on the interval
- ≺ – lexicographical order on the set of pairs defined as if , or and ; we write if , or
- – set of matrices A with elements , where is one of the sets , or
- – pth row of
- – qth column of
- – spectral norm in
- – matrix with unit elements
- – rank of the matrix
- – trace of the matrix
- – determinant of the matrix
- – identity matrix with and for
- – matrix with unique nonzero element, equal to 1, in position
- – nilpotent matrix with and for
- – eigenvalues of the matrix , where ; we usually assume that
- – singular values of the matrix , where , ; the singular values are ordered as
- – spectral norm of the matrix
- – condition number of the non-singular matrix
1.3. Machine Arithmetic Notations
We use the following notations from binary floating-point arithmetic, where codes and results in MATLAB®environment are written in typewriter font.
- – set of finite positive (negative) machine numbers
- – set of finite machine numbers
- – rounded value of ; is computed as by the command sym(x,’f’), where , and m is odd if
- – set of positive (negative) machine numbers; we have
- () – machine number right (left) nearest to ; is obtained as X + eps(X)
- – machine epsilon; we have , ; is obtained as eps(1), or simply as eps
- – rounding unit
- – maximal integer such that positive integers are machine numbers; we have ,
- – maximal machine integer degree of 2; we have
- – maximal machine number; it is also denoted as realmax and we have eps(realmax) = 2^971
- – minimal positive normal machine number; it is also denoted as realmin
- – minimal positive subnormal machine number; it is found as eps(0)
- – rounded value of
- – normal range; numbers are rounded with relative error less than
- Inf (-Inf) – positive (negative) machine infinity
- NaN – result of mathematically undefined operation, comes from Not a Number
- – extended machine set
1.4. Abbreviations
| AI | – | artificial intelligence |
| ARRE | – | average rounding relative error |
| BFCT | – | brute force computational technique |
| CPRS | – | computational problem with reference solution |
| FPA | – | double precision binary floating-point arithmetic |
| LLSP | – | linear least squares problem |
| LSM | – | least squares method |
| LSP | – | least squares problem |
| MAI | – | mathematical artificial intelligence |
| MRRE | – | maximal rounding relative error |
| NLF | – | Newton-Leibniz formula |
| NFP | – | numerical fixed point |
| RRE | – | rounding relative error |
| RTA | – | real time application |
| VPA | – | variable precision arithmetic |
1.5. Software and Hardware
The computations are done with the program system MATLAB®, Version 9.9 (R2020b), on Lenovo X1 Carbon 7th Generation Ultrabook.
1.6. Problems with Reference Solution
An effective approach to using BFCT is solving CPRS. CPRS are specially designed computational problems with a priory known, or reference, solutions. It is supposed that the numerical algorithm which is to be checked does not “know” this fact and solves the computational problem in the standard way. Consider for example the finite equation , where and x are scalars or vectors. Then a CPRS is obtained choosing , where is the reference solution. We usually choose to be a vector with unit elements, e.g. x_ref = ones(n,1) and .
Let be a solution of the equation and be an approximate solution computed in FPA. The absolute error and the relative error
of the computed solution , such that , depends on rounding of initial data and on rounding and other errors made during the computational procedure [15,16]. To eliminate effects of rounding of initial data we may consider CPRS with relatively small integer data, or more generally, with data consisting of machine numbers.
Example 1.
Computational algorithms and software for solving linear algebraic equations , where is invertible, may be checked choosing and , where x_ref = ones(n,1).
The computed solution is x_comp = A\b and we may compare the relative error norm(x_ref-x_comp)/sqrt(n) with the a priori error estimate eps*cond(A).
Example 2.
Let be a differentiable highly oscillating function with derivative . The numerical integration of may be a problem. For such integrands we may formulate a numerically difficult computational problem with reference solution . Systems with mathematical intelligence such as MATLAB® [6], Maple [8] and Mathematica [9,10] may find the integral with high accuracy by the NLF thus avoiding numerical integration.
Example 3.
To check the codes for eigenstructure analysis of a matrix we may choose , where are integer matrices with . The eigenvalues of A are equal to 1 (the reference solution). Computational algorithms such as the QR algorithm and software for spectral matrix analysis may produce wrong results even for matrices of moderate norm.
Example 4.
When solving the differential equation with initial condition we may choose a reference solution as follows. The function satisfies the differential equation , where
with initial condition .
An important observation is that for some computational problems such as finding extrema of functions, BFCT may produce better results than certain sophisticated algorithms used in modern computer systems for doing mathematics, see e.g. Section 7.
2. Machine Arithmetic
2.1. Preliminaries
In this section we consider computations in FPA obeying the IEEE Standard [14]. Numerical computations in MATLAB® are done according to this standard. The FPA consists of set of machine numbers and rules for performing operations, e.g. addition/subtraction, multiplication/division, exponentiation, etc. Rounding and arithmetic operations in FPA are performed with RRE of order . The sum and the product are computed as and .
A major source of errors in computations is the (catastrophic) cancellation when relatively exact close numbers are subtracted so that the information coded in their left-most digits is lost [17]. Thus catastrophic cancellation is the phenomenon when subtracting good approximations to close numbers may cause a bad approximation to their difference. Less known is that genuine addition in FPA may also cause large and even unlimited errors.
A tutorial example of cancellation is solving quadratic equations , . During the last 4000 years students are taught to use the formula , , without warning that this may be a bad way to solve numerically quadratic equations.
Similar considerations are valid for the use of explicit expressions for solving cubic and quartic algebraic equations. Because genuine subtraction is numerically dangerous. Genuine addition in FPA is not less dangerous.
2.2. Violation of Arithmetic Laws
In FPA the commutative law for addition and multiplication is valid but the associative law for addition and multiplication is violated, i.e. it may happen that
The distributive law is also violated. This may lead to unexpectedly large (in fact arbitrarily large) errors.
For example, we have the wrong result . The reason for this machine calculation is that is not a machine number (this is the smallest positive integer with this property). It lies in the middle of the successive machine numbers R and and is rounded to R. At the same time we have which is the correct answer. Thus we got the famous wrong equality arising in mathematical jokes.
This is not the end of the story. Consider the expression consisting of members, where there are R members equal to 1. We have . Computing S from left to right we get the wrong answer . Computing S starting with the ones, i.e. we get the correct answer . Now we have obtained the more impressive result . Summing (at least theoretically) sufficient number of units we compute the sum of 1’s as Inf and hence .
The associative law for multiplication is also violated in FPA. For example, the value of the expression is and it is computed correctly as
At the same time the machine computation of P from left to right gives
where is the symbol for infinity in FPA. Thus we got .
Similar false equalities may also be obtained by addition and subtraction of machine numbers. Set . In standard arithmetic we have . In FPA it is fulfilled . This corresponds to the wrong equality although E is a machine number at a good distance to .
We also have although the exact result is and should be rounded to -Inf. Thus we obtained . The reason is that the maximum positive machine number in FPA is and the number is set to . Moreover, the maximum positive integer that is still rounded to is while the number is set to Inf.
These entertaining exercises may produce undetermined results as well. For example, we have but the computed value is U = Inf/Inf - 1 = NaN. This may be interpreted as the exotic equality .
Working with positive numbers also leads to violation of the distributive law . In particular, we usually think that for it is fulfilled . But setting we get (x + x)/2 = 2*x/2 = x and x/2 + x/2 = 0 + 0 = 0. We stress that the minimal positive quantity that is still rounded to instead to 0 is .
The distributive law in the form (1/m + 1/n)/p = 1/m/p + 1/n/p, where at least one of the operands is not an integer degree of 2, is also violated. In this case the rounded values of both sides of the equality are usually neighboring machine numbers.
Example 5.
Let , , . Then and .
Example 5 illustrates the fact that machine subtraction of close numbers is usually performed with small relative error. Moreover, if the operands are machine numbers and then the machine subtraction is exact [17].
The rounded value of is computed by the command sym(X,’f’) in the form , where and m is odd when . In particular the command sym(realmax,’f’) will give 309 decimal digits of the integer = realmax.
2.3. Numerical Convergence of Series
We shall conclude our brief excursion in the machine summation of numbers with the consideration of numerical series with positive elements . For set .
Definition 1.
The symbol is called numerical series. The quantity is the n-th partial sum of this series.
The partial sums are computed in FPA as , , . Theoretically, the series is divergent when . In FPA there are three mutually disjoint possibilities according to the next definition.
Definition 2.
The series is said to be:
- numerically convergent if there is a positive and such that for ; the number S is called numerical sum of the series .
- numerically divergent if there is such that for ; in this there are now terms for
- numerically undefined if there is such that for and
Divergent numerical series may be (and very often are!) numerically convergent. For example, the divergent harmonic series with is numerically convergent in FPA to a sum . The divergent series with is numerically convergent to . Also, it is easy to prove the following assertion.
Proposition 1.
For any there is a series which is numerically convergent to S.
Proposition 1 for FPA is an analogue to the Riemann series theorem [18] which states that the members of a convergent real series which is not absolutely convergent may be reordered so that the sum of the new series to be equal to any prescribed real number.
2.4. Average Rounding Errors
We recall that the normal range of FPA is the interval , where numbers are rounded with RRE less than .
Let and be the rounded value of x. It is well known [14] that the RRE satisfies the estimate
The code sym(x,’f’) computes in the form , where m is odd if . Let . The expression between two successive machine numbers
in the interval is as follows. Let
Then
The maximum of in the interval is achieved for and is equal to
The graph of the function resembles a saw, see Figure 1.
For near to the maximum RRE is about , while for near to the maximum RRE is close to . In particular we have
That actual behavior of RRE is not governed by (1) but is considerably smaller, has been known to specialists in computer calculations from a long time. To clarify this problem we performed intensive numerical experiments.
BFCT showed that actual RRE is considerably lower than and lower than and this led to the definition and use of average RRE which are more realistic in comparison with the relative error . Based on this observation [19] we have defined and calculated an integral ARRE as the definite integral . This integral is of order
At the same time the average of the maximums of RRE is
Intensive numerical BFCT experiments [19] with rounding of large sequences of numbers had shown that the actual ARRE is about . This is 2.5 times less than the widely used bound in the literature [14]. In these experiments numbers had been excluded because . This explains why the multiplier of was computed as 0.40 instead of 0.35.
In another series of experiments we have computed and averaged the RRE for fractions , and for and m up to 1000 and we have computed the ratios . The results are shown in Table 1. The actual RRE in rounding of unit fraction (second column) is very close to the integral ARRE (3).
For fractions close to 1 the computed ARRE is larger than for fractions close to 2. This confirms the observation that rounding of , , is done with less (although not twice less) RRE for x close to the left limit than close to the right limit of the interval, see (2). For example, the result in field (4,2) of Table 1 is obtained by the code
for m = 1:1000
R(m) = double(abs((sym(1/m,’e’)-1/m))*m*2/eps);
end
mean(R)

Table 1.
Ratios for certain fractions.
| m | |||
| 10 | |||
| 100 | |||
| 1000 |
We stress that in such experiments we cannot use pseudo-random number generators such as rand, randn and randi from MATLAB® since they produce machine numbers for which the rounding errors are zero.
We summarize the above considerations in the next important proposition.
Proposition 2.
The known rounding error bounds in all computational algorithms realized in FPA may be reduced three times (!) if integral ARRE are used instead of maximum RRE.
3. Numerically Stable Computations
3.1. Lipschitz Continuous Problems
Numerical stability of computational procedures is a major issue in numerical analysis [15]. A large variety of computational problems (actually, almost all computational problems) may be formulated as follows, see [15,16]. Let and be given sets and let be a continuous function. We shall use the following informal definition.
Definition 3.
The computational problem is described by the function f, while the particular way of computing the result for a given data is the computational algorithm.
Thus the computational problem is identified with the pair , or with the equality . For many computational problems the function f is Lipschitz continuous.
Definition 4.
The computational problem is said to be (locally) Lipschitz continuous if there exist constants and such that
whenever . The problem is globally Lipschitz continuous if .
If the function f has locally bounded derivative it is (locally) Lipschitz continuous. The concept of Lipschitz continuity is illustrated by the next example.
Example 6.
Let , , and be a given constant. Then the following assertions take place.
- The function is Lipschitz continuous if and is not Lipschitz continuous if .
- The function is Lipschitz continuous if and is not Lipschitz continuous if .
- The function , , is Lipschitz continuous if and is not Lipschitz continuous if .
- The function for and , is differentiable on but is not Lipschitz continuous.
Suppose finally that the algorithm is realized in FPA, e.g. in MATLAB® computing environment.
Definition 5.
The computational algorithm is said to be numerically stable if the computed result is close to the result of a close problem with data .
Definition 5 includes the popular concepts of forward and backwards numerical stability. To make this definition formal, suppose that there exist non-negative constants such that
and , . Further on we have
Dividing the last inequality by we get the following estimate for the relative error in the computed solution
Definition 6.
The quantity is said to be relative condition number of the computational problem .
The remarkable formula (4) reveals the three main factors which determine the accuracy of the computed solution [16,19].
Proposition 3.
The accuracy of the computed solution depends on the following factors.
- The sensitivity of the computational problem relative to perturbations in the data d measured by the Lipschitz constant L of the function f
- The stability of the computational algorithm expressed by the constants
- The FPA characterized by the rounding unit ρ and the requirement that the intermediate computed results belong to the normal range
The error estimate (4) is used in practice as follows. For a number of problems the Lipschitz constant L may be calculated, or estimated as in the solution of linear algebraic equations and the computation of the eigenstructure of a matrix with simple eigenvalues. Finally, the value of is known exactly for FPA as well as for other machine environments.
The estimate of the constants may be a problem. Often the heuristic assumption and is made which gives
It follows from (5) that C will be large if L and/or are large and/or is small. The constant L is usually out user’s control. The quantities and may be changed by scaling of the computational problem
Definition 7.
The computational problem is said to be:
- well conditioned if ; in this case we may expect about true decimal digits in the computed solution
- poorly conditioned if ; in this case there may be no true digits in the computed solution
More precise classification of the conditioning (well, medium and poor) of computational problems is also possible. Computational problems which are not Lipschitz but Hölder continuous may also be analyzed, see e.g. [19].
The above considerations confirm a fundamental rule in numerical computations, namely that if the data d and/or some of the intermediate results in the computation of are large and/or the result is small then large relative errors in the computed solution may be expected, see Section 3.3.
For some computational problems there are a priory error estimates for the relative error in the computed solution in the form of explicit expressions in and d. The importance of such estimates is that they may be computed (or estimated) a priory, before solving the computational problem.
Most a priory error estimates are heuristic. Among computational problems with such estimates is the solution of linear algebraic equations and the computation of the eigenvalues of a matrix A with simple spectrum. To check the accuracy and practical usefulness of such error estimates by BFCT, a set of CPRS is designed and the error estimates are compared with the observed errors.
3.2. Hölder Continuous Problems
Definition 8.
The computational problem is said to be Hölder continuous with exponent if there exist constants and such that
whenever .
Hölder continuity implies uniform continuity but the converse is not true. It is supposed that . Indeed, if the problem is Lipschitz continuous and if the function f is constant.
The machine computation of may be accomplished with large errors of order when the exponent is small. Such cases arise in the calculation of a multiple zero of a smooth function , where , and . In this case .
Let and be the computed value of r. Then a heuristic accuracy estimate for the solution of a Hölder problem is
Experimental results confirming this estimate are presented later on.
A typical example of a Hölder problem is the computation of the roots of n-degree algebraic equation with multiple roots, where (the case is treated by a specific algorithm). There are three codes in MATLAB® that may be used for solving algebraic equations which may be characterized as follows.
- The code roots is fast and works, on middle power computer platforms, with equations of degree n up to several thousands but gives large errors in case of multiple roots. This code solves algebraic equations only.
- The code vpasolve works with VPA corresponding to 32 true decimal digits with equations of degree n up to several hundreds but may be slow in some cases. This code works with general equations as well finding one root at a time.
- The code fzero is fast but finds one root at a time. It may not work properly in case of multiple roots of even multiplicity. This code works with general finite equations as well.
3.3. Golden Rule of Computations
The results presented in this and previous sections confirm the Golden Rule in doing computations in both exact and machine arithmetic which may be formulated as follows.
Proposition 4.
(Golden Rule of Computations) If in a chain of numerical computations the final result is small relative to the initial data and/or to the intermediate results then large relative errors in the computed solution are to be expected.
The already mentioned catastrophic cancellation in subtraction of close numbers is a particular case of Proposition 4.
An important class of computations in FPA are the so called computations with maximum accuracy. Let the vector r with elements be the exact solution of the vector computational problem and let the vector with elements be the computed solution.
Definition 9.
The vector is computed with maximum accuracy if its elements satisfy .
Solutions with maximum accuracy are the best that we may expect from a computational algorithm implemented in FPA.
4. Extremal Elements of Arrays
Finding minimal and maximal elements of real and complex arrays is a part of many computational algorithms. This problem may look simple but it has pitfalls in some cases.
4.1. Vectors
Let be a given real n-vector. The problem of determining an extremal (minimal or maximal) element of w together with its index k arises as part of many computational problems. The solution of this problem is obtained in MATLAB® by the codes [U,K] = min(w) or [V,L] = max(w), where is the minimal element of the vector w and K is its index. Similarly, is the maximal element of the vector w and L is its index. These codes work for complex vectors as well if the complex numbers are ordered lexicographically by the relation ⪯, see [6].
An important rule here is that if there are several elements of w equal to its minimal element U then the computed index K is supposed to be the minimal one. Similarly, if there are several elements of w equal to its maximal element V then the computed index L is again the minimal one. The delicate point here is the calculation of indexes K and L. For example, for , where or , the codes min and max produce , and , as expected.
Due to rounding the above codes may produce unexpected results. Indeed, the performance of the codes depends on the form in which the elements of the vector w are written.
Example 7.
The quantities , and are equal but their rounded values are different. The rounded value of is computed by the codesym(X,’f’). It produces the answer in the form , where . We have and , . Hence .
Example 8.
Let w be a 3-vector with elements at any positions, where are defined in Example 7. Then the code [U,K] = min(w)
will give and K will be the index of B as an element of w. The code
[V,L] = max(w)
will give and L will be the index of C as an element of w. At the same time both codes are supposed to give and .
These details of the performance of the codes min and max may not be very popular even among experienced users of sophisticated computer systems for doing mathematics such as MATLAB®.
4.2. Matrices
Similar problems as in Section 4.1 arise in finding extremal (minimal or maximal) elements of multidimensional arrays and in particular of real and complex matrices A.
Consider a matrix with elements . Let the minimal element of A relative to the lexicographical order be . Then the code
[a,b] = min(A); [A_min,N] = min(a); A_min, ind = [b(N),N]
finds the minimal element of A and the pair of its indexes as
A_min, ind = i_1 i_2
where i_1 = ind(1), i_2 = ind(2). Here a and b are n-vectors and ind is a 2-vector.
If there is more than one minimal element then the computed pair of its indexes is minimal relative to the lexicographical order. This result, however, may depend on the way the elements of A are specified.
Finding minimal elements of matrices may be a part of improved algorithms to compute extrema of functions of two variables, see Section 7.2. A scheme for finding minimal elements of -arrays, , may also be derived and applied to the minimization of functions of n variables.
4.3. Application to Voting Theory
The above details in using the codes min and max from MATLAB® [6], although usually neglected, may be important. For example, in certain automatic voting computations (in which one of the authors of this paper had participated back in 2013) with the Hamilton method for the bi-proportional voting system used in Bulgaria, these phenomena actually occurred and caused problems. To resolve quickly the problem we applied BFCT using hand calculations (!) being in emergency situation.
The computational algorithms for realization of the Hamilton method must be improved replacing the fractional remainders by integer remainders [19] as follows. Let n parties with votes take part in the distribution of parliamentary seats by the Hamilton method [20]. Set and .
Next the rationals are represented as , where is the integer part of , is the fractional remainder and is the integer remainder of modulo V. Initially the kth party gets seats. If the sum of initial seats is less than S then the first parties with largest integer remainders get one seat more. Thus to avoid small errors in the computation of fractional remainders that may cheat the code max we must work with exactly computed integer remainders.
5. Problems with Reference Solution
5.1. Evaluation of Functions
Evaluation of functions f defined by an explicit expression
is a CPRS since may be found with high precision in a suitable computing environment. However, the relative error in computing y may be large even for well behaved functions f and arguments x far from the limits of the normal range [19]. The reason is that instead with the argument the corresponding computational algorithm works with the rounded value . At the same time for the computed quantity is usually exact to working precision.
Example 9.
We have
[cos(realmax);sin(realmax)] = -0.999987689426560
0.004961954789184
The computed result is correct to full precision although the argument realmax is written with 309 decimal digits, which may be displayed by the command sym(realmax,’f’).
Let the function f be locally Lipschitz continuous with constant in a neighborhood of x and let the result computed in FPA be . Then the relative error of is estimated as
where is the relative condition number of the computational problem .
Example 10.
Consider the vector , where . We should have but for large k this may not be so. Let the vector has elements , i.e.
X = pi*[2^47,2^48,2^49,2^50,2^51,2^52,2^53,2^54]
The command
Y = [cos(X);sin(X)]
gives the matrix
Y = 0.9999 0.9994 0.9976 0.9905 0.9622 0.8517 0.4509 -0.5934
0.0172 -0.0345 -0.0689 -0.1374 -0.2723 -0.5240 -0.8926 -0.8049
While the first column Y(:,1) of Y still resembles the exact vector [1;0], the next columns are heavily wrong with Y(:,8) being a complete catastrophe with relative error 170%. The commands Y1 = [C1;S1] and Y2 = [C2;S2], where C1 = vpa(cos(X)), S1 = vpa(sin(X)), C2 = cos(vpa(X)) and S2 = sin(vpa(X)) produce the same wrong result Y1 = Y2 = Y.
A way out from such wrong calculations is to evaluate standard trigonometric functions for arguments modulo .
Example 11.
The command
YY = [cos(mod(X,2*pi));sin(mod(X,2*pi))]
produces the matrix
YY = 1 1 1 1 1 1 1 1
0 0 0 0 0 0 0 0
which is exact to full precision.
We recall that for the rounded value of x is an even integer. For example, the quantity is rounded to which is demonstrated by the command sym(23*pi^32/20,’f’). Another instructive example is rounding integer degrees .
Example 12.
We have for but
sym([10^23;10^24;10^25],’f’) = 99999999999999991611392
999999999999999983222784
10000000000000000905969664
If then for most elementary and special functions f the quantity is computed with maximum accuracy.
If the function f is locally Lipschitz with constant then large relative computational errors in evaluation of may occur when is large, i.e. when and/or is large and/or is small. For the trigonometric functions above the quantities and were equal to 1 but the argument is large.
A standard approach to improve the performance of computational algorithms is to scale the initial and/or intermediate data to avoid large errors. In computing the matrix exponential , , the scaling is done by a scaling factor , , which is a binary degree in order to reduce rounding errors [15].
5.2. Linear Algebraic Equations
An instructive example, illustrating BFCT to the solution of vector algebraic equations with integer data, is designed as follows. Let be invertible matrix and . The command A = fix(100*randn(n)); generates a matrix with normally distributed with integer elements of moderate magnitude and zero mean. Choosing the reference solution as X_0 = ones(n,1) we get b = A*X_0. The computed solution is X_comp = A\b with relative error E_n = norm(X_comp - X_0)/sqrt(n).
The a priory relative error estimate is est = eps*cond(A). Usually is a small multiple of and this may be checked by BFCT. We consider three types of computed solutions as follows.
- Standard solution X_1 = A\b obtained by Gauss elimination with partial pivoting based on LR decomposition of A, where L is lower triangular matrix with unit diagonal elements, R is upper triangular matrix with nonzero diagonal elements and P is permutation matrix.
- Solution X_2 = R\(Q’*b) obtained by QR decomposition [Q,R] = qr(A) of A, where , the matrix Q is orthogonal and the matrix R is upper triangular.
- Solution X_3 = inv(A)*b based on finding the inverse of A.
Solution is computed as a default in MATLAB®and is accurate and fast. Solution is very accurate although more expensive and is also used. Solution is not recommended and is included here for tutorial purposes. Indeed, computing inv(A) and multiplying the vector b by this matrix are unnecessary operations which are expensive and reduce accuracy.
The above computational techniques are illustrated by the commands
n = 1000; A = fix(100*randn(n)); X_0 = ones(n); b = A*X_0;...
X_1 = A\b; [Q,R] = qr(A); X_2 = R\(Q’*b); X_3 = inv(A)*b;...
E_1 = norm(X_0-X_1)/sqrt(n);E_2 = norm(X_0-X_2)/sqrt(n);...
E_3 = norm(X_0-X_3)/sqrt(n);est = eps*cond(A);...
e_1 = E_1/est; e_2 = E_2/est; e_3 = E_3/est; [e_1;e_2;e_3]
Each execution of these commands produces different result because of the code randn. The computed quantity e_1 for systems with up to unknowns is usually less than 20, the quantity e_2 is about 40 and the quantity e_3 is less than 4. More precisely, intensive computations with showed that , and .
Tests with had also been done but they require more computational time. For such values of n we have observed average values , , .
The comparison of and with confirms, among others, the tutorial conclusion that solving linear equations by matrix inversion must definitely be avoided. Rather, the opposite is fact. If the inverse matrix is needed for some reason, it is found solving n linear equations for the columns of B, where is the kth column if .
Our main observation, based on BFCT, about comparison of the methods of Gauss elimination and QR decomposition for solving linear algebraic equations, is formulated in the next proposition.
Proposition 5.
For matrices of order up to 1000 the QR decomposition method gives error that is between 5 and 10 times less than the error of the Gauss elimination method.
In addition, the solution of a linear equation via QR decomposition is backward stable. Thus Proposition 5 is a message to the developer of MATLAB®, the respected MathWorks, Inc. Corporation.
The Gauss elimination method based on LR decomposition is preferred to the QR decomposition method because it requires twice less floating-point operations. Since fast computational platforms are now widely available, this consideration is no more valid.
As a rule the implementation of the code x = A\b gives good results for matrices with n of order . At the same time large errors in x may occur even for .
Example 13.
Consider the algebraic equation , where the matrices are defined by the relation (7) below. For we have . The computed results for are presented at Table 2. In cases there is a warning that the matrix is close to singular or badly scaled since is larger than . As shown in Table 2, for these two cases the relative error is indeed 25% and 100%, respectively.
5.3. Eigenvalues of Machine Matrices
The integer matrix
has double eigenvalue and Jordan form . The elements of A are integers of magnitude . This is far from the the quantity R such that integers may not be machine numbers.
Example 14.
The MATLAB® code e = eig(A)’ computes the row 2-vector e of eigenvalues of A as instead of . The relative error is 140% and there is no true digit in the computed vector (even the sign of the first computed eigenvalue is wrong). The trace of A is computed fortunately as trace(A) = 2 and is the sum of computed eigenvalues. The determinant is computed wrongly as det(A) = 0.2214.
Surprisingly, the vector p of the coefficients of the characteristic polynomial of A, computed as p = poly(A), is [1,-2,-0.9475]. The last element of the computed vector is not the computed determinant 0.2214, which may confuse the user. Moreover, the computed eigenvalues of A are the roots of this wrong characteristic polynomial and hence they are not computed from the Schur form of A as supposed.
Here we recall the modern paradigm in numerical spectral analysis and root finding of polynomials: the eigenvalues of a matrix are not computed as roots of its characteristic polynomial; rather the roots of any polynomial are computed as the eigenvalues of its companion matrix.
The Maple [8] code jordan(A), incorporated in MATLAB®, computes correctly the Jordan form of A. The vector of eigenvalue condition numbers, computed by the command condeig(A), is , where , is relatively large. This indicates that something is wrong. In reality things are even worse since the vector of eigenvalue condition numbers of the matrix A does not exist because A has one linearly independent eigenvector.
At this moment the user may, or may not be aware that something is wrong (with exception of the code jordan which is not very popular and is of restricted use). Now comes the time of BFCT to find the spectrum and the Jordan form of A as follows.
The sum of the eigenvalues of A is equal to the trace which is computed exactly. If the eigenvalues are close or equal, because the eigenvalue condition numbers are large, then we should have and . The Jordan form of A is then either or . But the only matrix with Jordan form is itself and hence the Jordan form of A must be . We have obtained the correct result using BFCT and simple logical reasoning.
The matrix (6) may be written as
for . Thus we have a family of matrices parametrized by the integer m. The trace of is equal to 2, the determinant of is equal to 1, the eigenvalues of are and the Jordan form of is .
Below we give the values of the coefficients and of the characteristic polynomial of A as found by the code poly(A), and of the eigenvalues of A, as computed by the code eig(A) in MATLAB®.
- For we have , and , where the quantity 1.0000 has at least 5 true decimal digits and is a small imaginary tail which may be neglected. This result seems acceptable.
- For we have , and , . With certain optimism these results may also be declared as acceptable.
- For a computational catastrophe occurs with (true), (completely wrong) and , (also completely wrong). Here surprisingly is computed as which differs from 1 (which is to be expected) but differs also from . It is not clear what and why had happened. Using the computed coefficients , the roots of the characteristic equation now are , instead of the computed and . This is a strange wrong result.
- We give also the results for which are full trash and are served without any warning for the user. We have , and . We also get for completeness.
In all cases the sum of the wrongly computed eigenvalues is almost exact which is a well known fact in the numerical spectral analysis of matrices [15].
The conclusion from the above considerations is that BFCT in this case, in contrast to the standard software, always give with 5 true decimal digits. This is a good approximation to the eigenvalues of the matrices for when the codes eig and poly fail.
6. Zeros of Functions
Computing zeros of functions and of polynomials in particular is a classical problem in numerical analysis. Although powerful sophisticated computational algorithms for this purpose have been developed, the use of BFCT in this area is still useful.
Consider first the scalar case. Computing zeros of functions , where , in a given interval , where f is a continuous function, may be a difficult problem. Here we distinguish three main tasks.
- Find one particular solution of equation in the interval T.
- Find the general solution of equation in the interval T.
- Find all roots of a given nth degree polynomial .
The condition guarantees that there is at least one solution in the interval . Whether f has zeros at the points is checked by direct computation.
Solving real and complex polynomial equations of nth of the form
and is done by the code vpasolve(P(x) == 0) from MATLAB®. It finds all roots of with quadrupole precision of 32 true decimal digits.
For the speed of the corresponding software on a medium computer platform is still acceptable. For and higher the performance of the code may be slow even on fast platforms and hence it may not be applicable to RTA (if such computations are ever needed in RTA). Note that we write this in end of year 2024.
A faster solution may be obtained by the code roots(p), where p is the vector of coefficients of . This code computes the column vector of roots of as the vector of eigenvalues of the companion matrix of using the QR algorithm, i.e. r = eig(compan(p)). The code roots(p) works relatively fast for n up to several thousands but may produce wrong results even for small values of n when the polynomial has multiple roots and the computational problem is poorly conditioned.
It is known that relative errors in computing multiple roots of equations in FPA, where f has a sufficient number of derivatives around a root , are of order , where n is the multiplicity of r. Correspondingly, relative errors for most computational algorithms for solving such equations are of order , where is a constant of order .
To estimate , consider the equation when the nth degree polynomial has n-tuple root . Denote the relative error in the computed vector as
The ratio is shown at Table 3 for the extended form of the polynomial , and values of n from 3 to 20. For the computed roots are exact and .
We see that the relative error in the computed solution for n up to 20 satisfies the heuristic estimate , where the average of is . Next we assume that for simplicity.
The polynomial may be found using the command expand((x-1)^n), or asking the intelligent dialogue computer system WolframAlpha [10]
Find the coefficients of the polynomial (x-1)^n
We stress that in all cases the code vpasolve(P(x) == 0) gives the exact solution vector ones(n,1).
Usually the computed roots are unacceptable if their relative error is greater than 1%. For example, it follows from Table 3 that the root of multiplicity 20 is computed by the code roots with relative error 32% which is unacceptable. It must be stressed that this is not due to program disadvantages of the code but rather to high sensitivity of the eigenvalues of the companion matrix to perturbations in A.
If the polynomial equation has a root of multiplicity n the relative error is estimated as . Solving the equation we get and . We summarize this slightly unexpected observation in a special proposition.
Proposition 6.
Relative errors in computing n-tuple roots of polynomials by the coderootsmay be unacceptable when .
Let now a continuous function f be given and suppose that we look for all roots of the equation in the interval , or for the set . Here use of BFCT seems necessary. A direct approach is to plot the graph of the function , . Let N be a sufficiently large integer, say . We may use the commands X = linspace(a,b,N); Y = abs(f(X)); and plot(X,Y) to plot the graph of the function , .
The zeros of f are marked as inverted peaks at the roots . Next the codes vpasolve(f,r_k) or fzero(f,r_k) may be used around each of the points to specify the roots with full accuracy. This approach is well known in the computational practice and is recommended in some MATLAB® guides.
More difficult problems are the solutions of nonlinear vector equations and of matrix equations , where x and are n-vectors, and X and are matrices. The MATLAB® code fsolve is intended to solve nonlinear vector problems, while the codes are, axxbc, care, dare, dlyap, dric, lyap, ric, sylv and others solve linear and nonlinear matrix equations. The performance of all these codes may be checked by BFCT and CPRS. This a challenging problem which will be considered elsewhere.
7. Minimization of Functions
7.1. Functions of Scalar Argument
The minimization of the expression , , where is a continuous function, is done in MATLAB® by a variant of the method of golden ratio. The corresponding code [x_0,y_0] = fminbnd(f,a,b) finds a local minimum in the interval T, where .
To find the global minimum of f in the interval T we may use the graph of the function f plotted by the commands x = linspace(a,b,n); y = f(x); plot(x,y). Then the approximate global minimum of f is determined visually, considering also the pairs and at the end points of T. The code
[x_min,y_min] = fminbnd(f,c-h,c+h)
is then used in a neighborhood of the approximate minimum . This approach requires human interference in the process and may be avoided as shown later.
The problem with the code fminbnd is not that it may find local minimums. The real problem with this and similar codes is that they can miss the global minimum even when the function f is unimodal, i.e. when it has a unique minimum. So BFCT for such functions is a must. The problem is that usually we do not know whether the function is unimodal or not and whether the computed minimum is minimum at all. The more so when performing complicated algorithms in RTA.
Example 15.
Consider the function
This function is unimodal with minimum . In some cases this minimum is found as
[x_min,y_min] = fminbnd(f,0,b)
for some . But in other cases it is not found correctly and here we should use BFCT. The code works well for but gives a completely wrong result for without warning. Indeed, we have the good result
[x_min;y_min] = fminbnd(f,0,16.85) = 0.999992123678799
1.000000000124073
and the bad result
[x_min;y_min] = fminbnd(f,0,16.86) = 16.859937887512295
2
The second result has 1586% relative error for and 100% relative error for .
The reason for the disturbing events in Example 15 is complicated. We may expect that for values of x such that the expression is less than since then is rounded to 2. The root of the equation is and we indeed have . But is much less then 16.86 and hence the code fminbnd works with certain sophisticated version of VPA instead with FPA. In particular, the quantity is much less than with . We shall summarize the above considerations in the next statement.
Proposition 7.
The software for minimization of functions of one variable such asfminbnd(f,a,b)from MATLAB® may fail to produce correct results even for some unimodular functions .
In contrast, BFCT can always be used to find the global minimum automatically. Let the function be unimodal. Consider the vectors X = linspace(a,b,n+1) with elements and with elements . The MATLAB® command [y,m] = min(Y) computes an approximation to the minimum . Finally, the (almost) exact minimum is computed between the neighboring elements of as
[x_min,y_min] = fminbnd(f,X(m-1),X(m+1))
7.2. Functions of Vector Argument
For the minimization of continuous functions of vector argument meets difficulties similar to those described in Section 7.1. And other specific difficulties as well. Unconstraint minimization is done in MATLAB® by the Nelder-Mead algorithm [23,24], realized by the code fminsearch [6]. We stress that the code finds a local minimizer of the function f, where .
The function f may not be differentiable which is an advantage of this algorithm. The algorithm compares the function values at the vertexes of a -simplex and then replaces the vertex with highest value of f by another vertex. The simplex usually (but not always, as shown below) contracts on a minimum of f which may be local or global. The corresponding command is
[x_min,y_min] = fminsearch(f,x_0)
where is the initial vector.
The computed result depends on the next five factors, among others:
- the computational problem
- the computational algorithm
- the FPA
- the computer platform
- the starting point
Factors 1-3 are usually out of control of the user. Factor 4 is partially under control, e.g. the user may buy another platform. Only factor 5, which is very important, is entirely under control. As mentioned above, the computed value depends on the starting point . This is denoted as .
Definition 10.
The point is said to be a numerical fixed point (NFP) of the computational procedure if .
The computed result is NFP of the computational procedure. NFP depends not only on the computational problem and the computational algorithm but also on the FPA and on the particular computer platform, where the algorithm is realized. Unfortunately, computed values for which are far from any actual minimum are often NFP of the computational procedures. They are served without warning to the user.
For a class of optimization problems the function f has the form
where , is a polynomial in x and are positive constants. Since when the function (8) has (at least one) global minimum .
Numerical experiments with functions f of type (8) show that not only the computed valus for and depend on the initial guess but that in many cases the code fminsearch produces a wrong solution for which is far from any minimizer of the function f. The reason is that the value of may become very small relative to c. Then is computed as c and the algorithm stops at a point which is far from any minimizer of f. Usually, no warning is issued for the user in such cases.This may be a problem when the minimization code is a part of an automatic computational procedure which is not under human supervision. In such cases application of the techniques of AI and MAI may be useful.
Example 16.
Let and consider the function of type (8)
i.e. , and . The function f is coded as
f = @(x)2-x(1)*x(2)*exp(1-x(1)^2/2-x(2)^2/2)
The function , , has two global minimizers
for which
It also has two global maximizers
for which
Let the initial guess for the code
[x_min,y_min] = fminsearch(f,x_0)
be . For we get the relatively good result
x_min = -1.000041440968428 -0.999998218805417
y_min = 1.000000001720503
For the slightly different value the computed result is a numerical fixed point which is not a minimizer. Indeed, we have
x_min = 6.430900000000000 6.430900000000000
y_min = 2.000000000000000
The second computed result in Example 16 is a numerical catastrophe with 543% relative error in and 100% relative error in . The reason is that for and is rounded to 2. The conclusion is that the algorithm of the moving simplex uses FPA rather than VPA; compare with Example 15.
The minimization problem in Example 16 is not unimodal since it has two solutions for and a unique solution for . Solving unimodal problems by the code fminsearch also leads to large errors. Consider the next unimodal problem for which the code also fails for moderate data.
Example 17.
f = @(x)2-x(1)*exp(1/2-x(1)^2/2-(x(2)-1)^2)
The minimization problem has unique solution , . For the code
[x_min,y_min] = fminsearch(f,[c,c])|
gives a quite acceptable result, namely
x_min = 1.000039724696251 1.000017661431510
y_min = 1.000000001889957
For a slightly different value of c the computed result is a numerical fixed point which is not a minimizer. Indeed, for the computed result is wrong, namely
x_min = 5.820000000000000 5.820000000000000
y_min = 2
There is 482% relative error in the computed argument and 100% relative error in the computed minimum .
The output of such situations is, at least for small n, to use BFCT as follows. Let and let be the function which has to be minimized, where . We choose positive integers and compute the grids
X_k = linspace(a_k,b_k,n_k)
and the quantities
Thus we construct the matrix which is a discrete analogue of the surface , .
Next the minimal element and its indexes are found by the BFCT described in Section 4.2. Now the approximate global minimum of f is , where may be used as the starting point for the code
[x_min,y_min] = fminsearch(f,x_0)
Extensive numerical experiments show that this code now works properly.
8. Canonical Forms of Matrices
8.1. Preliminaries
An interesting observation is that important properties of linear operators in n-dimensional vector spaces can be revealed for dimensions as low as , see [28]. In this section we consider some modified definitions of canonical forms and present instructive examples for the sensitivity of Jordan forms using BFCT.
8.2. Jordan and Generalized Jordan Forms
In this section we use some not very popular definitions of canonical forms, e.g. a definition of Jordan form of a matrix without mentioning eigenvalues and without using the concept of Jordan blocks.
Definition 11.
Let . The upper triangular bi-diagonal matrix is said to be a Jordan matrix if
- implies
- implies
for . The set of Jordan matrices is denoted as .
Definition 12.
The Jordan matrix J is spectrally ordered if for . The set of spectrally ordered Jordan matrices is denoted as .
Proposition 8.
The set consists of matrices and , where .
Definition 13.
The Jordan problem for a nonzero matrix is to find a pair such that . Here is the transformation matrix and is the Jordan form of A.
Note that we do not use explicitly the spectrum of A or the concept of Jordan blocks. Indeed, given a general matrix A (even with integer elements and of low size as in (6)) then a priori we know neither its spectrum nor its Jordan structure.
Remark.
The Jordan form is not unique and is defined only by the order of units on its bi-diagonal unless when is unique and is any invertible matrix.
The Jordan form may be defined uniquely to become a canonical Jordan form in terms of Group theory [29] and Integer partition theory [30] although this is rarely done in sufficient extent in the literature. The transformation matrix is always non-unique since e.g. the matrix , , is also a transformation matrix.
Example 18.
Zz If the matrix has a single eigenvalue then there are different orderings of the unit elements on the positions of the super diagonal of A.
Definition 14.
Let . The matrix is said to be a stabilizer of J if . The set of stabilizers of A is denoted as . The matrix is the center of .
Note that the set in general is not necessarily a group unless and is not a center in group-theoretical sense (we recall that the center of is the subgroup of matrices , ).
Example 19.
Let and . Then the following three cases are possible.
- If then is the group .
- If , , then is the set of matrices and , where .
- If then is the set of matrices , .
Example 20.
Definition 15.
The upper triangular bi-diagonal matrix is said to be a generalized Jordan matrix if
- implies
- implies .
The set of generalized Jordan matrices is denoted as .
Generalized Jordan matrices G have the structure of Jordan matrices, where the nonzero elements (if any) are not necessarily equal to 1. Hence they are less sensitive to perturbations in the matrix A.
There are two forms and of the elements of , where and . Note that we do not define spectrally ordered generalized Jordan matrices since they are not important for the computational practice.
Both Jordan matrices J and generalized Jordan matrices G are bi-diagonal, where the bi-diagonal elements of J are zeros or ones, while the bi-diagonal elements of G are correspondingly zeros or nonzero numbers.
Definition 16.
The generalized Jordan problem for a nonzero matrix is to find a pair such that . Here is the transformation matrix and is the generalized Jordan form of A.
Consider now perturbations in Jordan forms. Let , where and with being a small parameter. If the matrix has multiple eigenvalues then the transformation matrix and the Jordan form of may be discontinuous at the point . The situation with the transformation matrix is even more subtle.
If the matrix has simple eigenvalues then the matrices and depend continuously on . In particular and .
Next we consider matrices with real spectrum. Then the transformation matrices , the Jordan forms J and the generalized Jordan forms G are real as well.
For small size matrices A with rational elements (machine elements in particular) the matrices and are computed by the MATLAB® (Maple) command [X_A,J_A] = jordan(A) exactly.
Example 21.
Consider the matrix and let
Then the transformation matrix and the Jordan form of are
The code
[X,J] = jordan(A)
computes the matrices , exactly for . For the matrices and are computed as since ε is rounded to zero.
Example 22.
Consider the matrix and let
Then the Jordan forms of A are
The form is unachievable. For the form we have infinitely many transformation matrices , e.g.
where is arbitrary.
The code
[X,J] = jordan(A)
computes exactly the matrices (with ) and for and . For these matrices are computed wrongly as and .
Proposition 9.
Jordan forms of matrices A with multiple eigenvalues are sensitive to perturbations in A for three main reasons: 1) because for ; 2) because for (if ) and 3) because their nonzero elements (if any) are equal to 1.
8.3. Condensed Schur Form
Schur forms of matrices A satisfy the only condition for and are this less sensitive to perturbations in the nevertheless they may be discontinuous in a neighborhood of a matrix with multiple eigenvalues. The case of simple eigenvalues is studied in more detail, see e.g. [31].
Definition 17.
The matrix is said to be a Schur matrix if it is upper triangular. The set of Schur matrices is denoted as .
We recall that we study only cases . Now it is easy to see that if and only if .
Each matrix is unitary similar to a Schur matrix such that for some matrix . The matrix is the transformation matrix and the matrix is the condensed Schur form of A. The Schur problem for A is to describe the set of pairs and to study their sensitivity relative to perturbations in A.
Although less sensitive to perturbations in A, the solution of the Schur problem may also be sensitive and even discontinuous as a function of A at points , where the matrix has multiple eigenvalues.
Let and be a perturbation in A. The Schur form of A is A itself and in this case we may consider the trivial solution of the Schur problem for A. For arbitrary small the Schur forms of are with transformation matrices . Thus the solution changed from the trivial solution for V for .
Example 23.
Let , and . The command
[X,J] = schur(A)
gives the correct answer
X = 0 -1 J = 1.000000000000000 -0.000000000000001
1 0 0 1.000000000000000
For we have
X = 1 0 J = 1 0
0 1 0 1
due to rounding errors. Obviously the codeschurworks with FPA.
9. Least Squares Revisited
9.1. Preliminaries
In least squares methods (LSM) the aim is to minimize the sum of squared residuals. A not very popular fact is that a smaller residual may correspond to a larger error [21,22]. Moreover, this phenomenon may be observed on an infinite set of residual and errors. This may have far going consequences. So the LSM has to be revisited taking into account such cases.
A least squares problem (LSP) may arise naturally in connection with a given approximation scheme, or as an equivalent formulation of a zero finding method.
9.2. Nonlinear Problems
The solution of the (overdetermined) equation , where x and are vectors and f is a continuous function, may be reduced to minimization of the quantity . Such minimization problems arise also in a genuinely optimization statement in e.g. approximation of data.
Let be a continuous function and let the problem be unimodal, i.e. there is a unique (global) minimum , where . Denote by the distance between the vector and , or the absolute error of the vector when is interpreted as a computed solution.
Let and . Let be a sequence of computed solutions. Then it is possible that tends to 0 and tends to ∞ when , as the next example shows.
Example 24.
Let
The function φ is unimodal with minimum . Let . Then and as .
This result is easily extended to the case .
Example 25.
Let
The function φ has infinitely many minimums on the unit sphere . Let for , i.e. . Then and as .
Thus the residual and the error may have opposite behavior. This phenomenon, namely larger the remainder , smaller the error , is known as Remainders vs. Errors, see [22]. It may concern the stopping rule in the implementation of LSM.
9.3. Linear Problems
Consider the matrix of full column rank and let be a given vector which is not in the range of A. The linear least squares problem (LLSP) is to find the vector such that . This problem is unimodal and its theoretical solution is , where is the pseudo-inverse of the matrix A.
This representation of the solution is not used in computational practice since it is ineffective and may be connected with substantial loss of accuracy. Instead, the solution is found by QR decomposition of the matrix A. Let and , where the matrix is upper triangular and invertible, and . The solution is obtained by the code x = A\b, which in fact computes x = S\c.
Intensive experiments based on BFCT with random data show that the error of the “bad” solution is between 5 and 10 times larger than the error of the “ good” solution . In addition, finding requires much more computational time.
Let be two approximate solutions of the above LLSP which are different from the exact solution . Set and , . We have , where and are the maximal and minimal singular values of A. Next, it is possible [22] to choose so as and . It is fulfilled
We see that when the matrix A is poorly conditioned in the sense that the behavior of remainders and errors is opposite: larger the remainder, smaller the error. This fact deserves a separate formulation.
Proposition 10.
When is large, larger remainders may correspond to smaller errors. In this case checking the accuracy of the computed solutions by the remainders is misleading.
The situation with remainders and errors is indeed ironic. If the matrix A is well conditioned with close to 1 the computed approximations are most probably good and there is no need to check their accuracy by remainders. But if the matrix A is poorly conditioned and the accuracy test seems necessary, the accuracy check by remainders may lead to wrong conclusions. Note that this phenomenon is possible only if .
Example 26.
Consider the simplest case and , , where and is a small parameter. The only solution of the LSP is . Let and be two approximate solutions (the vector with error can hardly be recognized as approximate solution but we shall ignore this fact). We have
and
This is possible since the matrix B is very badly conditioned with and the estimate (9) is achieved.
Denote and let be a family of approximate solutions of the equation , where the function is differentiable. Let tends to as and denote by and the error and the remainder of the approximate solution . These relations define the remainder r as a parametric function of e and vice versa.
Proposition 11.
There exists a smooth function such that the following assertions hold true.
- The function is smooth and decreasing.
- The function is smooth and non-monotone in each interval , where .
- The function (whenever defined) is smooth and non-monotonic in each arbitrarily small subunterval of the interval , where .
Example 27.
Let ,
and . Then and
Let and , . We have and
Therefore
The differentiable function thus defined is non-monotone on each interval
This non-monotonicity means that for any there exist infinitely many points with and . Thus the LSM may be misleading not only for linear algebraic equations but also for LLSP for which the method had been specially designed.
10. Integrals and Derivatives
10.1. Integrals
The calculation of the definite integral is one of the oldest computational problems in numerical mathematical analysis. According to [25] a variant of the trapezoid rule was used in Babylon 50 years BCE for integrating the velocity of Jupiter along the ecliptic.
Usually the integral is solved for , , but the case when one or both of the limits a, b, are infinite and the integral is improper is also considered. There are many sophisticated algorithms and computer codes for solving such integrals, see [1]. In MATLAB® definite integrals of function of one variable are computed by the command integral(f,a,b).
In this section we apply BFCT to solving an integral with highly oscillating integrand by the standard trapezoidal rule [26].
Let be a partition of . Sophisticated integration schemes for computing I using values had been developed in the pre-computer ages (before 1950) when the computation of for n of order was a problem. Now BFCT allow to obtain results for large n up to , using simple quadratures such as the formula of trapezoids with equal spacing [27] described below as MATLAB® code
n = 10^m; X = linspace(a,b,n+1); Y = f(X); h = (b-a)/n; ...
T_n = h*(sum(Y(2:n)) + (Y(1) + Y(n+1))/2)
If the function f is twice continuously differentiable then the absolute error of the trapezoidal method with equal spacing is estimated as
where
Example 28.
Consider the integral , where , and
Then
For
we have
and .
For the number is relatively small and the function f is highly oscillating close to a, see Figure 2. Next we have
and .
The error and the ratio for and m up to 8 are shown in Table 4.
For n from to the error (which is both absolute and relative since ) decreases as while the ratio of the error and the estimate is approximately constant about . The behavior of the error is correctly evaluated but the bound for considerably overestimates the real behavior of although this bound is achieved for and is hence not improvable.
For n between and the accuracy of the computed solution does not increase with n and shows chaotic behavior due to accumulation of rounding errors. The result for and even for is satisfactory from practical viewpoint.
For the choice of as in Example 28 the MATLAB® code integral(f,a,b) produces the answer with error . At the same time the NLF gives the result with error . So in this case the code integral(f,a,b) does not use NLF.
10.2. Derivatives
Numerical differentiation of a scalar function f of scalar or vector argument x is used in many cases, i.e. when analytical expression is not available or is too complicated, when numerical algorithms are applied that use approximate derivatives f f, etc. In the simplest yet most spread case the derivative is approximated numerically by the first order finite difference , where is small but not too small. For given a x the behavior of as function of h resembles a saw, see Example 29 below.
Example 29.
Consider the first difference for the simplest non-constant function at the point . We have . The graph of the computed function for is shown at Figure 3. The graph of the exact function is the straight line in red.
Let and . When is too small, e.g. , the computed value of is , and the derivative is computed as 0 with 100% relative error. This numerical catastrophe may be avoided by BFCT revealing the behavior of for small values of h.
The general principle here is that h must be chosen as , and the problem is how to estimate the constant C especially in RTA. When no information for a constant is available, the heuristic rule is to set .
11. VPA versus FPA
There are many types of variable precision arithmetics (VPA) and computer languages in which the VPA are realized. Here we include systems using symbolic objects like , , etc. VPA may work with very high precision (actually, with infinite precision) but the performance of numerical algorithms with VPA may be slow and not suitable for RTA. In contrast, binary double-precision floating point arithmetic (FPA) works with a finite set of machine numbers, has finite precision and works relatively fast. Thus FPA is suitable for RTA.
12. Conclusion
The combination of BFCT and CPRS provides a powerful tool for solving problems and checking computed solutions and a priori accuracy estimates for many computational problems. Also, according to the authors, BFCT may become a useful complement in the implementation of techniques of artificial intelligence (AI) to the systems for doing mathematics such as MATLAB® [6,7] and Maple [8].
Our main results are summarized in Propositions 1, 2, 3, 4, 5, 6 and 19. Most of the results presented are valid for using BFCT in FPA. Using extended precision as in VPA, some of the observed effects may no more occur. This may be done at the price of considerable increase of the computational time thus excluding some RTA.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets generated during the current study are available from the author upon reasonable request.
Conflicts of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Stoer, J.; Bulirsch, R. Introduction to Numerical Analysis; Springer New York: New York, 2002; ISBN 978-0387954523. [Google Scholar] [CrossRef]
- Faires, D.; Burden, A. Numerical Analysis; Cengage Learning: Boston, 2016; ISBN 978-1305253667. [Google Scholar]
- Chaptra, S. Applied Numerical Methods with MATLAB for Engineers and Scientists (5th edition); McGraw Hill, 2017; ISBN 978-12644162604. [Google Scholar]
- Novak, K. Numerical Methods for Scientific Computing; Equal Share Press, 2022; ISBN 978-8985421804. [Google Scholar]
- Driscoll, T.; Braun, R. Fundamentals of Numerical Computations; SIAM, 2022. [Google Scholar] [CrossRef]
- TheMathWorks, Inc. MATLAB Version 9.9.0.1538559 (R2020b); The MathWorks, Inc.: Natick, MA, USA, 2020; Available online: www.mathworks.com.
- Higham, D.; Higham, N. MATLAB Guide, 3rd ed.; SIAM: Philadelphia, 2017; ISBN 978-1611974652. [Google Scholar]
- Maplesoft. Maple 2017.3. Ontario, 2017. Available online: www.maplesoft.com/ products/maple/.
- Mathematica. Available online: www.wolfram.com/mathematica/.
- WolframAlpha. Available online: www.wolframalpha.com/.
- Borbu, A.; Zhu, S. Monte Carlo Methods; Springer: Singapore, 2020; ISBN 978-9811329708. [Google Scholar] [CrossRef]
- Davies, A.; et al. Advancing mathematics by guiding human intuition with AI. Nature 2021, 600. [Google Scholar] [CrossRef] [PubMed]
- Fink, T. Why mathematics is set to be revolutionized by AI. Nature 2024, 629. [Google Scholar] [CrossRef]
- 754-2019; IEEE Standard for Floating-Point Arithmetic. IEEE Computer Society: NJ, 2019. [CrossRef]
- Higham, N. Accuracy and Stability of Numerical Algorithms; SIAM: Philadelphia, 2002; ISBN 0-898715210. [Google Scholar]
- Higham, N.; Konstantinov, M.; Mehrmann, V.; Petkov, P. The sensitivity of computational control problems. IEEE Control Systems Magazine 2004, 24, 28–43. [Google Scholar] [CrossRef]
- Goldberg, D. What every computer scientist should know about floating-point arithmetic. ACM Computing Surveys 1991, 23, 5–48. [Google Scholar] [CrossRef]
- Pugh, C. Real Mathematical Analysis; Springer Nature: Switzerland, 2015; ISBN 978-3319177700. [Google Scholar] [CrossRef]
- Konstantinov, M.; Petkov, P. Computational errors. International Journal of Applied Mathematics 2022, 1, 181–203. [Google Scholar] [CrossRef]
- Balinski, M.; Young, H. Fair Representation: Meeting the Ideal One Man One Vote, 2nd ed.; Brookings Institutional Press: New Haven and London, 2001; ISBN 978-0815701118. [Google Scholar] [CrossRef]
- Booth, A. Numerical Methods, 3rd ed.; LCCN 57004892; London, Butterworths Scientific Publications: London, 1966. [Google Scholar]
- Konstantinov, M.; Petkov, P. Remainders vs. errors. AIP Conference Proceedings 2016, 1789, 060007. [Google Scholar] [CrossRef]
- Lagarias, J.; Reeds, J.; Wright, M.; Wright, P. Convergence properties of the Nelder-Mead simplex method in low dimensions. SIAM Journal on Optimization 1998, 9, 112–147. [Google Scholar] [CrossRef]
- Nelder, J.; Mead, R. A simplex method for function minimization. Computer Journal 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Ossendrijver, M. Ancient Babylonian astronomers calculated Jupiter’s position from the area under a time-velocity graph. Science 2016, 351, 482–484. [Google Scholar] [CrossRef] [PubMed]
- Rahman, Q.; Schmeisser, G. Characterization of the speed of convergence of the trapezoidal rule. Numerische Mathematik 1990, 57, 123–138. [Google Scholar] [CrossRef]
- Atkinson, K. An Introduction to Numerical Analysis, 2nd ed.; John Wiley & Sons: New York, NY, USA, 1989; ISBN 978-0471500230. [Google Scholar]
- Glazman, M.; Ljubich, J. Finite-Dimensional Linear Analysis: A Systematic Presentation in Problem Form (Dover Books in Mathematics); Dover Publications: New York, NY, USA, 2006; ISBN 978-04866453323. [Google Scholar]
- Jackobson, N. Basic Algebra I; W. Freeman & Co Ltd.: London, UK, 1986; ISBN 978-07167114804. [Google Scholar]
- Andrews, G. The Theory of Partitions, (revisited edition); Cambridge University Press: Cambridge, 2008; ISBN 978-0521637664. [Google Scholar]
- Konstantinov, M.; Petkov, P. On Schur forms for matrices with simple eigenvalues. Axioms 2024, 13, 839. [Google Scholar] [CrossRef]
Figure 1.
Scaled rounding errors.
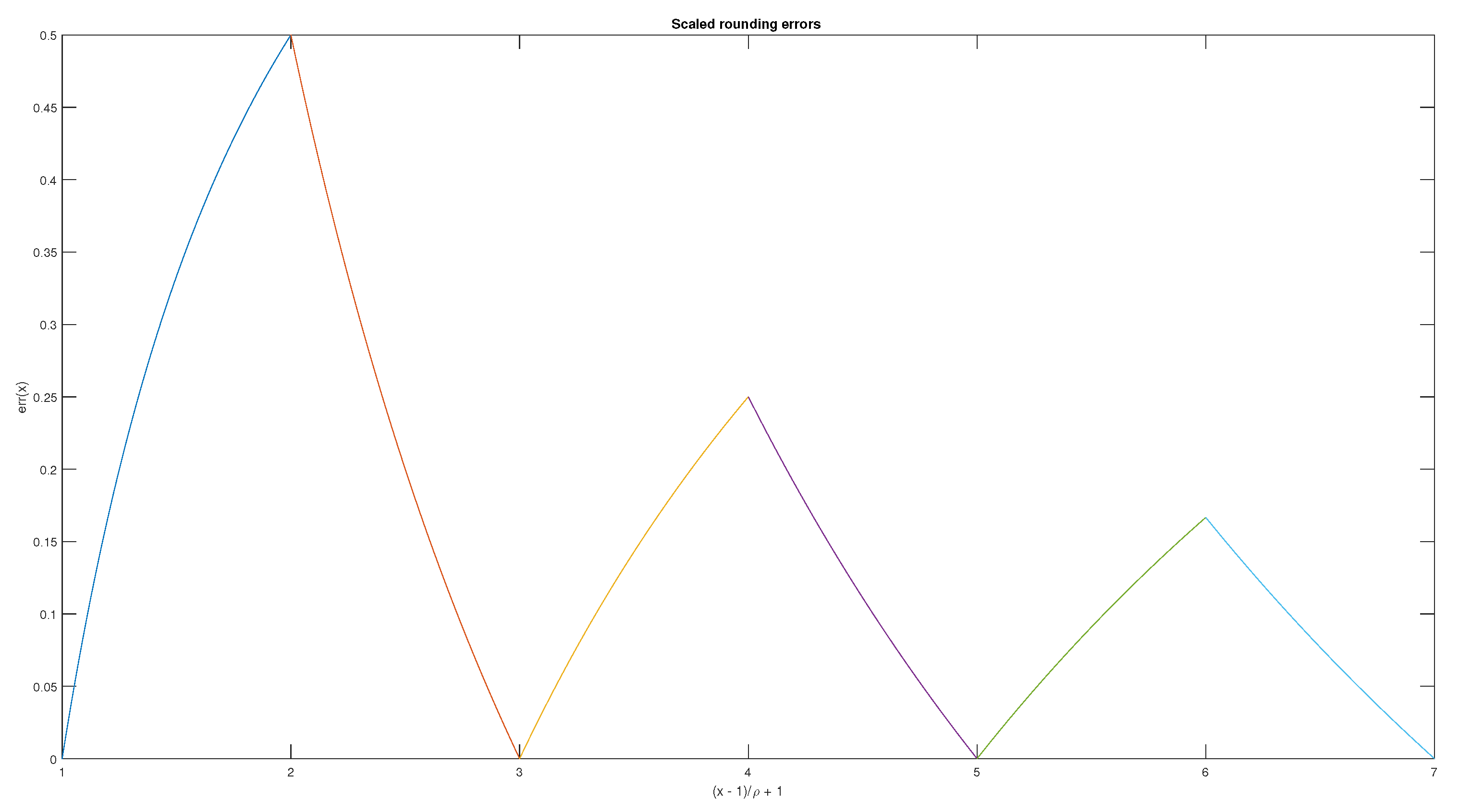
Figure 2.
Oscillating function.
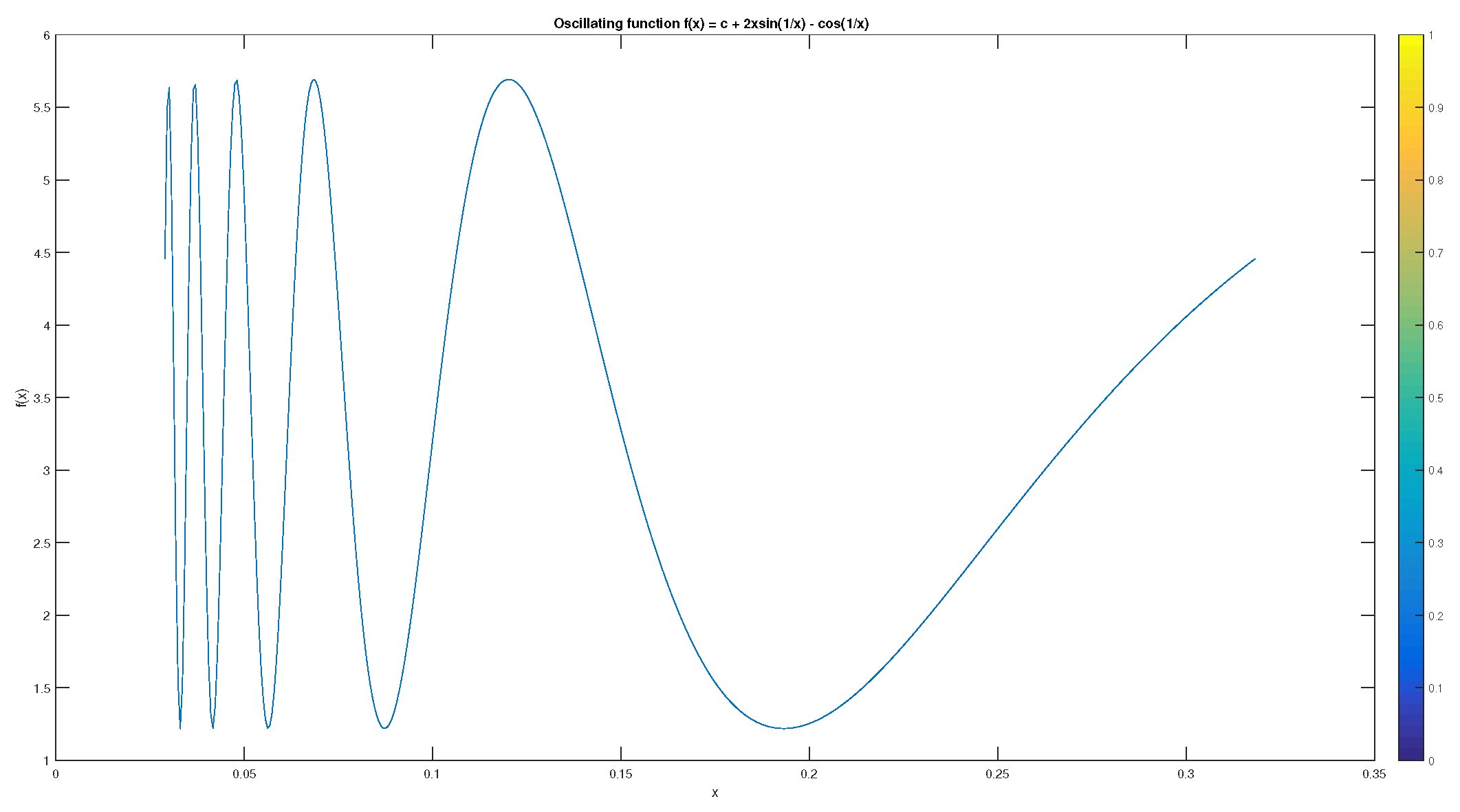
Figure 3.
Computed first difference of the function .
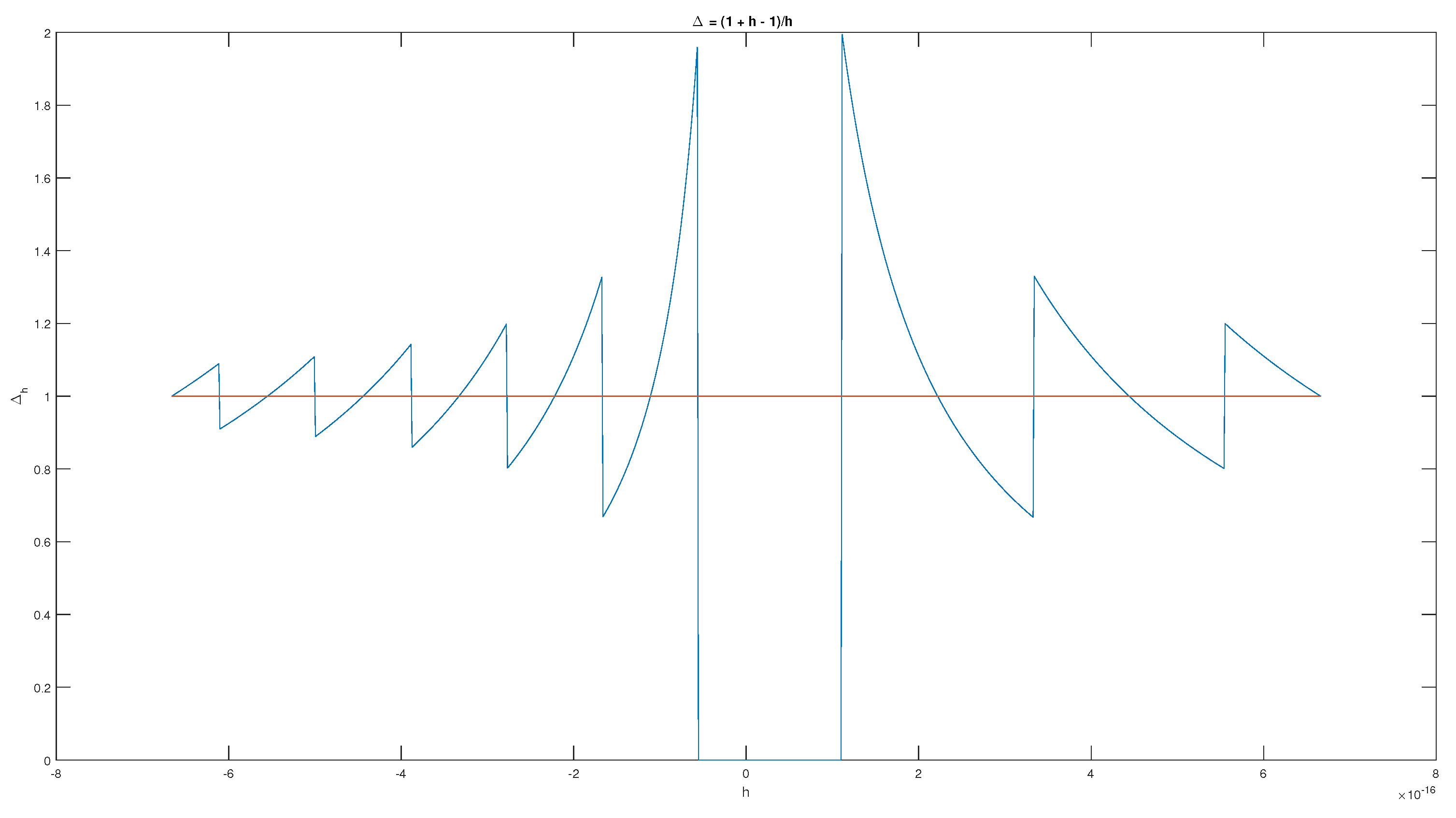
Table 2.
Errors and estimates for low order systems.
| m | err | est | err/est |
| 2 | 0.0349 | ||
| 3 | 0.0187 | ||
| 4 | 9.1475 | 0.0272 | |
| 5 | 1.0002 | 4.6283 | 0.2161 |
Table 3.
Constants in error estimates for code roots.
| n | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 1.73 | 1.78 | 1.53 | 1.95 | 1.62 | 1.60 | 1.84 | 1.72 | 2.03 | |
| n | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 1.76 | 2.04 | 1.94 | 2.10 | 1.92 | 2.06 | 2.01 | 1.97 | 1.91 |
Table 4.
Errors and estimates for the trapezoidal rule.
| n | ||
| 5 | ||
| 10 | ||
| 100 | ||
| 1 000 | ||
| 10 000 | ||
| 100 000 | ||
| 1 000 000 | ||
| 1 500 000 | ||
| 2 000 000 | ||
| 5 000 000 | ||
| 10 000 000 | ||
| 50 000 000 | ||
| 100 000 000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



