Submitted:
03 December 2024
Posted:
04 December 2024
You are already at the latest version
Abstract
Chronic stress, especially among young adults, is a pervasive threat that can lead to various mental and physical illnesses. Measuring stress is crucial for timely intervention, but existing methods like self-reporting scales and physiological sensors are often invasive, require specialized equipment, or suffer from response biases. This research investigates whether engagement patterns with popular short-form video content can serve as an indirect estimator of chronic mental stress levels. The underlying premise is that interacting with short videos through likes/reactions has become a habitual behavior, especially among youth, potentially alleviating biases from voluntary responses. The study aims to develop multimodal representations for short form videos in Indic languages and analyze engagement data from 22 participants to identify possible stressors and construct a causal model linking video content, engagement patterns, and inferred stress levels,this method could allow us to discreetly understand their mental health status, so we can provide help and support when needed.
Keywords:
Multi-Modal Representation
; Mental Stress
I. Introduction
Stress, a pervasive aspect of modern life, has become increasingly prevalent, significantly impacting our daily existence. The World Health Organization (WHO) has declared stress a ’world epidemic’ due to its rising incidence on health. Chronic stress, in particular, poses a substantial threat to our well-being, contributing to a range of physical and psychological problems, including cardiovascular diseases and mental health disorders such as anxiety and depression. Extended chronic stress has been linked to mental illnesses like anxiety and depression, as well as physical illnesses like obesity and cardiovascular diseases. Recognizing the pervasive threat of chronic stress to individuals of all ages, it is crucial to examine its impact during critical developmental stages, particularly during young adulthood. This period is marked by significant changes, as individuals transition from the shelter of family and loved ones to independence, exposing them to new experiences and perspectives. In India, where over 30% of students are first-time graduates, and educational facilities are unevenly distributed, this transition can be particularly challenging. The last decade has seen a significant migration of 37 lakh youth from their hometowns to other parts of India for higher education [1]. This period can also introduce various forms of stress, including family-related stress and pressure to perform well in e-games. As a result, young adults, with their entire lives ahead of them and burgeoning responsibilities, are more vulnerable to the effects of stress, which can lead to long- term negative consequences and negatively impact their aca- demic pursuits [2,3]. Common stressors for the adolescent population include academic pressure, romantic relationships, negotiating autonomy, and lack of financial security [4,5]. A key observation underlying our novel approach is the recent surge in consumption of short-form video content, particularly among adolescents and young adults [6]. For regular users of social media applications, liking and reacting to content has become a habitual behavior. Moreover, studies have shown that social interaction anxiety and social isolation are among the social factors that positively influence interpersonal attachment to short-form video apps [7]. Notably, liking a short video or TikTok requires little conscious effort, which may alleviate the bias associated with questionnaire-based estimators, where participants may have inhibitions stemming from their voluntary responses. With this premise, this research expedition aims to investigate the following question:
Can Engagement and Engagement patterns with short-form video contents like reels/shorts/tiktoks be an indirect estimator of chronic mental stress and can be used to identify plausible stressors?
II. Literature Review
A range of methods exist for measuring stress, including self-reporting scales, physiological and biochemical measures, and questionnaires [8,9,10,11]. Furthermore, various methods have been developed to identify and quantify stressors. For instance, [12] provides a comprehensive overview of methods, including check-list and interview measurements of stressful life events, as well as the measurement of stress hormones and immune response. Other studies have focused on non-invasive and unobtrusive sensors for measuring stress, and computational techniques for stress recognition and classification [13]. Additionally, [14] presents a method to objectively quantify stress levels, based on the identification of stress types and indicators, and the use of psychometric tests and well-documented stressors. However, existing methods are often invasive, require specialized equipment, or rely on voluntary participant responses, which may be biased by inhibitions.
This work is largely d into two major logical chunks. One is to develop a generic representation for a short for video content. Next, using the developed representation, can we try to learn the joint representation of user’s stressors and attributes of the learnt representation.
To this end, the rest of the paper is organized as follows. Section III, outlines the methodology that was adopted to de- velop such a representation. Section IV discusses the materials and methods this work used to try to analyze 22 participants’ short form video content interaction and their stressors. Section V, consolidates the results and discusses some interesting observations.
III. Methodology
This work employs a Hybrid Fusion-based soft parameter sharing model with joint representation. We utilize pre- trained models to extract modality-specific representations from videos and audio. The sequence of representations is then fed into an Attentive pooler, comprising an attention mechanism and Feed Forward layers. Subsequently, the representations are fused through simple concatenation, followed by another set of Feed Forward Layers. The final representation is then trained following a Multi-Task Learning Paradigm. The loss function is defined as the sum of individual losses for each task. In our case, each task is a simple classification task over different labels. Therefore, the cross-entropy loss Li for task i is given by:
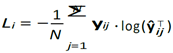
Where N is the number of samples in the dataset for task i, yij is the true label vector for the j-th sample in task i, and yˆij is the predicted probability distribution vector for the j-th sample in task i. The total loss Ltotal for multi-task learning is then the sum of the individual task losses:
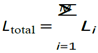
Where M is the number of tasks.
A. Dataset
Portrait Mode Videos are a relatively new phenomenon, and as such, there are limited datasets available, unlike conventional video recognition tasks. While datasets like Kinetics- 700 [15], HowTo100M [16], and others have contributed to the progress of video recognition, portrait mode video recognition remains a challenge, with only a few datasets available for pub- lic use. To the best of the authors’ knowledge, three datasets are available for portrait mode video recognition: S100-PM, 3Massiv PortraitMode-400. However, S100-PM is a portrait- only subset sampled from Kinetics-700. We chose to utilize the 3Massiv Dataset due to its relevance to the Indian context and its multilingual nature. According to the 3Massiv Report, the 3Massiv dataset comprises 50k labeled short videos from the Moj video sharing app, annotated for Audio Type, Video Type, Affective States, and concepts like comedy, romance, spanning across 11 languages. However, from the available links, only roughly half were functional, and we were able to download approximately 17k training samples, 5k test samples, and 5k validation samples. Figure 2 provides an overview of the downloadable subset of 3MASSIV. Although the videos were not evenly distributed across languages, the fraction of videos spanning various concepts and emotions across languages was fairly even.
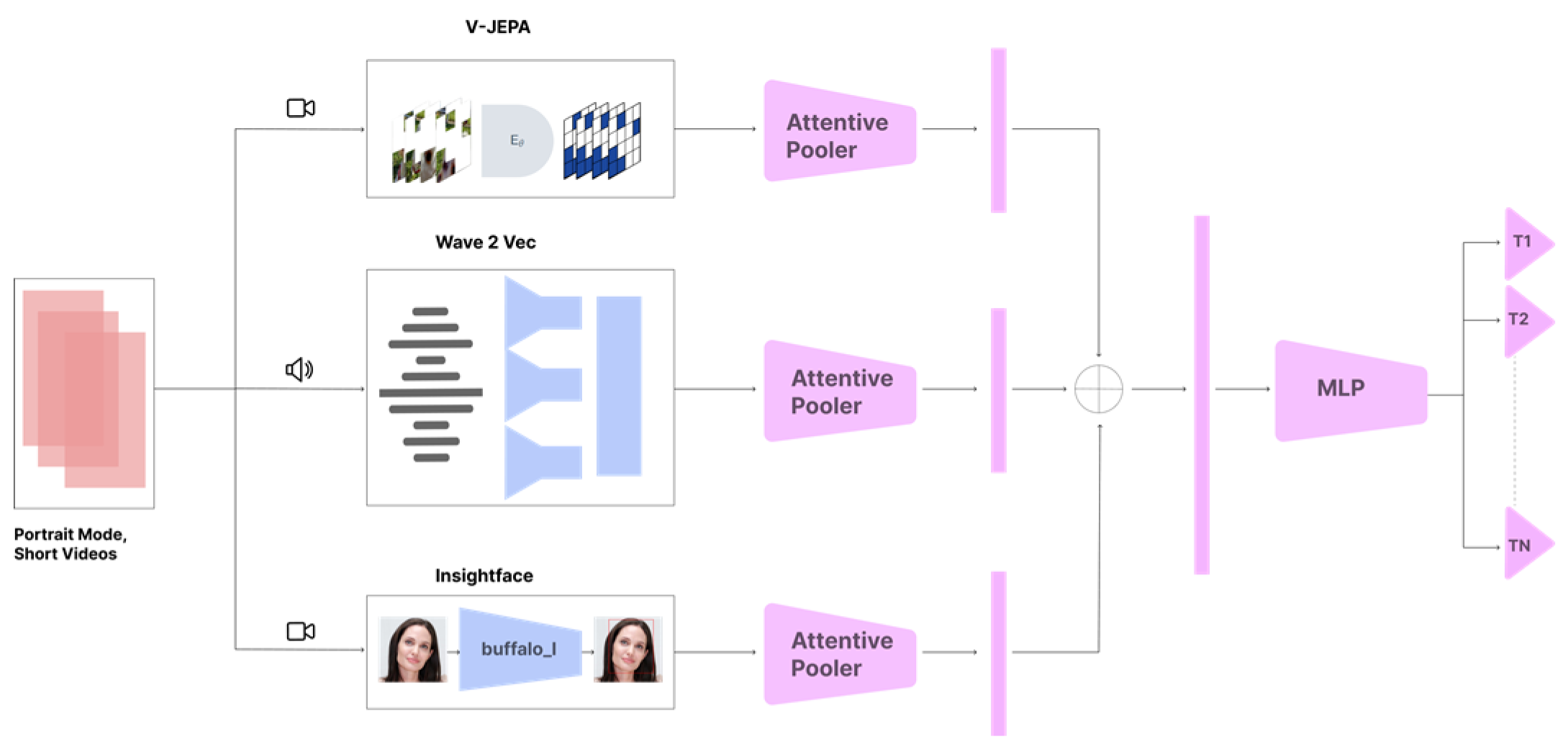
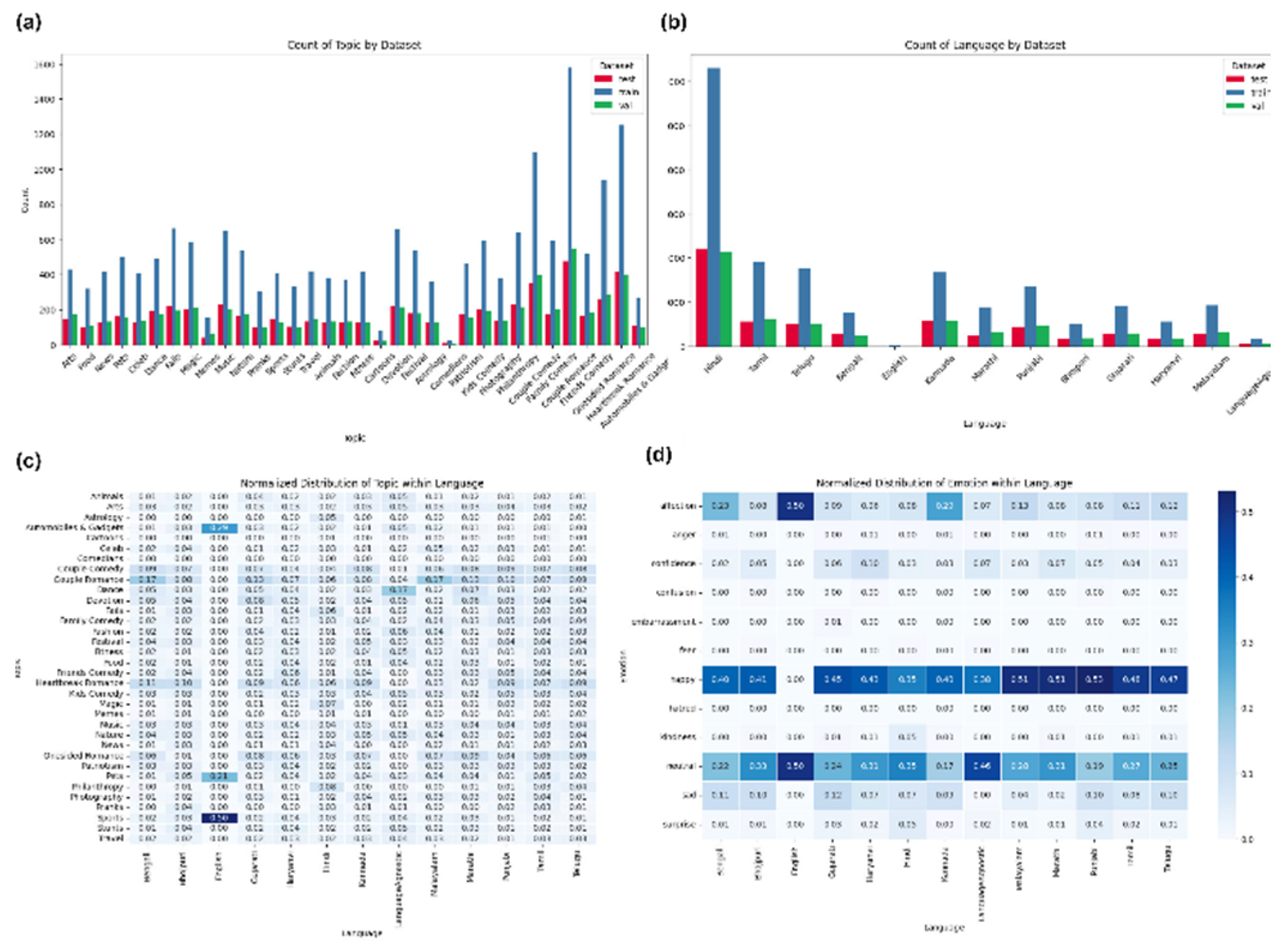
Figure 1.
Architecture Diagram of the proposed model. The model utilizes three pre-trained models: V-JEPA, IndicWav2Vec2, and InsightFace-Buffalo_L for video, audio, and faces, respectively. Blue blocks represent frozen parameters, and purple blocks represent trainable parameters. Modality-specific represen- tations undergo early fusion and are then passed onto a multi-task learning setup.
Figure 1.
Architecture Diagram of the proposed model. The model utilizes three pre-trained models: V-JEPA, IndicWav2Vec2, and InsightFace-Buffalo_L for video, audio, and faces, respectively. Blue blocks represent frozen parameters, and purple blocks represent trainable parameters. Modality-specific represen- tations undergo early fusion and are then passed onto a multi-task learning setup.
Figure 2.
Overview of dataset: (a) Distribution of the number of videos over several topics/concepts. (b) Distribution of videos over languages. (c) Distribution of topics, grouped by language. (d) Distribution of emotions in videos, grouped by language.
Figure 2.
Overview of dataset: (a) Distribution of the number of videos over several topics/concepts. (b) Distribution of videos over languages. (c) Distribution of topics, grouped by language. (d) Distribution of emotions in videos, grouped by language.
B. Pretrained Models Used
1) V-JEPA: V-JEPA (Video-Joint-Embedding Predictive Architecture) is primarily motivated by the predictive feature principle, which states that representations of temporally adjacent sensory stimuli should be predictive of each other. Driven by this principle, the architecture aims to learn to predict adjacent sensory stimuli in latent space in a self-supervised manner. Unlike approaches that predict in pixel space, which must dedicate significant model capacity and compute to cap- ture all low-level details in the visual input, V-JEPA’s approach in latent space provides flexibility to eliminate irrelevant or unpredictable pixel-level details from the target representation. Moreover, predicting in representation space has been shown to lead to versatile representations that perform well across many downstream tasks.
V-JEPA is trained on the objective of predicting a part of the video in the future given one part of the video. The model consists of an encoder module, Eθ, and a predictor, Pϕ. The scheme randomly samples segments from a video, passes them through the encoder to obtain the latent representation, and then uses the predictor to predict the continuation of that segment in the latent space. The model is trained on the L1 loss of latent space closeness loss with stop gradient,
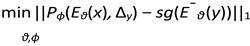
where sg(·) denotes a stop-gradient operation, which does not backpropagate through its argument, and E¯θ is an expo- nential moving average of the network Eθ. This training recipe is heavily inspired by Build Your Own Latent (BYOL) [17]. The method employs a masking strategy to sample regions x and y from the input video. To obtain the region y, the approach selects multiple spatially contiguous blocks with varying aspect ratios and replicates these spatial blocks across the entire temporal dimension of the video clip. Conversely, the region x is defined as the complement of y, comprising the unmasked portions of the video. By masking a large continuous block that spans the full temporal extent, the method mitigates potential information leakage arising from the spatial and temporal redundancies inherent in video data. This masking strategy results in a more challenging prediction task for the model, as it must learn to reconstruct substantial occluded regions within the spatio-temporal volume. We used the encoder module followed by an attention pooler to extract the video embeddings.
2) Wav2Vec2 & IndicWav2Vec2: Wave2Vec [18] is a self- supervised learning approach for speech representation learning, inspired by the success of self-supervised methods in computer vision, such as Word2Vec and BERT. The main objective of Wave2Vec is to learn a mapping function f : X → Z that maps raw speech waveforms x ∈ X to a high-level representation z ∈ Z in a latent space, capturing essential speech information.
The Wave2Vec model consists of three main components:
- Feature Encoder (genc): This component takes the raw waveform x and encodes it into a latent representation c = genc(x).
- Context Network (gar): This is an autoregressive network that models the temporal dependencies in the latent representation c, producing contextualized representations
- zt= gar(c1:t).
- Quantization Module (q): This component quantizes the continuous representations zt into a discrete latent space qt= q(zt).
The training objective of Wave2Vec is to optimize the following contrastive loss:
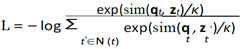 where sim(·, ·) is a similarity function (e.g., cosine similarity), κ is a temperature hyperparameter, and N(t) is a set of negative examples sampled from other time steps within the same utterance.
where sim(·, ·) is a similarity function (e.g., cosine similarity), κ is a temperature hyperparameter, and N(t) is a set of negative examples sampled from other time steps within the same utterance.
The contrastive loss encourages the quantized representations qt to be similar to the contextualized representations zt from the same time step, while being dissimilar to representations from other time steps (negative examples). After training, the learned representations zt can be used as input features for various downstream speech tasks, such as automatic speech recognition (ASR), speaker identification, and speech translation.
Wav2Vec2, built on Wav2Vec, simplifies the architecture by directly passing the raw waveform x through a Transformer encoder to obtain contextualized representations zt at each time step t, represented as zt = Transformer(x)t. In terms of the training objective, Wav2Vec 2.0, however, employs a different training objective called contrastive predictive coding (CPC). The CPC loss maximizes the mutual information between the input waveform x and its contextualized representation zt. Additionally, Wav2Vec 2.0 introduces a masking strategy similar to BERT, where a random set of time steps in the input waveform is masked, and the model is trained to recover the masked regions using the learned representations zt. We utilize Wav2vec from the SPRING-INX Foundation Models family from SPRING lab [19]. These include both self-supervised and fine-tuned models for Indian languages on 2000 hours of legally sourced and manually transcribed speech data for ASR system building in Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Odia, Punjabi, and Tamil.
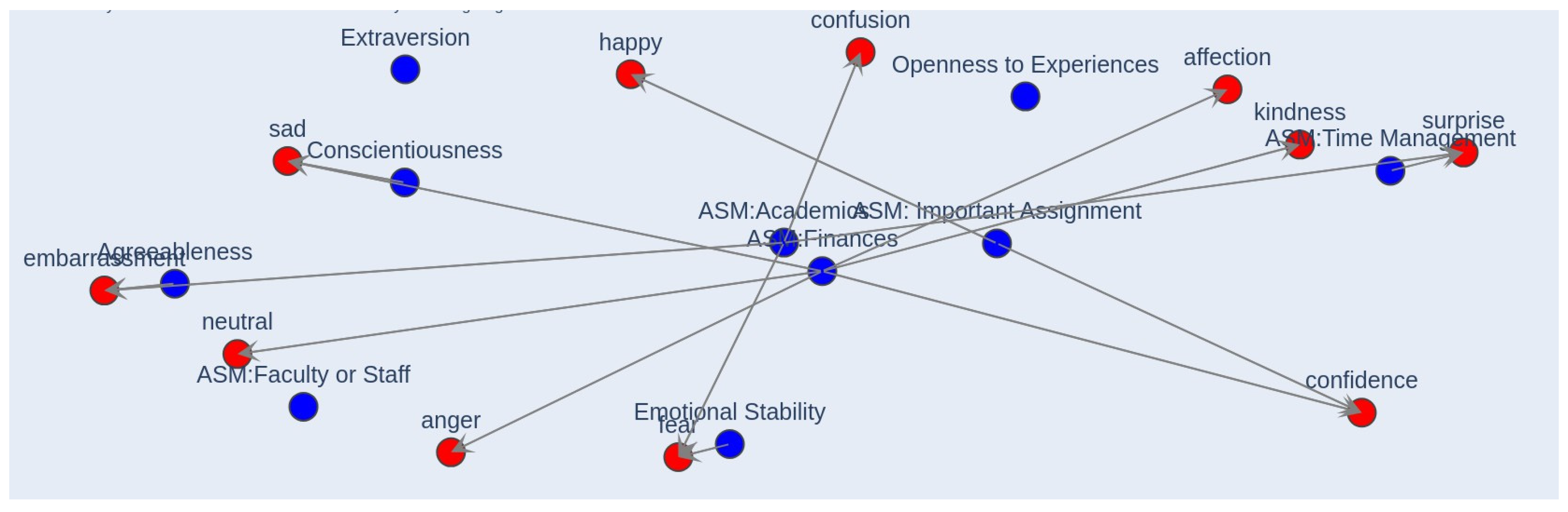
Figure 3.
Learned Causal Structure using Structure Learning Algorithm (Hill Climbing).
3) Insightface: Buffalol: InsightFace is an open-source facial analysis toolbox that provides cutting-edge models and algorithms for various face-related tasks, including detection, recognition, alignment, and attribute prediction. Among its most notable contributions is the BuffaloL family of models, which consists of pre-trained face recognition pipelines that have achieved state-of-the-art performance on several bench- marks. These models, trained on massive datasets comprising millions of face images, leverage powerful architectures and loss functions to learn highly discriminative facial embeddings, enabling accurate recognition and verification across diverse scenarios. The first step in the BuffaloL pipeline is face detection, which is handled by the RetinaFace model. RetinaFace is a single-stage dense face detector based on the RetinaNet architecture. It uses a Feature Pyramid Network (FPN) backbone to generate multi-scale features, which are then fed into two task-specific subnetworks: one for classifying anchor boxes as face/background, and another for regressing the face bounding boxes. Let I be the input image. The classification subnet predicts ci = ϕcls(I, ai), which is the probability of anchor ai being a face. The regression subnet predicts ˆti = ϕreg(I, ai), which are the parameterized face box coordinates relative to ai. At inference, faces are extracted as bk by filtering predictions with high scores ci > τcls and applying regression bk = δ(ai, ˆti). After detection, BuffaloL uses a ResNet- 50 backbone trained on the WebFace 600K dataset for face recognition. Let ϕ(I) represent the output embedding of this model for input I. During training, BuffaloL optimizes the angular softmax loss:
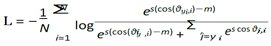 where θj,i = ϕ(Ii)T Wj, Wj are weights for class j, m is the angular margin, and s scales the logits.
where θj,i = ϕ(Ii)T Wj, Wj are weights for class j, m is the angular margin, and s scales the logits.
a) Face Alignment: For face alignment, BuffaloL uses a dense 2D106-point and 3D68-point face alignment model. This model takes a face image F and predicts 2D and 3D landmark coordinates 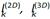 . The model is trained by minimizing the
. The model is trained by minimizing the 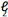 loss between predicted and ground truth landmarks:
loss between predicted and ground truth landmarks:
. The model is trained by minimizing the loss between predicted and ground truth landmarks: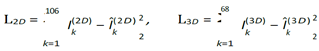
For our experiments, we propose to utilize the powerful face embeddings generated by the BuffaloL models. Specifically, we will sample 8 random frames from the dataset and extract the corresponding face embeddings using the face recognition model of the BuffaloL family. These embeddings, which capture intrinsic facial features in a high-dimensional vector space, will serve as the input representations for our downstream tasks. The keypoints obtained by face alignment are concatenated along this embedding, to also capture the movement of the face across the videos.
Table 1 Gives a performance comparison of baseline with the proposed method. We can observe that our method is able to perform at par with baselines methods.
IV. Case Study: Academic Stress Prediction Using Short-Form Video Content
We collected short-form video content through two distinct methods: a Chrome extension that monitored users’ short videos from YouTube or Instagram (Reels), and a custom-built app that presented users with a stratified sample of videos and randomly selected content for viewing. In both methods, the primary measure considered was whether the user ”liked” the content. However, future studies may employ more nuanced measures, such as facial reactions while watching, time spent on specific content, and so forth. We targeted participants who were currently enrolled in college. All participants were recruited from a private college in India, resulting in a total of 22 participants. Participants were provided with a PDF information sheet containing a link to a Google Form, which collected demographic information and presented a consent form. Upon signing, an automated script sent participants an email with a starter pack, comprising the Chrome extension or app, along with a user guide and video tutorial. The entire process was automated and hosted on Google Cloud and App Scripts. Once participants reached 50 video views, their session was terminated, and a Google Form was sent to them via email, containing psychometric questionnaires. We developed a Chrome Extension and an Android app to facilitate data collection. The Android app contained a pool of video content from various categories, employing stratified random sampling and displaying content to users in a scrollable format, similar to popular apps. The app logged like and watch information to a JSON file on disk. The Chrome extension, featuring a content script written for YouTube and Instagram, monitored the like button and worked on all Chromium-based browsers, catering to most users. The extension wrote to a database on Firebase through an HTTP server for CRUD operations, hosted on Google Cloud Run. Screenshots of the apps used is shown in Figure 4. We employed the materials proposed in [20], which introduced the Academic Stressor Measure (ASM). Additionally, we utilized the 10-Item Personality Inventory (TIPI) [21]. The ASM considered factors including academics, finances, important assignments, time management, and faculty/staff. The TIPI measured students’ big-five personality traits: conscientiousness, emotional stability, openness, extraversion, and agreeableness. We aggregated the ”liked” videos per person and fed them into the model developed with 3MASSIV dataset to classify them into different affective states: affection, anger, confidence, confusion, embarrassment, fear, happiness, kindness, neutrality, sadness, and surprise.
V. Results
We sought to identify associations within the data and determine whether meaningful relationships exist, indicating the potential to use short-form video content as an indirect estimator of stress with more precise modeling. Figure 5 illustrates the correlation analysis between affective states and measured academic stressors, revealing possible meaningful correlations. For instance, the correlation between faculty or staff as a stressor and confidence suggests that students may have had overly confident conversations, leading to friction. Similarly, the correlation between time management stressors and sadness or anger indicates that individuals may not be emotionally stable and might spend time on other coping mechanisms, causing a crisis in time management. Embarrassment-type content is correlated with stress from important assignments or academics, potentially stemming from the fear of embarrassment. While several interesting correlations are observed, to ensure that we are not observing spurious correlations, we will proceed to a causal discovery method: structure learning using Hill Climbing Search.
The Hill Climbing Search (HCS) algorithm is a popular approach for structure learning, which iteratively applies a series of local transformations to the current DAG to improve the likelihood of the data. Figure 3 illustrates the learned causal structure for our data, which removes spurious correlations and identifies edges through conditional independence tests. Several interesting causal relationships are observed, including:
- Financial stress and conscientiousness appear to cause consumption of sad content.
- Academic stress and agreeableness seem to cause consumption of content with embarrassment as an affective state.
- Academic stress, with positive emotional stability, ap- pears to cause consumption of content with fear as an affective state.
These findings suggest that there are interesting associations and relationships that can be mined from this method.
VI. Discussion
This study constitutes a pioneering effort in exploring short- form video content as a clinical estimation tool. In response to the need for a suitable representation of short-form video content, we developed a meaningful representation through multitask learning, leveraging pre-trained models such as V- JEPA, Indic Wav2Vec, and Insightface BuffaloL family of models. Furthermore, we investigated the associations between the learned representation and affective states of liked videos by participants, as measured through a psychometric questionnaire, in relation to academic stressors. Several avenues for future research emerge from this novel perspective. Firstly, the representation learning step can be improved by incorporating datasets like Portrait Mode Recognition, which offers 100k video instances with fine-grained conceptual annotations. Exploring various combinations of feature extraction and multimodal fusion techniques can also be considered. To enhance the representation space, we hypothesize that techniques like hierarchical contrastive learning may be effective. Additionally, incorporating techniques from causal representation learning can facilitate the development of a more nuanced probabilistic graphical model. Conducting a large-scale study with a participant pool of approximately 500 individuals will provide a more representative sample.
References
- H. Chhapia, “37 lakh migrated for education within India in a decade - Times of India.” [Online]. Available: https://timesofindia.indiatimes.com/education/news/37-lakh-migrated- for-education-within-india-in-a-decade/articleshow/29729578.cms.
- E. M. Cotella, A. S. Go´mez, P. Lemen, C. Chen, G. Ferna´ndez, Hansen, J. P. Herman, and M. G. Paglini, “Long-term impact of chronic variable stress in adolescence versus adulthood,” Progress in Neuro-Psychopharmacology and Biological Psychiatry, vol. 88, pp. 303–310, Jan. 2019. [CrossRef]
- K. Schraml, A. Perski, G. Grossi, and I. Makower, “Chronic Stress and Its Consequences on Subsequent Academic Achievement among Adolescents,” Journal of Educational and Developmental Psychology, vol. 2, no. 1, p. p69, Apr. 2012. [CrossRef]
- N. Mathew, D. C. Khakha, A. Qureshi, R. Sagar, and C. C. Khakha, “Stress and Coping among Adolescents in Selected Schools in the Capital City of India,” The Indian Journal of Pediatrics, vol. 82, no. 9, pp. 809–816, Sep. 2015. [CrossRef]
- R. Parikh, M. Sapru, M. Krishna, P. Cuijpers, V. Patel, and D. Michelson, ““It is like a mind attack”: stress and coping among urban school-going adolescents in India,” BMC Psychology, vol. 7, no. 1, p. 31, May 2019. [CrossRef]
- D. F. Roberts and U. G. Foehr, “Trends in Media Use,” The Future of Children, vol. 18, no. 1, pp. 11–37, 2008, publisher: Princeton University.
- X. Zhang, Y. Wu, and S. Liu, “Exploring short-form video application addiction: Socio-technical and attachment perspectives,” Telematics and Informatics, vol. 42, p. 101243, Sep. 2019. [CrossRef]
- C. W. Downs, G. Driskill, and D. Wuthnow, “A Review of Instrumen- tation on Stress,” Management Communication Quarterly, vol. 4, no. 1, pp. 100–126, Aug. 1990, publisher: SAGE Publications Inc. [CrossRef]
- S. Reisman, “Measurement of physiological stress,” in Proceedings of the IEEE 23rd Northeast Bioengineering Conference, May 1997, pp. 21–23. [CrossRef]
- P. Derevenco, G. Popescu, and N. Deliu, “Stress assessment by means of questionnaires,” Romanian journal of physiology, vol. 37, no. 1-4, pp. 39–49, Jan. 2000.
- I. Kokka, G. P. Chrousos, C. Darviri, and F. Bacopoulou, “Measuring Adolescent Chronic Stress: A Review of Established Biomarkers and Psychometric Instruments,” Hormone Research in Paediatrics, vol. 96, no. 1, pp. 74–82, Mar. 2023. [CrossRef]
- L. C. Towbes and L. H. Cohen, “Chronic stress in the lives of college students: Scale development and prospective prediction of distress,” Journal of Youth and Adolescence, vol. 25, no. 2, pp. 199–217, Apr. 1996. [CrossRef]
- N. Sharma and T. Gedeon, “Objective measures, sensors and compu- tational techniques for stress recognition and classification: A survey,” Computer Methods and Programs in Biomedicine, vol. 108, no. 3, pp. 1287–1301, Dec. 2012. [CrossRef]
- J. Aguilo´, P. Ferrer-Salvans, A. Garc´ıa-Rozo, A. Armario, Corb´ı, F. J. Cambra, R. Bailo´n, A. Gonza´lez-Marcos, G. Caja, S. Aguilo´, R. Lo´pez- Anto´n, A. Arza-Valde´s, and J. M. Garzo´n-Rey, “Project ES3: attempting to quantify and measure the level of stress.
- J. Carreira, E. Noland, C. Hillier, and A. Zisserman, “A short note on the kinetics-700 human action dataset,” arXiv preprint arXiv:1907.06987, 2019. [CrossRef]
- A. Miech, D. Zhukov, J.-B. Alayrac, M. Tapaswi, I. Laptev, and J. Sivic, “Howto100m: Learning a text-video embedding by watching hundred million narrated video clips,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 2630–2640.
- J.-B. Grill, F. Strub, F. Altche´, C. Tallec, P. Richemond, E. Buchatskaya, Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21 271– 21 284, 2020.
- A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449– 12 460, 2020.
- A. Gangwar, S. Umesh, R. Sarab, A. K. Dubey, G. Divakaran, S. V. Gangashetty et al., “Spring-inx: A multilingual indian language speech corpus by spring lab, iit madras,” arXiv preprint arXiv:2310.14654, 2023. [CrossRef]
- A. M. Flynn, B. A. Sundermeier, and N. R. Rivera, “A new, brief measure of college students’ academic stressors,” Journal of American College Health, pp. 1–8, 2022. [CrossRef]
- S. D. Gosling, P. J. Rentfrow, and W. B. Swann Jr, “A very brief measure of the big-five personality domains,” Journal of Research in personality, vol. 37, no. 6, pp. 504–528, 2003. [CrossRef]
Figure 4.
(a) Screen shot of Chrome Extension Used for data collection. (b) Screen shot of android app used for data collection.
Figure 4.
(a) Screen shot of Chrome Extension Used for data collection. (b) Screen shot of android app used for data collection.
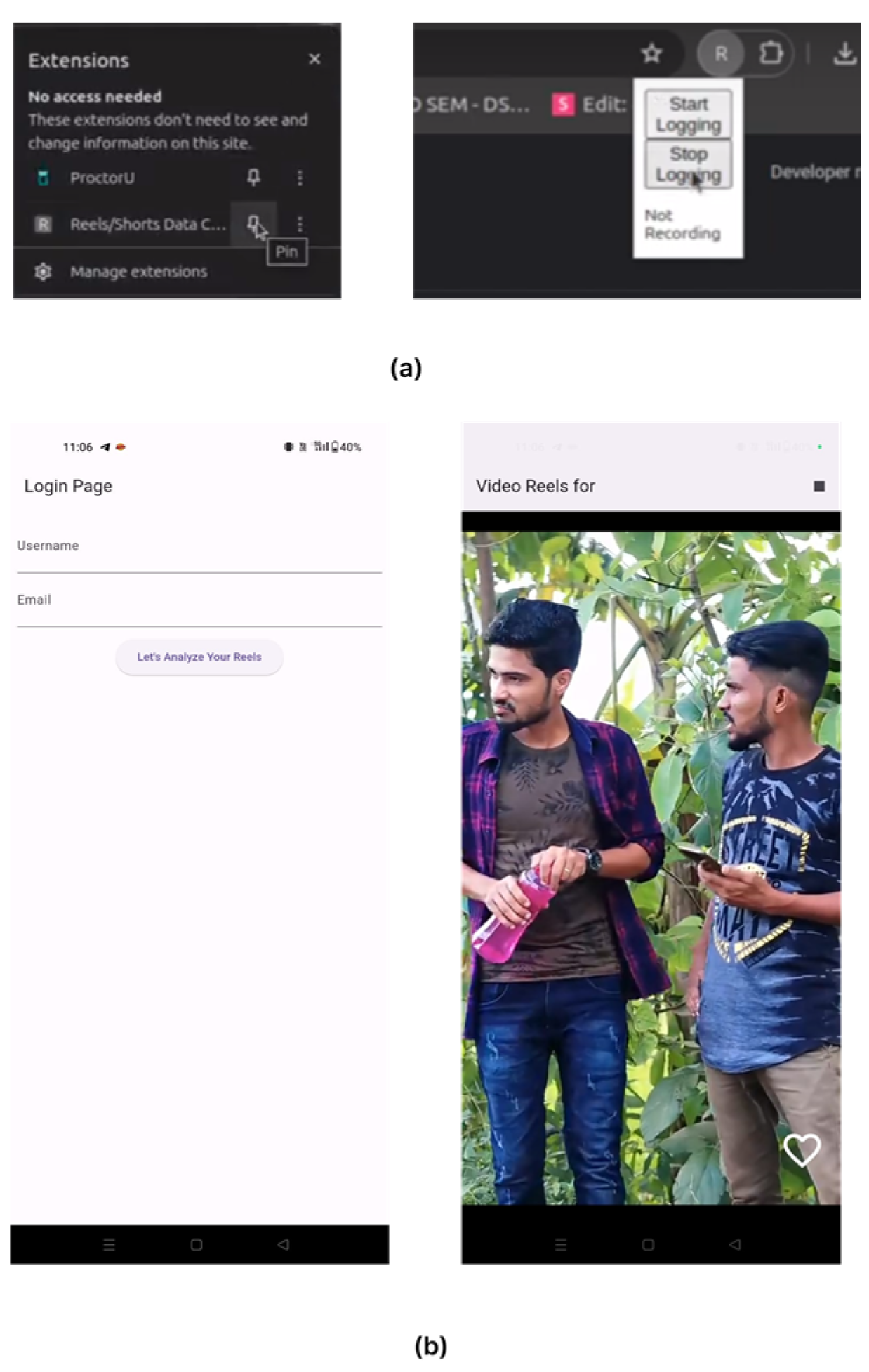
Figure 5.
Correlation analysis of effective states of consumed content with measured academic stressors.
Figure 5.
Correlation analysis of effective states of consumed content with measured academic stressors.
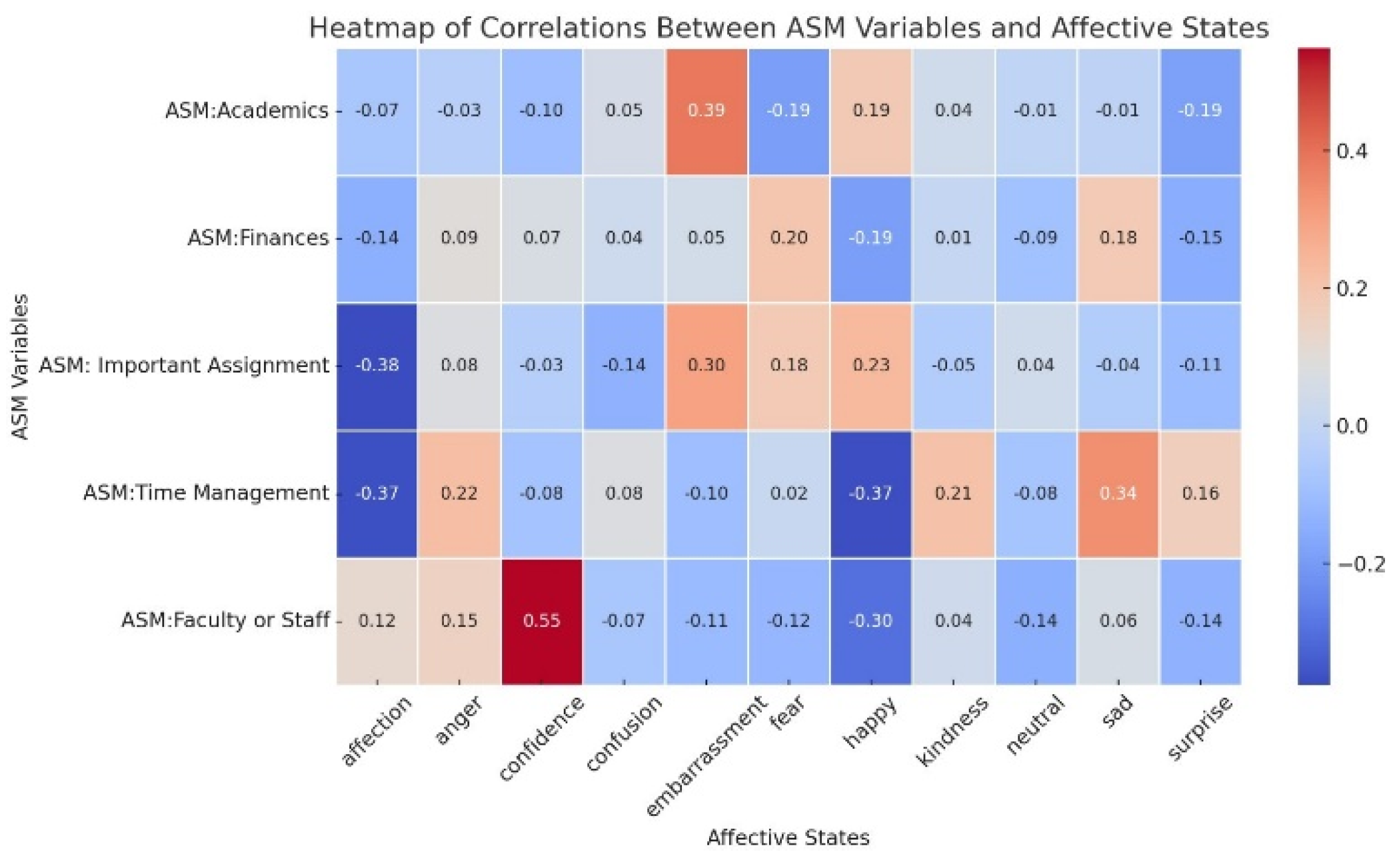

Table 1.
Performance Comparison with Baseline.
| Modality | Backbone | Top-1 | Top-3 | Top-5 |
| Visual | R(2+1)D-50 | 50.6 | 72.3 | 81.4 |
| Visual | R3D-50 | 52.7 | 74.5 | 83.6 |
| Visual | R3D-101 | 52.6 | 74.1 | 83.3 |
| Audio | VGG | 31.6 | 50.5 | 60.9 |
| Audio | CLSRIL23 | 31.2 | 50.1 | 60.6 |
| Visual, Audio | R3D-50 + VGG | 54.9 | 74.9 | 82.4 |
| Visual, Audio | R3D-50 + CLSRIL23 | 54.9 | 75.4 | 82.9 |
| Visual, Audio | R3D-50 + VGG + CLSRIL23 | 56.5 | 76.5 | 83.8 |
| Visual, AudioFace (Ours) |
V-JEPA+Wav2vec(Indic) + Buffalo_l |
58.93 | 78.34 | 87.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



