Submitted:
21 November 2024
Posted:
22 November 2024
You are already at the latest version
Abstract
Gender identification of authors in literary texts is a compelling area of research within computational linguistics and natural language processing. Analyzing the gender of authors can uncover biases and socio-cultural dynamics of the past, deepening our understanding of historical texts. Inspired by the historical context where women often used male pseudonyms to navigate the literary world, this study seeks to determine an author's gender, relying on their written works using various classifiers, including language models. Our contributions include compiling a large-scale dataset of literary texts and conducting extensive experiments with different classification models. Our results show that the best-performing model, GPT2, achieved an impressive accuracy of 0.925.
Keywords:
1. Introduction
- We present a thoroughly collected dataset comprising a diverse set of literary works span genres, time periods, and cultural contexts, including historical novels (e.g., Romola by Mary Ann Evans), short novels (e.g., Absalom’s Hair by Bjornstjerne Bjornson), long novels (e.g., Moby-Dick by Herman Melville), science fiction novels (e.g., The Confessions of Artemas Quibble by Arthur Train), dime novels (e.g., The Dock Rats of New York by Harlan Page Halsey), mystery adventure novels (e.g., The Danger Trail by James Oliver Curwood), and children’s fiction novels (e.g., Heidi by Johanna Spyri).
- We perform extensive comparative experiments with diverse classifiers and analyze their results. In our experiments, GPT2 and XLNet Model ( XLNet ) emerged as the top-performing models. GPT2 achieved the highest overall accuracy score of 0.930 and excelled in precision, recall, and F1 scores for both female and male categories, indicating robust and consistent performance across metrics. XLNet followed closely with a score of 0.910, also demonstrating strong precision and recall, particularly with F1 average of 0.860. Logistic Regression ( LR ) models with various configurations showed moderate performance, with scores around 0.830 to 0.840. The XGB classifier (XGB), especially when fine-tuned, also performed well, achieving a score of 0.850 and decent F1 scores, making it a solid choice among traditional machine learning methods.
2. Related Work
2.1. Linguistic Techniques
2.2. Deep Learning Techniques
2.3. Traditional Machine Learning Techniques
2.4. Ethical and Societal Considerations
2.5. Benchmark Datasets
2.6. The BookSCE Dataset
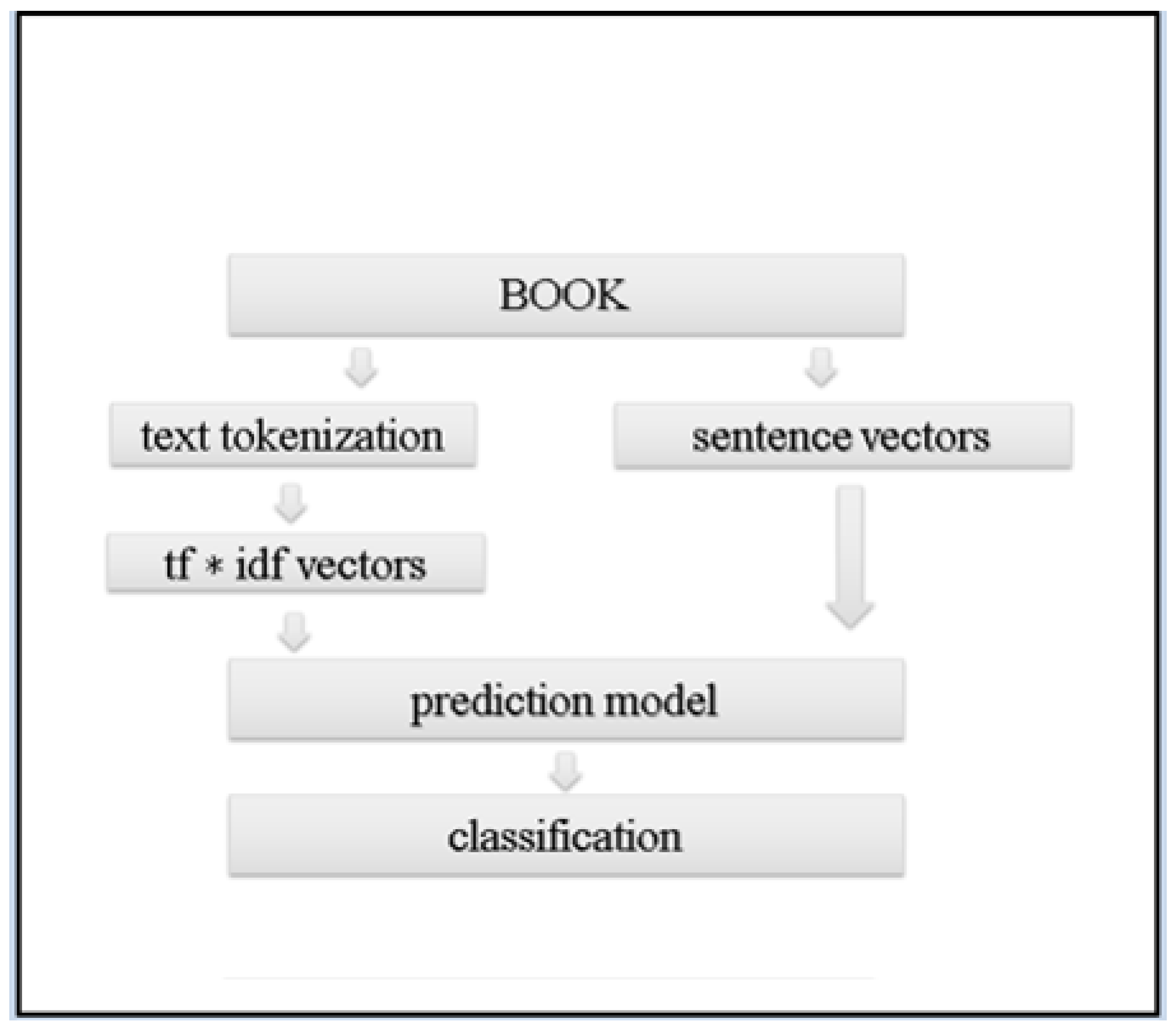
2.7. Methodology
2.8. Methodology
3. Experimental Study
3.1. Experimental Settings
3.1.1. Logistic Regression
3.1.2. Extreme Gradient Boosting Classifier
3.1.3. Support Vector Machine
3.1.4. Bidirectional Encoder Representations from Transformers
3.1.5. The Generative Pre-Trained Transformer 2
3.1.6. XLNet Model
3.1.7. RoBERTa
3.2. Data Preprocessing
4. Results
5. Case Study
6. Discussion and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sand, G. Indiana; None, Chicago Review Press, Incorporated, 2000.
- Sand, G. Valentine; Chicago Review Press, 2005.
- Lee, V. The Tower of the Mirrors and Other Essays on the Spirit of Places (1914). By: Vernon Lee: Vernon Lee Was the Pseudonym of the British Writer Violet Paget (14 October 1856 - 13 February 1935).; CreateSpace Independent Publishing Platform, 2017.
- Paget, V. A phantom lover, by Vernon Lee; IndyPublish. com, 1886.
- Tiptree, J. Her Smoke Rose Up Forever; S.F. MASTERWORKS, Orion, 2014.
- Tiptree, J. The Starry Rift; Orion, 2015.
- Boyd, R.L.; Ashokkumar, A.; Seraj, S.; Pennebaker, J.W., Eds. The Development and Psychometric Properties of LIWC-22; This article is published by LIWC.net, Austin, Texas 78703 USA in conjunction with the LIWC2022 software program.: New York, 2022. [CrossRef]
- Bamman, D.; Smith, N.A. Unsupervised Discovery of Biographical Structure from Text. Transactions of the Association for Computational Linguistics, 2 2014, pp. 363–375. [CrossRef]
- Bsir, B.; Zrigui, M. Bidirectional LSTM for Author GenderIdentification. 10th International Conference, ICCCI 2018, 2018. [CrossRef]
- Zhu, Z.; Ke, Z.; Cui, J.; Yu, H.; Liu, G. The construction of Chinese microblog gender-specific thesauruses and user gender classification. Applied Network Science 2018, 3, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1908.04577 2019, [arXiv:cs.CL/1810.04805]. [CrossRef]
- Cheng, N.; Chandramouli, R.; Subbalakshmi, K. Author gender identification from text. Digital Investigation 2011, 8, 78–88. [Google Scholar] [CrossRef]
- Cheng, N.; Chen, X.; Chandramouli, R.; Subbalakshmi, K. Gender Identification from E-mails. 2009 IEEE Symposium on Computational Intelligence and Data Mining, 2009, pp. 154 – 158. [CrossRef]
- Johannsen, A.; Hovy, D.; Søgaard, A. Cross-lingual syntactic variation over age and gender. Conference on Computational Natural Language Learning 2015, pp. 104–110. [CrossRef]
- Ford, E.; Shepherd, S.; Jones, K.; Hassan, L. Toward an Ethical Framework for the Text Mining of Social Media for Health Research: A Systematic Review. Sec. Health Informatics Volume 2 - 2020 2021, [2020.592237]. [CrossRef]
- Jaiswal, S.; Verma, A.K.; Mukherjee, A. Auditing Gender Analyzers on Text Data. Proceedings of the 2023 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining; Association for Computing Machinery: New York, NY, USA, 2024; p. 108–115. [CrossRef]
- Schwarzenberg, P.; Figueroa, A.R. Textual Pre-Trained Models for Gender Identification Across Community Question-Answering Members. IEEE Access 2023, 11, 3983–3995. [Google Scholar] [CrossRef]
- Lee-Thorp, J.; Ainslie, J.; Eckstein, I.; Ontanon, S. FNet: Mixing Tokens with Fourier Transforms, 2022, [arXiv:cs.CL/2105.03824]. [CrossRef]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices, 2020, [arXiv:cs.CL/2004.02984]. [CrossRef]
- PAN. Author Profiling. 2017. Available online: https://pan.webis.de/clef17/pan17-web/author-profiling.html. [CrossRef]
- Pritom, R.R. Gender Recognition Dataset. 2021. Available online: https://www.kaggle.com/datasets/rashikrahmanpritom/gender-recognition-dataset.
- Bisong, E., Ed. Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress Berkeley, CA: OTTAWA, ON, Canada, 2019. [CrossRef]
- Demir-Kavuk, O.; Akutsu, M.K.T.; Knapp, E.W. Prediction using step-wise L1, L2 regularization and feature selection for small data sets with large number of features. 2011 10th International Conference on Machine Learning and Applications 2011. [CrossRef]
- Oakes, M.; Gaizauskas, R.; Fowkes, H. A Method Based on the Chi-Square Test for Document Classification. TConference: SIGIR 2001: Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, September 9-13, 2001, New Orleans, Louisiana, USA 2001.
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A Comparative Analysis of XGBoost. Universidad Autónoma de Madrid November 2019. [CrossRef]
- CORTES, C.; VAPNIK, V. Support-Vector Networks. 1995 Kluwer Academic Publishers, Boston. Manufactured in The Netherlands. 1995. [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I.; others. Language models are unsupervised multitask learners. OpenAI blog 2019, 1, 9.
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv preprint arXiv:1906.08237 2019, [arXiv:cs.CL/1907.11692]. [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Duand, J.; Joshi†, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692 2020, [arXiv:cs.CL/1906.08237]. [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. (No Title) 2017, [arXiv:cs.LG/1412.6980]. [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv preprint arXiv:1711.05101 2019, [arXiv:cs.LG/1711.05101]. [CrossRef]
- Pontes, F.; Amorim, G.; Balestrassi, P.; Paiva, A.; Ferreira, J. Design of experiments and focused grid search for neural network parameter optimization. Neurocomputing 2016, 186, 22–34. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. Journal of Machine Learning Research 13 2012.
- Garrido-Merchán, E.C.; Gozalo-Brizuela, R.; González-Carvajal, S. Comparing BERT against Traditional Machine Learning Models in Text Classification. Journal of Computational and Cognitive Engineering 2023, pp. 1–7. [CrossRef]
- OpenAI.; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; Avila, R.; Babuschkin, I.; Balaji, S.; Balcom, V.; Baltescu, P.; Bao, H.; Bavarian, M.; Belgum, J.; Bello, I.; Berdine, J.; Bernadett-Shapiro, G.; Berner, C.; Bogdonoff, L.; Boiko, O.; Boyd, M.; Brakman, A.L.; Brockman, G.; Brooks, T.; Brundage, M.; Button, K.; Cai, T.; Campbell, R.; Cann, A.; Carey, B.; Carlson, C.; Carmichael, R.; Chan, B.; Chang, C.; Chantzis, F.; Chen, D.; Chen, S.; Chen, R.; Chen, J.; Chen, M.; Chess, B.; Cho, C.; Chu, C.; Chung, H.W.; Cummings, D.; Currier, J.; Dai, Y.; Decareaux, C.; Degry, T.; Deutsch, N.; Deville, D.; Dhar, A.; Dohan, D.; Dowling, S.; Dunning, S.; Ecoffet, A.; Eleti, A.; Eloundou, T.; Farhi, D.; Fedus, L.; Felix, N.; Fishman, S.P.; Forte, J.; Fulford, I.; Gao, L.; Georges, E.; Gibson, C.; Goel, V.; Gogineni, T.; Goh, G.; Gontijo-Lopes, R.; Gordon, J.; Grafstein, M.; Gray, S.; Greene, R.; Gross, J.; Gu, S.S.; Guo, Y.; Hallacy, C.; Han, J.; Harris, J.; He, Y.; Heaton, M.; Heidecke, J.; Hesse, C.; Hickey, A.; Hickey, W.; Hoeschele, P.; Houghton, B.; Hsu, K.; Hu, S.; Hu, X.; Huizinga, J.; Jain, S.; Jain, S.; Jang, J.; Jiang, A.; Jiang, R.; Jin, H.; Jin, D.; Jomoto, S.; Jonn, B.; Jun, H.; Kaftan, T.; Łukasz Kaiser.; Kamali, A.; Kanitscheider, I.; Keskar, N.S.; Khan, T.; Kilpatrick, L.; Kim, J.W.; Kim, C.; Kim, Y.; Kirchner, J.H.; Kiros, J.; Knight, M.; Kokotajlo, D.; Łukasz Kondraciuk.; Kondrich, A.; Konstantinidis, A.; Kosic, K.; Krueger, G.; Kuo, V.; Lampe, M.; Lan, I.; Lee, T.; Leike, J.; Leung, J.; Levy, D.; Li, C.M.; Lim, R.; Lin, M.; Lin, S.; Litwin, M.; Lopez, T.; Lowe, R.; Lue, P.; Makanju, A.; Malfacini, K.; Manning, S.; Markov, T.; Markovski, Y.; Martin, B.; Mayer, K.; Mayne, A.; McGrew, B.; McKinney, S.M.; McLeavey, C.; McMillan, P.; McNeil, J.; Medina, D.; Mehta, A.; Menick, J.; Metz, L.; Mishchenko, A.; Mishkin, P.; Monaco, V.; Morikawa, E.; Mossing, D.; Mu, T.; Murati, M.; Murk, O.; Mély, D.; Nair, A.; Nakano, R.; Nayak, R.; Neelakantan, A.; Ngo, R.; Noh, H.; Ouyang, L.; O’Keefe, C.; Pachocki, J.; Paino, A.; Palermo, J.; Pantuliano, A.; Parascandolo, G.; Parish, J.; Parparita, E.; Passos, A.; Pavlov, M.; Peng, A.; Perelman, A.; de Avila Belbute Peres, F.; Petrov, M.; de Oliveira Pinto, H.P.; Michael.; Pokorny.; Pokrass, M.; Pong, V.H.; Powell, T.; Power, A.; Power, B.; Proehl, E.; Puri, R.; Radford, A.; Rae, J.; Ramesh, A.; Raymond, C.; Real, F.; Rimbach, K.; Ross, C.; Rotsted, B.; Roussez, H.; Ryder, N.; Saltarelli, M.; Sanders, T.; Santurkar, S.; Sastry, G.; Schmidt, H.; Schnurr, D.; Schulman, J.; Selsam, D.; Sheppard, K.; Sherbakov, T.; Shieh, J.; Shoker, S.; Shyam, P.; Sidor, S.; Sigler, E.; Simens, M.; Sitkin, J.; Slama, K.; Sohl, I.; Sokolowsky, B.; Song, Y.; Staudacher, N.; Such, F.P.; Summers, N.; Sutskever, I.; Tang, J.; Tezak, N.; Thompson, M.B.; Tillet, P.; Tootoonchian, A.; Tseng, E.; Tuggle, P.; Turley, N.; Tworek, J.; Uribe, J.F.C.; Vallone, A.; Vijayvergiya, A.; Voss, C.; Wainwright, C.; Wang, J.J.; Wang, A.; Wang, B.; Ward, J.; Wei, J.; Weinmann, C.; Welihinda, A.; Welinder, P.; Weng, J.; Weng, L.; Wiethoff, M.; Willner, D.; Winter, C.; Wolrich, S.; Wong, H.; Workman, L.; Wu, S.; Wu, J.; Wu, M.; Xiao, K.; Xu, T.; Yoo, S.; Yu, K.; Yuan, Q.; Zaremba, W.; Zellers, R.; Zhang, C.; Zhang, M.; Zhao, S.; Zheng, T.; Zhuang, J.; Zhuk, W.; Zoph, B. GPT-4 Technical Report, 2024, [arXiv:cs.CL/2303.08774]. [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, 2023, [arXiv:cs.LG/1910.10683]. [CrossRef]
- D’Souza, J. A Review of Transformer Models, 2023. [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; Bikel, D.; Blecher, L.; Ferrer, C.C.; Chen, M.; Cucurull, G.; Esiobu, D.; Fernandes, J.; Fu, J.; Fu, W.; Fuller, B.; Gao, C.; Goswami, V.; Goyal, N.; Hartshorn, A.; Hosseini, S.; Hou, R.; Inan, H.; Kardas, M.; Kerkez, V.; Khabsa, M.; Kloumann, I.; Korenev, A.; Koura, P.S.; Lachaux, M.A.; Lavril, T.; Lee, J.; Liskovich, D.; Lu, Y.; Mao, Y.; Martinet, X.; Mihaylov, T.; Mishra, P.; Molybog, I.; Nie, Y.; Poulton, A.; Reizenstein, J.; Rungta, R.; Saladi, K.; Schelten, A.; Silva, R.; Smith, E.M.; Subramanian, R.; Tan, X.E.; Tang, B.; Taylor, R.; Williams, A.; Kuan, J.X.; Xu, P.; Yan, Z.; Zarov, I.; Zhang, Y.; Fan, A.; Kambadur, M.; Narang, S.; Rodriguez, A.; Stojnic, R.; Edunov, S.; Scialom, T. Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023, [arXiv:cs.CL/2307.09288]. [CrossRef]
- Rabaev, I.; Litvak, M.; Younkin, V.; Campos, R.; Jorge, A.M.; Jatowt, A. The Competition on Automatic Classification of Literary Epochs, 2023.


| Male | Female | Total | |
|---|---|---|---|
| Training | 5108 | 1320 | 6428 |
| Validation | 715 | 183 | 897 |
| Test | 709 | 188 | 898 |
| Total | 6532 | 1691 | 8223 |
| Model | Acc (avg) | Precisionf | Precisionm | Recallf | Recallm | F1f | F1m | F1 (avg) |
|---|---|---|---|---|---|---|---|---|
| LogisticRegression | 0.837 | 0.605 | 0.886 | 0.528 | 0.914 | 0.564 | 0.900 | 0.732 |
| LogisticRegression with L2 | 0.841 | 0.637 | 0.889 | 0.576 | 0.912 | 0.605 | 0.901 | 0.753 |
| LogisticRegression with L1 | 0.825 | 0.601 | 0.870 | 0.485 | 0.915 | 0.537 | 0.892 | 0.714 |
| XGB | 0.849 | 0.797 | 0.854 | 0.355 | 0.977 | 0.491 | 0.911 | 0.701 |
| XGB + XGBoost | 0.853 | 0.787 | 0.861 | 0.402 | 0.971 | 0.532 | 0.913 | 0.723 |
| SVM | 0.809 | 0.548 | 0.878 | 0.538 | 0.882 | 0.543 | 0.880 | 0.711 |
| BERT | 0.739 | 0.286 | 0.800 | 0.160 | 0.894 | 0.205 | 0.844 | 0.525 |
| GPT2 | 0.925 | 0.851 | 0.944 | 0.784 | 0.963 | 0.816 | 0.953 | 0.885 |
| XLNET | 0.907 | 0.806 | 0.931 | 0.735 | 0.953 | 0.769 | 0.942 | 0.856 |
| RoBERTa | 0.711 | 0.140 | 0.779 | 0.070 | 0.884 | 0.093 | 0.828 | 0.461 |
| Book Information | Female Name Recognition | ||||
|---|---|---|---|---|---|
| Author | Year | Book Name | GPT2 | XLNet | LR |
| Eliot, George | 1832 | Middlemarch | X | X | X |
| Eliot, George | 1859 | Adam Bede | V | V | X |
| Eliot, George | 1861 | Silas Marner | V | V | X |
| Eliot, George | 1860 | The Mill on the Floss | V | V | V |
| Eliot, George | 1876 | Daniel Deronda | V | X | X |
| Eliot, George | 1879 | Impressions of Theophrastus Such | X | V | X |
| Eliot, George | 1857 | Scenes of Clerical Life | V | V | V |
| Eliot, George | 1862 | Romola | V | V | X |
| Eliot, George | 1866 | Felix Holt, the Radical | V | V | X |
| Lee, Vernon | 1886 | A Phantom Lover | Yes | V | V |
| Lee, Vernon | 1903 | Penelope Brandling: A Tale of the Welsh coast in the Eighteenth Century. | V | V | X |
| Brontë, Anne | 1848 | The Tenant of Wildfell Hall | V | X | V |
| Acc | 0.833 | 0.750 | 0.333 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



