Submitted:
14 November 2024
Posted:
19 November 2024
You are already at the latest version
Abstract
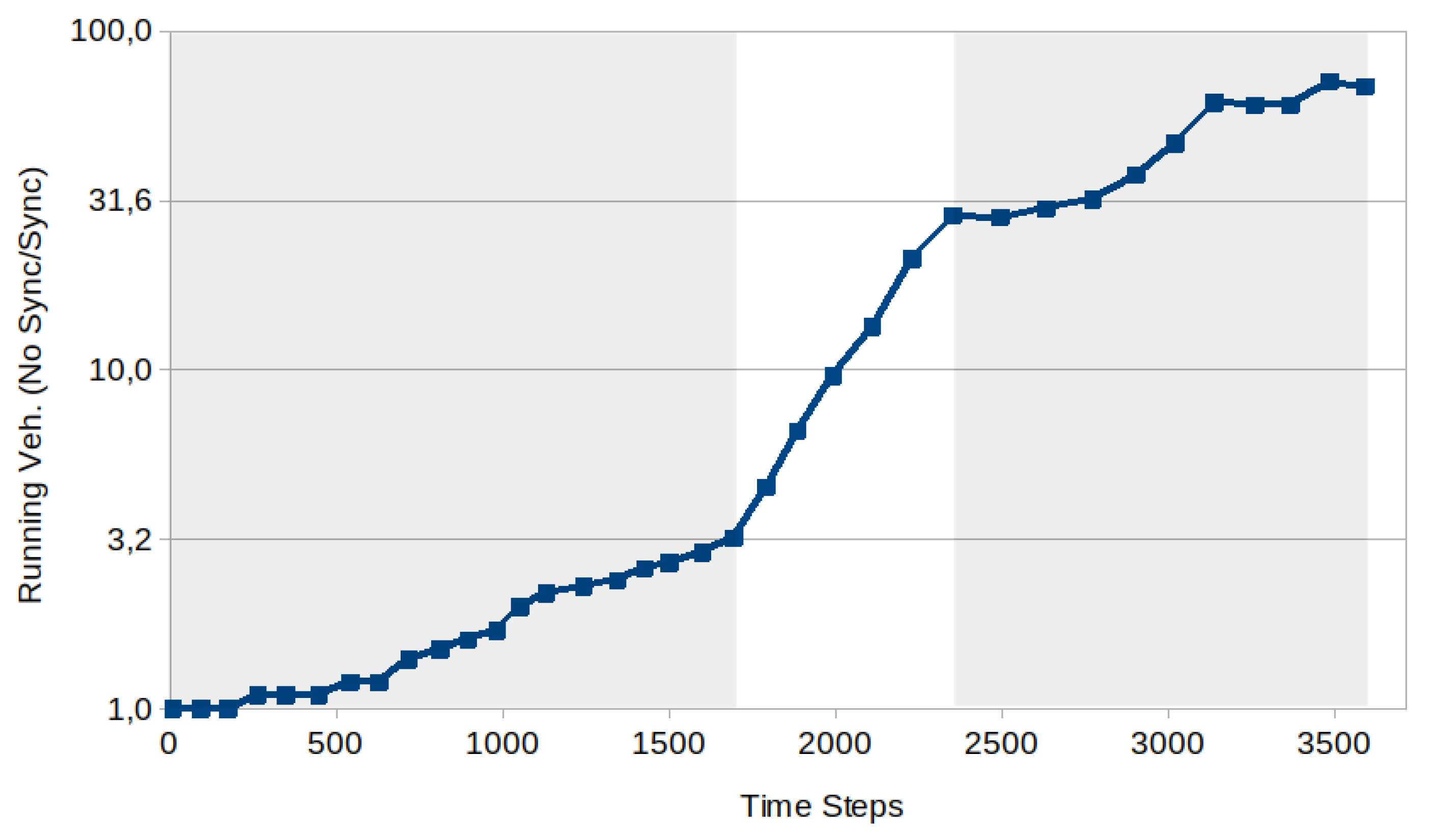
In this study, a comprehensive examination, both theoretically and practically, is undertaken on Multi-Agent Reinforcement Learning algorithms (MARL). The investigation is situated within the context of real adaptive traffic signal control (ATSC) scenarios, with the primary objective being to validate the algorithms theoretical framework and evaluate their effectiveness, robustness, and applicability in real-world settings. The study uses two traffic networks in the city of Bologna, Italy, as examples. Key findings underscore the necessity of situating the algorithms within the context of a Partially Observable Markov Decision Process (POMDP), inherently characterizing them as non-Markovian. The equations are reformulated within this framework. Simulation results reveal that one of the studied algorithms, MA2C, consistently achieves significant traffic de-congestion in the considered scenarios. In general, its performance continually improves over time, resulting in a reduction of running vehicles by a factor of approximately 70 at the conclusion of the simulation. A training strategy independent of the specific vehicle flow has been implemented, rendering it adaptable for use with various traffic loads.
Keywords:
1. Introduction
1.1. Related Work
1.2. Outline
2. Material and Methods
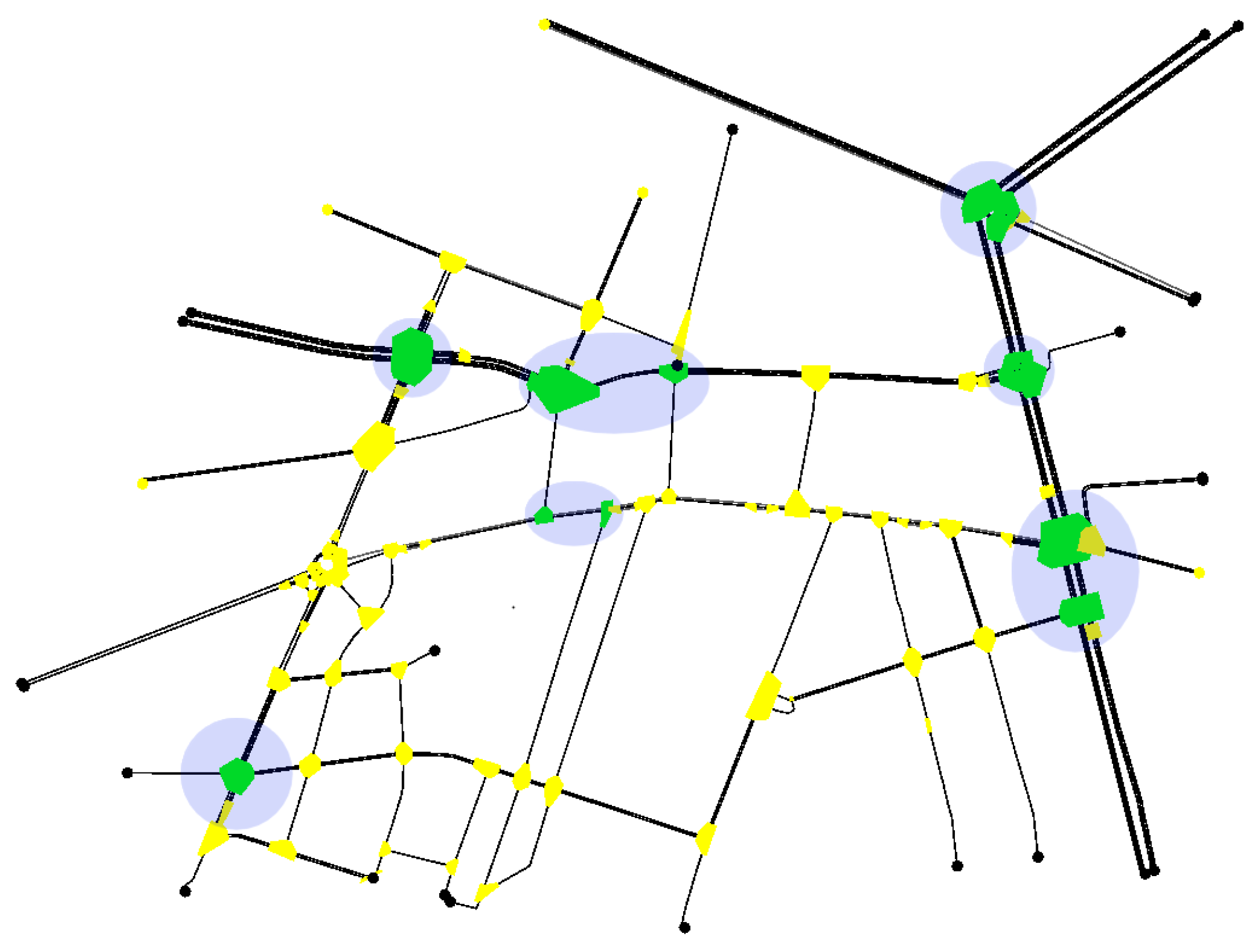
2.1. System Overview
2.2. System Formalization
2.2.1. Multi-Agent Formalization
- Agent: signalized intersection
- Environment: traffic network
-
Reward:The one-step reward for agent i at time t cumulates the queues (number of vehicles with speed less than 0.1 m/s) at the lanes corresponding to a certain signalized intersection in the interval :where is the set of lanes converging at a signalized intersection (agent) i. The one-step reward is accrued over multiple steps to form the Reward perceived by agent i (this step is different in MA2C, with respect to the other algorithms, as detailed in the following sections).
-
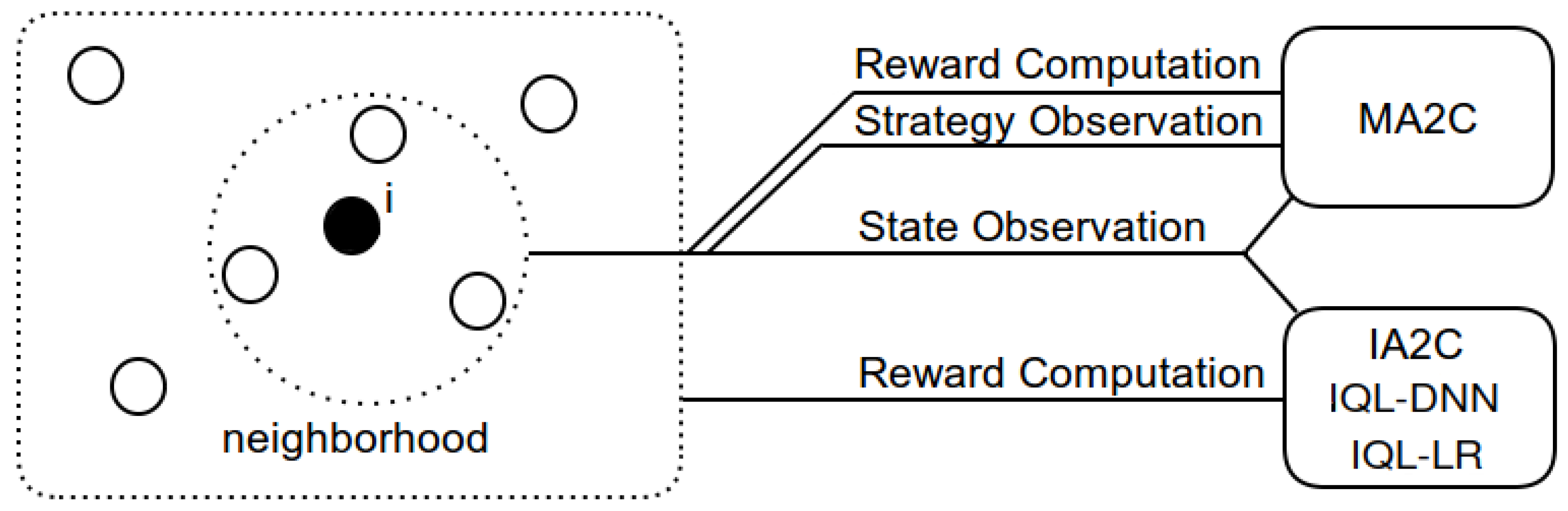
State (IA2C, IQL-DNN and IQL-LR):The state of the IA2C, IQL-DNN and IQL-LR agents at time t, , is computed by:where [veh] measures the total number of vehicles in the set of incoming lanes () at time t, within 50m from a signalized intersection (agent i).
- Action: is the action of agent i at time t (traffic light setting)
-
Policy:agent i’s policy at time t, , is a the probability distribution over its available actions
-
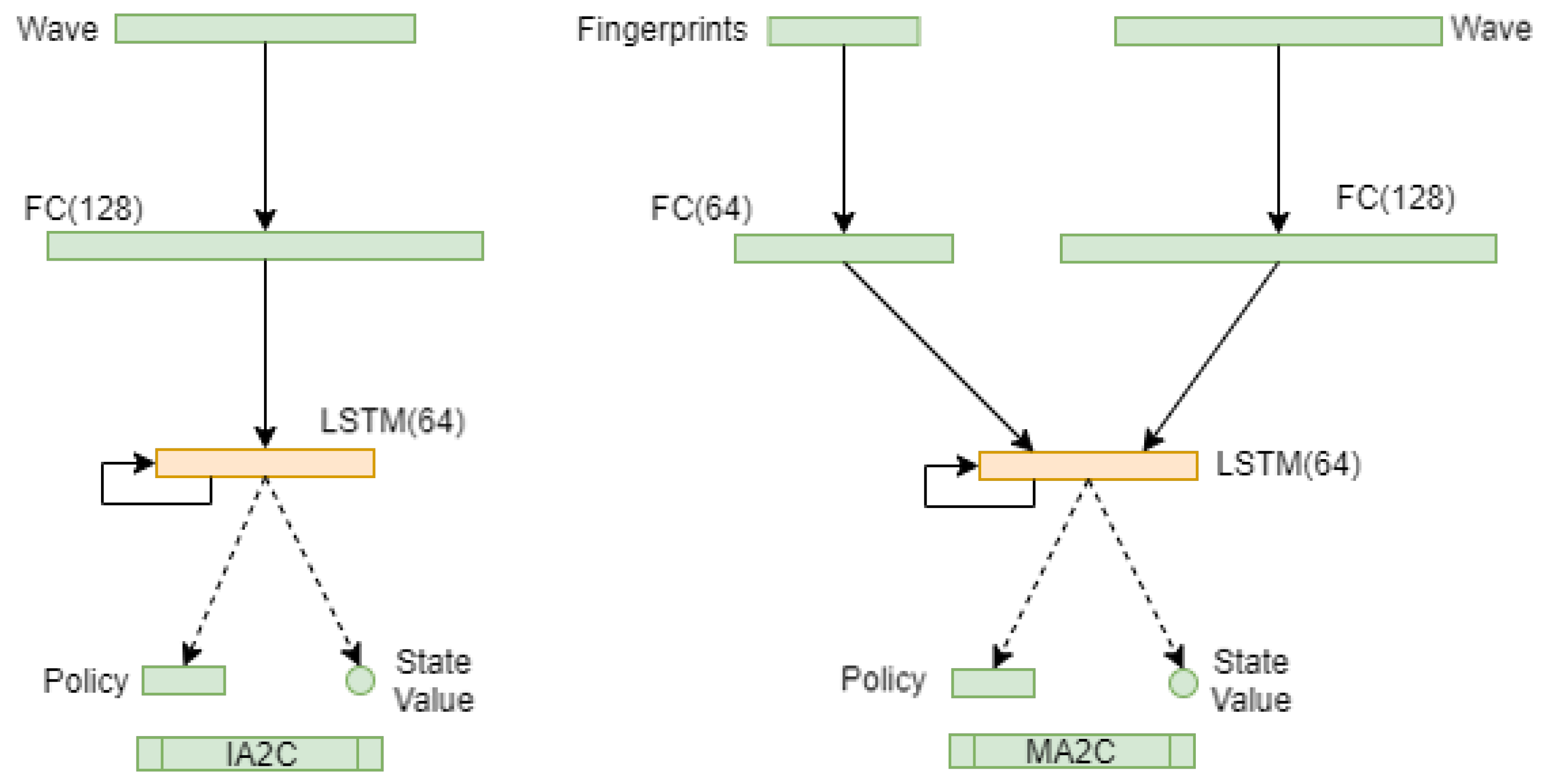
Fingerprints:policy vector set of agent i’s neighbor agents ()
- State (MA2C):where is a multiplication factor limiting the observation of neighbor agents () and is the state as defined in eq. (2).
2.3. Background
2.4. Markov Decision Process
- is a set of states, where denotes the agent’s state at time t.
- is a set of available actions, where denotes the action the agent performs at time t.
- is a transition function and denotes the probability of arriving at state when action is performed in state .
- is a reward function where is the reward when the agent transitions from state to state after performing action .
- is a discount factor.
2.4.1. Single Agent Recurrent Policy Gradients
2.4.2. Single Agent Recurrent Advantage Actor Critic
- and are the histories of past events registered by the two LSTM networks used to compute the regressors and
- is the n-step return [6], with ; the regressor for state value at (corresponding to the first time step of the next batch) is evaluated using the current parameters
- is the sampled advantage for actions
2.5. Multi-Agent Policy-Gradient Systems
2.5.1. Independent Advantage Actor-Critic (IA2C)
- with
2.5.2. Multi-Agent Advantage Actor-Critic (MA2C)
-
with
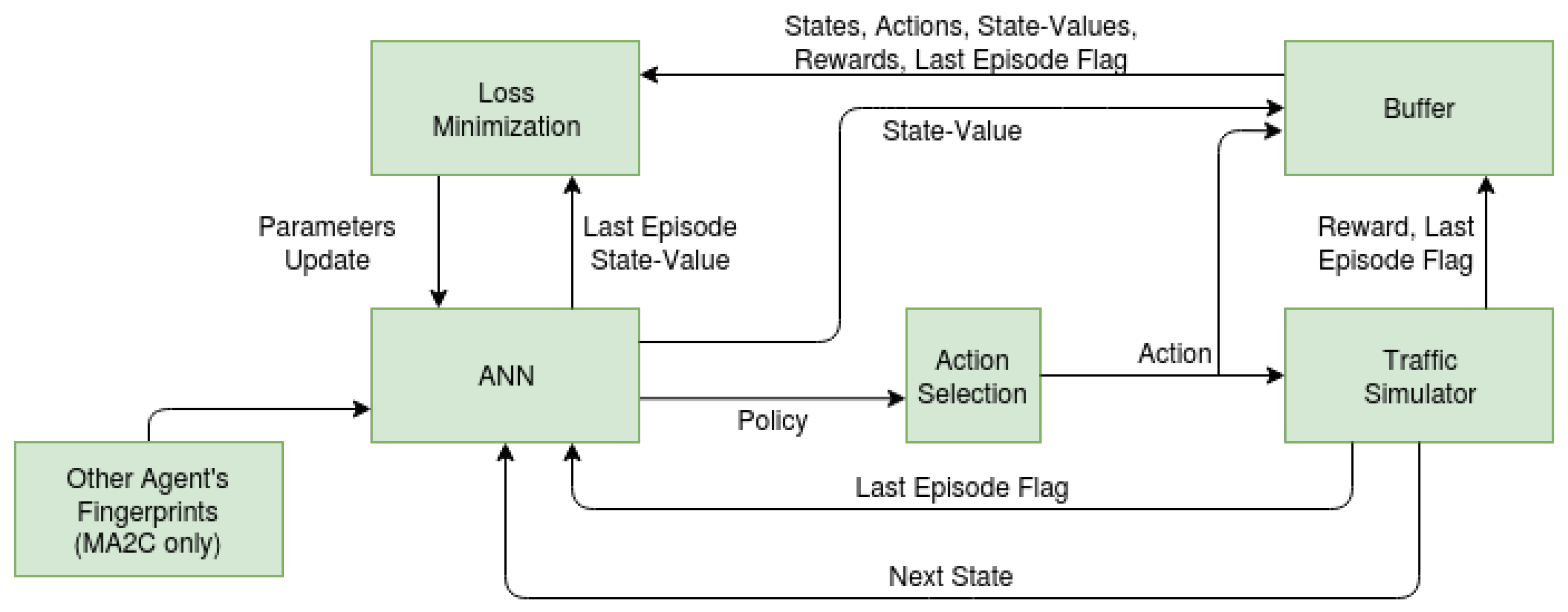
2.6. System Architecture
2.6.1. ANN Detail
3. Calculation
3.1. Algorithms
- Loading traffic networks with a varying number of vehicles.
- Evaluating the training graphs of IQL-DNN and IQL-LR.
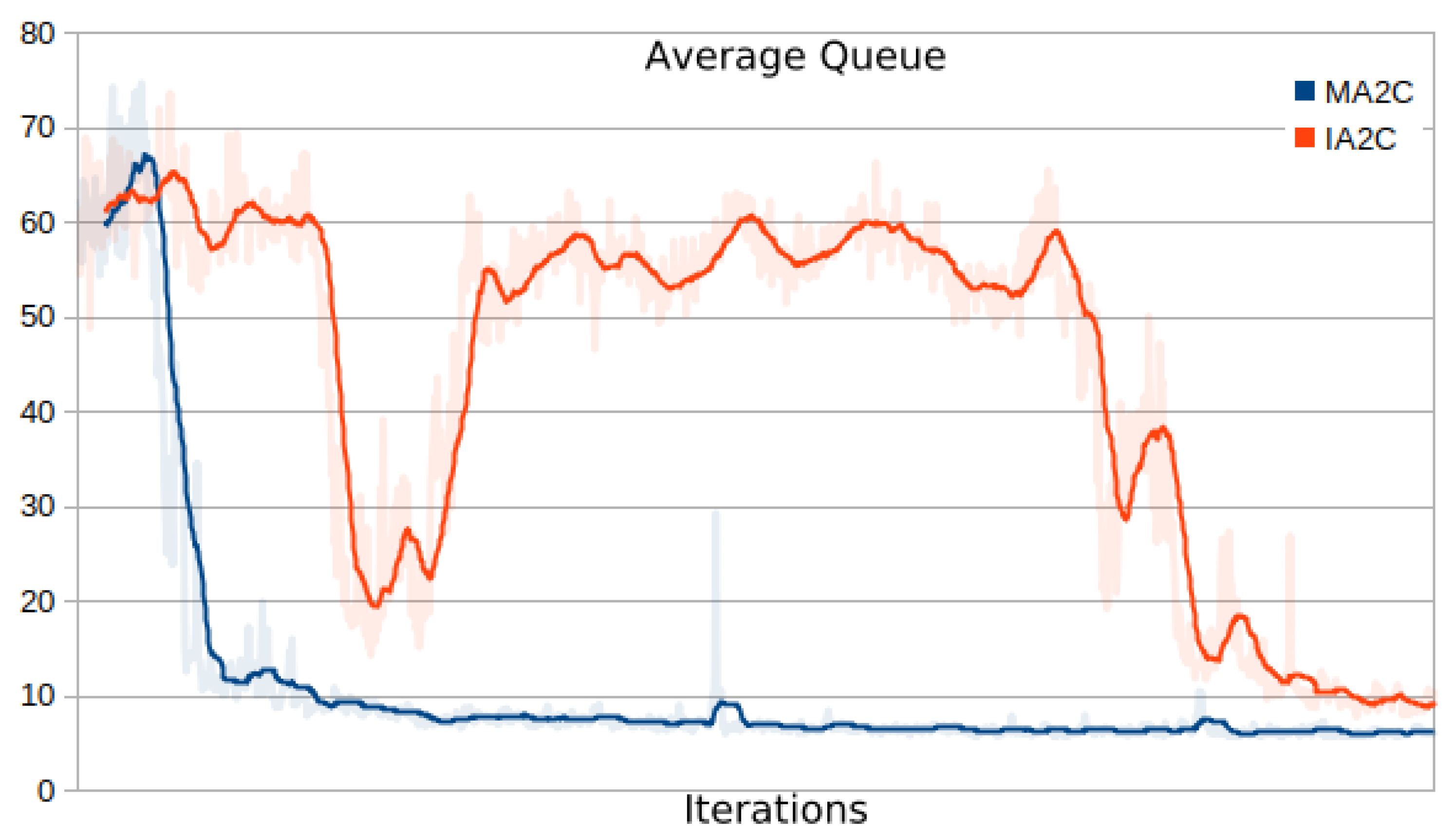
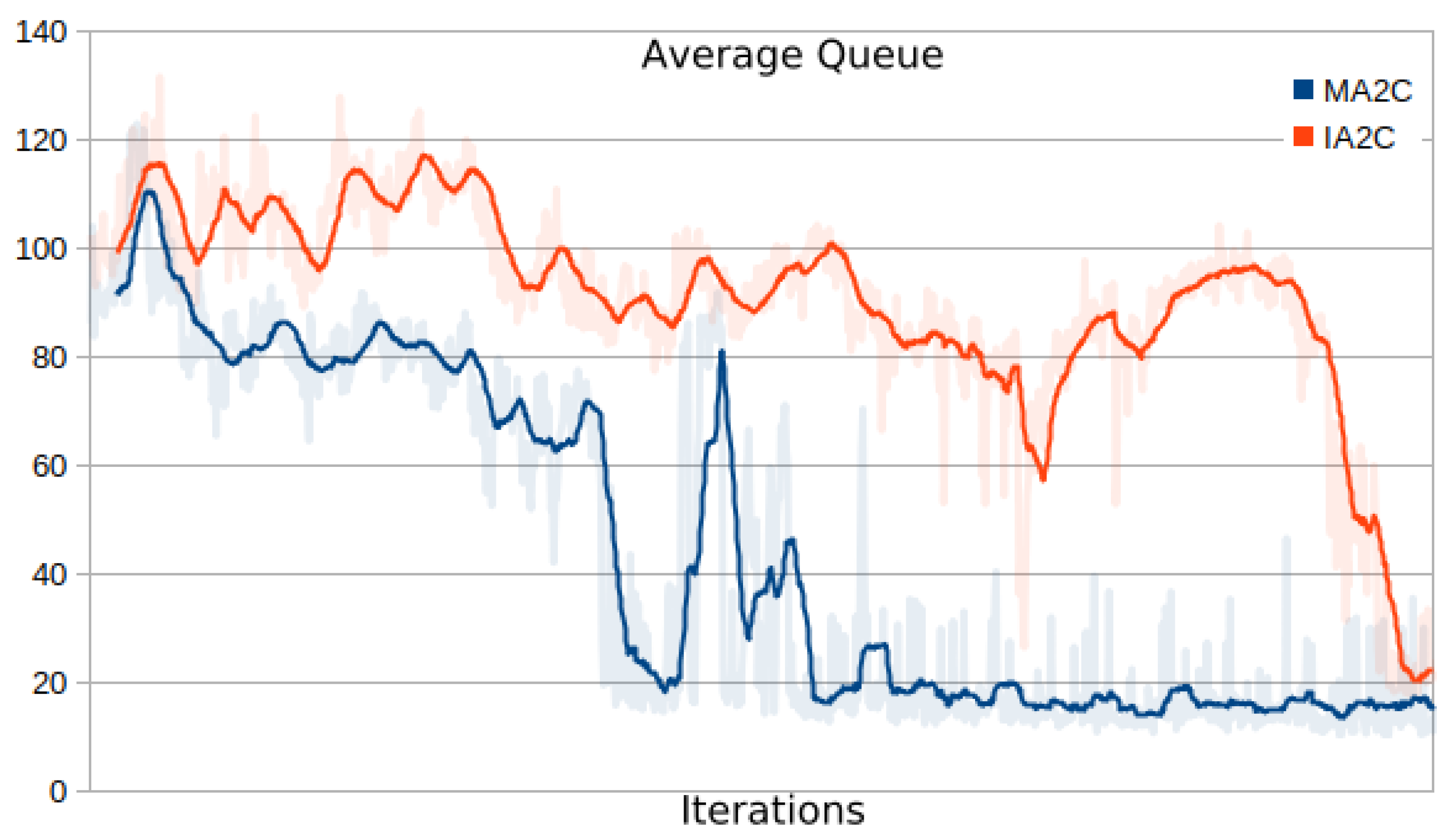
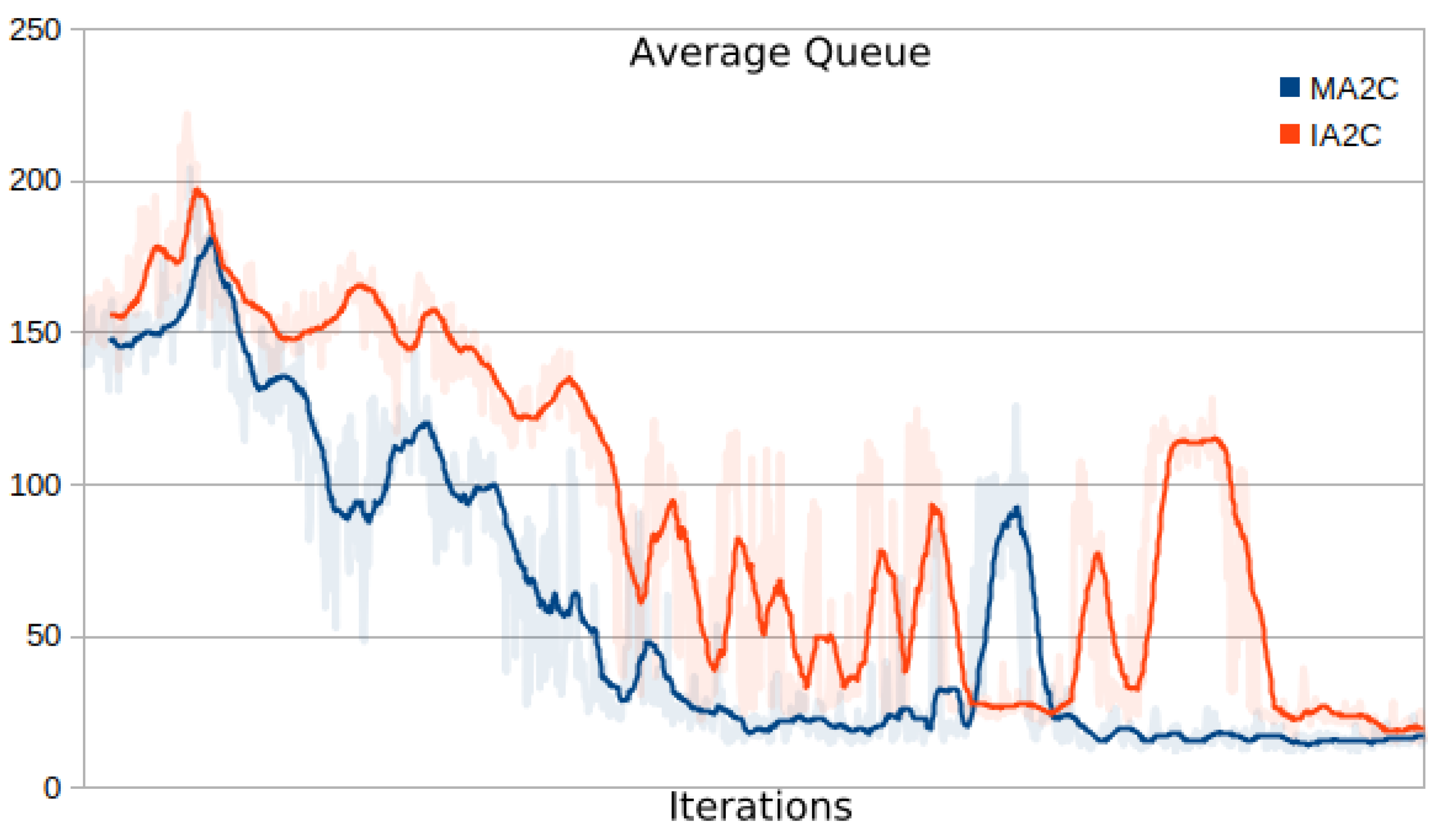
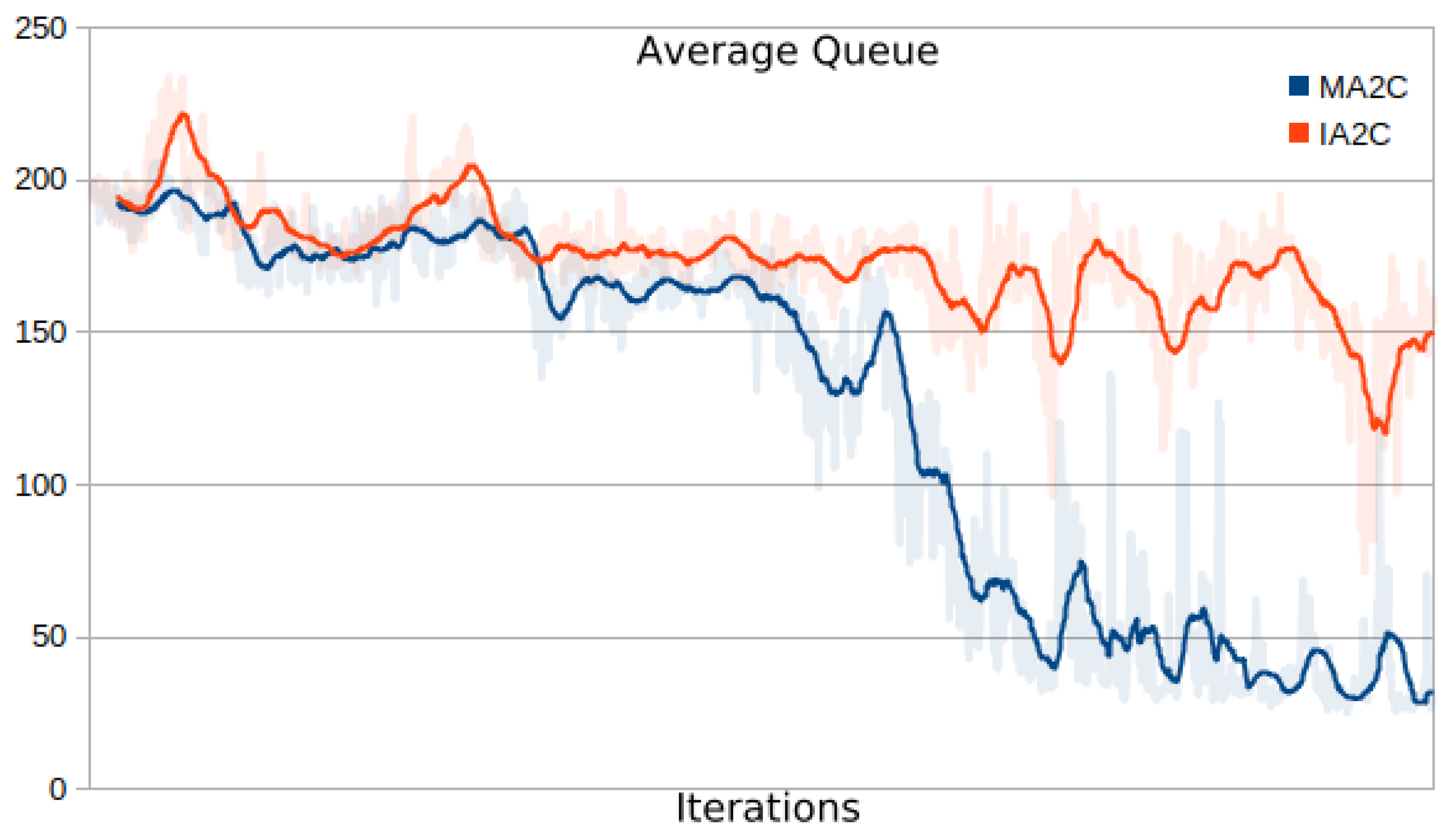
- Comparing the IA2C and MA2C learning curves
- Comparing MA2C with IA2C and Greedy
- Evaluating the behavior of the learning curves for IA2C and MA2C
- Evaluating the effects of the learned policies in terms of traffic volumes
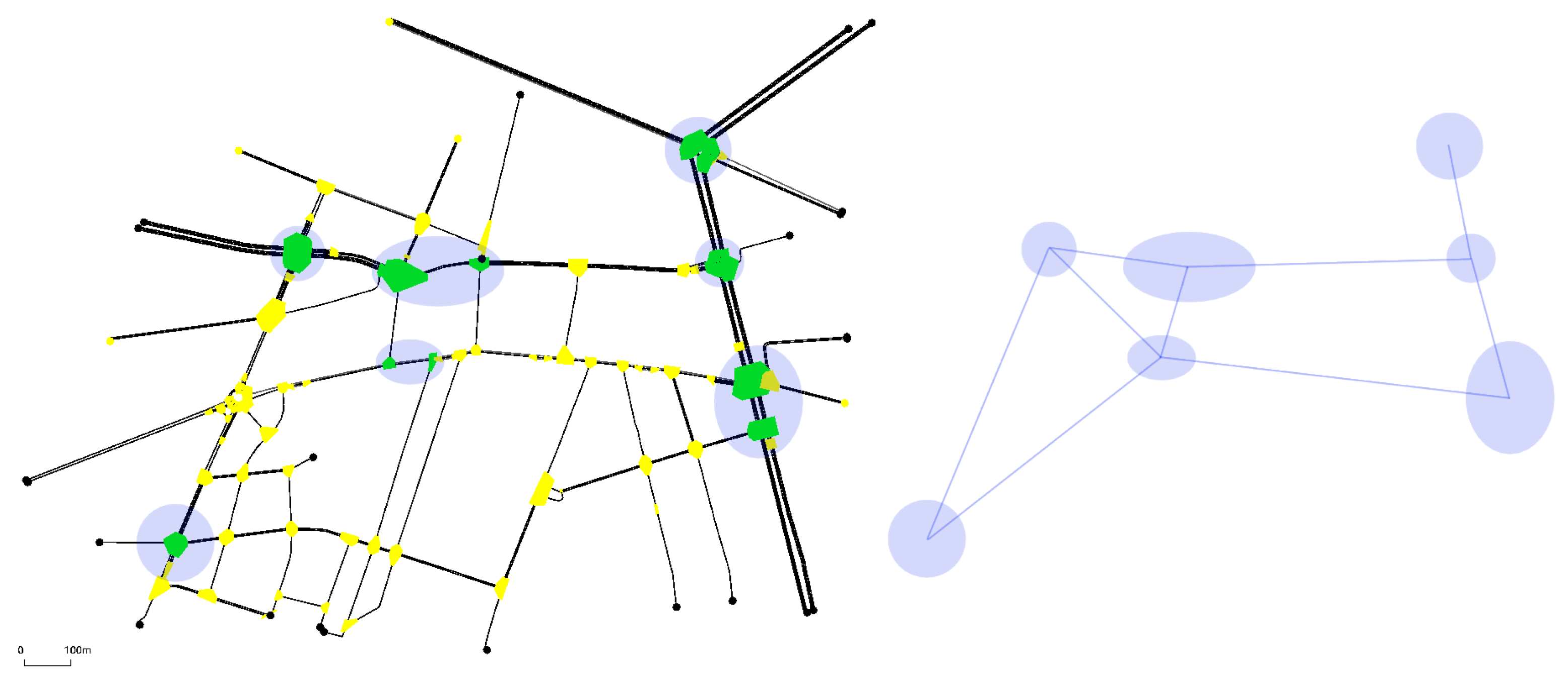
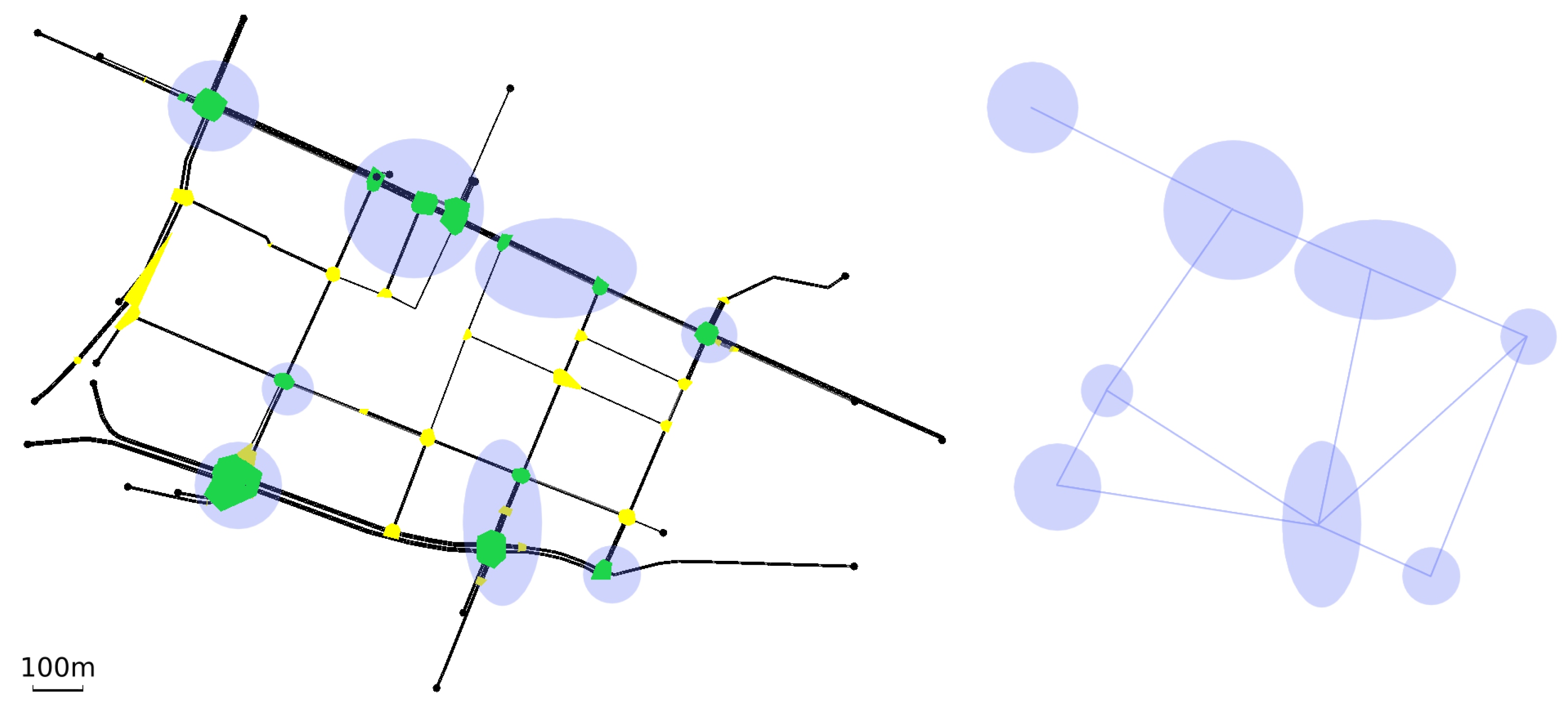
3.2. Traffic Networks
- One vehicle inserted per time step for the first 2000 time steps, then no more vehicles for the remaining time steps, totalling 2000 vehicles
- One vehicle inserted per time step for all 3600 time steps, totalling 3600 vehicles
- Two vehicles inserted per time step for the first 2000 time steps, then no more vehicles for the remaining time steps, totalling 4000 vehicles
3.3. IQL-DNN and IQL-LR
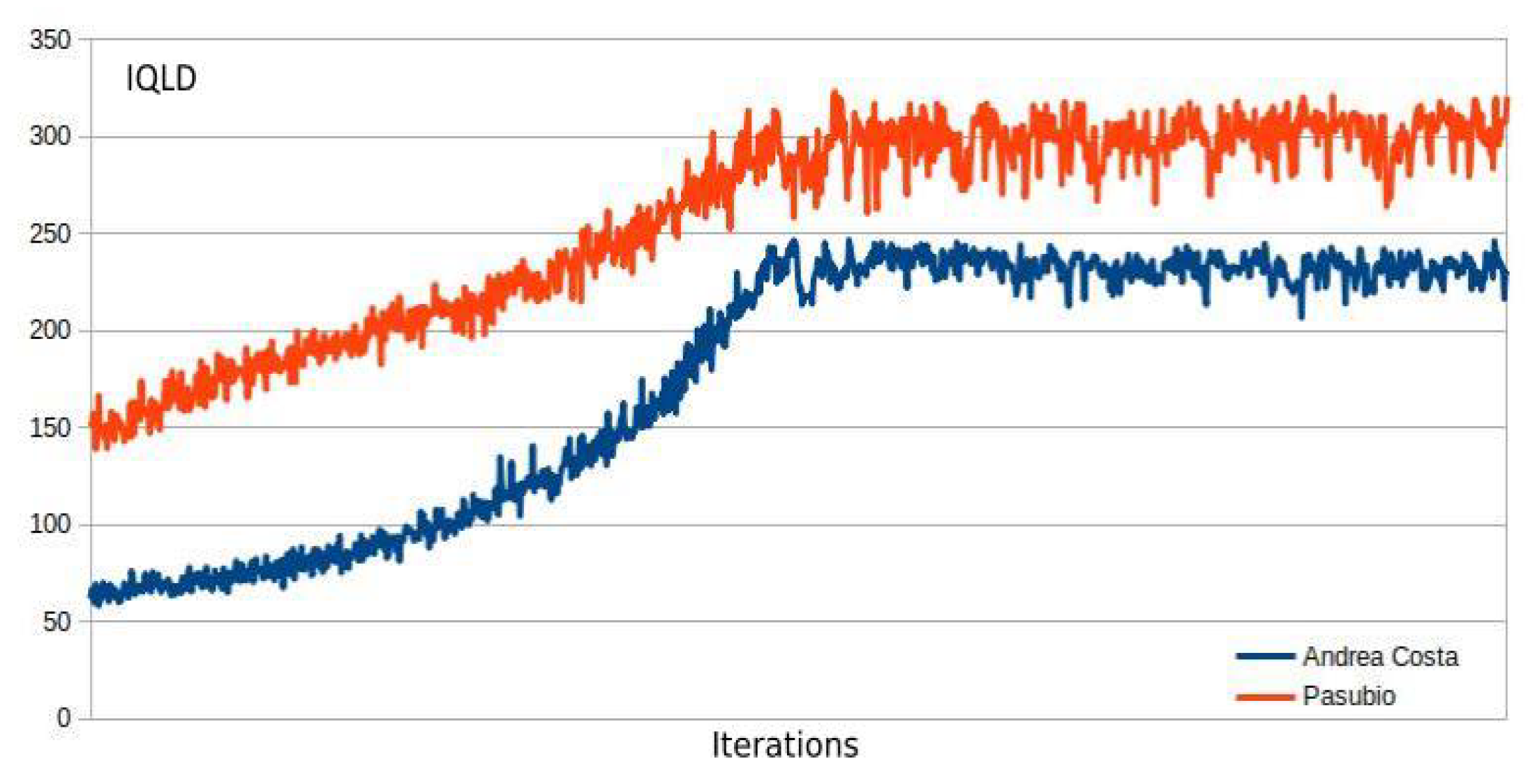
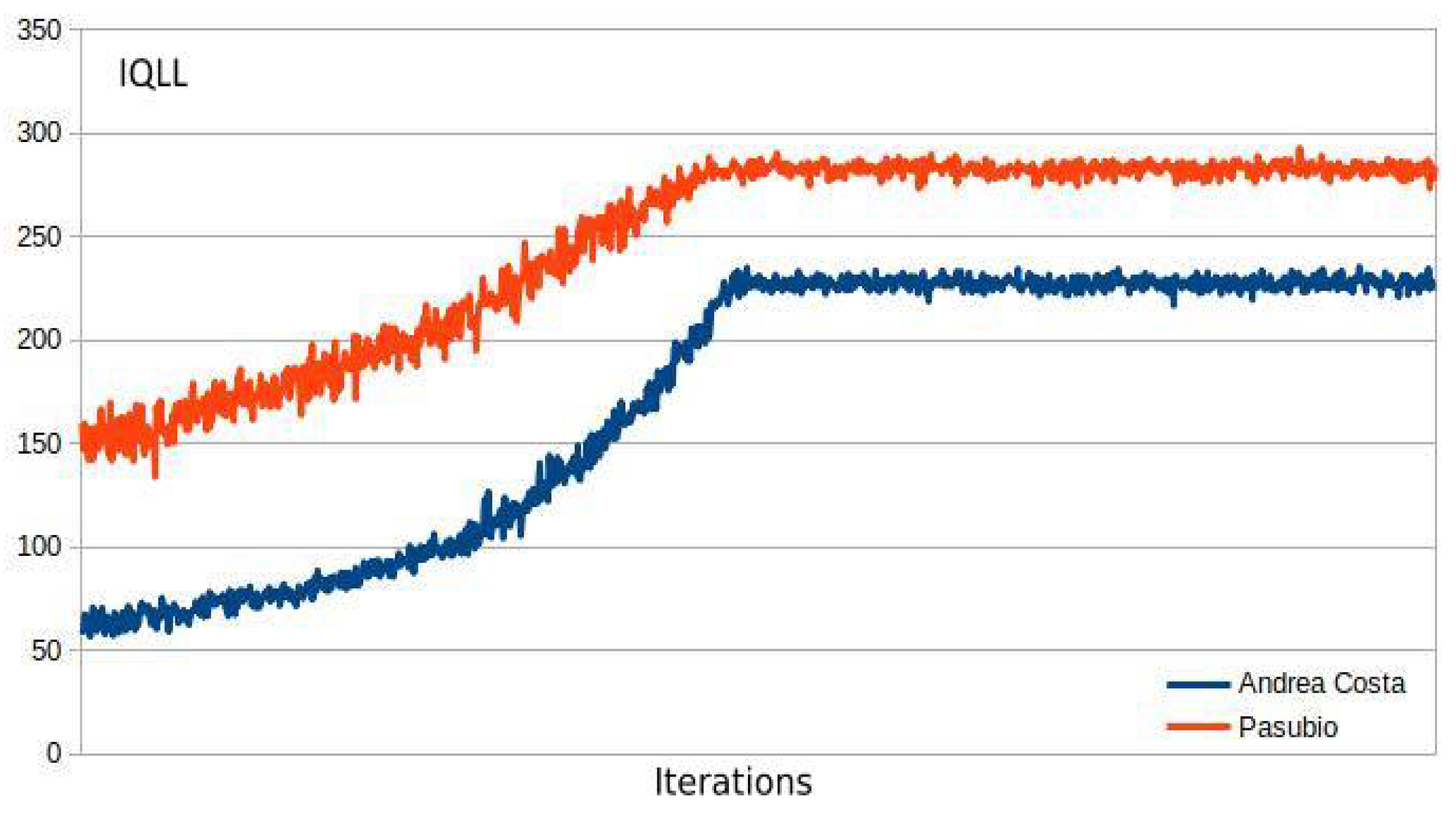
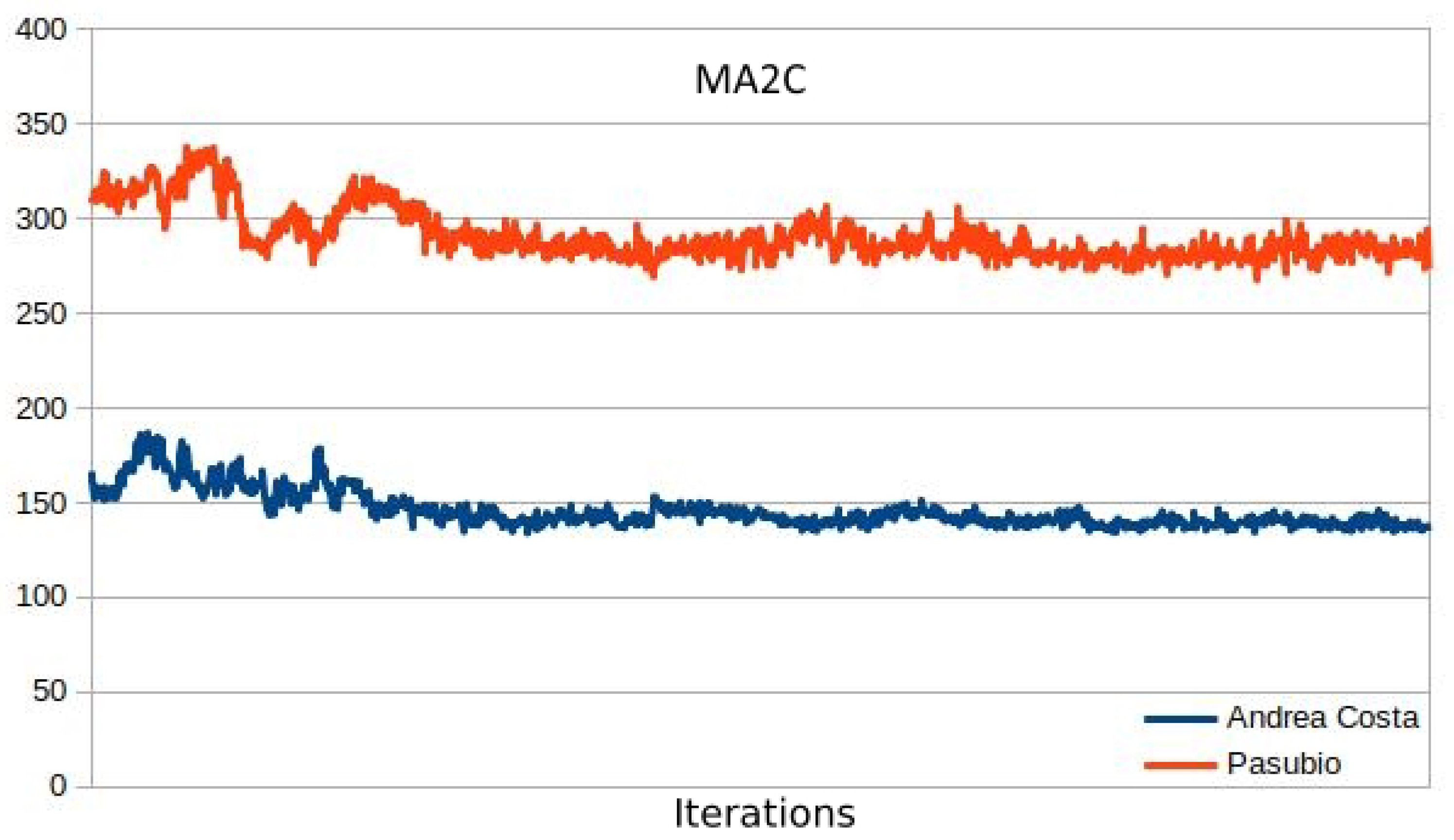
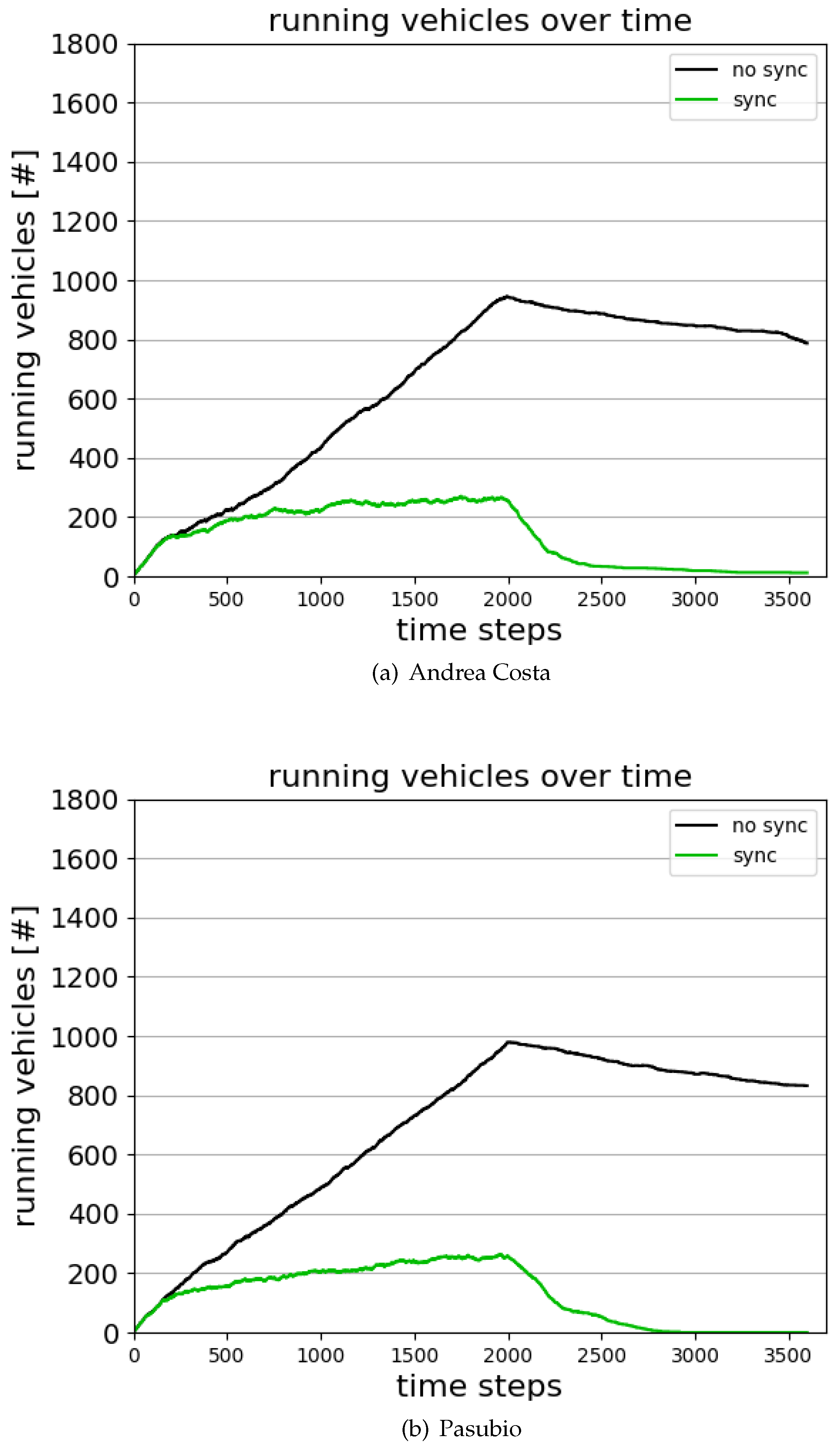
3.4. MA2C and IA2C Performance on the A. Costa Traffic Network
3.5. MA2C and IA2C on the Pasubio Traffic Network
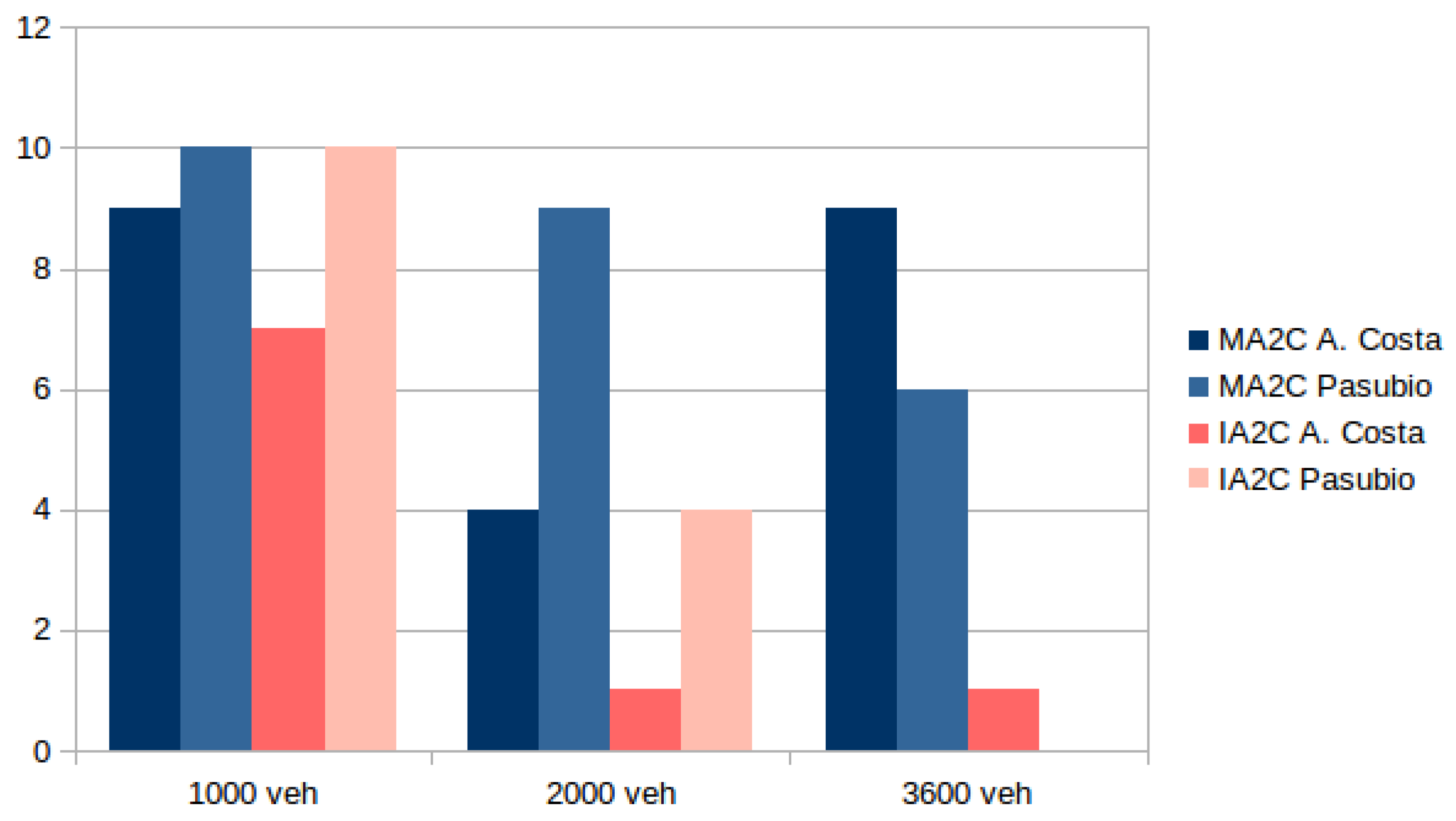
3.6. Further Tests
4. Convergence Stability
4.1. Theoretical Evaluation of the Learning Process
4.2. Experimental Evaluation of the Learning Process
4.3. Generalization
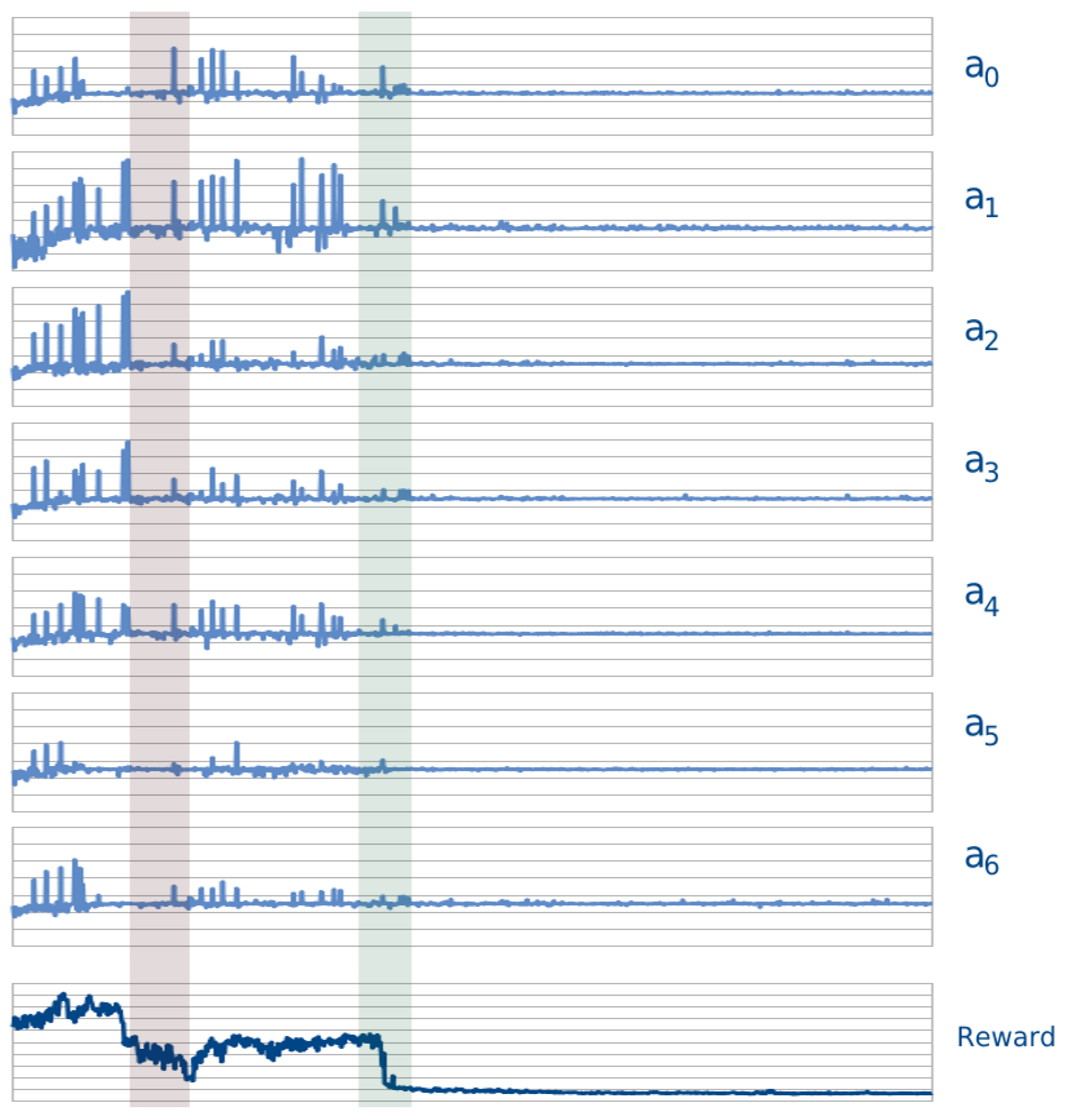
4.3.1. Random Learning
4.3.2. Policy Cross-Evaluation
Training MA2C with 2000 Vehicles:
Training MA2C with 3600 Vehicles:
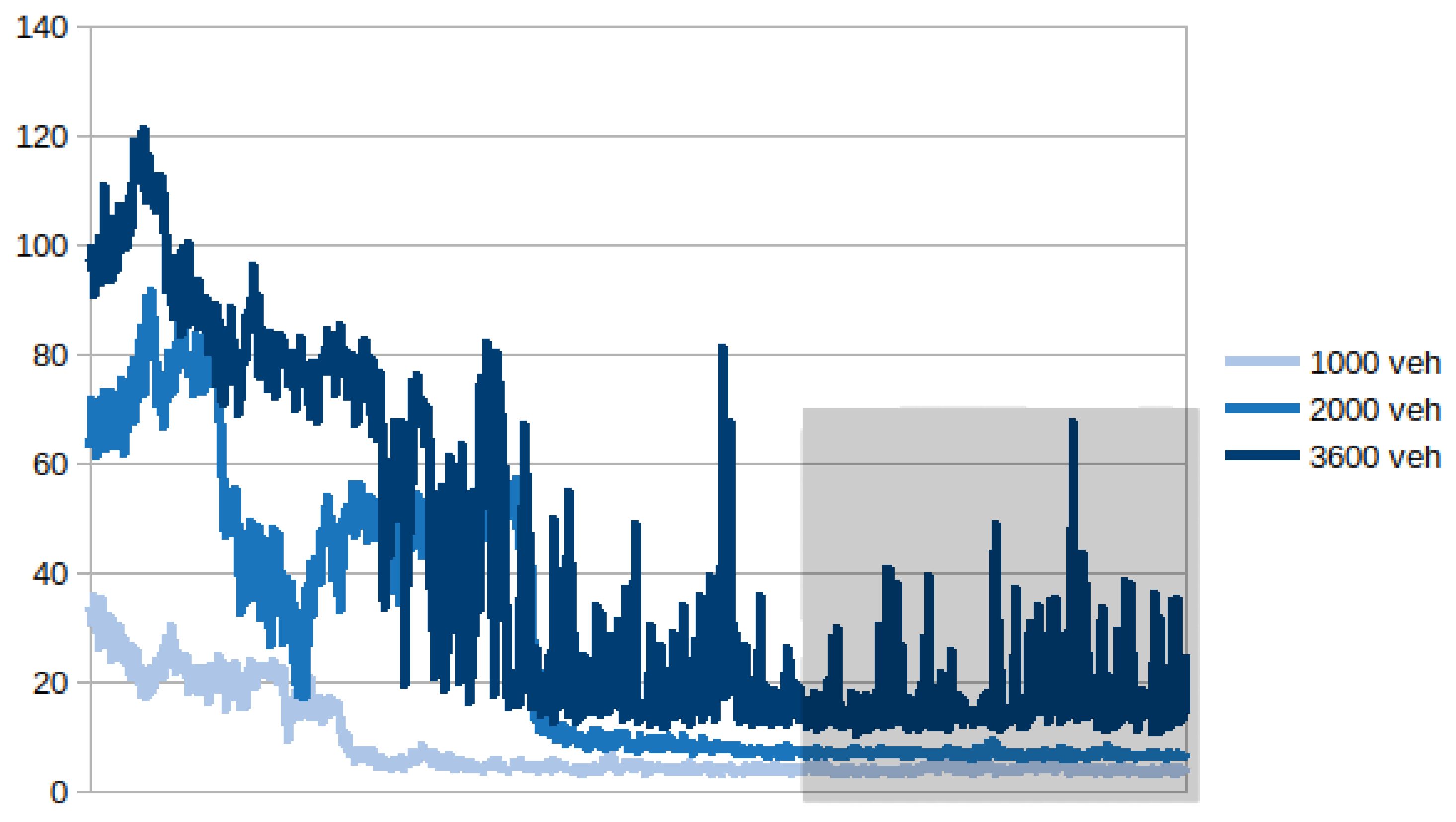
5. Results
- In the first part of the simulation (time steps [0, 2000]) a vehicle is pseudo-randomly inserted on the map for each time step and follows a pseudo-random path.
- In the second part of the simulation (time steps [2000, 3600]) no vehicle is inserted. Eventually, all the vehicles circulating on the map leave through one of the exit lanes or end their journey by reaching their destination.
6. Conclusions
Author Contributions
Acknowledgments
Glossary
| DP | Decision Process. |
| IA2C | Independent Advantage Actor Critic . |
| IQL-DNN | Independent Q-Learning Deep Neural Network. |
| IQL-LR | Independent Q-Learning Linear Regression. |
| MA2C | Multi-Agent Advantage Actor Critic . |
| MARL | Multi-Agent Reinforcement Learning . |
| MDP | Markovian Decision Process. |
| NMDP | Non Markovian Decision Process. |
| OD | Origin-Destination Matrix. |
| POMDP | Partially Observable Markovian Decision Process. |
| RL | Reinforcement Learning . |
| SUMO | Simulation of Urban MObility . |
| TSC | Traffic Signal Control. |
| Color should not be used for any figures in print. | |
References
- Ghazali, W.; Zulkifli, C.N.; Ponrahono, Z. The Effect Of Traffic Congestion On Quality Of Community Life. European Proceedings of Multidisciplinary Sciences 2017. [Google Scholar] [CrossRef]
- Karimi, H.; Ghadirifaraz, B.; Shetab Boushehri, S.N.; Hosseininasab, S.M.; Rafiei, N. Reducing traffic congestion and increasing sustainability in special urban areas through one-way traffic reconfiguration. Trasportation 2022. [Google Scholar] [CrossRef]
- Jilani, U.; Asif, M.; Zia, M.Y.I.; Rashid, M.; Shams, S.; Otero, P. A Systematic Review on Urban Road Traffic Congestion. Wireless Personal Communications 2023. [Google Scholar] [CrossRef]
- Sen, S.; Li, H.; Khazanovich, L. Effect of climate change and urban heat islands on the deterioration of concrete roads. Results in Engineering 2022, 16, 100736. [Google Scholar] [CrossRef]
- Liu, D.; Li, L. A traffic light control method based on multi-agent deep reinforcement learning algorithm. Nature 2023, 13. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement learning: an introduction; Adaptive computation and machine learning, MIT Press.
- Huang, J.; Cui, Y.; Zhang, L.; Tong, W.; Shi, Y.; Liu, Z. An Overview of Agent-Based Models for Transport Simulation and Analysis. Journal of Advanced Transportation 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Shoham, Y.; Leyton-Brown, K. Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations; Cambridge University Press, 2008. [CrossRef]
- Miletić, M.; Ivanjko, E.; Gregurić, M.; Kušić, K. A review of reinforcement learning applications in adaptive traffic signal control. IET Intelligent Transport Systems 2022, 16, n. [Google Scholar] [CrossRef]
- Chu, T.; Chinchali, S.; Katti, S. Multi-agent Reinforcement Learning for Networked System Control. 2020; arXiv:cs.LG/2004.01339. [Google Scholar]
- Jiang, Q.; Qin, M.; Shi, S.; Sun, W.; Zheng, B. Multi-Agent Reinforcement Learning for Traffic Signal Control through Universal Communication Method. 2022; arXiv:cs.AI/2204.12190. [Google Scholar]
- Wong, A.; Bäck, T.; Kononova, A.V.; Plaat, A. Deep multiagent reinforcement learning: challenges and directions.
- Chu, T.; Wang, J.; Codecà, L.; Li, Z. Multi-Agent Deep Reinforcement Learning for Large-scale Traffic Signal Control. 2019; arXiv:cs.LG/1903.04527. [Google Scholar]
- Lopez, P.A.; Wiessner, E.; Behrisch, M.; Bieker-Walz, L.; Erdmann, J.; Flotterod, Y.P.; Hilbrich, R.; Lucken, L.; Rummel, J.; Wagner, P. Microscopic Traffic Simulation using SUMO. 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, pp. 2575–2582. [CrossRef]
- Hunt, P.; Robertson, D.; Bretherton, R.D.; Royle, M. THE SCOOT ON-LINE TRAFFIC SIGNAL OPTIMISATION TECHNIQUE. Traffic engineering and control 1982, 23. [Google Scholar]
- Luk, J. Two traffic responsive area traffic control methods: SCAT and SCOOT. 1983.
- Gokulan, B.P.; Srinivasan, D. Distributed Geometric Fuzzy Multiagent Urban Traffic Signal Control. 11, 714–727. [CrossRef]
- Teodorović, D. Swarm intelligence systems for transportation engineering: Principles and applications. 16, 651–667. [CrossRef]
- Lee, J.; Abdulhai, B.; Shalaby, A.; Chung, E.H. Real-Time Optimization for Adaptive Traffic Signal Control Using Genetic Algorithms. Journal of Intelligent Transportation Systems 2005, 9, 111–122. [Google Scholar] [CrossRef]
- Huang, J.; Cui, Y.; Zhang, L.; Tong, W.; Shi, Y.; Liu, Z. An Overview of Agent-Based Models for Transport Simulation and Analysis. Journal of Advanced Transportation 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Wu, C.; Ma, Z.; Kim, I. Multi-Agent Reinforcement Learning for Traffic Signal Control: Algorithms and Robustness Analysis. 2020, pp. 1–7. [CrossRef]
- Huang, J.; Cui, Y.; Zhang, L.; Tong, W.; Shi, Y.; Liu, Z. An Overview of Agent-Based Models for Transport Simulation and Analysis. Journal of Advanced Transportation 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Lample, G.; Chaplot, D.S. Playing FPS Games with Deep Reinforcement Learning. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA; Singh, S.; Markovitch, S., Eds. AAAI Press, pp. 2140–2146.
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. CoRR 2016, abs/1602.01783. arXiv:1602.01783.
- Bieker, L.; Krajzewicz, D.; Morra, A.P.; Michelacci, C.; Cartolano, F. Traffic simulation for all: A real world traffic scenario from the city of Bologna. Lecture Notes in Control and Information Sciences 2015, 13, 47–60. [Google Scholar] [CrossRef]
- Zhang, C.; Vinyals, O.; Munos, R.; Bengio, S. A Study on Overfitting in Deep Reinforcement Learning. 2018; arXiv:cs.LG/1804.06893. [Google Scholar]
- Kolat, M.; Kővári, B.; Bécsi, T.; Aradi, S. Multi-Agent Reinforcement Learning for Traffic Signal Control: A Cooperative Approach. Sustainability 2023, 15. [Google Scholar] [CrossRef]
- Bera, S.; Rao, K.V. Estimation of origin-destination matrix from traffic counts: The state of the art. European Transport Trasporti Europei 2011, 49, 2–23. [Google Scholar]
- Ronca, A.; Paludo Licks, G.; De Giacomo, G. Markov Abstractions for PAC Reinforcement Learning in Non-Markov Decision Processes 2022.
- Grosnit, A.; Cai, D.; Wynter, L. Decentralized Deterministic Multi-Agent Reinforcement Learning. 2021; arXiv:cs.LG/2102.09745. [Google Scholar]
- Zhang, K.; Yang, Z.; Liu, H.; Zhang, T.; Basar, T. Fully Decentralized Multi-Agent Reinforcement Learning with Networked Agents. Proceedings of the 35th International Conference on Machine Learning; Dy, J.; Krause, A., Eds. PMLR, 2018, Vol. 80, Proceedings of Machine Learning Research, pp. 5872–5881.
- Zhu, R.; Ding, W.; Wu, S.; Li, L.; Lv, P.; Xu, M. Auto-learning communication reinforcement learning for multi-intersection traffic light control. Knowledge-Based Systems 2023, 275, 110696. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Z.; Başar, T. , K.G.; Wan, Y.; Lewis, F.L.; Cansever, D., Eds.; Springer International Publishing: Cham, 2021; pp. 321–384. doi:10.1007/978-3-030-60990-0_12.Algorithms. In Handbook of Reinforcement Learning and Control; Vamvoudakis, K.G., Wan, Y., Lewis, F.L., Cansever, D., Eds.; Springer International Publishing: Cham, 2021; Springer International Publishing: Cham, 2021; pp. 321–384. [Google Scholar] [CrossRef]
- Irpan, A. Deep Reinforcement Learning Doesn’t Work Yet. 2018. Available online: https://www.alexirpan.com/2018/02/14/rl-hard.html.
| 1 | The latter two Q-learning based RL algorithms differ from each other in the way they fit the Q-function, i.e., by linear regression or by a deep neural network [13] |
| 2 | SUMO [14] is a micro-traffic simulator capable of simulating traffic dynamics |
| 3 | Each agent observes the traffic flow in its proximity and its neighboring agents proximity; see Section 2.2.1 for a formal definition |
| 4 | In accordance with the literature on the subject, this work designates this quantity as the reward, notwithstanding the fact that the length of a vehicle queue is given (and perceived) as a penalty. |
| 5 |
Strategy and policy refer to similar entities. The former is more common in game theory, while the latter is more popular in reinforcement learning; in this work these two terms are used interchangeably |
| 6 | To lighten the notation, in some cases the dependence from will be omitted if clear from the context |
| 7 | In [13] and are referred as the frozen state-value and policy to include in the development an eventual frozen set of parameters staying constant during multiple learning steps. We prefer to avoid this terminology as in the implementation reported here the parameters are updated after each learning step |
| 8 | The MA2C spatial discount factor highlights the competitive character of the mixed cooperative-competitive game among the agents, as opposed to IA2C which is purely cooperative. |
| 9 |
Root Mean Squared Propagation is an unpublished algorithm first proposed by Geoffrey Hinton in the Coursera course “Neural Network for Machine Learning”, lecture 6, 2018 |
| 10 | For all the tests and the totally random learning experiment, the seeds used are: 10400, 20200, 31000, 3101, 122, 42, 20200, 33333. |
| 11 | In the main experiment of [13], on the city of Monaco, vehicle flows on specific roads are predetermined; some randomness is allowed, but it affects only a vehicle’s position on the starting road, while its route to its destination is deterministic. |
| 12 | In [13] a good behavior of IQL-DNN and IQL-LR is reported only for basic (unrealistic) experiments such as regular grids; in fact in Figure 9 and 10 in [13], they have been omitted due to their poor performance with a real traffic network. IQL based approaches are also reported to perform well in [28], where a 6 agents squared lattice traffic grid is adopted and in [28] with a 4 agent squared lattice. |
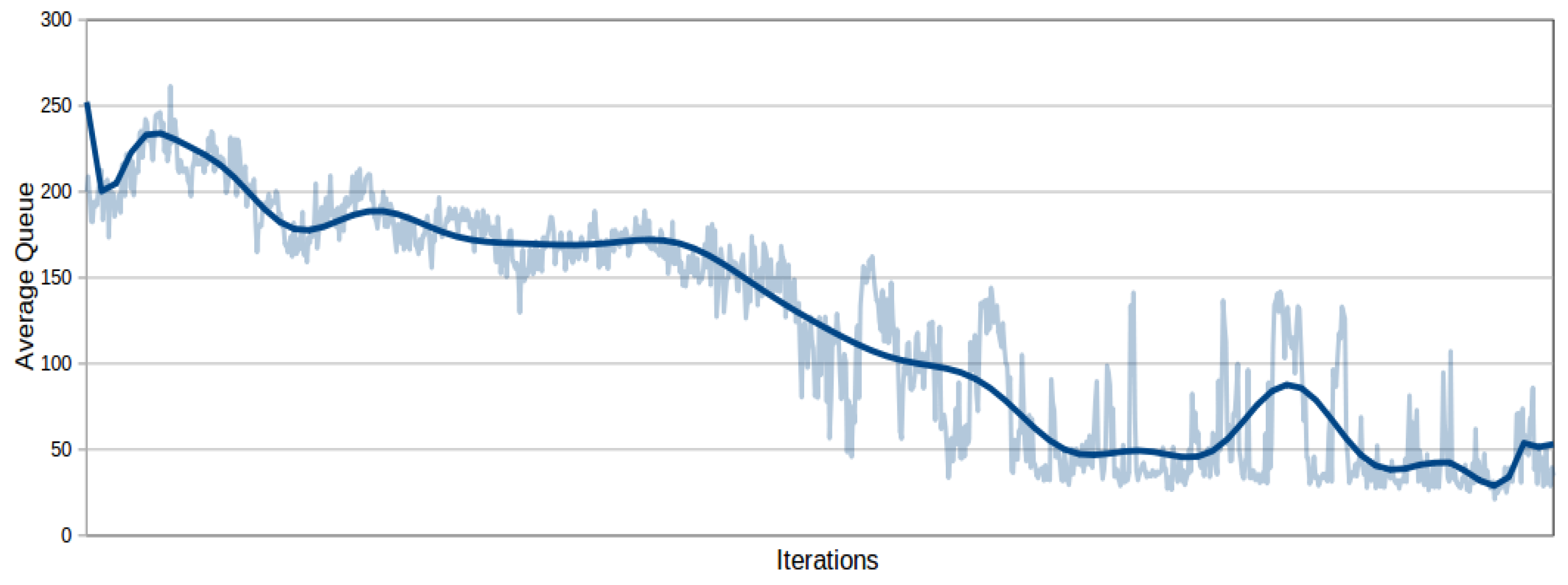
| 13 | This quantity includes the contributions of all the signalized intersections and is further averaged over the episode length; it will be referred to simply as "average queue" in the next sections. |
| 14 | Similarly to all the other experiments reported, every learning process has been repeated ten times, with similar results. |
| 15 | As highlighted in Section 2.3, the environment is partially observable (non-markovian). IQL-DNN and IQL-LR rely on the present information to forecast one step ahead so they are unable to exploit information from past time steps. |
| 16 | For a more in-depth exploration of MA2C and IA2C’s perception of the environment, please refer to Section 2.3. This section delves into the reasons why the Decision Process should be reformulated within the context of POMDP, which represents a broader class of Decision Processes compared to RDP. |
| 17 |
is the Kullback–Leibler divergence |

| Par. | Value | Description |
|---|---|---|
| 0.9 | spatial weighting factor | |
| 3600 [s] | total period of simulated traffic | |
| t | 5 [s] | interaction time between each agent and the traffic environment |
| 2 [s] | yellow time | |
| 2000,3600 [veh] | total number of vehicles | |
| 0.99 | discount factor, controlling how much expected future reward is weighted | |
| coefficient for used for gradient descent optimization | ||
| coefficient for | ||
| 40 | size of the batch buffer | |
| 0.01 | parameter to balance the entropy loss of policy to encourage early-stage exploration |
| Test | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Ave | Std |
|---|---|---|---|---|---|---|---|---|---|---|
| MA2C | 6.55 | 5.81 | 6.26 | 5.66 | 6.33 | 5.90 | 5.98 | 6.08 | 6.07 | 0.28 |
| IA2C | 8.38 | 8.43 | 8.36 | 8.15 | 7.8 | 8.09 | 8.7 | 8.75 | 8.33 | 0.30 |
| Greedy | 25.29 | 18.52 | 23.19 | 17.58 | 20.79 | 17.36 | 18.52 | 24.14 | 20.67 | 2.95 |
| Test | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Ave | Std |
|---|---|---|---|---|---|---|---|---|---|---|
| MA2C | 11.59 | 11.70 | 12.72 | 11.60 | 10.88 | 11.12 | 10.84 | 11.64 | 11.51 | 0.56 |
| IA2C | 18.89 | 18.88 | 20.72 | 19.55 | 17.56 | 19.75 | 18.06 | 19.25 | 19.08 | 0.92 |
| Greedy | 27.96 | 28.94 | 33.18 | 29.19 | 27.96 | 38.51 | 30.46 | 31.64 | 30.98 | 3.31 |
| Test | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Ave | Std |
|---|---|---|---|---|---|---|---|---|---|---|
| MA2C | 17.56 | 24.73 | 29.5 | 30.36 | 29.49 | 21.93 | 36.53 | 22.44 | 26.57 | 5.63 |
| IA2C | 61.22 | 79.24 | 70.99 | 73.06 | 70.06 | 101.67 | 57.67 | 29.47 | 67.92 | 19.16 |
| Greedy | 10.61 | 15.14 | 19.89 | 15.76 | 14.14 | 22.58 | 15.14 | 20.88 | 16.77 | 3.73 |
| Test | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Ave | Std |
|---|---|---|---|---|---|---|---|---|---|---|
| MA2C | 32.03 | 33.06 | 41.25 | 35.66 | 28.20 | 35.82 | 31.16 | 33.42 | 33.82 | 3.63 |
| Greedy: | 26.71 | 37.78 | 37.44 | 35.36 | 28.60 | 80.66 | 37.78 | 76.23 | 45.07 | 19.70 |
| Test | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Ave | Std |
|---|---|---|---|---|---|---|---|---|---|---|
| P. Random | 32.03 | 33.06 | 41.25 | 35.66 | 28.20 | 35.82 | 31.16 | 33.42 | 33.82 | 3.63 |
| Random | 31.54 | 35.45 | 59.39 | 33.29 | 28.73 | 49.50 | 34.56 | 40.45 | 39.11 | 9.71 |
| A. Costa | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Testing: 2000 veh. | Ave | Std | ||||||||
| MA2C | 6.55 | 5.81 | 6.26 | 5.66 | 6.33 | 5.90 | 5.98 | 6.08 | 6.07 | 0.28 |
| Greedy | 25.29 | 18.52 | 23.19 | 17.58 | 20.79 | 17.36 | 18.52 | 24.14 | 20.67 | 2.95 |
| Testing: 3600 veh. | Ave | Std | ||||||||
| MA2C | 9.20 | 8.9 | 28.54 | 20.69 | 9.16 | 8.73 | 8.86 | 9.09 | 12.90 | 7.05 |
| Greedy | 27.96 | 28.94 | 33.18 | 29.19 | 27.96 | 38.51 | 30.46 | 31.64 | 30.98 | 3.31 |
| Testing: 4000 veh. | Ave | Std | ||||||||
| MA2C | 133.3 | 141.6 | 143.6 | 140.2 | 131.9 | 144.0 | 140.3 | 138.3 | 139.1 | 4.17 |
| Greedy | 163.2 | 161.15 | 168.3 | 163.1 | 154.9 | 166.6 | 161.1 | 162.5 | 162.6 | 3.76 |
| Pasubio | ||||||||||
| Testing: 2000 veh. | Ave | Std | ||||||||
| MA2C | 17.56 | 24.73 | 29.5 | 30.36 | 29.49 | 21.93 | 36.53 | 22.44 | 26.57 | 5.63 |
| Greedy | 10.61 | 15.14 | 19.89 | 15.76 | 14.14 | 22.58 | 15.14 | 20.88 | 16.77 | 3.73 |
| Testing: 3600 veh. | Ave | Std | ||||||||
| MA2C | 32.03 | 33.06 | 41.25 | 35.66 | 28.20 | 35.82 | 31.16 | 33.42 | 33.82 | 3.63 |
| Greedy | 26.71 | 37.78 | 37.44 | 35.36 | 28.60 | 80.66 | 37.78 | 76.23 | 45.07 | 19.70 |
| Testing: 4000 veh. | Ave | Std | ||||||||
| MA2C | 255.9 | 240.7 | 241.6 | 267.4 | 261.6 | 255.4 | 248.8 | 250.7 | 252.7 | 8.65 |
| Greedy | 257.3 | 251.3 | 259.4 | 273.0 | 275.0 | 263.2 | 251.4 | 262.4 | 261.6 | 8.25 |
| A. Costa | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Testing: 2000 veh. | Ave | Std | ||||||||
| MA2C | 7.78 | 7.22 | 7.05 | 7.92 | 7.05 | 7.32 | 7.20 | 7.16 | 7.33 | 0.31 |
| Greedy | 25.29 | 18.52 | 23.19 | 17.58 | 20.79 | 17.36 | 18.52 | 24.14 | 20.67 | 2.95 |
| Testing: 3600 veh. | Ave | Std | ||||||||
| MA2C | 10.84 | 11.59 | 17.59 | 11.70 | 12.90 | 12.72 | 11.60 | 10.88 | 12.48 | 2.05 |
| Greedy | 27.96 | 28.94 | 33.18 | 29.19 | 27.96 | 38.51 | 30.46 | 31.64 | 30.98 | 3.31 |
| Testing: 4000 veh. | Ave | Std | ||||||||
| MA2C | 132.9 | 142.4 | 139.3 | 144.8 | 137.3 | 144.7 | 140.5 | 140.0 | 140.2 | 3.69 |
| Greedy | 163.2 | 161.15 | 168.3 | 163.1 | 154.9 | 166.6 | 161.1 | 162.5 | 162.6 | 3.76 |
| Pasubio | ||||||||||
| Testing: 2000 veh. | Ave | Std | ||||||||
| MA2C | 14.82 | 17.00 | 18.44 | 18.09 | 21.20 | 22.57 | 20.60 | 20.84 | 19.20 | 2.39 |
| Greedy | 10.61 | 15.14 | 19.89 | 15.76 | 14.14 | 22.58 | 15.14 | 20.88 | 16.77 | 3.73 |
| Testing: 3600 veh. | Ave | Std | ||||||||
| MA2C | 23.10 | 28.91 | 22.51 | 23.66 | 22.09 | 38.23 | 25.16 | 33.42 | 30.6 | 5.53 |
| Greedy | 26.71 | 37.78 | 37.44 | 35.36 | 28.60 | 80.66 | 37.78 | 76.23 | 45.07 | 19.70 |
| Testing: 4000 veh. | Ave | Std | ||||||||
| MA2C | 241.5 | 248.8 | 244.1 | 272.9 | 259.2 | 248.6 | 250.9 | 253.5 | 252.5 | 9.26 |
| Greedy | 257.3 | 251.3 | 259.4 | 273.0 | 275.0 | 263.2 | 251.4 | 262.4 | 261.6 | 8.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



