Submitted:
13 November 2024
Posted:
13 November 2024
You are already at the latest version
Abstract
We investigate the potential of embedding visualization tools, specifically Latent Lab, for supporting machine translation tasks with a focus on low-resource languages. Through empirical analysis of bilingual datasets comprising high-resource (Spanish, German, French) and low-resource (Dzongkha) languages, we explore how embedding visualization can facilitate the identification of cross-lingual token correspondences and dataset quality assessment. Our findings suggest that while embedding visualization tools offer promising capabilities for dataset preparation and quality control in machine translation pipelines, several technical modifications are necessary to fully realize their potential. We identify some challenges and propose concrete modifications to both the datasets and visualization tools to address these limitations.
Keywords:
1. Introduction
2. Our Approach
2.1. Dataset Selection
- -
- High-resource languages: Spanish, German, French
- -
- Low-resource language: Dzongkha
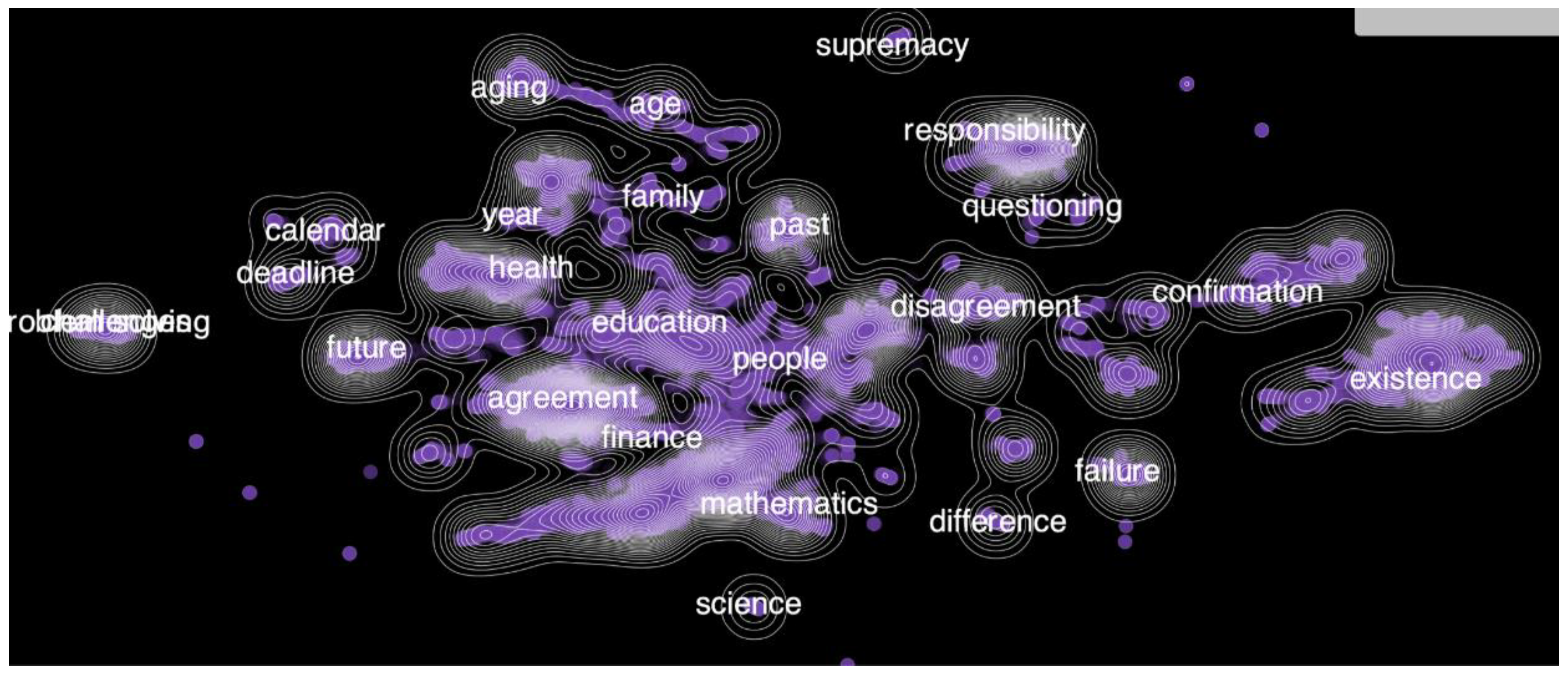
2.2. Embedding Generation and Visualization
3. Results and Analysis
3.1. Noise in Training Data
- -
- Entries consisting solely of punctuation marks (some of this may have been a kind of word art that was automatically flagged as Dzongkha-language text)
- -
- Presence of text in unrelated languages (e.g., Japanese text in Dzongkha dataset)
- -
- Misclassified non-linguistic content
3.2. Translation Quality
- -
- Incomplete translations of longer sentences
- -
- Inconsistent handling of proper nouns. We found that names in one language were replaced with a wholly different and unrelated name in their English translations, for example a German sentence promoting a company having the company name replaced with a different one in the English translation (the sentence “Deshalb haben wir livewire für menschen wie sie geschaffen” was translated as “We built LemonStand for people like you”, with the name “livewire” replaced with “LemonStand”).
- -
- Grammatically incorrect English translations, such as the sentence “aren’t they are they?” in the Dzongkha dataset. Errors like this did not lead to significant errors in Latent Lab’s visualization of the embedding space, however, they would cause problems in a future training step as described above, in which case proper noun tokens could get mismatched.
3.3. Distribution Imbalances
3.4. Technical Limitations
- -
- Latent Lab presently relies on the OpenAI API to generate embeddings, and we do not have control over the underlying embedding model
- -
- Limited access to full-resolution embedding vectors
- -
- Restricted front-end visualization capabilities
4. Proposed Improvements
-
Dataset Enhancement:
- -
- Manual construction of larger, cleaner datasets, eliminating noise
- -
- Comprehensive translation and its validation
- -
- Balanced content distribution, in particular ensuring that a variety of data is present in the set, and avoiding clusters of similar sentences
-
Technical Modifications:
- -
- Implementation of full-precision vector access
- -
- Enhanced visualization capabilities
- -
- Integration with custom embedding models
5. Conclusion and Future Work
Future Work Should Focus On:
- Implementing the proposed technical modifications
- Developing standardized protocols for dataset preparation
- Evaluating the impact of visualization-guided dataset improvements on translation quality
- Extending the approach to additional low-resource languages
References
- Google Translate Community Forum. "Google Translate has changed for the worse but why? Is there any way to fix it?" Available at: support.google.com/translate/thread/276974216.
- World Economic Forum. "Generative AI languages llm" Available at: weforum.org/agenda/2024/05/generative-ai-languages-llm/.
- Guo, Conia, et al. "Do Large Language Models Have an English Accent? Evaluating and Improving the Naturalness of Multilingual LLMs" arXiv:2410.15956v1. [CrossRef]
- Wendler, Veselovsky, et. al. “Do Llamas Work in English? On the Latent Language of Multilingual Transformers” https://arxiv.org/abs/2402.10588. [CrossRef]
- OPUS NLLB corpus. Available at: https://opus.nlpl.eu/NLLB/corpus/version/NLLB.
- MADLAD-400 Dataset. Available at: https://huggingface.co/datasets/allenai/MADLAD-400.
- Latent Lab. Available at: latentlab.media.mit.edu.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



