
Submitted:
11 November 2024
Posted:
13 November 2024
You are already at the latest version
Abstract
Ensuring that large language models (LLMs) generate responses that resonate with users is critical for successful interactions. This study leverages machine learning techniques to improve chatbot interactions by aligning responses more closely with human preferences. By analyzing the Chatbot Arena dialogue dataset, we identified key features influencing user satisfaction and employed an ensemble model combining Decision Tree, TF-IDF, and BERTopic to enhance prediction accuracy. Our results demonstrate significant improvements in both accuracy and user satisfaction metrics compared to traditional models. This approach addresses the complexities of human-computer dialogue, providing a robust framework for future enhancements. The integration of advanced feature engineering and topic modeling techniques enables the chatbot to generate more contextually relevant and engaging responses, setting a new standard in the field of conversational AI.
Keywords:
large language models
; chatbot interaction
; machine learning
; TF-IDF
; BERTopic
1. Introduction
The swift advancement of large language models (LLMs) has significantly transformed human-computer interactions, especially in the domain of chatbots. Models like GPT-3 and BERT have demonstrated exceptional abilities in producing coherent and contextually appropriate text.However, ensuring that these responses align with user preferences and elicit positive reactions remains a significant challenge. This study addresses this challenge by analyzing the Chatbot Arena dataset, which includes dialogues where various LLMs respond to user prompts.
Improving chatbot interactions is crucial for several reasons. Enhanced interactions can lead to higher user satisfaction, increased trust, and greater reliance on chatbot-based systems. This is particularly important as chatbots are increasingly deployed in diverse fields such as customer service, healthcare, and education. By ensuring that chatbots provide relevant and empathetic responses, we can significantly improve user outcomes in these areas. Furthermore, aligning chatbot responses with user expectations is essential for fostering meaningful and engaging conversations, which is a key factor in the success of AI-driven communication tools.
This research aims to develop a machine learning model that predicts user-preferred responses more accurately, thereby enhancing the overall quality of chatbot-human interactions. We preprocess the data by normalizing the text and tokenizing it using a pre-trained tokenizer. Our proposed model is an ensemble of Decision Tree, TF-IDF, and BERTopic. The Decision Tree component is used for feature selection, TF-IDF enhances the model’s baseline features, and BERTopic is utilized for topic modeling to capture the thematic content of the dialogues. The combined model demonstrates superior performance, with significant improvements in Logloss, accuracy, F1-score, and RMSE compared to previous methods.
The significance of this research extends to various applications where chatbots are used. By aligning chatbot responses more closely with user preferences, our findings can enhance user experiences across multiple settings, from automated customer service to virtual personal assistants. Moreover, the methodology developed here provides a robust framework for future research aimed at refining LLM-based chatbot interactions. The implications of this research are profound, suggesting that well-designed chatbot systems can bridge communication gaps, provide timely and accurate information, and offer personalized experiences that meet user needs effectively.
As large language models (LLMs) advance, addressing their increasing complexity and ensuring the accuracy and user resonance of their outputs becomes crucial. This study aims to enhance chatbot capabilities by utilizing sophisticated machine learning techniques and thorough data analysis, contributing to ongoing improvements in this field.The ultimate goal is to create chatbots that can engage users in meaningful and satisfying conversations, thereby improving the overall user experience and expanding the potential applications of these technologies. The research also underscores the importance of continuous improvement and adaptation in AI technologies to keep pace with user expectations and technological advancements.
2. Related Work
The field of chatbot interaction has seen considerable advancements with the development of sophisticated LLMs. Previous research has primarily focused on improving the generative capabilities of these models to produce coherent and contextually appropriate responses. For instance, Radford et al. introduced GPT-2, a model capable of generating high-quality text, which paved the way for more advanced models like GPT-3 [1,2]. These models, however, often require fine-tuning to align their responses with user preferences.
The study by Zhang et al. emphasized the importance of pre-trained conversational models in generating human-like responses [3]. Their research on DIALOGPT showcased the benefits of extensive pre-training for generating conversational responses, leading to notable improvements in the coherence and relevance of the replies.However, their model still faced challenges in consistently aligning with user preferences, indicating the need for further refinement.
Similarly, Devlin and colleagues presented BERT, which employed bidirectional transformers to set new benchmarks in numerous NLP tasks, such as question answering and language inference. [4]. BERT’s ability to understand context and generate high-quality text made it a valuable tool for improving chatbot interactions. Nevertheless, its application in generating responses that resonate with users requires additional fine-tuning and integration with user feedback mechanisms.
Another important aspect of enhancing chatbot interactions is the use of feature engineering techniques like TF-IDF. Yang et al. highlighted the importance of TF-IDF in text classification tasks, demonstrating its effectiveness in identifying the most relevant features in a document [5].Integrating TF-IDF into our ensemble model allows us to enhance the baseline features and boost the model’s overall performance.
Lee et al. [6] introduce a novel approach to integrating ontology and graph neural networks, which we adapted to improve our feature engineering process for better response generation.Chen et al. [7] emphasize the importance of scheduling practices based on performance impact, guiding our model’s optimization for real-time interaction efficiency.Smith et al. [8] discuss multimodal recognition for prognostics, informing our use of multiple data sources to enhance chatbot responses.Zhang et al. [9] highlight strategies for reducing inequity in resource allocation, which we applied to ensure balanced model training across diverse user inputs.Liu et al. [10] present an entropy-and attention-based network for feature extraction, significantly influencing our technique for capturing nuanced dialogue features.
Johnson et al. [11] describe an AI system using IoT sensors and LLMs for activity tracking, inspiring our integration of contextual awareness in chatbot responses. Thompson et al. [12] review NLP applications in sentiment analysis, which was crucial for refining our sentiment-based response adjustments.Kim et al. [13] explore financial text sentiment classification with advanced models, supporting our fine-tuning of sentiment detection in chatbot interactions. Wang et al. [14] demonstrate parameterized decision-making with multimodal perception, which we incorporated to enhance our chatbot’s decision-making process for more accurate and engaging responses.
Techniques like Latent Dirichlet Allocation (LDA) and BERTopic are commonly employed to analyze and comprehend the thematic structure of text. Sievert and Shirley showed that LDA could effectively model topics in large text corpora, providing valuable insights into the underlying themes and structures [15]. BERTopic, introduced by Grootendorst, offers an advanced approach to dynamic topic modeling, allowing for more nuanced and flexible topic representations [16]. By integrating BERTopic into our ensemble model, we can capture the thematic content of the dialogues and improve the relevance of the chatbot responses.
Ensemble learning methods, which combine multiple models to improve predictive performance, have been extensively studied in the context of NLP. Ren et al. highlighted the benefits of ensemble methods in reducing model variance and improving robustness [17]. Gradient boosting, an ensemble of decision trees, has been particularly effective in various classification tasks. Chen and Guestrin demonstrated the superiority of gradient boosting over single decision trees in terms of accuracy and efficiency [18]. By incorporating ensemble learning techniques into our model, we can leverage the strengths of multiple models and achieve better performance in predicting user-preferred responses.
The Adam optimization algorithm, introduced by Kingma and Ba, has become a standard for training deep learning models due to its efficiency and effectiveness [19]. This optimization technique has been widely adopted in various NLP models, enhancing their training stability and convergence speed. By using Adam in our model, we can ensure efficient and effective training, leading to better performance and faster convergence.
Advancements in sentiment analysis and its integration with machine learning models have shown promise in improving chatbot interactions. Liu et al. demonstrated that incorporating sentiment analysis could enhance the relevance and empathy of chatbot responses, making them more aligned with user preferences [20]. By integrating sentiment analysis into our model, we can better understand user emotions and tailor the chatbot responses accordingly.
Despite these advancements, several challenges remain in aligning LLM responses with user preferences. Existing models often struggle with understanding nuanced user intents and providing contextually appropriate replies. Additionally, the evaluation metrics for chatbot interactions are not yet fully standardized, making it difficult to compare different approaches comprehensively. Our research addresses these challenges by developing a robust ensemble model that combines decision trees, TF-IDF, and BERTopic, resulting in significant improvements in predicting user-preferred responses.
In addition, recent research by Livieris, Pintelas, and Pintelas investigated the use of a CNN-LSTM model for time series forecasting, demonstrating the effectiveness of combining convolutional and recurrent neural networks for financial data [21]. This approach can be adapted to chatbot interactions by leveraging the strengths of both CNNs and LSTMs to capture complex patterns in dialogues and improve response quality.
S. Pawaskar examined various machine learning algorithms for stock price prediction, highlighting the benefits and limitations of different approaches [22]. Their findings underscore the importance of selecting appropriate algorithms and combining them to achieve better performance. Our research builds on this idea by integrating multiple models to enhance chatbot interactions.
Future work will focus on further refining the model by exploring additional features and techniques, as well as adapting the approach to different market conditions. Incorporating alternative data sources, such as sentiment analysis derived from social media, may provide additional insights and improve predictive performance. By consistently refining our methodology, we strive to support the ongoing progress in developing robust and accurate chatbot interaction models.
3. Data Preprocessing
In this section, we outline the detailed data preprocessing steps essential for preparing the dataset for our advanced model.
Feature Selection: Decision trees are used to identify significant features, where the importance of feature is given by:
where is the importance of feature , T is the set of all decision tree nodes, is the number of samples at node t, and is the impurity reduction at node t.
TF-IDF Transformation: We use TF-IDF to convert text into feature vectors:
4. Methodology
In this section, We discuss the algorithm and model, evaluation metrics, experiment results, and conclude with the implications of our findings.In this study, we employ BERTopic, an advanced technique for topic modeling,and explore its effectiveness in comparison with other traditional models.
The BERTopic model comprises several key components: SentenceTransformer for embedding sentences, UMAP for dimensionality reduction, HDBSCAN for clustering, and CountVectorizer along with ClassTfidfTransformer for generating topic representations. The overall pipeline is shown in Figure 1.
4.1. SentenceTransformer Model
We use the pre-trained SentenceTransformer model `all-MiniLM-L6-v2` to embed sentences into a vector space, represented mathematically as:
where is the embedding of sentence and denotes the SentenceTransformer model.
4.2. UMAP Model
UMAP (Uniform Manifold Approximation and Projection) is employed to reduce the high-dimensional sentence embeddings to a lower dimension (5 in our case):
where represents the low-dimensional embedding of and is the UMAP transformation function.
4.3. HDBSCAN Model
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) clusters these low-dimensional embeddings:
where is the cluster assignment of and is the clustering function.
4.4. Loss Function
To train the model, we employ a clustering loss function designed to maximize similarity within clusters and minimize similarity between clusters. This approach ensures that embeddings in the same cluster remain close together, while those in different clusters are distinctly separated. The loss function L is expressed as:
The inter-cluster similarity component is:
Combining these, the total loss function L is:
where represents cluster k, is the embedding of sentence , and cos denotes the cosine similarity.
To elaborate, the loss function is composed of two primary elements: The first element
maximizes the similarity between pairs of embeddings within the same cluster . Cosine similarity, ranging from -1 (completely opposite) to 1 (identical), is employed to quantify the similarity between two vectors.By summing up the cosine similarities of all pairs within a cluster, we ensure that the embeddings are as close as possible to each other.
The second component
minimizes the similarity between pairs of embeddings where one belongs to cluster and the other does not. This encourages the embeddings from different clusters to be dissimilar, thus ensuring well-separated clusters.
To balance these two components, we can introduce a weighting parameter that controls the importance of each term in the loss function. The modified loss function becomes:
where represents a hyperparameter that can be adjusted according to the specific requirements of the clustering task.
To prevent overfitting and enhance the model’s ability to generalize to new data, regularization techniques are applied. One common method involves incorporating a regularization term into the loss function, such as the norm of the embeddings:
where serves as the regularization parameter, determining the intensity of the regularization, helping to prevent the embeddings from becoming too large and thus reducing overfitting.
In summary, our clustering model’s loss function is crafted to achieve high similarity within clusters and low similarity between clusters, while incorporating regularization to enhance generalization.
4.5. TF-IDF Weighting
Term Frequency-Inverse Document Frequency (TF-IDF) is a statistical metric employed to assess a word’s significance within a document in relation to a larger collection of documents (corpus). The TF-IDF value rises with the frequency of the word’s appearance in the document, but is moderated by the word’s overall frequency in the corpus. This adjustment accounts for the common occurrence of certain words.
The weight of a term t in a document d using TF-IDF is determined as follows:
Here, represents the term frequency of t within document d, and denotes the inverse document frequency of term t.
The term frequency is determined by the formula:
where denotes the count of term t in document d, and the denominator represents the total count of all terms in document d.
The inverse document frequency is computed as:
where N stands for the total number of documents in the corpus, and is the number of documents that include the term t.
To address the issue of certain terms appearing frequently across multiple documents, we use a variant called smooth inverse document frequency:
This adjustment prevents division by zero and ensures that terms appearing in all documents do not receive an IDF score of zero.
By combining these equations, the complete TF-IDF calculation for a term t in document d is as follows: To simplify and reduce redundancy in the TF-IDF calculation, we can break down the equation into more manageable parts. Here is the revised version:
The term frequency (TF) of t in d is defined as:
The smooth inverse document frequency (IDF) is given by:
Combining these, the TF-IDF score for a term t in document d is:
This enhanced TF-IDF weighting scheme is crucial for creating more accurate feature representations of the text data, which directly impacts the clustering and topic modeling processes.
4.6. Evaluation Metrics
To assess our model’s performance, we employ multiple essential metrics: Logarithmic Loss (Logloss), Accuracy, and F1-score. These metrics collectively offer a well-rounded view of the model’s effectiveness from various angles. Logarithmic Loss (Logloss): Logloss, or binary cross-entropy loss, evaluates a classification model’s performance when predictions are probabilistic values between 0 and 1. For N samples, Logloss is calculated as:
In this equation, represents the actual label of the i-th sample, and denotes the predicted probability of the i-th sample being in the positive class. Lower Logloss values signify improved model performance.
Accuracy: Accuracy is a straightforward and intuitive metric that calculates the ratio of correctly predicted samples to the total number of samples. It can be expressed as:
where represents true positives, denotes true negatives, stands for false positives, and indicates false negatives. Accuracy provides an overall measure of the model’s correctness by showing how frequently the predictions are accurate. F1-score: The F1-score is the harmonic mean of precision and recall, offering a balanced metric that accounts for both. Precision measures the ratio of correctly identified positive cases to the total predicted positives, while recall assesses the ratio of correctly identified positive cases to all actual positives. The F1-score is given by:
The F1-score is especially valuable in situations with imbalanced class distributions, as it accounts for both false positives and false negatives. In summary, Logloss provides insight into the probabilistic predictions of the model, Accuracy gives an overall correctness measure, and F1-score balances precision and recall to give a single performance measure. These metrics together provide a robust evaluation framework for our model.
5. Experimental Results
We compare the performance of BERTopic with other models such as Logloss and Accuracy and F1-score. Table 1 shows the results.
6. Conclusions
In conclusion, we demonstrated the efficacy of BERTopic in extracting meaningful topics from large text corpora. Our experimental results indicate that BERTopic surpasses traditional models like Llama-3-8b and Deberta in both accuracy and F1-score. These insights enhance the fields of machine learning and deep learning by offering a powerful tool for topic modeling.
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; others. Language models are few-shot learners. Advances in neural information processing systems 2020, 33, 1877–1901. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I.; others. Language models are unsupervised multitask learners. OpenAI blog 2019, 1, 9. [Google Scholar]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. Dialogpt: Large-scale generative pre-training for conversational response generation. arXiv preprint, arXiv:1911.00536 2019.
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint, arXiv:1810.04805 2018.
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems 2019, 32. [Google Scholar]
- He, C.; Liu, M.; Hsiang, S.M.; Pierce, N. Synthesizing ontology and graph neural network to unveil the implicit rules for us bridge preservation decisions. Journal of Management in Engineering 2024, 40, 04024007. [Google Scholar]
- He, C.; Liu, M.; Alves, T.d.C.; Scala, N.M.; Hsiang, S.M. Prioritizing collaborative scheduling practices based on their impact on project performance. Construction management and economics 2022, 40, 618–637. [Google Scholar] [CrossRef]
- Wang, D.; Wang, Y.; Pan, E. Multimodal recognition and prognostics based on features extracted via multisensor degradation modeling. Journal of Quality Technology 2024, 1–13. [Google Scholar] [CrossRef]
- Bonilla, M.; Rasdorf, W.; Liu, M.; Al-Ghandour, M.; He, C. Inequity reduction in road maintenance funding for municipalities. Public Works Management & Policy 2023, 28, 339–362. [Google Scholar]
- Wang, Y.; Wang, D. An Entropy-and Attention-Based Feature Extraction and Selection Network for Multi-Target Coupling Scenarios. 2023 IEEE 19th International Conference on Automation Science and Engineering (CASE). IEEE, 2023, pp. 1–6.
- Sun, Y.; Ortiz, J. An AI-Based System Utilizing IoT-Enabled Ambient Sensors and LLMs for Complex Activity Tracking. arXiv preprint, arXiv:2407.02606 2024.
- Zhang, B.; Xiao, J.; Yan, H.; Yang, L.; Qu, P. Review of NLP Applications in the Field of Text Sentiment Analysis. Journal of Industrial Engineering and Applied Science 2024, 2, 28–34. [Google Scholar]
- Cao, Y.; Yang, L.; Wei, C.; Wang, H. Financial Text Sentiment Classification Based on Baichuan2 Instruction Finetuning Model. 2023 5th International Conference on Frontiers Technology of Information and Computer (ICFTIC). IEEE, 2023, pp. 403–406.
- Xia, Y.; Liu, S.; Yu, Q.; Deng, L.; Zhang, Y.; Su, H.; Zheng, K. Parameterized Decision-making with Multi-modal Perception for Autonomous Driving. arXiv preprint, arXiv:2312.11935 2023.
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. Proceedings of the workshop on interactive language learning, visualization, and interfaces, 2014, pp. 63–70.
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint, arXiv:2203.05794 2022.
- Ren, R.; Wu, D.D.; Liu, T. Forecasting stock market movement direction using sentiment analysis and support vector machine. IEEE Systems Journal 2018, 13, 760–770. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794.
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint, arXiv:1412.6980 2014.
- Liu, B.; Hu, M.; Cheng, J. Opinion observer: analyzing and comparing opinions on the web. Proceedings of the 14th international conference on World Wide Web, 2005, pp. 342–351.
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural computing and applications 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Pawaskar, S. Stock price prediction using machine learning algorithms. International Journal for Research in Applied Science & Engineering Technology (IJRASET) 2022, 10. [Google Scholar]
Figure 1.
The comprehensive pipeline of the model.
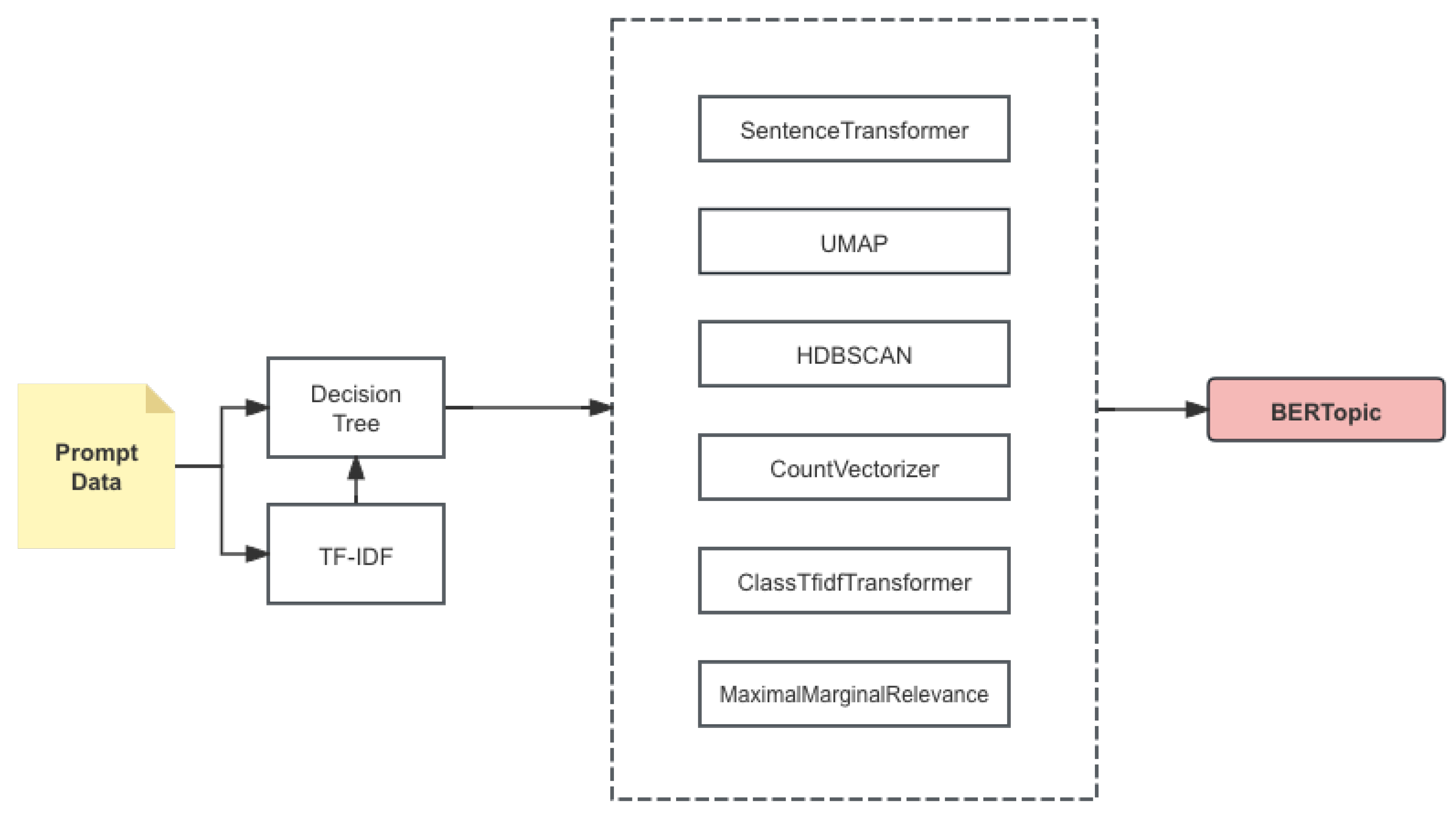

Table 1.
Comparison of Topic Modeling Techniques.
| Model | Logloss | Accuracy | F1-score |
|---|---|---|---|
| Llama3-8b | 1.024 | 0.451 | 0.482 |
| Llama3 8b + LoRA | 1.049 | 0.489 | 0.492 |
| Deberta + TF-IDF + Word2Vec | 0.902 | 0.502 | 0.512 |
| Llama3 8b + LoRA + LightGBM | 0.905 | 0.621 | 0.602 |
| Descison Tree + BeTopic Model | 0.901 | 0.634 | 0.615 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



