
Submitted:
04 November 2024
Posted:
05 November 2024
You are already at the latest version
Abstract
Natural Language Understanding (NLU) includes temporal text understanding, which can be complex and encompasses temporal common sense understanding. There are many challenges in comprehending common sense within a text. Currently, there are a limited number of datasets containing temporal common sense in English, and there is an absence of such datasets specifically for the Arabic language. In this study, an Arabic dataset was constructed based on an available English dataset. This dataset is considered a valuable resource for the Arabic community. Consequently, different multilingual pretrained language models (PLMs) were applied to both the English and new Arabic datasets. Based on this, the effectiveness of these models in Arabic and English is compared and discussed. After analyzing the errors, a new categorization of errors was proposed. Finally, the ability of the PLMs to understand the input text and predict temporal features was evaluated. Through this detailed categorization of errors and classification of temporal elements, this study establishes a comprehensive framework aimed at clarifying the specific challenges encountered by PLMs in temporal common sense understanding (TCU). This methodology underscores the urgent need for further research on PLMs’ capabilities for TCU tasks.
Keywords:
Common Sense
; Temporal Understanding
; Arabic Temporal Understanding
; Natural Language Understanding
; Reading Comprehension
; Transformers
; Transfer Learning
1. Introduction
Temporal text refers to a text that contains temporal features (time, event, and relation). The presence of these features can be explicit or implicit, making the task more challenging. Moreover, comprehending temporal common sense is crucial for understanding the inherent temporal aspects of the text. The term ‘common sense’ can be defined as "The basic level of practical knowledge and reasoning concerning everyday situations and events that are commonly shared among most people" [1]. Although humans possess this ability as part of their cognitive intelligence, it is challenging for machines to acquire it. For example, understanding temporal common sense enabling people to understand the order in which events occur. Humans innately understand that certain events precede others, such as falling ill before dying. However, machines face difficulties in acquiring this understanding as they require complex algorithms, and programming to infer the chronological sequence of events. In addition to event ordering, temporal aspects include the event duration. Humans find it relatively easy to predict the duration of activities, such as eating, opening a door, or walking. However, the limited datasets about the temporal understanding or extraction currently available primarily involve unusual events or unusual durations, posing a significant challenge for machines to predict the duration of routine events. There are more examples, including the frequency of the event, and humans know that lunch happens once a day. Additional temporal aspects will be discussed later in this study, including the typical time that the events occupied and the situation of the event. Therefore, the task of temporal common sense understanding (TCU) is complex. Figure 1 illustrates an example of a TCU challenge and how the model can fail to validate the correct answer.
The scope of this research is TCU, and it is evaluated as textual reading comprehension, which employs a multiple-choice format. Using the contextual information provided, a Multiple-Choice Reading Comprehension (MRC) system is responsible for selecting an appropriate response from a range of possible answers. To satisfy the requirements of the MRC task, which entails choosing the correct answer from a range of candidate alternatives, the suggested model must determine which answer is correct. In this study and based on the dataset, the model is asked to validate the plausibility of the answer, and each question might have more than one plausible answer. The effectiveness of deep learning in comprehending temporal common sense has been measured using a variety of models.
The model will take three inputs (context, question, and answer), and the model should learn to predict whether this answer is plausible. This model uses examples of textual training, where c is a context that is a passage of text, q is a question relevant to the context c, and a is an answer to question q. The model aims to learn a predictor l, which takes a context c, a corresponding question q and a candidate answer a as inputs and predicts the score that will be high if the answer is likely plausible and low otherwise. This predictor model could be formulated as the following formula:
This formula is applied so the model can be applied to various MRC tasks with multiple correct answers.
Challenges
The challenges will be classified into three main categories:
-
Implicit Temporal Features: Temporal reasoning is complicated because some events are vague. Therefore, the task of extracting and annotating the temporal feature will be difficult [2]. For example, the sentence "She visited her friend after finishing her work," is ambiguous since the word after does not state whether the visit actually happened immediately, a few hours later, or even the next day. According to that, the uncertainty about the precise timing of events makes it challenging for the model to accurately process temporal information.Implicit temporal features are another challenge. For instance, the temporal sequence in the sentence "Sara finished her breakfast and left for school" must be inferred because it suggests—without explicitly stating that Sara left for school soon after finishing her breakfast. Similarly, the statement "He often travels for work" suggests a regularity of events without providing information about how frequently the travels take place. The process of temporal reasoning is made more difficult by these implicit temporal cues, which force models to infer the frequency and sequence of events from the context.From the MC-TACO dataset [3], if the question concerns an event’s duration, all candidate responses belong to a duration type. The challenge is how to validate whether there is a logical duration for this event. Because each candidate’s answer has a different duration, categorizing the answers based on the temporal type of the question—for instance, duration—will not eliminate answers that do not fit into the category. Thus, the model should acquire temporal common sense knowledge. For example, the model should know that 30 seconds would be an illogical illness duration; that is, in this case, 30 seconds would be a valid duration but not a logical answer. Acquiring this knowledge is expensive and difficult.
- Limited Data: While there are few datasets available in English, there is currently no dataset specifically designed for TCU in Arabic. One of the most widely used English datasets is MC-TACO, which is designed to evaluate models on TCU. MC-TACO is small, lacks a specific training split, and consists of only evaluation and test sets. In addition, the evaluation set is quite small, contains only 3,783 question-answer pairs. Moreover, to the best of our knowledge, there is no dataset in English that is designed to cover all temporal featuers except MC-TACO. This scarcity of datasets significantly affects the development of models for TCU.
-
Lack of Knowledge: According to existing research, current language models lag behind human performance in the task of common sense understanding. For example, this is evident from the MC-TACO leaderboard. Numerous studies have shown that this performance gap can be overcome by relying on external sources that encapsulate the common sense knowledge [1,4,5,6]. For instance, as previously discussed, temporal reasoning involves understanding sequences of events, durations, and implicit time-related features, which are often not fully captured by existing datasets [5,6]. As a result, models struggle to make accurate predictions. Therefore, insufficient data restricts the improvement of these models.Existing models still struggle to understand the varying lengths of the different events. As, the duration of a verb describing an event can change depending on context. For example, the duration of the verb taking, the act of "taking a vacation" generally takes longer than "taking a shower". The latter can usually last for only a few minutes, whereas the former can last for several days or even weeks [3]. To address this issue, there should be a source of knowledge to help the model accurately capture this temporal context. The existing corpus that can be used for this purpose is skewed towards uncommon or unexpected event durations and rare events [3]. For example, the duration of "opening a door" is not mentioned unless it is longer than usual. Determining the duration of various events manually is expensive and time consuming. Addressing this gap requires constructing comprehensive knowledge bases (KBs) specifically designed for temporal information, or alternatively, developing more advanced models and algorithms that can learn and infer temporal common sense from the limited data available.
1.1. List of Contributions
This study makes several significant contributions to the field of Temporal common sense Understanding (TCU) using deep learning models.
- Constructing of a TCU Arabic Dataset1: An Arabic dataset is constructed to serve the TCU task. This construction will be highly impactful for the Arabic community and addresses the absence of such a resource. The dataset is based on an existing English dataset.
- Benchmarking for Temporal Understanding: To evaluate the ability of PLMs in understanding temporal features, a benchmark for temporal understating was established.
- Applying Multilingual Pre-Trained Language Models (PLMs): Examining the effectiveness of different multilingual PLMs to the MC-TACO (the original English dataset) and the Arabic dataset. Each model was assessed in terms of each temporal aspect.
- Analyzing Errors: By analyzing the errors, a new classification is suggested to identify specific issues, which will help improve the understanding of PLMs.
The rest of this paper is structured as follows: Section 2 reviews and discusses related works. The construction of an Arabic dataset for the TCU task is presented in Section 3. Section 3 also provides a detailed overview of the dataset statistics. Section 4 presents the evaluation metrics used in this study. In Section 5, the applied PLMs are explored. A detailed analysis of the results is presented in Section 6. Consequently, a methodology for evaluating the effectiveness of multilingual PLMs by analyzing and categorizing errors is proposed in Section 7. To understand the challenges affecting PLMs’ performance in TCU, a benchmark for assessing PLMs in temporal classification was presented in Section 8. Finally, Section 9 provides the conclusion of the study and suggests potential directions for future research.
2. Related Works
The first application of PLM to the MC-TACO dataset was in 2019, when Zhou et al.[3] applied BERT as a baseline model. The performance of BERT [7] fell significantly below human performance levels [3]. This led to the application of unit normalization for the inputs as a pre-processing step, resulting in slight improvements. Subsequently, RoBERTa [8] was applied without unit normalization or any pre-processing, and its performance was better than that of BERT with unit normalization [3].
Duration normalization was also proposed as a pre-processing step to improve the results. In 2020, Kaddari et al. [9] applied duration normalization with T5 [10]. The result of the proposed model outperformed other models without duration normalization, although the improvement was marginal compared with T5 without the preprocessing step. The state-of-the-art performance was achieved by applying DeBERTa-Large [11] without any preprocessing. It outperformed all models by a significant margin. This indicates that PLMs may be effective even without rule-based processing. Rule-based preprocessing, such as unit or duration normalization, is language-dependent, prone to errors, and labor-intensive due to manual coding.
Few studies have attempted to build specific language models for the TCU task, as proposed after the observed shortcomings of existing PLMs:
- TACOLM: This study highlights the inadequacies of PLMs in addressing TCU tasks, particularly their failure to recognize and learn from temporal dimensions. The study proposed an additional pre-training step designed to enrich models with temporal-related data, using two methodologies to construct the dataset for this enhanced pre-training phase [6].
- A Third Language Model for TCU: This model also utilized a continual training approach, introducing a different target masking strategy and employing various temporal-related datasets. Unlike TACOLM and ECONET, this study did not construct its dataset but used pre-existing temporal-related datasets, offering comprehensive coverage of all temporal dimensions [14].
Virgo et al.[5] demonstrated that recent PLMs are yet to reach human performance levels in an Event Duration task. Limited training data, covering only a finite number of events and their attributes, highlight the need to incorporate external event duration information to enhance effectiveness. A new QA dataset for the event duration was constructed from an existing dataset and used for intermediate tasks in the adaptive fine-tuning approach. While Kimuar et al. [14] used the existing dataset as is, Virgo et al. [5] focused solely on event duration, whereas [14] studied all aspects of Temporal Understanding.
Several adaptive fine-tuning techniques were explored for the English MC-TACO dataset [15,16] and adversarial fine-tuning [17]. Despite exploring alternative training methodologies and constructing specialized datasets, the outcomes from these studies still fall short of the performance levels achieved by more advanced PLMs, such as DeBERTa [11]. According to the leaderboard 2, these techniques perform worse than the DeBERTa-Large model [11], which uses the standard fine-tuning paradigm.
Although all suggested techniques have been surpassed by DeBERTa-v3, DeBERTa’s performance still falls significantly short of human performance on the same task. This gap emphasizes the complexity of temporal reasoning in NLU, and the ongoing need for research to refine and enhance the capabilities of language models in this critical area.
3. Dataset
TCU is an essential part of the larger field of natural language common sense comprehension. Despite the importance of the TCU, the availability of resources dedicated to this aspect in English is limited. Remarkably, there are no datasets in Arabic tailored to this specific domain. Currently, the only Arabic dataset that addresses common sense understanding is essentially an English translation that concentrates on common sense validation [18]. This disparity severely restricts the ability to assess the effectiveness of transformer-based models in understanding Arabic temporal common sense. The creation of a dataset is essential for the goals of this study, which includes evaluating and enhancing the effectiveness of transformer-based models in Arabic TCU.
Despite the challenges of the construction, such dataset promises to be a valuable addition to Arabic resources, allowing for a more sophisticated and culturally appropriate understanding of temporal common sense in Arabic. The construction of an Arabic TCU dataset is considered to have a crucial impact not only in the field of TCU, but also in the Arabic community. As this dataset would also greatly advance the Arabic Natural Language Understanding (NLU) by serving as a foundational resource for further research, in addition to the main goal which is to evaluate transformer-based models in the Arabic linguistic context.
3.1. Dataset Construction
The construction of a dataset from scratch is particularly resource-intensive. This challenge is compounded in the context of Arabic, where there is a conspicuous absence of temporal-related datasets and a general scarcity of resources. Given these constraints, the decision to adapt an existing dataset from English to Arabic was motivated by both the practicality and the unique requirements of the focus of this study.
The MC-TACO dataset [3] was selected for translation into Arabic because several key factors that align with the research objectives. First, MC-TACO is recognised, to the best of our knowledge, as the only data set that encompasses a wide range of temporal characteristics, making it exceptionally relevant for our study of TCU. Second, the dataset’s straightforward structure and use of simple sentences render it particularly amenable to translation, ensuring preservation of semantic integrity during this process.
MC-TACO was designed as a multiple-choice reading comprehension (MRC) task. The input of the model from the dataset consists of three components: an abstract or context, a question, and a corresponding answer. The model requires the output of a prediction score based on judgment of the plausibility value of the answer. The score should be close to one if the candidate answer is valid. The relatively concise nature of the information provided in the dataset, often encapsulated in three sentences, makes it feasible to employ a translation tool for the initial construction process. Google Translate was utilized for this purpose, with subsequent translations subjected to a thorough review by two native Arabic speakers specialized in proofreading to ensure accuracy and natural language use. The reviewers, who examined all the inputs individually, were from different Arabic countries, specifically Saudi Arabia and Morocco, as cultural differences might affect the understanding of the translated results. Finally, the overall results were reviewed to ensure consistency and accuracy.
The dataset encompasses approximately 13K question-answer pairs spanning five temporal dimensions, thereby offering a rich resource for exploring various aspects of temporal reasoning. The temporal dimensions included in MC-TACO are explained below.
- Event duration: How long does an event last?
- Temporal ordering: Typical order of events.
- Typical time: When did an event occur?
- Frequency: How often do events occur?
- Stationarity: whether a state is maintained long-term or indefinitely.
Table 1 presents statistical information for both the English and Arabic versions of the dataset. Table 2 presents statistics for the temporal features. Furthermore, Figure 2 illustrates the distribution of question-answer pairs across different temporal aspects. The dataset predominantly consists of question-answer pairs related to event duration, with frequency being the second most common aspect. On the other hand, the coverage of the stationarity feature is notably low, comprising only 870 pairs (7%).
A sample of the data set is presented in Figure 3. This figure provides a comprehensive overview of different temporal categories, illustrating an example of each one. Additionally, this figure includes a question along with its corresponding set of answers. The correct answers are highlighted in bold.
4. Evaluations
Although the dataset can be viewed as a binary classification task, where accuracy is a commonly used metric, it may not be the most appropriate metric in this case. The distribution of labels for the candidate’s responses is approximately one ‘no’ to two ‘yesses’, implying that a high level of accuracy (or a low error rate) can be achieved even by a model without real skill that simply predicts the majority class. Consequently, the accuracy can be a misleading metric for this type of dataset. Therefore, based on Zhou et al. [3], the two metrics used are the F1 score and exact match.
The F-measure is a single metric that trades the precision for recall. This factor is the weighted harmonic mean of the precision and recall, where the weight is denoted by variable . The default balanced F-measure, where = 1, is commonly written as , which is short for .
Exact Match (EM) is a strict version of accuracy, in which all labels must match exactly for the sample to be correctly classified. For MC-TACO, the model must correctly predict all answers to each question to be considered a correct prediction.
5. Models
Various experiments were conducted using different PLMs. Multilingual PLMs and Arabic versions of BERT were ap- plied to understand the Arabic dataset. Subsequently, a detailed comparison and analysis of the model results are presented. Two Arabic versions of BERT were adopted: AraBERTv2 and CAMeLBERT. AraBERTv2 is the latest version of AraBERT that was initially introduced by Antoun et al. [19]. This model was selected over other Arabic versions of BERT due to its superior performance, as evidenced by the model card on Hugging Face 3 and research conducted by Alammary et al. [20]. This study involved text classification specifically for the Arabic language. In this study, AraBERT-v2 exhibited better outcomes than XLM-RoBERTa. The CAMeLBERT model [21] 4 was not included in the analysis conducted by [20]. It would be valuable to compare this model with the current leading Arabic BERT model. Furthermore, the performance of AraBERTv02 is better than that of CAMelBERT, according to [21]. However, CAMeLBERT was the second-best model among all Arabic versions of BERT, based on research conducted by CAMeL Lab [21]. Therefore, it is worthwhile to compare these two models for this task. CAMeLBERT has different versions. CAMeLBERT-msa was selected among all others because the target dataset was written in MSA Arabic. Notably, AraBERT and CAMeLBERT are different from multilingual models because they are tailored to Arabic. AraBERT, CAMelBERT and multilingual BERT all have the same architecture because they are derived from the original BERT with some modifications. According to Inoue et al. [21], pretraining data size may not be an important factor in fine-tuning performance.
In this study, multilingual BERT was selected because BERT was the baseline model for the original dataset, and numerous versions of BERT have been designed specifically for the Arabic language. Furthermore, mDeBERtav3 and XLM-RoBERTa were specifically chosen because of the effectiveness of their original models on the English dataset.
6. Results
AraBERT and CAMeLBERT were pretrained only on the Arabic dataset. Therefore, Arabic versions of BERT were expected to outperform its multilingual counterpart and multilingual PLMs. The results of these experiments are presented in Table 3.
To assess the stability and variability of the system, additional runs were conducted, each with a different random seed. Three runs were conducted. Each run was independent, and its random processes, including data shuffling and GPU initialization, were influenced by its specific seed. From these three runs, the performance metrics were observed, and the standard error was calculated to deduce how much performance varied with the change in seeds. Finally, the reported performance metrics were based on running the system with a default random seed, which was equal to 42.
Based on the results presented in Table 3, multilingual DeBERTa-v3 achieved the best performance, followed by XLM-Roberta Large. Although AraBERTv02 and CAMeLBERT were trained on Arabic datasets, mDeBERTa-v3 outperformed them significantly. This may have occurred because the target task required common sense reasoning, suggesting that more advanced models like mDeBERTa-v3 could be necessary, explaining the performance discrepancy. Factors which can be attributed to the superior performance of mDeBERTa-v3 compared to other models are as follows:
- The depth of the architecture in XLM-RoBERTa-large has 24 layers, twice the number of layers as mDeBERTa-v3, XLM-RoBERTa base, and mBERT, which all have 12 layers. This difference could indicate that the number of layers might not produce the best performance.
- Although BERT and XLM-RoBERTa employ self-attention mechanisms, mDeBERTa-v3 may incorporate more advanced attention mechanisms, disentangled attention, specifically designed to capture precise linguistic dependencies. Consequently, this model can surpass the others in tasks requiring extensive linguistic analysis, such as the TCU.
- This is also evidenced by applying English DeBERTa-v3 Large to MC-TACO, which achieved state-of-the-art results. The success of DeBERTa-v3 in TCU demonstrates the effectiveness of transfer learning, which overcomes the problems of limited datasets and extensive labeling by leveraging the large knowledge base acquired during the pretraining process.
This study compared the performances of AraBERT-v02 and CAMeLBERT, both designed for the Arabic language. AraBERT-v02 showed better results than CAMeLBERT, possibly due to the former’s vocabulary size, which is twice that of CAMeLBERT.
Figure 4 presents the outcomes of the various models applied to the Arabic dataset. The F1 score is displayed for each temporal aspect, facilitating an assessment of the effectiveness of each model. The figure reveals several significant findings, which are summarized below:
- The strength of all models is the stationarity aspect. All the models scored above 74 in this aspect. mDEBERTa-v3 and XLM-RoBERTa large scored the same. Upon analyzing the data, it appears that this particular aspect may be less difficult than other aspects. This is mainly because the majority of the responses for this feature were either yes or no. Furthermore, certain responses are evidently unrelated and are easily dismissed by the models.
- The event duration was the most challenging feature for all models, with a mean discrepancy of 10 units less than the overall F1-score of each model. Due to the challenging nature of this aspect, some studies, including Virgo et al. [5], have suggested that an external source is required.
- Overall mDeBERTa-v3 is the most effective model, but it did not outperform all models in all aspects, and mDeBERTa-v3 demonstrated superiority in event duration and frequency.
- AraBERt-v02 and CAMeL-msa demonstrated superior performance compared with all other models in the Typical Time feature. Notably, the overall effectiveness of CAMeL was lower than those of the other models. Thus, it was necessary to identify the distinguishing factor of the typical time feature making the models trained on Arabic datasets perform better than other models. This might be because the typical time is closely related to the nature of the culture, making models fully trained on Arabic datasets more effective.
- mBERT had the lowest performance in all categories.
Although AraBERT and CAMeL models have different performance levels, it is important to analyze the differences in their predictions because they have numerous similarities in the model architecture and pretraining datasets. The distribution of the prediction percentages across the different temporal features is illustrated in Figure 5. The prediction of the probable order of events varied significantly between the two models, with most predictions differing by approximately 30%. Moreover, the percentage of identically incorrect predictions was the highest. The most similar predictions were those of frequency and event duration.
7. Error Analysis
The task undertaken by the TCU presents significant challenges, as evidenced by the results of the models in the previous section. This led to a manual investigation of the inputs to understand the challenges. Thus, by studying the MC-TACO dataset, certain questions pose difficulties, even for humans, which is substantiated by the dataset’s human performance metrics (87%). Consequently, errors encountered in this context can be classified into two main categories: human challenging errors, and linguistic and task complexity errors. Human challenging errors are instances where both the model and humans struggle to validate the given answers. On the other hand, linguistic and task complexity errors denote situations in which the model fails to grasp the intricacies of language use or validation of answer plausibility. The following sections present each type of error in detail and provide a more detailed analysis.
7.1. Human Challenging Errors
As previously mentioned, the first type of error, characterized by their complexity and the challenges they pose to both humans and models, can be approached with a degree of acceptance or tolerance compared to the second type. These errors fall into "uncertain zone," where they are neither fully correct nor entirely incorrect. For instance, from MC-TACO, consider the question related to the duration of an illness based on a provided context: "Dürer’s father passed away in 1502, and his mother died in 1513. How long was his mother ill?" one of the candidate’s answers is that she was ill for 30 years. Even though the gold label for this answer is "no," meaning that the answer is incorrect and considered as unlikely duration for illness, it is also possible to argue "yes," indicating that a 30-year duration could indeed represent a period of illness. This example highlights the subjective nature of certain inputs, emphasizing the complexity and potential ambiguity inherent in evaluating the validity of the answers provided for the TCU task.
The human performance metric displayed on the leaderboard of the MC-TACO, specifically the F1 score, was 87.1%, and the Exact Match (EM) rate was 75.8%. However, it is important to note that these measures, derived from a subset of the dataset, may not fully encapsulate accuracy. Despite this limitation, it can be assumed that challenging human errors account for approximately 22% of the total error rate, providing insight into the extent of the challenges posed by these types of questions.
Capturing inputs considered challenging for humans within a test set comprising 9,442 items is an arduous task. Implementing a voting mechanism across the entire test set could offer insight into the difficulty level of each question. However, the benchmark was derived from a sample of the total data [3], suggesting that a rough sampling of instances falling into this challenging category would be both practical and acceptable. This approach allows for the identification and analysis of particularly complex cases without the need to exhaustively review every item in the dataset, thereby providing a feasible method for gauging the extent of challenging human errors within the dataset.
Additionally, it is important to recognize that some answers may be culturally dependent, meaning that for certain cultures, an event or concept might be considered plausible, whereas for others, it might not. This variability introduces another layer of complexity, classifying instances as challenging human errors. This cultural dimension underscores the necessity of incorporating a diverse perspective when evaluating answers, as it highlights the subjective nature of understanding and interpreting information. Recognizing the influence of cultural context on what is deemed correct or incorrect is crucial for accurately assessing the scope of human challenging errors within the dataset. For instance, within the dataset, a question regarding the appropriate time for an interview illustrated the impact of cultural differences. In Saudi culture, interviews can be scheduled on Sundays, a practice that might differ from norms in other cultures, where the workweek typically begins on Monday. Furthermore, the start time for schools in Saudi Arabia is earlier than that in many other countries, reflecting another aspect of cultural variance. In addition, during Ramadan, eating late at night is very common to accommodate the fasting schedule. This contrasts with the dining habits of cultures that do not observe Ramadan. These examples highlight how cultural contexts significantly influence the interpretation of what constitutes a correct or plausible answer, thereby contributing to the categorization of such instances as challenging human errors within the dataset.
Some research has focused on the grounding of time expressions as a culturally dependent aspect. One notable study by Shwartz [22] analyzed time expressions across 27 languages, although Arabic was not included. This study aimed to define how the conceptual range of time periods, such as morning and noon, can vary significantly across different cultures. Additionally, it explores the impact of these cultural variations on PLMs. The findings of such studies are crucial because they highlight the challenges PLMs accurately understand and generate context-appropriate responses to time-related queries [22]. These variations in the perception of time can affect a model’s ability to provide correct and culturally sensitive answers, underscoring the importance of incorporating diverse cultural understanding into the development and training of language models.
Accordingly, the human challenging errors can have two subcategories: "Cultural Temporal Interpretation" or "Subjective Event Understanding".
In the exploration of PLMs navigate the complexities of culturally dependent temporal expressions and subjective understandings, it is crucial to examine the specific instances where errors occur. The following examples provide a comprehensive overview of various error types identified in this category, showcasing sample inputs alongside the expected responses and comparing these with the outputs generated by the PLMs. This comparative analysis not only highlights the discrepancies between expected and actual responses, but also offers insights into the models’ underlying challenges with cultural nuances and subjective interpretations. This examination can shed light on areas of improvement in PLMs the TCU task. Moreover, creating a dataset that can address this issue has great potential.
Examples
Table 4 presents the various scenarios that can be classified as Subjective Event Understanding. The analysis of each example is discussed in the following list, ordered according to the same sequence as the examples in the table.
- All the PLMs, in English and Arabic, predicted no. This outcome is indicative of a challenge for PLMs as well as touching upon human cognitive processes. The specificity of the duration-7.5 minutes-represents atypical time frame that is not commonly associated with the activity described.
- The response of all the PLMs, in English and Arabic is yes. This input could be considered human challenging, as it involves understanding the legislative process and the realistic pace at which laws and initiatives are typically passed, which varies significantly across different jurisdictions and over time.
- Not all the PLMs are able to predict the correct label. The scenario involving steam rising from a wet road after a summer rainstorm, with the duration specified as "steam rises for 30 minutes off a wet road before a summer rainstorm," presents a nuanced challenge that tests both temporal reasoning and contextual understanding. The question is inherently human challenging, not just because of the temporal aspect—quantifying the duration steam rises—but also because of the contextual misunderstanding in the provided response. The mention of steam rising "before" a rainstorm contradicts the common observation and understanding that steam typically rises "after" rain has fallen and heated by the warm road, creating a visual phenomenon observed by many.
Table 5 presents various scenarios that may be classified as Cultural Temporal Interpretation. The analysis of each example is discussed in the following list, ordered according to the same sequence as the examples in the table.
- All PLMs, in English and Arabic, predicted no. In fact, this case touches on cultural or geographical dependency. The perception of how often it rains in the summer varies significantly across different regions and climates, which makes this question inherently dependent on the cultural and geographic context. Where this information is not provided in the context.
- Labelling certain answers as no can be culturally dependent touches on broader themes of consumer behavior, store operating hours, and possibly societal norms regarding appropriate times for shopping. The assumption that purchasing a toy at midnight is unusual or incorrect may indeed vary by culture and locale. In some regions or during certain times (such as holidays or special sale events), late-night shopping can be common, while in others, it might be seen as atypical due to differing social norms and operational hours of businesses.
- Similar to the previous case, in some cultures and during holidays, baking is possible at 12 a.m.
7.2. Linguistic and Task Complexity Errors
This category encompasses a broad range of challenges encountered by language models, making it the most diverse category of errors. These errors are predominantly language dependent, significantly influenced by the specific tokenization methods used during model training. Additionally, linguistic features such as morphology and overall complexity contribute to the difficulties faced by models in processing and understanding language input accurately. Finally, validating the likelihood of provided answers can be challenging, and requires common sense knowledge.
A key aspect of linguistic complexity errors is their relationship with the structure and nuances of language, including how words are formed and combined. The way a model tokenizes input—breaking down sentences into words, subwords, or characters—affects its ability to understand and generate coherent responses. Morphological complexity, which involves the structure of words and their relationship with one another within a language, further complicates comprehension, especially in languages with rich inflectional systems.
Moreover, these types of errors can often be mitigated through strategic pre-processing steps, such as time normalization (converting time expressions to a standard format) [9] or unit normalization (standardizing measurements) [3]. Additionally, models vary in their ability to interpret numbers, whether presented in word form or as numerals, which can lead to inconsistencies in understanding and answering questions accurately.
Some models demonstrate proficiency in identifying the type of answer required (e.g., a date or a quantity) but falter when it comes to providing the correct specific response. This discrepancy may stem from the models’ training datasets, which might not adequately prepare them for the breadth of the task complexity they encounter in real-world applications. This limitation suggests the need for more comprehensive training approaches that better encapsulate the linguistic diversity and complexity inherent in natural languages. Moreover, enhancing the current dataset can assist the model in comprehending this complex task.
Table 6 illustrates a sample of errors in the complexity of the language and tasks. The analysis of each example is discussed in the following list, ordered according to the same sequence as the examples in the table.
- mBERT failed to predict this in both. For the Arabic dataset, XLM-R base, AraBERT, and CAMeL failed. While the human can easily validate the answer as no. However, this represents a more complex challenge for PLMs. The models must not only process the natural language of the question but also apply logical reasoning and background knowledge to identify the irrationality of the premise that a historical figure could die multiple times. This difficulty arises from the models’ reliance on patterns and data within their training corpus, which does not explicitly cover every aspect of common sense or logical reasoning needed to immediately flag the question’s premise as impossible.
- All the PLMs, in English and Arabic, predicted no. The difficulty lies not only in interpreting historical events and their timelines, but also in the nuanced understanding of the term "postwar slump" and its impact over time. The term "postwar slump" refers to the economic downturn following a significant conflict, in this case, likely World War I, considering the reference to the 1930s. The incorrect labelling of "decades" as possible answer by all PLMs could be referred to different reasons. The model’s failure to recognize "decades" as a plausible duration may indicate a gap in understanding the prolonged effects of postwar economic conditions or the specific historical context.
- All the PLMs, in English and Arabic, predicted no. Correctly interpreting and validating answers regarding the frequency of activities also involves common sense understanding and world knowledge, such as the typical behaviors of families with young children. PLMs must leverage this broader knowledge to make informed inferences about habitual actions.
8. PLMs Evaluation
A novel hypothesis proposes the assessment of PLMs’ proficiency in TCU tasks by categorizing inputs into five temporal dimensions. Under this framework, the model’s ability to categorize questions correctly suggests that it grasps the temporal features and understands the type of temporal question being asked. However, failing to provide the correct answer implies that the model struggles to apply logical reasoning or lacks the necessary world knowledge to determine whether an answer is plausible within the given temporal context.
Drawing inspiration from traditional Question Answering (QA) systems, where question classification is crucial for high performance, based on Huange et al. [23], and Kolomiyets et al. [24], our approach adapts this methodology for a modern context. Unlike QA systems, where classification directly aids in generating answers, here it serves as a diagnostic tool. This distinction is key, emphasizing that our goal is not to classify for the sake of classification, but to deepen our understanding of PLMs’ handling of temporal information.
Implementing this strategy requires utilization of all PLMs applied to the dataset for temporal classification. This foundational step ensures that the models understand the temporal dimension of queries. Following classification, the model performances on this task were compared with their TCU task performance, focusing on each temporal aspect. This comparison was designed to reveal correlations or discrepancies, providing insight into the models’ capabilities and areas that need refinement.
For example, a model proficient in classifying questions but faltering in providing accurate answers might indicate an understanding of temporal concepts, but a lack of application in complex scenarios. Such findings highlight the importance of enhancing models’ reasoning capabilities and understanding temporal contexts.
Our methodology not only offers a nuanced assessment of PLMs’ handling of temporal information but also points to potential improvements. By identifying specific weaknesses, this approach can guide the development of targeted training or fine-tuning strategies, thereby enhancing PLMs’ effectiveness in TCU tasks and beyond.
8.1. Results and Discussion
The classification task was implemented in both monolingual and cross-lingual settings, examining the models’ performance across different languages. In monolingual environments, specifically for Arabic and English, the classification accuracy reached an impressive rate of approximately 97%. This high level of accuracy underscores the effectiveness of PLMs in understanding temporal information in a single language context.
Figure 6 provided distinctly showcases the significant gap between classification accuracy and performance on TCU task. This discrepancy is notably pronounced, emphasizing the challenges PLMs face when transitioning from understanding temporal categories to applying this understanding in more complex TCU scenarios.
Given the similarity in outcomes between Arabic and English datasets, the analysis focused in-depth on the Arabic dataset to explore this phenomenon further. This targeted approach allows for a nuanced examination of where and how PLMs struggle, particularly in the context of language-specific nuances and temporal reasoning.
Figure 7 breaks down the gap across various temporal aspects, shedding light on the specific areas where discrepancies in performance are most stark. This visual representation serves as a critical tool for identifying the dimensions of temporal understanding that require further refinement in PLM, offering insights into potential focus areas for improving model training and development.
9. Conclusions
This study has made several contributions to the field of TCU, especially for Arabic. The scarcity of datasets has been addressed by constructing an Arabic version from the English dataset MC-TACO. Furthermore, this study examined the performance of several multilingual PLMs across both datasets. As a result, overall performance exhibited a significant gap between Arabic and English. Moreover, the results showed that, for the English dataset, models originally designed for English revealed a significant performance advantage over their multilingual counterparts. However, this is not the case for Arabic models with an Arabic dataset. This study highlighted the inherent complexity of the Arabic language and emphasized the significant scarcity of suitable datasets for this research area for Arabic language. Addressing this gap will require collaborative effort.
To evaluate PLMs’ understanding of TCU tasks, a new hypothesis is introduced. Based on this analysis, it was found that the challenge leading to the failure of PLMs lies in the complexity of common sense reasoning, rather than in understanding the temporal features.
Several issues must be addressed and considered as limitations of this study. First, the size of MC-TACO is quite small, and the split that has been suggested might be adapted to enhance the performance of PLMs in both languages. Additionally, the dataset contains inputs that might conflict with Arabic cultural standards, which might have limited the efficacy of the models with the Arabic dataset.
To address these issues, MC-TACO can be augmented using a temporal common sense dataset specifically designed for Arabic. This can enhance the model performance by overcoming cultural disparities. Addressing cultural issues could significantly reduce the potential for errors and misunderstandings in the mod’s output. construction of an extensive Arabic gold dataset was the optimal solution. However, this effort could require substantial investment in both resources and specialized knowledge.
Author Contributions
This study is part of a PhD research, primarily conducted by the first author. The research was supervised and guided by Hend Al-Khalifah and Simon O’Keefe, who provided valuable insights and feedback throughout the process.
Data Availability Statement
The dataset and the code are available from the corresponding author upon request.
Acknowledgments
The proofreaders who assisted in reviewing the dataset are appreciated for their contributions.
Abbreviations
The following abbreviations are used in this manuscript:
| BERT | Bidirectional Encoder Representations from Transformers |
| DeBERTa | Decoding-enhanced BERT with disentangled attention |
| EM | Exact Match |
| NLU | Natural Language Understanding |
| MRC | Multiple-Choice Reading Comprehension |
| MSA | Modern Standard Arabic |
| PLM | Pre-trained Language Model |
| RoBERTa | Robustly optimized BERT approach |
| TCU | Temporal Common Sense Understanding |
| XLM-RoBERTa | Multilingual version of RoBERTa |
References
- Sap, M.; Shwartz, V.; Bosselut, A.; Choi, Y.; Roth, D. Commonsense Reasoning for Natural Language Processing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts; Savary, A., Zhang, Y., Eds.; Association for Computational Linguistics: Online, 2020; pp. 27–33. [Google Scholar] [CrossRef]
- Schockaert, S.; Ahn, D.; Cock, M.D.; Kerre, E.E. Question Answering with Imperfect Temporal Information. Flexible Query Answering Systems; Springer: Berlin, Heidelberg, 2006; Lecture Notes in Computer Science; pp. 647–658. [Google Scholar] [CrossRef]
- Zhou, B.; Khashabi, D.; Ning, Q.; Roth, D. “Going on a vacation” takes longer than “Going for a walk”: A Study of Temporal Commonsense Understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 3363–3369. [Google Scholar] [CrossRef]
- Yang, Z.; Du, X.; Rush, A.; Cardie, C. Improving Event Duration Prediction via Time-aware Pre-training. In Findings of the Association for Computational Linguistics: EMNLP 2020; Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Online, 2020; pp. 3370–3378. [Google Scholar] [CrossRef]
- Virgo, F.; Cheng, F.; Kurohashi, S. Improving Event Duration Question Answering by Leveraging Existing Temporal Information Extraction Data. In Proceedings of the Thirteenth Language Resources and Evaluation Conference; European Language Resources Association: Marseille, France, 2022; pp. 4451–4457. [Google Scholar]
- Zhou, B.; Ning, Q.; Khashabi, D.; Roth, D. Temporal Common Sense Acquisition with Minimal Supervision. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Online, 2020; pp. 7579–7589. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, Minnesota, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Kaddari, Z.; Mellah, Y.; Berrich, J.; Bouchentouf, T.; Belkasmi, M.G. Applying the T5 language model and duration units normalization to address temporal common sense understanding on the MCTACO dataset. 2020 International Conference on Intelligent Systems and Computer Vision (ISCV), 2020; 1–4. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.M.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2019. [Google Scholar]
- He, P.; Gao, J.; Chen, W. DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing. The Eleventh International Conference on Learning Representations, ICLR 2023, OpenReview.net, 2023. Kigali, Rwanda, 1-5 May 2023. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26-30 April 2020. [Google Scholar]
- Han, R.; Ren, X.; Peng, N. ECONET: Effective Continual Pretraining of Language Models for Event Temporal Reasoning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Online and Punta Cana, Dominican Republic, 2021; pp. 5367–5380. [Google Scholar] [CrossRef]
- Kimura, M.; Pereira, L.K.; Kobayashi, I. Effective Masked Language Modeling for Temporal Commonsense Reasoning. 2022 Joint 12th International Conference on Soft Computing and Intelligent Systems and 23rd International Symposium on Advanced Intelligent Systems (SCIS&ISIS), 2022; 1–4. [Google Scholar] [CrossRef]
- Kimura, M.; Kanashiro Pereira, L.; Kobayashi, I. Toward Building a Language Model for Understanding Temporal Commonsense. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing: Student Research Workshop; Association for Computational Linguistics: Online, 2022; pp. 17–24. [Google Scholar]
- Kimura, M.; Kanashiro Pereira, L.; Kobayashi, I. Towards a Language Model for Temporal Commonsense Reasoning. In Proceedings of the Student Research Workshop Associated with RANLP 2021; INCOMA Ltd.: Online, 2021; pp. 78–84. [Google Scholar]
- Pereira, L.; Cheng, F.; Asahara, M.; Kobayashi, I. ALICE++: Adversarial Training for Robust and Effective Temporal Reasoning. In Proceedings of the 35th Pacific Asia Conference on Language, Information and Computation; Hu, K., Kim, J.B., Zong, C., Chersoni, E., Eds.; Association for Computational Lingustics: Shanghai, China, 2021; pp. 373–382. [Google Scholar]
- Tawalbeh, S.; AL-Smadi, M. Is this sentence valid? An Arabic Dataset for Commonsense Validation. arXiv 2020. [Google Scholar] [CrossRef]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection; Al-Khalifa, H., Magdy, W., Darwish, K., Elsayed, T., Mubarak, H., Eds.; European Language Resource Association: Marseille, France, 2020; pp. 9–15. [Google Scholar]
- Alammary, A.S. BERT Models for Arabic Text Classification: A Systematic Review. Applied Sciences 2022, 12, 5720. [Google Scholar] [CrossRef]
- Inoue, G.; Alhafni, B.; Baimukan, N.; Bouamor, H.; Habash, N. The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models. In Proceedings of the Sixth Arabic Natural Language Processing Workshop; Habash, N., Bouamor, H., Hajj, H., Magdy, W., Zaghouani, W., Bougares, F., Tomeh, N., Abu Farha, I., Touileb, S., Eds.; Association for Computational Linguistics: Kyiv, Ukraine (Virtual), 2021; pp. 92–104. [Google Scholar]
- Shwartz, V. Good Night at 4 pm?! Time Expressions in Different Cultures. In Findings of the Association for Computational Linguistics: ACL 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 2842–2853. [Google Scholar] [CrossRef]
- Huang, P.; Bu, J.; Chen, C.; Kang, Z. Question Classification via Multiclass Kernel-based Vector Machines. 2007 International Conference on Natural Language Processing and Knowledge Engineering, 2007; 336–341. [Google Scholar] [CrossRef]
- Kolomiyets, O.; Moens, M.F. A survey on question answering technology from an information retrieval perspective. Information Sciences 2011, 181, 5412–5434. [Google Scholar] [CrossRef]
| 1 | The dataset and the code are available from the corresponding author upon request. |
| 2 | |
| 3 | |
| 4 |
Figure 1.
Example of a TCU challenge showing a scenario where the model fails to validate the correct answer.
Figure 1.
Example of a TCU challenge showing a scenario where the model fails to validate the correct answer.

Figure 2.
Percentage of unique question-answer pairs in each temporal category
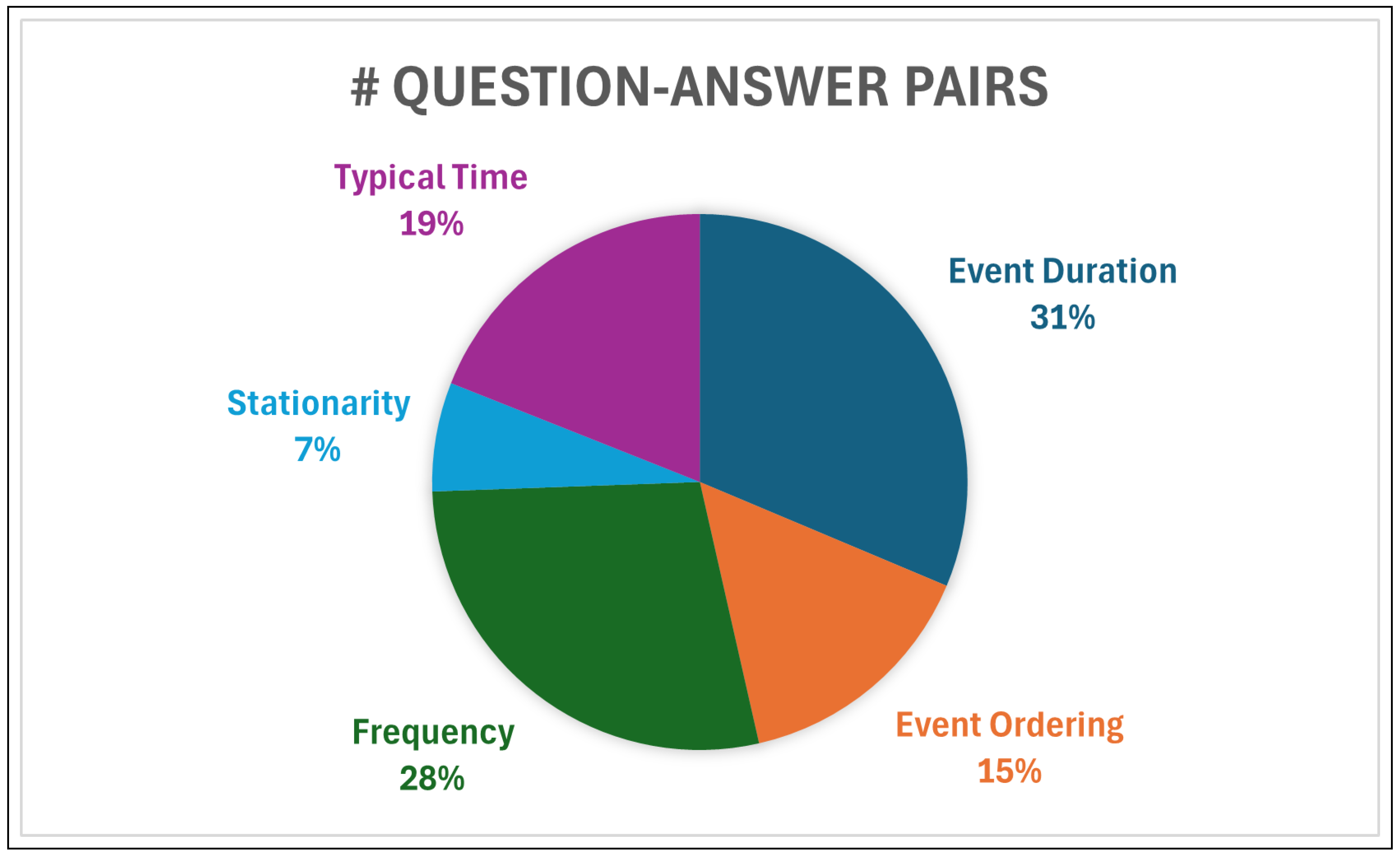
Figure 3.
Sample of the Dataset. Each row targets one temporal aspect from the five aspects covered by the original dataset. An example context for each aspect is provided from both the English and Arabic datasets. The English column is from the MC-TACO dataset and includes five different contexts, each representing one aspect. For each context, the question along with all candidate answers is provided, with the correct answers in bold. Note that there may be more than one correct answer for a question, and the number of answers for each question varies. The Arabic column is from the translated dataset.
Figure 3.
Sample of the Dataset. Each row targets one temporal aspect from the five aspects covered by the original dataset. An example context for each aspect is provided from both the English and Arabic datasets. The English column is from the MC-TACO dataset and includes five different contexts, each representing one aspect. For each context, the question along with all candidate answers is provided, with the correct answers in bold. Note that there may be more than one correct answer for a question, and the number of answers for each question varies. The Arabic column is from the translated dataset.
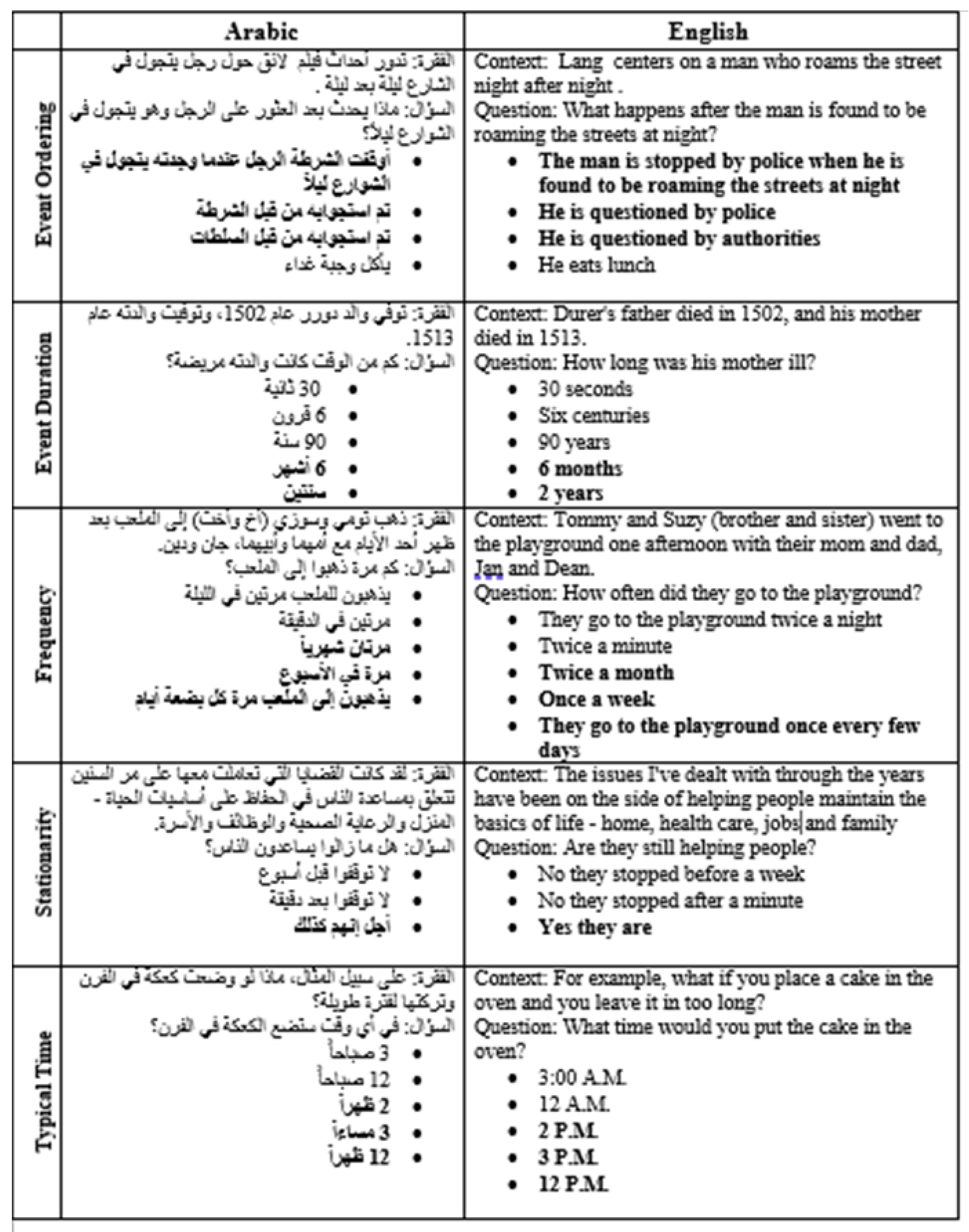
Figure 4.
Models Results- F1 Score for each Temporal Aspects
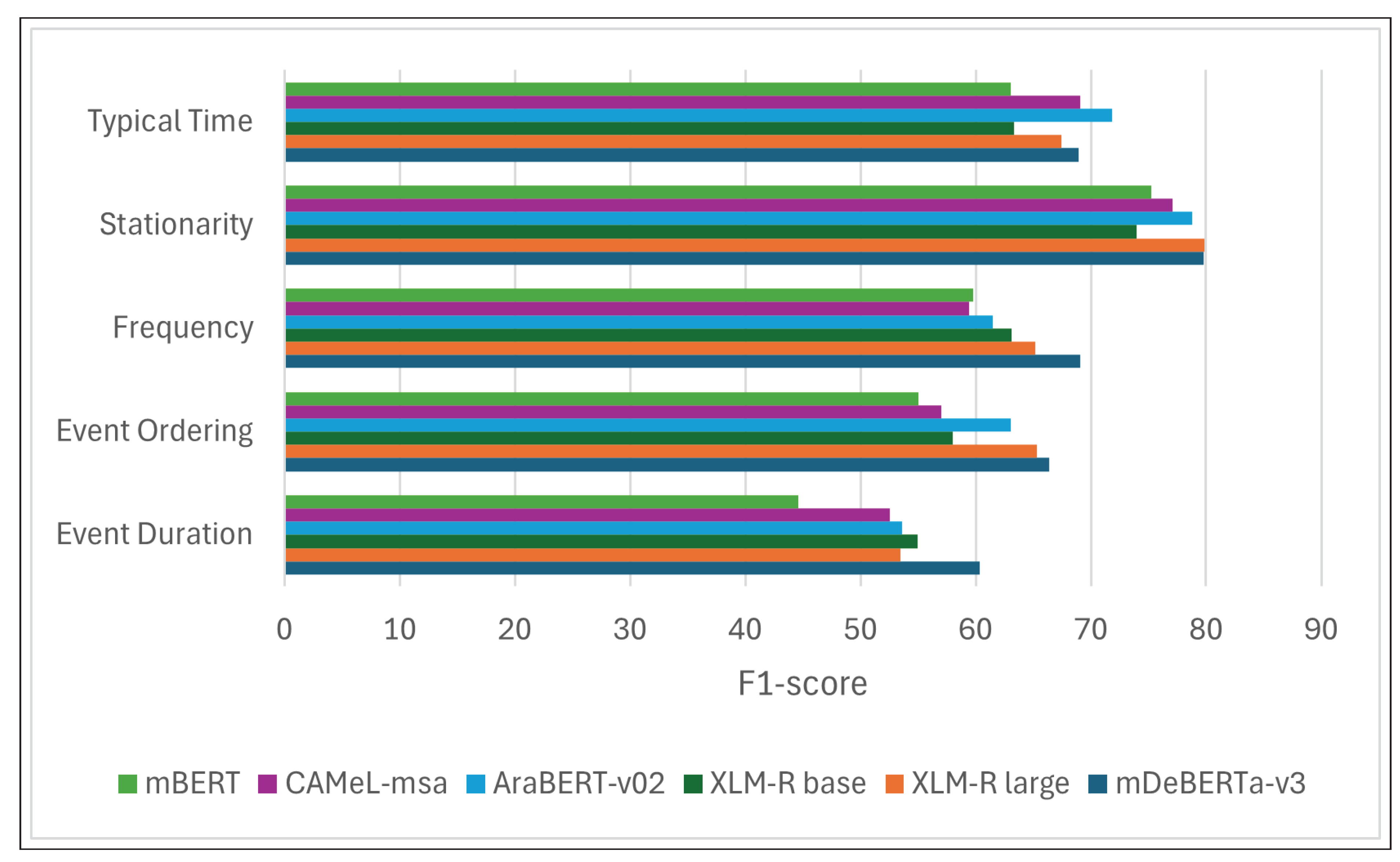
Figure 5.
Predictions of AraBERT vs. CAMeLBERT
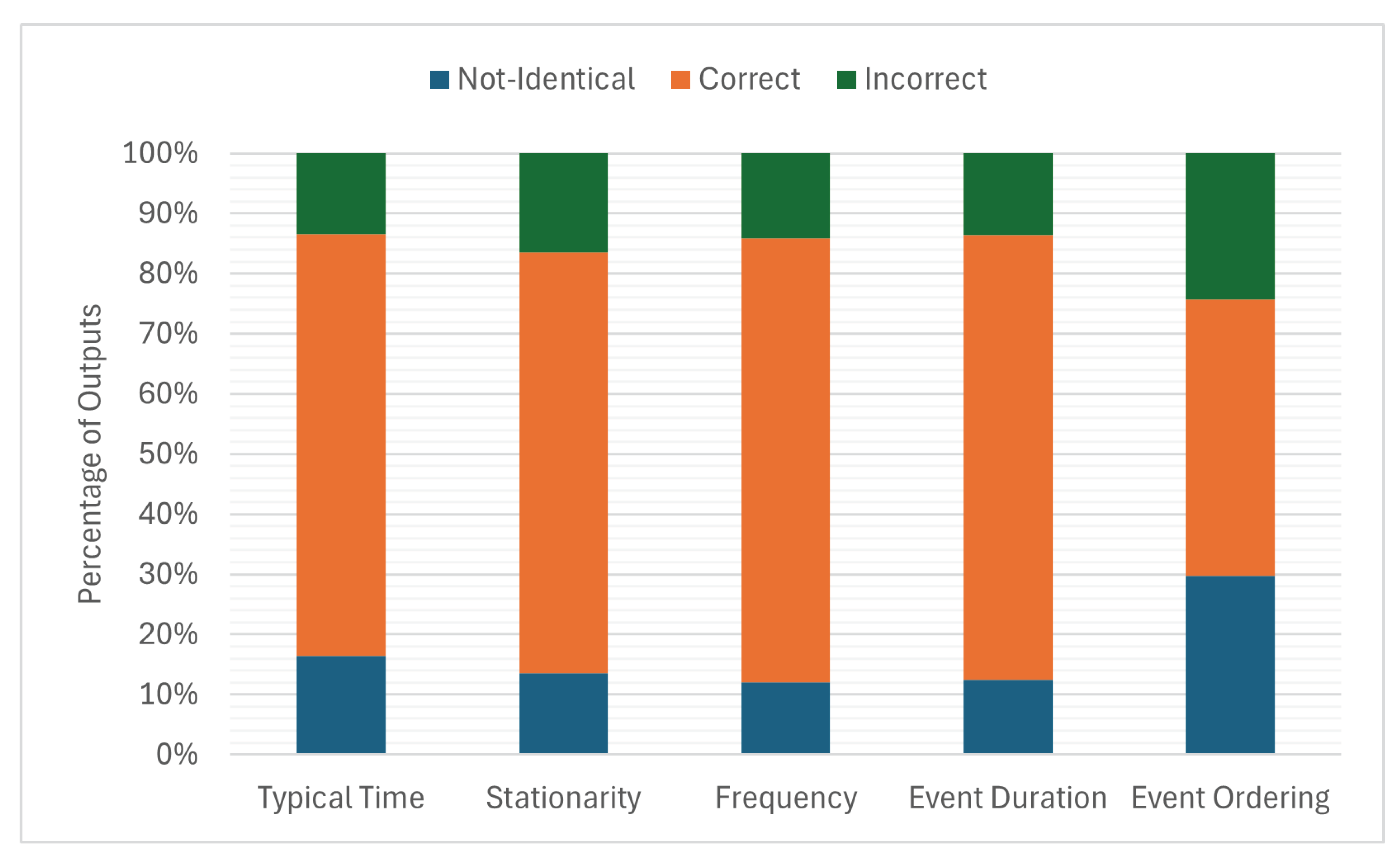
Figure 6.
The Results of TCU and Temporal Classification for Arabic and English
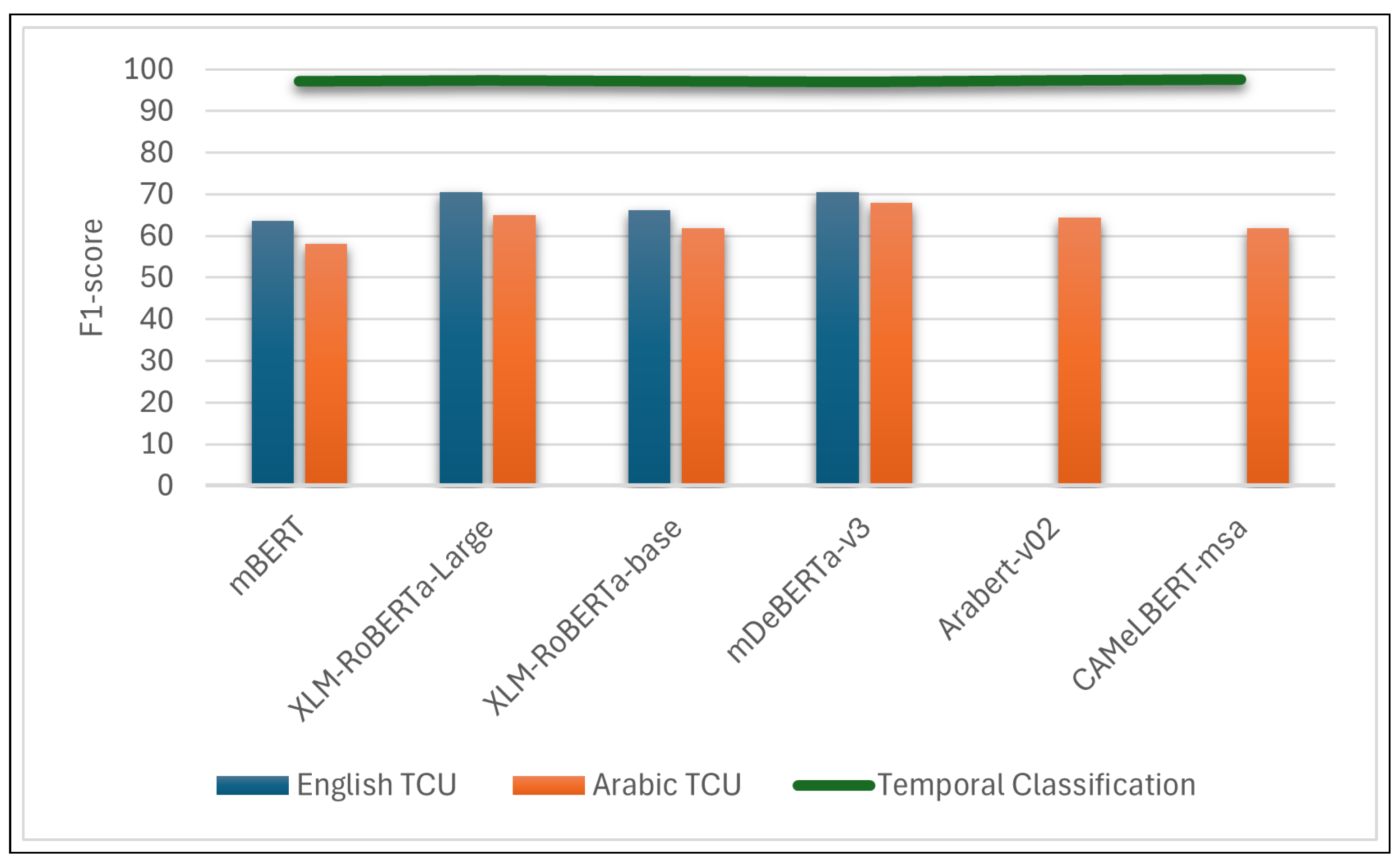
Figure 7.
Results of Arabic Temporal Classification Compared to TCU
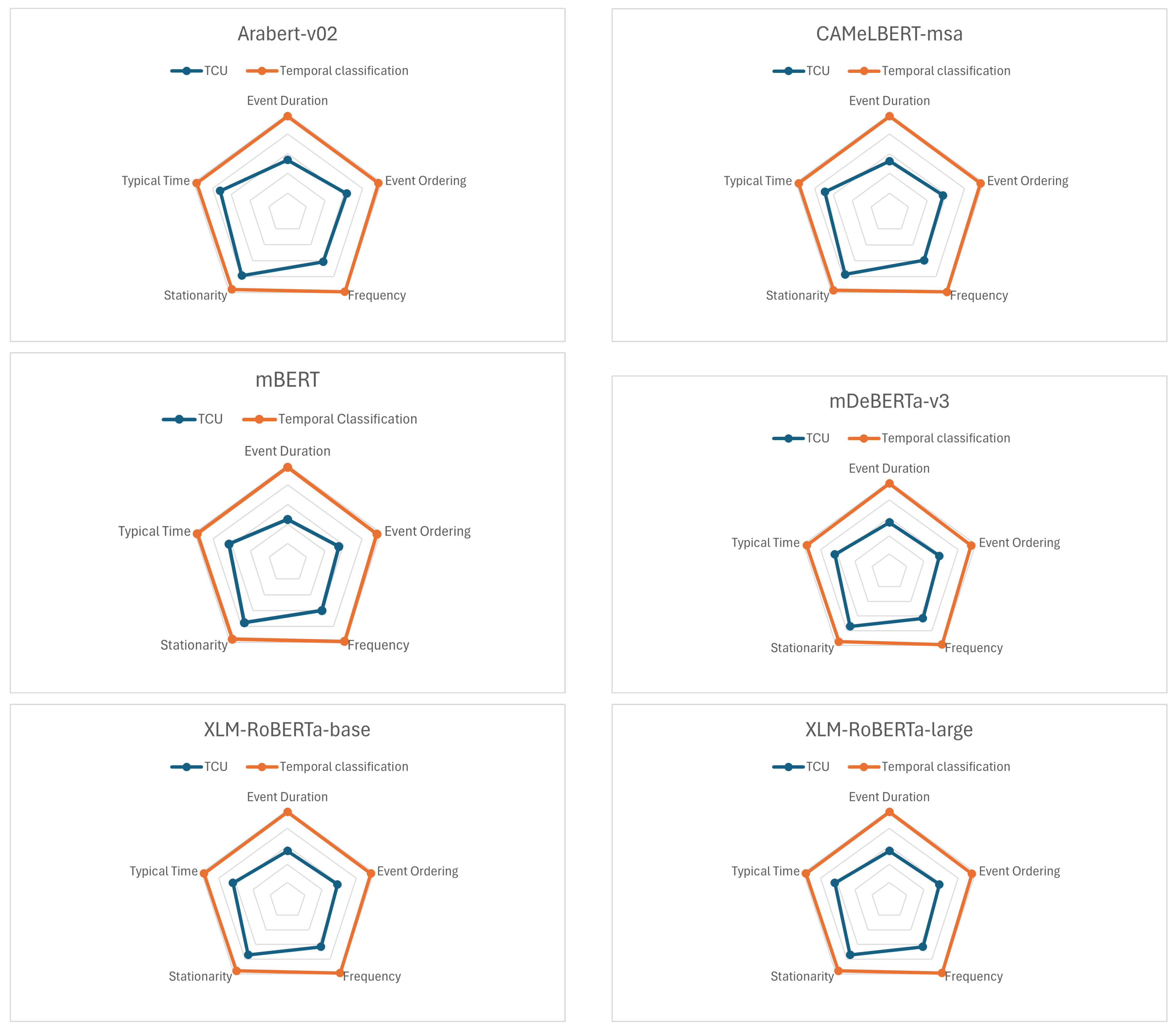

Table 1.
Dataset Statistics
| Measures | Arabic | English |
|---|---|---|
| # of unique questions | 1893 | 1893 |
| # of unique question-answer pairs | 13,225 | 13,225 |
| avg. context length | 15.2 | 17.8 |
| avg. question length | 6.5 | 8.2 |
| avg. answer length | 3 | 3.3 |
Table 2.
Temporal Category Statistics
| Category | # Unique Context | # Unique Questions | Avg. # of Candidates |
|---|---|---|---|
| Event Duration | 135 | 440 | 9.4 |
| Event Ordering | 26 | 370 | 5.4 |
| Frequency | 229 | 433 | 8.5 |
| Typical Time | 43 | 371 | 6.8 |
| Stationarity | 73 | 279 | 3.1 |
Table 3.
Results of Applying PLMs on the Arabic Dataset
| Model | F1 | EM |
|---|---|---|
| mBERT | 58.12 | 28 |
| Arabert-v02 | 64.46 | 34.01 |
| CAMeLBERT-msa | 61.76 | 32.51 |
| XLM-RoBERTa-Large | 64.99 | 36.19 |
| XLM-RoBERTa-base | 61.77 | 31.53 |
| mDeBERTa-v3 | 67.98 | 38.66 |
Table 4.
Subjective Event Understanding Errors Examples
| Context | Question | Answer | Label |
|---|---|---|---|
| It was huge and inefficient, and she should never have spent so many pesos on a toy, but Papa would not let her return it. | How long did she spend at the store buying the toy? | She spent 7.5 minutes at the store buying the toy | yes |
| California was first to require smog checks for clean air, pass anti- tobacco initiatives and bike helmets laws. | How often are such initiatives passed? | One a month | no |
| Most of us have seen steam rising off a wet road after a summer rainstorm. | How long does stream rise after a summer rainstorm? | Steam rises for 30 minutes off a wet road before a summer rainstorm. | no |
Table 5.
Cultural Temporal Interpretation Errors Examples
| Context | Question | Answer | Label |
|---|---|---|---|
| Most of us have seen steam rising off a wet road after a summer rainstorm. | How often does it rain in the summer? | a couple times every month | yes |
| It was huge and inefficient, and she should never have spent so many pesos on a toy, but Papa would not let her return it. | What time did she purchase the toy at the store? | Midnight | no |
| For example, what if you place a cake in the oven and you leave it in too long? | What time would you put the cake in the oven? | 12:00 a.m. | no |
Table 6.
Linguistic and Task Complexity Errors
| Context | Question | Answer | Label |
|---|---|---|---|
| However, more recently, it has been suggested that it may date from earlier than Abdalonymus’ death. | How often did Abdalonymus die? | every two years | no |
| Setbacks in the 1930s caused by the European postwar slump were only a spur to redouble efforts by diversifying heavy industry into the machine-making, metallurgical, and chemical sectors. | How long did the postwar slump last? | decades | yes |
| Tommy and Suzy (brother and sister) went to the playground one afternoon with their mom and dad, Jan and Dean. | How often did they go to the playground? | twice a month | yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



