
Submitted:
06 December 2024
Posted:
17 December 2024
You are already at the latest version
Abstract
This paper presents machine learning methods for approximate solutions of reaction-diffusion equations with multivalued interaction functions. This approach addresses the challenge of finding all possible solutions for such equations, which often lack uniqueness. The proposed method utilizes physics-informed neural networks (PINNs) to approximate generalized solutions.
Keywords:
reaction-diffusion equations
; multivalued interaction functions
; machine learning
; physics-informed neural networks
; approximate solutions
1. Introduction
In this paper we establish machine learning methods for approximate solutions of classes of reaction-diffusion equations with multivalued interaction functions allowing for non-unique solutions of the Cauchy problem. The relevance of this problem is primarily due to the lack of methods for finding all solutions for such mathematical objects. Therefore, there is an expectation that another approximate method will provide us with yet another solution for these problems. In addition, methods for approximate solutions of nonlinear systems with partial derivatives without uniqueness are mostly theoretical and are used primarily in qualitative research [1,2]. The availability of computational power for parallel computations and the creation of open-source software libraries such as PyTorch [3] have stimulated a new wave of development in IT and artificial intelligence methods. Sample-based methods for approximate solutions of such problems were first proposed in [4]. To date, such systems with smooth nonlinearities have been qualitatively and numerically studied. There is a need to develop a methodology for approximating generalized solutions of nonlinear differential-operator systems without uniqueness using recurrent neural networks, sample-based methods, and variations of the Monte Carlo method.
Let and be a sufficiently smooth function. We consider the problem:
with initial conditions:
where is a function satisfying the condition of at most linear growth:
We note that such nonlinearities appear in impulse feedback control problems, etc. [5,6,7,8,9]. Moreover, the global attractor for solutions of Problem 1 may be a nontrivial set in the general case and can have arbitrarily large fractal dimension. The convergence rate of solutions to the attractor may not be exponential; see [10,11,12,13,14] and references therein.
For a fixed let be a bounded domain with sufficiently smooth boundary and According to [1] (see the book and references therein), there exists a weak solution with of Problem (1)–(2) in the following sense:
for all where be a measurable function such that
Such inclusions with multivalued nonlinearities appear in problems of climatology (Budyko-Sellers Model), chemical kinetics (Belousov-Zhabotinsky equations), biology (Lotka–Volterra systems with diffusion), quantum mechanics (FitzHugh–Nagumo system), engineering and medicine (several syntheses and impulse control problems); see [1,2] and references therein.
The main goal of this paper is to develop an algorithm for approximation of solutions for classes of reaction-diffusion equations with multivalued interaction functions allowing for non-unique solutions of the Cauchy problem (1)–(2) via the so-called physics-informed neural networks (PINNs); [15,16,17] and references therein.
2. Methodology of Approximate Solutions for Reaction-Diffusion Equations with Multivalued Interaction Functions
Fix an arbitrary and a sufficiently smooth function We approximate the function f by the following Lipschitz functions satisfying the condition of at most linear growth (Pasch-Hausdorff envelopes):
see [18] and references therein. For a fixed consider the problem:
with initial conditions:
According to [2] and references therein, for each Problem (6)–(7) has an unique solution Moreover, [19] implies that each convergent subsequence of corresponding solutions to Problem (6)–(7) weakly converges to a solution u of Problem (1)–(2) in the space
endowed with the standard graph norm, where is a bounded domain with sufficiently smooth boundary and
Further, to simplify the conclusions we consider as f the following function:
We approximate it by the following Lipschitz functions:
Thus, the first step of the algorithm is to replace the function f in Problem (1)–(2) with considering Problem (6)–(7) for sufficiently large
Let us now consider Problem (6)–(7) for sufficiently large Theorem 16.1.1 from [15] allows us to reformulate Problem (6)–(7) as an infinite dimensional stochastic optimization problem over a certain function space. More exactly, let , let be a probability space, let and be independent random variables. Assume for all , that
Note that be Lipschitz continuous, and let satisfy for all that
Theorem 16.1.1 from [15] implies that the following two statements are equivalent:
Thus, the second step of the algorithm is to reduce the regularized Problem (6)–(7) to the infinite dimensional stochastic optimization problem in
However, due to its infinite dimensionality, the optimization problem (11) is not yet suitable for numerical computations. Therefore, we apply the third step, the so-called Deep Galerkin Method (DGM) [20], that is, we transform this infinite dimensional stochastic optimization problem into a finite dimensional one by incorporating artificial neural networks (ANNs); see [15,20] and references therein. Let be differentiable, let satisfy , and let satisfy for all that
where is the d-dimensional version of a function that is,
is the function which satisfies for all , with that
for each satisfying and for a function we denote by the realization function of the fully-connected feedforward artificial neural network associated to with layers with dimensions and activation functions defined as:
for all and for each satisfying the affine function from to associated to is defined as
for all
The final step in the derivation involves approximating the minimizer of using stochastic gradient descent optimization methods [15]. Let , , for each let and be random variables. Let for each
Let is defined as
for each and let satisfy for all that
Ultimately, for sufficiently large the realization is chosen as an approximation:
of the unknown solution u of (1)–(2) in the space W defined in (8).
So, the following theorem is justified.
Theorem 1.
Proof.
According to Steps 1–4 above, to derive PINNs, we approximate u in the space W defined in (8) by a deep ANN with parameters and minimize the empirical risk associated to over the parameter space . More precisely, we approximate the solution u of (1)–(2) by where
for a suitable choice of training data . Here denotes the number of training samples and the pairs , denote the realizations of the random variables X and T.
Analogously, to derive DGMs, we approximate u by a deep Galerkin method (DGM) with parameters and minimize the empirical risk associated to over the parameter space More precisely, we approximate the solution u of (1)–(2) by where
for a suitable choice (please, see the third (final) step above for details) of training data . Here denotes the number of training samples and the pairs , denote the realizations of the random variables X and T. □
The empirical risk minimization problems for PINNs and DGMs are typically solved using SGD or variants thereof, such as Adam [15]. The gradients of the empirical risk with respect to the parameters can be computed efficiently using automatic differentiation, which is commonly available in deep learning frameworks such as TensorFlow and PyTorch. We provide implementation details and numerical simulations for PINNs and DGMs in the next section.
3. Numerical Implementation
Let us present a straightforward implementation of the method as detailed in the previous Section for approximating a solution of Problem (1)–(2) with and the initial condition where
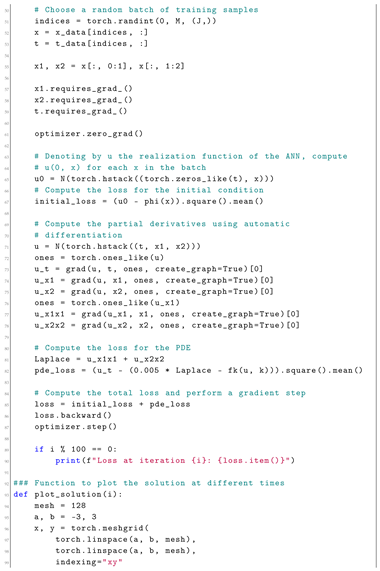
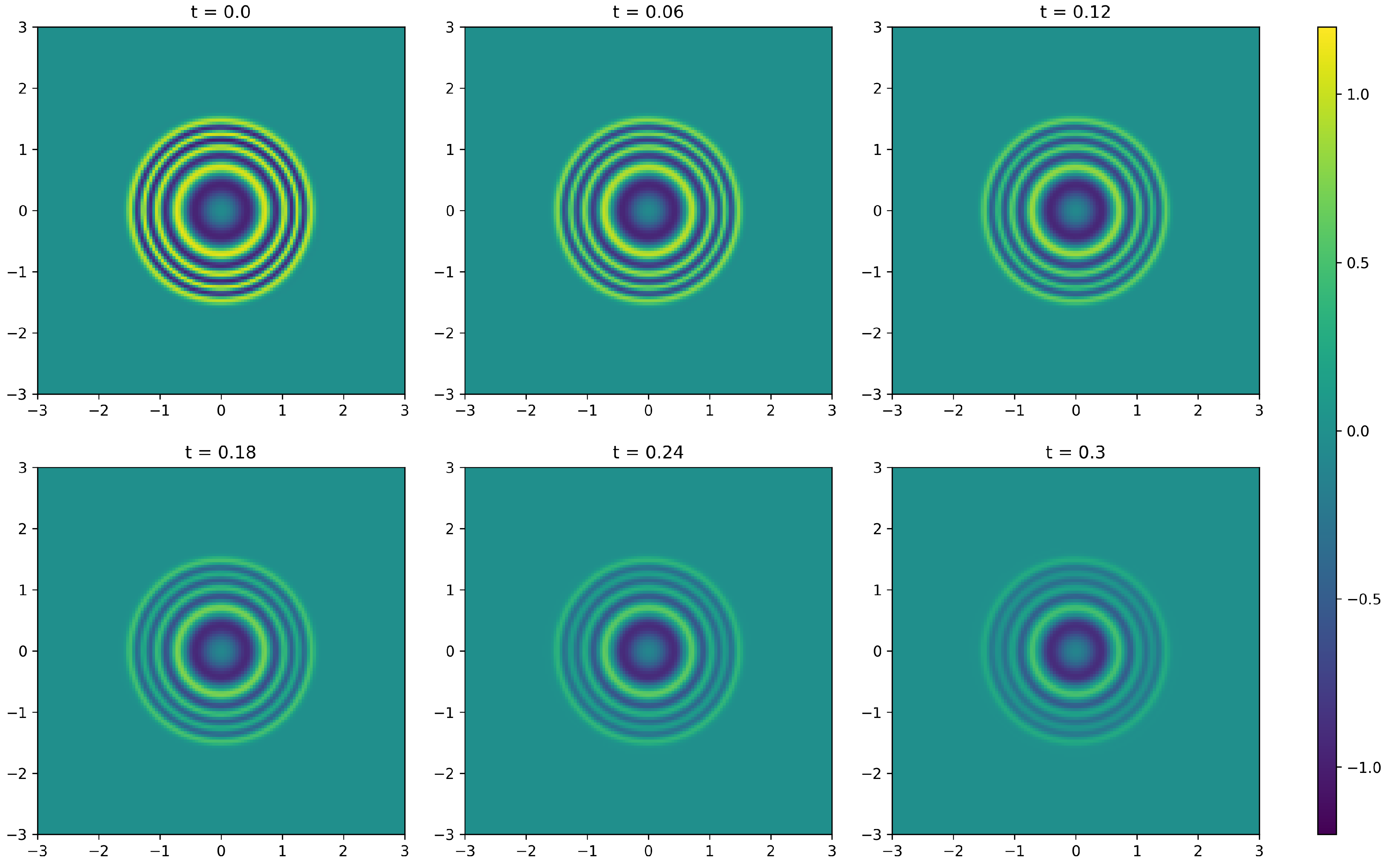
Let This implementation follows the original proposal by [16], where realizations of the random variable are first chosen. Here, is uniformly distributed over and follows a normal distribution in with mean and covariance A fully connected feed-forward ANN with 4 hidden layers, each containing 50 neurons, and employing the Swish activation function is then trained. The training process uses batches of size sampled from the preselected realizations of Optimization is carried out using the Adam SGD method. A plot of the resulting approximation of the solution u after training steps is shown in Figure 1.
 |
 |
 |
| Listing 1. Modified version of sourse code from Section 16.3 of [15]. |
4. Conclusions
In this paper, we presented a novel machine learning methodology for approximating solutions to reaction-diffusion equations with multivalued interaction functions, a class of equations characterized by non-unique solutions. The proposed approach leverages the power of physics-informed neural networks (PINNs) to provide approximate solutions, addressing the need for new methods in this domain.
Our methodology consists of four key steps:
- Approximation of the Interaction Function: We replaced the multivalued interaction function with a sequence of Lipschitz continuous functions, ensuring the problem becomes well-posed.
- Formulation of the Optimization Problem: The regularized problem was reformulated as an infinite-dimensional stochastic optimization problem.
- Application of Deep Galerkin Method (DGM): We transformed the infinite-dimensional problem into a finite-dimensional one by incorporating artificial neural networks (ANNs).
- Optimization and Approximation: Using stochastic gradient descent (SGD) optimization methods, we approximated the minimizer of the empirical risk, yielding an approximation of the unknown solution.
The numerical implementation demonstrated the effectiveness of the proposed method. We used a fully connected feed-forward ANN to approximate the solution of a reaction-diffusion equation with specific initial conditions. The results showed that the PINN method could approximate solutions accurately, as evidenced by the visual plots.
The key contributions of this paper are as follows:
- Development of a Machine Learning Framework: We established a robust framework using PINNs to tackle reaction-diffusion equations with multivalued interaction functions.
- Handling Non-Uniqueness: Our method addresses the challenge of non-unique solutions, providing a practical tool for approximating generalized solutions.
- Numerical Validation: We provided a detailed implementation and numerical validation, demonstrating the practical applicability of the proposed approach.
Future work could explore the extension of this methodology to other classes of partial differential equations with multivalued interaction functions, as well as further optimization and refinement of the neural network architectures used in the approximation process. The integration of more advanced machine learning techniques and the exploration of their impact on the accuracy and efficiency of the solutions also present promising avenues for research.
Author Contributions
All the authors contributed equally to this work.
Funding
“This research was funded by EIT Manufacturing asbl, 0123U103025, grant: “EuroSpaceHub - increasing the transfer of space innovations and technologies by bringing together the scientific community, industry and startups in the space industry”. The second and the third authors were partially supported by NRFU project No. 2023.03/0074 “Infinite-dimensional evolutionary equations with multivalued and stochastic dynamics”. The authors thank the anonymous reviewers for their suggestions, which have improved the manuscript..
Institutional Review Board Statement
The authors have nothing to declare.
Informed Consent Statement
The authors have nothing to declare.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Conflicts of Interest
The author have no relevant financial or non-financial interests to disclose.
References
- Zgurovsky, M.Z.; Mel’nik, V.S.; Kasyanov, P.O. Evolution Inclusions and Variation Inequalities for Earth Data Processing I: Operator Inclusions and Variation Inequalities for Earth Data Processing; Vol. 24, Springer Science & Business Media, 2010.
- Zgurovsky, M.Z.; Kasyanov, P.O. Qualitative and quantitative analysis of nonlinear systems; Springer, 2018.
- Paszke, A.; Sam, G.; Chintala.; Soumith.; Chanan, G. PyTorch, 2016. Accessed on June 5, 2024.
- Rust, J. Using randomization to break the curse of dimensionality. Econometrica: Journal of the Econometric Society 1997, pp. 487–516.
- Denkowski, Z.; Migórski, S.; Schaefer, R.; Telega, H. Inverse problem for the prelinear filtration of ground water. Computer Assisted Methods in Engineering and Science 2023, 3, 97–107. [Google Scholar]
- Eikmeier, A. On the existence of solutions to multivalued differential equations. PhD thesis, Dissertation, Berlin, Technische Universität Berlin, 2022, 2023.
- Papageorgiou, N.S.; Zhang, J.; Zhang, W. Solutions with sign information for noncoercive double phase equations. The Journal of Geometric Analysis 2024, 34, 14. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Papageorgiou, N.S. Sensitivity analysis of optimal control problems driven by dynamic history-dependent variational-hemivariational inequalities. Journal of Differential Equations 2023, 342, 559–595. [Google Scholar] [CrossRef]
- Peng, Z.; Gamorski, P.; Migórski, S. Boundary optimal control of a dynamic frictional contact problem. ZAMM-Journal of Applied Mathematics and Mechanics/Zeitschrift für Angewandte Mathematik und Mechanik 2020, 100, e201900144. [Google Scholar] [CrossRef]
- Cintra, W.; Freitas, M.M.; Ma, T.F.; Marín-Rubio, P. Multivalued dynamics of non-autonomous reaction–diffusion equation with nonlinear advection term. Chaos, Solitons & Fractals 2024, 180, 114499. [Google Scholar]
- Freitas, M.M.; Cintra, W. Multivalued random dynamics of reaction-diffusion-advection equations driven by nonlinear colored noise. Communications on Pure and Applied Analysis 2024, pp. 0–0.
- Zhao, J.C.; Ma, Z.X. GLOBAL ATTRACTOR FOR A PARTLY DISSIPATIVE REACTION-DIFFUSION SYSTEM WITH DISCONTINUOUS NONLINEARITY. Discrete & Continuous Dynamical Systems-Series B 2023, 28. [Google Scholar]
- Gu, A.; Wang, B. Random attractors of reaction-diffusion equations without uniqueness driven by nonlinear colored noise. Journal of Mathematical Analysis and Applications 2020, 486, 123880. [Google Scholar] [CrossRef]
- Zhang, P.; Gu, A. Attractors for multi-valued lattice dynamical systems with nonlinear diffusion terms. Stochastics and Dynamics 2022, 22, 2140013. [Google Scholar] [CrossRef]
- Jentzen, A.; Kuckuck, B.; von Wurstemberger, P. Mathematical introduction to deep learning: methods, implementations, and theory. arXiv preprint arXiv:2310.20360 2023.
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Beck, C.; Hutzenthaler, M.; Jentzen, A.; Kuckuck, B. An overview on deep learning-based approximation methods for partial differential equations. Discrete and Continuous Dynamical Systems-B 2023, 28, 3697–3746. [Google Scholar] [CrossRef]
- Feinberg, E.A.; Kasyanov, P.O.; Royset, J.O. Epi-Convergence of Expectation Functions under Varying Measures and Integrands. Journal of Convex Analysis 2023, 30, 917–936. [Google Scholar]
- Zgurovsky, M.Z.; Kasyanov, P.O.; Kapustyan, O.V.; Valero, J.; Zadoianchuk, N.V. Evolution Inclusions and Variation Inequalities for Earth Data Processing III: Long-Time Behavior of Evolution Inclusions Solutions in Earth Data Analysis; Vol. 27, Springer Science & Business Media, 2012.
- Sirignano, J.; Spiliopoulos, K. DGM: A deep learning algorithm for solving partial differential equations. Journal of computational physics 2018, 375, 1339–1364. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



