Submitted:
05 February 2024
Posted:
05 February 2024
You are already at the latest version
Abstract
"Deep fake" technologies are often associated with face-swapping algorithms based on images or videos. Although much research is focused on developing these techniques, there is still room for improvement, especially in human and visual assessment. In this study, we present an innovative approach to the problem of face replacement based on one model while preserving background features. Our model uses the Adaptive Attentional Denormalization method from FaceShifter while integrating identity features from the ArcFace and BiSeNet models to support the attribute extraction process. We used Fast GAN as a generative model to optimize and accelerate the training process on smaller data sets. Our research proves the effectiveness of the proposed approach by combining innovative methods and architectures in one coherent solution.
Keywords:
face deep-fake
; face swap
; image deep-fake
1. Introduction
Deep learning has been successfully used to power applications such as big data analytics, natural language processing, signal processing, computer vision, human-computer interaction, medical imaging and forensics. Recent advances in deep have also led to significant improvements in the generation of deepfakes. Deepfake is artificial intelligence-generated content that appears authentic to humans. The word deepfake is a combination of the words "deep learning" and "fake" and refers primarily to false content generated by an artificial neural network [1].
In the era of the growing popularity of "Deep fake" technology [2,3,4,5], more and more attention is paid to the possibilities of face manipulation in images and videos. Although fascinating, the ability to swap one face for another carries enormous potential and numerous challenges. Although many "Deep fake" techniques have already been developed and applied in various domains, from the film industry [6] to design applications, new opportunities and problems continue to emerge.
The phenomenon of deepfake in the context of face swapping, although controversial due to potential threats to security and privacy, also opens the door to innovation and creativity in image processing. It is used in medicine [7,8], entertainment [6,9,10], and in the army [11,12,13].
1.1 Related works
Referring to previous work [4] on comparisons of face replacement methods, there are two main approaches to the topic: "target-based" - based on extracting the identity of a person from the source image and placing it in the target image while maintaining all the characteristic features of the target image, and "source-based", where only facial attributes in the target video/image are modified [4]. The target-based solution gives the user more control over scene development. However, its implementation is more complicated because the ground truth that can be used in training is not so obvious.
Current work on deep-fake algorithms mainly revolves around three models: auto-encoder, gans and, recently, diffusion models. Due to their "compression nature" auto-encoders in their basic version are not the best choice for creating high-quality many-to-many deep fakes [14]. However, they are very suitable for creating one-to-one algorithms, i.e. trained for specific people [15,16]. GANs, on the other hand, are generative models that have long been considered SOTA in creating realistic samples. Two competing models seek a balance between the discriminator and the generator. These models are susceptible to collapse, and their training is relatively slow, but they are still leaders among generative models [4,17,18,19]. The last model is the diffusion model, which, through the use of interconnected popular U-net models (also used in GAN models) [20], aims to generate samples through sequential denoising guided by specific conditions [21,22]. This model achieves the best results regarding generation quality and mitigating the gan collapse problem. However, training such a model is currently very time-consuming, and the generation itself is not fast enough to successfully use it, for example, in real-time movies.
1.2 Challenges
Scientists and engineers face several significant challenges in deepfake algorithms and deep learning in general. One key and most recognizable problem is the lack of training data. Nowadays, open training datasets are used in research, but their scope and size are significantly limited compared to those on which current algorithms implemented in production are based. It is worth emphasizing that the size and quality of available training data sets directly and significantly impact the effectiveness and accuracy of deep learning models [23].
Another significant challenge is to develop target-based algorithms capable of effectively distinguishing identity features from other facial attributes, such as expressions or poses [24]. This development is necessary to create reliable deepfakes that faithfully imitate the face of a reference person. Effectively separating these attributes is crucial to obtaining realistic and compelling results.
Additionally, there is the problem of matching the face to the background of the head and taking into account various occlusions. This issue requires precise algorithm work to ensure the synthetically generated face harmoniously interacts with the surrounding environment while maintaining naturalness and visual consistency. Ensuring such coordination between the face and the background is another challenge to effectively address in creating advanced deepfakes. Post-processing can solve this aspect, but it adds an element to the generator and slows the operation.
Another significant challenge that deep learning algorithms must face is a phenomenon known as "collapse", which most often occurs during the model training phase. This phenomenon is characterized by a situation where the generative model begins to produce a limited variety of outputs, often focusing on generating very similar or even identical instances, which significantly limits its ability to produce diverse and realistic outputs. This problem is particularly pronounced in the case of GANs, where two networks – generative and discriminative – are trained simultaneously in a competing setting. Ideally, a generative network should learn to produce indistinguishable data from real data, while a discriminative network should learn to distinguish between real and generated data. However, in the case of "collapse", the generative network produces a limited range of results, which leads to a loss of the diversity and quality of the generated data. This collapse, in turn, may lead to a situation in which the discriminative network quickly identifies false data, limiting the effectiveness of the entire training process [25].
2. Related works
In the area of facial attribute manipulation, it is essential to distinguish between target-based and source-based methods. Target-based methods [15,17,18,19,22,26], allow face editing in the creator's environment, allowing users to influence the modelling process directly. In turn, source-based methods focus on adapting and changing existing materials, allowing for broad application in film post-production, education and digital art.
Algorithms such as DeepFaceLab [15] or faceswap [16], although effective in terms of face manipulation in one-to-one models, have limitations in the context of generalization to new faces not present in the training set. Many-to-many solutions such as FaceShifter [18] or SimSwap [17] use advanced identity embedding techniques, for example, those based on the ArcFace model [27], which allows for greater flexibility in the face-swapping process. However, these methods do not verify the full range of facial attributes, such as pose and facial expressions, which may result in inauthentic or unnatural results.
An innovative approach is presented by GHOST-A [19], where a specialized cost function is introduced, focusing on maintaining the direction of gaze. This solution significantly improves realism in the generated images but does not solve the problem of maintaining other key facial attributes. Moreover, integrating this function in a later phase of the training process and using additional blending and superresolution algorithms complicate the entire process and extend the training and use time.
The DiffFace algorithm [22] presents another step forward, using diffusion techniques and relying on an additional face-parser model, ensuring the training process's stability and consistency. However, the long training time is still challenging, hindering fast production cycles.
Overall, current techniques in facial attribute manipulation still suffer from challenges related to generalization, realism, and efficiency of the training process. Although significant progress has been achieved, especially in many-to-many models and diffusion model-based techniques, many areas still require further research and development. It is essential to strive to create methods capable of quickly and reliably adjusting the entire spectrum of facial attributes, which would be a significant step forward in this dynamically developing field.
3. Methodology
As part of the research, an algorithm was developed that extends previous achievements in manipulating facial attributes. The presented method focuses on improving the direct image generation process, introducing an innovative approach to the cost function. The critical innovation is eliminating the need to obtain training data from the same people, significantly simplifying the data collection process and eliminating the need for detailed labelling.
Several techniques have been used to achieve training acceleration, improve stability, and minimize training data requirements. These include the analysis of the hidden space in the discriminator obtained in the image reconstruction process using autoencoders [28]. Thanks to this, even with a limited amount of training data, the model can achieve satisfactory results.
The methodology's key element is using a pre-trained face-parser model [29], which enables effective image segmentation. This segmentation plays a double role: on the one hand, it supports the reconstruction of areas that should not be edited, and on the other, it serves as an indicator for preserving key facial attributes, such as emotions or the position of the eyes, nose, and mouth. Importantly, this segmentation is not used directly in the generation process in the evaluation phase, so it does not burden the algorithm's performance.
3.1 Architecture
In the deepfake model architecture based on Generative Adversarial Networks (GAN), we extract two main components: the generator and the discriminator.
The central part of the architecture is the generator shown in Figure 1, which consists of three key components: an attribute encoder, an identity encoder and processing blocks. The Attribute Encoder uses convolutional layers with batch normalization and Leaky ReLU activation functions for feature extraction. The input of the attribute encoder is a photo of the target, i.e. a photo of the face whose identity we will modify - Xt. The identity encoder uses a pre-trained face recognition model - ArcFace [27]. The input of the identity encoder in the proposed architecture is a source photo containing the face of the person whose identity we will transfer - Xs. This model provides vector representations of identity that are further transformed by fully connected layers and adapted for further processing in generating blocks. These blocks incorporate the Adaptive Attentional Denormalization (AAD) mechanism [18], which integrates pre-layers, identity embedding and attribute embedding, performing dynamic feature matching. This process is supported by residual connections [30], which enable information and gradients to propagate through the model. The generator is complemented by the use of the Skip Layer Excitation (SLE) technique [28,31], which, through channel multiplication, allows for the modulation of features generated in high-resolution blocks, which contributes to better separation of content attributes from style in the final image. The output is a ready-made photo of face Y with identity from Xs and background and attributes from Xt.
In the presented architecture, visible in Figure 1, attention is drawn to an additional module - the face segmenter [29]. Although it is not used directly in the production stage of image generation, it plays an invaluable role in the training phase of the model. An advanced, pre-trained bisenet parser [27] was used for the face segmentation. Its primary function is to identify areas that belong to the face and those that do not.
The bisenet parser works by analyzing the input image and classifying each pixel into the appropriate category, which allows for accurate separation of facial structures from the background and other image elements. The information obtained from this segmentation process is crucial because it informs and improves the loss functions used during training. This implementation makes it possible to significantly improve the learning process by ensuring a more accurate match between the generated images and the actual labelled data. Moreover, it indicates the location of individual parts of the face, translating into the accuracy of maintaining the attributes. A box blur was additionally used to prevent an inaccurate mapping of structures, responsible for averaging the values of logits obtained from the parser with a specific kernel.
Later in the work, in the next chapter, specific cost functions used in the model optimization process will be discussed in more detail. It is worth noting that the appropriate definition and application of the cost function are critical for the effectiveness of learning and the quality of the final product generated by the deepfake model, which emphasizes the importance of the face segmenter module in the overall architecture.
Figure 1.
Generator architecture.
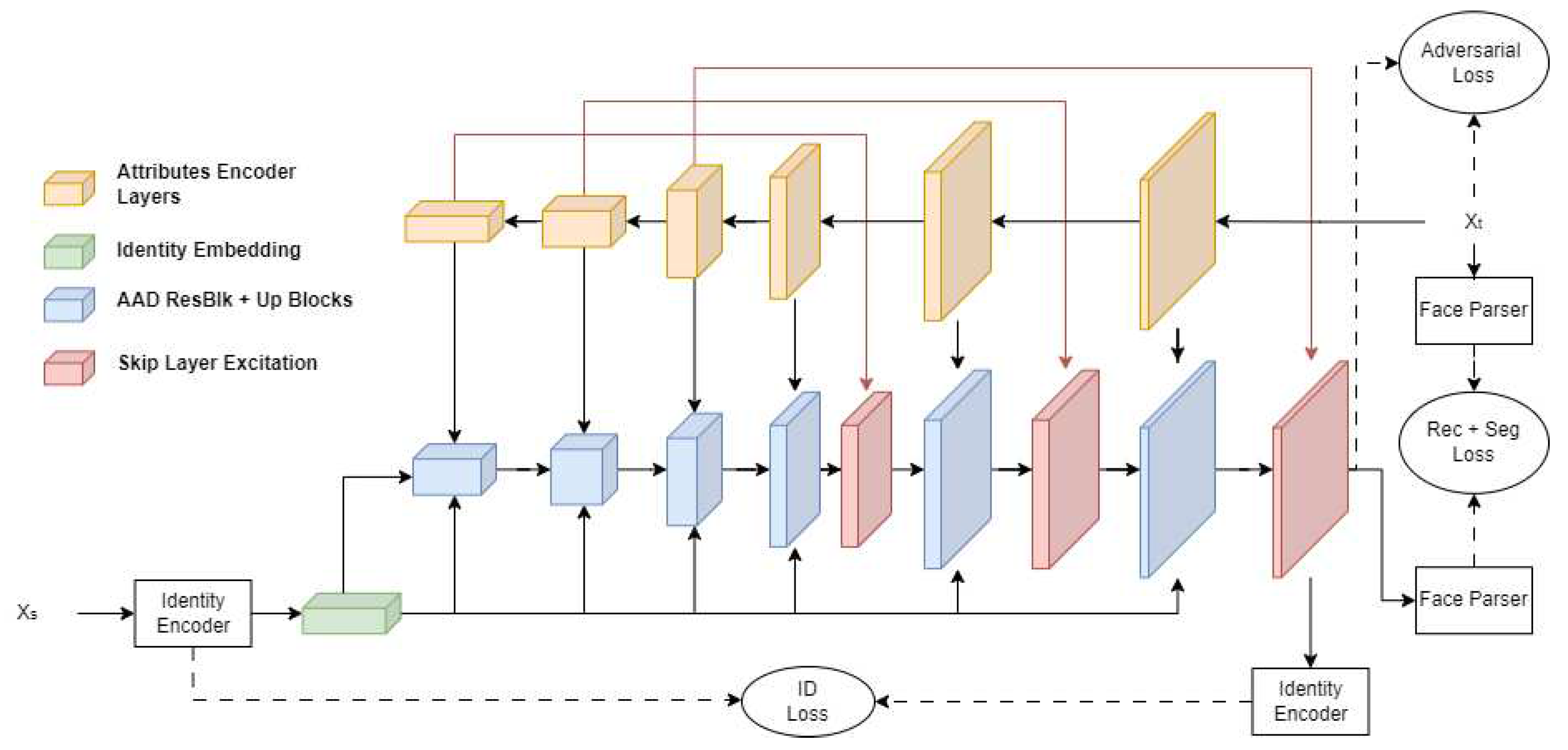
The discriminator, inspired by FastGAN [28], is designed to assess the reliability and quality of the generated images. A particular procedure for differentiable image editing has been introduced into the discriminator, increasing the input data's diversity without disturbing their structural integrity. The internal structure of the discriminator contains decoders that are responsible for the process of reconstructing images labelled as authentic. Using these decoders allows for a significant increase in the effectiveness and speed of model training. By carefully refining the discrimination process, the model can subtly but precisely evaluate the generated data, which is crucial for the credibility and realism of the generated deepfakes.
3.2 Loss Functions
The chapter on the cost function presents the critical elements of deepfake model optimization, which are intended to ensure the stability of the training process and the efficiency of image generation. Several cost functions have been introduced, necessary for learning complex many-to-many relationships in deepfake generation.
Identity Loss: The first one is the so-called identity loss, which plays a fundamental role in ensuring the accuracy of the identity of the generated faces. It uses a pre-trained face recognition model, like ArcFace [27], which generates high-dimensional representations (embeddings) of faces. During training, the embeddings of the source face and the generated output image are compared. Minimizing the cosine distance between these embeddings is one of the training goals, ensuring that the generated images retain vital features of the source identity.
Reconstruction Loss: The second function, reconstruction loss, focuses on calculating the mean squared error (MSE) between regions that are not part of the face of the target image and the generated output . A face segmenter such as Bisenet is used to determine these areas, which allows for a more accurate representation of the context in which the face is located.
Feature Loss: The following function, feature loss, is calculated as the mean squared error between the logits extracted by the Bisenet segmenter network. The mean square error between the features of the Xt target image blurred with box blur and the generated output is calculated, which helps to simulate the location of facial details more accurately.
Adversarial Loss: The essential cost function in GAN training is adversarial loss. It includes classifying images presented to the discriminator as true or false. This decision is a crucial element of the training process that pushes the generator to create more convincing images while also training the discriminator to refine their authenticity assessment.
The overall function of the generator can be described as follows:
The discriminator and its classification function also use the cost function for reconstructing real images – LPIPS [32]. It uses latent spaces as input to decoders, which are then classified. This combined cost function ensures the stability of the training process, reducing the risk of overfitting and preventing the so-called GAN collapse, where the generator starts producing useless results.
4. Experiments
This experimental chapter will focus on the practical application and analysis of the deepfake algorithm, developed to use a pre-trained segmentation network. The basic assumption of our approach is to demonstrate this network's usefulness in separating identifying features of identity from attributes. This separation method allows for visual manipulation while maintaining key elements of personal identification.
However, this process is not without its challenges. One of the main problems we have encountered is the localization variability of a person's facial features. Faces, being dynamic and complex structures, can exhibit significant variability in different contexts and situations. Therefore, to counteract this variability - output from the segmentation model is additionally blurred, which makes a loss function less strict. The applied cost function, based on a segmenter, shows promising results in separating and manipulating facial features in the context of creating realistic deepfakes.
In this section, we will analyze the performance of our algorithm in detail, paying attention to its effectiveness in various scenarios and conditions. We will present a series of experiments that were performed to investigate various aspects and potential limitations of our approach. By doing so, we want to not only demonstrate the capabilities of our method but also indicate directions for future research and improvements in the field of deepfake technology.
4.1 Implementation Details
To complete the training process of our deepfake algorithm, we used the popular VGGFace2 dataset, which contains a wide range of cropped celebrity faces. This set, marked in the literature as [31], was a key data source for training and testing our model.
We used photos with a resolution of 256x256 pixels as input images. We chose this size due to the optimal balance between the quality of details and computational requirements. Our model, inspired by FastGAN [26], is characterized by high scalability. Thanks to this, with minor modifications, it is possible to extend our method to process images of larger dimensions, which opens the way to even more detailed and realistic results.
The features obtained from the segmenter have dimensions of 19x32x32, where 19 is the number of classes, and 32x32 is the size of the segmentation mask. This mask is blurred using box blur with a kernel of 15.
In the context of optimization, we decided to use the Ad-am algorithm. Parameters B1 and B2 were set to 0.9 and 0.999, respectively. This choice of parameters ensured an effective and stable learning process while minimizing the risk of getting stuck in local minima.
The batch size, i.e. the number of data samples processed in one training step, was set to 32. This choice was a compromise between training efficiency and available computing resources.
Notably, our GAN is characterized by high training speed and stability. Thanks to this, we achieved satisfactory results after 25 training epochs, which in practice meant carrying out about 500,000 iterations.
4.2 Results
In the results section of our study, we present the transformation effects on seven randomly selected identities that were treated in various combinations as source or target. An important aspect is that these specific identities were not included in the training dataset.
Figure 2 shows that our FastFake algorithm successfully transfers the identity from the source while preserving the target's attributes. This preservation is crucial to our method, allowing for realistic and reliable face manipulations.
Additionally, as part of the experiments, we compared the impact of the kernel size used on the segmentation cost function on the result. The effects of this experiment are shown in Figure 3. As the kernel size increases, more "identities" are transferred to the resulting image at the expense of attributes.
4.3 Comparision with Other Methods
Many different methods have been proposed over the years in the field of many-to-many face replacement. We chose the most famous of them for our comparison. It should be emphasized that our goal was not to achieve the status of the SOTA (State of the Art) method, which would require building a larger and more complex GAN model and a much longer training process. Determining the superiority of one algorithm over another is not easy because it often depends on the specific purpose and use of the method. Moreover, no objective metrics would clearly determine that a given method is better than another. As part of this article, Figure 4 compares the algorithm's results with other known ones for several selected examples.
Our results are comparable to those obtained by the Ghost-A algorithm. However, our model is characterized by shorter training time and does not require a mixed training method based on data containing the same people. Our model can be trained on data uncategorized regarding identity with comparable outcome, which is its significant advantage.
The face parser in our approach forces the model to edit only facial areas. It is impossible to edit an area that is not a face - this prevents additional distortions and does not require additional processing when placing a face in the target image. Using a segmenter allows for greater precision and naturalness in the face manipulation process, which is an additional advantage of our method compared to other available solutions. It can also be noted that, compared to other methods, ours is characterized by a high degree of preservation of facial attributes.
4.4 Analysis
In this section, we will focus on analyzing what our method brings to the deepfake field, its shortcomings, and what areas of development lie ahead.
Our method was primarily intended to demonstrate the effectiveness of using a pre-trained face segmentation network to preserve attributes during identity manipulation. This method showed high efficiency and realism in our experiments, preserving most potential occlusions, such as glasses, landmarks and hair. However, we have noticed that when training with a higher weight for identity embedding or using faces that are structurally significantly different, artefacts appear in the locations around the eyes and mouth - to counter this problem, we introduced a simple blur to the cost function. These artefacts can also be reduced using a different GAN model that would penalize more for less realistic generations – however it’s not a part of research.
The GAN used is characterized by stability and speed of training, which is a great advantage in terms of repeatability of results and ease of adaptation to new configurations. The ability to conduct many experiments with different settings is precious in research on GAN-type generative models.
Our method eliminates the need to collect data for the same people, which opens up new possibilities for expanding it with data from sets that do not segregate identities. This improvement can significantly affect the efficiency and universality of the algorithm.
There are also other areas requiring further analysis and improvement. The parser model was pre-trained on other image dimensions and only partially adapted to our needs. Considering other, more advanced parsers and training them with additional elements can improve the accuracy and realism of the results.
Another challenge is communicating attributes such as lighting. Currently, lighting is added mainly by maintaining the realism of the result based on the background, which is always reconstructed/immutable. It is possible that extending model training to include lighting context could improve the quality and realism of the results.
In summary, our method makes a significant contribution to deepfake technology; however, many areas require further development and improvement. Future research should focus on improving the model, increasing the realism of the generated images, and better conveying subtle attributes such as lighting and gaze direction.
5. Conclusions
In this work, we presented the FastFake method, which demonstrates the possibility of using features obtained from the segmenter in editing unstructured attributes. Our results show that this method effectively implements face replacement while preserving key attributes and occlusions such as glasses, landmarks, and hair.
The critical aspect of our method is its speed and stability of training, which allows for quick iteration and experimentation, opening the way to further innovations in this field. However, as our experiments have shown, some areas require further work and improvement, especially in the context of more accurate transfer of attributes such as lighting and vision.
It is also worth noting that the development of deepfake technologies brings specific ethical and social challenges, especially in the context of the possibility of their abuse. Therefore, our study highlights the importance of responsible application and further development of ethical principles in this field. Additionally, while not the focus of this article, it is possible to secure one's deepfake creations with special hidden watermarks to mitigate misuse [33,34,35]. This highlighting is particularly important given the increasing ease of access to these technologies and their potential applications in various sectors.
In conclusion, FastFake is a promising step towards more advanced and ethically responsible deepfake technologies. Our study opens new research and practice opportunities while highlighting the need for further research to address existing technological and ethical challenges.
Author Contributions
Investigation, T.W.; methodology, T.W.; supervision, Z.P.; validation, Z.P.; resources T.W.; writing—original draft, T.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Centre for Research and Development, grant number CYBERSECIDENT/381319/II/NCBR/2018 on "The federal cyberspace threat detection and response system" (acronym DET-RES) as part of the second competition of the CyberSecIdent Research and Development Program—Cybersecurity and e-Identity.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mirsky, Y.; Lee, W. The Creation and Detection of Deepfakes: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- P, S.; Sk, S. DeepFake Creation and Detection:A Survey. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA); 2021; pp. 584–588. [Google Scholar]
- Mahmud, B.U.; Sharmin, A. Deep Insights of Deepfake Technology : A Review 2023. [CrossRef]
- Walczyna, T.; Piotrowski, Z. Quick Overview of Face Swap Deep Fakes. Appl. Sci. 2023, 13, 6711. [Google Scholar] [CrossRef]
- Walczyna, T.; Piotrowski, Z. Overview of Voice Conversion Methods Based on Deep Learning. Appl. Sci. 2023, 13, 3100. [Google Scholar] [CrossRef]
- Binderiya Usukhbayar Deepfake Videos: The Future of Entertainment 2020. [CrossRef]
- Yang, H.-C.; Rahmanti, A.R.; Huang, C.-W.; Li, Y.-C.J. How Can Research on Artificial Empathy Be Enhanced by Applying Deepfakes? J. Med. Internet Res. 2022, 24, e29506. [Google Scholar] [CrossRef] [PubMed]
- Medical Deepfakes Are The Real Deal Available online: https://www.mddionline.com/artificial-intelligence/medical-deepfakes-are-the-real-deal (accessed on Dec 10, 2023).
- Artificial Intelligence: Deepfakes in the Entertainment Industry Available online: https://www.wipo.int/wipo_magazine/en/2022/02/article_0003.html (accessed on Dec 10, 2023).
- Caporusso, N. Deepfakes for the Good: A Beneficial Application of Contentious Artificial Intelligence Technology. In; 2021; pp. 235–241 ISBN 978-3-030-51327-6. [CrossRef]
- Biddle, S. U.S. Special Forces Want to Use Deepfakes for Psy-Ops Available online: https://theintercept.com/2023/03/06/pentagon-socom-deepfake-propaganda/ (accessed on Dec 10, 2023).
- Nasu, H. Deepfake Technology in the Age of Information Warfare Available online: https://lieber.westpoint.edu/deepfake-technology-age-information-warfare/ (accessed on Dec 10, 2023).
- Bistron, M.; Piotrowski, Z. Artificial Intelligence Applications in Military Systems and Their Influence on Sense of Security of Citizens. Electronics 2021, 10, 871. [Google Scholar] [CrossRef]
- Zendran, M.; Rusiecki, A. Swapping Face Images with Generative Neural Networks for Deepfake Technology – Experimental Study. Procedia Comput. Sci. 2021, 192, 834–843. [Google Scholar] [CrossRef]
- Perov, I.; Gao, D.; Chervoniy, N.; Liu, K.; Marangonda, S.; Umé, C.; Dpfks, M.; Facenheim, C.S.; RP, L.; Jiang, J.; et al. DeepFaceLab: Integrated, flexible and extensible face-swapping framework 2021. [CrossRef]
- deepfakes deepfakes_faceswap Available online: https://github.com/deepfakes/faceswap (accessed on May 3, 2023).
- Chen, R.; Chen, X.; Ni, B.; Ge, Y. SimSwap: An Efficient Framework For High Fidelity Face Swapping. In Proceedings of the Proceedings of the 28th ACM International Conference on Multimedia; 2020; pp. 2003–2011. [CrossRef]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping 2020. [CrossRef]
- Groshev, A.; Maltseva, A.; Chesakov, D.; Kuznetsov, A.; Dimitrov, D. GHOST—A New Face Swap Approach for Image and Video Domains. IEEE Access 2022, 10, 83452–83462. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, 2015; pp. 234–241. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat GANs on Image Synthesis 2021. [CrossRef]
- Kim, K.; Kim, Y.; Cho, S.; Seo, J.; Nam, J.; Lee, K.; Kim, S.; Lee, K. DiffFace: Diffusion-based Face Swapping with Facial Guidance 2022. [CrossRef]
- Althnian, A.; AlSaeed, D.; Al-Baity, H.; Samha, A.; Dris, A.B.; Alzakari, N.; Abou Elwafa, A.; Kurdi, H. Impact of Dataset Size on Classification Performance: An Empirical Evaluation in the Medical Domain. Appl. Sci. 2021, 11, 796. [Google Scholar] [CrossRef]
- Olivier, N.; Baert, K.; Danieau, F.; Multon, F.; Avril, Q. FaceTuneGAN: Face Autoencoder for Convolutional Expression Transfer Using Neural Generative Adversarial Networks 2021. [CrossRef]
- Thanh-Tung, H.; Tran, T. On Catastrophic Forgetting and Mode Collapse in Generative Adversarial Networks 2020. [CrossRef]
- Wang, Y.; Chen, X.; Zhu, J.; Chu, W.; Tai, Y.; Wang, C.; Li, J.; Wu, Y.; Huang, F.; Ji, R. HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping 2021. [CrossRef]
- Deng, J.; Guo, J.; Yang, J.; Xue, N.; Kotsia, I.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5962–5979. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Zhu, Y.; Song, K.; Elgammal, A. Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis 2021. [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation 2018. [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition 2015. [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks 2019. [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric 2018. [CrossRef]
- Bistroń, M.; Piotrowski, Z. Efficient Video Watermarking Algorithm Based on Convolutional Neural Networks with Entropy-Based Information Mapper. Entropy 2023, 25, 284. [Google Scholar] [CrossRef] [PubMed]
- Kaczyński, M.; Piotrowski, Z.; Pietrow, D. High-Quality Video Watermarking Based on Deep Neural Networks for Video with HEVC Compression. Sensors 2022, 22, 7552. [Google Scholar] [CrossRef] [PubMed]
- Kaczyński, M.; Piotrowski, Z. High-Quality Video Watermarking Based on Deep Neural Networks and Adjustable Subsquares Properties Algorithm. Sensors 2022, 22, 5376. [Google Scholar] [CrossRef] [PubMed]
Figure 2.
Results.

Figure 3.
Results from models trained on different kernels in Feature loss.
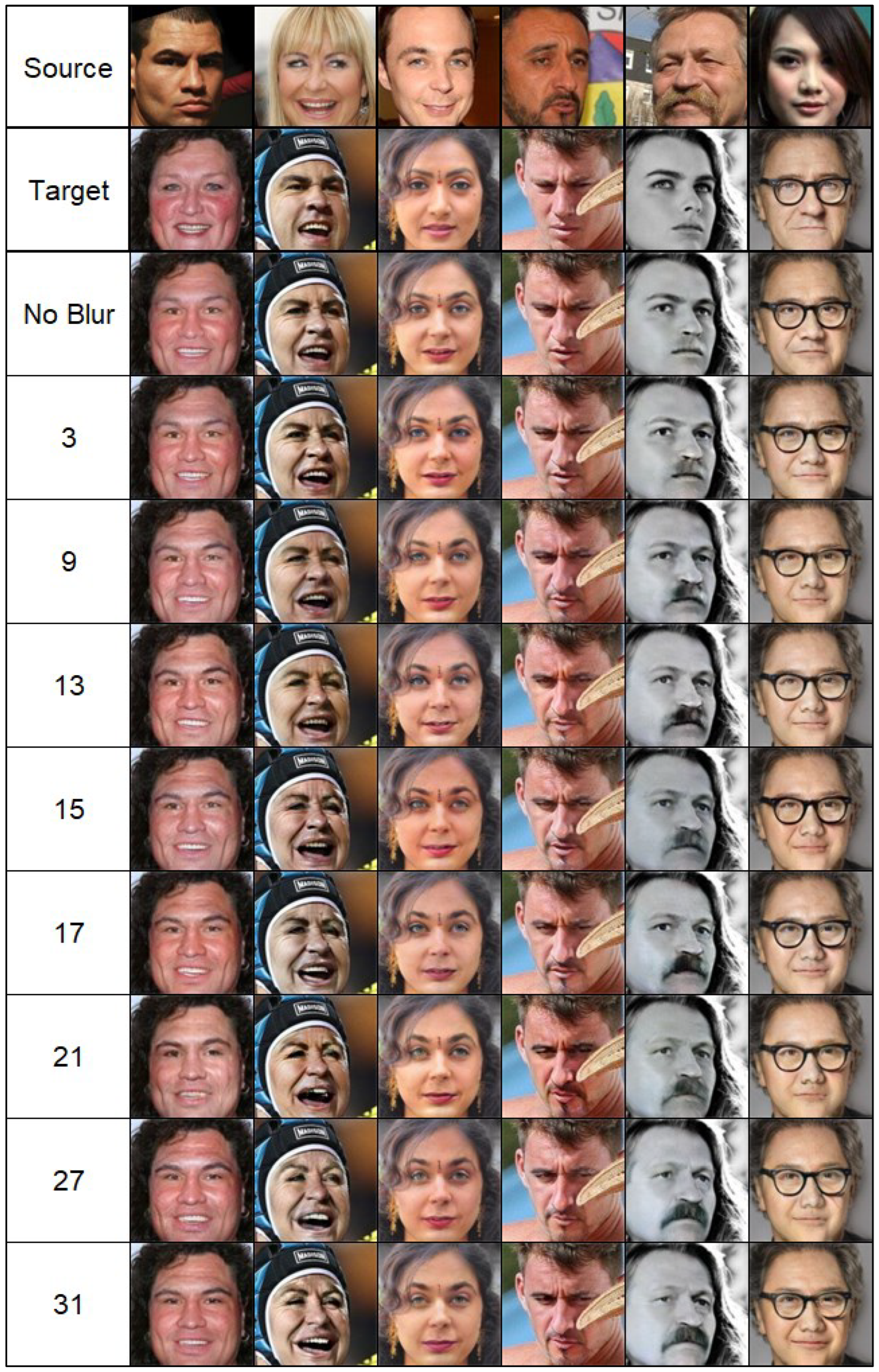
Figure 4.
Comparision with other methods.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



