Submitted:
30 October 2023
Posted:
30 October 2023
You are already at the latest version
Abstract
s: The lack of historical employment data for college graduates, the need to solve the system cold-start problem and the consideration of reciprocity of job recommendation in job recommendation, lead to low recommendation satisfaction and immature application of the existing job recommendation methods. The article presents a new approach to job recommendation using college graduates as the object of study. In the screening stage, a semantic keyword iterative algorithm is applied to compute the similarity between the resume and recruitment texts. This algorithm enhances the intersectionality of keywords in the calculation process, maximizing the utilization of resume information to enhance the accuracy of text similarity calculations. The ranking phase utilizes in-school data to build a social network between college graduates and graduated students, and solves the system's cold-start problem by using the social network to recommend jobs for college graduates where graduated students are employed. Building upon the amalgamation of the semantic keyword iterative algorithm and the social network job recommendation method outlined above, we introduce a dual-dimensional matching approach involving specialty and salary. This enhancement is designed to elevate the reciprocity of job recommendations. The analysis of the results indicates that the average satisfaction rate (AR) and normalized discounted cumulative gain (NDCG) values for the newly proposed job recommendation method surpass those of other methods, demonstrating its superior effectiveness. The method caters to the preferences of graduate job seekers, aligns with job recruitment requirements, and offers extensive job search assistance to a broad spectrum of graduates.
Keywords:
job recommendation
; semantic keyword matching
; reciprocity
; social networks
; college graduates
1. Introduction
The advancement of higher education has facilitated an expansion in student enrollment within colleges and universities, consequently leading to a yearly increase in the number of graduates.According to statistics, China’s college graduates in 2023 have reached 11.58 million, representing a year-on-year growth of 820,000. A substantial influx of new graduates has entered the job market, intensifying the competition for employment [1,2]. Concurrently, some graduates encounter challenges due to undefined employment goals, decision-making difficulties, and information overload [3,4,5]. These factors contribute to a decline in the overall employment rate. To assist graduates in securing employment, colleges offer career guidance; however, there exists a deficiency in tailored recommendations for individual cases [6]. Current job search platforms predominantly cater to social job seekers, and the exploration and implementation of personalized recommendations for graduates are still underdeveloped. Additionally, given the multitude of majors and diverse employment fields, providing tailored job recommendations for graduates becomes a more intricate challenge [7]. The following issues afflict the current job recommendation methodology: (a)The content-based approach heavily depends on semantic matching technology, while the current technology still grapples with limitations in understanding and extracting semantics. This results in poor accuracy when calculating the relevance of resumes to jobs. (b) Collaborative filtering-based methods rely on user behavioral data to model interest preferences, but the sparse user data of first-time graduates makes it challenging to accurately capture their interests. (c) The specific group of graduates differs from the rich historical behavioral data that social users have, and the system faces the cold-start problem, thus limiting the effectiveness of the recommendation model.
In addressing the aforementioned issues, this study proposes an enhanced semantic matching algorithm. This algorithm employs keyword expansion and iterative computation to prevent the loss of semantic information when calculating the similarity between resume and job text. Building upon this foundation and leveraging the social network relationships among graduates, personalized suggestions are deduced by relying on the recommendation results of similar users. This approach aims to address the cold-start problem in graduate recommendations and provide accurate and reliable recommendation results. The approach integrates information from both semantic and social network dimensions, with the goal of enhancing the performance of graduate job recommendation methods. Moreover, this paper emphasizes professional matching and salary matching, aspects of considerable concern for both parties in job search and recruitment. It incorporates the calculation of dimensions related to "professional matching and salary matching," thereby further fortifying the reciprocity of job recommendations.
2. Related Works
2.1. Research on Job Recommendation Based on Keyword Matching
The keyword matching-based job recommendation method is essentially a content-based approach. It reveals job seeker preferences and job recruitment requirements by extracting keywords and calculating the similarity between the two, ultimately generating a list of job recommendations. Bansal [8] used an LDA model to extract keywords to mine job seekers’ preferences and recommend the best jobs for job seekers; Lacic [9] employs a self-encoder architecture to encode a job seeker’s session within the session domain and utilizes k-nearest neighbor methods for inference to analyze potential jobs and provide job recommendations for the job seeker. While keyword matching offers certain advantages compared to traditional job recommendation methods, it also has limitations in terms of semantic matching and struggles with the effective processing of sparse short texts. For instance, the Boolean search-based model utilizes a keyword matching technique to align the requirements outlined in the job posting with the qualification information from the user’s resume. However, the model encounters limitations in semantic extraction [10]. Moreover, the constrained information within resume and recruitment texts poses challenges in effectively extracting the personality preferences of job seekers. This limitation has prompted the development of building behavioral preference models for users, achieved through the collection of their implicit data. Subsequently, these models are utilized to recommend satisfactory jobs that align with users’ preferences [11]. On this foundation, the development of constructing user profiles by analyzing the behavioral data of job seekers on e-recruitment platforms to extract personality preferences, with the aim of establishing a unidirectional job recommendation model for job seekers, began to unfold [12]. At present, the employed keyword matching in job recommendation involves extracting keywords from the text for a basic match. However, the information within the job seeker’s resume is limited, resulting in the extraction of fewer keywords. This limitation impedes the accurate alignment of resume information with recruitment details, thereby lowering the accuracy and satisfaction levels of job recommendations. In addition, the current keyword matching does not start from semantic matching and reciprocal matching [13].
2.2. Research on Job Recommendation Based on Social Network
Social networks are essentially the fusion of social elements and network structures, representing virtual networks established with the primary intent of facilitating social interaction [14,15]. In the era of the Internet’s evolution, numerous third-party suites have been integrated into social networking platforms, enhancing the diversity and integration of these social platforms. The integration of job recommendations with social networks is intended to assist job seekers in identifying more suitable and satisfying employment opportunities [16,17,18]. Integrating social networks into the process of generating job recommendations not only diminishes operational costs but also enhances the precision of job recommendations [16]. Through his research, Alejandro [19] illustrates that engaging in recruiting and job searching on social networks can effectively address issues such as the low accuracy of job recommendations stemming from sparse user data. Job recommendation methods established on career-oriented social networks exhibit superior performance in suggesting satisfactory jobs for job seekers by effectively capturing their preferences [20]. Moreover, disseminating job postings via social networking platforms and suggesting vacancies to friends within social networks can significantly enhance the accuracy of recommendations [21]. The greater the activity level of social network users and the extent of their contacts, the higher the precision of job recommendations [22]. Social networks not only facilitate efficient job searching for job seekers but also assist employers in identifying more suitable candidates for recruitment. Social networks can furnish more dependable hiring references for recruiting employers, as they commonly utilize platforms like Facebook to acquire information about potential candidates [23]. Given that information posted on social networks, such as Facebook, is typically personal rather than professional, employers can form a more precise assessment of a candidate’s character [24]. While the integration of social networks can enhance the effectiveness of job recommendations, college graduates, as newcomers in the workplace, often lack a well-established professional social circle. Hence, there is significant research significance in integrating the academic data of college graduates with the employment information of graduated students to establish a social network for college graduates, thereby facilitating the recommendation of satisfactory job opportunities for them.
2.3. Research on Job Recommendation Based on Reciprocity
Reciprocal recommendation is to provide recommendations based on the common preferences of both users [25]. Reciprocal recommendations have been successfully employed in various domains, including online dating systems [25], online mentoring systems [26], and online recruitment systems [27]. Reciprocity-based job recommendation implies that the recommended job not only aligns with the preferences of the job seeker but also meets the requirements and preferences of the recruiter [13,28]. To achieve reciprocity in job recommendation, existing research predominantly employs distinct recommendation methods tailored to the characteristics of diverse users. For instance, Malinowski [28] devised two job recommendation systems tailored to the distinct preferences of both job seekers and recruiters, effectively addressing the requirements of each party. A job recommender system, utilizing a model of latent factors derived from the explicit profile information of both the job seeker and the job, can exhibit notable performance in achieving reciprocity [29,30]. Hybrid recommendation methods, when integrated with reciprocal recommendation approaches, can further enhance the accuracy of job recommendations. For instance, employing Support Vector Machine (SVM) predictive modeling to estimate the likelihood of a company’s response to an application, within a hybrid recommendation method that integrates content and collaborative filtering, can enhance the accuracy of job recommendations [31]. These personalized job recommendation systems comprehensively account for the bidirectional preferences of both job seekers and recruiters. They address the limitations of reciprocal recommendation, consequently enhancing the success rate of job recommendations. However, the evaluation is solely focused on the accuracy of one-way recommendation results and does not provide a side-by-side comparison with other one-way job recommendation methods.
2.4. The Application of Job Recommendation in The Field of Colleges
At present, relatively robust personalized employment platforms, such as ’Wisdom Link Recruitment Network’ and ’58job,’ are geared towards social users. Nevertheless, the research and application of job recommendations specifically for college graduates remain relatively limited. There are collaborative filtering-based job recommendation algorithms that cluster graduates into different groups based on their characteristics and recommend jobs to graduates, considering their preferences [32]. Additionally, there are content-based job algorithms that utilize historical employment information to calculate the relevance between graduates and jobs, subsequently providing unidirectional recommendations for jobs that are related to graduates [33]. However, these algorithms often result in a narrow focus for recommendations, which is not conducive to recommending a variety of job types. Therefore, Shi [34] proposes to integrate key technologies, such as graduate feature technology, similarity algorithms, and neighbor selection mechanisms, to establish a graduate employment recommendation system, with the aim of broadening the scope of recommendation results. Assudani [35] highlights the challenges associated with broadening the diversity of job recommendations and constructing a multi-category job database as key difficulties in the recommendation process. Leveraging existing campus employment portals has become a novel research focus for recommending suitable graduate candidates to companies from the recruiter’s perspective. Since college graduates, as new users of the job recommendation system, lack historical behavioral data, the system faces difficulty in capturing graduates’ job search preferences [34,36]. This challenge directly influences the accuracy and satisfaction of the recommendations. Therefore, research on job recommendation in the college domain can effectively leverage campus data to capture the job search preferences of college graduates and provide recommendations for satisfying job opportunities.
3. Proposed Job Recommendation Method
The job recommendation model comprises three distinct phases, as illustrated in Figure 1. The initial screening stage employs a semantic keyword iterative algorithm to calculate the similarity between the resume text and the job posting text. This calculation is then used to filter the candidate job set based on text similarity. The second stage is the ranking stage, in which entropy aggregation is conducted using three dimensions: professional similarity, salary matching, and social network. Based on the calculated values, the set of job recommendations is determined, and subsequently, the jobs are returned to college graduates for scoring. The third stage is the evaluation stage, in which the model assesses the satisfaction and reciprocity of the job recommendation outcomes using metrics such as Average Satisfaction (AR) and Normalized Discounted Cumulative Gain (NDCG).
3.1. Screening Phase
3.1.1. Text Information Extraction And Processing filtering stage
The resume texts of college graduates and job recruitment texts are presented in Table 1 and Table 2, respectively. The resume text includes essential information, such as gender, hometown, graduation college, major, research direction, and job preferences. The job recruitment text encompasses details on job positions, workplaces, salary levels, company nature (state-owned or private enterprises), as well as academic, skill, and professional requirements.
In this study, the Jieba precise mode was employed to perform word segmentation on both resume and job recruitment texts. To enhance the precision of word segmentation, a specialized vocabulary related to the profession was incorporated. Punctuation marks and stop words have been removed from the text. Subsequently, Term Frequency-Inverse Document Frequency (TFIDF) values are calculated, and keywords are extracted based on their respective TFIDF values.
3.1.2. The Semantic Keyword Iterative Algorithm
Quattrone et al. [37] pointed out that traditional similarity calculation methods, such as cosine similarity, suffer from low utility when dealing with sparse data. Traditional methods rely solely on word frequency to calculate text similarity, making them susceptible to discarding keywords with low frequency, thus resulting in reduced calculation accuracy [38,39]. Considering that college graduates, as new users of the job recommendation system, lack historical information and encounter sparse data issues, this study addresses this challenge by employing a semantic keyword iterative algorithm. The proposed algorithm utilizes a keyword correlation matrix to calculate text similarity, effectively resolving the computational accuracy problem caused by discarding low-frequency keywords. This approach enhances the accuracy of the job recommendation system, enabling it to provide more reliable recommendations to college graduates, despite their limited historical data.
The keyword correlation matrix is calculated using equation(1-5). First, the TFIDF algorithm was used to calculate the ’ keyword-text ’ matrix, referred to as matrix. KD is an matrix, represents the number of keywords, represents the number of texts, represents the number of times the keyword appears in the text; for example, represents the number of times the keyword appears in the text .
The keyword correlation matrix is calculated based on the KD matrix. The specific calculation process is as follows:
Step 1.
The first step is to define the initial similarity value of the keyword and the text . The principle of definition is that each keyword or text is the same as itself and has certain differences from other keywords and texts. represents the initial similarity value between keywords and , and represents the initial similarity value between text and .
Step n
represents the similarity value between keywords and in the nth iteration, and represents the similarity value between text and in the nth iteration. The definitions of and are given in Equations (4)–(5).
Where
The calculated value of in step n must be incorporated into the text similarity calculation of in step . The calculated value of in step n must be incorporated into the keyword similarity calculation of in step , and the iterative calculation is carried out in turn. ,,, in Eq. (4) and Eq. (5) are elements of matrix. is the mutual reinforcement factor. When keywords and represent the same document, the mutual reinforcement factor . In the other cases, the value range of is (0,1). The value of was experimentally obtained. In this study, the best result was obtained when .
To further address the issue of data sparsity, the resume text of graduates was expanded with additional keywords. Specifically, the two most similar keywords, excluding those already present in the resume text, were added to enhance their content. This expanded resume text was then used to match the job recruitment text. A keyword relevance matrix was obtained through the iterative process described above. Finally, the match degree (MD) between the graduates’ resume text and the job recruitment text was calculated using Equation (6).
indicates the number of extended-resume document keywords. represents the frequency score of keyword in the nth resume document and represents the frequency score of keyword in the job document. is a parameter used to determine whether the keyword in the resume document is the original keyword. When , is the original keyword in the document. When is a rich keyword, the value of is equal to the calculated value of the keyword correlation matrix. The candidate working set was obtained according to the similarity value calculated using the keyword correlation matrix.
3.2. Ranking Stage
In the realm of employment, the level of professional alignment between job seekers and job positions constitutes a critical factor influencing the outcome of job searches. Given the disparity between job availability and the demand for skilled individuals in the job market, employers are increasingly prioritizing the degree of professional compatibility between job roles and candidates [40]. Rational choice theory posits that individuals are rational decision-makers who weigh the costs and potential benefits when arriving at decisions [41].Researchers, such as Jung et al. [42] have employed the potential Dirichlet distribution method online to extract themes from a substantial volume of employee comments, and their analysis has highlighted salary as a pivotal factor influencing job satisfaction. Hence, the degree of salary alignment emerges as a significant determinant affecting job recommendation satisfaction. Regular equivalence theory, a fundamental doctrine within communication theory, demonstrates that an individual’s behavior is influenced by the information, attitudes, and actions of others within a network [38]. When two individuals share more common social circles, their behavioral preferences tend to exhibit greater similarity, fostering a propensity to establish connections [43,44]. Therefore, in this study, the utilization of social networks to recommend jobs for recent college graduates, leveraging the employment choices of alumni, can effectively enhance satisfaction and reciprocity in job recommendations.
In the ranking stage, this study employed three critical dimensions–professional matching, salary matching, and social network–to conduct entropy aggregation. The recommended job set is generated by calculating the entropy aggregation. Professional matching assesses the degree of compatibility between the skills and qualifications of college graduates and the professional requirements specified in job recruitment posts. Salary matching evaluates the level of correspondence between the expected salary of college graduates and the actual salary offered by the employing companies. Social networks analyze the social connections and relationships between college graduates and other graduate students, taking into consideration potential networking opportunities or affiliations that may influence job recommendations.
3.2.1. Professional Matching
First, the random walk probability was used to calculate the connection between graduated students and work, and then the professional matching score between the target and graduated students was calculated. We organized all the professional attributes of the job, job, and graduated students into a graphic . Professional job attributes include professional skills. In the figure, represents the set of nodes of the graduated students, represents the set of working nodes, and represents the set of professional attribute nodes of the work, that is, , as shown in Figure 2 and Figure 3.
Figure 2 shows the initial correlation model representing the graduated student node with its contracted job node. No edges were inserted in the initial correlation model. Starting with wandering, the edges connecting the node of the graduated student and the node of the signed job of this graduate are inserted, as shown in Figure 3. Start to randomly travel from the graduated student node , according to the probability ∂ decides whether to continue to travel or stop this travel to return to the starting node . Based on the above principle, if every job and job specialty attribute node is visited, the probability will converge to a number, and then the edge of the graduated student node to the job node will be removed.
The algorithm ends if every starting node is visited; otherwise, it continues to wander from the starting graduated student node. In this study, ∂ is taken as 0.7 by experiment, and the calculation formula is defined as follows:
denotes the probability of visiting node , PR denotes the probability of being visited, and ∂ denotes the probability of random wandering. denotes the set of nodes pointing from , and denotes the set of nodes pointing to node . PR denotes the probability that the start node visits job node , If is a job signed by the graduated student , then PR .
Calculate the professional matching value between the graduate student and the graduate using Equation (8).
represents the professional matching value between college graduates and graduate students. denotes the set of specialized attributes of college graduate and denotes the set of specialized attributes of graduated student . The probability of wandering with the graduate most similar to the college graduate as the starting node is the specialty match value. For example, the match value between and is the highest, and the wandering probability of graduated students as the starting node is used as the professional match value for college graduates .
3.2.2. Salary Matching
In this study, salary matching is performed using a two-dimensional Euclidean metric, with the metric factors being the average and maximum salary offered by the job and the entry and incentive salary desired by the graduate. The average salary represents the monthly remuneration received by each employee and the maximum salary denotes the highest amount paid by the company. Entry-level salary refers to the minimum salary required for college graduates, and incentive salary refers to the maximum salary desired by college graduates. The average and maximum salaries are viewed as a two-dimensional point , where represents the average salary for the job, and represents the maximum salary for the job. Entry and incentive salaries are viewed as two-dimensional points , where denotes the entry salary and denotes the incentive salary.
The value of defaulted to zero when the average salary of the job was lower than the entry salary expected by college graduates. Similarly, the value of defaulted to zero when the maximum salary of the job was lower than the incentive salary desired by college graduates. When choosing a job, college graduates look at the average and highest salary of the job with a bias, so when calculating the weight, δ is added to improve the accuracy of the calculation, and the value of δ ranges from 0 to 1. In this study, the value of δ is taken as 0.6 by experiment, which is calculated as follows:
3.2.3. Social Relationship
Interactive behaviors such as contacting and interacting between college graduates and those who have graduated can constitute a social network structure. In this paper, social networks between college graduates and graduated students are quantified using the "common friend set" and "intersection group" metrics. The common friends set pertains to the set of friends shared by college graduates and graduated students who "share the same hometown and college." The common intersection group refers to the set of individuals with "the same major and the same tutor." To account for differences in economic and consumption levels across cities, grouping based on hometown helps minimize variations in the salary requirements of graduates. Moreover, if a college graduate and a graduated student share the same major and have the same mentor, there is a high degree of similarity in their research directions, indicating a strong similarity in job search preferences. Considering the potential impact of the annual economic climate on the employment of current graduates, this study also incorporated the timing of their graduation into the job recommendation process.
Equation 13 represents the social network common friend set of college graduate and graduated student . Equation 14 represents the common intersection group of college graduates and graduated students . represents the summation of the number of common friends between college graduates and graduated students, and represents the summation of the common intersection group of college graduates and graduated students. represents the total number of friends of the college graduates and graduated students. If is a friend of college graduate , equals one; otherwise, it equals zero. If is also a friend of a graduated student , equals 1; otherwise, it equals 0. denotes the time difference between graduation time of college graduates and graduation time of graduated students.
3.2.4. Entropy Aggregation
Entropy aggregation is used to convert professional match values, salary match values, and social networks into a decision matrix, which is computed to produce a recommended job set. The calculation process is illustrated in Figure 4.
The in the above matrix represents a total of jobs, and represents the score value of the ith job in the jth column. There were three columns in the matrix: professional, salary, and social relationships. Decision matrix A is obtained by entropy aggregation. The decision matrix is normalized to obtain matrix B. Finally, the entropy values are obtained using equations (17),(18), and (19).
Let , is the number of column dimensions of the matrix (there are three dimensions in this study: professional matching, salary matching, and social relationship), and the entropy weight of the jth column is obtained by the calculation of Equation (18).
Finally, the entropy weights of each column of the work attributes are summarized to obtain the final ranking score .
3.3. Experimental Evaluation
3.3.1. Recommendation Method
To rigorously assess the efficacy of the job recommendation approach proposed in this study, it will be subject to evaluation and comparison against existing recommendation methods. The description of the recommended method is provided as follows:
TF-C [37]: This method employs cosine similarity to compute the resemblance between the text within a college graduate’s resume and the content of the job posting. The system then produces a list of job recommendations based on similarity scores for college graduates to evaluate. The rating scale ranges from 1 (unsatisfactory) to 5 (satisfactory), with a total score of 5.
MS [45]: In the screening stage, a semantic keyword matching approach is employed to evaluate the likeness between the content of the college graduate’s resume and the text of the job posting. Subsequently, a list of job recommendations is generated based on similarity and submitted to college graduates for scoring.
GERS [34]: Employment characteristics of graduates are analyzed using a two-dimensional matrix of graduate preferences. Subsequently, the system calculates the similarity between graduates to identify jobs chosen by neighboring graduates, generating a recommendation list.
RSCF [46]: The similarity between graduates’ resumes and job descriptions is integrated with a collaborative filtering algorithm based on graduates’ similarity to calculate a list of job recommendations. The recommended jobs are then provided to college graduates for scoring.
JRSR: Utilizing the job recommendation method introduced in this paper, the screening stage employs a semantic keyword iterative algorithm to compute the similarity between resume text and recruitment text. In the ranking stage, three dimensions—"professional matching, salary matching, and social network"—are employed to generate a set of job recommendations using entropy aggregation. This collection is then returned to college graduates for scoring.
To evaluate the influence of the historical employment information of graduated students on recommendation performance, this study divides the employment data into two distinct sets: the logistics engineering work sample set and the management and science work sample set. Subsequently, the job recommendation method (JRSR) proposed in this study was applied separately to each work sample set, generating two sets of recommendation results. Finally, the performance of the job recommendation method is assessed and compared based on the evaluation results from both sets of work samples.
3.3.2. Evaluation of Indicators
In this study, the recommendation outcomes were evaluated using the average satisfaction rate (AR) and normalized discounted cumulative gain (NDCG). The average satisfaction rate (AR) was used to assess the average satisfaction of college graduates with recommended jobs. Normalized Discounted Cumulative Gain (NDCG) was used to assess the reciprocity of job referral methods.
The Average Satisfaction Rate (AR) indicator was calculated using the ratings of college graduates for recommended jobs. The calculation formula is as follows:
represents the rating (on a scale of 1-5) of graduate for job ranked in the recommendation set. denotes the ranking of the job in the recommendation set (the rankings are 1, 2, 3, 4, and 5; the value of i is an integer between 1 and 5). denotes the number of jobs in the recommendation set (the number of recommended jobs in this study was five). is the number of graduates.
The Normalized Present Cumulative Gain (NDCG) calculates the reciprocity of the recommendation results based on the ranking and rating of the job in the recommendation list. The calculation formula is as follows:
Where,
The in the equation represents the rank of the recommended job in the recommendation set; for example, job is ranked 3 in the recommendation set, and the value of equals 3. The in the equation is the ranking from highest to lowest based on the ratings of the college graduates for the recommended jobs, for example, job , where the target graduates rated the lowest and ranked 5; therefore, the value of e is 5. There are a total of five candidate jobs in the recommended list, so the rankings are a total of five places.
4. Analysis and Discussion of Experimental Results
4.1. Experimental settings
Logistics engineering, management, and science represent a multidisciplinary domain that bridges the realms of management and technology, integrating engineering and scientific principles. It maintains strong connections with various fields, including transportation engineering, industrial engineering, computer technology, mechanical engineering, environmental engineering, architecture, and civil engineering. Consequently, this study focuses on graduates in logistics engineering, management, and science, given their versatile qualifications and adaptability. The data on graduates’ resumes come from the personal contents of university graduates registered in the university employment program, and the data on job samples come from the information on jobs signed by graduated students at several universities. For the experimental data in this paper, the total number of target graduates is 110, the total number of graduated graduates is 320, and the total number of remaining work samples after screening out the same jobs is 280. All the above data are from the two majors of logistics engineering and management and science. To assess the generalizability of the recommended methods proposed in this paper, additional experimental data has been incorporated for comparative evaluation. This paper includes employment data for students who graduated from five colleges in the last five years, encompassing a total of 1,200 graduates and 1,027 jobs across various majors under the management disciplines of business management, accounting, financial management, marketing, and tourism management.
During the screening stage, a semantic keyword iterative algorithm is employed to assess the similarity between the resume text of college graduates and the job recruitment text. In the ranking stage, the top 110 jobs with the highest degree of similarity undergo entropy aggregation, employing the three dimensions of "professional matching, salary matching, and social network" to generate a list of job recommendations. Finally, the jobs in the job recommendation list are returned to the college graduates for scoring. 1 (indicating dissatisfaction) to 5 (indicating satisfaction). This rating process serves as the means to evaluate the efficacy of the job recommendation method proposed in this paper.
4.2. Experimental data analysis
The primary focus of this paper is to investigate the employment situation of students majoring in logistics engineering and management and science. Therefore, the employment data related to these two majors, including 110 targeted graduates, 320 graduateds, and a total of 280 work samples, were analyzed for data visualization. Figure 5, Figure 6, Figure 7 and Figure 8 illustrate the percentage distribution of college graduates and graduated hometowns, secondary colleges, majors, and mentors, respectively. The horizontal axis represents the percentage of college graduates in the dataset, while the vertical axis represents the percentage of graduated students in the dataset.
Figure 5, Figure 6, Figure 7 and Figure 8 illustrate the distribution of hometown, secondary college, major, and advisor proportions for college graduates and graduated students. The horizontal axis represents the percentage of college graduates’ hometowns within the dataset of college graduates, while the vertical axis represents the percentage of graduated students’ hometowns within the dataset of graduated students. The highest proportion of hometowns in the college graduate dataset is 3.6%, compared to 7% in the graduated student dataset. For the secondary college with the highest proportion in the college graduate dataset, it accounts for 20%, while in the graduated student dataset, it is 24%. The major with the highest proportion in the college graduate dataset is 17.5%, in contrast to 11% in the graduated student dataset. Additionally, the top advisor proportion in the college graduate dataset is 28%, while in the graduated student dataset, it is merely 1.18%. Through meticulous data analysis, a notable and substantial social interconnection emerges between college graduates and graduated students, encompassing facets such as hometowns, secondary colleges, majors, and advisors. This interconnectedness serves as the bedrock for cultivating a closely-woven social network, which in turn provides the fundamental groundwork for calculating probabilities in the context of random walks.
To analyze the social connections between college graduates and those who have already graduated more clearly, this paper subdivided the four dimensions (hometown, second-level college, major, and mentor) together to generate a social relationship network, as shown in Figure 9. The analysis demonstrates a strong social connection across the four dimensions of hometowns, secondary colleges, majors, and mentors between college graduates and graduated students. This emphasizes the viability of utilizing social networks to facilitate the recommendation of job opportunities endorsed by graduated students to college graduates.
4.3. Result analysis
This article employs five job recommendation methods (TF-C, MS, GERS, RSCF, JRSR) to compute the recommended work set and subsequently conducts an analysis of the outcomes utilizing evaluation metrics.
4.3.1. Evaluation Analysis of Average Satisfaction Rate
Figure 10 presents a comparative chart illustrating the average satisfaction rates among the five job recommendation methods. The graph clearly indicates that JRSR attains a notably higher average satisfaction rate when contrasted with the remaining four job recommendation methods. Among these five approaches, TF-C demonstrates the lowest average satisfaction rate, registering at a mere 2.631. Meanwhile, the average satisfaction rates for the other three job recommendation methods, namely MS, GERS, and RSCF, exhibit relatively close values.The job recommendation method introduced in this paper, JRSR, records an average satisfaction rate of 3.743. In comparison to the four benchmark methods, it showcases a maximum improvement of 1.112 and a minimum improvement of 0.502. This compellingly suggests that the job recommendation method presented in this study, JRSR, excels in discerning the job preferences of college graduates, ultimately resulting in more gratifying job recommendations.
The experimental data in this paper were non-normally distributed. To test for a significant difference in the AR@5 assessment values of the JRSR, TF-C, MS, GERS, and RSCF methods, the Wilcoxon signed-rank test was employed. As indicated in Table 3 (p < 0.05), there is a significant difference between the assessed values of JRSR and the other four methods.
4.3.2. Evaluation Analysis of Normalized Discounted Cumulative Gain
Figure 11 illustrates the results of Normalized Discounted Cumulative Gain (NDCG@5) for the five job recommendation methods. The graph clearly demonstrates that among these methods, JRSR attains the highest NDCG@5 score, reaching 0.938. Among the four benchmark methods, TF-C achieves the lowest NDCG@5 score at 0.675, while GERS reaches the highest score at 0.859. When compared to TF-C and GERS, the proposed JRSR method exhibits a remarkable improvement in NDCG@5, with enhancements of 38.96% and 9.19%, respectively. This emphasizes the effectiveness of the JRSR job rec-ommendation method presented in this paper in aligning the preferences and re-quirements of college graduates with job opportunities.
The experimental data were non-normally distributed. In this paper, the Wilcoxon signed-rank test was used to assess whether there was a significant difference in the NDCG@5 assessment values of the JRSR, TF-C, MS, GERS, and RSCF methods. As evident from Table 4, with p < 0.05, there is a significant difference between the assessment values of JRSR and the other four methods.
4.3.3. Comparative Analysis of The Recommendation Results Under different Job Sample sets
To assess the impact of historical employment information on recommendation outcomes, this study categorizes the job placements of graduates into two groups: the ”Logistics Engineering Job Sample Set” and the “Management and Science Job Sample Set”, as illustrated in Figure 12. The AR@5 evaluation score for the Logistics Engineering sample set is 3.728, surpassing that of the Management and Science sample set by 0.467. This indicates a stronger preference among college graduates for jobs closely aligned with their majors. In terms of NDCG@5, the Logistics Engineering sample set achieves a score of 0.971, while the Management and Science sample set scores 0.866, resulting in a 0.105 higher NDCG@5 score for the Logistics Engineering sample set. This demonstrates the potential for major alignment to enhance the mutual effectiveness of job recommendations.
4.3.4. Comparative Analysis of Evaluated Values for Different Recommendation List Lengths
To assess the recommendation performance of job recommendation methods under varying sample sizes and diverse recommendation list lengths, this paper expands the sample size in the experimental data and computes recommendation lists of varying lengths. The experimental dataset employed for this comparative analysis comprises 110 targeted graduates, 1,200 graduated students, and 1,027 job positions. It encompasses various specializations within the management disciplines, including business management, accounting, financial management, marketing, and tourism management.

Table 5.
AR assessment values for different recommended list lengths.
| AR@5 | AR@10 | AR@15 | AR@20 | |
|---|---|---|---|---|
| TF-C | 2.532 | 2.528 | 2.471 | 2.418 |
| MS | 2.862 | 2.959 | 2.762 | 2.561 |
| GERS | 3.158 | 3.269 | 3.136 | 2.948 |
| RSCF | 3.258 | 3.163 | 3.216 | 3.117 |
| JRSR | 3.462 | 3.298 | 3.272 | 3.189 |
By examining both Figure 10 and Figure 13, it is evident that the assessed values of AR@5 for the five recommended methods exhibited a decline with the augmentation of data. The most substantial decrease occurred in the case of JRSR, dropping from 3.743 to 3.462, representing a 7.5% reduction. As the length of the recommendation lists increases for the five methods, their AR evaluations decrease. In Figure 14, it is evident that the assessed value of AR@20 significantly exceeds that of AR@5, with the MS value-added reaching its peak at 0.301 and the TF-C value-added registering its lowest at 0.114. It is evident that both the size of the experimental data sample and the length of the recommendation list directly impact the recommendation satisfaction rate.
Table 6.
NDCG Assessment Values for Different Recommended List Lengths.
| NDCG@5 | NDCG@10 | NDCG@15 | NDCG@20 | |
|---|---|---|---|---|
| TF-C | 0.638 | 0.641 | 0.612 | 0.591 |
| MS | 0.692 | 0.662 | 0.659 | 0.658 |
| GERS | 0.804 | 0.725 | 0.698 | 0.701 |
| RSCF | 0.791 | 0.751 | 0.759 | 0.741 |
| JRSR | 0.881 | 0.858 | 0.862 | 0.816 |
By combining Figure 11 and Figure 14, it is apparent that as the sample size of the experimental data expands, the assessed values of NDCG@5 for the five recommended methods decrease. The most substantial decrease is observed in MS, where it is 0.089, while the smallest decrease is in RSCF, where it is 0.03. Moreover, with the increase in the length of the recommended list, there is a decrease in its NDCG assessment. The most significant decrease is observed for GERS at 12.81%, while the smallest decrease is for MS at 4.9%. It is evident that both the size of the experimental data sample and the length of the recommendation list impact the normalized present cumulative gain assessment value.
4.3. Discussion
In Figure 10 and Figure 11, both the average satisfaction rate and the normalized discounted cumulative gain (NDCG) of the JRSR job recommendation method, as proposed in this paper, outperform the other four recommendation methods. This robustly underscores the effectiveness and superiority of the JRSR approach in job recommendation. In contrast to the TF-C and MS methods, JRSR employs a keyword iterative calculation approach to determine the similarity between the resume text of college graduates and job recruitment text. This methodology not only mitigates the problem of neglecting low-frequency keywords but also enhances inter-keyword cross-referencing, resulting in a more robust semantic matching of text similarity. The job recommendation method GERS recommends job selections for graduates by calculating the similarity of employment characteristics among graduates and suggesting the choices of neighboring graduates as pre-recommended items [31]. This method is a collaborative filtering recommendation approach, which narrows down the recommendation scope. However, it simplifies the calculation of similarity in employment characteristics among graduates. In contrast, the JRSR recommendation method, when calculating the similarity in employment characteristics among graduates, establishes a social network based on academic data from graduates. This approach not only effectively computes the similarity in employment characteristics among graduates but also addresses the system cold start problem caused by a lack of employment data for college graduates. Compared to the recommendation method RSCF, which combines content-based and collaborative filtering approaches [43], the JRSR recommendation method adds dimensions of major matching and salary matching. By employing multiple methods and dimensions, JRSR matches the preferences and job requirements of college graduates, thereby enhancing the reciprocity of job recommendations.
In recent years, China has vigorously developed higher education, leading to an increasing number of college graduates. The application of job recommendation systems has provided assistance to graduates in finding employment. However, current job recommendation methods face several pressing issues, such as the problem of discarding low-frequency keywords during information matching, resulting in lower accuracy, issues related to major structure matching, salary matching, and system cold start problems. In response to the aforementioned issues, this study proposes a new job recommendation method. Experimental evaluations indicate that the job recommendation method proposed in this study outperforms existing recommendation methods in terms of recommendation performance. However, job recommendation for college graduates is a complex and practically significant subject, deserving further in-depth research. Future research can be conducted in the following areas: (a) Job recommendation methods should not only focus on satisfaction and accuracy but also consider the scalability of the recommendation methods and the diversity of data. (b) Further research on the selection of employment characteristics, refining salary models, and improving the efficiency of job recommendation methods from the perspective of salary matching. (c) Utilizing more vocational assessment tools to help graduates gain a more objective and comprehensive understanding of themselves, clarify more precise employment intentions, and conduct in-depth studies on graduates’ personal satisfaction and organizational satisfaction after entering the workforce to enhance the quality of job recommendations.
5. Conclusion
In response to the issue of low accuracy resulting from the omission of low-frequency keywords during the keyword matching calculation, this study employed a text similarity calculation method based on a semantic keyword iteration algorithm during the filtering phase. This method effectively mitigated the problem of discarding low-frequency keywords, thereby enhancing calculation accuracy.The study addressed the issues of major structure matching and salary matching between college graduates and jobs, leading to a significant improvement in job recommendation satisfaction.
For the first time, this study introduces graduate social networks and historical employment information of past graduates. Jobs held by previous graduates are recommended to recent graduates, serving as a strategy to address the cold-start problem of the system. With the augmentation of both the sample size in the experimental data and the length of the job recommendation list, there is a concurrent decrease in the average satisfaction rate (AR) and the normalized present cumulative gain (NDCG) of the job recommendation method.
Evaluation based on the Average Satisfaction Rate (AR) and Normalized Discounted Cumulative Gain (NDCG) metrics demonstrated that the job recommendation method for college graduates proposed in this study outperforms baseline recommendation methods in terms of recommendation performance.
Author Contributions
Conceptualization, J.P., Y.H., and J.J. ; Methodology, J.P.,Y.H.; Software, J.P.; Validation, J.P., J.J., and Y.H.; formal analysis, J.P.; investigation, J.P. and Y.H.; resources, J.P. and J.J.; data curation, J.P.; writing—original draft preparation, J.P.; writing—review and editing, J.P., J.J., and Y.H.; visualization, J.P.,; supervision, J.P.; project administration, J.P. All authors have read and agreed to the published version of the manuscript.
Funding
This work has received funding from the National Natural Science Foundation of China (Grant 71861019). The paper solely reflects the views of the authors. The Commission is not responsible for the contents of this paper or any use made thereof.
Data Availability Statement
The data used to support the findings of this study are available from the first author upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mok, K.H.; Montgomery, C. Remaking higher education for the post-COVID-19 era: Critical reflections on marketization, internationalization and graduate employment. Higher Education Quarterly2021,75(3), 373-380. [CrossRef]
- Zhao, Y.; He, F.; Feng, Y.Research on the Industrial Structure Upgrading Effect of the Employment Mobility of Graduates from China’s "Double First-Class" Colleges and Universities. Sustainability2022,14. [CrossRef]
- Maurer, S.D. ; Liu,Y. Developing effective e-recruiting websites: Insights for managers from marketers. Business Horizons2007, 50(4),305-314. [CrossRef]
- Liu, H. ; Wang,Z. Research on Causes and Countermeasures for the Difference between Employment Expectation and Actual Employment of College Graduates. in International Conference on Education2016,447-454.
- Ntale, P.D.; Sempebwa, J. Designing Organizations for Collaborative Relationships: the Amenability of Social Capital to Inter-Agency Collaboration in the Graduate Employment Context in Uganda. Employee Responsibilities and Rights Journal2022. 34(3), 291-318. [CrossRef]
- Evans, S. Social Recruiting. 2011.
- Rafter, R.; Bradley, K. Personalised Retrieval for Online Recruitment Services 2000.
- Bansal, S.; Srivastava,A. Topic Modeling Driven Content Based Jobs Recommendation Engine for Recruitment Industry. Procedia Computer Science2017, 122, 865-872. [CrossRef]
- Lacic, E. Using autoencoders for session-based job recommendations. User Modeling and User-Adapted Interaction 2020,30, 617-658. [CrossRef]
- Mostafa, L.; Beshir, S. Job candidate rank approach using machine learning techniques, Advanced Machine Learning Technologies and Applications: Proceedings of AMLTA 2021. Springer International Publishing2021, 225-233.
- Reusens, M. Explicit versus implicit job interests for recommendation: A job recommender system for the Flemish governmental employment services. Decision Support Systems2017. 98. [CrossRef]
- Rafter, R.; Bradley,K.; Smyth, B. Automated collaborative filtering applications for online recruitment services. in Adaptive Hypermedia and Adaptive Web-Based Systems: International Conference, AH 2000 Trento, Italy, August 28–30, 2000,363-368.
- Reusens, M.; Lemahieu, W.; Baesens, B. Evaluating recommendation and search in the labor market. Knowledge-Based Systems2018, 152, 62-69. [CrossRef]
- Zhang, Z.J. Personalized recommendation algorithm for social networks based on comprehensive trust. Applied Intelligence 2017, 47(3), 659-669. [CrossRef]
- Liu, J.Q.Joint Recommendations in Multilayer Mobile Social Networks. Ieee Transactions on Mobile Computing2020,19(10),2358-2373. [CrossRef]
- Malherbe, E.; Diaby, M.; Cataldi, M.; Viennet, E.; Aufaure, M. A. Field selection for job categorization and recommendation to social network users. In 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2014 , 588-595.
- Chala, S.; Fathi, M. Job Seeker to Vacancy Matching using Social Network Analysis. in IEEE International Conference on Industrial Technology (ICIT) 2017,1250-1255.
- Urdaneta-Ponte, M.C.; Oleagordia-Ruiz, I. ; Mendez-Zorrilla,A. Using LinkedIn Endorsements to Reinforce an Ontology and Machine Learning-Based Recommender System to Improve Professional Skills. Electronics2022, 11(8). [CrossRef]
- Corbellini, A. An architecture and platform for developing distributed recommendation algorithms on large-scale social networks.Journal of Information Science2015, 41(5), 686-704. [CrossRef]
- Rivas, A. Hybrid job offer recommender system in a social network. Expert Systems2019, 36(4), e12416. [CrossRef]
- Van Hoye, G.; Van Hooft, E.A.; Lievens, F. Networking as a job search behaviour: A social network perspective. Journal of Occupational and Organizational Psychology2009, 82(3), 661-682. [CrossRef]
- Skeels, M.M. ; Grudin. J. When social networks cross boundaries: a case study of workplace use of facebook and linkedin. in Acm International Conference on Supporting Group Work2009,95-104.
- Zhitomirsky-Geffet, M. ; Bratspiess, Y. Perceived Effectiveness of Social Networks for Job Search. Libri 2015, 65(2), 105-118. [CrossRef]
- Palank, J., Face it:‘Book’no secret to employers. The Washington Times 2006, 17.
- Xia, P.Reciprocal Recommendation System for Online Dating.In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015,234-241.
- Liu, J. An intelligent medical guidance and recommendation model driven by patient-physician communication data. Frontiers in Public Health 2023,11. [CrossRef]
- Ullah, Z. ; Jamjoom,M. A smart secured framework for detecting and averting online recruitment fraud using ensemble machine learning techniques. PeerJ Computer Science2023, 9, e1234. [CrossRef]
- Jochen, M. Matching people and jobs: A bilateral recommendation approach, Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS’06), IEEE Computer Society 2006.
- Jochen, M.; Weitzel, T.; Keim,T. Decision support for team staffing: An automated relational recommendation approach, Decision Support Systems2008 ,45(3),429-447. [CrossRef]
- Hong, W.; Zheng, S.; Wang, H.; Shi, J. A job recommender system based on user clustering. J. Comput.2013, 8(8), 1960-1967. [CrossRef]
- Özcan, Gözde, and Sule Gündüz Ögüdücü, Applying different classification techniques in reciprocal job recommender system for considering job candidate preferences, 2016 11th International Conference for Internet Technology and Secured Transactions (ICITST). IEEE2016,pp. 235-240.
- Zhou, Q.; Liao, F.; Chen, C.; Ge, L. Job recommendation algorithm for graduates based on personalized preference. CCF Transactions on Pervasive Computing and Interaction2019, 1, 260-274. [CrossRef]
- Li, S.; Chuancheng, Y.; Hongguo, W.; Yanhui, D. An Employment Recommendation Algorithm Based on Historical Information of College Graduates. In 2018 9th International Conference on Information Technology in Medicine and Education (ITME). IEEE2018,708-711.
- Shi, S.; Lv, H. A Framework of Graduate Employment Recommendation System and Key Technologies, 6th International Conference on Information Engineering for Mechanics and Materials,Atlantis Press2016,169-174.
- Assudani, P. J.; Kadu, R. K.; Sheikh, R.; Khanna, T. Smart College Campus Recruitment System. International Journal of Next-Generation Computing2022, 13(5).
- Reusens, M. A note on explicit versus implicit information for job recommendation. Decision Support Systems 2017, 98, 26-35. [CrossRef]
- Quattrone, G. Effective retrieval of resources in folksonomies using a new tag similarity measure. Computer Science 2011,545-550.
- Zhang, M.; Ma, J.; Liu, Z.; Sun, J.; Silva, T.A research analytics framework-supported recommendation approach for supervisor selection. British Journal of Educational Technology2016, 47(2), 403-420. [CrossRef]
- Quattrone, G. ; Capra, L. Effective retrieval of resources in folksonomies using a new tag similarity measure, Proceedings of the 20th ACM international conference on Information and knowledge management2011, 545-550.
- Li, W., Research on personalised recommendation algorithm for college students’ employment. Applied Mathematics and Nonlinear Sciences. [CrossRef]
- Scott, Allen,J. The Cultural Economy of Cities. International Journal of Urban & Regional Research2010, 21 (2), 323-339. [CrossRef]
- Jung, Y.; Yongmoo,S. Mining the voice of employees: A text mining approach to identifying and analyzing job satisfaction factors from online employee reviews, Decision Support Systems2019, 123. [CrossRef]
- Lou, T.; Tang, J.; Hopcroft, J.; Fang, Z. Learning to predict reciprocity and triadic closure in social networks, ACM Transactions on Knowledge Discovery from Data (TKDD)2013 ,7 (2),1-25. [CrossRef]
- Malherbe, E.; Diaby, M.; Cataldi, M.; Viennet, E.; Aufaure, M. A. Field selection for job categorization and recommendation to social network users. In 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2014 , 588-595.
- Ishitani, Y.Model-based information extraction method tolerant of OCR errors for document images. International Journal of Computer Processing of Oriental Languages2002 ,15 (2), 165-186. [CrossRef]
- Zhang, Y.; Yang, C.; Niu, Z. A research of job recommendation system based on collaborative filtering. In 2014 seventh international symposium on computational intelligence and design2014, 1,533-538.
Figure 1.
Job Recommendation Model Framework.
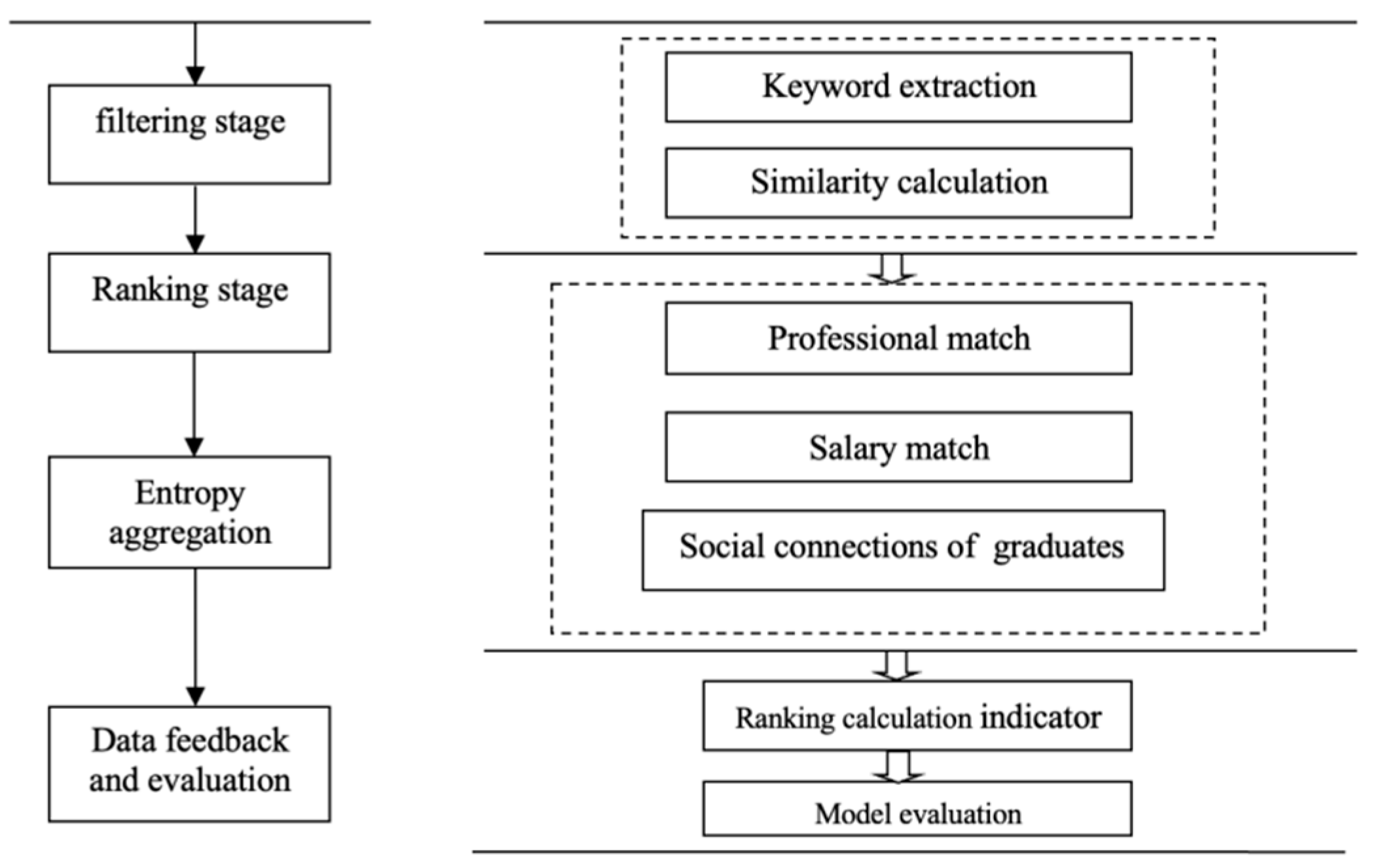
Figure 2.
Initial correlation model.
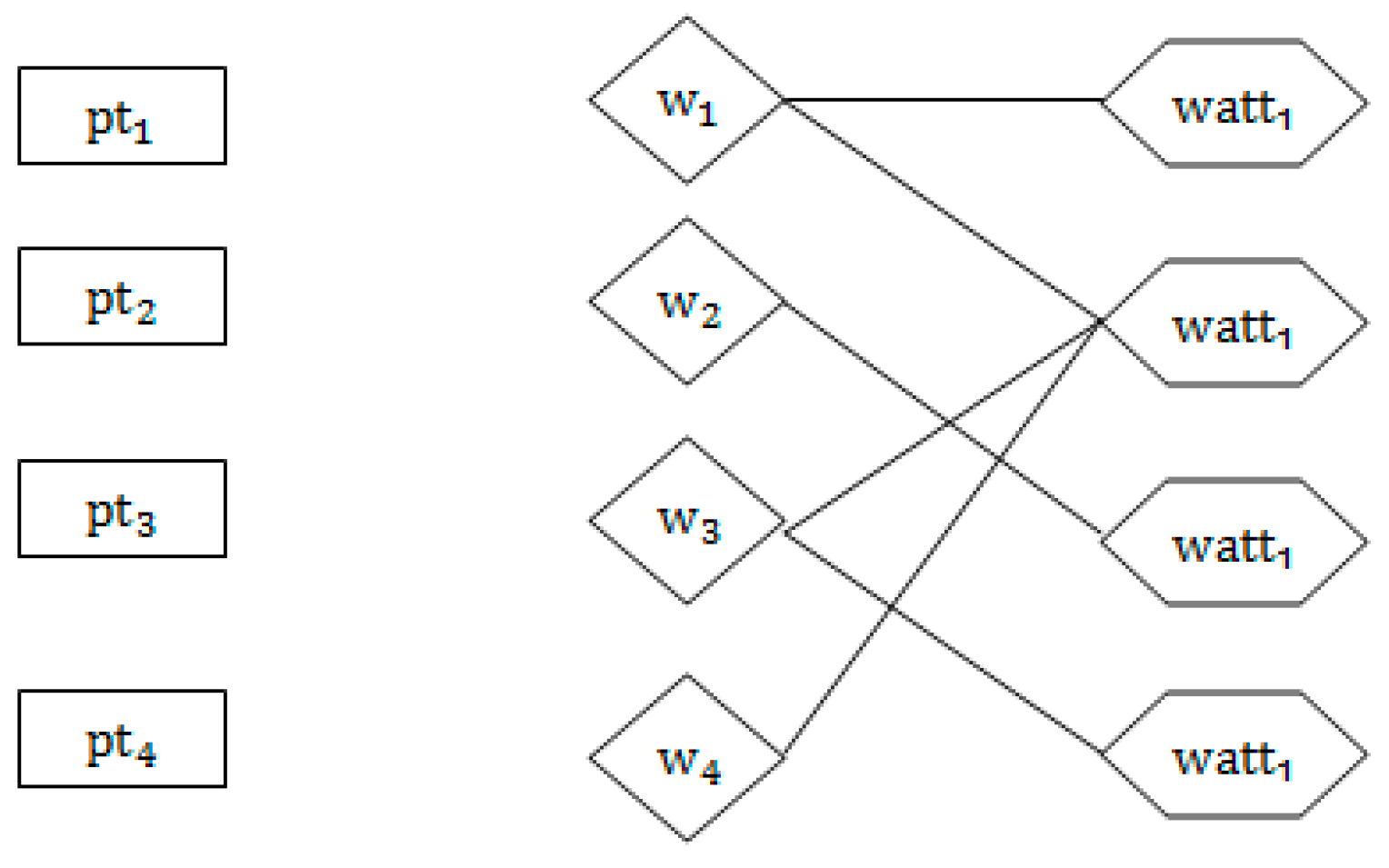
Figure 3.
Correlation model.
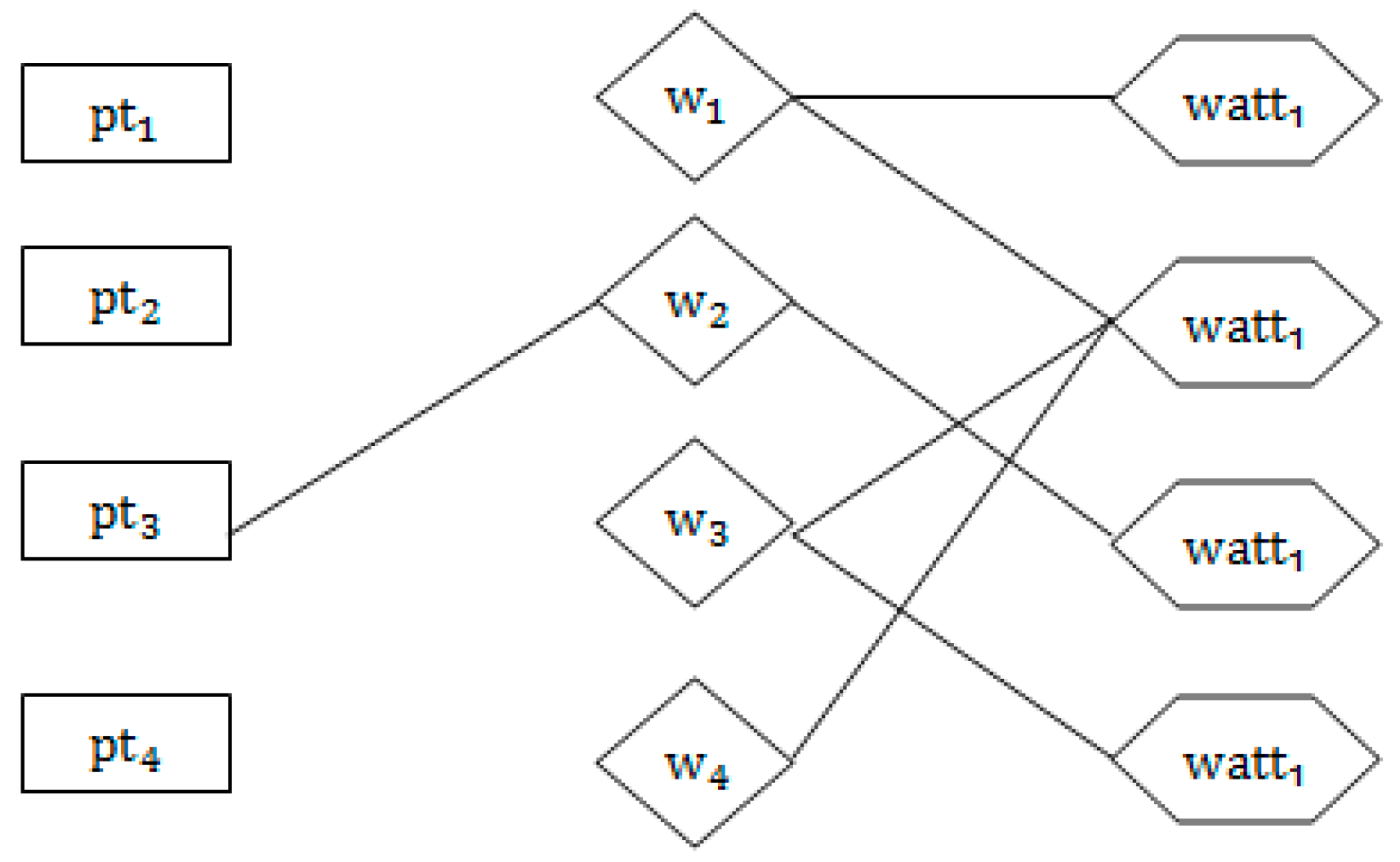
Figure 4.
Ranking calculation process.
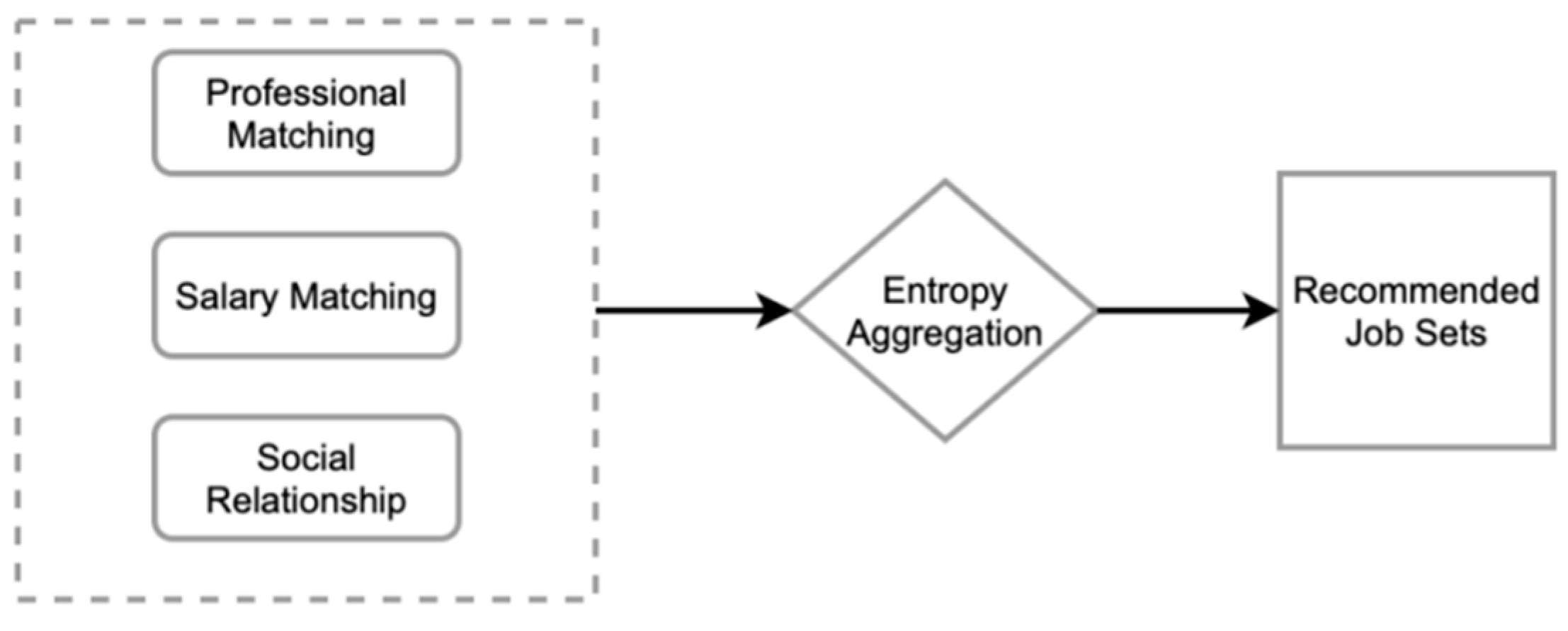
Figure 5.
Comparison of High School Graduates and Graduated Students’ Hometown Data Sets.
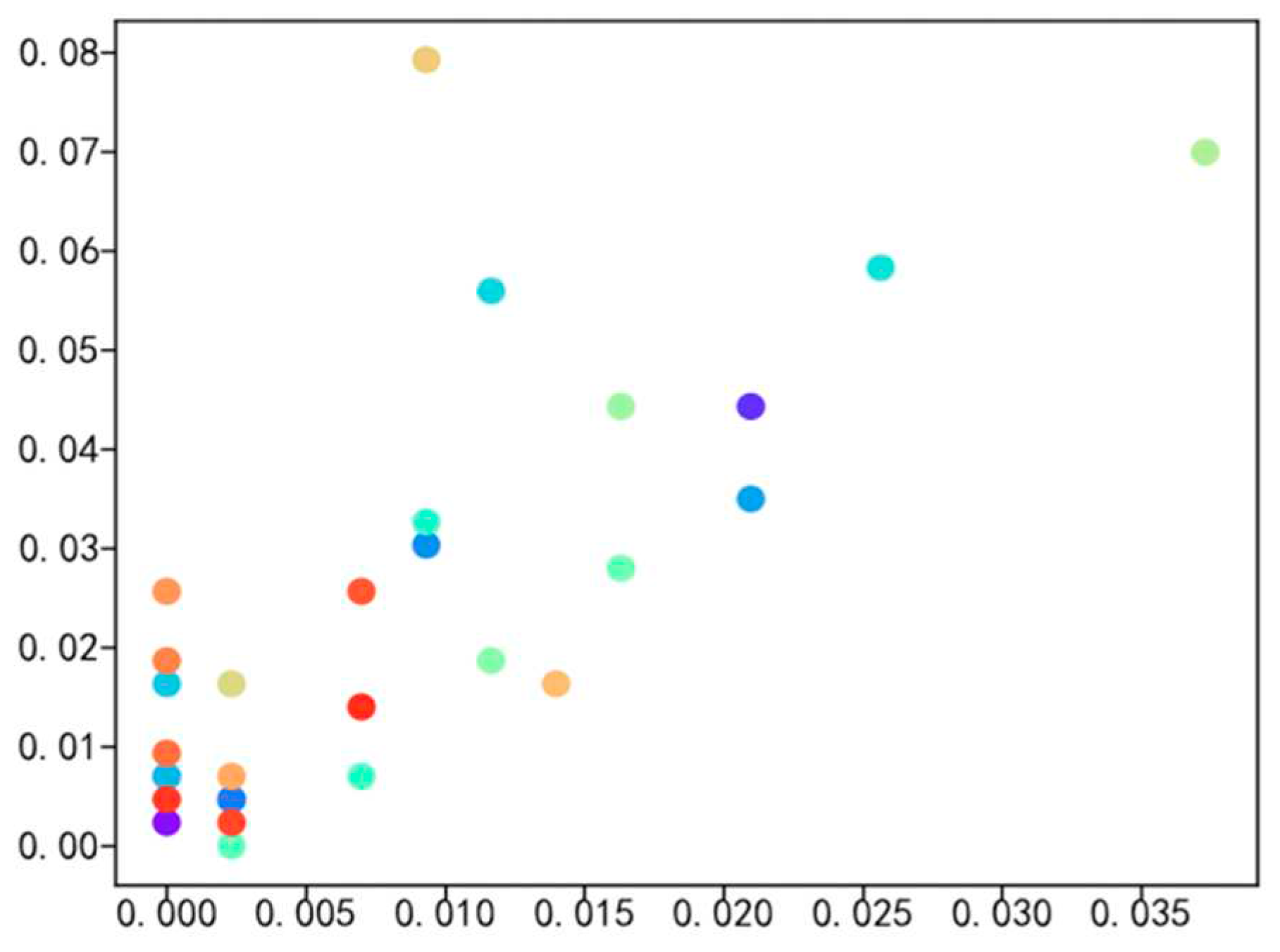
Figure 6.
Comparison of High School Graduates and Graduated Students Secondary College Data Sets.
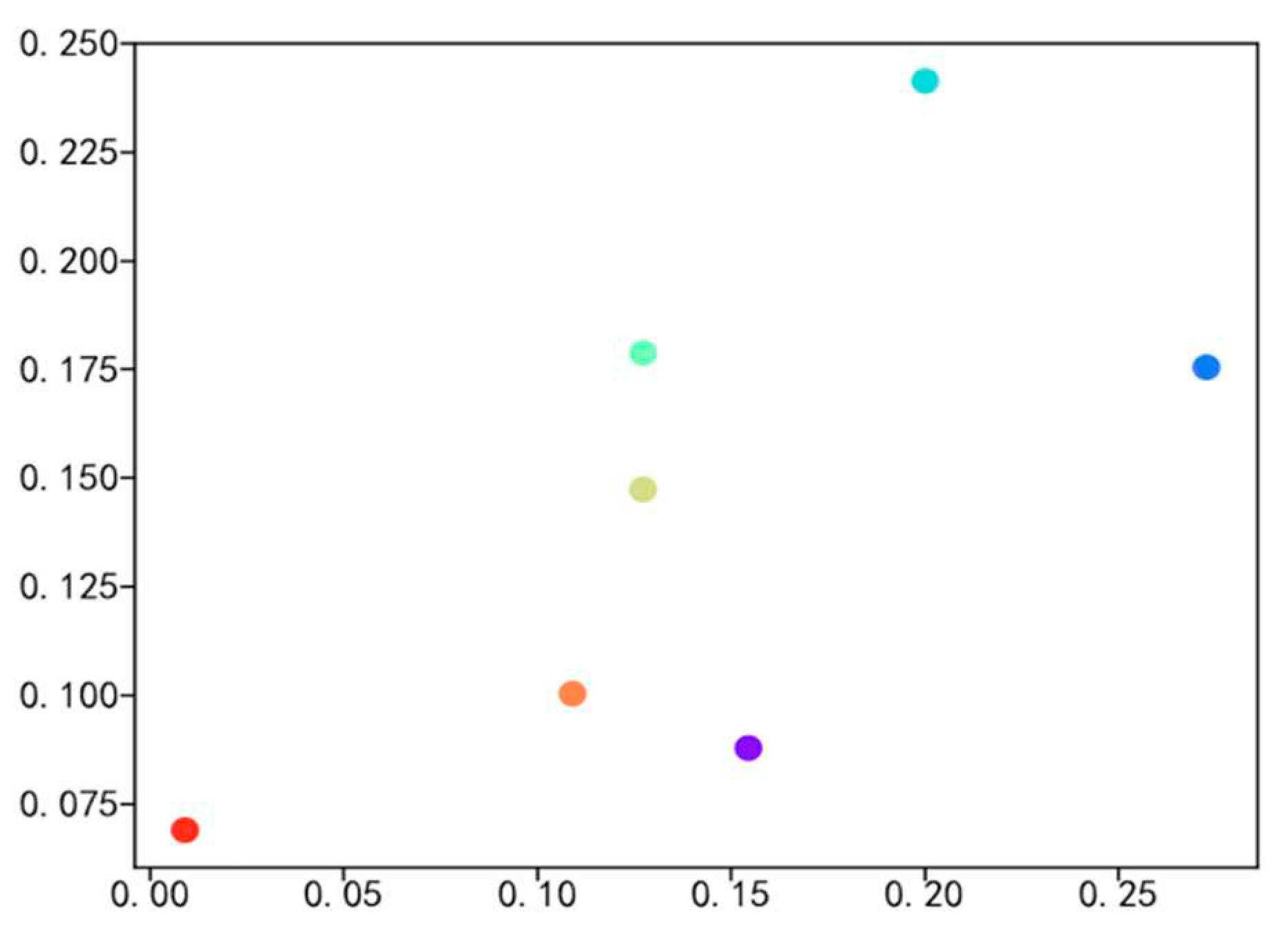
Figure 7.
Comparison of High School Graduates and Graduated Students Major Data Sets.
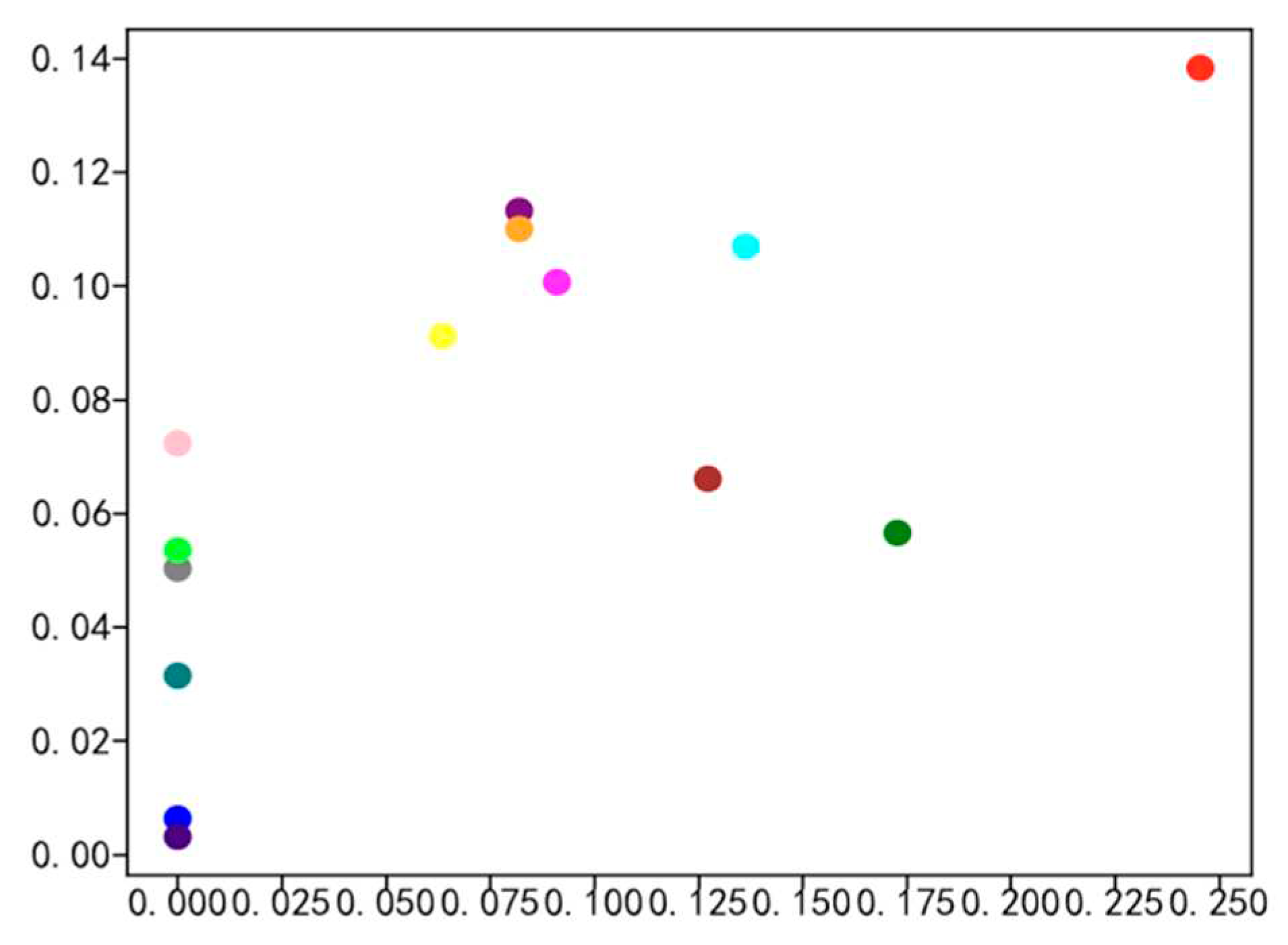
Figure 8.
Comparison of High School Graduates and Graduated Student Mentor Datasets.
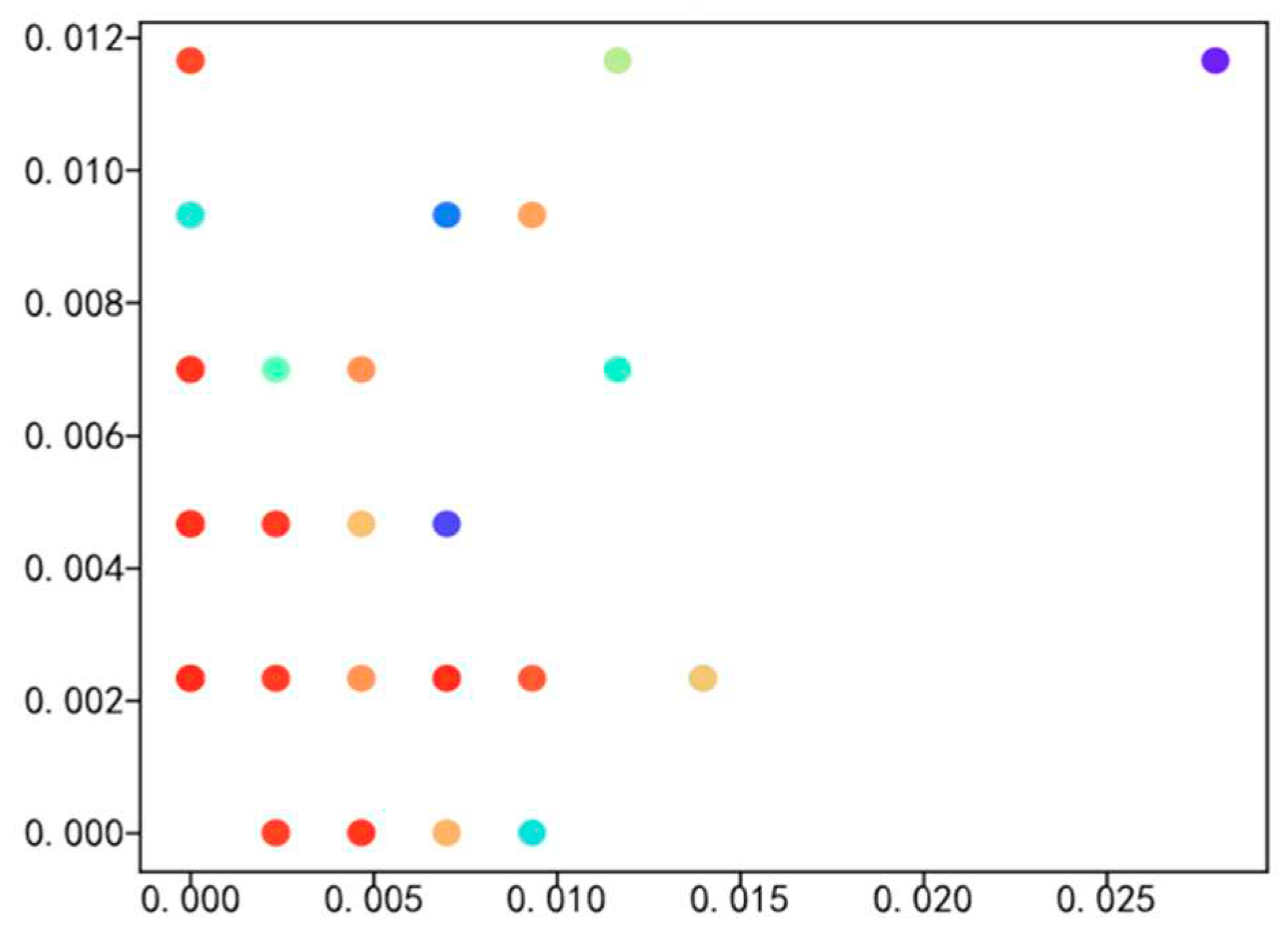
Figure 9.
Social network diagram of college graduates and graduateds.
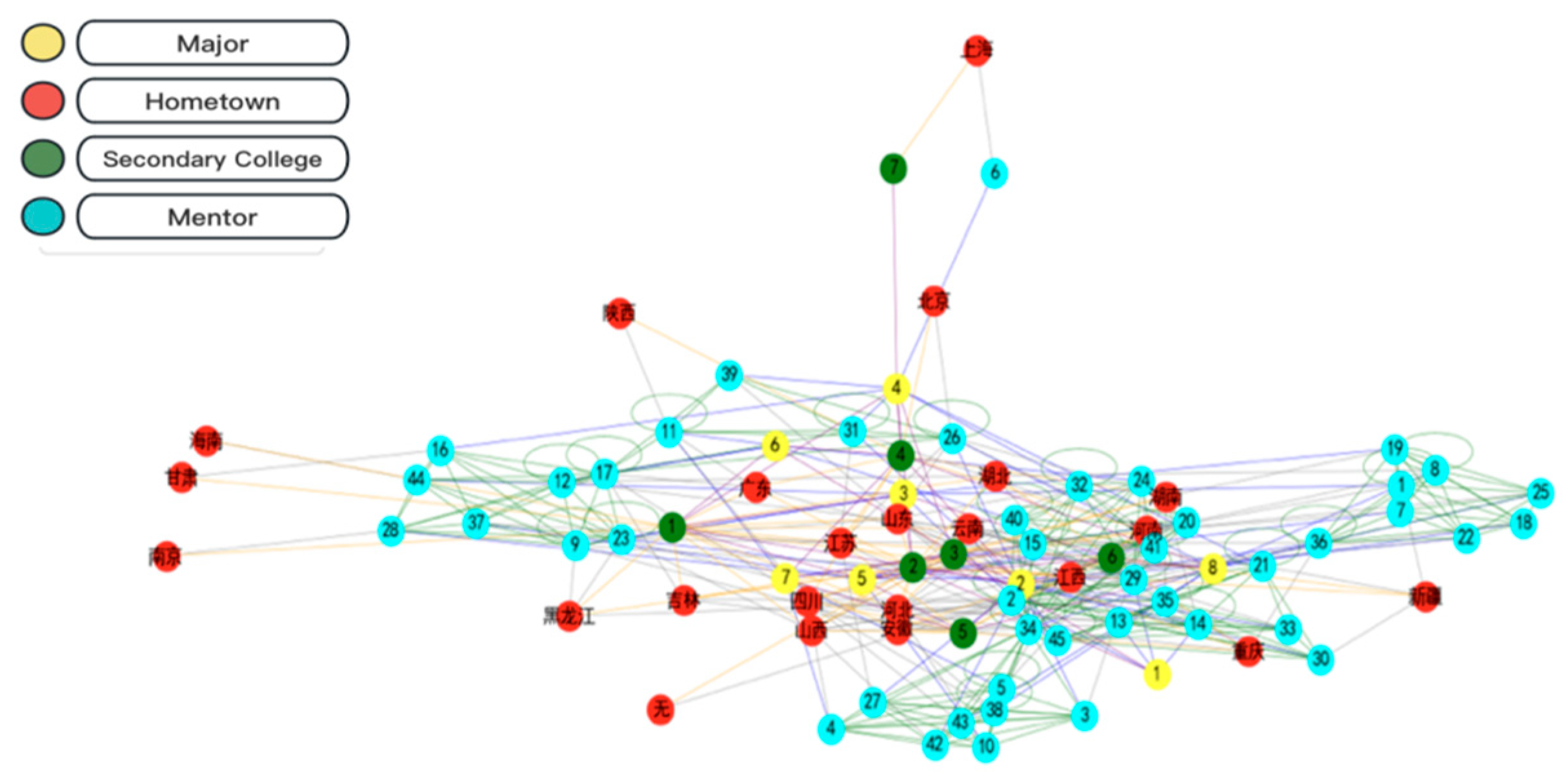
Figure 10.
Average satisfaction rate.
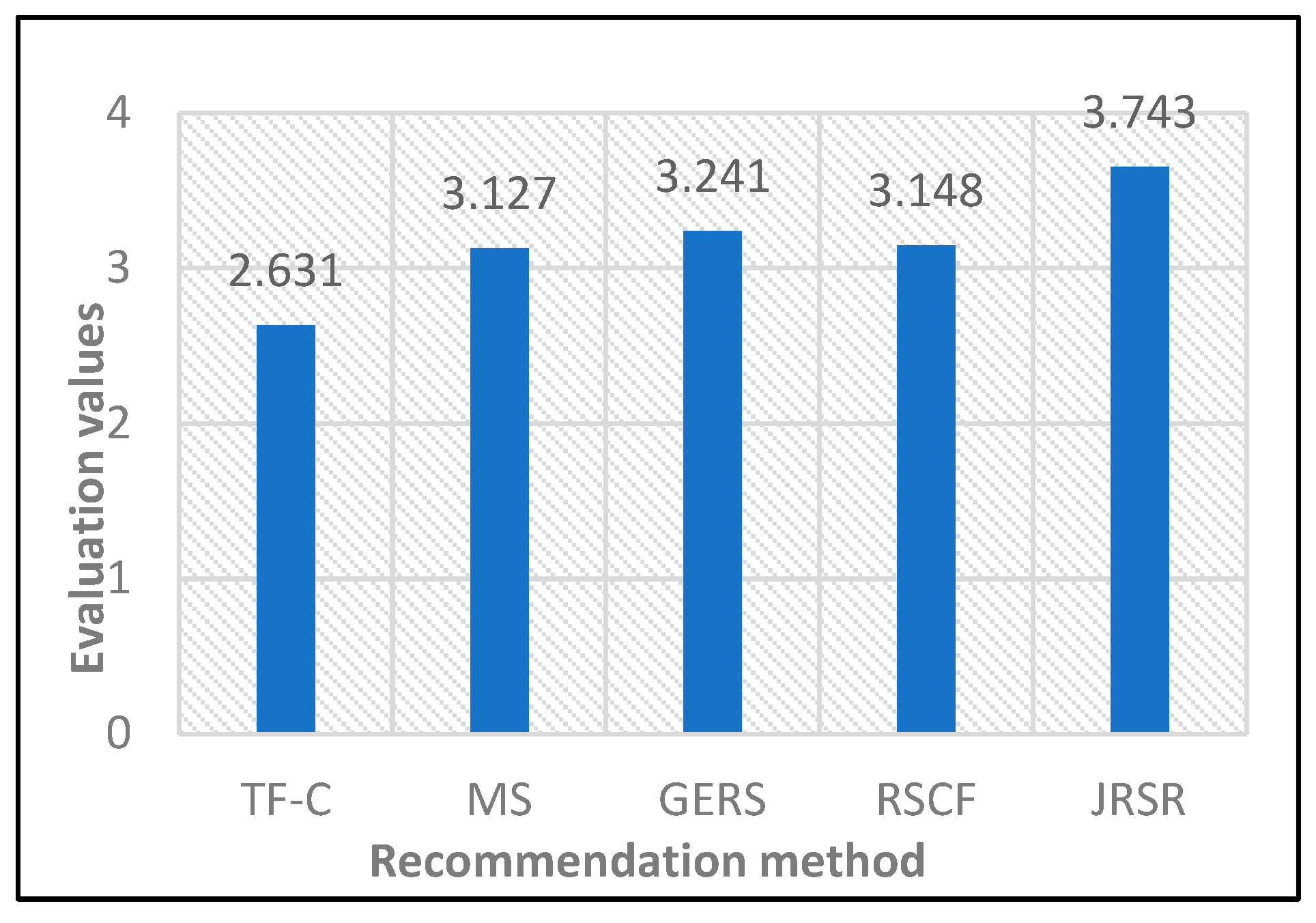
Figure 11.
Normalized present cumulative gain.
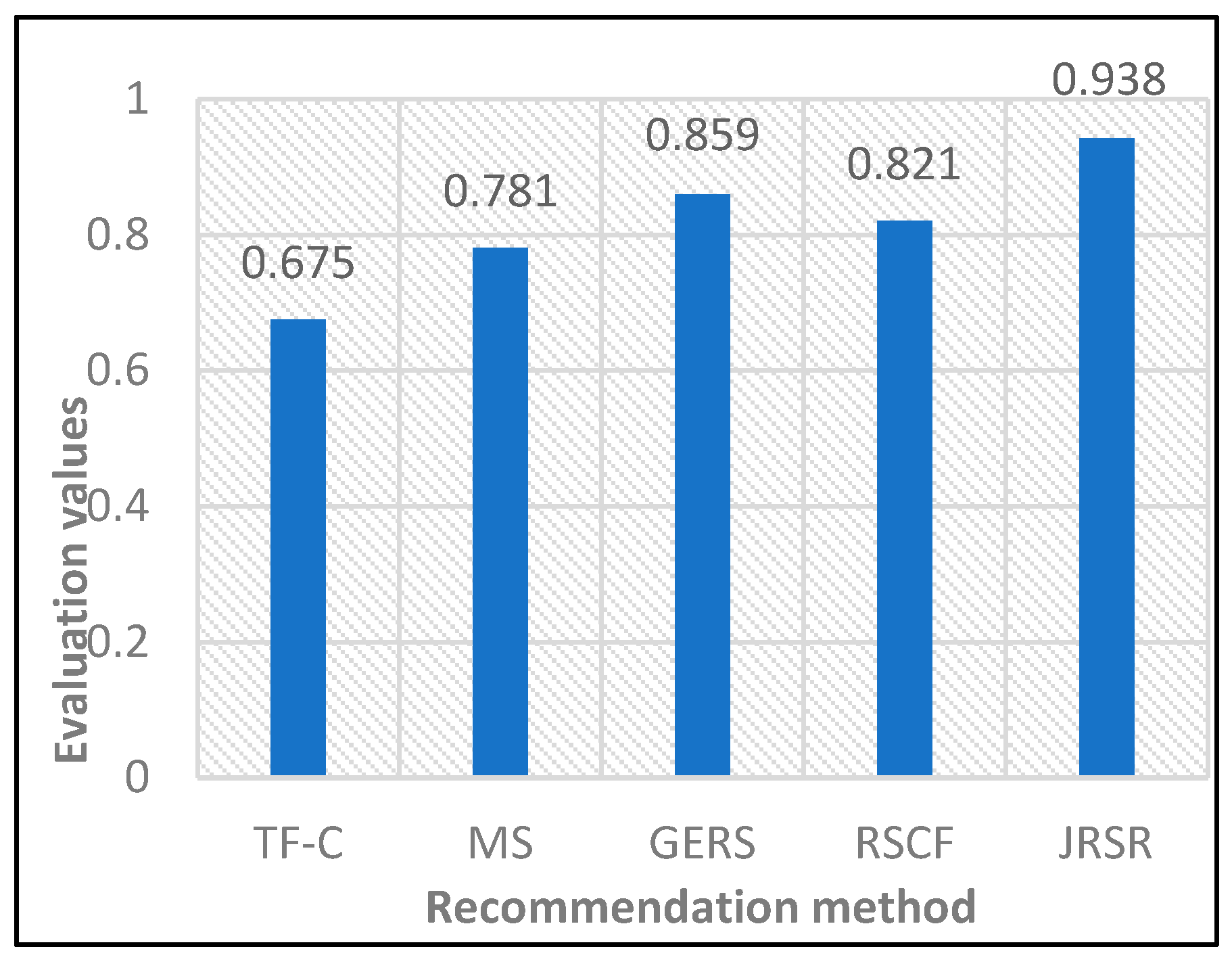
Figure 12.
Evaluation Results of Separate Use of Historical Employment Information for Logistics and Management Section.
Figure 12.
Evaluation Results of Separate Use of Historical Employment Information for Logistics and Management Section.
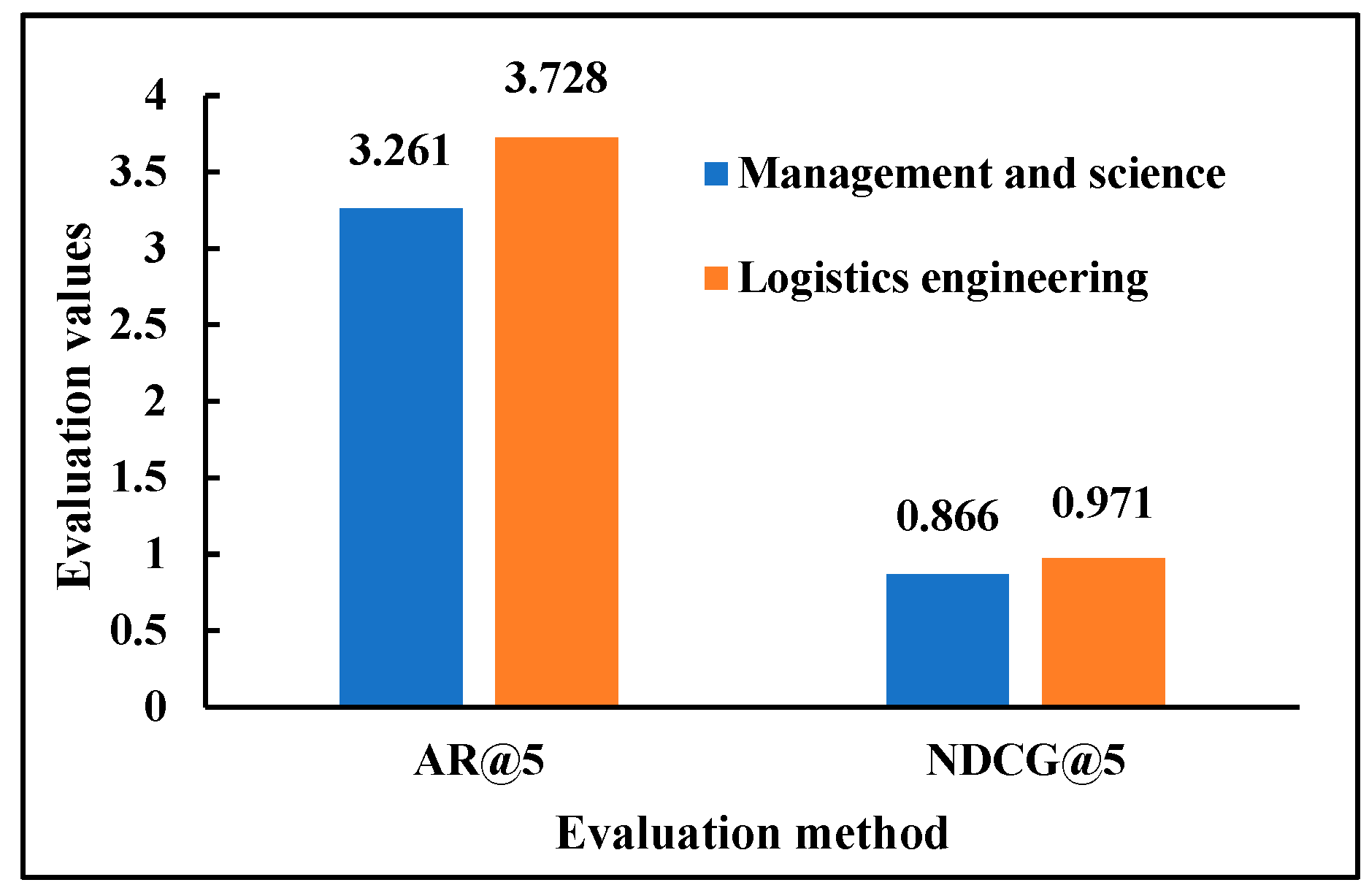
Figure 13.
Analysis of AR evaluation values for different recommendation list lengths.
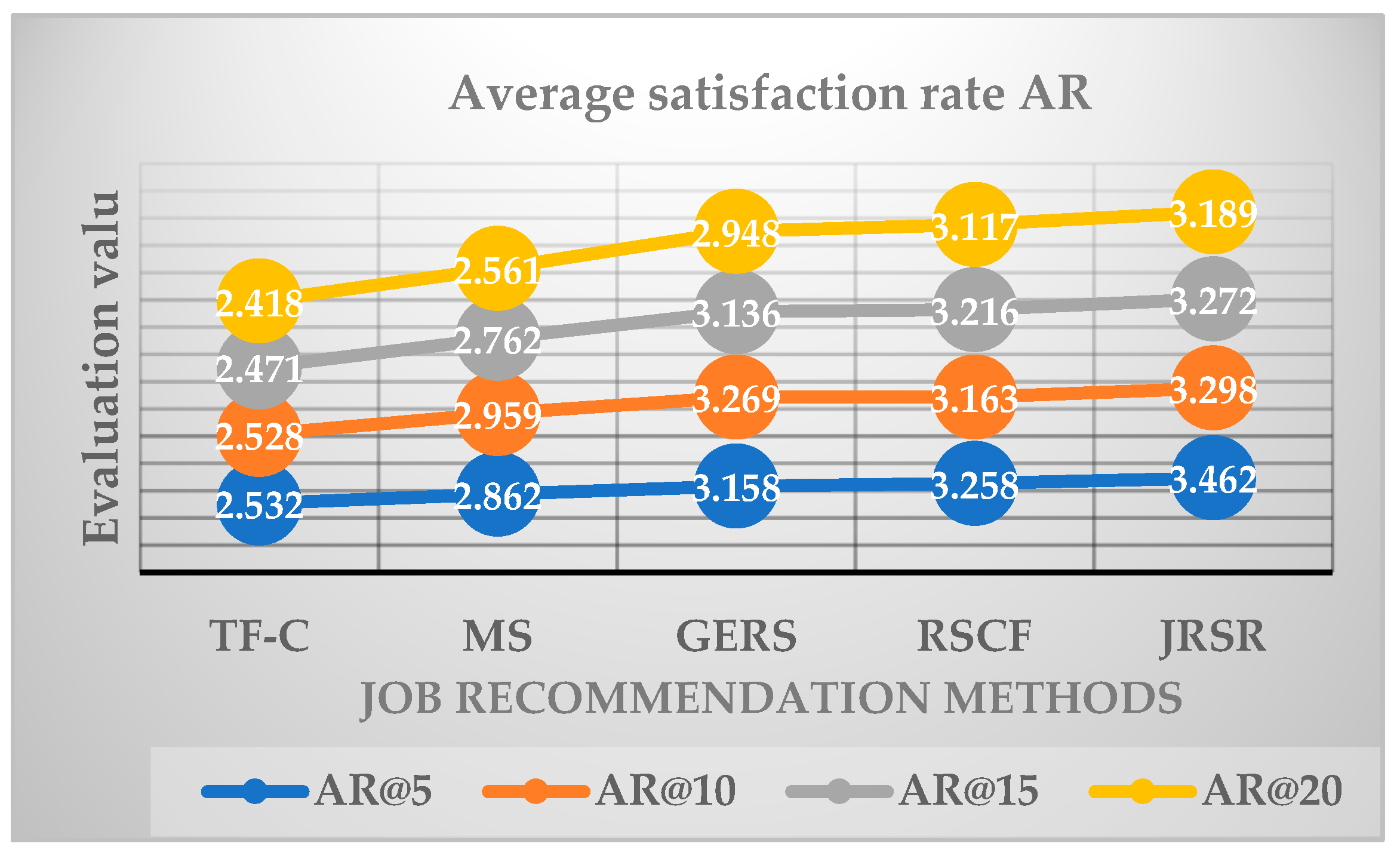
Figure 14.
Analysis of NDCG Evaluation Values for Different Recommended List Lengths.
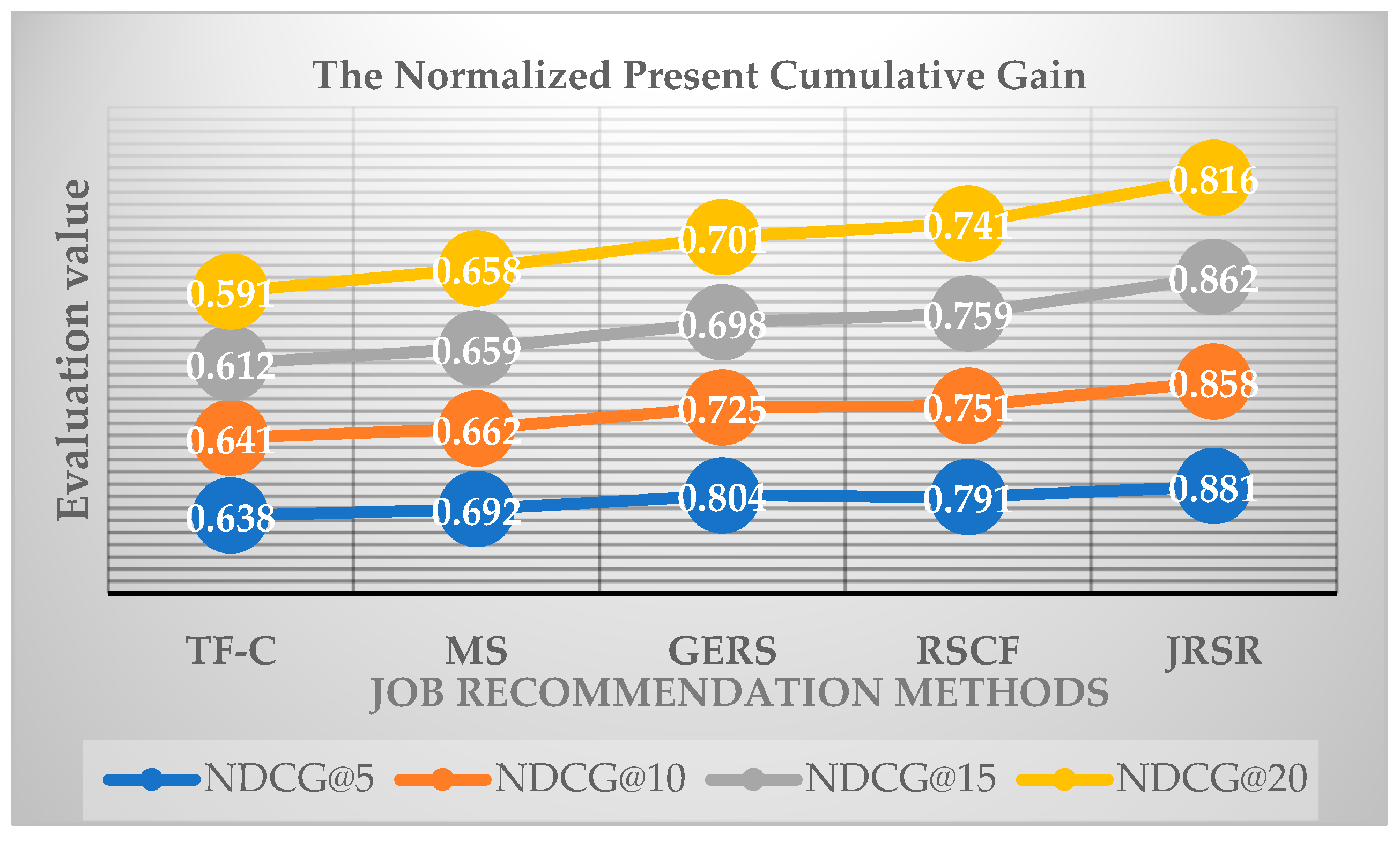
Table 1.
Resume information of logistics graduates.
| Logistics graduate resume information | |
| Name: Zhang Gender: Female Graduate school: xx university, logistics engineering Research direction: supply chain management supervisor: Li xx Address: Kunming, Yunnan Province |
Expected salary¥: 3000-5000 Expected work location: Southwest Desired position: engaged in logistics related work Expected working environment: office environment; corporate culture; work prospects and so on |
Table 2.
Job Recruitment Information.
| Job recruitment information | |
| Recruitment company: xxx Salary level¥: 5000-6000 Job responsibilities: Manage supply chain; cost control Working environment: office environment; corporate culture; employment prospects... Working location: Kunming, Yunnan |
Education requirements: graduate degree or above English level: College English Level 6 Job requirements: Applicants are logistics related majors, supply chain research direction is preferred, candidates should be skilled in using matlab software and so on |
Table 3.
Wilcoxon signed rank test for AR@5.
| Recommendation Model | TF-C | MS | GERS | RSCF |
|---|---|---|---|---|
| JRSR | 0.000 | 0.000 | 0.000 | 0.000 |
Table 4.
Wilcoxon signed rank test for NDCG@5.
| Recommendation Model | TF-C | MS | GERS | RSCF |
|---|---|---|---|---|
| JRSR | 0.002 | 0.001 | 0.000 | 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



