
Submitted:
12 October 2023
Posted:
17 October 2023
You are already at the latest version
Abstract
Anomaly detection in equipment processes plays an important role in the oil and gas sector. Algorithms for detecting anomalies in measured data are best understood in computer science and mathematics. Therefore, a possible transfer of knowledge from the latter knowledge area to the former can play a significant role. This paper addresses such a task by analyzing bibliometric data of Computer Science and Mathematics papers published in MDPI journals and publications found on the SPE search platform. It is shown that the main algorithms both extensively studied in MDPI publications and found in SPE publications and reflecting the anomaly detection problem are Random Forest, Support Vector Machine, Long-term Memory Method and Recurrent Neural Network. The main advantages and disadvantages of these methods are briefly described. Examples of classical, highly cited publications describing the work of these algorithms are given. Examples of papers describing their application in the oil and gas industry are given. The sections of SPE disciplines with the largest number of publications using the above algorithms that are frequently used for anomaly detection are presented.
Keywords:
anomaly detection
; MPDI
; SPE
; Computer Science and Mathematics
; bibliometric data
; algorithms
Introduction
Relevance of the subject
Anomaly detection is a vital tool in the oil and gas sector, enhancing safety, security, environmental management, regulatory compliance, maintenance strategies, and operational efficiency. It identifies unusual patterns in sensor data, enabling early detection of abnormalities, preventing accidents and equipment failure, monitoring environmental variables, reducing risks, and proactively responding to suspicious activities. Data integrity and anomaly detection are crucial for preventing errors and cybersecurity breaches [1,2,3,4,5].
The aim of this study
The objective of this study was to identify the most promising tasks for transferring knowledge from the field of sciences “Computer Science and Mathematics” on the problem of “Anomaly Detection” to the field of oil and gas sector.
To achieve this objective, the following questions are proposed to be answered:
- Which analytical approaches in the field of anomaly detection are the most developed in publications in the field of “Informatics and Mathematics” sciences?
- Which analytical approaches in the field of anomaly detection are most in demand in the oil and gas industry?
It is assumed that knowledge transfer is most appropriate if this knowledge is developed in the field of “Computer Science and Mathematics” and is in demand in the oil and gas industry.
Publications in the field of “Computer Science and Mathematics” are taken from MDPI journals. Data on publications in the field of Oil and Gas are taken from the SPE search platform.
The identification of promising issues for knowledge transfer was based on the use of bibliometric methods.
Literature review
A review of the literature shows that most publications are devoted to the use of anomaly detection to improve the safety and efficiency of oil and gas operations. The following are typical studies related to this topic.
The paper [6] presents an approach for fault detection and identification using a Self-Organizing Map algorithm, which is crucial for preserving industrial plant health and increasing reliability and efficiency in oil and gas operations. The intuitive and easy-to-understand results of this algorithm are presented.
Machine learning algorithms, including random forest, support vector machine, k-nearest neighbor, gradient boosting, and decision tree, have been used to develop anomaly detection models for pipeline leaks in oil and gas operations. The support vector machine algorithm outperformed other algorithms in detecting pipeline leakage, proving its efficiency as an accurate model for pipeline leak detection [7].
The authors propose a systematic flight data analytics framework for anomaly detection in flight operations applicable to both online and offline regimes. This comprehensive and reusable pipeline aims to identify hazardous and inefficient operations, improving safety and efficiency in oil and gas operations [8].
The paper [9] introduces a two-step methodology utilizing machine learning classification algorithms for anomaly detection in industrial processes, aimed at enhancing safety and efficiency in oil and gas operations.
Anomaly detection sensors can be used in oil and gas well-monitoring systems to detect network traffic anomalies, improving safety and efficiency. These sensors are designed to operate within existing well-monitoring infrastructure and compare against pre-set and moving averages to detect and report anomalies [10].
The paper [11] proposes an unsupervised method for anomaly detection in industrial machines, utilizing statistical features to calculate failure severity indicators and interrupt operation before breakdown, thereby improving safety and efficiency in oil and gas operations.
The article [12] discusses anomaly detection techniques for improving safety and efficiency in oil and gas operations. It provides an overview of current research directions, including definitions, modes, outputs, and literature, to guide selecting the appropriate approach for specific application domains.
This study [13] analyses 290 research articles from 2000-2020 on ML models for anomaly detection in the oil and gas industry and identifies 29 different models used in their application.
No publications were found that explored the potential of transferring knowledge from computer science and mathematics on the subject of anomaly detection, for application in the oil and gas industry. Consequently, the topic proposed in the title of the paper has novelty.
Materials and Methods
Data
This research used bibliometric data from the MDPI publisher website, up to September 11, 2023, for “anomaly detection” query. The query included filters for years between 2019 and 2023, subjects like Computer Science and Mathematics, and article types like articles and reviews. A total of 2151 tsv outcomes were exported.
The employment of data from MDPI publisher offers several benefits. Firstly, it provides open access to all publications. Secondly, it encompasses a broad range of topics, as evidenced by the inclusion of the topic “anomaly detection” in 52 journals. Additionally, the exported bibliometric data comprises 16 fields, which include the essential fields required for our study, namely TITLE, JOURNAL, KEYWORDS, ABSTRACT, and DOI.
Journals with 20 or more publications at the time of export:
Applied Sciences → 735, Electronics → 409, Mathematics → 127, Symmetry → 102, Entropy → 90, Information → 75, Future Internet → 72, Algorithms → 57, Processes → 55, ISPRS International Journal of Geo-Information → 41, Computers → 39, Buildings → 34, Journal of Imaging → 27, Big Data and Cognitive Computing → 25, Journal of Sensor and Actuator Networks → 25, Journal of Cybersecurity and Privacy → 20 articles.
Clustering of bibliometric records
The Carrot2 program [14,15] with the Lingo3G algorithm was used for document clustering with the following parameters that differ from the defaulters: algorithm: minLabelWords: 2, maxWordDf: 0.8, phraseDfThresholdScalingFactor: 0.05. A detailed description of the Carrot2 program, the Lingo3G algorithm, and its parameters can be found at https://carrotsearch.com/lingo3g/.
Clustering was conducted utilizing the KEYWORDS and ABSTRACT fields. The texts of these fields were subjected to the following preprocessing steps:
- First, the texts were subjected to stemming using the Krovetz method, which allowed the terms to be normalized while preserving their readability.
- A dictionary of normalized keywords was then compiled.
- Only terms from the above dictionary were kept in the ABSTRACT field.
- The original KEYWORDS and ABSTRACT fields in the bibliometric records were replaced with the transformed ones.
- The bibliometric data thus obtained were further used in the demo version of Carrot2.
Explanation of text preprocessing in progress
The Krovetz algorithm is characterized by its ability to make minimal alterations to the spelling of terms. In this sense, it can be considered as an intermediate approach that lies between lemmatization and stemming [16,17]. This feature is important not only in the context of record clustering but also when automatically assigning headers to clusters and subclusters. For example, using Porter stemming will render headers unreadable.
A good practice of text pre-processing is to remove stop words, but the choice of the list of stop words is subjective. Here, this procedure was replaced by leaving in the texts of abstracts only those terms that the authors themselves considered significant and included in the list of keywords. A dictionary of terms left in the texts of the abstracts was compiled from the list of all keywords. The common text utilities grep and sed were used for this purpose.
The test version of the Carrot2 program has a limit on the amount of data to be analyzed. Using the full texts of 2151 annotations caused these limits to be exceeded.
The use of preprocessing not only made the records more consistent, but also made it possible to meet the limitations imposed by the test version of the program.
Search for publications in SPE search (search.spe.org)
After identifying the main methods used for anomaly detection, obtained by analyzing the bibliometric data of MDPI publications, a search was conducted for publications related to oil and gas topics and the problem of anomaly detection. For this purpose, the SPE search engine was used, to which queries of the following form were set: “anomaly detection” AND “method”, for example: “anomaly detection” AND “Random Forest”.
Next, according to the results of each query, reading the abstracts of the found publications and additional information on the method, the following items were compiled: Advantages, Drawbacks, Highly cited publication, Table with Publications demonstrating the application of the method, SPE Disciplines to which the found publications were referred.
In the absence of publications related to a particular method and anomaly detection problem, a search for examples of publications close in meaning to the problem, e.g., Outlier Detection, Deviation Detection, Out-of-Distribution Detection, Fault Detection, was conducted.
Obviously, the number of publications found should be considered only as an estimate of the frequency of occurrence of articles on the topic being searched. This may be sufficient to select a specific anomaly detection method. The next stage of the research may require more complex queries, for example, to produce systematic reviews.
Results
Clustering of bibliometric records
Using the methodology described in the previous section allowed us to identify 29 clusters out of 2151 bibliometric records, with 61.0% of the documents falling into the main clusters. Figure 1 shows the clustering results for the six main clusters. In addition, a complete enumeration of all clusters is given in the form of a list to provide more detailed information.
The topics within the clusters and their corresponding sub-clusters reflect the methods used for anomaly detection, as well as the diverse range of domains in which they can be used.
The full range of clusters and their sub-clusters are presented in the list below.
The format of the list is as follows: cluster name, number of documents assigned to the cluster, number of sub-clusters in the cluster. It should be reminded that the algorithm used can assign each document to several categories.
- Anomaly Detection (339 Docs, 14 Subclusters)
- Neural Network (373 Docs, 14 Subclusters)
- Machine Learning (370 Docs, 14 Subclusters)
- Deep Learning (305 Docs, 14 Subclusters)
- Real Time (228 Docs, 14 Subclusters)
- Network Traffic (171 Docs, 14 Subclusters)
- Time Series (125 Docs, 14 Subclusters)
- Future Research (107 Docs, 14 Subclusters)
- Security Privacy (69 Docs, 14 Subclusters)
- Blockchain Technology (38 Docs, 14 Subclusters)
- High Resolution (24 Docs, 11 Subclusters)
- Quality Assessment (18 Docs, 14 Subclusters)
- Wind Energy (19 Docs, 13 Subclusters)
- Signal Ratio (16 Docs, 13 Subclusters)
- Particle Swarm Optimization (15 Docs, 12 Subclusters)
- Knowledge Graph (13 Docs, 10 Subclusters)
- Fuzzy Sets (14 Docs, 12 Subclusters)
- Dimension Reduction (13 Docs, 12 Subclusters)
- Persistent Threat (13 Docs, 10 Subclusters)
- Texture Features (13 Docs, 13 Subclusters)
- Semantic Segmentation (11 Docs, 10 Subclusters)
- Energy Sector (12 Docs, 13 Subclusters)
- Electronic Control (13 Docs, 13 Subclusters)
- Hyperspectral Image (10 Docs)
- Maintenance Activity (9 Docs)
- Useful Life (8 Docs)
- Decision Boundary (8 Docs)
- Damage Severity (7 Docs)
- Other Topics (839 Docs)
The first four clusters show the greatest degree of overlap with the approaches used in anomaly detection. We therefore provide a complete list of their sub-clusters, emphasizing the methods used.
ANOMALY DETECTION (339 docs, 14 subclusters)
Intrusion Detection (72), Time Series Data (72), Outlier Detection (51), Long Short-term Memory (45), Support Vector Machine (38), Log Anomaly Detection (32), Random Forest (29), Anomalous Behavior (30), Data Mining (29), Cyber-physical System (23), Video Surveillance (18), Industry 4.0 (19), Attention Mechanism (17), Fraud Detection (16)
NEURAL NETWORK (373 docs, 14 subclusters).
Detection System (143), Convolution Neural Network (105), Long Short-term Memory (73), Recurrent Neural Network (67), Artificial Neural Network (57), Support Vector Machine (38), Random Forest (37), Attention Mechanism (23), Graph Neural Network (23), Computer Vision (21), Generative Adversarial Network (18), Adversarial Attack (10), Activity Recognition (10), Fraud Detection (5).
MACHINE LEARNING (370 docs, 14 subclusters)
Detection System (188), Intrusion Detection (88), Random Forest (61), Support Vector Machine (56), Artificial Intelligence (46), Big Data (33), Convolution Neural Network (27), Data Mining (26), Fraud Detection (15), Generative Adversarial Network (15), Edge Computing (13), Traffic Pattern (11), Activity Recognition (10), Social Media (9)
DEEP LEARNING (305 docs, 14 subclusters).
Detection System (147), Intrusion Detection (56), Long Short-term Memory (51), Convolution Neural Network (48), Recurrent Neural Network (44), Computer Vision (30), Random Forest (28), Artificial Intelligence (29), Generative Adversarial Network (21), Big Data (20), Reinforcement Learning (18), Video Surveillance (16), Defect Detection (15), Adversarial Attack (13).
For completeness, we present the total occurrence of the highlighted methods in the list of keywords and annotations of all 2151 records.
Random Forest → 115 rows, 176 matches;
Support Vector Machine → 104 rows, 144 matches;
Long Short-term Memory → 107 rows, 142 matches;
Recurrent Neural Network → 51 lines, 64 matches;
Convolution Neural Network → 15 lines, 20 matches;
Generative Adversarial Network → 57 lines, 96 matches;
Reinforcement Learning → 27 lines, 60 matches.
The Random Forest and Support Vector Machine classification methods are widely studied and are considered classical approaches. Therefore, it is not surprising that they are widely used in the field of anomaly detection when normal and abnormal instances are separated into separate classes.
Long Short-Term Memory (LSTM) and Recurrent Neural Network (RNN) can be identified as a set of techniques effective for sequential data processing tasks. Different types of sensors and logs serve as suitable data sources for these techniques, especially in the context of time series analysis.
Results of a search of SPE publications and a description of the main features of the methods
For this purpose, the SPE search engine was used, to which queries of the following form were set: “anomaly detection” AND “method”, for example: “anomaly detection” AND “Random Forest”.
Number of results returned for queries made from December 2018 to December 2023:
”Support Vector Machine” AND “anomaly detection” → 57
”Long Short-term Memory” AND “anomaly detection” → 53
”Random Forest” AND “anomaly detection” → 63
”Convolution Neural Network” AND “anomaly detection” → 3
”Recurrent Neural Network” AND “anomaly detection” → 35
”Generative Adversarial Network” AND “anomaly detection” → 6
”Reinforcement Learning” AND “anomaly detection” → 0
”Reinforcement Learning” → 0
Our focus was on bibliometric data only, not full text.
This simple search provides only a rough estimate of the occurrence of relevant publications on the topic.
For a more comprehensive study, it becomes necessary to select semantic equivalents of the phrase “anomaly detection” for each analytical technique, such as Outlier Detection, Deviation Detection, Out-of-Distribution Detection, and Fault Detection.
Conclusion
Clustering Computer Science and Mathematics related documents according to their bibliometric entries on the topic of anomaly detection provides an easily interpretable list of publication topics, which can be further extended for in-depth literature analysis. The dominant anomaly detection methods include Random Forest and Support Vector Machine for classifying normal and abnormal states, while Long-term Memory Method and Recurrent Neural Network are effective for tasks involving sequential data like time series from sensors or logs.
The SPE search platform publications primarily use the same anomaly detection methods for engineering problems in the oil and gas sector, suggesting that the knowledge gained from Computer Science and Mathematics can be applied to these problems. The SPE search platform found no studies on methodology for addressing the limitations of anomaly detection methods. It seems more practical to search for solutions in articles related to mathematics and computer science to mitigate the problems encountered when using these techniques in applied engineering problems.
In the oil and gas industry, anomaly detection problems are most often encountered in Production and Well Operations (Well & Reservoir Surveillance and Monitoring), Reservoir Description and Dynamics (Reservoir Characterization) and Well Drilling (Drilling Operations). The result is easy to understand, as the above tasks form the basis of engineering tasks in development.
Possible applications of the findings
This study could serve, for example, as a preliminary step towards preparing a systematic review on the suitability of using the Long Short-term Memory method for anomaly detection in well integrity monitoring. In justifying the feasibility of the Long Short-term Memory method, the review should not only demonstrate its applicability but also consider ways to overcome possible shortcomings based on the relevant literature. This approach is analogous to a typical systematic review in medicine, looking at the side effects of a drug in the treatment of a particular disease.
References
- Qassab A., Bhadran V., Sudevan V., et al. Autonomous Inspection System for Anomaly Detection in Natural Gas Pipelines // Day 4 Thu, November 12, 2020. Abu Dhabi, UAE: SPE, 2020. P. D041S105R002. [CrossRef]
- Snyder J., Scott S., Kassim R. Self-Adjusting Anomaly Detection Model for Well Operation and Production in Real-Time // Day 1 Tue, April 09, 2019. Oklahoma City, Oklahoma, USA: SPE, 2019. P. D011S002R005. [CrossRef]
- Santos P., Aldren L., Melvin E., et al. AI Augmented Engineering Intelligence for Industrial Equipment // Day 2 Wed, September 06, 2023. Aberdeen, Scotland, UK: SPE, 2023. P. D021S006R003. [CrossRef]
- Beduschi F., Turconi F., De Gregorio B., et al. Optimizing Rotating Equipment Maintenance Through Machine Learning Algorithm // Day 3 Wed, November 17, 2021. Abu Dhabi, UAE: SPE, 2021. P. D031S088R001. [CrossRef]
- Irani Z.S., George R., Dayal R. Technology for Continuous Cyber Monitoring of Offshore Assets // Day 3 Wed, October 04, 2023. Abu Dhabi, UAE: SPE, 2023. P. D031S101R003. [CrossRef]
- Concetti L., Mazzuto G., Ciarapica F.E., Bevilacqua M. An Unsupervised Anomaly Detection Based on Self-Organizing Map for the Oil and Gas Sector // Applied Sciences. 2023. Vol. 13, No 6. P. 3725. [CrossRef]
- Aljameel S.S., Alomari D.M., Alismail S., et al. An Anomaly Detection Model for Oil and Gas Pipelines Using Machine Learning // Computation. 2022. Vol. 10, No 8. P. 138. [CrossRef]
- Coelho E Silva L., Murça M.C.R. A data analytics framework for anomaly detection in flight operations // Journal of Air Transport Management. 2023. Vol. 110. P. 102409. [CrossRef]
- Quatrini E., Costantino F., Di Gravio G., Patriarca R. Machine learning for anomaly detection and process phase classification to improve safety and maintenance activities // Journal of Manufacturing Systems. 2020. Vol. 56. P. 117–132. [CrossRef]
- He X., Robards E., Gamble R., Papa M. Anomaly Detection Sensors for a Modbus-Based Oil and Gas Well-Monitoring System // 2019 2nd International Conference on Data Intelligence and Security (ICDIS). South Padre Island, TX, USA: IEEE, 2019. P. 1–8. [CrossRef]
- Da Silva Arantes J., Da Silva Arantes M., Fröhlich H.B., et al. A novel unsupervised method for anomaly detection in time series based on statistical features for industrial predictive maintenance // International Journal of Data Science and Analytics. 2021. Vol. 12, No 4. P. 383–404. [CrossRef]
- Musa T.H.A., Bouras A. Anomaly Detection: A Survey // Proceedings of Sixth International Congress on Information and Communication Technology / ed. Yang X.-S., Sherratt S., Dey N., Joshi A. Singapore: Springer Singapore, 2022. Vol. 217. P. 391–401. [CrossRef]
- Nassif A.B., Talib M.A., Nasir Q., Dakalbab F.M. Machine Learning for Anomaly Detection: A Systematic Review // IEEE Access. 2021. Vol. 9. P. 78658–78700. [CrossRef]
- Osiński S., Weiss D. Carrot2: Design of a Flexible and Efficient Web Information Retrieval Framework // Advances in Web Intelligence / ed. Hutchison D., Kanade T., Kittler J., et al. Berlin, Heidelberg: Springer Berlin Heidelberg, 2005. Vol. 3528. P. 439–444. [CrossRef]
- Carpineto C., Osiński S., Romano G., Weiss D. A survey of Web clustering engines // ACM Computing Surveys. 2009. Vol. 41, No 3. P. 1–38. [CrossRef]
- Krovetz R. Viewing morphology as an inference process // Artificial Intelligence. 2000. Vol. 118, No 1–2. P. 277–294. [CrossRef]
- NMAM Institute of Technology, Dept. of Computer Science and Engineering, Nayak A.S., Kanive A.P. Survey on Pre-Processing Techniques for Text Mining // International Journal of Engineering and Computer Science. 2016. [CrossRef]
- Breiman L. Random Forests // Machine Learning. 2001. Vol. 45, No 1. P. 5–32. [CrossRef]
- AlSaihati A., Elkatatny S., Mahmoud A., Abdulraheem A. Early Anomaly Detection Model Using Random Forest while Drilling Horizontal Wells with a Real Case Study // Day 3 Thu, May 27, 2021. Abu Dhabi, UAE: SPE, 2021. P. D032S040R001. [CrossRef]
- Alharbi B., Liang Z., Aljindan J.M., et al. Explainable and Interpretable Anomaly Detection Models for Production Data // SPE Journal. 2022. Vol. 27, No 01. P. 349–363. [CrossRef]
- Akinsete O., Oshingbesan A. Leak Detection in Natural Gas Pipelines Using Intelligent Models // Day 2 Tue, August 06, 2019. Lagos, Nigeria: SPE, 2019. P. D023S009R001. [CrossRef]
- Tewari S., Dwivedi U.D., Shiblee M. Assessment of Big Data Analytics Based Ensemble Estimator Module for the Real-Time Prediction of Reservoir Recovery Factor // Day 4 Thu, March 21, 2019. Manama, Bahrain: SPE, 2019. P. D041S038R003. [CrossRef]
- Del Pino Fiorillo M.A. Automating Dynamometer Charts Interpretation with Machine Learning // Day 2 Thu, June 15, 2023. Port of Spain, Trinidad and Tobago: SPE, 2023. P. D021S010R003. [CrossRef]
- Chang C.-C., Lin C.-J. LIBSVM: A library for support vector machines // ACM Transactions on Intelligent Systems and Technology. 2011. Vol. 2, No 3. P. 1–27. [CrossRef]
- Akkurt R., Sankaranarayanan B., Simoes V., et al. An Unsupervised Stochastic Machine Learning Approach for Well Log Outlier Identification // Proceedings of the 10th Unconventional Resources Technology Conference. Houston, Texas, USA: American Association of Petroleum Geologists, 2022. [CrossRef]
- Alotaibi B., Aman B., Nefai M. Real-Time Drilling Models Monitoring Using Artificial Intelligence // Day 2 Tue, March 19, 2019. Manama, Bahrain: SPE, 2019. P. D021S001R004. [CrossRef]
- Szegedy C., Wei Liu, Yangqing Jia, et al. Going deeper with convolutions // 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. P. 1–9. [CrossRef]
- Zhang H., Zeng Y., Bao H., et al. Drilling and Completion Anomaly Detection in Daily Reports by Deep Learning and Natural Language Processing Techniques // Proceedings of the 8th Unconventional Resources Technology Conference. Online: American Association of Petroleum Geologists, 2020. [CrossRef]
- Mercante R., Netto T.A. Virtual Multiphase Flowmeter Using Deep Convolutional Neural Networks // SPE Journal. 2023. P. 1–14. [CrossRef]
- Zhang K., Wang Y., Li G., et al. Prediction of Field Saturations Using a Fully Convolutional Network Surrogate // SPE Journal. 2021. Vol. 26, No 04. P. 1824–1836. [CrossRef]
- Marhon S.A., Cameron C.J.F., Kremer S.C. Recurrent Neural Networks // Handbook on Neural Information Processing / ed. Bianchini M., Maggini M., Jain L.C. Berlin, Heidelberg: Springer Berlin Heidelberg, 2013. Vol. 49. P. 29–65. [CrossRef]
- Alakeely A., Horne R.N. Simulating the Behavior of Reservoirs with Convolutional and Recurrent Neural Networks // SPE Reservoir Evaluation & Engineering. 2020. Vol. 23, No 03. P. 0992–1005. [CrossRef]
- Ezechi C.G., Okoroafor E.R. Integration of Artificial Intelligence with Economical Analysis on the Development of Natural Gas in Nigeria; Focusing on Mitigating Gas Pipeline Leakages // Day 3 Wed, August 02, 2023. Lagos, Nigeria: SPE, 2023. P. D031S018R004. [CrossRef]
- Yin Q., Yang J., Tyagi M., et al. Machine Learning for Deepwater Drilling: Gas-Kick-Alarm Classification Using Pilot-Scale Rig Data with Combined Surface-Riser-Downhole Monitoring // SPE Journal. 2021. Vol. 26, No 04. P. 1773–1799. [CrossRef]
- Hochreiter S., Schmidhuber J. Long Short-Term Memory // Neural Computation. 1997. Vol. 9, No 8. P. 1735–1780. [CrossRef]
- Kara M.C., Majeran M., Peterson B., et al. A Machine Learning Workflow to Predict Anomalous Sanding Events in Deepwater Wells // Day 3 Wed, August 18, 2021. Virtual and Houston, Texas: OTC, 2021. P. D031S033R002. [CrossRef]
- Nivlet P., Bjorkevoll K.S., Tabib M., et al. Towards Real-Time Bad Hole Cleaning Problem Detection Through Adaptive Deep Learning Models // Day 2 Mon, February 20, 2023. Manama, Bahrain: SPE, 2023. P. D021S073R005. [CrossRef]
- Aditama P., Koziol T., Dillen Dr.M. Development of an Artificial Intelligence-Based Well Integrity Monitoring Solution // Day 3 Wed, November 02, 2022. Abu Dhabi, UAE: SPE, 2022. P. D031S110R004. [CrossRef]
- Ledig C., Theis L., Huszar F., et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network // 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI: IEEE, 2017. P. 105–114. [CrossRef]
- Zhang Z., Song W., Wang W. Broadband reconstruction of seismic signal with generative recurrent adversarial network // Second International Meeting for Applied Geoscience & Energy. Houston, Texas: Society of Exploration Geophysicists and American Association of Petroleum Geologists, 2022. P. 2178–2182. [CrossRef]
- Marques F., Costa P., Castro F., Parente M. Self-Supervised Subsea SLAM for Autonomous Operations // Day 1 Mon, May 06, 2019. Houston, Texas: OTC, 2019. P. D011S002R006. [CrossRef]
- Sutton R.S., Barto A.G. Reinforcement Learning: An Introduction // IEEE Transactions on Neural Networks. 1998. Vol. 9, No 5. P. 1054–1054. [CrossRef]
- Alzahrani M., Alotaibi B., Aman B. Novel Stuck Pipe Troubles Prediction Model Using Reinforcement Learning // Day 2 Tue, February 22, 2022. Riyadh, Saudi Arabia: IPTC, 2022. P. D021S042R003. [CrossRef]
- Miftakhov R., Al-Qasim A., Efremov I. Deep Reinforcement Learning: Reservoir Optimization from Pixels // Day 2 Tue, January 14, 2020. Dhahran, Kingdom of Saudi Arabia: IPTC, 2020. P. D021S052R002. [CrossRef]
Figure 1.
Themes of the six main clusters and their sub-clusters of 2151 documents using the Lingo3G algorithm.
Figure 1.
Themes of the six main clusters and their sub-clusters of 2151 documents using the Lingo3G algorithm.
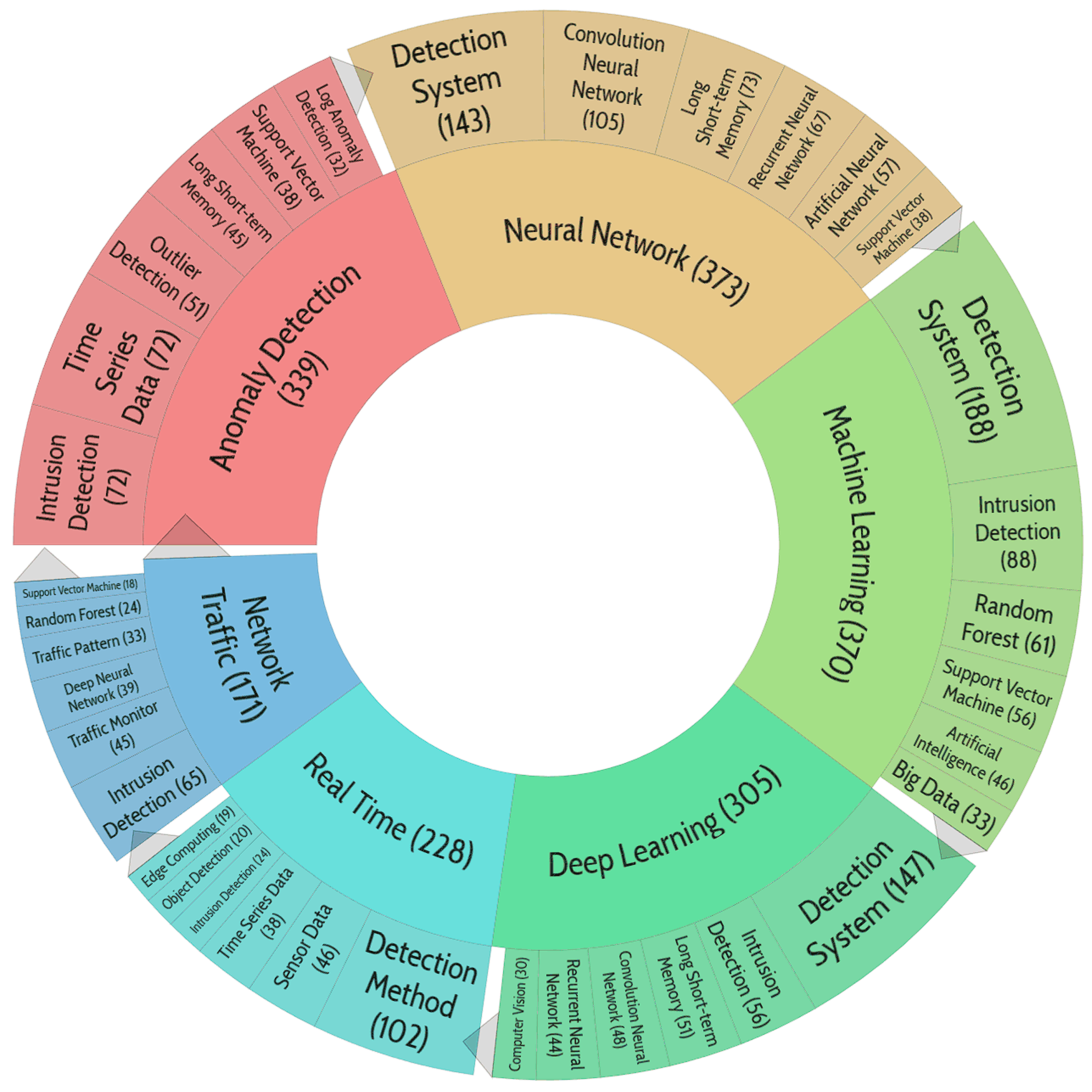

Table 1.
Publications demonstrating the application of the Random Forest algorithm to anomaly detection problems.
Table 1.
Publications demonstrating the application of the Random Forest algorithm to anomaly detection problems.
| Title and Reference | Short summary |
|---|---|
| Early Anomaly Detection Model Using Random Forest while Drilling Horizontal Wells with a Real Case Study [19] | This paper presents a machine learning model to predict drilling surface torque for early detection of operational problems. The model uses real horizontal drilling data from the day before the stuck pipe incident. It predicts surface drilling torque based on typical patterns observed over the past 24 hours, using train and test a random forest model. The model is integrated with the Mahalanobis metric to assess the closeness of real observations to the predicted normal trend. |
| Explainable and Interpretable Anomaly Detection Models for Production Data [20] | This study compares machine-learning models on two datasets for anomaly detection. It aims to understand how these models make decisions. The models used include K-nearest neighbors, logistic regression, support vector machines, decision tree, random forest, and rule fit classifier. In one data set, the rule fit classifier outperformed the remaining models in both F1 and complexity, where F1. In the second data set, random forest outperformed the rest in prediction performance with F1, yet it had the lowest complexity metric. |
| Leak Detection in Natural Gas Pipelines Using Intelligent Models [21] | This study investigates the effectiveness of intelligent models in detecting small leaks in natural gas pipelines using operational parameters like pressure, temperature, and flowrate. Five models were used: Gradient Boosting, Decision Trees, Random Forest, Support Vector Machine, and Artificial Neural Network. Results showed Random Forest and Decision Tree models were most sensitive, with a 0.1% leak detection rate in 2 hours. All models had high reliability, but low accuracy, with Artificial Neural Network and Support Vector Machine performing best. |
| Assessment of Big Data Analytics Based Ensemble Estimator Module for the Real-Time Prediction of Reservoir Recovery Factor [22] | Estimating reservoir recovery factor is a challenging task due to high uncertainty, large inexactness, noise, and high dimensionality in reservoir measurements. The paper presents a big data-driven ensemble estimator module, which uses wavelet-associated ensemble models to estimate reservoir recovery factor. The module uses bagging and random forest ensembles to correlate reservoir properties with the recovery factor, and the Relief algorithm to understand their significance. The random forest showing the highest coefficient of correlation and minimal estimation errors. |
| Automating Dynamometer Charts Interpretation with Machine Learning [23] | The aim of the study was to create a mathematical model for the interpretation of Dynamometer Charts from Sucker Rod Pumps. The paper describes a data processing pipeline for obtaining, normalizing, transforming, and evaluating graphs. About 1,000 models were trained and tested, including support vector machines, decision trees, K-nearest neighbors and neural networks. The XGBoost algorithm performed best, although Random Forest algorithms were significantly more accurate in certain conditions. |
Table 2.
Publications demonstrating the application of the SVM algorithm to anomaly detection problems.
Table 2.
Publications demonstrating the application of the SVM algorithm to anomaly detection problems.
| Title and Reference | Short summary |
|---|---|
| An Unsupervised Stochastic Machine Learning Approach for Well Log Outlier Identification [25] | Outlier detection is crucial in Log Quality Control workflows, and machine learning implementations must address challenges. This paper presents a stochastic outlier detection algorithm using the One-Class Support Vector Machine (1CSVM) method. This method creates outlier flags for all data vectors, providing a proxy for uncertainty. It is robust, efficient, and more efficient than processing all wells set at once. The methodology's unique feature is weighting input data vectors based on petrophysics and measurement physics. This automated workflow is ideal for unconventional applications involving large volumes of legacy data. |
| Real-Time Drilling Models Monitoring Using Artificial Intelligence [26] | Drilling and Workover operations are evolving at a rapid pace, requiring more data to predict drilling problems. This paper presents a new approach using the Wellsite Information Transfer Specification Markup Language, applying an improved mechanism to monitor and evaluate anomaly detection models and demonstrating the benefits of iterative improvements. A regression classifier model using a support vector machine was developed to predict the expected number of alerts. |
Table 3.
Publications demonstrating the application of the Convolution Neural Network to anomaly detection problems.
Table 3.
Publications demonstrating the application of the Convolution Neural Network to anomaly detection problems.
| Title and Reference | Short summary |
|---|---|
| Drilling and Completion Anomaly Detection in Daily Reports by Deep Learning and Natural Language Processing Techniques [28] | Unconventional oil & gas fields generate vast amounts of data, making data-driven methods challenging for analysis. Different activity coding systems and missing data make automatic anomaly detection difficult. An automatic text classification method was proposed using machine learning and natural language processing techniques for daily drilling and completion reports. Based on 460,000 operation records from 1,700 wells worldwide, Word2vec was used, and CNN was found to be the best method for text classification. |
| Virtual Multiphase Flowmeter Using Deep Convolutional Neural Networks [29] | This paper proposes a low-cost, instantaneous model for measuring oil, gas, and water volume in petroleum wells using artificial intelligence. The system uses pressure and temperature sensors from wells and opening control valve state to train a deep neural network with a convolutional layer to output fluid volume rate. The Schlumberger OLGA multiphase flow simulator software is used to provide data. Tests show the approximation achieves up to 99.6% accuracy, potentially replacing expensive multiphase meters or serving as a redundant digital sensor. |
| Prediction of Field Saturations Using a Fully Convolutional Network Surrogate [30] | The study focuses on developing surrogate models for predicting field saturations using a fully convolutional encoder/decoder network based on dense convolutional networks. The model extracts multiscale features from input data and uses these to recover input image resolution. It uses static and dynamic reservoir parameters as input features and outputs water-saturation distributions. This approach offers precision and cost-effectiveness, making it useful for production optimization and history matching. |
Table 4.
Publications demonstrating the application of the Recurrent Neural Network to anomaly detection problems.
Table 4.
Publications demonstrating the application of the Recurrent Neural Network to anomaly detection problems.
| Title and Reference | Short summary |
|---|---|
| Simulating the Behavior of Reservoirs with Convolutional and Recurrent Neural Networks [32] | Recurrent neural networks and convolutional neural networks have been applied to model reservoir behavior from data. Recurrent neural networks have the ability to retain information from previous patterns, making them suitable for interpreting permanent downhole gauge records. Convolutional neural networks, with specific design modifications, are as capable in modeling sequences of information and reliable in making inferences to cases not seen during training. The study discusses the differences in processing information and memory handling between these two architectures. |
| Integration of Artificial Intelligence with Economical Analysis on the Development of Natural Gas in Nigeria; Focusing on Mitigating Gas Pipeline Leakages [33] | Artificial intelligence is used to develop models using gas flow data to detect potential leakages in Nigeria's natural gas reserves. Machine learning algorithms like Recurrent Neural Networks and K-nearest neighbors are trained and evaluated for accuracy and precision. The results show that recurrent neural networks outperform K-nearest neighbors in leak detection, but all models possess high reliability. |
| Machine Learning for Deepwater Drilling: Gas-Kick-Alarm Classification Using Pilot-Scale Rig Data with Combined Surface-Riser-Downhole Monitoring [34] | Deepwater drilling often faces gas kicks due to the narrow mud-weight window. Traditional methods have time lag and can lead to severe gas influxes. A novel machine-learning model uses pilot-scale rig data and surface-riser-downhole monitoring for early detection and risk classification. Four ML algorithms are developed. The long short-term memory recurrent neural network algorithm showed the best performance, it is selected and deployed to early detect gas kicks and classify the corresponding kick alarms. The model achieves high recall, accuracy, precision, recall, and detection time delay. |
Table 5.
Publications demonstrating the application of the Long Short-term Memory algorithm to anomaly detection problems.
Table 5.
Publications demonstrating the application of the Long Short-term Memory algorithm to anomaly detection problems.
| Title and Reference | Short summary |
|---|---|
| A Machine Learning Workflow to Predict Anomalous Sanding Events in Deepwater Wells [36] | This study develops a predictive machine learning model using sensor and simulation data to inform Control Room Operators before significant damage occurs, using an anomaly detection architecture. The problem is addressed using Principal Component Analysis and Long Short-Term Memory Autoencoders, which reconstruct the original input. An alarm is triggered when the real-time anomaly score exceeds the training threshold. |
| Towards Real-Time Bad Hole Cleaning Problem Detection Through Adaptive Deep Learning Models [37] | The study presents an adaptive predictive deep-learning model that uses equivalent circulating density measurements, model results, and drilling data to predict potential bad hole cleaning conditions. The model has two components: an anomaly detector and a predictor. It uses Long Short-Term Memory cells to account for data correlations and generate future data conditioned to past observations. The approach is demonstrated on two real examples from offshore Norway. |
| Development of an Artificial Intelligence-Based Well Integrity Monitoring Solution [38] | The goal of an artificial intelligence-based well integrity monitoring solution was to create models to identify well annulus leakage events, accounting for the well type and all relevant anomalies. Artificial intelligence models were created using Long Short-Term Memory Autoencoders and classifier to identify complex irregularities. |
Table 6.
Publications demonstrating the application of the Generative Adversarial Network to anomaly detection problems.
Table 6.
Publications demonstrating the application of the Generative Adversarial Network to anomaly detection problems.
| Title and Reference | Short summary |
|---|---|
| Broadband reconstruction of seismic signal with generative recurrent adversarial network [40] | The resolution of seismic data depends on frequency and bandwidth, and complex exploration objects require higher resolution algorithms. Traditional methods can affect signal to noise ratio, reducing data reliability. A new method based on a generative recurrent adversarial network (GRAN) is proposed to generate pseudo sample sets constrained by geological layers and train the GRAN model for broadband seismic data reconstruction. The method's applicability is proven through blind well tests and is applied to actual work area seismic data processing, achieving excellent results. |
| Self-Supervised Subsea SLAM for Autonomous Operations [41] | The study proposes a deep learning-based Simultaneous Localization and Mapping (SLAM) method to estimate the 3D structure of a vehicle's surrounding environment from a single video. This method predicts a depth map of a given video frame while estimating the vehicle's movement between frames. The method is self-supervised and uses Generative Adversarial Networks to improve depth map prediction results. The study evaluates the method on the KITTI dataset and a private dataset of subsea inspection videos, showing it outperforms existing SLAM methods in depth prediction and pose estimation tasks. |
Table 7.
Publications demonstrating the application of the Reinforcement Learning algorithm to anomaly detection problems.
Table 7.
Publications demonstrating the application of the Reinforcement Learning algorithm to anomaly detection problems.
| Title and Reference | Short summary |
|---|---|
| Novel Stuck Pipe Troubles Prediction Model Using Reinforcement Learning [43] | This paper defines the stuck pipe prediction problem as a multi-class problem considering the dynamic nature of drilling operations. A reinforcement learning-based algorithm is proposed to solve this problem, with performance and evaluation results shared. The algorithm's accuracy is demonstrated, and performance improvement through feedback channel retraining is demonstrated. The reinforcement logic connects solutions to operation reporting, enhancing accuracy through neural networks. |
| Deep Reinforcement Learning: Reservoir Optimization from Pixels [44] | This paper uses Deep Reinforcement Learning to optimize the Net Present Value of waterflooding by altering the water injection rate. This is the first demonstration of AI's potential in understanding reservoir physics directly, without considering reservoir petrophysical properties or the number of wells in the reservoir. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



