
Submitted:
07 September 2023
Posted:
11 September 2023
You are already at the latest version
Abstract
Due to the high computational burden and the high nonlinearity of the responses, crashworthiness optimizations are notoriously hard-to-solve challenges. Among various approaches, methods like the Successive Response Surface Method (SRSM) have stood out for their efficiency in enhancing baseline designs within a few iterations. However, these methods have limitations that restrict their application. Their minimum iterative resampling required is often computationally prohibitive. Furthermore, surrogate models are conventionally constructed using Polynomial Response Surface (PRS), a method that is poorly versatile, prone to overfitting, and incapable of quantifying uncertainty. Furthermore, the lack of continuity between successive response surfaces results in suboptimal predictions. This paper introduces the Multi-Fidelity Successive Response Surface (MF-SRS), a Gaussian process-based method, which leverages a nonlinear multi-fidelity approach for more accurate and efficient predictions compared to SRSM. After initial testing on synthetic problems, this method is applied to a real-world crashworthiness task: optimizing a bumper crossmember and crash box system. Results, benchmarked against SRSM and the Gaussian Process Successive Response Surface (GP-SRS) – a single-fidelity Gaussian process-driven extension of SRSM, show that MF-SRS offers distinct advantages. Specifically, it improves upon the specific energy absorbed optimum value achieved by SRSM by 14.1 %, revealing its potential for future applications.
Keywords:
crashworthiness optimization
; MF-SRS
; SRSM
; multi-fidelity
; design optimization
; Gaussian Process
; NARGP
1. Introduction
At present, the automotive industry is mainly facing two pivotal challenges. The first is the growing importance of road and vehicle safety, which has raised legislative requirements and forced the inclusion of more effective protection systems in vehicles. The second challenge is the rising interest in environmental sustainability and energy transition, which is driving the automotive industry towards higher lightweighting standards, aiming to reduce fuel and battery consumption. In response to these dual challenges, substantial efforts are being made to develop vehicles that are both crashworthy and lightweight, thereby addressing these seemingly contradictory issues at the same time [1].
Over the past decades, the widespread usage of surrogate models, often called metamodels, has fundamentally transformed the approach to complex real-world optimization challenges. These methods, introduced as metamodeling techniques by Sacks et al. nearly 35 years ago [2], have evolved into Metamodel-Based Optimisation (MBO), a highly effective strategy for tackling complex black-box "expensive-to-evaluate" functions [3].
This category of functions is particularly prevalent in engineering applications, which are typically underpinned by time-intensive numerical simulations such as Finite Element Analysis (FEA) and Computational Fluid Dynamics (CFD). These simulations require large computational resources, often monopolising high-performance computing architectures for hours or even full days [4].
To cope with this issue, surrogate models have emerged as an innovative solution to reduce the vast number of function evaluations required, hence optimising resource utilisation. These models operate as an abstraction of an underlying phenomenon – generating a "model of the model", as referred to by Kleijnen [5]. Surrogate modeling operates by utilizing a set of sampling evaluations. Typically, this process begins with the design space being sampled through Design of Experiment (DoE) techniques. Subsequent numerical simulations at these sampled points are executed and results used to fit surrogate models over the variable domain [6].
A broad spectrum of metamodeling techniques have been advanced over recent years to aid complex engineering designs that are reliant on simulation-based methods. These include Gaussian Process (GP) [7], Polynomial Response Surface (PRS) [8,9], Support Vector Regression (SVR) [10], Radial Basis Function (RBF) [11], and Neural Network (NN) [12,13]. In the specific context of optimizing crashworthiness problems, PRS, RBF, and GP stand out as the most commonly used and most successful metmodels [14,15].
Alongside regression methods, various global search strategies can be useful in attempting to identify an optimal global solution in crashworthiness optimization. Given the highly nonlinearity of these problems, which commonly results in the presence of multiple local minima, methodologies such as Genetic Algorithms (GA) [16], Evolutionary Algorithms (EA) [17,18], and Simulated Annealing (SA) [19] are particularly suitable, but they often come with a high computational cost that might be unaffordable. In contrast, gradient-based methods are generally not recommended, particularly for the optimization of frontal collisions, as they exhibit increased sensitivity to bifurcations compared to lateral impacts. However, these methods may prove useful as local search strategies for refining the solution identified by a global optimisation algorithm.
Regardless of the regression model considered, the use of global response surfaces is generally discouraged due to the high nonlinearity of crash load cases. In contrast, an iterative approach based on the successive construction of response surfaces is recommended, especially when the optimum approaches regions of the variable domain with very high gradients or even discontinuities. This approach, commonly known as the Successive Response Surface Method (SRSM), has been shown to be effective in crashworthiness applications, as demonstrated by the research of Stander et al. and Kurtaran et al. [20,21,22].
Although SRSM has proven capable of identifying the optimal region for various crashworthiness problems, its application has some limitations. First, SRSM relies on iterative resampling, which could be a practical challenge since crashworthiness simulations are very time-consuming. Another potential drawback is the lack of continuity between successive approximations, making it difficult to incorporate information from previous iterations [14,23]. Finally, to our current understanding, the method does not seem well suited for integrating valuable data derived from response evaluations of lower fidelity models. These models, which are comparatively cheaper to evaluate, are often available or can be generated through automated process chains. The effectiveness of such models has been shown in the work of Acar et al. [24].
This paper proposes an approach that further enhances the SRSM and aims to overcome most of its existing limitations. The main contributions of this research are the following:
- We extend the SRSM to achieve qualitatively superior optima and potentially improve its computational efficiency. This is accomplished by leveraging GP, adaptive sampling techniques, and multi-fidelity metamodeling.
- Unlike conventional multi-fidelity methods (e.g., basic co-kriging), our approach is based on a method able to effectively handle complex nonlinear correlations between different fidelities. We also quickly show how this method benefits from parallel job scheduling on a High Performance Computer (HPC), enhancing its overall efficiency.
The organization of this paper unfolds as follows. In Section 2, we briefly outline a common iterative process used to optimize crashworthiness problems and provide the necessary mathematical notation. Then, in Section 3, we review the key steps of the sequential response surface methodology. Section 4 then provides a brief overview of multi-fidelity metamodeling based on GPs and touches on its potential applications. In which, we distinguish between linear and non-linear multi-fidelity approaches and emphasize the superiority of the latter through a selection of pedagogical examples. The paper continues in Section 5, where we present the workflow of our extension of SRSM based on multi-fidelity metamodeling. In Section 6, we test the proposed approach on a set of multi-fidelity benchmark functions, in addition to a crashworthiness use case. Finally, in Section 7, we outline the conclusions and consider potential future research directions.
2. Crashworthiness Optimization: Problem Formulation
Describing a generic crashworthiness design optimization problem using appropriate mathematical notation is relatively straightforward. Assuming that continuous design variables are to be handled in a single objective constrained problem, we can mathematically formulate the problem as follows:
where is the vector of the d design variables, and denote the physical lower and upper bounds on these variables, f is the objective function, and with is j-th of the constraint functions necessary to set inequality constraints. Note that both the objective and constraint functions map from the d-dimensional real space to the real numbers, so that and , respectively. The goal is to find the optimal , the vector that minimizes the response of the objective function f.
3. Successive Response Surface
Due to the high computational burden and the challenge of globally capturing the nonlinearities within the variable domain, the problem, as formulated above, is not yet ready for resolution. The SRSM can navigate us towards a more feasible formulation for such a problem by employing two main adjustments. Initially, the "expensive-to-evaluate" response functions associated with FEA simulations are substituted with response surface models. Specifically, f and are replaced with and respectively, such that and . These surrogate models are nothing but regression models constructed on an initial dataset of observations, commonly referred to as Design of Experiment (DoE): .
Many authors have used polynomial response surface models as a simple but effective way of generating a surrogate model [22,25,26]. The function is given for a general quadratic polynomial surface approximation:
where are the design points used to train the model, are the associated evaluated response values, are the constants to be determined, and includes both bias errors and random errors. The minimum number of numerical simulations, denoted , required to construct a given approximation depends on the number of design variables. For instance, in the case of a quadratic approximation, . The D-optimal sampling is frequently employed to explore the variable domain. For a deeper understanding of the PSR and D-optimal criterion, we recommend readers refer to the work of Myers and Montgomery [8].
Moreover, we substitute the original optimization problem with a succession of less-complex and smaller problems. Ideally, these sub-problems should be located in a sub-region of the variable domain and should still provide the same optimal solution of the original problem. We can formulate the k-th sub-problem by readjusting Eq. 1, , as follows:
where and define the k-th subregion, called Region of Interest (RoI) by some authors [27,28].
The domain of the variables can be translated and narrowed by adjusting the bounds of each variable. In this way, the focus of optimization can be shifted to only the new simplified domain of interest. Several heuristic schemes using different measures to evaluate the accuracy of the metamodel have been proposed and used to automate the so-called "panning and zooming" strategy. In this article, we briefly introduce the bounds adjustment scheme which has been successfully used to solve a variety of crashworthiness optimization problems [20,21,29]. As shown in Figure 1, subproblem is centered on the optimal design of the subproblem, i.e. . Moreover, the size of the subregion is a fraction of the subregion. This reduction of the feature domain along a generic i-th variable is determined by the fraction parameter , which is computed as follows:
From Eq. 9, it is quite clear that is equal to when the optimum is located at the lower and upper bounds. This extreme case results in pure panning, i.e. pure translation of the RoI, when . Conversely, when the optimum lies at the midpoint between and , is equal to , resulting in pure zooming or domain shrinkage. It is quite clear that and represent the upper and lower boundary values, respectively, of the fraction parameter .
The maximum value of , represented by for, is selected as the fraction to be applied across all design variables. This choice preserves the aspect ratio of the design region throughout the iterative process. Using the fraction parameter value , we can establish the upper and lower bounds of the i-th design variable for the -th subregion as follows:
4. Multi-fidelity metamodeling
Multi-fidelity modeling techniques are increasingly gaining momentum in the design optimization field, offering a viable solution to reduce the computational cost of high-fidelity response evaluations without compromising accurate metamodel predictions. Even though these techniques may be of different nature, being based on either linear regression or neural networks, the most common building block of multi-fidelity schemes is GP regression [30,31]. GPs are well suited to many MF-metamodel methods due to their ability to capture highly non-linear responses in as few functions as possible, which is the reason this study focuses on GP methods.
4.1. Background on Gaussian Process
Within the context of black-box expensive to evaluate functions, a common goal is to discern the connection between the design variables and a generic black-box function, f. This task can be accomplished by initially retrieving a dataset of input and output observation pairs (for the sake of clarity we recall that ) and then fitting a regression model to the collected observations. Before conditioning on such observations, a GP is defined by its mean function and kernel function (or covariance function):
It is common practice to assume that, before conditioning GP on the observations, the mean function is zero across the variable domain, especially since uncertainty about the mean can be accommodated by including an additional term in the kernel [32]. As a result, the structure that a GP can capture is entirely dictated by its covariance function k. This function, which depends on a vector of hyperparameters , yields the positive-definite symmetric covariance matrix . By maximizing the log-marginal likelihood (Eq. 13), it is possible to calculate vector .
Once the hyperparameters are identified, it is possible to infer the posterior distribution by conditioning the joint Gaussian distribution to make predictions on unseen data:
where refers to a new given input, to its prediction, and . The posterior mean and its related uncertainty, namely the posterior variance , can be therefore employed to make predictions. For more details on the conditioning of the Gaussian distribution and some examples of covariance functions, we suggest that the reader refer to the work of Rasmussen and Williams [7].
4.2. Linear Multi-fidelity metamodeling
In this section we briefly present a common linear multi-fidelity technique used in engineering disciplines to integrate computational models of varying fidelity (accuracy) to make predictions. This autoregressive scheme was proposed by Kennedy and O’Hagan in 2000 [30], commonly referred to as AR1, and is still widely viewed as a reference point. Although most practical problems involve only two fidelities, we generalize the problem by assuming that we have s levels of information sources available. Therefore, for a generic level t, we define to be the output of a given input . We can then, for each level, group inputs and outputs into a generic database by ordering the data by increasing fidelity, i.e., . In other words, is the output of the least accurate model, while is the output of the most accurate model. That being said, we present the autoregressive scheme of Kenny and O’Hagan in Eq. 17:
In Eq. 17 serves as a scaling factor to denote the magnitude of correlation among different fidelity outputs, is a GP with mean and covariance function , and are the GPs predicting data at fidelity level t and , respectively. This linear autoregressive scheme relies on the Markov property, asserting that when the closest point is known, no further information about can be gained from any other model output [33]:
4.3. Nonlinear Multi-fidelity metamodeling
Although Kennedy and O’Hagan’s scheme has already beem proven successful in literature [34,35], there are cases that are very common in realistic modeling scenarios, where cross-correlations between models of different fidelity, while very informative, show a more complex pattern than a simple linear correlation. In such a case, a linear autoregressive scheme might work well only in narrow ranges of the input parameters, but would not be able to learn a more comprehensive nonlinear correlation in the global domain. With this in mind, we briefly introduce the nonlinear autoregressive multi-fidelity GP regression (NARGP) algorithm introduced by Perdikaris et al. [36], which aims to extend the Kennedy and O’hagan scheme to more complex nonlinear and space-dependent correlations. We assume the design datasets to have a nested structure such as and we generalize the scheme of Eq. 17:
where the mapping between a low-model and its higher fidelity counterpart is denoted by the unknown function . To enable flexible and nonlinear multi-fidelity algoritms, a GP prior is assigned to z. Since is also assigned a GP prior, the posterior distribution of , because of the functional composition of two priors, is no longer Gaussian.
The generalization outlined in Eq. 19 does not come without implications in terms of computational cost and implementation complexity. This is mainly because of the need to use variational Bayesian methods to approximate intractable integrals. Therefore, to favor an algorithmic complexity closer to that of GP regression, Perdikaris et al. proposed a reformulation of the generalized scheme in which the GP prior is replaced by the GP posterior of the first inference level :
where to is assigned the prior of Eq. 21 and Eq. 22:
where , and are squared exponential anisotropic kernel functions based on Automatic Relevance Determination (ARD) weights (for additional details, please refer to [7]) and , , represent their hyperparameters. With this scheme, it is possible to infer the high fidelity response through by projecting the lower fidelity posterior onto a latent manifold of dimension .
The lowest fidelity level of the proposed recursive scheme is still a common GP regressor with kernel function . Therefore, its posterior distribution is still Gaussian. However, as for all other levels, the predictions have to be made given a test point . Therefore, for , the posterior distribution is no longer Gaussian and is defined by the following integral:
5. Multi-fidelity Successive Response Surface
As mentioned in the introduction, it is quite clear that the SRSM method has some limitations that limit its application to specific real-world scenarios. In this section, we introduce our improved version of SRSM, tailored for multi-fidelity crashworthiness problems, which we will refer to as Multi-fidelity Successive Response Surface (MF-SRS). We will provide an overview of the main workflow and then discuss its key components, highlighting the improvements over the traditional approach.
The general workflow of the MF-SRS approach is shown in the Figure 2. The first step is to formulate the optimization problem as described in Section 2. Therefore, it is necessary to define the d design variables with their respective bounds, the objective function, and any constraint functions with associated thresholds. Next, we can start the variable domain exploration phase using a hybrid sampling strategy. In this phase, we start with an Optimal Latin Hypercube Design (OLHD) to set the highest fidelity DoE, . Samples of lower fidelity are distributed by sequential sampling to gather information about areas left unexplored by the OLHD.
After generating the datasets for each fidelity level and computing their respective responses, the datasets undergo preprocessing, which includes scaling of input variables and normalizing the response values. These preprocessed datasets are then fed into the NARGP model, creating a metamodel for each response function. The accuracy of these metamodels is assessed using a cross-validation based error procedure. If the metamodels do not meet user-defined accuracy targets, infill algorithms can be optionally employed to add more samples. Within the original variable domain, an initial solution is extracted using metamodel-based optimization with an evolutionary algorithm. The identified optimum is verified Finite Element Analysis (FEA) simulations with the obtained optimal design variables to measure any deviations from the initial prediction. This result is incorporated into the respective DoEs and serves as the center of the RoI for the subsequent iteration. After adjusting the range of variables using the Pan & Zoom method, new exploratory samples are added to the RoI based on the reused samples. The metamodels are then updated with this augmented data. The process iterates until a convergence criterion is met or until a predefined maximum iteration limit is reached.
5.1. Adaptive Sampling: OLHD and MIPT
Since it is assumed that no a priori information is available about the nature of the response functions, the first stage of the workflow is necessarily a step of pure exploration of the variable domain. In this sampling step, we distribute samples according to a "hybrid" sampling strategy. The highest fidelity points are distributed according to a scheme of pre-optimized Latin Hypercubes Designs [37]. As demonstrated by the work of Crombecq et al. [38], these datasets have been optimized for several hours in order to maximize their projective- and space-filling properties. Please note that space-filling properties refer to the ability of a design to uniformly cover the domain of interest, ensuring that the entire input space is adequately represented without leaving large gaps. A dataset with good projective properties, instead, ensures that if we consider only a subset of its dimensions (i.e., we project the design onto a lower dimensional space), the resulting dataset still has desirable space-filling properties in that lower dimensional space. Therefore, unlike the statistical factorial experimental designs commonly used in the SRSM [20], pre-optimized Latin hypercubes allow extracting as much information as possible from each individual sample while avoiding space-near points and repetitive values. We use the database developed by Dam et al. [37], available at https://www.spacefillingdesigns.nl/. Although this database is extensive, it has its limitations, it only provides datasets for specific combinations of number of samples and design variables. If the required DoE is not available in this database, we rely on the translational propagation algorithm of Viana et al. to quickly generate optimal or near-optimal Latin hypercube designs [39].
Once the highest fidelity DoE is generated, we employ a sequential sampling strategy to build all the remaining lower-fidelity designs.
For this purpose, we use a Monte Carlo method originally developed by Crombeq et al.[38] and extended by Lualdi et al. [6]: mc-inter-proj-th (MIPT). Starting from a pre-existing design, this method is able to add samples with unit granularity, ensuring an optimal trade-off between space-filling and projective properties. As shown in Figure 3, by using the OLHD points, the MIPT algorithm is able to construct an optimal second layer of samples of lower fidelity. This process is repeated iteratively if more than two levels of fidelity are required. Please see Appendix A for more details on the formulation of the MIPT algorithm. The versatility of this algorithm allows us to apply the same adaptive sampling logic across iterative steps. Unlike one-shot sampling methods such as LHDs, the MIPT method enables the inheritance and reutilization of samples used in previous iterations. This feature is critical in crashworthiness optimization, both to extract the full potential of each individual FEM simulation and to avoid running unnecessarily expensive crashworthiness simulations.
To conclude on the topic of sampling, it is important to emphasize that the MIPT samples are introduced in a purely exploratory fashion, independent of the response function values. While this approach may seem less than optimal at first, it remains one of the most robust and effective strategies, especially when dealing with multiple response functions. Balancing different functions within the same domain can pose challenging problems.
5.2. Multi-fidelity Response Surface and sample reuse
To achieve maximum performance from the regression model, it is essential to preprocess the data obtained from the DoEs. By leveling out the differences in absolute values that may exist both in the different ranges of the input variables and in the response evaluations associated with different black-box functions, it is possible to avoid unwanted biases and distortions in the metamodel. Therefore, we scale the input variables to a unit hypercube and standardize the response values to obtain new distributions with unit mean and zero variance.
The scaled and normalized values of the designs are fed into the NARGP algorithm to infer a posterior distribution of each response function, as explained in Section 4.3. In addition to the regression model and data fusion approach, another significant difference from the original SRSM method is the selection of points for metamodel training. Given the significant computational effort involved in a passive safety FEM analysis, it is imperative to utilize all the information gained from previous iterations. Therefore, in the MF-SRS method, we retain points from previous iterations, both inside and outside the RoI. This strategy ensures a metamodel with a more reliable global trend, allowing us to use fewer points in each iteration for further exploration of the RoI. Refer to Figure 4 for a visualization of how the RoI and the addition of new samples evolve from the initial domain. Please note that both the number of samples and the zoom have been magnified for clarity.
Note that it is always a good practice to evaluate the accuracy of the metamodels at the end of the training phase and to add any samples if the reliability of the prediction is poor. Some authors recommend using an additional 10-30 % of the initial samples as test points to evaluate the accuracy of the metamodel alone [40]. Given the enormous computational cost this would imply in the context of crashworthiness optimization, our approach is based on Loeppky’s et al. [41] guidelines for choosing a sufficiently representative initial number of samples (rule ) and the leave-one-out Cross-Validation approach presented by Viana et al. This method evaluates the quality of metamodels without necessitating additional FEM simulations. For an in-depth understanding, readers can refer to [39].
5.3. Adjustment of the RoI
Regarding the definition of the boundaries of the new region of interest, we stick to the original algorithm already presented in Eq. 9, 10 and 11. As previously discussed, while the boundaries of the new RoI at a given iteration do not define the limits of the metamodel limits, they do set the boundaries for both the optimization algorithm and iterative resampling. Unless otherwise stated, in this article we will use =0.6 and =0.9 as defaults.
5.4. Optimization approach: Differential Evolution, Trust Region and verification step
Numerous single-objective optimization methods have been developed to date, encompassing both local and global optimization techniques. Typically, selecting the right optimization algorithm is crucial for locating the optimum, especially when surface response models are not in use. Yet, as Duddeck pointed out [15], when metamodel-based optimization approaches are employed, the selection of the optimization algorithm becomes less critical if the surrogate models accurately capture the physical properties. This statement highlights the importance of accurate metamodeling for effective optimization of complex engineering design problems.
Our proposed optimization strategy employs a hybrid approach. Initially, we leverage a probability-based global optimization algorithm to rapidly identify an optimal point. Subsequently, using this point as a starting reference, a local method refines the solution. This secondary step ensures that potential local enhancements are duly captured and not overlooked. The Differential Evolution (DE) algorithm is selected as the global optimization method in our approach due to its remarkable convergence properties, capability to address non-linear constraints, adaptability for parallelization, and straightforward implementation. This stochastic global search algorithm excels in managing nondifferentiable, nonlinear, and multimodal objective functions. Furthermore, its efficacy is validated in prior studies on structural optimization applications [42,43,44]. Based on our experience, the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) could be a compelling global method, delivering a performance comparable to the DE algorithm. For detailed information on DE and CMA-ES, please refer to [45,46] and [47] respectively. As a local optimization method, our choice falls on the Trust Region, a popular gradient-based optimization algorithm well suited for nonlinear problems. Its use is primarily motivated by the need to manage the quality of the model approximation in nonlinear optimization. The basic idea is to iteratively refine an estimate of the optimum based on local information. Like other local optimization methods, trust-region methods are sensitive to the starting point. If the function has multiple local optima, the method is expected to converge to a different optimum depending on where you start [48]. Therefore, its use must be combined with a global optimization method such as DE.
In our approach, a local optimization is performed starting from each member of the last population of the DE algorithm. Since optimization on metamodels is very fast compared to the computational burden of a function evaluation, we adopt a DE population size of 20 and we repeat the entire optimization process (global and local optimization) 10 times.
Verification serves as the final step of the optimization phase. The optimal solution derived from the metamodel is validated through a FEA to confirm the accuracy of the metamodel’s prediction compared to the actual ground truth value.
5.5. Convergence criterion
We use two stopping criteria to determine if the problem has achieved convergence: the maximum number of iterations and the Average Relative Function Tolerance (ARFT). The process is halted when either of these criteria is satisfied. The maximum number of iterations is determined by the user, based on the specific problem at hand. The ARFT formula, inspired by the criterion presented by Querin et al. [49], is provided below:
Here, denotes the number of pairs of successive iterations under consideration, and is a very small number introduced to prevent division by zero when equals zero. Convergence is achieved when drops below a specified threshold :
By default, we set and . This ensures that the optimization will stop if the average relative change in the objective function over the last three iterations is less than 1 %. Unless otherwise stated, in this paper we will use =4.
6. Results and Discussion
In this chapter, we evaluate the effectiveness of MF-SRS through a series of experiments on both synthetic problems and a real-world engineering challenge. We begin with a visual illustration on two well-known problems from the literature to demonstrate the robustness of a multi-fidelity regression model capable of capturing both linear and nonlinear correlations. We continue with optimization tests on multi-fidelity benchmark functions to compare the convergence of the SRSM with the MF-SRS. We conclude with a comprehensive section dedicated to the design optimization of a vehicle front structure subsystem, focusing specifically on a crash box and a bumper crossmember.
6.1. Synthetic illustrative problems
We begin with a visual illustration of two well-known problems in the literature of multifidelity functions: The Forrester function and the Sinusoidal Wave function have been presented in the works of [50] and [36], respectively. We break down the mathematical formula of the Forrester into its fidelities in Eq. 26,, while the high- and low-fidelity functions of the Sinusoidal Wave are described in Eq. 28,.
The multi-fidelity Forrester function is:
The multi-fidelity Sinusoidal Wave function is:
The inclusion of these formulas is important to show the different types of mappings between the fidelities of these two functions. The dominance of the "linear mapping" in the Forrester function is clearly seen in the term, while the quadratic mapping between the fidelities of the sine wave is also recognizable. The overall trend of these functions and the correlation between their fidelities is visualized in Figure 5.
To caution readers against drawing simplistic conclusions, we would like to point out that the idea of a linear mapping between the high-fidelity and the low-fidelity representations in the Forrester function is just a simplification, commonly used for illustrative purposes in multi-fidelity contexts. This does not mean that a plot of over will yield a perfect straight line over the entire range of the function. Indeed, this would have been the case if there were no deviations induced by the bias term , which is linear in x but not in .
To observe the practical implications of the theory outlined in chapter Section 4, we approach comparing GP, AR1, and NARGP methods on these two functions. As a rule of thumb for these experiments, we always use twice as many high-fidelity observations for the low-fidelity level. Note that this number depends strongly on the problem at hand, and especially on the "cost" ratio of the fidelities. While comparing GP and multi-fidelity models may seem unfair, it serves as an insightful exercise. This comparison highlights the capability of multi-fidelity models to assimilate valuable information from alternative sources, potentially leverage it for faster convergence.
The results for the Forrester function, based on 5 observations, are shown in Figure 6. Without delving into error metrics, it is straightforward to observe that the multi-fidelity methods perform similarly and represent the function with greater precision compared to GP. The most notable differences are at the bounds of the domain and within the valley of the optimum.
A different scenario can be seen in Figure 7. Based on 7 high-fidelity observations, the GP and AR1 methods appear to have a remarkably similar posterior distribution that deviates significantly from the true sinusoidal trend. While the subpar metamodeling of GP can be justified by the low sampling rate with respect to the period of the function, the performance of the AR1 is rather surprising. It seems to struggle to exploit the information from the low-fidelity observations. In contrast, NARGP, while not a perfect representation of the original function, seems to capture its periodic pattern and average amplitude, providing a much more accurate approximation. These results echo the key observations of Perdikaris et al. and suggest that NARGP may be a superior and more reliable option for navigating intricate relationships between fidelities.
6.2. Results on benchmark functions
We continue our experiments with tests on benchmark functions, aiming to evaluate the convergence performance of the MF-SRS method in terms of speed and effectiveness. We aim to compare our method with its simplified variant, GP-SRS, which relies solely on GP and high-fidelity, and with the SRSM method based on PRS. Given our primary focus on crashworthiness problems, the objective remains to identify the best achievable local optimum with the least number of function evaluations. Our general expectation is to see a clear predominance of Gaussian process based methods over polynomial regression based approaches. We also hope to see possibly more efficient convergence of MF-SRS than GP-SRS, especially in the first few iterations, although we do not necessarily expect superior performance in the long run.
For this evaluation, we leverage the work of van Rijn & Schmitt [51], who have gathered a set of well-known benchmark functions from literature, each with at least two levels of fidelity. The mathematical formula of those functions and further details regarding the input variables can be found in the Appendix B. Specifically, we investigate:
For the first problem, the goal is to either maximize, or minimize the negative counterpart of the Currin function. We specify that each method starts with an equal set of high-fidelity points, 10 in this case. After each iteration, both GP-SRS and SRSM add six more high-fidelity samles, while MF-SRS introduces only four. The ratio of low-fidelity to high-fidelity samples remains constant at 2:1. For these analytical functions, which do not come with any evaluation cost, we will consistently use twice the number of low-fidelity samples compared to high-fidelity samples, simarly to what is shown in [36].
The comparison between MF-SRS and GP-SRS of the first four iterations is shown in Figure 8. The first iteration highlights the value of low-fidelity samples: while GP-SRS suffers from severe overfitting complications, making it difficult to extract valuable information, MF-SRS shows a more stable progression, guiding the optimization towards the optimum despite having fewer high-fidelity samples. Both methods appear to converge quickly to the global minimum. In a second two-dimensional test, we focus on minimizing a double-constrained Branin function. We impose a constraint on the objective function itself, thereby preserving the nearly flat region where the three global minima of the function lie. In addition, we further narrow down this region through a constraint applied to the Himmelblau function, as shown by Eqs 30,, and .
From the first four iterations shown in Figure 9, it is quite clear that the combination of the given constraints poses a significant challenge for accurate representation, especially with only 15 high-fidelity observations available. However, while the GP-SRS method bounces between opposite sides of the variable domain during the initial iteration steps, the MF-SRS method exhibits more stable behavior. It guides the RoI towards a global minimum from the first iteration, consistently avoiding the infeasible region.
We then analyze the convergence behavior of both problems and include the SRSM approach into the comparison for a more comprehensive evaluation. It is important to note that, for the SRSM method, a quadratic PRS was used. As explained in Section 3, this requires a minimum of six observations when dealing with two variables. Our expectations were indeed met. For both problems, the SRSM method is significantly the slowest to converge and consistently produces qualitatively worse results than the other methods at almost every iteration (see Figure 10). The initial investment in MF-SRS seems to pay off, as it consistently outperforms the other methods in making more accurate predictions, especially in the early steps. The lack of high-fidelity points does not seem to affect its performance, and the efficient use of all available points seems to be a key feature contributing to its effectiveness. The choice of MF-SRS over GP-SRS under these conditions would depend on the computational cost associated with different fidelity levels, as well as the potential for job submissions that utilize multiple computing resources.
As our final synthetic problem, we examine the Borehole function, an eight-dimensional problem. This function models the flow of water through a borehole drilled from the ground surface through two different aquifer layers. The flow rate of water, expressed in cubic meters per year , is described by the properties of both the borehole and the aquifers. The borehole function is often used to compare different types of metamodels and to perform feature importance analysis. Since the optimum of this function is known, we aim to minimize the problem and to compare the predictions of the surface response models at the initial stage.
Considering the complexity of this problem, we initiate the process with a dataset of 80 high-fidelity samples for each method. In each subsequent iteration, we add 4, 6, and 9 new samples for the MF-SRS, GP-SRS, and SRSM methods, respectively. It is important to note that, for the SRSM method, a linear polynomial form was employed due to the prohibitively high cost associated with such a large number of function evaluations. Indeed, this form requires samples, which, although still quite expensive, is more manageable than the samples that would be required otherwise.
The initial prediction performance is depicted on the left side of Figure 11, where it is compared with the ground-truth values. The MF-SRS method demonstrates remarkable accuracy across the entire domain represented. The GP-SRS prediction is also strong, although it exhibits a larger average deviation from the ideal diagonal prediction. Notably, towards the minimum values, GP-SRS predictions are affected by a consistent bias that progressively shifts values toward the upper region of the graph. On the other hand, the SRSM method, based on PRS, exhibits the least accuracy, with a consistently higher level of uncertainty across the considered range when compared to the other two methods.
These initial prediction results are echoed in the convergence performance, illustrated on the right side of Figure 11. While none of the methods manage to reach the global optimum, MF-SRS notably outperforms the other two methods, especially in terms of efficiency, requiring 15 iterations as compared to 25 and 34 (according to the convergence criterion defined in Eq. 24) for GP-SRS and SRSM, respectively. The fact that GP-SRS, despite several additional high-fidelity observations, fails to reach the same local minimum identified by the multi-fidelity method suggests that GP-SRS may have been guided towards a local minimum by a less accurate initial prediction.
6.3. Engineering use case: Crash box design
In this section, we address the design of an aluminum crash box for an urban electric vehicle, a critical real-world engineering problem. Positioned between the bumper and longitudinal rails, this energy-absorbing device is crucial for the vehicle crashworthiness. It not only protects passengers and minimizes vehicle damage but can also reduce repair costs. Therefore, maximizing the energy-absorbing capability of the crash box is essential.
In this use case, we examine a structural system consisting of a bumper beam cross member, the crash box, and the crash box flange. This structure is attached to the rear end of the crash box and is subjected to compression by a rigid body, the impactor, moving at a constant velocity of 1.5 m/s. All structural components are made of AA 5083, an aluminum alloy known for its good ductility and high strength-to-weight ratio.
6.3.1. Key Performance Indicators (KPIs)
When evaluating crashworthiness of crush boxes, a number of Key Performance Indicators (KPIs) are often examined [54,55]. These KPIs provide quantifiable metrics to assess the effectiveness of a crash-box under crushing loads. An essential indicator is the total Energy Absorbed (EA). This quantifies the work done on the structure to induce deformation due to the impact and is defined by Eq. 34:
where is the crushing length and denotes the resultant impact force over the displacement x. Maximizing EA is a common objective function, as long as it does not overweight the structure. To avoid this problem, it is often replaced by the Specific Energy Absorbed (SEA), which is the absorbed energy per unit mass of material:
where m is the sum of the mass of the crash box and the bumper beam in this case. Another important indicator is the mean crushing force which is given by Eq. 36:
The mean crushing force is a required element for the calculation of the Undulation of Load Carrying Capacity (ULC). This indicator evaluates the stability of the structure under crushing and is given by Eq. 37:
Finally, we introduce Crushing Force Efficiency (CFE), which relates the maximum peak resistance force to the average force :
These two critical parameters shown in Eq. 38 directly affect the deceleration experienced by vehicle passengers during a collision. Ideally, an absorber will have a CFE equal to one, meaning that the crush box absorbs energy uniformly throughout the deformation process and behaves in a controlled manner under crash conditions.
6.3.2. Problem Formulation
An overview of the structural system to be analyzed is given Figure 12. Note that there are two V-notch crush initiators (sometimes called triggers) and at the top and bottom of the crash box. These are strategically placed engineering features introduced into the crash box components of the vehicle structure to control the deformation path during a collision.
As design variables, we consider the thicknesses of the crash box ( and ), the flanges () and the bumper cross member (). Additionally, we consider the distance from the flanges to the first trigger (), the distance between the two triggers (), and the angle (), which symmetrically, adjusts the tilt of both the top and bottom faces of the crash box with respect to the horizontal plane. The last three variables imply a change in the geometry of the crash box, classifying the problem as a mixture of size and shape optimisation. A detailed description of the design variables and their respective bounds is given in Table 1.
The main objective is to maximise the SEA within certain passive safety constraints. First, we set a value for the maximum peak deformation force and a maximum value for the average deformation force . This is to ensure that the crash-box deforms before the longitudinal members, thus ensuring a step-wise increasing deformation curve [56]. With reference to Figure 13 we set a threshold of 61.75 kN for (5 % safety margin) and a threshold of 50 kN for .
To ensure effective energy absorption, we set a minimum threshold for the energy absorption of the bumper crossmember after 35 ms, aligning with the expected timing of the first peak force due to crash box deformation. This constraint prevents excessively stiff bumper configurations that could cause premature deformation of the crash box. Additionally, we require that and . Although these constraints are typically applied to crashboxes alone, in this context, they are employed to ensure an adequate trade-off between force fluctuations and the initial peak relative to the mean force value. The complete formulation of this optimization problem is provided in Appendix C.1.
6.3.3. High- and Low-Fidelity Model
Before diving into the optimization we need to distinguish the two fidelities for the MF-SRS method. To determine an optimal mesh size for the high-fidelity model, we performed a mesh sensitivity analysis by varying the average element size. As shown in Figure 14, reducing the mesh size below 2 mm has minimal impact on the response functions considered. However, this size reduction significantly increases the simulation time. For example, on a 2x AMD EPYC 7601 (32 cores, 2,2 GHz) per node of our HPC cluster, the time changes from 20 minutes to 1 hour and 26 minutes. Based on this analysis, we chose an average mesh size of 2 mm for the high-fidelity model.
Beyond mesh size, the presence of damage model, which defines the failure criterion for element deletion, is another significant factor that affects the duration of a simulation. Disabling this feature in our aluminum material card results in approximately a 25 % reduction in simulation time for the 2 mm finite element model. In addition, increasing the mesh size to 5 mm dramatically drops the simulation time to approximately 3 minutes and 10 seconds. While this coarser finite element model is obviously less accurate and deviates from the response of the high-fidelity model, we propose its utility as a low-fidelity model. We believe that it can capture significant global information that, when integrated with high-fidelity runs, contributes significantly to the prediction of response functions. The two models are illustrated in Figure 15.
For a more thorough understanding of the use case, we carried out additional simulations to provide a broader view of the correlation between the high-fidelity and low-fidelity models. This additional analysis serves to stress the complex relationship between the two models, allowing for a more sound interpretation of the results. Detailed results and discussions from these additional simulations are provided in Appendix C.2.
6.4. Results of the engineering use case
In this section, we present the results of the crash box optimization, comparing the three approaches introduced so far: SRSM, GP-SRS and MF-SRS. For the MF-SRS approach, we use a high-fidelity DoE consisting of 60 points, with an addition of 4 more high-fidelity points at each iteration. Since the "cost" of low fidelity simulations is less than one-sixth of the high-fidelity ones, we set the 2:1 ratio that has shown great results so far. In contrast, the GP-SRS approach uses a slightly larger DoE of 70 points and adds 5 high-fidelity points to each iteration. The SRSM method also starts with a 70 point DoE and iteratively adds 8 high-fidelity points at each iteration based on the linear polynomial criterion.
To achieve faster and more robust convergence, at each iteration, we record the best feasible value using the criterion given in formula 24 based on . If this value does not improve, we retain the best feasible value achieved in prior iterations. If all designs at a specific iteration fail to meet the constraints, we mark the point in red. From the results shown in Figure 16, the performance of MF-SRS stands out. It is clearly the most effective approach, achieving a 13.1 % and a 14.1 % SEA improvement over GP-SRS and SRSM, respectively. Besides the improved optimum, the fast convergence and the ability to accurately predict the feasibility limits of the domain are remarkable. This is particularly evident in the result of the first iteration where, despite the deficit of 10 high-fidelity points, MF-SRS still manages to identify an optimum that outperforms the other approaches.
The performance of GP-SRS is solid, although with a slower progression than expected. We believe that with more relaxed convergence criteria, it may eventually surpass the maximum obtained by MF-SRS, albeit at a significantly higher computational cost.
Conversely, SRSM appear to be the least robust approach. Despite the rapid improvement in the fourth iteration, the best reported point often does not match with the verification point, a discrepancy that is curious considering the predictive potential offered by the 8 new high-fidelity samples added at each iteration. From a computational point of view, SRSM seems to be the most "expensive" and, in terms of prediction, the most unreliable of the methods investigated. Further details of the optimal designs of response values and input variable are provided in Table 2 and Appendix C.3, respectively.
The iteration by iteration evolution of the MF-SRS method is shown in the parallel coordinates plot in Figure 17. The light gray lines represent designs that violate the constraints and are therefore unfeasible, while the blue lines denote feasible designs. It is clear that the density of the darker lines increases around the optimal design, which is shown in orange. This provides further evidence of the robust convergence of the MF-SRS method.
The deformation force versus impactor displacement pattern is shown in Figure 18. Although very similar in the first peak force (about 45 mm), the higher energy absorption is in the crash box folding behavior with a higher average force value. As for the bumper design, the MF-SRS method has probably room for improvement given the lower energy absorption.
6.5. Parallel Job Submission on HPC
While we have primarily assessed convergence curves on an iteration-wise basis, careful observers may rightly argue that this comparison does not fully account for efficiency. Specifically, the MF-SRS method incurs an extra cost due to low-fidelity simulations, different methods add a different number of high-fidelity samples at each iteration, and the MF-SRS starts with a DoE with 10 fewer high-fidelity samples. Taking these factors into account, in this section we delve into how the curves in Figure 16 adjust when viewed in terms of cumulative computational time, with a particular focus on the HPC logic implications.
Before presenting the results, we outline some assumptions:
- We use a cluster of with 2x32 cores each (AMD EPYC 7601 processors);
- Only one job is submitted on each node at a time. Parallel job submissions across different nodes are allowed, but splitting a single node among multiple jobs is not;
- We use a greedy job scheduler that ideally distributes jobs across nodes once the optimization problem is defined. We assume that the availability of nodes at any given time does not affect the formulation of the optimization problem;
- We assume that the computational cost of low-fidelity jobs is equivalent to a unit cost. Therefore, given the cost ratio, we know that a high-fidelity job has a cost of 6.25 units for this particular problem.
Bear in mind that the job scheduler prioritizes parallelization of high-fidelity jobs across available nodes. It allocates low-fidelity jobs only after all the more demanding high-fidelity simulations are completed.
Assuming the availability of 5, 7, and 8 nodes, the results are displayed in Figure 19, from left to right, respectively. The top row illustrates the prioritization of multi-fidelity DoE jobs according to the described scheduling logic. The bottom row presents the full convergence curve, plotted against the cumulative computational cost. The chosen node configurations ideally suit each of the three methods investigated. In fact, with regard to the MF-SRS method, 5 nodes in parallel guarantee an exact division (without remainder) both for the number of high fidelity samples of the DoE and for the number of samples added iteratively. Similarly, 7 and 8 nodes are scenarios that favor the GP-SRS and SRSM methods, respectively. We observe that, due to the additional cost of the additional simulations with the coarse mesh, the first iteration of the multi-fidelity approach is no longer vertically aligned with the other two. However, due to its cost-ratio advantage and limited use of high-fidelity points, the MF-SRS method consistently emerges as the most efficient approach, regardless of the number of nodes available. Any unused nodes can be eventually assigned to handle batches of low-fidelity jobs, efficiently utilizing computational resources while waiting for more resource-intensive simulations to complete. These results emphasize how parallel job scheduling can be leveraged to make the MF-SRS method even more efficient and competitive.
7. Conclusions
In this paper, we introduced the MF-SRS method, a novel optimization approach that leverages Gaussian processes to better handle the inherent complexity of crashworthiness problems.
While the traditional SRSM is effective in some aspects, it has been found to have significant limitations, particularly in the prohibitive use of costly function evaluations and the shortcomings associated with the PSR method. The proposed MF-SRS method attempts to address these challenges by employing a multi-fidelity approach which captures in-depth information from both high-fidelity and low-fidelity models, wisely reuses information from previous iterations, and queries new data at unexplored locations via adaptive infill seed criteria. This combination results in a more robust and versatile framework compared to SRSM.
Our experiments, ranging from benchmark functions to a real-world crashworthiness application, were encouraging. Compared to both SRSM and the GP-SRS, MF-SRS consistently demonstrated superior performance. In particular, compared to SRSM, it achieved a remarkable 14.1 % improvement in the optimal value of the specific energy absorption, demonstrating stability and accuracy in the optimization process. In this particular scenario, given a low-fidelity model with a coarse mesh and no element erosion, MF-SRS demonstrated its ability to decode intricate relationships among different fidelities.
In our future research, we plan to primarily investigate the optimal ratio of high- and low-fidelity points per iteration and within the initial DoE, with the aim of adaptively adjusting these numbers based on the given problem. While NARGP stands out as a promising multi-fidelity approach, the rapidly evolving field introduces exciting alternatives at a rapid pace. Of particular interest are Multi-Fidelity Bayesian Neural Network approaches, which offer the potential to address uncertainties in sampling and to capture intricate correlations between fidelities, thanks to the neural network framework. Finally, tailoring specific covariance functions relevant to certain iterations within the GP-SRS method offers another intriguing avenue of exploration.
Author Contributions
Conceptualization, P.L. and R.S.; methodology, P.L.; software, P.L.; validation, P.L.; formal analysis, P.L., R.S. and T.S.; investigation, P.L.; resources, P.L. and R.S.; data curation, P.L.; writing—original draft preparation, P.L. and R.S.; writing—review and editing, R.S. and T.S.; visualization, P.L.; supervision, R.S. and T.S.; project administration, R.S.; funding acquisition, R.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Acknowledgments
We would like to express our sincere gratitude to Dr. Andrew Harrison and Mr. Thomas Grünheid-Ott for their valuable contributions.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AR1 | Auto-Regressive order 1 |
| GP | Gaussian Process |
| GP-SRS | Gaussian Process Successive Response Surface |
| MF-SRS | Multi-Fidelity Successive Response Surface |
| NARGP | Non-linear Auto-Regressive Gaussian Process |
| PRS | Polynomial Response Surface |
| SRSM | Successive Response Surface Method |
Appendix A
The main idea behind the mc-inter-proj-th (MIPT) [38] method is discarding candidates which lie too close to each other based on projected distance based on a threshold value. The remaining points are then ranked on their intersite distance. Therefore, this Monte Carlo method looks as follows:
where the threshold is defined by a tolerance parameter in which has a domain of :
The tolerance parameter defines the balance between the space-filling and non-collapsing properties. Low values of lead to a reduction of the projected distance constraint. Therefore, fewer candidates are discarded. On the other hand, high values of result in a strict constraint to be satisfied. This reduces the chance of finding a valid candidate [6].
Appendix B
The Currin function is given by:
The Branin function is given by:
The Himmelblau function is given by:
The Borehole function is given by:
Where:
Appendix C
Appendix C.1
The crash box optimization problem, from a mathematical point of view, is defined as follows:
Appendix C.2
In Figure A1, we illustrate the SEA correlation between the two fidelities with respect to the variables and , holding all other variables constant. This correlation is visualized by a 20x20 grid showing the ground-truth values derived from numerical simulations.
Figure A1.
Contour plots representing SEA values across a 20x20 grid. From left to right: high-fidelity ground-truth values, low-fidelity ground-truth values, and the absolute error between the two fidelity levels.
Figure A1.
Contour plots representing SEA values across a 20x20 grid. From left to right: high-fidelity ground-truth values, low-fidelity ground-truth values, and the absolute error between the two fidelity levels.
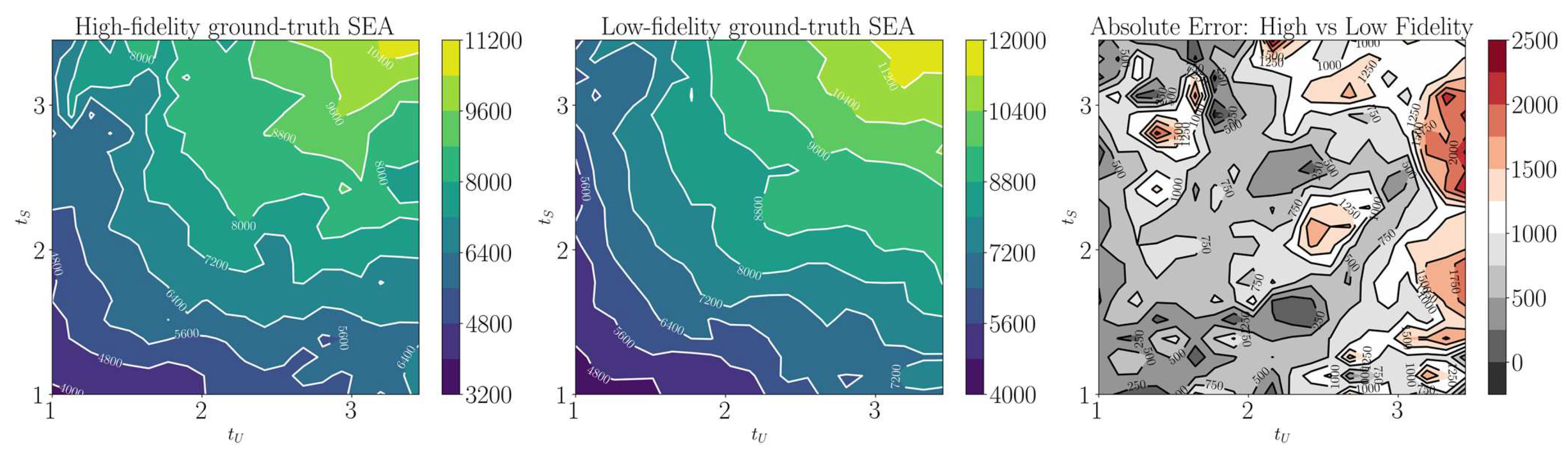
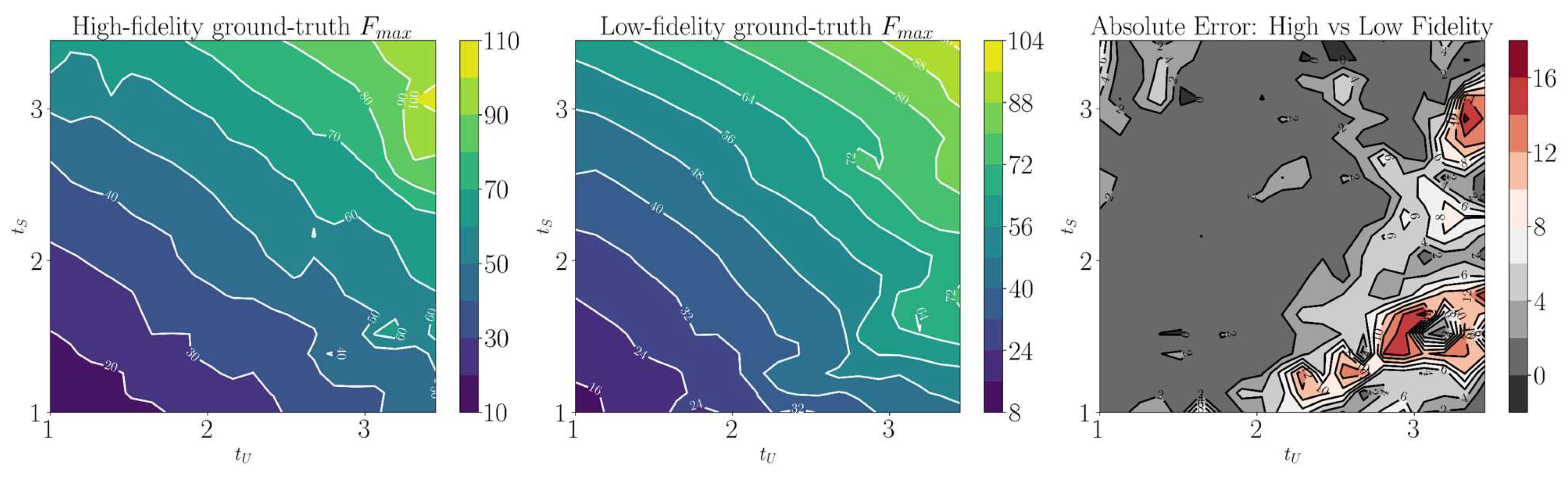
Although the low-fidelity model roughly mirrors the pattern of its high-fidelity counterpart, it is noticeable that the relationship between the two is not uniform across the 2D domain. In certain local regions, the absolute error exceeds 2000 J/kg, indicating a complex, non-linear relationship that requires careful management in the learning process. A similar relationship can be observed in , as shown in Figure A2.
Figure A2.
Contour plots representing values across a 20x20 grid. From left to right: high-fidelity ground-truth values, low-fidelity ground-truth values, and the absolute error between the two fidelity levels.
Figure A2.
Contour plots representing values across a 20x20 grid. From left to right: high-fidelity ground-truth values, low-fidelity ground-truth values, and the absolute error between the two fidelity levels.
Appendix C.3

Table A1.
Summary of the optimal design variables of each method.
| Method | [mm] | [mm] | [mm] | [mm] | [mm] | [mm] | [deg] |
|---|---|---|---|---|---|---|---|
| SRSM | 2.1 | 2.6 | 1.0 | 1.0 | 30.1 | 40.0 | 1.0 |
| GP-SRS | 2.3 | 2.5 | 1.2 | 1.7 | 33.2 | 31.1 | 2.8 |
| MF-SRS | 2.4 | 2.7 | 1.0 | 1.5 | 36.2 | 30.0 | 2.7 |
References
- O’Neill, B. Preventing passenger vehicle occupant injuries by vehicle design–a historical perspective from IIHS. Traffic injury prevention 2009, 10, 113–126. [Google Scholar] [CrossRef] [PubMed]
- Sacks, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and Analysis of Computer Experiments. Statistical Science 1989, 4. [Google Scholar] [CrossRef]
- Bartz-Beielstein, T.; Zaefferer, M. Model-based methods for continuous and discrete global optimization. Applied Soft Computing 2017, 55, 154–167. [Google Scholar] [CrossRef]
- Khatouri, H.; Benamara, T.; Breitkopf, P.; Demange, J. Metamodeling techniques for CPU-intensive simulation-based design optimization: a survey. Advanced Modeling and Simulation in Engineering Sciences 2022, 9, 1–31. [Google Scholar] [CrossRef]
- Kleijnen, J.P.C. A Comment on Blanning’s “Metamodel for Sensitivity Analysis: The Regression Metamodel in Simulation”. Interfaces 1975, 5, 21–23. [Google Scholar] [CrossRef]
- Lualdi, P.; Sturm, R.; Siefkes, T. Exploration-oriented sampling strategies for global surrogate modeling: A comparison between one-stage and adaptive methods. Journal of Computational Science 2022, 60, 101603. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian processes for machine learning; Adaptive computation and machine learning, MIT: Cambridge, Mass. and London, 2006. [Google Scholar]
- Myers, R.H.; Montgomery, D.C.; Anderson-Cook, C.M. Response surface methodology: Process and product optimization using designed experiments, fourth edition / raymond h. myers, douglas c. montgomery, christine m. anderson-cook ed.; Wiley series in probability and statistics; Wiley: Hoboken, New Jersey, 2016. [Google Scholar]
- Montgomery, D.C. Design and Analysis of Experiments, 10. edition ed.; John Wiley & Sons, Inc: Hoboken, 2021. [Google Scholar]
- Gunn, S.R. Support Vector Machines for Classification and Regression; s.n, 1998.
- Wang, T.; Li, M.; Qin, D.; Chen, J.; Wu, H. Crashworthiness Analysis and Multi-Objective Optimization for Concave I-Shaped Honeycomb Structure. Applied Sciences 2022, 12. [Google Scholar] [CrossRef]
- Pawlus, W.; Robbersmyr, K.; Karimi, H. Performance evaluation of feedforward neural networks for modeling a vehicle to pole central collision 2011.
- Omar, T.; Eskandarian, A.; Bedewi, N. Vehicle crash modelling using recurrent neural networks. Mathematical and Computer Modelling 1998, 28, 31–42. [Google Scholar] [CrossRef]
- Fang, J.; Sun, G.; Qiu, N.; Kim, N.H.; Li, Q. On design optimization for structural crashworthiness and its state of the art. Structural and Multidisciplinary Optimization 2017, 55, 1091–1119. [Google Scholar] [CrossRef]
- Duddeck, F. Multidisciplinary optimization of car bodies. Structural and Multidisciplinary Optimization 2008, 35, 375–389. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in natural and artificial systems: An introductory analysis with applications to biology, control, and artificial intelligence / John H. Holland, 1st mit press ed. ed.; 1992.
- Bäck, T. Evolutionary algorithms in theory and practice: Evolution strategies, evolutionary programming, genetic algorithms / Thomas Bäck; Oxford University Press: Oxford and New York, 1996. [Google Scholar]
- Slowik, A.; Kwasnicka, H. Evolutionary algorithms and their applications to engineering problems. Neural Computing and Applications 2020, 32, 12363–12379. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science (New York, N.Y.) 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Kurtaran, H.; Eskandarian, A.; Marzougui, D.; Bedewi, N.E. Crashworthiness design optimization using successive response surface approximations. Computational Mechanics 2002, 29, 409–421. [Google Scholar] [CrossRef]
- Stander, N.; Craig, K.J. On the robustness of a simple domain reduction scheme for simulation–based optimization. Engineering Computations 2002, 19, 431–450. [Google Scholar] [CrossRef]
- Liu, S.T.; Tong, Z.Q.; Tang, Z.L.; Zhang, Z.H. Design optimization of the S-frame to improve crashworthiness. Acta Mechanica Sinica 2014, 30, 589–599. [Google Scholar] [CrossRef]
- Naceur, H.; Guo, Y.Q.; Ben-Elechi, S. Response surface methodology for design of sheet forming parameters to control springback effects. Computers & Structures 2006, 84, 1651–1663. [Google Scholar] [CrossRef]
- Acar, E.; Yilmaz, B.; Güler, M.A.; Altin, M. Multi-fidelity crashworthiness optimization of a bus bumper system under frontal impact. Journal of the Brazilian Society of Mechanical Sciences and Engineering 2020, 42, 1–17. [Google Scholar] [CrossRef]
- Lönn, D.; Bergman, G.; Nilsson, L.; Simonsson, K. Experimental and finite element robustness studies of a bumper system subjected to an offset impact loading. International Journal of Crashworthiness 2011, 16, 155–168. [Google Scholar] [CrossRef]
- Aspenberg, D.; Jergeus, J.; Nilsson, L. Robust optimization of front members in a full frontal car impact. Engineering Optimization 2013, 45, 245–264. [Google Scholar] [CrossRef]
- Nilsson, L.; Redhe, M. (Eds.) An investigation of structural optimization in crashworthiness design using a stochastic approach. Livermore Software Corporation, 2004.
- Redhe, M.; Giger, M.; Nilsson, L. An investigation of structural optimization in crashworthiness design using a stochastic approach. Structural and Multidisciplinary Optimization 2004, 27, 446–459. [Google Scholar] [CrossRef]
- Stander, N.; Reichert, R.; Frank, T. Optimization of nonlinear dynamical problems using successive linear approximations 2000. [CrossRef]
- Kennedy, M.C.; O’Hagan, A. Predicting the Output from a Complex Computer Code When Fast Approximations Are Available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef]
- Le Gratiet, L. Recursive co-kriging model for Design of Computer experiments with multiple levels of fidelity with an application to hydrodynamic.
- Duvenaud, D. Automatic model construction with Gaussian processes. PhD thesis, Apollo - University of Cambridge Repository, 2014. [CrossRef]
- A. O. Hagan. A Markov Property for Covariance Structures 1998.
- Forrester, A.I.J.; Sóbester, A.; Keane, A.J. Engineering design via surrogate modelling: A practical guide; J. Wiley: Chichester West Sussex England and Hoboken NJ, 2008. [Google Scholar]
- Perdikaris, P.; Karniadakis, G.E. Model inversion via multi-fidelity Bayesian optimization: a new paradigm for parameter estimation in haemodynamics, and beyond. Journal of the Royal Society, Interface 2016, 13. [Google Scholar] [CrossRef] [PubMed]
- Perdikaris, P.; Raissi, M.; Damianou, A.; Lawrence, N.D.; Karniadakis, G.E. Nonlinear information fusion algorithms for data-efficient multi-fidelity modelling. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 2017, 473, 20160751. [Google Scholar] [CrossRef]
- van Dam, E.R.; Husslage, B.; den Hertog, D.; Melissen, H. Maximin Latin Hypercube Designs in Two Dimensions. Operations Research 2007, 55, 158–169. [Google Scholar] [CrossRef]
- Crombecq, K.; Laermans, E.; Dhaene, T. Efficient space-filling and non-collapsing sequential design strategies for simulation-based modeling. European Journal of Operational Research 2011, 214, 683–696. [Google Scholar] [CrossRef]
- Viana, F.A.C.; Venter, G.; Balabanov, V. An algorithm for fast optimal Latin hypercube design of experiments. International Journal for Numerical Methods in Engineering 2010, 82, 135–156. [Google Scholar] [CrossRef]
- Hao, P.; Feng, S.; Li, Y.; Wang, B.; Chen, H. Adaptive infill sampling criterion for multi-fidelity gradient-enhanced kriging model. Structural and Multidisciplinary Optimization 2020, 62, 353–373. [Google Scholar] [CrossRef]
- Loeppky, J.L.; Sacks, J.; Welch, W.J. Choosing the Sample Size of a Computer Experiment: A Practical Guide. Technometrics 2009, 51, 366–376. [Google Scholar] [CrossRef]
- Gao, B.; Ren, Y.; Jiang, H.; Xiang, J. Sensitivity analysis-based variable screening and reliability optimisation for composite fuselage frame crashworthiness design. International Journal of Crashworthiness 2019, 24, 380–388. [Google Scholar] [CrossRef]
- Fiore, A.; Marano, G.C.; Greco, R.; Mastromarino, E. Structural optimization of hollow-section steel trusses by differential evolution algorithm. International Journal of Steel Structures 2016, 16, 411–423. [Google Scholar] [CrossRef]
- Loja, M.; Mota Soares, C.M.; Barbosa, J.I. Optimization of magneto-electro-elastic composite structures using differential evolution. Composite Structures 2014, 107, 276–287. [Google Scholar] [CrossRef]
- Storn, R. On the usage of differential evolution for function optimization. In Proceedings of the 1996 Biennial conference of the North American Fuzzy Information Processing Society; Smith, M.H.E., Ed. IEEE; 1996; pp. 519–523. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution – A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. Journal of Global Optimization 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Hansen, N.; Auger, A.; Ros, R.; Mersmann, O.; Tušar, T.; Brockhoff, D. COCO: a platform for comparing continuous optimizers in a black-box setting. Optimization Methods and Software 2021, 36, 114–144. [Google Scholar] [CrossRef]
- Conn, A.R.; Gould, N.I.M.; Toint, P.L. Trust-region methods; MPS-SIAM series on optimization; SIAM: Philadelphia, Pa, 2000. [Google Scholar] [CrossRef]
- Querin, O.M.; Victoria, M.; Alonso, C.; Ansola, R.; Martí, P. Chapter 3 - Discrete Method of Structural Optimization**Additional author for this chapter is Prof. Dr.-Ing. Dr.-Habil. George I. N. Rozvany. In Topology design methods for structural optimization [electronic resource]; Querin, O.M., Ed.; Academic Press: London, United Kingdom, 2017; pp. 27–46. [Google Scholar] [CrossRef]
- Forrester, A.I.; Sóbester, A.; Keane, A.J. Multi-fidelity optimization via surrogate modelling. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 2007, 463, 3251–3269. [Google Scholar] [CrossRef]
- van Rijn, S.; Schmitt, S. MF2: A Collection of Multi-Fidelity Benchmark Functions in Python. Journal of Open Source Software 2020, 5, 2049. [Google Scholar] [CrossRef]
- Xiong, S.; Qian, P.Z.G.; Wu, C.F.J. Sequential Design and Analysis of High-Accuracy and Low-Accuracy Computer Codes. Technometrics 2013, 55, 37–46. [Google Scholar] [CrossRef]
- Dong, H.; Song, B.; Wang, P.; Huang, S. Multi-fidelity information fusion based on prediction of kriging. Structural and Multidisciplinary Optimization 2015, 51, 1267–1280. [Google Scholar] [CrossRef]
- Mortazavi Moghaddam, A.; Kheradpisheh, A.; Asgari, M. A basic design for automotive crash boxes using an efficient corrugated conical tube. Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering 2021, 235, 1835–1848. [Google Scholar] [CrossRef]
- Xiang, Y.; Wang, M.; Yu, T.; Yang, L. Key Performance Indicators of Tubes and Foam-Filled Tubes Used as Energy Absorbers. International Journal of Applied Mechanics 2015, 07, 1550060. [Google Scholar] [CrossRef]
- Kröger, M. Methodische Auslegung und Erprobung von Fahrzeug-Crashstrukturen. PhD thesis, Hannover : Universität, 2002. [CrossRef]
Figure 1.
Sequential update of the region of interest.
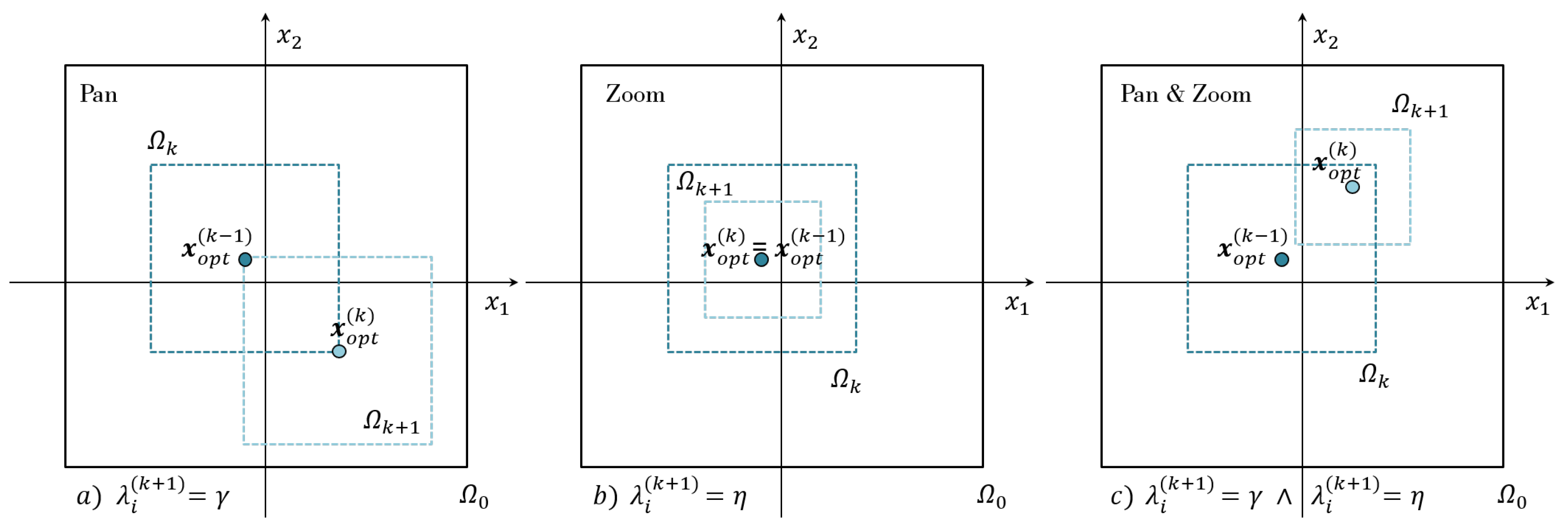
Figure 2.
Overview of the MF-SRS framework.
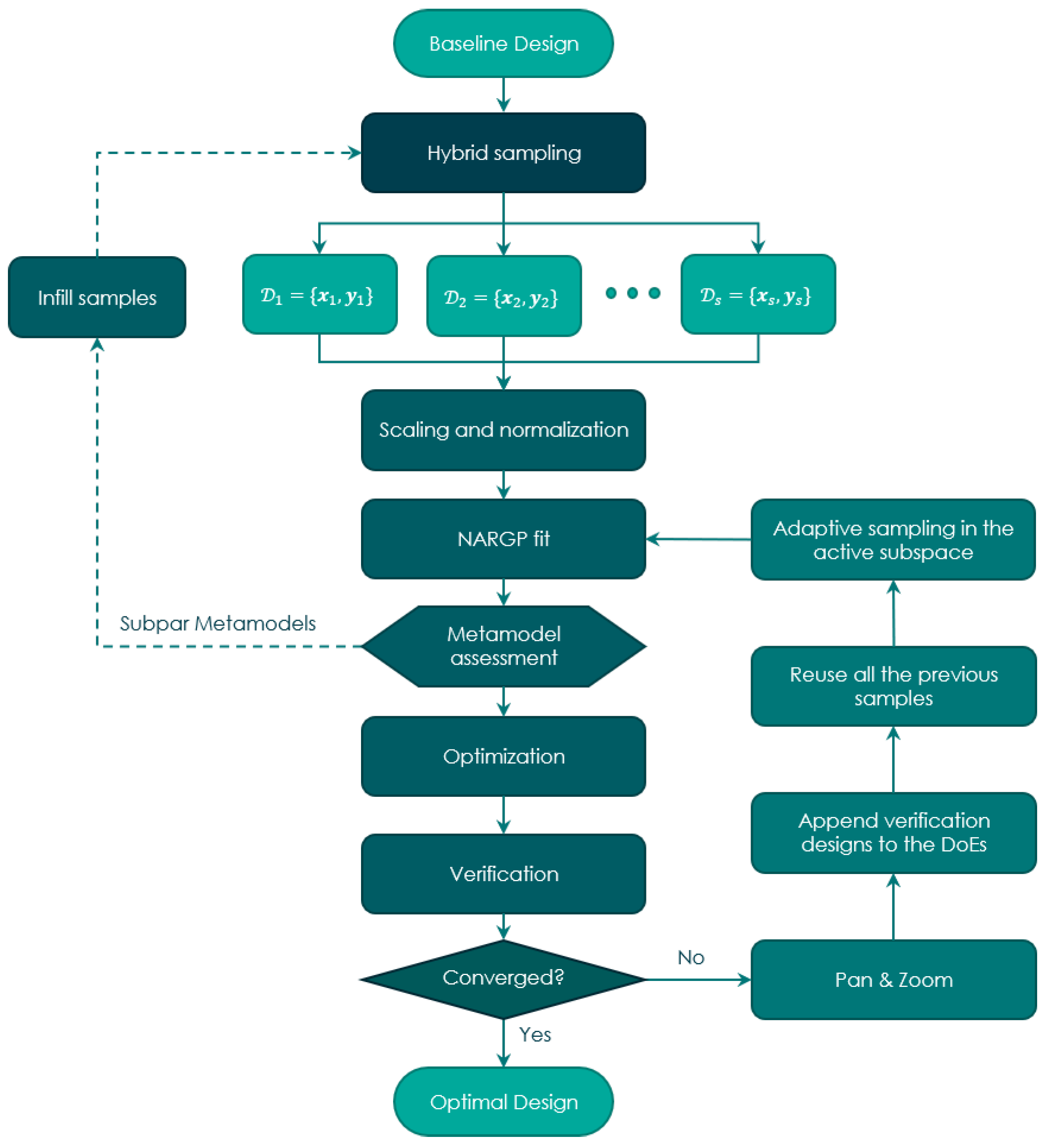
Figure 3.
From left to right, sampling in order of decreasing fidelity: OLHD with 10 samples (), MIPT adds 20 samples, MIPT adds 80 samples.
Figure 3.
From left to right, sampling in order of decreasing fidelity: OLHD with 10 samples (), MIPT adds 20 samples, MIPT adds 80 samples.
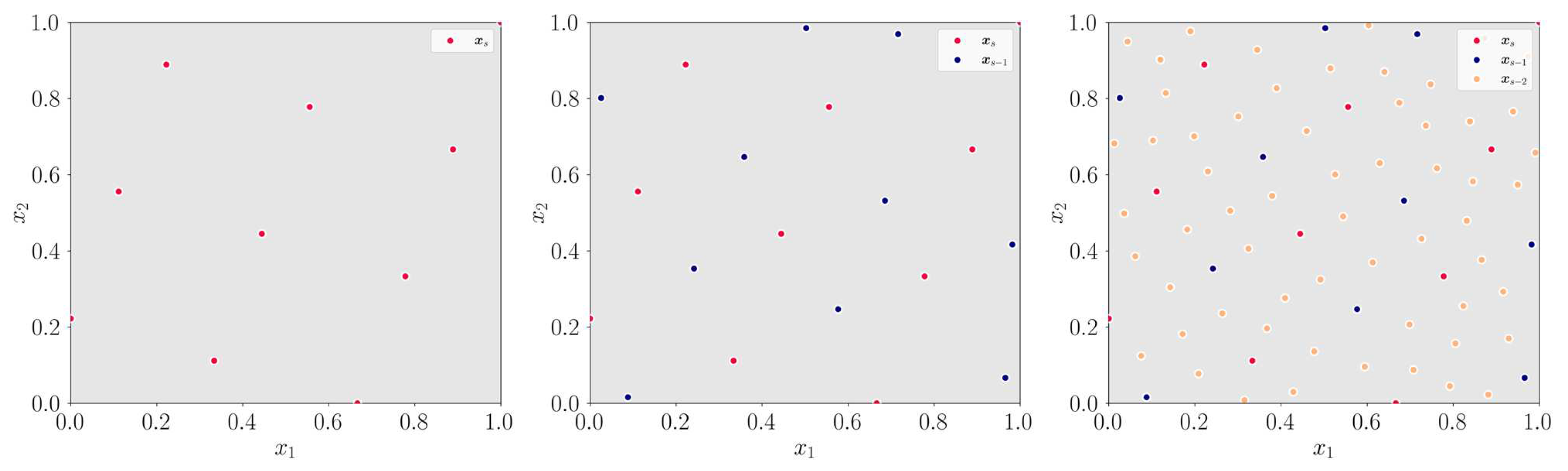
Figure 4.
Progressing from left to right, the figures depict the evolution of the RoI and the subsequent addition of samples over three iterations. High-fidelity samples are represented in red, low-fidelity samples in purple, and samples from prior iterations that fall outside the RoI are shown in gray.
Figure 4.
Progressing from left to right, the figures depict the evolution of the RoI and the subsequent addition of samples over three iterations. High-fidelity samples are represented in red, low-fidelity samples in purple, and samples from prior iterations that fall outside the RoI are shown in gray.
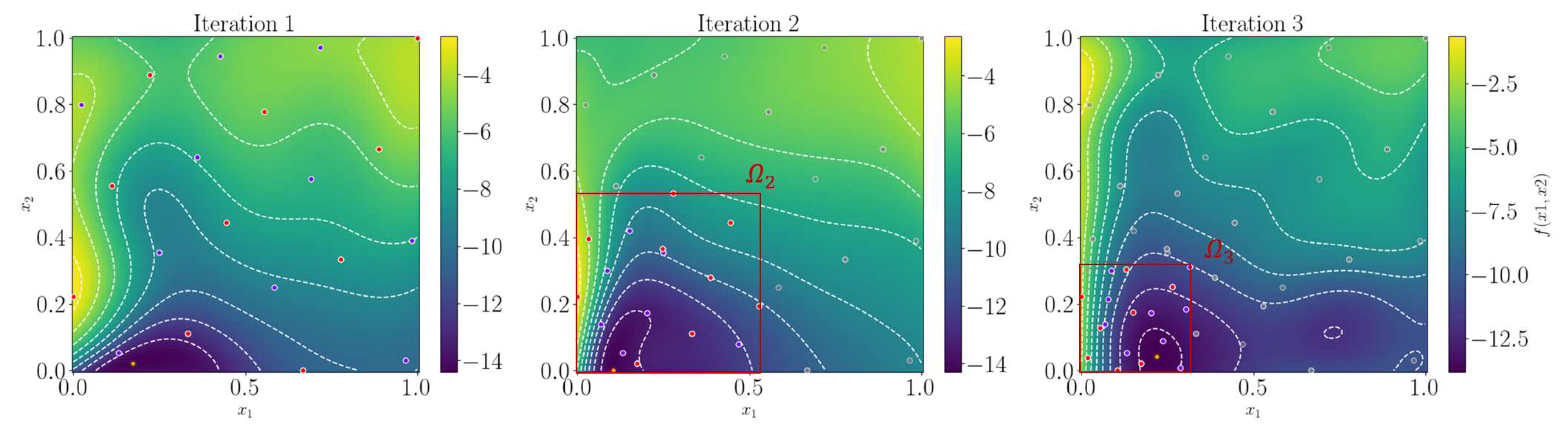
Figure 5.
The first row shows the ground-truth values of the Forrester (first column) and Sinusoidal Wave (second column). The bottom row illustrates the respective mapping between the fidelities.
Figure 5.
The first row shows the ground-truth values of the Forrester (first column) and Sinusoidal Wave (second column). The bottom row illustrates the respective mapping between the fidelities.
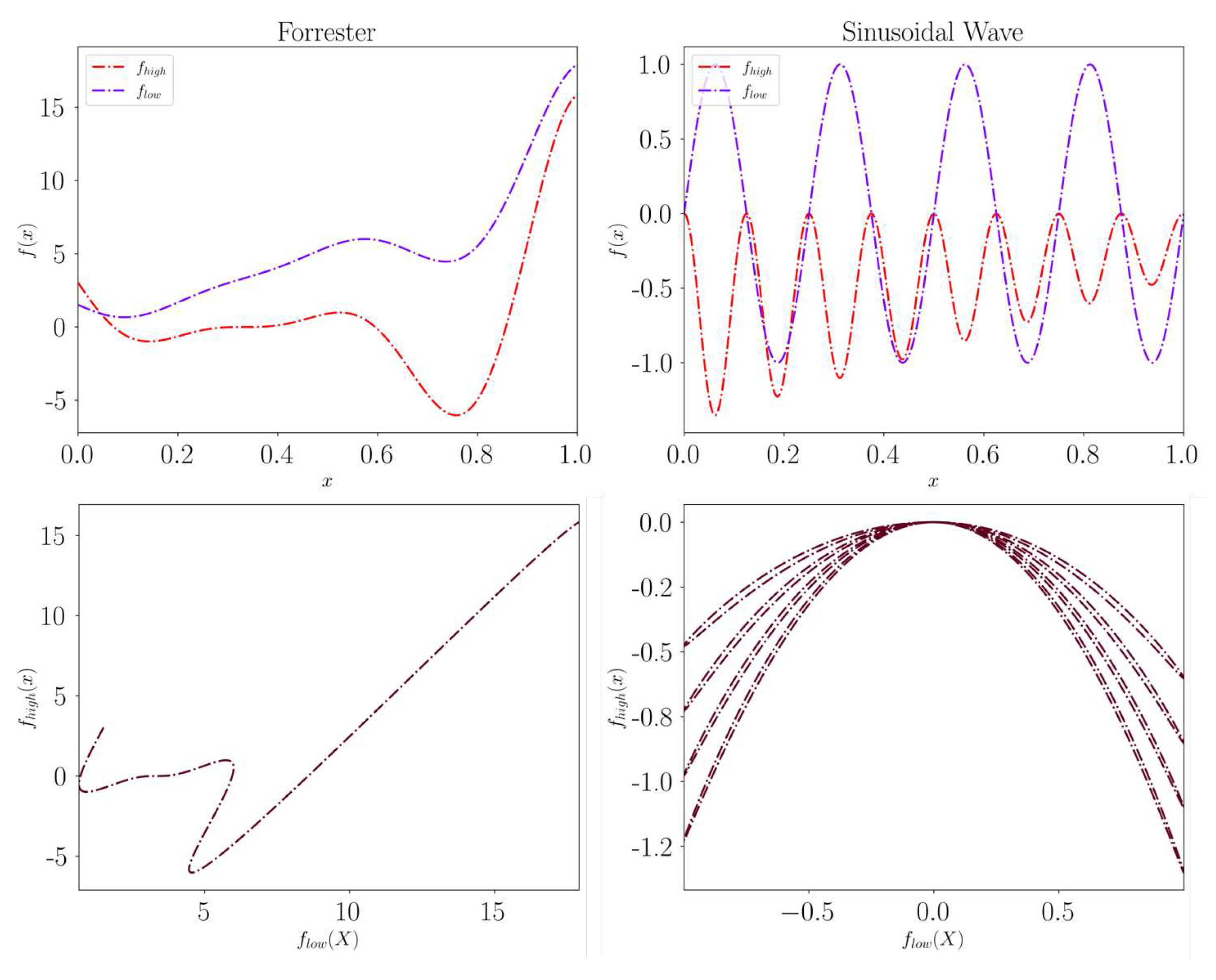
Figure 6.
From left to right: GP, AR1, and NARGP reconstructions of the Forrester function. All use 5 high-fidelity observations; multi-fidelity methods also use 10 low-fidelity observations.
Figure 6.
From left to right: GP, AR1, and NARGP reconstructions of the Forrester function. All use 5 high-fidelity observations; multi-fidelity methods also use 10 low-fidelity observations.
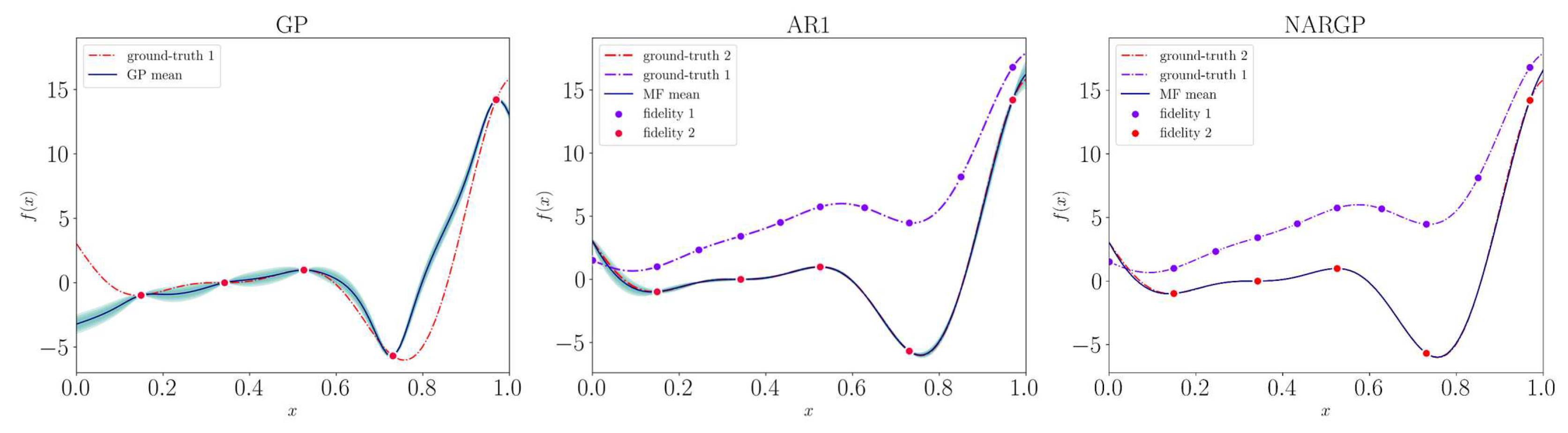
Figure 7.
From left to right: GP, AR1, and NARGP reconstructions of the Sinusoidal Wave function. All use 7 high-fidelity observations; multi-fidelity methods also use 14 low-fidelity observations.
Figure 7.
From left to right: GP, AR1, and NARGP reconstructions of the Sinusoidal Wave function. All use 7 high-fidelity observations; multi-fidelity methods also use 14 low-fidelity observations.
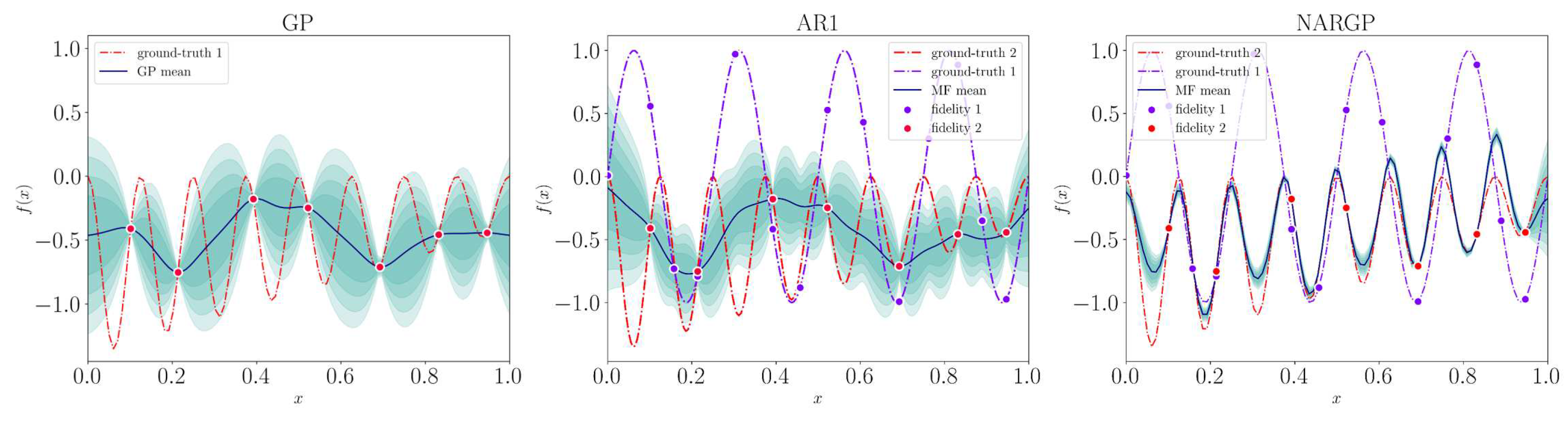
Figure 8.
First four iterations for the Currin function: MF-SRS (top row) and GP-SRS (bottom row) are shown. Red dots represent high-fidelity observations, purple dots low-fidelity ones.
Figure 8.
First four iterations for the Currin function: MF-SRS (top row) and GP-SRS (bottom row) are shown. Red dots represent high-fidelity observations, purple dots low-fidelity ones.
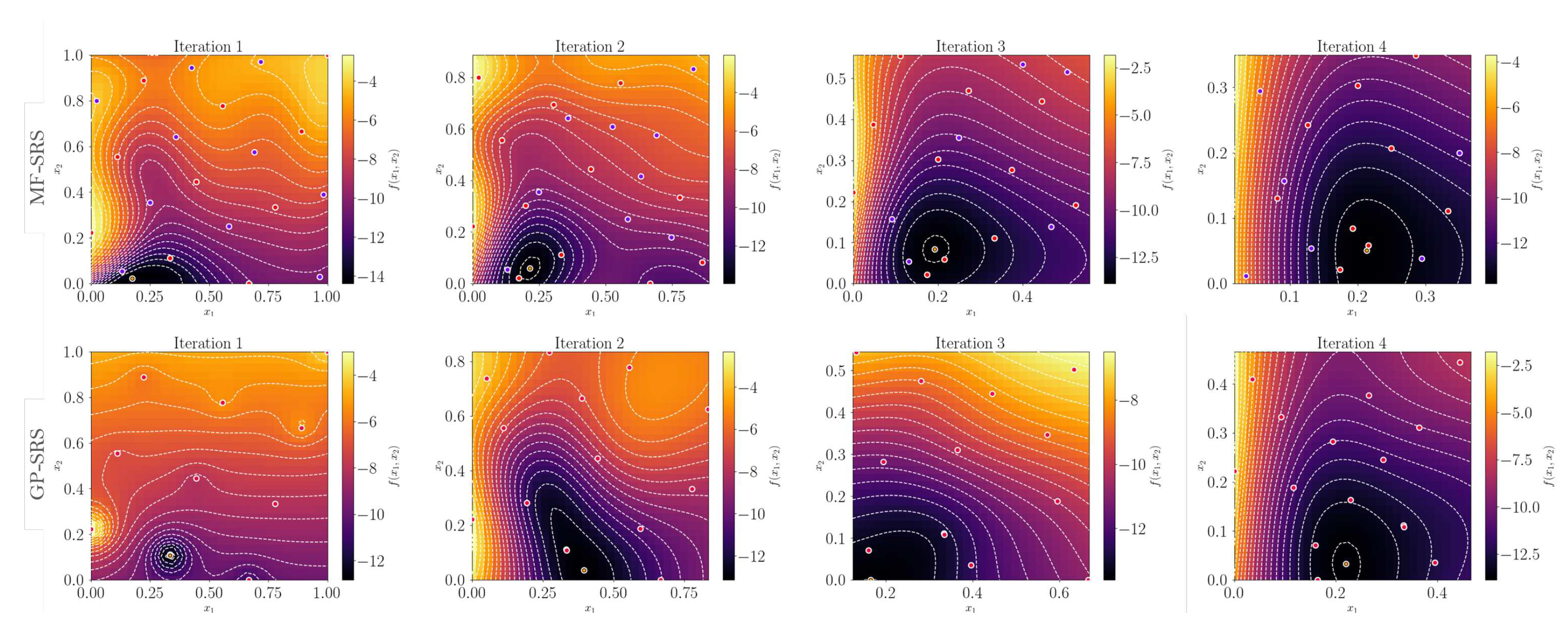
Figure 9.
First four iterations for the constrained Branin function: MF-SRS (top row) and GP-SRS (bottom row) are shown. Red dots represent high-fidelity observations, purple dots represent low-fidelity observations, and gray areas represent unfeasible regions.
Figure 9.
First four iterations for the constrained Branin function: MF-SRS (top row) and GP-SRS (bottom row) are shown. Red dots represent high-fidelity observations, purple dots represent low-fidelity observations, and gray areas represent unfeasible regions.
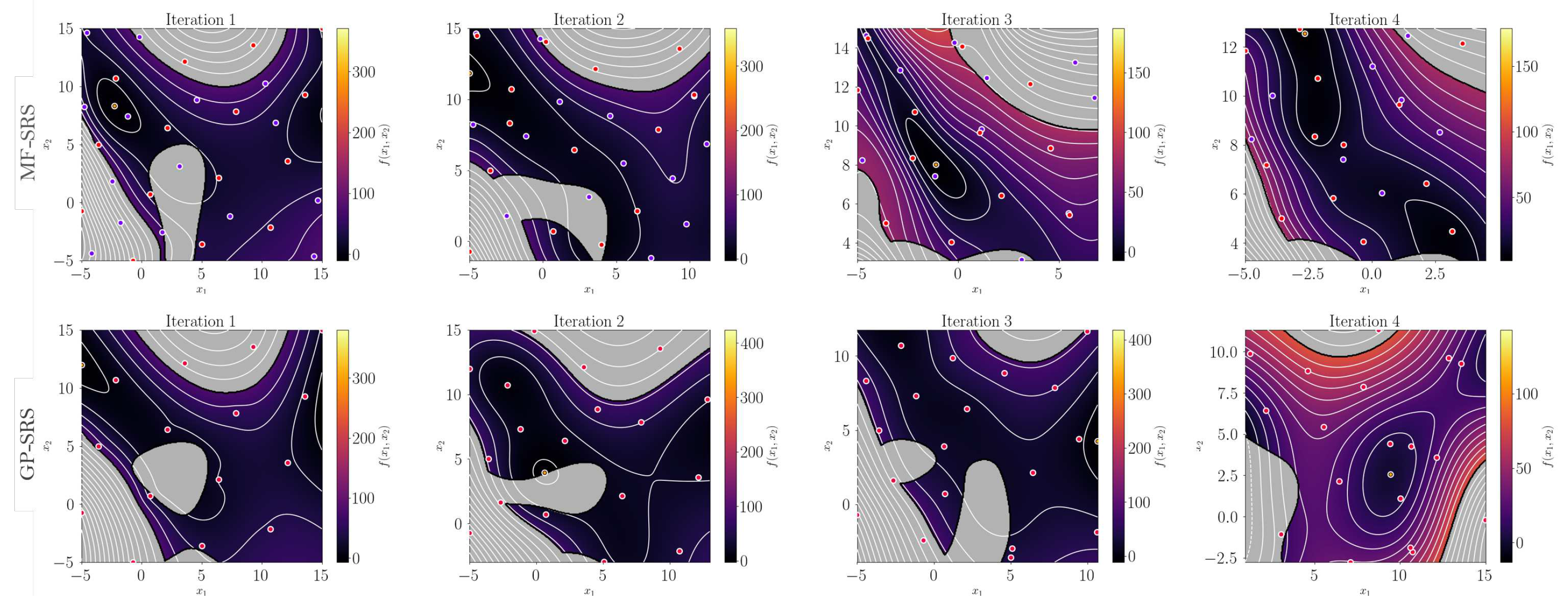
Figure 10.
Convergence history of the SRSM, GP-SRS and MF-SRS methods for the Currin function (left) and the constrained Branin function (right).
Figure 10.
Convergence history of the SRSM, GP-SRS and MF-SRS methods for the Currin function (left) and the constrained Branin function (right).
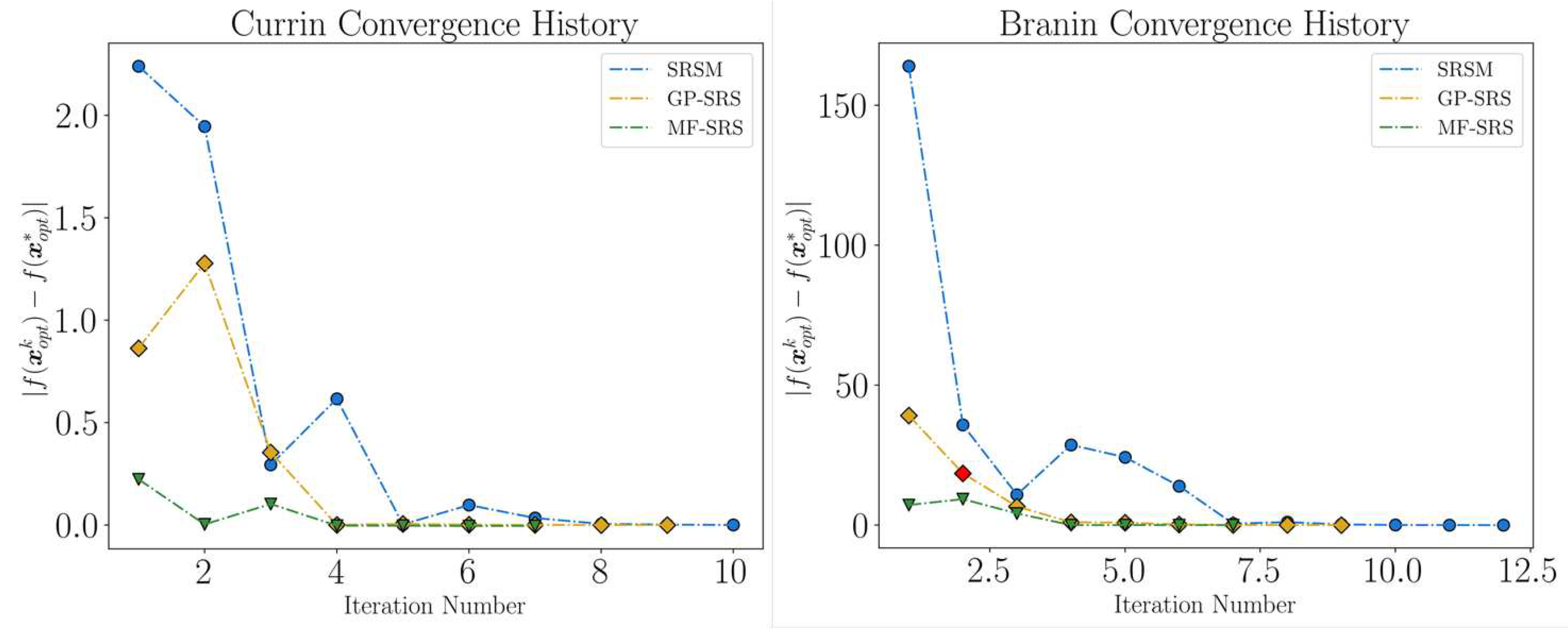
Figure 11.
Ground-truth vs. prediction plot (left) and convergence history (right) of the SRSM, GP-SRS and MF-SRS methods for the Borehole function.
Figure 11.
Ground-truth vs. prediction plot (left) and convergence history (right) of the SRSM, GP-SRS and MF-SRS methods for the Borehole function.
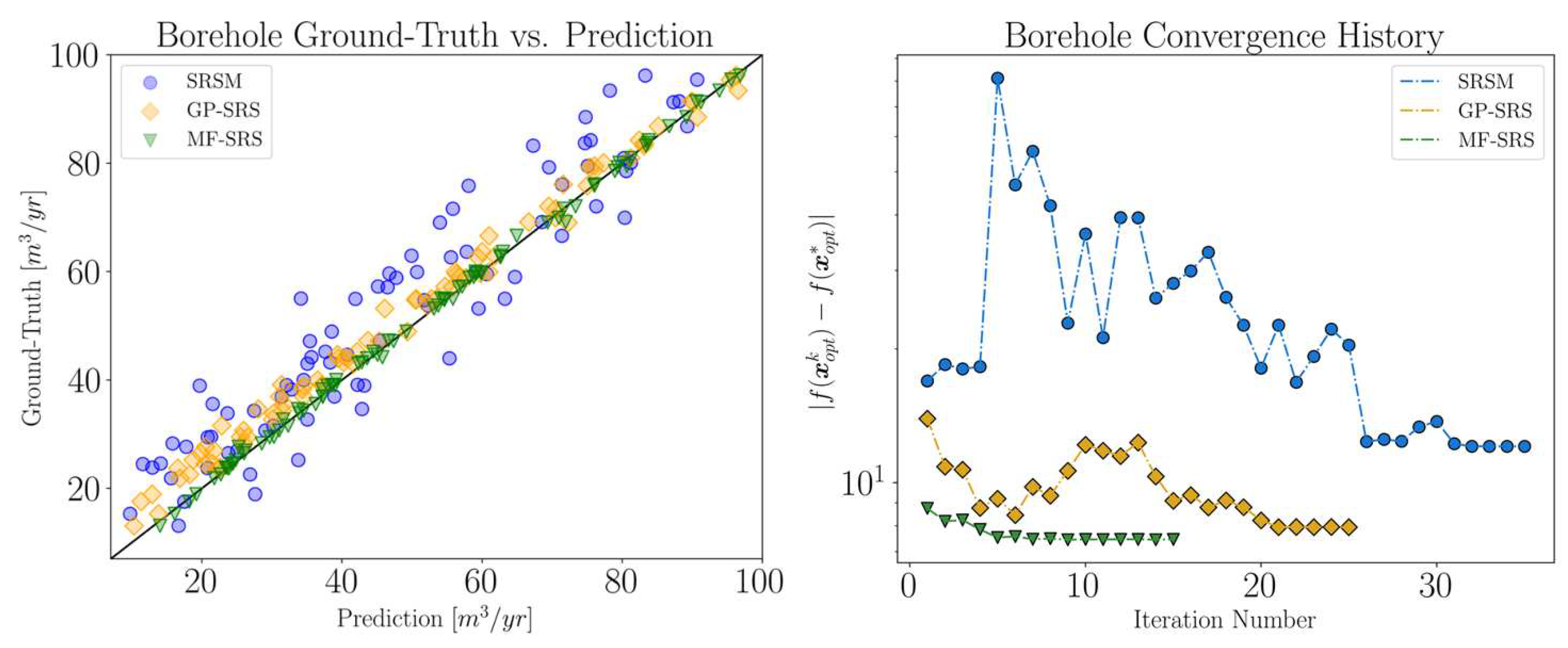
Figure 12.
Overview of the FEA model components: impactor, crash box, and bumper beam. The design variables of the optimization problem are highlighted in blue.
Figure 12.
Overview of the FEA model components: impactor, crash box, and bumper beam. The design variables of the optimization problem are highlighted in blue.
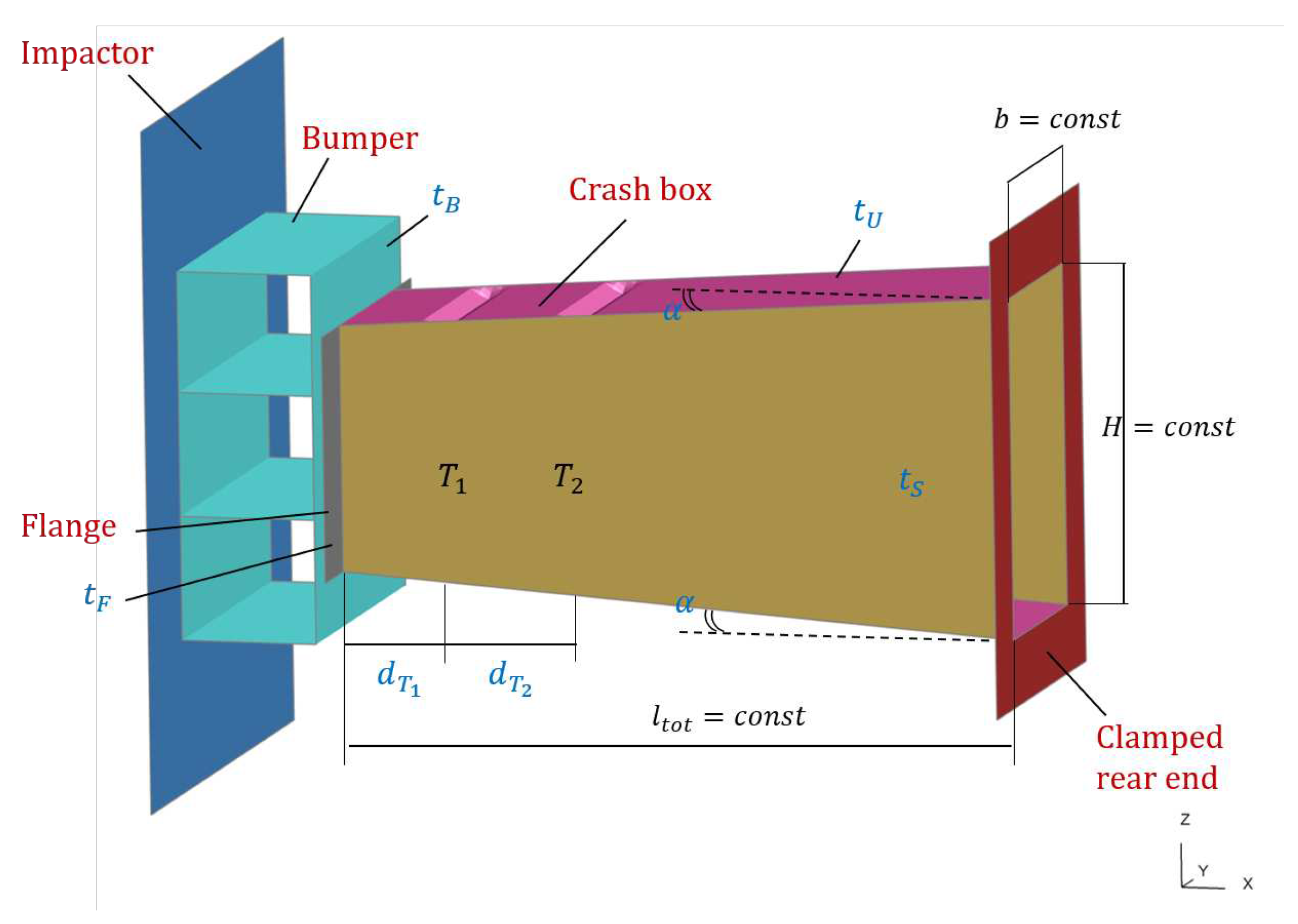
Figure 13.
Example of a step-wise increasing force curve with the smallest possible differences in the force levels of the individual components. Figure inspired by [56].
Figure 13.
Example of a step-wise increasing force curve with the smallest possible differences in the force levels of the individual components. Figure inspired by [56].
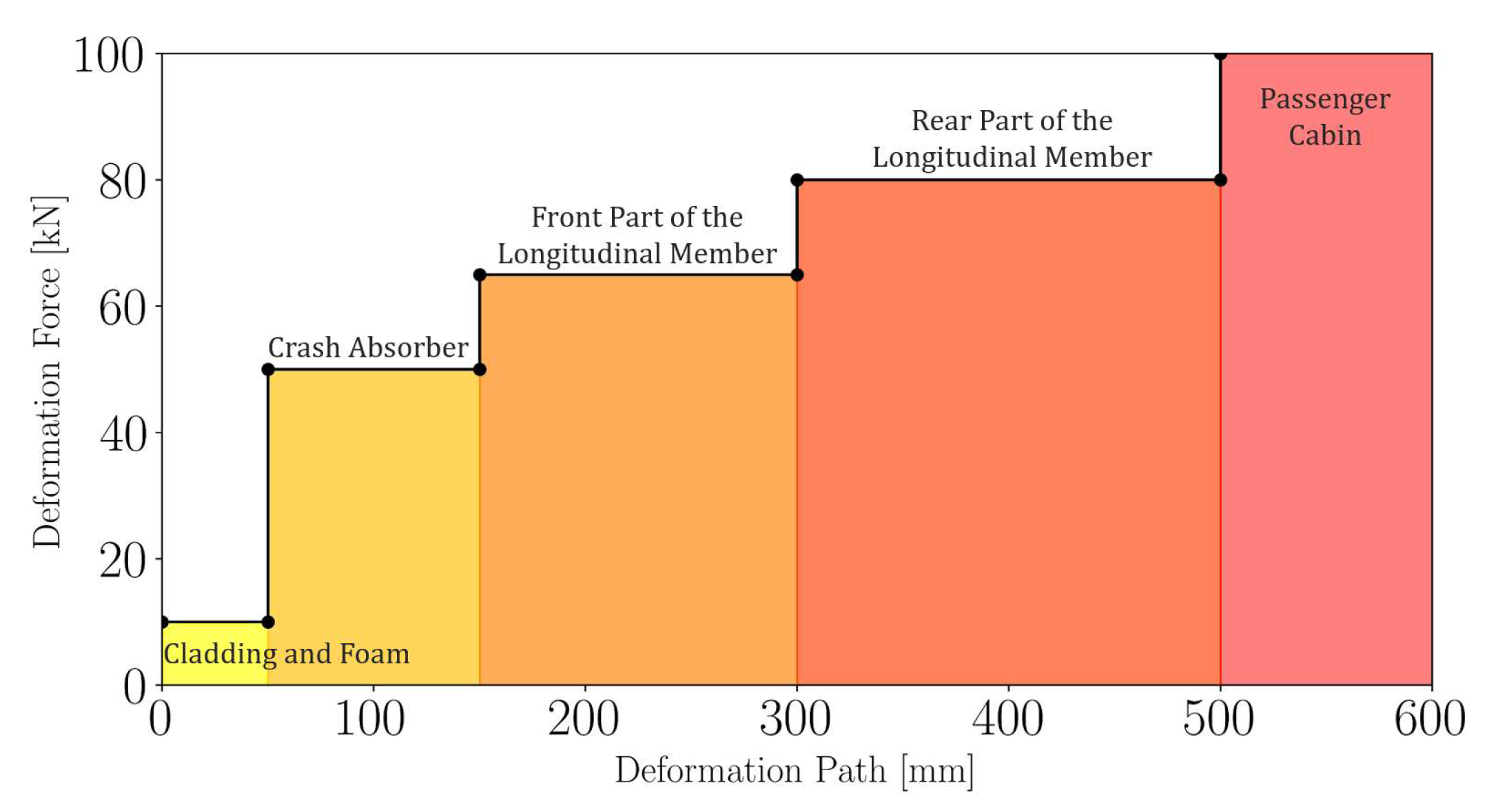
Figure 14.
Mesh sensitivity analysis to assess the impact of the element size on the response functions.
Figure 14.
Mesh sensitivity analysis to assess the impact of the element size on the response functions.
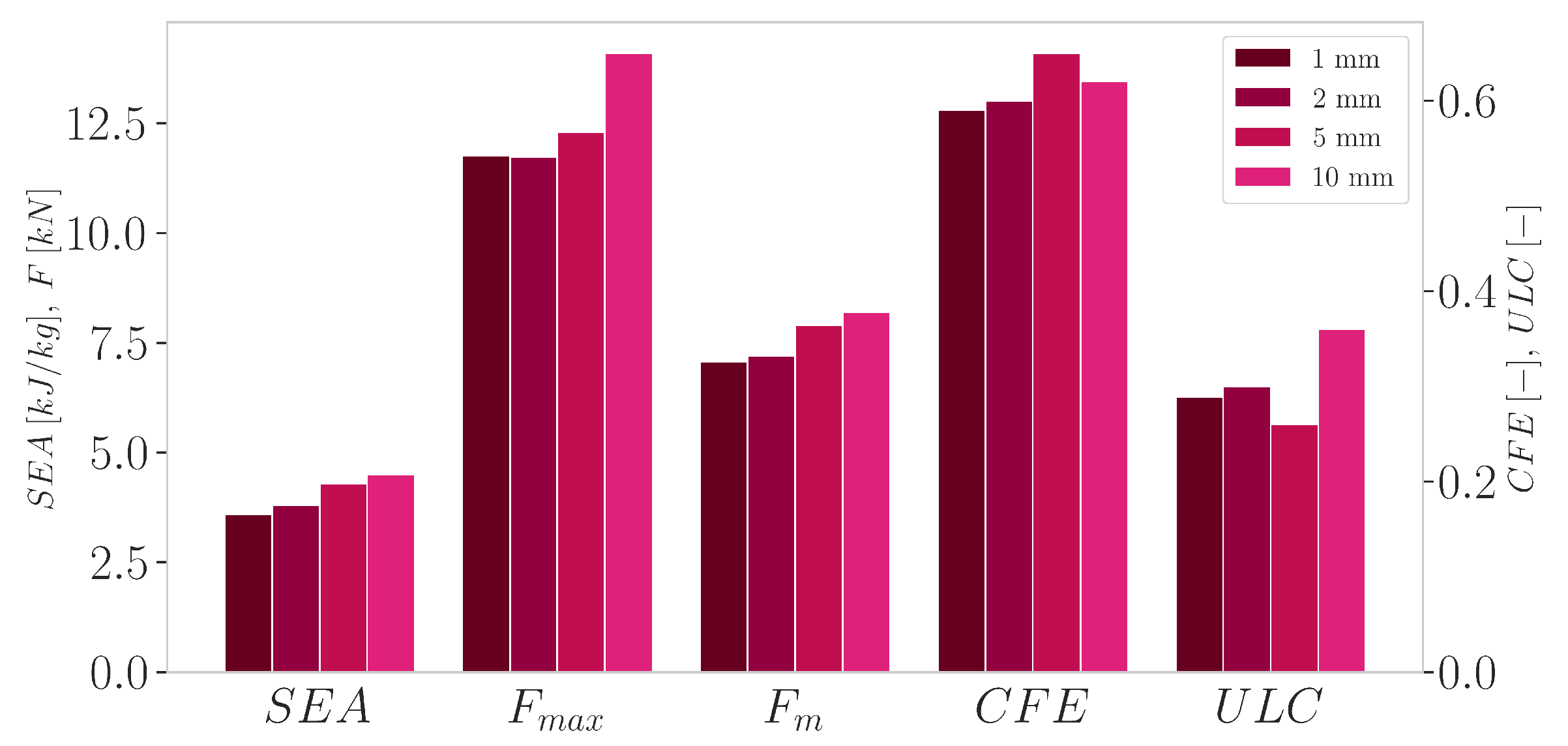
Figure 15.
High-fidelity model, 23548 shell elements with element erosion (a) and low-fidelity model, 5090 shell elements without element erosion (b).
Figure 15.
High-fidelity model, 23548 shell elements with element erosion (a) and low-fidelity model, 5090 shell elements without element erosion (b).
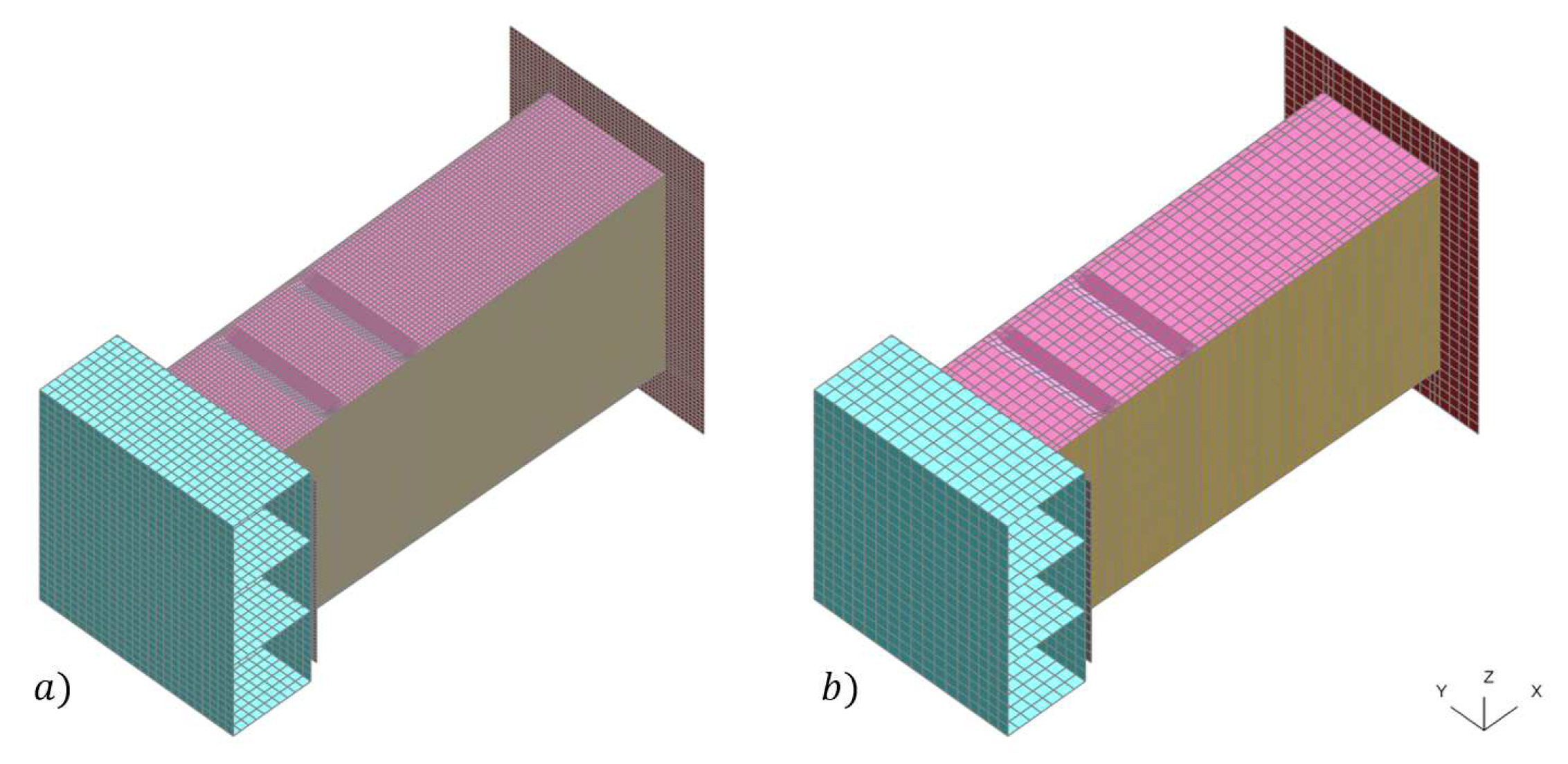
Figure 16.
Convergence history of the SRSM, GP-SRS and MF-SRS methods for the crash box design.
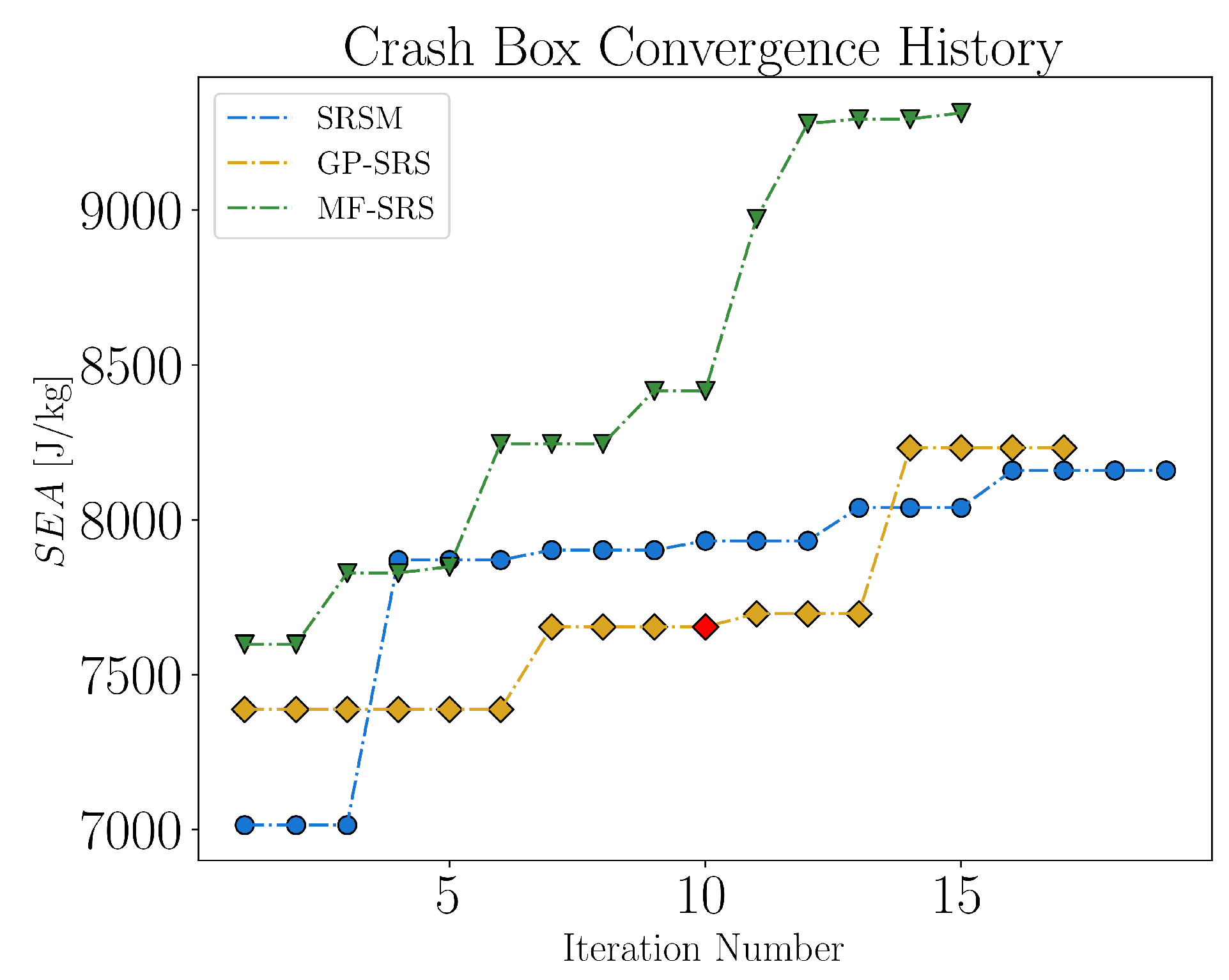
Figure 17.
Parallel coordinates plot of the MF-SRS method: Unfeasible designs are highlighted in grey, feasible designs in blue and the optimal design in orange.
Figure 17.
Parallel coordinates plot of the MF-SRS method: Unfeasible designs are highlighted in grey, feasible designs in blue and the optimal design in orange.
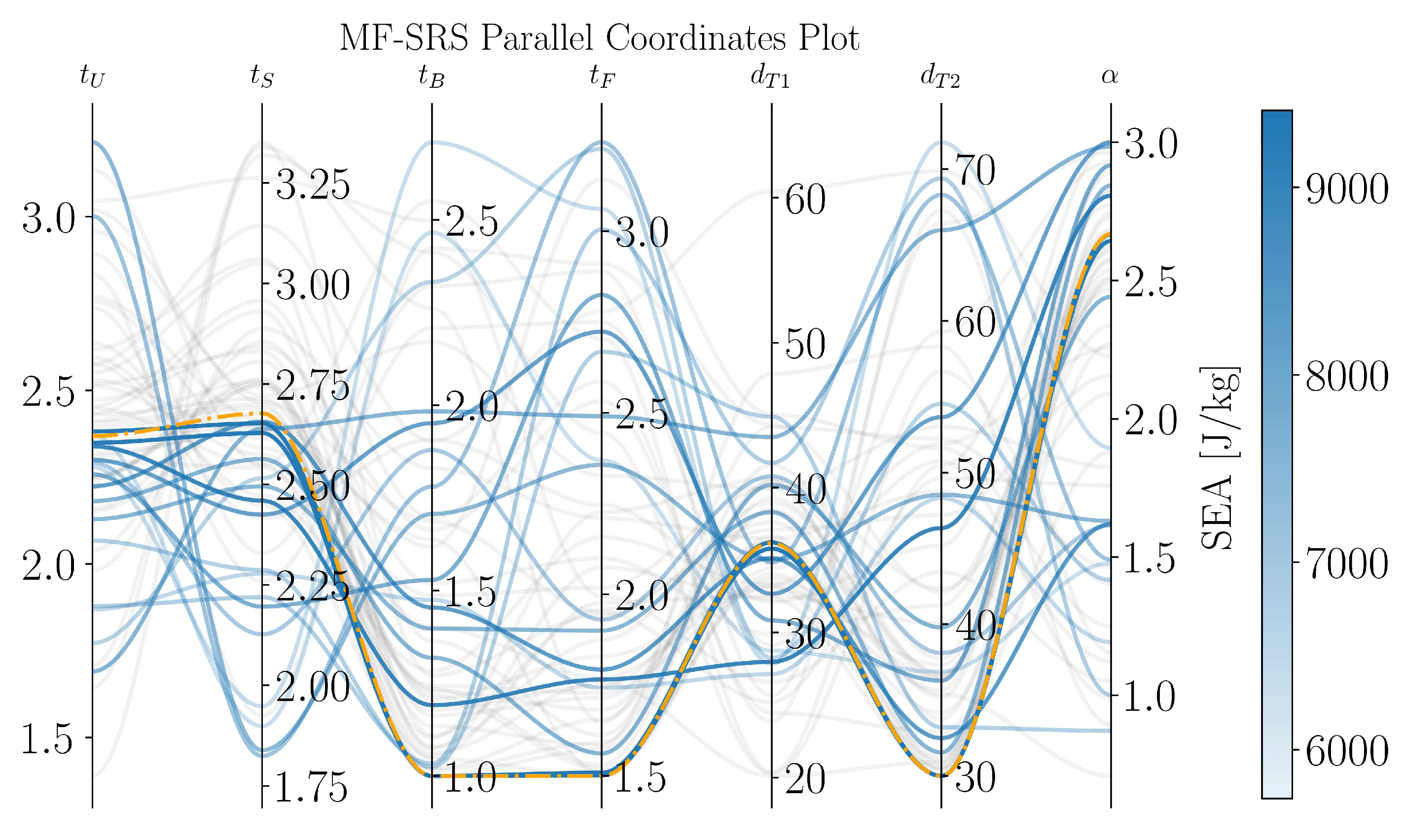
Figure 18.
Force vs. Displacement plots of the optimal designs for the SRSM, GP-SRS, and MF-SRS approaches.
Figure 18.
Force vs. Displacement plots of the optimal designs for the SRSM, GP-SRS, and MF-SRS approaches.
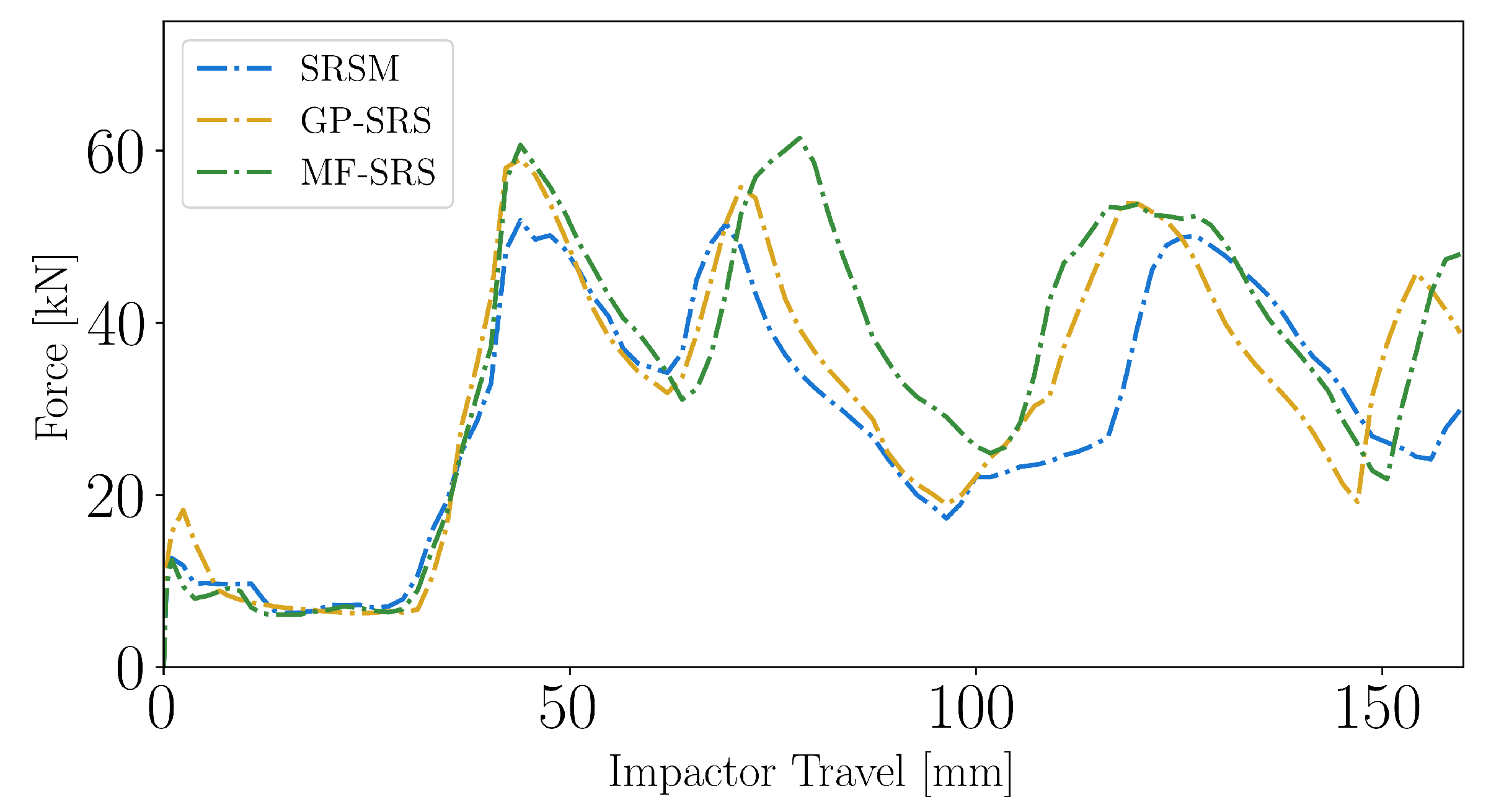
Figure 19.
The job schedule of the multi-fidelity DoE (top row) and the convergence curves over the cumulative cost (bottom row) in the case of 5,7, and 8 nodes available on the HPC.
Figure 19.
The job schedule of the multi-fidelity DoE (top row) and the convergence curves over the cumulative cost (bottom row) in the case of 5,7, and 8 nodes available on the HPC.
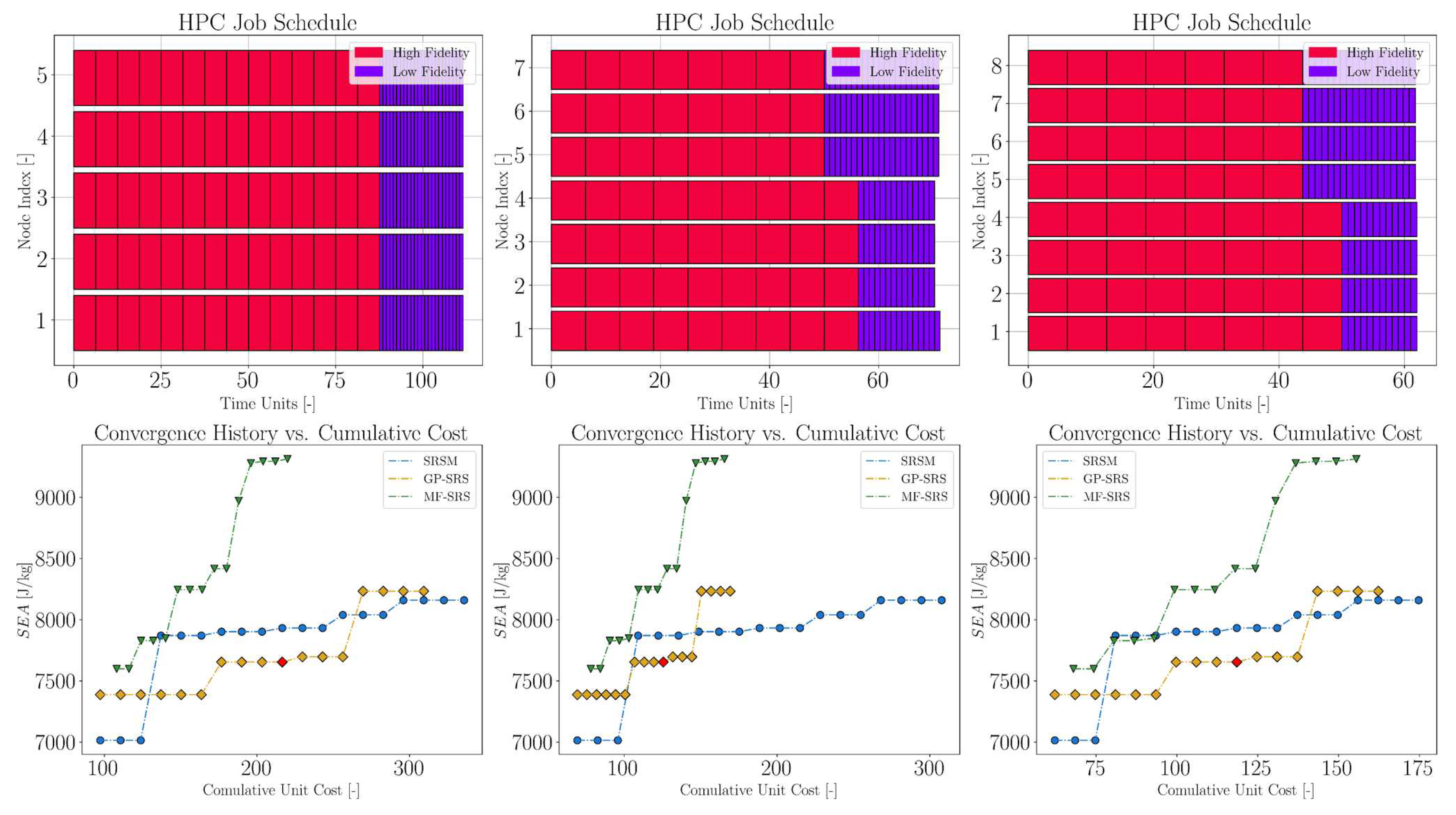
Table 1.
Summary of design variables.
| Variable Design | Label | Unit | Lower Bound | Upper Bound |
|---|---|---|---|---|
| Upper crash box thickness | 1.0 | 3.5 | ||
| Side crash box thickness | 1.0 | 3.5 | ||
| Bumper crossmember thickness | 1.0 | 3.0 | ||
| Flange thickness | 1.0 | 4.0 | ||
| Flange to distance | 20.0 | 70.0 | ||
| to distance | 30.0 | 100.0 | ||
| Angle to horizontal plane | 1.0 | 3.5 |
Table 2.
Summary of the response functions of the optimal designs of each method. The best achievable SEA value among the three methods is highlighted in bold.
Table 2.
Summary of the response functions of the optimal designs of each method. The best achievable SEA value among the three methods is highlighted in bold.
| Method | [J/kg] | [kN] | [kN] | [J] | |||
|---|---|---|---|---|---|---|---|
| SRSM | 19 | 8159.8 | 51.9 | 26.9 | 271.9 | 0.52 | 0.48 |
| GP-SRS | 17 | 8233.2 | 59.0 | 28.5 | 260.8 | 0.51 | 0.48 |
| MF-SRS | 15 | 9313.5 | 61.5 | 31.9 | 244.2 | 0.51 | 0.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



