
Submitted:
01 July 2023
Posted:
03 July 2023
You are already at the latest version
Abstract
The analysis of network structure is essential to many scientific areas, ranging from biology to sociology. As the computational task of clustering these networks into partitions, i.e., solving the community detection problem, is generally NP-hard, heuristic solutions are indispensable. The exploration of expedient heuristics has led to the development of particularly promising approaches in the emerging technology of quantum computing. Motivated by the substantial hardware demands for all established quantum community detection approaches, we introduce a novel QUBO based approach that only needs number-of-nodes many qubits and is represented by a QUBO-matrix as sparse as the input graph's adjacency matrix. The substantial improvement on the sparsity of the QUBO-matrix, which is typically very dense in related work, is achieved through the novel concept of separation-nodes. Instead of assigning every node to a community directly, this approach relies on the identification of a separation-node set, which - upon its removal from the graph - yields a set of connected components, representing the core components of the communities. Employing a greedy heuristic to assign the nodes from the separation-node sets to the identified community cores, subsequent experimental results yield a proof of concept. This work hence displays a promising approach to NISQ-ready quantum community detection, catalyzing the application of quantum computers for the network structure analysis of large scale, real world problem instances.}
Keywords:
Quantum Computing
; Community Detection
; QUBO
; NISQ
1. Introduction
In the era of digitization, the amount of collected data is rising rapidly. This poses substantial problems in data analysis as the algorithms employed there typically have superlinear and thus deficient runtime for many relevant datasets. In this work, we investigate a new approach to cope with this problem in the domain of graph structure analysis. Graphs are one of the central data structures used in information theory and find application in a vast range of scientific disciplines [1,2,3]. The task of identifying the inherit structure of a graph is known as community detection [4]. In practice, the use of corresponding clustering methods allows for the discovery of structural information from real world networks in domains ranging from social science to biology [5,6].
Although no exact definition has been agreed upon, a graph is typically said to inherit a community structure if it can be partitioned in a way such that the number of edges within the partitions is higher than the number of edges between the partitions [5]. While some approaches exist that can provably find existing community structures, all of them are NP-hard [7,8,9,10]. This indicates a general NP-hardness of community detection and hence poses a demand for efficient heuristics to acquire solutions in reasonable time. Motivated by recent advancements and promising results in solving NP-hard problems in the field of quantum computing (QC) [11,12,13,14], we investigate possible advantages in building such heuristics by utilizing the more powerful algorithmic toolset available in QC.
In general, quantum computers allow for the application of quantum mechanical effects to do computation. Based on the concepts of superposition and entanglement, quantum computers can solve many computational problems provably faster than classical computers [15,16,17]. In the case of community detection, related work has shown promising results using the popular modularity maximization approach [12,18]. Modularity is a measure for the quality of a given partitioning based on comparing the edge distribution of the given graph to the edge distribution of a graph with the same node degree but inheriting no community structure [19]. The more these distributions differ, the higher the modularity indicating a clearer community structure. While this approach is provably optimal in the sense that no other approach could detect a community structure when modularity maximization cannot [7], its implementation on a quantum computer is cumbersome, especially for current quantum computers.
Present implementations of modularity maximization on quantum computers make use of the intrinsic quadratic nature of the modularity [12,18]. Simulating the time evolution of a specific quantum physical system, i.e., typically the transverse field Ising Model under adiabatic time evolution, a quantum heuristic solver for quadratic unconstraint binary optimization (QUBO) problems (e.g., modularity maximization) can be implemented on a quantum computer [12,20]. Even though no quantum speedups where proven for solving NP-hard optimization problems with this approach yet, many cases of potential scaling advantages have been identified, with modularity maximization being one of them [12,13,14].
A critical limitation of the established quantum modularity maximization approach hindering its execution on near term quantum hardware is the size of the search space in optimization. Scaling linearly in the number of nodes and the number of communities, the required amount of quantum bits (qubits) needed for representing a specific solution quickly exceeds the number of qubits available in present noisy intermediate scale quantum (NISQ) hardware [21].
Motivated by these results, we develop a novel approach to community detection, specialized for (quantum heuristic) QUBO solving that uses a smaller search space than the state-of-the-art quantum modularity maximization approach. This objective led to the sociologically inspired approach of defining a community by its extreme ends, similar to, e.g., differentiating political parties by their position on the left-right spectrum. For graphs, we translate this idea to the existence of, what we will later define as, a bijective set of separation nodes. The removal of the nodes contained in this set then yields connected components, which represent the "cores" of the communities. We subsequently conduct experiments, that indicate that this essentially solves the hard part of the community detection problem, as the community assignment for the separation nodes can typically be obtained using a greedy optimizer.
This idea allows for a quantum-classical hybrid detection of communities while merely using one qubit for every node in the graph with a single call to a QUBO solver. We show empirically that such a set of separation nodes can be found for graphs inheriting community structure and introduce a quantum heuristic approach to find them, constituting a proof-of-concept.
This paper is structured in the following way: In Section 2 we describe the current state of the art of quantum community detection, in Section 3 the separation node set approach to (quantum) community detection is introduced to then get evaluated in Section 4 before concluding the findings in Section 5.
2. Related Work
With the advent of quantum optimization heuristics like quantum annealing, possible quantum advantages have been explored for many optimization problems [22]. Easily allowing for a binary encoding of solutions and showing promising performance, community detection quickly became a popular problem in quantum optimization [23].
Representing community detection natively as a QUBO problem in the basic case of partitioning into communities, modularity maximization was the first approach used in quantum community detection [18]. For a given graph , the modularity of a partitioning into and according to is given by
for given node degrees and denoting the entries of the adjacency matrix A of G. Straightforward calculations yield the resulting QUBO matrix which is sufficient to apply practically all currently available quantum optimization heuristics.
This approach to can be generalized to communities by introducing one-hot encoding. Here, the community assignment of a node is encoded by a k-dimensional bit string with and if the node is assigned to community l. The resulting optimization term is hence given by:
In order to formulate this as a QUBO problem, we have to add a suitably weighted penalty term (for details, see [24]) to the optimization term to indirectly enforce the one-hot encoding by if every node is assigned to exactly one community and otherwise:
Apart from capitalizing on the inherent QUBO form of modularity maximization, many other quantum computing based approaches to community detection like Quantum Genetic Algorithms and Quantum Walks have been proposed in recent literature [25,26]. A particularly promising approach for near term application on large graphs is based on exploiting the quadratic nature of regularity checking related to Szemeredi’s Regularity Lemma (SRL) [27]. While similar to our approach, as the QUBO problems solved only involve qubits, it works fundamentally differently, as communities are identified iteratively. In essence, the algorithm proposed in [27] executes the following steps:
- Randomly split the given graph into two equally sized partitions and delete all edges inside the partitions to yield a bipartite graph
-
Find subsets and such that and where is the solution to the quadratic program given by:Here, denotes the link density of two disjoint sets , given by and represents the number of edges connecting and .
- Identify to be a community and repeat steps 1) and 2) for the subgraph induced on G by .
While this approach has a solid graph theoretic foundation, the high number of needed solver calls and the dense QUBO matrix still pose nontrivial hardware execution challenges in the NISQ era.
Aiming to minimize the demands to the QUBO solver, we propose a radically different approach that only needs a single QPU call and whose QUBO matrix is topologically identical to adjacency matrix of the given graph and hence, equally sparse. The approach presented in this work essentially purifies a solution of relaxed community detection problem, i.e., the final community structure is represented by the solution of a QUBO problem which is based on classically computed, probabilistic community assignments for each node. While we introduce a particularly efficient approach to calculate the needed input for the QUBO problem, many other approaches to relaxed community detection have been proposed in related work like semidefinite programming or convexification [28,29,30,31].
As derived in detail in the next section, our approach requires a solution for a novel relaxation of the community detection problem as input to the QUBO problem formulation. In essence, our approach demands for an estimate value for each edge, specifying whether it connects nodes belonging to different or the same communities. While such estimates could in principle be computed based on the output of solvers for the relaxed community detection problem by using, e.g., the KL-divergence of the community affiliations of neighboring nodes, we introduce a specialized estimation method tailored to this task. Notably, metrics like the edge betweenness centrality [32] also do not yield satisfactory results for our approach, as the difference in values between separation- and non-separation-edges is seemingly too small.
3. Concept
In the following, we explore the idea of performing community detection based on finding a suitable set of nodes separating the communities as defined in Definition 1 in a rigorous mathematical manner. Meeting the demand from the derived QUBO formulation for a separation edge estimator, we subsequently introduce a promising heuristic approach based on the concept of modularity.
3.1. Separation-node sets
The approach presented in this paper consists of two steps:
- (1)
- identifying a set of nodes separating communities and thus revealing the fundamental community structure (Section 3.2 and Section 3.3)
- (2)
- classifying the community of each separation-node to finalize the community detection (Section 3.4)
Either using a trivial, greedy approach introduced in Section 3.4 or a slight adaptation of the well-known QUBO-formulation of modularity maximization [33] to perform (2), the main objective of this paper is the development of a QUBO-approach realizing (1). To provide a more formal definition of (1), we now introduce the concept of separation-node sets. In the following, we use to denote the set of all separation-node sets.
Definition 1.
For a graph and a ground truth community structure C partitioning V, we call a set of separation-nodesiff the connected components partitioning the graph induced by are distributed such that is a refinement of C.
Equivalent to this definition, one could also demand the existence of a refinement map mapping each connected component onto a community such that . Utilizing the notion of separation-node sets, (1) can be formulated as finding a smallest set of separation-nodes whose associated refinement map is ideally bijective. An example of a set of separation-nodes satisfying these conditions is depicted in Figure 1b, which is part of Figure 1 displaying the proposed approach. As it will become apparent in the evaluation, such well behaved separation node sets can also be found in graphs with application near topologies.
The surjectivity of ensures that each community gets detected and its injectivity ascertains that no communities get split. In the following, we will call separation-node sets injective, surjective or bijective iff the respective refinement function satisfies these conditions. In order to formulate a QUBO problem where the optimal solution represents the minimal separation-node set, we start by stating an alternate, more convenient definition of minimal separation-node sets.
Theorem 1.
For an adequate penalty term P ensuring the separation-node set properties, the following equation states an equivalent definition of the set containing all minimal separation-node sets .
Here, we used as a 0-flag for separation-nodes, to denote the entries of the adjacency matrix, as a mapping of nodes to their ground truth community and the Kronecker delta . For a penalty term P ensuring the validity of the separation-node set definition by penalizing incident node pairs from strictly different communities where neither node is element of the sought-after separation-node set, see the following definition:
Proof.
See Appendix A.1. □
Therefore, the task of finding a smallest set of separation-nodes for any given graph is native to the concept of QUBO. Its formulation can be reduced to approximating for incident node pairs . This can be understood as calculating the probability of an edge being an interconnection of adjacent nodes belonging to different communities, or more formally, a separation-edge.
Most interestingly, we can show that solving the QUBO problem stated in Equation (5) is NP-hard for a specific estimator. To see this, we start by observing a substantial similarity of our QUBO formulation with the QUBO formulation of the Max-Clique problem as stated in [34]:
for a given graph and its corresponding adjacency matrix A with entries . Choosing the estimator by , it becomes apparent, that the QUBO formulations are identical if we specify to use a complete graph of size as an input to our QUBO formulation. Leaving an extensive mathematical analysis of the NP-hardness for more realistic estimators to future work, this shows that the problem of finding a minimal separation-node set is NP-hard when treating the estimator as a variable. This result supports the pursuit of the proposed approach of using quantum computing in order to find a minimal separation-node.
Returning to the initial goal of finding bijective separation-node sets, we now explore their surjectivity. A significant discovery regarding surjectivity is illustrated in Figure 2, showing no-free-lunch when using Theorem 1 to find surjective separation-node sets. This necessitates the addition of a penalty term to the QUBO formulation in order to ensure surjectivity when building upon Theorem 1. For the formulation of a suitable penalty term, see Appendix A.2.
As our formulation results in a PUBO (polynomial unconstrained binary optimization) problem of degree , we conjecture that this constraint cannot be realized in QUBO form without the addition of ancillary variables. Using the standard quadratization approach with the Rosenberg polynomial [35], a QUBO formulation of this term demands superpolynomially many ancillary variables, i.e., . In the context of quantum annealing, this scaling beyond a quadratic number of qubits makes the surjective separation-node approach overly complex compared to the standard modularity maximization. In the gate model, the QAOA can be used to solve PUBO problems in principle, but as current hardware limitations prohibit adequate evaluation, we leave the exploration of the surjectivity constraint to future work.
As a consequence of not enforcing surjectivity, there exists a possibility that the number of communities is incorrect after step (1) of detecting the fundamental community structure by separation-node set identification. Modifying step (2) slightly, this could in principle be compensated by iteratively increasing the number of possible communities until no further improvement of the modularity can be achieved. A clever way to do this could be the elbow-method as known in clustering [36]. For the alternative greedy approach for the second step (2), the possibility of merging communities could be allowed.
Fortunately, conducted experiments show that topological structures precluding free lunch are scarce in practice. Therefore, we will omit the explicit demand for surjective separation-node sets in the following.
Analog to the surjectivity, there exist graph topologies like the one displayed in Figure 3 showing no-free-lunch when using Theorem 1 to find injective separation-node sets. Hence, it appears necessary to ensure injectivity explicitly using a penalty term when building upon Theorem 1 in principle, as well. The formulation of such a penalty term also turns out to be rather tedious, as can be seen in Appendix A6. In this case, we end up with an even higher dimensional PUBO problem for the injectivity than for the surjectivity. Luckily, compared to the surjectivity, the injectivity of a separation-node set is of less importance, as the second step (2) could easily be adapted to cope with this. Analog to the case of surjectivity, we observe such topological structures preventing free lunch quite rarely in conducted experiments, resulting in the analog dismissal of an explicit demand for the separation-node sets to be injective in practice.
In summary, the apparent infrequence of topological structures preventing free lunch regarding bijectivity renders the QUBO-formulation stated in Theorem 1 to be a well-founded starting point for the stated proposition of QUBO based community detection via separation-node sets.
While this approach provides exact results for a perfect classification of separation-edges, it fully relies on a suitable estimation heuristic. Although many known measures for various edge properties exist (as described in Section 2), none showed to be entirely suitable for detecting separation-edges according to pretesting conducted for this paper. Consequently, we now motivate a novel approach tailored for exactly this task based on the concept of modularity.
3.2. Modularity-based separation-edge estimation
Motivated by the proven optimality of modularity and by the fact that at its core, modularity stems on essentially estimating whether each node pair is likely to belong to the same or different communities, we start by showing how this idea can be used to estimate . For this, recall the definition of the entries of the modularity matrix:
As before are the entries of the respective adjacency matrix, while denotes the expected value of the number of edges between and , . Upon closer inspection, we observe two main cases:
- , iff less connectivity between and was to be expected, indicating that and likely belong to the same community
- , iff more connectivity between and was to be expected, indicating that and likely belong to different communities
As the matrix entries are normalized to the interval of by the division with , we can see that using proper rescaling to the interval of , i.e., via , this allows for an estimation of the term in principle.
In practice however, this approach yields extremely bad estimations, as only the entries of the modularity matrix are relevant, corresponding to a given edge . For these, it quickly becomes apparent that is typically larger than 0, making this exact idea infeasible in practice. These considerations motivate an adaptation of modularity for the estimation of separation-edges as proposed in the following.
3.3. Edge neighborhood connectivity based separation-edge estimation
Exploiting the mathematical structure of modularity for a straightforward separation-edge estimation, we now introduce a promising generalization of the previous approach, which we coin as the neighborhood connectivity of an edge. Instead of merely taking the direct connection between two nodes into account (i.e., an edge), the neighborhood connectivity of an edge considers connections between the neighborhoods of the nodes. In this context, the neighborhood of a node is defined as the set of nodes with the shortest path of length r to v.
Based on this idea, we can rephrase the basic case of our generalization, i.e., modularity, as merely counting the number of unique edges on paths of length 1 between the 0-neighborhoods and of the respective nodes and . The here proposed generalization introduces the following two new notions:
- (1)
- Consider connections between r-neighborhoods with radius
- (2)
- Also consider paths of length 2
Stating this more precisely in mathematical form, we now define the neighborhood connectivity of an edge given a path length l, and a neighborhood size r:
In this definition, denotes the number of unique edges contained in paths of length l connecting the r-neighborhoods of the given nodes which do not involve nodes or edges contained by the -neighborhoods (as this would result in possible double counting of edges). Analogously to the definition of modularity, denotes the expected value corresponding to and acts as a normalization factor denoting the highest possible number can assume.
These values can be calculated based on a simple breadth-first search with depth r iterating of the neighborhood layers while choosing and as starting nodes. As for the expected value calculation, the configuration model has shown to be an adequate choice (which is in line with modularity). For details on this, we refer to our implementation which can be made available upon request to the authors.
Our preferred method of combining the results into the neighborhood connectivity of a given edge based on all is the dot product with a weight vector w with entries such that their sum equals 1:
As we know that the standard modularity value is of little use, we chose . We consider the remaining weights as hyperparameters, for which have proven to be suitable values according to conducted experiments.
3.4. Assigning the separation-nodes to communities
As stated in Section 3.1, we propose two different approaches to assigning the separation-nodes to communities, i.e., (1) a greedy strategy and (2) modularity maximization. In the experiments conducted in this paper, the greedy strategy was mainly employed for all experiments. It works as follows:
- (1)
- Count the number of edges to every know community for each separation-node.
- (2)
- Assign the node with the most edges to a single community to that community.
- (3)
- Update the counts for every neighboring separation-node.
- (4)
- Repeat steps two and three until every separation-node is properly assigned to a community.
This algorithm has a runtime of the number of separation nodes S times the number of communities , and hence runs very efficiently.
As the results calculated based on the edge neighborhood connectivity did not always show reasonable quality to use this greedy optimizer sensibly, we chose to use the standard of modularity maximization for these special cases. Fortunately, the well-known QUBO approach to this [18], can be easily adapted to our situation, i.e., by clamping the values of the known community assignments, where clamping is to be understood in the same way as it is used in quantum Boltzmann machines [37]. This yields a QUBO problem of size , which often can be solved a lot quicker than the original problem, as in practice.
4. Evaluation
The evaluation aims at the examination of the validity of the following two claims:
- (1)
- the assignment of separation-nodes to their communities is computationally easy, given a good enough estimator
- (2)
- neighborhood connectivity allows for proof of concept results
As we will show in the following, both claims appear to be valid according to the conducted experiments.
For investigating claim (1), we propose to check, if the greedy separation-node assignment as described in Section 3.4 is sufficient to assign the nodes of a well behaved separation-nodes to the correct communities. If this approach is indeed sufficient to obtain (nearly) perfect solutions, we reason that the claim is most likely valid.
In order to eliminate the possibility of an insufficient separation-node set, we use a synthetic dataset with known community structure, allowing for the use of a perfect estimator for the separation-edges. In order to find a very good separation-node set, we utilize a simple simulated annealing approach to solve the associated QUBO as defined in 5. Regarding the synthetic dataset, we choose the stochastic block model (SBM) [38] which is a widely used tool for benchmarking in the realm of community detection. Aiming to achieve realistic results, we use a graph of size , structured into seven equally sized communities with varying intra- and interconnections between the communities, resembling three different difficulties, according to the phase transition of community detection on SBMs (for details on the phase transition, see [9]). As it becomes apparent in the corresponding Figure 4, the greedy separation-node assignment indeed yields optimal or at least close to optimal results, indicating the validity of claim (1).
Having seen solid results for the optimal estimator, we now want to investigate the performance of the here presented "neighborhood connectivity" approach for real world data and hence explore claim (2). For this, we choose the greedy separation-node assignment, so that the separation-node identification displays the only non-trivial task, capable of solving the problem instances. Choosing standard real world benchmark graphs of varying size, we can observe stable results for most datasets in Figure 5, while often achieving 90 to 95% optimal results.
Motivated by these proof of concept results, we now investigate the performance of the proposed estimator (edge neighborhood connectivity) in order to explore its optimal mission scenario. For this, we again resort to equally formed SBM benchmark graphs with slightly higher intra-community connection probabilities, as they offer the comparison with ground truth information. Concretely, we chose these probabilities to be 0.75 for the easy case, 0.625 for the medium case and 0.5 for the hard case, which was the easy case for the experiments conducted with the perfect estimator (and picked previously as the hardest case to still yield perfect results).
Analogously to the perfect estimator, the identified separation-node sets were all valid and bijective in a small test run on 10 graphs. Switching the main optimization goal, we now examine the size of the identified separation-node sets for graphs of different difficulty, as displayed in Figure 6. Here, we can see, that the sizes of the separation-node sets found are substantially larger than the best known solution, this becomes apparent especially for easy problem instances. Interestingly, the performance quality increases for harder problems in relative perspective, showing promising scaling behavior.
Although the separation-node sets found are well behaved, the combination with the greedy separation-node assignment to communities does yield substantially worse results than the perfect estimator, as shown in Figure 7.
Subsequent experiments show, that the performance for the medium and hard datasets can be improved significantly by exchanging the greedy approach for a simulated annealing based one, as shown in Figure 8.
As described in the caption of Figure 8, simulated annealing based on the QUBO as described in Section 3.4 seems to be a suboptimal choice to assign separation-nodes to communities. We suspect that the reason for this resides in the large size of the search space for the given problem instances due to the employed one-hot encoding. As identified separation-node sets are typically sized up to 200 nodes (compared to the roughly 120 nodes for the perfect estimator), the search space for the problem instances thus contains roughly possible solutions, as 7 different communities exist.
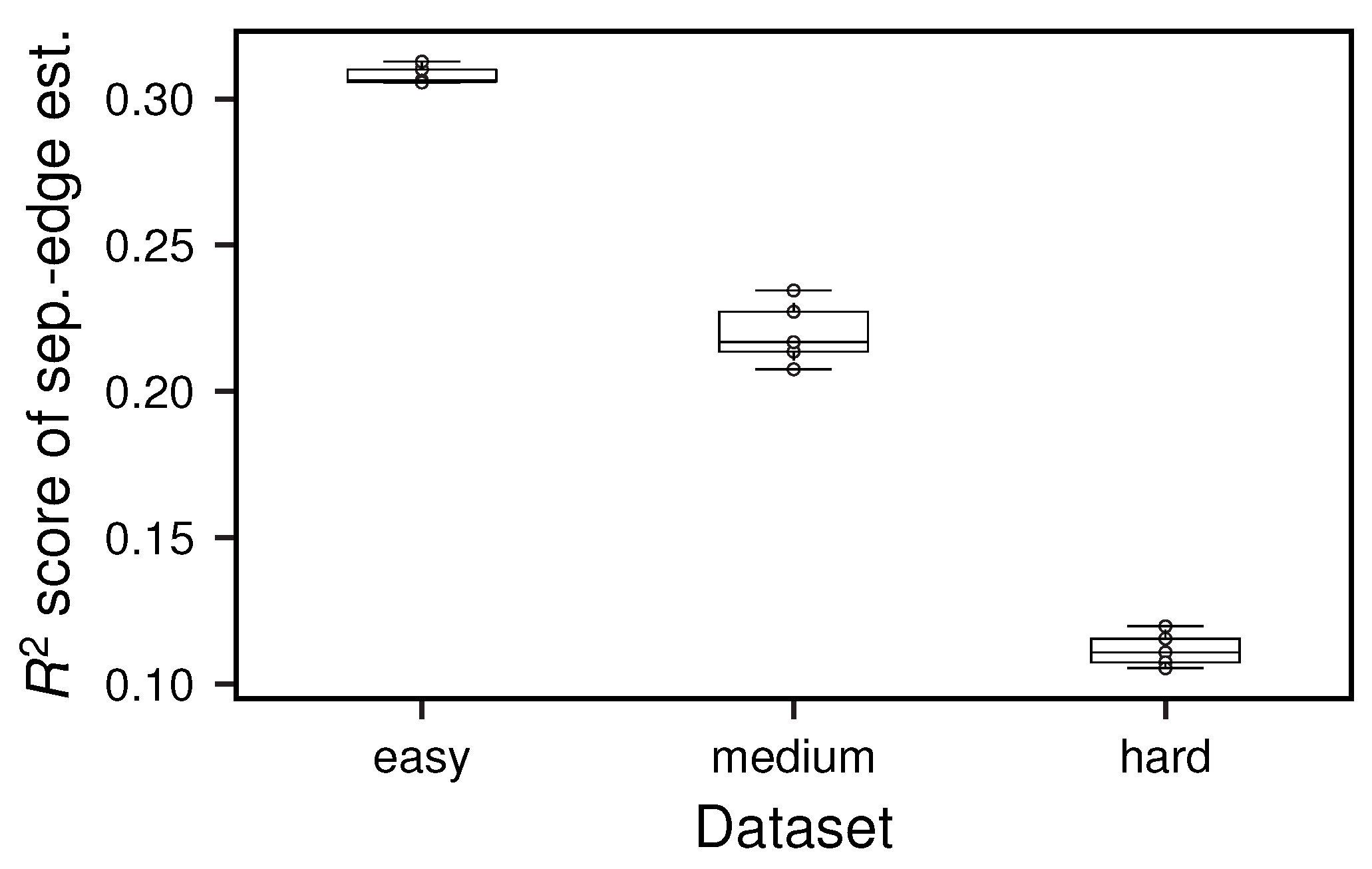
In order to put the results of the developed separation-edge estimator based on edge neighborhood connectivity into perspective with an optimal estimator, we now investigate its score in Figure 9. Interestingly, the worse performance for larger datasets has no impact on the validty and bijectivity of the subsequently identified separation-node set, which is very promising in regards to scaling.
5. Conclusion
Having set out with the goal of developing a quantum community detection approach that allows for the analysis of large graphs in the NISQ era, we presented the idea of identifying communities via their borders. The derived separation-node set based approach was shown to yield (close to) optimal results depending on the accuracy of the classical separation-edge estimator. The therefore proposed heuristic approach based on the introduced concept of "edge neighborhood connectivity" enabled for proof of concept results on real world data. In particular, as our approach merely requires qubits and as the corresponding QUBO is as sparse as the input graph , separation-node based community detection resembles the least hardware demanding quantum computing approach to community detection to the best of our knowledge. The underlying trade-off necessary for this accomplishment clearly is the more demanding classical part in this hybrid approach (i.e., the separation-edge estimation). We firmly encourage future work on this heuristic, while conjecturing the incorporation of solutions of the relaxed community detection problem as highly beneficial. Furthermore, the exploration of adaptations of similar known metrics like edge betweenness centrality [47] also seem very interesting. Overall, we conclude our approach to be highly promising for accelerating the possibility of solving real world community detection problems using quantum computers and thus opening up a path towards network structure analysis in big data.
Author Contributions
Conceptualization, J.S., M.S. and S.F.; methodology, J.S., J.N. and D.B.; software, J.S. and D.O.; validation, J.S., M.S. and S.F.; formal analysis, J.S.; investigation, J.S., J.N. and D.B.; resources, J.S.; data curation, J.S. and D.O.; writing—original draft preparation, J.S. and D.O.; writing—review and editing, J.S., D.O., J.N., D.B., M.S., S.F.; visualization, J.S. and D.O.; supervision, M.S. and S.F.; project administration, J.S.; funding acquisition, J.N. All authors have read and agreed to the published version of the manuscript.
Funding
This publication was created as part of the Q-Grid project (13N16179) under the “quantum technologies - from basic research to market” funding program, supported by the German Federal Ministry of Education and Research.
Data Availability Statement
The data presented in this study are openly available in on github at https://github.com/jonas-stein/qcd/graphs.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Remaining Proofs
Appendix A.1. Proving theorem IV.1
In the following, we provide a proof for Theorem 1, which states the following equation:
Where, by definition, we have:
Aiming to prove “⊆” and “⊇” individually, we first prove some lemmata.
Lemma A1.
All satisfying represent sets of separation-nodes.
Proof.
Let x be a binary vector such that and let S be the corresponding set of nodes. In order to prove the desired statement by contradiction, assume , which is equivalent to the existence of a connected component of the graph induced by not being a subset of one community. Then at least two nodes must exist, that are connected via a path and belong to different communities. On this path, there must exist two adjacent nodes the belong to different communities with neither of them being an element of S. Therefore must be bigger than 0, yielding a contradiction. □
Lemma A2.
The following equation states an alternative definition of the set containing all sets of separation-nodes.
Proof.
Using Lemma A1 to show “⊇”, we now show “⊆”. Let be an arbitrary separation-node set and x the corresponding binary vector 0-flagging the nodes belonging to S. Assuming , at least two adjacent nodes belonging to different communities exist following the definition of P. These nodes subsequently belong to the same connected component of the graph induced by implicating that no community can exist, that resembles a superset of the nodes inducing the connected component . Therefore, S can not be a set of separation-nodes as the corresponding refinement map can not exist, yielding a contradiction and showing . □
Lemma A3.
For every satisfying , there exists a superset such that , with Q defined such that and corresponding to .
Proof.
Let be a set of nodes such that the corresponding penalty term is bigger than zero. This implicates the existence of a pair of incident nodes being part of the same community while neither nor . Then the set (without loss of generality, we could also define while achieving the same) has a smaller QUBO-value compared to S: With a decrement of at least 4 in the the penalty term (i.e., taking its weighting of 2 into account) and an increment in the cost function (i.e., the sum of the ’s) of 1, we get , completing the proof. □
Corollary A1.
.
Proof.
This result follows directly from application of Lemma A3, as would violate the minimality property of x. □
With these lemmata, we are now ready to prove Theorem 1:
Proof.
Let be defined such that:
We start by proving “⊆”: Let and x its corresponding 0-flag vector, then we know by Corollary A1, that . Therefore . It is sufficient to show, that . For this, we assume, that there exists an such that . Now, as two possibilities exist:
- 1.
- and the separation-node set is smaller than S.
- 2.
- and the separation-node set is much smaller than S.
As we can see using Lemma A3, we can reduce the latter case to the former case by iteratively eradicating all penalties. Now, using Corollary A1, is a separation-node set and by definition of , yielding a contradiction to the minimality of and thereby proving “⊆”.
We now prove “⊇”: Let and let be the node set corresponding to . As we can see using Lemma A3, must be zero, otherwise could not be minimal in the sense of satisfying its definition. Therefore, is a separation-node set according to Lemma A2. Assuming yields , for an arbitrary and thus two cases are possible:
- 1.
- .
- 2.
- .
The former yields a contradiction to being minimal and the latter yields a contradiction to the minimality of . □
Appendix A.2. Constructing penalty terms for the in- and surjectivity constraints
In this section, we formulate penalty terms realizing the in- and surjectivity constraints for separation-node sets. Instead of solving this seemingly non-straightforward task directly, we will realize the individual constraints with terms that are larger than 0 iff the constraint is satisfied and 0 otherwise. Exploiting the possibilities of PUBO, we will show that the respective terms can be used to build penalty functions using a moderate amount of ancillary variables.
Lemma A4.
The separation-node set associated with the 0-flag vector is surjective iff for all .
Proof.
This equivalence can be trivially observed by closely inspecting the sum and is left as an exercise to the reader. □
As the heuristic approaches presented in this work only allow for the estimation of for adjacent node pairs , no direct estimation for seems accessible. However, we can use the estimation of for adjacent node pairs, to estimate for non-adjacent node pairs:
Here, denotes a function that returns the set of all simple paths between and . To allow for this convenient notation, we introduced as the projection, mapping the indices of the path entries of the elements of to their global indices from . In practice, these paths could be found using techniques presented in [48].
The value inside the sign function resembles the number of simple, intracommunity paths between and . A general upper bound for the number of paths with these properties is , i.e., the number of all subsets of V containing and . For practical purposes, this term clearly is unsuitable, as small errors in the estimation of add up very quickly. Neglecting applicability concerns for reasons described in Section 3.1, we now show how to build a PUBO penalty function associated to the surjectivity term used in Lemma A4.
Lemma A5.
Given a function for arbitrary representing a constraint via , the following penalty terms can be used to ensure that in PUBO:
Proof.
Clearly, ⇔ and thus ⇔. □
When denoting the surjectivity constraint from Lemma A4 as , we can see, that for every . Therefore, we can use Lemma A5 to formulate a penalty term for the surjectivity constraint at the expense of at most ancillary qubits.
With these results, we are now ready to formulate the following PUBO penalty term for injectivity.
Lemma A6.
is positive for every and not contained in the separation-node set iff the separation-node set associated with the 0-flag vector is injective, and 0, otherwise.
Proof.
Here, is positive, iff a simple path between and exists, that consists exclusively of nodes assigned to the community of which are not part of the separation-node set, and 0, otherwise. □
Analogously to Lemma A4, we can observe, that . Thus, we can use Lemma A5 at the expense of less than of ancillary qubits for every single node pair and . As injectivity demands the positiveness of for all node pairs and , ancillary qubits suffice to construct a penalty term for injectivity. The selection of appropriate node pairs and can be done using the term .
References
- Bondy, J.A.; Murty, U.S.R. Graph Theory with Applications; Elsevier: New York, 1976. [Google Scholar]
- Mashaghi, A.R.; Ramezanpour, A.; Karimipour, V. Investigation of a protein complex network. Eur. Phys. J. B - Condens. Matter Complex Syst. 2004, 41, 113–121. [Google Scholar] [CrossRef]
- Shah, P.; Ashourvan, A.; Mikhail, F.; Pines, A.; Kini, L.; Oechsel, K.; Das, S.R.; Stein, J.M.; Shinohara, R.T.; Bassett, D.S.; Litt, B.; Davis, K.A. Characterizing the role of the structural connectome in seizure dynamics. Brain 2019, 142, 1955–1972. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Physics Reports 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proceedings of the National Academy of Sciences 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed]
- Fani, H.; Bagheri, E. Community detection in social networks. Encyclopedia with Semantic Computing and Robotic Intelligence 2017, 01, 1630001. [Google Scholar] [CrossRef]
- Nadakuditi, R.R.; Newman, M.E.J. Graph Spectra and the Detectability of Community Structure in Networks. Phys. Rev. Lett. 2012, 108, 188701. [Google Scholar] [CrossRef]
- Brandes, U.; Delling, D.; Gaertler, M.; Goerke, R.; Hoefer, M.; Nikoloski, Z.; Wagner, D. Maximizing Modularity is hard, 2006. [CrossRef]
- Decelle, A.; Krzakala, F.; Moore, C.; Zdeborová, L. Inference and Phase Transitions in the Detection of Modules in Sparse Networks. Phys. Rev. Lett. 2011, 107, 065701. [Google Scholar] [CrossRef]
- Newman, M.E.J. Equivalence between modularity optimization and maximum likelihood methods for community detection. Phys. Rev. E 2016, 94, 052315. [Google Scholar] [CrossRef]
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.S.L.; Buell, D.A.; Burkett, B.; Chen, Y.; Chen, Z.; Chiaro, B.; Collins, R.; Courtney, W.; Dunsworth, A.; Farhi, E.; Foxen, B.; Fowler, A.; Gidney, C.; Giustina, M.; Graff, R.; Guerin, K.; Habegger, S.; Harrigan, M.P.; Hartmann, M.J.; Ho, A.; Hoffmann, M.; Huang, T.; Humble, T.S.; Isakov, S.V.; Jeffrey, E.; Jiang, Z.; Kafri, D.; Kechedzhi, K.; Kelly, J.; Klimov, P.V.; Knysh, S.; Korotkov, A.; Kostritsa, F.; Landhuis, D.; Lindmark, M.; Lucero, E.; Lyakh, D.; Mandra, S.; McClean, J.R.; McEwen, M.; Megrant, A.; Mi, X.; Michielsen, K.; Mohseni, M.; Mutus, J.; Naaman, O.; Neeley, M.; Neill, C.; Niu, M.Y.; Ostby, E.; Petukhov, A.; Platt, J.C.; Quintana, C.; Rieffel, E.G.; Roushan, P.; Rubin, N.C.; Sank, D.; Satzinger, K.J.; Smelyanskiy, V.; Sung, K.J.; Trevithick, M.D.; Vainsencher, A.; Villalonga, B.; White, T.; Yao, Z.J.; Yeh, P.; Zalcman, A.; Neven, H.; Martinis, J.M. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef]
- Shaydulin, R.; Ushijima-Mwesigwa, H.; Safro, I.; Mniszewski, S.; Alexeev, Y. Network Community Detection on Small Quantum Computers. Advanced Quantum Technologies 2019, 2, 1900029. [Google Scholar] [CrossRef]
- Denchev, V.S.; Boixo, S.; Isakov, S.V.; Ding, N.; Babbush, R.; Smelyanskiy, V.; Martinis, J.; Neven, H. What is the Computational Value of Finite-Range Tunneling? Phys. Rev. X 2016, 6, 031015. [Google Scholar] [CrossRef]
- Albash, T.; Lidar, D.A. Demonstration of a Scaling Advantage for a Quantum Annealer over Simulated Annealing. Phys. Rev. X 2018, 8, 031016. [Google Scholar] [CrossRef]
- Grover, L.K. A fast quantum mechanical algorithm for database search. Proceedings of the twenty-eighth annual ACM symposium on Theory of computing - STOC ’96; Philadelphia, Pennsylvania, USA: Association for Computing Machinery, 1996; pp. 212–219. [Google Scholar] [CrossRef]
- Shor, P.W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM Journal on Computing 1997, 26, 1484–1509. [Google Scholar] [CrossRef]
- Lloyd, S. Universal Quantum Simulators. Science 1996, 273, 1073–1078. [Google Scholar] [CrossRef]
- Ushijima-Mwesigwa, H.; Negre, C.F.A.; Mniszewski, S.M. Graph Partitioning Using Quantum Annealing on the D-Wave System. Proceedings of the Second International Workshop on Post Moores Era Supercomputing; Association for Computing Machinery: New York, NY, USA, 2017; PMES’17, p. 22–29. [Google Scholar] [CrossRef]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed]
- Kadowaki, T.; Nishimori, H. Quantum annealing in the transverse Ising model. Phys. Rev. E 1998, 58, 5355–5363. [Google Scholar] [CrossRef]
- Preskill, J. Quantum Computing in the NISQ era and beyond. Quantum 2018, 2, 79. [Google Scholar] [CrossRef]
- Dalyac, C.; Henriet, L.; Jeandel, E.; Lechner, W.; Perdrix, S.; Porcheron, M.; Veshchezerova, M. Qualifying quantum approaches for hard industrial optimization problems. A case study in the field of smart-charging of electric vehicles. EPJ Quantum Technol. 2021, 8, 12. [Google Scholar] [CrossRef]
- Akbar, S.; Saritha, S.K. Towards quantum computing based community detection. Computer Science Review 2020, 38, 100313. [Google Scholar] [CrossRef]
- Zahedinejad, E.; Crawford, D.; Adolphs, C.; Oberoi, J.S. Multiple Global Community Detection in Signed Graphs. Proceedings of the Future Technologies Conference (FTC) 2019; Arai, K., Bhatia, R., Kapoor, S., Eds.; Springer International Publishing: Cham, 2020; pp. 688–707. [Google Scholar]
- Sedghpour, A.S.; Nikanjam, A. Overlapping Community Detection in Social Networks Using a Quantum-Based Genetic Algorithm. Proceedings of the Genetic and Evolutionary Computation Conference Companion; Association for Computing Machinery: New York, NY, USA, 2017; GECCO ’17, p. 197–198. [Google Scholar] [CrossRef]
- Mukai, K.; Hatano, N. Discrete-time quantum walk on complex networks for community detection. Phys. Rev. Res. 2020, 2, 023378. [Google Scholar] [CrossRef]
- Reittu, H.; Kotovirta, V.; Leskelä, L.; Rummukainen, H.; Räty, T. Towards analyzing large graphs with quantum annealing. 2019 IEEE International Conference on Big Data (Big Data), 2019, pp. 2457–2464. [CrossRef]
- Chan, E.Y.K.; Yeung, D.Y. A Convex Formulation of Modularity Maximization for Community Detection. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence - Volume Volume Three. AAAI Press, 2011, IJCAI’11, p. 2218–2225.
- Chen, Y.; Li, X.; Xu, J. CONVEXIFIED MODULARITY MAXIMIZATION FOR DEGREE-CORRECTED STOCHASTIC BLOCK MODELS. The Annals of Statistics 2018, 46, 1573–1602. [Google Scholar] [CrossRef]
- Abdalla, P.; Bandeira, A.S. Community detection with a subsampled semidefinite program. Sampl. Theory, Signal Process. Data Anal. 2022, 20, 6. [Google Scholar] [CrossRef]
- Li, W. Visualizing network communities with a semi-definite programming method. Information Sciences 2015, 321, 1–13. Security and privacy information technologies and applications for wireless pervasive computing environments. [CrossRef]
- Brandes, U. A faster algorithm for betweenness centrality. The Journal of Mathematical Sociology 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Negre, C.F.; Ushijima-Mwesigwa, H.; Mniszewski, S.M. Detecting multiple communities using quantum annealing on the D-Wave system. PLoS ONE 2020, 15, 1901–09756. [Google Scholar] [CrossRef]
- Chapuis, G.; Djidjev, H.; Hahn, G.; Rizk, G. Finding Maximum Cliques on the D-Wave Quantum Annealer. J. Signal Process. Syst. 2019, 91, 363–377. [Google Scholar] [CrossRef]
- Rosenberg, I.G. Reduction of bivalent maximization to the quadratic case. Cahiers du Centre d’etudes de recherche operationnelle 1975, 17, 71–74. [Google Scholar]
- Thorndike, R.L. Who belongs in the family? Psychometrika 1953, 18, 267–276. [Google Scholar] [CrossRef]
- Amin, M.H.; Andriyash, E.; Rolfe, J.; Kulchytskyy, B.; Melko, R. Quantum Boltzmann Machine. Phys. Rev. X 2018, 8, 021050. [Google Scholar] [CrossRef]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Social Networks 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Fred, A.L.N.; Jain, A.K. Robust data clustering. 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings. 2003, 2, II. [Google Scholar] [CrossRef]
- Kuncheva, L.; Hadjitodorov, S. Using diversity in cluster ensembles. 2004 IEEE International Conference on Systems, Man and Cybernetics (IEEE Cat. No.04CH37583), 2004, Vol. 2, pp. 1214–1219 vol.2. [CrossRef]
- Danon, L.; Díaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. Journal of Statistical Mechanics: Theory and Experiment 2005, 2005, P09008. [Google Scholar] [CrossRef]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. Journal of Anthropological Research 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behavioral Ecology and Sociobiology 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Knuth, D.E. The Stanford GraphBase: A Platform for Combinatorial Algorithms. Proceedings of the Fourth Annual ACM-SIAM Symposium on Discrete Algorithms; Society for Industrial and Applied Mathematics: USA, 1993; SODA ’93, p. 41–43. [Google Scholar]
- Palla, G.; Derényi, I.; Farkas, I.; Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef]
- Newman, M.E.J. Modularity and community structure in networks. Proceedings of the National Academy of Sciences 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Li, Y.; Li, W.; Tan, Y.; Liu, F.; Cao, Y.; Lee, K.Y. Hierarchical Decomposition for Betweenness Centrality Measure of Complex Networks. Sci. Rep. 2017, 7, 46491. [Google Scholar] [CrossRef]
- Sedgewick, R. Algorithms in c, Part 5: Graph Algorithms, Third Edition; third ed.; Addison-Wesley Professional, 2001. [Google Scholar]
Figure 1.
Outline of the workflow for the approach proposed approach of community detection via separation-node identification. The computationally expensive tasks of identifying a set of separation-nodes (subfigure 1b) and classifying the communities for these nodes (subfigure 1d) are performed using quantum computing, while the computationally cheap tasks of removing the classified separation-nodes and identifying the resulting connected components (subfigure 1c) are done classically.
Figure 1.
Outline of the workflow for the approach proposed approach of community detection via separation-node identification. The computationally expensive tasks of identifying a set of separation-nodes (subfigure 1b) and classifying the communities for these nodes (subfigure 1d) are performed using quantum computing, while the computationally cheap tasks of removing the classified separation-nodes and identifying the resulting connected components (subfigure 1c) are done classically.
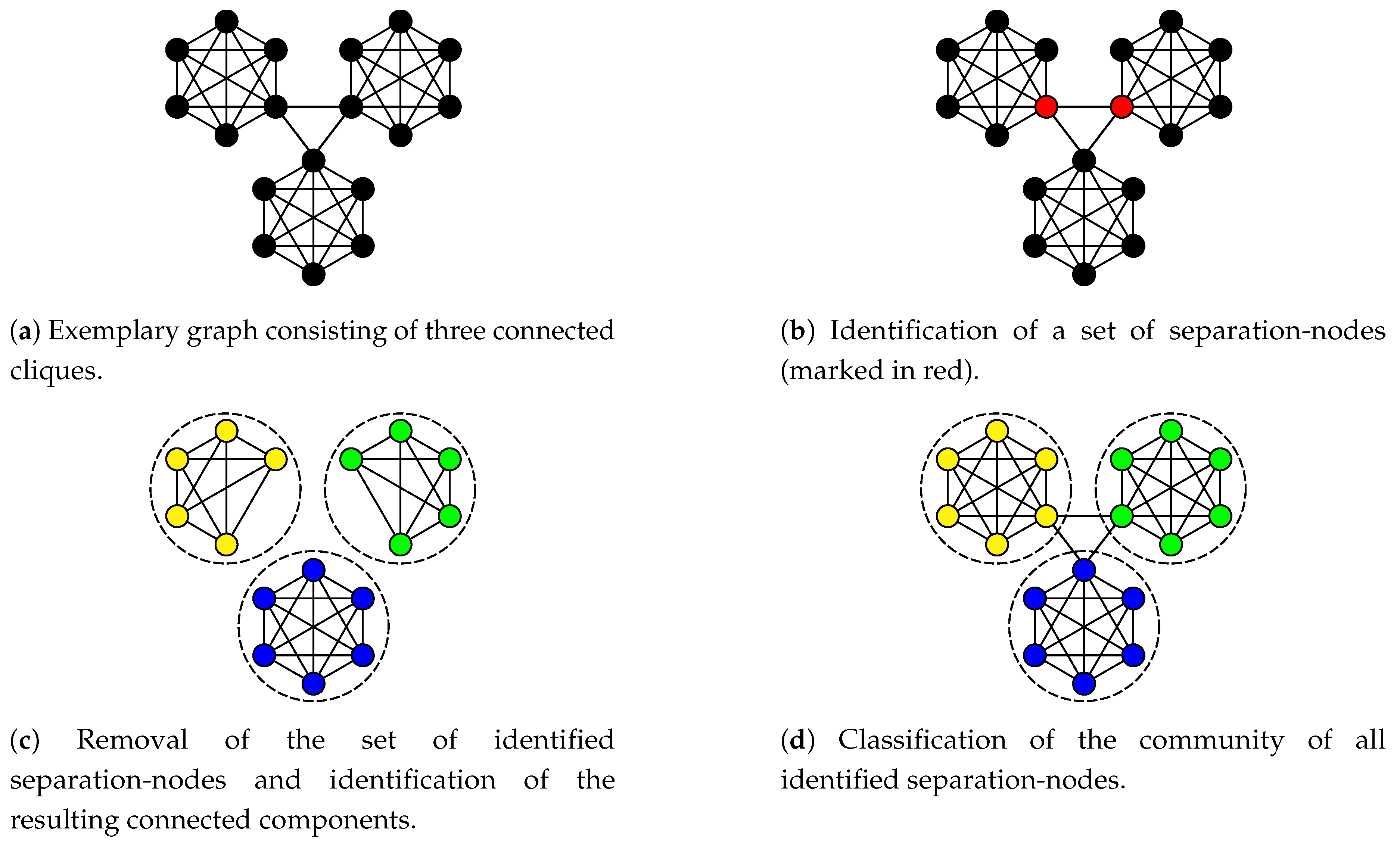
Figure 2.
Counterexample proving no-free-lunch when using Theorem 1 to find surjective separation-node sets.
Figure 2.
Counterexample proving no-free-lunch when using Theorem 1 to find surjective separation-node sets.
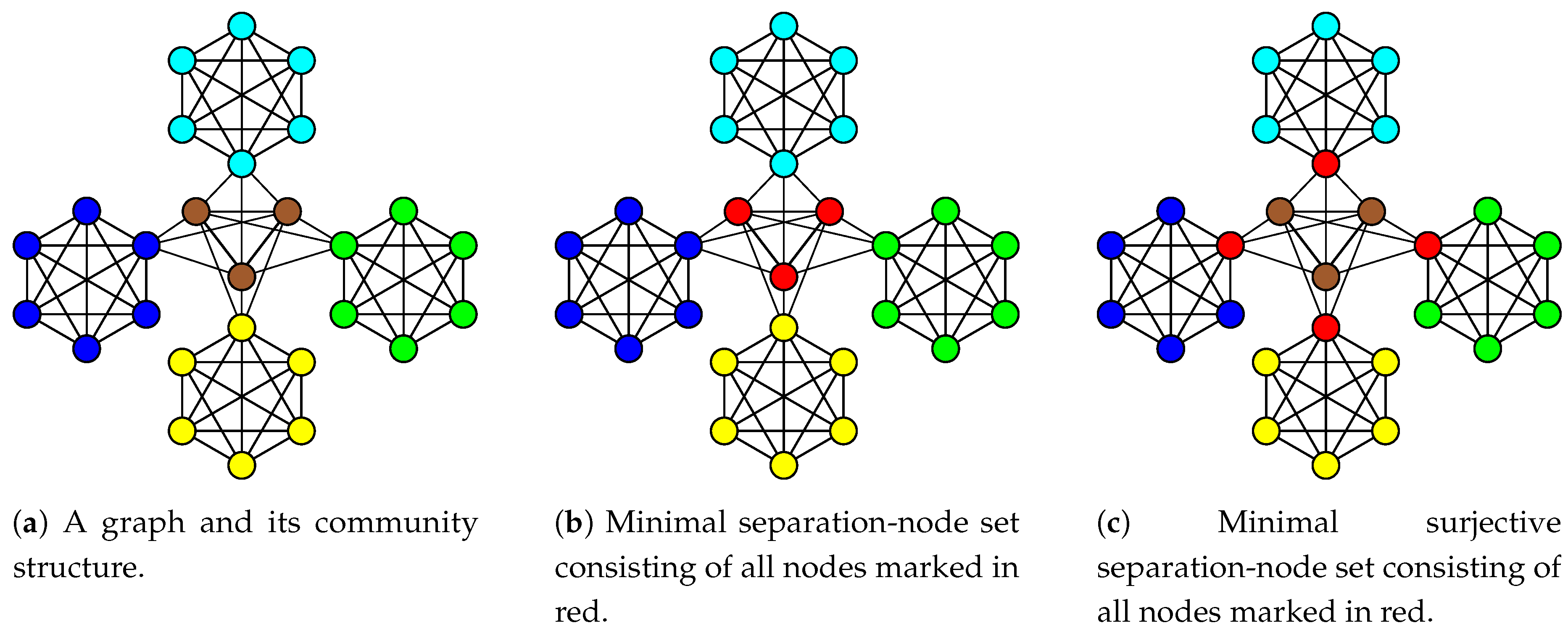
Figure 3.
Counterexample indicating no-free-lunch when using Theorem 1 to find injective separation-node sets.
Figure 3.
Counterexample indicating no-free-lunch when using Theorem 1 to find injective separation-node sets.
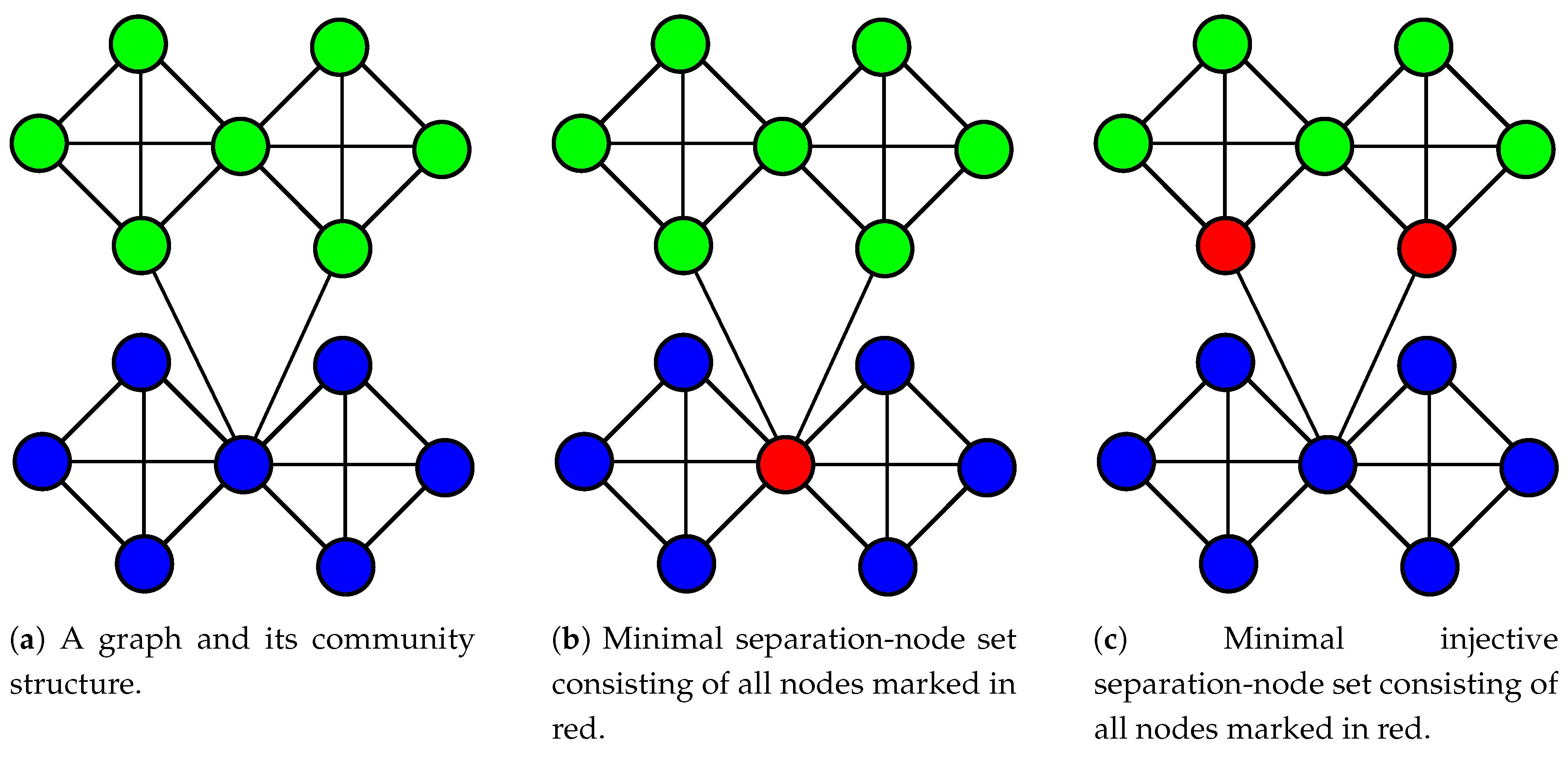
Figure 4.
This figure shows the NMI score of the presented approach for 50 different graphs each, based on ground truth and a perfect separation-edge estimator coupled with the greedy separation-node assignment. The NMI score as defined in [39,40] was used, as it resembles a well proven measure for the accuracy of a community given ground truth [41]. The different probabilities for intra-community edges in the chosen SBM model resemble different difficulties according to the phase transition known for this model. The lower the stated probability, the harder the problem. The probabilities were chosen such that the hardest graphs barely differed from a null model inheriting no measurable structure up to the hardest that still allowed perfect NMI scores.
Figure 4.
This figure shows the NMI score of the presented approach for 50 different graphs each, based on ground truth and a perfect separation-edge estimator coupled with the greedy separation-node assignment. The NMI score as defined in [39,40] was used, as it resembles a well proven measure for the accuracy of a community given ground truth [41]. The different probabilities for intra-community edges in the chosen SBM model resemble different difficulties according to the phase transition known for this model. The lower the stated probability, the harder the problem. The probabilities were chosen such that the hardest graphs barely differed from a null model inheriting no measurable structure up to the hardest that still allowed perfect NMI scores.
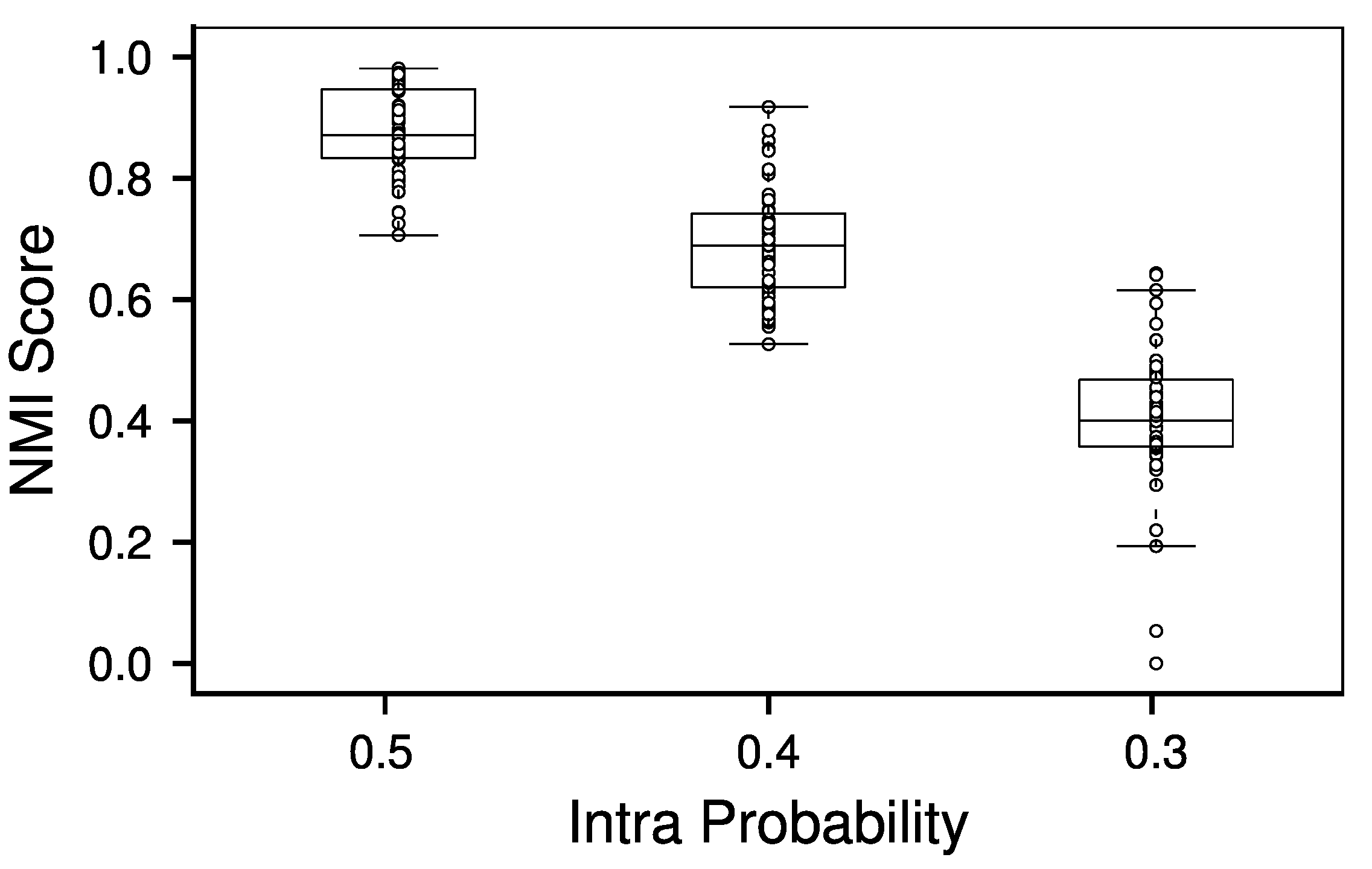
Figure 5.
This box plot displays the fraction of the achieved modularity score by the best known solution for selected standard benchmark datasets: (1) the social network of a karate club [42], (2) the social interactions between dolphins [43], (3) the collectively appearing characters in the book "Les Miserables" [44], (4) protein protein interacations [45] and (5) jointly bought political books [46]. Each graph was analyzed 10 times using simulated annealing. Our approach clearly does not work well for the karate club network. Closer inspections yield that the connected components resulting from the found separation-node sets often only consist of single nodes, indicating suboptimality in using neighborhood connectivtiy for this dataset.
Figure 5.
This box plot displays the fraction of the achieved modularity score by the best known solution for selected standard benchmark datasets: (1) the social network of a karate club [42], (2) the social interactions between dolphins [43], (3) the collectively appearing characters in the book "Les Miserables" [44], (4) protein protein interacations [45] and (5) jointly bought political books [46]. Each graph was analyzed 10 times using simulated annealing. Our approach clearly does not work well for the karate club network. Closer inspections yield that the connected components resulting from the found separation-node sets often only consist of single nodes, indicating suboptimality in using neighborhood connectivtiy for this dataset.
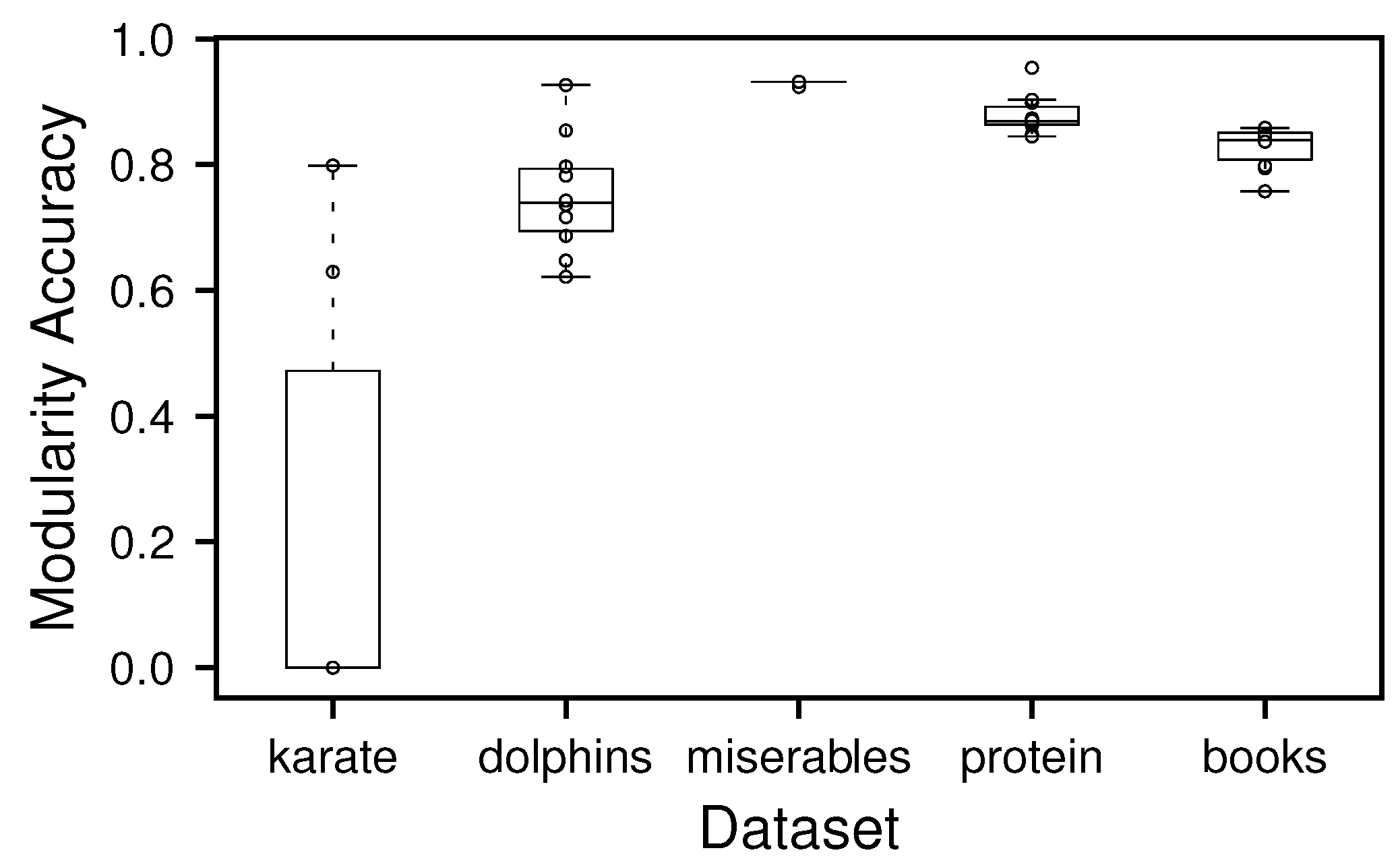
Figure 6.
The y-axis depicts the deviation factor from the best known separation-node set in size. Notably, the absolute sizes of the identified separation-node sets are typically similar over the different difficulties, while they rise slightly for larger graphs.
Figure 6.
The y-axis depicts the deviation factor from the best known separation-node set in size. Notably, the absolute sizes of the identified separation-node sets are typically similar over the different difficulties, while they rise slightly for larger graphs.
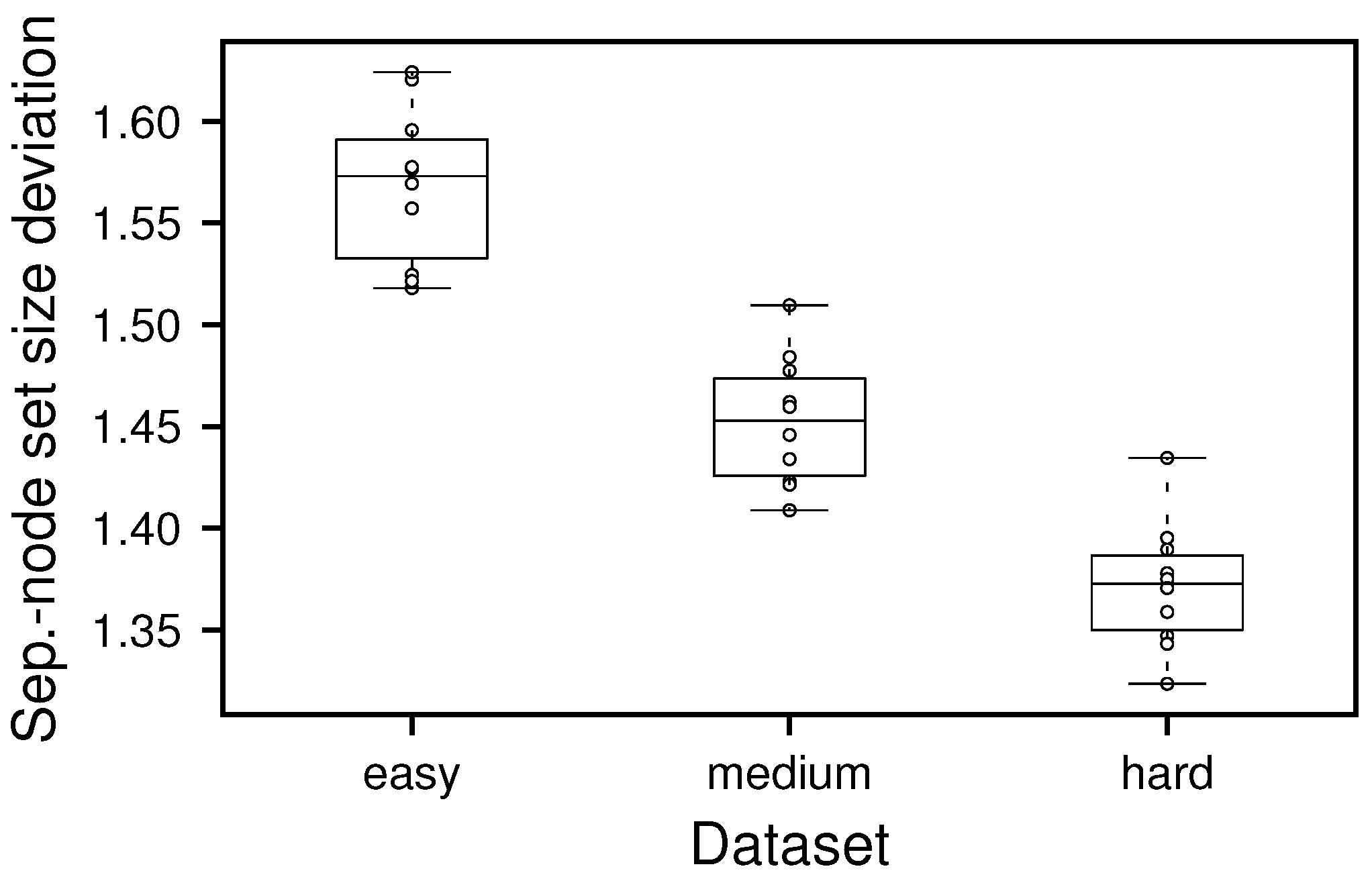
Figure 7.
This figure depicts the normalized mutual information score of the selected SBM benchmark graphs using the greedy assignment of separation-nodes to communities. A substantial drop off in performance can be observed for the harder datasets.
Figure 7.
This figure depicts the normalized mutual information score of the selected SBM benchmark graphs using the greedy assignment of separation-nodes to communities. A substantial drop off in performance can be observed for the harder datasets.
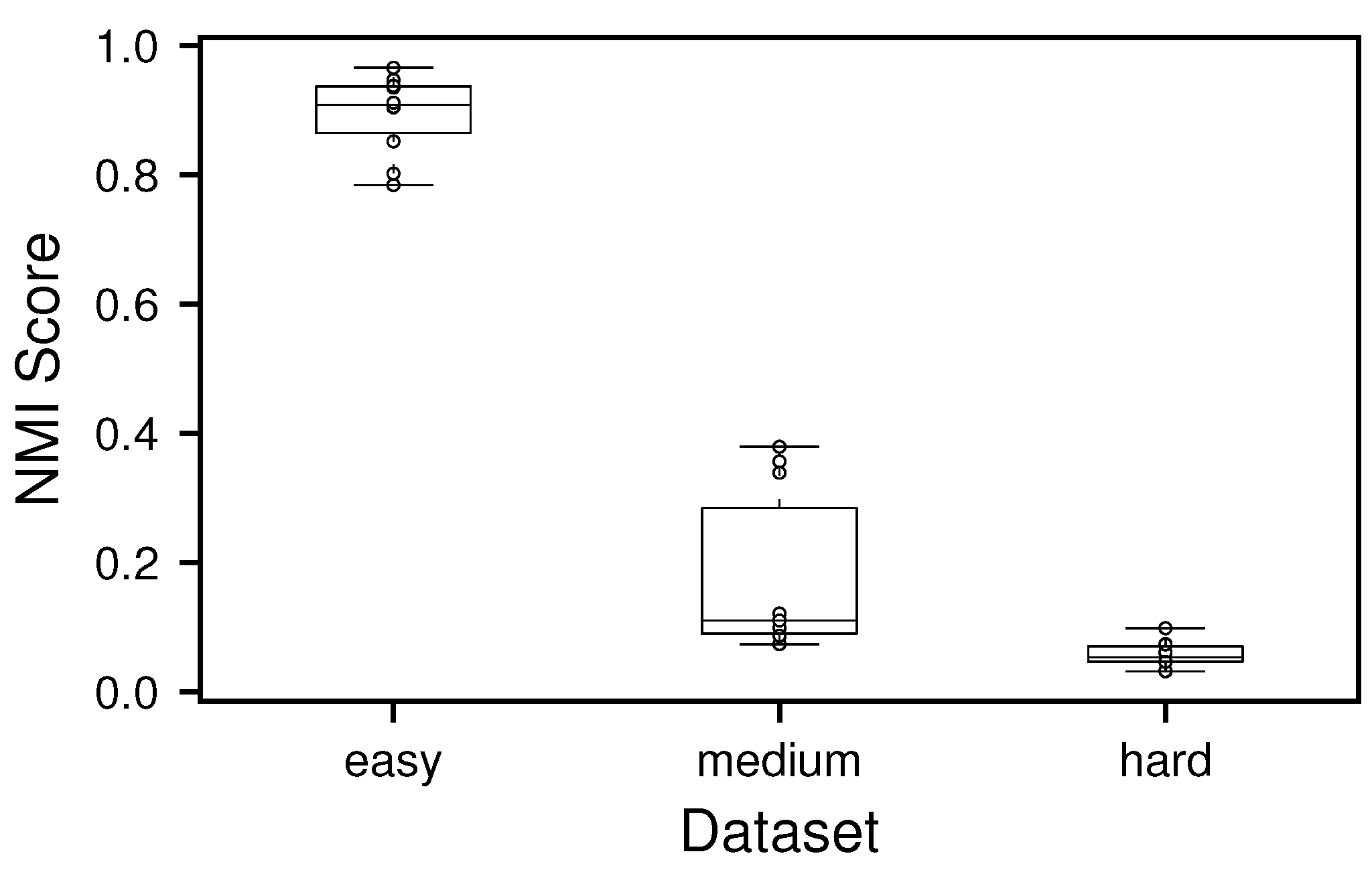
Figure 8.
This figure depicts the normalized mutual information score of the selected SBM benchmark graph using a simulated annealing based approach of assigning the separation-nodes to communities. The worse performance for the easy dataset clearly indicates that the chosen simulated annealing approach based on the QUBO as described in Section 3.4 is suboptimal in general.
Figure 8.
This figure depicts the normalized mutual information score of the selected SBM benchmark graph using a simulated annealing based approach of assigning the separation-nodes to communities. The worse performance for the easy dataset clearly indicates that the chosen simulated annealing approach based on the QUBO as described in Section 3.4 is suboptimal in general.
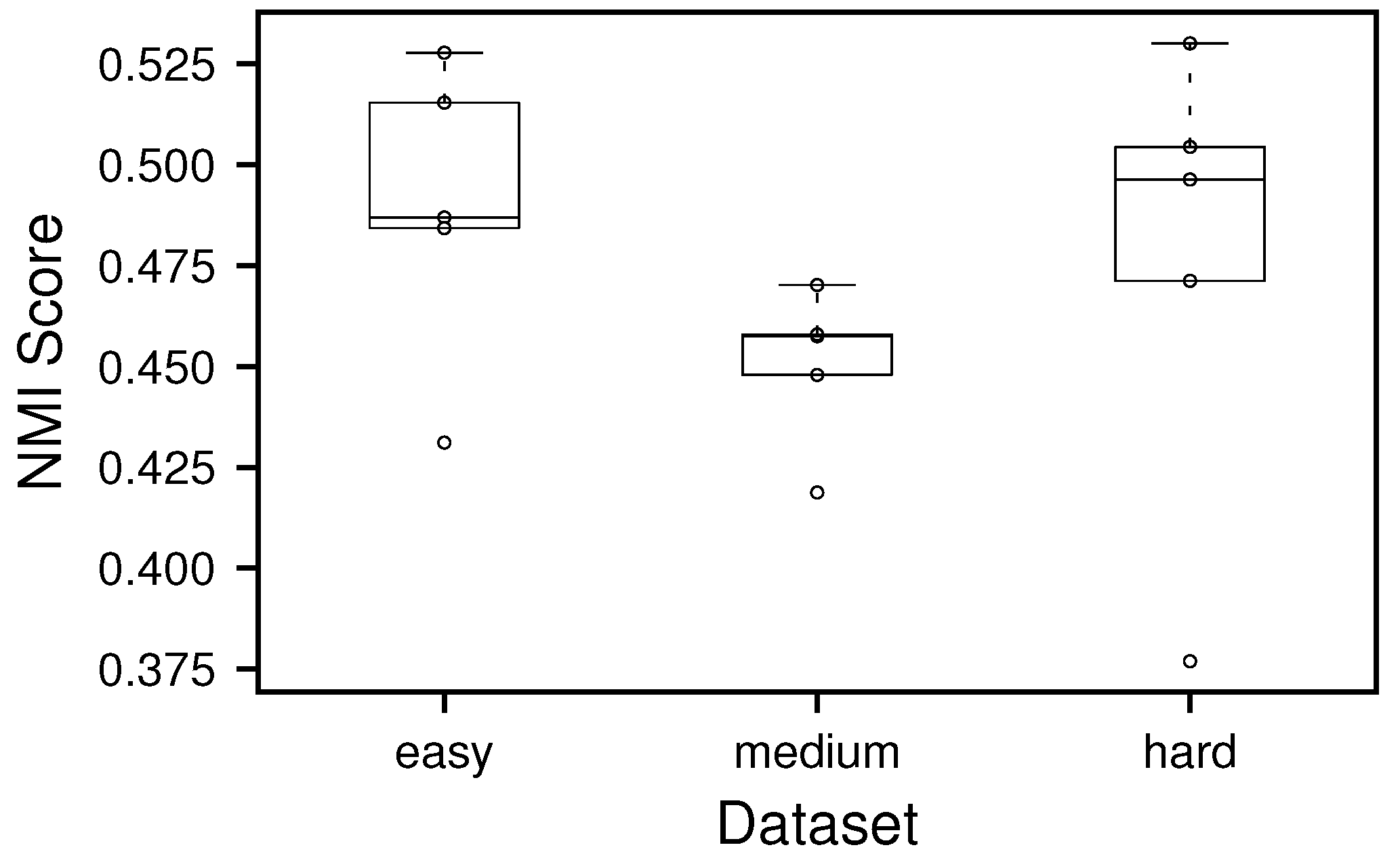
Figure 9.
score of the edge neighborhood connectivity based separation-edge estimator. In practice, an score of 30% implies that merely 30% of the variability of the ground truth has been accounted for. A strict trend towards worse results for harder datasets is clearly visible. This shows that the performance of the estimator decreases for harder problem instances as to be expected while still yielding somewhat accurate results.
Figure 9.
score of the edge neighborhood connectivity based separation-edge estimator. In practice, an score of 30% implies that merely 30% of the variability of the ground truth has been accounted for. A strict trend towards worse results for harder datasets is clearly visible. This shows that the performance of the estimator decreases for harder problem instances as to be expected while still yielding somewhat accurate results.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



