
Submitted:
22 May 2023
Posted:
23 May 2023
You are already at the latest version
Abstract
Numerous goods and services are now offered through online platforms due to the recent growth of online transactions like e-commerce. Users have trouble locating the product that best suits them from the numerous products available in online shopping. Many studies in deep learning-based recommender systems (RSs) have focused on the intricate relationships between the attributes of users and items. Deep learning techniques have used consumer or item-related traits to improve the quality of personalized recommender systems in many areas, such as tourism, news, and e-commerce. Various companies, primarily e-commerce, utilize sentiment analysis to enhance product quality and effectively navigate today's business environment. Customer feedback regarding a product is gathered through sentiment analysis, which uses contextual data to split it into separate polarities. The explosive rise of the e-commerce industry has resulted in a large body of literature on e-commerce from different perspectives. Researchers have made an effort to categorize the recommended future possibilities for e-commerce study as the field has grown. There are several challenges in e-commerce, such as fake reviews, frequency of user reviews, advertisement click fraud, and code-mixing. In this review, we introduce an overview of the preliminary design for e-commerce. Second, the concept of deep learning, e-commerce, and sentiment analysis are discussed. Third, we represent different versions of the commercial dataset. Finally, we explain various difficulties facing RS and future research directions.
Keywords:
E-commerce
; Sentiment analysis
; Natural language processing
; Deep learning
; Spam
; Product reviews.
1. Introduction
Due to the ongoing COVID-19 virus, which led to numerous nations' directives for their populations to stay home, e-commerce has increased significantly. E-commerce has supplanted traditional retail outlets as the primary way for consumers to meet their consumption demands due to the closure of most physical stores and concern over COVID-19 infections. It is normal practice for online merchants to ask for feedback on goods and services through text reviews and ratings [1]. Today's e-commerce websites serve as a sizable marketplace for the purchase and sale of goods, and many of them offer a review section where customers may express their opinions on the value of the goods they've purchased [2].
The number of online retailers implementing sophisticated personalization algorithms is steadily rising in the global e-commerce market. The only e-commerce behemoths with access to Amazon.com and other pioneers using recommendation systems in retail stores like its own. Recently, e-commerce websites like Amazon, eBay, and Alibaba have altered how people consume goods due to the growth of digital applications and websites. Due to the massive growth in vendors that have recently begun creating goods, major and small online retailers can now afford to personalize their services [3]. The primary channel of e-commerce transactions has evolved to become the Internet. From banks offering Internet banking to hotels, airports, and airline tickets, consumer businesses of all types and industries strive to reach millions of online customers. More and more businesses rely on e-commerce [4].
Most e-commerce platforms allow customers to give reviews for goods and services to glean data, such as the customer's assessment of the items and a description of any unfavorable reviews. Sentiment analysis must be performed on the customer reviews and ratings [5]. The advantages of using e-commerce websites to do business online, such as loyalty, faster delivery, simple setup, time savings, cost-effectiveness, and flexibility, are depicted in Figure 1 [6].
Consumer delight has been enhanced by business needs that involve sentiment analysis through improved consumer satisfaction with products and market distinctiveness. The importance of sentiment analysis to organizations cannot be overstated since it enables them to comprehend how consumers feel about their brands. Customer satisfaction analysis with sentiment analysis occurs when customers can express their thoughts and experiences about products in comments made in natural language [7].
Deep learning, defined as neural networks with numerous layers of perceptrons, has been demonstrated to be beneficial for feature presentation, sentence categorization, word representation, and text synthesis. Evaluating sentiments requires well-known algorithms, such as convolution neural networks (CNNs), long short-term memory networks (LSTM), recurrent neural networks (RNN), bidirectional-LSTM (Bi-LSTM), and integrated deep-learning approaches [8].
Through applying a nonlinear structure, deep learning extracts the high dimensional representations from data and applies them to various issues. Additionally, it can manage large amounts of data and other high-dimensional data types, such as audio and visual data. The best results have been produced by deep learning in several areas, including speech recognition, natural language processing (NLP), and recommendation systems (RSs). Several deep learning has performed more convolutional recommender systems in terms of performance [9].
This paper is organized as follows. Section 1 introduced the importance of enhancing the quality of products and the advantages of e-commerce. Section 2 introduced the overall analysis methodology as preprocessing, feature extraction, feature selection, and literature overview. Section 3 demonstrated a recommendation based on the review's sentiment, especially in e-commerce. Section 4 introduces some applications of recommendation systems in different domains. Section 5 presents a recommendation system based on deep learning and summarizes some deep learning algorithms for reviews. Section 6 contained word embedding technologies such as word2vec and how to improve the big dataset's performance. Section 7 presented some popular datasets in the field of e-commerce. Section 8 introduced performance evaluation techniques to measure the performance of methods. Section 9 presented difficulties and challenges for RSs in general and e-commerce reviews and future directions. Finally, Section 10 concludes the paper.
2. Methods and Literature Overview
The RS is an effective technological tool that seeks to anticipate consumers' needs by giving them the data or services they need without directly asking them. Most social media platforms and e-commerce applications utilize RS to increase user efficiency. For users, RS facilities choose exploration and reduce information overload. Figure 2 demonstrates the stages of this research, beginning with the e-commerce dataset to analyze and evaluate reviews.
2.1. Preprocessing
More training time is required for big datasets, and stop words reduce prediction accuracy. Text preprocessing is necessary to reduce the use of computer resources and improve prediction accuracy. The model's performance is improved and more accurate predictions are made because of text preprocessing. As indicated in Figure 2, the preprocessing phase involves the following processes:
- Tokenization: For a computer to understand the text, it is essential to decompose words into a machine-understandable one. Word, character, and partial word tokenization are the three main categories that broadly classify tokenization. Tokenization is used to obtain tokens. A vocabulary is created using tokens [10]. The technique of breaking up uninterrupted text into words, symbols, and components, like rewriting sentences into words, is called tokenization. It should be accurate and effective because it greatly affects how well the subsequent analysis performs [11].
- Stemming: Breaking down words into their base form to reduce the number of word groups or classes in text data. It lessens the amount of inflection in speech. Stemming helps us to quality and effectively classify data [12]. Stemming shortens word suffixes or prefixes without considering the meaning of the word. For example, the word "driv" is taken from "driving," which is not a legal word [13]. Stemming is applied to improve the performance of classifiers while reducing the number of features present in the feature space and rooting different configurations of features to unique properties. Stemming works quickly and eliminates multiple errors that improve index size [14].
- Lemmatization: It is the process of transforming tokens into the base word lemma by performing morphological analysis to eliminate infections [15]. It maps words to either their original form or a meaning statement. This is crucial for determining if words are the description of products or opinions [16]. It may be enforced using the utils framework's lemmatize functionality. Just the optimal template package has had to be activated for this functionality. To convert the lemma into a sequence of bytes, create a clone of the preferred lemma. The relationship between the normalized form of a word and one of the words in a phrase is called lexeme [17].
- Part of Speech (POS) tagging: Following tokenization, each word is given a lexical, such as a noun, verb, adjective, or adverb [18]. An adjective is denoted by "JJ," whereas a noun is denoted by the tag "NN," an adverb by "RB," and a verb by "VB." The relevant characteristics are easily detected and retrieved since tagging is a crucial component of the data preprocessing phase [13]. POS provides details of word usage in sentences. In this process, tokens such as nouns, pronouns, adjectives, and verbs are tagged with POS. Adjectives are essential in understanding the opinions expressed in comments. POS tagging marks the words with the correct POS tagging to know the sentiments and opinions in the sentence or the comments for further processing [19].
- N-grams: For the classifier to forecast the words that will appear next, N-grams (bigrams were utilized) is a method of grouping n-words [20]. Text features in supervised machine learning algorithms are shaped via-gram. This is n consecutive tokens taken from the provided text. N can have values such as 1, 2, and 3. A value of n equal to 1 is called a unigram, n equal to 2 is called a bigram, and n equal to 3 is called a trigram [21].
- Padding: Because there are short and very long evaluations in the consumer reviews databases, sentiment analysis presents challenges for the classifier. CNN-related padding is the number of pixels that were added to reviews by a network. Padding is just the last addition of zeros to our input review to guarantee that each customer review has the same length [22].
2.2. Feature Extraction
Documents must be transformed as vectors. This procedure, also known as vectorization, is crucial for examining text. It is a feature extraction approach in which a document is divided into sentences, which are divided into words, and then a feature map or matrix is generated [23]. Words are encoded as floating-point values or integers depending on the approach employed and fed into machine learning (ML) algorithms [24]. The following paragraph discusses a few techniques:
- Term frequency and inverse Document Frequency (TF-IDF)
The TF-IDF vectorizer technique weights each word according to its frequency in the text and its frequency of occurrence. TF-IDF statistic aims to reveal a word's importance inside a text or set of articles [25]. This method is a standard method for sentiment analysis and is mainly used in the information retrieved to rank how essential a term is to a specific text in a corpus. The IDF score of a term decrease as its occurrence in more document [26]. The formula TF*IDF is used to indicate the weighted average of each score. The high TF*IDF represents a rare occurrence [5]. The TF-IDF equation is shown in Eq. (1) where N is the total number of documents, tfi,j j indicates how many times i occurred in the document, and dfi is the number of documents that included i [10].
- Count vectorization
One of the most straightforward and generally successful strategies is the count vectorizer. A word's weight is established by counting the number of times it appears in a document. While tokenizing the text documents, the count vectorizer method builds a word vocabulary. In contrast to the TF-IDF vectorizer, which scores words and produces floats, the count vectorizer delivers integers after counting words [27].
- Bag of Words (Bow)
The Bow model is one of NLP's most often utilized knowledge models. A unigram model of each word is constructed by tracking how frequently it appears in the text. When the bag of words approaches, each word is given a unique subjective score and is only considered [28]. Text categorization is done using count vectorization and term frequency algorithms. The BoW model is among the earliest and most used methods for converting text into a numerical vector. As a result of not taking into count word order, sentence structure, or grammatical construction and instead focusing simply on the presence of a word, it has the drawback of causing the text's syntactic information to be lost [29].
2.3. Feature Selection (FS)
Feature selection work is categorized using the filter, embedding, and wrapper models. These categories are discussed as follows:
- Filter model
This method of feature selection is the most popular. This model uses correction matrices to selectively remove pertinent elements that strongly correlate to the target. The filter model measures the overall features of the input variables based on distance, dependency, and consistency to choose pertinent subsets [30].
- Wrapper model
The machine learning technique may be used as a performance indicator. FS performance may be effective. If reducing the classifier's error rate is the primary objective using the ML algorithm as a performance measure makes sense. As a part of the feature evaluation function, the wrapper model constructs the feature subset using ML techniques. Two steps were used to make the wrapper model operate:
- The training data and the best feature subset found by the subset of the search method are combined to evaluate the classifier's accuracy.
- In the second training and testing phase, the classifier is evaluated using the best subset of features and test data [31].
- Embedded model
The feature selection procedure is carried out iteratively by embedded algorithms as part of the model training. As a consequence, the model carefully emphasizes just the most crucial elements that have the greatest impact on the model training process [30].
3. Recommendation Based on the Sentiment of the Review
Sentiment analysis (SA), often known as opinion, is an NLP process that entails sifting through abstract data and text sources to extract subjective information. To classify user input as either good or negative, emotion categorization is the goal. For instance, the word "wonderful" had a good connotation; however, when combined with a word that denotes something negative such as "not," the meaning may drastically change. Reviews of products, films, and accommodations have all been explored in circumstances where emotion classification has been used [32]. SA has been widely used in different platforms in social media like Facebook and Twitter, blogs websites like Medium, recommendation systems like Amazon and Netflix, and other open discussion forums like Reddit. The value of sentiment analysis is generally acknowledged in various application domains, including business and biomedicine. Businesses can analyze consumer feedback in business intelligence and e-commerce to enhance customer services, create a better product, or enhance marketing campaigns to bring more consumers [33]. Figure 3 shows the main approaches to sentiment analysis. Technological advancement significantly impacted this profession and assisted in its further growth [34].
A different e-commerce platform website that has a wealth of data on it and uses tremendous forecast sentiment. Products become more profitable as the products learn from the dataset and are improved. These days, users are also attempting to forecast user attributes on social media platforms [35]. Sales may be impacted by the connections between the product's amount of sales, the number of user reviews, the quality of those reviews, the number of online comments, and the emotional content of user feedback [1]. Sentiment analysis may acquire data from various sources, including Twitter, Facebook, and blogs, provide quantifiable outcomes, and get around corporate intelligence challenges. The sentiment analysis effectively catches the grammatically accurate material. However, sentiment analysis does not capture slang, colloquial language, unusual acronyms, and misspelled words. Furthermore, social media texts are typically brief and evaluated singly. In certain situations, a single word might have a distinct polarity [36].
4. Applications of Recommendation System
Over the last few decades, RSs have been an essential component of the majority of the web-based on many domains such as e-commerce, healthcare, e-tourism, e-learning, research, and social media monitoring.
- E-commerce
RS benefits the customer and product communities in an e-commerce environment. RSs are required to obtain pertinent items and more individualized recommendations of products. In recent years, the client has received more relevant and engaging recommended products thanks to the user of demographic recommendation [37]. To suggest products to customers, e-commerce companies use recommendation mechanisms. The product recommendations are based on the top sellers on the websites, the demographics of the target market, or an analysis of historical data. Using the behavior of purchasing customers as a guide to future purchases [38]. Wang et al. [39] used clustering representation to design a new e-commerce product RS. A fundamental issue with k nearest neighbor methods is the selection of surrounding object sets. Choosing the neighboring object sets created the innovation neighbor factor and leveraged the dynamic selection approach. Then, the e-commerce-based product RS was created by combining the attention process with the recurrent neural network. Large e-commerce databases have problems with data sparsity and information overload due to the system's structure.
Patro et al. [40] presented a hybrid action related K-nearest neighbor (KNN) similarity of the product RS. The suggested technique combines hybrid filtering to add feature vectors to the user behavior matrix. The KNN approach requires a lot of computing time because it must determine the distance between each review and each training sample.
Users can post reviews about any product or subject on social media and e-commerce websites. The purpose of reviews written by sincere customers is to share their positive or negative experiences with a product with the hope that it will help other customers make a decision [41].
- Healthcare
Users are discouraged from finding timely access to reliable and helpful information for improving their health due to the vast data generated on Internet medical platforms [42]. Because medical records are so sensitive, the enormous volume of data created every second presents a significant potential for analysis to aid healthcare professionals in making patient-centered choices and raises privacy and security issues. As a result, it has become essential to use RSs to make effective decisions on patient care [43].
- E-tourism
E-tourism systems aim to provide the best deals for expanding vocation and travel possibilities. The advisory system for travel dining, lodging, and tourist attractions has been implemented in this area. Scalability, rarity, new users, and goods have all been addressed in RSs by creating a hybrid system.
- E-learning
E-learning advice systems created based on conventional e-learning systems have gained popularity among educational institutions. These programs help students choose classes, topics, and learning resources they are interested in and provide an engaging learning environment and online discussion forums [44].
- Research
The recommender system is more effective than traditional information approaches in the research field. It is a key component of many successful websites on the Internet, including Amazon, Youtube, and Yahoo. This characteristic prevents the researcher from multiple points of entry. Additionally, it allows the researcher to stay within the list of significant studies pertinent to the research point [20].
- Social media monitoring
Gathering and evaluating a sizeable amount of text-based data from various social media sites is possible. SA is applied to understand the final data and derive meaningful conclusions from the massive and distributed social media data [45].
5. Recommendation System Based on the Deep Learning
Building recommendation models has benefited from the advancement of deep learning in recent years, particularly neural network-based models. Since Deep learning has recently shown phenomenal success when used in NLP. Since it employs several nonlinear processing unit layers, it can efficiently learn a variety of representations and abstractions from the raw data [46]. Numerous neural networks have been employed in sentiment categorization up to this point, including the LSTM, Bi-LSTM, CNN, RNN, Autoencoder, and gated recurrent unit (GRU). CNN and RNN-based hybrid networks perform better than either type of network when used alone, as presented in Figure 4 [47].
- Long Short-Term Memory (LSTM)
LSTM is an RNN that detects order dependency in sequence prediction problems. RNNs have difficulties with short-term memory. The vanishing gradient problem and gradient exploding problem, which were significant problems of simple RNN, were overcome by LSTM [47].
- Bi-directional Long Short Memory (Bi-LSTM)
An adaptation of LSTM is Bi-LSTM. It is a sequence processing model that employs two LSTMs per layer, one receiving the input sequence in the forward direction and the other in the reverse direction. Bi-LSTM efficiency increases the quantity of information that is available to the network.
Balakrishnan et al. [48] presented a prediction model CNN-RNN-Bi-LSTM using many transformers. Compared to supervised machine learning, the study demonstrates that deep learning of word embedding techniques and Bidirectional Encoder representations are more effective at analyzing the sentiments contained in the text. The advantages and disadvantages of deep learning algorithms are given in Table 1.
- Convolutional Neural Network (CNN)
CNNs are deep neural network-based architectures that use a grid based on a structure to analyze input. Convolution, pooling, and fully linked layers, among others, are some of the layers that make up CNN's hidden layer. In one or more convolutional layers, the convolutional operation has been used. Using the convolutional procedure, feature maps were created from input data for convolutional layers [54]. Onan et al. [54] built a unique deep-learning system to examine the sentiment of product evaluations gathered from the Twitter network. The categorization sentiment network used the CNN with LSTM after obtaining a feature vector from Twitter data using TF-IDF weighted glove word embedding. Lazib et al. [55] combined a bidirectional LSTM and a CNN. The CNN model captures the relevant syntactic features between tokens and cues along the shortest syntactic path of the constituent and dependency analysis tree. At the same time, the Bi-LSTM learns contextual expressions along sentences. The F-score of the model was 90.82%.
- Autoencoder (AE)
AE is a feedforward neural network trained to transform input into a reconstructible representation. Using autoencoder to learn low-dimensional representations in bottleneck layers or directly filling gaps in interaction matrices in reconstruction are two main applications of autoencoders in RSs [56]. Tsai et al. [57] created a collaborative filtering predictor using a neural network and a cold start item-rating-based denoising autoencoder. In contrast to the neural network collaborative filtering (NNCF) predictor, which predicts ratings in the sparse user-item matrix, features are extracted from the textual description of the item. Finally, the user-item matrix learning is completed by adding the multiplayer perceptron.
- Recurrent Neural Network (RNN)
RNNs also contain input, output, and hidden layers like a regular neural network. RNNs vary in that they can be in different states at different times. Sequential data processing with RNNs is efficient. Model training usually makes use of two of them that were created to overcome the problem of disappearing gradients for LSTM and GRU networks [22].
- Gated Recurrent Unit (GRU)
Although LSTM outperforms ordinary RNNs in terms of performance, it requires more processing since it employs larger weight matrices. The GRU cell is intended to reduce the computational complexity of the LSTM by merging the input and forget gate into a single update gate and the hidden cell states into a single state [58].
- RNN-CNN
A model combines RNN and CNN models is known as the RNN-CNN model. Both LSTM-CNN and GRU-CNN are included in the combined RNN-CNN model architecture. The input is processed using the RNN layer to learn to represent and order the feature in the data. The CNN layer will then utilize the output from the RNN layer as input and search for pairs of key characteristics [59]. Table 2 gives some of the studies that used deep learning algorithms.
Sangeetha and Kumaran [60] used support vector machines (SVM) and RNN with LSTM to analyze sentiment analysis in online products. NLP enables the extraction of meaningful information from online reviews by allowing SA through the use of NSP on the Internet. It designates an entity's positive or negative polarity. The feature words were supplied to the SVM classifier and RNN-LSTM techniques for determining the sentiment direction reviews using asymmetrical weighting.
Hu et al. [61] modeled a user profile for an online Rs for the product based on SA and reviewer credibility. The five modules that comprise the strategy-enhanced recommendations offered include trait Extraction, candidate trait sentiment assignment, user interest mining, and recommendation modules. The proposed recommendation approach employs numerical rating and sentiment expressions about features, consumer preference profiles, and reviewer credibility of quantitative analysis of alternative numerical items. It offers a smaller MAE and a smaller F-score.
Xu et al. [62] devised a continuous naïve Bayes technique to classify user attitudes regarding online items using customer reviews. The simulation research demonstrates how well the advised technique addresses customer reviews for online product SA on Amazon products. Zhao et al. [63] employed a web scrapping method to extract useful reviewer comments for the product. They used feature selection and sentiment prediction, the earth warm algorithm, and the neural network technique were used. Improvements are made to the classifier's operating system and time complexity.

Table 2.
A summary of the studies that depend on deep learning algorithms.
| Study | Techniques | Advantages | Disadvantages |
|---|---|---|---|
| Hajek et al. [64] | Deep feedforward neural network (DFFNN) |
Created a deep feedforward neural network and convolutional model to identify fraudulent positive and negative reviews in Amazon datasets. | Features that are specific to reviewers and products weren't properly utilized. |
| Gandhi et al. [65] | LSTM combined with word2vec | Long short memory and worword2vec efficient word representations, both of which aid in effective sentiment analysis. | The model's performance is around 93% to improve the model by using bidirectional LSTM. |
| Meng et al. [66] | Feature Enhanced Attention CNN-Bi-LSTM | Using Bi-LSTM to capture local aspects of phrases enhances the quality of context encoding and product semantic information. | Need more layers. |
| Dhariyal and Ravi et al. [67] | Probabilistic Neural Network (PNN) |
CNN-Probabilistic Neural Network (PNN) with word2vec gave better accuracy 81.9% than CNN. | Load all data into RAM and use a lot of memory. |
6. Word Embedding
A technique for language modeling and feature learning that also uses words with related meanings. With neural networks, value learning is possible [68]. Using word embeddings to create dense word vectors that extract and convert more information from sparse inputs by translating high dimensional data onto a low dimensional vector space. Using statistical patterns of the language found in the corpus, it displays the semantic links between phrases in geometric space. While the context may be inferred from nearby words, word connections in the three dimensions can also be detected [69]. There are several methods like word2vec, Glove, and Fast text.
- Word2vec
This approach depicts words as continuous vectors in N-dimensional space to compare words. It adopts the idea of interpreting a word's meaning according to the context in which it appears [24]. This context is used to represent the words in a vast corpus. Words are represented as vectors in word2vec, a two-layer neural that analyzes a text. Two models, Continuous Bags of words (CBOW) and Skip Gram (SG), make up most of word2vec. The CBOW model uses context words to predict target words are used to predict target words. The larger dataset, the better performance of the SG model [7].
- Glove
Glove represents the word according to the coexistence statistics of the dataset. The main flow of word2vec and Glove is the ability to create random vectors within vectors within the word rather than the dataset [70].
- FastText
Word2vec's successor, FastText, can get around this drawback. In the representation stage, FastText generates a word using the n-gram technique. Because of this, embedding a word that is not present in the corpus is improved. Its key drawback is this method's higher memory usage while operating [71].
- Embedding language models (ELMo)
A deeply contextualized text representation is ElMo. ElMo aids in addressing the shortcomings of traditional word embedding techniques like TF-IDF, Latent Semantic Analysis, and n-gram models. Based on the circumstances in which words are used, ELMo creates embeddings to words to capture the word's meaning and obtain extra contextual data [7].
Table 3.
Summarizes sentiment analysis for e-commerce reviews.
| Study | Techniques | Advantages | Disadvantages |
|---|---|---|---|
| Jain and Roy et al. [72] | LSTM encoder-decoder model | -Locating and fixing any misspelled or short-form terms. -Calculating a single sentiment score by averaging the ratings of all reviews of all product evaluations. |
Taking into account two user reviews to predict a single sentiment score. The algorithm won't be able to estimate the sentiment score for a product that hasn't received any user reviews. |
| Misztal-Radecka et al. [73] | Meta-user2vec | -Using the user2vec technique for new users and creating embedding of users' metadata label of item representation. | Shorten the training period for complex RS when meta embedding is employed as input. |
| Vijayaragavan et al. [74] | Kano model | -Using an approach based on part-of-speech criteria to overcome the word segmentation problem in sentiment orientation detection. | Depend only on qualitative examination of customer demands. |
| Yang et al. [75] | Convolutional Neural Network and Bi-directional Gated Recurrent unit | -Sentiment lexicon and deep learning methods are combined in the model. The sentiment and context features are extracted using CNN and GRU to weigh the result. | Positive and negative categories alone do not meet high preferences for sentiment refining. |
| Sasikala and Mary et al. [76] | Conv2D | -A hyperparameter has to be specified since deep learning-modified neural networks outperform traditional classification methods. | It cannot provide the reader with all the details needed to understand the context of the entire work. |
| Xu et al. [62] | BERT model | -Classifying user opinions of products based on customer reviews using product sentiment analysis of Amazon product | Depending on old domain and new domain knowledge. |
| Karn, Arodh Lal, et al. [4] | Growing Hierarchical Self-Organizing Map (GHSOM) | -The effectiveness of the Hybrid recommendation model for developing customized recommendations in e-commerce. | Need more information from user reviews. |
| Zhao et al. [77] | Deep learning modified neural network | -Analyzing online product reviews using deep learning modified neural network (DLMN) with a significant mean absolute error and minimum accuracy. | Understand the meaning a word conveys. It usually lacks all the information needed to fully understand the context. |
7. Datasets
There are various datasets with various sizes and versions of user-item interaction records, as listed in Table 4.
- Public Amazon review: A helpful resource for evaluating items based on consumer reviews is the dataset from Amazon.com. Anytime consumers buy online, by leaving a review expressing why it is great or bad and rating it with a star in the system [78]. The dataset includes 2.5 million reviews annually and eight attributes (product ID, review text, review time, reviewer ID, reviewer name, helpful rating, overall Rating, and Unix review time). It involves 373.699 products. 1.755.144 consumers have given those product reviews, which include reviews and ratings of various products and product metadata (descriptions. Price, brand, and image features) and links( viewed/bought graphs) [79]. It contains product reviews and metadata for the categories of jewelry, clothes, and shoes [12].
Table 4.
List of popular e-commerce datasets.
| Dataset Name | No. of users | No. of actions | No. of items | Average No. of actions per user | Average No. of actions per item | Sparsity (%) [80] |
|---|---|---|---|---|---|---|
| Amazon Electronic [81] | 941k | 1m | 9k | - | - | 99.9993 |
| Amazon 1 [82] | 20m | 143m | 6m | - | - | 99.9993 |
| Amazon video game [83] | 1.5m | 2.6m | 71k | 3.57 | 32.47 | 99.9994 |
| Amazon Beauty [83] | 0.052m | 0.3m | 57k | 7.6 | 6.9 | 99.9992 |
| Amazon movies& tv [83] | 3.8m | 8.7m | 182k | 2.3 | 48.1 | 99.9987 |
| Epinions [82] | 22k | 922k | 296k | 4.05 | - | - |
| Ciao [84] | 12k | 484k | 107k | 4.21 | - | - |
| Tmall [85] | 57k | 18m | 40k | - | - | - |
| Taobao [86] | 10k | 848k | 412k | - | - | - |
| Yoochoose [82] | 9.5m | 50k | 33m | 55.989 | 60.858 | - |
| Aliexpress [87] | 1506.850k | 2.260.923k | 49.221k | - | - | - |
- Amazon-Electronics: Dataset was utilized by Capgemini in a data science competition. It offers statistics about electronics sales on Amazon, including customer reviews of various electronics products as well as information on each item's category and sale time [81]. The dataset contains four categories of users, items, brands, and categories. The Amazon Electronic dataset contains 183.807 user-item interaction records with 6 types and 6 relationships. Additionally, the rating for the dataset range from 1 to 5 [88]. It contains 192.403 users, 63.001 items, and 1.689.188 interactions [89]. Table 5 depicts the Amazon dataset applied in some techniques with limitations.
- Tmall: The e-commerce data was gathered utilizing interactions with the Tmall.com website for the previous years. For Tmall, the number of events in a day as a whole was considered while setting event session timestamps [90]. Between May and November 2015, this dataset documents user activity on the Tmall e-commerce platform, including actions like viewing, buying, adding to a cart, and adding favorites. Alibaba is the supplier. There are 27.155 items, 22.014 users, 44.717 add-to-chart behavior, and 485.483 click behaviors [88].
- Taobao: One of China's biggest e-commerce platforms, provided user behavior between 25 November and 3 December 2017. The dataset includes a variety of user actions, such as clicks and purchases. It includes sequences of user behaviors. Taobao records contain Taobao transaction records of real users, some of which have been flagged as fraudulent by real offline research and industry experts. It contains 42.182 users, 27.664 items, and 284.138 records [91].
8. Performance Evaluation
As shown in Table 5, ture positive (TP), false positive (FP), true negative (TN), and false negative (FN) are used to evaluate a method's performance and utility [96]. The higher the classifier value, the better classifier will perform.
Table 5.
Explanation of most prevalent evaluation metrics.
| Metric | Calculation | explanation |
|---|---|---|
| Accuracy | The most popular statistic for classification issues is called accuracy, and it measures the proportion of properly predicted examples of all examples. | |
| Recall (Sensitivity) | The proportion of positive samples correctly identified as all positive samples. | |
| Precision | The proportion of samples correctly classified as positive compared to the total number of samples expected to be positive. | |
| Specificity | The recall metric's inverse is called specificity. | |
| F-score | 2* | Calculates the harmonic mean of these two measures, which helps to quantify both recall and precision. |
| ROC curve | ------ | An illustration of the connection between FPR and TPR. A graphic representation of the precision/recall performance outcomes. |
| AUC | Area under ROC | Determines the probability that a relevant item will receive a higher rating than an irrelevant one picked randomly. |
9. Challenges and Future Research Directions
This section's main goal is to provide light on the direction that reaches into recommender systems are going as well as the obstacles that will stand in the way of that progress in the near and distant future.
9.1. Main Challenges in RSs
Despite a significant advancement in recommender system development, several problems still prevent the formulation of reliable recommendations. It specifically highlights the main challenges and commercialization concerns raised in the area of recommender systems. This section briefly introduces the most prevalent: cold start, sparsity, scalability, synonymy, privacy issue, shilling attack, and gray sheep.
-
Cold start: The system has a cold start when new users or products are introduced, making it possible to make predictions. Two circumstances can lead to a cold start:
- Sparsity: the users' restricted intent to rank a small number of things leads to data sparsity. As a result of the lack of user awareness or incentives to evaluate objects, the reported user-item matrix includes empty or unknown ratings, which is contrary to the majority of RSs. Therefore, the RSs may make irrational suggestions to users who don't leave feedback or rate anything [99].
- Scalability: due to the millions of people and products on the web, it takes a lot of processing power to analyze user similarity and generate suggestions. Scalability problems have increased significantly due to the quick expansion of the e-commerce industry. Modern RS techniques are required to offer quick results for large-scale applications. RSs can seek a large number of potential neighbors in real-time, but contemporary e-commerce websites demand that users look for a large number. When consumers have many data, algorithms also struggle with performance issues [100].
- Synonymy: This issue occurs when the same items are represented by two or more names in the system or when the same item has distinct entries or names. Many recommender systems fall short of recognizing these distinctions, which lowers the accuracy of their recommendations. Numerous techniques address this issue, including demographic filtering and singular value decomposition [101].
- Privacy issue: Along with the difficulty of maintaining user privacy, the privacy of the user's personality presents a new challenge. Because it is even more sensitive than other information in the user's profile, personality information is included in the user's profile. At least some phases can lead to privacy problems, first when data is gathered or shared without the user's express consent. Data sets may be exposed to de-anonymization attempts or leak to outside parties after being kept [102].
- Shilling attack: In a specific kind of attack called a shilling attack, a malicious user profile is added to an existing collaborative filtering dataset to change the results of RSs. Shellers update the rating database's suggestions by adding a few dishonest "shilling profiles" and, as a result, the system certain inappropriate items [103]. This issue occurs when a malicious person joins the system by pretending a bad individual tries to sway public opinion about a certain thing in one of two ways. Either by making that object more or less popular. The system is significantly less reliable as a result of shilling attacks. Finding the attackers immediately and removing the bogus user accounts and ratings from the system is one way to deal with this issue [101].
- Gray sheep: is unique to collaborative filtering systems when the input one user provides does not match any user neighborhood. In this case, the system cannot forecast pertinent items for that user with any degree of accuracy. This issue can be solved by using content-based methods where predictions are based on the user profile and item features [43].
9.2. Challenges in E-Commerce Reviews
- Fake Review Detection
Fake reviews and other misleading content have seriously threatened users in recent years. Users have suffered dramatically as a result of fraudulent and misleading evaluations. Initiated a few years ago, the phony problem is rapidly developing in the field of study [12] .crowdsourced fake reviews have more verbs, adverbs, pronouns, and antecedents [104]. When a review is written or produced without the author using the goods or services being reviewed, the review is called fake. In Figure 5, fake reviews may be categorized as opinion-based misinformation created and spread by malicious actors-reviews review spammer to confuse and defraud consumers [38]. There are two primary methods for producing fake reviews. First, using a human-generated approach by paying people to produce material for human websites that appears legitimate but isn't. In this scenario, the reviewer hasn't even seen the product but writes about them. Second, by automating the development of fake reviews using text generation algorithms in a computer-generated approach. Therefore, technological advancement greatly encourages and provides both possibilities and incentives for manipulating consumer decisions [105].
Some businesses employ reviewers to fabricate reviews and use them to either promote their goods or disparage those of rival brands. Untruthful reviews, reviews of only certain brands, and non-reviews were the three criteria in Figure 5 they used to classify spam reviews [106]. The goal of fake reviewers' rapid influence on the review object's overall score and manipulation of the review's emotional tenor was achieved by having them write many reviews in a short time. In addition, review metadata such as review length, purchase history, time, and location are crucial sources of information for behavioral analysis.
- Frequency of user review
A real reviewer would not be seen as normal if they posted too many reviews of the same product. According to recent research, just 5-8% of spammers publish reviews more frequently than once every day [107].
- Reviews using Hashtags
Hashtags were formally used to group social posts into categories. The hash sign is used even in informal written expressions, such as reviews, after more than 10 years of social media. Numerous reviews include emotional signs that indicate the customer's feelings about the product favorably and negatively [108].
- Grammatical mistakes
Informally written texts frequently contain grammatical faults, which may be repaired to a limited extent. Identifying users' spelling errors consistently is quite challenging. If these mistakes can be addressed and fixed, the precision of sentiment analysis and NLP jobs may increase. According to earlier studies, a review's usefulness was negatively impacted by poor writing, including repetition, poor grammar, and spelling errors. Usefulness review is significantly influenced by its presentation, such as its style, language, grammar, and structure [109].
- Code mixing
Code mixing is the practice of combining words and sentences from other languages in a single statement. New language models are needed to conduct sentiment analysis on code-mixed data [96]. The difficulty in language modeling for texts written in the Hindi and English language combination known as Hinglish.
- Advertisement click fraud
One of the key sources of income for websites now comes from online advertising. For each click that results in a visitor visiting the advertiser's website, advertisers pay the publisher a predetermined amount. Due to the high financial stakes involved in Internet advertising, malicious actors attempt to gain an unfair advantage [110]. By measuring the click-through rate, you can determine whether a person is legitimate or illegal to ensure security [111]. When a human or computer program clicks on a certain link, numerous models look for click fraud to determine if the user is legitimate or not by analyzing the click-through rate to offer security.
- Federated learning
Federated learning is an area of research rapidly gaining community interest in machine learning because it enables collaborative training while maintaining the privacy of the nodes that contribute data to the task. Federated learning helps to find distributed solutions that protect data security and privacy [47].
- Cross-domain based on deep neural architectures
Because users have different interests across multiple domains, a single domain RS is to be made while learning from the source domain in the target domain. Transfer learning is often recommended across domains because it is the best approach for tasks in one domain when using knowledge transfer mechanisms from other domains. According to experts, deep learning is the best option for transfer learning because it can learn at a high level across different domain variants [48].
- Word sense disambiguation (WSD)
Words can have different meanings depending on the context and domain in which they are used. As an illustration, the word "curved" has a favorable connotation when used on tv and a possible negative connotation when used on mobile [96].
9.3. Future Directions
- Artificial intelligence in the Recommender system
The application of artificial intelligence (AI) methods, tools, systems, or algorithms to assist online product and service transactions is known as AI in e-commerce. AI in e-commerce is a fundamental prerequisite for knowledge progress since it provides the context required to describe, interpret, or explain events to construct and test new theories. Following the development of explainable AI, "Explainable Recommendation systems" aim to provide customers with helpful recommendations accompanied by the justification that typically pertains to the justifications for making these recommendations or the benefits of choosing the proposed alternatives. These factors are crucial because they will increase the system's persuasion, customer comprehension, and satisfaction while providing an immediate benefit for the user [46].
- Blockchain
Using blockchain technology is the best option to create a centralized RS in this direction. It is a centralized, distributed public ledger that guarantees high security and privacy. Blockchain has recently been proposed as the foundation for building efficient decentralized infrastructure that can provide various functions and diverse services such as secure transactions, cryptocurrencies, identity management, and supply chain management [42]. Current RSs are based on data from online users, which includes both good and bad users, making them susceptible to fraud in the real world. The truth of RSs will differ from the real truth due to the rising number of fake ratings or feedback. The ease with which information from publicly accessible sources is a crucial factor in fraudulent actions. The strategies of RSs will be impacted by fraudulent actions. The strength of RSs will be impacted by fraudulent users' ability to conceal their purpose and undermine detection mechanisms with the help of learning from regular users. Utilizing blockchain concepts of RS trust management is one such approach. A similar understanding of reality is shared by all users of the shared ledger technology known as blockchain [112].
- Transfer learning
One of the most advanced AI approaches is transfer learning which enables a trained model to impart its knowledge to an untrained model. The problems caused by a lack of human labeling and a lack of data can be effectively handled through transfer learning. This is because it transfers the information learned in one area to another by finding tagged data from related fields when the target field has less data [113]. The data, distribution, and task similarity are used in transfer learning. The new model employs the previously learned characteristics without specific training data. Training data may be employed to adapt the model to a new task. Using this method, information from one domain may be applied to another. This technology has developed as a transfer learning technique because it may provide excellent accuracy and outcomes while needing substantially less training time than training a new model from the start [7].
- Increasing the system's accuracy
By adding reviewer-centric features to increase accuracy. To determine the frequency of spam reviews originating from a spammer by adding timestamps to comments. Word2vec and Glove are two examples of deep learning algorithms that might be used to improve accuracy. TF-IDF is an option for accounting for additional characteristics. It is possible to get information from other websites to improve the model's capacity for training.
- Using metamodeling strategies
Combining deep learning and unsupervised learning techniques has been a major study area. Systems designed to establish their objectives and create problem-solving strategies while navigating a new environment are producing intriguing results and showing signs of excellent effectiveness while reducing or even doing away with the requirement for data-hungry supervision. The strategy maximizes the capacity to learn a variety of tasks learning. Using fewer training data and including automated model creation and decision-making skills [114].
10. Conclusion
As the services grow, it is essential to provide a variety of RS that may assist consumers in effectively receiving item information and making selections amidst the quickly rising volume of item information. Particularly in e-commerce, recommender systems are being researched as technology. An overview of deep learning and related methodologies was offered in this study. The primary research focuses in the field of RS are sentiment analysis, word embedding, and some challenges that face RS. In recent years, sentiment analysis has developed into an essential instrument for collecting and analyzing various forms of data, assisting in the decision-making processes that result in the advancement of corporations, for both individuals and businesses are crucial. Before purchasing a specific product, customers utilized them to make informed judgments, and businesses benefited from their use and how satisfied customers were with their offerings. For instance, word2vec, word2vec with bigram, and Glove, TF-IDF with (unigram, Bigram, Trigram). One of the most significant tools, customer feedback, is made available to an online business via product reviews. An online company like Amazon withespectable number of product reviews from consumers dispdisplays Reviews of a product currently influence decision-making in a significant way. In future studies, researchers will look at sophisticated methods for opinion and product feature extraction models that can handle the property in review prediction. With the significant increase in false reviews, the e-commerce community has paid close to reducing false reviews.
References
- Cai, Y.; Ke, W.; Cui, E.; Yu, F. A Deep Recommendation Model of Cross-Grained Sentiments of User Reviews and Ratings. Inf. Process. Manag. 2022, 59, 102842. [Google Scholar] [CrossRef]
- Tahseen, T.; Kabir, M.Md.J. A Comparative Study of Deep Learning Neural Networks in Sentiment Classification from Texts. In Machine Learning and Autonomous Systems; Chen, J.I.-Z., Wang, H., Du, K.-L., Suma, V., Eds.; Springer Nature Singapore: Singapore, 2022; Volume 269, pp. 289–305. ISBN 9789811679957. [Google Scholar]
- Almahmood, R.J.K.; Tekerek, A. Issues and Solutions in Deep Learning-Enabled Recommendation Systems within the E-Commerce Field. Appl. Sci. 2022, 12, 11256. [Google Scholar] [CrossRef]
- Karn, A.L.; Karna, R.K.; Kondamudi, B.R.; Bagale, G.; Pustokhin, D.A.; Pustokhina, I.V.; Sengan, S. Customer Centric Hybrid Recommendation System for E-Commerce Applications by Integrating Hybrid Sentiment Analysis. Electron. Commer. Res. 2022. [Google Scholar] [CrossRef]
- Geetha, M.P.; Karthika Renuka, D. Improving the Performance of Aspect Based Sentiment Analysis Using Fine-Tuned Bert Base Uncased Model. Int. J. Intell. Netw. 2021, 2, 64–69. [Google Scholar] [CrossRef]
- Alamdari, P.M.; Navimipour, N.J.; Hosseinzadeh, M.; Safaei, A.A.; Darwesh, A. A Systematic Study on the Recommender Systems in the E-Commerce. IEEE Access 2020, 8, 115694–115716. [Google Scholar] [CrossRef]
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A Survey on Sentiment Analysis Methods, Applications, and Challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Shi, Z.; Law, C.L.; Lim, R.; Teh, L.L.; Fan, Y. A Deep Learning Approach in Predicting Products' Sentiment Ratings: A Comparative Analysis. J. Supercomput. 2022, 78, 7206–7226. [Google Scholar] [CrossRef]
- Lee, S.; Kim, D. Deep Learning Based Recommender System Using Cross Convolutional Filters. Inf. Sci. 2022, 592, 112–122. [Google Scholar] [CrossRef]
- Demircan, M.; Seller, A.; Abut, F.; Akay, M.F. Developing Turkish Sentiment Analysis Models Using Machine Learning and E-Commerce Data. Int. J. Cogn. Comput. Eng. 2021, 2, 202–207. [Google Scholar] [CrossRef]
- Umer, M.; Ashraf, I.; Mehmood, A.; Kumari, S.; Ullah, S.; Sang Choi, G. Sentiment Analysis of Tweets Using a Unified Convolutional Neural Network-long Short-term Memory Network Model. Comput. Intell. 2021, 37, 409–434. [Google Scholar] [CrossRef]
- Baishya, D.; Deka, J.J.; Dey, G.; Singh, P.K. SAFER: Sentiment Analysis-Based FakE Review Detection in E-Commerce Using Deep Learning. SN Comput. Sci. 2021, 2, 479. [Google Scholar] [CrossRef]
- Ali, S.; Wang, G.; Riaz, S. Aspect Based Sentiment Analysis of Ridesharing Platform Reviews for Kansei Engineering. IEEE Access 2020, 8, 173186–173196. [Google Scholar] [CrossRef]
- Nath Sharma, S.; Sadagopan, P. Influence of Conditional Holoentropy-Based Feature Selection on Automatic Recommendation System in E-Commerce Sector. J. King Saud Univ. - Comput. Inf. Sci. 2022, 34, 5564–5577. [Google Scholar] [CrossRef]
- Nandwani, P.; Verma, R. A Review on Sentiment Analysis and Emotion Detection from Text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Birim, Ş.Ö.; Kazancoglu, I.; Kumar Mangla, S.; Kahraman, A.; Kumar, S.; Kazancoglu, Y. Detecting Fake Reviews through Topic Modelling. J. Bus. Res. 2022, 149, 884–900. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, Z.; Yao, X.; Yang, Q. A Machine Learning-Based Sentiment Analysis of Online Product Reviews with a Novel Term Weighting and Feature Selection Approach. Inf. Process. Manag. 2021, 58, 102656. [Google Scholar] [CrossRef]
- Vidanagama, D.U.; Silva, A.T.P.; Karunananda, A.S. Ontology Based Sentiment Analysis for Fake Review Detection. Expert Syst. Appl. 2022, 206, 117869. [Google Scholar] [CrossRef]
- Karthik, R.V.; Ganapathy, S. A Fuzzy Recommendation System for Predicting the Customers Interests Using Sentiment Analysis and Ontology in E-Commerce. Appl. Soft Comput. 2021, 108, 107396. [Google Scholar] [CrossRef]
- Sharaf, M.; Hemdan, E.E.-D.; El-Sayed, A.; El-Bahnasawy, N.A. A Survey on Recommendation Systems for Financial Services. Multimed. Tools Appl. 2022, 81, 16761–16781. [Google Scholar] [CrossRef]
- Ahuja, R.; Chug, A.; Kohli, S.; Gupta, S.; Ahuja, P. The Impact of Features Extraction on the Sentiment Analysis. Procedia Comput. Sci. 2019, 152, 341–348. [Google Scholar] [CrossRef]
- Liu, T.; Wu, Q.; Chang, L.; Gu, T. A Review of Deep Learning-Based Recommender System in e-Learning Environments. Artif. Intell. Rev. 2022, 55, 5953–5980. [Google Scholar] [CrossRef]
- Varun, E.; Ravikumar, P. Community Mining in Multi-Relational and Heterogeneous Telecom Network. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC); IEEE: Bhimavaram, February, 2016; pp. 25–30. [Google Scholar]
- Nandwani, P.; Verma, R. A Review on Sentiment Analysis and Emotion Detection from Text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Dey, S.; Wasif, S.; Tonmoy, D.S.; Sultana, S.; Sarkar, J.; Dey, M. A Comparative Study of Support Vector Machine and Naive Bayes Classifier for Sentiment Analysis on Amazon Product Reviews. In Proceedings of the 2020 International Conference on Contemporary Computing and Applications (IC3A); IEEE: Lucknow, India, February, 2020; pp. 217–220. [Google Scholar]
- Qureshi, M.A.; Asif, M.; Hassan, M.F.; Abid, A.; Kamal, A.; Safdar, S.; Akbar, R. Sentiment Analysis of Reviews in Natural Language: Roman Urdu as a Case Study. IEEE Access 2022, 10, 24945–24954. [Google Scholar] [CrossRef]
- Sarlis, S.; Maglogiannis, I. On the Reusability of Sentiment Analysis Datasets in Applications with Dissimilar Contexts. In Artificial Intelligence Applications and Innovations; Maglogiannis, I., Iliadis, L., Pimenidis, E., Eds.; IFIP Advances in Information and Communication Technology; Springer International Publishing: Cham, 2020; Volume 583, pp. 409–418. ISBN 978-3-030-49160-4. [Google Scholar]
- Punde, A.; Ramteke, S.; Shinde, S.; Kolte, S. Fake Product Review Monitoring & Removal and Sentiment Analysis of Genuine Reviews. Int. J. Eng. Manag. Res. 2019, 9, 107–110. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A Comprehensive Survey on Sentiment Analysis: Approaches, Challenges and Trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Otchere, D.A.; Ganat, T.O.A.; Ojero, J.O.; Tackie-Otoo, B.N.; Taki, M.Y. Application of Gradient Boosting Regression Model for the Evaluation of Feature Selection Techniques in Improving Reservoir Characterisation Predictions. J. Pet. Sci. Eng. 2022, 208, 109244. [Google Scholar] [CrossRef]
- Dhal, P.; Azad, C. A Comprehensive Survey on Feature Selection in the Various Fields of Machine Learning. Appl. Intell. 2022, 52, 4543–4581. [Google Scholar] [CrossRef]
- Patil, R.C.; Chandrashekar, N.S. Sentimental Analysis on Amazon Reviews Using Machine Learning. In Ubiquitous Intelligent Systems; Karuppusamy, P., García Márquez, F.P., Nguyen, T.N., Eds.; Springer Nature Singapore: Singapore, 2022; Volume 302, pp. 467–477. ISBN 978-981-19254-0-5. [Google Scholar]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Alhumoud, S.O.; Al Wazrah, A.A. Arabic Sentiment Analysis Using Recurrent Neural Networks: A Review. Artif. Intell. Rev. 2022, 55, 707–748. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, A.P.; Jayaraman, R. Sentimental Analysis for E-Commerce Site. In Data Intelligence and Cognitive Informatics; Jacob, I.J., Kolandapalayam Shanmugam, S., Bestak, R., Eds.; Springer Nature Singapore: Singapore, 2022; pp. 73–83. ISBN 9789811664595. [Google Scholar]
- Kumar, A.; Garg, G. Systematic Literature Review on Context-Based Sentiment Analysis in Social Multimedia. Multimed. Tools Appl. 2020, 79, 15349–15380. [Google Scholar] [CrossRef]
- Karthik, R.V.; Ganapathy, S. A Fuzzy Recommendation System for Predicting the Customers Interests Using Sentiment Analysis and Ontology in E-Commerce. Appl. Soft Comput. 2021, 108, 107396. [Google Scholar] [CrossRef]
- Patro, S.G.K.; Mishra, B.K.; Panda, S.K.; Kumar, R. Fuzzy Logics Based Recommendation Systems in E-Commerce: A Review. Proceedings of 2nd International Conference on Smart Computing and Cyber Security; Pattnaik, P.K., Sain, M., Al-Absi, A.A., Eds.; Lecture Notes in Networks and Systems. Springer Nature Singapore: Singapore, 2022; Vol. 395, pp. 107–120. [Google Scholar]
- Wang, K.; Zhang, T.; Xue, T.; Lu, Y.; Na, S.-G. E-Commerce Personalized Recommendation Analysis by Deeply-Learned Clustering. J. Vis. Commun. Image Represent. 2020, 71, 102735. [Google Scholar] [CrossRef]
- Patro, S.G.K.; Mishra, B.K.; Panda, S.K.; Kumar, R.; Long, H.V.; Taniar, D.; Priyadarshini, I. A Hybrid Action-Related K-Nearest Neighbour (HAR-KNN) Approach for Recommendation Systems. IEEE Access 2020, 8, 90978–90991. [Google Scholar] [CrossRef]
- Bathla, G.; Singh, P.; Singh, R.K.; Cambria, E.; Tiwari, R. Intelligent Fake Reviews Detection Based on Aspect Extraction and Analysis Using Deep Learning. Neural Comput. Appl. 2022, 34, 20213–20229. [Google Scholar] [CrossRef]
- Himeur, Y.; Sohail, S.S.; Bensaali, F.; Amira, A.; Alazab, M. Latest Trends of Security and Privacy in Recommender Systems: A Comprehensive Review and Future Perspectives. Comput. Secur. 2022, 118, 102746. [Google Scholar] [CrossRef]
- Himeur, Y.; Sayed, A.; Alsalemi, A.; Bensaali, F.; Amira, A.; Varlamis, I.; Eirinaki, M.; Sardianos, C.; Dimitrakopoulos, G. Blockchain-Based Recommender Systems: Applications, Challenges and Future Opportunities. Comput. Sci. Rev. 2022, 43, 100439. [Google Scholar] [CrossRef]
- Dongre, S.; Agrawal, J. Comprehensive Review of Learnable and Adaptive Recommendation Systems. In Emerging Technologies in Data Mining and Information Security; Dutta, P., Chakrabarti, S., Bhattacharya, A., Dutta, S., Shahnaz, C., Eds.; Lecture Notes in Networks and Systems; Springer Nature Singapore: Singapore, 2023; Volume 490, pp. 247–259. ISBN 978-981-19405-1-4. [Google Scholar]
- Nasreen Taj, M.B.; Girisha, G.S. Insights of Strength and Weakness of Evolving Methodologies of Sentiment Analysis. Glob. Transit. Proc. 2021, 2, 157–162. [Google Scholar] [CrossRef]
- Bhuvaneshwari, P.; Rao, A.N.; Robinson, Y.H.; Thippeswamy, M.N. Sentiment Analysis for User Reviews Using Bi-LSTM Self-Attention Based CNN Model. Multimed. Tools Appl. 2022, 81, 12405–12419. [Google Scholar] [CrossRef]
- Tahseen, T.; Kabir, M.Md.J. A Comparative Study of Deep Learning Neural Networks in Sentiment Classification from Texts. In Machine Learning and Autonomous Systems; Chen, J.I.-Z., Wang, H., Du, K.-L., Suma, V., Eds.; Springer Nature Singapore: Singapore, 2022; Volume 269, pp. 289–305. ISBN 9789811679957. [Google Scholar]
- Balakrishnan, V.; Shi, Z.; Law, C.L.; Lim, R.; Teh, L.L.; Fan, Y. A Deep Learning Approach in Predicting Products' Sentiment Ratings: A Comparative Analysis. J. Supercomput. 2022, 78, 7206–7226. [Google Scholar] [CrossRef]
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A Survey on Sentiment Analysis Methods, Applications, and Challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A Comprehensive Survey on Sentiment Analysis: Approaches, Challenges and Trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Bhuvaneshwari, P.; Rao, A.N.; Robinson, Y.H.; Thippeswamy, M.N. Sentiment Analysis for User Reviews Using Bi-LSTM Self-Attention Based CNN Model. Multimed. Tools Appl. 2022, 81, 12405–12419. [Google Scholar] [CrossRef]
- Duarte, V.; Zuniga-Jara, S.; Contreras, S. Machine Learning and Marketing: A Systematic Literature Review. IEEE Access 2022, 10, 93273–93288. [Google Scholar] [CrossRef]
- Li, Z. Literature Classification Model of Deep Learning Based on BERT-BiLSTM——Taking COVID-19 as an Example. In Applied Intelligence and Informatics; Mahmud, M., Kaiser, M.S., Kasabov, N., Iftekharuddin, K., Zhong, N., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, 2021; Volume 1435, pp. 336–348. ISBN 978-3-030-82268-2. [Google Scholar]
- Onan, A. Sentiment Analysis on Product Reviews Based on Weighted Word Embeddings and Deep Neural Networks. Concurr. Comput. Pract. Exp. 2021, 33. [Google Scholar] [CrossRef]
- Lazib, L.; Qin, B.; Zhao, Y.; Zhang, W.; Liu, T. A Syntactic Path-Based Hybrid Neural Network for Negation Scope Detection. Front. Comput. Sci. 2020, 14, 84–94. [Google Scholar] [CrossRef]
- Mu, R. A Survey of Recommender Systems Based on Deep Learning. IEEE Access 2018, 6, 69009–69022. [Google Scholar] [CrossRef]
- Tsai, C.-Y.; Chiu, Y.-F.; Chen, Y.-J. A Two-Stage Neural Network-Based Cold Start Item Recommender. Appl. Sci. 2021, 11, 4243. [Google Scholar] [CrossRef]
- Seo, S.; Kim, C.; Kim, H.; Mo, K.; Kang, P. Comparative Study of Deep Learning-Based Sentiment Classification. IEEE Access 2020, 8, 6861–6875. [Google Scholar] [CrossRef]
- Gowandi, T.; Murfi, H.; Nurrohmah, S. Performance Analysis of Hybrid Architectures of Deep Learning for Indonesian Sentiment Analysis. In Soft Computing in Data Science; Mohamed, A., Yap, B.W., Zain, J.M., Berry, M.W., Eds.; Communications in Computer and Information Science; Springer Singapore: Singapore, 2021; Volume 1489, pp. 18–27. ISBN 9789811673337. [Google Scholar]
- Sangeetha, J.; Kumaran, U. Comparison of Sentiment Analysis on Online Product Reviews Using Optimised RNN-LSTM with Support Vector Machine. Webology 2022, 19, 3883–3898. [Google Scholar] [CrossRef]
- Hu, S.; Kumar, A.; Al-Turjman, F.; Gupta, S.; Seth, S. Shubham Reviewer Credibility and Sentiment Analysis Based User Profile Modelling for Online Product Recommendation. IEEE Access 2020, 8, 26172–26189. [Google Scholar] [CrossRef]
- Xu, F.; Pan, Z.; Xia, R. E-Commerce Product Review Sentiment Classification Based on a Naïve Bayes Continuous Learning Framework. Inf. Process. Manag. 2020, 57, 102221. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, Z.; Yao, X.; Yang, Q. A Machine Learning-Based Sentiment Analysis of Online Product Reviews with a Novel Term Weighting and Feature Selection Approach. Inf. Process. Manag. 2021, 58, 102656. [Google Scholar] [CrossRef]
- Hajek, P.; Barushka, A.; Munk, M. Fake Consumer Review Detection Using Deep Neural Networks Integrating Word Embeddings and Emotion Mining. Neural Comput. Appl. 2020, 32, 17259–17274. [Google Scholar] [CrossRef]
- Gondhi, N.K.; Chaahat; Sharma, E.; Alharbi, A.H.; Verma, R.; Shah, M.A. Efficient Long Short-Term Memory-Based Sentiment Analysis of E-Commerce Reviews. Comput. Intell. Neurosci. 2022, 2022, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Meng, W.; Wei, Y.; Liu, P.; Zhu, Z.; Yin, H. Aspect Based Sentiment Analysis With Feature Enhanced Attention CNN-BiLSTM. IEEE Access 2019, 7, 167240–167249. [Google Scholar] [CrossRef]
- Dhariyal, B.; Ravi, V. P. Soft Computing and Signal Processing; Reddy, V.S., Prasad, V.K., Wang, J., Reddy, K.T.V., Eds.; Advances in Intelligent Systems and Computing; Springer Singapore: Singapore, 2020; Volume 1118, pp. 1–16. ISBN 9789811524745. [Google Scholar]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Ezaldeen, H.; Misra, R.; Bisoy, S.K.; Alatrash, R.; Priyadarshini, R. A Hybrid E-Learning Recommendation Integrating Adaptive Profiling and Sentiment Analysis. J. Web Semant. 2022, 72, 100700. [Google Scholar] [CrossRef]
- Salur, M.U.; Aydin, I. A Novel Hybrid Deep Learning Model for Sentiment Classification. IEEE Access 2020, 8, 58080–58093. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Shi, Z.; Law, C.L.; Lim, R.; Teh, L.L.; Fan, Y. A Deep Learning Approach in Predicting Products' Sentiment Ratings: A Comparative Analysis. J. Supercomput. 2022, 78, 7206–7226. [Google Scholar] [CrossRef]
- Jain, S.; Roy, P.K. E-Commerce Review Sentiment Score Prediction Considering Misspelled Words: A Deep Learning Approach. Electron. Commer. Res. 2022. [Google Scholar] [CrossRef]
- Misztal-Radecka, J.; Indurkhya, B.; Smywiński-Pohl, A. Meta-User2Vec Model for Addressing the User and Item Cold-Start Problem in Recommender Systems. User Model. User-Adapt. Interact. 2021, 31, 261–286. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, A.; Liu, D.; Bian, Y. Customer Preferences Extraction for Air Purifiers Based on Fine-Grained Sentiment Analysis of Online Reviews. Knowl.-Based Syst. 2021, 228, 107259. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Wang, J.; Sherratt, R.S. Sentiment Analysis for E-Commerce Product Reviews in Chinese Based on Sentiment Lexicon and Deep Learning. IEEE Access 2020, 8, 23522–23530. [Google Scholar] [CrossRef]
- Sasikala, P.; Mary Immaculate Sheela, L. Sentiment Analysis of Online Product Reviews Using DLMNN and Future Prediction of Online Product Using IANFIS. J. Big Data 2020, 7, 33. [Google Scholar] [CrossRef]
- Sasikala, P.; Mary Immaculate Sheela, L. Sentiment Analysis of Online Product Reviews Using DLMNN and Future Prediction of Online Product Using IANFIS. J. Big Data 2020, 7, 33. [Google Scholar] [CrossRef]
- Alharbi, N.M.; Alghamdi, N.S.; Alkhammash, E.H.; Al Amri, J.F. Evaluation of Sentiment Analysis via Word Embedding and RNN Variants for Amazon Online Reviews. Math. Probl. Eng. 2021, 2021, 1–10. [Google Scholar] [CrossRef]
- Nasir, M.; Ezeife, C.I. Semantic Enhanced Markov Model for Sequential E-Commerce Product Recommendation. Int. J. Data Sci. Anal. 2023, 15, 67–91. [Google Scholar] [CrossRef]
- Zhan, Z.; Xu, B. Analyzing Review Sentiments and Product Images by Parallel Deep Nets for Personalized Recommendation. Inf. Process. Manag. 2023, 60, 103166. [Google Scholar] [CrossRef]
- Wu, X.; Li, Y.; Wang, J.; Qian, Q.; Guo, Y. UBAR: User Behavior-Aware Recommendation with Knowledge Graph. Knowl.-Based Syst. 2022, 254, 109661. [Google Scholar] [CrossRef]
- Marcuzzo, M.; Zangari, A.; Albarelli, A.; Gasparetto, A. Recommendation Systems: An Insight Into Current Development and Future Research Challenges. IEEE Access 2022, 10, 86578–86623. [Google Scholar] [CrossRef]
- Islek, I.; Oguducu, S.G. A Hierarchical Recommendation System for E-Commerce Using Online User Reviews. Electron. Commer. Res. Appl. 2022, 52, 101131. [Google Scholar] [CrossRef]
- Li, Z.; XiaoBo, C. Recommendation Algorithm of Influence and Trust Relationship. Multimed. Tools Appl. 2022, 81, 15635–15652. [Google Scholar] [CrossRef]
- Shi, H.; Qian, J.; Zhu, N.; Zhang, T.; Cui, Z.; Wu, Q.; Feng, S. RecNet: A Resource-Constraint Aware Neural Network for Used Car Recommendation. Int. J. Comput. Intell. Syst. 2022, 15, 91. [Google Scholar] [CrossRef]
- Wang, H.; Zeng, Y.; Chen, J.; Han, N.; Chen, H. Interval-Enhanced Graph Transformer Solution for Session-Based Recommendation. Expert Syst. Appl. 2023, 213, 118970. [Google Scholar] [CrossRef]
- Ahmed, A.; Saleem, K.; Khalid, O.; Rashid, U. On Deep Neural Network for Trust Aware Cross Domain Recommendations in E-Commerce. Expert Syst. Appl. 2021, 174, 114757. [Google Scholar] [CrossRef]
- Dai, F.; Gu, X.; Li, B.; Zhang, J.; Qian, M.; Wang, W. Meta-Graph Based Attention-Aware Recommendation over Heterogeneous Information Networks. In Computational Science – ICCS 2019; Rodrigues, J.M.F., Cardoso, P.J.S., Monteiro, J., Lam, R., Krzhizhanovskaya, V.V., Lees, M.H., Dongarra, J.J., Sloot, P.M.A., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, 2019; Volume 11537, pp. 580–594. ISBN 978-3-030-22740-1. [Google Scholar]
- Wei, T.; Wu, Z.; Li, R.; Hu, Z.; Feng, F.; He, X.; Sun, Y.; Wang, W. Fast Adaptation for Cold-Start Collaborative Filtering with Meta-Learning. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM); IEEE: Sorrento, Italy, 2020; pp. 661–670. [Google Scholar]
- Dang, T.K.; Nguyen, Q.P.; Nguyen, V.S. Evaluating Session-Based Recommendation Approaches on Datasets from Different Domains. In Future Data and Security Engineering; Dang, T.K., Küng, J., Takizawa, M., Bui, S.H., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, 2019; Volume 11814, pp. 577–592. ISBN 978-3-030-35652-1. [Google Scholar]
- Song, J.; Qu, X.; Hu, Z.; Li, Z.; Gao, J.; Zhang, J. A Subgraph-Based Knowledge Reasoning Method for Collective Fraud Detection in E-Commerce. Neurocomputing 2021, 461, 587–597. [Google Scholar] [CrossRef]
- Jha, B.K. Sentiment Analysis for E-Commerce Products Using Natural Language Processing. 2021, 25. [Google Scholar]
- Zhang, Y.; Sun, J.; Meng, L.; Liu, Y. Sentiment Analysis of E-Commerce Text Reviews Based on Sentiment Dictionary. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA); IEEE: Dalian, China, 2020; pp. 1346–1350. [Google Scholar]
- Zhao, X.; Sun, Y. Amazon Fine Food Reviews with BERT Model. Procedia Comput. Sci. 2022, 208, 401–406. [Google Scholar] [CrossRef]
- Alroobaea, R. Sentiment Analysis on Amazon Product Reviews Using the Recurrent Neural Network (RNN). Int. J. Adv. Comput. Sci. Appl. 2022, 13. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A Comprehensive Survey on Sentiment Analysis: Approaches, Challenges and Trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Herce-Zelaya, J.; Porcel, C.; Tejeda-Lorente, Á.; Bernabé-Moreno, J.; Herrera-Viedma, E. Introducing CSP Dataset: A Dataset Optimized for the Study of the Cold Start Problem in Recommender Systems. Information 2022, 14, 19. [Google Scholar] [CrossRef]
- Panda, D.K.; Ray, S. Approaches and Algorithms to Mitigate Cold Start Problems in Recommender Systems: A Systematic Literature Review. J. Intell. Inf. Syst. 2022, 59, 341–366. [Google Scholar] [CrossRef]
- Fayyaz, Z.; Ebrahimian, M.; Nawara, D.; Ibrahim, A.; Kashef, R. Recommendation Systems: Algorithms, Challenges, Metrics, and Business Opportunities. Appl. Sci. 2020, 10, 7748. [Google Scholar] [CrossRef]
- Chandini, K.; Papa, G. Business Opportunities, Metrics, Challenges, and Algorithms in Recommendation Systems.
- Roy, D.; Dutta, M. A Systematic Review and Research Perspective on Recommender Systems. J. Big Data 2022, 9, 59. [Google Scholar] [CrossRef]
- Milano, S.; Taddeo, M.; Floridi, L. Recommender Systems and Their Ethical Challenges. AI Soc. 2020, 35, 957–967. [Google Scholar] [CrossRef]
- Patil, D.; Preethi, N. A Comparison of Similarity Measures in an Online Book Recommendation System. In Intelligent Communication Technologies and Virtual Mobile Networks; Rajakumar, G., Du, K.-L., Vuppalapati, C., Beligiannis, G.N., Eds.; Lecture Notes on Data Engineering and Communications Technologies; Springer Nature Singapore: Singapore, 2023; Volume 131, pp. 341–349. ISBN 978-981-19184-3-8. [Google Scholar]
- Mewada, A.; Dewang, R.K. A Comprehensive Survey of Various Methods in Opinion Spam Detection. Multimed. Tools Appl. 2022. [Google Scholar] [CrossRef]
- Salminen, J.; Kandpal, C.; Kamel, A.M.; Jung, S.; Jansen, B.J. Creating and Detecting Fake Reviews of Online Products. J. Retail. Consum. Serv. 2022, 64, 102771. [Google Scholar] [CrossRef]
- Mewada, A.; Dewang, R.K. Research on False Review Detection Methods: A State-of-the-Art Review. J. King Saud Univ. - Comput. Inf. Sci. 2022, 34, 7530–7546. [Google Scholar] [CrossRef]
- Boumhidi, A.; Benlahbib, A.; Nfaoui, E.H. Cross-Platform Reputation Generation System Based on Aspect-Based Sentiment Analysis. IEEE Access 2022, 10, 2515–2531. [Google Scholar] [CrossRef]
- Sreesurya, I.; Rathi, H.; Jain, P.; Jain, T.K. Hypex: A Tool for Extracting Business Intelligence from Sentiment Analysis Using Enhanced LSTM. Multimed. Tools Appl. 2020, 79, 35641–35663. [Google Scholar] [CrossRef]
- Kashyap, R.; Kesharwani, A.; Ponnam, A. Measurement of Online Review Helpfulness: A Formative Measure Development and Validation. Electron. Commer. Res. 2022. [Google Scholar] [CrossRef]
- Mikkili, B.; Sodagudi, S. Advertisement Click Fraud Detection Using Machine Learning Algorithms. In Smart Intelligent Computing and Applications, Volume 1; Bhateja, V., Satapathy, S.C., Travieso-Gonzalez, C.M., Adilakshmi, T., Eds.; Smart Innovation, Systems and Technologies; Springer Nature Singapore: Singapore, 2022; Volume 282, pp. 353–362. ISBN 9789811696688. [Google Scholar]
- Narayan, A.; Madhu Kumar, S.D.; Chacko, A.M. A Review of Financial Fraud Detection in E-Commerce Using Machine Learning. In Intelligent Data Engineering and Analytics; Bhateja, V., Yang, X.-S., Chun-Wei Lin, J., Das, R., Eds.; Smart Innovation, Systems and Technologies; Springer Nature Singapore: Singapore, 2023; Volume 327, pp. 237–248. ISBN 978-981-19752-3-3. [Google Scholar]
- Dong, M.; Yuan, F.; Yao, L.; Wang, X.; Xu, X.; Zhu, L. A Survey for Trust-Aware Recommender Systems: A Deep Learning Perspective. Knowl.-Based Syst. 2022, 249, 108954. [Google Scholar] [CrossRef]
- Lin, P.; Luo, X. A Survey of Sentiment Analysis Based on Machine Learning. In Natural Language Processing and Chinese Computing; Zhu, X., Zhang, M., Hong, Y., He, R., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, 2020; Volume 12430, pp. 372–387. ISBN 978-3-030-60449-3. [Google Scholar]
- Sengupta, S.; Basak, S.; Saikia, P.; Paul, S.; Tsalavoutis, V.; Atiah, F.; Ravi, V.; Peters, A. A Review of Deep Learning with Special Emphasis on Architectures, Applications and Recent Trends. Knowl.-Based Syst. 2020, 194, 105596. [Google Scholar] [CrossRef]
Figure 1.
Advantages of e-commerce platforms.
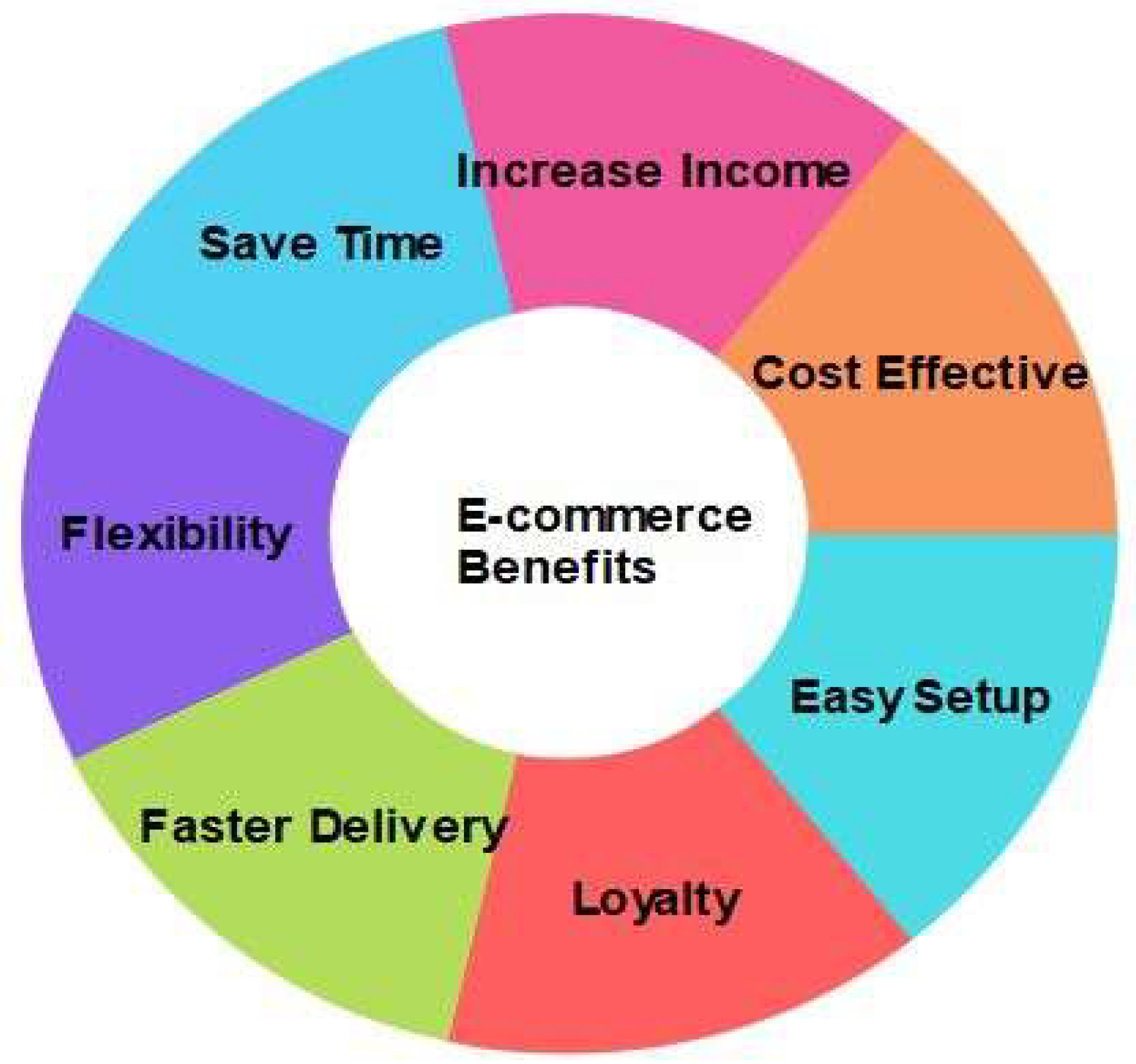
Figure 2.
The overall methodology analysis of E-commerce reviews.
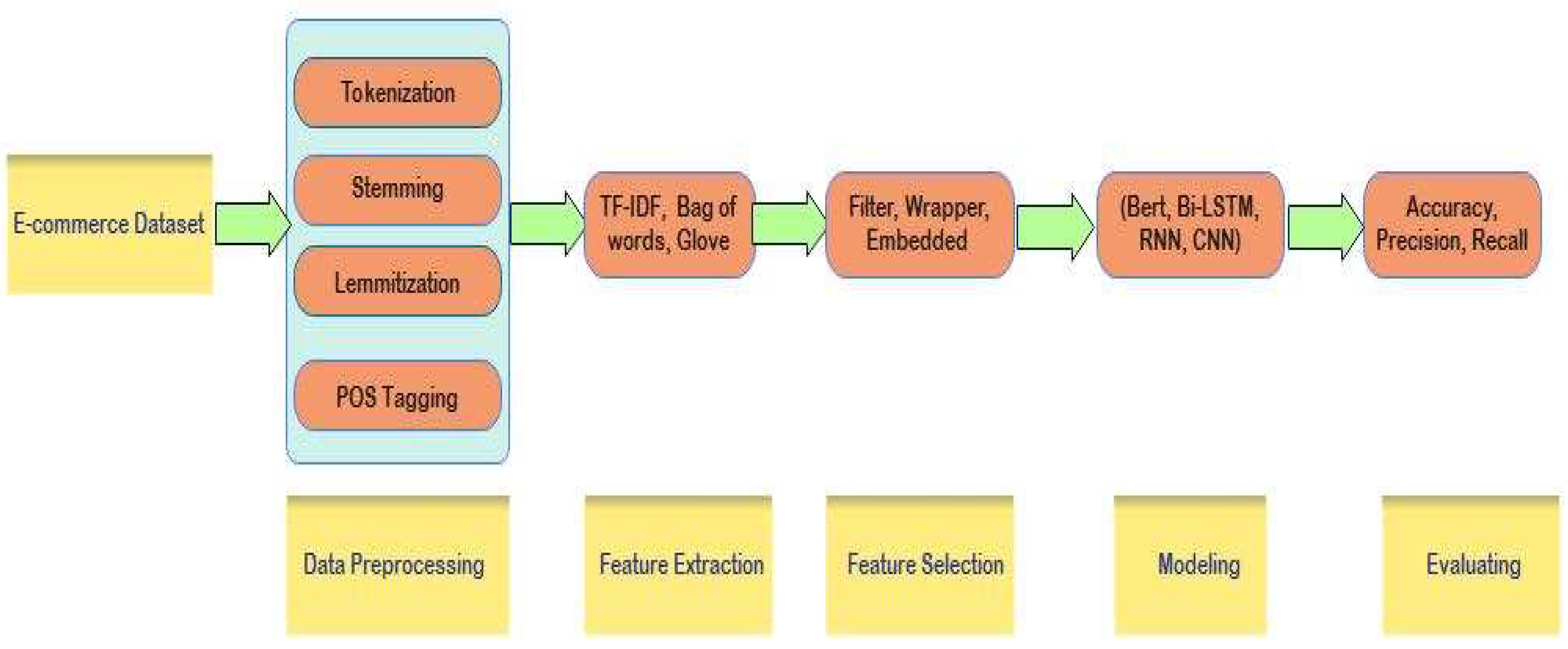
Figure 3.
Sentiment Analysis approaches [34].
Figure 3.
Sentiment Analysis approaches [34].
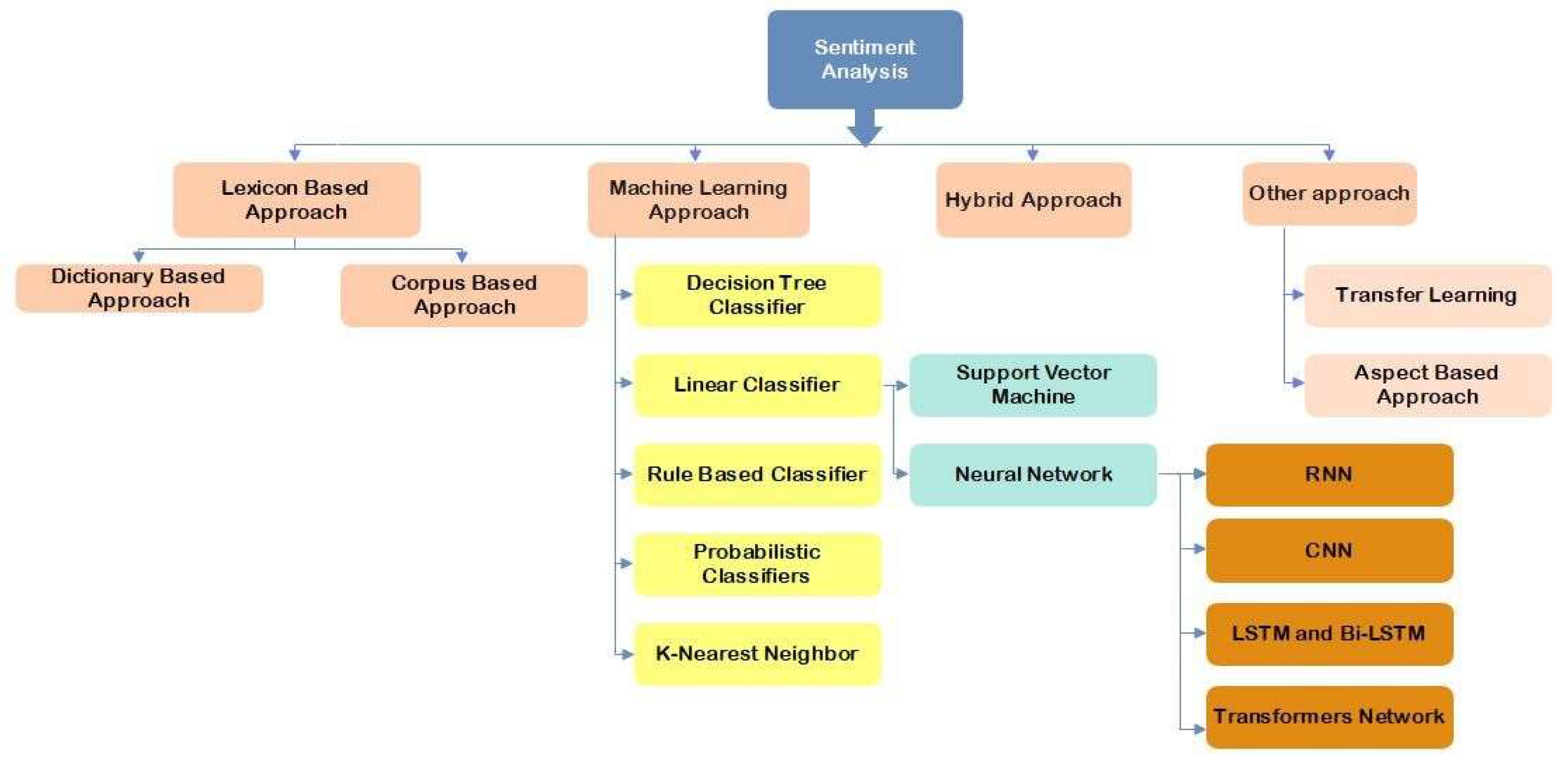
Figure 4.
Architectural classification of deep learning.
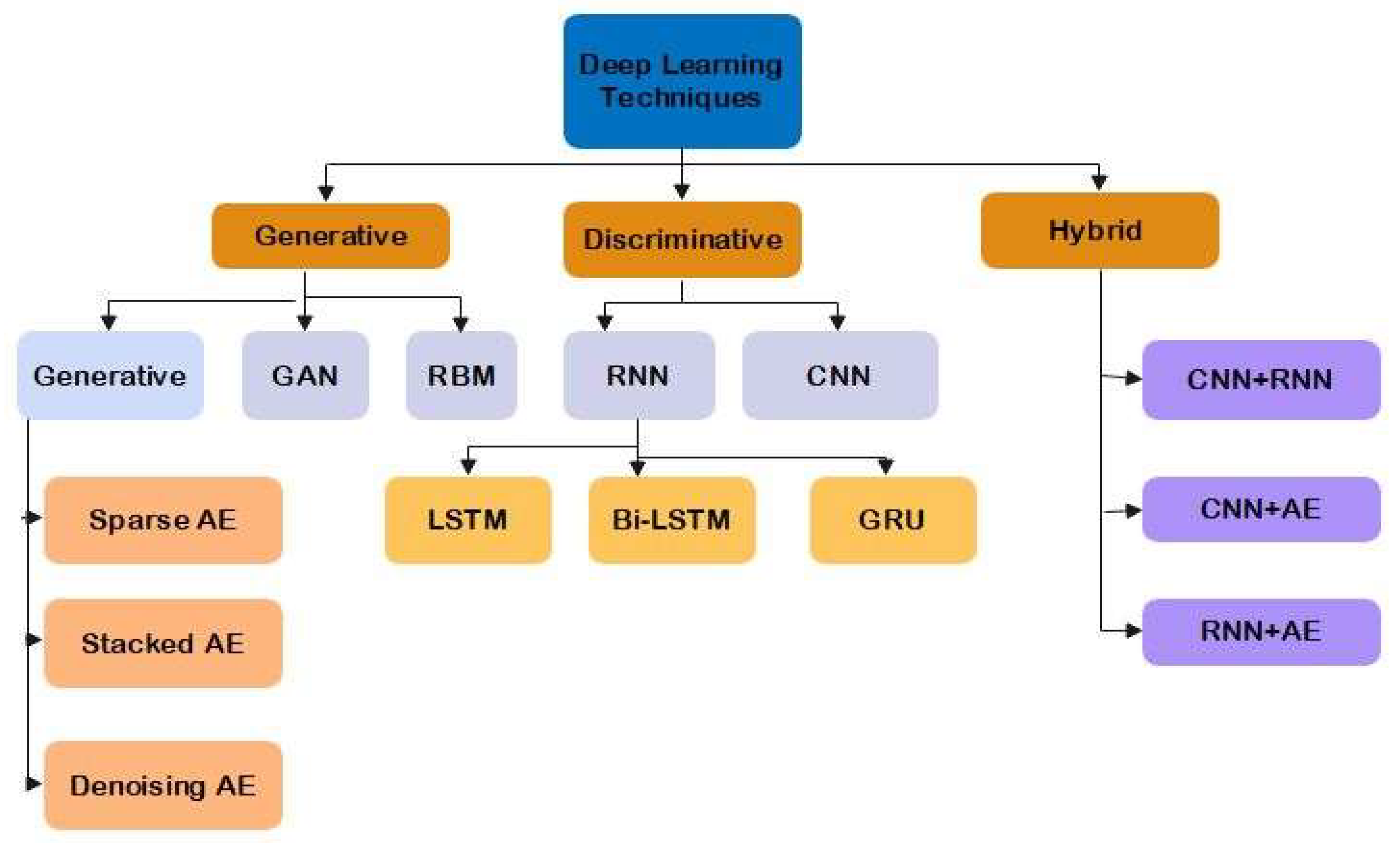
Figure 5.
Review types of detecting spam [87].
Figure 5.
Review types of detecting spam [87].
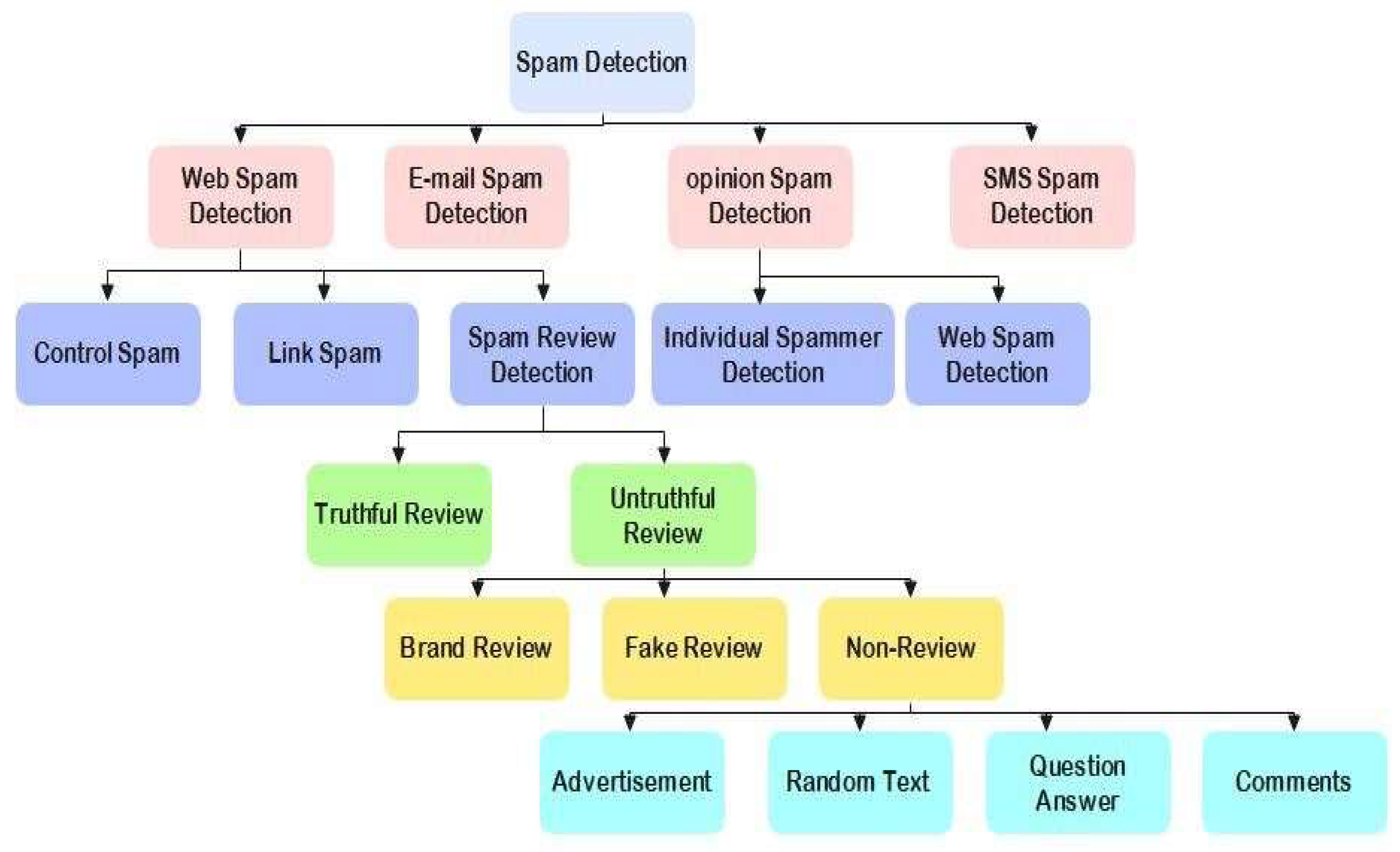
Table 1.
Pros and cons of the different deep learning algorithms.
| Technique | Advantage | Disadvantage |
|---|---|---|
| CNN [49] | -Accuracy in identifying images. -Quick trainning |
-Depends on data for images. |
| RNN [50] | -Capture sequential data. | -Need more time than other models |
| DNN [50] | -Simple to implement -Less time is needed for training |
-Overfitting problem |
| Autoencoder [51] | -constructing dense representations. | -expensive to compute. |
| LSTM [51] | -Overcome the drawback of RNN. -long-lasting memory. |
-Unable to save data that far away from the current location. |
| Bi-LSTM [52] | -extrapolate the structural characteristics from the tree's structure. | -computation time is high. -high cost for double LSTM cells |
| BERT [53] | -The capacity to capture the context and bidirectional flow. | -Massive computational resources are needed for pretraining due to the enormous number of parameters. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



