
Submitted:
17 May 2023
Posted:
18 May 2023
You are already at the latest version
Abstract
Zearalenone is one of the most prevalent estrogenic mycotoxins produced mainly by Fusarium family fungi, and harmed the heath of animals. Zearalenone hydrolase is an important enzyme capable of degrading zearalenone into a non-toxic compound. Although previous research has investigated the catalytic mechanism of zearalenone hydrolase, information on its dynamic interaction with zearalenone remains unknown. This study aimed to develop a pipeline for identifying the allosteric pathway of zearalenone hydrolase. Using an identity analysis, we identified hub genes whose sequences can generalize a set of sequences in a protein family. We then utilized a neural relational inference (NRI) model to identify the allosteric pathway of the protein throughout the entire molecular dynamics simulation. The production run lasted 1 microsecond, and we analyzed residues 139-222 for the allosteric pathway using the NRI model. We found that the cap domain of the protein opened up during catalysis, resembling a hemostatic tape. We used umbrella sampling to simulate the dynamic docking phase of the ligand-protein complex and found that the protein took on a square sandwich shape. Our energy analysis using both MMPBSA and PMF analysis showed discrepancies, with scores of -8.45 kcal/mol and -1.95 kcal/mol, respectively. MMPBSA, however, obtained a similar score to that of a previous report.
Keywords:
Zearalenone hydrolase
; Neural Relational Inference
; Umbrella sampling
; MMPBSA
; bmDCA
INTRODUCTION
Zearalenone (ZEN), produced by mold fungi mainly belonging to the Fusarium family, is a prevalent grain toxin in agriculture today. ZEN is a xenoestrogen that binds to estrogen receptors of cells, leading to a hormonal imbalance in the body, which may in consequence lead to numerous diseases such as prostate or ovarian cancers. ZEN pollution generates significant economic losses and poses a substantial health risk to humans and cattle [1,2,3]. Research on ZEN removal procedure is an important topic that has garnered serious attention. Currently, there are three types of methods for degrading ZEN, physical degradation, chemical degradation, and biodegradation. Common physical degradation methods include activated carbon adsorption or direct pressure cooking from 120°C to 140°C to break down the ZEN structure [4]. Common chemical methods include super-oxidation of ozone [5], peroxidation of hydrogen peroxide [6], and oxidation of didodecyldimethylammonium bromide [7]. Biological degradation of ZEN supplies green and environment-friend measures and alternatives to high-energy-consuming methods and chemical reagents. As a result, an increasing amount of effort is focused on developing strategies to employ microbes and their enzymes. Among all the enzymes known to be capable of degrading ZEN, zearalenone hydrolase (ZHD) has received great attention for its specificity and high efficiency. Since the discovery of ZHD101 [8] which can achieve complete degradation in a relatively brief duration, and is by far the most potent ZEN-degrading enzyme found in nature, other types of hydrolases such as those found in Trichoderma aggressivum [9], Rhinocladiella mackenziei [10], Pseudomonas putida [11], and Fonsecaea monophora [12] have been discovered.
To improve the degrading efficiency of hydrolase on zearalenone and enhance its stability to the reaction temperature, methods of rational design have generally been used. Within rational design, molecular mechanics (MM) descriptions of enzymes provide fundamental knowledge of the molecular structure and conformational changes when reacting with substrate molecules and environmental factors. By constructing a protein dynamics simulation of hydrolase ZHD607 from Phialophora americana, the mutant experiments on the plasticity of loop 136-142, which structurally locates opposite the entrance to the pocket of ZHD607, the enzymatic activity was improved [13].
Due to the lack of detailed knowledge about the structural changes of the inter-substrate binding of zearalenone hydrolase and the specific binding mode of the active center of the substrate, rational design and molecular modification of these ZHD molecules are lagging behind. The motion mechanism, conformational change, and movement locus of enzymes may interfere with the activity and thermal stability. To study the actual molecular state of the ZHD, we will perform a molecular dynamic simulation of the representative enzyme, explore the potential allosteric sites, and reveal the correlation in multi-state ZHD structure along with some stringent residues that could deliver extensive effects on the molecular motion mechanism. We will also use umbrella sampling to discover the pathways during catalytic reaction to identify the critical residues when the enzyme contacts the substrate.
MATERIALS AND METHODS
Lactone hydrolases co-evolutionary relation analysis
We selected the zearalenone hydrolase ZHD607 as a seed sequence to be blasted against the NCBI database using the Blastp program (https://blast.ncbi.nlm.nih.gov/Blast.cgi). We then performed multiple sequence alignment using ClustalW and ClustalOmega software (http://www.ebi.ac.uk/clustalW) to identify the hub genes. This alignment was later delineated using ESPript software (https://espript.ibcp.fr/ESPript/cgi-bin/ESPript.cgi) [14].
Molecular Dynamics analysis of lacton hydrolase
We predicted the structure of ZEN hydrolases using Uni-fold of Hermite. Implementing the charmm36-jul2021 force field for our molecular dynamic simulation, we built the topology of the ligand ZEN with CGenFF [15] and later coupled it to our ZHD system as a compound. We used the steepest descent minimization to reduce the system, applied a particle number, volume, and temperature equilibrium (NVT) system to stabilize the temperature system for 1 ns, with its coupling method being V-rescale. We used the particle number, pressure, and temperature equilibrium (NPT) system to minimize the pressure coupling error for 1 ns, and its temperature coupling method was V-rescale, and the pressure coupling method was Berendsen. The system's temperature coupling was attached at 310K, the optimal temperature for most enzymes of this category. We performed MD for 1 μs, and the temperature and pressure coupling method were similar to an NPT run. We analyzed the trajectory by using gmx trjconv, while RMSD and RMSF analyses were performed using gmx rms and gmx rmsf software [16].
Umbrella sampling
For Umbrella Sampling, we selected one specific frame where ZEN was near the cavity of ZHD for the pulling process. The pulling force was applied along the direction (-0.5, -0.5, 0.5), forcing ZEN to go deeper into the cavity for 500 ps. The system was coupled using V-rescale at a temperature of 310K, and the pressure coupling was Parrinello-Rahman. Only h-bonds of ZHD were constrained. The pulling rate of change of the reference position was 0.01 nm/ps, and we set the harmonic force constant at 1000 kJ/(mol • nm2). Trajectory analysis selected 1250 frames for distance analysis (by gmx distance) sieving 98 windows for the succeeding simulation. After the pulling process, we performed 100 ns of NPT simulation to obtain an equilibrated state. During the NPT simulations, the temperature coupling was V-rescale, and the pressure coupling was C-rescale. The production run of each window was 5 ns. PMF analysis was performed using the Weighted Histogram Analysis Method (WHAM) [17], and we selected the 6th and 97th windows out of 98 for further analysis for 200 ns.
Structural pathway and Energy Analysis
We used neural relational inference (NRI) (https://github.com/juexinwang/NRI-MD) to mine the underlying pathway of hydrolase and learn its long-range allosteric interactions [18]. For alanine scanning, we used gmx MMPBSA (https://github.com/Valdes-Tresanco-MS/gmx_MMPBSA) [19,20], using the 5th PBRadii and a temperature of 310K. PB method was used along with rediopt as 0, istrng as 0.15, and fillratio as 4. Second structure analysis was conducted by gmx do dssp and gmx density.
RESULTS
Evolutional analysis of hydrolase and Hub enzymes definition
There 452 hydrolase sequences were obtained from 2 iterations of PSI-BLAST as a starting set. A pipeline was used to narrow the candidates down to 384 sequences with a length ranging from 240 to 300 amino acids. These 384 sequences underwent iterative BLASTp analysis, and the identity for each sequence was calculated using a gradient of 60%, 70%, 80%, 90%, and 95%. A violin plot was used to identify hub sequences based on their identity (Figure S1). As shown in Figure S1, the number of representative sequences gradually decreased as identity increased from 60% to 95%. When the identity was above 60 degrees and at 80%, eight representatives remained.
To gain a better understanding of the differences between the hub genes, Boltzmann machine learning direct coupling analysis (bmDCA) was used to analyze the correlation between various residues, bmDCA analysis was performed for eight hub genes, and the consensus sequence among them was found to be dcaZHD. Multiple sequence alignment revealed the local functional sequences: LIP in β3, GMSRS in the loop between the cap domain and the hydrolase domain, and SGA in α3. RmZHD from R. mackenziei, NbZHD (GenBank ID: WP_138717259) from Nonomuraea basaltis, and SbZHD (GenBank ID: WP_111491235) from Streptacidiphilus bronchialis, which were selected for the following MD simulations, were aligned with dcaZHD to inspect the conservative sequence (Figure 1A). RmZHD was also aligned with the eight hub genes. LIP, GMSRS, and SGA were also identified as conservative sequences (Figure 1B).
Extensive simulation of molecular states
The 1 μs simulation time scale encompasses both binding and releasing of the enzyme to the substrate, which breaks the energy barrier before separating from ZHD. RMSD analysis was employed to assess the motion range of ZHD, revealing the essential stability of NbZHD (Figure 2A), indicated by the higher, flatter RMSD line than that of SbZHD, which suggests less stability. The RMSF analysis shows that the enzyme-activity-related atom range distinguishing SbZHD from NbZHD is from around 2000 to 3300 atoms, beyond which the better correspondence implies that the molecular extensive motion of residues 139 to 222 contributes to degrading ZEN (Figure 2B). Following the 945 ns simulation, the ligand had concatenated into the cavity of ZHD, which marks the initial stage of the subsequent pulling process.
To further investigate the motion mechanism, deep learning-based graph network was used to discover the pathway of ZHD. The orange spheres represented each residue in the pathway, which may contribute to the catalytic and motion mechanisms. The upper grey domain pertains to the cap domain, while the teal domain belongs to the α/β hydrolase domain. As seen in Figure 3A,B, a pathway consisting of eight residues across the cap domain provides a novel insight into this enzyme's motion mechanism. Another pathway also contains seven residues, covering only the forehead of the cap domain, but one residue at the end differs from the previous. This pathway discloses a possible low-fluctuation motion mechanism, whose probability can reach up to 0.9999. In this case, the seven residue pathways may reveal the mechanism of ZHD in motion. Table 1 illustrates several possible pathways consisting of seven residues, with possibilities exceeding 99.9%, and two eight-residue pathways. Based on pathways 1 and 2, the eight residues pathway always begins with Y209, R139, V145, M155, P174, A176, and L178 but differs at the end, which is either A186 or Q183. However, the varying residues at the end won't alter the essentiality of the motion mechanism. Both eight-residue pathways completely open up the cap domain to the oblique top in the opposite direction. The seven-residue pathway starts from the midpoint of the cap domain (Figure 3C), revealing a more realistic entrance to ZEN that is tighter than the prior pathways in both sense and probability, beginning with Q183, E177, P174, L154, L149, Q146, and ending with I202.
Motion paradigm from umbrella sampling
In pursuit of an accurate protein motion paradigm, we performed umbrella sampling of 98 windows to investigate the pulling process, commencing at the reaction coordinate of -0.6 nm for 8 Å. Before the production run, protein conformation was constrained, and each window was equilibrated for 100 ps by NPT. Each window was then simulated for 5 ns, and the whole simulation lasted 490 ns. The curve met the local minima at a reaction coordinate of -1.257 nm, which marked the docking phase. Below the reaction coordinate of -0.648 nm, the PMF decreased gradually, indicating the ligand's entry into the cavity (Figure 4). The structure at the inflection point defined the boundary between docking and receiving the ligand, signifying that the binding energy growth rate had reached the maximum. The lowest energy conformation emanated from the structure to the left down, representing the docking phase at -1.25 nm (State 1). The structure at -0.75 nm (State 3) showed the ligand at the protein's gate, with the PMF being a local maximum. The structure situated at the center of the PMF analysis was at -1.02 nm (State 2) and had energy of -2.23 kcal/mol. The PMF showed that the binding free energy of the docking process was -1.95 kcal/mol, with the PMF graph starting from -2.6 kcal/mol at the catalytic center to -0.65 kcal/mol at the gate.
Based on the essential motion of key residues in the long-range period, we presumed that ZEN moves linearly into the catalytic center and follows the same path out. An NRI search for the most compact region between the center-of-mass (COM) of the ligand and protein was conducted in the equilibrated state. The 6th and 97th windows were concatenated to form one consistent window, and the production run of these two windows was rerun from the NPT equilibrated state for another 200 ns. As the ligand had adapted to the catalytic core, the system was situated at the potential well, making the ligand work like a Trojan to be released. A total of 433 frames from the 7th window and 926 frames from the 97th window constituted the training data for the NRI model. The NRI model highlighted residues for ligand release and incorporation in this shorter duration. The motion residues of the cap domain started from M207, R139, and V145 and ended with Q152, while the α/β hydrolase started from D45, A38, S62, and ended with L66. The backside of ZHD showed four motion residues from each domain, and the front side of ZHD contained the ligand (Figure 5).
Alanine scanning mutations for inspecting energy shifting
To validate our assumptions, we executed alanine mutations to minimize any potential ionic connection creation in the pathway and determine whether the motion mechanism is natural. We selected R139 from the cap domain and D45 from the hydrolase domain, as they are motion residues of each domain that contain one charged amino acid. We used MM/PBSA (Molecular Mechanics with Poisson-Boltzmann and Surface Area solvation) for alanine mutation, which is based on binding energy calculation from molecular dynamics sampling. As the charge of the residue decreases, both mutants exhibited the diverse characteristics of ΔGcomplex. The substantially increased ΔGcomplex of D45A might damage its enzymatic stability, while R139A showed the opposite (Figure 6A,B). The ΔGbind of D45A is consistent with the wild type, while the ΔGbind of R139A is more stable (Figure 6C,D). Through alanine scanning, we obtained the binding free energy of NbZHD twice and listed them in Table 2.
DISCUSSIONN
The deconstruction of ZEN by hydrolases is attributed to a few enzyme candidates, among which ZHD is the most efficient [8]. A novel enzyme, RmZHD, which is more thermally stable than ZHD101, was discovered from the organism R. mackenziei CBS 650.93. Electrostatic influence analysis shows that three residues, Asp34, His128, and Val130 located at the catalytic core of ZHD, make significant contributions to the synergistic reaction. While Asp34 and His128 can increase the energy barrier and impede the reaction, Val130 plays the opposite role [21]. Apart from residues that interact with ZEN, the allosteric residues in the protein can affect the deconstruction of ZEN. Identifying the allosteric pathway provides insight into the mobility pattern of the protein. In light of this, we developed a program with the help of NRI to identify the allosteric pathway of the specific protein family targeting particular substrates. We selected eight hub genes that represent the family's general features and then used extensive 1 μs simulation and umbrella sampling to determine the allosteric pathway of separate stages. Finally, alanine scanning analyzed the energy shift of charged polar residues in the allosteric pathway to reveal the residues critical to altering energy barriers. The findings of these analyses decipher the deconstruction of ZEN by hydrolases and bear potential implications for future research in this field.
Hub genes survey extensive character of protein
Higher sequence identity indicates greater sequence similarity. Sequences that have a high number of instances above a specific identity level are more representative, and hub genes can be derived from them. The degree of a given sequence is quantified as the number of sequences present above the specified identity level [22]. However, selecting the appropriate identity level can be challenging. Using a 60% or 70% identity threshold may result in hub genes that represent more sequences from the family, but with an excessive number of representative sequences. Conversely, a 90% or 95% identity threshold may result in hub genes that represent fewer sequences from the family. Therefore, eight hub genes from the 80% identity threshold were chosen for further study, as they represent a comparatively higher number of sequences.
Umbrella sampling and molecular dynamics inspect conformation veer
By utilizing umbrella sampling and molecular dynamics simulation, we employed the NRI model to identify allosteric residues across various stages. The NRI model utilizes GNN [23] to learn the network dynamics' embedding by constraining the training error between the reproduced and simulated trajectories. The derived embedding separates the crucial functions of the residues throughout the conformational shift, providing insights into the mechanisms of protein allostery. The realistic motion paradigm of NbZHD can be depicted based on the allosteric pathway. Initially, the ZEN flows around the ZHD while the cap domain of the protein unwinds like a hemostatic tape along the motion residues pathway. Once NbZHD captures the ligand, the catalytic reaction commences. From a general perspective, NbZHD represents a box with a dual compartment (Figure 7). The docking of the ligand is followed by the counterclockwise rotation of the cap domain and the clockwise rotation of the hydrolase domain, as depicted in the docking statement. After the reaction, NbZHD operates like a square sandwich where the upper compartment rotates to the left and the lower compartment rotates to the right. Although the concatenated simulation exhibits a plunge curve of RMSD between the receiving and docking states, higher vibrancy is noticeable before the ZEN docks (Figure S3). Nonetheless, the role of ZEN has been overlooked so far; what is its trajectory? We used the morph program by Pymol for analysis (Videos S1–S3). Video S1 illustrates the process of the ZEN beginning to rotate in the course of departure, while Video S2 and Video S3 showcase the ZEN traversing through the side view and front view, respectively. Contradicting our initial assumption, the ZEN does not get ejected from the cavity of NbZHD but emerges through the aperture of the hydrolase domain. From the latter two videos, we observed that the aperture is located in the middle of the backside of the α-helix, i.e., α3 and α4. The ZEN passes through the tunnel between the loop 30-37 and the head of α4 (residues 102 and 103) before crossing the middle of α3 (residues 75-89) and α4 (residues 102-113) [24].
Sub-protein and energy analysis conveys detailed conformation shifting
Analyzing the structure of D45 and R139, in conjunction with two mutants A45 and A139, could provide insights into why neither D45 nor R139 should be mutated. The carboxyl group of the D45 side chain can create an electrostatic force that attracts the M1 backbone amino, creating a distance of 2.6 Å (Figure 8A,B). However, the replacement of D45 with alanine (D45A) cannot support a similar or shorter distance of the electrostatic force that can contribute to pulling the hydrolase domain along the pathway D45→ A38→ S62→ L66. This applies to R139 as well. On the other side of R139, the electro-negativity of the sulfur atom in M207 can attract the imino of the R139 sidechain at a distance of 3.8 Å (Figure 8C,D). However, the substitution of arginine with alanine (R139A) can only offer the shortest electrostatic attraction distance of 5.7 Å. The second structural changes were examined using the dssp program of GROMACS. A comparison was made using Figure 9A(a), which is a plot of the late 500 ns of a long-range simulation, and Figure 9A(b), which is a plot of a concatenated simulation from two different windows. During the long-range simulation, the ligand often collapses in the potential well. Examining the comparison between the two simulations helps identify the residues that conform to different structures during the catalytic simulation. Residues D170 to R190 exhibit different structures in the two simulations. While these residues are distributed evenly in the long-range simulation, regardless of mass or charge, they huddle together in the concatenated simulation in the late 4 nm (Figure 9B,C). These residues can be regarded as a channel that provides a tunnel through which the ligand passes to the hydrolase domain. Therefore, residues D170-R190 are named as the bolt in the following discussion. Based on the data presented in Figure S4A, the bolt in the unbound state (colored violetpurple) is less tight than that in the State 2 (colored slate), leaving a narrower channel for ZEN to pass through. However, the bolt in previously studied structures is tighter than that in NbZHD. Despite this, convincing evidence has yet to demonstrate that ZEN enters the catalytic core through the bolt, although it is possible that the space around the bolt could play a role in this process. Clear changes in catalytic efficiency have been observed in mutant D157K and E171K of ZHD101 whose corresponding bolt is V153-H173 (colored olive), where D157K decreased and E171K increased kcat/KM through their respective charge changes [25]. Theoretical research has shown that mutant V153H can increase the interaction between M241-Y245, inducing the sidechain of H242, one of the catalytic triad [24], and positioning it into a positive catalytic conformation [26] (Figure S4B). The bolt of ZHD607, characterized by V156-A176 (colored red), displays similar features as ZHD101 (Figure S4D). Mutations I160Y and G163N in ZHD607 have a notable impact on enzymatic activity, with G163N decreasing activity while I160Y increases it 3.4-fold. According to Yao et al., the I160Y mutation alters the positions of I160 and P135, reducing the distance between Y160 and P135, and stabilizing ZEN in the catalytic pocket, as observed through molecular dynamics simulation [13].
The calculation of free energy in molecular dynamics can be divided into two types: two-end-state calculation and enhanced sampling calculation. MMPBSA is a method of two-end-state calculation while umbrella sampling is a method of enhanced sampling calculation. MMPBSA is one of the methods of two-end-state calculation while umbrella sampling is one of the methods of enhanced sampling calculation. The mean binding energy of NbZHD is -8.45 kcal/mol. The binding energy of D45A and R139A mutants are -8.13 kcal/mol and -8.76 kcal/mol, respectively. However, the PMF calculation yielded a different result from MMPBSA, which was -1.95 kcal/mol. In the QM/MM study of RmZHD, the binding free energy from the docking state to the end of the catalytic reaction is -6 kcal/mol, which is more consistent with our result from MMPBSA.
Conclusion
This study aimed to develop a pipeline for detecting the motion paradigm of the zearalenone hydrolase protein family. Eight hub genes were selected through identity analysis, and molecular dynamics simulations conducted on the residues 139-222 from ZHD indicated the allosteric pathway was Q183→ E177→ P174→ L154→ L149→ Q146→ I202. Umbrella sampling was used to capture the instant docking dynamic simulation for NbZHD, enabling the identification of the allosteric pathway at this time point: M207→ R139→ V145→ Q152 at the cap domain and D45→ A38→ S62→ L66 at the hydrolase domain. MMPBSA was used to validate the binding energy of some residues on the pathway, including alanine mutants. The binding energy of D45A was -8.13 kcal/mol, R139A was -8.76 kcal/mol, and the unaltered binding energy was -8.45 kcal/mol. Our study revealed two distinct stages in the behavior of ZHD, before and after ZEN docking. Before docking, ZHD acts like a hemostatic tape, and after docking, it works like a square sandwich and digests ZEN vertically. The findings of this study can improve our understanding of how ZHD moves in the liquid phase.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Funding
This work was supported by the National Key Research and Development Program of China (2021YFC2100300) and Key R&D projects in Hubei Province, China (2021BCA113).
CRediT Authorship Contribution Statement
Conceptualization, Xizhi Hong and Jiangke Yang; Data curation Xizhi Hong; Data representation Xizhi Hong and Zhenggang Han; Validation Xizhi Hong; Writing – original draft, Xizhi Hong and Jiangke Yang; Writing – review & editing, Xizhi Hong and Jiangke Yang; Supervision Jiangke Yang; Funding acquisition, Jiangke Yang, Yihan Liu. All authors have read and agreed to the published version of the manuscript.
References
- Bennett JW, M Klich. Mycotoxins. Clin Microbiol Rev 2003;16(3):497-516. [CrossRef]
- Lei Y, Zhao L, Ma Q, Zhang J, Zhou T, Gao C, et al. Degradation of zearalenone in swine feed and feed ingredients by Bacillus subtilis ANSB01G. World Mycotoxin J 2014;7(2):143-151. [CrossRef]
- Gruber-Dorninger C, Jenkins T, Schatzmayr G. Global Mycotoxin Occurrence in Feed: A Ten-Year Survey. Toxins 2019; 11(7): 375. [CrossRef]
- Bullerman LB, A. Bianchini. Stability of mycotoxins during food processing. Int J Food Microbiol 2007;119(1):140-146. 1: 2007;119(1). [CrossRef]
- Yang K, Li K, Pan L, Luo X, Xing J, Wang J, et al. Effect of Ozone and Electron Beam Irradiation on Degradation of Zearalenone and Ochratoxin A. Toxins 2002; 24;12(2):138. [CrossRef]
- Abd Alla ESAM. Zearalenone: Incidence, toxigenic fungi and chemical decontamination in Egyptian cereals. Food / Nahrung 1997;41(6):362-365. [CrossRef]
- Bai X, Sun C, Xu J, Liu D, Han Y, Wu S, et al. Detoxification of zearalenone from corn oil by adsorption of functionalized GO systems. Appl Surf Sci 2018;430:198-207. [CrossRef]
- Kakeya H, Takahashi-Ando N, Kimura M, Onose R, Yamaguchi I, OSADA H. Biotransformation of the Mycotoxin, Zearalenone, to a Non-estrogenic Compound by a Fungal Strain of Clonostachys sp. Biosci Biotechnol Biochem 2002;66(12):2723-2726. [CrossRef]
- Chen S, Pan L, Liu S, Pan L, Li X, Wang B. Recombinant expression and surface display of a zearalenone lactonohydrolase from Trichoderma aggressivum in Escherichia coli. Protein Expr. Purif 2021;187:105933. [CrossRef]
- Zheng Y, Liu W, Chen CC, Hu X, Liu W, Ko TP, et al. Crystal Structure of a Mycoestrogen-Detoxifying Lactonase from Rhinocladiella mackenziei: Molecular Insight into ZHD Substrate Selectivity. ACS Catal 2018;8(5):4294-4298. [CrossRef]
- Altalhi AD, El-Deeb B. Localization of zearalenone detoxification gene(s) in pZEA-1 plasmid of Pseudomonas putida sp. strain ZEA-1 and expressed in Escherichia coli. Mal J Microbiol 2007;3(2):29-36. [CrossRef]
- Jiang T, Wang M, Li X, Wang H, Zhao G, Wu P, et al. The replacement of main cap domain to improve the activity of a ZEN lactone hydrolase with broad substrate spectrum. Biochem Eng J 2022;182:108418. [CrossRef]
- Yu X, Tu T, Luo H, Huang H, Su X, Wang Y, et al. Biochemical Characterization and Mutational Analysis of a Lactone Hydrolase from Phialophora americana. J Agric Food Chem 2020;68(8):2570-2577. [CrossRef]
- Robert X, Gouet P. Deciphering key features in protein structures with the new ENDscript server. Nucleic Acids Res 2014;42(W1):W320-W324. [CrossRef]
- Vanommeslaeghe K, Jr MacKerell AD. Automation of the CHARMM General Force Field (CGenFF) I: Bond Perception and Atom Typing. J Chem Inf Model 2012;52(12):3144-3154. [CrossRef]
- Van Der Spoel D, Lindahl E, Hess B, Groenhof G, Mark AE, Berendsen HJC. GROMACS: Fast, flexible, and free. J Comput Chem 2005;26(16):1701-1718. [CrossRef]
- Ferrenberg AM, Swendsen RH. Optimized Monte Carlo data analysis. Phys Rev Lett 1989;63(12):1195-1198. [CrossRef]
- Zhu J, Wang J, Han W, Xu D. Neural relational inference to learn long-range allosteric interactions in proteins from molecular dynamics simulations. Nat Commun 2002;13(1):1661. [CrossRef]
- Miller BR III, Jr McGee TD, Swails JM, Homeyer N, Gohlke H, Roitberg AE. MMPBSA.py: An Efficient Program for End-State Free Energy Calculations. J Chem Theory Comput 2012;8(9):3314-3321. [CrossRef]
- Valdés-Tresanco MS, Valdés-Tresanco ME, Valiente PA, Moreno E. gmx_MMPBSA: A New Tool to Perform End-State Free Energy Calculations with GROMACS. J Chem Theory Comput 2021;17(10):6281-6291. [CrossRef]
- Zhou J, Zhu L, Chen J, Wang W, Zhang R, Li Y, et al. Degradation mechanism for Zearalenone ring-cleavage by Zearalenone hydrolase RmZHD: A QM/MM study. Sci Total Environ 2020;709:135897. [CrossRef]
- Bauer TL, Buchholz PCF, Pleiss J. The modular structure of α/β-hydrolases. FEBS J 2020;287(5):1035-1053. [CrossRef]
- Scarselli F, Tsoi AC, Gori M, Hagenbuchner M. Graphical-Based Learning Environments for Pattern Recognition. In: Fred, A., Caelli, T.M., Duin, R.P.W., Campilho, A.C., de Ridder, D. (eds) Structural, Syntactic, and Statistical Pattern Recognition. SSPR /SPR 2004; Lecture Notes in Computer Science, vol 3138. Springer, Berlin, Heidelberg. [CrossRef]
- Peng W, Ko TP, Yang Y, Zheng Y, Chen CC, Zhu Z, et al. Crystal structure and substrate-binding mode of the mycoestrogen-detoxifying lactonase ZHD from Clonostachys rosea. RSC Adv 2014;00:1-5. [CrossRef]
- Lin M, Tan J, Xu Z, Huang J, Tian Y, Chen B, et al. Computational design of enhanced detoxification activity of a zearalenone lactonase from Clonostachys rosea in acidic medium. RSC Adv 2019;9:31284–31295. [CrossRef]
- Liu Y, Wan Y, Zhu J, Yu Z, Tian X, Han J, et al. Theoretical Study on Zearalenol Compounds Binding with Wild Type Zearalenone Hydrolase and V153H Mutant. Int J Mol Sci 2018;19:2808. [CrossRef]
Figure 1.
Multiple sequence alignment of represented zearalenone hydrolase and hub enzymes. (A) MSA of RmZHD, NbZHD, SbZHD and a consensus sequence dcaZHD. (B) MSA of RmZHD and 8 hub genes.
Figure 1.
Multiple sequence alignment of represented zearalenone hydrolase and hub enzymes. (A) MSA of RmZHD, NbZHD, SbZHD and a consensus sequence dcaZHD. (B) MSA of RmZHD and 8 hub genes.
Figure 2.
RMSD and RMSF anlysis of 1 μs simulation are calculated for motion-residue sampling. (A) RMSD of 1 μs simulation of NbZHD and SbZHD. (B) RMSF of 1 μs simulation of NbZHD and SbZHD at atomic level. (C) RMSF of 1 μs simulation of NbZHD and SbZHD at residues level and the grey perspective marked zone, i.e., R139-R222 is selected for sampling motion-residue.
Figure 2.
RMSD and RMSF anlysis of 1 μs simulation are calculated for motion-residue sampling. (A) RMSD of 1 μs simulation of NbZHD and SbZHD. (B) RMSF of 1 μs simulation of NbZHD and SbZHD at atomic level. (C) RMSF of 1 μs simulation of NbZHD and SbZHD at residues level and the grey perspective marked zone, i.e., R139-R222 is selected for sampling motion-residue.
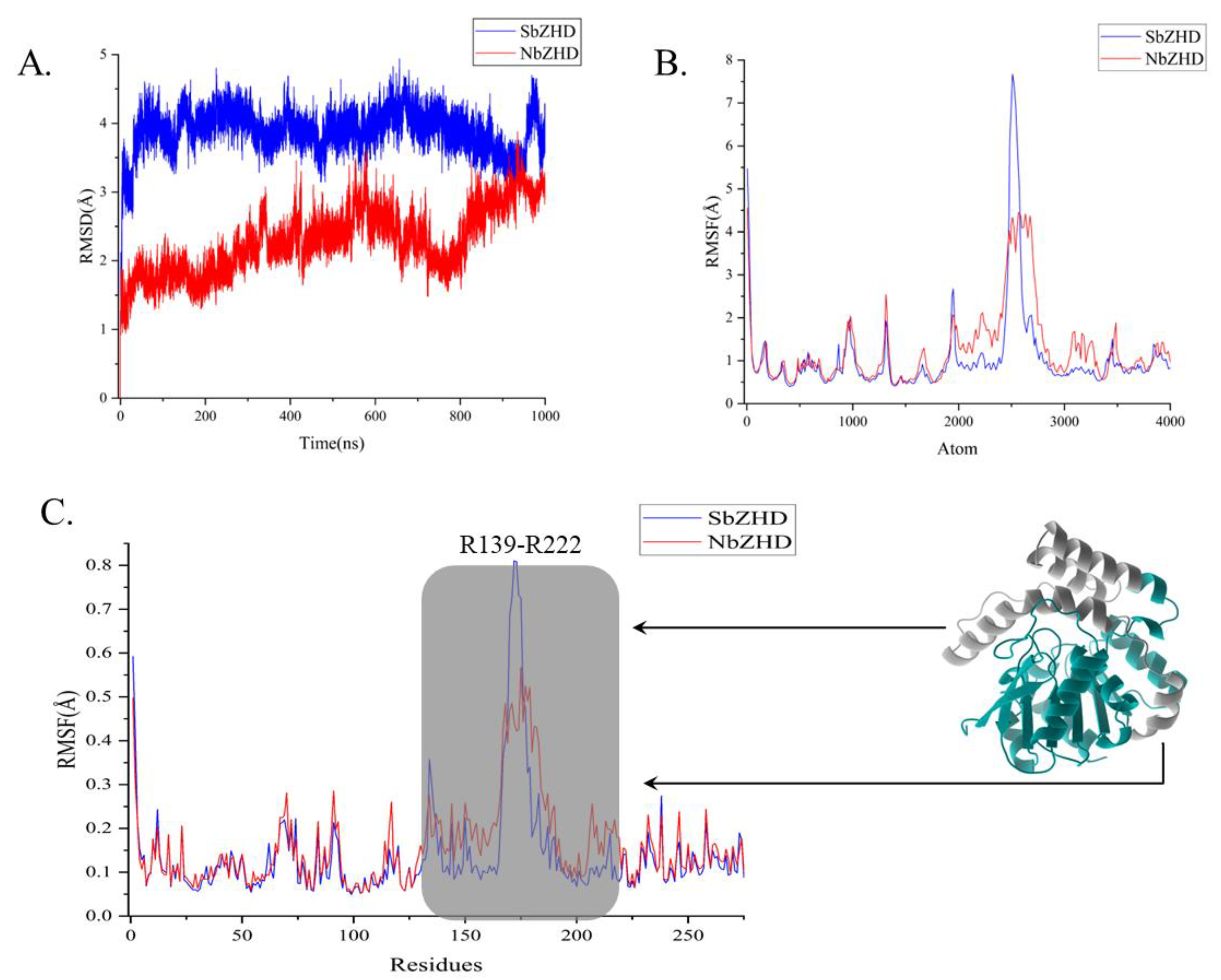
Figure 3.
The diagrams indicated the allosteric pathway and the corresponded amino acids from 1 μs molecular dynamics simulation. (A,B) two pathways that contain 8 residues. (C) A pathway that contains 7 residues with the highest probability.
Figure 3.
The diagrams indicated the allosteric pathway and the corresponded amino acids from 1 μs molecular dynamics simulation. (A,B) two pathways that contain 8 residues. (C) A pathway that contains 7 residues with the highest probability.

Figure 4.
PMF analysis of pulling process. The left one is when the zearalenone adapting the catalytic center, the middle one is when the complex state in the inflection point and the right one is when the zearalenone in the releasing state.
Figure 4.
PMF analysis of pulling process. The left one is when the zearalenone adapting the catalytic center, the middle one is when the complex state in the inflection point and the right one is when the zearalenone in the releasing state.
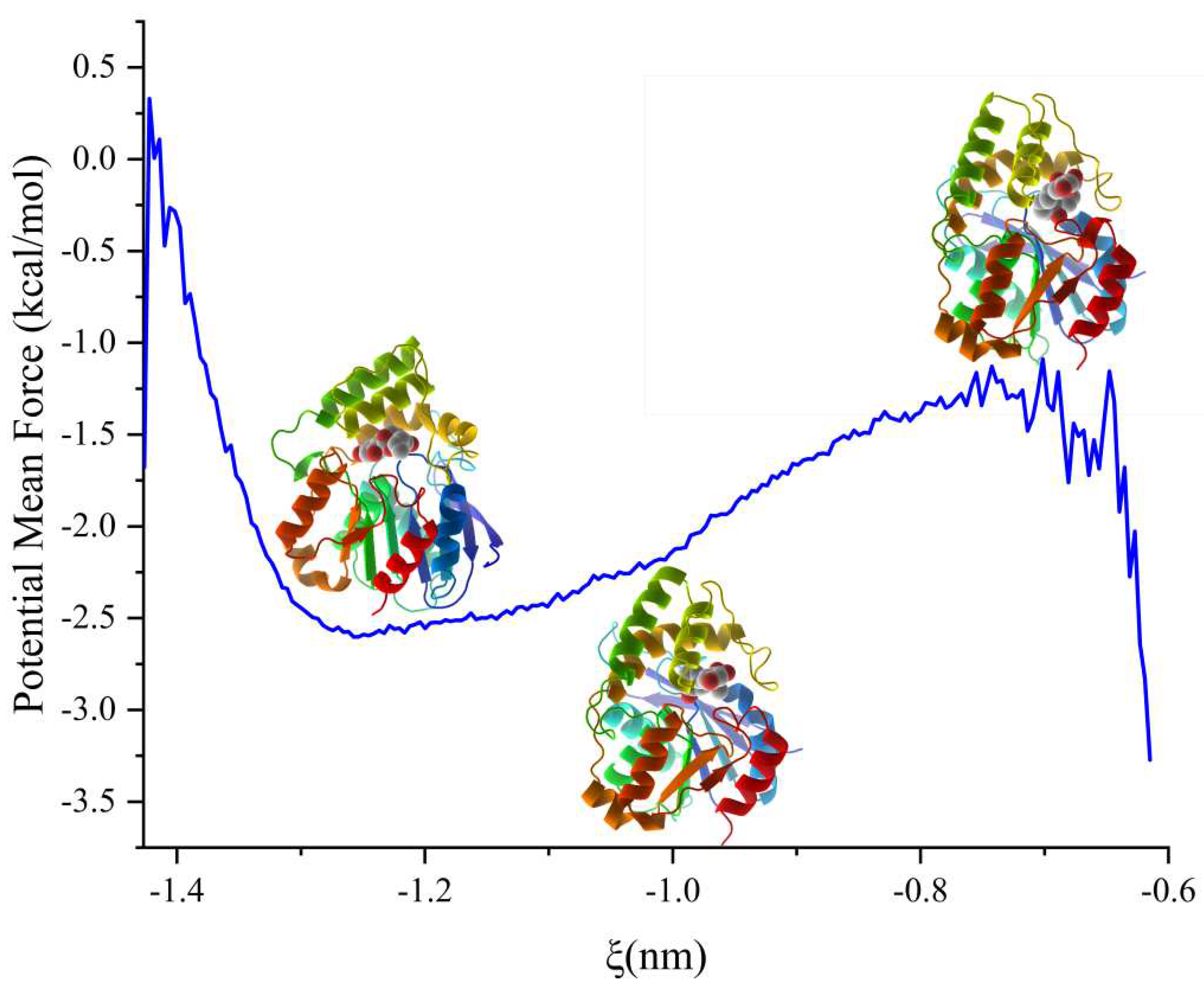
Figure 5.
The diagrams indicated the allosteric pathway and the corresponded amino acids from umbrella sampling. (A) The highest probability pathway from concatenated windows. (B) The frontside with the ligand.
Figure 5.
The diagrams indicated the allosteric pathway and the corresponded amino acids from umbrella sampling. (A) The highest probability pathway from concatenated windows. (B) The frontside with the ligand.
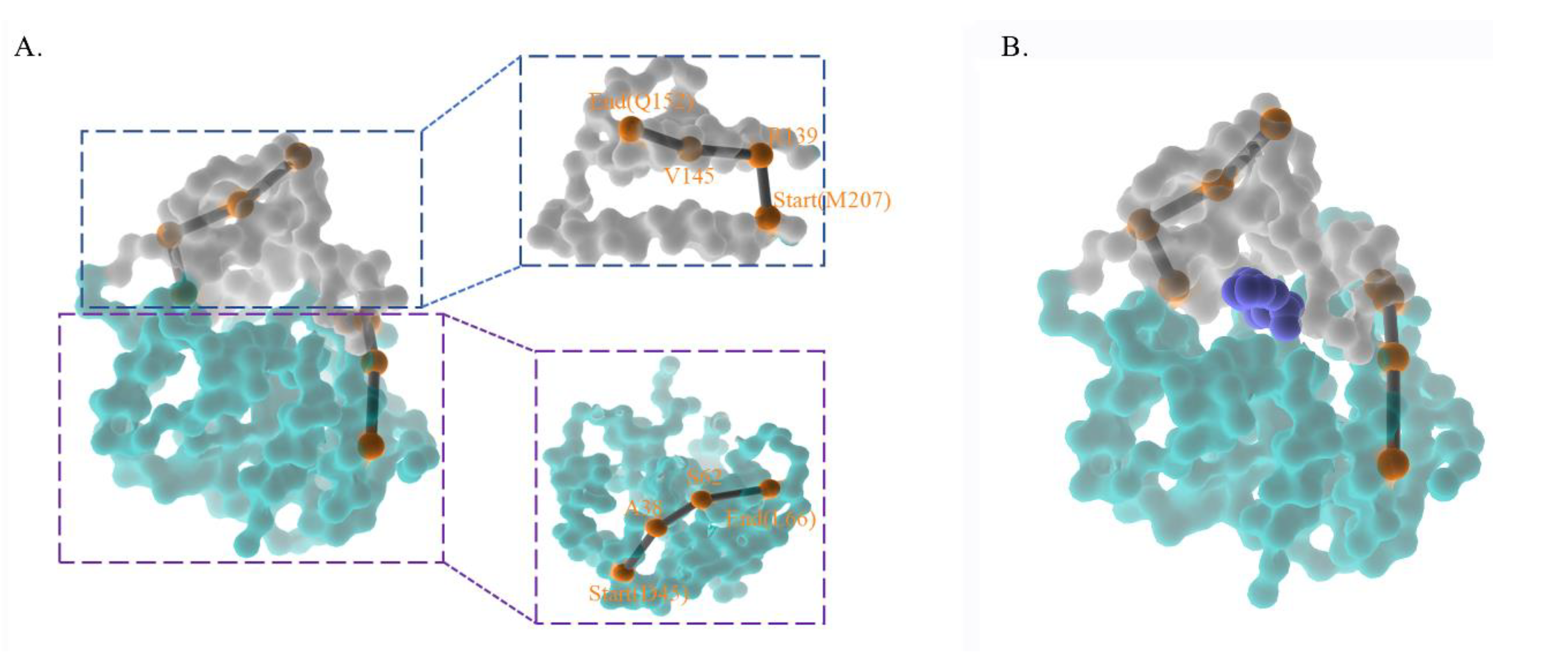
Figure 6.
The energy variation of the widetype and mutant enzymes. (A,B) ΔG of complex from two mutant D45A and R139A. (C,D) ΔG of binding from two mutant D45A and R139A.
Figure 6.
The energy variation of the widetype and mutant enzymes. (A,B) ΔG of complex from two mutant D45A and R139A. (C,D) ΔG of binding from two mutant D45A and R139A.
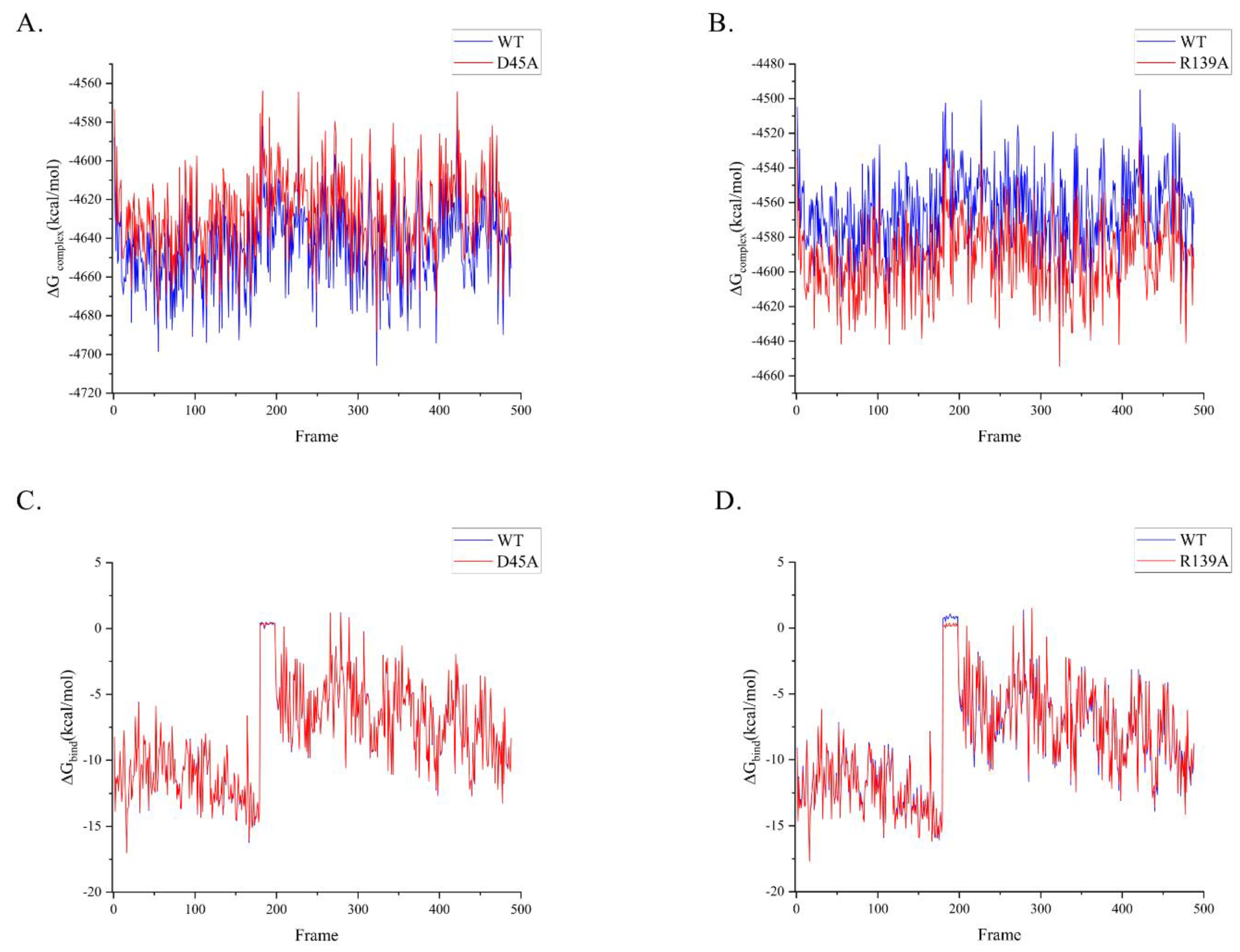
Figure 7.
The generative vision of the paradigm. At first, the ligand is docking in the ZHD, and the cap domain is counterclockwise rotating while the hydrolase domain is clockwise. After the emission of the ligand, both domains of ZHD will rotate in the opposite direction.
Figure 7.
The generative vision of the paradigm. At first, the ligand is docking in the ZHD, and the cap domain is counterclockwise rotating while the hydrolase domain is clockwise. After the emission of the ligand, both domains of ZHD will rotate in the opposite direction.
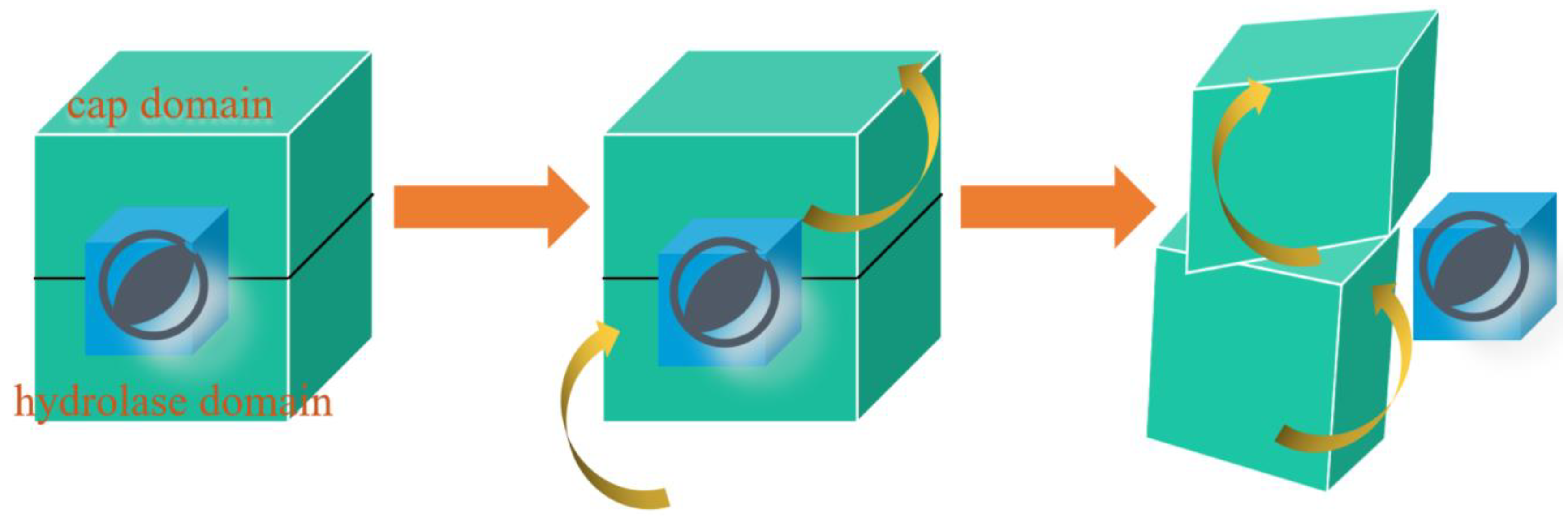
Figure 8.
The diagrams indicated the mutant sites and corresponding residues. (A,B) The residues interface of D45 and its mutant A45 with M1. (C,D) The residues interface of R139 and its mutant A139 with M207. The shorter ionic bonds, the stronger binds them.
Figure 8.
The diagrams indicated the mutant sites and corresponding residues. (A,B) The residues interface of D45 and its mutant A45 with M1. (C,D) The residues interface of R139 and its mutant A139 with M207. The shorter ionic bonds, the stronger binds them.
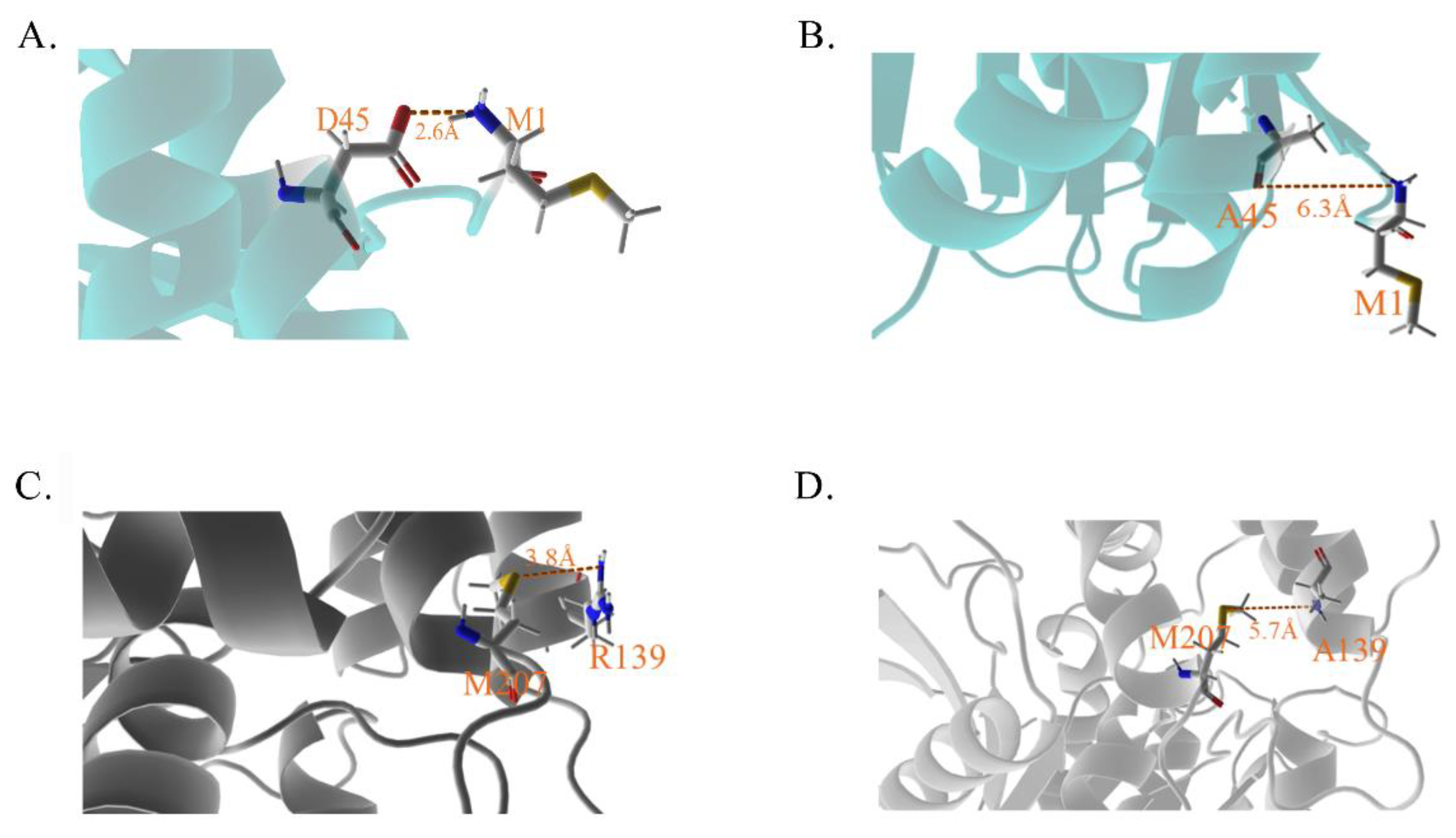
Figure 9.
Secondary structure analysis inspects the local shifting including density and charge density. (A) Secondary structure analysis across the time scale, (a) belongs to the late 500 ns simulation of long-range simulation and (b) belongs to the concatenated window with 1361 frames, each frame separated 2 ps summing 2.7 ns. (B,C) Mass density of residues 170 to residues 190 along the coordinate and charge density of them based on the comparison of the concatenated one and the long-range one.
Figure 9.
Secondary structure analysis inspects the local shifting including density and charge density. (A) Secondary structure analysis across the time scale, (a) belongs to the late 500 ns simulation of long-range simulation and (b) belongs to the concatenated window with 1361 frames, each frame separated 2 ps summing 2.7 ns. (B,C) Mass density of residues 170 to residues 190 along the coordinate and charge density of them based on the comparison of the concatenated one and the long-range one.
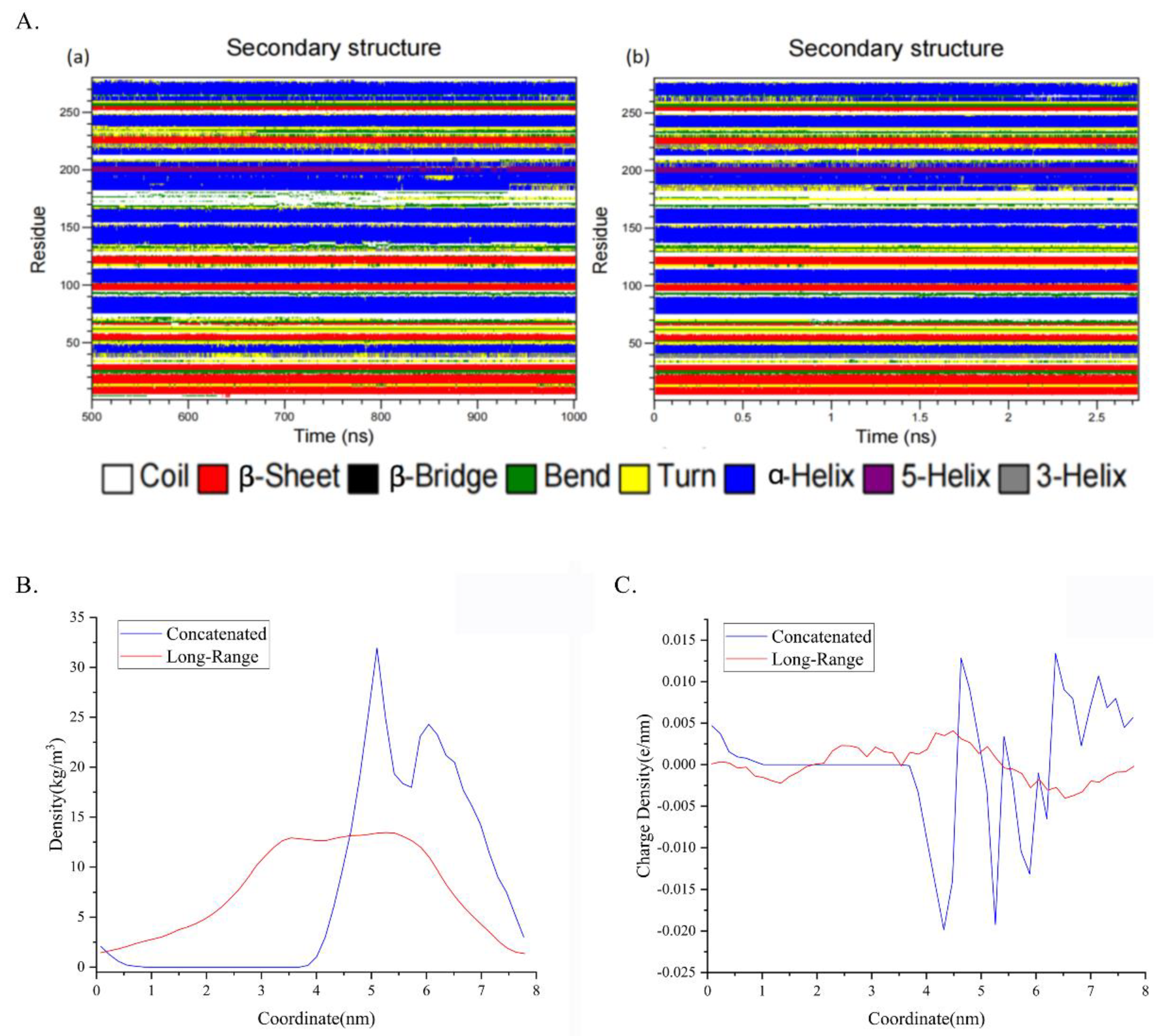

Table 1.
11 pathways that contains 7 residues with over 99.9% probability and 2 pathways with 8 residues.
Table 1.
11 pathways that contains 7 residues with over 99.9% probability and 2 pathways with 8 residues.
| Item | Number of AA | Pathway | Probability |
|---|---|---|---|
| 1 | 8 | 209→ 139→ 145→ 155→ 174→ 176→ 178→ 183 | 85.778% |
| 2 | 8 | 209→ 139→ 145→ 155→ 174→ 176→ 178→ 186 | 81.800% |
| 3 | 7 | 183→ 177→ 174→ 154→ 149→ 146→ 202 | 99.999% |
| 4 | 7 | 184→ 177→ 174→ 154→ 149→ 146→ 202 | 99.974% |
| 5 | 7 | 181→ 177→ 174→ 154→ 149→ 146→ 202 | 99.971% |
| 6 | 7 | 184→ 176→ 175→ 154→ 150→ 146→ 202 | 99.935% |
| 7 | 7 | 182→ 176→ 175→ 154→ 150→ 146→ 202 | 99.935% |
| 8 | 7 | 184→ 176→ 174→ 154→ 149→ 146→ 202 | 99.922% |
| 9 | 7 | 182→ 176→ 174→ 154→ 149→ 146→ 202 | 99.922% |
| 10 | 7 | 184→ 176→ 175→ 154→ 149→ 146→ 202 | 99.914% |
| 11 | 7 | 182→ 176→ 175→ 154→ 149→ 146→ 202 | 99.913% |
| 12 | 7 | 181→ 176→ 175→ 154→ 150→ 146→ 202 | 99.907% |
| 13 | 7 | 186→ 176→ 175→ 154→ 149→ 146→ 202 | 99.901% |
Table 2.
Energy analysis of NbZHD and its mutants D45A and R139A. NbZHD(1) stands for the first time calculation with D45A; NbZHD(2) stands for the second time calculation with R139A; NbZHD is the average of NbZHD(1) and NbZHD(2). The below data is reported in the unit of kcal/mol.
Table 2.
Energy analysis of NbZHD and its mutants D45A and R139A. NbZHD(1) stands for the first time calculation with D45A; NbZHD(2) stands for the second time calculation with R139A; NbZHD is the average of NbZHD(1) and NbZHD(2). The below data is reported in the unit of kcal/mol.
| Enzyme | ΔVDW | ΔEEL | ΔEMM | ΔGSOLV | ΔGGAS | ΔGbind |
|---|---|---|---|---|---|---|
| NbZHD(1) | -31.84±7.06 | -2.97±1.03 | -34.81±8.09 | 26.68±5.42 | -34.82±7.74 | -8.14±3.74 |
| D45A | -31.84±7.06 | -3.00±1.04 | -34.84±8.10 | 26.71±5.43 | -34.84±7.75 | -8.13±3.74 |
| NbZHD(2) | -31.84±7.06 | -2.97±1.03 | -34.81±8.09 | 26.07±5.21 | -34.82±7.74 | -8.75±3.97 |
| R139A | -31.84±7.06 | -2.96±1.03 | -34.80±8.09 | 26.04±5.32 | -34.80±7.74 | -8.76±3.94 |
| NbZHD | -31.84±7.06 | -2.97±1.03 | -34.81±8.09 | 26.38±5.32 | -34.82±7.74 | -8.45±3.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



