
Submitted:
11 February 2020
Posted:
12 February 2020
You are already at the latest version
Abstract
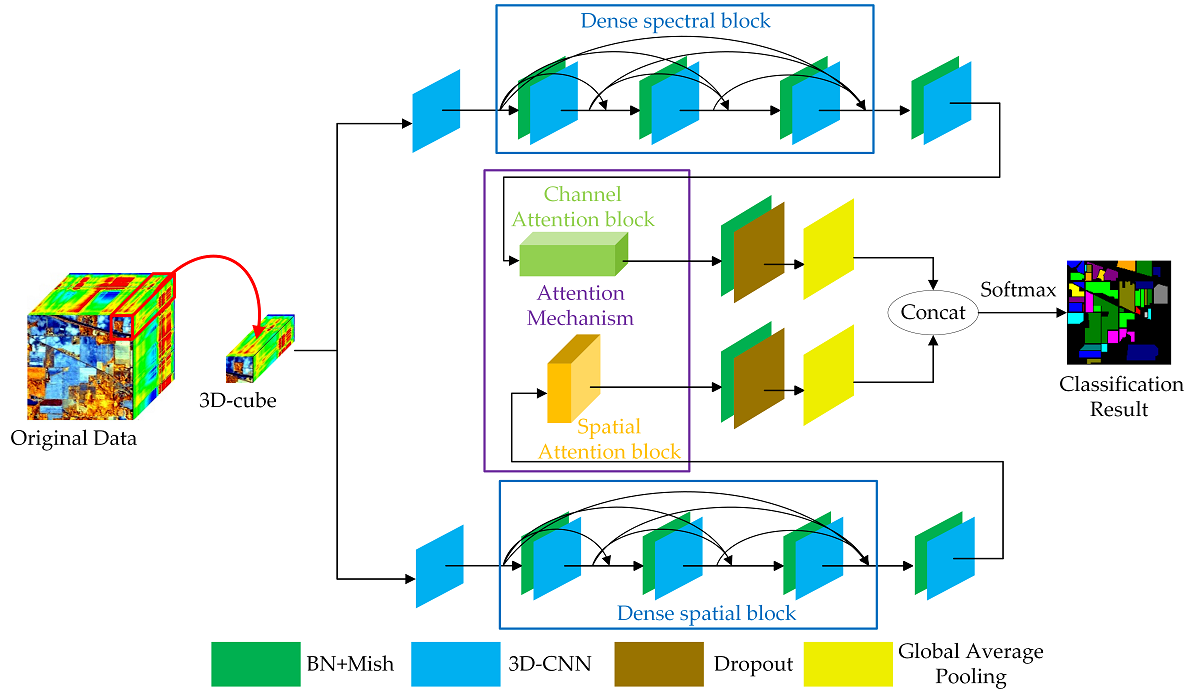
In recent years, researchers have paid increasing attention on hyperspectral image (HSI) classification using deep learning methods. To improve the accuracy and reduce the training samples, we propose a double-branch dual-attention mechanism network (DBDA) for HSI classification in this paper. Two branches are designed in DBDA to capture plenty of spectral and spatial features contained in HSI. Furthermore, a channel attention block and a spatial attention block are applied to these two branches respectively, which enables DBDA to refine and optimize the extracted feature maps. A series of experiments on four hyperspectral datasets show that the proposed framework has superior performance to the state-of-the-art algorithm, especially when the training samples are signally lacking.
Keywords:
hyperspectral image classification
; deep learning
; channel-wise attention mechanism
; spatial-wise attention mechanism
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



