Submitted:
03 November 2017
Posted:
03 November 2017
You are already at the latest version
Abstract
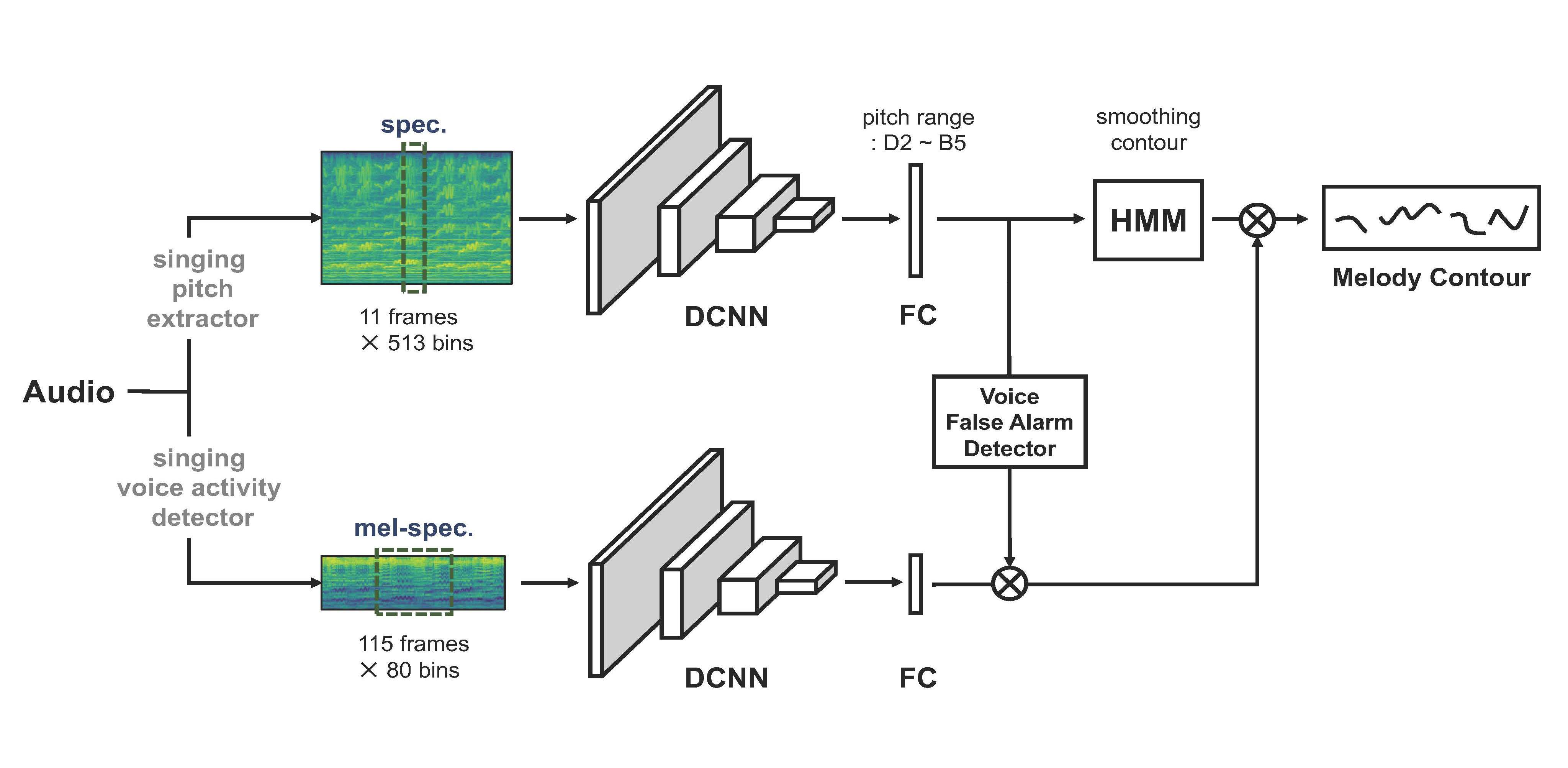
Singing melody extraction is the task that identifies the melody pitch contour of singing voice from polyphonic music. Most of the traditional melody extraction algorithms are based on calculating salient pitch candidates or separating the melody source from the mixture. Recently, classification-based approach based on deep learning has drawn much attentions. In this paper, we present a classification-based singing melody extraction model using deep convolutional neural networks. The proposed model consists of a singing pitch extractor (SPE) and a singing voice activity detector (SVAD). The SPE is trained to predict a high-resolution pitch label of singing voice from a short segment of spectrogram. This allows the model to predict highly continuous curves. The melody contour is smoothed further by post-processing the output of the melody extractor. The SVAD is trained to determine if a long segment of mel-spectrogram contains a singing voice. This often produces voice false alarm errors around the boundary of singing segments. We reduced them by exploiting the output of the SPE. Finally, we evaluate the proposed melody extraction model on several public datasets. The results show that the proposed model is comparable to state-of-the-art algorithms.
Keywords:
convolution neural networks
; melody extraction
; singing voice activity detection
; voice false alarm detection
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



