Submitted:
01 July 2026
Posted:
01 July 2026
You are already at the latest version
Abstract
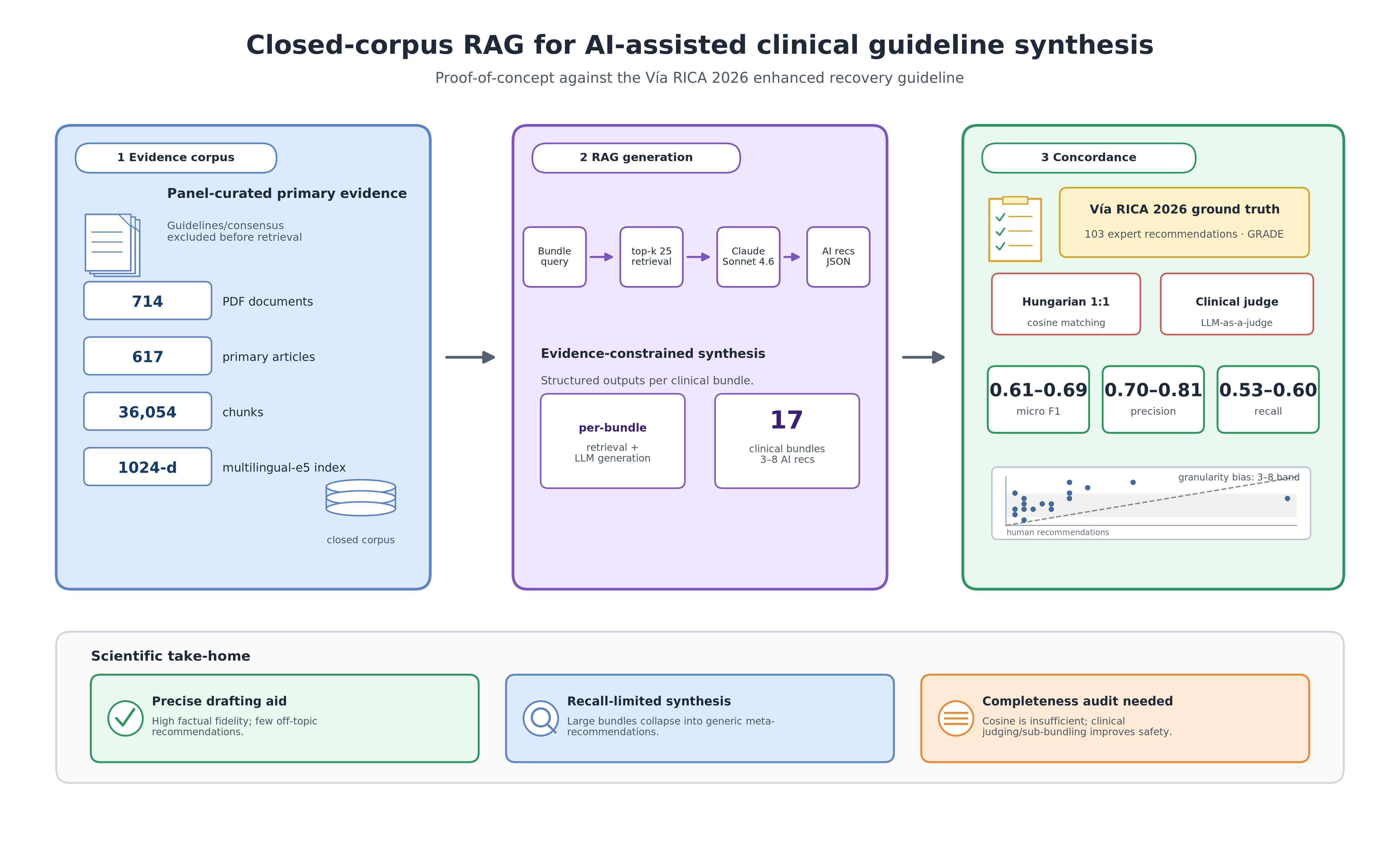
Clinical practice guidelines such as the Spanish Enhanced Recovery After Surgery protocol Vía RICA require intensive expert synthesis of primary evidence that large language models (LLMs) might partly automate, yet their ability to reproduce clinically actionable recommendations remains poorly quantified. We quantitatively evaluate an LLM (Claude Sonnet 4.6) generating recommendations against the 103 expert-curated recommendations of Vía RICA 2026, organised in 17 clinical bundles. The model used the panel's own closed corpus (617 articles, 36,054 chunks) through a retrieval-augmented generation pipeline with multilingual embeddings. Concordance was assessed under a dual framework: optimal 1:1 bipartite matching (Hungarian) on cosine similarity, and an LLM-as-a-judge clinical adjudicator (Claude Sonet 4.6)—whose agreement with two independent clinicians (Cohen's \( \kappa \)= 0.57 and 0.88) fell within the range of human inter-rater variability (human--human \( \kappa \) = 0.64)—over 499 borderline pairs. The two schemes bracket a micro F1 of 0.61–0.69 and reveal three findings: (i) a systematic granularity bias, the LLM producing 3–8 recommendations per bundle regardless of ground-truth size; (ii) failure of cosine similarity to discriminate within narrow clinical domains; and (iii) high factual precision (0.70–0.81) despite low structural exhaustiveness. The results delimit the current utility of generative AI for guideline elaboration.
Keywords:
clinical practice guidelines
; enhanced recovery after surgery
; generative artificial intelligence
; large language models
; retrieval-augmented generation
; LLM-as-a-judge
; multilingual embeddings
; concordance evaluation
; knowledge extraction
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



