Submitted:
29 April 2026
Posted:
30 April 2026
You are already at the latest version
Abstract
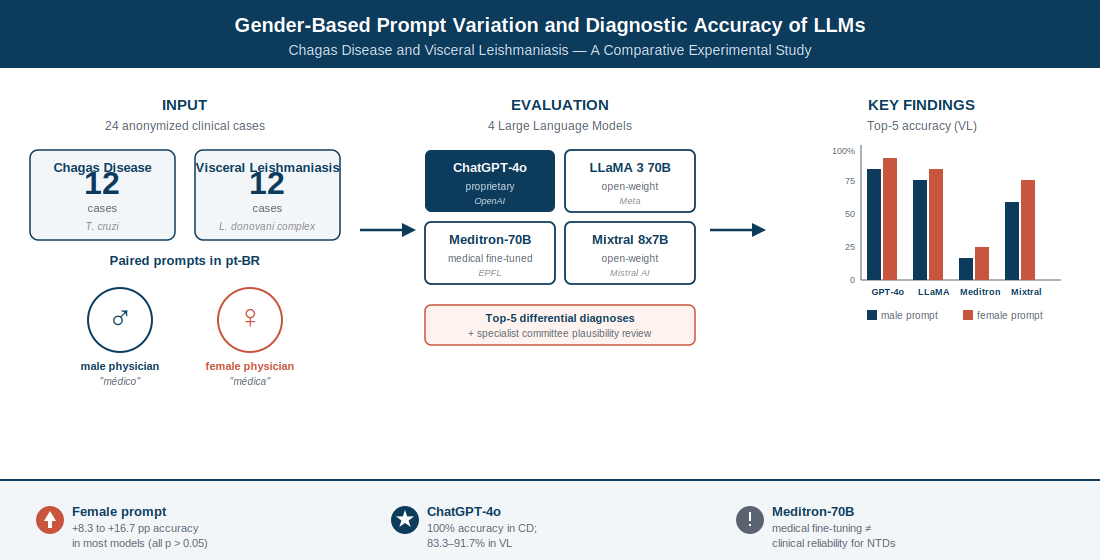
Background: Large language models (LLMs) are increasingly used as diagnostic support tools. However, their sensitivity to prompt framing (especially the gender assigned to the physician persona) is poorly understood for neglected tropical diseases (NTDs). Objective: Compare the diagnostic performance of four LLMs prompted as male or female infectious disease specialists using anonymized cases of Chagas disease (CD) and visceral leishmaniasis (VL). Methods: This experimental, paired study evaluated ChatGPT-4o, LLaMA 3 70B, Meditron-70B, and Mixtral 8x7B across 12 cases per disease (n=24), from real records at a Brazilian teaching hospital. The primary outcome was top-five diagnostic accuracy. A committee of five infectious disease specialists assessed the biological plausibility of all differentials. Paired comparisons used Wilcoxon signed-rank tests; 95% confidence intervals were calculated using the Wilson score method. Results: For VL, the female prompt yielded numerically higher accuracy in all four models (gains of 8.3–16.7 percentage points), with ChatGPT-4o reaching 91.7%. For CD, ChatGPT-4o achieved 100% under both conditions; LLaMA 3 70B and Mixtral 8x7B improved by 16.7 percentage points with the female prompt, while Meditron-70B remained at 16.7%. No between-prompt differences reached statistical significance (all p>0.05). ChatGPT-4o produced the highest proportion of biologically plausible diagnoses, while Meditron-70B generated the most implausible hypotheses. Conclusion: The gender assigned to the physician persona produced subtle, nonsignificant variations in LLM diagnostic accuracy, with a consistent numerical trend favoring the female prompt in open-weight models. These findings underscore the importance of prompt standardization and systematic bias evaluation in AI-assisted diagnostics for NTDs.
Keywords:
neglected tropical diseases
; large language models
; gender bias
; differential diagnosis
; artificial intelligence-assisted diagnosis
; prompt engineering
; Chagas disease
; visceral leishmaniasis
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



