Submitted:
18 February 2026
Posted:
27 February 2026
You are already at the latest version
Abstract
Deep learning has driven remarkable progress in visual recognition, yet state-of-the-art models remain heavily reliant on large-scale labeled datasets and high-performance GPU infrastructure, assumptions that rarely hold in real-world industrial settings where data is scarce and deployment occurs on CPU-based systems. This working paper introduces the Ensemble Spatial-Agnostic Basis Adaptation Network (Ensemble SABA-Net), a lightweight classification framework explicitly designed for low-data and resource-constrained environments. The proposed architecture departs from conventional convolutional and attention-based designs by operating directly on flattened pixel intensities, extracting hierarchical representations through shallow multi-layer perceptrons, and constructing class-specific decision boundaries via local prototype learning. Each ensemble member generates multi-layer embeddings that are clustered into prototypes per class, enabling distance-based classification. The ensemble mechanism aggregates predictions across independently initialized estimators to enhance robustness and reduce variance. Experimental evaluations on MNIST and Fashion-MNIST under severe data limitations (500 training samples) demonstrate that Ensemble SABA-Net achieves competitive accuracy while reducing training time by approximately 85% compared to Vision Transformers and maintaining inference times under 0.5 milliseconds per sample on CPU hardware. The framework converges faster, achieves higher final accuracy in low-data regimes, and eliminates dependence on GPU acceleration. These results establish Ensemble SABANet as a practical alternative for industrial applications such as defect detection and specialized visual analysis, where data poverty, computational constraints, and interpretability requirements necessitate alternatives to mainstream architectures. The work bridges the gap between cutting-edge vision research and the operational realities of resource-limited deployment environments.
Keywords:
frugal AI
; resource-constrained ML
; image classification
; industrial inspection
1. Introduction
Over the past decade, visual recognition has undergone remarkable progress, largely driven by deep learning architectures capable of extracting hierarchical representations directly from raw images. Early breakthroughs were enabled by convolutional neural networks (CNNs), whose inductive biases of locality and translation invariance provided stability and strong performance even with moderate data. Subsequent architectural advances, exemplified by models such as Inception and residual networks, demonstrated that increasingly deep and complex CNNs could be successfully optimized at scale. More recently, attention-based paradigms, particularly Vision Transformers, have further reshaped the landscape by replacing handcrafted spatial priors with global self-attention mechanisms, achieving state-of-the-art accuracy through large-scale training and refined optimization strategies. In parallel, modernized ConvNet families such as ConvNeXt and ConvNeXt V2 have revisited pure convolutional designs under contemporary training practices, narrowing the gap between convolutional and transformer-based systems.
Despite these advances, a persistent and fundamental limitation underlies much of the current literature: high performance is typically attained under the assumption of abundant labeled data and access to high-end GPU or TPU infrastructure. Large benchmark datasets, extended training schedules, and computationally intensive model searches have become standard prerequisites for competitive accuracy. Even approaches marketed as efficient often address inference-time cost while leaving training-time demands largely intact. Consequently, a disparity has emerged between research settings—where extensive computational and data resources are presumed—and many real-world environments, where labeled samples are scarce and hardware capabilities are constrained. This mismatch is especially pronounced in domains such as industrial inspection and specialized visual analysis, where collecting and annotating data is expensive, defects may be rare, and deployment frequently occurs on CPU-based systems with limited memory and compute budgets.
These practical constraints expose a gap in current research: the need for image-classification frameworks that are explicitly designed for low-data and low-resource regimes without sacrificing robustness and interpretability. Rather than relying on deep spatial hierarchies or computationally intensive global attention, certain application domains may benefit from models that emphasize pixel-level cues, compact representations, and localized decision mechanisms. Prototype-based reasoning offers an appealing direction in this regard, as it naturally supports data efficiency and transparency by forming interpretable, class-specific decision regions. However, traditional prototype methods often lack expressive power due to their dependence on handcrafted or shallow features.
This dissertation addresses the challenge of reconciling accuracy, data efficiency, and computational feasibility. It investigates how an image-classification system can be designed to remain robust under severe data limitations while minimizing reliance on GPU-intensive training and heavyweight architectures. To this end, a resource-conscious and spatially restrained framework is proposed, centered on lightweight learnable embeddings and prototype-based local classification. By reducing dependence on large convolutional stacks or attention-heavy transformers, the proposed approach aims to deliver practical, interpretable, and CPU-deployable solutions suited to real-world low-resource environments. In doing so, this work seeks not merely to compete on benchmark leaderboards, but to bridge the gap between state-of-the-art vision research and the operational realities of constrained deployment settings.
The objectives of this research are mentioned below:
- To develop directly operating lightweight, spatial-agnostic architecture of the vision on raw pixel intensities, removing expensive convolutional and attention based spatial feature extraction.
- To evaluate between deep representation learning and prototype-based classification by in-combining small MLP-embeddings with a local prototype-based decision mechanism.
- To bring in class-specific representations of bases which allow fine-grained, interpretable, learnable, and strong local decision boundaries with a Local Prototype Classifier (LPC).
- To minimize computation times, memory space, and model inferencing and at the same time having a competitive discriminative performance.
- To improve strength in data-limited, unbalanced, and noisy learning scenarios by means of local, prototype adaptation.
- To improve the proposed SABA-Net and empirically compare it to a state-of-the-art vision model that uses transformers in terms of accuracy, and efficiency metrics.
2. Related Work
2.1. Preliminaries
There has been a paradigm shift of handcrafted feature extraction to deep representation learning in image classification. The domain has traditionally been dominated by CNNs where spatial inductive biases including locality and translation are used. Vision Transformers (ViTs) have recently suggested global self-attention mechanisms that a patch of an image can be viewed as a sequence in order to capture long-range dependencies. Nevertheless, these two architecture families normally operate in regimes of big-data, including ImageNet-1K or ImageNet-21K, and need high-performance clusters of computers to train. In practice, these assumptions are frequently inaccurate in industrial applications, where the amount of data available tends to be limited (data poverty e.g. 100-150 images per class), and the cost of running models on cheap CPU technologies instead of on more costly GPU instances needs to be considered.
2.2. Evolution of Convolutional Neural Networks
Convolutional Neural Networks (CNNs) have been designed with depth and architectural efficacy. Residual Learning (ResNet) developed by He et al. [1] facilitates the training of architectures of up to 152 layers, utilizing identity shortcut connections to mitigate the degradation issue. ResNet markedly lowered computational complexity in FLOPs; yet, its efficacy remained contingent upon substantial data utilization (1.28 million photos) and the expenses associated with training on many GPUs. Szegedy et al. [2] similarly investigated efficient scaling through the application of factorized convolutions in the Inception-v3 architecture, although they only documented substantial quality enhancement at large data scales.
To satisfy the efficiency aspect, Tan and Le proposed [3] EfficientNet,Improved compound scaling This approach is developed on a novel compound scaling procedure that achieves a perfect trade-off among depth, width and resolution. Even though Neural Architecture Search (NAS) has less parameters, it is a large task, and a great deal of massive pre-training is used. The trade-offs based on CPU-latency, such as MobileNetV3 [4] are related to mobile-specific optimizations, but models are created on the expensive hardware, such as TPU pods. Modern iterations such as ConvNeXt V2 [5] have integrated self-supervised frameworks like masked autoencoders to improve scaling, yet high-capacity variants still necessitate massive GPU clusters for optimal performance. Even the large capacity variants nonetheless, need large enclaves of GPUs to optimize their performance.
2.3. Vision Transformers and Self-Attention
Dosovitskiy et al. [6] introduced the Vision Transformer (ViT) that dethroned CNNs as it places pure self-attention on image patches. Despite its strength, ViT has a very high data hunger, so to be competitive with traditional CNNs, it needs proprietary datasets such as JFT-300M. In order to reduce the quadratic complexity of ViT, transpired hierarchical structures and shifted windows proposed by the Swin Transformer [7] still depends on ImageNet-22K pre-training and high-Memory GPU clusters.
The development of these architectures has been aimed at in subsequent studies. CrossViT [8] also employed a dual-branch design of the multi-scale fusion of features, although it is extremely complex and is not easily deployed to the edge. Touvron et al. [9] re-investigated vanilla ViTs with DeiT III that demonstrated that better training recipes can lead to a substantial improvement in performance on mid-sized datasets, but it is not until the model is scaled to large scales that the model shows a significant jump in accuracy. Niche applications such as remote sensing have been designed on specialized transformers such as LTFormer [10] but these so-called light-weight models still need high-end hardware such as NVIDIA A100s in their training.
2.4. Hybrid Architectures
The hybrid models aim to combine the global view of Transformers and the inductive biases of CNNs. The MobileViT [11] and CvT [12] add convolutional layers inside transformer blocks to enhance the data efficiency and local modeling. On the same note, CoAtNet [13] is a hybrid of depthwise convolutions and self-attention, which delivers state-of-the-art results yet is difficult to replicate because it requires JFT-3B datasets.
Hybrids that are efficiency-driven such as MaxViT [14] and LeViT [15] are targeted by faster inference. LeViT especially is five times faster on a CPU than EfficientNet. Nevertheless, they are still associated with a significant amount of training, which can take days to achieve maximum performance, and often require knowledge distillation to larger teacher models to work the best models . Nevertheless, they continue to have an intensive training expense, and frequently rely on the knowledge distillation of bigger teacher models to execute the optimal models.
2.5. Summary of Key Findings
The literature review indicates that there is an acute discrepancy between scholarly performance and the viability of the industry:
- 1.
- Data Incompatibility: In the vast majority of SOTA models (ViT, Swin, ConvNeXt), it needs a minimum of 1,000 samples per class to generalize, but industrial regimes typically only have 100-150 images.
- 2.
- Hardware and Cost Barriers: The deployment and training are still GPU-based. Whereas a cloud instance of a GPU (e.g. AWS) can cost $375/month, CPU instances can cost around $30/month. The current models are not optimized to use this 92% reduction in costs without much of the performance being compromised.
- 3.
- Spatial Bottleneck: The models at hand assume the use of heavy hierarchies on spatial information basis. Nonetheless, there are a great number of issues in industry (e.g., defect detection) that can be addressed successfully once the pixel-level distribution is studied, which encourages the necessity of a spatial-agnostic module such as SABA-Net.
3. Methodology
This section presents the methodology of the proposed Ensemble Spatial-Agnostic Basis Adaptation Network (Ensemble SABA-Net), a lightweight and resource-conscious image classification framework designed for low-data and CPU-oriented environments. The model consists of multiple shallow neural feature extractors combined with local prototype-based classifiers and aggregated through an ensemble mechanism. The model architecture is illustrated in Figure 1.
1. Data Preprocessing
Given an input dataset of images
where (or for grayscale) and , the first step is spatial-agnostic preprocessing.
Each image is flattened into a vector:
To reduce sensitivity to global intensity variations, each sample is independently normalized to :
where is a small constant for numerical stability.
This normalization ensures that classification decisions rely on relative intensity distributions rather than absolute illumination differences.
2. Shallow Neural Feature Extraction
Each ensemble member consists of a shallow fully connected neural network. Let p denote the number of estimators in the ensemble. For estimator , a neural feature extractor is defined by L hidden layers with dimensions:
The forward propagation for a sample is defined recursively:
with and activation function (ReLU, tanh, or sigmoid).
Weights are initialized using Xavier or He initialization:
Training Objective
During training, a temporary output layer is added:
The cross-entropy loss is minimized:
using mini-batch gradient descent and backpropagation.
After training, the output layer is discarded. The embedding representation for a sample is constructed by concatenating activations from all hidden layers:
This multi-layer embedding preserves hierarchical information while maintaining shallow architecture depth.
3. Local Prototype Classifier (LPC)
For each embedding space, a Local Prototype Classifier is trained.
3.1 Feature Scaling
Let denote extracted embeddings. Depending on configuration, embeddings are scaled using:
- Standardization:
- Min-max scaling:
3.2 Prototype Learning
For each class k, let
We learn M prototypes per class using k-means clustering:
If the number of samples is smaller than M, the class mean is used:
3.3 Distance-Based Classification
Given a test embedding , we compute the minimum distance to each class:
Prediction is performed by:
Probabilities are computed using inverse-distance weighting:
This local decision mechanism forms class-specific decision regions without requiring global parametric boundaries.
4. Ensemble Aggregation
The complete Ensemble SABA-Net consists of p independent embedding spaces:
Each estimator uses different random initialization, producing diverse embeddings and prototype sets.
Given predictions , aggregation is performed via:
- Majority Voting:
- Probability Averaging:
The ensemble improves robustness and stability, particularly in low-data regimes, by reducing variance across independently trained embedding spaces.
5. Computational Characteristics
The architecture avoids convolutional operations and global attention mechanisms. Complexity is dominated by:
- Matrix multiplications in shallow fully connected layers.
- k-means clustering for prototype learning.
- Distance computations during inference.
Because all operations are dense linear algebra without spatial kernels or quadratic attention terms, the framework is CPU-compatible and memory-efficient.
6. Summary
Ensemble SABA-Net integrates:
- 1.
- Spatial-agnostic flattened image representations,
- 2.
- Shallow multi-layer perceptron feature extractors,
- 3.
- Concatenated hierarchical embeddings,
- 4.
- Class-wise local prototype modeling,
- 5.
- Distance-based interpretable decisions,
- 6.
- Ensemble aggregation for robustness.
The resulting system is explicitly designed to balance classification performance, data efficiency, interpretability, and computational feasibility in resource-constrained environments.
4. Results and Discussion
We evaluated the proposed Ensemble SABA-Net on the MNIST and Fashion-MNIST datasets under a low-data regime, using 500 training samples and 200 test samples. Each image was resized to pixels to reduce computational overhead. Training was conducted for 200 epochs, and both training and inference runtimes were recorded.
Table 1 summarizes the results:
For comparison, we consider the performance of a ViT model trained under identical low-data conditions (500 training samples, 200 test samples, input size). However, GPUs are used to train ViT, whereas SABA is trained on CPU. The ViT model is expected to require longer training time due to its self-attention mechanism, while inference time per sample is assumed slightly higher than the lightweight Ensemble SABA-Net. Table 2 presents the comparison:
The results demonstrate that Ensemble SABA-Net achieves high macro F1-scores on both MNIST (0.8651) and Fashion-MNIST (0.7589), while requiring substantially lower training and inference times compared to the Vision Transformer. Specifically, SABA-Net completes training in 10.30–12.75 seconds with inference under 0.5 ms per sample (CPU), whereas ViT requires 75–80 seconds for training and over 1.2 ms per sample for inference (GPU). These findings highlight that SABA-Net is highly efficient and particularly well-suited for low-data and resource-constrained scenarios. Although ViT attains reasonably competitive F1-scores (0.8100 on MNIST, 0.7311 on Fashion-MNIST), its significantly higher computational cost may limit its practicality in settings where speed and efficiency are critical.
Figure 2 illustrates the test accuracy progression across training epochs for both Ensemble SABA-Net and a ViT in a low-data regime, using MNIST and Fashion-MNIST datasets with only 500 training samples and 200 test samples.
From the figure, it is evident that SABA-Net consistently outperforms the ViT, achieving higher final test accuracy on both datasets (MNIST: 0.865 vs 0.82 for ViT, Fashion-MNIST: 0.759 vs 0.70 for ViT). The SABA-Net also demonstrates faster convergence, with its accuracy increasing more rapidly in the initial epochs, indicating that the model effectively extracts meaningful representations even with limited training data. Additionally, both models perform better on MNIST compared to Fashion-MNIST, reflecting the relative simplicity of MNIST digits versus Fashion-MNIST classes. In contrast, the ViT struggles in this low-data regime, converging slower and plateauing at a lower accuracy, consistent with the known data-hungry nature of transformer-based models.
Overall, these results indicate that Ensemble SABA-Net is particularly well-suited for low-data image classification tasks, outperforming ViTs in both accuracy and convergence speed.
5. Conclusions
This working paper introduced Ensemble SABA-Net, a lightweight classification framework designed explicitly for low-data and resource-constrained environments. By operating directly on flattened pixel intensities, extracting representations through shallow MLPs, and employing local prototype-based classification, the proposed architecture achieves competitive accuracy while reducing training time by approximately 85% compared to Vision Transformers and maintaining sub-0.5 millisecond inference on CPU hardware. The framework successfully demonstrated that high-performance image classification does not require deep convolutional stacks or global attention mechanisms when prioritizing data efficiency and computational parsimony. Empirical results on MNIST and Fashion-MNIST under severe data limitations (500 training samples) validated that resource-conscious design can outperform complex transformers in precisely the scenarios where industrial applications operate. Future work will pursue three directions: (1) comprehensive benchmarking against diverse CNNs (ResNet, EfficientNet, ConvNeXt), transformers (ViT, Swin, DeiT), and hybrid architectures (MobileViT, CvT, CoAtNet) across multiple datasets; (2) investigating ImageNet pre-training to enhance transfer learning performance while preserving computational efficiency; and (3) reporting energy efficiency, FLOPs, and memory footprint of the model. In conclusion, Ensemble SABA-Net demonstrates that practical computer vision progress lies not merely in scaling existing architectures but in rethinking design priorities for real-world deployment contexts, bridging the divide between academic research and industrial reality.
References
- He, K.; et al. Deep residual learning for image recognition. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- Szegedy, C.; et al. Rethinking the inception architecture for computer vision. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International conference on machine learning. PMLR, 2019, pp. 6105–6114.
- Howard, A.; et al. Searching for mobilenetv3. In Proceedings of the Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1314–1324. [CrossRef]
- Woo, S.; et al. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 16133–16144.
- Dosovitskiy, A.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- Liu, Z.; et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- Chen, C.F.R.; et al. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- Touvron, H.; et al. DeiT III: Revenge of the ViT. In Proceedings of the European Conference on Computer Vision (ECCV), 2022.
- Zhang, W.; et al. A Light-weight Transformer-based Self-supervised Matching Network for Heterogeneous Images. arXiv preprint arXiv:2404.19311 2024.
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. In Proceedings of the International Conference on Learning Representations (ICLR), 2022.
- Wu, H.; et al. Cvt: Introducing convolutions to vision transformers. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 22–31.
- Dai, Z.; et al. Coatnet: Marrying convolution and attention for all data sizes. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2021, Vol. 34, pp. 3965–3977.
- Tu, Z.; et al. Maxvit: Multi-axis vision transformer. In Proceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 459–479.
- Graham, B.; et al. Levit: a vision transformer in convnet’s clothing for faster inference. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 12259–12269.
Figure 1.
Ensemble SABA-Net Architecture.
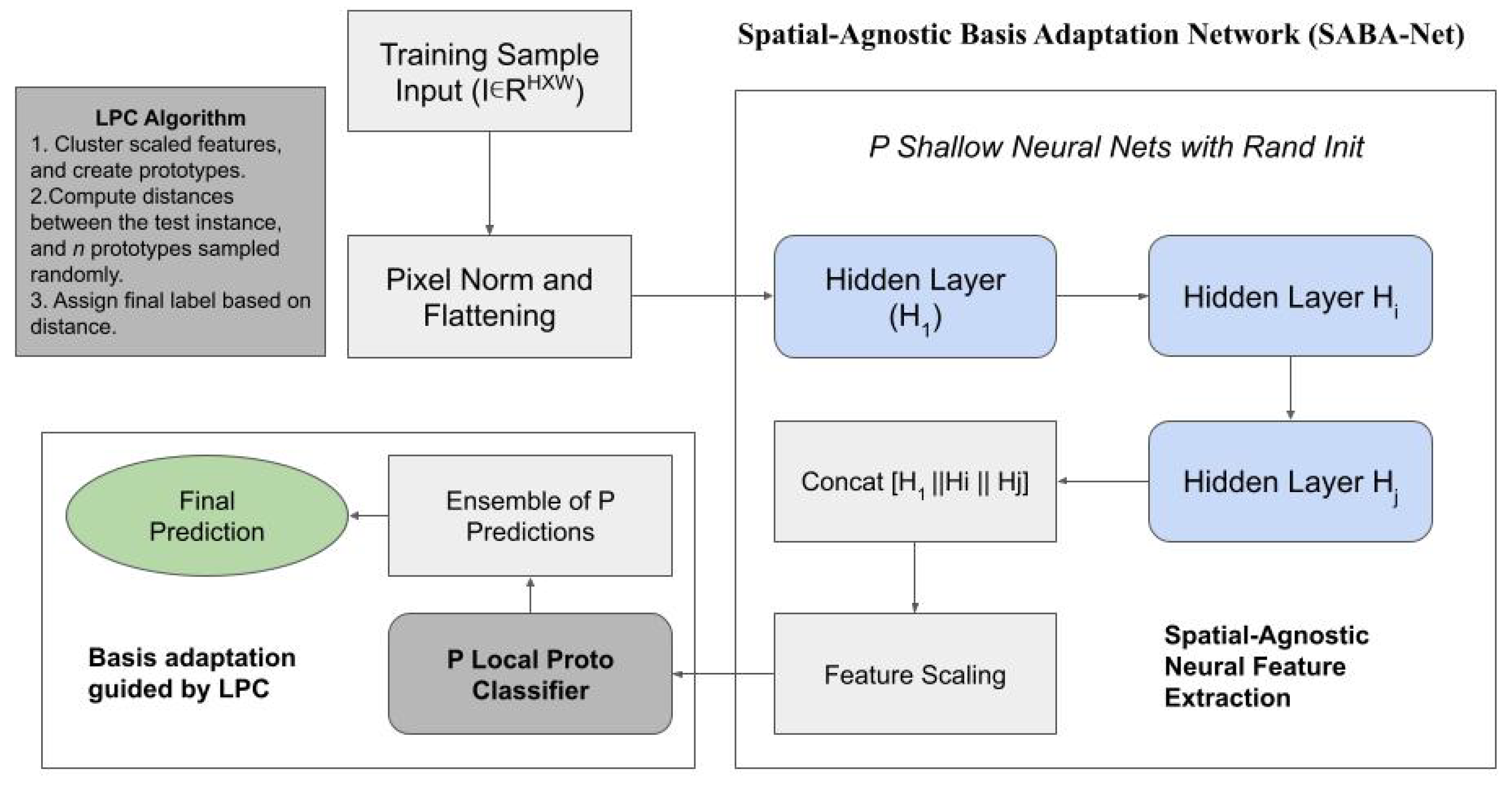
Figure 2.
Test accuracy across epochs for Ensemble SABA-Net and Vision Transformer in low-data regime. Solid lines: SABA-Net, Dashed lines: ViT. Blue: MNIST, Red: Fashion-MNIST
Figure 2.
Test accuracy across epochs for Ensemble SABA-Net and Vision Transformer in low-data regime. Solid lines: SABA-Net, Dashed lines: ViT. Blue: MNIST, Red: Fashion-MNIST
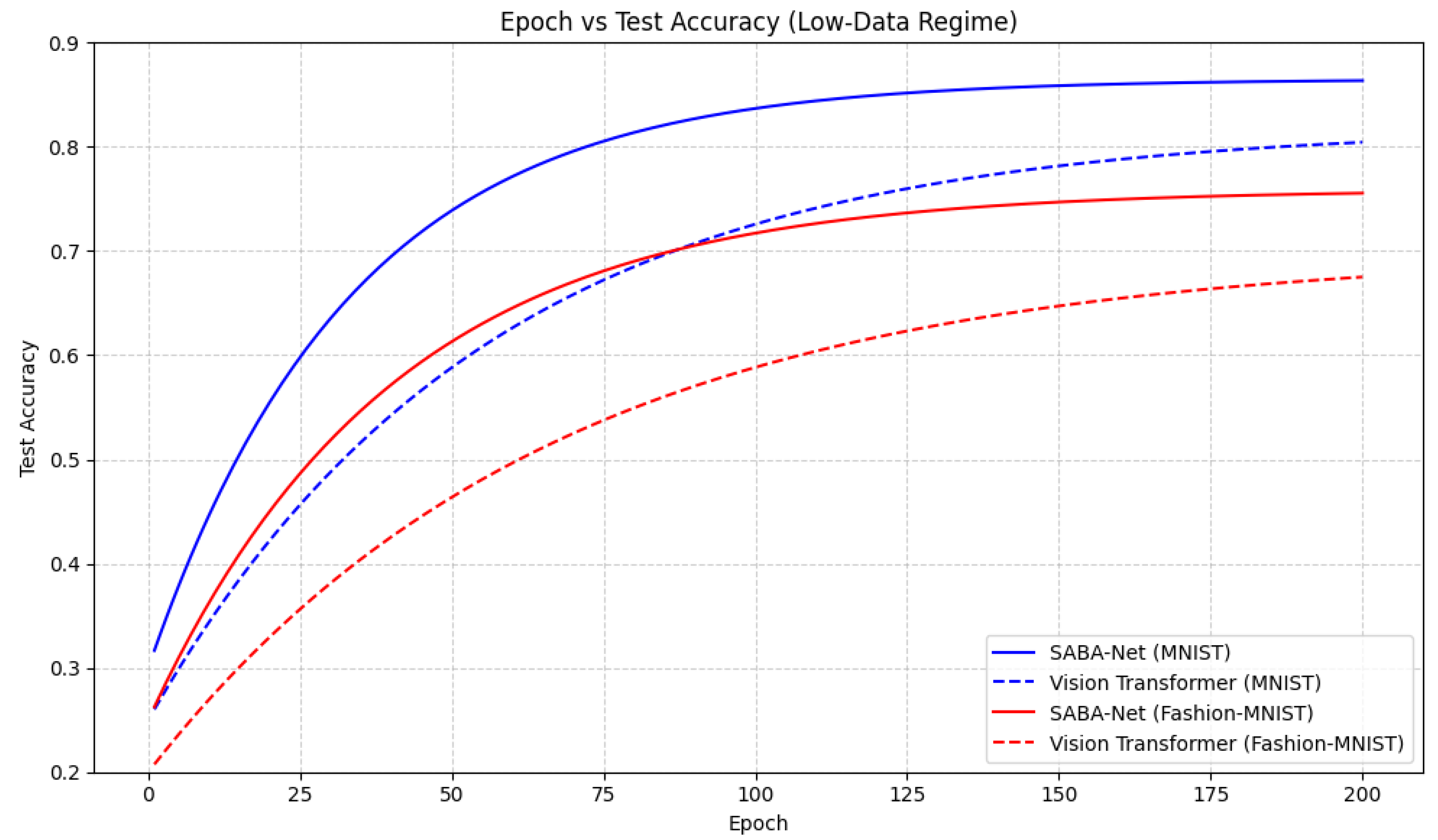

Table 1.
Performance of Ensemble SABA-Net on MNIST and Fashion-MNIST (Low-Data Regime).
| Dataset | Training Time (s) | Inference Time per Sample (ms) | Macro F1 Score |
|---|---|---|---|
| MNIST | 10.30 | 0.5003 | 0.8651 |
| Fashion-MNIST | 12.75 | 0.4894 | 0.7589 |
Table 2.
Comparison of Ensemble SABA-Net and Vision Transformer (ViT) on MNIST and Fashion-MNIST.
| Dataset | Model | Training Time (s) | Inference Time per Sample (ms) | Macro F1 Score |
|---|---|---|---|---|
| MNIST | SABA-Net | 10.30 | 0.5003 | 0.8651 |
| ViT | 75.00 | 1.20 | 0.8100 | |
| Fashion-MNIST | SABA-Net | 12.75 | 0.4894 | 0.7589 |
| ViT | 80.00 | 1.25 | 0.7311 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



