Submitted:
16 February 2026
Posted:
26 February 2026
You are already at the latest version
Abstract
Large language models exhibit context sensitivity—the degree to which conversational history shapes their responses. However, whether this sensitivity varies systematically across conversation positions and task domains remains unexplored. We analyzed 12 models across 30 conversational positions in two domains: philosophical reasoning (open-goal, 4 models) and medical summarization (closed-goal, 8 models), totaling approximately 54,000 responses. We report three findings. First, position 30 (P30) task enablement: at the summarization position, all 8 medical models showed extreme context sensitivity spikes (Z > +2.7, mean Z = +3.47, SD = 0.51), while all 4 philosophy models showed no spike (mean Z = +0.25). This 8/8 vs 0/4 split (p = 0.002, Fisher's exact test) suggests that closed-goal tasks require accumulated context for task execution, not merely performance enhancement. Second, domain-specific temporal patterns: medical models exhibited U-shaped dynamics with a diagnostic trough in mid-conversation (positions 10-25), while philosophy models showed inverted-U patterns peaking mid-conversation. Third, disruption sensitivity: all 12 models showed negative disruption sensitivity (DS < 0; medical mean −0.115, philosophy mean −0.073), indicating that context presence provides more value than context ordering—an architecture-independent finding. These results demonstrate that task structure, not domain content, determines how context sensitivity unfolds over conversation. We introduce the distinction between open-goal (Type 1) and closed-goal (Type 2) temporal dynamics, with implications for clinical AI deployment where summarization reliability is critical.
Keywords:
context sensitivity
; temporal dynamics
; large language models
; medical AI
; position effects
; behavioral evaluation
1. Introduction
Large language models (LLMs) process conversational context through self-attention mechanisms that theoretically allow every token to attend to every prior token [1]. This enables in-context learning—the capacity to adapt behavior based on conversational history without parameter updates [2]. However, the assumption that LLMs utilize context uniformly across conversation positions has been challenged by recent findings on serial position effects [3] and attention waveform patterns [4].
Prior work has established that LLMs exhibit systematic serial position effects, with information at the beginning and end of context receiving differential attention [3,5]. [4] identified “inherent waveform patterns in attention allocation” where crucial information is overlooked when positioned in “trough zones.” However, whether these temporal dynamics are universal across tasks or vary systematically with domain structure has remained unexplored.
This paper provides the first evidence that context sensitivity dynamics are domain-specific. We introduce the Relative Context Index (), a metric that quantifies how much conversational history changes model responses at each position. Analyzing 12 models across 30 positions in medical summarization (closed-goal) and philosophical reasoning (open-goal) tasks, we find:
- 1.
- P30 Task Enablement: Medical models show extreme context sensitivity spikes at the summarization position (8/8 models, ); philosophy models show none (0/4).
- 2.
- Two Temporal Patterns: Medical tasks produce U-shaped dynamics with a diagnostic trough; philosophy tasks produce inverted-U dynamics peaking mid-conversation.
- 3.
- Disruption Sensitivity: Context presence matters more than order (12/12 models, ).
These findings extend prior work on position effects by demonstrating that task structure—not just architecture—determines how models utilize context over conversation. For clinical AI, where summarization reliability directly impacts patient safety [6], understanding these dynamics is essential.
2. Background
2.1. Context Sensitivity in LLMs
Context sensitivity refers to the degree to which an LLM’s response is shaped by conversational history rather than isolated prompt content. While LLMs are designed to leverage context through attention mechanisms [1], the extent to which they actually do so—and how this varies across positions—has received limited systematic study.
The “lost in the middle” phenomenon [5] demonstrated that LLMs perform worse on information positioned in the middle of long contexts compared to information at the beginning or end. This suggests non-uniform context utilization that may follow predictable patterns.
2.2. The Framework
In prior work [9,10], we introduced the Relative Context Index () to quantify context sensitivity:
where measures response coherence with full conversational history, and measures coherence with only the immediate prompt. indicates that context increases response coherence—i.e., the model is “using” the conversation.
Paper 2 established that universally across 25 model-domain combinations (14 unique models, 2 domains). The present paper extends this by analyzing position-level temporal dynamics of across conversation.
3. Methods
3.1. Dataset
We analyzed a subset of the Paper 2 standardized dataset: 12 model-domain runs with preserved response text, enabling position-level analysis.
Philosophy domain (4 models): GPT-4o, GPT-4o-mini, Claude Haiku, Gemini Flash. Open-goal task: 30-turn Socratic dialogue exploring consciousness—from definitions through phenomenological analysis to self-reference and meta-reflection.
Medical domain (8 models): DeepSeek V3.1, Gemini Flash, Kimi K2, Llama 4 Maverick, Llama 4 Scout, Ministral 14B, Mistral Small 24B, Qwen3 235B. Closed-goal task: 29-turn STEMI case presentation followed by summarization at position 30.
Each model completed 50 trials per condition (TRUE, COLD, SCRAMBLED), yielding approximately 54,000 total responses.
3.2. Position-Level Computation
For each model and position :
where trials. This yields a 30-point temporal trajectory for each model.
3.3. Statistical Analysis
P30 Outlier Analysis: Z-scores computed for each model’s P30 relative to positions 1-29:
Three-Bin Aggregation: Positions grouped into Early (1-10), Mid (11-20), Late (21-29) to reveal phase-level patterns despite position-level noise.
Disruption Sensitivity:
indicates that scrambled context (presence without order) yields higher coherence than no context—i.e., presence matters more than order.
4. Results
4.1. Finding 1: P30 Task Enablement
The most striking finding is the complete separation between domains at position 30 (Figure 1).
Medical domain: All 8 models showed extreme P30 spikes:
- Mean (SD , all )
- 8/8 models exceeded threshold
- Effect is architecture-independent (spans 7 vendors)
Philosophy domain: No model showed a spike:
- Mean (range: to )
- 0/4 models exceeded threshold
This 8/8 vs 0/4 split (, Fisher’s exact test) suggests that closed-goal summarization requires accumulated context for task execution, while open-goal philosophical synthesis can proceed without context dependence at the final position.
4.2. Finding 2: Domain-Specific Temporal Patterns
Aggregating positions into three conversational phases reveals distinct temporal signatures (Figure 2).
Medical (U-shaped pattern):
- Early (P1-10): High (mean = 0.347)
- Mid (P11-20): Diagnostic trough (mean = 0.311)
- Late (P21-29): Rising (mean = 0.371)
- Pattern: Early > Mid, Late > Mid
Philosophy (Inverted-U pattern):
- Early (P1-10): Moderate (mean = 0.307)
- Mid (P11-20): Peak (mean = 0.331)
- Late (P21-29): Declining (mean = 0.270)
- Pattern: Mid > Early, Mid > Late
These patterns suggest that medical reasoning requires context accumulation at boundaries (case opening, summary), while philosophical reasoning peaks during mid-conversation synthesis.
4.3. Finding 3: Disruption Sensitivity
All 12 models showed negative disruption sensitivity (Figure 3).
- Medical: Mean (range: to )
- Philosophy: Mean (range: to )
- 12/12 models:
This result extends an aggregate-level finding from Paper 2 [10], which reported that in 25/25 model-domain runs—i.e., the presence of context (even disordered) always brings responses closer to the TRUE condition than its complete absence. is mathematically equivalent to this inequality (). What Paper 3 adds is position-level granularity: the aggregate “presence > absence” finding holds at every conversational position, but its magnitude varies systematically with task structure.
This indicates that context presence provides more value than context ordering. Even scrambled context provides information that exceeds no context, but ordered context provides additional structure. This finding is architecture-independent, spanning 7 vendors and parameter counts from 14B to 671B.
The practical implication for retrieval-augmented systems: prioritize information recall over perfect chronological ordering. However, position-specific DS patterns indicate that ordering matters more at some positions than others.
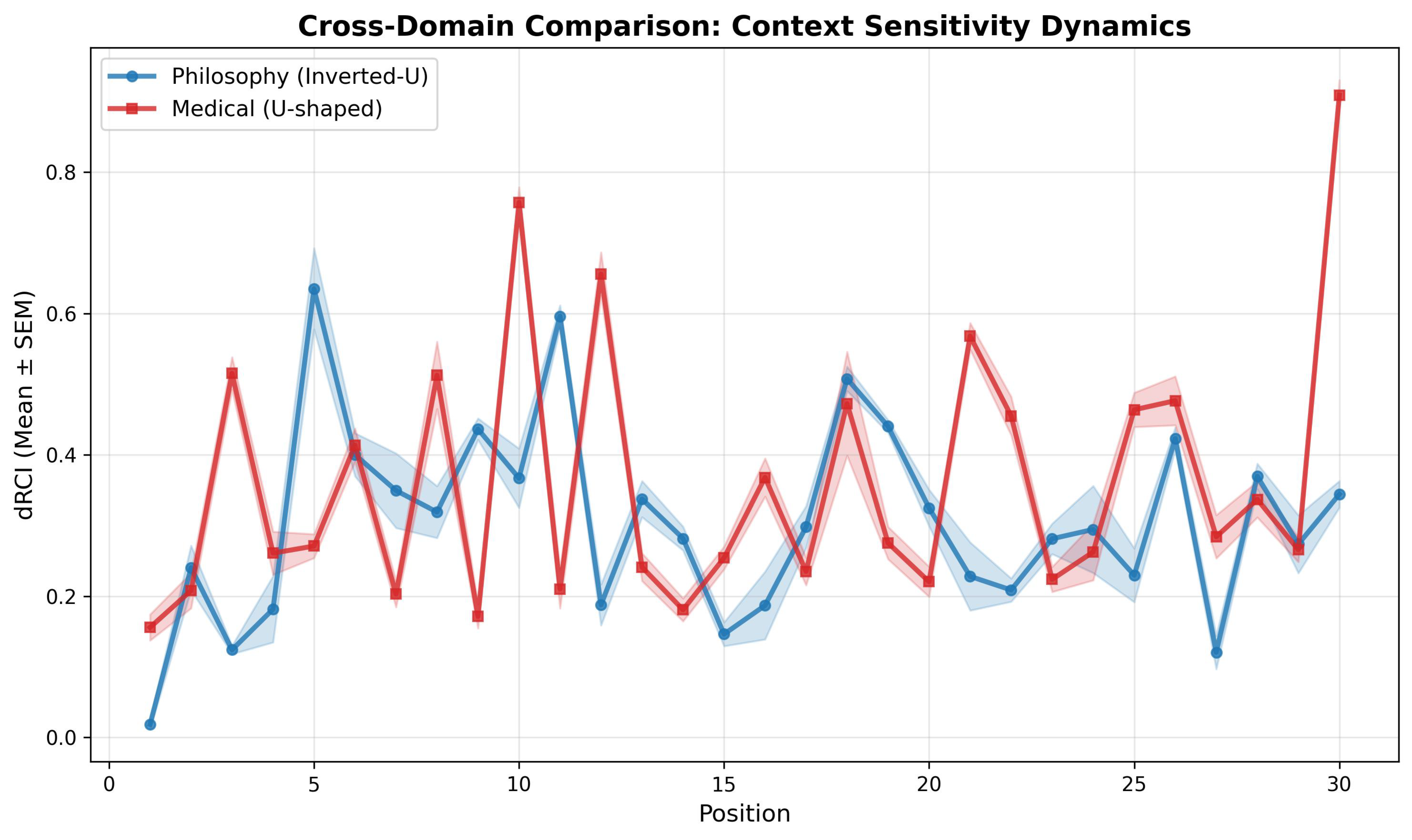
4.4. Finding 4: Position-Level Dynamics
Figure 4 shows the full position-level trajectories. While individual positions show task-specific variation (prompt-dependent oscillations), the aggregate patterns confirm the domain-specific dynamics described above.
5. Discussion
5.1. Two Fundamental Patterns
Our findings support a distinction between two fundamental patterns of context sensitivity dynamics:
Type 1 (Open-Goal): Tasks without definitive endpoints (philosophical reasoning, creative writing, hypothesis generation) show inverted-U temporal dynamics. Context sensitivity peaks mid-conversation during synthesis, then declines as the conversation reaches natural saturation.
Type 2 (Closed-Goal): Tasks with guideline-bounded outputs (medical summarization, legal analysis, diagnostic reasoning) show U-shaped dynamics with task enablement spikes. Context is essential at boundaries—initial framing and final synthesis—with a “diagnostic trough” during information accumulation.
This distinction aligns with Chen et al.’s (2024) observation of “trough zones” in attention allocation, but extends it by showing that trough location is domain-dependent rather than architecture-dependent.
5.2. Clinical Implications
The P30 task enablement finding has direct clinical relevance. Medical summarization at position 30 showed for all 8 models—meaning that without full context, models cannot execute the summarization task meaningfully. In COLD conditions, models produced generic templates or refusals rather than case-specific summaries.
This aligns with recent work on clinical AI safety [6], which documented omission rates of 3.45% in medical summarization. Our findings suggest that such omissions may be position-dependent: summarization quality depends critically on the accumulated context, and models that show high variability at P30 (high Var_Ratio, as documented in our companion Paper 5) pose elevated clinical risk.
5.3. Mechanistic Interpretation
The diagnostic trough (positions 10-25 in medical) may reflect a phase where models are “accumulating” rather than “synthesizing” information. During case presentation, each new clinical fact adds to the context, but the model is not yet required to integrate this information into a coherent output. At position 30, the summarization prompt triggers synthesis, and context sensitivity spikes as the model must draw on the full accumulated history.
Philosophy shows the opposite pattern because open-goal tasks require continuous synthesis—each response must build on prior exchanges—rather than deferred integration.
5.4. Limitations
Several limitations warrant acknowledgment:
- 1.
- Two domains: We tested medical and philosophy only. Whether the Type 1/Type 2 distinction generalizes to other domains (coding, legal, creative) requires further study.
- 2.
- Position-level noise: Raw trajectories show prompt-specific oscillations. The inverted-U and U-shape patterns emerge clearly only in phase-level aggregation.
- 3.
- Scaling hypothesis: Preliminary observation suggests Type 2 task enablement may scale logarithmically with context length (), but with only two anchor points (P10, P30), this remains speculative.
- 4.
- Model count: Philosophy had 4 models vs medical’s 8, limiting cross-domain statistical power.
6. Conclusions
We provide the first evidence that context sensitivity dynamics in LLMs are domain-specific. Medical summarization (closed-goal) produces U-shaped temporal patterns with diagnostic troughs and extreme P30 task enablement (8/8 models, ). Philosophical reasoning (open-goal) produces inverted-U patterns with mid-conversation peaks and no P30 spike (0/4 models).
These findings demonstrate that task structure—not domain content—determines how context sensitivity unfolds over conversation. The universality of disruption sensitivity (, 12/12 models) confirms that context presence matters more than order, an architecture-independent property.
For clinical AI deployment, understanding these dynamics is critical: summarization reliability depends on position-specific context integration, and models with high output variability at P30 may pose elevated patient safety risks.
Acknowledgments
This research builds on human-AI collaborative methodology established in Paper 1. AI systems (Claude, ChatGPT, DeepSeek) assisted with data analysis, visualization, and manuscript preparation. The framework, findings, and interpretations remain the author’s sole responsibility.
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser Polosukhin, I. Attention is all you need. Advances in Neural Information Processing Systems 2017, 30. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; et al. Language models are few-shot learners. Advances in Neural Information Processing Systems 2020, 33. [Google Scholar]
- Guo, X.; Vosoughi, S. Serial position effects of large language models. Findings of the Association for Computational Linguistics: ACL 2025 2025, 927–953. [Google Scholar]
- Chen, Y.; et al. Fortify the shortest stave in attention: Enhancing context awareness of large language models for effective tool use. In Proceedings of the 62nd Annual Meeting of the ACL, 2024; pp. 11160–11174. [Google Scholar]
- Liu, N. F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; Liang, P. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics 2024, 12, 104–123. [Google Scholar] [CrossRef]
- Asgari, E.; et al. A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation. npj Digital Medicine 2025, 8(1), 274. [Google Scholar] [CrossRef] [PubMed]
- Polonioli, A. Moving LLM evaluation forward: lessons from human judgment research. Frontiers in Artificial Intelligence 2025, 8, 1592399. [Google Scholar] [CrossRef] [PubMed]
- Singhal, K.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Laxman, M. M. Context curves behavior: Measuring AI relational dynamics with ΔRCI. Preprints.org 2026a, 202601.1881. [Google Scholar] [CrossRef]
- Laxman, M. M. Standardized Context Sensitivity Benchmark Across 25 LLM-Domain Configurations. Preprints.org 2026b, 202602.1114. [Google Scholar] [CrossRef]
Figure 1.
P30 Z-score analysis. Medical domain (left): all 8 models exceed (orange dashed line). Philosophy domain (right): no model exceeds threshold. 8/8 vs 0/4 split, (Fisher’s exact test).
Figure 1.
P30 Z-score analysis. Medical domain (left): all 8 models exceed (orange dashed line). Philosophy domain (right): no model exceeds threshold. 8/8 vs 0/4 split, (Fisher’s exact test).
Figure 2.
Three-bin temporal analysis. Medical domain (left) shows U-shaped pattern: Early (0.347), Mid (0.311), Late (0.371). Philosophy domain (right) shows inverted-U: Early (0.307), Mid (0.331), Late (0.270).
Figure 2.
Three-bin temporal analysis. Medical domain (left) shows U-shaped pattern: Early (0.347), Mid (0.311), Late (0.371). Philosophy domain (right) shows inverted-U: Early (0.307), Mid (0.331), Late (0.270).
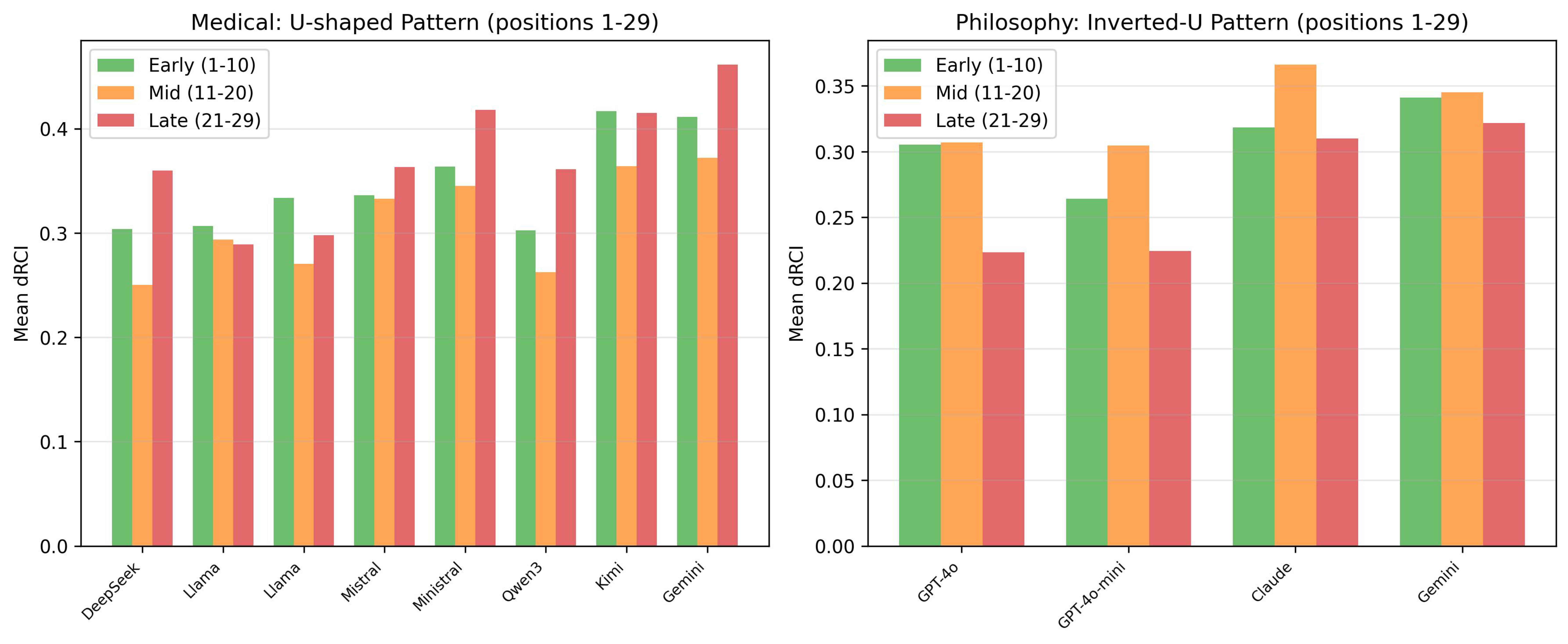
Figure 3.
Disruption sensitivity by model. All 12 models show (bars point left), indicating presence > order. Medical mean , Philosophy mean .
Figure 3.
Disruption sensitivity by model. All 12 models show (bars point left), indicating presence > order. Medical mean , Philosophy mean .
Figure 4.
Cross-domain grand mean with SEM bands. Medical (red) shows U-shaped pattern with dramatic P30 spike ( for all 8 models). Philosophy (blue) shows inverted-U without P30 spike.
Figure 4.
Cross-domain grand mean with SEM bands. Medical (red) shows U-shaped pattern with dramatic P30 spike ( for all 8 models). Philosophy (blue) shows inverted-U without P30 spike.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



