
Submitted:
29 January 2026
Posted:
29 January 2026
You are already at the latest version
Abstract
The Shapley value stands as the predominant point-valued solution concept in cooperative game theory and has recently become a foundational method in interpretable machine learning. In that domain, a prevailing strategy to circumvent the computational intractability of exact Shapley values is to approximate them by reframing their computation as a weighted least squares optimization problem. We investigate an algorithmic framework by Benati et al. (2019), discuss its feasibility for feature attribution and explore a set of methodological and theoretical refinements, including an approach for sample reuse across strata and a relation to Unbiased KernelSHAP. We conclude with an empirical evaluation of the presented algorithms, assessing their performance on several cooperative games including practical problems from interpretable machine learning.
Keywords:
cooperative game theory
; importance sampling
; stratified sampling
; Shapley value
; interpretable machine learning
1. Introduction
The original KernelSHAP paper by Lundberg and Lee [1] from 2017 was a landmark success for interpretable machine learning. Its primary achievement was making the Shapley value [2] — a theoretically optimal but computationally intractable [3,4,5] concept from cooperative game theory [6] — practical for explaining machine learning models. Lundberg and Lee [1] discovered that the exact Shapley values for a prediction could be recovered as the solution to a specially weighted least squares regression problem. By sampling a manageable number of coalitional inputs and solving this approximate regression, KernelSHAP provided a single, consistent metric for feature importance. The accompanying open-source shap library SHAP [1] fueled its widespread use, making it a predominant standard for model interpretation, particularly in the model-agnostic setting.
The follow-up work on Unbiased KernelSHAP by Covert and Lee [7] represents a success in methodological rigor. It addresses the problem that the original KernelSHAP algorithm has not been proven to be unbiased and does not provide uncertainty estimates. While not as publicly visible as the initial breakthrough, this refinement solidified SHAP’s foundation as a robust, statistically sound tool.
According to Lundberg and Lee [1], KernelSHAP was developed without knowledge of prior articles on cooperative game theory like Charnes et al. [8] and Ruiz et al. [9], who decades earlier had already derived the precise weighting scheme that makes a least-squares regression yield the Shapley value when complete data is available. This outlines a fascinating case of parallel innovation across disciplines. Cooperative game theory, with the Shapley value [2] as its most important solution concept, had long been a mature and applied field providing rigorous solutions to real-world problems of fair division and coalitional analysis, from allocating airport landing fees among airlines based on runway use [10] to measuring the voting power of political blocs in a legislature [11,12,13]. Yet, the field of machine learning, increasingly reliant on inscrutable black-box models, had not seen its own predictions as precisely such a system — where input features act as cooperating agents whose joint effort produces a model’s output. Lundberg and Lee’s pivotal contribution [1] was to bridge this conceptual gap. They recognized that the abstract "game" defined by a model’s prediction function was a natural domain for Shapley’s theory. By doing so, they inadvertently reinvented a specific computational tool — the weighted least-squares approximation — from the game theory literature, but with a transformative new purpose: not to analyze economic coalitions, but to explain the inner logic of artificial intelligence.
Whereas KernelSHAP [1] and its unbiased variant [7] are very widely used, the methods from Benati et al. [14] — which are equally based on the least squares formulation of the Shapley value — have received comparatively little attention. This article represents, to our knowledge, their first application in explainable artificial intelligence. We adapt the ideas from Benati et al. [14] as general TU game approximation algorithms, terming their weighted sampling strategy LSS (Least Squares Sampling). Regarding their proposal for stratification, we differentiate S-LSS, an algorithm without sample reuse across strata, from SRS-LSS, an algorithm with sample reuse across strata suggested in Benati et al. [14].
The objective of this paper is neither to introduce a novel Shapley value estimator nor to perform a broad comparison of approximation algorithms. Instead, the contribution of this work is a detailed structural, theoretical, and algorithmic analysis of the methods LSS, S-LSS and SRS-LSS from Benati et al. [14]. We compare the variances of the LSS and S-LSS estimators in detail. We point out how sample reuse across strata may introduce non-zero covariance terms between strata for SRS-LSS. We prove that LSS and UKS approximate the same underlying problem, thereby only differing in their respective sampling strategies. Finally, we test how the unbiased Shapley estimators LSS, S-LSS and SRS-LSS perform in comparison to KernelSHAP and UKS for both classical cooperative games and real-world applications from interpretable machine learning.
The remainder of this article is structured as follows. In Section 2, we summarize basic ideas from cooperative game theory, including linear solution concepts and the Shapley value, and introduce the BShap (Baseline Shapley) model for interpretable machine learning. Section 3 briefly reviews Monte Carlo methods, along with stratified sampling and importance sampling for variance reduction. A summary of results on approximating linear solution concepts by means of importance sampling on the coalition space from our previous work [15] is presented in Section 4. The central developments of this paper are detailed in Section 5. We formally introduce the LSS, S-LSS and SRS-LSS estimators, compare variances of LSS and S-LSS, investigate the emergence of non-zero covariance terms between strata for SRS-LSS and clarify the similarities and differences between LSS and UKS. The empirical performance of the algorithms introduced in Section 5 is analyzed in Section 6 using two types of cooperative games and three real-world explainability scenarios, thereby numerically substantiating our previous analytical claims. The paper concludes in Section 7 with a summary and recommendations.
2. Preliminaries on Cooperative Game Theory, the Shapley Value and the BShap Model for Interpretable Machine Learning
Following the expositions in Chakravarty et al. [6], Peters [16], and Benati et al. [14], this section offers a concise introduction to transferable utility (TU) cooperative games and point-valued solution concepts such as the Shapley value. Additionally, we briefly describe two representative TU games — the airport game and the weighted voting game — and the model from interpretable machine learning which we utilize in our analysis and our numerical experiments in Section 6.
2.1. Transferable Utility Games and Their Characteristic Functions
We investigate transferable utility games (TU games), cooperative games where a coalition’s earnings are expressed as a scalar [6,16]. This implies that the utility can be distributed without restriction among the players.
Following [6,16], a TU game is formally defined as a pair . Here, is the player set and is the characteristic function, which assigns a real value to each coalition representing its total utility from cooperation. We adopt the standard normalization .
It is frequently convenient to represent a coalition S by an indicator vector . We define and its inverse . This mapping allows functions and operators defined on or to be used interchangeably; for instance, and denote the same value, and .
2.2. Linear Solution Concepts for TU Games
Let denote the set of all TU games on player set N. A point-valued solution concept is a function that returns a vector for each game . Each entry quantifies the value assigned to player i. These concepts are employed to evaluate individual influence or to distribute a coalition’s payoff among its members .
A key property of a point-valued solution concept is linearity [14]. This requires that can be written as
with ⊙ denoting the Hadamard product of vectors, standing for weights depending only on S and the player, and denoting values depending upon S, v, and the player.
2.3. The Shapley Value
The Shapley value [2] represents the most prominent solution concept in cooperative game theory. In recent years, it has been extensively adopted in machine learning and explainable artificial intelligence [1,17,18,19]. Formally, for any player , the Shapley value is the expected marginal contribution , taken over all sets S of players that precede i in a uniformly random permutation of N, i.e.,
where stands for a uniform distribution, denotes the set of all permutations of N, and gives the set of players preceding i in a permutation .
Let be the vector of Shapley values, and let represent any approximation, with its i-th entry. Where no ambiguity arises, we use to mean .
It follows directly from () that the Shapley value belongs to the class of linear solution concepts introduced in SubSection 2.2. The coefficients are specified by and
Note that the Shapley value exhibits symmetry, i.e., two players that contribute equally to each coalition have the same Shapley value meaning there holds
for any game and any players with . It also exhibits efficiency, i.e., for all games there holds .
2.4. Airport Games
Airport games, proposed by Littlechild and Thompson [10], address the problem of distributing runway construction costs among players whose aircrafts require different runway lengths. Costs are encoded in a vector , where corresponds to player i. The characteristic function is
2.5. Weighted Voting Games
Weighted voting games [6,16,21] represent voting bodies in which players possess different voting weights (e.g., parliamentary seats), collected in . A coalition S succeeds when for a predetermined quota C. This yields a characteristic function defined by
2.6. Baseline Shapley (BShap) for Interpretable Machine Learning
Our numerical experiments in Section 6 apply the Shapley value framework to attribute a model’s prediction to its input features. Here, the prediction task is interpreted as a cooperative game with features as players. Given a model and an input , the characteristic function specifies the value of a feature subset S.
We adopt Baseline Shapley (BShap), a method originally suggested in [1] and formalized by Sundararajan and Najmi [24]. The value is defined deterministically relative to a single baseline vector , where features not in S are set to their baseline counterparts:
with denoting the set of features not in S. The subtrahend in (8) ensures the normalization as introduced in SubSection 2.1. Note that this normalization would not be needed for the algorithms based on marginal contributions investigated in our article [15], but becomes crucial for the algorithms based on least square formulations of the Shapley value discussed in Section 5.
Our specific baseline: In the applications in Section 6, the baseline is taken as the expected feature vector over the training distribution:
with representing the training data distribution. This anchors Shapley values to the prediction of an average sample, providing a natural reference point. The resulting attributions thus explain the deviation of from this baseline.
3. Preliminaries on Monte Carlo Methods for Estimation
In this section, we first introduce the use of Monte Carlo methods for estimating expectations together with two techniques for variance reduction. We draw mainly from the short overviews provided by Rubinstein and Kroese [25] and Botev and Ridder [26] as well as from the textbook by Rubinstein and Kroese [27].
Let be a d-dimensional discrete (or continuous) random variable with a sample space and a probability mass function (or probability density function, respectively), which may be known or unknown. Denote a specific realization of by . For a function , we want to estimate the expectation
This expectation is frequently intractable in closed form, either because is unknown (and only i.i.d. samples are given) or because the defining sum or integral is computationally infeasible. Monte Carlo methods circumvent this analytical hurdle through simulation.
We begin with Crude Monte Carlo as the foundational method, then present importance sampling and stratified sampling for variance reduction which we examine in this paper. A finite variance of is assumed throughout this manuscript.
3.1. Crude Monte Carlo Method
Crude Monte Carlo proceeds by drawing an i.i.d. sample and averaging the values. This yields the standard estimator [26]:
According to [26], the estimator is unbiased, i.e. , and its variance is
3.2. Stratified Sampling for Variance Reduction
Stratified sampling is a well-established Monte Carlo variance reduction technique [26]. It separates the sample space into ℓ disjoint strata such that with for . Suppose L is a discrete random variable taking values in with known probabilities . We can rewrite as
with standing for the expectation over the conditional probability distribution of given that . Our stratified estimator of becomes
where denotes the estimated value of in stratum , i.e.,
with the sample of size being drawn i.i.d. from the conditional probability distribution of given that . To ensure fair comparisons to other Monte Carlo techniques, we always assume (up to rounding errors), where stands for the overall sample budget. The estimator is unbiased [26], i.e.,
3.3. Importance Sampling for Variance Reduction
Importance sampling introduces another probability mass (or density) function , such that . This allows (9) to be rewritten as
A Monte Carlo approximation based on (13) is
where . As shown in [25], this estimator is unbiased, i.e. , and its variance is analogous to the crude Monte Carlo case
With a properly selected , the variance of the importance sampling estimator is less than or equal to that of the crude Monte Carlo estimator. This follows from comparing (11) and (15), yielding
which holds because can always be chosen as the trivial case. We apply importance sampling in the context of TU games in Section 4.
4. Approximating Linear Solution Concepts via Importance Sampling
The exact calculation of a linear solution concept, i.e., (1), for a TU game normally requires summing up terms whose number grows exponentially in the number of players n. Therefore, approximation algorithms are needed to estimate these values in real-world situations, especially in the context of applications in interpretable machine learning [1,17,18,19] where one can typically not exploit any special structure of the underlying game for computing Shapley values exactly. In this section, we briefly summarize some ideas from [14] and the general framework for importance sampling on the coalition space for linear solution concepts which we recently proposed in [15] and will apply in Section 5.
Benati et al. [14] consider a uniform sampling strategy on the coalition space for approximating linear solution concepts, i.e. they simply adopt the uniform distribution . Let us regard it as the crude Monte Carlo method on the coalition space. Although sampling subsets from the uniform distribution is both straightforward and unbiased, it is obviously not an optimal — or even recommendable — sampling strategy for all linear solution concepts or problem settings. For example, when approximating the Shapley value by sampling coalitions using (), small or large coalitions obtain larger weights resulting in a strong influence on the estimator. However, when sampling uniformly from the coalition space, they may extract only a few samples resulting in a less accurate estimator.
To enable more efficient sampling, we apply the importance sampling technique from SubSection 3.3. By appropriately reweighting the estimator, importance sampling allows us to draw samples from a non-uniform, user-defined distribution while maintaining an unbiased estimate of the underlying linear solution concept.
Theorem 1.
[15] For all , let
be a probability distribution and with be a sample of size τ generated by sampling with replacement according to . Then,
is an importance sampling estimator of the linear solution concept .
The following proposition connects our importance sampling estimator from Theorem 1 established in Pollmann and Staudacher [15] to a finding from Benati et al. [14], p. 95.
Proposition 1.
The importance sampling estimator from Theorem 1 has the following properties:
- (a)
- It is unbiased, i.e.,
- (b)
- Its variance is given by
- (c)
- It is consistent in probability, i.e.,
We note that Theorem 1 and Proposition 1 subsume both the crude Monte Carlo method (setting ) and stratified sampling. The latter is covered because any stratum estimator for a linear solution concept can be written in the form of (16), allowing direct application of these results.
5. Least Squares Approaches for Approximating Shapley Values
This section covers the idea of approaching the approximation of Shapley values as a least squares problem. First, we give an introduction to the family of least square values in Section 5.1, followed by an overview about Shapley value approximation algorithms in this setting in Section 5.2. In Section 5.3, Section 5.4, and Section 5.5, we compare these algorithms and put them into the overall context.
5.1. The Family of least Square Values
The family of least square values was proposed by Ruiz et al. [9] and comprises a generalization of the formulation of the Shapley value as a least squares problem, which was already proposed earlier by Charnes et al. [8].
Essentially, this family consists of all solution concepts that can be obtained as minimizers of a weighted least squares problem, where the weights determine the relative importance of different coalition sizes. These weights are given by the function that assigns a weight to each coalition size with for at least one s. Clearly, per definition, m is symmetric in a sense of assigning the same weight to coalitions of the same cardinality in order to retrieve symmetric solutions like the Shapley value. We denote by a payoff vector for a given game with being the payoff for player i. In the following, we use the shorthand notation . Recall that a payoff vector is called efficient if .
With these definitions established, any solution concept belonging to the family of least square values can be expressed as the optimizer of the following weighted least squares problem:
with m being the weight function that is specific to the particular solution concept.
These expressions illustrate how the resulting allocation depends on the weight function m.
Least square values as linear solution concepts
Let us briefly point out why all members of the family of least square values are linear solution concepts in the sense of the definition from SubSection 2.2. Benati et al. [14] showed that (21) can be rewritten as
where is the all-ones vector and the individual elements of are given by
From (23), it follows directly that this representation satisfies the definition of linear solution concepts provided in SubSection 2.2.
The Shapley value in the context of least square values
The family of least square values was introduced by Ruiz et al. [9] after Charnes et al. [8] had demonstrated that the Shapley value can be expressed as a least squares optimization problem. In detail, the vector of Shapley values is the solution to problem (20) when m is defined as
and therefore, via (22), one obtains
5.2. Shapley Value Approximation Algorithms
In this subsection, we provide an introduction to Shapley value approximation algorithms that are based on the formulation of the Shapley value as a least squares problem. The algorithms discussed below are not meant to be an exhaustive list, but rather represent those algorithms we will analyse and test in the rest of the article. Specifically, the first three algorithms have been proposed by Benati et al. [14] in the context of stochastic approximations of cooperative games and are based on the family of least square values defined in SubSection 5.1, while the latter two have their origins in the machine learning world.
Additionally, we would like to draw attention to the absence of the projection method proposed by Benati et al. [14], which ensures efficiency and symmetry of the obtained estimators. Although this approach potentially improves the accuracy of the estimators (or at least never makes their accuracy worse), it is not agnostic to the underlying characteristic function, as it requires prior knowledge about symmetric players, which is an information that we assume to be unavailable — in particular, in the context of interpretable machine learning. Nevertheless, one could still achieve estimator efficiency through a single evaluation of , similar to Castro et al. [28], who proposed filling the “efficiency gap” post hoc. However, since such additional considerations lie outside the scope of this work, we exclude them equally from all algorithms.
Least Squares Sampling (LSS)
This paragraph deals with an algorithm proposed by Benati et al. [14] that approximates (23) by using importance sampling as defined in Theorem 1. Specifically, we refer to the estimator in Equation (22) on p. 97 in the paper [14] combined with their weighted sampling strategy. In the following, we name this algorithm LSS.
The idea of LSS is to sample coalitions with replacement according to
such that, by combining (24), (25), (26), and (28), one obtains
Then, based on Theorem 1 as well as (23) and (29), an approximation of the Shapley value of player i is given by
where is obtained by sampling times with replacement according to p.
Equation (31) serves as the basis for Algorithm 1. Note that one evaluation of v can be used to update all players, reducing the number of evaluations of v and increasing convergence speed.
| Algorithm 1 LSS |
|
Since (31) is an importance sampling estimator of a linear solution concept in the sense of Theorem 1, which can easily be obtained via (23) and (30), LSS inherits the properties stated in Proposition 1. Thus, the estimator is unbiased, and we can use (18) to calculate its variance:
Proposition 2.
The variance of the LSS estimator is given by
with
for all .
Proof.
Using (18) and setting results in
where . Here, the term is excluded from the variance calculation since it is added once at the beginning of the LSS algorithm, but it is not part of the sampling procedure and thus, there is no randomness to it, and it does not influence the variance of . As a result, we construct a temporary solution concept of the game, , that does not contain the constant term .
Stratified Least Squares Sampling (S-LSS)
This paragraph discusses another algorithm proposed by Benati et al. [14], which approximates the Shapley value through what the authors introduce as their stratification strategy. Specifically, we refer to equations (23) and (24) on p. 97 in the paper [14] without any reuse of samples across strata. In the following, we refer to this method as S-LSS.
The stratification according to [14] comes into play when approximating the individual addends in (21), where a reformulation of (22) results in
Based on that formulation, approximations of , denoted by , are obtained as
with being an i.i.d. sample of size from according to the uniform probability distribution .
Then, based on (27), one obtains an estimator of as
forming the basis for Algorithm 2.
| Algorithm 2 S-LSS |
|
Clearly, by using the formulation given in (35), the estimators can be seen as estimators of individual solution concepts in the sense of Theorem 1 by setting
as well as
and .
Therefore, the individual stratum estimators are unbiased, and (18) can be used to calculate their variances:
Proposition 3.
In the context of the S-LSS algorithm, the variance of is given by
for all and .
Proof.
Based on the individual stratum estimator variances given by Proposition 3, Benati et al. [14] stated the overall variance of the estimated Shapley value of player i as
Perhaps surprisingly and contrary to what might be expected from the definition of stratified sampling in SubSection 3.2, S-LSS does not guarantee a smaller variance compared to LSS, as we discuss in SubSection 5.3 and show empirically in Section 6.
Sample Reuse Stratified Least Squares Sampling (SRS-LSS)
Benati et al. [14] proposed a third algorithm, which is based on the S-LSS algorithm and reuses samples across strata. Specifically, we refer to the final three sentences in subsection 4.2 on p. 97 in the paper [14]. In the following, we refer to this method as SRS-LSS.
The central idea is to reuse one evaluation in (35) to update all stratum estimators where and , hence the name. To achieve that, samples of size are drawn from with probabilities . Based on the elements of , all stratum estimators with are updated with a single evaluation . As a side effect, the number of evaluations of v that are used to update player j’s stratum, i.e., , are dependent on the generated samples, which is why, in Algorithm 3, we need to keep track of their values as well. This essentially means that all become estimators themselves, which is why we denote them by . Additionally, we use to denote unnormalized estimators of before dividing by .
| Algorithm 3 SRS-LSS |
|
One needs to guarantee that for all and in order for SRS-LSS to function properly and avoid divisions by zero. One straightforward approach is to repeatedly generate samples until this condition is satisfied, or alternatively, to employ a conditional probability distribution that accounts for which elements have not yet been sampled. In the remainder of this work, we rely on the results from the following proposition, and therefore, we do not incorporate additional safeguards into Algorithm 3.
Proposition 4.
Let as for all . Then, with probability approaching one asymptotically, each stratum estimator receives at least one sample, i.e.,
Proof.
The probability of a player belonging to a random coalition of size is given by . Thus, we have
Since Benati et al. [14] did not include a variance analysis of the SRS-LSS estimator in their work, we refer to SubSection 5.4 for a detailed discussion of the variance of the obtained estimator.
KernelSHAP (KS)
Let us now introduce the KernelSHAP algorithm, one of the predominant Shapley approximation algorithms in the machine learning world. It was developed by Lundberg and Lee [1], without knowledge of prior works like [8] and [9]. The optimization objective is
to calculate the Shapley values for the cooperative game [7]. Here, denotes a probability mass function satisfying and such that
where
is the Shapley kernel and
is a normalization constant [7]. As noted in SubSection 2.1, all functions defined on are implicitly also defined on N.
Since solving (40) requires optimizing over the elements in , a set that grows exponentially in n, KernelSHAP approximates Shapley values by generating a sample of size and solving the approximate optimization problem defined over the sampled subsets only, i.e.,
Based on the Lagrangian, Covert and Lee [7] derived the closed-form solution
The resulting estimator is consistent in probability, but assessing its unbiasedness or variance is challenging due to terms like . While the unbiasedness or variance of or can be analyzed individually [7], their interaction complicates the analysis of the final Shapley value estimator.
The KernelSHAP algorithm will not be further analyzed theoretically in this work. Due to its setup, it is unclear how the obtained estimator fits the framework defined by Theorem 1 or Monte Carlo estimators introduced in Section 3 in general. To the best of our knowledge, no analytic solution for its variance or a proof of its unbiasedness has been derived up today, which is why the unbiased KernelSHAP algorithm was introduced, guaranteeing unbiasedness and facilitating the variance analysis of the obtained Shapley value estimator.
Unbiased KernelSHAP (UKS)
The UKS algorithm [7] is a continued development of the KernelSHAP algorithm from the previous paragraph, where we pointed out that it is unclear if the KernelSHAP estimator is unbiased due to the interactions between and .
Considering the original optimization problem defined in (40), its Lagrangian with multiplier is given by
whereby Z is a random variable taking values from and being distributed according to p defined by (41). With that formulation given, the closed-form solution of the original problem can be derived as
Clearly, cannot be computed exactly for large n, since it depends on v, and thus, needs evaluations of v in order to be exact. Nevertheless, since A does not depend on v and the probability distribution p is known, A can be pre-computed and is exact, which is the main improvement introduced by UKS in contrast to the original KernelSHAP algorithm.
Thus, UKS estimates all players’ Shapley values via
where is defined in (45) as for the KernelSHAP algorithm, i.e., , and is given by
with
Following the results provided in [7], the resulting Shapley value estimator is unbiased and consistent in probability. Furthermore, its covariance is given by
with
and
5.3. Comparison of LSS and S-LSS
In this subsection, we first clarify the relationship between the two algorithms LSS and S-LSS which we introduced at the beginning of SubSection 5.2, followed by a detailed comparison of variances.
Algorithm Comparison
For comparing the algorithms LSS and S-LSS, we start with the following proposition:
Proposition 5.
In the sense of the definition of stratified sampling provided in Section 3.2, S-LSS is not a valid stratification scheme of LSS.
Proof.
As stated in Section 3.2, stratification divides the sample space into strata , such that for and .
By observing the strata definitions given in (34), one obtains that their sample spaces have the intersection
Clearly, for any coalition size , this set is nonempty, since it contains at least one element of the form , whereby the dots indicate the presence of distinct players other than j and . Therefore, S-LSS does not form a valid partition of the sample space as required by our definition in SubSection 3.2. □
We note in passing that the structure of the overlap between strata is such that it does not introduce a bias in the Shapley estimator defined by S-LSS.
In order to generate a deeper understanding regarding the relationship between LSS and S-LSS, we explain how Benati et al. [14] derived the LSS algorithm from the initial formulation given by (21). Via (21) and (22), one directly obtains
which matches the formulation proposed in (23) with weights given by (24). Therefore, one evaluation of v for a given S in (51) corresponds to updating all where in (50). This implicit update of all where is encapsulated by the weight function .
As a result, stratifying by s and j, as done in the case of S-LSS, cannot be derived from LSS in the same way as defined in Section 3.2, since LSS is an algorithm that simultaneously updates multiple strata of S-LSS with a single sampled element, i.e., with one evaluation of v.
We conclude that the statement from SubSection 3.2, which points out that stratified sampling always yields a variance less than or equal to that of the crude Monte Carlo method, does not apply here, since S-LSS is not a valid stratification scheme of LSS. Therefore, in order to understand how their variances compare, we calculate both algorithms’ variances on two selected examples.
Variance Comparison in the Absence of Variance Within Strata
First, let us compare the variances of the LSS and S-LSS estimator in the context of an example game characterized by large variance between strata and no variance within strata. In particular, we consider a cardinality game with players and the characteristic function
Lemma 1.
On the game defined by (52) with , the variance of the LSS estimator is greater zero for all players, i.e.,
Proof.
First, we obtain that the Shapley values of the game are given by for all , since all i are symmetric. Without loss of generality, we fix one player in order to simplify notations. Then, by using Proposition 2, we derive
Inserting into (32), multiplying by , and using the identities defined by (37) as well as
results in
Dividing by , we obtain
□
Lemma 2.
On the game defined by (52) with , the variance of the S-LSS estimator is zero for all players, i.e.,
as long as for all and .
Proof.
Without loss of generality, we fix and in order to simplify notations.
To calculate the variances of the individual stratum estimators via (36), the exact values of the stratum estimators are required. By using the identity (37), these are given by
□
Corollary 1.
There exist games for which the variances of all players’ S-LSS estimators are smaller than those the corresponding LSS estimators, i.e.,
as long as the sample allocation scheme of S-LSS satisfies for all and .
Proof.
The proof is straightforward and follows directly from Lemmas 1 and 2. □
Variance comparison in the presence of variance within strata
Let us now consider a weighted voting game as defined in (6) with
as a second example. Here, we use concrete numbers in order to simplify calculations. In detail, we are interested in the variances of the Shapley value estimators of player 2 with Shapley value .
To simplify our later reasoning, we first calculate the population and estimator variances for all strata of the S-LSS estimator in Table 1.
Lemma 3.
On the game defined by (55), the variance of player 2’s LSS estimator is given by
Lemma 4.
On the game defined by (55), the variance of player 2’s S-LSS estimator with equal sample allocation is given by
Proof.
Corollary 2.
There exist games for which the variance of a player’s S-LSS estimator with equal sample allocation is larger than that of the LSS estimator, i.e., for some .
Proof.
The proof is straightforward and directly follows from Lemmas 3 and 4. □
Although an equal sample allocation scheme might be a reasonable choice, especially when calculating all players’ Shapley values, one might still ask whether alternative allocation procedures could further reduce the variance of the S-LSS estimator. While our goal is to treat characteristic functions — and, in the context of explainable machine learning, the machine learning models behind them — as black boxes without relying on internal knowledge, let us examine a sample allocation strategy that makes use of a priori information about the variances within strata. Interestingly, we will see that even this variance-informed allocation performs worse than the LSS method on the weighted voting game defined by (55).
Lemma 5.
On the game defined by (55), the variance of player 2’s S-LSS estimator with an optimum sample allocation, i.e., a sample allocation that is tailored to player 2 in order to minimize the variance of their estimator, is given by
Proof.
By inserting the estimator variances from Table 1 into (38), we obtain
whereby is the fraction of that is used for estimating the stratum with and is the fraction of that is used for estimating the stratum with .
Therefore, we get the proxy minimization problem
Let us now set
with its derivative given by
Setting , we get
with being the only solution in . Furthermore, since
we obtain that indeed is a minimum with value Thus, via (56), the minimum variance of the S-LSS estimator is given by
□
Corollary 3.
There exist games for which the variance of a player’s S-LSS estimator with optimum sample allocation, i.e., a sample allocation that is tailored to that specific player in order to minimize the variance of their estimator, is larger than that of the LSS estimator, i.e., for some .
Proof.
The proof is straightforward and directly follows from Lemmas 3 and 5. □
Concluding Variance Comparison of LSS and S-LSS
Recapitulating the results from the previous two paragraphs, we obtain:
Theorem 2.
Depending on the specific cooperative game, the variance of a player’s Shapley value estimator may be smaller under either LSS or S-LSS, even when the S-LSS algorithm uses an optimal, player-specific sample allocation.
Proof.
The proof is straightforward and directly follows from Corollaries 1 and 3. □
To summarize the results in this subsection so far, Proposition 5 demonstrates that S-LSS is not the stratified variant of LSS in a sense of the definition provided in Section 3.2, and Theorem 2 states that neither of both algorithms is preferable over the other one on all cooperative games. Since the proof of Theorem 2 builds on the calculation of both algorithms’ theoretical variances on two distinct games, it does not provide an intuitive explanation why S-LSS may perform worse than LSS in some settings. Therefore, we provide an explanation in the following.
Since Benati et al. [14] did not provide a sample allocation scheme for the S-LSS algorithm, we first derive a proportional sample allocation similar to SubSection 3.2, which is motivated by the fact that all coalition sizes are equally likely in the context of LSS, i.e.,
with , whereby is the probability mass function from (28).
Furthermore, once a random coalition of some size is sampled, the probability of any player being in it is the same for all players, i.e.,
Then, the overall probability that a random coalition belongs to a specific stratum of the S-LSS algorithm — which is the case when meets a specific size s and, additionally, some specific player j is in it — is given by
As we established at the beginning of this subsection, the statement on variance reduction for a stratified estimator with stratum sample sizes proportional to the probabilities of sampled elements belonging to a stratum from SubSection 3.2 does not apply in this context since S-LSS is not a valid stratified variant of LSS. However, the proportional sample allocation will come out as a useful starting point for our subsequent explanations. Moreover, as established in Theorem 2, the exact choice of the applied sample allocation scheme does not alter the fact that S-LSS can perform worse than LSS, since the increased variance of S-LSS was also observed under an optimal allocation scheme. Additionally, as we will show later, sample allocation strategies other than the proportional sample allocation do not change the outcome and conclusions of our following reasoning.
Hence we set all . Then, we obtain
On the other hand, let us now find out how often a sample is expected to belong to a stratum of S-LSS when actually running LSS, which is denoted by . Via (57), we obtain
Finally, by comparing (58) and (59), we observe
for all and . Clearly, (60) shows that the expected sample size for stratum is larger by a factor of when executing LSS in comparison to the corresponding sample size of S-LSS with a proportional sample allocation. This is due to the fact that LSS actually updates multiple strata with one evaluation of v, see the beginning of this subsection. We conclude that S-LSS might eliminate the variance between the estimators of different strata (similar to the definition provided in SubSection 3.2), but taking into account the results from Proposition 3, one obtains the dependency on when quantifying the stratum estimators’ variances, which results in larger variances of the individual stratum estimators due to smaller .
This underscores our observations from the previous paragraphs. Whenever the variances within strata are small, e.g., in the context of the game defined by (52), the small sample sizes for each stratum are enough for S-LSS to provide accurate stratum estimators, and the variance between the strata is eliminated by algorithm design. Contrary, if the variances within strata are larger, e.g., in the context of the game defined by (55), the reduced amount of samples available for individual strata of the S-LSS algorithm might increase the stratum estimators’ variances more than the stratified algorithm design reduces the overall variance.
This result does not only apply to our chosen sample allocation scheme, i.e., the proportional sample allocation. Clearly, from (60), one obtains that there are too little samples available for the individual stratum estimators in comparison to LSS, and any other sample allocation scheme would also have the drawback that there exists at least one stratum for which there are fewer samples available in comparison to LSS. Additionally, we highlight that even an optimized sample allocation cannot account for the reduced amount of samples available, see Lemma 5 and Corollary 3.
In summary, we recommend using LSS whenever one expects large variances within the strata of S-LSS and a small variance between the stratum estimators. On the other hand, whenever one expects a large variance between the stratum estimators and small variances within strata, we recommend choosing S-LSS. In the latter case, if one has information about the exact variances of individual strata or a good approximation of them, one could distribute the sample sizes across strata similar to the procedure from Lemma 5. Additionally, we highlight that several improvements can be made in order to reduce the mutual shortcomings of both algorithms. One approach is the reuse of samples across strata in order to eliminate the sample size inequality from (60), which was proposed by Benati et al. [14] and introduced as SRS-LSS in SubSection 5.2. However, as we will point out in SubSection 5.4, this approach adds covariance terms to the overall variances of the Shapley value estimators. Another improvement could be some kind of two-stage algorithm, where the first stage is used to decide whether the LSS or S-LSS algorithm should be executed in the second stage.
Finally, we visualize the behavior of LSS and S-LSS when applied to different cooperative games. Figure 2 illustrates the previously obtained results by plotting the variances of LSS and S-LSS against weighted voting games with different quotas. As expected, the variances show a clear dependence to the underlying game, determining whether LSS or S-LSS performs better.
5.4. Analysis of the Variance of SRS-LSS
Since Benati et al. [14] did not address the variance of the SRS-LSS algorithm, we derive:
Proposition 6.
Proof.
Recall the closed-form formulation of the Shapley value as a member of the family of least square values in (27). By using the stratification scheme introduced in (34), one obtains the estimator
with
With these definitions in place, the variance of the Shapley value estimator is given by
where
and
Then, via (63), we rewrite
for all , but since samples are independent for , the equation can be simplified to
Next, from line 12 in Algorithm 3, we derive
with , , and .
Proof.
Theorem 3.
For SRS-LSS, the covariance terms in (61) do not vanish in general.
Proof.
To simplify notations, we first obtain from (62) that the constant, non-zero term can be ignored when demonstrating that might occur. Therefore, we define
Now, we demonstrate by example that may be non-zero. For this purpose, we define a weighted voting game with and quota , such that the only winning coalition of size 2 is . Let us now fix , such that the corresponding sample is obtained as . Without loss of generality, we set the sample size to .
In Proposition 4, we established that the probability of at least one value being zero converges to zero as . For , this probability is given by
where . We denote this event by B and its complement by , such that .
Although in this example the probability of failing to sample at least one element from each stratum is relatively large, we proceed under the standard assumption that this probability is negligible, which is justified for large . Therefore, we calculate the conditional expectations in Table 2 based on the assumption that B does not occur.
Based on Table 2, the conditional covariance between and can be calculated as
Although conditioning on is necessary for computing the covariance, it may slightly affect its numerical value. The true (unconditional) covariance could differ marginally. Accounting for the undefined cases would require specifying a particular strategy to handle such edge cases, which was not proposed for the SRS-LSS algorithm and lies beyond the scope of this investigation. Nevertheless, the key point remains that the covariance does not vanish. As can be observed from the and columns in Table 2, these quantities have a clear positive correlation. Since players 1 and 3 together form the only winning coalition of size 2, large realizations of necessarily coincide with large realizations of . This dependence confirms that , and as a result, we have . □
From Theorem 3, it follows that reusing evaluations of the characteristic function introduces non-zero covariance terms. These terms are hard to characterize, which complicates the exact computation of the SRS-LSS estimator’s theoretical variance and its comparison to LSS and S-LSS. A detailed analysis of (62) together with the resulting influence on (61) might be a question for further research. In the meantime, we rely on empirical observations of the SRS-LSS estimator’s variance in the numerical experiments in Section 6, which indicate a significantly reduced variance of SRS-LSS in comparison to LSS and S-LSS.
5.5. Comparison of LSS and UKS
In the following, we compare LSS (Algorithm 1) with UKS (see the end of SubSection 5.2). First, we show how UKS fits into the general importance sampling framework defined by Theorem 1 and discuss the relationship between both algorithms within this context. Subsequently, we compare their variances.
Before going into detail, we note that the formulation of UKS derived in the following was already proposed by Fumagalli et al. [30]. The authors identify UKS as a special case of their SHAPley Interaction Quantification framework, which enables a reformulation of the algorithm similar to ours. Nevertheless, we present our derivations for several reasons. First, our derivation of UKS is, from our perspective, more intuitive. Second, while Fumagalli et al. [30] suggest that their framework enables a particular formulation of UKS that arises specifically from their approach, this form of UKS can also be directly obtained by expanding the matrices and vectors in (46) without using the indirection via their SHAPley Interaction Quantification framework. Third, UKS has not yet been formally integrated into the importance sampling framework defined by Theorem 1, which allows us to directly apply our results from Proposition 1. Finally, and most importantly, to the best of our knowledge, we are the first to demonstrate that UKS approximates the same underlying problem as LSS, establishing a novel link between the two algorithms.
We refer to Appendix A, which shows that our following results are consistent with those of Fumagalli et al. [30].
Algorithm Comparison
First, recall the definition of LSS given in (30) with being defined in (24), m in (25), in (26), and p in (28). Since we have only derived so far and not directly, inserting m into results in
for the case , and
for the case . Thus, can be rewritten as
Now, let us turn our attention to the UKS algorithm:
Proposition 7.
We now aim to show that both algorithms share the same weight function w and the same initial term, i.e., and . To prepare for this, we first carry out some reformulations in order to simplify the upcoming calculations. Readers only interested in the final result may skip ahead to Theorem 4.
Lemma 6.
Proof.
Lemma 7.
Proof.
The article by Fumagalli et al. [30] shows that the off-diagonal entries of the inverse of A as defined in (47) are given by
Its denominator can be reformulated as
and thus,
For the diagonal entries, Fumagalli et al. [30] provides
and similarly to (72), its numerator can be derived as
□
Proposition 8.
The constant terms of both algorithms are equal, i.e.,
Proof.
From (47) one directly obtains that is an eigenvector of A with eigenvalue . Thus, we have . With that given, rewriting t from Proposition 7 results in
□
Lemma 8.
For any and , there holds
Proof.
Using Lemma 7, we derive
and thus,
Furthermore, also based on Lemma 7,
and therefore,
□
Proposition 9.
For all with and ,
Proof.
From Proposition 7, we obtain
Using Lemma 7, we derive
Rewriting the Shapley kernel from (42) to follow our general notation for cooperative games results in
□
Proposition 10.
For all with and ,
Proof.
From Proposition 7, we have
Using Lemma 7, we derive
□
Theorem 4.
The estimators obtained via LSS and UKS are both importance sampling estimators for the same linear solution concept in a sense of Theorem 1, differing only in their respective sampling strategies.
Proof.
Proposition 7 shows that UKS can also be written in this form, sharing the same constant term , see Proposition 8. Moreover, by combining propositions 9 and 10, one obtains
for , which is identical to the weight function of LSS defined in (68).
Therefore, we conclude that both algorithms are importance sampling estimators of the same problem
with .
We illustrate the result from Theorem 4 in Figure 3 which visualizes the different sampling strategies of LSS and UKS for .
Variance Comparison
In the previous section, we showed that UKS fits the importance sampling framework introduced by Theorem 1, see Proposition 7 and Theorem 4. Therefore, although Covert and Lee [7] already provided (49) as the variance for the UKS estimator, we can now use a different formulation:
Proposition 11.
The variance of the UKS estimator is given by
with
Proof.
In Figure 4, we use Proposition 11 to compute the variances of UKS and Proposition 2 for those of LSS. As expected, neither LSS nor UKS outperforms the other, since they implement the same algorithm while differing only in their respective sampling strategies. The effectiveness of any given sampling strategy depends on the characteristics of the underlying problem, such as the parameters of the weighted voting game. Obviously, there exist problems for which sampling strategies other than the one employed in LSS or UKS achieve superior performance. More broadly, this illustrates that no single sampling strategy is universally optimal, and selecting the most effective one requires tailoring it to the specific problem.
6. Empirical Results
We validate our results by applying the algorithms introduced in SubSection 5.2 to approximate Shapley values for airport games, weighted voting games, and three real-world interpretable machine learning problems.
The algorithms introduced in SubSection 5.2 were implemented in Python. Both the implementations and test problems can be freely accessed via the first author’s GitHub repository
https://github.com/tim-pollmann/shapley-least-squares (accessed on 27 January 2026).
We consistently assume that all players’ Shapley values must be estimated. Although not universal, this is common in explainable machine learning, where one seeks to explain a prediction using all features.
Before proceeding, we note that each algorithm uses different parameters to determine the number of sampled coalitions and thus, evaluations of the characteristic function v. For fair comparisons, we introduce a unified sample budget T, ensuring each algorithm performs T evaluations of v, up to negligible rounding errors.
The overall sample budget T, introduced above, sets the total number of v evaluations per algorithm. We now express the parameters of each algorithm from SubSection 5.2 in terms of T.
For LSS (Algorithm 1) and UKS (see the end of SubSection 5.2), this is a one-to-one mapping, i.e., . Note that we ignore the single evaluation of v needed for calculating the initial term , since it is negligible in comparison to the rounding errors of other algorithms, especially for large T.
S-LSS (Algorithm 2) divides the sample space based on distinct values of s, for each . We use the heuristically motivated proportional sample allocation from (58) to obtain
Finally, SRS-LSS (Algorithm 3) divides the sample space into distinct sets. Thus, for simplicity, noting that alternative sample allocation schemes across strata may provide better results, we set
We conclude that the deviation from the true total sample budget T is 1 for LSS and UKS, while the upper bounds of their deviations are given by for S-LSS and for SRS-LSS. We consider these deviations to be negligible in our subsequent analysis, in particular for large T.
Note that for SRS-LSS (Algorithm 3), it is not guaranteed that the algorithm runs successfully in the sense that every stratum receives at least one sample, compare Proposition 4. In our mean squared error comparisons, we mandate for any that at least half of all runs must be successful for the results to be displayed in the final figure.
With these definitions established, we proceeded with our experiments.
Figure 5 confirms the theoretical variances of LSS and S-LSS presented in Propositions 2 and 3, respectively. Moreover, it underscores our results from Theorem 2, where we demonstrated that one or the other algorithm might achieve a smaller variance, depending on the underlying cooperative game. Furthermore, we validate that LSS and UKS perform as expected with respect to the theoretical variances presented in Propositions 2 and 11 as Figure 5 clearly illustrates that the derived theoretical variances are accurate and that, depending on the specific problem, either LSS or UKS may slightly outperform the other, as one sampling strategy might be better suited to the given task than the other method, see Theorem 4.
As for mean squared error comparisons, we first look at an airport game with 100 players specified in Castro et al. [31] and compare the approximation methods from SubSection 5.2 in Figure 6. Note that the graph for SRS-LSS begins only at a sample size of 50,000, as Proposition 4 fails too frequently with smaller sample budgets. With players, guaranteeing at least one sample per stratum becomes more challenging.
Figure 7 compares mean squared errors for our Monte Carlo estimators from SubSection 5.2 for a weighted voting game with 50 players and normally distributed weights, which was previously employed in the software EPIC [22,23]. It can be found on the GitHub page of the second author via https://github.com/jhstaudacher/EPIC/blob/master/test_cases/normal_sqrd/normal_sqrd.n50.q249646.csv.
Figure 8 compares mean squared errors for our Monte Carlo estimators from SubSection 5.2 for a weighted voting game with 150 players and uniformly distributed weights, which was previously employed in the software EPIC [22,23]. It can be found on the GitHub page of the second author via https://github.com/jhstaudacher/EPIC/blob/master/test_cases/uniform/uniform.n150.q35951.csv. Note that the graph for SRS-LSS begins only at a sample size of 150,000, as Proposition 4 fails too frequently with smaller sample budgets. With players, guaranteeing at least one sample per stratum becomes even more challenging than in the airport game from Figure 6.
Figure 9 uses the standard diabetes dataset (442 patients, 10 baseline features) where the target is disease progression after one year. We train a Gradient Boosting Regressor and evaluate the approximation methods from SubSection 5.2 by their mean squared error against exact reference Shapley values.
In Figure 10, the California housing dataset (20,640 entries, 8 features) predicts median house value in hundreds of thousands of dollars. Using an MLP Regressor, we compare approximation methods by their mean squared error on Shapley value estimation against exact references.
Figure 11 uses the classic wine dataset (178 instances, 13 features, 3 wine classes). We train a Random Forest Classifier and evaluate the approximation methods from SubSection 5.2 via mean squared error in estimating Shapley values for predicting the probability of class 0 only.
Let us summarize the comparisons of mean squared errors of all algorithms for approximating the Shapley value from SubSection 5.2 in Figure 6, Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11 succinctly. As expected, LSS and UKS perform more or less equally for all six test problems. SRS-LSS outperforms the other three provably unbiased algorithms LSS, S-LSS and UKS for all test problems. This observation is consistent with the results shown in Figure 1 in Benati et al. [14], where only LSS and SRS-LSS were compared. Therefore, we conclude that the covariance terms established in Theorem 3 do not significantly affect the overall variances of individual players’ Shapley value estimators negatively. S-LSS performs worst for five test problems with the notable exception of the airport game with 100 players in Figure 6 where S-LSS is even faster than KernelSHAP (KS). Not surprisingly, KS is consistently faster than UKS and LSS. For the three large cooperative games in Figure 6, Figure 7 and Figure 8 SRS-LSS converges faster than KS, whereas that comparison reverses for the machine learning tasks in Figure 9, Figure 10 and Figure 11.
7. Summary, Conclusions and Outlook
The celebrated KernelSHAP approach by Lundberg and Lee [1] as well as its later refinement Unbiased KernelSHAP (UKS) proposed by Covert and Lee [7] compute the Shapley value as a least squares optimization problem. While these two algorithms are extremely well established in the machine learning community, the methods from the paper by Benati et al. [14] — which are also based on the least square formula for the Shapley value — have received fairly little attention. To our knowledge, we are the first to apply them in the context of explainable artificial intelligence. We formulate the ideas from Benati et al. [14] as approximation algorithms for general TU games. We refer to their weighted sampling strategy as LSS (Least Square Sampling). As for their approach towards stratification, we distinguish S-LSS with no reuse of samples across strata and SRS-LSS with sample reuse across strata as proposed in Benati et al. [14].
As the result of our thorough and detailed analysis of LSS, S-LSS and SRS-LSS, we presented three key findings.
First, in Proposition 5, we showed that S-LSS as proposed in [14] is not a valid stratified variant of LSS in the sense of the definition provided SubSection 3.2,i.e., for S-LSS the strata overlap. Therefore, we demonstrated that S-LSS might reduce the variance of the obtained estimator, but it could also lead to an increase in comparison to LSS, see Theorem 2.
Second, in Theorem 3, we showed that the SRS-LSS approach proposed by Benati et al. [14] introduces covariance terms between stratum estimators, making its theoretical variance difficult to analyze. Although empirical results suggest that the variance is significantly reduced in comparison to LSS and S-LSS, a theoretical analysis remains an open research question.
Third, in Theorem 4, we established that LSS and UKS are importance sampling estimators in the sense of Theorem 1, addressing the same underlying problem but differing in their respective sampling strategies. Therefore, neither LSS nor UKS is superior over the other one. Which algorithm’s variance is smaller depends on the underlying problem and whether the respective sampling strategy is suitable for this problem or not.
As noted in the introduction, this paper’s aim is neither to propose a new Shapley value estimator nor to compare numerous approximation algorithms. Rather, the focus is on providing structural, theoretical, and algorithmic insight into the methods from Benati et al. [14]. While antithetic sampling — as discussed, for instance, in [32] — could be integrated into the SRS-LSS algorithm, this would have vastly exceeded the scope of this study. In the future, it could be worthwhile to investigate whether there are algorithmic approaches comparable to sophisticated stratification strategies [28,33,34] which could be successfully incorporated to enhance the performance of SRS-LSS. Definitely, our theoretical and numerical results suggest that the SRS-LSS estimator — which is unbiased — justifies more attention. Another, perhaps even more pressing question, is why SRS-LSS outperforms KernelSHAP for weighted voting games and airport games while KernelSHAP exhibits superior performance for our test problems from interpretable machine learning. We have yet to identify the properties of the characteristic function responsible for this phenomenon.
Author Contributions
Conceptualization, T.P. and J.S.; Methodology, T.P. and J.S.; Software, T.P.; Validation, J.S.; Formal Analysis, T.P. and J.S.; Writing—original draft, T.P. and J.S.; Writing—review & editing,, T.P. and J.S.. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| uniform distribution | |
| ⊙ | Hadamard product of vectors |
| estimator or estimated value | |
| all-ones vector with dimension being clear from context | |
| all-zeros vector with dimension being clear from context | |
| indicator function, 1 if condition is satisfied, 0 otherwise | |
| n | number of players |
| N | player set, |
| v | characteristic function, |
| S | coalition, |
| indicator vector corresponding to coalition S, | |
| subset corresponding to indicator vector , | |
| weight vector, | |
| value vector, | |
| linear solution concept, | |
| Shapley value | |
| p | probability mass function used for sample generation, |
| sample size | |
| sampled coalition, | |
| sample consisting of coalitions, , |
Appendix A. Comparison of Our Results Against the SHAPley Interaction Quantification (SHAP-IQ) Formulation of UKS
Fumagalli et al. [30] state that choosing the probability mass function
with being the -th harmonic number ensures that UKS is equal SHAP-IQ for the Shapley value.
In detail, they state that the estimator obtained via UKS can be rewritten as
where .
By comparing this formulation to (70) and Proposition 8, one obtains that it shares the same initial term with the formulation of UKS derived by us.
Next, we compare the functions and . For , we find
If , we obtain
which matches the case in (79).
On the other hand, if , we have
which matches the case in (79).
References
- Lundberg, S.M.; Lee, S. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar] [CrossRef]
- Shapley, L. S. A value for n-person games. Contributions to the Theory of Games 1953, 28, 307–317. [Google Scholar]
- Deng, X.; Papadimitriou, C. H. On the complexity of cooperative solution concepts. Math. Oper. Res. 1994, 19, 257–266. [Google Scholar] [CrossRef]
- Faigle, U.; Kern, W. The Shapley value for cooperative games under precedence constraints. Int. J. Game Theory 1992, 21, 249–266. [Google Scholar] [CrossRef]
- Fernández, J.R.; Algaba, E.; Bilbao, J.M.; Jiménez, A.; Jiménez, N.; López, J.J. Generating functions for computing the Myerson value. Ann. Oper. Res. 2002, 9, 143–158. [Google Scholar] [CrossRef]
- Chakravarty, S.R.; Mitra, M.; Sarkar, P. A Course on Cooperative Game Theory; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Covert, I.; Lee, S. Improving KernelSHAP: Practical Shapley Value Estimation Using Linear Regression. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics; Banerjee, A., Fukumizu, K., Eds.; PLMR, 2021; Volume 130, pp. 3457–3465. Available online: http://proceedings.mlr.press/v130/covert21a/covert21a.pdf (accessed on 27 January 2026).
- Charnes, A.; Golany, B.; Keane, M.; Rousseau, J. Extremal Principle Solutions of Games in Characteristic Function Form: Core, Chebychev and Shapley Value Generalizations. In Econometrics of Planning and Efficiency; Springer Netherlands: Dordrecht, 1988; Volume 11, pp. 123–133. [Google Scholar] [CrossRef]
- Ruiz, L.M.; Valenciano, F..; Zarzuelo, J.M. The Family of Least Square Values for Transferable Utility Games. Games Econ. Behav. 1998, 24, 109–130. [Google Scholar] [CrossRef]
- Littlechild, S.C.; Thompson, G.F. Aircraft landing fees: a game theory approach. Bell J. Econ. 1977, 8, 186–204. [Google Scholar] [CrossRef]
- Algaba, E.; Bilbao, J.M.; Fernández-García, J.R. The distribution of power in the European Constitution. Eur. J. Oper. Res. 2007, 176, 1752–1766. [Google Scholar] [CrossRef]
- Kóczy, L.A. Beyond Lisbon. Demographic trends and voting power in the European Union Council of Ministers. Math. Soc. Sci. 2012, 63, 152–158. [Google Scholar] [CrossRef]
- Kóczy, L.A. Brexit and Power in the Council of the European Union. Games 2021, 12, 51. [Google Scholar] [CrossRef]
- Benati, S.; López-Blázquez, F.; Puerto, J. A stochastic approach to approximate values in cooperative games. Eur. J. Oper. Res. 2019, 279, 93–106. [Google Scholar] [CrossRef]
- Pollmann, T.; Staudacher, J. On Importance Sampling and Multilinear Extensions for Approximating Shapley Values with Applications to Explainable Artificial Intelligence. Preprints 2026. [Google Scholar] [CrossRef]
- Peters, H. Game theory: A Multi-leveled approach, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Rozemberczki, B.; Watson, L.; Bayer, P.; Yang, H.; Kiss, O.; Nilsson, S.; Sarkar, R. The Shapley value in machine learning. In The 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence, IJCAI-ECAI; de Raedt, L., Ed.; International Joint Conferences on Artificial Intelligence Organization: Vienna, Austria, 2022; pp. 5572–5579. [Google Scholar] [CrossRef]
- Chen, H.; Covert, I.C.; Lundberg, S.M.; Lee, S. Algorithms to estimate Shapley value feature attributions. Nat. Mach. Intell. 2023, 5, 590–601. [Google Scholar] [CrossRef]
- Molnar, C. : Interpreting Machine Learning Models With SHAP. LeanPub. 2023. Available online: https://leanpub.com/shap.
- Borm, P.; Hamers, H.; Hendrickx, R. Operations research games: A survey. Top 2001, 9, 139–199. [Google Scholar] [CrossRef]
- Fatima, S.S.; Wooldridge, M.; Jennings, N.R. A linear approximation method for the Shapley value. Artif. Intell. 2008, 172, 1673–1699. [Google Scholar] [CrossRef]
- Staudacher, J.; Kóczy, L.Á.; Stach, I.; Filipp, J.; Kramer, M.; Noffke, T.; Olsson, L.; Pichler, J.; Singer, T. Computing power indices for weighted voting games via dynamic programming. Oper. Res. 2021, 31, 123–145. [Google Scholar] [CrossRef]
- Staudacher, J.; Wagner, F.; Filipp, J. Dynamic Programming for Computing Power Indices for Weighted Voting Games with Precoalitions. Games 2021, 13, 6. [Google Scholar] [CrossRef]
- Sundararajan, M.; Najmi, A. The Many Shapley Values for Model Explanation. In Proceedings of the 37th International Conference on Machine Learning; Daumé, III, H. Singh, A., Eds.; PMLR: London, UK, 2020; Volume 119, pp. 9269–9278. Available online: http://proceedings.mlr.press/v119/sundararajan20b/sundararajan20b.pdf (accessed on 27 January 2026).
- Rubinstein, R.; Kroese, D. Monte Carlo methods. Wiley Interdiscip. Rev. Comput. Stat. 2012, 4, 48–58. [Google Scholar] [CrossRef]
- Botev, Z.; Ridder, A. Variance reduction. In Wiley statsRef: Statistics Reference Online; Wiley: Hoboken, NJ, USA, 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Rubinstein, R.Y.; Kroese, D.P. Simulation and the Monte Carlo method; John Wiley & Sons: Hoboken, New Jersey, USA, 2007. [Google Scholar] [CrossRef]
- Castro, J.; Gómez, D.; Molina, E.; Tejada, J. Improving polynomial estimation of the Shapley value by stratified random sampling with optimum allocation. Comput. Oper. Res. 2017, 82, 180–188. [Google Scholar] [CrossRef]
- Hunter, D. An Upper Bound for the Probability of a Union. J. Appl. Probab. 1976, 13, 597–603. [Google Scholar] [CrossRef]
- Fumagalli, F.; Muschalik, M.; Kolpaczki, P.; Hüllermeier, E.; Hammer, B. HAP-IQ: Unified Approximation of any-order Shapley Interactions. In Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: USA, 2023; Volume 36, pp. 11515–11551. [Google Scholar]
- Castro, J.; Gómez, D.; Tejada, J. Polynomial calculation of the Shapley value based on sampling. Comput. Oper. Res. 2009, 36, 1726–1730. [Google Scholar] [CrossRef]
- Staudacher, J.; Pollmann, T. Assessing Antithetic Sampling for Approximating Shapley, Banzhaf, and Owen Values. AppliedMath 2023, 3, 957–988. [Google Scholar] [CrossRef]
- Neyman, J. On the Two Different Aspects of the Representative Method: The Method of Stratified Sampling and the Method of Purposive Selection. J. R. Stat. 1934, 97, 558–625. [Google Scholar] [CrossRef]
- Burgess, M.A.; Chapman, A.C. Approximating the Shapley Value Using Stratified Empirical Bernstein Sampling. IJCAI 2021, 73–81. [Google Scholar]
Figure 1.
Let be a cooperative game with and , , , and . The player 1 and player 2 axes should be interpreted in a discrete way such that 0 denotes the exclusion and 1 specifies the inclusion of a player. The blue plane is the solution to problem (20) with m being defined as (25) and being obtained from (26). As a result, the coefficients defining this plane are the Shapley values of the game , i.e., , and .
Figure 1.
Let be a cooperative game with and , , , and . The player 1 and player 2 axes should be interpreted in a discrete way such that 0 denotes the exclusion and 1 specifies the inclusion of a player. The blue plane is the solution to problem (20) with m being defined as (25) and being obtained from (26). As a result, the coefficients defining this plane are the Shapley values of the game , i.e., , and .
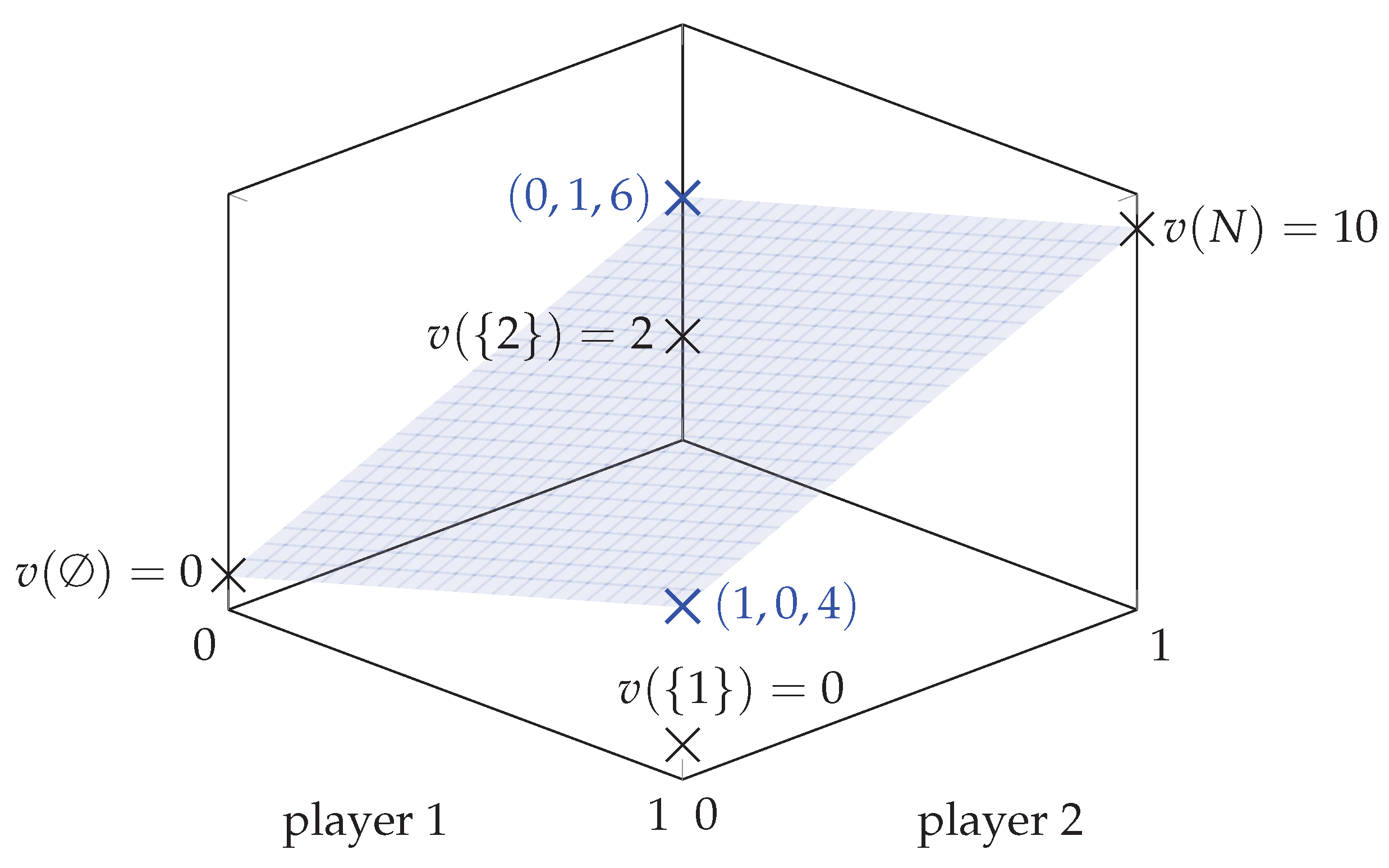
Figure 2.
Theoretical variance comparison of LSS and S-LSS evaluated on the weighted voting game defined by (7). The sample budget is , and the sample sizes of S-LSS are distributed according to (58) with ceiling operations applied whenever the result is not an integer. The crosses denote the mean variance across all players’ Shapley values, while the dots specify the variance of .
Figure 2.
Theoretical variance comparison of LSS and S-LSS evaluated on the weighted voting game defined by (7). The sample budget is , and the sample sizes of S-LSS are distributed according to (58) with ceiling operations applied whenever the result is not an integer. The crosses denote the mean variance across all players’ Shapley values, while the dots specify the variance of .
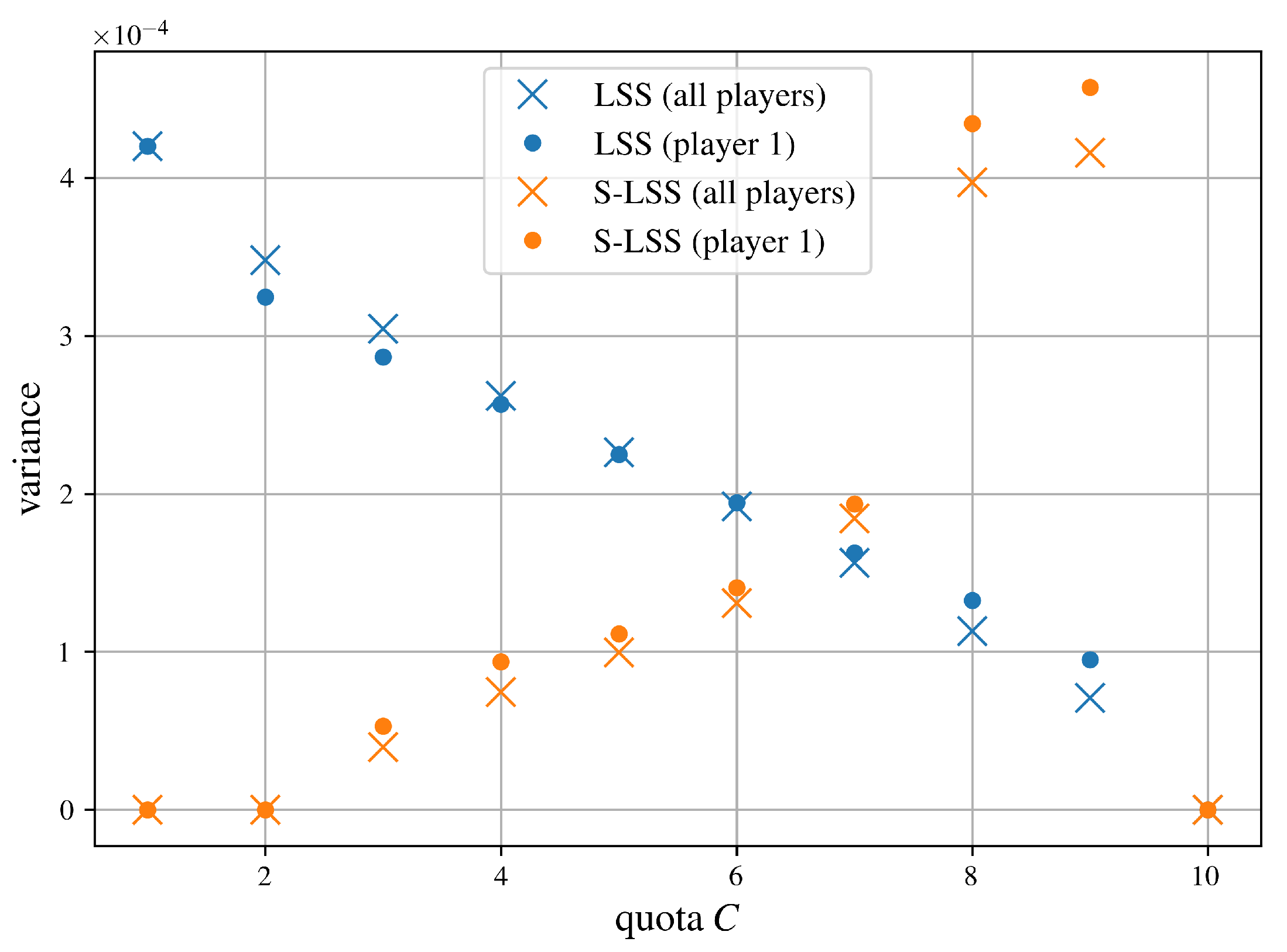
Figure 3.
The different sampling distributions of LSS and UKS for .
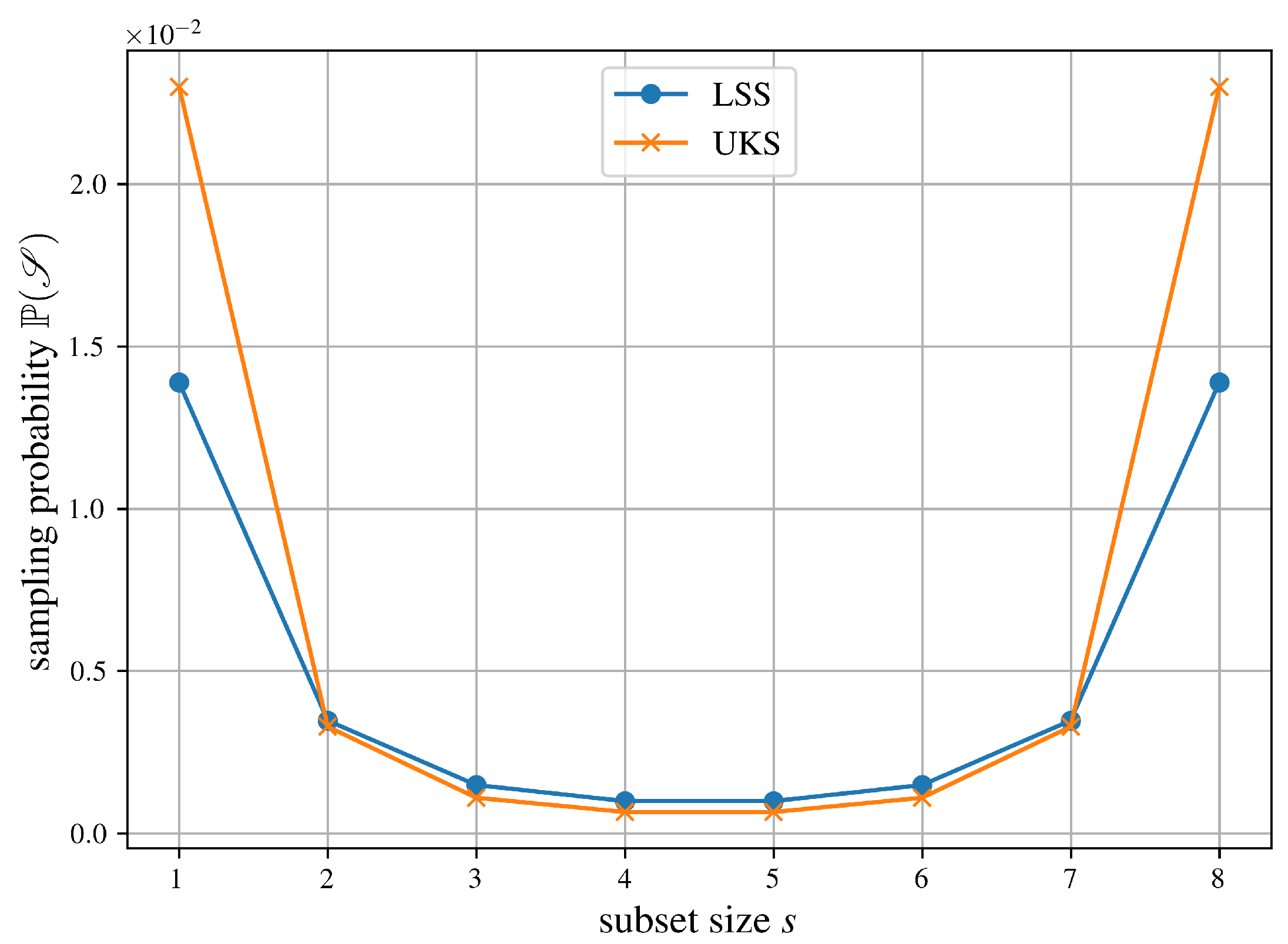
Figure 4.
Theoretical variance comparison of LSS and UKS evaluated the weighted voting games defined by (7). The number of evaluations of v is . The crosses represent the mean variance across all players’ Shapley values, while the dots denote the variance for player .
Figure 4.
Theoretical variance comparison of LSS and UKS evaluated the weighted voting games defined by (7). The number of evaluations of v is . The crosses represent the mean variance across all players’ Shapley values, while the dots denote the variance for player .
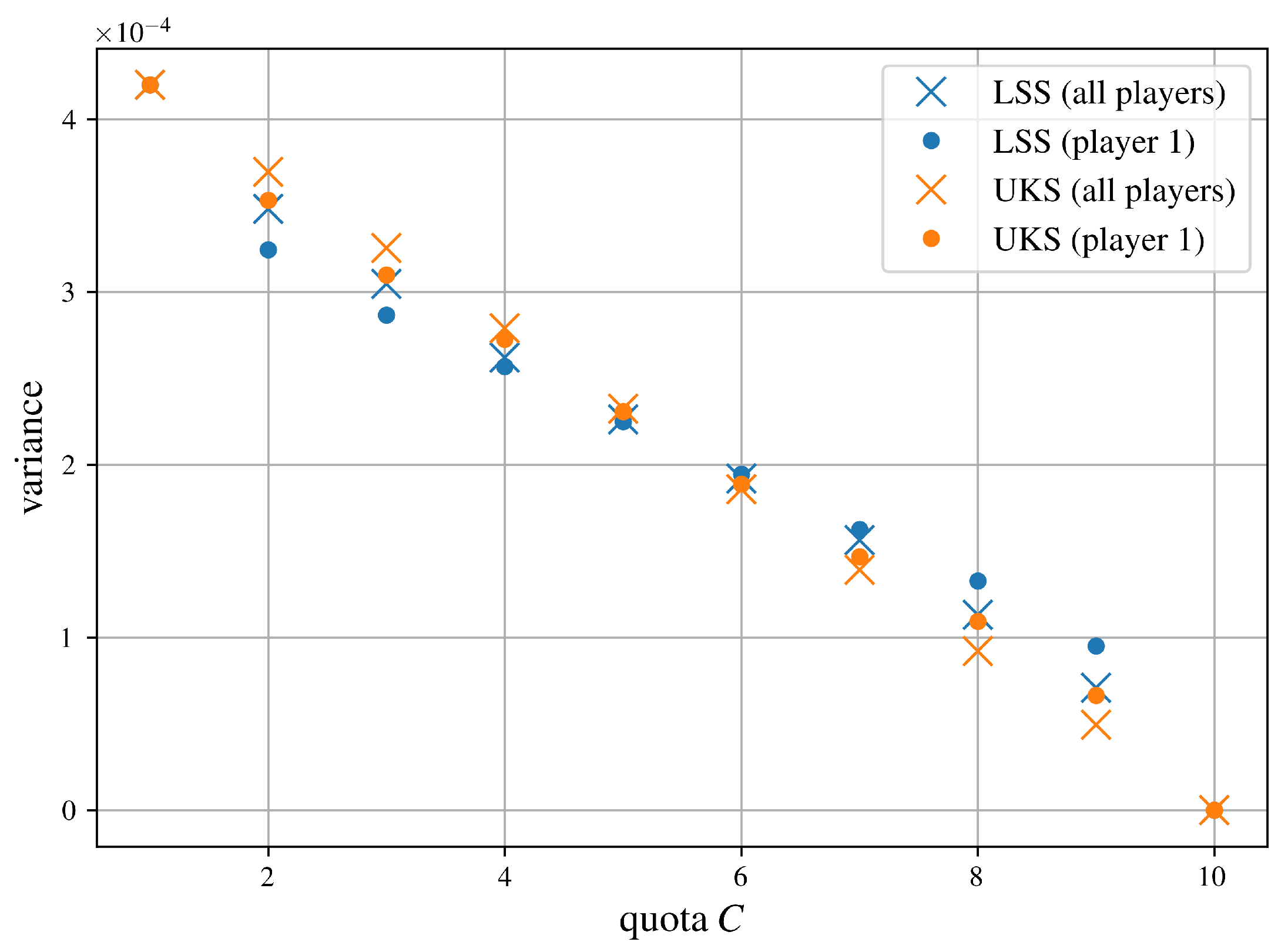
Figure 5.
Empirical variance validation of obtained via LSS, S-LSS and UKS evaluated on the weighted voting games defined by (7). The overall sample budget is . The crosses represent the theoretical variances, while the dots denote the empirical variances. The empirical variances were obtained over 5000 runs.
Figure 5.
Empirical variance validation of obtained via LSS, S-LSS and UKS evaluated on the weighted voting games defined by (7). The overall sample budget is . The crosses represent the theoretical variances, while the dots denote the empirical variances. The empirical variances were obtained over 5000 runs.
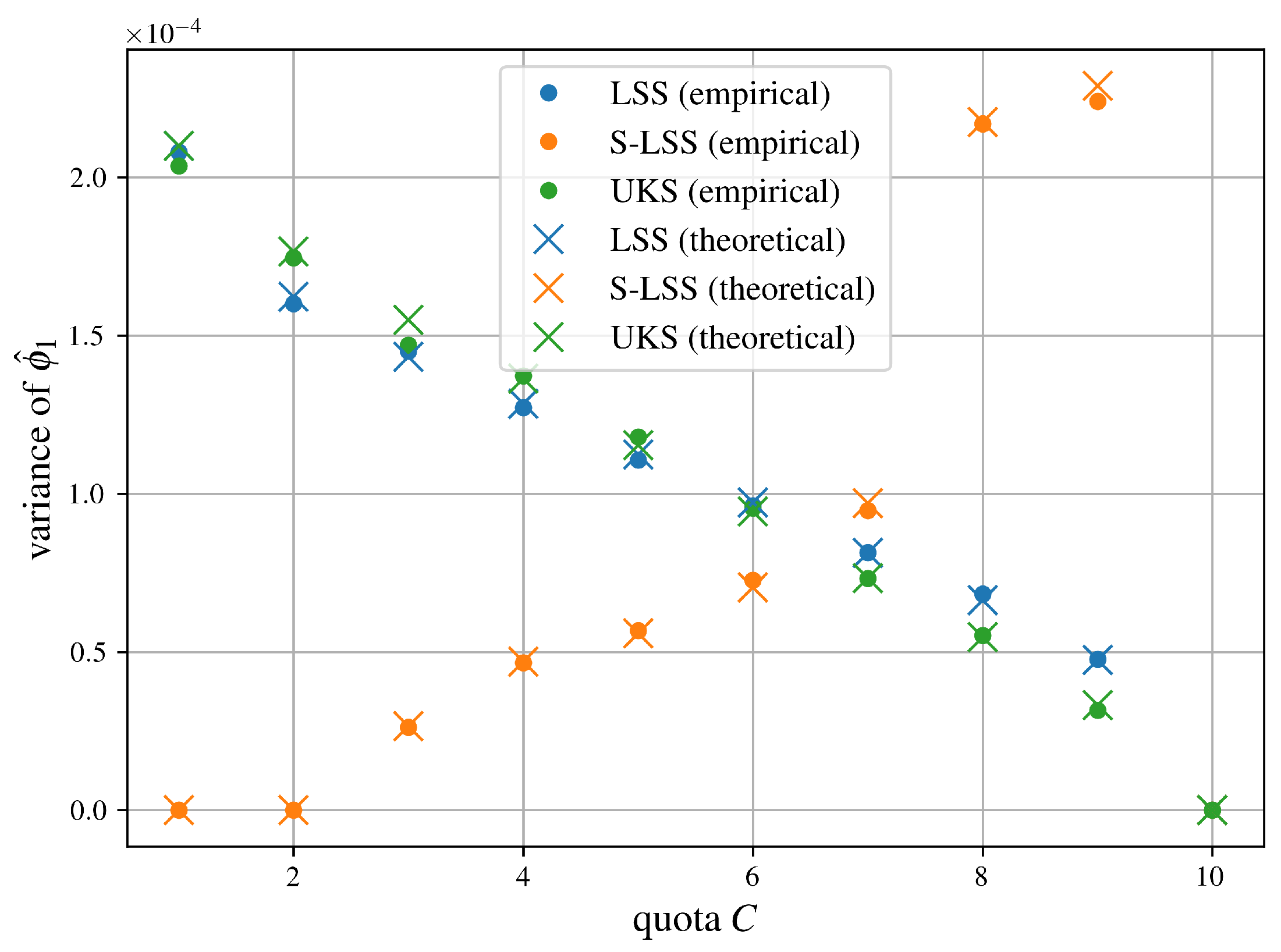
Figure 6.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on an airport game with 100 players. The mean squared errors were averaged over 250 runs.
Figure 6.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on an airport game with 100 players. The mean squared errors were averaged over 250 runs.
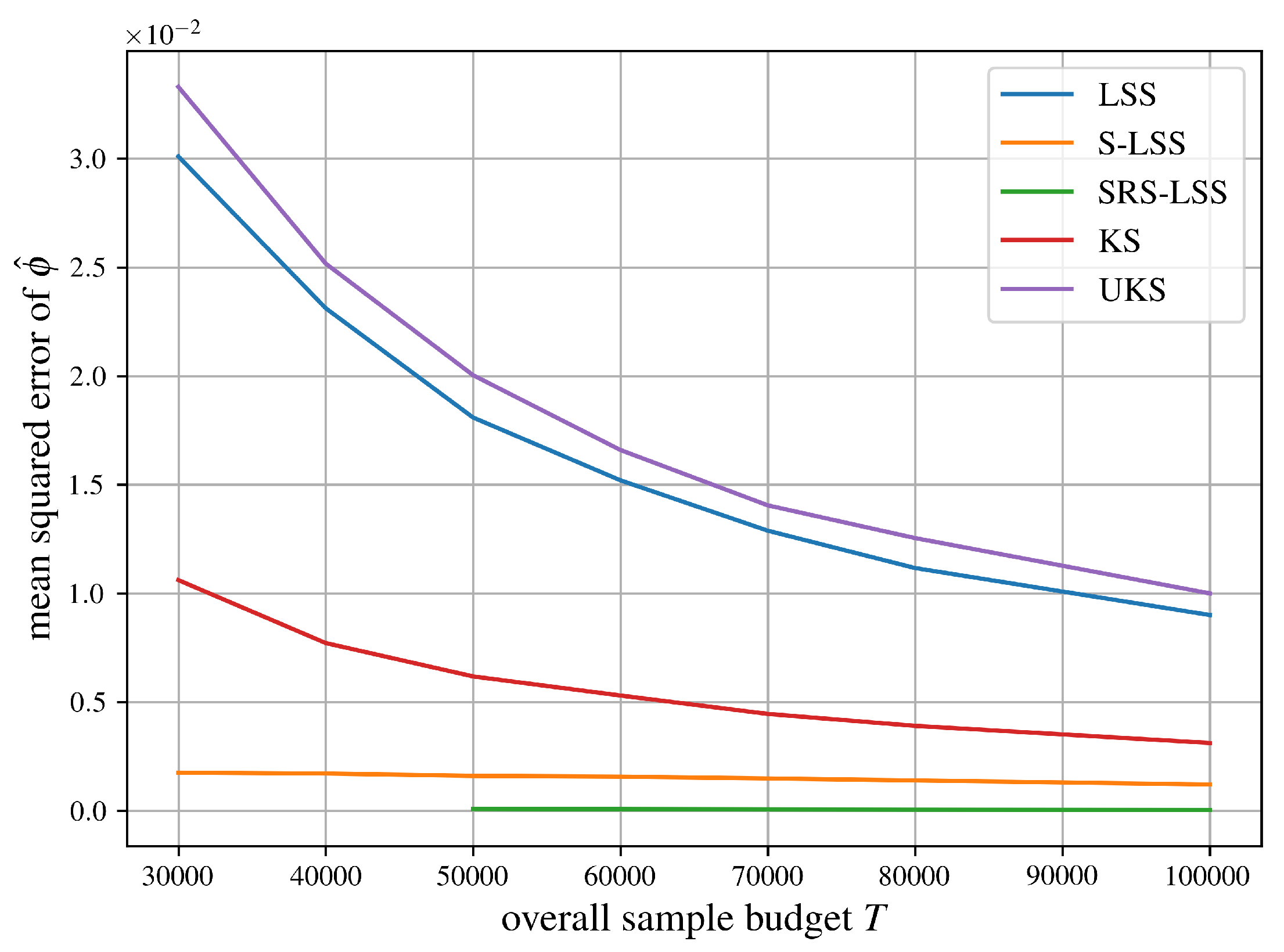
Figure 7.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on a weighted voting game with 50 players. The mean squared errors were averaged over 250 runs.
Figure 7.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on a weighted voting game with 50 players. The mean squared errors were averaged over 250 runs.
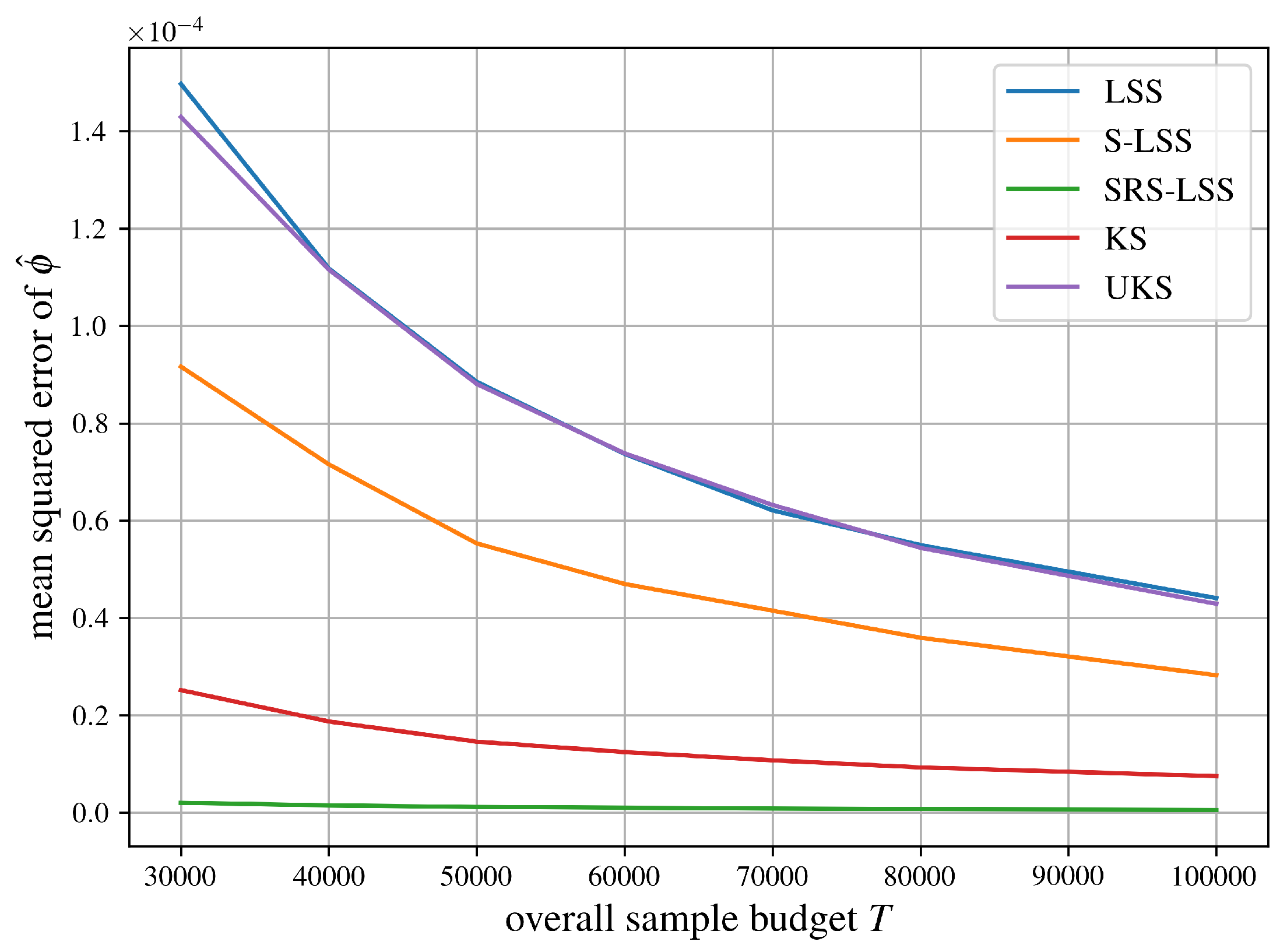
Figure 8.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on a weighted voting game with 150 players. The mean squared errors were averaged over 250 runs.
Figure 8.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on a weighted voting game with 150 players. The mean squared errors were averaged over 250 runs.
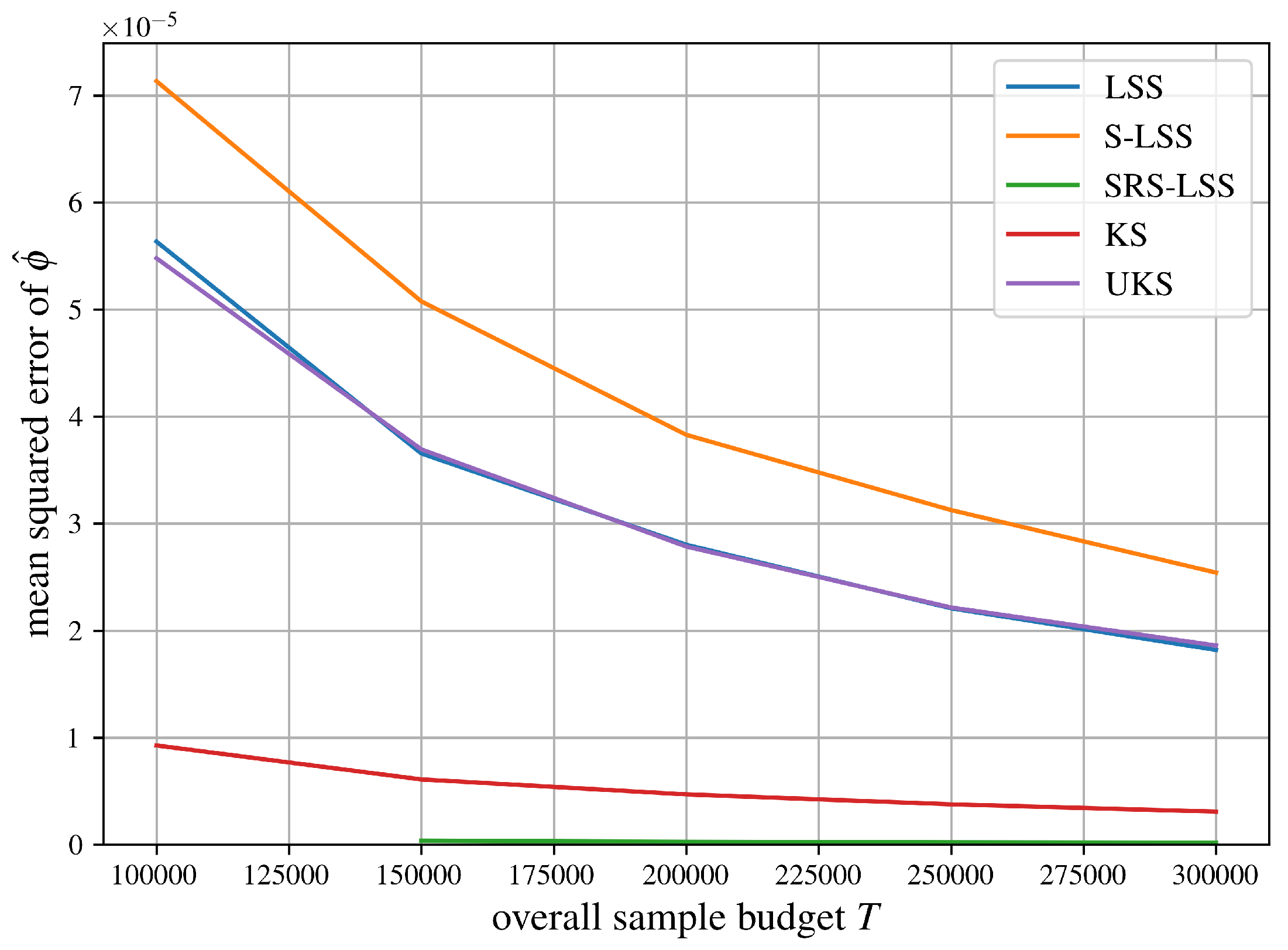
Figure 9.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on the diabetes example. The mean squared errors were averaged over 250 runs.
Figure 9.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on the diabetes example. The mean squared errors were averaged over 250 runs.
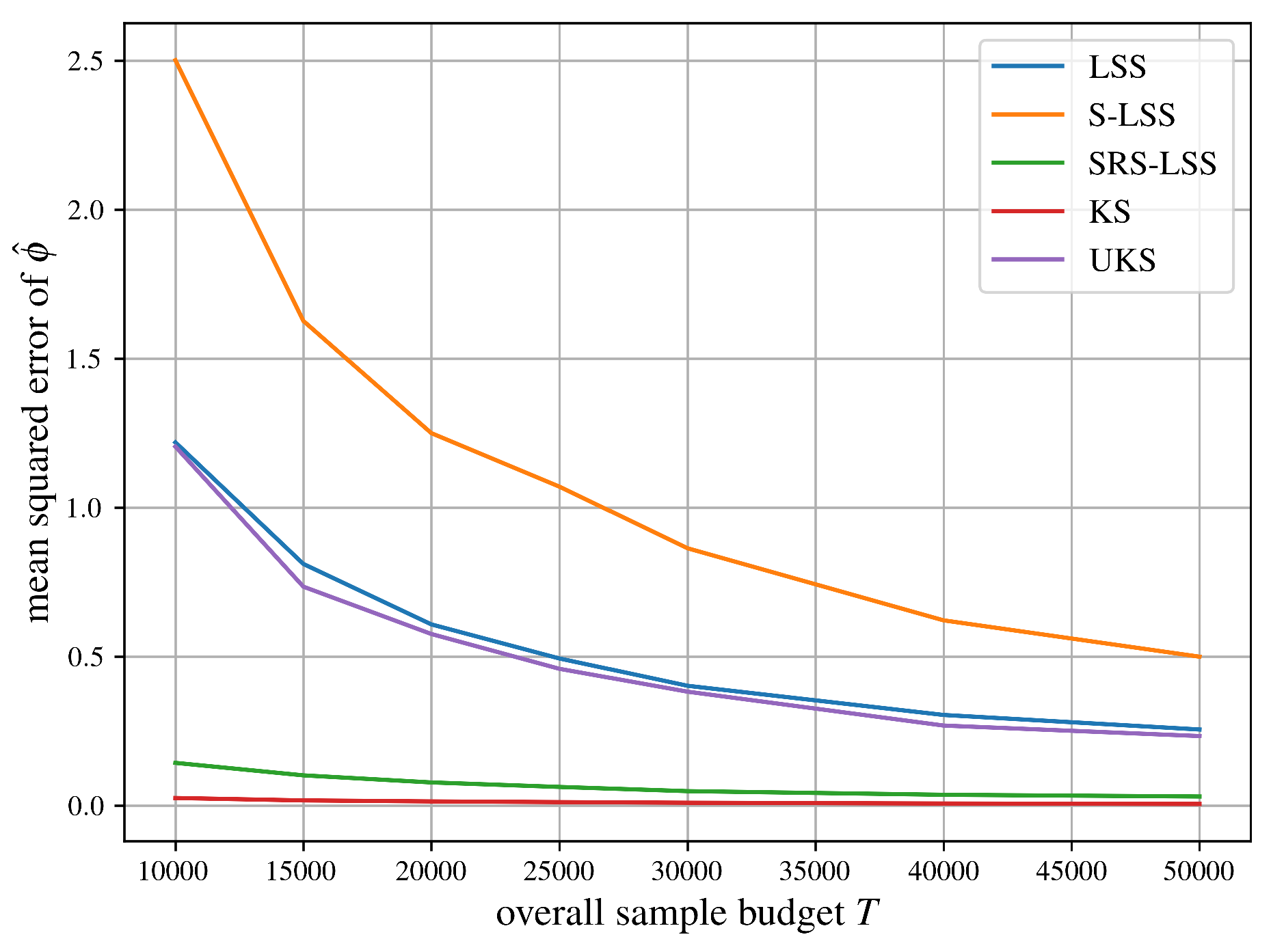
Figure 10.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on the California housing example. The mean squared errors were averaged over 250 runs.
Figure 10.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on the California housing example. The mean squared errors were averaged over 250 runs.
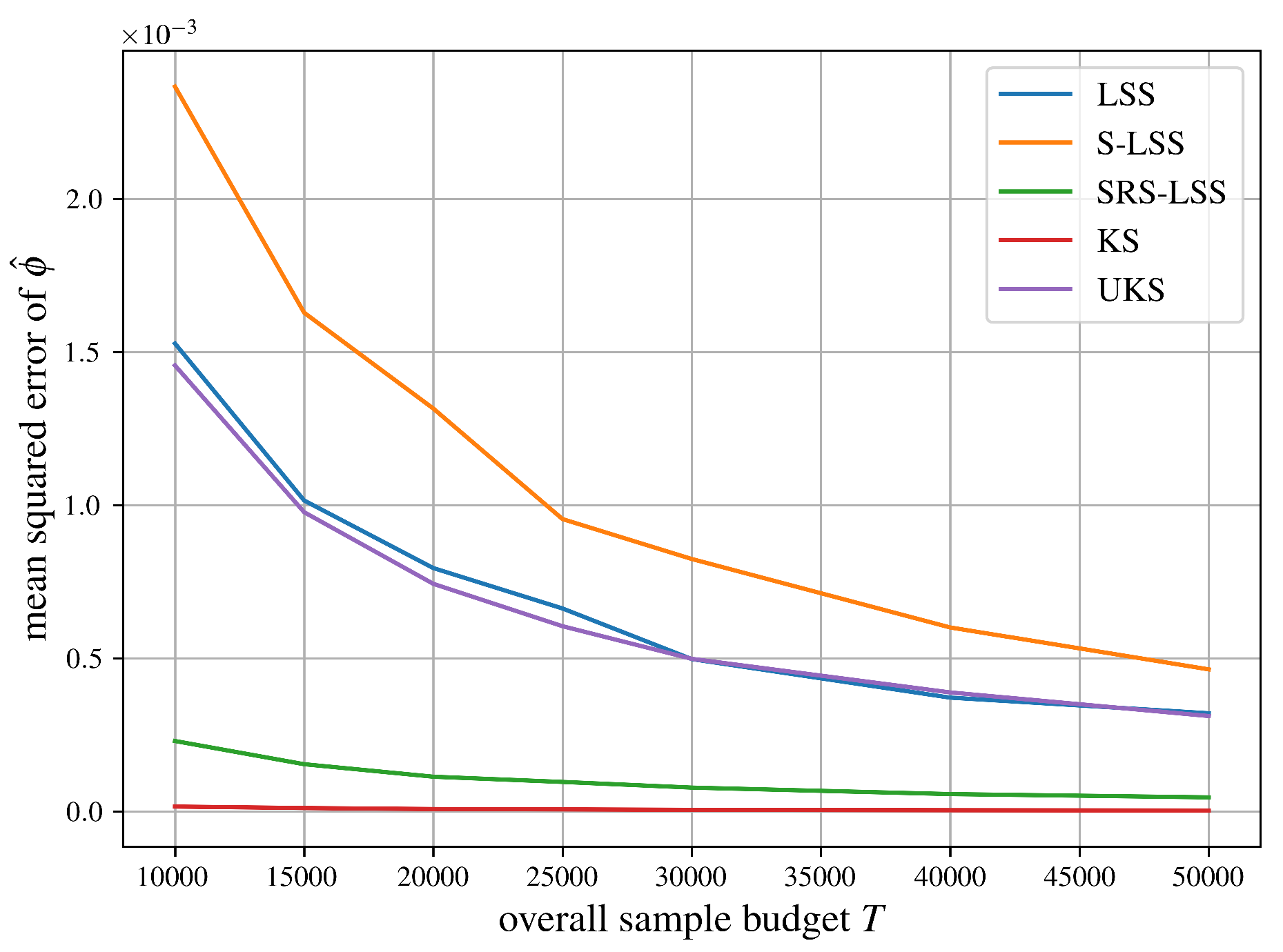
Figure 11.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on the wine example. The mean squared errors were averaged over 250 runs.
Figure 11.
Empirical mean squared error comparison of obtained via LSS, S-LSS, SRS-LSS, KS and UKS evaluated on the wine example. The mean squared errors were averaged over 250 runs.
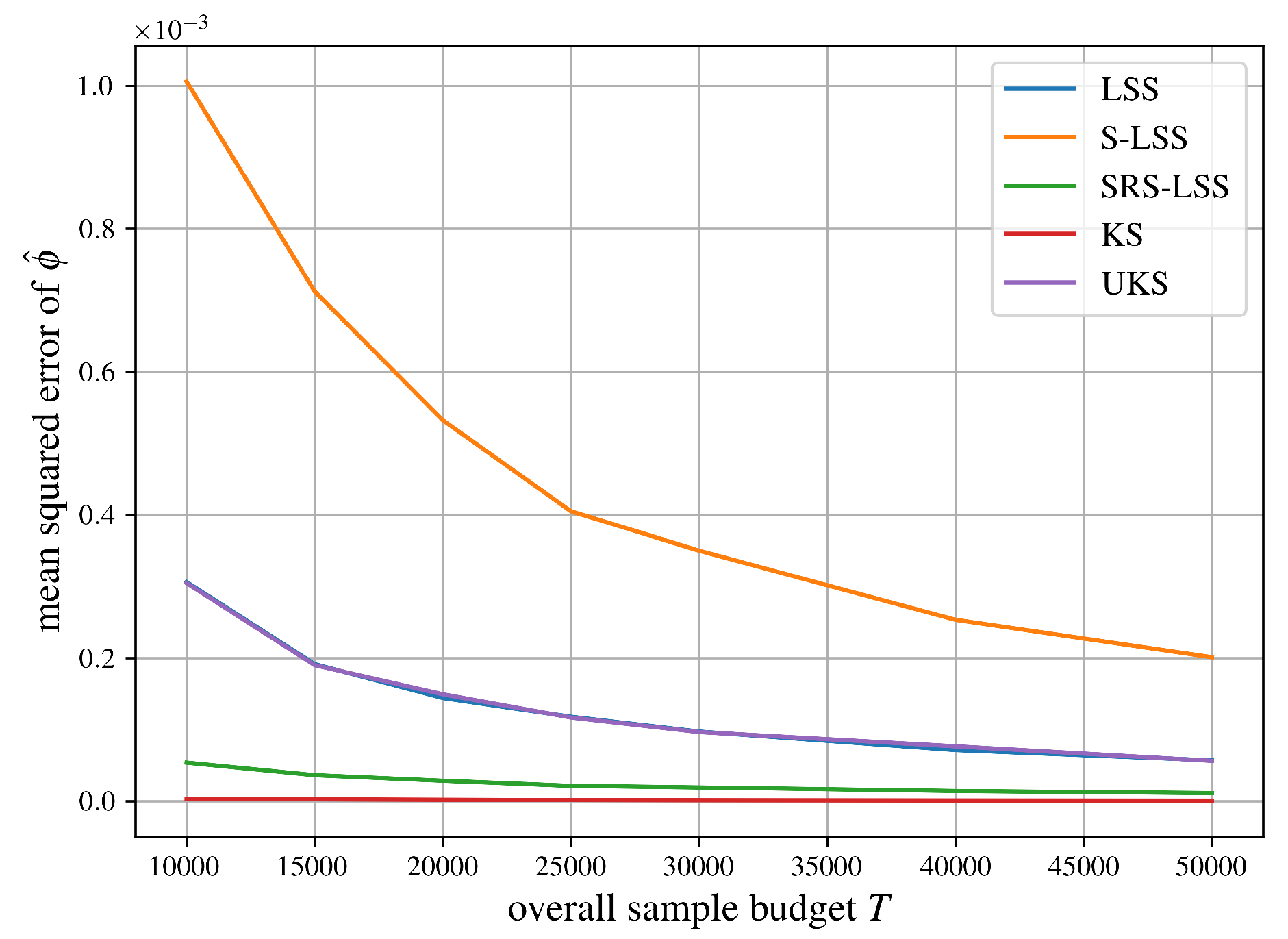

Table 1.
Population and estimator variances for all strata of the S-LSS estimator.
| s | j | elements | population var. | estimator var. |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | |
| 1 | 2 | 0 | 0 | |
| 1 | 3 | 0 | 0 | |
| 2 | 1 | 0 | 0 | |
| 2 | 2 | |||
| 2 | 3 |
Table 2.
All valid realizations of the sample (order ignored) when , together with their respective probabilities as well the corresponding resulting values of , , and . The last row shows the expected values over all valid realizations, i.e., conditioned on .
Table 2.
All valid realizations of the sample (order ignored) when , together with their respective probabilities as well the corresponding resulting values of , , and . The last row shows the expected values over all valid realizations, i.e., conditioned on .
| #permutations | elements of | |||||
|---|---|---|---|---|---|---|
| 1 | ||||||
| 0 | 0 | 0 | ||||
| 1 | ||||||
| 0 | 0 | 0 | ||||
| 1 | ||||||
| 1 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



