Submitted:
27 January 2026
Posted:
28 January 2026
Read the latest preprint version here
Abstract
Urban Embodied Agents (UrbanEAs) are emerging to interact with complex, large-scale city environments, generating vast, heterogeneous data streams. While embodied agent research has focused on controlled indoor environments, these settings lack the complexity of the physical world. In contrast, urban environments present distinct challenges, including environmental variability, limited observability, and interaction complexity. These challenges hinder the effectiveness of conventional agents. Therefore, establishing a comprehensive data lifecycle to fuse multi-domain data from terrain, aerial, and space is an essential strategy for developing actionable embodied capabilities from raw urban streams. Distinct from existing surveys that follow a model-centric paradigm for urban computing, we systematically propose and review a comprehensive Data Lifecycle from a multi-domain data perspective, which is essential for the UrbanEA. First, we propose a unified framework containing four key stages of this lifecycle: Data Perception, Data Management, Data Fusion, and Task Application. Next, we establish a taxonomy for each stage of the lifecycle. Finally, we outline the social impact of the data lifecycle of UrbanEA and open research problems. Our survey provides a rigorous roadmap for designing the robust, high-performance data frameworks essential for these UrbanEAs.
Keywords:
data lifecycle
; urban computing
; embodied agent
; multimodal data
; data fusion
1. Introduction
Modern cities are complex systems, dynamically interwoven with physical elements (such as buildings and roads), social structures, economic activities, and environmental factors [1,2]. They are not only the cornerstones of modern civilization but are also continuously evolving, driven by cultural, economic, and technological advancements [3]. Contemporary cities have evolved beyond being collections of physical spaces to become hubs of diverse information sources, composed of Internet of Things (IoT) devices, geospatial data, and sensor data [4,5].
Against this backdrop, the concept of the “Urban Embodied Agent" (UrbanEA) [6] has emerged. It is an intelligent system (such as an autonomous vehicle, robot, or virtual avatar) that possesses a physical or virtual body to directly perceive, reason about, and execute actions within complex urban environments. By leveraging these core capabilities, such agents are envisioned to help address critical urban problems, including delivery and transportation. Compared to conventional urban agents, the core distinction lies in this embodiment: conventional agents may only analyze and predict within digital space (e.g., traffic flow models), whereas an UrbanEA uses its physical form to perceive and execute actions, interacting with the world directly [7].
To fulfill this vision, the UrbanEA’s core capability lies in its data lifecycle, which defines the entire pipeline from data perception to embodied application. As shown in Figure 1, this pipeline contains the following stage:
- Data Perception. The agent perceives multimodal data from multiple domains (handheld, vehicle, drone, satellite) to comprehensively perceive the physical world, marking the starting point of the data lifecycle.
- Data Management. Task-driven storage architectures (such as graph, vector, and spatio-temporal databases) organize and query massive, heterogeneous urban perception data, laying a solid foundation for subsequent fusion and interaction.
- Data Fusion. In this stage, the fusion strategies address the data gaps and construct a unified urban cognition.
- Task Application. The structured data, after being processed through fusion, supports advanced UrbanEA tasks such as Urban Scene Question-Answering (SQA), Vision-Language Navigation (VLN), and Human-Agent Collaboration (HAC), and generates a positive social impact.
Despite its importance, successfully implementing this end-to-end data lifecycle in urban settings remains insufficient. Existing embodied agent research focuses on indoor environments [8], which are relatively controlled, limited in scale, and structurally stable, while urban settings are different. Therefore, UrbanEA presents unique data-centric challenges that impact every stage of this lifecycle:
- Environmental Variability. Urban environments are inherently dynamic and uncertain, unlike controlled indoor settings. Data Perception in outdoor scenes must handle dramatic variations in illumination (diurnal cycles, sunlight-shadow contrasts) and challenging weather conditions (rain, snow, fog), all of which degrade perception performance.
- Limited Observability. Urban environments are vast, but individual sensors have limited coverage. Any single sensor (e.g., a vehicle-mounted camera or LiDAR) suffers from blind spots and occlusions due to its limited Field of View (FoV) and detection range. This results in spatially incomplete perceptual information, making it impossible to achieve a globally consistent scene understanding during Data Fusion.
- Interaction Complexity. An urban environment is beyond a collection of physical spaces but a complex social environment composed of numerous intelligent agents. The behavior of these agents is not simple physical motion but is driven by a multi-layered set of rules. Their behavior follows both explicit rules (e.g., traffic laws) and implicit social norms (e.g., driving habits, pedestrian etiquette, intentions signaled through body language). Understanding these interactions requires interpreting subtle cues like posture, gaze, and intent, which are far harder to capture and model during the Data Fusion and Task Application stages than simple physical motion.
These challenges highlight the complexity of the data lifecycle in urban environments, making it difficult for single-domain data to comprehensively capture the scene. To address these limitations, utilizing multi-domain data for UrbanEA has emerged as a promising strategy [13,15]. By integrating perspectives from diverse domains—such as a vehicle’s terrain perception, a drone’s aerial view, and a satellite’s global map—the system can mitigate the limitations of individual sensors and reduce blind spots to construct a more spatially complete scene understanding.
However, as shown in Table 1, existing reviews tend to adopt a task-centric or model-centric perspective, such as foundation models [10,12] or the graph neural network [9], which may not fully align with the requirements of this multi-domain approach.
Specifically, urban computing surveys primarily focus on digital agents designed for passive analytical tasks, such as traffic and weather prediction. In these frameworks, data is often treated as static inputs for offline reasoning, rather than the interactive streams required by physical agents to actively perceive and intervene in the world. Meanwhile, although existing embodied agent surveys discuss physical interaction, they generally focus on controlled indoor environments, leaving the spatio-temporal gaps inherent in complex, city-scale environments largely unaddressed. Therefore, a systematic review covering the end-to-end lifecycle, from data perception to final application, for UrbanEA is still needed. To fill this gap, we present the first comprehensive survey on the data lifecycle for UrbanEA. Our research focuses on the entire pipeline, investigating how to efficiently store, query, and fuse this complex data to support downstream embodied agent applications. Our contributions are summarized as follows:
1) Unified Data Lifecycle Framework. We propose a systematic framework that organizes the existing UrbanEA research into an end-to-end pipeline. Unlike existing surveys that focus on isolated tasks or specific domain data, our framework integrates Data Perception, Management, Fusion, and Application, providing a holistic view of how urban data flows from raw sensors to an embodied agent.
2) Fine-grained Multi-stage Taxonomy. We establish a taxonomy for each stage of the lifecycle to clarify technical boundaries. Specifically, we categorize perception by modalities and domains, classify management by storage structure and capability, and taxonomy fusion strategies based on the specific Domain Gaps (Representation, Quality, Spatio-temporal, and Semantic) in the real world.
3) Forward-looking Research Roadmap. We identify cross-stage challenges and synthesize them into a strategic roadmap spanning Method-level, System-level, and Societal-level dimensions. By extending the discussion beyond technical metrics to broader social impacts, we aim to provide insights that may inspire future research in the UrbanEA community.
The rest of the survey is organized as follows: Sec. Section 2 reviews the urban sensing and simulation in data perception. Sec. Section 3 discusses the pipeline for data management. Sec. Section 4 surveys data fusion techniques to bridge key multi-domain data gaps. Sec. Section 5 presents downstream task applications, and Sec. Section 6 explores the broader social impacts. Sec. Section 7 discusses future outlook and open challenges. Sec. Section 8 finally concludes the paper.
2. Data Perception: Sensing and Simulation
2.1. How to Perceive the City?
2.1.1. Vision Perception
For the visual sense ability, we divide it into the following main categories. The multimodal data captures distinct aspects of the environment, often complementing each other. We visualize the vision perception in the terrain domain as the example, as shown in Figure 2.
•RGB Images: These are standard color images, akin to what a human eye or a typical camera perceives. They are rich in texture, color, and semantic information, making them invaluable for tasks like object recognition, classification, and scene understanding (e.g., identifying road signs in autonomous driving, describing visual elements in spatial description). An RGB image can be represented as a three-dimensional tensor, denoted as . Its dimensions are the image height H, width W, and 3 color channels (Red, Green, Blue). However, they are 2D projections and are sensitive to lighting conditions, lacking direct information about the 3D structure or distance to objects.
•Depth Images: Unlike RGB images that capture color, depth images encode distance information. Each pixel value typically represents the distance from the sensor to the corresponding point in the scene. A depth image can be represented as a 2D matrix, denoted as . Its dimensions are the image height H and width W. The value at each pixel is a scalar representing the distance from the sensor to that point in the scene. This provides explicit geometric cues crucial for obstacle avoidance, navigation, and 3D reconstruction, often used in drone operation and robot tasks.
•Lidar Point Clouds: Light Detection and Ranging (Lidar) sensors actively emit laser beams and measure the reflected light to create a sparse but accurate 3D map of the surroundings. A Lidar point cloud is an unordered set of points, denoted as . It consists of N points, where N is variable. Each point contains at least its coordinates in 3D space. It often includes reflection intensity, i, as well. These point clouds provide precise geometric structure and distance measurements over considerable ranges, largely independent of ambient light. While excellent for geometry, they typically lack the rich color and texture information found in RGB images.
•Radar Point Clouds: Radar sensors use radio waves instead of light. Radar data is also a set of points, denoted as . It consists of M detections, where M is typically much smaller than the number of Lidar points, N. is the velocity vector of the detection. Similar to Lidar, they can generate point clouds representing detected objects. Radar’s key advantage is its robustness in adverse weather conditions (rain, fog, snow), where Lidar and cameras might struggle. However, Radar typically provides lower resolution and less detailed shape information compared to Lidar or cameras.
2.1.2. Multi-sensory Perception
In urban settings, multi-sensory technology, which integrates auditory (e.g., traffic sounds, water features), tactile (e.g., pavement textures, wind), even olfactory (e.g., floral scents, garbage odor), and thermal (e.g., temperature), is being applied to smart city fields like environmental monitoring [17] and public security [18,19]. Sensing within environments is multi-sensory, extending well beyond the visual sensing [20]. To this end, efforts focused on combining audio and visual information, with various works aiming to train agents that can both see and hear by using integrated audio-visual simulations [21,22,23,24,25]. The domain of visual-tactile learning focuses on building realistic tactile simulation systems to allow agents to understand the world through physical interaction [26,27,28,29,30]. Multiply [31] proposes a multi-sensory sensing simulator. This platform incorporates a wide array of interactive data—including visual, audio, tactile, and thermal information—directly into large language models, thereby establishing a direct and powerful correlation among words, actions, and percepts.
2.2. Where to Perceive the City?
The urban perception requires a system capable of synergistically processing information from different observational dimensions [13,32,33]. We divide the urban perception based on the data domain, including handheld, vehicle, drone, plane, and satellite as shown in Figure 3. These platforms demonstrate spatio-temporal heterogeneity, resulting in a spatio-temporal gap as discussed in Section 4.1.
•Handheld. The data from handheld devices is designed for close-quarters mapping and typically has a shorter range. For example, some professional handheld scanners have a flexible scanning range from to 10 meters, making them ideal for detailed exterior facade work [34]. The terrain handheld scanners can achieve accuracies around 5-10 mm. The use of handheld devices for data acquisition suffers from low efficiency, limited coverage, and data inconsistencies caused by manual handling, as the Quality Gap discussed in Sec Section 4.1.
•Vehicle. These systems are designed for efficient corridor mapping and possess a range optimized for capturing roadside features from a moving vehicle [35,36]. The vehicle systems experience a slight reduction in accuracy compared to handheld static scanners, but they still deliver exceptional results suitable for most urban mapping tasks, capturing high-density data within 30 meters to 100 meters of the vehicle’s path. In urban environments, tall buildings lead to GPS signal drift, while pedestrians and other vehicles create dynamic obstructions. These deficiencies may introduce the Spatio-Temporal Gap as discussed in Sec Section 4.1.
•Drone. Drones operate in a unique low-altitude domain, which allows them to achieve exceptionally high spatial resolutions with both photogrammetric and LiDAR sensors. For most professional urban mapping applications, drones can easily achieve a Ground Sample Distance (GSD) between 1 cm and 5 cm per pixel [37]. While its high flexibility is an advantage, it also causes variations in scale and perspective, posing a challenge for precise camera pose estimation.
•Plane. For urban mapping projects, the aerial plane typically delivers a GSD in the range of 5 cm to 30 cm. A GSD of 5-15 cm is sufficient for creating highly detailed and geometrically accurate city-wide 3D models at LOD2 (differentiated roof structures) and LOD3 (architectural models with major facade elements). At this resolution, it is possible to clearly identify individual buildings, roads, vegetation, and major infrastructure elements [38]. However, it is difficult to capture fine terrain-level details.
•Satellite. Satellites operate from low Earth orbit at altitudes that dwarf aerial platforms, yet technological advancements have enabled them to achieve remarkable spatial resolutions [39,40]. The commercial constellations offer panchromatic imagery with a native spatial resolution of approximately 30 cm. Although it provides wide coverage, it suffers from the spatio-temporal resolution with cloud-based occlusion, which may introduce the Density gap.
2.3. City Scene Simulators
The development of robust and reliable perception for outdoor environments relies on the simulation environments when the Internet agent is towards an embodied agent [41]. Existing indoor simulators [42,43,44,45] collect data from the handheld camera or scan sensors. Compared to indoor settings where controlled experiments can be collected from handheld cameras or scanner sensors, outdoor environments present challenges for real-world experimentation due to their complexity, dynamic nature, and safety concerns. Therefore, as shown in Figure 4, we classify the city simulators based on the perceptual capabilities an agent requires to move from observation to action:

Table 2.
Comparison with existing Urban Embodied Agent simulators.
| Environment | Year | Kinematics | Platform | Category | Modality | Data Source | Engine | |||
| RGB | Depth | Radar | Lidar | |||||||
| Cityscapes [46] | 2016 | ✗ | Terrain | Open-Loop | ✓ | ✗ | ✗ | ✗ | Street View | - |
| CARLA [16] | 2017 | ✓ | Terrain | Closed-Loop | ✓ | ✓ | ✓ | ✓ | Vehicle | UE 4 |
| xView [47] | 2018 | ✗ | Aviation | Open-Loop | ✓ | ✗ | ✗ | ✗ | Satellite | - |
| TouchDown [48] | 2019 | ✗ | Terrain | Open-Loop | ✓ | ✗ | ✗ | ✗ | Street View | - |
| Nuscenes [49] | 2020 | ✗ | Terrain | Open-Loop | ✓ | ✗ | ✓ | ✓ | Vehicle | Nuscenes-Kit |
| Waymo [50] | 2020 | ✗ | Terrain | Open-Loop | ✓ | ✗ | ✓ | ✓ | Vehicle | Waymax |
| KITTI-360 [51] | 2022 | ✗ | Terrain | Open-Loop | ✓ | ✗ | ✗ | ✓ | Vehicle | - |
| STPLS3D [52] | 2022 | ✗ | Aviation | Open-Loop | ✗ | ✗ | ✗ | ✓ | Drone | - |
| SensatUrban [53] | 2022 | ✗ | Aviation | Open-Loop | ✗ | ✗ | ✗ | ✓ | Drone | - |
| UrbanBIS [54] | 2023 | ✗ | Aviation | Open-Loop | ✓ | ✗ | ✗ | ✓ | Drone | - |
| AerialVLN [55] | 2023 | ✓ | Aviation | Open-Loop | ✓ | ✓ | ✗ | ✗ | Drone | UE 4 |
| GRUTopia [56] | 2024 | ✓ | Terrain | Closed-Loop | ✓ | ✗ | ✗ | ✗ | Virtuality | Isaac Sim |
| OpenUAV [57] | 2024 | ✓ | Aviation | Open-Loop | ✓ | ✓ | ✗ | ✗ | Drone | UE 4 |
| UnrealZoo [58] | 2024 | ✓ | Terrain | Closed-Loop | ✓ | ✗ | ✗ | ✗ | Virtuality | UE 4/5 |
| MetaUrban [59] | 2025 | ✓ | Terrain | Closed-Loop | ✓ | ✓ | ✗ | ✓ | Virtuality | Gym |
| OpenFly [60] | 2025 | ✓ | Aviation | Closed-Loop | ✓ | ✓ | ✗ | ✓ | Drone | UE 4, Google Earth, GTA V |
2.3.1. Open-Loop Simulator
In this category, simulators function as replay platforms for real-world data logs. Their primary role is to evaluate the sensing system. These evaluations range in complexity, from semantic understanding that answers the question, “What is it?" Open-Loop Simulator can be divided into unimodal simulators and multimodal simulators. Unimodal simulators represent the foundational layer of virtual environment design, focusing on generating data for a single sensor modality. The goal is to train and validate specific sensing algorithms in a controlled manner for terrain and aerial simulation domains, such as StreetLearn [61], Cityscapes [46], xView [47], SensatUrban [53], UrbanBIS [54], and STPLS3D [52]. The multimodal simulator involves the integration of multiple, synchronized sensor streams. This is designed to replicate the comprehensive sensor suites of outdoor vision sensing, allowing for the development and testing of algorithms that create a more robust and reliable world model by combining the strengths of different modalities, such as Nuscenes [49], Waymo [50], KITTI-360 [51], AerialVLN [55].
2.3.2. Closed-Loop Simulator
This paradigm completes the sensing-action cycle. By enabling an agent’s behaviors to interact with the simulation world, these simulators are equipped to evaluate the agent’s capability: guiding action based on sensing. They move beyond passive observation to address the interaction problem for an autonomous agent: “How should I react to it?" This simulator focuses on the active, full-stack validation, testing the entire “sensing-to-action" loop and allowing for the evaluation of complex behaviors [62]. For terrain-based systems, including GRUTopia [56], UnrealZoo [58], and MetaUrban [59], leverage powerful physics and rendering engines like Isaac Sim and UE4/5, moving beyond sensing tasks. These environments simulate complex and dynamic weather phenomena (rain, fog, snow), realistic diurnal cycles with changing illumination, and intricate multi-agent interactions. In aviation-based simulation, like OpenUAV [57], and OpenFly [60] facilitate intricate interactions with the environment. A key evolution lies in the fidelity of control. This allows for the simulation of smooth, physically plausible flight dynamics, enabling agents to perform complex maneuvers and precise navigation that mimic real-world dexterity.
2.4. Discussion
Simulators are essential tools for showing the urban perception environment and developing UrbanEAs. However, existing simulators suffer from the “Sim-to-Real" gap. This gap manifests in two key areas: physical realism, such as accurately modeling sensor noise or complex weather and lighting effects, and behavioral realism, which involves simulating unpredictable human behaviors like varied driving habits or pedestrian movements. The core challenge is how to effectively quantify and reduce this gap. One of the future directions is to establish a “Real-to-Sim-to-Real" reinforcement loop. This means using high-fidelity data from the real world to build and continuously refine the next generation of simulators, which in turn can train more capable agents.
3. Data Management: Storage and Querying
UrbanEAs operate in a data-intensive environment as detailed in Section 2. However, this raw data deluge is difficult to use directly for the downstream embodied agent task. For instance, data fusion can fail with misaligned timestamps, semantic relationships between objects remain implicit, and safety-critical tasks may lack the necessary data freshness and consistency. The fundamental challenge is thus to transform this unstructured data torrent into a well-organized and queryable knowledge base that supports both real-time perception and long-term learning [63,64].
Effective data management provides the structured backbone required for robust fusion (Section 4), real-time task execution (Section 5), and auditable systems that respect social considerations (Section 6). Navigating the inherent trade-offs between latency, scale, and query complexity under the data lifecycle challenges (Section 1) requires specialized solutions. We therefore examine six complementary storage architectures that form the basis of modern urban data systems (summarized in Table 3): Data Lakes, Multi-model and Graph Databases, Vector Databases, Time-Series Databases, and Spatio-temporal Databases.
We illustrate their respective roles using a running example in this section, as shown in Figure 5: an autonomous vehicle (ego-agent) approaching a busy, rainy intersection. Its view is partially occluded by a large truck, while a roadside unit (RSU) detects an ambulance coming from the blind spot. This scenario, involving sensor noise (rain), occlusions (truck), and multi-source asynchronous data (vehicle sensors vs. RSU), requires a sophisticated data management strategy to ensure safety. The following subsections will examine how various database paradigms address these specific issues.
3.1. General & Unified Architectures
•Data Lakes. The evolution of UrbanEA data management began with large-scale autonomous driving datasets such as NuScenes [49] and Waymo Open Dataset [50]. These datasets established a baseline practice: organizing multimodal streams (cameras, LiDAR, radar) via relational metadata while storing high-volume unstructured data (images, point clouds) as separate files linked by unique identifiers. NuScenes exemplifies this paradigm by providing temporal indexing for synchronized sensor data, global identifiers enabling cross-modal annotation (“annotate 3D once, project to 2D everywhere"), and standardized coordinate transformation APIs for multimodal fusion. For example, the complete transformation chain from LiDAR to camera frame is formalized as:
Then, the projection of a LiDAR point onto the image plane can be expressed as:
where K is the camera intrinsic matrix, T represents the rigid body transformation matrices, and denotes taking the first three dimensions of the homogeneous coordinate. Every matrix in these equations is directly supplied by the dataset management system [49].
However, while these datasets excel at providing synchronized data for offline training, they are fundamentally limited to static, post-collection dissemination and cannot support the real-time, streaming requirements of production UrbanEAs systems. This limitation motivated the development of Data Lake architectures [86,87], which provide a principled framework for managing continuous, heterogeneous data streams from city-scale platforms. Unlike the static datasets above, Data Lakes adopt a “schema-on-read" philosophy: raw data is ingested in its native format without predefined schemas, with structure imposed only at query time [67,86]. This design fundamentally shifts the paradigm from “publish once" to “continuously sensing and govern."
The architectural evolution of Data Lakes reflects urban escalating demands for real-time capabilities. The Lambda Architecture [65,88] was designed with parallel batch and speed layers to concurrently support both historical analytics and real-time updates, which in turn allows agents to utilize archival data for training while also accessing live streams for immediate decision-making. Kappa Architecture [66] simplified this by focusing solely on stream processing, optimizing for the low-latency responsiveness critical to reactive UrbanEA. More advanced Zone-Based Governance models, including Data-Pond [89] and Functional Data Lake [90,91], organize data into logical zones (Raw → Curated → Analytics) with progressive quality control, ensuring that agents access appropriately validated data for different tasks.
The Data Lakehouse [67] represents the latest development, integrating the flexibility of data lakes with the robust data management and transactional guarantees of data warehouses, thus providing a promising solution for UrbanEA systems that require both exploratory analytics and reliable operational queries. For city setting, Data Lakes offer three strategic advantages: (1) maximized raw data retention with full lineage tracking, enabling reprocessing as models evolve; (2) real-time streaming ingestion via architectures like Kappa, supporting continuous UrbanEAs; (3) multi-zone governance that enforces data quality standards across the pipeline from raw sensors to agent decision-making. In a rainy urban intersection, multimodal streams typically include multi-camera images, LiDAR point clouds, ego-state signals, and roadside trajectories. A data lake retains these raw assets, while an accompanying catalog captures calibration, timestamps, and lineage. This schema-on-read design preserves weather artefacts and occlusion evidence for later fusion and auditing without imposing premature structure.
•Multi-model Databases. UrbanEAs generate data with fundamentally different structures: structured metadata (relational), spatial relationships (graph), and sensor streams (time-series). Multi-model databases [92,93] offer a unified approach to the heterogeneity problem by natively supporting diverse data models within one system, a capability that data lakes and other single-model architectures only partially provide.
Based on their architectural design, multi-model systems are generally classified into two main categories [94,95]. The first, Polyglot Persistence, involves dedicating separate, specialized database systems to each data type (such as PostgreSQL for metadata, Neo4j for scene graphs, and InfluxDB for sensor streams). While this approach optimizes performance for individual modalities, it introduces significant complexity for holistic tasks that depend on cross-database queries and data integration [96]. Conversely, the second category, Unified Multi-Model Databases [97], integrates various data models within a single instance. This design enables seamless cross-model queries to be executed within a unified transactional context. Such a paradigm is highly suitable for the consolidated data management needs of urban applications; a query like “retrieve all vehicles (relational) that were spatially near (graph) the incident location during the last 5 minutes (time-series)" can be processed as a single atomic operation, eliminating the need for cross-system coordination. In the rainy intersection scenario, such unified queries can simultaneously express occlusion and priority constraints while returning the associated sensor slices for the relevant time window.
For UrbanEAs, the most significant advantage of multi-model databases is their capacity to unify heterogeneous data management. This unification, in turn, simplifies data pipelines and reduces the overhead associated with schema conversion. These systems can also strike a balance between low-latency responses for real-time sensing and high-throughput processing for offline analysis by employing diverse indexing strategies tailored to each specific data model [98]. Notable examples include Sinew [68], which merges document and graph models to achieve flexible schema evolution; NoAM [69], which is tailored for aggregation-oriented NoSQL workloads; and UniBench [70], a comprehensive benchmark used to evaluate the performance of multi-model databases across varied query patterns.
3.2. Semantic & Relational Architectures
•Graph Databases. Beyond data lakes and multi-model paradigms, traditional data models struggle to natively express the complex relationships that govern urban systems [99,100,101]. This limitation manifests as the Semantic Gap, where raw data lacks explicit relational context for high-level reasoning [102]. To bridge this gap, graph-based architectures leverage graph databases [103,104,105,106] and graph neural networks to model entity relationships as graphs , where nodes represent entities and edges encode their relationships [107], such as modeling the `occludes` relationship between the vehicle and the truck. This provides the explicit relational context needed for downstream reasoning tasks like scene question answering. In the intersection scenario, perception outputs are materialized into a temporally indexed scene graph where nodes represent the ego vehicle, the truck, the ambulance, lanes and signals, and edges encode relations such as occludes, located_on_lane, has_priority, and approaching_from_blind_spot. Each relation carries the originating timestamp and pointers to the source frames in the lake, grounding semantic reasoning back to raw data without ambiguity. In UrbanEA, two distinct yet complementary graph representation paradigms have emerged, each serving different scales and purposes. The first paradigm, scene graphs, follows a bottom-up, task-specific approach. Scene graphs are typically generated in an end-to-end manner directly from sensor inputs (e.g., multi-view images or LiDAR scans) to capture the immediate perceptual context of a scene [74,108]. For example, Sg-CityU [74] constructs urban scene graphs that decompose complex 3D environments into structured object-centric representations with spatial relationships, simplifying downstream tasks like spatial reasoning and navigation. T2SG (Traffic Topology Scene Graph) [108] specializes in modeling road-level topology for autonomous driving: it represents lanes as nodes and their connectivity (e.g., predecessor, successor) and control relationships (e.g., governed by a specific traffic light) as edges. The second paradigm, knowledge graphs (KGs), adopts a top-down, ontology-driven approach aimed at building comprehensive, reusable knowledge bases for entire urban domains [107,109,110]. A landmark example is nuScenes Knowledge Graph (nSKG) [73], which transforms the nuScenes autonomous driving dataset into a structured KG comprising approximately 43 million RDF triples. nSKG is constructed by first defining formal ontologies, and then systematically extracting and mapping instance data from the dataset’s annotations into this ontological framework [73]. This dichotomy reflects a fundamental trade-off: scene graphs prioritize speed, task-relevance, and tight integration with perception models, making them suitable for real-time, tactical decision-making; KGs prioritize completeness, semantic richness, and long-term knowledge persistence, making them ideal for strategic reasoning, offline simulation, and cross-domain knowledge integration [111].
Beyond static storage, graph-based architectures enable advanced reasoning through graph neural networks (GNNs) [112]. GNNs operate by iteratively propagating and aggregating information across graph edges, where each node updates its representation by combining information from its neighbors through learnable transformations, enabling the model to reason about both local interactions and global context [9]. In urban applications, (spatio-temporal graph neural networks) STGNNs extend this by jointly modeling spatial topology (e.g., road network connectivity) and temporal dynamics (e.g., traffic flow evolution), making them indispensable for predictive tasks such as trajectory forecasting and traffic prediction [9]. A representative application is SemanticFormer [113], which leverages the rich semantic context provided by nSKG to perform multi-modal trajectory prediction. SemanticFormer employs a hierarchical heterogeneous graph encoder that captures interactions between agents, road elements, and traffic rules by applying attention mechanisms over meta-paths—semantically meaningful sequences of relations (e.g., vehicle →on_lane→ lane →governed_by→ traffic_light).
From a systems perspective, graph databases such as Neo4j [71] and JanusGraph [72] provide the infrastructure for storing and querying large-scale urban KGs using declarative languages like SPARQL and Cypher. These systems support multi-hop traversal queries essential for tasks like multi-step path planning (e.g., “Find all lanes connected to the current lane that are not controlled by a red light") [105]. In practice, hybrid architectures are increasingly common: structured metadata and time-series data are stored in relational or time-series databases (as discussed previously), while complex relational and semantic information is offloaded to graph databases, with both systems queried in a federated manner [107]. Real-world applications demonstrate the power of this paradigm: Urban Region Graph [99] uses graph-based spatial representations for urban village detection; knowledge-driven site selection systems like KnowSite [109] leverage urban KGs to recommend optimal commercial locations by reasoning over multi-hop relationships between venues, demographics, and transportation networks, outperforming purely data-driven approaches [107].
•Vector Databases. Another limitation of relational models is their reliance on exact, token-based queries, making them ill-suited for vague, natural language queries [85,114]. Vector databases address this by encoding multimodal data into high-dimensional vectors and leveraging Approximate Nearest Neighbor (ANN) search algorithms [75,77,78,115] for rapid, content-based semantic retrieval. The core operation is to measure the semantic similarity between a query vector Q and data vectors in the database, often using cosine similarity [116]:
The system returns items with the highest similarity scores [117]. In the intersection, retrieving similar rainy intersection segments helps interpret degraded visuals when occlusion and glare lower confidence. This capability is crucial for advanced human-agent interaction, particularly for supporting the Scene Question Answering (SQA) tasks in section V. The demand for such advanced interactive tasks, exemplified by work like NuScenes-QA [118], has spurred the need for vector databases, making it possible to query vast visual scenes using natural language [74,118,119,120].
3.3. Spatio-temporal & Dynamic Architectures
•Time-Series Databases. In data of UrbanEAs, time-series databases serve two primary roles [121]. First, they manage high-frequency sensor data streams from embodied agents. For instance, in autonomous driving research, vehicles generate continuous streams of IMU data (at 100+ Hz), GPS trajectories (at 10 Hz), LiDAR scans (at 10-20 Hz), and vehicle dynamics (velocity, acceleration, steering angle at 50+ Hz). These streams are ingested into time-series databases for real-time monitoring, offline analysis, and model training [49,50]. Systems like Gorilla [79], originally developed by Facebook for operational monitoring, demonstrate the capability to handle billions of data points per day with high write throughput and efficient compression, making them suitable for city-scale deployments. Similarly, Apache IoTDB [80] provides a unified time-series database specifically designed for IoT applications, with native support for irregular sampling intervals and multi-tenant isolation—features particularly valuable for managing heterogeneous sensor deployments across different urban districts or infrastructure operators. CrocodileDB [122] introduces resource-efficient query execution by exploiting temporal slackness in query deadlines, enabling graceful performance degradation under resource constraints—a critical capability for edge deployment scenarios in UrbanEA systems where computational resources may be limited. Second, in the context of interactive and reinforcement learning environments, time-series databases store the complete decision-making history of agents. For example, in EmbodiedCity [123], an agent’s trajectory, observations, actions, and rewards over an entire episode are logged as time-series data, enabling replay, debugging, and offline reinforcement learning. Similarly, in multi-agent driving scenarios studied in DriveLM [120], the synchronized time-series logs of all agents’ states and decisions are crucial for understanding emergent behaviors and training coordination strategies.
Beyond basic storage and retrieval, time-series databases increasingly support advanced analytics directly within the database engine. For instance, TimescaleDB [81] provides built-in functions for continuous aggregation (e.g., computing moving averages in real-time as data arrives), time-bucketing (grouping data into regular intervals for analysis), and hyperfunctions (domain-specific aggregations like percentile estimation over time). Around urgent braking events at the intersection, event-centric windows organize ego-state streams for fusion and audit.
•Spatio-Temporal Databases. In data of UrbanEAs, spatio-temporal databases are critical for the simultaneous management of both spatial and temporal dimensions, a requirement that pure time-series databases do not fully address [124,125,126,127]. A primary role is enabling hybrid systems. Recent empirical studies validate this approach by integrating PostgreSQL with extensions like PostGIS (for spatial capabilities) and Timescale (for temporal optimization) [128,129]. This combination demonstrates substantial query time reductions for both stationary (e.g., parking monitoring) and non-stationary (e.g., railway track monitoring) sensor data. Crucially, these studies reveal that for trajectory data, lightweight BRIN (Block Range Index) indexes can outperform traditional R-trees in both query performance and storage overhead, challenging conventional wisdom in spatial indexing. A second role is trajectory and mobility data management. Urban trajectories (vehicles, drones, pedestrians) are spatio-temporal objects. Specialized systems like MobilityDB [82] extend databases with native support for moving objects, enabling queries such as “find all vehicles that passed through region R between time and " or “compute the speed profile of agent A over the last hour," which is foundational for traffic analysis and behavior mining [130]. More recently, the integration with machine learning frameworks has enabled in-database prediction [12,131,132,133]. The emergence of foundation models for Spatio-Temporal Data represents a paradigm shift, allowing pre-trained models to be deployed directly on spatio-temporal data streams for real-time forecasting (e.g., traffic prediction, demand estimation) without moving data to external systems. In the intersection scenario, alignment operators synchronize the RSU ambulance trajectory with the ego timeline and unify coordinate frames, producing per-timestamp bundles ready for fusion.
3.4. Discussion
Effective data management in urban embodied systems transforms raw, heterogeneous sensor streams into actionable knowledge through layered architectures. It begins with Data Lakes that retain raw assets and lineage, continues with Graph Databases that render critical relations explicit and queryable, and relies on Spatio-temporal Databases to synchronize heterogeneous streams in time and space while unifying coordinate frames. Together, these components produce coherent, analysis-ready data for fusion and downstream tasks.
We observe two trends. The first is an evolution from static datasets to dynamic data platforms. The future paradigm of data management will shift from publishing one-off, static datasets to building dynamic, open data ecosystems where the community can continuously upload, annotate, query, and simulate, thereby accelerating iteration across the entire field [42]. The second is the concept of data as a queryable world model. When data management and querying technologies reach their zenith, the managed, structured data asset itself constitutes an implicit, inferable world model, blurring the lines between raw data, information, and knowledge. This offers a novel and exciting avenue for building more general and powerful UrbanEA [32,134].
4. Data Fusion: Bridging Domain Gaps
Data in UrbanEA is beyond the passive feed from a single domain, but an active perception combining multi-domain information. This combination is essential, acting like the assembly of “puzzle pieces" which resolves inconsistencies between sources and fills the blind spots of individual sensors. Only through this process can a scattered collection of data become a coherent and complete urban “tapestry". Without effective fusion, the UrbanEA is left with a collection of scattered, independent, and potentially contradictory perceptual puzzle pieces.
However, this fusion process presents challenges, stemming from the heterogeneity of multi-domain data [13,14]. While the previous section detailed the preparation of each “puzzle piece," including the preprocessing and management of individual data streams, this section explores how to stitch them together into a unified understanding [135]. We will begin by analyzing the four core “gaps" that impede data fusion: at the data level, the Representation Gap and the Quality & Density Gap; at the spatio-temporal dimension, the Spatio-Temporal Gap; and at the cognitive level, the Semantic Gap. After defining these challenges, we will introduce the primary fusion strategies developed to bridge them. These include Early Fusion, Feature-Level Fusion, Late Fusion, and Prior-Based Fusion, which will be illustrated with state-of-the-art research examples [136].
4.1. The Domain Gap between Multi-Domain Data
The challenges in fusing multi-domain data can be analyzed from four perspectives: data structure, data quality, spatio-temporal basis, and information level. These perspectives reveal four obstacles, or “gaps," that must be addressed: the Representation Gap, the Quality & Density Gap, the Spatio-temporal Gap, and the Semantic Gap [137], as shown in Figure 6.
•Representation Gap. The representation gap refers to the fundamental differences in the most basic data structures, mathematical representations, and organizational methods across various data domains, as shown in Figure 6 (a). For example, satellite images are regular 2D grids composed of pixels, while point clouds are sparse, unordered sets of 3D points in a Cartesian coordinate system [138]. Meanwhile, 3D meshes are frequent in vehicles. They consist of vertices, edges, and faces, and implicit representations are continuous field functions [139]. These data structures are not compatible, requiring algorithms to incorporate specialized modules to process and convert these heterogeneous representations for effective fusion [140].
•Quality & Density Gap. The quality & density gap, as shown in Figure 6 (b), describes the inconsistencies across different data domains in terms of their precision, completeness, noise levels, and data point density, as well as the disparity between real-world collected data and idealized (e.g., synthetic) data [141]. This gap is manifested in several ways. For instance, point clouds from low-altitude domain offer high geometric precision, and the reconstruction in the ideal world needs complete and clean data. However, in the real-world data collection, they face challenges such as noise, holes, and uneven density among domains [142,143]. While image data from vehicle is dense, its quality degrades under complex illumination conditions (such as overexposure, shadows, and reflections), and it cannot directly provide geometric information [144,145,146]. Furthermore, the artifacts and imperfections common in real-world data create a “sim-to-real" gap when compared to clean, idealized synthetic training data [147,148,149].
•Spatio-Temporal Gap. The spatio-temporal gap refers to the difficulty of aligning data from different sensors and different points in time within a unified spatial coordinate system and temporal sequence, as shown in Figure 6 (c). This gap has two aspects. Spatially, the coordinate systems of different domains are difficult to unify perfectly. The perception algorithms are sensitive to accurate sensor parameters, and even minor pose errors can severely impact quality [150,151]. Temporally, because urban scenes contain moving objects (like vehicles), the content of data collected at different moments will be inconsistent, leading to deformative and elongated artifacts in the final projection [152].
•Semantic Gap. The semantic gap refers to the cognitive disparity between low-level, raw sensory data (such as pixels and points) and high-level, human-understandable scene semantics (such as object categories, functional attributes, and spatial relationships), as shown in Figure 6 (d). [153]. The algorithms can directly process pixel colors and 3D coordinates , but they cannot understand concepts like “the window", “the door", “the stair". To bridge this gap, researchers introduce techniques like semantic segmentation and language models as semantic priors [154,155]. This injects high-level knowledge into the sensing pipeline to meet the demands of advanced tasks, such as scene understanding, which is a key requirement from industrial partners [156].
Figure 7.
The different fusion strategy in the multi-domain data for Urban Embodied Agents.

4.2. Fusion Strategies for Multi-Domain Data
The fusion strategies designed to bridge domain gaps can be primarily classified into the following categories according to the stage at which they occur in the model fusion pipeline, including Raw-data-level Fusion, Hierarchical Feature Fusion, and Decision-level Fusion [157,158].
•Raw-data-level Fusion. In Raw-data-level Fusion, raw or independently preprocessed data from different modalities are merged, such as combining RGB images from satellites and depth maps from drones into a unified RGB-D data stream. This unified representation is then fed into a single encoder to extract high-level features. For instance, Muturi et al. [159] handle heterogeneous representations from the outset to bridge the Representation Gap. Additionally, the depth information can compensate for the lack of texture in images, improving the overall quality and robustness of the data to bridge the Quality & Density Gap. Shang et al. [160] integrate RGB images and depth information (from pre-trained depth models or consumer-level depth sensors) to enhance the performance in few-shot novel view synthesis.
•Hierarchical Feature Fusion. Hierarchical Feature Fusion combines features from different domains at various levels of abstraction [115], such as enriching a geometric model with high-level context from a pre-trained semantic segmentation backbone (such as CNN [161,162], ViT [163], PointNet [164]). For instance, the SUDS model [165] utilizes a joint optimization framework through a composite loss function to fuse multiple data domains, enabling the understanding of large-scale dynamic urban scenes and overcoming the limited observability to achieve a city-scale dynamic scene. GAANet [166] unifies cross-domain features in graph space via global graph interaction and local attention alignment, eliminating geometric and semantic gaps for robust fusion. To handle large-scale scenes, VastGaussian [167] and CityGaussian [168] also adopt a “divide-and-conquer" strategy, partitioning the scene into multiple cells for parallel optimization before merging. To address common Quality & Density Gap, such as illumination variation, they introduce a method that uses a CNN during optimization to separate the scene’s stable geometric colors from transient lighting effects.
•Decision-level Fusion. Decision-level Fusion, also known as Late Fusion, is a straightforward strategy where each data domain is processed independently through separate network streams. These individual networks extract high-level features or form initial predictions, and the fusion only occurs at the very end of the decoder or classifier of individual sub-networks. For instance, a model might separately process features corresponding to different levels of detail. Horizon-GS [169,170] uses a “coarse-to-fine" training strategy to establish a geometric model before addressing the gap between the aerial data (sparse 3D data) and terrain data (real street-view images). The City3D [171] method uses a height map from terrain to guide the reconstruction of aerial LiDAR point clouds. This not only ensures the semantic correctness of the result (addressing the Semantic Gap) but also helps handle issues like missing walls (addressing the Quality & Density Gap). CrossView-GS [172] uses a multi-branch architecture, training models on different view sets independently to serve as priors. It tries to capture Internet video to bridge the Quality & Density Gap when using cross-view data with large disparities.
5. Task Application: From Perception to Social Interaction
Having established the challenges of multi-domain data management in Section III and the fusion strategies in Section IV, this section introduces how to apply this processed data to UrbanEA tasks. Traditional urban tasks, such as Traffic Flow Prediction and Point-of-Interest (POI) Recommendation, primarily operate as “Digital Agents" [173,174]. These systems typically process aggregated data from a global perspective to mine patterns or forecast trends within a digital space. Their output is generally limited to information or suggestions, without direct physical intervention. In contrast, UrbanEA are defined by their physical or virtual body and their ability to interact with the environment. They perceive the environment, reason about physical constraints, and execute actions that actively change their state or the environment.
We introduce UrbanEA tasks, including Urban Scene QA (SQA), Vision-Language Navigation (VLN), and Human-Agent Collaboration (HAC). These tasks need to bridge the four Gaps. For instance, an agent cannot answer a complex question (SQA) without first bridging the Semantic Gap between raw sensor data and human-level concepts. Similarly, a navigation agent (VLN) inherently fails if it cannot resolve the Spatio-Temporal Gap to form a coherent world model. This section will explore how each of these applications leverages structured and fused data to achieve sophisticated cognitive capabilities in complex urban environments.
5.1. Urban SQA
Figure 8.
Definition of Urban Scene QA (SQA) for Urban Embodied Agents.
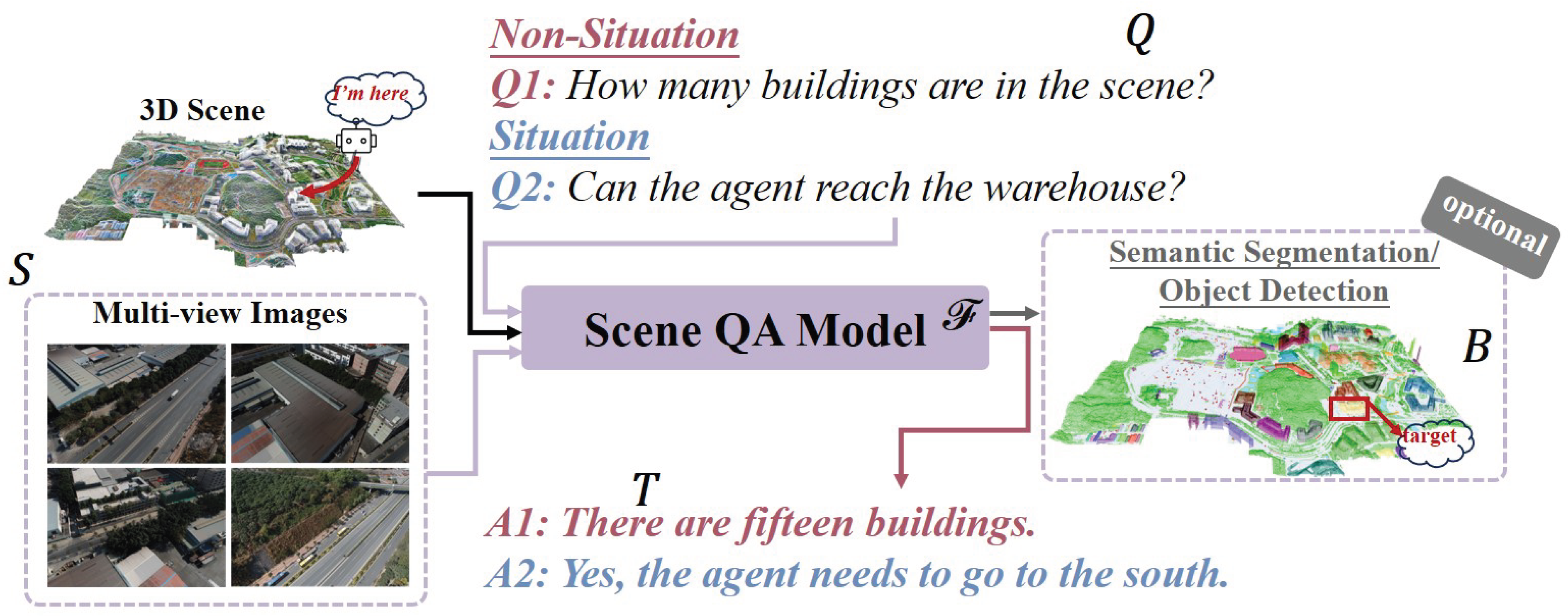
1) Definition. Urban SQA enables intelligent systems to answer queries about their spatial context, making it a key task for environmental interpretation [175]. The goal is to develop a model () that takes a scene representation (S) and a query (Q) as input to produce a textual answer (T). Optionally, the model can also output spatial grounding (B) via bounding boxes to localize entities. The scene representation S includes a point cloud () or multi-view images (), while a query Q can be text () or an egocentric image (). The task can thus be expressed as:
Effectively performing SQA requires the model to fuse spatial understanding with multimodal processing. The question in SQA can be divided into Situation (such as “Can the agent reach the warehouse from the current position?") and Non-Situation (such as “How many buildings are in the scene?"), based on whether the query includes the agent’s situation.
2) Classification. SQA can be categorized into two levels based on how the information required to answer a query is represented and acquired.
•Passive SQA. The first level, referred to as Passive SQA. In this task, the agent is a passive observer, relying on static information to answer questions without needing to explore or acquire new data through its own actions. It can be further divided into the following two sub-categories based on the difference in the scope of information: Road-level QA and City-level QA. The first is referred to as Road-level QA, which corresponds to road-level scene understanding, where the model analyzes a single, independent snapshot of the environment (e.g., a street-view image or a single frame of lidar data) to answer a question. Recent progress in autonomous driving research has stimulated the development of numerous SQA datasets designed to enhance road-level understanding capabilities, such as Nuscenes-QA [118], NuInstruct [176], NuPrompt [177], DriveLM [120], and VLAAD [119]. After the data fusion, researchers employ cross-attention or the multi-layer perceptron mechanisms to achieve deep interaction between vision and language [118,120,177]. However, road-level QA focuses on instance-level queries and limited data in the roadside, which leads to an insufficient assessment of broader city scene comprehension and complex reasoning abilities.
To overcome the limitations of road-level Question Answering (QA), the field has progressed towards City-level QA, a paradigm that grants agents access to a comprehensive, prior model of an entire city for macroscopic spatial reasoning [74,178,179,180,181]. A challenge in this domain is maintaining information fidelity during the compression of vast urban data. To mitigate these challenges, researchers have primarily adopted two strategies. The first approach, hierarchical urban modeling, transforms vast and unstructured urban scenes into structured and queryable formats using a Relational Database or Graph Database, as discussed in Sec Section 3.2. For instance, GeoProg3D [181] and Sg-CityU [74] construct a structured tree or graph to abstract complex spatial information into objects and their interrelations, which simplifies spatial reasoning. SOBA [178] and EarthVQANet [182] involve using semantic segmentation to decompose large scenes into individual object units for analysis. The second strategy is to augment the compressed scene representation by integrating external information, such as using the geographic information based on the Spatio-Temporal Database, as discussed in Sec Section 3.2. This approach compensates for details lost during compression. OpenCity3D [180] and CityBench [179] align perception models with real Geographic Information Systems (like OpenStreetMap) to provide precise geographic coordinates and place names.
•Active Embodied QA. To move beyond the cognitive bottlenecks of city-level QA, caused by the information loss and lack of dynamics in static models, Active Embodied QA (AEQA) shifts the agent from a passive analyst to an active explorer to gather high-fidelity, real-time information. Existing works includes EmbodiedCity [123] and CityEQA [183]. These datasets introduce tasks requiring an embodied agent to actively navigate and explore complex urban environments to answer open-vocabulary questions, assessing integrated navigation, sensing, and reasoning skills. The core advantage of AEQA is to transform an agent from a passive receiver of static information into an active explorer of the physical world, overcoming perceptual limitations through active action, and to locate and resolve ambiguity in complex environments. In road-level QA and city-level QA, a model is limited by the quality and viewpoint. For example, due to lighting effects, a black car appeared gray from a static viewpoint, leading to an incorrect judgment by agents. However, the agent in AEQA could actively adjust its observation pose by moving to the car’s side, which reduced the impact of the lighting and allowed it to obtain the object’s true attribute [183].
5.2. Vision-Language Navigation
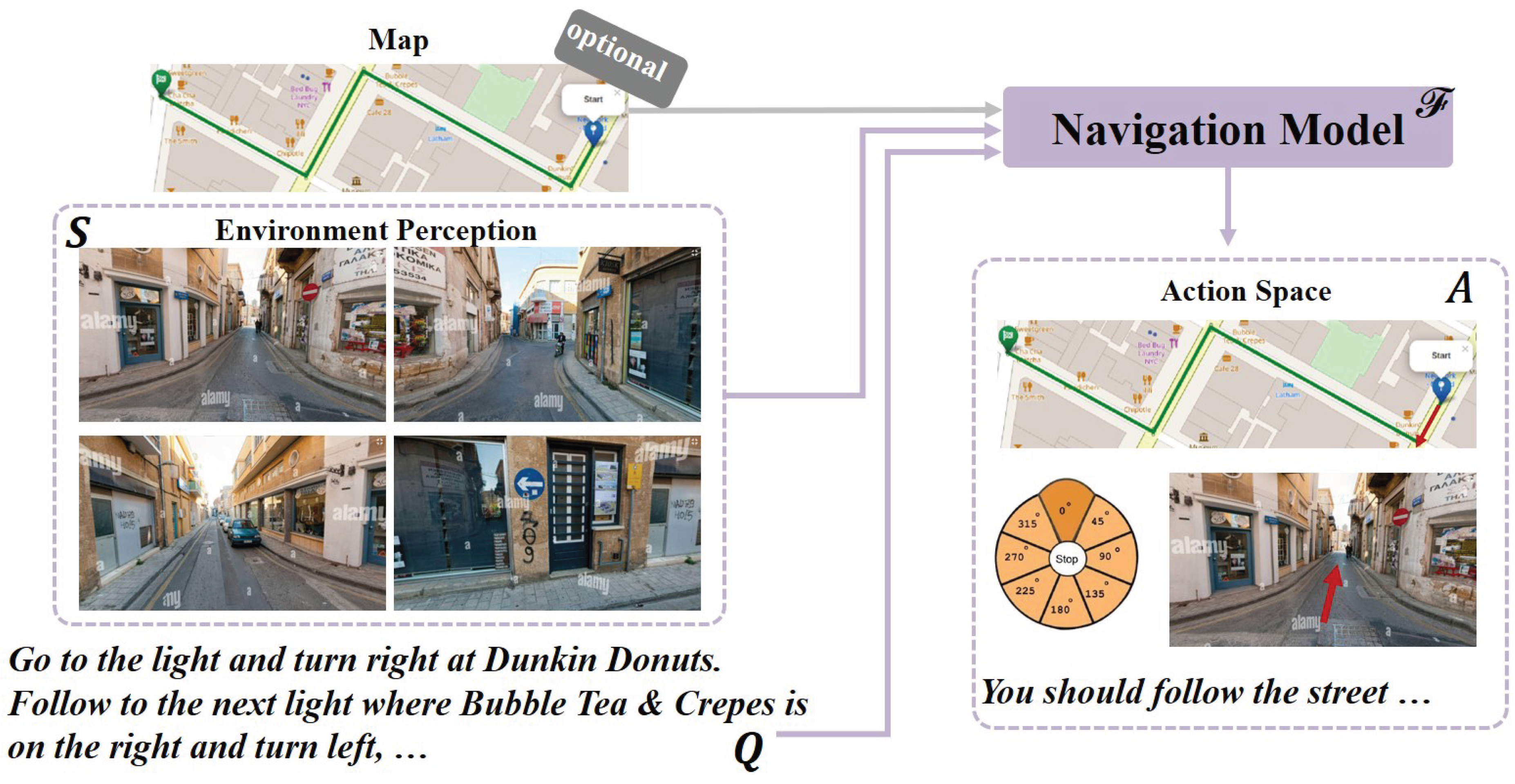
1) Definition. Vision-and-Language Navigation (VLN) is a multimodal task requiring an embodied agent to navigate a realistic environment based on natural language instructions [184]. The core components involve the agent, the environment it perceives and acts within, and the language instruction guiding its movement. The VLN task necessitates a model or agent, denoted by , designed to process two inputs: the scene representation S perceived from the environment, and a series of natural language instructions . The objective is to generate a sequence of actions that directs the agent through the environment to fulfill the goal specified by the instruction Q. This process can be represented as the mapping:
2) Classification. VLN tasks can be categorized based on their operational platform and observational perspective required of the agent . These tasks fall into two main paradigms: Terrain-View Navigation and Aerial-View Navigation.
•Terrain-View Navigation. It focuses on an agent’s ability to perform navigation from a first-person, terrain-level perspective (such as that of a pedestrian or vehicle). They primarily utilize environments from static datasets, like street-view panoramas and predefined navigation graphs, to evaluate foundational skills like landmark recognition and path adherence. Datasets such as Touchdown [48] and map2seq [185] rely on simulated scenarios and fixed paths, which limit the agent’s adaptive decision-making in complex, unpredictable real-world situations. Due to the semantic gap between instructions and first-person perception, researchers explore introducing auxiliary semantic data in vector databases and route and navigation data in time-series format to mitigate this gap. Research efforts expand training sets by automatically generating actions and instructions from unlabeled videos (e.g., VLN-video [186]), or by leveraging large language models to synthesize diverse auxiliary data, such as navigation rationales and landmark descriptions (e.g., FLAME [187], NavAgent [188]). Regarding multimodal fusion, strategies have evolved from early methods like direct feature vector concatenation (e.g., RconCAT [189]) and novel style-transfer fusion (e.g., VLN-Trans [190]), to utilizing large language models as a universal interface that converts all visual and historical information into natural language prompts for fusion and decision-making (e.g., Velma [188]).
•Aerial-View Navigation. It focuses on an agent (typically a drone) performing navigation using a third-person, top-down “bird’s-eye" view. The core of this approach is leveraging external prior knowledge, such as geographic maps and top-down satellite imagery, to provide a global context for the agent’s navigation plan. This Hybrid Spatio-Temporal Architecture directly tackles the pain point of navigating vast and unfamiliar environments, which is unavailable from a limited, first-person perspective. The primary challenge in this paradigm is aligning the provided language instructions to the specific spatial and visual features of the exo-viewpoint. These tasks includes AerialVLN [55], OpenUAV [191], CityNav [192]. For instance, CityNav [192] incorporates an internal 2D spatial map representing landmarks mentioned in the instructions, which has been shown to markedly enhance navigation performance at a city scale. UAV-VLA [193] utilizes satellite imagery as a primary information domain for mission planning. In the image, the agent decomposes the high-level instruction and navigates to the destination. AVDN [194] is built within a simulator that uses top-down satellite images to represent the drone’s visual observations. This gives both the agent and the human commander a bird’s-eye view of the environment, simplifying the navigation challenge by providing inherent global context.
Figure 9.
Definition of Vision-Language Navigation for Urban Embodied Agents.
5.3. Human-Agent Collaboration
1) Definition. Human-Agent Collaboration (HAC) in urban environments enables a hybrid team of intelligent agents and human participants to work together towards a common purpose. The core task is to design a system function that can process a collective goal (G), system-level input (I), and sensing information from the urban scene (S) to produce a coherent final output (O). This collaborative process is defined by the interaction of several key components. The system itself is composed of a heterogeneous set of n participants, , and the communication channels C. P includes both embodied agents and human participants. Each embodied agent operates based on its internal model and goal , while a human participant acts based on their expertise and assigned role . The overall system task can be formally expressed as:
HAC necessitates the ability to decompose a high-level collective goal (G) into actionable sub-tasks and to coordinate the actions of both agent and human participants () through structured communication channels (C) to achieve a unified result within the complex urban environment [195,196]. In contrast to AI systems, Human-Agent Collaboration (HAC) leverages human strengths to build more efficient, robust, and trustworthy systems[197,198,199].
2) Classification. Urban Human-Agent Collaboration (HAC) tasks can be categorized based on their primary operational focus. There are two types of HAC tasks: Environment-centric HAC tasks, which aim to optimize the urban system, and Human-centric HAC tasks, which focus on assisting or interacting with individuals or groups within the city.
•Environment-centric Human-Agent Collaboration. In this category, the primary objective is to integrate AI agents into the urban fabric to enhance system-wide efficiency, planning, and management. Agents act as decision-support tools or autonomous managers for urban infrastructure distribution [200,201,202,203,204]. These tasks often involve large-scale simulation, data analysis, and long-term optimization, with humans setting high-level goals and overseeing the system. For instance, some multi-agent frameworks try to employ a hierarchical architecture to process task data, effectively allocating responsibilities between robots and humans to balance safety and efficiency [205].
Figure 10.
Definition of Human-Agent Collaboration for Urban Embodied Agents.
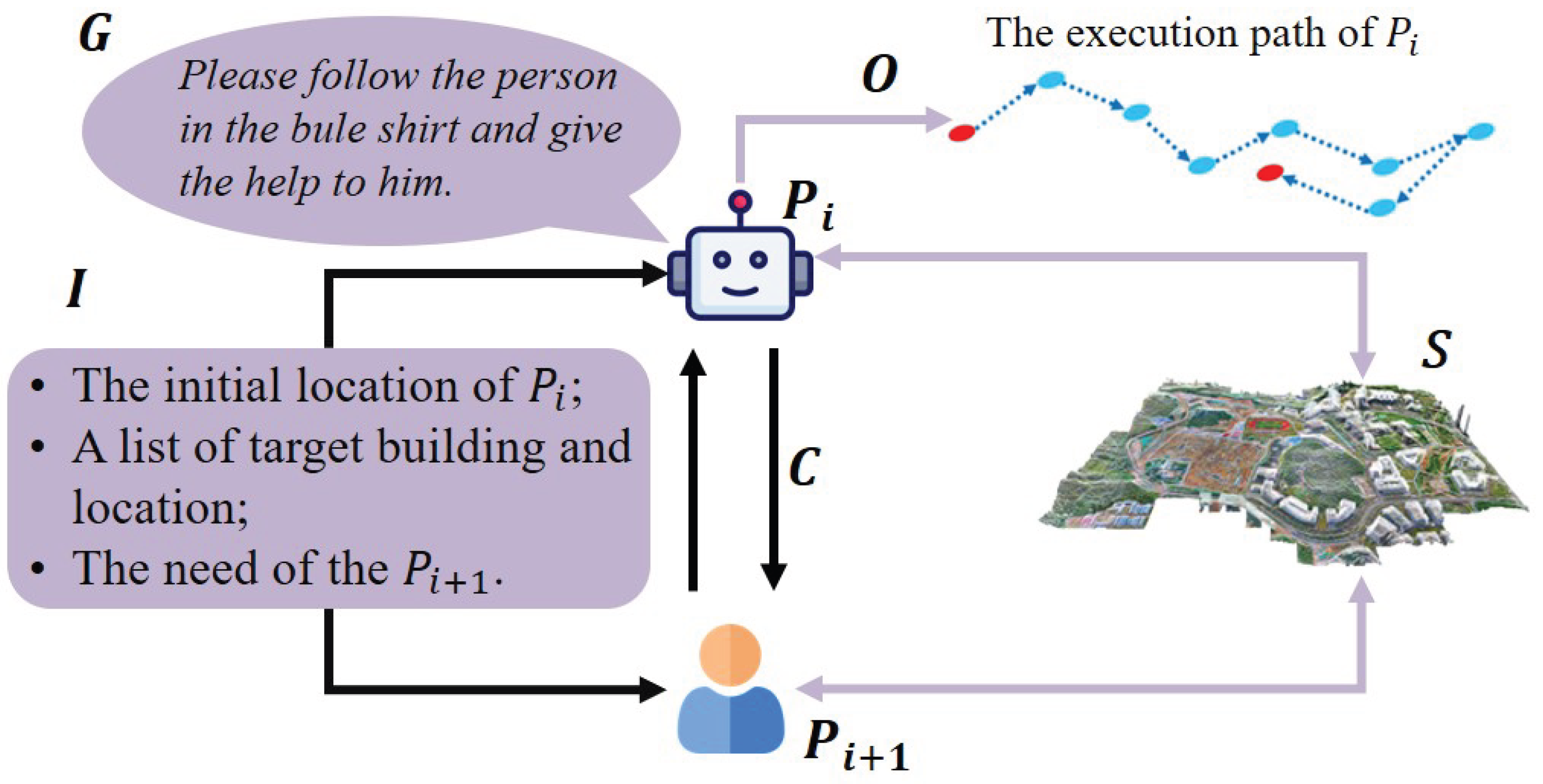
•Human-centric Human-Agent Collaboration. This category emphasizes the direct interaction and coordination between humans and agents to accomplish specific tasks within the urban environment and spatio-temporal data. Achieving this requires the data architecture capable of fusing inputs, ranging from human intent to real-time sensor streams, and leveraging specialized storage paradigms to support complex reasoning and action. The challenge in this task is bridging the gap between high-level, often ambiguous human intent and the low-level, concrete actions of agents. Try to address this challenges, the researchers try to build the agents with two capabilities: grounding human commands in the physical world and managing dynamic task execution over time. First, the agent can interpret the human’s command by fusing the natural language instruction with both real-time environmental sensing and external world knowledge [206]. A command like “find a safe place to land" requires the system to semantically link the abstract concept of `safety’ to visual and spatial features from its sensors. This process relies on a Vector Database to perform semantic search (connecting language to visual patterns) and Graph or Relational Databases to query structured world knowledge (e.g., GIS data identifying open areas, no-fly zones). This fusion of linguistic, perceptual, and knowledge-based data allows the agent to transform an abstract goal into a concrete, localized target [207,208,209,210].
5.4. Discussion
The progression of tasks from passive scene understanding to active interaction reveals that future breakthroughs will depend on building more comprehensive world models. Future world models must learn universal principles, not just memorize patterns. This will allow a navigation agent trained on a US grid-style road network to successfully adapt to the unfamiliar roundabouts of Europe. Besides, the world models will be embedded with social intelligence. For tasks like HAC, future agents will learn to understand unwritten social norms (e.g., driving etiquette, personal space), moving beyond following traffic laws to become more intuitive and effective collaborators in society.
6. Social Impact
The urban environment is a socio-physical environment that integrates social behavior with physical scene [211,212]. This section aims to explore the profound potential of the UrbanEA to drive positive societal change, focusing on the social impacts it can deliver across the following domains.
6.0.1. Transportation
Modern urban transportation faces congestion and pollution due to the increasing number of vehicles, while complex road networks and unforeseen incidents continually threaten road safety [213,214]. Meanwhile, lagging public transportation planning leads to inefficient service, and the aging of critical infrastructure is difficult to maintain due to a lack of effective monitoring [215]. For instance, in the traffic flow management [216,217,218], the agent fuses real-time data from the terrain-level domain and the drone domain to perceive traffic flow dynamics, enabling adaptive traffic signal control to alleviate urban congestion, reduce carbon emissions, and improve the commuting experience [219].
6.0.2. Energy
In the context of the energy transition, despite the potential of clean energy sources like solar, planning for and maximizing their deployment in complex urban environments remains a challenge. Traditional energy management methods are macroscopic and static, incapable of performing fine-grained, dynamic management and optimization for energy-consuming units within a city [220,221,222]. For instance, the agent uses detailed 3D building models to calculate the solar conditions and shadow occlusions for every rooftop, generating a city-wide “solar map" [223,224,225].
6.0.3. Climate Change
The high-density buildings and surfaces of cities exacerbate problems like the “Urban Heat Island" (UHI) effect. The challenge for cities in adapting to climate change is the lack of tools capable of accurately simulating these risks. Macroscopic climate models are insufficient for guiding specific adaptations at the street and community levels. The agent fuses satellite, drone, and terrain data to accurately simulate the formation and distribution of the urban heat island effect [226]
6.0.4. Healthy Care
Factors within cities, such as air and noise pollution, the uneven distribution of green spaces, and “pedestrian-unfriendly" designs, invisibly harm public health and increase the risk of chronic diseases [227]. Through its multi-dimensional perception and analytical capabilities, the UrbanEA can quantify and visualize these health determinants, integrating public health goals into every aspect of urban planning. The agent integrates data from various urban sensors to generate dynamic, visual maps of air and noise pollution. This provides citizens with “healthy route" suggestions and helps environmental agencies pinpoint pollution sources, thereby improving the city’s overall living environment quality [228,229].
7. Outlook and Discussion
In this section, we summarize these challenges and suggest potentially feasible research directions, organizing them into methodological, systemic, and societal challenges.
7.1. Method-Level Challenges
7.1.1. Robust Fusion with Imbalanced Multi-domain Data
This is a challenge that directly extends the discussion of the Quality & Density Gap in Section III. Future UrbanEA must operate reliably in the real world, where data domains, quality, and quantity are imbalanced. This imbalance manifests in several ways: viewpoint imbalance (e.g., massive volumes of terrain-level street views vs. limited aerial drone imagery), quality imbalance (e.g., high-precision professional LiDAR data vs. noisy crowd-sourced images), and temporal imbalance (e.g., static historical map data vs. sparse real-time sensor streams) [230].
Future research will explore new fusion architectures that not only fuse this heterogeneous data but also enable robust inference and decision-making when critical data is missing or of low quality, preventing the model from being overwhelmed by an abundance of poor data.
7.1.2. Continual Learning and Incremental City Updates
The majority of current UrbanEAs perform one-shot understanding on a static dataset, generating a static snapshot of a city. However, a city is a constantly evolving entity [3,231]. A future challenge is to evolve the agent’s cognition from static snapshots to a dynamic world model capable of continual learning and incremental updates.
This requires solving critical problems such as catastrophic forgetting (forgetting old scenes when learning new ones), model drift, and efficiently managing never-ending data streams. Achieving this goal would elevate the solution to the Spatio-temporal Gap from handling minute-long sequences to managing year-long urban evolution.
7.2. System-Level Challenges
7.2.1. High-Fidelity Simulators and the Sim-to-Real Loop
While existing urban simulators like CARLA [16] and MetaUrban [201] are powerful, a sim-to-real gap persists, both in terms of perceptual realism (e.g., simulation of lighting, sensor noise) and behavioral realism (e.g., pedestrian and vehicle driving habits).
A future direction is to leverage the UrbanEA itself to advance simulator development. By constructing ultra-high-fidelity digital twins from real-world data, we can extract physical materials, lighting properties, and behavioral patterns of traffic agents to build the next generation of more realistic simulators. This forms a “Real-to-Sim-to-Real” loop: real-world data improves the simulator, the improved simulator trains and validates better agents, and those agents then better perceive and influence the real world.
7.2.2. Multi-Agent Collaboration and Swarm Intelligence
The city of the future will be a massive distributed system composed of thousands of independent agents with only local sensing (e.g., autonomous vehicles, drones, infrastructure sensors). A challenge, and the key to the emergence of swarm intelligence, is enabling these agents to collaborate efficiently and safely [232,233].
Future research must address communication bottlenecks, decentralized decision-making consistency, and collaboration among heterogeneous agents. In this vision, the unified world model built by the urban perception can serve as a “digital bedrock", providing an authoritative and consistent environmental representation for all other micro-agents to query and interact with, thus enabling the leap from single-agent intelligence to large-scale swarm intelligence.
7.3. Societal-Level Challenges
7.3.1. Causal Reasoning by Fusing Social Knowledge
This represents the leap across the Semantic Gap. Current fusion operates at the level of physical sensing (geometry, appearance), whereas a future agent must be able to fuse non-physical, abstract social knowledge [234].
By integrating information like social media trends, news events, event schedules, and weather alerts, the agent can transition from answering `“what is happening” to explaining “why it is happening”. This fusion of sensing with abstraction will transform the UrbanEAs from a powerful descriptive tool into an explanatory and predictive tool with rudimentary causal reasoning, providing the true intelligence required for the advanced tasks outlined in Section VI.
7.3.2. Fairness and Data Bias
The challenge of imbalanced multi-domain data transcends a technical concern, posing an issue of social equity. Data perception often mirrors existing socio-economic disparities, leading to the over-representation of affluent areas and the under-representation of marginalized communities [235,236]. An agent trained on such data would develop a biased worldview; it will learn to equate data-richness with importance, effectively rendering data-poor areas invisible [237,238,239].
Future research will create fusion methods that can be audited. It must focus on developing fairness-aware fusion algorithms. These methods must not only audit and quantify data-driven disparities but also actively correct for them. The goal is to ensure the agent’s decisions promote allocative equity, ensuring that urban services and resources (discussed in Section VI) are distributed justly, even when the input data itself is unjust [240].
8. Conclusions
In this paper, we comprehensively survey the emerging field of data lifecycle for UrbanEA. We systematically review the existing work on this entire data lifecycle, including data perception, data management, data fusion, and downstream task applications. We compare mainstream simulators and data management architectures in terms of what they contain and how they are constructed. We analyze the mainstream multi-domain data fusion strategies, highlighting the three core challenges in this field (environmental variability, scale limitation, and interaction complexity) and the four major Gaps in multi-domain data fusion. Finally, we point out potential research opportunities with existing tasks, and list several promising future directions for the field, such as continual learning, causal fusion, and large-scale multi-agent collaboration.
References
- Bettencourt, L.M. The origins of scaling in cities. science 2013, 340, 1438–1441.
- Dong, L.; Duarte, F.; Duranton, G.; Santi, P.; Barthelemy, M.; Batty, M.; Bettencourt, L.; Goodchild, M.; Hack, G.; Liu, Y.; et al. Defining a city — delineating urban areas using cell-phone data. Nat. Cities 2024, 1, 117–125. [CrossRef]
- Yang, L.; Luo, Z.; Zhang, S.; Teng, F.; Li, T. Continual Learning for Smart City: A Survey. IEEE Trans. Knowl. Data Eng. 2024, 36, 7805–7824. [CrossRef]
- Cengiz, B.; Adam, I.Y.; Ozdem, M.; Das, R. A survey on data fusion approaches in IoT-based smart cities: Smart applications, taxonomies, challenges, and future research directions. Inf. Fusion 2025, 121. [CrossRef]
- Bibri, S.E.; Huang, J. Artificial intelligence of things for sustainable smart city brain and digital twin systems: Pioneering Environmental synergies between real-time management and predictive planning. Environ. Sci. Ecotechnology 2025, 26, 100591. [CrossRef]
- Xu, F.; Zhang, J.; Gao, C.; Feng, J.; Li, Y. Urban generative intelligence (ugi): A foundational platform for agents in embodied city environment. arXiv preprint arXiv:2312.11813 2023.
- Song, Y.; Sun, P.; Liu, H.; Li, Z.; Song, W.; Xiao, Y.; Zhou, X. Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI. IEEE Trans. Knowl. Data Eng. 2024, 36, 6962–6976. [CrossRef]
- Zhang, Y.; Ma, Z.; Li, J.; Qiao, Y.; Wang, Z.; Chai, J.; Wu, Q.; Bansal, M.; Kordjamshidi, P. Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models. Transactions on Machine Learning Research.
- Jin, G.; Liang, Y.; Fang, Y.; Shao, Z.; Huang, J.; Zhang, J.; Zheng, Y. Spatio-Temporal Graph Neural Networks for Predictive Learning in Urban Computing: A Survey. IEEE Trans. Knowl. Data Eng. 2023, 36, 5388–5408. [CrossRef]
- Zhang, W.; Han, J.; Xu, Z.; Ni, H.; Liu, H.; Xiong, H. Urban Foundation Models: A Survey. KDD '24: The 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Spain; pp. 6633–6643.
- Lu, Y.; Tang, H. Multimodal Data Storage and Retrieval for Embodied AI: A Survey. arXiv preprint arXiv:2508.13901 2025.
- Liang, Y.; Wen, H.; Xia, Y.; Jin, M.; Yang, B.; Salim, F.; Wen, Q.; Pan, S.; Cong, G. Foundation Models for Spatio-Temporal Data Science: A Tutorial and Survey. KDD '25: The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Canada; pp. 6063–6073.
- Zou, X.; Yan, Y.; Hao, X.; Hu, Y.; Wen, H.; Liu, E.; Zhang, J.; Li, Y.; Li, T.; Zheng, Y.; et al. Deep learning for cross-domain data fusion in urban computing: Taxonomy, advances, and outlook. Inf. Fusion 2024, 113. [CrossRef]
- Song, S.; Li, X.; Li, S.; Zhao, S.; Yu, J.; Ma, J.; Mao, X.; Zhang, W.; Wang, M. How to Bridge the Gap Between Modalities: Survey on Multimodal Large Language Model. IEEE Trans. Knowl. Data Eng. 2025, 37, 5311–5329. [CrossRef]
- Liu, H.; Tong, Y.; Han, J.; Zhang, P.; Lu, X.; Xiong, H. Incorporating Multi-Source Urban Data for Personalized and Context-Aware Multi-Modal Transportation Recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 723–735. [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on robot learning. PMLR, 2017, pp. 1–16.
- Bisio, I.; Delfino, A.; Grattarola, A.; Lavagetto, F.; Sciarrone, A. Ultrasounds-Based Context Sensing Method and Applications Over the Internet of Things. IEEE Internet Things J. 2018, 5, 3876–3890. [CrossRef]
- Phipps, A.; Ouazzane, K.; Vassilev, V. Enhancing Cyber Security Using Audio Techniques: A Public Key Infrastructure for Sound. 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom). China; pp. 1428–1436.
- Li, K.; Liu, M. Combined influence of multi-sensory comfort in winter open spaces and its association with environmental factors: Wuhan as a case study. Build. Environ. 2023, 248. [CrossRef]
- Yin, C.; Chen, P.-Y.; Yao, B.; Wang, D.; Caterino, J.; Zhang, P. SepsisLab: Early Sepsis Prediction with Uncertainty Quantification and Active Sensing. KDD '24: The 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Spain; pp. 6158–6168.
- Chen, C.; Jain, U.; Schissler, C.; Gari, S.V.A.; Al-Halah, Z.; Ithapu, V.K.; Robinson, P.; Grauman, K. SoundSpaces: Audio-Visual Navigation in 3D Environments. European Conference on Computer Vision. United Kingdom; pp. 17–36.
- Chen, C.; Schissler, C.; Garg, S.; Kobernik, P.; Clegg, A.; Calamia, P.; Batra, D.; Robinson, P.; Grauman, K. Soundspaces 2.0: A simulation platform for visual-acoustic learning. Advances in Neural Information Processing Systems 2022, 35, 8896–8911.
- Clarke, S.; Gao, R.; Wang, M.; Rau, M.; Xu, J.; Wang, J.-H.; James, D.L.; Wu, J. REALIMPACT: A Dataset of Impact Sound Fields for Real Objects. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Canada; pp. 1516–1525.
- Gan, C.; Gu, Y.; Zhou, S.; Schwartz, J.; Alter, S.; Traer, J.; Gutfreund, D.; Tenenbaum, J.B.; McDermott, J.H.; Torralba, A. Finding Fallen Objects Via Asynchronous Audio-Visual Integration. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 10513–10523.
- Gao, R.; Li, H.; Dharan, G.; Wang, Z.; Li, C.; Xia, F.; Savarese, S.; Fei-Fei, L.; Wu, J. Sonicverse: A Multisensory Simulation Platform for Embodied Household Agents that See and Hear. 2023 IEEE International Conference on Robotics and Automation (ICRA). United Kingdom; pp. 704–711.
- Narang, Y.; Sundaralingam, B.; Macklin, M.; Mousavian, A.; Fox, D. Sim-to-Real for Robotic Tactile Sensing via Physics-Based Simulation and Learned Latent Projections. 2021 IEEE International Conference on Robotics and Automation (ICRA). China; pp. 6444–6451.
- Gao, R.; Si, Z.; Chang, Y.-Y.; Clarke, S.; Bohg, J.; Fei-Fei, L.; Yuan, W.; Wu, J. ObjectFolder 2.0: A Multisensory Object Dataset for Sim2Real Transfer. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 10588–10598.
- Gao, R.; Dou, Y.; Li, H.; Agarwal, T.; Bohg, J.; Li, Y.; Fei-Fei, L.; Wu, J. The Object Folder Benchmark : Multisensory Learning with Neural and Real Objects. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Canada; pp. 17276–17286.
- Gao, R.; Chang, Y.Y.; Mall, S.; Fei-Fei, L.; Wu, J. ObjectFolder: A Dataset of Objects with Implicit Visual, Auditory, and Tactile Representations. In Proceedings of the Conference on Robot Learning, 2021.
- Calandra, R.; Owens, A.; Jayaraman, D.; Lin, J.; Yuan, W.; Malik, J.; Adelson, E.H.; Levine, S. More Than a Feeling: Learning to Grasp and Regrasp Using Vision and Touch. IEEE Robot. Autom. Lett. 2018, 3, 3300–3307. [CrossRef]
- Hong, Y.; Zheng, Z.; Chen, P.; Wang, Y.; Li, J.; Gan, C. MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 26396–26406.
- Zhang, W.; Han, J.; Xu, Z.; Ni, H.; Liu, H.; Xiong, H. Towards urban general intelligence: A review and outlook of urban foundation models. arXiv preprint arXiv:2402.01749 2024.
- Fadhel, M.A.; Duhaim, A.M.; Saihood, A.; Sewify, A.; Al-Hamadani, M.N.; Albahri, A.; Alzubaidi, L.; Gupta, A.; Mirjalili, S.; Gu, Y. Comprehensive systematic review of information fusion methods in smart cities and urban environments. Inf. Fusion 2024, 107. [CrossRef]
- El-Omari, S.; Moselhi, O. Integrating 3D laser scanning and photogrammetry for progress measurement of construction work. Autom. Constr. 2008, 18, 1–9. [CrossRef]
- Navares-Vázquez, J.C.; Qiu, Z.; Arias, P.; Balado, J. HoloLens 2 performance analysis for indoor/outdoor 3D mapping. J. Build. Eng. 2025, 108. [CrossRef]
- Rashdi, R.; Garrido, I.; Balado, J.; Del Río-Barral, P.; Rodríguez-Somoza, J.L.; Martínez-Sánchez, J. Comparative Evaluation of LiDAR systems for transport infrastructure: case studies and performance analysis. Eur. J. Remote. Sens. 2024, 57. [CrossRef]
- Seifert, E.; Seifert, S.; Vogt, H.; Drew, D.; van Aardt, J.; Kunneke, A.; Seifert, T. Influence of Drone Altitude, Image Overlap, and Optical Sensor Resolution on Multi-View Reconstruction of Forest Images. Remote. Sens. 2019, 11, 1252. [CrossRef]
- Girindran, R.; Boyd, D.S.; Rosser, J.; Vijayan, D.; Long, G.; Robinson, D. On the Reliable Generation of 3D City Models from Open Data. Urban Sci. 2020, 4, 47. [CrossRef]
- Zhang, H.K.; Roy, D.P.; Yan, L.; Li, Z.; Huang, H.; Vermote, E.; Skakun, S.; Roger, J.-C. Characterization of Sentinel-2A and Landsat-8 top of atmosphere, surface, and nadir BRDF adjusted reflectance and NDVI differences. Remote. Sens. Environ. 2018, 215, 482–494. [CrossRef]
- Xiao, C.; Zhou, J.; Xiao, Y.; Huang, J.; Xiong, H. ReFound: Crafting a Foundation Model for Urban Region Understanding upon Language and Visual Foundations. KDD '24: The 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Spain; pp. 3527–3538.
- Duan, J.; Yu, S.; Tan, H.L.; Zhu, H.; Tan, C. A Survey of Embodied AI: From Simulators to Research Tasks. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 230–244. [CrossRef]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A Platform for Embodied AI Research. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). South Korea; pp. 9338–9346.
- Puig, X.; Undersander, E.; Szot, A.; Cote, M.D.; Yang, T.Y.; Partsey, R.; Desai, R.; Clegg, A.; Hlavac, M.; Min, S.Y.; et al. Habitat 3.0: A Co-Habitat for Humans, Avatars, and Robots. In Proceedings of the The Twelfth International Conference on Learning Representations.
- Szot, A.; Clegg, A.; Undersander, E.; Wijmans, E.; Zhao, Y.; Turner, J.; Maestre, N.; Mukadam, M.; Chaplot, D.S.; Maksymets, O.; et al. Habitat 2.0: Training home assistants to rearrange their habitat. Advances in neural information processing systems 2021, 34, 251–266.
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Niessner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 2432–2443.
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27-30 June 2016; pp. 3213–3223. [CrossRef]
- Lam, D.; Kuzma, R.; McGee, K.; Dooley, S.; Laielli, M.; Klaric, M.; Bulatov, Y.; McCord, B. xview: Objects in context in overhead imagery. arXiv preprint arXiv:1802.07856 2018.
- Chen, H.; Suhr, A.; Misra, D.; Snavely, N.; Artzi, Y. TOUCHDOWN: Natural Language Navigation and Spatial Reasoning in Visual Street Environments. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). USA; pp. 12530–12539.
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020; pp. 2446–2454.
- Liao, Y.; Xie, J.; Geiger, A. KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3292–3310. [CrossRef]
- Chen, M.; Hu, Q.; Yu, Z.; Thomas, H.; Feng, A.; Hou, Y.; McCullough, K.; Ren, F.; Soibelman, L. STPLS3D: A Large-Scale Synthetic and Real Aerial Photogrammetry 3D Point Cloud Dataset. In Proceedings of the 33rd British Machine Vision Conference Proceedings, BMVC 2022, 2022.
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds. Int. J. Comput. Vis. 2022, 130, 316–343. [CrossRef]
- Yang, G.; Xue, F.; Zhang, Q.; Xie, K.; Fu, C.-W.; Huang, H. UrbanBIS: a Large-scale Benchmark for Fine-grained Urban Building Instance Segmentation. SIGGRAPH '23: Special Interest Group on Computer Graphics and Interactive Techniques Conference. United States; pp. 1–11.
- Liu, S.; Zhang, H.; Qi, Y.; Wang, P.; Zhang, Y.; Wu, Q. AerialVLN: Vision-and-Language Navigation for UAVs. 2023 IEEE/CVF International Conference on Computer Vision (ICCV). France; pp. 15338–15348.
- Wang, H.; Chen, J.; Huang, W.; Ben, Q.; Wang, T.; Mi, B.; Huang, T.; Zhao, S.; Chen, Y.; Yang, S.; et al. Grutopia: Dream general robots in a city at scale. arXiv preprint arXiv:2407.10943 2024.
- Wang, X.; Yang, D.; Wang, Z.; Kwan, H.; Chen, J.; Wu, W.; Li, H.; Liao, Y.; Liu, S. Towards realistic uav vision-language navigation: Platform, benchmark, and methodology. arXiv preprint arXiv:2410.07087 2024.
- Zhong, F.; Wu, K.; Wang, C.; Chen, H.; Ci, H.; Li, Z.; Wang, Y. UnrealZoo: Enriching Photo-realistic Virtual Worlds for Embodied AI. arXiv preprint arXiv:2412.20977 2024.
- Wu, W.; He, H.; He, J.; Wang, Y.; Duan, C.; Liu, Z.; Li, Q.; Zhou, B. MetaUrban: An Embodied AI Simulation Platform for Urban Micromobility. International Conference on Learning Representation 2025.
- Gao, Y.; Li, C.; You, Z.; Liu, J.; Li, Z.; Chen, P.; Chen, Q.; Tang, Z.; Wang, L.; Yang, P.; et al. OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation. arXiv preprint arXiv:2502.18041 2025.
- Mirowski, P.; Banki-Horvath, A.; Anderson, K.; Teplyashin, D.; Hermann, K.M.; Malinowski, M.; Grimes, M.K.; Simonyan, K.; Kavukcuoglu, K.; Zisserman, A.; et al. The streetlearn environment and dataset. arXiv preprint arXiv:1903.01292 2019.
- Liu, Y.; Liu, S.; Chen, B.; Yang, Z.-X.; Xu, S. Fusion-Perception-to-Action Transformer: Enhancing Robotic Manipulation With 3-D Visual Fusion Attention and Proprioception. IEEE Trans. Robot. 2025, 41, 1553–1567. [CrossRef]
- Liu, Y.; Chen, W.; Bai, Y.; Liang, X.; Li, G.; Gao, W.; Lin, L. Aligning Cyber Space With Physical World: A Comprehensive Survey on Embodied AI. IEEE/ASME Trans. Mechatronics 2025, 30, 7253–7274. [CrossRef]
- Zheng, Y.; Yao, L.; Su, Y.; Wang, Y.; Zhao, S.; Zhang, Y.; Chau, L.-P. A Survey of Embodied Learning for Object-centric Robotic Manipulation. Mach. Intell. Res. 2025, 22, 588–626. [CrossRef]
- Warren, J.; Marz, N. Big Data: Principles and best practices of scalable realtime data systems; Simon and Schuster, 2015.
- Kreps, J. Questioning the Lambda Architecture. O’Reilly Radar, 2014.
- Azzabi, S.; Alfughi, Z.; Ouda, A. Data Lakes: A Survey of Concepts and Architectures. Computers 2024, 13, 183. [CrossRef]
- Tahara, D.; Diamond, T.; Abadi, D.J. Sinew: a SQL system for multi-structured data. In Proceedings of the Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, 2014, pp. 815–826.
- Bugiotti, F.; Cabibbo, L.; Atzeni, P.; Torlone, R. Database Design for NoSQL Systems. International Conference on Conceptual Modeling. COUNTRY; pp. 223–231.
- Zhang, C.; Lu, J.; Xu, P.; Chen, Y. UniBench: A Benchmark for Multi-model Database Management Systems. Technology Conference on Performance Evaluation and Benchmarking. Brazil; pp. 7–23.
- Neo4j, Inc.. Neo4j, 2010.
- The JanusGraph Project. JanusGraph, 2017.
- Mlodzian, L.; Sun, Z.; Berkemeyer, H.; Monka, S.; Wang, Z.; Dietze, S.; Halilaj, L.; Luettin, J. nuScenes Knowledge Graph - A comprehensive semantic representation of traffic scenes for trajectory prediction. 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). France; pp. 42–52.
- Sun, P.; Song, Y.; Liu, X.; Yang, X.; Wang, Q.; Li, T.; Yang, Y.; Chu, X. 3D Question Answering for City Scene Understanding. MM '24: The 32nd ACM International Conference on Multimedia. Australia; pp. 2156–2165.
- Meta AI Research. FAISS, 2017.
- Wang, J.; Yi, X.; Guo, R.; Jin, H.; Xu, P.; Li, S.; Wang, X.; Guo, X.; Li, C.; Xu, X.; et al. Milvus: A purpose-built vector data management system. In Proceedings of the Proceedings of the 2021 international conference on management of data, 2021, pp. 2614–2627.
- Malkov, Y.A.; Yashunin, D.A. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 824–836. [CrossRef]
- Jegou, H.; Douze, M.; Schmid, C. Product Quantization for Nearest Neighbor Search. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 117–128. [CrossRef]
- Pelkonen, T.; Franklin, S.; Teller, J.; Cavallaro, P.; Huang, Q.; Meza, J.; Veeraraghavan, K. Gorilla: A fast, scalable, in-memory time series database. Proceedings of the VLDB Endowment 2015, 8, 1816–1827.
- Wang, C.; Qiao, J.; Huang, X.; Song, S.; Hou, H.; Jiang, T.; Rui, L.; Wang, J.; Sun, J. Apache IoTDB: A Time Series Database for IoT Applications. Proc. Acm Manag. Data 2023, 1, 1–27. [CrossRef]
- Timescale. TimescaleDB, 2018.
- Zimányi, E.; Sakr, M.; Lesuisse, A. MobilityDB: A mobility database based on PostgreSQL and PostGIS. ACM Transactions on Database Systems (TODS) 2020, 45, 1–42.
- OSGeo, P.P.. PostGIS. https://postgis.net/, 2025.
- Li, R.; He, H.; Wang, R.; Ruan, S.; He, T.; Bao, J.; Zhang, J.; Hong, L.; Zheng, Y. TrajMesa: A Distributed NoSQL-Based Trajectory Data Management System. IEEE Trans. Knowl. Data Eng. 2021, PP, 1–1. [CrossRef]
- He, H.; Xu, Z.; Li, R.; Bao, J.; Li, T.; Zheng, Y. TMan: A High-Performance Trajectory Data Management System Based on Key-Value Stores. 2024 IEEE 40th International Conference on Data Engineering (ICDE). Netherlands; pp. 4951–4964.
- Sawadogo, P.; Darmont, J. On data lake architectures and metadata management. J. Intell. Inf. Syst. 2020, 56, 97–120. [CrossRef]
- Hai, R.; Koutras, C.; Quix, C.; Jarke, M. Data Lakes: A Survey of Functions and Systems. IEEE Trans. Knowl. Data Eng. 2023, 35, 12571–12590. [CrossRef]
- Liu, R.; Isah, H.; Zulkernine, F. A Big Data Lake for Multilevel Streaming Analytics. 2020 1st International Conference on Big Data Analytics and Practices (IBDAP). Thailand; pp. 1–6.
- Inmon, B. Data Lake Architecture: Designing the Data Lake and avoiding the garbage dump; Technics Publications, LLC, 2016.
- Jarke, M.; Quix, C. On warehouses, lakes, and spaces: the changing role of conceptual modeling for data integration. Concept. Model. Perspect. 2017, pp. 231–245.
- Ravat, F.; Zhao, Y. Data Lakes: Trends and Perspectives. International Conference on Database and Expert Systems Applications. Austria; pp. 304–313.
- Lu, J.; Holubová, I. Multi-model Data Management: What’s New and What’s Next? In Proceedings of the EDBT, 2017.
- Yeo, J.; Cho, H.; Park, J.-W.; Hwang, S.-W. Multimodal KB Harvesting for Emerging Spatial Entities. IEEE Trans. Knowl. Data Eng. 2017, 29, 1073–1086. [CrossRef]
- Kosmerl, I.; Rabuzin, K.; Sestak, M. Multi-Model Databases - Introducing Polyglot Persistence in the Big Data World. 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO). Croatia; pp. 1724–1729.
- Khine, P.P.; Wang, Z. A Review of Polyglot Persistence in the Big Data World. Information 2019, 10, 141. [CrossRef]
- Kolev, B.; Valduriez, P.; Bondiombouy, C.; Jiménez-Peris, R.; Pau, R.; Pereira, J. CloudMdsQL: querying heterogeneous cloud data stores with a common language. Distrib. Parallel Databases 2015, 34, 463–503. [CrossRef]
- Bimonte, S.; Gallinucci, E.; Marcel, P.; Rizzi, S. Data variety, come as you are in multi-model data warehouses. Inf. Syst. 2022, 104. [CrossRef]
- Mihai, G. Multi-Model Database Systems: The State of Affairs. Ann. Dunarea de Jos Univ. Galati. Fascicle I. Econ. Appl. Informatics 2020, 26, 211–215. [CrossRef]
- Xiao, C.; Zhou, J.; Huang, J.; Zhu, H.; Xu, T.; Dou, D.; Xiong, H. A Contextual Master-Slave Framework on Urban Region Graph for Urban Village Detection. 2023 IEEE 39th International Conference on Data Engineering (ICDE). United States; pp. 736–748.
- Fang, Z.; Long, Q.; Song, G.; Xie, K. Spatial-Temporal Graph ODE Networks for Traffic Flow Forecasting. arXiv 2021, arXiv:2106.12931.
- Guo, S.; Lin, Y.; Wan, H.; Li, X.; Cong, G. Learning Dynamics and Heterogeneity of Spatial-Temporal Graph Data for Traffic Forecasting. IEEE Trans. Knowl. Data Eng. 2021, 34, 5415–5428. [CrossRef]
- Wang, Z.; Han, F.; Zhao, S. A Survey on Knowledge Graph Related Research in Smart City Domain. ACM Trans. Knowl. Discov. Data 2024, 18, 1–31. [CrossRef]
- Kaliyar, R.K. Graph databases: A survey. 2015 International Conference on Computing, Communication & Automation (ICCCA). India; pp. 785–790.
- Robinson, I.; Webber, J.; Eifrem, E. Graph databases: new opportunities for connected data; " O’Reilly Media, Inc.", 2015.
- Desai, M.; G Mehta, R.; P Rana, D. Issues and challenges in big graph modelling for smart city: an extensive survey. International Journal of Computational Intelligence & IoT 2018, 1.
- Sun, J.; Zhang, J.; Li, Q.; Yi, X.; Liang, Y.; Zheng, Y. Predicting Citywide Crowd Flows in Irregular Regions Using Multi-View Graph Convolutional Networks. IEEE Trans. Knowl. Data Eng. 2020, 34, 2348–2359. [CrossRef]
- Liu, Y.; Ding, J.; Fu, Y.; Li, Y. UrbanKG: An Urban Knowledge Graph System. ACM Trans. Intell. Syst. Technol. 2023, 14, 1–25. [CrossRef]
- Lv, C.; Qi, M.; Liu, L.; Ma, H. T2SG: Traffic Topology Scene Graph for Topology Reasoning in Autonomous Driving. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 17197–17206.
- Liu, Y.; Ding, J.; Li, Y. KnowSite: Leveraging Urban Knowledge Graph for Site Selection. SIGSPATIAL '23: 31st ACM International Conference on Advances in Geographic Information Systems. Germany; pp. 1–12.
- Liu, J.; Li, T.; Ji, S.; Xie, P.; Du, S.; Teng, F.; Zhang, J. Urban flow pattern mining based on multi-source heterogeneous data fusion and knowledge graph embedding. IEEE Trans. Knowl. Data Eng. 2021, PP, 1–1. [CrossRef]
- Zareian, A.; Karaman, S.; Chang, S.-F. Bridging Knowledge Graphs to Generate Scene Graphs. European Conference on Computer Vision. United Kingdom; pp. 606–623.
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Transactions on Neural Networks 2008, 20, 61–80.
- Sun, Z.; Wang, Z.; Halilaj, L.; Luettin, J. SemanticFormer: Holistic and Semantic Traffic Scene Representation for Trajectory Prediction Using Knowledge Graphs. IEEE Robot. Autom. Lett. 2024, 9, 7381–7388. [CrossRef]
- He, H.; Li, R.; Ruan, S.; He, T.; Bao, J.; Li, T.; Zheng, Y. TraSS: Efficient Trajectory Similarity Search Based on Key-Value Data Stores. 2022 IEEE 38th International Conference on Data Engineering (ICDE). Malaysia; pp. 2306–2318.
- Sun, F.; Qi, J.; Chang, Y.; Fan, X.; Karunasekera, S.; Tanin, E. Urban Region Representation Learning with Attentive Fusion. 2024 IEEE 40th International Conference on Data Engineering (ICDE). Netherlands; pp. 4409–4421.
- Lim, J.-H.; Kang, W.J.; Singh, S.; Narasimhalu, D. Learning similarity matching in multimedia content-based retrieval. IEEE Trans. Knowl. Data Eng. 2001, 13, 846–850. [CrossRef]
- Chen, Y.; Sampathkumar, H.; Luo, B.; Chen, X.-W. iLike: Bridging the Semantic Gap in Vertical Image Search by Integrating Text and Visual Features. IEEE Trans. Knowl. Data Eng. 2012, 25, 2257–2270. [CrossRef]
- Qian, T.; Chen, J.; Zhuo, L.; Jiao, Y.; Jiang, Y.-G. NuScenes-QA: A Multi-Modal Visual Question Answering Benchmark for Autonomous Driving Scenario. Proc. AAAI Conf. Artif. Intell. 2024, 38, 4542–4550. [CrossRef]
- Park, S.; Lee, M.; Kang, J.; Choi, H.; Park, Y.; Cho, J.; Lee, A.; Kim, D. VLAAD: Vision and Language Assistant for Autonomous Driving. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW). United States; pp. 980–987.
- Sima, C.; Renz, K.; Chitta, K.; Chen, L.; Zhang, H.; Xie, C.; Beißwenger, J.; Luo, P.; Geiger, A.; Li, H. DriveLM: Driving with Graph Visual Question Answering. European Conference on Computer Vision. Italy; pp. 256–274.
- Ragab, M.; Gong, P.; Eldele, E.; Zhang, W.; Wu, M.; Foo, C.-S.; Zhang, D.; Li, X.; Chen, Z. Evidentially Calibrated Source-Free Time-Series Domain Adaptation With Temporal Imputation. IEEE Trans. Knowl. Data Eng. 2025, 38, 290–306. [CrossRef]
- Tang, D.; Shang, Z.; Elmore, A.J.; Krishnan, S.; Franklin, M.J. CrocodileDB in action: resource-efficient query execution by exploiting time slackness. Proceedings of the VLDB Endowment 2020, 13, 2937–2940.
- Gao, C.; Zhao, B.; Zhang, W.; Mao, J.; Zhang, J.; Zheng, Z.; Man, F.; Fang, J.; Zhou, Z.; Cui, J.; et al. EmbodiedCity: A Benchmark Platform for Embodied Agent in Real-world City Environment. arXiv preprint arXiv:2410.09604 2024.
- Li, R.; He, H.; Wang, R.; Huang, Y.; Liu, J.; Ruan, S.; He, T.; Bao, J.; Zheng, Y. JUST: JD Urban Spatio-Temporal Data Engine. 2020 IEEE 36th International Conference on Data Engineering (ICDE). United States; pp. 1558–1569.
- Guo, Y.; Wang, T.; Chen, Z.; Shao, Z. A Storage Model with Fine-Grained In-Storage Query Processing for Spatio-Temporal Data. 2025 IEEE 41st International Conference on Data Engineering (ICDE). China; pp. 669–682.
- Shi, H.; Du, S.; Yang, Y.; Zhang, J.; Li, T.; Zheng, Y. A Knowledge-Guided Pre-Training Temporal Data Analysis Foundation Model for Urban Computing. IEEE Trans. Knowl. Data Eng. 2025, 37, 6259–6271. [CrossRef]
- Chen, J.; Zhang, A. On Hierarchical Disentanglement of Interactive Behaviors for Multimodal Spatiotemporal Data with Incompleteness. KDD '23: The 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. United States; pp. 213–225.
- Vitale, V.N.; Di Martino, S.; Peron, A.; Russo, M.; Battista, E. How to manage massive spatiotemporal dataset from stationary and non-stationary sensors in commercial DBMS?. Knowl. Inf. Syst. 2023, 66, 2063–2088. [CrossRef]
- Chen, M.; Li, Z.; Huang, W.; Gong, Y.; Yin, Y. Profiling Urban Streets: A Semi-Supervised Prediction Model Based on Street View Imagery and Spatial Topology. KDD '24: The 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Spain; pp. 319–328.
- Vasudevan, A.B.; Dai, D.; Van Gool, L. Talk2Nav: Long-Range Vision-and-Language Navigation with Dual Attention and Spatial Memory. Int. J. Comput. Vis. 2020, 129, 246–266. [CrossRef]
- Mao, Y.; Zhou, H.; Chen, L.; Qi, R.; Sun, Z.; Rong, Y.; He, X.; Chen, M.; Mumtaz, S.; Frascolla, V.; et al. A Survey on Spatio-Temporal Prediction: From Transformers to Foundation Models. ACM Comput. Surv. 2025, 58, 1–36. [CrossRef]
- Xie, P.; Ma, M.; Li, T.; Ji, S.; Du, S.; Yu, Z.; Zhang, J. Spatio-Temporal Dynamic Graph Relation Learning for Urban Metro Flow Prediction. IEEE Trans. Knowl. Data Eng. 2023, 35, 9973–9984. [CrossRef]
- Li, Z.; Xia, L.; Tang, J.; Xu, Y.; Shi, L.; Xia, L.; Yin, D.; Huang, C. UrbanGPT: Spatio-Temporal Large Language Models. KDD '24: The 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Spain; pp. 5351–5362.
- Liu, Y.; Chen, W.; Bai, Y.; Liang, X.; Li, G.; Gao, W.; Lin, L. Aligning Cyber Space With Physical World: A Comprehensive Survey on Embodied AI. IEEE/ASME Trans. Mechatronics 2025, 30, 7253–7274. [CrossRef]
- Huang, J.; Yong, S.; Ma, X.; Linghu, X.; Li, P.; Wang, Y.; Li, Q.; Zhu, S.C.; Jia, B.; Huang, S. An embodied generalist agent in 3D world. In Proceedings of the Proceedings of the 41st International Conference on Machine Learning, 2024, pp. 20413–20451.
- Li, S.; Tang, H. Multimodal alignment and fusion: A survey. arXiv preprint arXiv:2411.17040 2024.
- Christodoulides, A.; Tam, G.K.; Clarke, J.; Smith, R.; Horgan, J.; Micallef, N.; Morley, J.; Villamizar, N.; Walton, S. Survey on 3D Reconstruction Techniques: Large-Scale Urban City Reconstruction and Requirements. IEEE Trans. Vis. Comput. Graph. 2025, PP, 1–20. [CrossRef]
- zyeşil, O.; Voroninski, V.; Basri, R.; Singer, A. A survey of structure from motion*. Acta Numerica 2017, 26, 305–364.
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. In Seminal graphics: pioneering efforts that shaped the field; 1998; pp. 347–353.
- Xu, L.; Xiangli, Y.; Peng, S.; Pan, X.; Zhao, N.; Theobalt, C.; Dai, B.; Lin, D. Grid-guided Neural Radiance Fields for Large Urban Scenes. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Canada; pp. 8296–8306.
- Zhang, Q.; Wei, Y.; Han, Z.; Fu, H.; Peng, X.; Deng, C.; Hu, Q.; Xu, C.; Wen, J.; Hu, D.; et al. Multimodal fusion on low-quality data: A comprehensive survey. arXiv preprint arXiv:2404.18947 2024.
- Wolff, K.; Kim, C.; Zimmer, H.; Schroers, C.; Botsch, M.; Sorkine-Hornung, O.; Sorkine-Hornung, A. Point Cloud Noise and Outlier Removal for Image-Based 3D Reconstruction. 2016 Fourth International Conference on 3D Vision (3DV). USA; pp. 118–127.
- Melas-Kyriazi, L.; Rupprecht, C.; Vedaldi, A. PC2: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Canada; pp. 12923–12932.
- Henderson, P.; Ferrari, V. Learning Single-Image 3D Reconstruction by Generative Modelling of Shape, Pose and Shading. Int. J. Comput. Vis. 2019, 128, 835–854. [CrossRef]
- Wu, C.; Liu, Y.; Dai, Q.; Wilburn, B. Fusing Multiview and Photometric Stereo for 3D Reconstruction under Uncalibrated Illumination. IEEE Trans. Vis. Comput. Graph. 2010, 17, 1082–1095. [CrossRef]
- Kerl, C.; Souiai, M.; Sturm, J.; Cremers, D. Towards Illumination-Invariant 3D Reconstruction Using ToF RGB-D Cameras. 2014 2nd International Conference on 3D Vision (3DV). Japan; pp. 39–46.
- Bai, K.; Zhang, L.; Chen, Z.; Wan, F.; Zhang, J. Close the Sim2real Gap via Physically-based Structured Light Synthetic Data Simulation. 2024 IEEE International Conference on Robotics and Automation (ICRA). Japan; pp. 17035–17041.
- Stoffregen, T.; Scheerlinck, C.; Scaramuzza, D.; Drummond, T.; Barnes, N.; Kleeman, L.; Mahony, R. Reducing the Sim-to-Real Gap for Event Cameras. European Conference on Computer Vision. United Kingdom; pp. 534–549.
- Kohler, T.; Batz, M.; Naderi, F.; Kaup, A.; Maier, A.; Riess, C. Toward Bridging the Simulated-to-Real Gap: Benchmarking Super-Resolution on Real Data. IEEE Trans. Pattern Anal. Mach. Intell. 2019, PP, 1–1. [CrossRef]
- Fink, L.; Rückert, D.; Franke, L.; Keinert, J.; Stamminger, M. LiveNVS: Neural View Synthesis on Live RGB-D Streams. SA '23: SIGGRAPH Asia 2023. Australia; pp. 1–11.
- Stier, N.; Ranjan, A.; Colburn, A.; Yan, Y.; Yang, L.; Ma, F.; Angles, B. FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction. 2023 IEEE/CVF International Conference on Computer Vision (ICCV). France; pp. 18377–18386.
- Rematas, K.; Liu, A.; Srinivasan, P.; Barron, J.; Tagliasacchi, A.; Funkhouser, T.; Ferrari, V. Urban Radiance Fields. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 12922–12932.
- Chu, T.; Zhang, P.; Liu, Q.; Wang, J. BUOL: A Bottom-Up Framework with Occupancy-Aware Lifting for Panoptic 3D Scene Reconstruction From a Single Image. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Canada; pp. 4937–4946.
- Huang, Z.; Jampani, V.; Thai, A.; Li, Y.; Stojanov, S.; Rehg, J.M. ShapeClipper: Scalable 3D Shape Learning from Single-View Images via Geometric and CLIP-Based Consistency. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Canada; pp. 12912–12922.
- Wang, C.; Jiang, R.; Chai, M.; He, M.; Chen, D.; Liao, J. NeRF-Art: Text-Driven Neural Radiance Fields Stylization. IEEE Trans. Vis. Comput. Graph. 2023, 30, 4983–4996. [CrossRef]
- Mittal, P.; Cheng, Y.-C.; Singh, M.; Tulsiani, S. AutoSDF: Shape Priors for 3D Completion, Reconstruction and Generation. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 306–315.
- Zhao, F.; Zhang, C.; Geng, B. Deep Multimodal Data Fusion. ACM Comput. Surv. 2024, 56, 1–36. [CrossRef]
- Meng, L.; Tan, A.-H.; Xu, D. Semi-Supervised Heterogeneous Fusion for Multimedia Data Co-Clustering. IEEE Trans. Knowl. Data Eng. 2013, 26, 2293–2306. [CrossRef]
- Muturi, T.W.; Kyem, B.A.; Asamoah, J.K.; Owor, N.J.; Dzinyela, R.; Danyo, A.; Adu-Gyamfi, Y.; Aboah, A. Prompt-guided spatial understanding with rgb-d transformers for fine-grained object relation reasoning. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5280–5288.
- Shang, Y.; Lin, Y.; Zheng, Y.; Fan, H.; Ding, J.; Feng, J.; Chen, J.; Tian, L.; Li, Y. Urbanworld: An urban world model for 3d city generation. arXiv preprint arXiv:2407.11965 2024.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE on compute Rvision and pattern recognition, 2015, abs/1512.03385.
- Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention. Springer 2015; 234-241.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations.
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660.
- Turki, H.; Zhang, J.Y.; Ferroni, F.; Ramanan, D. SUDS: Scalable Urban Dynamic Scenes. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Canada; pp. 12375–12385.
- Zheng, Z.; Zhou, M.; Shang, Z.; Wei, X.; Pu, H.; Luo, J.; Jia, W. GAANet: Graph Aggregation Alignment Feature Fusion for Multispectral Object Detection. IEEE Trans. Ind. Informatics 2025, 21, 8282–8292. [CrossRef]
- Lin, J.; Li, Z.; Tang, X.; Liu, J.; Liu, S.; Liu, J.; Lu, Y.; Wu, X.; Xu, S.; Yan, Y.; et al. VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 5166–5175.
- Liu, Y.; Luo, C.; Fan, L.; Wang, N.; Peng, J.; Zhang, Z. CityGaussian: Real-Time High-Quality Large-Scale Scene Rendering with Gaussians. European Conference on Computer Vision. Italy; pp. 265–282.
- Jiang, L.; Ren, K.; Yu, M.; Xu, L.; Dong, J.; Lu, T.; Zhao, F.; Lin, D.; Dai, B. Horizon-Gs: Unified 3D Gaussian Splatting for Large-Scale Aerial-To-Ground Scenes. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 26789–26799.
- Vuong, K.; Ghosh, A.; Ramanan, D.; Narasimhan, S.; Tulsiani, S. AerialMegaDepth: Learning Aerial-Ground Reconstruction and View Synthesis. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 21674–21684.
- Huang, J.; Stoter, J.; Peters, R.; Nan, L. City3D: Large-Scale Building Reconstruction from Airborne LiDAR Point Clouds. Remote. Sens. 2022, 14, 2254. [CrossRef]
- Zhang, C.; Cao, Y.; Zhang, L. CrossView-GS: Cross-view Gaussian Splatting For Large-scale Scene Reconstruction. arXiv preprint arXiv:2501.01695 2025.
- Feng, J.; Liu, T.; Du, Y.; Guo, S.; Lin, Y.; Li, Y. CityGPT: Empowering Urban Spatial Cognition of Large Language Models. KDD '25: The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Canada; pp. 591–602.
- Li, Y.; Pan, Y.; Zhu, G.; He, S.; Xu, M.; Xu, J. Charging-Aware Task Assignment for Urban Logistics with Electric Vehicles. IEEE Trans. Knowl. Data Eng. 2025, PP, 1–14. [CrossRef]
- Lee, L.-H.; Braud, T.; Hosio, S.; Hui, P. Towards Augmented Reality Driven Human-City Interaction: Current Research on Mobile Headsets and Future Challenges. ACM Comput. Surv. 2021, 54, 1–38. [CrossRef]
- Ding, X.; Han, J.; Xu, H.; Liang, X.; Zhang, W.; Li, X. Holistic Autonomous Driving Understanding by Bird'View Injected Multi-Modal Large Models. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 13668–13677.
- Wu, D.; Han, W.; Liu, Y.; Wang, T.; Xu, C.-Z.; Zhang, X.; Shen, J. Language Prompt for Autonomous Driving. Proc. AAAI Conf. Artif. Intell. 2025, 39, 8359–8367. [CrossRef]
- Wang, J.; Zheng, Z.; Chen, Z.; Ma, A.; Zhong, Y. EarthVQA: Towards Queryable Earth via Relational Reasoning-Based Remote Sensing Visual Question Answering. Proc. AAAI Conf. Artif. Intell. 2024, 38, 5481–5489. [CrossRef]
- Feng, J.; Zhang, J.; Liu, T.; Zhang, X.; Ouyang, T.; Yan, J.; Du, Y.; Guo, S.; Li, Y. CityBench: Evaluating the Capabilities of Large Language Models for Urban Tasks. KDD '25: The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Canada; pp. 5413–5424.
- Bieri, V.; Zamboni, M.; Blumer, N.S.; Chen, Q.; Engelmann, F. OpenCity3D: What do Vision-Language Models Know About Urban Environments?. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). United States; pp. 5147–5155.
- Yasuki, S.; Miyanishi, T.; Inoue, N.; Kurita, S.; Sakamoto, K.; Azuma, D.; Taki, M.; Matsuo, Y. GeoProg3D: Compositional Visual Reasoning for City-Scale 3D Language Fields. arXiv preprint arXiv:2506.23352 2025.
- Wang, J.; Ma, A.; Chen, Z.; Zheng, Z.; Wan, Y.; Zhang, L.; Zhong, Y. EarthVQANet: Multi-task visual question answering for remote sensing image understanding. ISPRS J. Photogramm. Remote. Sens. 2024, 212, 422–439. [CrossRef]
- Zhao, Y.; Xu, K.; Zhu, Z.; Hu, Y.; Zheng, Z.; Chen, Y.; Ji, Y.; Gao, C.; Li, Y.; Huang, J. CityEQA: A Hierarchical LLM Agent on Embodied Question Answering Benchmark in City Space. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. China; pp. 12476–12491.
- Gu, J.; Stefani, E.; Wu, Q.; Thomason, J.; Wang, X. Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Ireland; pp. 7606–7623.
- Schumann, R.; Riezler, S. Generating Landmark Navigation Instructions from Maps as a Graph-to-Text Problem. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). COUNTRY; pp. 489–502.
- Li, J.; Padmakumar, A.; Sukhatme, G.; Bansal, M. VLN-Video: Utilizing Driving Videos for Outdoor Vision-and-Language Navigation. Proc. AAAI Conf. Artif. Intell. 2024, 38, 18517–18526. [CrossRef]
- Xu, Y.; Pan, Y.; Liu, Z.; Wang, H. FLAME: Learning to Navigate with Multimodal LLM in Urban Environments. Proc. AAAI Conf. Artif. Intell. 2025, 39, 9005–9013. [CrossRef]
- Schumann, R.; Zhu, W.; Feng, W.; Fu, T.-J.; Riezler, S.; Wang, W.Y. VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View. Proc. AAAI Conf. Artif. Intell. 2024, 38, 18924–18933. [CrossRef]
- Xiang, J.; Wang, X.; Wang, W.Y. Learning to Stop: A Simple yet Effective Approach to Urban Vision-Language Navigation. Findings of the Association for Computational Linguistics: EMNLP 2020. COUNTRY; pp. 699–707.
- Zhu, W.; Wang, X.; Fu, T.-J.; Yan, A.; Narayana, P.; Sone, K.; Basu, S.; Wang, W.Y. Multimodal Text Style Transfer for Outdoor Vision-and-Language Navigation. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. COUNTRY; pp. 1207–1221.
- Wang, X.; Yang, D.; Wang, Z.; Kwan, H.; Chen, J.; Wu, W.; Li, H.; Liao, Y.; Liu, S. Towards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology. In Proceedings of the The Thirteenth International Conference on Learning Representations.
- Lee, J.; Miyanishi, T.; Kurita, S.; Sakamoto, K.; Azuma, D.; Matsuo, Y.; Inoue, N. CityNav: A Large-Scale Dataset for Real-World Aerial Navigation. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5912–5922.
- Sautenkov, O.; Yaqoot, Y.; Lykov, A.; Mustafa, M.A.; Tadevosyan, G.; Akhmetkazy, A.; Cabrera, M.A.; Martynov, M.; Karaf, S.; Tsetserukou, D. UAV-VLA: Vision-Language-Action System for Large Scale Aerial Mission Generation. 2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI). Australia; pp. 1588–1592.
- Fan, Y.; Chen, W.; Jiang, T.; Zhou, C.; Zhang, Y.; Wang, X. Aerial Vision-and-Dialog Navigation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 3043–3061.
- Tran, K.T.; Dao, D.; Nguyen, M.D.; Pham, Q.V.; O’Sullivan, B.; Nguyen, H.D. Multi-agent collaboration mechanisms: A survey of llms. arXiv preprint arXiv:2501.06322 2025.
- Feng, X.; Chen, Z.-Y.; Qin, Y.; Lin, Y.; Chen, X.; Liu, Z.; Wen, J.-R. Large Language Model-based Human-Agent Collaboration for Complex Task Solving. Findings of the Association for Computational Linguistics: EMNLP 2024. United States; pp. 1336–1357.
- Zou, H.P.; Huang, W.C.; Wu, Y.; Miao, C.; Li, D.; Liu, A.; Zhou, Y.; Chen, Y.; Zhang, W.; Li, Y.; et al. A Call for Collaborative Intelligence: Why Human-Agent Systems Should Precede AI Autonomy. arXiv preprint arXiv:2506.09420 2025.
- Fu, J.; Han, H.; Su, X.; Fan, C. Towards human-AI collaborative urban science research enabled by pre-trained large language models. Urban Informatics 2024, 3, 1–15. [CrossRef]
- Han, J.; Ning, Y.; Yuan, Z.; Ni, H.; Liu, F.; Lyu, T.; Liu, H. Large Language Model Powered Intelligent Urban Agents: Concepts, Capabilities, and Applications. arXiv preprint arXiv:2507.00914 2025.
- Wu, W.; He, H.; Zhang, C.; He, J.; Zhao, S.Z.; Gong, R.; Li, Q.; Zhou, B. Towards Autonomous Micromobility through Scalable Urban Simulation. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). United States; pp. 27553–27563.
- Wu, W.; He, H.; He, J.; Wang, Y.; Duan, C.; Liu, Z.; Li, Q.; Zhou, B. Metaurban: An embodied ai simulation platform for urban micromobility. arXiv preprint arXiv:2407.08725 2024.
- Zheng, Y.; Lin, Y.; Zhao, L.; Wu, T.; Jin, D.; Li, Y. Spatial planning of urban communities via deep reinforcement learning. Nat. Comput. Sci. 2023, 3, 748–762. [CrossRef]
- Ali, M.I.; Gao, F.; Mileo, A. Citybench: A configurable benchmark to evaluate rsp engines using smart city datasets. In Proceedings of the International semantic web conference. Springer, 2015, pp. 374–389.
- Romeu-Guallart, P.; Zamora-Martinez, F. SML2010. UCI Machine Learning Repository 2014.
- Xu, H.; Yuan, J.; Zhou, A.; Xu, G.; Li, W.; Ban, X.; Ye, X. Genai-powered multi-agent paradigm for smart urban mobility: Opportunities and challenges for integrating large language models (llms) and retrieval-augmented generation (rag) with intelligent transportation systems. arXiv preprint arXiv:2409.00494 2024.
- Li, A.; Wang, Z.; Zhang, J.; Li, M.; Qi, Y.; Chen, Z.; Zhang, Z.; Wang, H. UrbanVLA: A Vision-Language-Action Model for Urban Micromobility. arXiv preprint arXiv:2510.23576 2025.
- Zhang, Z.; Chen, M.; Zhu, S.; Han, T.; Yu, Z. MMCNav: MLLM-empowered Multi-agent Collaboration for Outdoor Visual Language Navigation. ICMR '25: International Conference on Multimedia Retrieval. United States; pp. 1767–1776.
- Chen, W.; Yu, X.; Shang, L.; Xi, J.; Jin, B.; Zhao, S. Urban Emergency Rescue Based on Multi-Agent Collaborative Learning: Coordination Between Fire Engines and Traffic Lights. arXiv preprint arXiv:2502.16131 2025.
- Wang, X.; Yang, D.; Liao, Y.; Zheng, W.; Dai, B.; Li, H.; Liu, S.; et al. UAV-Flow Colosseo: A Real-World Benchmark for Flying-on-a-Word UAV Imitation Learning. arXiv preprint arXiv:2505.15725 2025.
- Jiang, K.; Cai, X.; Cui, Z.; Li, A.; Ren, Y.; Yu, H.; Yang, H.; Fu, D.; Wen, L.; Cai, P. KoMA: Knowledge-Driven Multi-Agent Framework for Autonomous Driving With Large Language Models. IEEE Trans. Intell. Veh. 2024, 10, 4655–4668. [CrossRef]
- Zheng, Y.; Xu, F.; Lin, Y.; Santi, P.; Ratti, C.; Wang, Q.R.; Li, Y. Urban planning in the era of large language models. Nature Computational Science 2025, pp. 1–10.
- Gao, C.; Lan, X.; Li, N.; Yuan, Y.; Ding, J.; Zhou, Z.; Xu, F.; Li, Y. Large language models empowered agent-based modeling and simulation: a survey and perspectives. Humanit. Soc. Sci. Commun. 2024, 11, 1–24. [CrossRef]
- Lin, Z.; Gao, K.; Wu, N.; Suganthan, P.N. Scheduling Eight-Phase Urban Traffic Light Problems via Ensemble Meta-Heuristics and Q-Learning Based Local Search. IEEE Trans. Intell. Transp. Syst. 2023, 24, 14415–14426. [CrossRef]
- Ouyang, K.; Liang, Y.; Liu, Y.; Tong, Z.; Ruan, S.; Zheng, Y.; Rosenblum, D.S. Fine-Grained Urban Flow Inference. IEEE Trans. Knowl. Data Eng. 2020, 34, 2755–2770. [CrossRef]
- Mouratidis, K. Time to challenge the 15-minute city: Seven pitfalls for sustainability, equity, livability, and spatial analysis. Cities 2024, 153. [CrossRef]
- Hamissi, A.; Dhraief, A. A Survey on the Unmanned Aircraft System Traffic Management. ACM Comput. Surv. 2023, 56, 1–37. [CrossRef]
- Ahmed, A.; Outay, F.; Farooq, M.U.; Saeed, S.; Adnan, M.; Ismail, M.A.; Qadir, A. Real-time road occupancy and traffic measurements using unmanned aerial vehicle and fundamental traffic flow diagrams. Pers. Ubiquitous Comput. 2023, 27, 1669–1680. [CrossRef]
- Yu, X.; Wang, J.; Yang, Y.; Huang, Q.; Qu, K. BIGCity: A Universal Spatiotemporal Model for Unified Trajectory and Traffic State Data Analysis. 2025 IEEE 41st International Conference on Data Engineering (ICDE). China; pp. 4455–4469.
- Liu, A.; Zhang, Y. CrossST: An Efficient Pre-Training Framework for Cross-District Pattern Generalization in Urban Spatio-Temporal Forecasting. 2025 IEEE 41st International Conference on Data Engineering (ICDE). China; pp. 2935–2948.
- Perera, A.T.D.; Javanroodi, K.; Mauree, D.; Nik, V.M.; Florio, P.; Hong, T.; Chen, D. Challenges resulting from urban density and climate change for the EU energy transition. Nat. Energy 2023, 8, 397–412. [CrossRef]
- Jin, X.; Zhang, C.; Xiao, F.; Li, A.; Miller, C. A review and reflection on open datasets of city-level building energy use and their applications. Energy Build. 2023, 285. [CrossRef]
- Wang, L.; Shao, J.; Ma, Y. Does China's low-carbon city pilot policy improve energy efficiency?. Energy 2023, 283. [CrossRef]
- Lindahl, J.; Johansson, R.; Lingfors, D. Mapping of decentralised photovoltaic and solar thermal systems by remote sensing aerial imagery and deep machine learning for statistic generation. Energy AI 2023, 14. [CrossRef]
- Gasparyan, H.A.; Davtyan, T.A.; Agaian, S.S. A Novel Framework for Solar Panel Segmentation From Remote Sensing Images: Utilizing Chebyshev Transformer and Hyperspectral Decomposition. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 1–11. [CrossRef]
- Lodhi, M.K.; Tan, Y.; Wang, X.; Masum, S.M.; Khan, M.; Ullah, N. Harnessing rooftop solar photovoltaic potential in Islamabad, Pakistan: A remote sensing and deep learning approach. Energy 2024. [CrossRef]
- Golestani, Z.; Borna, R.; Khaliji, M.A.; Mohammadi, H.; Ghalehteimouri, K.J.; Asadian, F. Impact of Urban Expansion on the Formation of Urban Heat Islands in Isfahan, Iran: A Satellite Base Analysis (1990–2019). J. Geovisualization Spat. Anal. 2024, 8, 1–15. [CrossRef]
- Fan, X.; Ji, T.; Jiang, C.; Li, S.; Jin, S.; Song, S.; Wang, J.; Hong, B.; Chen, L.; Zheng, G.; et al. Mousi: Poly-visual-expert vision-language models. arXiv preprint arXiv:2401.17221 2024.
- Elgendy, H.; Sharshar, A.; Aboeitta, A.; Ashraf, Y.; Guizani, M. Geollava: Efficient fine-tuned vision-language models for temporal change detection in remote sensing. arXiv preprint arXiv:2410.19552 2024.
- Zhuo, L.; ZHANG, E.; Shuo, P.; Sichun, L.; Ying, L.; WITLOX, F. Assessing urban emergency medical services accessibility for older adults considering ambulance trafficability using a deep learning approach. Sustainable Cities and Society 2025, p. 106804.
- Li, J.; Wang, S.; Zhang, J.; Miao, H.; Zhang, J.; Yu, P. Fine-grained Urban Flow Inference with Incomplete Data. IEEE Trans. Knowl. Data Eng. 2022, PP, 1–1. [CrossRef]
- Yang, M.; Li, X.; Xu, B.; Nie, X.; Zhao, M.; Zhang, C.; Zheng, Y.; Gong, Y. STDA: Spatio-Temporal Deviation Alignment Learning for Cross-City Fine-Grained Urban Flow Inference. IEEE Trans. Knowl. Data Eng. 2025, 37, 4833–4845. [CrossRef]
- Kennedy, J. Swarm intelligence. In Handbook of nature-inspired and innovative computing: integrating classical models with emerging technologies; Springer, 2006; pp. 187–219.
- Han, X.; Zhu, C.; Zhu, H.; Zhao, X. Swarm Intelligence in Geo-Localization: A Multi-Agent Large Vision-Language Model Collaborative Framework. KDD '25: The 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Canada; pp. 814–825.
- Gao, C.; Xu, F.; Chen, X.; Wang, X.; He, X.; Li, Y. Simulating Human Society with Large Language Model Agents: City, Social Media, and Economic System. WWW '24: The ACM Web Conference 2024. Singapore; pp. 1290–1293.
- Liu, Y.; Zhang, X.; Ding, J.; Xi, Y.; Li, Y. Knowledge-infused Contrastive Learning for Urban Imagery-based Socioeconomic Prediction. WWW '23: The ACM Web Conference 2023. United States; pp. 4150–4160.
- Akhtar, Z.; Qazi, U.; Sadiq, R.; El-Sakka, A.; Sajjad, M.; Ofli, F.; Imran, M. Mapping Flood Exposure, Damage, and Population Needs Using Remote and Social Sensing: A Case Study of 2022 Pakistan Floods. WWW '23: The ACM Web Conference 2023. United States; pp. 4120–4128.
- Yan, A.; Howe, B. Fairness-Aware Demand Prediction for New Mobility. Proc. AAAI Conf. Artif. Intell. 2020, 34, 1079–1087. [CrossRef]
- Wang, G.; Zhang, Y.; Fang, Z.; Wang, S.; Zhang, F.; Zhang, D. FairCharge: A data-driven fairness-aware charging recommendation system for large-scale electric taxi fleets. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 2020, 4, 1–25.
- Rong, C.; Feng, J.; Ding, J. GODDAG: Generating Origin-Destination Flow for New Cities Via Domain Adversarial Training. IEEE Trans. Knowl. Data Eng. 2023, 35, 10048–10057. [CrossRef]
- Zhou, Q.; Wu, J.; Zhu, M.; Zhou, Y.; Xiao, F.; Zhang, Y. LLM-QL: A LLM-Enhanced Q-Learning Approach for Scheduling Multiple Parallel Drones. IEEE Trans. Knowl. Data Eng. 2025, 37, 5393–5406. [CrossRef]
Figure 1.
Overview of the proposed multi-domain data lifecycle for Urban Embodied Agents, from perception to social impact, where Sim. denotes the simulator and Arch. denotes the Architecture.
Figure 1.
Overview of the proposed multi-domain data lifecycle for Urban Embodied Agents, from perception to social impact, where Sim. denotes the simulator and Arch. denotes the Architecture.
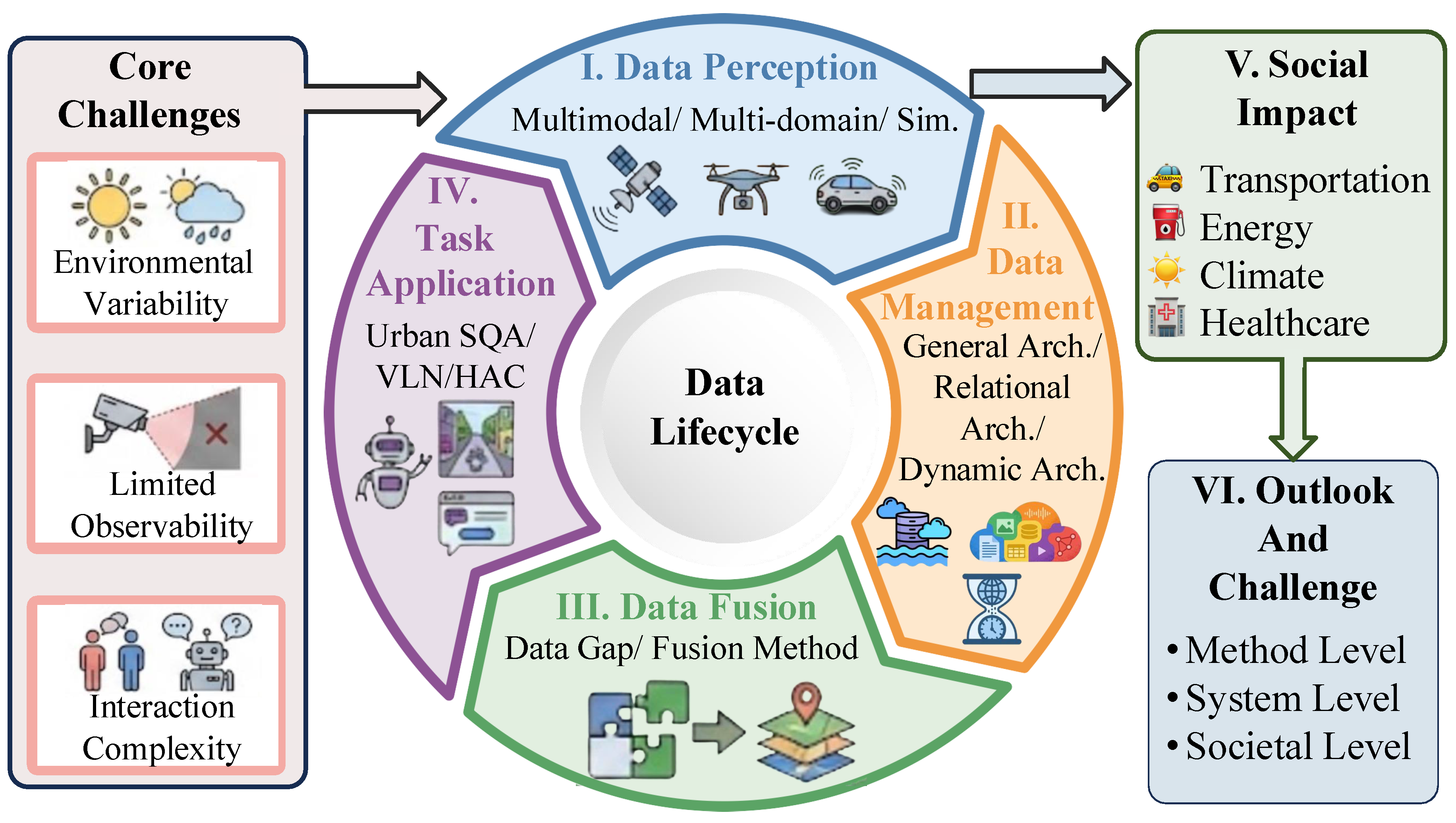
Figure 2.
Vision perception for Urban Embodied Agents. We visualize some cases in Carla Simulators [16].
Figure 2.
Vision perception for Urban Embodied Agents. We visualize some cases in Carla Simulators [16].
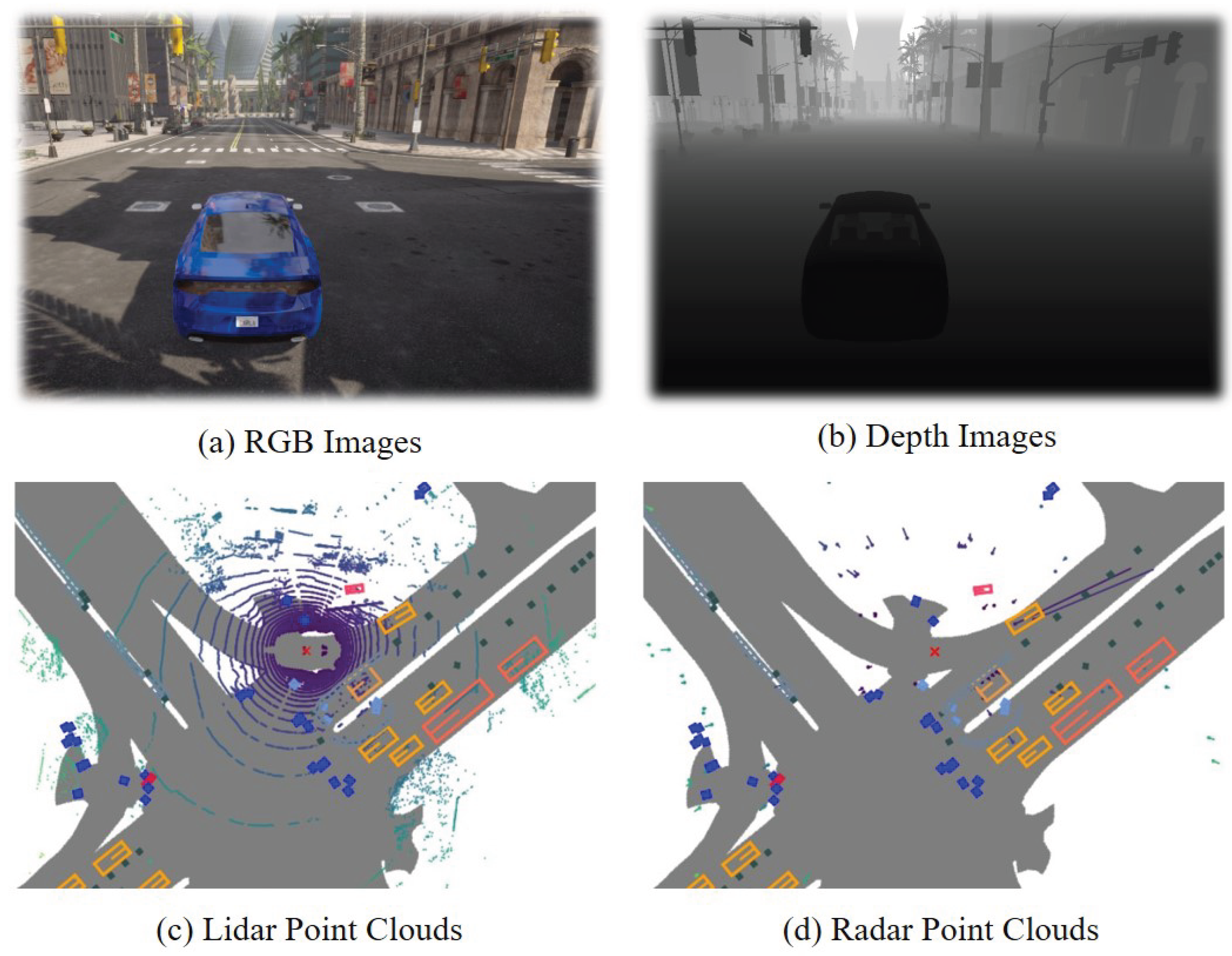
Figure 3.
Comparison between multi-domain data in Urban Embodied Agents.
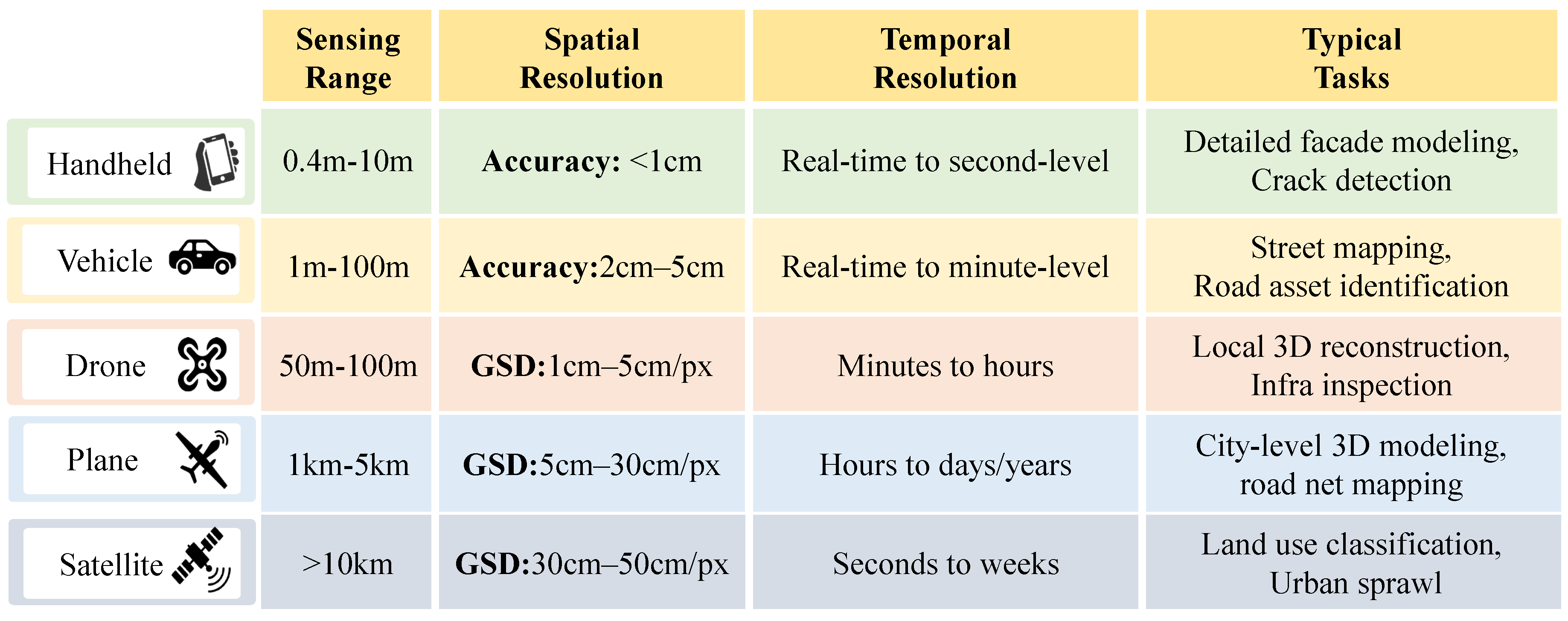
Figure 4.
Existing simulators for Urban Embodied Agents. They are classified into open-loop and closed-loop simulators.
Figure 4.
Existing simulators for Urban Embodied Agents. They are classified into open-loop and closed-loop simulators.
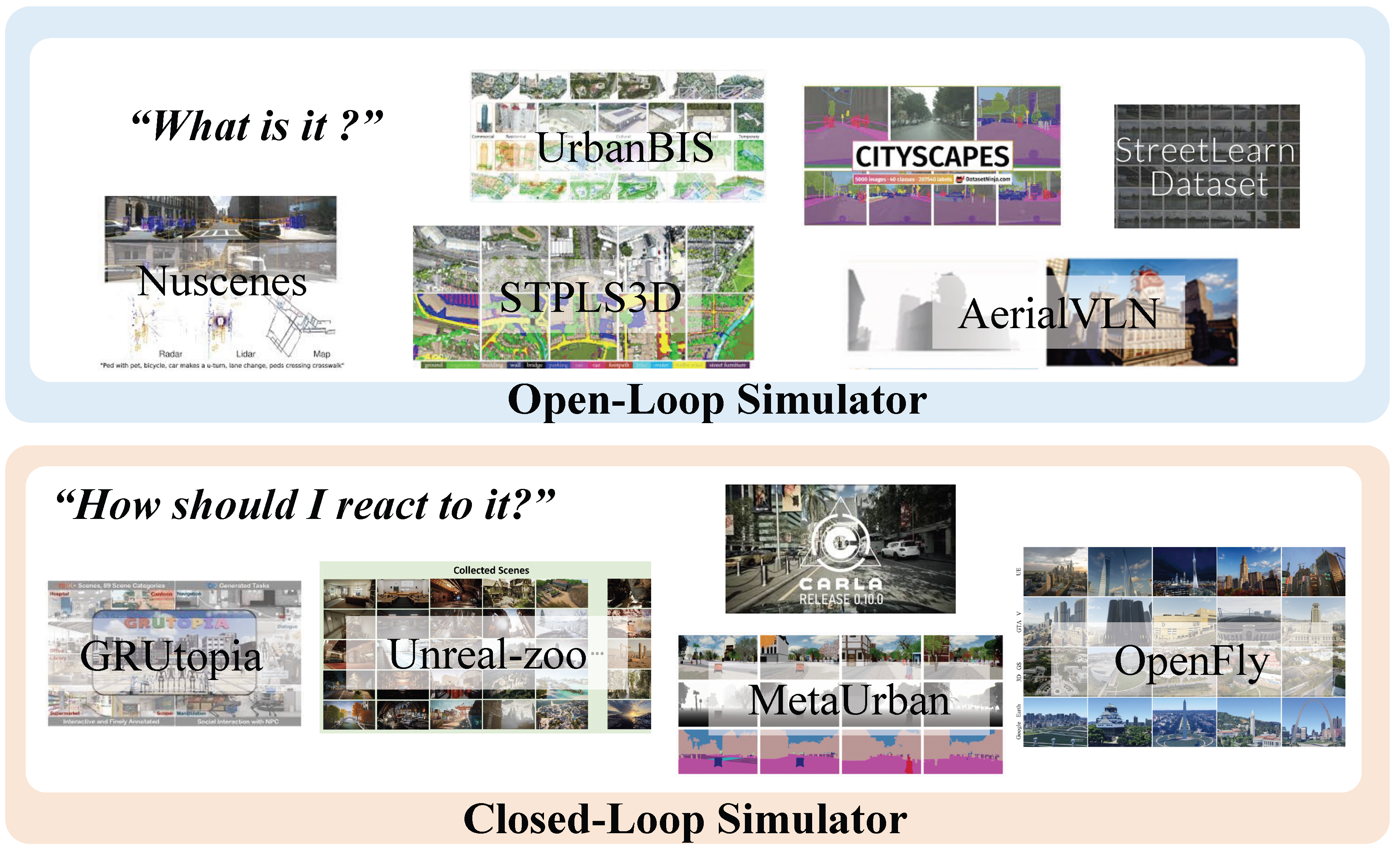
Figure 5.
The example using DBs for the Urban Embodied Agents.
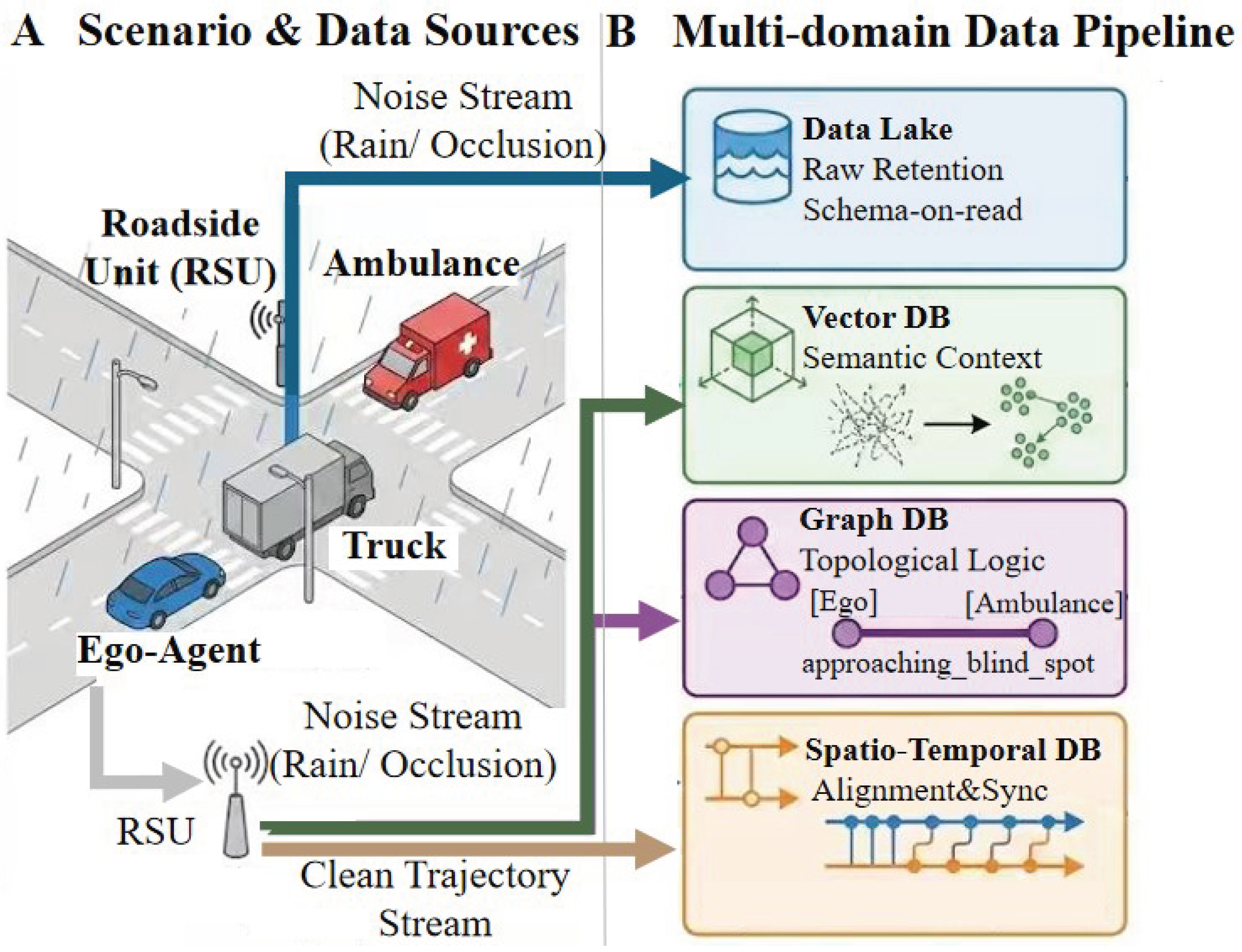
Figure 6.
The domain gap between multi-domain data for Urban Embodied Agents.
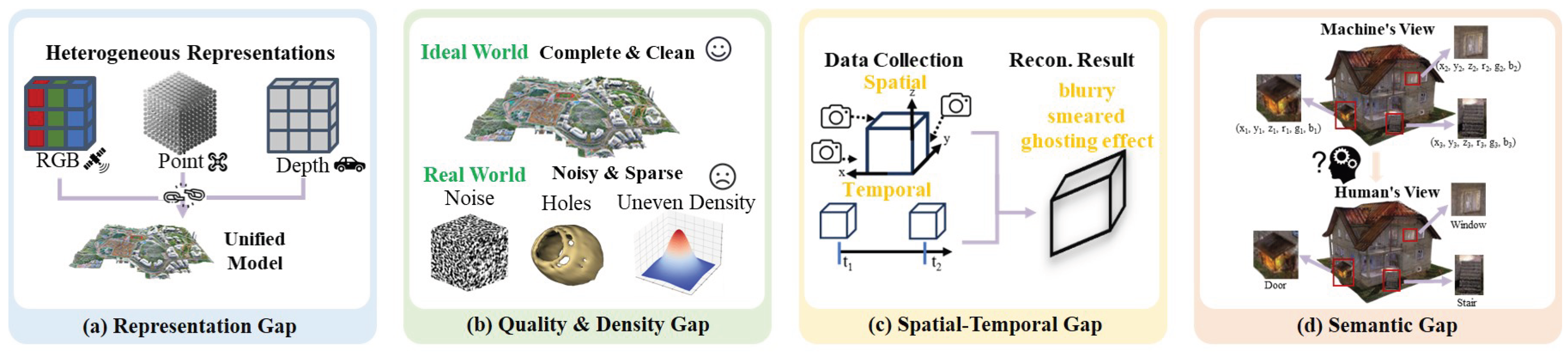
Table 1.
Comparison with existing surveys for the model-centric urban computing survey and indoor embodied agent survey.
Table 1.
Comparison with existing surveys for the model-centric urban computing survey and indoor embodied agent survey.
| Survey | Year | Venue | City Platform | Multi-domain Data | Embodied Agent | Data Life-cycle | Primary Perspective |
|---|---|---|---|---|---|---|---|
| Xu et al. [6] | 2023 | arXiv | ✓ | Model-centric | |||
| Jin et al. [9] | 2023 | IEEE TKDE | ✓ | Model-centric | |||
| Yang et al. [3] | 2024 | IEEE TKDE | ✓ | ✓ | Model-centric | ||
| Zhang et al. [10] | 2024 | ACM KDD | ✓ | ✓ | Model-centric | ||
| Cengiz et al. [4] | 2025 | Information Fusion | ✓ | ✓ | Model-centric | ||
| Lu et al. [11] | 2025 | arxiv | ✓ | ✓ | Data-centric | ||
| Liang et al. [12] | 2025 | ACM KDD | ✓ | ✓ | Model-centric | ||
| Zou et al. [13] | 2025 | Information Fusion | ✓ | ✓ | Model-centric | ||
| Song et al. [14] | 2025 | IEEE TKDE | ✓ | Model-centric | |||
| Our Work | - | - | ✓ | ✓ | ✓ | ✓ | Data-centric |
Table 3.
Comparative Evaluation of Storage Architectures for Urban Embodied Agents.
| Architecture | Core Abstraction | Core Capabilities | Performance Profile | Typical Systems | |||||
| Heterogeneity | Relational Semantics |
Semantic Search |
Temporal Analysis |
Read Latency |
Write Throughput |
Scalability | |||
| Data Lakes | Raw Files | ✓ | ✗ | ✗ | ✗ | High | High | High | Lambda Arch. [65], Kappa Arch. [66], Lakehouse [67] |
| Multi-model DBs | Unified Model | ✓ | ✓ | ✓ | ✓ | Variable | Medium | Medium | Sinew [68], NoAM [69], UniBench [70] |
| Graph DBs | Nodes & Edges | ✗ | ✓ | ✗ | ✗ | Low | Low | High | Neo4j [71], JanusGraph [72], nSKG [73], Sg-CityU [74] |
| Vector DBs | High-dim Vectors | ✗ | ✗ | ✓ | ✗ | Low | Low | High | FAISS [75], Milvus [76], HNSW [77], PQ [78] |
| Time-Series DBs | Time/Value Pairs | ✗ | ✗ | ✗ | ✓ | Low | High | High | Gorilla [79], Apache IoTDB [80], TimescaleDB [81] |
| Spatio-Temporal DBs | Time/Spatial Info | ✗ | ✓ | ✗ | ✓ | Variable | Medium | High | MobilityDB [82], PostGIS [83], TrajMesa [84],TMan [85] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



