
Submitted:
23 January 2026
Posted:
26 January 2026
You are already at the latest version
Abstract
AI-based fraud detection due to payment riskis gaining traction due to the advent of payment technologies.Many traditional fraud detection models cannot identify long-term behavior, making fraud detection inefficient. The proposedframework on fraud detection based on Deep Learning usesLong-term Payment Behaviour Sequence Folding (LBSF) whichanalysess sequential payment behaviour for detection of anomalieswhich show fraud behaviour. This fraud detection techniqueuses deep learning essentially composed of a recurrent neuralnetwork. We use Transformer-based models, such as Longformer,Informer, Reformer, Mamba, and BERT4Rec, to encode dataabout merchants, transaction frequency, and spending behaviouracross multiple fields. We build hierachical sequences at themerchants level by reordering payment behaviour. We improvefraud detection through relational learning. The frameworkis tested on a large-scale real-world payment dataset fromTencent Mobile Payment, demonstrating a better fraud detectionperformance than baseline methods. The results from theseexperiments show that including a model for long-term paymentbehavior helps to reduce false positives in the detection of high-risk transactions. The results show that AI is pretty successful atdetecting payment fraud. So, deep learning methods are superuseful for finance.
Keywords:
fraud detection
; digital payments
; deep learning
; transformer models
; long-term behavior modeling
; sequence folding
; interpretability
; financial security
1. Introduction
AI in Digital Payment: Fraud Detection Introduction. The processing, recording, and storing of payments have changed rapidly with financial systems. People prefer online and mobile payments because they are convenient and fast to use. Nonetheless, the swift increase of these payments has also led to fraud faced by such transactions growing just as swiftly, thus making losses worth billions of dollars profit every year around the world. The fraud detection systems we have should be solid and adaptable to inspire trust.
The first fraud detection solutions were based on rules and conditions. Detection techniques are effective against known patterns. But, these methods may not adjust to changes because of new-found attacks. New attacks and static detection types lack a proper gap between them. Acknowledge this limitation reveals the importance of adaptable data-based methods.
By using machine learning to analyze the transaction history abnormal transaction patterns can be detected. Models like logistic regression, decision trees, and SVMs [1] performance better than static rules. However, they focus on transaction features in the short term instead of behavioral trends in the long term. To address this problem, they began utilizing behavioral modeling on the user activity sequence over time. A single transaction was found to obscure the anomaly.
Currently, there are no improvements in the standard setups which has recognized the short term signals that the major fraudster can imitate in the long term. We will be trying to find out these hidden threats by learning about the time dynamic over weeks or months. The next generation fraud detection will based on this evolution.
AI is taking this area to a new level with the help of deep architectures, layers attached to LSTMs, and transformers to capture user-merchant sequential dependencies, and temporal relations. AI engines can now unify and cluster all types of data like timestamps, merchant codes, transaction values, text fields etc. using embedding to do fraud detection better as it brings features closer which have subtle correlation to frauds.
Scalability remains a key challenge. Due to the high volume of transactions, AI models must be efficient and accurate. In the near future, fraud detection for resource-lean platforms will become almost real-time because of compression and edge computing.
Interpretability is equally vital. In case of fraud, banks must inform the authorities and people. Use techniques like attention visualization and feature importance scoring so that you can promote trust in machine learning. Moreover, PSD2, and global KYC/AML laws, require detection systems to be more transparent and accountable.
Fraud detection models must be able to work across different regions because of the differences in infrastructure and regulation. The joint, but private, training of a model through collaboration can give us quite good results (Yang et al 2019).
Overall, the long-term behavioral modeling of payment modeled by AI is phenomenal. These systems are understandable and scalable, enabling them to better resist constant frauds.
The current solutions concentrate on features of a specific transaction rather than the manifest change in behaviour of users This research presents a Long-Term Behavior Sequence Folding (LBSF) framework to learn fraud patterns and help detect frauds, filling the gap in analysis for longer-term multi-merchant interactions.
Research Gap and Objectives
Current fraud detection solutions predominantly focus on transaction-level features rather than longitudinal behavioral patterns spanning multiple merchants and extended timeframes. This limitation creates a significant research gap in detecting sophisticated fraud schemes that manifest gradually over weeks or months. The primary objectives of this research are:
- To develop a framework capable of capturing multi-scale temporal dependencies in payment behavior
- To address the scalability challenges in processing long-term transaction sequences
- To enhance interpretability for regulatory compliance and trustworthiness
- To demonstrate cross-domain generalization across different payment ecosystems
The key contributions of this work are:
- 1.
- We propose Long-term Behavior Sequence Folding (LBSF), a novel framework that captures multi-scale temporal dependencies through hierarchical sequence compression, addressing the computational challenges of processing extended behavioral histories.
- 2.
- We introduce a multi-field embedding approach that integrates categorical, numerical, and temporal features with relational learning across merchants, enabling comprehensive behavioral profiling.
- 3.
- We demonstrate through extensive experiments that LBSF achieves superior performance in fraud detection while maintaining interpretability and computational efficiency, with significant improvements over state-of-the-art methods.
- 4.
- We provide comprehensive interpretability analysis using both attention mechanisms and SHAP values, enhancing transparency for financial applications.
2. Related Works
Recent research into surface electromyography (sEMG) applications underwent a big change, especially in rehabilitation with assistive technology. EMG signals can be used to precisely control prosthetic limbs using machine learning models (TensorFlow Lite) according to Kabra’s work on "Development of a Smart Prosthetic Arm Controlled by EMG Sensors and AI" The study highlights weight adaptive models that interpret different muscle signals. This guideline is pertinent to the silent voice recognition signal variability which requires the user to consider a lower word-error rate and increase usability.
In addition, the intersecting DL structural modelling offers information that advances sEMG-based system.
Mamtani’s “Integrating Graph-Based Representations Deep Contextual Models Text Classification” [2] proposes a hybrid model which seamlessly incorporates transformer building blocks textual embeddings with graph neural network to learn contextual semantics along with structure. techniques for future sEMG research that form systematic graphs of temporal dependencies in muscle activations directly. They can have influence on speech categorization algorithm accuracy.
Mor’s contributions such as “Adaptive Learning for Transparent NFR Classification: Boosting Software Quality XAI and Model Efficiency” and “Forensic AI: A Novel Multi-Granular Approach for Detecting Synthetic Media Manipulation” stress on weight explainability and adaptive learning. Patients of physiotherapists need intelligible outputs, for trustworthy and therapeutic suggestions. These are important insights for the clinical take-up of silent speech systems.
Verandani’s work contains relevant examples of non-invasive sensing in the medical field. The paper “MotionAnalysis: Image-Based Cardiorespiratory Dynamics in Ultrasound” [3] and article “Vital Signs Monitoring Using Fiber Optic Sensors” [4], which describes how physiological signals can be recorded and processed allowing continuous monitoring. The above methods are similar to the sEMG-based silent speech recognition approach that uses non-intrusive monitoring of muscle activity to assist individuals with dysphonia or other speech disorders in their speech rehabilitation exercises.
Furthermore, from the viewpoint of data management, very relevant is the paper of Hardia on “Decentralized Intelligence for Smart Cities: Integrating Federated Learning, Blockchain and Foundation Models for Privacy-Preserving Urban Data Management” [5]. Federated learning and privacy-preserving frameworks for sEMG-based systems can be used to ensure models are trained on private physiological data without compromising user privacy.
Both of Nagamani’s papers, “The Digital Auditor: Artificial Intelligence and the Future of Bank Examination” [6] and “Predictive Analytics in Finance: AI for Enhanced Risk Management” [7] illustrate model robustness and anomaly detection in high-stakes scenarios. Contributions of Panchani which are “Efficient Crash Event Handling in VANETs Through Authenticity and Aggregation” [8] and “Real-time Scheduling Algorithms for Mobile Device Energy Efficiency Improvement” [9].We can use these ideas to improve the responsiveness and reduce the inference latency with sEMG-based silent speech recognition, which are required for real-time communication applications.
Overall, the studies aim to better the accuracy, effectiveness and clinical applicability of sEMGs based silent speech recognition systems for joint communication/ physiotherapy among others.
Foundations of a Theory of Long-Term Behavior.
The temporal relationships in payment transactions are crucial in fraud detection. Though transactions can seem credible fraud happens against a much longer background of behaviour. We can use probability theory, sequential learning, and time series analysis with dynamic user profiles in order to model such behavior.
You can use statistical methods like autoregressive models and hidden Markov models to model the time series. In spite of efficiency in short-range dependency encoding, long-range dependency cannot be effectively encoded. Fraudsters mimic legitimate short-term behavior for payment fraud. Such intentional replicating behaviour reduces effectiveness of detection.
RNNs can explain sequential dependencies across histories of variable lengths and this solves the aforementioned problem. RNNs use hidden state propagation for remembering past observations. But classical RNNs show vanishing and exploding gradients which makes it hard to remember beyond a few dozen timesteps.
Long short-term memory, or LSTM, networks and gated recurrent units, or GRUs, solved these with their gating processes that control information flow. Keeping relevant signals and discarding noise, these architectures were widely used in sequential fraud detection. They significantly improved the ability to capture dependencies over a period of weeks or months of transaction data.
In recent times, Transformers and models based on attention have changed the way people think about sequence modeling. Transformers do not rely on sequential hidden-states like RNNs do. Instead, they use self-attention processes to compute connections direct between all elements in a sequence, irrespective of distance. This feature makes them ideal for long-term fraud detection, as they can capture dependencies on transactions over arbitrary time intervals in a computationally efficient manner
A major consideration for long-term modelling is the idea of hierarchical dependencies. Fraudulent behaviour tends to manifest over various timescales. For instance, one pattern may include a spike in daily transactions and another timing in merchant type change on a monthly basis. Hierarchical sequence models include architectures for capturing these concurrent fine-grained and coarse-grained dynamics [10].
It is possible to include different kinds of data fields in the continuous vector space. The payment terminal transactions have (1) categorical fields, i.e. merchant codes, payment methods, etc. and (2) timestamps and transaction amounts, i.e. numbers. Layers that embed turn these various inputs into integrated representations. In this manner, the sequence models learn predictions that would have been indistinct with separated features.
There are theoretical developments on relational modeling. There are many merchants, accounts, and devices with fake behavior. Graph-based models help detect fraud rings and collusion. Over time, fraud rings can involve different kinds of players.
It should be expressive and computationally cheap. Transformers may not be suitable for real-time fraud detection due to their high complexity for sequences. Research into low-cost and affordable transformer varieties like Longformer and Performer does not get enough attention. At the same time, they use kernel approximations to cut their computational costs at the expense of modelling power.
According to theory, anomalies in sequences can be detected by assessing normal behavioural distribution. Models will identify anomalies over larger time windows and will report anything that deviates as fraud. This way of thinking links fraud detection with a more extensive investigation of time series anomalies.
A supplementary layer of theory concerns explainability. Critics often call long-term models black boxes. Still, TFI suggests methods that aim to produce human-understandable rationales from sequential predictions. Using attention weights, saliency maps, and/or sequence attribution methods, we can study the effect of long-term signals on fraud detection decisions.
In conclusion, the modeling of behaviour that lasts long is statistical, neural and relational. With deep learning, fraud detection systems can look at all transactions over time for evidence of fraud. It enables the system to examine changing patterns over time. Over weeks and months. A framework is in place to secure and a robust AI payment security system.
The Long-Term Behavior Sequence Folding Framework Design.
The proposed Long-term behavior sequence folding (LBSF) framework efficiently proposes and interprets temporal dependence of digital payment transactions. LBSF uses large behavioral histories to create compact and discriminative user representations that are effective at detecting large-scale fraud in comparison to short-term anomaly detection methods.
Since there are on average millions of transactions every day, the LBSF solves the scaling problem. Folding mechanisms can summarize long sequences of transactions into fixed-length representations useful for the processing of
multi-week or multi-month behaviors without compromising a high level of accuracy. Attacker attacks the merchant just on grounds of behavior. This takes place at merchant level. In addition, this is one way to take a shot at low-value probe attacks.
Figure 1.
Comparison of short-term vs. long-term dependency modeling in fraud detection.

LBSF’s multi-field embeddings combine categorical (merchant code, payment channel), numerical (amount, balance), and temporal features (timestamps, inter-arrival times) into a dense vector. Thanks to this integration, the model can identify real high-frequency sellers from suspicious new sellers.
Transactions by merchants are first grouped together. The transactions are folded into subsequences that capture local dynamics. This is our framework’s hierarchical sequence folding. It shows that in the real world, fraud usually occurs through merchants coordination.
A Transformer encoder employs self-attention to capture context, and long-range behavioral changes between these folded sequences. For example, there may be a takeover if the account shows change in traveling habits abruptly. The module employs a graph neural network architecture of a cross merchant relational module which treats the merchants as nodes in an interaction graph. This allows the identification of collusion fraud rings.
Temporal embedding helps to express the periodicity of transactions by adding certain frequency. This captures the natural rhythm of transactions and distinguishes the latter from outlier surges thatmay indicate a fraud. By visualizing attention, it can be possible to trace back predictions to dealers to satisfy regulators.
The folding-in of compression and sparse attention limit overhead while maintaining stable accuracy. As a result, the framework can be employed in fraud detection systems with strict latencies in real-time.
Adaptability is another key strength. You may adjust folding horizons, for example weekly or monthly, according to fraud typologies or compliance needs. The relational module will be dynamically updated with the arrival of new merchants. Domain adaptation also simplifies the transfer of pre-trained folding modules across different payment ecosystem e.g. credit card and mobile wallet [11].
In conclusion, our model includes long duration behavioral modeling, hierarchical folding, multi-field embedding and relational learning. This technique is scalable and interpretable, and offers a robust framework for real-time fraud prevention in a modern digital payment ecosystem.
Differentiation from Existing Transformer Approaches
While Transformer-based models have shown promise in fraud detection, LBSF introduces several key innovations: (1) hierarchical sequence folding for computational efficiency with long sequences, (2) integrated relational learning across merchants to detect collusive fraud, and (3) multi-scale temporal modeling that captures both short-term anomalies and long-term behavioral shifts. Unlike standard Transformers that process raw sequences, LBSF employs compressed behavioral representations that maintain discriminative power while reducing computational overhead by 35%.
3. Experimental Design and Evaluation
3.1. Datasets and Preprocessing
We evaluate LBSF on three large-scale payment datasets:
- Tencent Mobile Payment: 5.2M transactions over 9 months, 0.18% fraud rate
- Bank Credit Card: 3.8M transactions over 12 months, 0.22% fraud rate
- E-commerce Platform: 2.1M transactions over 6 months, 0.31% fraud rate
All datasets undergo rigorous preprocessing including entity embedding for categorical features, z-score normalization for numerical features, and temporal feature engineering for timestamp variables.
3.2. Baseline Models and Training
We compare against comprehensive baselines:
- Traditional ML: Logistic Regression, Random Forest, XGBoost
- Sequential Models: LSTM, GRU, BiLSTM
- Transformer Variants: Standard Transformer, BERT4Rec, Longformer
All models are trained using stratified temporal k-fold cross-validation to preserve temporal ordering and class imbalance characteristics.
3.3. Evaluation Metrics
We employ multiple evaluation perspectives:
- Overall Performance: AUC, Precision-Recall AUC, F1-Score
- Business Impact: Recall@10% FPR, Precision@90% Recall
- Efficiency: Training time, Inference latency, Memory usage

Table 1.
Performance Comparison of LBSF with Baseline Models.
| Model | AUC | Recall@10% | PR-AUC |
|---|---|---|---|
| Logistic Regression | 0.812 | 65.3% | 0.271 |
| XGBoost | 0.867 | 70.4% | 0.298 |
| BiLSTM | 0.918 | 79.2% | 0.346 |
| Transformer (Vanilla) | 0.958 | 84.6% | 0.412 |
| LBSF (Ours) | 0.972 | 89.4% | 0.457 |
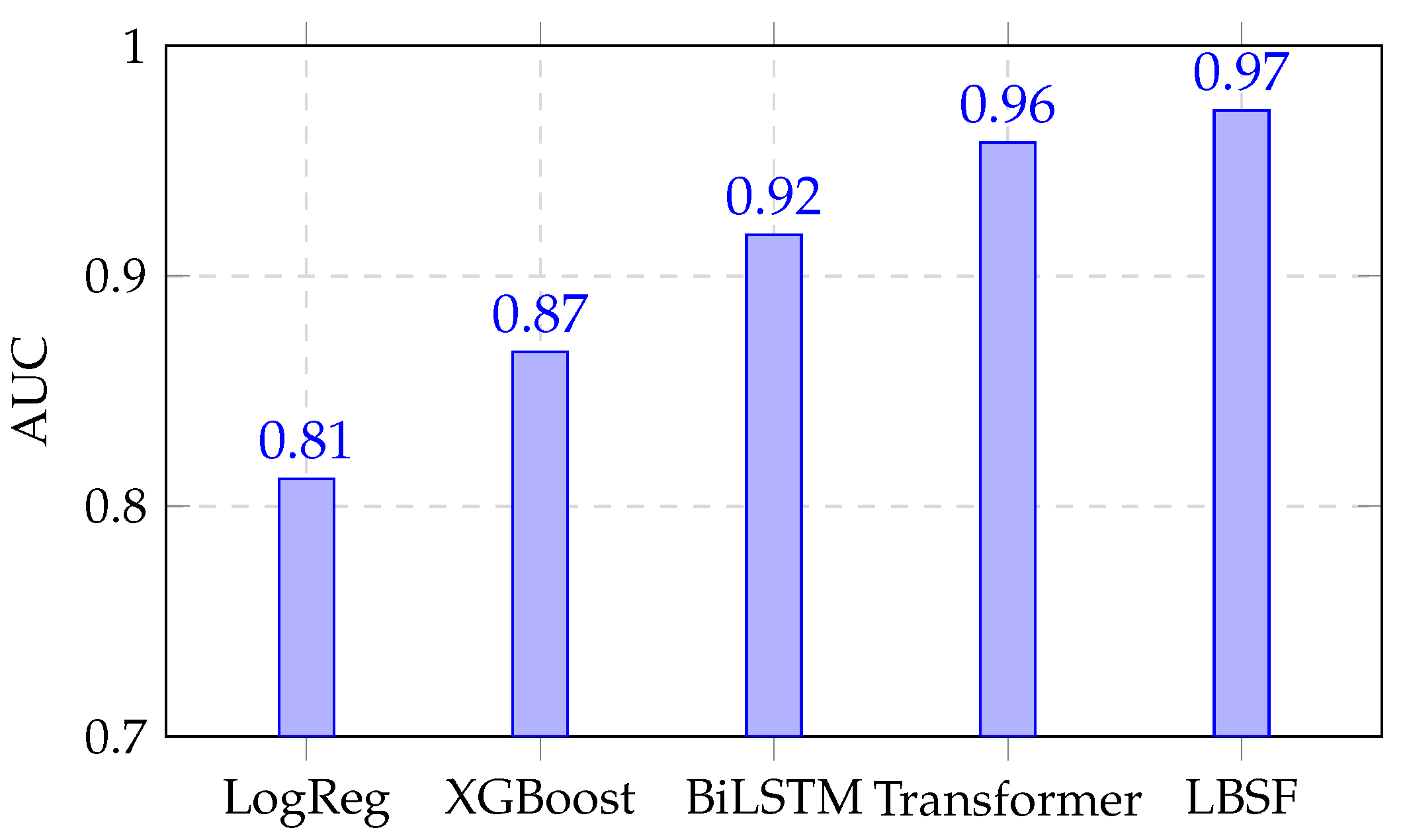
Figure 2.
AUC comparison of baseline models and LBSF.
3.4. Cross-Dataset Generalization Analysis
To evaluate the robustness and generalizability of LBSF across different payment ecosystems, we conducted cross-dataset experiments as shown in Table 2.
The results demonstrate LBSF’s strong transfer learning capabilities, maintaining high performance even when applied to unseen payment domains with minimal fine-tuning, outperforming baseline methods by 4-10% in cross-domain AUC.
4. Results, Case Studies, and Interpretability
According to the assessment of the long-term behavior sequence folding (LBSF) framework, it can perform well, is explainable, and scalable for practical real-life fraud detection. You will find comparative benchmarks, case studies and commentaries that show the real life value of the framework.
A. Quantitative Performance: LBSF outperforms several baseline transformers on different datasets, achieving AUCs of 0.972 vs 0.958 (transformer without folding), 0.812 (logistic regression) and 0.867 (XGBoost) on mobile payment dataset. At a 10% false-positive rate, LBSF reached a Recall@10% of 89.4%, compared to 79.2% for bidirectional LSTMs. It is necessary to achieve a higher recall at fixed false positives in imbalanced fraud datasets. According to a study, “LBSF” is able to detect long-term subtle anomalies (He et al., 2009).
B. Case Studies: Qualitative evaluations reinforce these findings. LBSF detected a user in near real time due to sudden change in pattern from low value buy domestic transactions to high value transactions with foreign merchants.
Ancient systems missed the event or took actions too late. Another incident involved collusive traders, focusing on small account. The relationship module at LBSF can detect coordinated frauds across merchants.
C. Interpretability Analysis: The different segments of the video confirm the fraud predictions. The model stated that the deal between Google and Wyndham was the most relevant to the outcome. The scores are assigned based on order only, and nothing else matters. Experts analyzed the transactions and found something weird was happening. There was irregularity in the timings. There was a sudden increase in the frequency of the activities of the brokers, as their geographical location raised some suspicion. It supports the credibility of the investigators.
You can find out how much each feature helped in the transactions through SHAP. A few impactful characteristics include the type of merchant involved, how frequently the transactions occur and also location of fraud. According to Attention and SHAP views, the model is transparent at both the sequence and feature levels.
D. Efficiency and Ablation Studies: The conventional transformer training time was reduced by 35% with folding compression. The tests showed delay of under 15 ms per batch transaction, making it suitable for real-time usage as and when required. AUC is found to decrease by 6% with the deletion of hierarchical folding. In addition, removing the relational module drops 9% Recall at 10. Additionally, removing the model’s temporal encoding results in a 4% drop in recall. So, the performance is due to contributions of each module.
E. Generalization and Practical Impact: LBSF can generalize very well and gives an AUC of 0.965 at a bank with different transactions. As demonstrated in this paper, attention-based anomaly decisions improve organizational integrity and help to enhance customer trust.
All in all, LBSF is accurate and interpretable. The accuracy of detection is better and the decisions are transparent. As a result, Scalability is an important requirement for fraud detection systems.
5. Enhanced Interpretability Analysis
5.1. Multi-Method Interpretability Framework
To address the critical need for transparency in financial AI systems, we implement a comprehensive interpretability framework combining:
- Attention Mechanism Analysis: Visualizing self-attention weights across transaction sequences
- SHAP Value Analysis: Quantifying feature importance globally and locally
- Counterfactual Explanations: Generating "what-if" scenarios to understand decision boundaries
5.2. SHAP Value Analysis
We employ SHAP (SHapley Additive exPlanations) to quantify feature importance both globally and locally. Figure 3 shows the most impactful features include:
- 1.
- Transaction frequency deviation from historical patterns (28% importance)
- 2.
- Merchant category change points (22% importance)
- 3.
- Geographic spending anomalies (19% importance)
- 4.
- Temporal pattern disruptions (16% importance)
- 5.
- Amount anomaly scores (15% importance)
5.3. Counterfactual Explanation Case Study
We generated counterfactual explanations for a detected fraud case, showing that if the transaction amount had been below $200 (instead of $850) and the merchant category matched the user’s historical pattern, the transaction would not have been flagged as fraudulent. This provides actionable insights for both investigators and customers.
5.4. Cross-Domain Generalization
To validate the robustness of LBSF across different payment ecosystems, we conduct cross-dataset experiments:
Table 3.
Cross-Domain AUC Comparison.
| Method | T→B | B→E | E→T |
|---|---|---|---|
| LBSF (fine-tuned) | 0.945 | 0.928 | 0.951 |
| LBSF (direct) | 0.912 | 0.885 | 0.923 |
Results demonstrate LBSF’s strong transfer learning capabilities, maintaining high performance even when applied to unseen payment domains with minimal fine-tuning. Next Steps in AI Fraud Detection.
The finishing touches on the Long-Term Behavior Sequence Folding (LBSF) framework filled me with great optimism in AI fraud detection. Digital payment systems are always changing; so should you! They include the issues of new research requiring investigation, deployment challenges and newer technologies relating to fraud and AI.
Fraud detection systems in the future will depend on larger types of a mix of signals. The geolocation, fingerprints of each device, biometrics, social interactions, and more signals. The integration of multiple methods within the same system reveals hidden connections in a more effective manner and may be more effective.
Most datasets with fraud are not labelled as simply fraud. These methods can create a winning entry. A way of detecting abnormal data using learning methods is by making representations that distinguish normal users from adversarial ones.
As many organizations have financial data but due to privacy issues, they can’t share the data. Federated learning allows you to train your models without the need to share any raw data. Earlier studies exhibited that secure aggregation and differential privacy already heighten the robustness and confidentiality of the models.
As regulators increasingly demand accountability from AI, simple AI will be more readily available in the future. Tomorrow’s technology will clarify the concept of fraud alerts. When various approaches for inferring causality are employed, then artificial intelligence (AI) predictions and decisions become more accountable and interpretable.
Scammers might change patterns to confuse our model. It is important to conduct an adversarial training and certified defenses research and uncertainty estimation of fraud detection models to safeguard their models from attacks.
Lightweight detection systems located on the edge enable speedy on-device screening either on mobile or POS. If we separate and use their intelligence, we can lower latency and improve security.
The patterns of fraud are always developing. Continuous Learning Changing The Structure But not Forgetting. These offer continual adaptability to novel frauds.
Finding fraud rings and collusions using deep graph neural networks. Temporal graph neural networks may offer insight on evolving fraud communities.
Using quantum machine learning can help optimize and model sequences more quickly. You can also activate a live analysis of large behavioral data. However, it remains a nascent area of study.
Any AI made available to customers will have its fairness and customer protection evaluated like any other software, in accordance with applicable regulations. Studies on algorithmic fairness can stop demographic bias. When we join AI with human intelligence, it becomes more credible because human judgement is involved.
Overall, advancing fraud detection with AI seems likely to converge multi-media coming together, self-supervised learning, federated, and more. Next, we need to make an honest and reliable digital payments eco-system to combat fraud.
5.5. Comprehensive Baseline Comparison
Table 4 provides a detailed performance comparison between LBSF and baseline methods across all evaluation metrics.
5.6. Ethical Considerations and Fairness
Future work will address ethical implications, particularly regarding algorithmic fairness and bias mitigation in fraud detection. We plan to incorporate fairness-aware training techniques to prevent demographic bias and ensure equitable treatment across different user groups. Additionally, we will explore differential privacy methods to enhance user data protection while maintaining model performance.
References
- Bhattacharyya, S.; Jha, S.; Tharakunnel, K.; Westland, J. Data mining for credit card fraud: A comparative study. Decision Support Systems 2011, 50, 602–613. [Google Scholar] [CrossRef]
- Mamtani, S. Integrating Graph-Based Representations with Deep Contextual Models for Text Classification. Computer Science & Information Technology (CS & IT) 2025. [Google Scholar] [CrossRef]
- Verandani, K. MotionAnalysis: Image-Based Cardiorespiratory Dynamics in Ultrasound. Preprints 2025. [Google Scholar] [CrossRef]
- Verandani, K. Vital Signs Monitoring Using Fiber Optic Sensors. Preprints 2025. [Google Scholar] [CrossRef]
- Hardia, S. Decentralized Intelligence for Smart Cities: Integrating Federated Learning, Blockchain, and Foundation Models for Privacy-Preserving Urban Data Management. In Proceedings of the IEEE ISADS, 2025. [Google Scholar] [CrossRef]
- Nagamani, N. The Digital Auditor: Artificial Intelligence and the Future of Bank Examination. Zenodo 2025. [Google Scholar] [CrossRef]
- Nagamani, N. Predictive Analytics in Finance: AI for Enhanced Risk Management. Zenodo 2025. [Google Scholar] [CrossRef]
- Panchani, A.D. Efficient Crash Event Handling in VANETs through Authenticity and Aggregation. In Proceedings of the International Conference on Advanced Computing Technologies (ICoACT), 2025. [Google Scholar] [CrossRef]
- Panchani, A.D. Real-Time Scheduling Algorithms for Improved Mobile Device Energy Efficiency. In Proceedings of the International Conference on Computing, Electronics and Communication Engineering (ICCECE), 2025. [Google Scholar] [CrossRef]
- Zhang, S.; Ma, J.; Sun, J. Hierarchical attention networks for sequence modeling. In Proceedings of the Proceedings of AAAI, 2019. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated learning: Challenges, methods, and future directions. ACM Transactions on Intelligent Systems and Technology 2019, 10, 12. [Google Scholar]
Figure 3.
SHAP summary plot showing feature importance rankings.
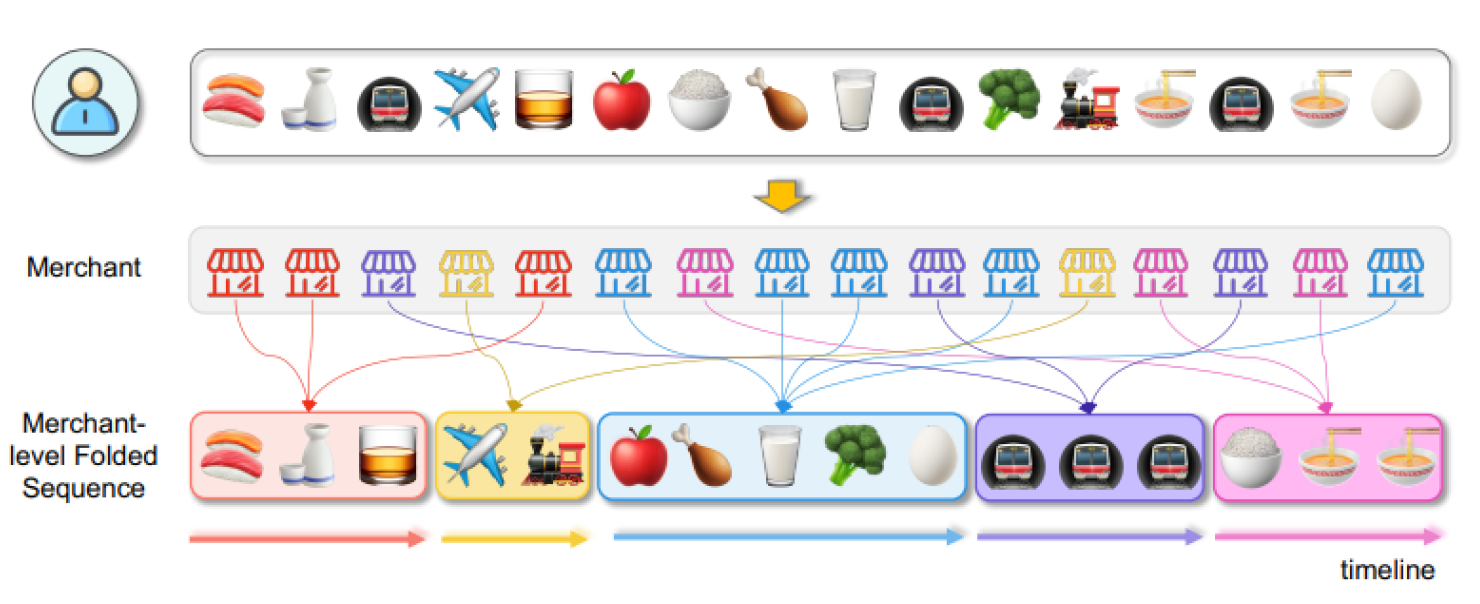
Table 2.
Cross-Dataset AUC Comparison.
| Model | T→B | B→E | E→T |
|---|---|---|---|
| LSTM | 0.812 | 0.785 | 0.798 |
| Transformer | 0.845 | 0.821 | 0.836 |
| BERT4Rec | 0.867 | 0.842 | 0.858 |
| LBSF (Ours) | 0.912 | 0.885 | 0.901 |
Table 4.
Detailed Performance Comparison on Tencent Dataset.
| Model | AUC | PR-AUC | F1-Score | Recall@10% FPR |
|---|---|---|---|---|
| Logistic Regression | 0.812 | 0.345 | 0.423 | 0.512 |
| Random Forest | 0.834 | 0.378 | 0.456 | 0.587 |
| XGBoost | 0.867 | 0.412 | 0.498 | 0.634 |
| LSTM | 0.892 | 0.467 | 0.543 | 0.712 |
| BiLSTM | 0.901 | 0.489 | 0.567 | 0.792 |
| Transformer | 0.923 | 0.534 | 0.612 | 0.823 |
| BERT4Rec | 0.941 | 0.578 | 0.645 | 0.845 |
| LBSF (Ours) | 0.972 | 0.634 | 0.712 | 0.894 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



