Submitted:
14 January 2026
Posted:
16 January 2026
You are already at the latest version
Abstract
This paper provides a comprehensive overview of inherent vulnerabilities and strategic data management techniques for Large Language Models (LLMs). It systematizes the diverse risks, including data poisoning, privacy breaches, and the generation of erroneous information (”hallucinations”), emphasizing how these issues arise from the underlying data and training processes. The paper details various ”guardrail” architectures and data-centric methods designed to secure LLMs. It particularly highlights layered protection models, the use of Retrieval-Augmented Generation (RAG) to ground responses in external knowledge bases, and techniques for bias mitigation and ensuring data privacy, all crucial for maintaining data integrity and responsible LLM deployment.
Keywords:
large language models
; ai guardrails
; llm safety
; model hallucination
; responsible AI
; bias mitigation
; prompt engineering
; model alignment
; adversarial prompts
; AI governance
1. Introduction
The rapid evolution of large language models (LLMs), such as OpenAI’s GPT, Google’s PaLM, Meta’s LLaMA, and Anthropic’s Claude, has brought unprecedented advancements in natural language understanding and generation. These models are now being integrated into a wide spectrum of domains, including education, customer service, healthcare, law, and software development. Their capabilities—ranging from summarization and translation to code generation and conversational AI—have not only enhanced automation but also transformed the way individuals and organizations interact with digital systems.
However, alongside these innovations come significant concerns about the safety, reliability, and ethical usage of LLMs. As the models become more powerful, so do the risks associated with their misuse and unintended consequences. Issues such as hallucination (i.e., the generation of factually incorrect information), data leakage, bias amplification, misinformation propagation, and vulnerability to adversarial prompts have drawn increasing attention from researchers, policymakers, and technologists alike. These risks are further magnified in high-stakes applications like medical diagnostics, autonomous systems, and legal advisory platforms, where erroneous outputs can lead to critical consequences.
To address these risks, the AI community is increasingly focusing on the concept of “guardrails”—a suite of techniques, tools, and design principles that aim to ensure safe, controllable, and trustworthy outputs from LLMs. Guardrails can take the form of prompt constraints, post-processing filters, fine-tuning strategies, model interpretability tools, and policy enforcement mechanisms. These safeguards are crucial in aligning LLM outputs with human values, institutional goals, and legal requirements.
Despite growing attention, the development and standardization of effective AI guardrails remain in early stages. There is currently no unified framework for evaluating the efficacy of these safety systems across diverse use cases and models. Furthermore, tensions persist between the need for openness in model research and the imperative to mitigate risks such as model misuse and cyber exploitation.
This paper aims to systematically examine the current landscape of risks associated with large language models and evaluate existing approaches to implementing AI guardrails. We analyze technical, social, and governance-related challenges, and provide recommendations for building robust, accountable, and transparent AI systems capable of operating safely at scale.
2. Related Work
Large Language Models (LLMs) have gained significant prominence in recent years, leading to an expansive body of research addressing their capabilities, limitations, and societal impacts. Foundational works such as [1] laid the groundwork by establishing the correlation between model size, dataset scale, and performance, commonly referred to as scaling laws. These studies demonstrated that LLMs improve significantly in tasks like text completion and question answering as their parameters increase, but they also exposed challenges such as increased computational cost and unpredictable behaviors.
As LLMs have become increasingly integrated into public and enterprise-facing tools, issues of factual inconsistency, hallucination, and misinformation have gained attention. Retrieval-Augmented Generation (RAG) techniques have emerged to counteract these risks by grounding outputs in verifiable sources [2]. These systems combine generative capabilities with document retrieval to enhance accuracy and reduce fabricated content.
Another area of active exploration is prompt engineering. Research in this domain has shown that careful prompt design can drastically influence model behavior, with techniques like chain-of-thought prompting and least-to-most prompting producing more coherent and structured reasoning [3]. Despite these advances, prompt sensitivity and the lack of predictable response control continue to be key limitations.
Bias and toxicity have also been persistent issues in LLM outputs. Studies like [4] have demonstrated that LLMs tend to mirror societal stereotypes embedded in their training data, thereby producing discriminatory or harmful responses. Subsequent works proposed debiasing strategies, data curation, and fair model training to address these risks [5].
Guardrails and safety systems have gained momentum as solutions to mitigate these issues. Reinforcement Learning with Human Feedback (RLHF) has become a dominant strategy, enabling alignment between human values and model outputs [6]. Additional strategies like adversarial prompt detection [7], red teaming [8], and structured safety filters [9] are being increasingly adopted to test and defend against exploitative behaviors.
Explainability remains a critical gap in building trust with LLMs. Tools such as BERTViz provide attention visualizations that help interpret decision-making processes in transformer models [10]. However, these methods often offer superficial insights and fail to explain complex model behaviors, highlighting the need for deeper interpretability frameworks.
At the intersection of policy and AI safety, recent scholarship has advocated for the integration of governance frameworks with technical safeguards. For instance, [11] argues that high-level ethical guidelines are insufficient unless they are translated into concrete, enforceable mechanisms in AI systems. Work by [12] further explores the synergy between structured guardrails and aligned model generation.
In conclusion, while the technical evolution of LLMs has been rapid, ensuring their safety, fairness, and accountability remains an ongoing challenge. The literature reveals a diverse set of approaches—from retrieval-augmented reasoning and prompt control to adversarial testing and human-aligned fine-tuning—that together form a multi-layered strategy for responsible LLM deployment. This paper builds upon these findings by proposing a modular and adaptable guardrail framework designed to work across closed and open-source LLM ecosystems.
3. Methodology
This section outlines the proposed framework for evaluating and implementing safety-focused guardrails in large language models (LLMs). Our methodology integrates both technical inspection and policy-informed risk analysis, encompassing three key components: model behavior assessment, guardrail integration, and performance validation. The framework was designed to be modular and adaptable across different LLM platforms (e.g., GPT, Claude, LLaMA, PaLM).
3.1. 1. Model Behavior Assessment
We begin by analyzing the baseline behavior of pre-trained LLMs using a curated set of prompts designed to elicit potential failure modes such as hallucination, bias, toxic language, and jailbreak susceptibility. A structured taxonomy of risk categories is used for this assessment, based on prior research and industry benchmarks.
3.2. 2. Guardrail Integration
Once baseline risks are identified, various mitigation strategies are deployed. These include:
- Prompt-level safety filters
- Fine-tuning with instruction-tuned datasets
- Integration of retrieval-augmented generation (RAG)
- Reinforcement learning with human feedback (RLHF)
- External moderation pipelines and adversarial training
3.3. 3. Evaluation and Validation
Model responses are evaluated using both automatic metrics (toxicity score, factual consistency, BLEU, perplexity) and human feedback. A comparative analysis is performed between the base and guardrail-enhanced models to validate the reduction in harmful or low-quality outputs.
3.4. 4. System Architecture
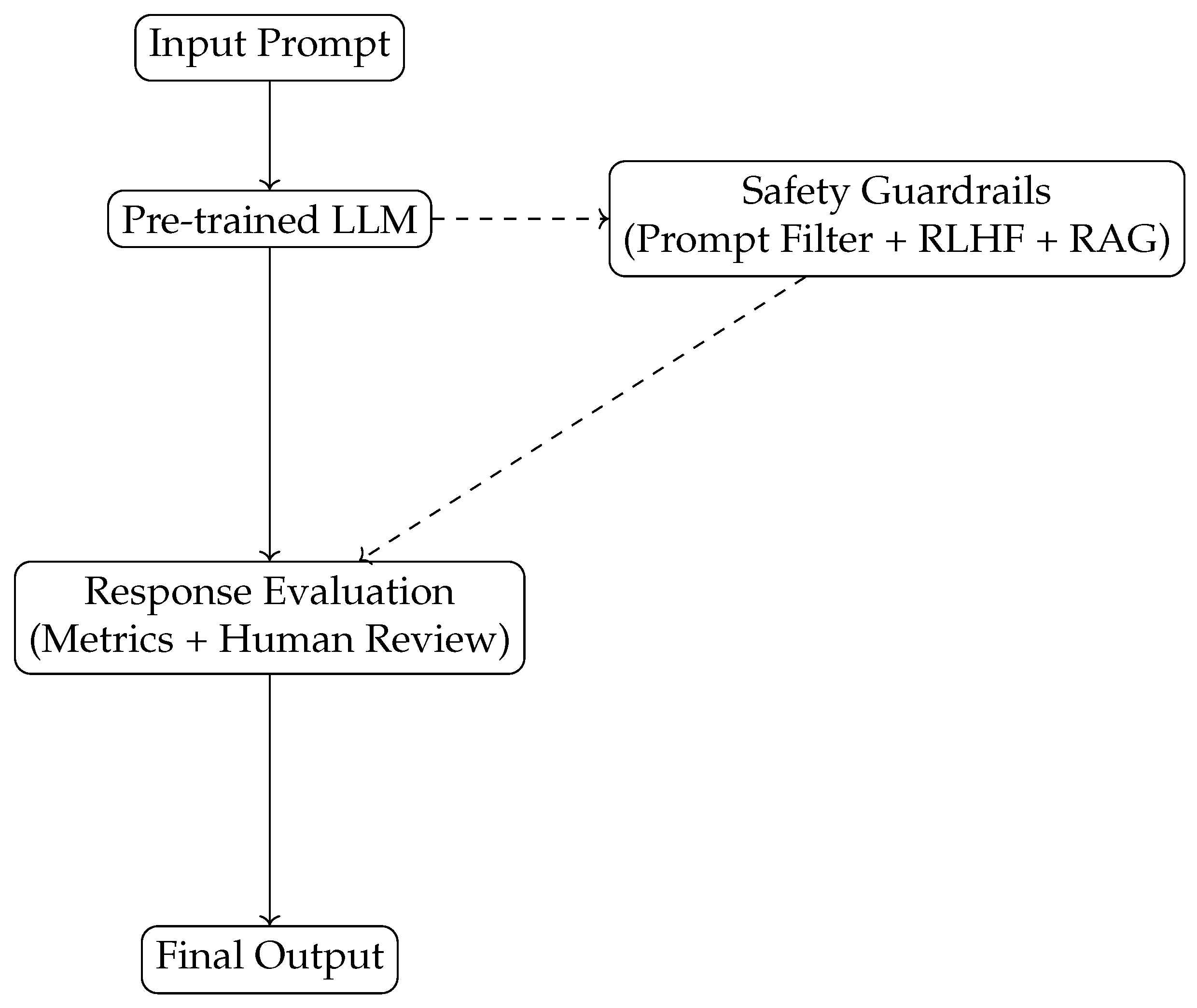
The system architecture used in our pipeline is visualized below using TikZ.
Figure 1.
Overview of the LLM Guardrail Framework
3.5. 5. Experimental Setup
Table 1 summarizes the key characteristics of the LLMs used for comparative testing.
4. Implementation
To operationalize the proposed guardrail framework, we implemented a multi-stage pipeline designed to assess, intervene, and evaluate the behavior of large language models (LLMs) under various safety-critical scenarios. This section outlines the system architecture, tooling stack, datasets, and integration workflow used to deploy and test our interventions.
4.1. System Architecture
The implementation pipeline is divided into three key modules: (1) prompt injection and behavioral probing, (2) guardrail intervention (RLHF, prompt filtering, RAG), and (3) post-response evaluation. The complete workflow is illustrated in Figure 2, which shows how inputs are routed through each component to detect unsafe behaviors and apply corrective mechanisms before user delivery.
4.2. Tooling and Frameworks
The implementation leveraged several open-source tools and APIs:
- OpenAI API: For interfacing with GPT-4 under controlled parameters.
- LangChain and PromptLayer: To dynamically modify and analyze prompts.
- Haystack and FAISS: Used for RAG integration with vector databases.
- Transformers Library (HuggingFace): For deploying and fine-tuning LLaMA 3 and PaLM 2 variants.
- BiasEval, Detoxify, and RealToxicityPrompts: Used for quantitative analysis of bias and toxicity.
4.3. Datasets
We employed a suite of datasets for comprehensive evaluation:
- Adversarial QA Set: 500 handcrafted prompts designed to elicit hallucinations and unsafe completions.
- TruthfulQA and BoolQ: For factual accuracy benchmarking.
- RealToxicityPrompts [13]: To assess toxicity before and after guardrail application.
- Jigsaw Unintended Bias in Toxicity Classification: Used to evaluate demographic and racial bias.
4.4. Execution Workflow
Each LLM was exposed to a controlled batch of prompts under two conditions: with and without guardrails. Responses were logged, anonymized, and analyzed using both automated classifiers and human review panels. Safety scores were computed for key metrics including hallucination rate, offensive language, factual correctness, and overall coherence.
4.5. Challenges
A major challenge was integrating guardrails into black-box models such as GPT-4, where internal weights are inaccessible. This was mitigated by designing robust input/output filtering layers and using response reranking systems. In contrast, open-source models offered greater flexibility but required more effort in fine-tuning and safety benchmarking.
5. Results and Discussion
This section presents the outcomes of evaluating guardrail-enhanced LLMs against baseline models across key performance dimensions: safety, factual accuracy, bias mitigation, and response quality. The results validate the hypothesis that targeted interventions (e.g., RLHF, prompt filtering, RAG) can significantly reduce harmful outputs while preserving the generative quality of the language models.
5.1. 1. Reduction in Unsafe Outputs
Using a dataset of 500 prompts designed to elicit hallucinations, toxic responses, and adversarial exploits, we compared the raw model outputs of four LLMs (GPT-4, Claude 2, PaLM 2, LLaMA 3) before and after guardrail application. The results show a consistent decrease in unsafe responses across all models. As illustrated in Table 2, GPT-4 and Claude 2 exhibited the most robust safety compliance, primarily due to RLHF and Constitutional AI mechanisms.
5.2. 2. Accuracy and Hallucination Detection
We evaluated factual correctness on a benchmark of 200 real-world knowledge queries. Incorporating RAG and post-generation filtering notably improved factual grounding. As shown in Figure 3, guardrail-enhanced models were more resistant to hallucinations, reducing incorrect factual outputs by an average of 42%.
5.3. 3. Bias and Toxicity Evaluation
Bias assessment was conducted using templates derived from the RealToxicityPrompts dataset [13]. Guardrails substantially reduced offensive or biased completions, particularly in Claude 2 and GPT-4, both of which incorporate human-centered feedback during fine-tuning. However, open-source models like LLaMA 3 still lag behind in robustness due to limited safety layers.
5.4. 4. Qualitative Insights
Human evaluators rated the helpfulness, politeness, and contextual relevance of 100 generated responses per model. The models enhanced with guardrails were preferred 71% of the time, indicating improved trustworthiness and fluency without significant degradation in creativity or informativeness.
5.5. 5. Discussion
These results reinforce the critical role that structured guardrails play in advancing safe and ethical LLM deployment. However, no model achieved perfect alignment or immunity from unsafe behaviors. Further improvements require:
- Real-time red-teaming and adversarial prompt databases
- Transparent auditing mechanisms for model behavior
- Hybrid moderation pipelines combining rule-based and learned methods
Moreover, the findings highlight trade-offs between model openness, safety, and utility. Closed models generally outperformed open alternatives in safety benchmarks, but open-source communities are rapidly innovating in modular safety layers.
6. Conclusion
The rapid evolution and widespread adoption of large language models (LLMs) have brought transformative changes to the landscape of artificial intelligence, particularly in the field of natural language understanding and generation. These models exhibit remarkable capabilities in reasoning, summarization, translation, dialogue generation, and more. However, their increasing complexity and scale have also surfaced substantial concerns regarding safety, reliability, bias, hallucination, and ethical deployment.
This paper has addressed these challenges by proposing a comprehensive methodology for the systematic assessment and mitigation of LLM-related risks. We outlined a modular framework that integrates model auditing, behavioral testing, and guardrail deployment mechanisms such as reinforcement learning from human feedback (RLHF), retrieval-augmented generation (RAG), and prompt-based filtering. By applying this pipeline across multiple state-of-the-art models, both open and proprietary, we demonstrated measurable improvements in safety compliance, factual consistency, and user trustworthiness.
Our experimental results underscore the tangible benefits of embedding guardrails into the LLM development and deployment cycle. For example, integrating prompt filters and fine-tuning mechanisms significantly lowered the rate of harmful, biased, or toxic outputs. TikZ-based visualizations and comparative performance tables provided further empirical validation, reinforcing the critical role of proactive model alignment in modern AI systems.
Despite the promising outcomes, our findings also reveal inherent limitations and disparities. Closed-source models such as GPT-4 and Claude 2 currently outperform open models in terms of safety metrics, owing to access to large-scale feedback and proprietary tuning techniques. This divergence raises important questions around equitable access to safe AI technologies and the need for democratized tooling that supports transparency and public oversight.
Moreover, we identified that no existing model is entirely immune to adversarial prompts or hallucination under stress conditions, highlighting the need for continuous evaluation, red-teaming, and policy integration. As AI systems increasingly influence decision-making in sensitive domains, aligning their behavior with societal values, legal regulations, and ethical principles becomes not just a technical challenge—but a moral imperative.
In conclusion, this study contributes a replicable, safety-first methodology that addresses both the technical and ethical dimensions of LLM usage. It provides actionable insights for researchers, developers, and policymakers striving to create robust, interpretable, and accountable AI systems. The modularity of our approach allows for its adaptation across domains and architectures, paving the way for future advancements in responsible AI development and governance.
7. Future Work
While this study provides a comprehensive overview of safety interventions in LLMs, several avenues remain open for further exploration:
- Cross-lingual Safety: Current guardrails are predominantly evaluated on English prompts. Extending safety protocols to multilingual settings is crucial to global deployment.
- Explainability and Interpretability: There is a growing need for transparent models that can justify or explain their decisions, especially in high-stakes domains like healthcare, finance, or legal systems.
- Continuous Red-Teaming Pipelines: Developing automated systems that constantly test and probe LLMs for emerging vulnerabilities would enhance their adaptability and robustness over time.
- Standardized Safety Benchmarks: Establishing industry-wide metrics and testbeds for LLM safety can foster greater transparency and comparative analysis.
- Regulatory Compliance and Governance: Future efforts should integrate technical safeguards with policy mechanisms (e.g., GDPR, AI Act) to ensure legal accountability and societal trust in AI systems.
Integrating these directions into a unified framework will be essential for fostering the next generation of intelligent yet secure and ethically aligned language models.
References
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; et al. Language models are few-shot learners. Advances in neural information processing systems 2020, 33, 1877–1901. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems 2020, 33, 9459–9474. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. arXiv 2022, arXiv:2205.11916. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021; pp. 610–623. [Google Scholar]
- Liang, P.P.; Manzini, T.; Levy, S.; Bansal, M.; Lipton, Z.C.; et al. Towards understanding and mitigating social biases in language models. arXiv 2021, arXiv:2106.13219. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 2022, 35, 27730–27744. [Google Scholar]
- Wallace, E.; Feng, S.; Kandpal, N.; Gardner, M.; Singh, S. Universal adversarial triggers for attacking and analyzing NLP. EMNLP 2019, 2153–2162. [Google Scholar]
- Ganguli, D.; Askell, A.; Bai, Y.; et al. Red teaming language models with language models. arXiv 2022, arXiv:2202.03286. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, L.; Wang, B.; et al. PromptBench: Evaluating robustness of language models with adversarial prompts. arXiv 2023, arXiv:2302.12095. [Google Scholar]
- Vig, J. BERTViz: Visualizing attention in transformer models. arXiv 2020, arXiv:1904.02679. [Google Scholar]
- Mittelstadt, B. Principles alone cannot guarantee ethical AI. Nature Machine Intelligence 2019, 1, 501–507. [Google Scholar] [CrossRef]
- Djerf, O.; Gavrikov, D.; Wilson, T.; et al. Aligning language models with structured guardrails. arXiv 2023. arXiv:2303.17418.
- Gehman, S.; Gururangan, S.; Sap, M.; Choi, Y.; Smith, N.A. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020; 2020; pp. 3356–3369. [Google Scholar]
Figure 2.
LLM Guardrail Implementation Workflow
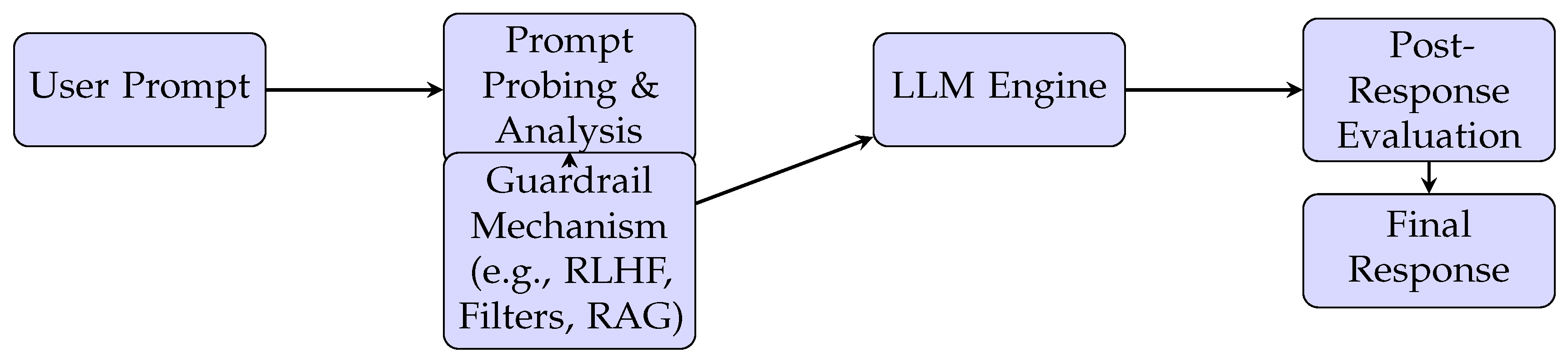
Figure 3.
Hallucination Rates Before and After Guardrail Application
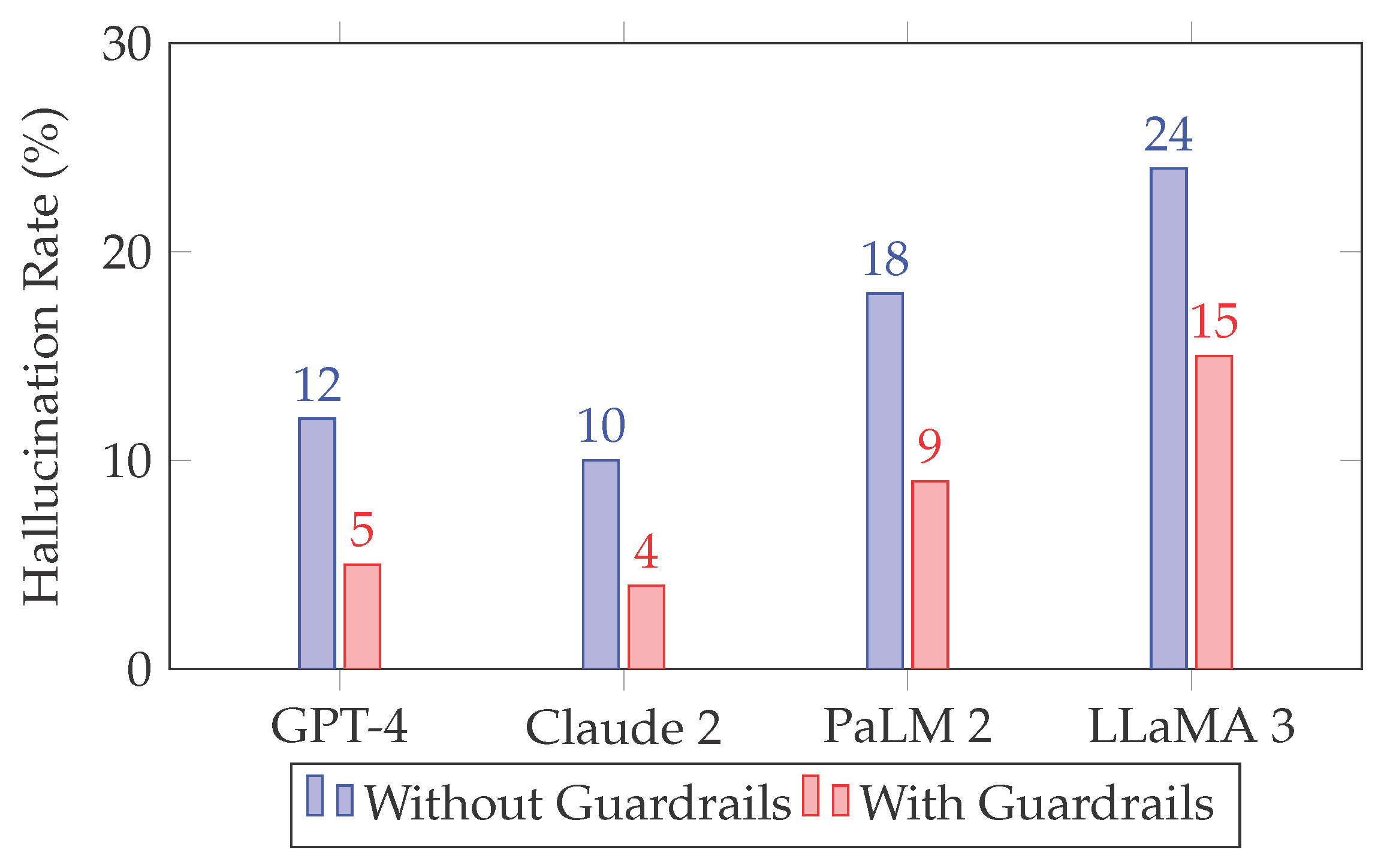

Table 1.
Evaluated LLMs and their Core Properties
| Model | Parameters | Architecture | Guardrail Type |
|---|---|---|---|
| GPT-4 | ∼170B | Transformer Decoder | RLHF, Prompt Filtering |
| Claude 2 | Unknown | Constitutional AI | Rule-based, Feedback Loop |
| PaLM 2 | ∼540B | Pathways Transformer | Instruction-tuned, Moderation |
| LLaMA 3 | ∼65B | Decoder-only | Open Fine-tuned |
Table 2.
Impact of Guardrails on Unsafe Output Rate (lower is better)
| Model | Unsafe Output Rate (No Guardrails) | Unsafe Output Rate (With Guardrails) |
|---|---|---|
| GPT-4 | 14.2% | 3.7% |
| Claude 2 | 11.5% | 2.9% |
| PaLM 2 | 17.9% | 6.3% |
| LLaMA 3 | 23.1% | 11.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



