
Submitted:
13 January 2026
Posted:
14 January 2026
You are already at the latest version
Abstract
This paper publishes 735,000 historical passenger entries from the German North Sea port of Bremen, created between 1830 and 1939, and now structured, enriched, and processed into a research-ready database. It provides an overview of the original archival documents and their datafication, beginning with a historical account of why the passenger lists were created and which information they recorded. Building on extensive prior work—largely carried out by family researchers—the lists were transcribed manually and first made available online in 2003. To enhance their analytical value, we computationally post-processed these data through: (1) data cleaning, especially addressing spelling variants and transcription errors; (2) data normalisation, including conversion into standardised formats; and (3) data augmentation by adding identifiers, geographic information, and multiple classifications. Finally, we discuss limitations of the resulting dataset as well as its analytical potential.
Keywords:
migration
; dataset
; historical sources
; Bremen
1. Summary
Data derived from historical documentation of overseas ship voyages offers valuable, large-scale insight into migration dynamics. The archives of Bremen—alongside Hamburg one of Germany’s principal North Sea ports—preserve a substantial corpus of paper-based passenger lists. This paper reports the transformation of these sources into an enriched digital dataset comprising more than 735,000 individual records. Our work builds on a first transcription and indexing of the original material by a group of family researchers from 1999 onward. Despite being a major achievement, this primary compilation of records had limited analytical utility due to spelling and structural inconsistencies, transcription errors, and missing normalisation, authority data, controlled vocabularies, and contextual information.
This data paper outlines the post-processing of the primary dataset. We document the workflow used to clean and normalise key data fields, correct systematic errors, and enrich the records with additional metadata. Specifically, we provide harmonised versions of demographic attributes (age, gender, marital status, nationality, religion, and ethnicity), standardise occupational titles and link them to established classification schemes. We further classify these occupation descriptors by economic sector and training level to facilitate comparative socio-economic analysis. The enriched dataset also contains normalised data on the voyages, such as ISO-standardised departure dates, cleaned ship names, travel classes and ports. In addition, we georeference ports of departure and arrival by assigning latitude/longitude coordinates and country identifiers, thereby enabling spatial analyses and mappings of shipping routes. The processed dataset substantially improves data quality and interoperability, enabling more rigorous analyses in historical migration, labour history, and historical demography, particularly with regard to Central European overseas emigration.
Published data:
- The passenger lists dataset: ’CHUP_Passengerlists.csv’
Figure 1.
Flowchart of the datafication process from paper-based sources to a digital, post-processed database. MAUS is the database created by the Bremen Society for Family Research.
Figure 1.
Flowchart of the datafication process from paper-based sources to a digital, post-processed database. MAUS is the database created by the Bremen Society for Family Research.
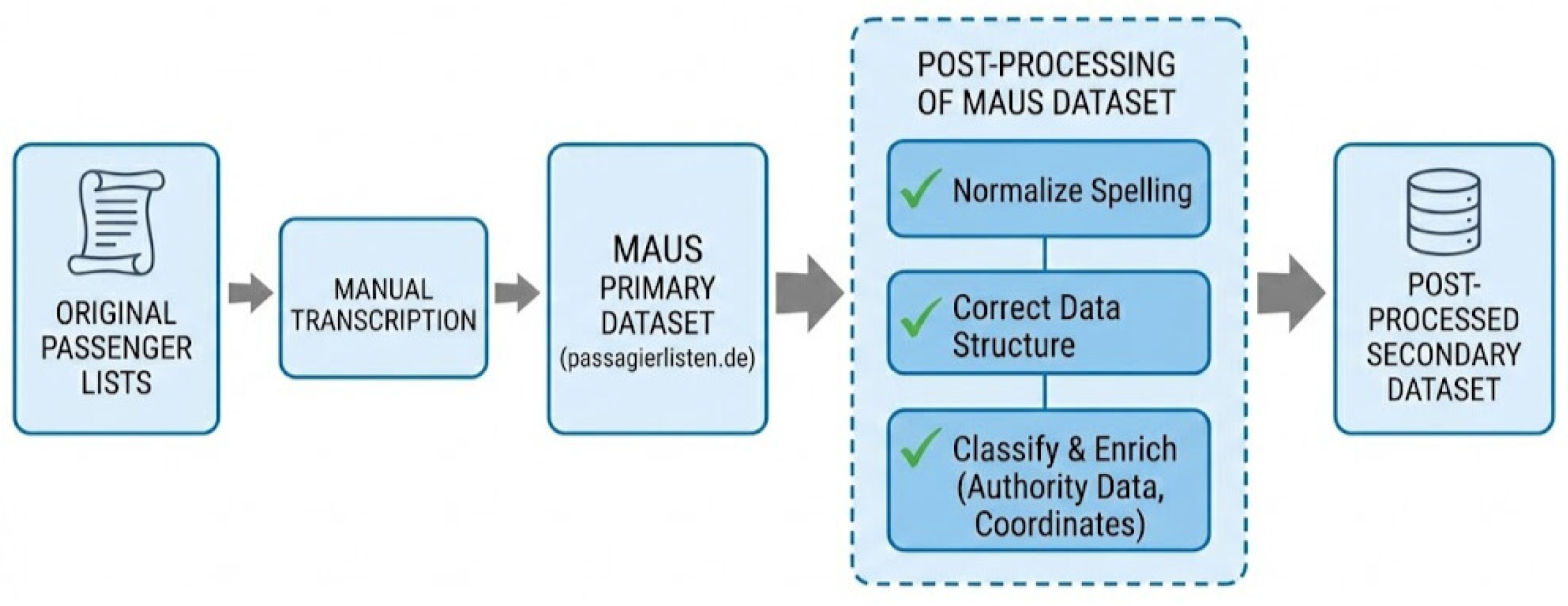
2. Historical Background
2.1. State of Research
Migration, as a universal phenomenon with profound social, cultural, political, and economic implications, has long been a subject of interdisciplinary research. Internationally, historical migration studies have developed in tandem with population history and historical demography, emphasising the interaction of demographic regimes, economic conjunctures, and institutional frameworks. Foundational approaches examine the causes, structures, and consequences of migration in comparative perspective, from global and Atlantic histories to colonial settings, and draw on concepts such as migration systems, transnationalism, and diaspora formation. These perspectives inform the historiography of early modern and modern European migration, embedding it within broader demographic transitions and processes of global integration [4].
Within the german scholarship, migration history — especially early modern and nineteenth-century overseas emigration — has been closely intertwined with historical demography and population studies. Building on this tradition, Arthur E. Imhof highlighted the importance of rigorous demographic methods (family reconstitution, parish registers, and longitudinal life-course data) for reconstructing population dynamics; his work on life expectancy and demographic structures in German territories set a methodological benchmark for linking fertility, mortality, and mobility [27,28]. Christian Pfister, in turn, synthesised population history for 1500–1800 and—through his climate history—underscored how subsistence stress, climatic variability, and crisis mortality shaped household strategies that included migration as an adaptive response; in his Bevölkerungsgeschichte und historische Demographie 1500–1800 he integrates macro- and micro-analyses and explicitly situates mobility within demographic regimes and environmental constraints [29,30]. For the early modern period, Hans Ulrich Pfister’s regional study of the Zurich Knonau district demonstrates how confessional, kinship, and informational networks conditioned destination choice and channelled streams towards North America; he argues that a “need for stability”—preserving confession, language, and social ties—shaped destinations and reduced perceived risk, a finding that refines economically reductive push-pull models [31]. These contributions — Imhof’s demographic rigour, Christian Pfister’s integration of environment and demography, and Hans Ulrich Pfister’s network- and stability-oriented account of emigration — anchor German-language migration historiography in the analytical frameworks of historical demography and population history [1,2,4].
From the 1970s and 1980s onwards, empirically grounded and theoretically informed studies multiplied. As Bickelmann noted, earlier works were often speculative; his own analysis of Weimar-era transatlantic migration combines qualitative and quantitative evidence—contemporary publications, archival records, imperial statistics, and U.S. immigration data—to reconstruct social mechanisms, demographic patterns, and the regulatory context [1]. This mirrors broader methodological shifts in population and social history towards integrating class, gender, skill, and policy regimes. Complementing these national-level analyses, Heinrich Imhof’s regional analyse of the emigration of the town Wittgenstein (North Rhine-Westphalia, Germany) to North America (18th–19th centuries) foregrounds household economies, local hardship, and the practical organisation of departures, adding fine-grained evidence on decision-making and trajectories from a micro-regional perspective [33].
Within this broader framework, Bremen has attracted sustained attention as a port of embarkation and administrative hub of migration control. Regional studies from the 1920s, such as W. Ehlers’ Bremen als Auswandererhafen (1924), already highlighted the city’s national significance [1,2]. Subsequently, P. Marschalck [3] produced a seminal inventory of sources on emigration via Bremen and Bremerhaven (State Archive, Chamber of Commerce, North German Lloyd), underpinning later regional and quantitative work Inventar der Quellen zur Geschichte der Wanderungen, besonders der Auswanderung, in Bremer Archiven (1986). Since the 1970s, genealogical and social-historical approaches have deepened the field; the MAUS society’s digital database passagierlisten.de [7] provides open access to Bremen passenger lists (1830–1939) and has enabled large-scale analyses. Recent studies using these data—e.g. Lumpe & Lumpe (2017)—identify gendered differences in occupational skill profiles and validate the representativeness of the lists vis-à-vis official statistics [8]. Collectively, these works position Bremen as one of Europe’s most thoroughly documented emigration ports and a key locus for historically and demographically informed migration research. Thus, our attempt to develop and provide a post-processed version of the MAUS dataset follows Lumpe and Lumpe’s approach and aims to enable computational analyses on a larger dataset.
2.2. Overview of European and German Migration History in the 19th and 20th Centuries
When dealing with data providing insight into historical migration patterns, one should first define the abundant term migration. According to Oltmer[9], migration refers to changes in residence that bring about lasting transformations in the lives of the individuals involved. Moreover, such movements influence the social structures and cultural configurations of both origin and destination societies[16]. Migration and migration studies, therefore, possess a strong societal, cultural, political, economic, and historical dimension. Migration involving permanent changes of residence can occur within a country (internal migration) or across national borders (international migration). Only in the case of international movements, it is appropriate to speak of emigration and immigration[1].
Emigration — and the immigration it necessarily implies elsewhere [10] — has been defined in both older and more recent scholarly literature as a permanent cross-border change of residence[9,11]. Such movements are typically driven by push factors in the country of origin and pull factors in the destination [8,10]. A further distinction can be made between overland and overseas emigration[1,12].
Research on 19th- and 20th-century European emigration indicates that overseas migration significantly outweighed overland migration in quantitative terms[9]. Between 1850 and 1920 alone, approximately 55 million Europeans left the continent by sea. This transatlantic mass emigration was largely a result of the growing disparity between population growth and the limited availability of economic opportunities. Europe’s population increased rapidly from 187 million in 1800 to 468 million by 1913[9]. The resulting lack of employment opportunities acted as a push factor. The existing desire to emigrate was further facilitated by the spatial compression brought about by the expansion of the railway network and the introduction of steamships in the second half of the 19th century as they made traveling long distances easier and faster[9]. Additionally, the states actively promoted emigration and steered it into organized channels—whether to relieve pressure on their own country or to establish new markets abroad through the emigrants, thereby stimulating their own economy—at least in theory [1].
In the 19th and early 20th centuries, more precisely until the 1960s, ships represented the only opportunity of transatlantic transport for most of the population. Furthermore, compared to internal migration, overseas migration is more precisely traceable in statistical terms due to the passenger lists kept at ports of departure and arrival[1,9]. To capture emigration statistically, census data have long been used as an additional data source[34].
Five ports in particular emerged as the principal gateways for European emigration. These included Le Havre in northwestern France (from 1820 onward), with its main routes towards the US (especially New York) and Canada, as well as the British port cities of Liverpool and London (from ca. 1815/1820), mainly calling at the ports in the US, Canada, Australia and New Zealand. Liverpool and Le Havre experienced the highest traffic of emigrants roughly between 1830 and 1860[13,14,15]. By contrast, emigration via London had already begun to decline by the 1840s. This was due to the increasing number of emigrants embarking via the port of Liverpool in the 1840s [16] because of its strategically favourable location on the Irish Sea and Atlantic Ocean and its well-developed harbour infrastructure. From the mid-19th century onward, the main centers of overseas emigration gradually shifted to the German port cities of Hamburg and Bremen[17].
Since the 1830s, European emigrants also departed the continent via Bremen and, more specifically, Bremerhaven[2]. The silting of the Weser near Bremen had already rendered it impassable for larger vessels as early as the 17th century, prompting the city of Bremen to take over and lease out the harbor at Vegesack. To accommodate the growing number of emigrants, however, ’Bremer-Haven’ was founded in 1827 at the mouth of the Geeste River[6], literally as a haven. By 1832, around 10,000 Europeans — most of whom had awaited embarkation in Bremen — left the continent via Bremerhaven. The founding of the North German Lloyd (Norddeutscher Lloyd) in 1857 subsequently established Bremen/Bremerhaven as the most important German port for transoceanic emigration. During the peak years prior to World War I—specifically in 1906, 1907, and 1913—more than 200,000 emigrants per year departed from this port [2,16,18]. Following World War I and the substantial reduction of the German merchant fleet, overseas emigration via German ports did not regain momentum until the 1920s[1]. However, the high pre-war levels of passenger traffic through Bremen/Bremerhaven were never fully reached again [2]. On this point, however, researchers take different positions: On the one hand, some scholars such as Hofmeister refer to Bremen/Bremerhaven as "[...] wohl der wichtigste Auswandererhafen des Kontinents [...]" (’arguably the most important emigration port on the continent’) [2] up until 1960. On the other hand, the number of emigrants recorded at both ports reveal that, from 1932 on, Hamburg gradually began to surpass Bremen[1,8]: between 1913 and 1936, a total of 724,854 emigrants departed via Hamburg, compared to 677,438 via Bremen [1]. The main shipping routes from Bremen included the United States, which was the destination of most German emigrants, followed by Brazil, Argentina, and Canada [1].
German emigration from 1800 to the mid-20th century occurred in several phases, significantly influenced by economic and political developments in both countries of origin and destination[1].
During the three emigration waves until the First World War, speaking between 1816 and 1914, approximately 5.5 million Germans emigrated overseas — sometimes entire village communities[9]. The primary destination, accounting for roughly 90% of all emigrants, was the United States[19]. The first wave of emigration (1846–1857) was closely linked to the liberal movements of the mid-19th century and the failed 1848 revolution (the Forty-Eighters)[20]. Regarding the scale of emigrants and the problematic conditions they were facing—such as poor hygiene aboard ships, inadequate provisions during the voyage, and exploitation by unscrupulous emigration agents—governmental efforts to regulate and protect emigrants began as early as the 1830s [1]. Bremen issued the first regulation on October 1st 1832, the "Verordnung wegen der Auswanderer mit hiesigen oder fremden Schiffen" (‘Regulation concerning emigrants traveling on local or foreign ships’), which, among other provisions, mandated the keeping of passenger lists [7]. Five years later, in 1837, Hamburg also adopted a regulation for the protection of emigrants [20]. Moreover, on 22 March 1849, the German National Assembly submitted a legislative proposal (§ 136) guaranteeing freedom of emigration and putting emigrants under the protection and care of the Reich. However, this law never came into legal force.
The legal situation changed two decades later. Beginning in 1868, the right to emigrate to non-German countries was governed by the Freedom of Movement Act and the Passport Act of the North German Confederation, though restrictions could apply to men subject to compulsory military service [20]. During this period—marked by the political transition surrounding the foundation of the German Imperium (Deutsches Kaiserreich) in 1871—the second wave of emigration (1864–1873) took place, during which approximately 3 million Germans left their home for overseas destinations. Article 4, Paragraph 1 of the Imperial Constitution affirmed that the regulation of emigration and emigration legislation fell within the jurisdiction of the federal government [20,21]. Article 59 further addressed the emigration of military reservists and militia members [21].
The third wave of German emigration can be identified for the period between 1880 and 1893, where around 1.8 million Germans emigrated, again primarily to the United States [1,18]. This wave was increasingly shaped by restrictive U.S. immigration legislation. On 3 August 1882, in response to mass immigration from Europe and Asia, the United States passed an Immigration Act. In addition to the specific Chinese Exclusion Act, this legislation prohibited certain groups—regardless of nationality—from immigrating to the United States, including convicts and illiterate individuals [22]. Indeed, such destination-country legislation had a more significant impact on German emigration than did German laws themselves. The Imperial Law of 9 June 1897 finally established comprehensive protections for emigrants and sought to regulate emigration at the state level, particularly to safeguard the domestic labor market[1,19,20].
After 1897, the number of German emigrants stagnated and remained relatively constant until the First World War. For this two-decade period, Mönckmeier no longer referred to ’German emigration’ per se, but instead described a "movement of the international labor market" (Mönckmeier, 1912, as cited in Bickelmann, 1980[1]).
During the First World War, public sentiment in the United States—previously the main destination of the so-called New Immigration Wave—turned increasingly hostile toward immigrants. Subsequent Immigration Acts introduced literacy as a core requirement for admission[22]. Additionally, legislation such as the Sedition Act, Espionage Act, and Trading with the Enemy Act (1917–1918) specifically targeted German immigrants, who were perceived as "agents of the German enemy" [22].
Although German emigration to overseas destinations resumed gradually following the war — marking the first emigration phase of the 20th century (1919–1923)[1] — it was significantly curtailed by stringent U.S. immigration policies. Bickelmann notes that the "Auswanderungsfieber" (‘emigration fever’)[1] of the 19th century was rekindled, but that a growing discrepancy emerged between the desire to emigrate and actual opportunities for immigration[1]. In response to U.S. immigration restrictions, the Weimar Republic began directing emigration efforts toward other countries, especially in South America[1]. Generally, the Weimar Constitution of 11 August 1919 enshrined the right to emigrate as a fundamental right [22]. In 1921, German and global emigration levels returned to pre-war levels, prompting the U.S. to indirectly implement a quota system. The Emergency Quota Act (also known as the Johnson Quota Act), enacted on 19 May 1921, limited immigration to 3% of each nationality’s representation in the 1910 U.S. Census. Nevertheless, German emigration peaked in 1923, with approximately 115,431 Germans emigrating overseas that year [1]. Just three years later, a new Immigration Act (1924) reduced this quota to 2% of the ’foreign born’ population recorded in the 1910 census [22].
During the second German emigration wave of 1924–1930, emigration initially declined sharply but then stabilised between 50,000 and 60,000 emigrants per year between 1925 and 1929, before gradually decreasing again after 1929 [1].
In contrast, the third phase of German emigration (1931–1939) was marked by a drastic decline in emigration numbers [1]. Unlike during the Imperial period, emigrants from 1931 onward were subjected to a so-called Reichsfluchtsteuer (‘Reich Flight Tax’) imposed under the emergency decree of 8 December 1931 [20]. Moreover, the Nazi regime increasingly restricted emigration, particularly for demographic policy reasons, so that from 1931 onward, German emigration nearly came to a standstill [1,20]. By 1932, the number of emigrants had already fallen to one-third of the 1930 level [1]. Beginning in 1933, a growing proportion of emigrants were Jewish citizens whose emigration was initially facilitated by the Nazi regime due to its racist ideology — until emigration was outright prohibited for the Jewish population in 1941[1,20]. In the immediate years (1938–1939) preceding the Second World War, a slight increase in German overseas emigration was again observable[1], before it ceased entirely with the onset of the war in 1939.
3. The Passenger Lists of Bremen Port: Archival Material and Structure
The passenger lists of Bremen were mandated by the law enacted for the protection of emigrants: the Regulation Concerning Emigrants on Local or Foreign Ships, issued on 1 October 1832 by the Free Hanseatic City of Bremen[7], which was superseded in 1897 by a nationwide german regulation law. This measure aligned with U.S. immigration legislation, which had required passenger arrival lists since as early as 1820[8]. Through these passenger lists, information about the voyages and passengers was requested and recorded.
Ship captains were required to submit a complete passenger list of all passengers on board to the "Nachweisungsbureau für Auswanderer" (’Emigrants’ Registration Office’), established by the Bremen Chamber of Commerce in 1851[7]. In addition, "four copies of each emigration list had to be compiled by the shipping companies itself, in Bremen predominantly the Norddeutsche Lloyd (NDL), or by agencies who attracted emigrants for a commission"[8].
The majority of the surviving Bremen passenger lists—approximately 95%—are currently held in the archive of the Bremen Chamber of Commerce. However, the extant collection no longer covers the entire period during which the lists were compiled (1832–1939).
In 1875, an official directive mandated the destruction of all existing, current, and future passenger lists due to limitations in storage capacity. Only the records from the most recent three years were to be preserved. This policy was implemented and maintained until 1907. Additionally, passenger lists from October 1905 onward were destroyed during an air raid in the Second World War in 1944 [7,8].
As a result, only a fraction of the original records from the 19th and early 20th centuries has survived, meaning the remaining Bremen passenger lists are no longer representative of the first three major waves of German overseas emigration.
The extant collection in the Bremen Chamber of Commerce archive consists primarily of lists from the period 1920 to 1932. According to Lumpe and Lumpe, approximately 67% of the lists from this period—3,017 of an original total of more than 4,500—have been preserved [7,8]. However, the documentation is also incomplete for this period, as many lists that were stored in the Soviet Union after the Second World War were not returned to the archive. Notably, the records for the years 1924 and 1929 are particularly incomplete[8].
Each passenger list referred to one specific crossing with a specific ship on a specific date and had a fixed port of departure and arrival (See Figure 2. Depending on the number of travelers, it consisted of several sheets, each of which offered space for 30 or 31 entries. The sheets measured 47 x 36 cm and were numbered by hand consecutively in the bottom right-hand corner and usually also in the top quarter. The different travel classes were always listed on separate sheets and also noted on the sheets by hand [7].
The header contained information about the date of the voyage, the ship, the port of departure, the port of arrival, the stage-ports, the travel agency and the class of travel. Below, the lists were organised in a tabular structure: the rows contained the passengers numbered in ascending order. The columns contained 12 categories, each with instructions for filling in the information:
- surname and forename: free text
- gender: choice (male - female)
- age: three columns (over ten: fill in the age in numbers; 1-10; babies)
- discharge certificate (For German men up to the age of 25: has the discharge certificate (from military service) been submitted?): fill in as yes or no
- marital status: free text
- place of living hitherto: free text
- nationality: free text
- state or province: free text
- occupation hitherto: free text
- occupational position hitherto: free text
- destination (place and state): free text
Moreover, two types of passenger lists were in circulation, and both underwent changes over the course of the period from 1830 to 1939. As a result, not all data categories were consistently recorded. First, it was only in 1924 that a clear legal definition was established in Germany specifying who qualified as an emigrant[8]. Second, some categories were added at a later stage: the ethnic affiliation (from 1935 onward) and religious affiliation (from 1937 onward) of passengers were not collected until the mid-1930s.
4. Data Description
4.1. The Primary Dataset by the MAUS
Motivated by genealogical research interests, the digitisation of passenger lists commenced in 1999. From July 1999 onward, the data was recorded by manual transcription. A team of family researchers — organised by MAUS (Society for Family Research e.V., Bremen) in cooperation with the Bremen Chamber of Commerce — compiled a database containing 735,545 records. Transcribing and entering the data was not strictly done verbatim, but according to guidelines published online [7]. Accordingly, this paper details only how the original categories were mapped to the MAUS database. First, the column with information on stage-ports throughout the journey and the column to check male passenger’s military discharge certificates were omitted from the database. Furthermore, the occupation, gender, and age fields — originally divided into sub-columns — were consolidated (e.g. profession and position were merged into a single column) Finally, six meta-columns were added by MAUS to enhance the usability of the dataset.
Generally, the data can be categorised into three types of information:
- 1.
- Metadata: Contextual fields added during or after the transcription stage in order to manage, organize, or trace provenance. These columns help document and structure the dataset.
- 2.
- Passenger information: Person-level attributes such as name, age, gender, and nationality, along with other demographic details. These data enable research on migration trends and the social, cultural, and economic backgrounds of passengers.
- 3.
- Voyage details: Voyage-specific information such as departure date, ship name, and ports involved. These data support analyses of shipping routes and link temporal and geographical information to migration patterns.
In total, the primary dataset by MAUS is made up of 40 columns. More details on the structure of the MAUS dataset can be found in Table 1: all columns without _cleaned are part of the MAUS database.
Regarding representativeness, Lumpe & Lumpe note that “the MAUS-dataset is—compared with official statistics—overall representative in terms of gender (except for 1920), marital status (except for 1920 and 1921), and age, as well as in terms of destination countries, origin provinces in the German Reich, and economic sectors”[8]. This assessment holds only within the limitations of the surviving source material: since the lists for the 19th century up to 1904 have largely been lost (see Chapter 2), the database contains very few entries for this period (which does not imply that no emigration via Bremen occurred at the time). The same caveat applies to the years 1924 and 1929, for which only a limited number of lists have been preserved, resulting in correspondingly few entries in the MAUS database[2].. Nach dem sehr guten, aber auch sehr langen, historischen Exkurs
4.2. Processing
To preserve the integrity and traceability of the primary dataset, all original values were retained without modification during processing. Data cleaning and standardisation were implemented by appending additional columns containing cleaned and harmonised versions of the original fields, thereby clearly distinguishing between primary (original) and secondary (processed) data.
Table 1 and Table 2 provide an overview of the structure of the processed dataset (name_here.csv). Table 1 lists all columns, specifies their data types, and provides a brief description of each column’s content. Using the departure date as a temporal reference, the time span covered by the entries in each cleaned column is reported in the ‘Explanation’ column. Table 2 summarieses data coverage and value distributions for each column in the processed dataset. For every field, the table reports the total number of observations, the number and proportion of distinct unambiguous values, the number and proportion of ambiguous entries, and the proportion of missing values. The original data were neither standardised nor error-free; they contained divergent spellings, typographical mistakes, and heterogeneous formats. As shown in Table 2,the normalisation of such irregularities generally led to a reduction in the number of distinct values per column, as orthographic variants and typographical errors were consolidated into standardised representations. The methodologies applied during processing are described in detail in the Methods section.
Not all columns were subjected to normalisation or cleaning. The metadata columns (id, archiv_ident, remark, and pdf) were left unchanged, as they serve to identify entries in the dataset, link them to the corresponding analogue lists in the Bremen State Archive, and provide contextual information. Preserving these values in their original form ensures traceability and consistency across the dataset. For certain person-related fields such as first_name, last_name, or captain, normalisation was not undertaken because the original spelling of personal names could not be reliably verified. Moreover, for some variables, cleaning would not have yielded substantial additional analytical value. In other cases, the high number of distinct and often ambiguous entries would have rendered systematic post-processing prohibitively resource-intensive. This applies in particular to the previous_residence and emigration_destination columns, which were therefore not normalised.
Beyond these column-specific decisions about cleaning and normalisation, it is also important to characterise the temporal coverage and overall completeness of the dataset. Figure 3 presents the annual number of entries based on the date_of_departure_cleaned column from 1830 on wards. While the database contains several hundred entries for the period 1830–1860, the overwhelming majority of records stem from passenger lists dating from 1907 to 1939. The lower number of entries for the nineteenth century does not point to an actual drop in emigration; it results from archival loss, since passenger lists for 1875–1907 were destroyed and are missing from the database.
The dataset also exhibits substantial variation in completeness across variables. Some core fields (such as id, date_of_departure, or last_name) are populated for nearly all entries, whereas more detailed socio-economic or biographical variables (e.g. occupation, amount_of_money, or previous_US_stay) contain large proportions of missing values. To visualise this pattern at the level of individual cells, Figure 4 displays a missing-data matrix for the entire dataset, with blue cells indicating valid entries and white cells representing empty values.
Unless otherwise noted, all processing steps, summaries, and figures in the upcoming sections are based on the complete set of passengers who departed via Bremen as recorded in the primary database, irrespective of nationality. No filter restricting the sample to German nationals was applied (German nationals constitute approx. 41.57% according to nationality_cleaned). For each column, calculations use all records with non-missing values for that field, so denominators may vary by column depending on data availability.
4.3. Metadata
The primary passenger list database contains the following meta-columns:
- Id: Assigns a unique ID to all entries in the database.
- archiv_ident: Contains the archival signature of the corresponding list.
- notes: Provides space for notes on duplicate passengers.
- pdf: Holds dates of departure for some voyages.
None of these columns were normalised during processing because these data were not transcribed from analog source material but were added by MAUS to enhance the dataset’s usability.
4.4. Data About the Passengers
This data category contains information on the individuals recorded on each passenger list. Processing was performed for the columns listed below. We decided to focus on these columns as they are essential for analytic purposes on an individual passenger level.
-
age; age_cleaned:In the primary dataset, age was typically recorded as an integer. On rare occasions, dates of birth were given instead. Particularly for children, stating their ages in months instead of years was not uncommon. The result of the post-processing are integer age values for 96.8% of passengers. Figure 5 shows the age distribution in the cleaned age field, with the blue line indicating the mean across all valid entries (31.1 years). Figure 6 displays the yearly share of five age groups for the period of 1920-1939. Noticeably, two age groups of passengers 40-59 and 60+ years old gain significantly in their respective shares from 1930 on, indicating a upward shift in the age of passengers.
-
occupation; occupation_cleaned:The occupation column contains short occupational titles that describe the passengers’ professional status and position. The dataset holds normalised job titles for the most frequent 76% of all non-empty entries.
-
occupation_hisco:Provides unique numerical identifier for 93% of cleaned job titles based on the stanardised classification scheme ‚HISCO’[26].
-
occupation_sector:Contains numerical classifiers (0–9) based on the KldB2010 occupational classification scheme developed by the German Federal Employment Agency (’Bundesagentur für Arbeit’)[23]. Classifications were assigned to 91% of the cleaned job titles. Figure 7 summarizes the overall distribution: agriculture and education dominate, each accounting for roughly 30% of classified occupations, followed by production and manufacturing (19.8%) and commercial services (10.8%). Figure 8 traces sectoral affiliation of passengers from 1920 to 1940 in yearly shares. Three broad patterns emerge. First, traditional primary and industrial sectors contract over time: agriculture shows a clear downward trajectory from the early 1920s into the late 1930s, and production/manufacturing also declines steadily across the period. Second, several service and administrative fields expand: education/healthcare rises gradually; company organisation, accounting, law and administration grows from a small base; and commercial services increase modestly from the late 1920s onward. Third, smaller occupational domains remain limited in overall share but gain modest visibility in the mid- to late-1930s: the humanities, media, and arts exhibit brief upward fluctuations; transport and logistics records intermittent increases; the natural sciences rise from a near-zero baseline; and military employment shows a slight uptick at the close of the decade. Taken together, these trajectories suggest a gradual shift in the occupation of passengers away from agrarian and industrial work and toward education, public administration, and other service sectors over the interwar period.
-
occupation_training_level:Contains numerical classifiers (1–4) derived from the KldB2010 occupational classification scheme[23], capturing the typical qualification and task complexity associated with each occupation. Training-level categories were manually assigned to 91% of all non-empty job titles. Figure 9 summarises the distribution of training level classes. Two categories dominate almost equally: technically oriented occupations account for 44.2% of classified occupations, closely followed by helper and semi-skilled labour at 43.5%. More demanding profiles are far less common, with complex specialist activities comprising 7.3% and highly complex tasks 5.0%. Overall, the passenger sample is thus heavily concentrated in occupations requiring basic to intermediate training, while advanced or highly specialised roles remain a small minority. Figure 10 traces the annual shares of training levels from 1920 to 1940. Three main patterns stand out. First, helper and semi-skilled labour declines markedly over time: after occupying a substantial portion of the early 1920s passenger profile, its share falls steadily from the early 1930s onward, reaching only marginal levels in the late 1930s. Second, technically oriented activities move in the opposite direction. Despite fluctuations in the early 1920s, and the late 1930s respectivly, this category expands strongly, indicating a gradual shift toward more formally trained, technical work. Third, higher-qualification occupations increase moderately in this period, with complex specialist activities rising slowly from a low baseline and highly complex task increasing especially toward the late 1930s. These developments suggest an interwar transition among passengers away from low-skilled labour and toward more technical and specialist occupational profiles, with a modest but noticeable expansion of highly qualified roles.
-
gender; gender_cleaned:The gender column initially contained 13 unique and often flawed values. They were normalised to 3 specific values: ’m’ (male), ’w’ (female), ’uneindeutig’ (ambiguous). Figure 11 displays the gender distribution among passengers, with males (53.6%) slightly more represented than females (46.4%).
-
marital_status; marital_status_cleaned:Originally, this column contained 59 distinct values, which were standardised to six categories: ’ledig’ (single), ’verheiratet’ (married), ’geschieden’ (divorced), ’verwitwet’ (widowed), ’getrennt lebend’ (separated), and ’uneindeutig’ (ambiguous). Figure 12 presents the yearly distribution of passengers’ marital status between 1920 and 1940. Single and married passengers together account for the overwhelming majority of cases. Up to the early 1930s, single passengers are consistently more numerous than married ones; thereafter, the distribution shifts in favour of married passengers. This pattern is consistent with an increasing share of established families among emigrants in the years following the Nazi seizure of power. Widowed (3.7% of all passengers), divorced (0.4%), and separated (< 0.1%) individuals occur only rarely in the dataset.
-
religion; religion_cleaned:The religion of passengers was required to be specified from 1937 onward. The primary religion column contained 117 distinct values across 8914 total entries. These values include a large number of inconsistent abbreviations. We applied linguistic normalisation on orthography, expanded abbreviations, and harmonised lexical variants (e.g., ‘Islam’/‘Muslim’) — while keeping labels as close as possible to the original German terminology and without collapsing distinct denominations into broader categories. The normalised religion column holds 27 unique values. Table 3 shows the distribution of values in religion_cleaned. The three most frequent entries are ’mosaisch’ (jewish), ’katholisch’ (catholic) and ’evangelisch’ (protestant).
-
ethnicity; ethnicity_cleaned:The primary ethnicity field contained 350 distinct values indicating ethnic affiliation, including nouns, adjectives, and abbreviations. We standardised these entries to non-abbreviated German adjectives, staying as close as possible to the originals. Historical or obsolete affiliations present in the source were converted to adjectival forms without recoding to contemporary categories (e.g., ‘CSR’ → ‘tschechoslowakisch’, not ‘Czech’ or ‘Slovak’). For compound identifiers (e.g., ‘Deutsch-Russe’ (‘German-Russian’)) and negated forms (e.g., ‘nicht-arisch’ (‘non-Aryan’)), we retained both components and the hyphenation. The ethnicity_cleaned column contains 82 unique values.
-
nationality; nationality_cleaned:The nationality contained orthographic variants and 488 unique values. We standardised the column by de-abbreviating the nationality descriptors, transforming adjectives to nouns and translating english entries to german. The nationality_cleaned column now holds 97 distinct nationalities.
-
state_or_province; state_or_province_cleaned:This column contains information on the country or province of previous residence of the passengers and originally had 1761 distinct entries. After normalisation, the cleaned column holds 956 differing values.
4.5. Data About the Voyage
This data category provides information on the voyage, including, among others, the names of the captain and the ship, the route with its departure and arrival ports and the travel class of passengers. We applied processing on the columns listed below.
-
date_of_departure; date_of_departure_cleaned:In the primary database, this column contained departure dates in various formats including different spellings of month names, two-digit years, and typographical errors. To ensure consistency and ease of use, the dates were standardised to ISO-8601 format (YYYY-MM-DD).
-
port_of_departure; port_of_departure_cleaned:The original column contained 40 distinct entries that state the name of the city in which the port of departure is located. Unsurprisingly, the vast majority of voyages started from the port in Bremen (98.86%). Sometimes the corresponding country was also entered. After processing, the column port_of_departure_cleaned now contains 17 distinct entries.In order to standardize the data and improve the usability of the data, we added three more columns:
-
port_of_departure_country:Contains the country in which the port of departure is located. For entries where this was not specified, we added it.
-
port_of_departure_LAT and port_of_departure_LON:These columns record the latitude and longitude of the cities of the departure ports in decimal degrees, georeferencing each record.
-
port_of_arrival; port_of_arrival_cleaned:The port of destination column (port_of_arrival) contained 338 distinct entries in the primary database, consisting of the name of the port and partly the country. As the entries contained orthographical mistakes and spelling variants, we used a matching-based process in order to merge these to 289 distinct entries in the column port_of_arrival_cleaned. In order to standardise the data and improve its usability, we added four more columns:
-
port_of_arrival_LAT; port_of_arrival_LON:These columns contain longitude and latitude geodata. Thus they enable map-based visualisations, e.g. Figure 13 , which shows the most frequent arrival ports plotted on a digitised historical map depicting the shipping routes of the Lloyd shipping company Bremen. The map was created by Paul Langhans and produced by Justus Perthes’ Geografische Anstalt in Gotha in the first decade of the 20th century. Georeferencing was performed in QGIS, an open-source geographic information system.
-
port_of_arrival_country:States the country in which the port of arrival is located. In some cases, the country of the arrival port was already provided in the primary database. We separated coun try and port city in these cases; if not given, we added the country information manually.
-
port_of_arrival_US_state:We also enriched the port data with information on the US-State of arrival, if the port was located in the United States. The majority (about 80%) of the passengers arrived at US-based ports, with more than 75% of them landing at the port of New York. The remaining entries indicate other arrival ports in South America, Canada, and Europe.
-
ship; ship_cleaned:The column ship in the primary database contained 519 distinct entries, including name variants of ships due to spelling mistakes. By correcting erroneous orthography, we merged the variants to 512 distinct entries in the column.ship_cleaned.
-
travel_class; travel_class_cleaned:In the primary database, the travel class was stated in 145 variants, e.g. ‘Klasse 2’, ‘2, Klasse’, ‘II. Klasse’, all meaning ‘2. Klasse’. By post-processing the column, we merged the variants to 16 distinct values, taking into account historical designations (see section 5.1.5.).
5. Methods
5.1. Data Processing
5.1.1. General Workflow
We primarily used a workflow based on a string matching algorithm to clean and standardize the primary dataset. The procedure consisted of three core steps:
- 1.
- Extraction of Unique Values: For each target column, all unique values were first extracted from the original dataset to create a list of distinct entries.
- 2.
- Manual Orthographic Normalisation: Each unique entry in this extracted list was manually reviewed and corrected to merge spelling variants into standardised forms, remove extraneous whitespace, correct typographical errors and clearly mark ambiguous or missing entries according to the project guidelines.
- 3.
- Matching and Column Augmentation: The normalised values were then matched back to their original occurrences in the dataset. To preserve data integrity and traceability, original data was not overwritten. Rather, new columns were added to store these cleaned, standardised versions alongside the original entries.
In cases where additional contextual information or normative data (such as geographic coordinates or standardised occupation identifiers) were beneficial, this information was appended using the same matching approach. For certain data columns, recurring and systematic errors required additional automated cleaning using regular expressions, or other specialised workflows and methodologies that go beyond matching-based cleaning, which will be detailed in this section.
5.1.2. Date Fields
Originally, departure dates were usually given in the form of ’dd. Month yy(yy)’. The month was usually written out in full or given as an abbreviation (e.g. ’January’ or ’Jan’). Sometimes mistakes in the spelling of months, or flaws in its transcription occur. A mapping dictionary was used to unify different representations of months to numerical values (’January’:’01’). The year was stated in full for all entries of the 19th century, while just the last two digits were given for entries from the 20th century. We therefore added the leading digits ’19’ to all such two-digit years and transformed the date format to the ISO standard of ’yyyy-mm-dd’.
The cleaned departure dates were used as a reference point in time, in order to convert birth dates stated in the age column to actual numerical age values. An exemplary passenger boarding a ship on 23.08.1939 provided his birth date, 15.11.1878, instead of the actual age. The departure date is used as a temporal reference, therefore it is possible to conclude the passenger was 60 years old at the time of departure. The age of children was regularly stated in months, or as a mix of years and months (e.g. ’1 Jahr 5 Monate’, ’18 Monate’). Using regular expressions, we converted cases like this into years. Noticeable individual cases in the age calculation were checked manually.
5.1.3. Occupation Fields
The occupational titles were semi-manually normalised: basic clean-up was carried out using regular expressions to correct reoccurring errors in orthography, as well as to split the occupation and the education level titles (e.g. splitting ’Maurermeister’ into ’Maurer’ and ’Meister’). We also resolved common abbreviations like ’Angeh.’(’Angehörig’), or ’Angest.’ (’Angestellt’), provided these could be clearly resolved. These steps were performed for the most frequent 76% of all occurring job titles. We chose this cut to be able to compile a reliable dataset that nevertheless allows for quantitative analysis. We manually matched the titles to their corresponding identifiers from the HISCO [26] occupational classification scheme. Manual classification was also conducted to annotate sectors and the required training level based on the job titles (see section 2.3). However, there were some special cases:
(1) Entries that do not refer to professions in the narrower sense, including: ’Gattin’, ’Ehefrau’, ’Witwe’, ’Angehöriger’ (wife, spouse, widow, relative). These passengers often stated their (former) husbands job description, combined with an indication of their relationship to the working person, leading to expressions like ’Ehefrau Maurer’, ’Landwirtschaft Gattin’, or ’Kaufmann Angehörig’ on the lists. These cases have been annotated as follows: HISCO ID: -1, as it is not an income-generating profession; sector: the sector of the referenced working person (meaning husband, mother, father) is adopted (0-9); the training level is left empty.
(2) Entries that do not refer to income-generating professions in the narrow sense but have a common sector (9 = education): ’Schüler’, ’Student’, ’Studienassessor’ (Pupil, student, study assessor). In their case, the HISCO ID is -1, as no income is generated, the sector is 9, and the training level is also empty.
(3) Occupations based on standing property (’Privatier’, ’Rentier’ (private individuals or pensioners)). These cases could only be classified by assigning the HISCO ID -1. The sector and education level remain empty, as they cannot be derived from the entries.
(4) Generic job titles not precisely specified (e.g. ’Arbeiter’, ’Hilfsarbeiter’, ’Taglöhner’ (labourer, unskilled worker, day labourer)) were classified as follows: As the HISCO scheme takes such generic job titles into account, the corresponding encodings were adopted from HISCO (e.g. 99900: ’Worker, No Further Information’, 99910: ’Labourer’, 99920: ’Day-Labourer’)[26]. The sector was left empty as these activities are present in various sectors; the training level is specified as 1.
(5) Unclear entries or entries without a clear profession. For these cases, the HISCO ID, sector and training level classifications were all left blank, as no information was available.
(6) Unemployed passengers, for whom we entered -1 for HISCO and left the sector and training level encoding empty.
(7) Occupations with non-explicit abbreviations. We combined the annotation approaches for ambiguous entries (5) and those denoting a non-income-generating ((1), (2)) occupation. If only the first two or three letters were given (’A.G.’ or ’Ang.’), it was no longer possible to distinguish between ’Angehöriger’ (relative) and ’Angestellt’ (employee). Therefore, such ambiguous designations were maintained in the database in the column ’occupation_cleaned’ to prevent falsifying the data. The HISCO ID is left blank as it is unclear whether the entry designates a labour-generating profession or not. The sector is annotated according to the given profession if identifiable, e.g. ’Kaufmann Ang’ is assigned sector 6. The training level is left empty.
This procedure was chosen to prevent the data from being distorted in two directions:
(a) certain occupations would have been overrepresented by specifying the HISCO code of the husband/relative; (b) leaving the values blank would suggest that a correspondingly large number of unemployed people had traveled.
5.1.4. Geographical Information
Furthermore, we have combined the quantitative matching approach with a qualitative manual procedure when dealing with the state_or_province column. The distinct values in this column included numerous abbreviations and spelling variants. After a basic orthographic transformation, the entries were thus checked manually. Toponyms in other languages were translated into German if they could be determined using geographical databases such as GeoNames [25]. Abbreviations were also resolved, e.g. ’Bay’ in ’Bavaria’. If abbreviations were not clear or self-explanatory, the person’s previous place of residence (’previous_residence’) was queried in order to obtain a clue as to which province or state might be referenced. This also helped to avoid over-normalisation: e.g. this comparison made it possible to determine that the abbreviation ’NL’ should be resolved to ’Niederlausitz’ instead of ’Netherlands’. If the places of residence were not in the same area for all entries that had a certain abbreviation under state_or_province, the abbreviation was not resolved. Terms such as ’Kreis’ (district), ’Provinz’ (province) or ’Herzogtum’ (dukedom) have been adopted in order to remain as close as possible to the original data and avoid interpretations. Moreover circa 150 entries in the state or province column did contain misplaced occupation data due to file delimiter issues, those cases were also manually corrected. Georeferencing the ports of departure and arrival was conducted using the Openstreetmap Nominatim API.
5.1.5. Travel Classes
Normalizing the travel_class column was complicated because accommodation categories were not standardised until 1934. In this year, consistent travel classes were enforced by the association of major shipping companies on the North Atlantic route (the Atlantic Conference). This is why it was only from 1934 onward that there were three standardised travel classes: first class (called cabin class since 1936), tourist class and third class. Prior to this, the following travel classes were common from 1900 onwards: First class (’1. Klasse’); Second class (’2. Klasse’); Steerage (’Zwischendeck’), the ‘wooden class’, so to speak, that was used for mass accommodation, preferably by emigrants who wanted to save their money for building their new life in the destination country; Third class (’3. Klasse’), that was introduced in place of the steerage in the early 20th century. However, this was not an abrupt change, but rather a process: steerage and third class existed in parallel on different ships. Finally, the Tourist class (’Touristenklasse’) was introduced in the 1920s as leisure travelers increasingly became the target audience of shipping companies. This class was an intermediate class between the second and third class. However, as the dataset encompasses entries from the 19th and 20th centuries (see Figure 3), the travel class designations were heterogeneously stated. In order to not distort the data, we have not equated the steerage deck (’Zwischendeck’) with 3rd class (’3. Klasse’).
5.1.6. Other Fields
Several structural errors concerning database integrity were also identified and corrected during post-processing throughout the entire database. In some instances, entries in the primary database were misaligned or placed into incorrect columns. While many of these errors likely arose due to inappropriate or inconsistent use of the field separator within data entries, other potential causes could include transcription errors, inadvertent data shifts during earlier processing stages, or anomalies introduced during previous data migrations. Where a misalignment of data was detected, manual corrections were applied.
6. Discussion
The work presented in this data descriptor transforms a heterogeneous, partly error-prone transcription of the Bremen passenger lists into a structured, enriched, and openly accessible research dataset. Building on MAUS’ original compilation of 735,545 records from the Bremen Chamber of Commerce and State Archive, we have cleaned and standardised core fields, added temporal, spatial, and occupational metadata, and documented the underlying processing steps. In practical terms, we have (a) normalized key person-level attributes (age, gender, marital status, nationality, religion, ethnicity and occupation) and voyage-level information (departure dates, ports, travel classes); (b) created geospatial variables by linking ports of departure and arrival to their respective coordinates; (c) mapped the occupational data to established classification schemes (HISCO and KldB2010), including sector and training-level classifications for the majority of non-empty occupation entries. While these standardisation steps required considerable manual and semi-manual effort, they should substantially increase the analytic value of the Bremen passenger list dataset for fields such as historical migration studies, labour history and historical demography.
These gains must be considered in light of several clear limitations. First and most fundamentally, the dataset is constrained by the survival of the underlying sources. As discussed above, large parts of lists from the nineteenth-century were destroyed, and lists from 1875–1907 are entirely missing; further gaps occur in the interwar period, notably for 1924 and 1929. The overwhelming majority of entries comes from the years 1907–1939. The dataset is therefore not representative of German overseas emigration across the entire period from 1830 to 1939, and long-term trend analyses must account for archival loss. Second, many data fields exhibit substantial amounts of empty values. While most core fields such as departure date, ship name, and passenger names are nearly complete, more detailed socio-economic attributes (occupation, literacy, amount of money carried, ethnicity, etc.) are often sparsely populated. Third, cleaning and classification themselves entail interpretive choices and residual uncertainty. Normalising orthography, resolving abbreviations, and mapping historical occupational titles onto contemporary classification schemes manually can introduce subtle biases. Fourth, the categories themselves are historically situated and, in some cases, shaped by discriminatory regimes. Mandating passengers to declare their ethnicity (from 1935 onward) and religion (from 1937 onward) reflects the racialised and antisemitic logic of the Nazi state. Hence, interpreting the data requires engagement with the broader historical, political, and social context discussed in this paper.
The labour-intensive post-processing carried out here also points towards future work on methodological automation. Many of the standardisation tasks we performed – including the harmonisation of spelling variants, the resolution of abbreviations, the inference of missing attributes from contextual information, and the mapping of occupations to controlled vocabularies – could in principal be automated. Developing these workflows for historical migration sources would not only support future extensions of the Bremen dataset, but also provide reusable infrastructure for work with passenger lists and related serial records.
A second avenue for future work concerns linkage and integration with other datasets. Because the Bremen lists capture emigrants at the point of departure, they form a natural bridge to census records, list from the arrival ports or similar data sources. Systematic record linkage could enable researchers to follow individuals beyond the port. Finally, the enriched dataset necessitates ethical reflection. The combination of person-level and contextual information enables analyses of how social composition and family configurations. Yet working with personal data such as ethnicity and religion – especially covering the era around the NS-reign - entails the risk of reinforcing racialised classifications and the coercive administrative regimes that generated them.
Author Contributions
For research articles with several authors, a short paragraph specifying their individual contributions must be provided. The following statements should be used “Conceptualization, M.R.; methodology, M.R. and T.P.; software, T.P. and S.G.; validation, P.S.; investigation, T.P. and P.S.; data curation, T.P., P.S. and S.G.; writing—original draft preparation, T.P. and P.S.; writing—review and editing, T.P., P.S. and M.R.; supervision, M.R.; project administration, T.P. and P.S.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in the study are openly available on Zenodo under Creative Commons Attribution 4.0 International (CC BY 4.0) at [DOI]
Acknowledgments
We would like to thank the MAUS - Gesellschaft für Familienforschung for their agreement to working with their data, especially Karl Wesling.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bickelmann, H. Deutsche Überseeauswanderung in der Weimarer Zeit; Franz Steiner Verlag: Wiesbaden, 1980. [Google Scholar]
- Hofmeister, A. Familiengeschichtliche Quellen zur Auswanderung in Bremer Archiven . In Die MAUS (Gesellschaft für Familienforschung in Bremen);Genealogie und Auswanderung: Über Bremen in die Welt; Papierflieger Verlag: Clausthal-Zellerfeld, Germany, 2002; pp. 29–44. [Google Scholar]
- Marschalck, P. Inventar der Quellen zur Geschichte der Wanderungen, besonders der Auswanderung, in Bremer Archiven; Selbstverlag des Staatsarchivs der Freien Hansestadt Bremen: Bremen, Germany, 1986. [Google Scholar]
- Bade, K. J. Historische Migrationsforschung. Eine autobiographische Perspektive . In Historical Social Research (GESIS); 2018; Volume 30. [Google Scholar]
- Schulte Beerbühl, M.; Rössler, H. Kaufleute und Zuckerbäcker: Zum Verhältnis von Migrations- und Familienforschung am Beispiel der deutschen Englandwanderung des 18. und 19. Jahrhunderts. In Die MAUS (Gesellschaft für Familienforschung in Bremen);Genealogie und Auswanderung: Über Bremen in die Welt; Papierflieger Verlag: Clausthal-Zellerfeld, Germany, 2002; pp. 107–120. [Google Scholar]
- Wesling, K. Über Bremen in die Welt: Die Bremer Passagierlisten 1920–1939 . In Die MAUS (Gesellschaft für Familienforschung in Bremen);Genealogie und Auswanderung: Über Bremen in die Welt; Papierflieger Verlag: Clausthal-Zellerfeld, Germany, 2002; pp. 151–158. [Google Scholar]
- Die Maus (Gesellschaft für Familienforschung in Bremen), Handelskammer Bremen & Staatsarchiv Bremen Bremer Passagierlisten. 2024. Available online: https://passagierlisten.de/ (accessed on 28 April 2025).
- Lumpe, Ch.; Lumpe, C. German emigration via Bremen in the Weimar Republic (1920–1932) . MAGKS Joint Discussion Paper Series in Economics, No. 53-2017, Philipps-University Marburg. 2017. Available online: https://hdl.handle.net/10419/174349 (accessed on 08 June 2025).
- Oltmer, J. Globale Migration: Geschichte und Gegenwart, 3rd ed.; C. H. Beck: München, Germany, 2016. [Google Scholar]
- Gould, J. D. European inter-continental emigration 1815–1914: Pattern and Causes . The Journal of European Economic History 1979, 8(3), 593–679. [Google Scholar]
- Tetzlaff, H. W. Das deutsche Auswanderungswesen . Dissertation, Göttingen, Georg-August University, 1953. [Google Scholar]
- Bade, K. J. Migration in European History; Blackwell: Oxford, 2003. [Google Scholar]
- Nugent, W. Crossings: The Great Transatlantic Migrations, 1870–1914; Indiana University Press: Indiana, 1992. [Google Scholar]
- Hatton, T. J.; Williamson, J. G. The Age of Mass Migration; Oxford University Press: Oxford, England, 1998. [Google Scholar]
- Cohn, R. L. Mass Migration under Sail: European Immigration to the Antebellum United States; Cambridge University Press: Cambridge, England, 2009. [Google Scholar]
- Oltmer, J. Migration im 19. und 20. Jahrhundert; R. Oldenbourg: München, Germany, 2010. [Google Scholar]
- Benscheidt, A.; Kube, A. Brücke nach Übersee: Auswanderung über Bremerhaven 1830–1974; Wirtschaftsverlag N. W: Bremerhaven, 2006. [Google Scholar]
- Bade, K. J. Europa in Bewegung: Migration vom späten 18. Jahrhundert bis zur Gegenwart; C. H. Beck Verlag: München, 2002. [Google Scholar]
- Oltmer, J. Migration steuern und verwalten. Deutschland vom späten 19. Jahrhundert bis zur Gegenwart; Vandenhock & Ruprecht Verlage: Göttingen, Germany, 2003. [Google Scholar]
- Dölemeyer, B. Auswanderung . In Handwörterbuch zur deutschen Rechtsgeschichte, Bd. 1., 2. Lieferung; Cordes, A., Ed.; 2008; pp. Sp. 389–392. [Google Scholar]
- Verfassungen Deutschlands. Deutsches Reich (2018). Verfassungen der Welt. Available online: https://www.verfassungen.de/de67-18/verfassung71-i.htm (accessed on 27 June 2025).
- Wilhelm, C. Auswanderung aus Bayern und Einwanderung in Nordamerika im Spiegel der Gesetze. In Good bye Bayern, Grüß Gott America: Auswanderung aus Bayern nach Amerika seit 1683; Katalogbuch zur Ausstellung; Hamm, M., Henker, M., Brockhoff, E., Eds.; Haus der Bayerischen Geschichte: Augsburg, Germany, 2004. [Google Scholar]
- Bundesagentur für Arbeit. Klassifikation der Berufe (KldB), 2nd ed.; 2020; Available online: https://statistik.arbeitsagentur.de/DE/Navigation/Grundlagen/Klassifikationen/Klassifikation-der-Berufe/KldB2010-Fassung2020/Onlineausgabe-KldB-2010-Fassung2020/Onlineausgabe-KldB-2010-Fassung2020-Nav.html (accessed on 13 March 2025).
- Dahl, C. M.; Johansen, T.; Vedel, C. Breaking the HISCO Barrier: Automatic Occupational Standardisation with OccCANINE . arXiv.org. 2024. Available online: https://arxiv.org/abs/2402.13604 (accessed on 01 April 2025).
- GeoNames. (n.d.). GeoNames. Available online: https://www.geonames.org/ (accessed on 15 May 2025).
- International Institute of Social History (IISG). History of Work (HISCO) . 2002. Available online: https://iisg.amsterdam/en/data/data-websites/history-of-work (accessed on 01 April 2025).
- Imhof, A. E. Einführung in die historische Demographie; Beck: München, Germany, 1977. [Google Scholar]
- Imhof, A. E. Lebenserwartungen in Deutschland vom 17. bis 19. Jahrhundert; VCH - Acta Humaniora: Weinheim, Germany, 1990. [Google Scholar]
- Pfister, C. Bevölkerungsgeschichte und historische Demographie 1500–1800; Oldenbourg: München, Germany, 1994. [Google Scholar]
- Pfister, C. Klimageschichte der Schweiz 1525–1860. Das Klima der Schweiz und seine Bedeutung in der Geschichte von Bevölkerung und Landwirtschaft (mehrbändig); Haupt: Bern, Switzerland, 1984-1988. [Google Scholar]
- Pfister, H. U. Die Auswanderung aus dem Knonauer Amt 1648–1750. Ihr Ausmass, ihre Strukturen und ihre Bedingungen; H. Rohr: Zürich, Switzerland, 1987. [Google Scholar]
- Pfister, H. U. Swiss Migration to America in the 1730s. A Representative Family: The Pfister Family of Höri, Canton Zürich and the Feaster Family in America. Swiss-American Historical Society Review 2003, 39(1), 3–22. [Google Scholar]
- Imhof, H. Hoffnung auf ein besseres Leben. Auswanderer aus Wittgenstein nach Amerika im 18. und 19. Jahrhundert . In Regionales Werk; Heinrich Imhof: Bad Berleburg, Germany, 2018. [Google Scholar]
- Ravenstein, G. The Laws of Migration. Journal of the Statistical Society of London 1885, 48(2), 167–235. [Google Scholar] [CrossRef]
Figure 2.
Digitized passenger list of the ship BREMEN (12 May 1923), Archive Reference Code: AIII15-12.05.1923_N; Image Rights: MAUS
Figure 2.
Digitized passenger list of the ship BREMEN (12 May 1923), Archive Reference Code: AIII15-12.05.1923_N; Image Rights: MAUS
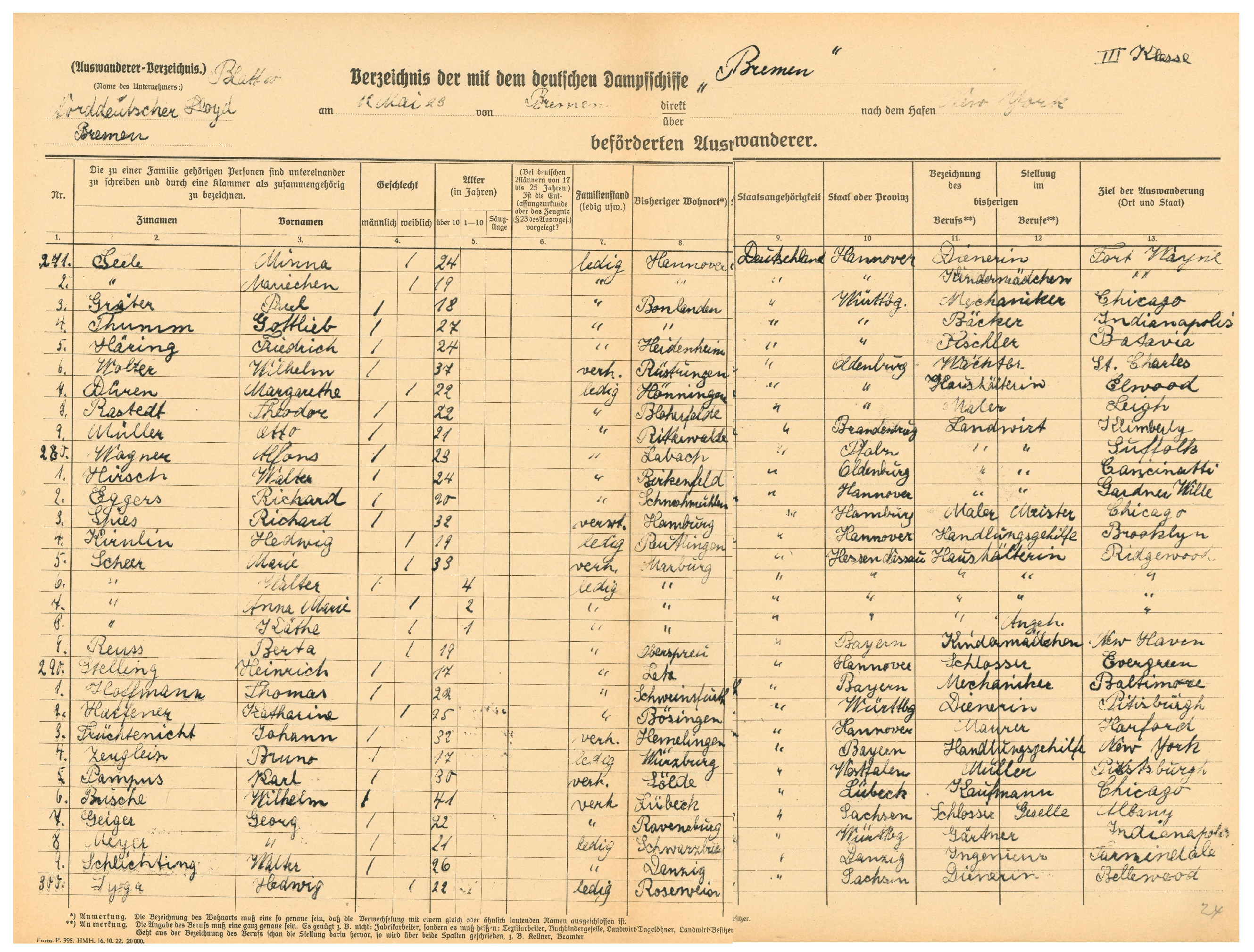
Figure 3.
Annual number of entries based on the date_of_departure column. The pronounced difference in record counts between the nineteenth and twentieth centuries reflects archival loss rather than lower emigration: passenger lists for the years 1875–1907 were destroyed, so no data are available for this period.
Figure 3.
Annual number of entries based on the date_of_departure column. The pronounced difference in record counts between the nineteenth and twentieth centuries reflects archival loss rather than lower emigration: passenger lists for the years 1875–1907 were destroyed, so no data are available for this period.
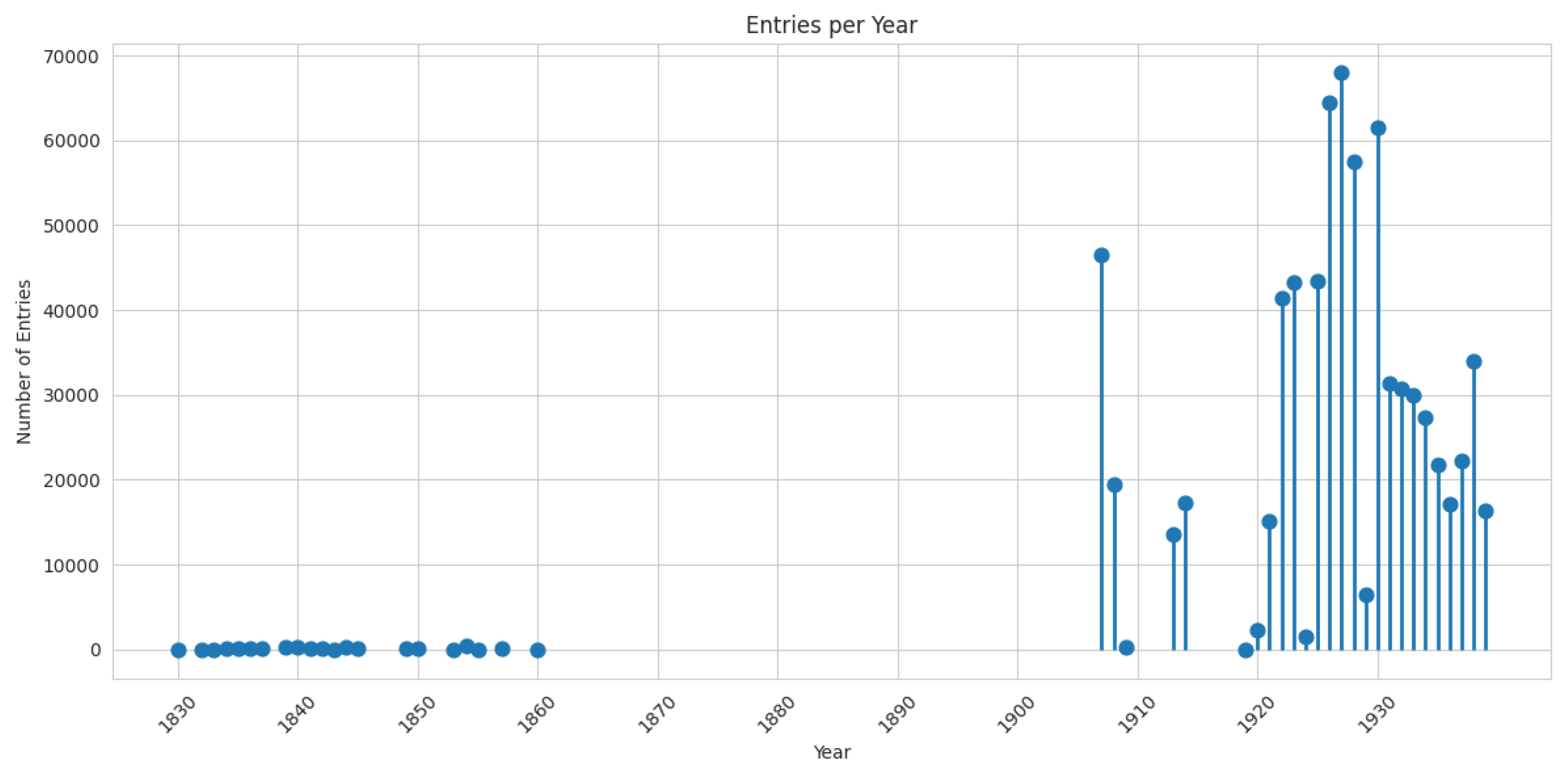
Figure 4.
Missing data matrix. Blue: valid entry values, white: empty data.
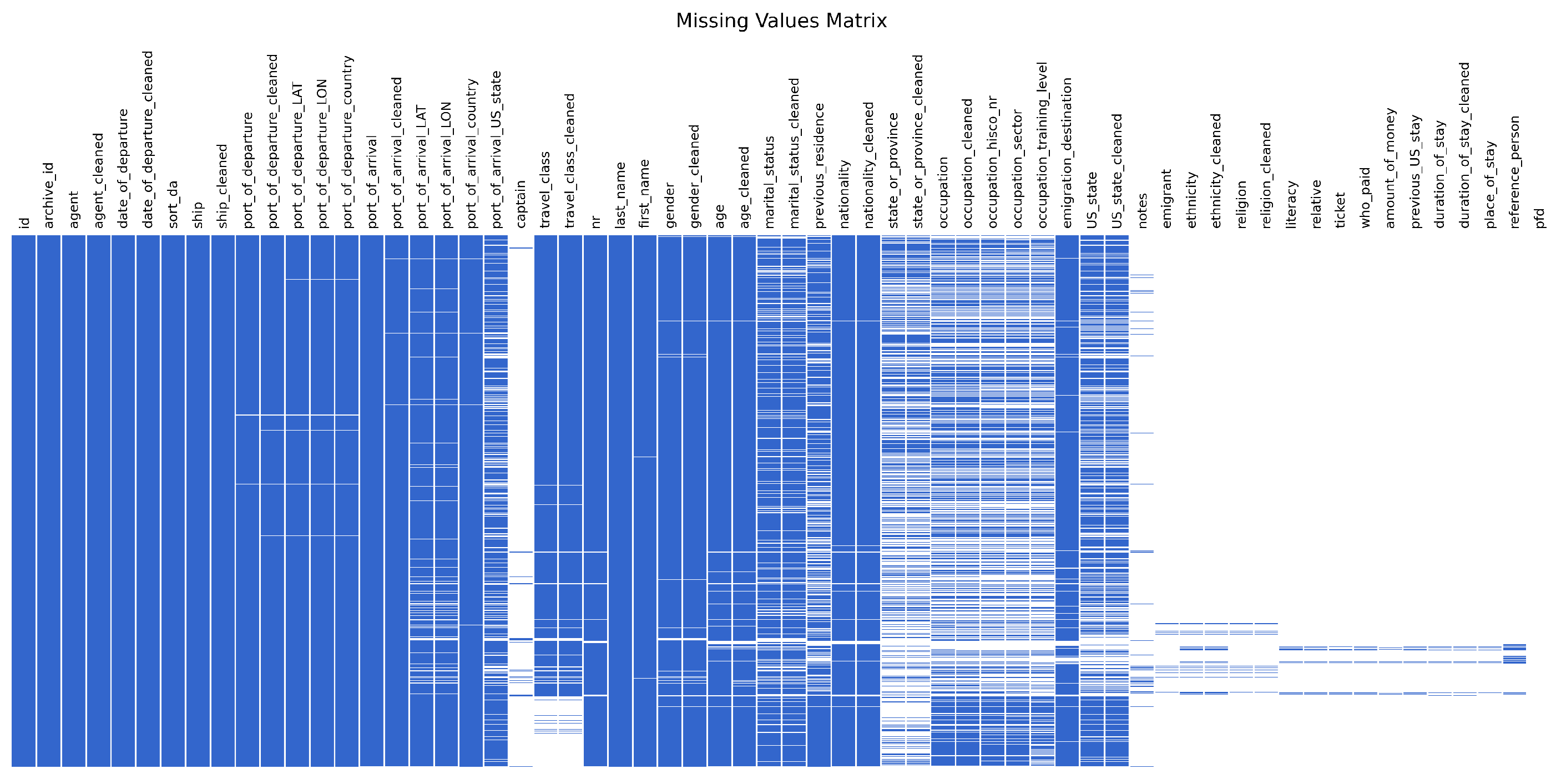
Figure 5.
Total age distribution across all valid entries and mean age (blue line).
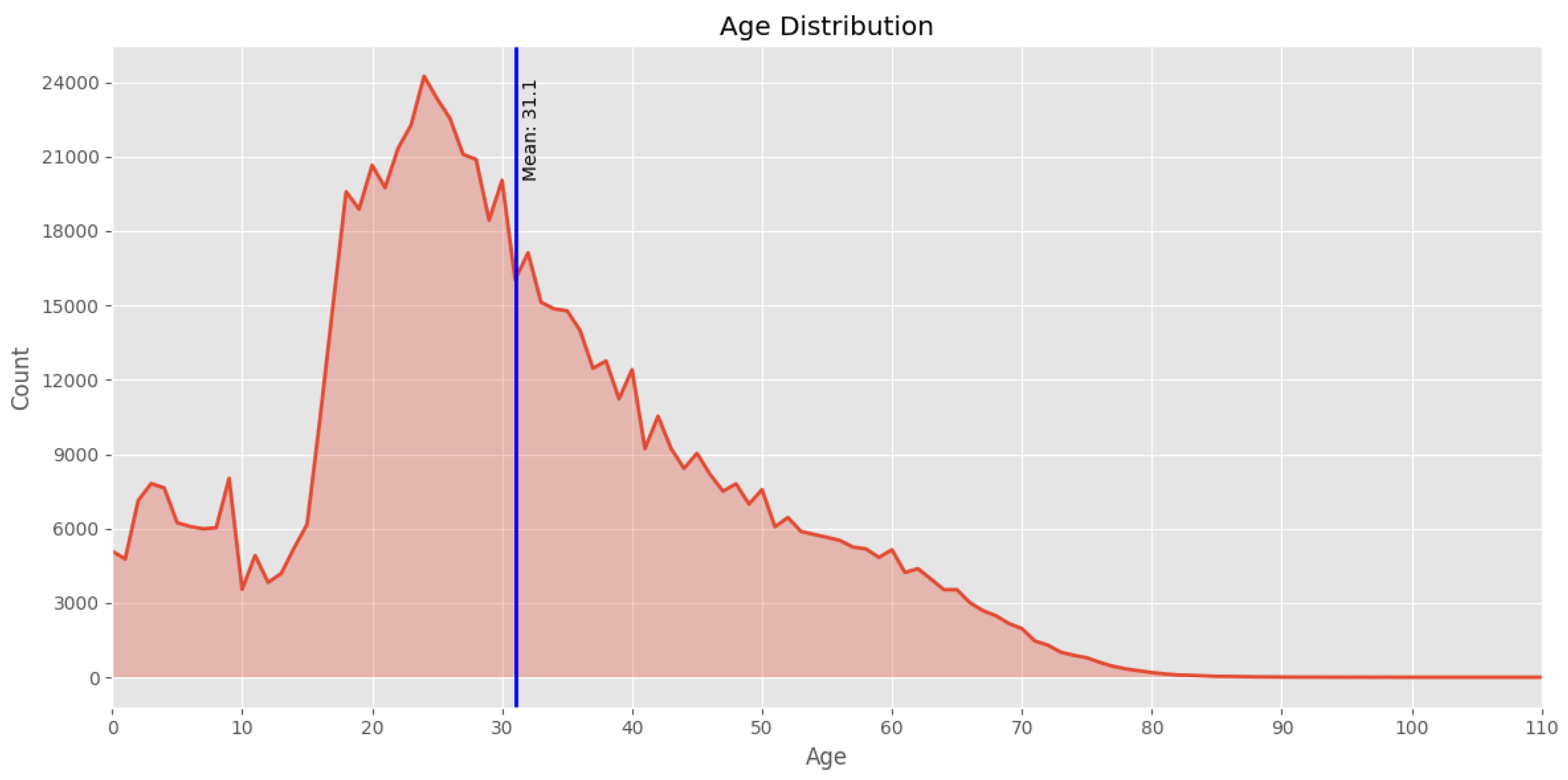
Figure 6.
Relative distribution of age groups between 1920 and 1940).
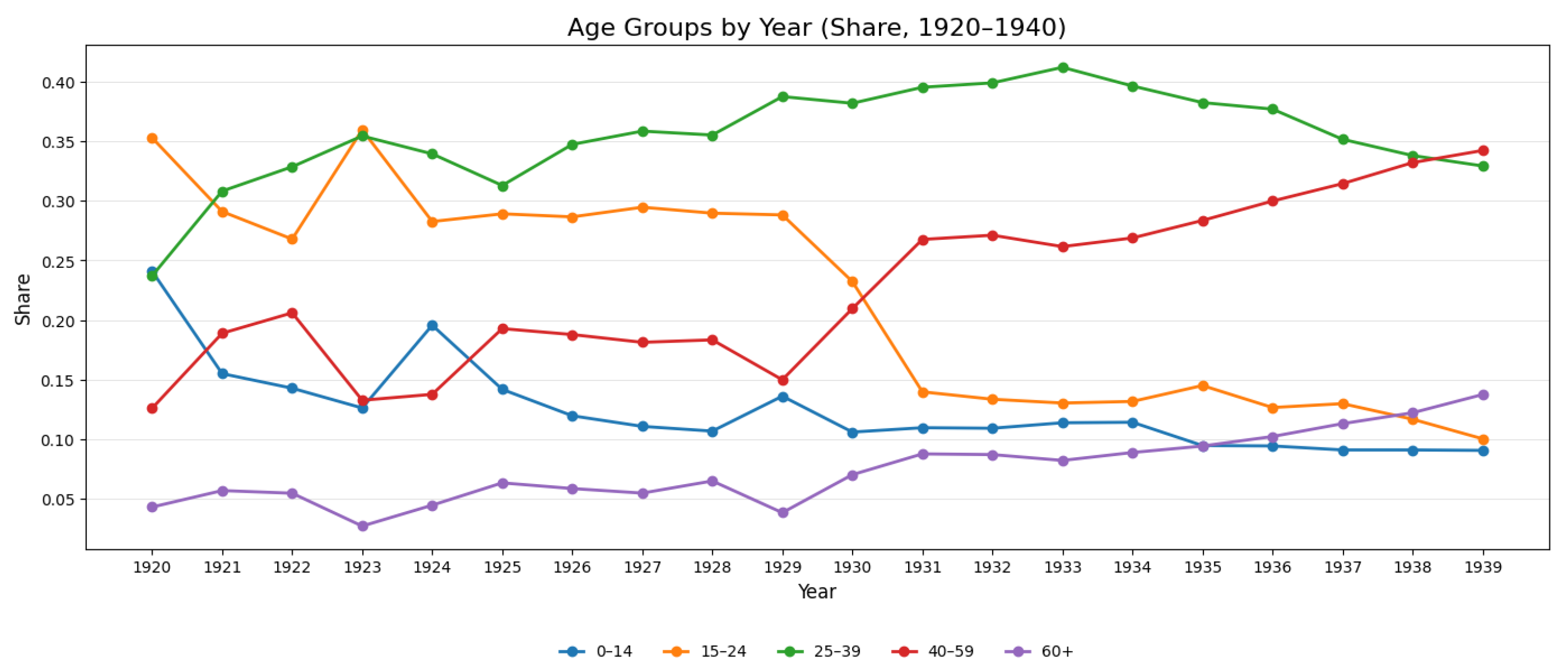
Figure 7.
Distribution of manual occupational sector classification.
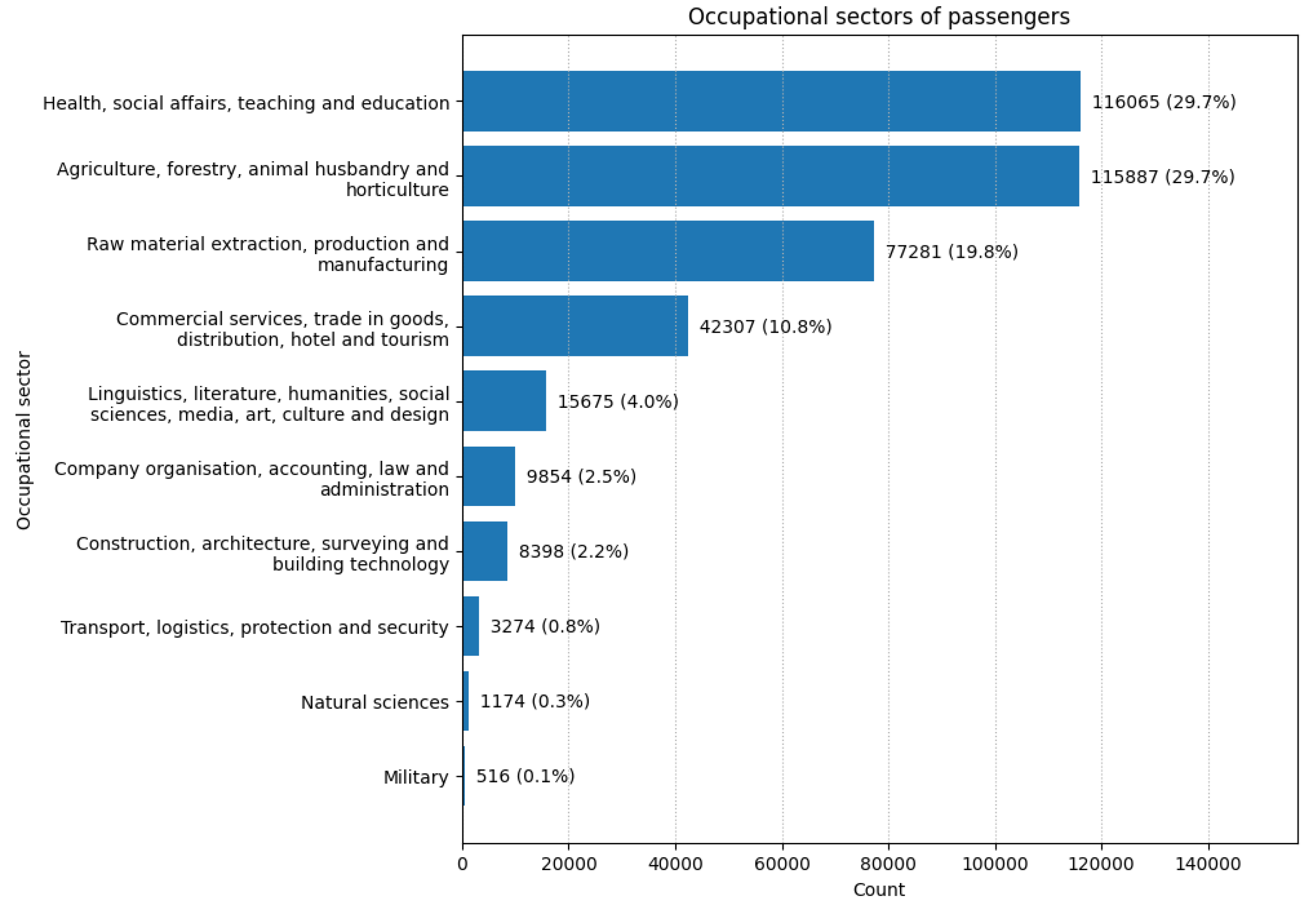
Figure 8.
Relative distribution of manual occupational sector classification over time (1920 - 1940) with trend lines.
Figure 8.
Relative distribution of manual occupational sector classification over time (1920 - 1940) with trend lines.
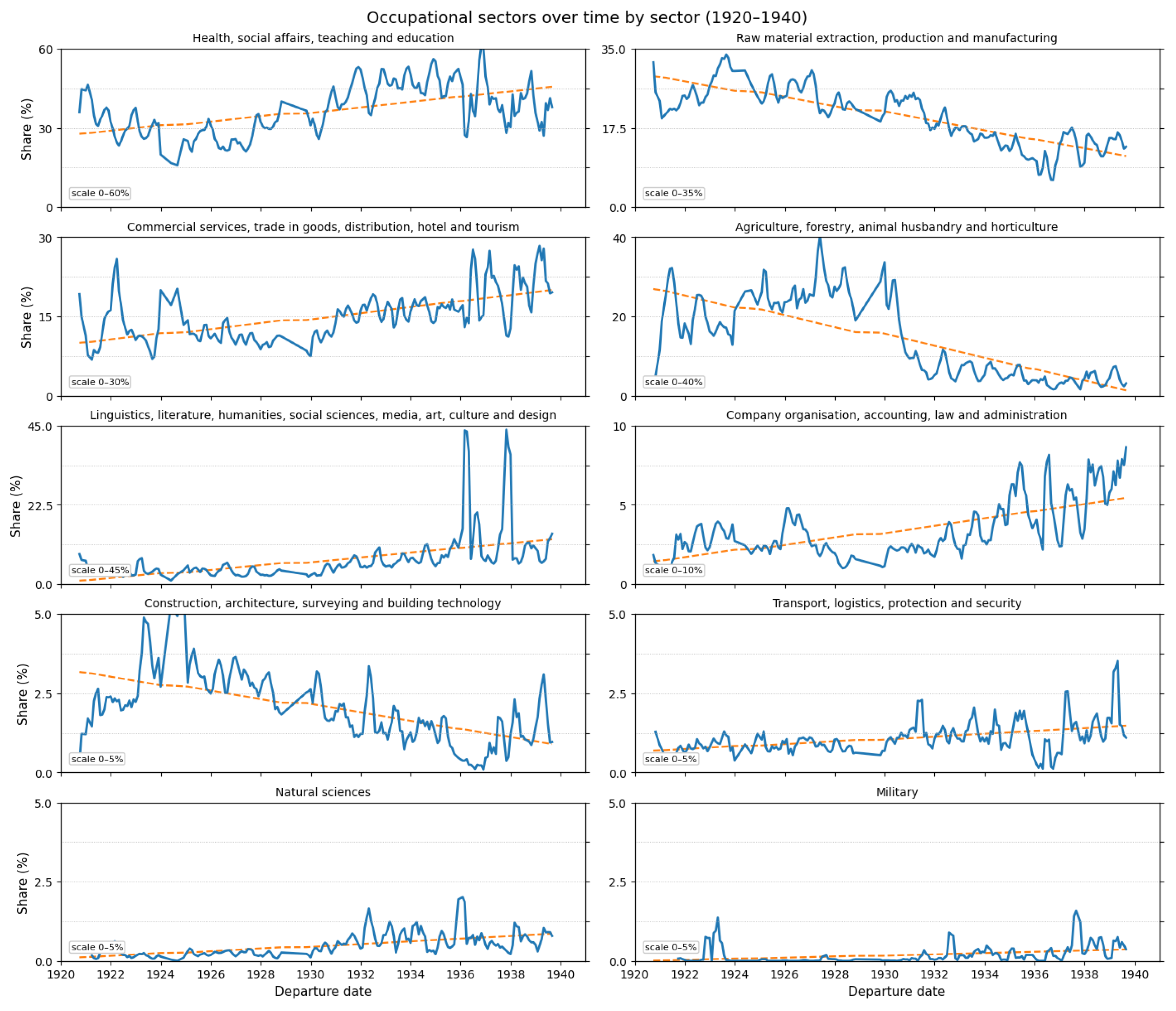
Figure 9.
Distribution of manual training level classification.
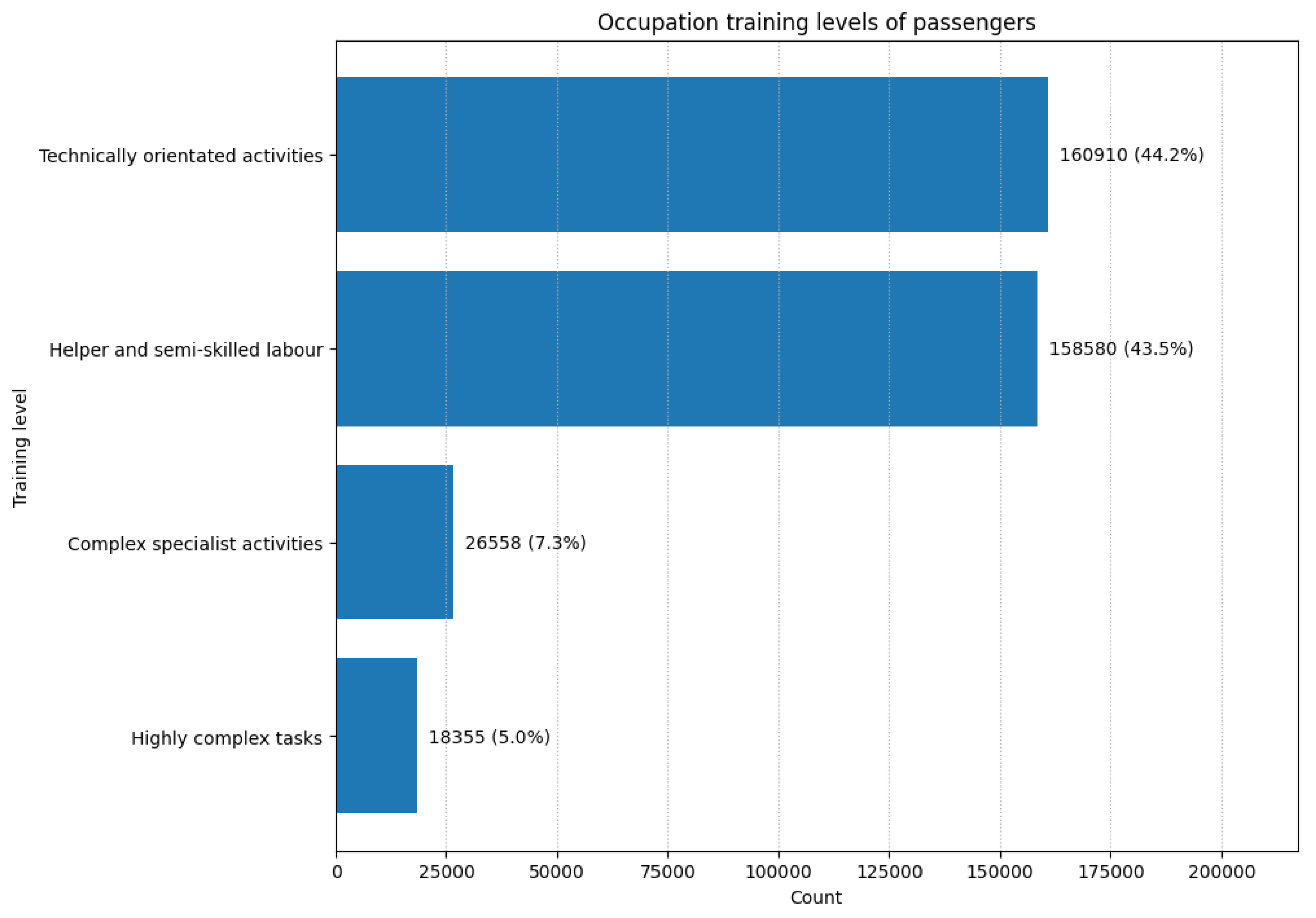
Figure 10.
Shares of manual training level classification categories (1920-1940)
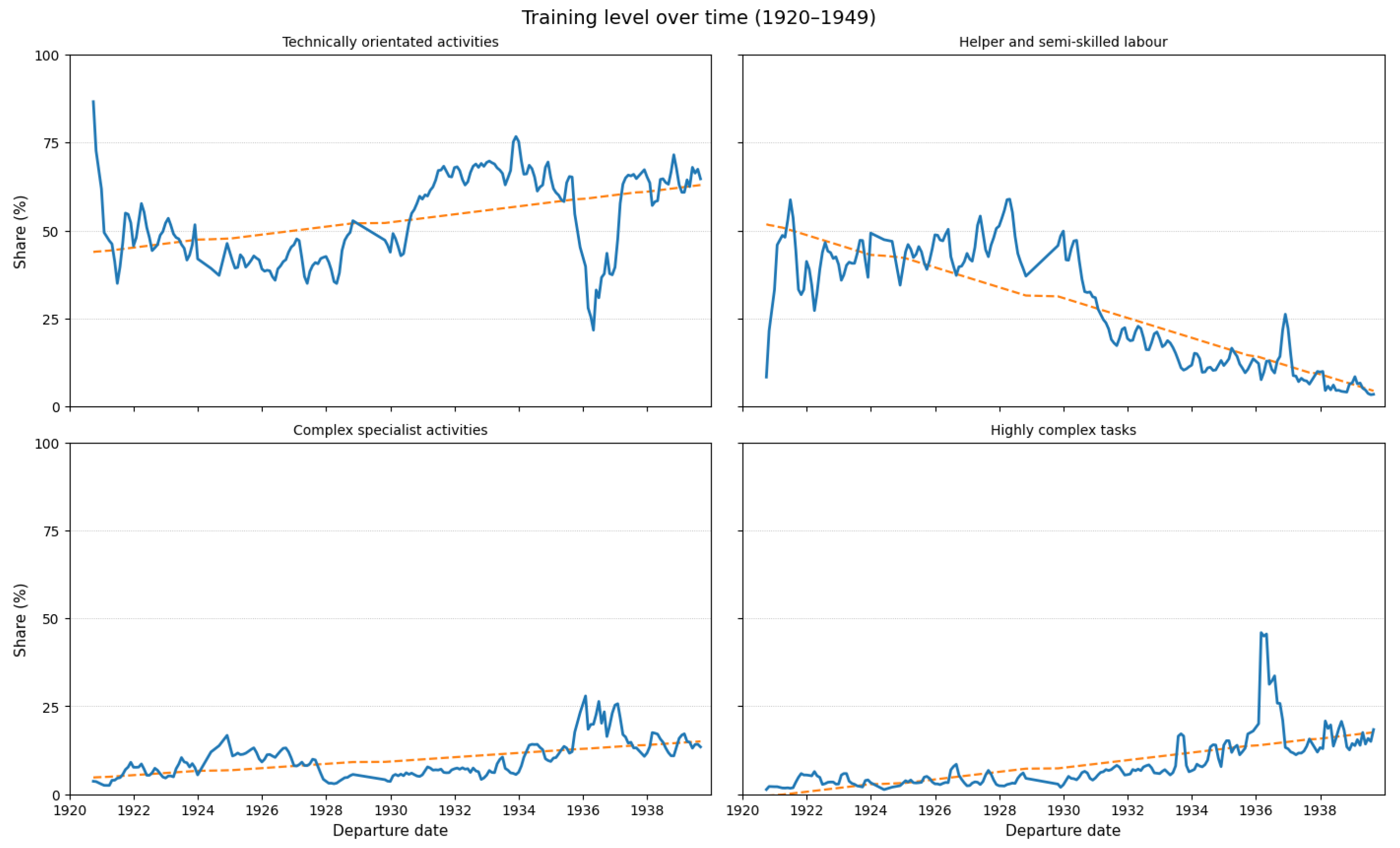
Figure 11.
Gender Distribution in ’gender_cleaned’ column.
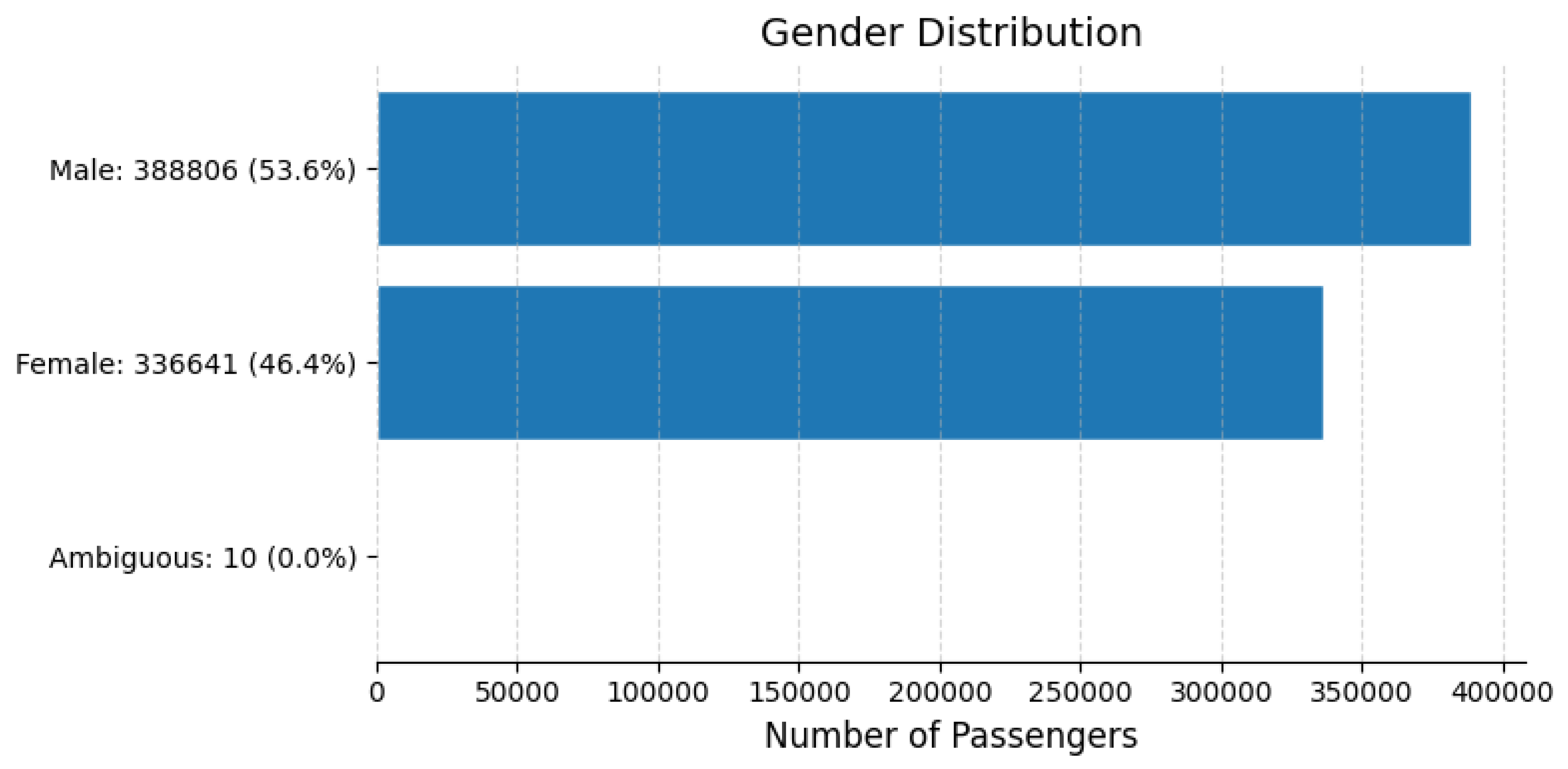
Figure 12.
Yearly distribution of marital statuses from 1920-1940.
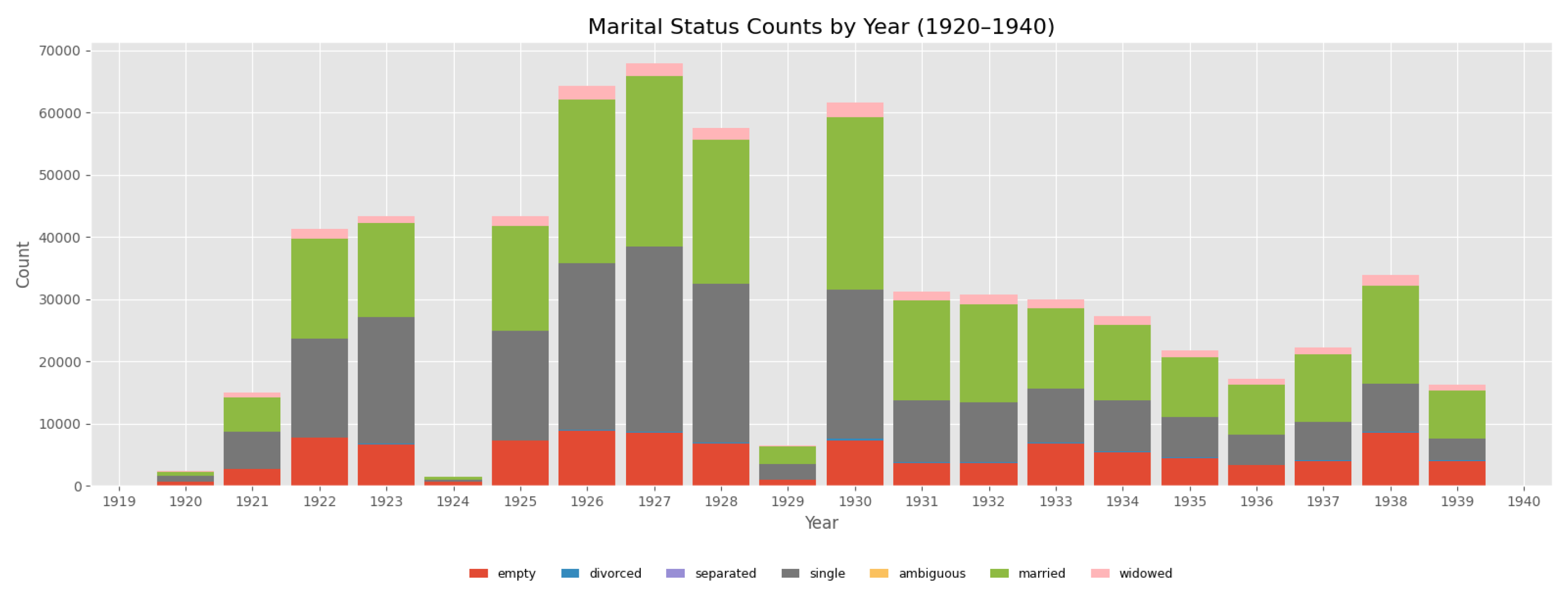
Figure 13.
20 most frequent ports of arrival on georeferenced map depicting the shipping routes of the Lloyd company Bremen.
Figure 13.
20 most frequent ports of arrival on georeferenced map depicting the shipping routes of the Lloyd company Bremen.
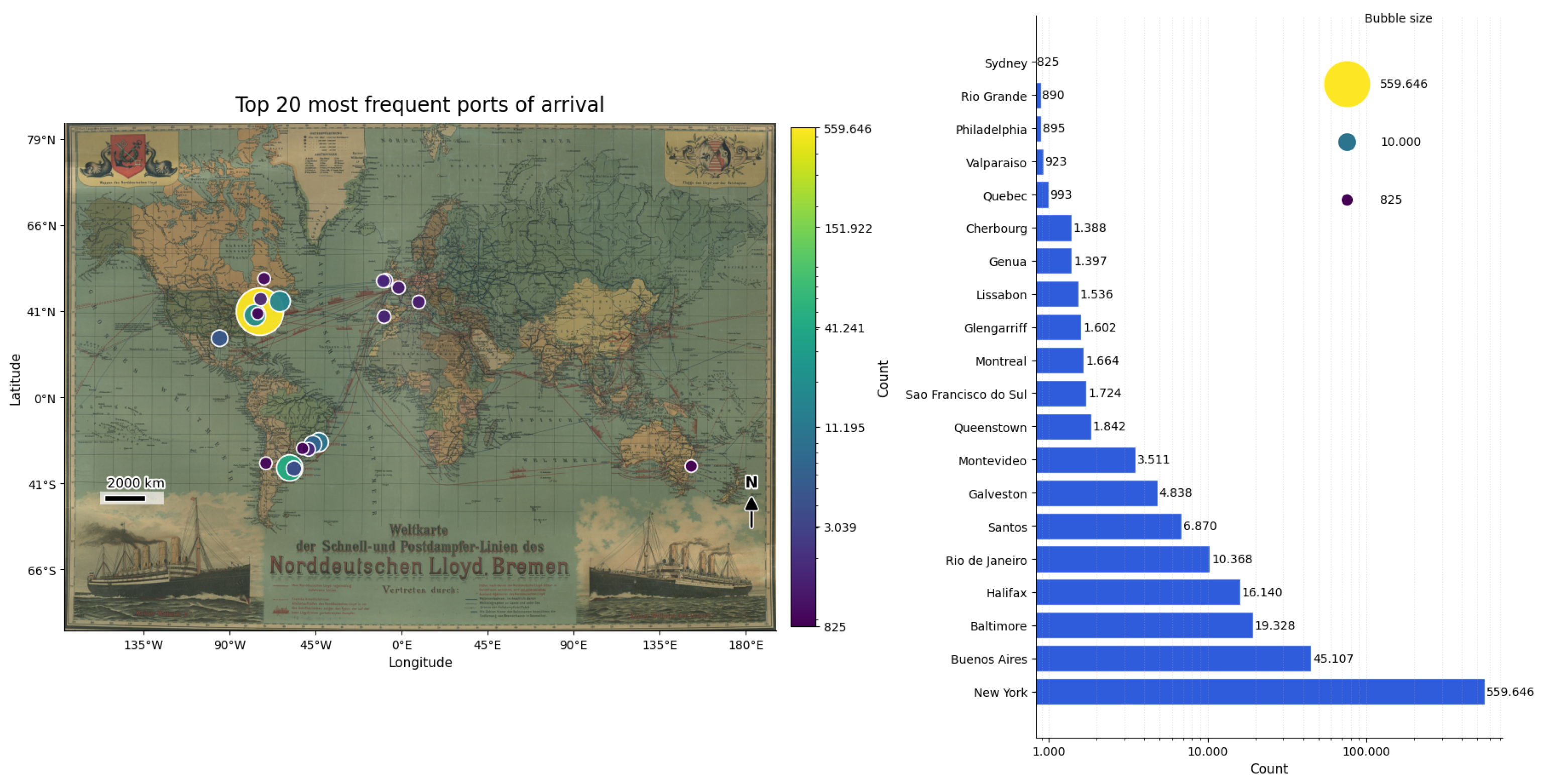

Table 1.
Overview of the processed dataset structure. The Explanation column provides a timespan with valid entries for each cleaned column based on the date of departure.
Table 1.
Overview of the processed dataset structure. The Explanation column provides a timespan with valid entries for each cleaned column based on the date of departure.
| Column Name | Data Type | Explanation |
|---|---|---|
| id | int | Data entry identifier |
| archive_id | string | Archival identifier |
| agent | string | Carrier name |
| agent_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| date_of_departure | string | Date of departure |
| date_of_departure_cleaned | object | Departure date converted to ISO standard |
| sort_da | int | — |
| ship | string | Ship name |
| ship_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| port_of_departure | string | Port of departure |
| port_of_departure_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| port_of_departure_LAT | float | Latitude of departure port |
| port_of_departure_LON | float | Longitude of departure port |
| port_of_departure_country | string | Country of departure |
| port_of_arrival | string | Port of destination |
| port_of_arrival_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| port_of_arrival_LAT | float | Latitude of arrival port |
| port_of_arrival_LON | float | Longitude of arrival port |
| port_of_arrival_country | string | Country of destination |
| port_of_arrival_US_state | string | US-State of destination |
| captain | string | Captain of ship |
| travel_class | string | Travel class |
| travel_class_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| nr | object | Passenger number |
| last_name | string | Last name of passenger |
| first_name | string | First name of passenger |
| gender | string | Gender of passenger |
| gender_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| age | object | Age of passenger |
| age_cleaned | object | Dates of birth → numeric age (e.g. birth: 1878-11-15) |
| → age on 1939-02-25: 60 years | ||
| marital_status | string | Marital status of passenger |
| marital_status_cleaned | string | Timespan: 1832-04-16 to 1939-08-23 |
| previous_residence | string | Previous residence of passenger |
| nationality | string | Nationality / citizenship of passenger |
| nationality_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| state_or_province | string | State/province of previous residence |
| state_or_province_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| occupation | string | Occupation and professional position |
| occupation_cleaned | string | Timespan: 1830-03-24 to 1939-08-23 |
| occupation_hisco_nr | object | Numeric categorisation per HISCO schema |
| occupation_sector | int | Classification: sector of occupation |
| occupation_training_level | int | Classification: training/education level |
| emigration_destination | string | Destination of passenger |
| US_state | string | US-State of destination |
| US_state_cleaned | string | Timespan: 1853-08-09 to 1939-08-23 |
| notes | string | Remarks / Notes |
| emigrant | string | Passenger emigrant status |
| ethnicity | string | Ethnicity of passenger |
| ethnicity_cleaned | string | Timespan: 1935-08-10 to 1939-08-23 |
| religion | string | Religion of passenger |
| religion_cleaned | string | Timespan: 1937-01-16 to 1939-08-23 |
| literacy | string | Writing and reading ability of passenger |
| relative | string | Relatives of passenger |
| ticket | string | Valid ticket (y/n) |
| who_paid | string | Person paying for the ticket |
| amount_of_money | string | Amount of money passenger is carrying |
| previous_US_stay | string | Previous residence/stay on US territory |
| duration_of_stay | string | Duration of stay |
| duration_of_stay_cleaned | string | Timespan: 1832-04-16 to 1937-01-07 |
| place_of_stay | string | Place of stay |
| reference_person | string | Contact person |
| pfd | string | dates of departure for certain voyages |
Table 2.
Data coverage per field. N=735,545.
| Column Name | Unambiguous | Distinct | Ambiguous | Missing | |||
|---|---|---|---|---|---|---|---|
| id | 735,545 | 100.00% | 735,545 | 0 | 0.00% | 0 | 0.00% |
| archive_id | 735,544 | 100.00% | 4,701 | 0 | 0.00% | 1 | 0.00% |
| agent | 735,464 | 99.99% | 118 | 0 | 0.00% | 81 | 0.01% |
| agent_cleaned | 735,369 | 99.98% | 80 | 24 | 0.00% | 152 | 0.02% |
| date_of_departure | 735,543 | 100.00% | 2,330 | 0 | 0.00% | 2 | 0.00% |
| date_of_departure_cleaned | 735,133 | 99.94% | 2,318 | 0 | 0.00% | 412 | 0.06% |
| sort_da | 735,545 | 100.00% | 2 | 0 | 0.00% | 0 | 0.00% |
| ship | 735,542 | 100.00% | 519 | 0 | 0.00% | 3 | 0.00% |
| ship_cleaned | 735,445 | 99.99% | 511 | 26 | 0.00% | 74 | 0.01% |
| port_of_departure | 733,683 | 99.75% | 40 | 0 | 0.00% | 1,862 | 0.25% |
| port_of_departure_cleaned | 732,777 | 99.62% | 17 | 0 | 0.00% | 2,768 | 0.38% |
| port_of_departure_LAT | 731,864 | 99.50% | 15 | 0 | 0.00% | 3,681 | 0.5% |
| port_of_departure_LON | 731,864 | 99.50% | 15 | 0 | 0.00% | 3,681 | 0.5% |
| port_of_departure_country | 731,865 | 99.50% | 10 | 0 | 0.00% | 3,680 | 0.5% |
| port_of_arrival | 735,091 | 99.94% | 338 | 0 | 0.00% | 454 | 0.06% |
| port_of_arrival_cleaned | 732,215 | 99.55% | 296 | 16 | 0.00% | 3,314 | 0.45% |
| port_of_arrival_LAT | 696,203 | 94.65% | 240 | 0 | 0.00% | 39,342 | 5.35% |
| port_of_arrival_LON | 696,203 | 94.65% | 240 | 0 | 0.00% | 39,342 | 5.35% |
| port_of_arrival_country | 732,331 | 99.56% | 123 | 16 | 0.00% | 3,198 | 0.43% |
| port_of_arrival_US_state | 587,201 | 79.83% | 11 | 0 | 0.00% | 148,344 | 20.17% |
| captain | 15,287 | 2.08% | 141 | 0 | 0.00% | 720,258 | 97.92% |
| travel_class | 624,957 | 84.97% | 145 | 0 | 0.00% | 110,588 | 15.03% |
| travel_class_cleaned | 624,852 | 84.95% | 14 | 105 | 0.01% | 110,588 | 15.03% |
| nr | 724,457 | 98.49% | 54,052 | 0 | 0.00% | 11,088 | 1.51% |
| last_name | 735,524 | 100.00% | 185,497 | 0 | 0.00% | 21 | 0.00% |
| first_name | 734,354 | 99.84% | 43,542 | 0 | 0.00% | 1,191 | 0.16% |
| gender | 725,528 | 98.64% | 14 | 0 | 0.00% | 10,017 | 1.36% |
| gender_cleaned | 725,447 | 98.63% | 2 | 10 | 0.00% | 10,088 | 1.37% |
| age | 714,556 | 97.15% | 15,492 | 0 | 0.00% | 20,989 | 2.85% |
| age_cleaned | 711,899 | 96.79% | 284 | 203 | 0.03% | 23,443 | 3.19% |
| marital_status | 619,515 | 84.23% | 57 | 0 | 0.00% | 116,030 | 15.77% |
| marital_status_cleaned | 619,461 | 84.22% | 5 | 54 | 0.01% | 116,030 | 15.77% |
| previous_residence | 547,056 | 74.37% | 99,264 | 0 | 0.00% | 188,489 | 25.63% |
| nationality | 717,455 | 97.54% | 487 | 0 | 0.00% | 18,090 | 2.46% |
| nationality_cleaned | 717,206 | 97.51% | 94 | 250 | 0.03% | 18,089 | 2.46% |
| state_or_province | 311,375 | 42.33% | 1,751 | 0 | 0.00% | 424,170 | 57.67% |
| state_or_province_cleaned | 311,342 | 42.33% | 955 | 33 | 0.00% | 424,170 | 57.67% |
| occupation | 428,318 | 58.23% | 10,559 | 0 | 0.00% | 307,227 | 41.77% |
| occupation_cleaned | 425,302 | 57.82% | 7,107 | 39 | 0.01% | 310,204 | 42.17% |
| occupation_hisco_nr | 399,603 | 54.33% | 251 | 0 | 0.00% | 335,942 | 45.67% |
| occupation_sector | 390,431 | 53.08% | 10 | 0 | 0.00% | 345,114 | 46.92% |
| occupation_training_level | 364,403 | 49.54% | 4 | 0 | 0.00% | 371,142 | 50.46% |
| emigration_destination | 703,728 | 95.67% | 35,092 | 0 | 0.00% | 31,817 | 4.33% |
| US_state | 516,322 | 70.20% | 151 | 0 | 0.00% | 219,223 | 29.8% |
| US_state_cleaned | 478,864 | 65.1% | 52 | 37,394 | 5.08% | 219,287 | 29.81% |
| notes | 24,069 | 3.27% | 8,866 | 0 | 0.00% | 711,476 | 96.73% |
| emigrant | 9,286 | 1.26% | 94 | 0 | 0.00% | 726,259 | 98.74% |
| ethnicity | 16,937 | 2.30% | 350 | 0 | 0.00% | 718,608 | 97.7% |
| ethnicity_cleaned | 16,925 | 2.3% | 80 | 11 | 0.00% | 718,609 | 97.7% |
| religion | 8,929 | 1.21% | 117 | 0 | 0.00% | 726,616 | 98.79% |
| religion_cleaned | 8,914 | 1.21% | 26 | 14 | 0.00% | 726,617 | 98.79% |
| literacy | 7,913 | 1.08% | 123 | 0 | 0.00% | 727,632 | 98.92% |
| relative | 8,098 | 1.10% | 7,556 | 0 | 0.00% | 727,447 | 98.9% |
| ticket | 7,567 | 1.03% | 11 | 0 | 0.00% | 727,978 | 98.97% |
| who_paid | 7,800 | 1.06% | 85 | 0 | 0.00% | 727,745 | 98.94% |
| amount_of_money | 5,599 | 0.76% | 138 | 0 | 0.00% | 729,946 | 99.24% |
| previous_US_stay | 7,196 | 0.98% | 7 | 0 | 0.00% | 728,349 | 99.02% |
| duration_of_stay | 5,689 | 0.77% | 846 | 0 | 0.00% | 729,856 | 99.23% |
| duration_of_stay_cleaned | 5,157 | 0.70% | 546 | 0 | 0.00% | 730,388 | 99.3% |
| place_of_stay | 4,113 | 0.56% | 625 | 0 | 0.00% | 731,432 | 99.44% |
| reference_person | 16,071 | 2.18% | 11,415 | 0 | 0.00% | 719,474 | 97.82% |
| pfd | 703 | 0.1% | 49 | 0 | 0.00% | 734,842 | 99.90% |
Table 3.
Distribution of unique values of religion_cleaned.
| Religion | Religion (German) | Count |
|---|---|---|
| Mosaic (Jewish) | mosaisch | 3,186 |
| Catholic | katholisch | 2,477 |
| Protestant | evangelisch | 1,936 |
| Roman Catholic | römisch-katholisch | 1,065 |
| Hebrew | hebräisch | 56 |
| Jewish | jüdisch | 49 |
| Greek Catholic | griechisch-katholisch | 27 |
| Greek Orthodox | griechisch-orthodox | 26 |
| Ambiguous / unclear | uneindeutig | 14 |
| Mohammedan (Muslim) | mohammedanisch | 13 |
| No information given | keine Angabe | 12 |
| Israelite | israelisch | 10 |
| Protestant | protestantisch | 10 |
| Lutheran | lutherisch | 9 |
| “Believer in God” | gottgläubig | 7 |
| None | ohne | 6 |
| Others | andere | 25 |
| Sum | 8,903 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



