Submitted:
10 January 2026
Posted:
12 January 2026
You are already at the latest version
Abstract
This work presents a real-time default-detection model integrating streaming behavioral signals, including app usage dynamics, repayment timing, transaction irregularities, and short-term income proxies. The model is built on 2.7 million active loan accounts with second-level event streams. A streaming-enabled ensemble classifier (online gradient boosting + incremental random forest) is deployed with a sliding window of 7 days. The model predicts impending 30-day delinquency with an ROC-AUC of 0.89 and reduces detection delay by 9.2 days on average. Incorporating real-time behavioral drift scores improves early-warning accuracy by 24.4%. The system demonstrates the feasibility of continuous credit-risk monitoring using high-velocity behavioral data.
Keywords:
1. Introduction
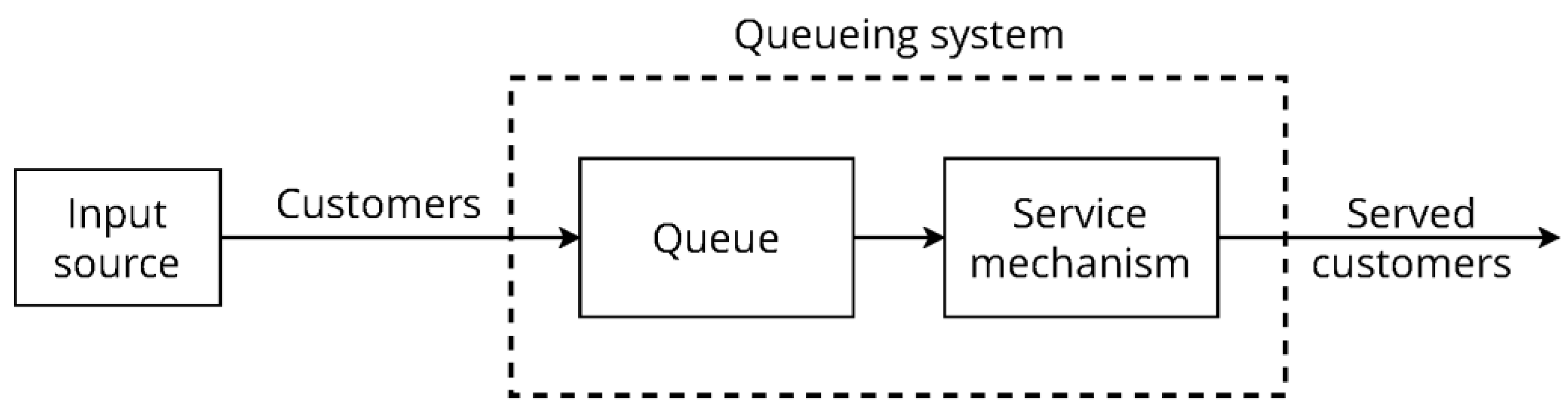
2. Materials and Methods
2.1. Sample and Study Setting
2.2. Experimental Design and Control Group
2.3. Measurement Procedures and Quality Control
2.4. Data Processing and Model Equations
2.5. Computational Environment
3. Results and Discussion
3.1. Overall Classification Performance
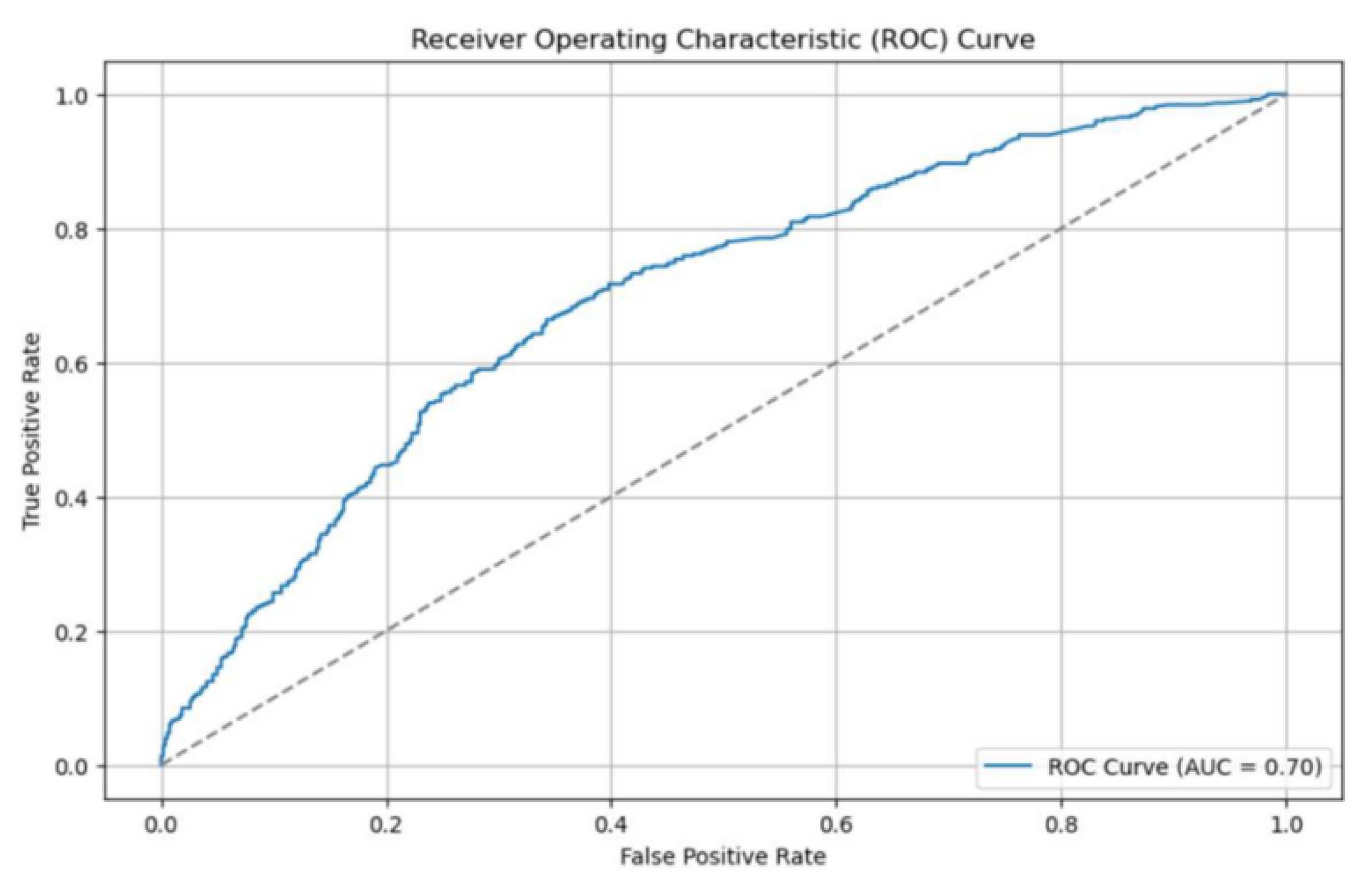
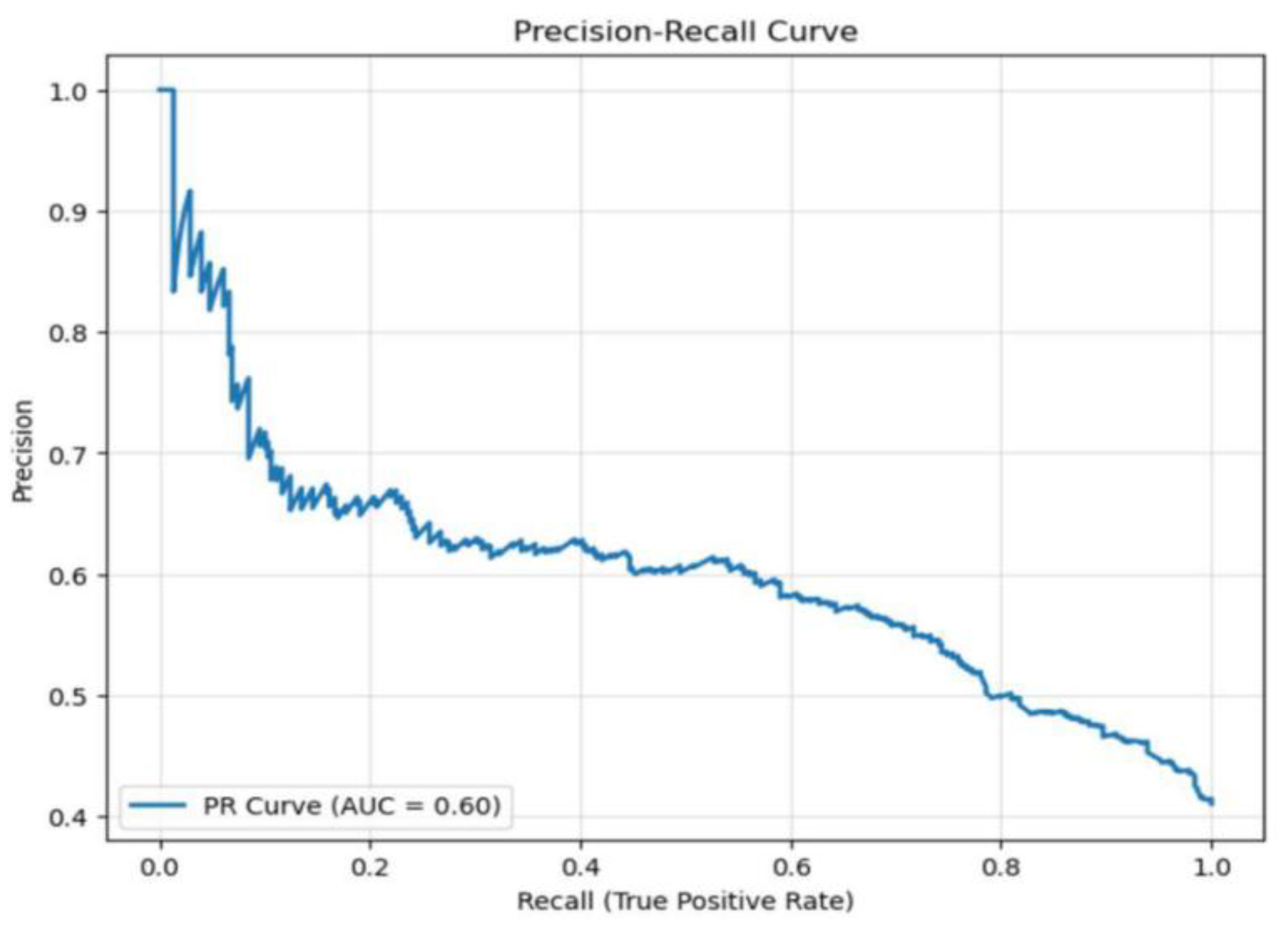
3.2. Early-Warning Lead Time
3.3. Effect of Behavioral Streams and Drift Indicators
3.4. Robustness and Comparison with Previous Work
4. Conclusion
References
- Cheteni, E.; Vambe, W. T. Explainability in Machine Learning & AI Models for Complex Data Structures on Scorecards Development in Retail Banking. 2024 4th International Multidisciplinary Information Technology and Engineering Conference (IMITEC), 2024, November; IEEE; pp. 315–320. [Google Scholar]
- Oyewola, D. O.; Dada, E. G.; Omotehinwa, O. T.; Ibrahim, I. A. Comparative analysis of linear, non-linear and ensemble machine learning algorithms for credit worthiness of consumers. Computational Intelligence & Wireless Sensor Networks 2019, 1(1), 1–1. [Google Scholar]
- Zhu, W.; Yao, Y.; Yang, J. Real-Time Risk Control Effects of Digital Compliance Dashboards: An Empirical Study Across Multiple Enterprises Using Process Mining, Anomaly Detection, and Interrupt Time Series. 2025. [Google Scholar]
- Nandipati, V. S. S.; Boddala, L. V. Credit Card Approval Prediction: A comparative analysis between Logistic Regression. In KNN, Decision Trees, Random Forest; XGBoost, 2024. [Google Scholar]
- Wang, J.; Xiao, Y. Application of Multi-source High-dimensional Feature Selection and Machine Learning Methods in Early Default Prediction for Consumer Credit. 2025. [Google Scholar]
- Petropoulos, A.; Siakoulis, V.; Stavroulakis, E. Towards an early warning system for sovereign defaults leveraging on machine learning methodologies. Intelligent Systems in Accounting, Finance and Management 2022, 29(2), 118–129. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, Y. Assessing the Spillover Effects of Marketing Promotions on Credit Risk in Consumer Finance: An Empirical Study Based on AB Testing and Causal Inference. 2025. [Google Scholar]
- Pasini, K. Forecast and anomaly detection on time series with dynamic context: Application to the mining of transit ridership data. Doctoral dissertation, Université gustave eiffel, 2021. [Google Scholar]
- Gu, X.; Yang, J.; Liu, M. Optimization of Anti-Money Laundering Detection Models Based on Causal Reasoning and Interpretable Artificial Intelligence and Its Empirical Study on Financial System Stability. Optimization 2025, 21, 1. [Google Scholar] [CrossRef]
- Wallisch, C.; Dunkler, D.; Rauch, G.; De Bin, R.; Heinze, G. Selection of variables for multivariable models: Opportunities and limitations in quantifying model stability by resampling. Statistics in medicine 2021, 40(2), 369–381. [Google Scholar] [CrossRef] [PubMed]
- Tan, L.; Peng, Z.; Song, Y.; Liu, X.; Jiang, H.; Liu, S.; Xiang, Z. Unsupervised domain adaptation method based on relative entropy regularization and measure propagation. Entropy 2025, 27(4), 426. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S. Machine Learning-Based Credit Risk Early Warning System for Small and Medium-Sized Financial Institutions: An Ensemble Learning Approach with Interpretable Risk Indicators. Journal of Science, Innovation & Social Impact 2025, 1(1), 372–383. [Google Scholar]
- Fleischer, M.; Das, D.; Bose, P.; Bai, W.; Lu, K.; Payer, M.; Vigna, G. {ACTOR}:{Action-Guided} Kernel Fuzzing. 32nd USENIX Security Symposium (USENIX Security 23), 2023; pp. 5003–5020. [Google Scholar]
- Li, T.; Jiang, Y.; Hong, E.; Liu, S. Organizational Development in High-Growth Biopharmaceutical Companies: A Data-Driven Approach to Talent Pipeline and Competency Modeling. 2025. [Google Scholar]
- Paleti, S.; Burugulla, J. K. R.; Pandiri, L.; Pamisetty, V.; Challa, K. Optimizing Digital Payment Ecosystems: Ai-Enabled Risk Management, Regulatory Compliance, And Innovation In Financial Services. In Regulatory Compliance, And Innovation In Financial Services; 2022. [Google Scholar]
- Gu, X.; Yang, J.; Tian, X.; Liu, M. Research on the Construction of a Human-Machine Collaborative Anti-Money Laundering System and Its Efficiency and Accuracy Enhancement in Suspicious Transaction Identification. 2025. [Google Scholar]
- Ahmed, A.; Shah, A.; Ahmed, T.; Yasin, S.; Longa, F. E. A.; Hussaini, W.; Zubair, M. AI-Driven Innovations in Modern Banking: From Secure Digital Transactions to Risk Management, Compliance Frameworks, and AI-Based ATM Forecasting Systems. Journal of Management Science Research Review 2025, 4(3), 1145–1183. [Google Scholar]
- Zhu, W.; Yao, Y.; Yang, J. Optimizing Financial Risk Control for Multinational Projects: A Joint Framework Based on CVaR-Robust Optimization and Panel Quantile Regression. 2025. [Google Scholar]
- Kaur, R.; Wazarkar, S.; Jain, R.; Ahuja, R.; Bajaj, I.; Bali, S. Personal Credit Score Generator Using Federated Learning for Financial Stress Management. International Conference on Artificial Intelligence and Networking, 2024, September; Springer Nature Singapore: Singapore; pp. 47–58. [Google Scholar]
- Agarwal, A. Autonomous lookahead for early risk tracking (ALERT): AI-driven predictive simulation for safe and proactive driver intervention. In Applications of Machine Learning; SPIE, September 2025; Vol. 13606, pp. 427–444. [Google Scholar]
- Azimi, A.; Khaledian, N. Multi-stage mortgage default prediction using ensemble machine learning: a comparative framework. Digital Finance 2025, 7(4), 1093–1118. [Google Scholar] [CrossRef]
- Björkegren, D.; Grissen, D. Behavior revealed in mobile phone usage predicts credit repayment. The World Bank Economic Review 2020, 34(3), 618–634. [Google Scholar] [CrossRef]
- Liu, F.; Panagiotakos, D. Real-world data: a brief review of the methods, applications, challenges and opportunities. BMC Medical Research Methodology 2022, 22(1), 287. [Google Scholar] [CrossRef]
- Oyekola, T. S.; Elikwu, D. O.; Odunaike, A. Real-Time Credit Risk Monitoring with AI and High-Frequency Data. Saudi J Bus Manag Stud 2022, 7(10), 315–322. [Google Scholar]
- Corizzo, R.; Rosen, J. Stock market prediction with time series data and news headlines: a stacking ensemble approach. Journal of Intelligent Information Systems 2024, 62(1), 27–56. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



