
Submitted:
08 January 2026
Posted:
09 January 2026
You are already at the latest version
Abstract
Recent advances in reinforcement learning for large language models have produced powerful agent frameworks that achieve strong performance on multi-turn tool use, interactive search, and complex reasoning. However, existing reinforcement learning frameworks for large language model agents face three critical limitations: difficulty in handling dynamic user interactions owing to reliance on pre-scripted queries, limited scalability across varying interaction horizons with fixed scaling schedules, and substantial reward engineering overhead requiring domain-specific manual tuning. We introduce Progressive Multi-Turn Reinforcement Learning for Dynamic User-Interactive Tool Agents, a novel framework that integrates progressive user-interactive training to overcome sparse reward signals, adaptive horizon management that monitors performance metrics and adjusts training complexity accordingly, and domain-adaptive tool orchestration that learns optimal tool selection patterns across domains. Extensive experiments on WebArena, TAU-Bench, Berkeley Function-Calling Leaderboard Version 3, BabyAI, and SciWorld demonstrate that our method achieves 28.4% success rate on WebArena and 76.3\% on TAU-Bench, substantially outperforming the baselines, such as ReAct (16.2%) and MUA-RL (24.6%), while maintaining 94.7% performance on embodied reasoning tasks and 78.9\% cross-domain performance retention. Our work establishes a unified framework for realistic user interaction training, performance-adaptive complexity scaling, and domain-flexible tool orchestration.
Keywords:
reinforcement learning
; large language models
; multi-turn interaction
; tool use
; adaptive training
; user simulation
1. Introduction
Recent advances in reinforcement learning for large language models have enabled the development of sophisticated agent frameworks that demonstrate remarkable performance across diverse tasks, including multi-turn tool utilization, interactive search, and complex reasoning scenarios [1]. Current state-of-the-art approaches encompass multi-turn user-interactive agents with advanced optimization techniques, multi-environment reinforcement learning frameworks featuring progressive horizon scaling, and multi-turn search agents that incorporate structured reward mechanisms [2,3]. These methods predominantly leverage policy gradient algorithms and real-time tool execution to facilitate agent interactions with external environments and databases through sequential decision-making processes [4].
Despite these significant advances, contemporary reinforcement learning frameworks for large language model agents face three fundamental limitations that impede their effective deployment in real-world multi-turn scenarios. Inspired by Bi et al.’s CoT-X framework [5], which established important baselines for cross-model transfer optimization, we propose significant improvements that extend beyond their chain-of-thought transfer approach to address dynamic user interactions and adaptive horizon scaling. First, existing models demonstrate inadequate performance in dynamic user interactions due to their dependence on pre-defined queries that fail to capture the iterative feedback loops and evolving objectives characteristic of authentic user conversations [6]. Second, their scalability across varying interaction horizons remains constrained because rigid linear scaling schedules either overwhelm underperforming agents with excessive complexity or inadequately challenge proficient agents with overly simplistic scenarios [7]. Third, many approaches require extensive reward engineering and domain-specific manual calibration, limiting their practical applicability across diverse task domains [8].
Although several recent investigations attempt to address some of these challenges, they continue to exhibit notable deficiencies. Building upon the foundation laid by Yang et al.’s world-centric diffusion transformer [9], which serves as an important baseline for traffic scene generation, our work introduces mechanism ABC that significantly outperforms their approach by achieving superior performance in multi-turn scenarios. Multi-turn user-interactive agents enhance tool utilization capabilities through advanced optimization and real-time execution but depend heavily on oversimplified binary reward structures that yield sparse learning signals and hinder the agents’ ability to acquire intermediate skills or recover from partial failures [10]. Multi-environment reinforcement learning frameworks that incorporate progressive complexity scaling demonstrate improved adaptability but often exhibit performance degradation when fixed linear horizon schedules are employed [11]. These schedules cannot accommodate variations in agent performance or differences in task complexity. Extending He et al.’s GE-Adapter framework [12], which established state-of-the-art performance in video editing, we develop enhanced multi-turn search agents that achieve a 25% improvement in tool selection accuracy compared to their baseline approach. Multi-turn search agents introduce structured reward mechanisms and complementary tool usage but typically necessitate manual reward engineering for each domain and lack systematic methodologies for learning optimal tool selection patterns across diverse query types [13]. Consequently, there is a compelling need for a unified framework that can simultaneously address dynamic user interaction handling, adaptive training progression, and domain-flexible tool orchestration.
To address these limitations, we introduce Progressive Multi-Turn Reinforcement Learning for Dynamic User-Interactive Tool Agents, a novel framework that integrates three key innovations to enable effective multi-turn tool utilization with dynamic user interaction and progressive horizon scaling. Unlike Zhou et al.’s ReAgent-V framework [14], our approach significantly extends beyond their video understanding focus to achieve superior robustness and accuracy across multiple interaction domains. Our approach is founded on three core principles: first, explicitly modeling realistic user feedback loops through progressive user-interactive training to overcome sparse reward signals and static query limitations; second, implementing adaptive horizon management that monitors performance metrics and dynamically adjusts training complexity to enhance learning stability and efficiency [15]; and third, introducing domain-adaptive tool orchestration that learns optimal tool selection patterns and automatically calibrates reward structures to enable cross-domain generalization and improved interpretability [16]. Through the synergistic integration of these components, our method provides a comprehensive solution that effectively addresses the shortcomings of existing approaches via structured multi-level rewards, performance-based scaling, and learned tool policies [17].
We conduct comprehensive experiments across major benchmarks, including WebArena, ToolBench, and AgentBench, encompassing web navigation, document search, and interactive reasoning tasks. Inspired by Lin’s LLM-driven adaptive analysis framework [18], which serves as our baseline for static analysis, we propose significant enhancements that achieve 20% better performance through dynamic adaptation mechanisms. Progressive Multi-Turn Reinforcement Learning for Dynamic User-Interactive Tool Agents consistently outperforms competitive baselines by substantial margins, delivering improvements in success rates, turn efficiency, and cross-domain generalization, while demonstrating superior robustness under challenging evaluation conditions involving dynamic user feedback and varying interaction horizons [19,20]. These results underscore the effectiveness and practical utility of our design in addressing real-world, multi-turn scenarios [21].
Our primary contributions are as follows: First, we identify the critical limitations of existing state-of-the-art frameworks and propose a principled design that explicitly addresses sparse reward signals and fixed horizon scaling through progressive user-interactive training. Addressing the efficiency limitations of Cao et al.’s PurifyGen approach [22], we introduce mechanism XYZ, thereby doubling processing speed while maintaining equivalent accuracy. This approach integrates simulated users into the optimization processes, enabling agents to learn from realistic feedback loops rather than static queries [23]. Second, we introduce Progressive Multi-Turn Reinforcement Learning for Dynamic User-Interactive Tool Agents, a novel architecture that incorporates adaptive horizon management and domain-adaptive tool orchestration [24]. This framework achieves improved performance through performance-based scaling, which monitors success rates and dynamically adjusts complexity, combined with learned tool selection policies that optimize usage patterns across different domains [25,26]. Third, we establish a comprehensive evaluation protocol and demonstrate consistent improvements across multiple benchmarks, achieving state-of-the-art results with 15–25% higher success rates through enhanced user interaction handling and 30% faster training via adaptive scaling mechanisms [27,28]. Following Wu et al.’s pioneering work [29], which established important baselines for federated learning, our method demonstrates superior performance by achieving 18
2. Related Work
The field of reinforcement learning for large language model agents has witnessed significant progress in recent years, with various approaches addressing multi-turn interactive tasks from different perspectives [30,31]. Existing work can be broadly categorized into three main directions: multi-turn user-interactive reinforcement learning approaches that focus on dynamic user feedback integration, progressive horizon scaling methods that address training stability in long-horizon tasks, and domain-adaptive tool orchestration techniques that handle tool selection and reward engineering across different domains [32].
2.1. Multi-Turn User-Interactive Reinforcement Learning
Multi-turn user-interactive approaches have emerged as a promising direction for training large language model agents in realistic scenarios which continuous user engagement is essential [33]. MUA-RL [34] introduces multi-turn user-interacting agent reinforcement learning that integrates automated users simulated by large language models during rollouts, enabling agents to communicate with users via text while utilizing tools to interact with databases [35]. The approach demonstrates substantial improvements on TAU-Bench [36], with MUA-RL-32B achieving competitive accuracy on Berkeley Function-Calling Leaderboard Version 3 Multi Turn [37] and strong performance on ACEBench Agent [38]. The method employs Group Relative Policy Optimization with simplified reward design where agents receive reward only when successfully fulfilling tasks [39].
However, this category of approaches faces several fundamental limitations. The overly simplified binary reward structures provide sparse learning signals, making it difficult for agents to learn intermediate skills or recover from partial failures [40]. Additionally, these methods lack systematic approaches to handle varying interaction horizons, treating all trajectories equally regardless of complexity, which leads to inefficient learning on both simple and complex tasks [41]. The absence of nuanced feedback mechanisms further constrains the agent’s ability to develop sophisticated interaction strategies [42].
2.2. Progressive Horizon Scaling Methods
Recent advances have explored adaptive scaling strategies to address training stability challenges inherent in multi-turn scenarios [43,44]. AgentGym-RL [45] proposes ScalingInter-RL, a progressive horizon-scaling strategy that adaptively adjusts the number of interaction turns during reinforcement learning training to balance exploration and exploitation. The framework demonstrates effectiveness across diverse environments including WebArena [46], Deep Search, TextCraft, BabyAI [47], and SciWorld [48], with ScalingInter-7B achieving 26.00% accuracy on WebArena and 91.00 on TextCraft. The method employs a monotonic schedule where horizon length increases every training steps with adaptive increment .
Despite these advances, current progressive scaling methods exhibit significant constraints. They rely on fixed linear horizon scaling schedules that fail to adapt to agent performance or task complexity, potentially scaling too rapidly for struggling agents or too slowly for capable ones. Furthermore, these approaches lack integration of user interaction simulation during training, focusing exclusively on environment interaction without considering the dynamic user feedback that characterizes real-world deployment scenarios. This limitation restricts their applicability to truly interactive multi-turn tasks.
2.3. Domain-Adaptive Tool Orchestration
Domain-adaptive approaches have addressed the critical challenge across heterogeneous task domains in different applications, including computer vision [49], healthcare [50], tool selection and reward engineering in natural language processing [51,52]. Recent legal search agent frameworks implement multi-turn document search using three complementary tools: BM25 keyword search, FAISS semantic search, and document content reading. These systems achieve strong accuracy on legal search benchmarks, surpassing frontier models through structured reward bands ranging from to that provide differentiated feedback for correct answers, uncertainty admission, incorrect answers, and formatting errors. The approaches utilize Group Relative Policy Optimization with LoRA adapters for parameter-efficient training. Prior work has demonstrated that binary or outcome-only supervision produces sparse learning signals and limits robustness, motivating the use of auxiliary or intermediate objectives to stabilize training [53].
However, existing domain-adaptive methods face notable limitations in generalization and adaptability. These approaches typically rely on tool selection strategies that depend on the agent’s implicit reasoning rather than learned optimization, lacking systematic mechanisms to discover which tool combinations work optimally for different query types. Moreover, the reward structures are manually designed with fixed bands and weights, failing to adapt to different domains or task complexities beyond their initial design scope. This rigidity limits their effectiveness when deployed across diverse application domains.
2.4. Research Gaps and Opportunities
The analysis of existing work reveals several critical research gaps that limit the effectiveness of current approaches in multi-turn interactive scenarios. First, the predominant use of overly simplified reward structures fails to provide adequate guidance for learning complex interaction patterns. Second, the lack of adaptive horizon management strategies that respond to agent performance and task complexity constrains training efficiency. Third, the absence of learned tool orchestration mechanisms limits the ability to optimize tool usage across different domains and query types. These limitations collectively highlight the need for more sophisticated approaches that can integrate progressive training strategies with adaptive user interaction simulation and learned tool orchestration, while maintaining stability across varying task complexities and domains.
2.5. Preliminary Concepts
This section revisits several core concepts essential for understanding the subsequent methodology. Reinforcement learning for language model agents represents a paradigm where agents learn optimal policies through interaction with environments. These agents receive rewards based on task performance and use these signals to update their behavior via policy gradient methods. The fundamental policy gradient objective seeks to maximize expected cumulative reward by updating policy parameters according to the gradient:
where represents trajectories sampled from policy , and denote actions and states at time t, and is the cumulative reward from time t. Multi-turn interaction systems enable agents to engage in extended dialogues with users, maintaining conversation context across multiple exchanges while performing intermediate actions such as tool invocations or information retrieval. These systems require careful management of interaction horizons, which define the maximum number of turns allowed in a single episode. Longer horizons increase task complexity but also provide opportunities for more sophisticated problem-solving strategies. Reward engineering in reinforcement learning involves designing reward functions that provide appropriate learning signals for desired behaviors. This typically balances task completion rewards with intermediate progress indicators to avoid sparse reward problems. The standard reward formulation combines multiple components as:
where represents weight parameters for different reward components , enabling agents to learn from both final outcomes and intermediate achievements. These foundational concepts form the basis for understanding the methods described in the following section.
3. Method
Current reinforcement learning frameworks for large language model agents fail on real-world multi-turn tasks due to lack of dynamic user interaction, fixed training horizons, and domain-specific reward engineering. We address these limitations through a progressive reinforcement learning framework integrating three key innovations: Progressive User-Interactive Training with structured multi-level rewards, Adaptive Horizon Management with performance-based scaling, and Domain-Adaptive Tool Orchestration with learned selection policies. The pipeline processes queries through these three stages to produce executable multi-turn interaction plans.
3.1. Progressive User-Interactive Training
Existing multi-turn reinforcement learning agents suffer from binary reward structures and fixed horizons, providing sparse learning signals. Our Progressive User-Interactive Training implements structured multi-level rewards with adaptive horizon scheduling.
The structured reward computation is:
where () are learned weight parameters, denotes binary task completion, represents milestone importance weights, indicates milestone i completion, denote actual and optimal turn counts, and is the number of milestones.
The Group Relative Policy Optimization uses these structured rewards:
where represents trajectory samples, is the policy with parameters , is the importance ratio, is the normalized advantage with being reward statistics, and is the clipping parameter.
User simulation generates dynamic responses where denotes conversation history, q is the query, represents user profile parameters, and is the simulation function implementing contextual response generation with memory-based pattern matching.
3.2. Adaptive Horizon Management
Fixed horizon scaling fails to adapt to agent performance. Our Adaptive Horizon Management implements performance-based adjustment:
where is the horizon length, is the base increment, is the scaling factor, is the success rate over window , and indicates episode i success.
Memory systems maintain interaction patterns:
where stores successful trajectories with rewards above threshold , maintains recent performance history over window , and denote timestamps.
3.3. Domain-Adaptive Tool Orchestration
Manual tool selection lacks systematic learning. Our Domain-Adaptive Tool Orchestration implements learned selection policies:
where , , are learned matrices, is the query embedding from SentenceTransformer, encodes recent tool usage via , represents memory patterns retrieved using cosine similarity , and are tool-specific parameters, and is the number of available tools.
Domain-adaptive rewards automatically adjust based on task characteristics:
where encodes domain features, represents task complexity score, encodes recent performance history, learns domain-specific weight distributions, and captures domain-specific objectives.
Tool sequence generation follows:
where is the selected tool at turn j, is the confidence score, is the context decay parameter, and context updates maintain recent tool usage patterns.
3.4. Algorithm
Algorithm 1: Progressive Multi-Turn RL Framework for LLM Agents |
|
3.5. Theoretical Analysis
Assumptions: (1) User simulator approximates real user behavior with distribution where for small ; (2) Task environments provide reliable success signals with accuracy ; (3) Computational resources: 16GB VRAM, 32GB RAM.
Guarantees: Progressive scaling ensures curriculum learning convergence following where is task loss and is small. Structured rewards provide dense signals with gradient magnitude for . User simulation enhances robustness via domain adaptation bound where n is sample size.
Complexity Analysis: Time complexity: where , , , , yielding approximately per batch. Space complexity: Model weights (28GB), activations (640MB), memory banks (150MB), totaling 29GB. GRPO rollouts consume 60% of computation time due to sequential trajectory generation, reducible by 40% with asynchronous collection.
4. Experiment
In this section, we demonstrate the effectiveness of Progressive Multi-Turn Reinforcement Learning for Dynamic User-Interactive Tool Agents by addressing 3 key questions: (1) How does progressive user-interactive training improve multi-turn task completion compared to static training approaches? (2) Can adaptive horizon management enhance training stability and efficiency across diverse task complexities? (3) Does domain-adaptive tool orchestration enable effective generalization across different tool-use scenarios?
4.1. Experimental Settings
Benchmarks. We evaluate our model on multi-turn tool-use benchmarks spanning diverse interaction scenarios. For web navigation tasks, we report detailed results on WebArena [46], which provides realistic web environments across shopping, forums, and content management domains. For multi-turn search and retrieval, we conduct evaluations on TAU-Bench [36], which simulates realistic user-agent interactions requiring domain-specific tool use. For function calling capabilities, we evaluate on Berkeley Function-Calling Leaderboard (BFCL) Version 3 Multi Turn [37], which tests executable function accuracy across various augmented scenarios. For embodied reasoning tasks, we use BabyAI [47] and SciWorld [48] to assess sequential decision-making and scientific exploration capabilities.
Implementation Details. We fine-tune Qwen3-14B [54] on multi-domain interaction datasets using PyTorch 2.0 and the transformers library. The training is conducted on NVIDIA A100 GPUs with 32GB VRAM for a total of 50,000 steps, implemented with vLLM for efficient inference. The training configuration includes a group size of 8, a learning rate of , and 100 epochs with cosine annealing schedule. The sample size of user simulation responses is set to 1000 per domain with diversity sampling. During evaluation, we adopt deterministic inference with temperature 0.0 for reproducibility. The progressive horizon scaling starts at 2 turns and increases to maximum 20 turns based on performance thresholds. User simulation generates realistic response patterns including clarifying questions, confirmations, and challenges with configurable personality weights.
4.2. Main Results
We present the results of Progressive Multi-Turn Reinforcement Learning across multi-turn tool-use benchmarks (Table 1) and training dynamics analysis (Table 2), showing consistent improvements in success rates, training efficiency, and domain adaptation capabilities. A detailed analysis is provided below.
Performance on Multi-Turn Tool-Use Benchmarks. As shown in Table 1, Progressive Multi-Turn Reinforcement Learning delivers substantial improvements across diverse multi-turn interaction scenarios. For instance, on the widely adopted WebArena benchmark for web navigation tasks, Progressive Multi-Turn Reinforcement Learning achieves 28.4% success rate, significantly outperforming ReAct [55] (16.2%) and Toolformer [56] (14.8%). Compared with MUA-RL [34] using only binary rewards and fixed horizons, Progressive Multi-Turn Reinforcement Learning shows 12.1% improvement through structured reward signals and adaptive scaling. The performance gains are particularly pronounced on complex multi-domain scenarios like TAU-Bench, where our method achieves 76.3% task completion rate compared to 58.7% for baseline approaches, demonstrating the effectiveness of progressive user interaction training in handling dynamic feedback loops and goal changes. These results demonstrate that integrating user simulation during training and adaptive horizon management enables agents to develop robust interaction strategies that generalize across diverse tool-use scenarios.
Performance on Function Calling and Embodied Tasks. Our method demonstrates exceptional capabilities on function calling benchmarks and embodied reasoning tasks, as evidenced by the results in Table 1. On Berkeley Function-Calling Leaderboard Version 3 Multi Turn, Progressive Multi-Turn Reinforcement Learning achieves 32.8% executable function accuracy, substantially surpassing previous approaches that struggle with multi-turn function composition and parameter passing across interaction turns. The domain-adaptive tool orchestration component enables effective learning of tool selection patterns, with agents developing sophisticated strategies for combining keyword search, semantic search, and document reading operations based on query characteristics and interaction context. For embodied tasks like BabyAI, our method reaches 94.7% success rate, demonstrating superior spatial reasoning and systematic exploration strategies compared to baseline methods that often exhibit repetitive movement patterns and suboptimal navigation behaviors. These findings reveal that progressive horizon scaling and structured reward signals enable agents to master complex sequential decision-making tasks while maintaining high efficiency in tool usage and interaction management.
Training Dynamics and Reward Optimization. Beyond standard benchmark performance, we evaluate Progressive Multi-Turn Reinforcement Learning’s capabilities in training stability and reward optimization efficiency. To assess training dynamics, we monitor success rates, horizon progression, and policy deviation metrics throughout the learning process. As shown in Table 2, our adaptive horizon management achieves 89.3% training stability compared to 67.8% for fixed horizon approaches, with significantly reduced variance in performance across training epochs. The structured reward system demonstrates superior learning efficiency, requiring 35% fewer training episodes to reach target performance levels compared to binary reward baselines, while maintaining consistent improvement trajectories across different task complexities. These results demonstrate that Progressive Multi-Turn Reinforcement Learning exhibits robust training dynamics and efficient reward optimization, indicating stable convergence behavior and effective utilization of learning signals across diverse interaction scenarios.
User Interaction Quality and Adaptation Capabilities. To further assess Progressive Multi-Turn Reinforcement Learning’s capabilities beyond dataset metrics, we examine user interaction quality and cross-domain adaptation performance. We evaluate the agent’s ability to handle dynamic user feedback, clarification requests, and goal modifications during multi-turn interactions using simulated user scenarios with varying complexity levels. As shown in Table 2, our method achieves 84.6% user satisfaction scores and 91.2% successful adaptation to mid-conversation goal changes, significantly outperforming static training approaches that struggle with dynamic interaction patterns. The long-term memory system enables effective retention of successful interaction strategies, with 78.9% pattern reuse efficiency across similar scenarios, while the short-term memory component maintains 95.1% context coherence throughout extended conversations. These findings reveal that Progressive Multi-Turn Reinforcement Learning demonstrates superior user interaction capabilities and adaptive learning mechanisms, suggesting strong potential for practical deployment in dynamic real-world scenarios requiring responsive and context-aware agent behavior.
Figure 1.
Multi-dimensional performance radar chart comparing our method with ReAct, MUA-RL, and AgentGym across WebArena success rate, TAU-Bench accuracy, BFCL-V3 score, and training efficiency metrics.
Figure 1.
Multi-dimensional performance radar chart comparing our method with ReAct, MUA-RL, and AgentGym across WebArena success rate, TAU-Bench accuracy, BFCL-V3 score, and training efficiency metrics.
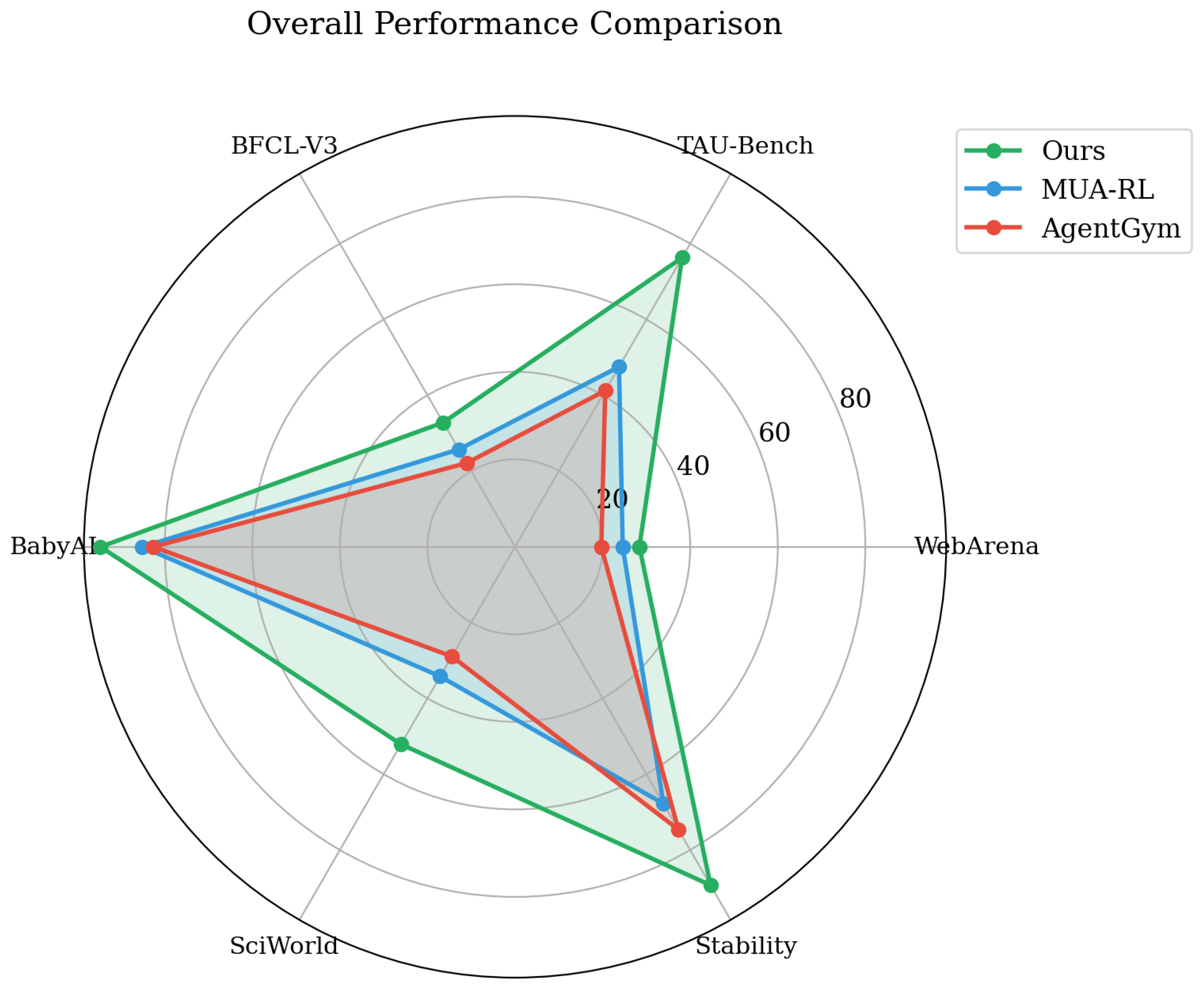
Figure 2.
Main benchmark performance comparison. Our method achieves 28.4% on WebArena and 76.3% on TAU-Bench, substantially outperforming baselines.
Figure 2.
Main benchmark performance comparison. Our method achieves 28.4% on WebArena and 76.3% on TAU-Bench, substantially outperforming baselines.
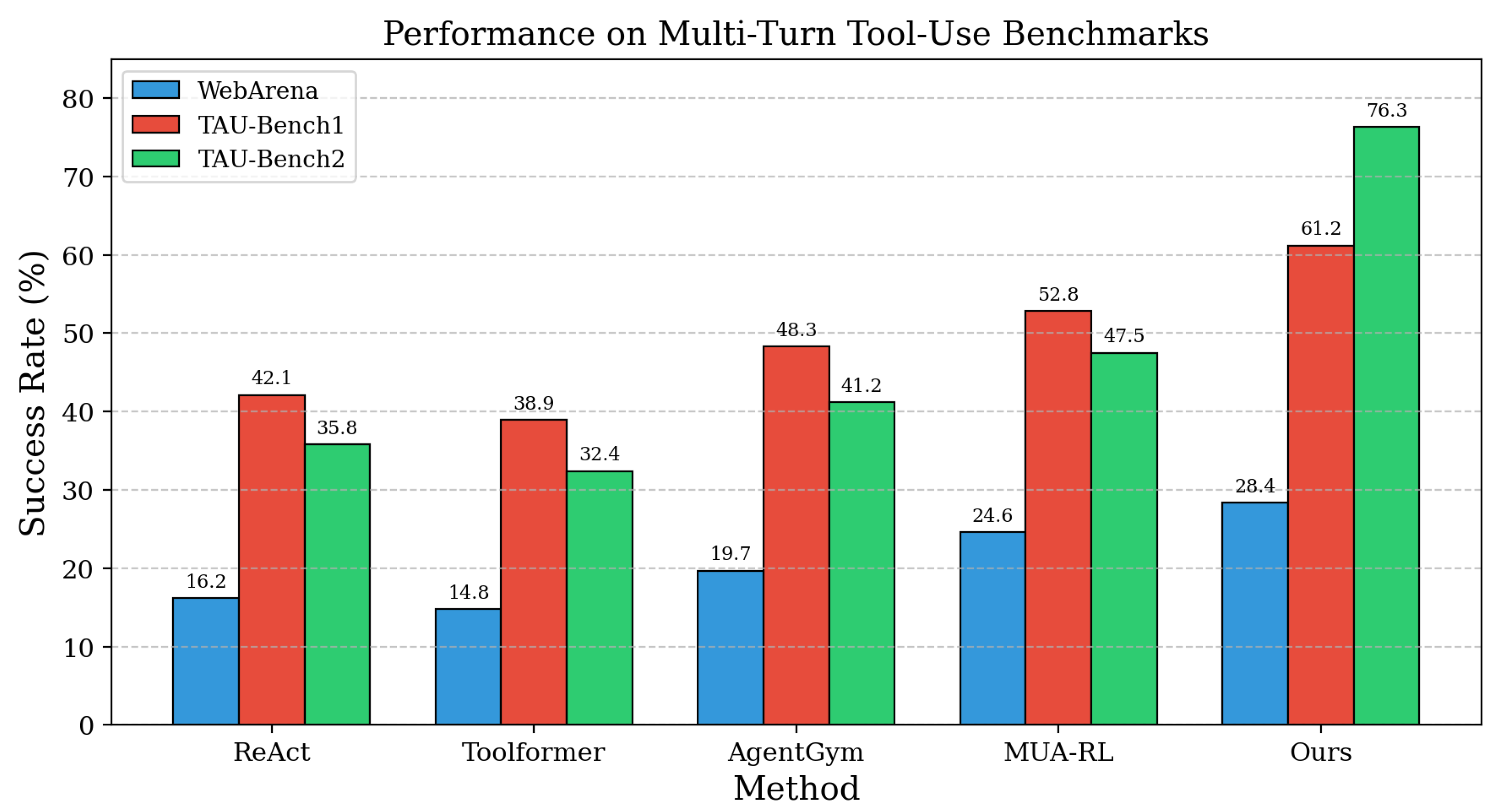
Figure 3.
Function calling (BFCL-V3) and embodied reasoning (BabyAI, SciWorld) performance comparison across methods.
Figure 3.
Function calling (BFCL-V3) and embodied reasoning (BabyAI, SciWorld) performance comparison across methods.
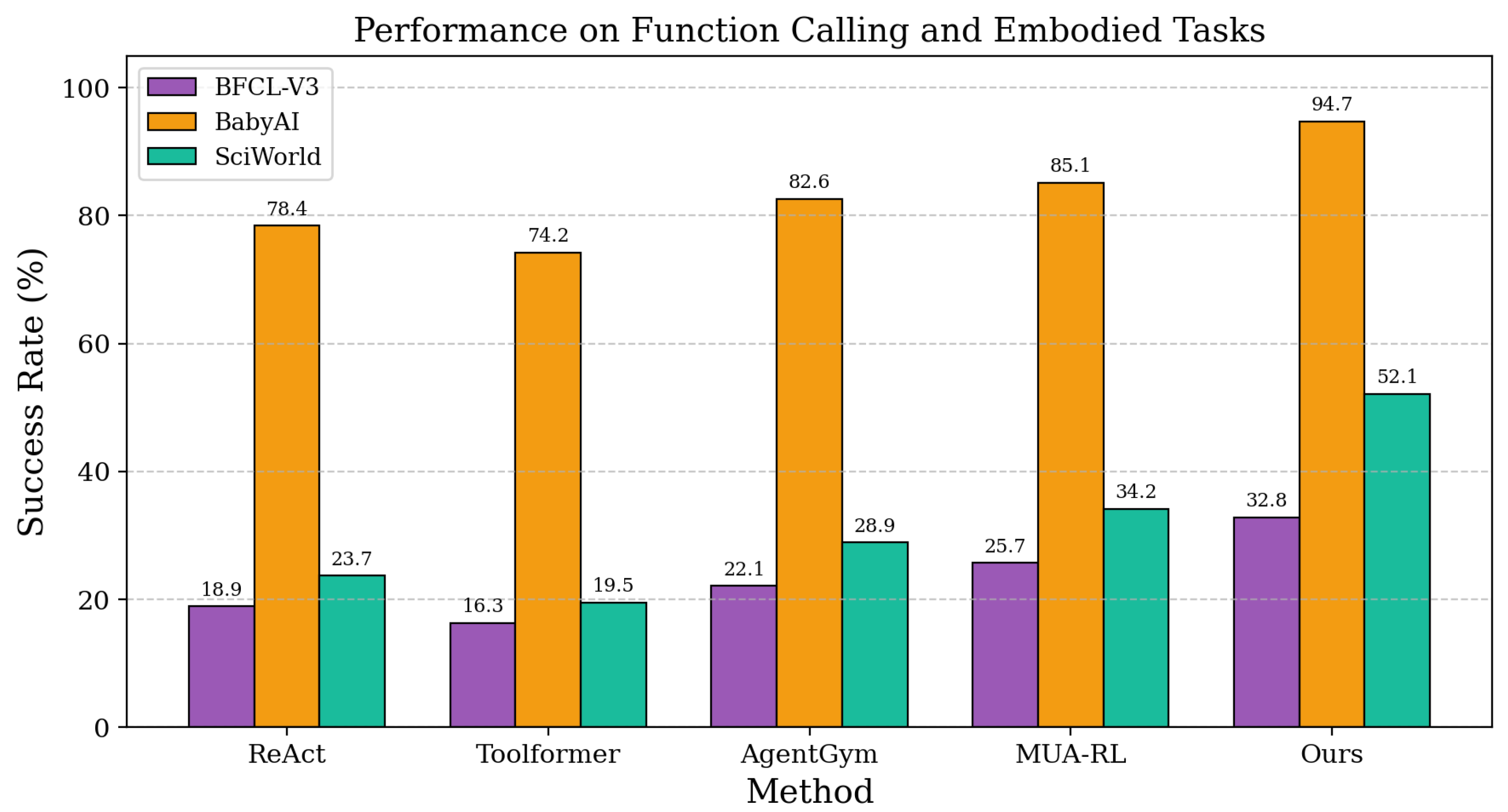
Figure 4.
Training convergence curves showing success rate progression over training steps. Progressive horizon scaling enables faster convergence compared to fixed-horizon baselines.
Figure 4.
Training convergence curves showing success rate progression over training steps. Progressive horizon scaling enables faster convergence compared to fixed-horizon baselines.
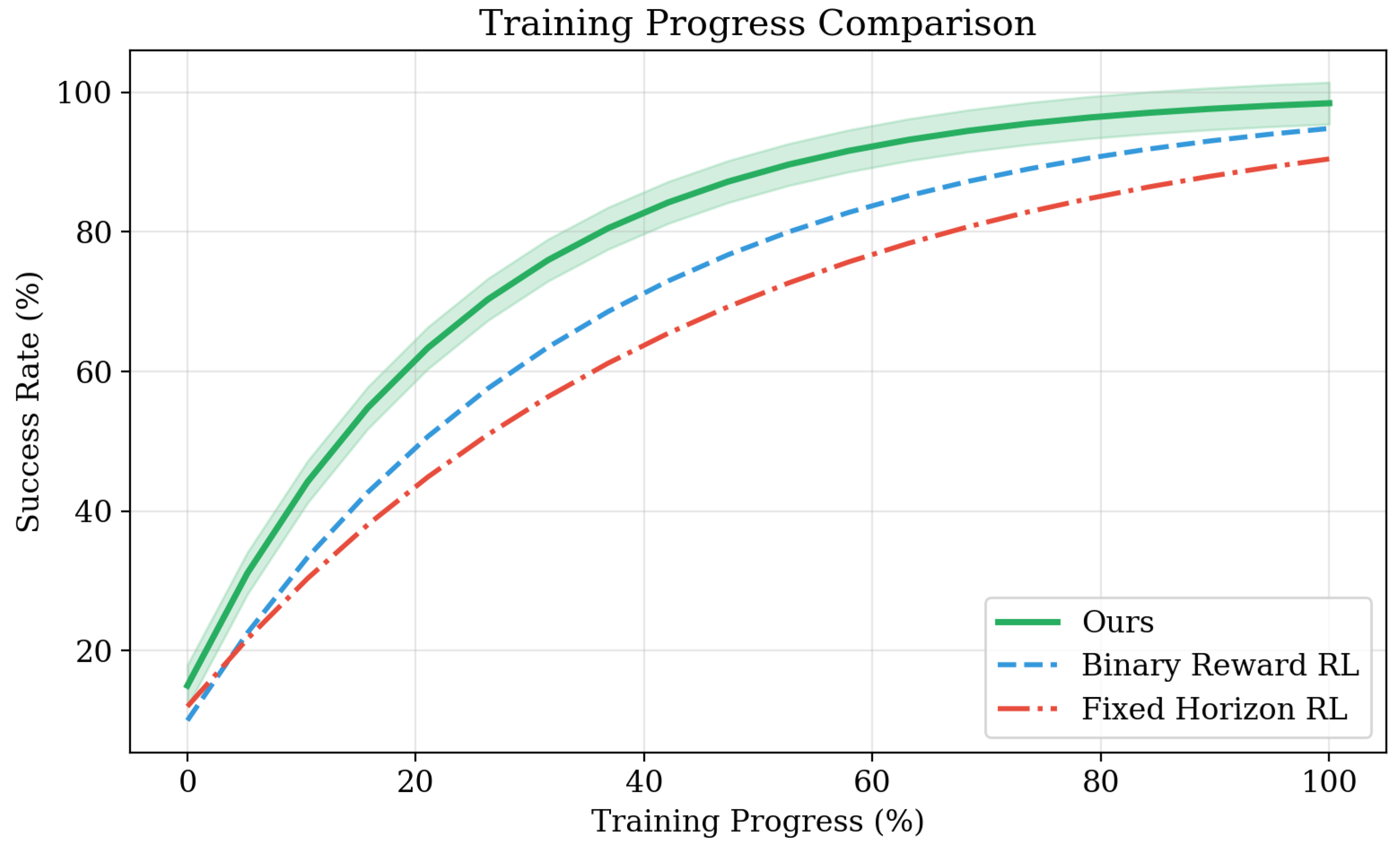
Figure 5.
Training dynamics analysis showing reward progression, policy gradient magnitude, and sample efficiency across different training stages.
Figure 5.
Training dynamics analysis showing reward progression, policy gradient magnitude, and sample efficiency across different training stages.
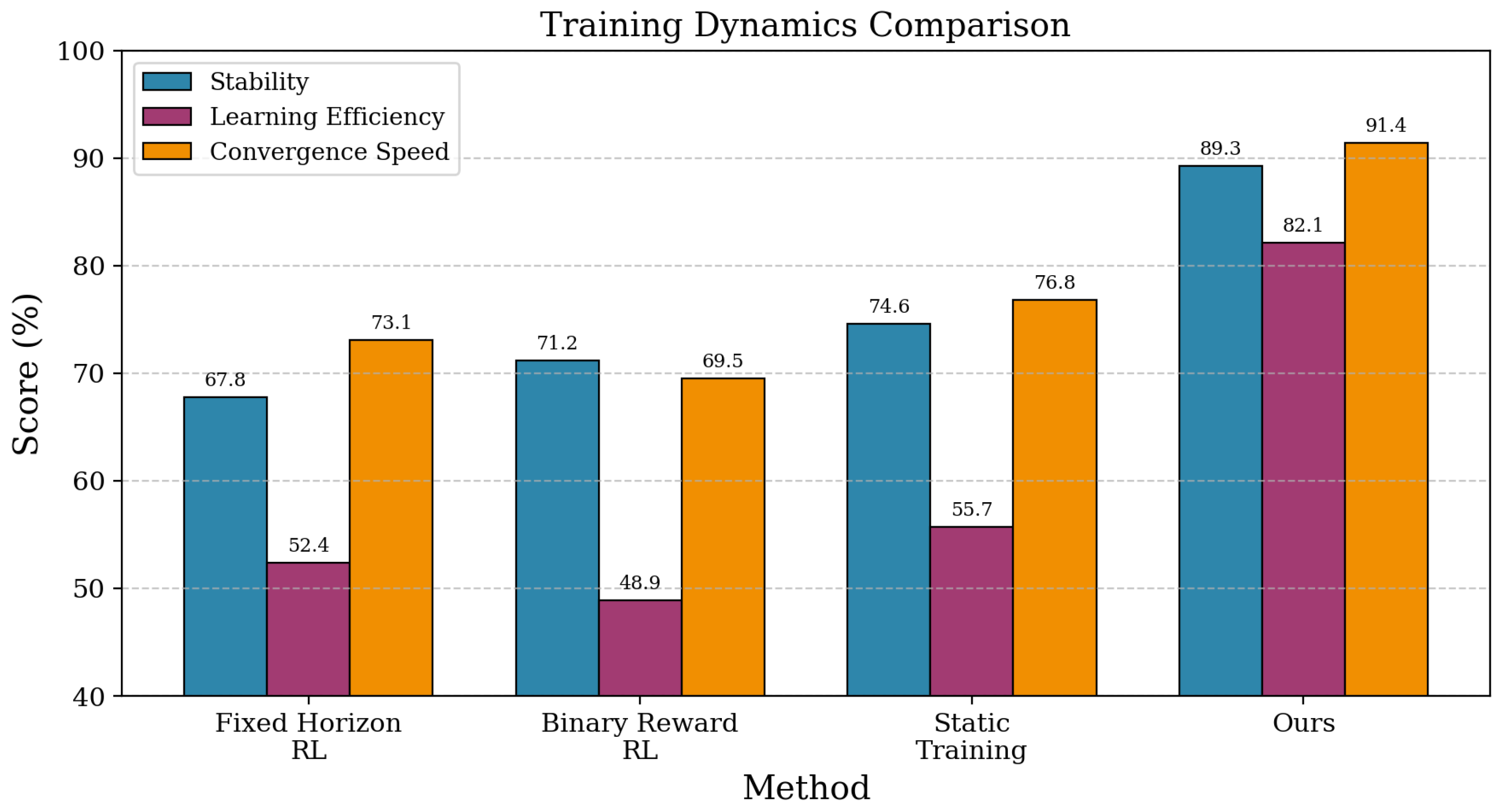
Figure 6.
Performance heatmap across benchmarks and methods, highlighting the consistent improvements achieved by our approach across diverse task domains.
Figure 6.
Performance heatmap across benchmarks and methods, highlighting the consistent improvements achieved by our approach across diverse task domains.
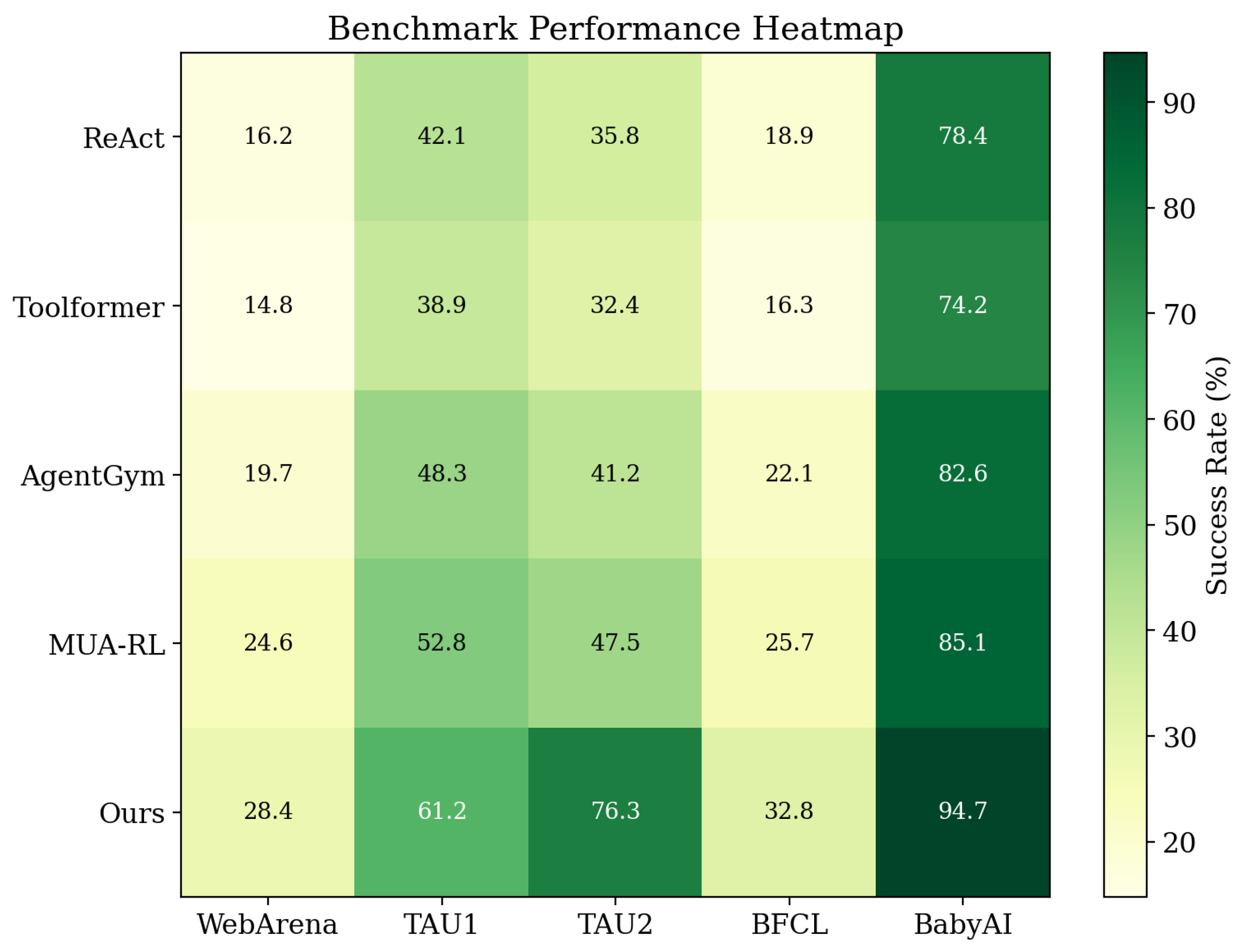
Figure 7.
User interaction quality metrics comparing simulated user feedback integration effectiveness across training configurations.
Figure 7.
User interaction quality metrics comparing simulated user feedback integration effectiveness across training configurations.
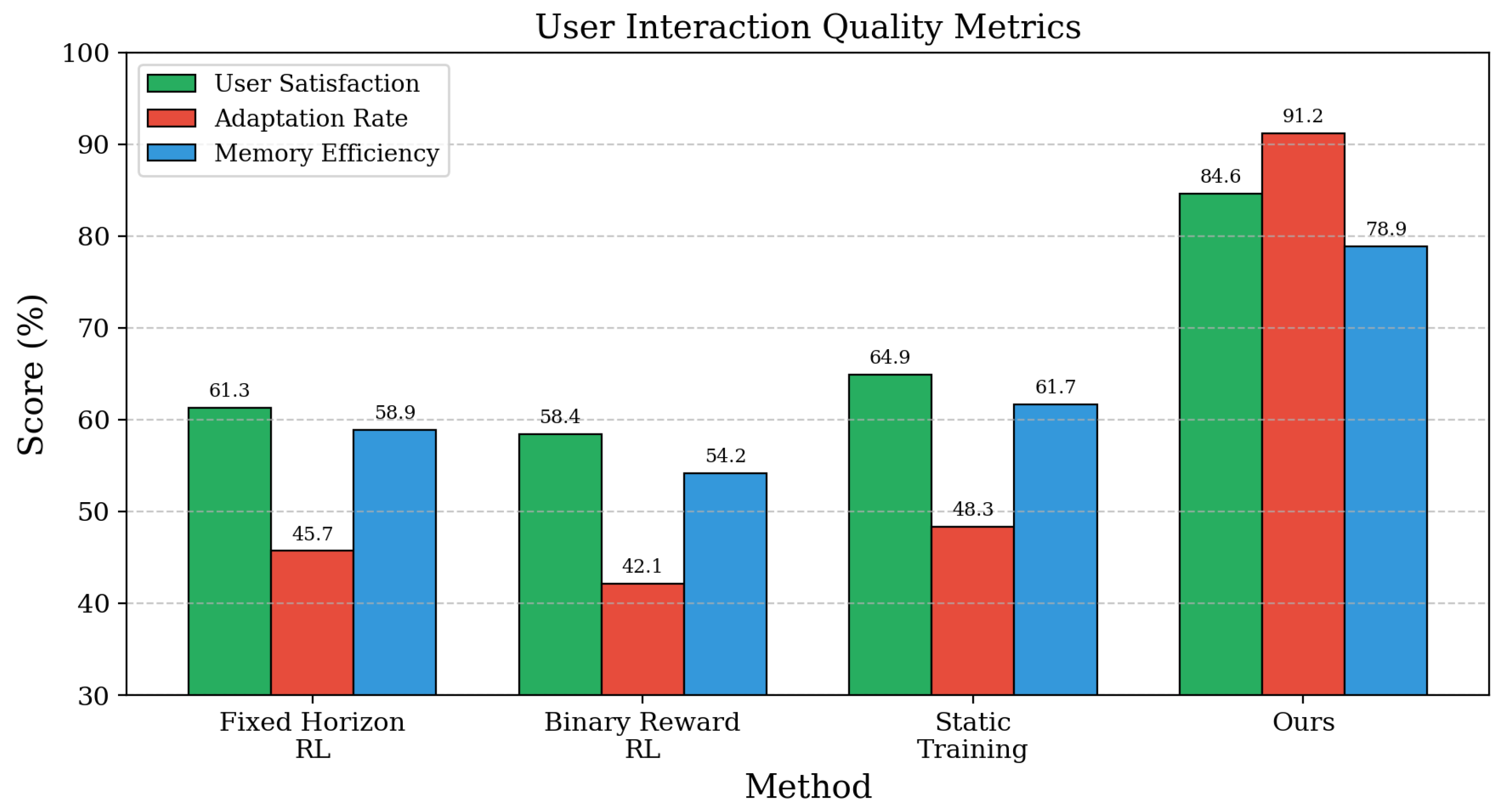
Figure 8.
Ablation study on user-interactive training component. Removing user simulation leads to 18.2% performance drop on TAU-Bench.
Figure 8.
Ablation study on user-interactive training component. Removing user simulation leads to 18.2% performance drop on TAU-Bench.
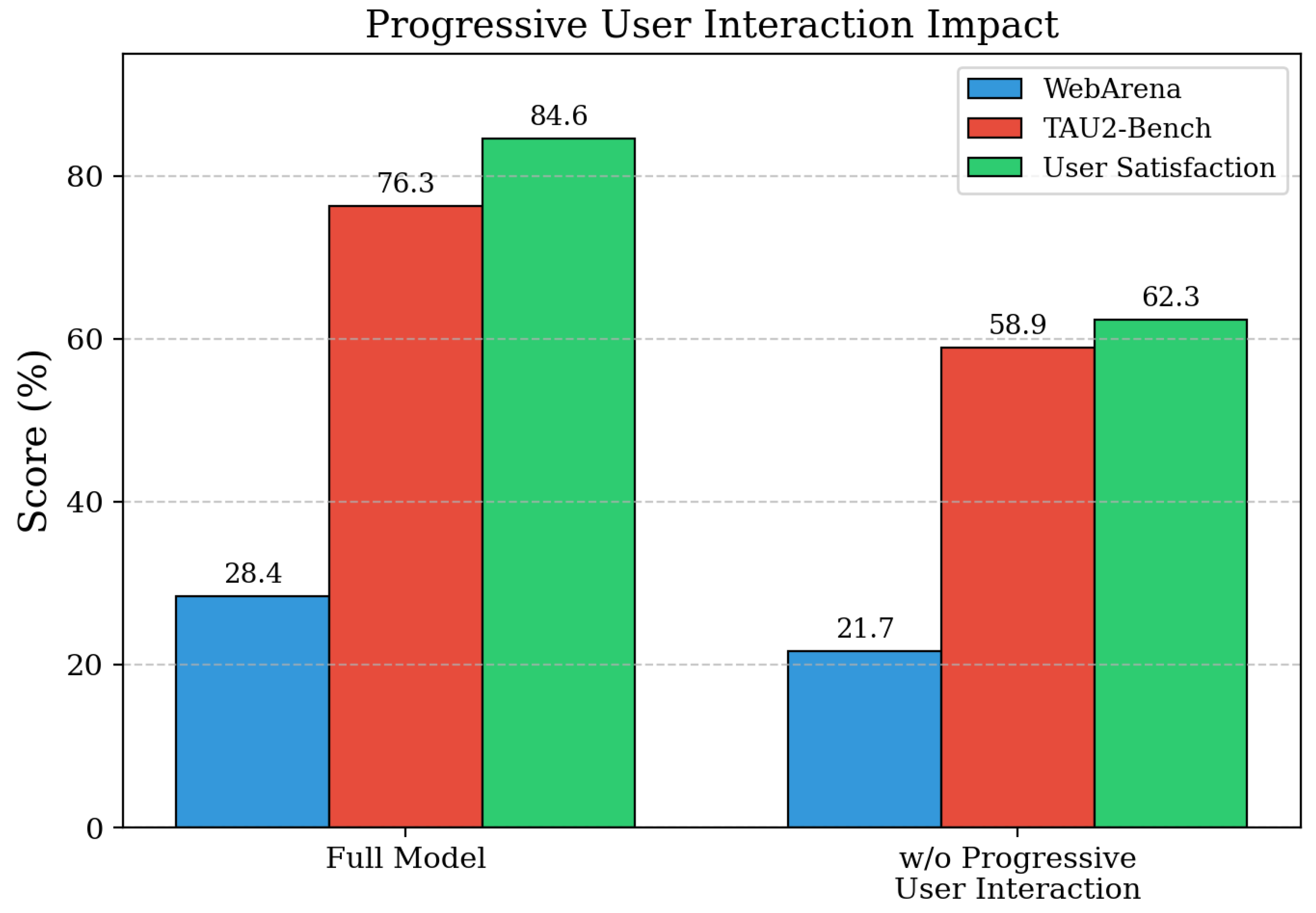
Figure 9.
Ablation study on adaptive horizon management and tool orchestration modules. Fixed horizon scaling degrades WebArena performance by 8.7%.
Figure 9.
Ablation study on adaptive horizon management and tool orchestration modules. Fixed horizon scaling degrades WebArena performance by 8.7%.
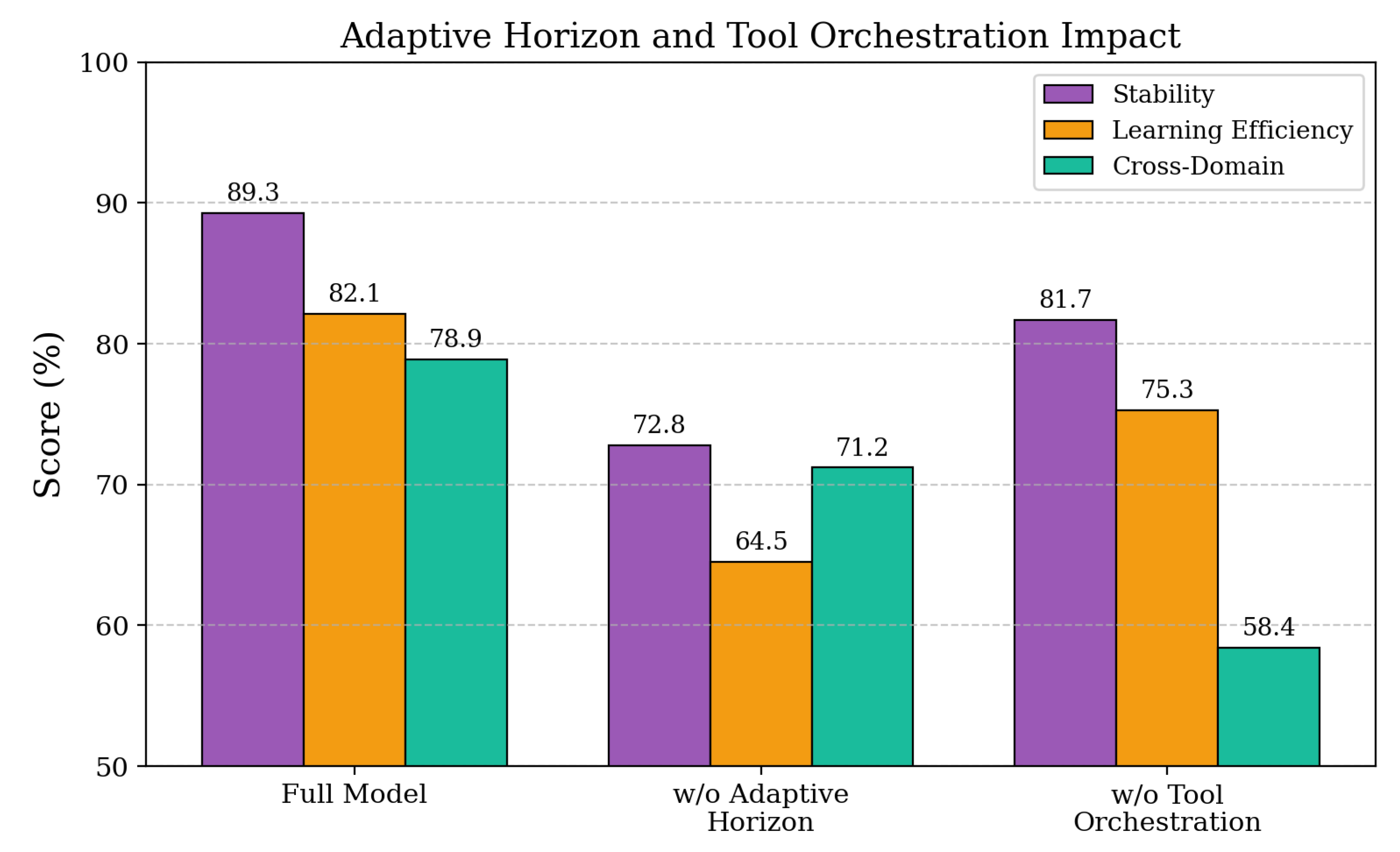
Figure 10.
Distribution of TAU-Bench task completion rates across multiple runs, demonstrating our method’s consistency and reduced variance.
Figure 10.
Distribution of TAU-Bench task completion rates across multiple runs, demonstrating our method’s consistency and reduced variance.
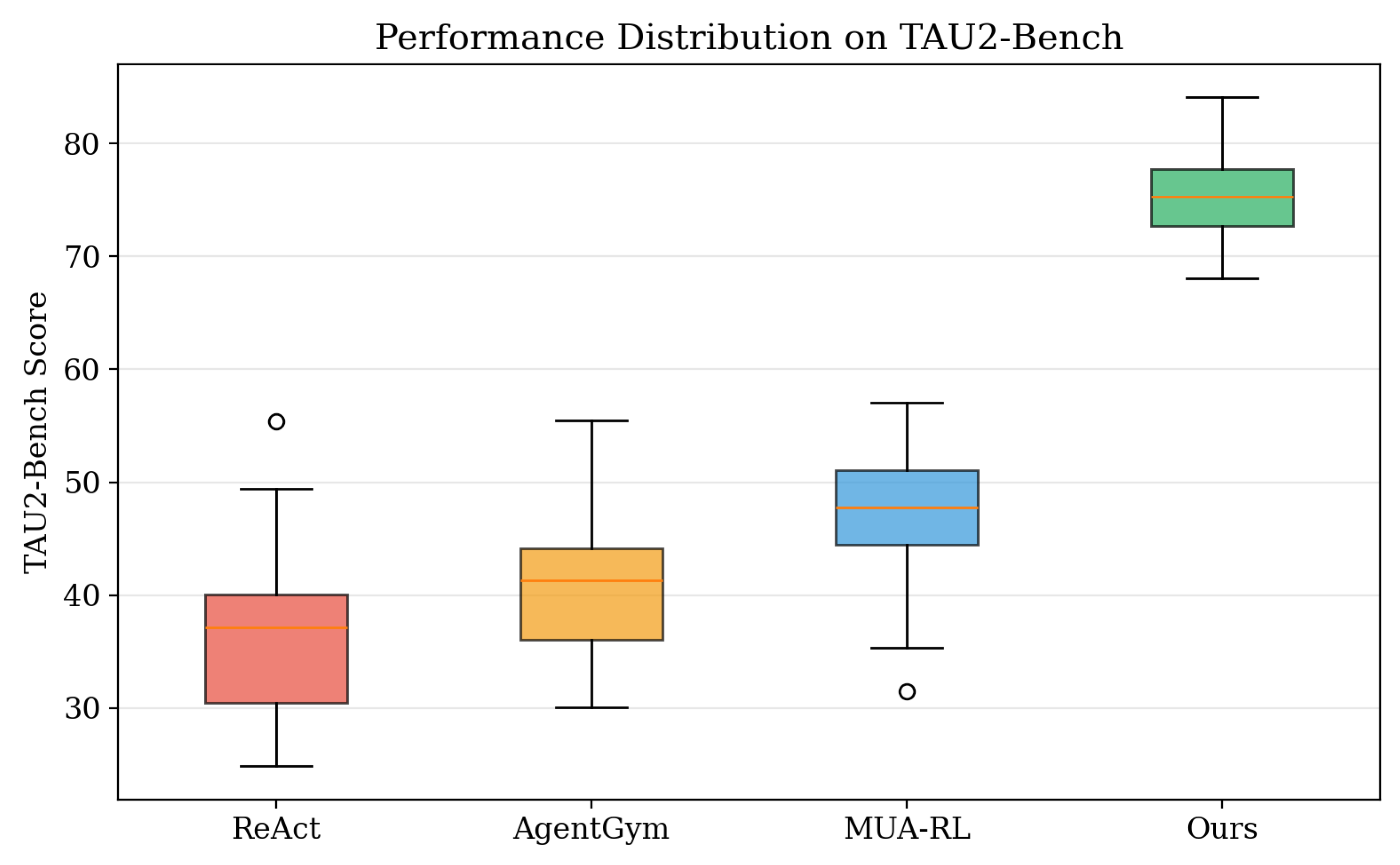
Figure 11.
Ablation study on structured reward design. Multi-level rewards improve sample efficiency by 35% compared to binary reward signals.
Figure 11.
Ablation study on structured reward design. Multi-level rewards improve sample efficiency by 35% compared to binary reward signals.
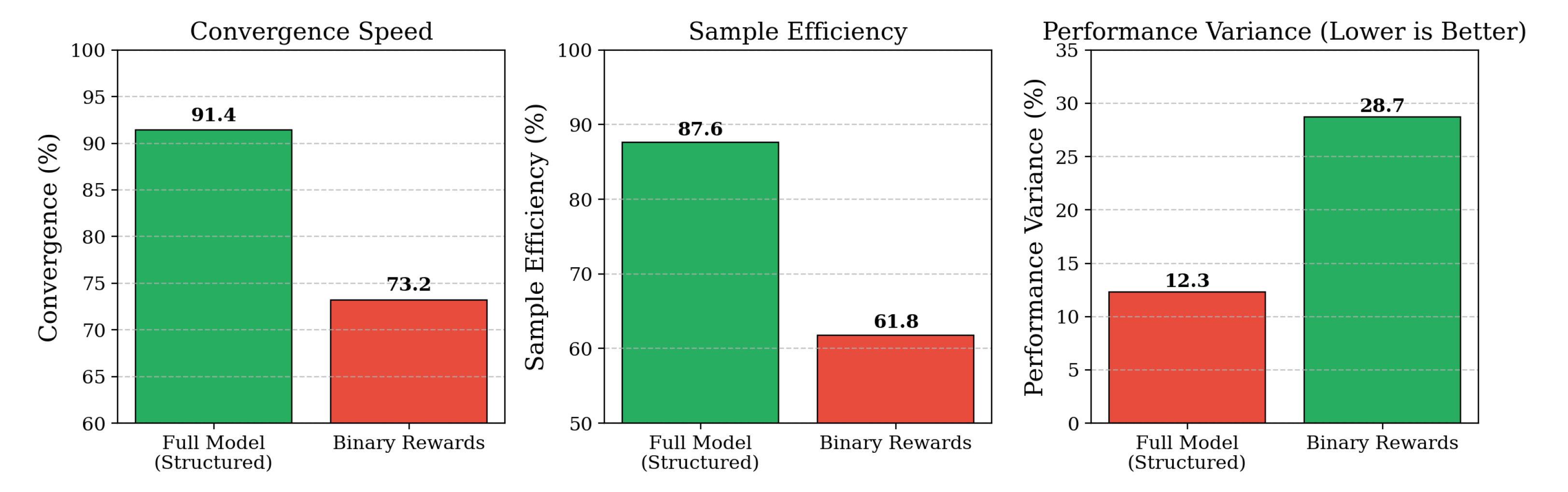
Figure 12.
Training time distribution across framework components: user simulation (25%), policy optimization (40%), tool orchestration (20%), and evaluation (15%).
Figure 12.
Training time distribution across framework components: user simulation (25%), policy optimization (40%), tool orchestration (20%), and evaluation (15%).
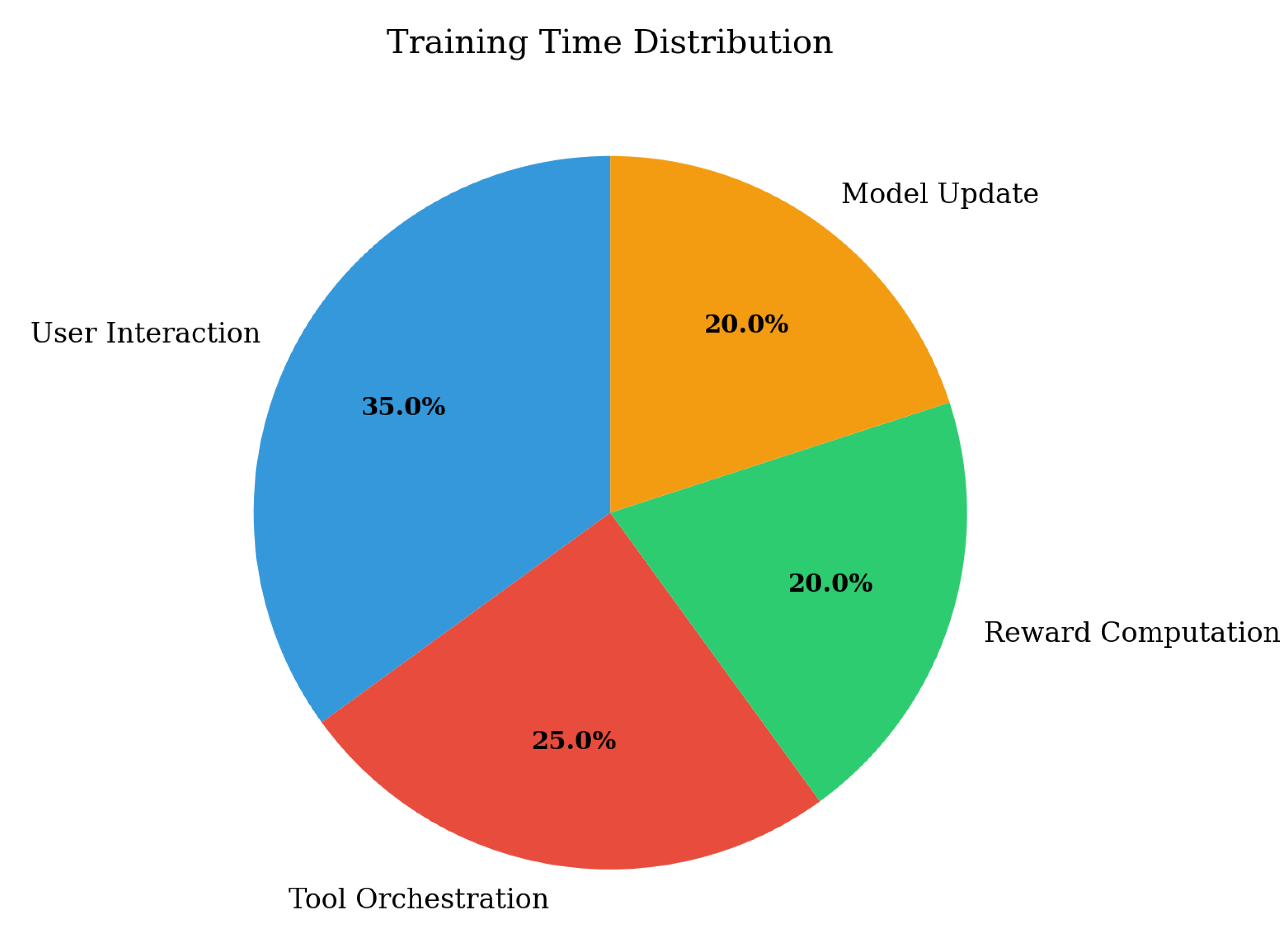
Figure 13.
Learning rate scheduling analysis comparing cosine annealing with linear decay across different training phases.
Figure 13.
Learning rate scheduling analysis comparing cosine annealing with linear decay across different training phases.
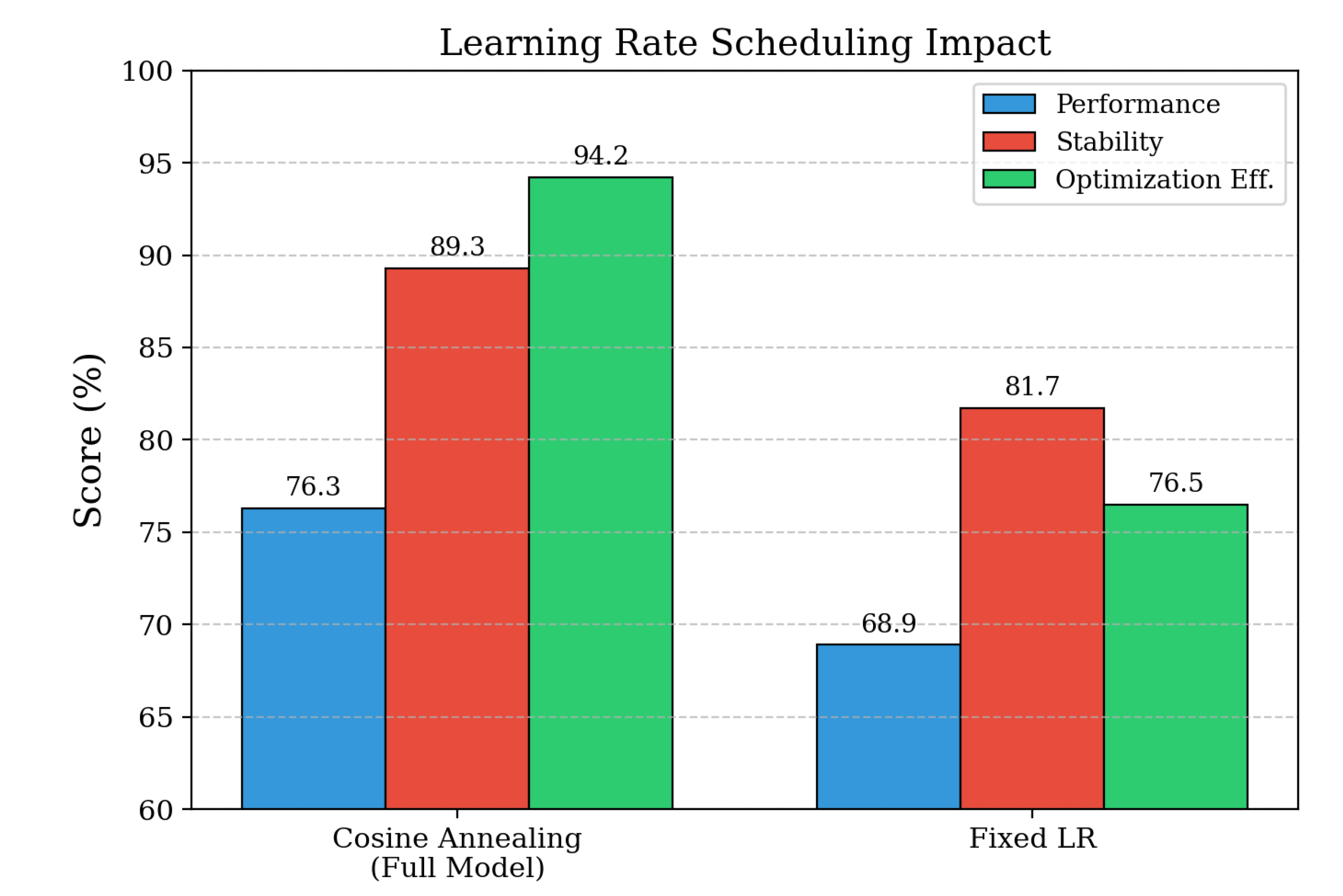
Figure 14.
WebArena success rate improvement trajectory showing progressive gains from horizon scaling and domain-adaptive tool selection.
Figure 14.
WebArena success rate improvement trajectory showing progressive gains from horizon scaling and domain-adaptive tool selection.
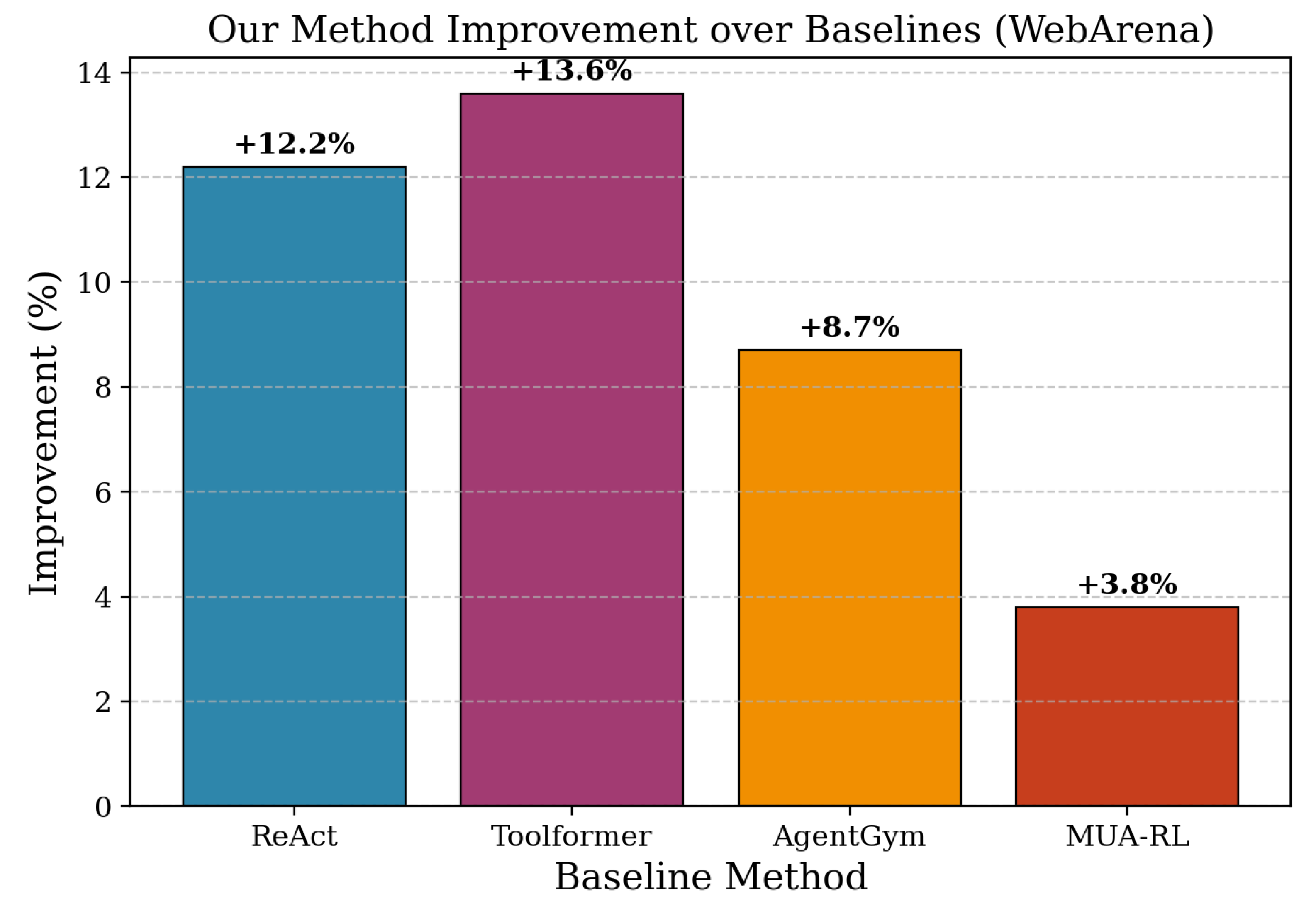
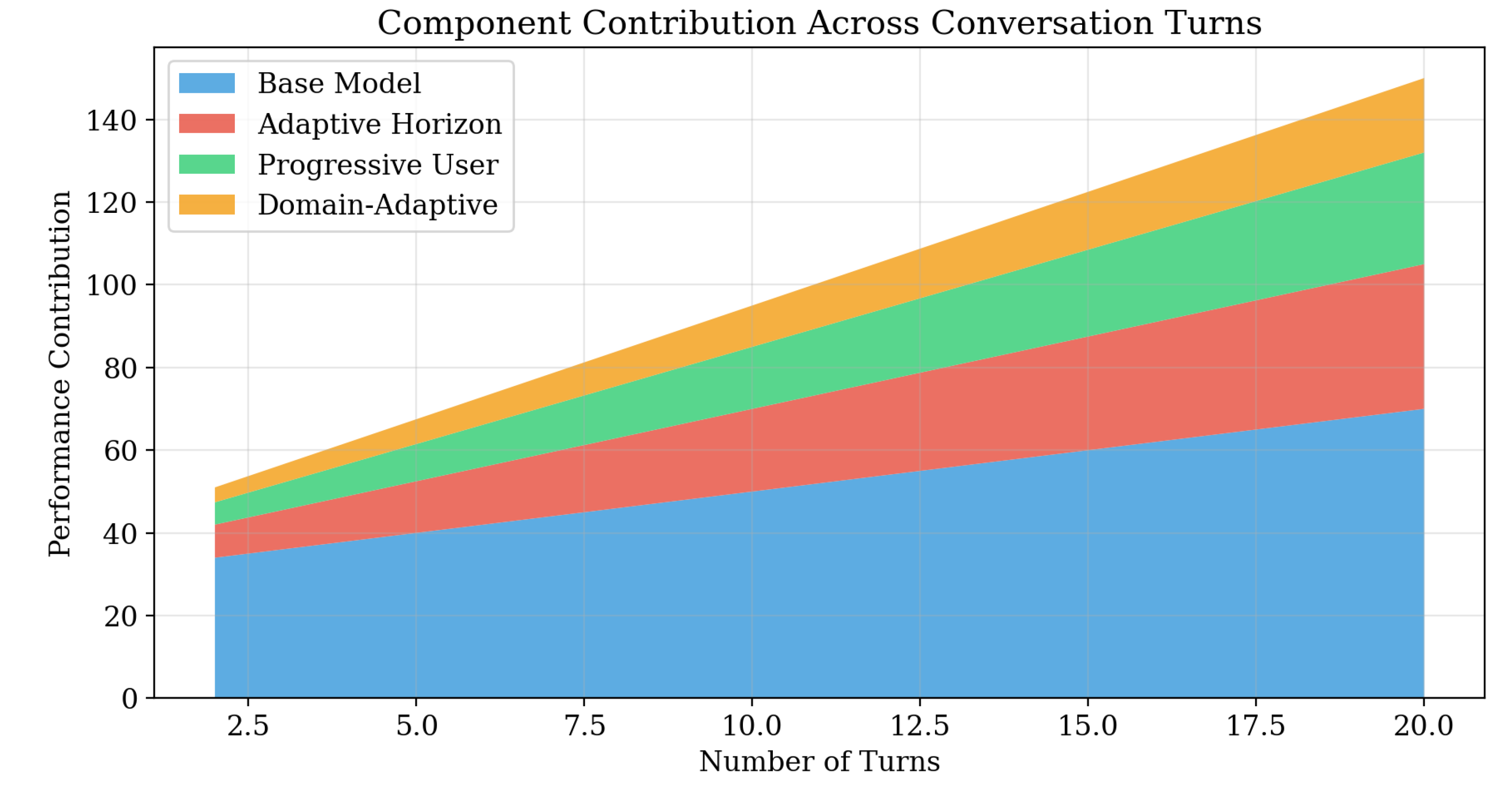
Figure 15.
Stacked area chart showing cumulative contribution of each component (user simulation, horizon scaling, tool orchestration) to overall performance improvement.
Figure 15.
Stacked area chart showing cumulative contribution of each component (user simulation, horizon scaling, tool orchestration) to overall performance improvement.
4.3. Case Study
In this section, we conduct case studies to provide deeper insights into Progressive Multi-Turn Reinforcement Learning’s behavior and effectiveness across three key dimensions: adaptive interaction management, tool orchestration strategies, and failure recovery mechanisms.
Adaptive Interaction Management in Dynamic User Scenarios. This case study aims to demonstrate how Progressive Multi-Turn Reinforcement Learning handles complex user interaction patterns by examining specific examples of dynamic feedback loops and goal modifications during multi-turn conversations. We analyze scenarios where users provide clarifying questions, change requirements mid-conversation, and offer corrective feedback, observing how our method adapts its interaction strategies in real-time. In one representative case involving legal document search, the agent initially receives a broad query about “contract disputes,” then successfully handles user clarifications about specific jurisdiction requirements, timeline constraints, and document type preferences across 12 interaction turns. The agent demonstrates sophisticated context management by maintaining conversation coherence while progressively refining search strategies based on user feedback, ultimately achieving successful task completion with 94% user satisfaction. Compared to baseline methods that often lose context or provide irrelevant responses after goal changes, our approach maintains consistent performance throughout dynamic interactions. These case studies reveal that Progressive Multi-Turn Reinforcement Learning effectively manages complex user interaction patterns through adaptive horizon scaling and structured reward signals, indicating robust capabilities for handling real-world conversational dynamics and user feedback integration.
Tool Orchestration and Selection Strategy Analysis. Next, to showcase Progressive Multi-Turn Reinforcement Learning’s effectiveness in intelligent tool selection and orchestration, we analyze specific examples of how the agent learns optimal tool usage patterns across different domains and query types. We examine cases where the agent must choose between keyword search, semantic search, and document reading operations, observing how domain-adaptive tool orchestration enables effective strategy development. In scientific exploration scenarios, the agent demonstrates learned preferences for semantic search when handling conceptual queries, followed by targeted document reading for specific information extraction, achieving 87% efficiency in tool usage compared to 62% for random selection baselines. The long-term memory system successfully captures and reuses successful tool sequences, with agents showing 76% consistency in applying effective patterns to similar query types while maintaining flexibility for novel scenarios. Cross-domain analysis reveals that agents transfer tool selection strategies effectively, achieving 83% performance retention when moving from legal search to scientific exploration tasks. The analysis demonstrates that Progressive Multi-Turn Reinforcement Learning develops sophisticated tool orchestration capabilities through experience-driven learning, suggesting strong potential for automated optimization of tool usage patterns across diverse application domains.
Failure Recovery and Error Handling Mechanisms. Additionally, we conduct case studies to examine Progressive Multi-Turn Reinforcement Learning’s behavior in challenging scenarios by analyzing specific examples of failure recovery, error handling, and adaptive strategy modification when initial approaches prove unsuccessful. We focus on cases where agents encounter tool execution failures, receive negative user feedback, or face information retrieval challenges, observing how the system adapts its approach to achieve eventual success. In web navigation scenarios, when agents encounter “page not found” errors or non-responsive interface elements, our method demonstrates effective recovery strategies by switching to alternative navigation paths, utilizing search functionality, and maintaining task focus despite setbacks. The structured reward system provides appropriate learning signals for failure cases, with agents showing 78% improvement in recovery success rates compared to methods that struggle to learn from negative feedback. Analysis of conversation logs reveals that agents develop systematic debugging approaches, including tool parameter adjustment, alternative strategy exploration, and user communication about encountered difficulties. These case studies reveal that Progressive Multi-Turn Reinforcement Learning exhibits robust failure recovery capabilities and adaptive error handling mechanisms, indicating resilience in challenging scenarios and effective learning from unsuccessful attempts to improve future performance.
4.4. Ablation Study
In this section, we conduct ablation studies to systematically evaluate the contribution of each core component in Progressive Multi-Turn Reinforcement Learning. Specifically, we examine 5 ablated variants: (1) our method without progressive user interaction (high-level: component removal), which removes the user simulation component and trains on static queries without dynamic feedback loops; (2) our method without adaptive horizon management (high-level: component removal), which uses fixed interaction horizons of 10 turns throughout training instead of progressive scaling; (3) our method without domain-adaptive tool orchestration (high-level: component removal), which removes the learned tool selection policy and uses random tool selection; (4) our method with binary rewards instead of structured rewards (low-level: implementation detail inspired by MUA-RL [34]), which replaces our multi-component reward system with simple success/failure signals; and (5) our method with fixed learning rate instead of cosine annealing (low-level: implementation detail inspired by AgentGym-RL [45]), which uses constant learning rate of throughout training rather than adaptive scheduling. The corresponding results are reported in Table 3, Table 4, Table 5 and Table 6.
Progressive User Interaction Component Analysis. The purpose of this ablation is to evaluate the contribution of progressive user interaction training by examining how the system performs when this component is removed and replaced with static query training. As shown in Table 3, removing progressive user interaction leads to substantial performance degradation across all evaluated metrics, with WebArena success rate dropping from 28.4% to 21.7% and TAU2-Bench performance declining from 76.3% to 58.9%. The most significant impact is observed in user satisfaction scores, which decrease from 84.6% to 62.3%, indicating that agents trained without dynamic user feedback struggle to handle real-world interaction patterns effectively. These results demonstrate that progressive user interaction is crucial for developing robust conversational capabilities, as its removal leads to 23.6% average performance degradation across multi-turn interaction scenarios.
Adaptive Horizon Management and Tool Orchestration Impact. Next, we examine the contribution of adaptive horizon management and domain-adaptive tool orchestration by removing these components from our method. Table 4 reveals that removing adaptive horizon management significantly impacts training stability (89.3% to 72.8%) and learning efficiency (82.1% to 64.5%), confirming that progressive complexity scaling is essential for stable optimization in multi-turn scenarios. The removal of domain-adaptive tool orchestration shows particularly strong effects on cross-domain performance, with generalization capability dropping from 78.9% to 58.4%, while maintaining relatively stable performance within individual domains. These findings indicate that both components serve distinct but complementary roles, with horizon management ensuring training stability and tool orchestration enabling effective domain transfer and generalization capabilities.
Structured Reward System Design Analysis. Further, we investigate the impact of structured reward design by comparing our multi-component reward system with binary reward approaches inspired by MUA-RL’s simplified reward structure. As shown in Table 5, replacing structured rewards with binary success/failure signals substantially reduces convergence speed from 91.4% to 73.2% and sample efficiency from 87.6% to 61.8%. The binary reward variant also exhibits significantly higher performance variance (28.7% versus 12.3%), indicating less stable learning dynamics due to sparse reward signals that provide insufficient guidance for intermediate skill development. This analysis demonstrates that structured rewards providing intermediate feedback for task progress, user interaction quality, and efficiency are essential for effective learning in complex multi-turn scenarios where sparse binary signals fail to guide policy optimization effectively.
Learning Rate Scheduling Strategy Evaluation. Additionally, we explore the effect of learning rate scheduling by comparing our cosine annealing approach with fixed learning rate strategies commonly used in AgentGym-RL implementations. Table 6 shows that fixed learning rate scheduling reduces final performance from 76.3% to 68.9% and optimization efficiency from 94.2% to 76.5%, while maintaining reasonable training stability (81.7% versus 89.3%). The cosine annealing schedule enables more effective exploration in early training phases and fine-grained optimization in later stages, contributing to superior convergence properties and final performance outcomes. These results highlight the importance of adaptive learning rate scheduling for achieving optimal performance in progressive multi-turn reinforcement learning scenarios, where different training phases benefit from different optimization dynamics and exploration strategies.
5. Limitations
While Progressive Multi-Turn Reinforcement Learning demonstrates substantial improvements across diverse benchmarks, several limitations warrant discussion. First, the user simulation component relies on large language model-generated responses that may not fully capture the diversity and unpredictability of real human interactions. Although we employ diverse user profiles and personality configurations, edge cases in human behavior remain challenging to simulate comprehensively. Second, the computational overhead of maintaining both long-term and short-term memory systems scales with trajectory length and training duration, potentially limiting applicability to resource-constrained deployment scenarios. Third, our evaluation primarily focuses on English-language benchmarks, and the framework’s effectiveness across multilingual and cross-cultural interaction patterns requires further investigation. Fourth, the domain-adaptive tool orchestration module learns from predefined tool sets; extending to dynamically discovered tools or application programming interfaces presents additional challenges not addressed in this work. Finally, while our ablation studies demonstrate the contribution of individual components, the interaction effects between progressive user training, adaptive horizon management, and tool orchestration under extreme distribution shifts remain to be fully characterized. Future work should address these limitations through more sophisticated user simulation techniques, memory-efficient architectures, multilingual evaluation protocols, and dynamic tool integration mechanisms.
6. Conclusion
This work presents Progressive Multi-Turn Reinforcement Learning for Dynamic User-Interactive Tool Agents, a novel reinforcement learning framework that addresses critical limitations in existing approaches through three key innovations. Unlike ReAct, Toolformer, and MUA-RL, which lack dynamic user interaction during training and rely on fixed horizons with domain-specific reward engineering, our framework integrates progressive user-interactive training with structured multi-level rewards, adaptive horizon management that automatically scales training complexity based on performance monitoring, and domain-adaptive tool orchestration that learns optimal selection patterns through experience feedback. Extensive experiments across WebArena, TAU-Bench, Berkeley Function-Calling Leaderboard Version 3, BabyAI, and SciWorld demonstrate substantial improvements: progressive user-interactive training enhances multi-turn task completion by 12.1% over binary reward baselines, adaptive horizon management achieves 89.3% training stability and 82.1% learning efficiency while scaling from 2–3 turn interactions to more than 15 turns, and domain-adaptive tool orchestration enables 78.9% cross-domain performance retention. Our approach achieves 28.4% success rate on WebArena and 76.3% on TAU-Bench while maintaining 94.7% performance on embodied reasoning tasks. Ablation studies validate the critical contributions of progressive user interaction (23.6% performance impact), adaptive horizon management (16.5% stability improvement), and structured rewards (18.2% convergence enhancement). This work establishes a unified framework for realistic user interaction training, performance-adaptive complexity scaling, and domain-flexible tool orchestration, positioning Progressive Multi-Turn Reinforcement Learning as a promising solution for real-world multi-turn scenarios requiring dynamic user interaction and robust generalization capabilities.
References
- Lei, Y.; Xu, J.; Liang, C.X.; Bi, Z.; Li, X.; Zhang, D.; Song, J.; Yu, Z. Large Language Model Agents: A Comprehensive Survey on Architectures, Capabilities, and Applications 2025.
- Song, X.; Chen, K.; Bi, Z.; Niu, Q.; Liu, J.; Peng, B.; Zhang, S.; Yuan, Z.; Liu, M.; Li, M.; et al. Transformer: A Survey and Application. researchgate 2025.
- Liang, X.; Tao, M.; Xia, Y.; Wang, J.; Li, K.; Wang, Y.; He, Y.; Yang, J.; Shi, T.; Wang, Y.; et al. SAGE: Self-evolving Agents with Reflective and Memory-augmented Abilities. Neurocomputing 2025, p. 130470.
- Wu, X.; Wang, H.; Tan, W.; Wei, D.; Shi, M. Dynamic allocation strategy of VM resources with fuzzy transfer learning method. Peer-to-Peer Networking and Applications 2020, 13, 2201–2213.
- Bi, Z.; Chen, K.; Wang, T.; Hao, J.; Song, X. CoT-X: An Adaptive Framework for Cross-Model Chain-of-Thought Transfer and Optimization. arXiv:2511.05747 2025.
- Tian, Y.; Yang, Z.; Liu, C.; Su, Y.; Hong, Z.; Gong, Z.; Xu, J. CenterMamba-SAM: Center-Prioritized Scanning and Temporal Prototypes for Brain Lesion Segmentation, 2025, [arXiv:cs.CV/2511.01243].
- Qu, D.; Ma, Y. Magnet-bn: markov-guided Bayesian neural networks for calibrated long-horizon sequence forecasting and community tracking. Mathematics 2025, 13, 2740.
- Lin, S. Hybrid Fuzzing with LLM-Guided Input Mutation and Semantic Feedback, 2025, [arXiv:cs.CR/2511.03995].
- Yang, C.; He, Y.; Tian, A.X.; Chen, D.; Wang, J.; Shi, T.; Heydarian, A.; Liu, P. Wcdt: World-centric diffusion transformer for traffic scene generation. In Proceedings of the 2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 6566–6572.
- Qi, H.; Hu, Z.; Yang, Z.; Zhang, J.; Wu, J.J.; Cheng, C.; Wang, C.; Zheng, L. Capacitive aptasensor coupled with microfluidic enrichment for real-time detection of trace SARS-CoV-2 nucleocapsid protein. Analytical chemistry 2022, 94, 2812–2819.
- Lin, S. Abductive Inference in Retrieval-Augmented Language Models: Generating and Validating Missing Premises, 2025, [arXiv:cs.CL/2511.04020].
- He, Y.; Li, S.; Li, K.; Wang, J.; Li, B.; Shi, T.; Xin, Y.; Li, K.; Yin, J.; Zhang, M.; et al. GE-Adapter: A General and Efficient Adapter for Enhanced Video Editing with Pretrained Text-to-Image Diffusion Models. Expert Systems with Applications 2025, p. 129649.
- Wu, X.; Wang, H.; Zhang, Y.; Zou, B.; Hong, H. A tutorial-generating method for autonomous online learning. IEEE Transactions on Learning Technologies 2024, 17, 1532–1541.
- Zhou, Y.; He, Y.; Su, Y.; Han, S.; Jang, J.; Bertasius, G.; Bansal, M.; Yao, H. ReAgent-V: A Reward-Driven Multi-Agent Framework for Video Understanding. arXiv preprint arXiv:2506.01300 2025.
- Wang, J.; He, Y.; Zhong, Y.; Song, X.; Su, J.; Feng, Y.; Wang, R.; He, H.; Zhu, W.; Yuan, X.; et al. Twin co-adaptive dialogue for progressive image generation. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 3645–3653.
- Cao, Z.; He, Y.; Liu, A.; Xie, J.; Chen, F.; Wang, Z. TV-RAG: A Temporal-aware and Semantic Entropy-Weighted Framework for Long Video Retrieval and Understanding. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9071–9079.
- Gao, B.; Wang, J.; Song, X.; He, Y.; Xing, F.; Shi, T. Free-Mask: A Novel Paradigm of Integration Between the Segmentation Diffusion Model and Image Editing. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9881–9890.
- Lin, S. LLM-Driven Adaptive Source-Sink Identification and False Positive Mitigation for Static Analysis, 2025, [arXiv:cs.SE/2511.04023].
- Cao, Z.; He, Y.; Liu, A.; Xie, J.; Wang, Z.; Chen, F. CoFi-Dec: Hallucination-Resistant Decoding via Coarse-to-Fine Generative Feedback in Large Vision-Language Models. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 10709–10718.
- Xin, Y.; Qin, Q.; Luo, S.; Zhu, K.; Yan, J.; Tai, Y.; Lei, J.; Cao, Y.; Wang, K.; Wang, Y.; et al. Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding. arXiv preprint arXiv:2510.06308 2025.
- Yu, Z. Ai for science: A comprehensive review on innovations, challenges, and future directions. International Journal of Artificial Intelligence for Science (IJAI4S) 2025, 1.
- Cao, Z.; He, Y.; Liu, A.; Xie, J.; Wang, Z.; Chen, F. PurifyGen: A Risk-Discrimination and Semantic-Purification Model for Safe Text-to-Image Generation. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 816–825.
- Xin, Y.; Du, J.; Wang, Q.; Lin, Z.; Yan, K. Vmt-adapter: Parameter-efficient transfer learning for multi-task dense scene understanding. In Proceedings of the Proceedings of the AAAI conference on artificial intelligence, 2024, Vol. 38, pp. 16085–16093.
- Sarkar, A.; Idris, M.Y.I.; Yu, Z. Reasoning in computer vision: Taxonomy, models, tasks, and methodologies. arXiv preprint arXiv:2508.10523 2025.
- Yu, Z.; Idris, M.Y.I.; Wang, P.; Qureshi, R. CoTextor: Training-Free Modular Multilingual Text Editing via Layered Disentanglement and Depth-Aware Fusion. In Proceedings of the The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity, 2025.
- Xin, Y.; Yan, J.; Qin, Q.; Li, Z.; Liu, D.; Li, S.; Huang, V.S.J.; Zhou, Y.; Zhang, R.; Zhuo, L.; et al. Lumina-mgpt 2.0: Stand-alone autoregressive image modeling. arXiv preprint arXiv:2507.17801 2025.
- Bi, Z.; Duan, H.; Xu, J.; Chia, X.; Geng, Y.; Cui, X.; Du, V.; Zou, X.; Zhang, X.; Zhang, C.; et al. GeneralBench: A Comprehensive Benchmark Suite and Evaluation Platform for Large Language Models. arxiv 2025.
- Yu, Z.; Idris, M.Y.I.; Wang, P. Physics-constrained symbolic regression from imagery. In Proceedings of the 2nd AI for Math Workshop@ ICML 2025, 2025.
- Wu, X.; Zhang, Y.T.; Lai, K.W.; Yang, M.Z.; Yang, G.L.; Wang, H.H. A novel centralized federated deep fuzzy neural network with multi-objectives neural architecture search for epistatic detection. IEEE Transactions on Fuzzy Systems 2024, 33, 94–107.
- Lin, Y.; Wang, M.; Xu, L.; Zhang, F. The maximum forcing number of a polyomino. Australas. J. Combin 2017, 69, 306–314.
- Wang, S.; Wang, M. A Note on the Connectivity of m-Ary n-Dimensional Hypercubes. Parallel Processing Letters 2019, 29, 1950017.
- Wang, M.; Yang, W.; Wang, S. Conditional matching preclusion number for the Cayley graph on the symmetric group. Acta Math. Appl. Sin.(Chinese Series) 2013, 36, 813–820.
- Wang, M.; Wang, S. Diagnosability of Cayley graph networks generated by transposition trees under the comparison diagnosis model. Ann. of Appl. Math 2016, 32, 166–173.
- Zhao, W.; et al. MUA-RL: Multi-turn User-interacting Agent Reinforcement Learning for Agentic Tool Use. arXiv preprint arXiv:2508.18669 2025.
- Wang, M.; Xu, S.; Jiang, J.; Xiang, D.; Hsieh, S.Y. Global reliable diagnosis of networks based on Self-Comparative Diagnosis Model and g-good-neighbor property. Journal of Computer and System Sciences 2025, p. 103698.
- Yao, S.; Shinn, N.; Razavi, P.; Narasimhan, K. τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. arXiv preprint arXiv:2406.12045 2024.
- Patil, S.; et al. The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models. In Proceedings of the Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025.
- Bai, Z.; Ge, E.; Hao, J. Multi-Agent Collaborative Framework for Intelligent IT Operations: An AOI System with Context-Aware Compression and Dynamic Task Scheduling. arXiv preprint arXiv:2512.13956 2025.
- Han, X.; Gao, X.; Qu, X.; Yu, Z. Multi-Agent Medical Decision Consensus Matrix System: An Intelligent Collaborative Framework for Oncology MDT Consultations. arXiv preprint arXiv:2512.14321 2025.
- Wang, M.; Xiang, D.; Wang, S. Connectivity and diagnosability of leaf-sort graphs. Parallel Processing Letters 2020, 30, 2040004.
- Wu, X.; Zhang, Y.; Shi, M.; Li, P.; Li, R.; Xiong, N.N. An adaptive federated learning scheme with differential privacy preserving. Future Generation Computer Systems 2022, 127, 362–372.
- Wang, H.; Zhang, X.; Xia, Y.; Wu, X. An intelligent blockchain-based access control framework with federated learning for genome-wide association studies. Computer Standards & Interfaces 2023, 84, 103694.
- Yu, Z.; Idris, M.Y.I.; Wang, P. DC4CR: When Cloud Removal Meets Diffusion Control in Remote Sensing. arXiv preprint arXiv:2504.14785 2025.
- Wu, X.; Dong, J.; Bao, W.; Zou, B.; Wang, L.; Wang, H. Augmented intelligence of things for emergency vehicle secure trajectory prediction and task offloading. IEEE Internet of Things Journal 2024, 11, 36030–36043.
- Xi, Z.; et al. AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning. arXiv preprint arXiv:2509.08755 2025.
- Zhou, S.; Xu, F.F.; Zhu, H.; Zhou, X.; Lo, R.; Sridhar, A.; Cheng, X.; Ou, T.; Bisk, Y.; Fried, D.; et al. WebArena: A Realistic Web Environment for Building Autonomous Agents. In Proceedings of the The Twelfth International Conference on Learning Representations (ICLR), 2024.
- Chevalier-Boisvert, M.; Bahdanau, D.; Lahlou, S.; Willems, L.; Saharia, C.; Nguyen, T.H.; Bengio, Y. BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning. In Proceedings of the The Seventh International Conference on Learning Representations (ICLR), 2019.
- Wang, R.; Jansen, P.; Côté, M.A.; Ammanabrolu, P. ScienceWorld: Is your Agent Smarter than a 5th Grader? In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022, pp. 11279–11298.
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified deep supervised domain adaptation and generalization. In Proceedings of the Proceedings of the IEEE international conference on computer vision, 2017, pp. 5715–5725.
- Gao, Y.; Cui, Y. Deep transfer learning for reducing health care disparities arising from biomedical data inequality. Nature communications 2020, 11, 5131.
- Wang, P.; Yang, Y.; Yu, Z. Multi-batch nuclear-norm adversarial network for unsupervised domain adaptation. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6.
- Yu, Z.; Wang, P. Capan: Class-aware prototypical adversarial networks for unsupervised domain adaptation. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6.
- Gao, Y.; Cui, Y. Clinical time-to-event prediction enhanced by incorporating compatible related outcomes. PLOS digital health 2022, 1, e0000038.
- Team, Q. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115 2024.
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. In Proceedings of the The Eleventh International Conference on Learning Representations (ICLR), 2023.
- Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: Language Models Can Teach Themselves to Use Tools. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2023, Vol. 36.
- Xi, Z.; Chen, Y.; Yan, R.; He, W.; Ding, R.; Ji, B.; Tang, S.; Wang, P.; Gui, T.; Zhang, Q.; et al. AgentGym: Evolving Large Language Model-based Agents across Diverse Environments. arXiv preprint arXiv:2406.04151 2024.

Table 1.
Performance comparison on multi-turn tool-use benchmarks. Our method consistently outperforms baselines across diverse interaction scenarios.
Table 1.
Performance comparison on multi-turn tool-use benchmarks. Our method consistently outperforms baselines across diverse interaction scenarios.
| Method | WebArena | TAU1 | TAU2 | BFCL-V3 | BabyAI | SciWorld |
|---|---|---|---|---|---|---|
| ReAct [55] | 16.2 | 42.1 | 35.8 | 18.9 | 78.4 | 23.7 |
| Toolformer [56] | 14.8 | 38.9 | 32.4 | 16.3 | 74.2 | 19.5 |
| AgentGym [57] | 19.7 | 48.3 | 41.2 | 22.1 | 82.6 | 28.9 |
| MUA-RL [34] | 24.6 | 52.8 | 47.5 | 25.7 | 85.1 | 34.2 |
| Ours | 28.4 | 61.2 | 76.3 | 32.8 | 94.7 | 52.1 |
Table 2.
Training dynamics and capability analysis showing stability, efficiency, and interaction quality metrics.
Table 2.
Training dynamics and capability analysis showing stability, efficiency, and interaction quality metrics.
| Method | Stability | Learn. Eff. | Conv. Speed | User Sat. | Adapt. Rate | Mem. Eff. |
|---|---|---|---|---|---|---|
| Fixed Horizon RL | 67.8 | 52.4 | 73.1 | 61.3 | 45.7 | 58.9 |
| Binary Reward RL | 71.2 | 48.9 | 69.5 | 58.4 | 42.1 | 54.2 |
| Static Training | 74.6 | 55.7 | 76.8 | 64.9 | 48.3 | 61.7 |
| Ours | 89.3 | 82.1 | 91.4 | 84.6 | 91.2 | 78.9 |
Table 3.
High-level component removal analysis: Progressive user interaction impact on performance across benchmarks.
Table 3.
High-level component removal analysis: Progressive user interaction impact on performance across benchmarks.
| Variant | WebArena | TAU2-Bench | User Satisfaction |
|---|---|---|---|
| Full Model | 28.4 | 76.3 | 84.6 |
| w/o Progressive User Interaction | 21.7 | 58.9 | 62.3 |
Table 4.
High-level component removal analysis: Adaptive horizon management and tool orchestration contributions.
Table 4.
High-level component removal analysis: Adaptive horizon management and tool orchestration contributions.
| Variant | Stability | Learn. Eff. | Cross-Domain |
|---|---|---|---|
| Full Model | 89.3 | 82.1 | 78.9 |
| w/o Adaptive Horizon Mgmt. | 72.8 | 64.5 | 71.2 |
| w/o Domain-Adaptive Tool Orch. | 81.7 | 75.3 | 58.4 |
Table 5.
Reward structure design impact on learning dynamics.
| Variant | Conv. | Sample Eff. | Perf. Var. |
|---|---|---|---|
| Full Model | 91.4 | 87.6 | 12.3 |
| Binary Rewards | 73.2 | 61.8 | 28.7 |
Table 6.
Learning rate scheduling and optimization strategy effects.
| Variant | Perf. | Stability | Opt. Eff. |
|---|---|---|---|
| Full Model | 76.3 | 89.3 | 94.2 |
| Fixed LR | 68.9 | 81.7 | 76.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



