Submitted:
19 February 2026
Posted:
20 February 2026
You are already at the latest version
Abstract
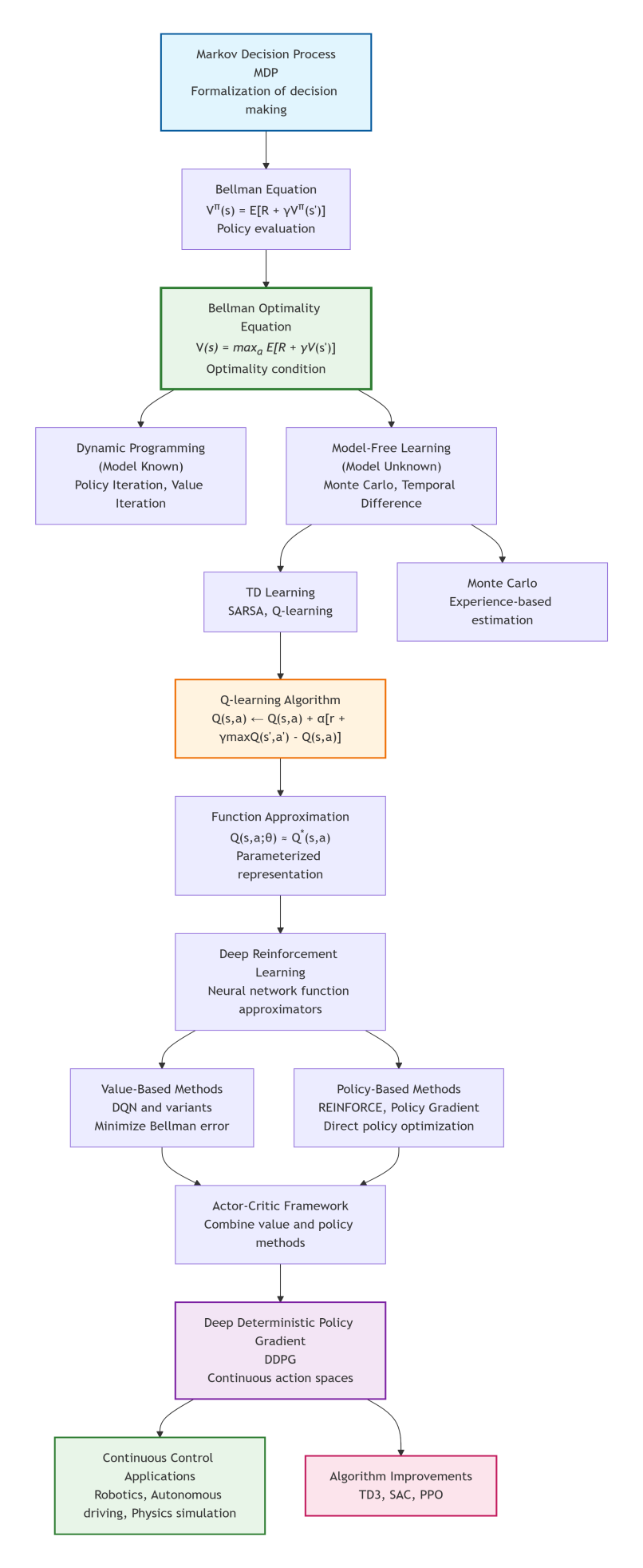
Following the evolution from theoretical foundations to advanced deep learning algorithms, a coherent overview of reinforcement learning (RL) is proposed in this tutorial. We begin with the mathematical formalization of sequential decision-making via Markov decision processes (MDPs). In MDP, Bellman equation and Bellman optimality equation play important roles, they provide for policy evaluation and the fundamental condition for optimal behavior, respectively. The movement from these equations to practical algorithms is explored, starting with model-based dynamic programming and progressing to model-free temporal-difference (TD) learning. As a pivotal model-free algorithm, Q-learning directly implements the Bellman optimality equation through sampling. To handle high-dimensional state spaces, function approximation and deep reinforcement learning emerge, exemplified by Deep Q-Networks (DQN). Thereafter, actor-critic methods address the challenge of continuous action spaces. As a typical actor-critic scheme, the deep deterministic policy gradient (DDPG) algorithm is illustrated in detail on how it adapts the principles of optimality to continuous control by maintaining separate actor and critic networks. Finally, the tutorial concludes with a unified perspective, observing the development of RL as a logical progression from defining optimality conditions to developing scalable solution algorithms. Furthermore, future directions are summarized.
Keywords:
reinforcement learning
; tutorial
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



