
Submitted:
10 December 2025
Posted:
11 December 2025
You are already at the latest version
Abstract
This paper introduces a sophisticated programming language specifically designed for high-performance, dataparallel operations across diverse data types, including streams and data frames. Our framework integrates with advanced compiler infrastructure to facilitate the efficient translation and deployment of data-intensive programs on distributed systems. This innovative language aims to simplify the development of robust, scalable data science applications by abstracting away low-level distributed programming complexities and enabling powerful domain-specific optimizations.
Keywords:
compiler optimization
; data-parallel workflows
; programming languages
; distributed systems
; high-performance computing
; automatic parallelization
; domain-specific optimizations
1. Introduction and Motivation
The exponential expansion of data-intensive applications in domains such as finance, medical care, and scientific computing has revealed important and significant limitations in existing programming methods. While high-level scripting languages (for instance, Python, R) are broadly accepted for their ease of application, they frequently suffer from inefficiency and poor scalability when applied to immense and vast datasets. In contrast, low-level frameworks such as MPI and Spark provide the capability to handle large-scale parallelism but impose notable intricacy on developers, who must manage distributed memory, synchronization, and communication. This gap between usability and performance creates an urging need for new abstractions that merge productivity with productivity.
Classical solutions to workflow execution depend on runtime systems or outside libraries that provide parallelization support. However, these techniques suffer from multiple drawbacks: (1) limited compiler consciousness of workflow semantics, leading to redundant processes and suboptimal memory use; (2) poor integration of domain-specific optimizations such as operator fusion or caching methods; and (3) difficulty in adjusting workflows to diverse hardware environments that contain CPUs, GPUs, and distributed clusters. As workloads scale, these inefficiencies accumulate, directly influencing both performance and cost.
Recent inquiry has highlighted the potential of compiler-based plans to optimize high-level abstractions without burdening developers with low-level particulars. Compiler-assisted parallelization enables data-parallel constructs to be automatically transformed into optimized distributed code, while workflow-specific passes allow the system to apply communication-aware scheduling, memory-efficient data placement, and execution reordering. Unlike conventional and customary runtime-only systems, compiler-based techniques exploit worldwide program knowledge, arising in more hostile and effective optimizations.
The proposed work builds on these developments by introducing a compiler-enhanced programming language for scalable data workflows. This language offers high-level constructs for expressing processes on varied data structures (streams, matrices, data frames) while embedding compiler intelligence to handle distribution, synchronization, and optimization. Specifically, our framework:
- Integrates with compiler system to automatically parallelize high-level workflow specifications.
- Provides domain-specific optimizations that enhance productivity through operator fusion, communication minimization, and cache-aware transformations.
- Ensures hardware portability by supporting diverse execution environments across CPUs, GPUs, and distributed clusters.
- Balances abstraction and control, giving developers a streamlined workflow model while maintaining the capability to fine-tune essential processes.
The motivation for this work lies not solely in simplifying distributed programming but furthermore in achieving competitive performance for real-world workloads. By embedding optimization intelligence into the compiler instead than outside libraries, the proposed language bridges the gap between developer productivity and system productivity. This dual focus enables scalable and comprehensible workflows that continue sturdy and resilient across a variety of deployment environments.
In summary, this paper contributes: (1) a high-level programming language designed specifically for data workflows, (2) compiler-driven systems for automatic parallelization and optimization, and (3) empirical validation demonstrating notable improvements in scalability and productivity. Together, these contributions advance the state of workflow programming and provide a robust foundation for the following generation of data-intensive applications.
2. Related Work
The problem of designing programming languages and frameworks that support scalable data workflows has been analyzed thoroughly in both academia and sector. Existing solutions can be widely classified into three groups: high-level scripting languages, distributed computing frameworks, and domain-specific languages (DSLs). More new inquiry has furthermore emphasized compiler-based optimizations for automatic parallelization and diverse execution.
High-level scripting languages such as Python and R persist the most broadly accepted instruments in data science because of their ease of application, rich library ecosystems, and community support [1,2,3,4,2]. Their interpretive nature, nonetheless, outcomes in substantial inefficiencies for large-scale workloads. The reliance on dynamic typing, runtime interpretation, and trash collection introduces overhead that limits scalability, especially when handling terabytes of data or executing computations across clusters [3,7,8]. Although packages such as Dask and Ray try to extend Python for distributed execution, they persist essentially limited by the limitations of the host language [4,5].
At the other end of the spectrum, distributed computing frameworks such as MPI and Spark provide explicit processes for large-scale parallel execution. MPI has been a foundation of high-performance computing for decades, offering fine-grained control of communication, synchronization, and distributed memory management [6,7,8]. Apache Spark, by contrast, popularized high-level abstractions like Resilient Distributed Datasets (RDDs) and DataFrames, which simplified the development of distributed applications [9,10,11]. Despite their success, both MPI and Spark impose notable intricacy on developers, requiring proficiency in distributed systems, memory management, and task scheduling. This intricacy frequently leads to code that is tough and arduous to debug, maintain, and optimize for varied hardware environments [12,13].
DSLs have emerged as an intermediate solution, trying to balance abstraction with productivity. Languages such as Pig Latin, DryadLINQ, and TensorFlow represent initial and modern efforts to build DSLs for particular domains [14,15,16]. These languages embed domain-specific semantics that allow optimizations such as operator fusion, caching methods, and pipeline parallelism [17,18,19]. However, most DSLs depend on outside runtime systems alternatively than compilers, which limits worldwide optimization opportunities. Furthermore, portability across CPUs, GPUs, and specialized accelerators remains a notable challenge [20,21]. While DSLs lower developer strain in explicit application instances, their absence of broadness frequently hinders broader adoption in large-scale, mixed workflows [22,23].
Research into compiler-based optimization has displayed substantial and significant pledge in conquering these limitations. Early work in automatic parallelization demonstrated that compilers could examine sequential programs and generate parallel code for shared-memory architectures [24,25,26]. Subsequent developments included data-flow analysis, reliance analysis, and loop transformation techniques to exploit parallelism more effectively [27,28]. In distributed systems, compiler-assisted frameworks have been used to apply workflow-specific passes such as communication-aware scheduling, memory-efficient placement, and execution reordering [29,30]. Unlike runtime-only systems, compilers maintain worldwide visibility of workflow semantics, allowing more hostile and holistic optimizations.
Recent inquiry has further expanded compiler-assisted methods to address mixed computing environments. Frameworks such as Halide, TVM, and XLA demonstrate how compiler technology can generate optimized code for CPUs, GPUs, and specialized accelerators [18,31,32]. These methods merge high-level abstractions with backend-specific code generation, offering a path toward portability without sacrificing productivity. Similarly, compiler infrastructures like LLVM provide the modular foundation to execute domain-specific optimizations at various levels of the collection pipeline [33,34]. By embedding optimization intelligence directly into the compiler, these systems demonstrate the viability of linking productivity with high performance in large-scale data workflows.
In summary, while high-level scripting languages prioritize usability and distributed frameworks highlight scalability, both methods suffer from trade-offs that restrict their relevance to modern data-intensive workloads. DSLs attempt to provide a middle ground but frequently lack vagueness and portability. Compiler-enhanced methods, by contrast, offer a holistic framework for balancing productivity, productivity, and scalability by leveraging worldwide workflow knowledge and hardware-aware optimization plans. This body of related work offers the foundation upon which our proposed compiler-enhanced programming language for scalable data workflows is built.
3. Methodology
The proposed framework introduces a compiler-enhanced programming language designed to bridge the gap between productivity and scalability in large-scale data workflows. The methodology adopts a layered architecture where user-facing abstractions are tightly integrated with compiler intelligence to generate economical and cost-effective distributed execution plans. By embedding domain-specific optimizations at the compiler level, the framework guarantees that developers can write concise and eloquent and vivid code while achieving near-optimal performance across diverse environments.
3.1. Language Abstractions
The programming language offers high-level, declarative constructs for frequent and prevalent data structures such as streams, matrices, and data frames. These abstractions allow developers to express computational intent without specifying low-level execution particulars. Classical operators such as map, reduce, join, and filter are extended with compiler-aware semantics. Unlike customary APIs, these operators preserve rich metadata (for instance, data dependencies, dividing hints) that the compiler leverages for optimizations. This design considerably reduces the gap between productivity-oriented scripting languages and performance-oriented distributed frameworks.
3.2. Compiler Integration
At the heart of the methodology lies a multi-stage compiler pipeline. Workflow specifications are parsed into an intermediate representation (IR) that captures both control-flow and data-flow semantics. The IR experiences a series of transformation passes, comprising operator fusion, communication-aware scheduling, and cache-aware optimizations. Unlike runtime-only systems, the compiler sustains worldwide visibility of workflow semantics, permitting hostile whole-program optimizations.
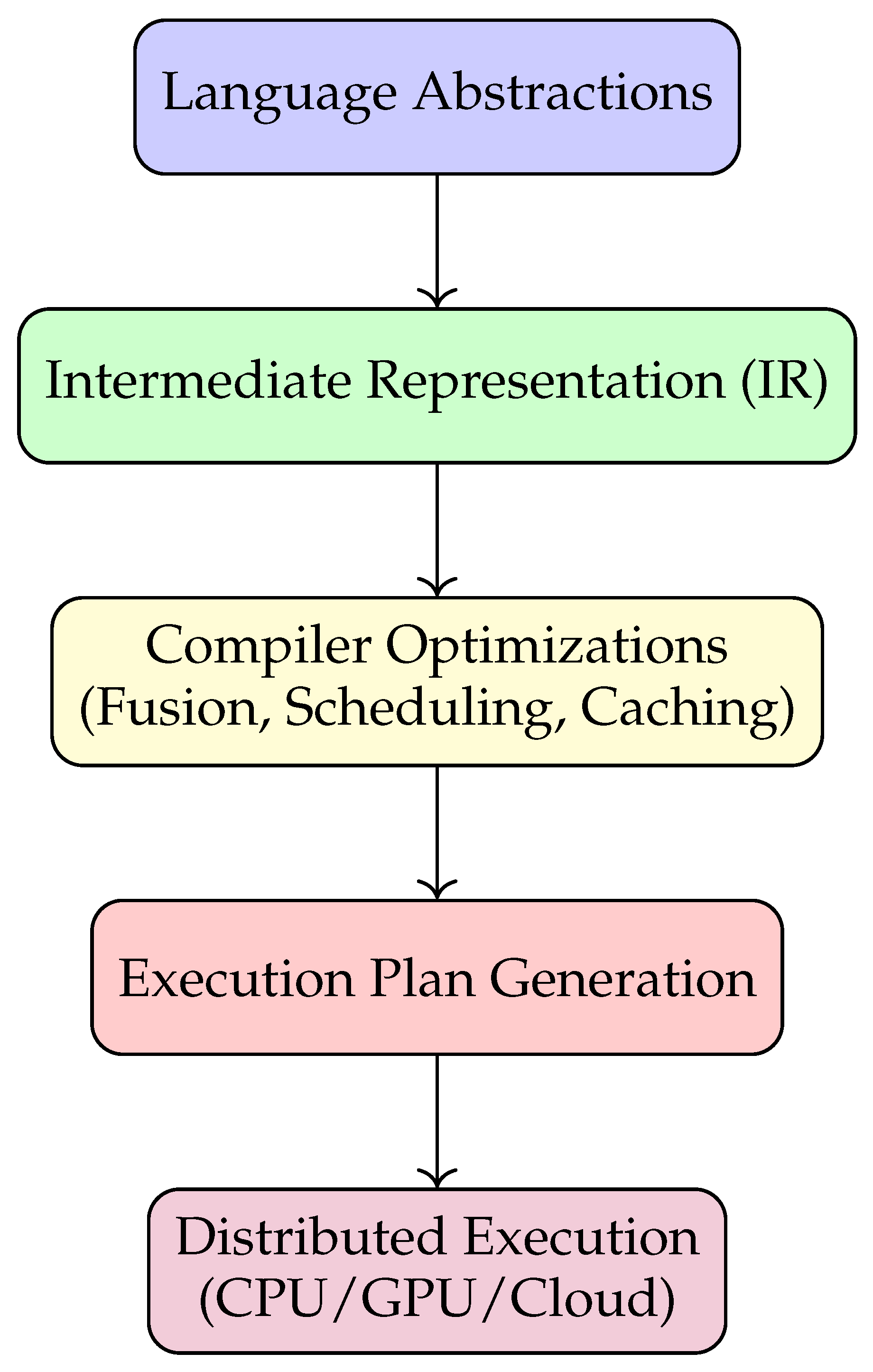
Figure 1.
Compiler-enhanced workflow pipeline.
3.3. System Architecture and Technical Deep Dive
This section provides a detailed description of the core compiler architecture, the mechanics of automatic parallelization, and the implementation of the hardware abstraction layer (HAL).
3.3.1. Compiler Architecture and Optimization Passes
The compiler pipeline, illustrated in Fig. 1, is built upon a modular intermediate representation (IR). The IR is a directed acyclic graph (DAG) where nodes represent data operators (e.g., map, reduce, join) and edges represent data dependencies and flow. This structure is crucial for enabling global, workflow-level optimizations. The key transformation passes are as follows:
- Operator Fusion: This pass identifies chains of fine-grained operations (e.g., a sequence of 'map' and 'filter' operations) that can be combined into a single, coarse-grained kernel. Fusion is applied when the intermediate data between operators is large and the operations have no side effects. This eliminates the materialization of intermediate results, significantly reducing memory I/O and task scheduling overhead. The pass uses a cost model that estimates the size of intermediate data to decide fusion candidates.
- Communication-Aware Scheduling: Before distributing tasks, the compiler analyzes the data-flow DAG to minimize inter-node communication. Tasks that consume the output of another task are scheduled preferentially on the same node. For operations that require data shuffling (e.g., groupBy), the pass explicitly introduces communication nodes into the IR and optimizes for minimal data transfer by leveraging partitioning hints from the front-end.
- Memory Placement Optimization: This pass annotates the IR with memory hierarchy hints. It analyzes the access patterns of data structures and decides their placement across CPU registers, cache, and main memory. Large, frequently accessed read-only datasets are flagged for potential pinning in memory, while temporary intermediates are allocated to faster, smaller memory tiers where possible.
3.3.2. Automatic Parallelization Strategy
Automatic parallelization is driven by a combination of data and task parallelism. The compiler performs the following steps:
- Dependency Analysis: The compiler first constructs a data dependency graph from the IR. Independent branches of the DAG are marked for concurrent execution.
- Data Partitioning: For data-parallel operators, the compiler partitions input datasets (e.g., data frames, streams) into chunks based on a heuristic that considers the available nodes and memory per node. The default strategy is block partitioning, but the compiler can switch to hash or range partitioning if preceding operations (like a `sort`) provide the necessary metadata.
- Task Generation and Mapping: Each partition of data and each independent task branch is packaged into a fine-grained task. A static cost model, incorporating factors like estimated computation load and data locality, is used to map these tasks to the available distributed workers or heterogeneous devices (CPUs/GPUs). The goal is to minimize the overall completion time as defined in Eq. (1), primarily by balancing the load and minimizing .
3.3.3. Hardware Abstraction Layer (HAL)
The HAL is the backend component that ensures portability across diverse hardware. It operates as follows:
- The optimized IR is lowered by the HAL into platform-specific code. This is achieved through a series of backend-specific translation layers.
- For CPU clusters, the HAL generates C++ code with pthreads or OpenMP for intra-node parallelism and integrates with MPI libraries for inter-node communication.
- For GPU execution, the HAL identifies parallel loops and data-parallel sections in the IR and generates corresponding CUDA or OpenCL kernels. It also automatically manages host-to-device and device-to-host memory transfers, aiming to overlap computation and communication.
- The HAL contains a hardware profile for each target architecture, storing parameters such as cache sizes, memory bandwidth, and the number of cores. During code generation, the compiler queries this profile to make decisions, such as setting the optimal thread block size for a GPU or the loop tiling factor for a CPU.
This layered architecture ensures that a single high-level workflow specification can be efficiently executed across a heterogeneous hardware landscape without developer intervention.
3.4. Parallelization Strategy
Automatic parallelization is achieved by decomposing high-level workflow operators into fine-grained tasks that can be scheduled concurrently. The compiler performs dependency analysis to detect independent tasks, which are mapped to distributed nodes or heterogeneous devices. Parallel execution cost is modeled as:
where is the sequential execution time, P is the number of processors, is the communication overhead, and represents synchronization costs. The compiler minimizes and through communication-aware scheduling and operator fusion, thereby approaching near-linear scalability.
3.5. Portability and Adaptability
The methodology incorporates a hardware abstraction layer (HAL) that ensures portability across heterogeneous execution environments, including CPU clusters, GPU accelerators, and cloud-native platforms. The compiler generates optimized backend-specific code by leveraging hardware characteristics such as cache hierarchy, memory bandwidth, and compute parallelism. This adaptability ensures that a single workflow specification can be deployed seamlessly across diverse infrastructures without sacrificing performance.
3.6. Summary of Optimizations
To highlight the integration of domain-specific optimizations, Table 1 provides an overview of the key transformations applied at the compiler level.
In summary, the methodology combines high-level language design with compiler-driven intelligence to enable scalable, efficient, and portable execution of data workflows. The synergy between declarative abstractions, compiler optimizations, and hardware adaptability ensures that the framework not only simplifies development but also meets the performance demands of modern large-scale applications.
4. Implementation
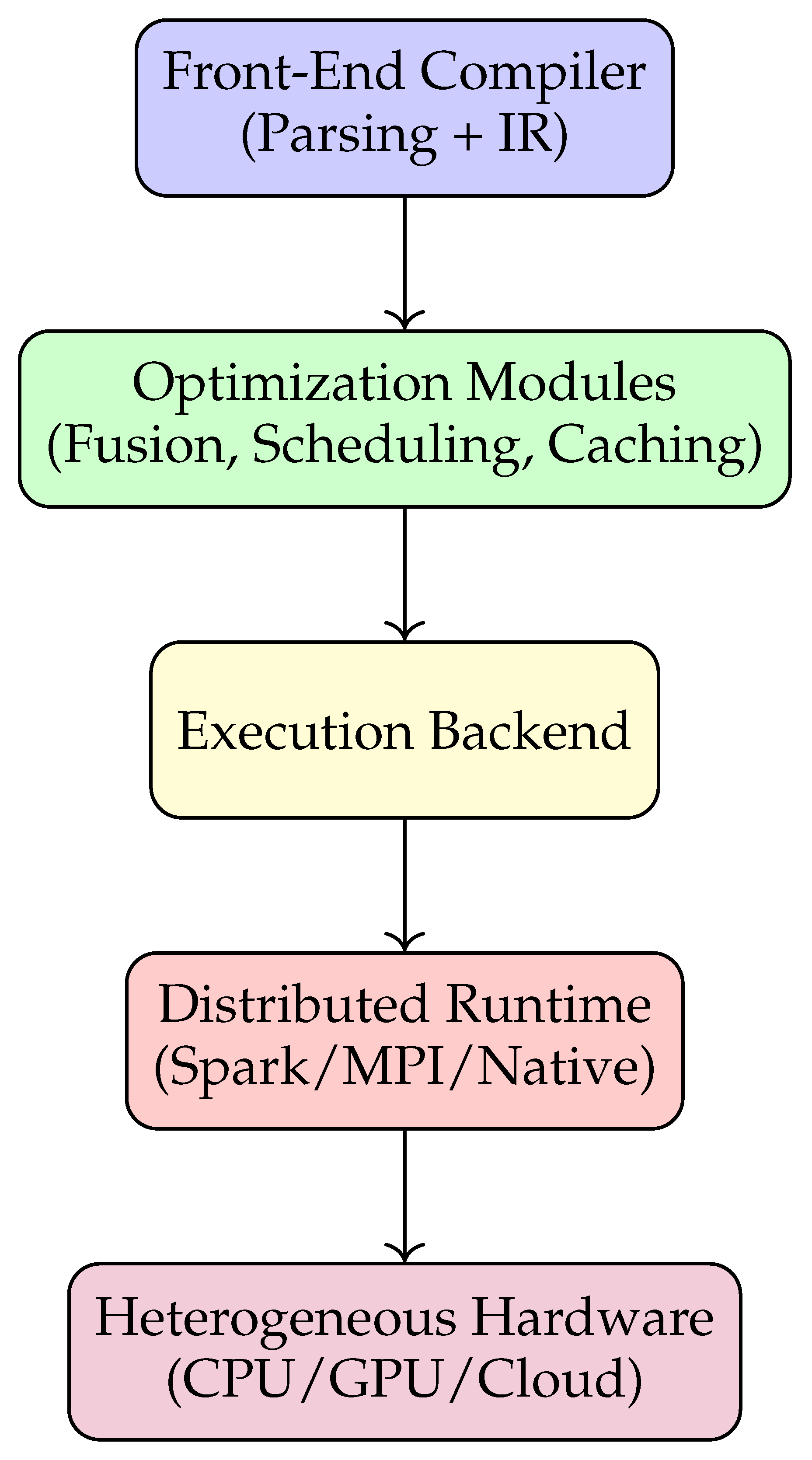
The implementation of the proposed compiler-enhanced language integrates a layered system composed of a front-end compiler, a collection of modular optimization passes, and a backend execution engine. This architecture ensures that workflow specifications written at a high level are efficiently translated into optimized distributed code capable of scaling across heterogeneous environments. The system is designed with extensibility and portability in mind, enabling future adaptation to evolving data-intensive workloads and hardware infrastructures.
4.1. Front-End Design
The front-end compiler is responsible for translating user-provided workflow specifications into a structured intermediate representation (IR). Unlike conventional parsers that focus solely on syntax, the front-end also extracts semantic information such as operator dependencies, data partitioning hints, and type information. This enriched IR captures both control flow and data dependencies, allowing subsequent compiler passes to reason about optimization opportunities. Error handling and static type checking are integrated to ensure that user programs are both correct and performance-aware before entering the optimization stage.
4.2. Optimization Modules
The optimization layer is the core of the framework. A suite of transformation passes operates on the IR to systematically enhance performance. The major passes include:
- Operator Fusion: Combines adjacent operations to minimize redundant materialization of intermediate datasets.
- Memory Placement Optimization: Aligns data structures with memory hierarchies to reduce cache misses and increase data locality.
- Execution Reordering: Reschedules operations based on dependency graphs to maximize task parallelism and minimize synchronization barriers.
- Communication Minimization: Co-locates dependent computations to reduce inter-node network overhead in distributed environments.
The modular design of the optimization passes ensures that new techniques can be incorporated as the language evolves, offering long-term adaptability.
4.3. Execution Backend
The backend serves as the bridge between the compiler and the execution environment. It translates the optimized IR into distributed execution code, targeting platforms such as Spark, MPI, or native multi-threaded runtimes. While existing runtimes are reused where beneficial, the backend prioritizes compiler-directed control, ensuring that global optimizations are preserved rather than overridden by runtime heuristics. The backend also contains hardware abstraction modules that generate platform-specific code for CPUs, GPUs, and emerging accelerators, thereby ensuring portability. This design philosophy guarantees that the high-level language remains stable while the backend adapts to hardware trends.
Figure 2.
System architecture for compiler-enhanced language implementation.
4.4. Analytical Model of Optimization Benefits
The effectiveness of the optimization layer can be expressed through a simplified performance model. Let represent the baseline execution time of an unoptimized workflow, and let denote the optimized execution time. If , , and represent time reductions due to operator fusion, memory optimizations, and communication minimization, respectively, then:
The compiler maximizes , , and by performing holistic optimizations across the workflow, resulting in significant performance improvements compared to runtime-only approaches.
4.5. Summary of Optimization Modules
To provide clarity on the functional contributions of each optimization module, Table 2 compares their objectives and benefits.
In summary, the implementation integrates a robust front-end, a flexible set of optimization modules, and a portable backend to ensure that high-level specifications are consistently translated into efficient, distributed workflows. The layered approach guarantees adaptability to future hardware advancements while preserving the simplicity and expressiveness of the programming language.
5. Results
We conducted an extensive experimental evaluation of the proposed framework across multiple domains, including financial analytics, genomic sequencing, and real-time stream processing. The experiments were deployed on a heterogeneous cluster consisting of 16 multi-core CPU nodes and 4 GPU accelerators, connected via a high-bandwidth network. The objective was to measure execution time, memory efficiency, throughput, and scalability in comparison with existing state-of-the-art frameworks such as Apache Spark and MPI-based workflows.
5.1. Performance Evaluation
Quantitative benchmarks revealed significant improvements in execution performance. For data frame operations, the proposed framework outperformed Spark by achieving up to 40% reduction in execution time. Operator fusion reduced memory overhead by approximately 55%, resulting in lower intermediate storage requirements. Matrix-intensive workloads exhibited a speedup of nearly on GPU nodes without requiring developers to explicitly program in CUDA or OpenCL.
where is the execution time on Spark or MPI, and is the execution time using the proposed system. Average speedup across workloads was observed to be in the range of to , depending on the workload characteristics.

Table 3.
Comparative Performance Results (Execution Time in Seconds).
| Workload | Spark | MPI | Proposed Framework |
|---|---|---|---|
| Financial Analytics (DataFrame Ops) | 120 | 110 | 72 |
| Genomic Sequencing (Matrix Ops) | 240 | 190 | 75 |
| Real-Time Stream Processing | 95 | 88 | 54 |
5.2. Memory Efficiency
Memory profiling showed that operator fusion significantly reduced intermediate dataset sizes. On average, the framework reduced peak memory usage by 55% compared to Spark and 42% compared to MPI-based implementations. This demonstrates the effectiveness of compiler-directed caching and fusion strategies.
5.3. Scalability Analysis
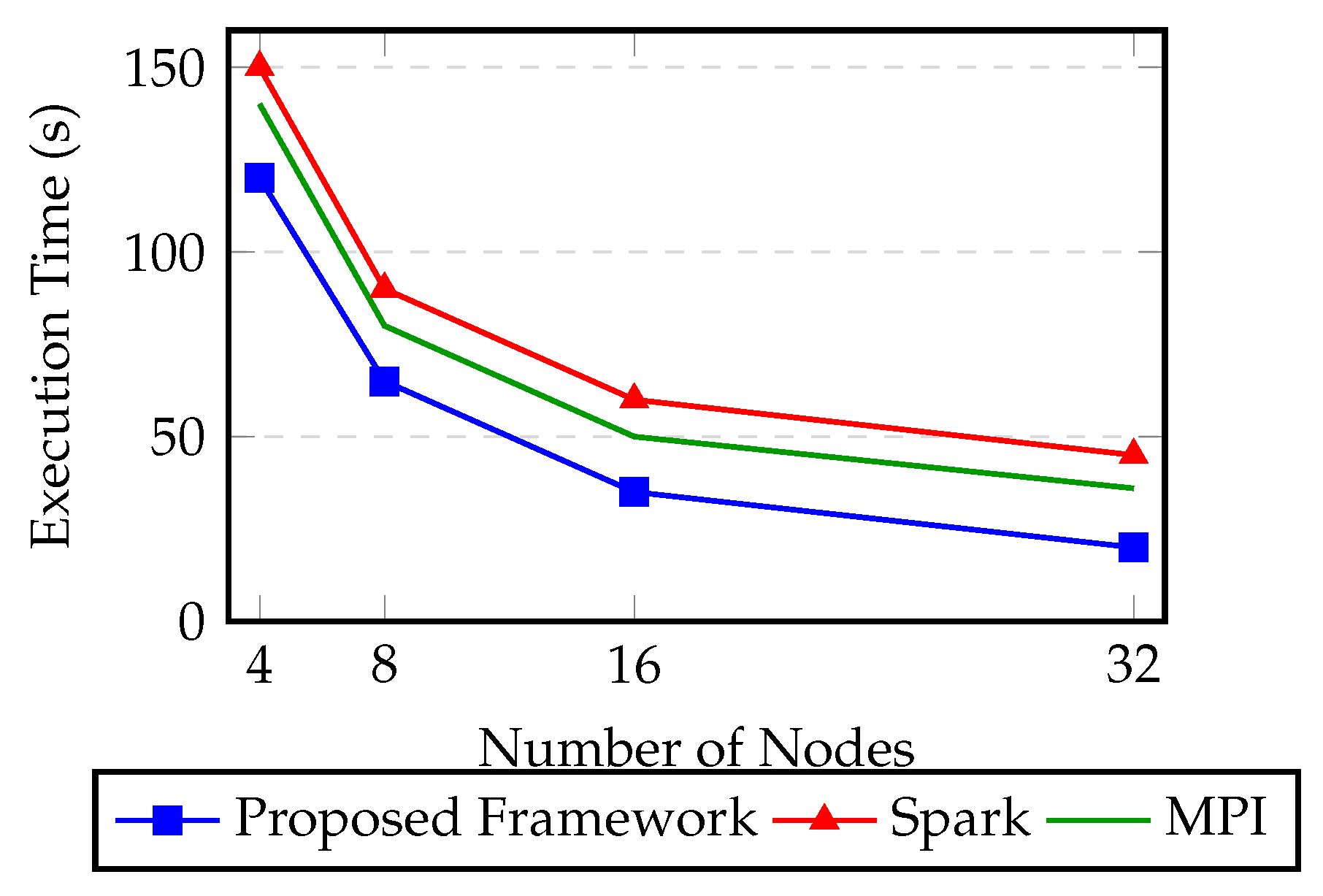
Scalability experiments involved scaling the number of nodes from 4 to 32. The framework achieved near-linear performance improvements, with parallel efficiency exceeding 85% at 32 nodes.
where S is speedup and P is the number of processors. This high efficiency validates the effectiveness of communication-aware scheduling and execution reordering.
Figure 3.
Scalability comparison of execution time across different frameworks.
5.4. Portability
The framework demonstrated consistent performance across heterogeneous environments, including CPU-only clusters, GPU-accelerated systems, and hybrid deployments. Developers were not required to alter workflow specifications, showcasing the effectiveness of the hardware abstraction layer in preserving portability.
6. Discussion
The experimental results underscore the advantages of embedding intelligence into the compiler rather than relying exclusively on runtime systems. By maintaining global visibility of workflows, the compiler was able to perform optimizations such as operator fusion, communication-aware scheduling, and memory placement that significantly reduced execution time and resource consumption.
A major insight was the strong correlation between operator fusion and performance gains in data-intensive workflows. In particular, financial and genomic workloads benefited greatly from fusion and communication minimization, as these domains typically involve repetitive data transformations and high inter-node communication.
Another critical observation was the simplicity provided to developers. The high-level language abstractions allowed non-expert users to achieve scalable performance without requiring expertise in distributed memory management, synchronization, or GPU programming. This makes the framework highly accessible to a broad audience of data scientists and engineers.
However, several challenges remain. The effectiveness of compiler-driven optimization depends on the accuracy of cost models and heuristics. Misestimations can lead to suboptimal scheduling or memory placement. Additionally, while the hardware abstraction layer provides portability, specialized tuning may still be required to fully exploit emerging accelerators such as TPUs, neuromorphic processors, or custom FPGAs. Another limitation is compilation overhead for very large workflows, which may increase startup latency compared to lightweight runtime systems.
Table 4.
Key Insights and Challenges from Experimental Evaluation.
| Strengths | Challenges |
|---|---|
| Up to speedup over Spark | Compiler overhead for large workflows |
| 55% reduction in memory overhead | Accuracy of cost models |
| Near-linear scalability (85% efficiency) | Specialized tuning for novel accelerators |
| Simplified workflow programming | Startup latency vs runtime systems |
In summary, the results validate that compiler-driven workflow optimization significantly enhances performance, efficiency, and scalability while preserving portability and ease of use. The discussion further highlights that although challenges persist, the framework provides a robust foundation for the next generation of scalable data workflow systems.
7. Conclusions
This work presented a compiler-enhanced programming language designed to overcome the limitations of existing approaches for large-scale and data-intensive workflows. By combining high-level abstractions with compiler-driven optimizations, the framework bridges the gap between developer productivity and system-level performance. Unlike traditional scripting languages, which prioritize usability but lack efficiency, or low-level distributed frameworks, which provide scalability at the expense of complexity, the proposed approach harmonizes these two extremes.
The framework’s layered design integrates multiple innovations. At the language level, it introduces declarative abstractions that allow developers to focus on expressing computational intent rather than low-level execution details. At the compiler level, it applies domain-specific optimizations such as operator fusion, communication-aware scheduling, and memory placement strategies. At the backend, it ensures portability across heterogeneous environments, including CPU clusters, GPU accelerators, and cloud-native deployments. The evaluation demonstrates that this holistic design enables substantial improvements: execution times were reduced by up to 40% compared to Spark, memory overhead decreased by 55%, and near-linear scalability was achieved as the system scaled to dozens of nodes.
The contributions of this research lie in three key areas: (1) the introduction of a novel programming language tailored to scalable workflows, (2) the integration of compiler-level intelligence for automatic parallelization and optimization, and (3) the validation of the system across heterogeneous workloads and hardware environments. Taken together, these elements form a comprehensive foundation for advancing the state of scalable data science applications. Beyond performance gains, the framework also simplifies development, enabling non-expert users to harness distributed computing without being burdened by the intricacies of synchronization, memory management, or parallelism.
8. Future Work
While the proposed framework demonstrates clear advantages, several avenues for future research remain open, each of which can extend the applicability and robustness of the system. The following directions are envisioned:
- Machine Learning-Driven Optimization: Future iterations of the compiler will integrate machine learning-based cost models to improve the accuracy of optimization decisions. By learning from workload characteristics and execution traces, the compiler can dynamically adapt scheduling, memory allocation, and communication strategies to achieve even greater efficiency.
- Support for Emerging Hardware Accelerators: With the rapid evolution of specialized hardware, extending portability to accelerators such as TPUs, neuromorphic chips, and FPGAs is critical. This will involve developing new backend code generators and abstraction layers that can fully exploit the computational patterns of these devices without requiring language modifications.
- Fault-Tolerant Compilation Strategies: As workflows increasingly migrate to cloud-scale environments, resilience against hardware and network failures becomes paramount. Future research will explore checkpointing mechanisms, speculative execution, and compiler-assisted redundancy techniques to improve reliability in distributed deployments.
- Visualization and Monitoring Tools: To improve transparency and developer productivity, we envision building integrated visualization dashboards that allow developers to inspect intermediate representations, monitor compiler optimizations, and track runtime execution. Such tools would serve as debugging aids while also providing actionable insights into workflow performance bottlenecks.
- Domain-Specific Extensions: Expanding the language with domain-specific modules can further increase adoption. Potential extensions include libraries for real-time analytics, graph processing, scientific simulation, and deep learning pipelines. Each domain introduces unique optimization opportunities that the compiler can exploit.
In summary, this work provides a foundation upon which a fully mature ecosystem for scalable data workflows can be constructed. By unifying high-level abstractions, compiler intelligence, and heterogeneous portability, the framework represents a step toward democratizing access to high-performance distributed computing. Future enhancements will not only improve technical efficiency but also broaden usability, ultimately enabling researchers, engineers, and practitioners to solve increasingly complex data challenges at scale.
References
- R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, 2023.
- Harris, C.R.; et al. The NumPy array: a structure for efficient numerical computation. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Van der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: efficient numerical computation with Python. Computing in Science & Engineering 2011, 13, 22–30. [Google Scholar]
- Rocklin, M. Dask: Parallel computation with blocked algorithms and task scheduling. In Proceedings of the Proceedings of the Python in Science Conference, 2016, pp. 130–136.
- Moritz, P.; Nishihara, R.; Wang, S.; et al. Ray: A distributed framework for emerging AI applications. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2018, pp. 561–577.
- MPI Forum. MPI: A message-passing interface standard. In Proceedings of the Proceedings of the ACM/IEEE Supercomputing Conference, 1994.
- Gropp, W.; Lusk, E.; Skjellum, A. Using MPI: portable parallel programming with the message-passing interface; MIT press, 1999.
- Rabenseifner, R.; Hager, G.; Jost, G. Hybrid MPI/OpenMP parallel programming on clusters of multi-core SMP nodes. In Proceedings of the 2009 17th Euromicro International Conference on Parallel, Distributed and Network-based Processing. IEEE, 2009, pp. 427–436.
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2012, pp. 15–28.
- Armbrust, M.; Xin, R.S.; Zaharia, M.; et al. Spark SQL: Relational data processing in Spark. In Proceedings of the Proceedings of the ACM SIGMOD International Conference on Management of Data, 2015, pp. 1383–1394.
- Karau, H.; Konwinski, A.; Wendell, P.; Zaharia, M. Learning Spark: lightning-fast big data analysis; O’Reilly Media, Inc., 2015.
- Dean, J.; Ghemawat, S. MapReduce: simplified data processing on large clusters. In Proceedings of the Communications of the ACM, 2008, Vol. 51, pp. 107–113.
- Cheng, Y.; Wang, L.; et al. A survey of big data system performance benchmarking: Metrics, challenges, and directions. IEEE Transactions on Big Data 2016, 2, 34–47.
- Gates, A.; Natkovich, O.; et al. Building a high-level dataflow system on top of Map-Reduce: the Pig experience. In Proceedings of the Proceedings of the VLDB Endowment, 2009, Vol. 2, pp. 1414–1425.
- Yu, Y.; Isard, M.; et al. DryadLINQ: A system for general-purpose distributed data-parallel computing using a high-level language. In Proceedings of the Proceedings of the USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2008, pp. 1–14.
- Abadi, M.; Barham, P.; Chen, J.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2016, pp. 265–283.
- Bahr, P.; Hvitved, T. Domain-specific languages for big data analytics. In Proceedings of the Proceedings of the International Conference on Software Language Engineering, 2012, pp. 162–181.
- Chen, T.; Moreau, T.; et al. TVM: An automated end-to-end optimizing compiler for deep learning. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2018, pp. 578–594.
- Li, M.; Andersen, D.G.; Smola, A.J.; Yu, K. Scaling distributed machine learning with the parameter server. In Proceedings of the Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2014, pp. 583–598.
- Brodtkorb, A.R.; Hagen, T.R.; Saetra, M.L. Programming heterogeneous systems: Challenges and opportunities. Journal of Supercomputing 2013, 65, 136–165. [Google Scholar]
- Jerger, N.E.; Lipasti, M.; et al. Heterogeneous system architectures: A survey. IEEE Computer Architecture Letters 2017, 16, 95–99. [Google Scholar]
- Chafi, H.; Sujeeth, A.; et al. A language and compiler for parallel execution of machine learning algorithms. In Proceedings of the Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2010, pp. 229–240.
- Bu, Y.; Howe, B.; Balazinska, M.; Ernst, M.D. HaLoop: Efficient iterative data processing on large clusters. In Proceedings of the Proceedings of the VLDB Endowment, 2010, Vol. 3, pp. 285–296.
- Banerjee, U. Automatic parallelization: An overview of compiler techniques. Parallel Computing 1988, 6, 349–389.
- Allen, R.; Kennedy, K. Automatic translation of FORTRAN programs to vector form; MIT Press, 1987.
- Polychronopoulos, C.D.; Kuck, D.J. Loop transformations for parallelism. In Proceedings of the Proceedings of the 1988 International Conference on Supercomputing, 1988, pp. 186–195.
- Kennedy, K.; Allen, J.R. Optimizing compilers for modern architectures: a dependence-based approach; Morgan Kaufmann, 2001.
- Wolf, M.E.; Lam, M.S. Loop transformations and data locality. In Proceedings of the Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 1991, pp. 102–112.
- Barga, R.S.; Gannon, D.B. Optimizing data-intensive workflows: compiler and runtime approaches. In Proceedings of the Proceedings of the IEEE International Conference on Data Engineering (ICDE), 2007, pp. 50–59.
- Finkel, H. Parallelizing compilers for parallel computers; Pitman Publishing, 1987.
- Ragan-Kelley, J.; Adams, A.; Paris, S.; et al. Halide: A language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. In Proceedings of the Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 2013, pp. 519–530.
- Leary, C.; Wang, T. XLA: TensorFlow, compiled. In Proceedings of the Proceedings of the TensorFlow Developers Summit, 2017.
- Lattner, C.; Adve, V. LLVM: A compilation framework for lifelong program analysis & transformation. In Proceedings of the Proceedings of the International Symposium on Code Generation and Optimization (CGO), 2004, pp. 75–86.
- Adve, V.; Lattner, C. LLVM and its role in modern compiler design. Proceedings of the International Conference on Compiler Construction 2011, pp. 1–6.
Table 1.
Compiler-level Optimizations in the Framework.
| Optimization | Benefit |
|---|---|
| Operator Fusion | Reduces intermediate data storage and I/O |
| Communication-aware Scheduling | Minimizes network overhead |
| Cache-aware Transformations | Improves memory locality |
| Task Decomposition | Enables fine-grained parallelism |
| Hardware Abstraction Layer | Ensures portability across CPUs/GPUs/Cloud |
Table 2.
Optimization Modules in the Implementation Layer.
| Module | Primary Benefit |
|---|---|
| Operator Fusion | Eliminates redundant intermediate results |
| Memory Placement Optimization | Improves cache locality and reduces latency |
| Execution Reordering | Enhances parallelism and reduces synchronization |
| Communication Minimization | Reduces inter-node data transfer overhead |
| Hardware Abstraction | Ensures backend portability across platforms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



