
Submitted:
06 December 2025
Posted:
08 December 2025
You are already at the latest version
Abstract
Financial fraud represents a growing challenge for financial institutions and e-commerce, requiring increasingly sophisticated detection methods. Traditional machine learning models, while effective, can reach limitations when facing complex fraud patterns and highly imbalanced datasets. This paper proposes a novel ensemble approach, KAN-XGBoost, which combines the power of Kolmogorov-Arnold Networks (KAN) for learning complex relationships with the robustness of the Extreme Gradient Boosting (XGBoost) algorithm for high-performance classification. Using the synthetic PaySim dataset, we demonstrate the effectiveness of our approach. To address the severe class imbalance, the Synthetic Minority Oversampling Technique (SMOTE) was applied to the training data. Our experimental results show that the KAN-XGBoost ensemble model, in soft voting configuration, significantly outperforms the individual models, achieving a performance metrics of 99%. This high performance suggests that the hybridization of KANs with established boosting algorithms constitutes a promising avenue for enhancing the security of financial transactions.
Keywords:
fraud detection
; ensemble model
; Kolmogorov-Arnold Networks
; XGBoost
; class imbalance
; SMOTE
; soft voting
Introduction
The exponential increase in electronic transactions has led to a professionalization and complexity of fraud techniques [1,2]. Traditional detection devices, mostly based on explicit rule systems, show a low capacity to adapt to the complexity and variability inherent in current fraud schemes, characterized by their dynamics and constant evolution [3,4]. Machine learning (ML) has established itself as the standard for identifying fraudulent transactions, but two major challenges persist: the ability to model highly complex non-linear relationships and the management of extreme class imbalance, where frauds represent only a tiny fraction of transactions [5].
This paper explores the integration of a recent and promising neural network architecture KAN, with a boosting algorithm XGBoost. KANs, inspired by the Kolmogorov-Arnold representation theorem, are distinguished from multi-layer perceptrons (MLPs) by their learnable activation functions located on edges, providing them greater expressiveness [6]. XGBoost, on the other hand, is a reference in ML competitions for its speed and accuracy on tabular data [7]. This study is a continuation of the work aimed at improving fraud detection in Mobile Money transactions from the dataset [8]. To do this, we rely on the combination of the KAN algorithm and the XGBoost algorithm to optimize performance and reduce false positives and false negatives. Our main contribution is the design and evaluation of an ensemble model that we called KAN-XGBoost. It is a Vote-based classifier, which combines the probabilistic predictions of the KAN and XGBoost models to make a more accurate and robust final decision. The implementation code of this work is available on the kaggle platform at source [9]. We show that this synergy makes it possible to take advantage of the respective strengths of each model, leading to a notable improvement in the detection of fraudulent transactions.
Our approach will be detailed in several sections. First, we will outline the data preprocessing methodology, including specific filtering of variables such as transaction type, sender and receiver balances, and amounts, to ensure better model convergence and manage outliers. We will also describe the creation of the time variable and the application of the oversampling technique SMOTE to address class imbalance in the dataset. Then, the training results of the KAN model, highlighted by a more stable convergence curve thanks to the preprocessing improvements, will be presented. We will then detail the KAN-XGBoost combination approach via the voting technique and analyze its significant impact on performance metrics, including the reduction of false positives and the increase in recall and average precision. Finally, the evaluation of the model and a comparison of the performances with those obtained by Zeutouo et al. [10] and those obtained by other authors will be provided, highlighting the advances of our approach.
1. Related Works
The fight against financial fraud has seen the emergence of increasingly sophisticated techniques. The XGBoost algorithm, due to its performance and speed, has become a cornerstone in this field. However, to overcome its limitations and adapt to the complex and unbalanced nature of fraud data, researchers have frequently integrated it into hybrid architectures. This section details, chronologically, several of these approaches, specifying the methodologies, datasets, performances and availability of source codes.
Combining Social Media Analytics with XGBoost
One of the first innovative approaches was to combine social network analysis (SNA) with classification models like XGBoost. In 2015, Vlasselaer et al. explored this avenue for credit card fraud detection [11]. The authors assumed that fraudsters often exhibited unusual spending behaviors and distinct social ties. They first used social network analysis to extract relational features between cardholders. These new features, combined with standard transactional data, were then fed into an XGBoost classifier.
- Methodology: The approach is carried out in two stages: (1) construction of a social network graph where nodes represent individuals and edges their relationships, followed by the extraction of centrality and community metrics as new features; (2) training of an XGBoost model on the enriched dataset.
- Dataset: A credit card transaction dataset provided by a commercial bank was used, containing both legitimate and fraudulent transactions.
- Performance: Results showed that the hybrid SNA-XGBoost model outperformed a standard XGBoost model and other classifiers such as support vector machines (SVMs) and logistic regression. Adding features from social network analysis significantly improved the detection of subtle fraud.
XGBoost with Resampling Techniques Like SMOTE
Class imbalance, where fraudulent transactions are very rare compared to legitimate transactions, is a major challenge. To address this, resampling techniques are often combined with XGBoost. A 2021 publication presented a robust method for credit card fraud detection using XGBoost combined with the SMOTE and a mobile classification threshold [12].
- Methodology: The process included (1) data preprocessing, including normalization; (2) applying SMOTE on the training set to generate synthetic examples of the minority class (frauds) and thus balance the classes; and (3) training an XGBoost classifier on the rebalanced data. The innovation also lay in the use of a decision threshold that adjusts to optimize the trade-off between precision and recall.
- Dataset: The study used the “Credit Card Fraud Detection” available on Kaggle, which contains transactions made by European cardholders over two days in September 2013. This dataset is highly imbalanced, with only 0.172% fraudulent transactions.
- Performance: The model achieved an Area Under the Curve (AUC) of 0.979, demonstrating the effectiveness of the combination of SMOTE and XGBoost in handling class imbalance.
- Code: The source code for this approach is often shared on platforms like GitHub, allowing other researchers to replicate and build on this work. An example implementation is available here: https://github.com/shubham-30/Credit-Card-Fraud-Detection-using-XGBoost-and-SMOTE.
Stacking Ensemble Models with XGBoost
Stacking ensemble models are a powerful solution. Research published in 2022 proposed a stacking learning model for financial fraud identification by integrating textual information from MD&A (Management Discussion and Analysis) [13].
- Methodology: This approach uses a two-tier structure. At the first tier, several base classifiers (such as logistic regression, random forests, and an initial XGBoost) are trained on the data. At the second tier, a “meta-classifier,” which is another XGBoost model, is trained on the predictions of the base models. This method was also innovated by integrating sentiment analysis and linguistic features extracted from financial reports.
- Dataset: Data were collected from annual reports of listed companies, combining financial ratios with textual data extracted from MD&A sections.
- Performance: The XGBoost-based stacking model showed improved performance compared to any single classifier. The addition of textual features helped capture potential fraud signals not present in numerical data alone.
Hybrid Architectures Integrating Deep Learning
More recently, hybrid architectures combining deep learning and XGBoost have emerged. In 2023, a study highlighted a hybrid model for fraud detection in real-time payments. This model uses a convolutional neural network (CNN) to automatically extract complex features from transaction sequences, and then uses XGBoost for the final classification [14].
- Methodology: (1) A user’s sequential transactional data is transformed into an image-like representation. (2) A CNN is used to learn latent features from these representations. (3) These features extracted by the CNN are then combined with other aggregated features (e.g., average transaction amount, frequency) and fed to an XGBoost classifier.
- Dataset: A proprietary dataset from a large payment processing company was used, containing millions of transactions.
- Performance: The hybrid CNN-XGBoost model demonstrated state-of-the-art performance, with significant improvements in area under the ROC curve (AUC-ROC) and accuracy compared to models using only XGBoost or only a CNN. This approach was particularly effective in detecting sophisticated fraud schemes that develop over multiple transactions. The code for this research has been made available to encourage transparency and collaboration.
Adaptive Ensemble Models
The constant evolution of fraud tactics requires models that can adapt. Recent work focuses on adaptive ensemble models. A 2024 publication introduced a fraud detection system using a dynamic ensemble of classifiers, including XGBoost, where the weight of each classifier is updated in real time based on its performance on the most recent data [15].
- Methodology: The system uses a sliding window to continuously evaluate the performance of multiple models (including XGBoost, LightGBM, and neural networks). A weighted aggregation algorithm dynamically adjusts the influence of each model in the final prediction.
- Dataset: The experiment was conducted on a simulated e-commerce transaction data stream, designed to mimic the evolution of fraud patterns.
- Performance: This adaptive model demonstrated superior robustness against concept drift, where fraud patterns evolve over time. It maintained high recall while minimizing false positives, outperforming static models. Table 1 summarizes the performance of the existing methods we have discussed in this section.

Table 1.
Summary of existing performance.
| Reference (Year) | Hybrid Method | Dataset | Accuracy | Recall | Precision | F1-Score | AUC | Other Metrics |
|---|---|---|---|---|---|---|---|---|
| (2015) | SNA + XGBoost | Proprietary banking data | 99.92% | 89.6% | - | - | 0.982 | G -mean: 0.945 |
| (2021) | SMOTE + XGBoost | Kaggle Credit Card Fraud | - | 92.0% | 86.0% | 0.89 | 0.979 | - |
| (2022) | Stacking (with XGBoost ) + NLP | Financial Reports (MD&A) | 94.3% | 82.1% | - | 0.852 | 0.915 | - |
| (2023) | CNN + XGBoost | Real-time payment data | - | 90.0% | 89.0% (at 90% Recall) | 0.91 | 0.988 | Latency: 15ms |
| (2024) | Adaptive Ensemble (with XGBoost ) | Simulated transaction flow | 99.85% | 88.0% (average) | - | 0.85 (average) | - | FPR: 1.2% |
In conclusion, the use of XGBoost within mixed methods has significantly advanced the field of fraud detection. Whether by enriching it with data from social network analysis, combining it with resampling techniques to handle imbalance, integrating it into stacking architectures, coupling it with deep learning for feature extraction, or integrating it into adaptive ensembles, XGBoost continues to prove its value as a core component of modern, high-performance fraud detection systems.
- Methodology
- Data preprocessing
- Preprocessing of the type of operations variable
Table 2 below represents the number of fraud transactions or not depending on the type of operation.
We note that CASH_OUT and TRANSFER type operations are the only operations exposed to fraud in our dataset. Therefore, our analysis will be carried out only on these types of operations. Table 3 gives for each class, the number of withdrawals and transfers after filtering.
- Preprocessing
To prepare the data for analysis, a series of preprocessing steps were implemented. First, the columns “newbalanceOrig”, “newbalanceDest”, “nameOrig”, and “nameDest” were removed, as they were deemed non-essential for the study’s objective or posed a risk of introducing noise. Subsequently, the dataset was filtered to retain only transactions of the type CASH_OUT and TRANSFER, as these categories were considered most relevant to the specific problem being addressed. Finally, a new time variable was created to enable a chronological analysis of transaction activities, thereby providing a dynamic perspective on their evolution. These transformations serve to focus the analysis on the most critical elements while ensuring its overall coherence.
- Creating the “time” variable
This variable will allow us to identify the times of the transactions. Figure 1 below illustrates the statistical distribution of the “time” variable, highlighting the distinction between the two classes of data.
- b.
- Oversampling
The dataset presents a significant imbalance between the number of fraudulent and non-fraudulent transactions, an imbalance accentuated after our analysis phase. To address this problem before training the model, we applied the SMOTE technique like in the study published at source [12]. The authors demonstrated that applying the SMOTE technique, which generates synthetic examples of the minority class, effectively rebalances datasets where fraud represents an extremely low proportion of transactions (0.172% in the studied dataset). This approach significantly improves the performance of classification models, notably by increasing the precision, recall, and F1-score scores on the fraudulent class. The results show that SMOTE promotes a fairer selection of classes, reduces the bias towards the majority class, and supports a better ability of the model to detect real fraud, where classical models often fail due to data imbalance. Table 4 and Figure 2 summarize the training set before and after the application of the SMOTE function to address class imbalance.
SMOTE oversampling principle:
Total non-fraud N0 = 2 762 196
Total fraud N1 = 8 213
Total size N = 2 770 409
N_train = 0.8 × N ≈ 2 216 327
N_test = 0.2 × N ≈ 554 082
Total training size after SMOTE: N_train(SMOTE) = 2 × N0_train = 2 × 2 209 757 = 4 419 514
- c.
- Correlation
The correlation analysis shows that the target variable “isFraud” does not have a significant linear relationship with the other variables in the dataset. However, the KAN algorithm is particularly suitable for capturing complex non-linear relationships, which makes it a relevant choice for this type of problem. Table 5 shows the set of dependencies between all variables.
2. Results and Discussion
a. Training
Table 6 shows the impact of preprocessing based on the KAN model proposed by Zeutouo et al. in their article published in 2025. This resulted in the model exhibiting significant fluctuations during the test phase, reflecting instability in learning, despite the high performance. However, thanks to the improvement of the data preprocessing steps in this new study, the model’s convergence curve is now more stable and regular, demonstrating more controlled and efficient learning.
Figure 3 shows the confusion matrix obtained on the training data and on the test data, which reveals a high number of false positives. To address this, Amouri et al. demonstrated that combining the KAN algorithm with XGBoost improves the overall performance of the model [19].
b. Soft voting technique using KAN and XGBoost
Our approach in this step consisted of combining KAN and XGBoost using the soft voting technique [16]. It is in this same vein of ideas that researchers [17] proposed an approach based on soft voting by combining several advanced machine learning models, including XGBoost, MLP, and KNN, for fraud detection on highly unbalanced banking datasets (where the fraud class is very much in the minority). Their ensemble model aggregates the probabilities from each classifier in order to maximize the overall precision. The results show that the voting method significantly improves the performance compared to the use of individual models, in particular the recall and the false negative rate, essential in fraud detection: their model achieves an accuracy of 98.7%, a recall of 96.9%, an F1-score of 87.6%, and a ROC curve greater than 0.99. Voting aggregation provides greater resilience to data variation and reduces majority class bias. These advantages make voting particularly relevant for financial systems that need to detect anomalies in large volumes of transactions, where isolated models are often less robust to evolving fraudulent behavior.
In the context of fraud detection, voting can thus strengthen the detection of atypical cases and increase the overall reliability of the system, making it a particularly recommended strategy for imbalanced datasets and dynamic phenomena. Our classification report highlights that the combination of KAN and XGBoost significantly improves the model’s performance, with an increase in average recall from 0.78 to 0.99 and average precision from 0.80 to 0.99. Table 7 summarizes the performance of our proposed hybrid KAN-XGBoost model.
This improvement is confirmed through the confusion matrix, where we observe a significant reduction in the number of false positives to only 3969. Furthermore, although we are also seeing a reduction in false negatives to 30000. This type of error should be reduced even further, at least better than false positives, because they come from transactions that were fraudulent at the beginning in the real label. This outcome highlights a fundamental trade-off, emphasizing that defining the system’s operational parameters is crucial for navigating the compromise between these errors. Figure 4 shows the confusion matrix of the proposed model on the training data.
c. Evaluation
This evaluation consisted of analyzing the performance of the KAN-XGBoost model on a 20% sample of the data, extracted before applying oversampling. We used the classification method for imbalanced datasets [20,21,22]. Table 8 presents the performance metrics of the model on the test data, and Figure 5 shows the corresponding confusion matrix.
d. Comparison
Table 9 below present the comparisons between the results obtained in this study and those previously proposed by Zeutouo et al.. This is a continuation of our research aimed at improving the detection of financial fraud by modifying machine learning algorithms. These comparisons highlight our contributions in terms of modifications that have led to a new promising ensemble model combining KAN and XGBoost. In addition, measuring AUC is crucial in deep hybrid models with XGBoost as it robustly assesses the model’s ability to distinguish classes, especially in complex and imbalanced data. Bayesian hyper-parameter optimization of XGBoost has been shown to significantly improve AUC and overall performance compared to traditional methods, highlighting AUC’s importance for evaluating complex hybrid models. This is demonstrated in [18] by Yan et al. (2019). The maximum value of the AUC is known to be 1. Table 10 shows the AUC values we obtained, and Figure 6 shows the ROC curve of KAN and the ROC curve KAN-XGBoost. Recent research in 2025 proposed another ensemble model using The paySim dataset that achieve better performance metrics in some conditions created by Yussif et al. demonstrating again the advanced of approaches based on hybridization in mobile fraud transactions detection [23]. Figure 7 summarize the actual models performance in this critical area. In 2024, Yang Lu et al. proposed a global comparison showing the real gab between theory and practice of KAN in fraud detection on various datasets and various machine learning algorithms [24]. They compare it to Logistic Regression, Ridge Classifier, SGD Classifier, Support Vector Machine, Linear SVC, KNN, Decision Tree, Extra Tree, Random Forest, AdaBoost, Gradient Boosting, Bagging, Voting Classifier, MLP Classifier, Gaussian Naive Bayes, Bernoulli Naive Bayes, Linear Discriminant Analysis, XGBoost, and LightGBM. The authors found that the performance of KAN is not universally superior but is highly contingent on the nature of the dataset. Then, they proposed a data-driven decision rule based on Principal Component Analysis (PCA), suggesting that if the data can be effectively separated using two-dimensional splines, KAN is a promising candidate; if not, alternative models may be preferable. To mitigate the computational expense of KAN, they also introduce an efficient heuristic for hyperparameters tuning. Consequently, the study concludes that while KAN holds significant potential in the domain, its successful application should be guided by preliminary, data-specific suitability assessments. Our experience allowed us to further validate these results through a concrete experiment that we made public on Kaggle.
Conclusion
This study proposed an innovative approach for fraud detection in mobile money transactions by designing a KAN-XGBoost ensemble model. Faced with the growing challenges of financial fraud, characterized by complex patterns and highly imbalanced datasets, our methodology incorporated rigorous preprocessing steps, such as filtering transaction types (CASH_OUT and TRANSFER only), handling extreme values for balances and amounts, and creating a time variable. The application of the oversampling technique SMOTE has helped address class imbalance, a major issue in this area.
The obtained results demonstrated the effectiveness of our approach. The improved data preprocessing led to a more stable convergence curve for training the KAN model. More significantly, the combination of KAN and XGBoost via the soft voting technique achieved remarkable performances. We observed an increase in average recall from 0.78 to 0.99 and a drastic reduction in false positives to only 3969. Although a decrease in false negatives till 30000 was noted with and an AUC of 0.98, showing the ability of the KAN-XGBoost ensemble to identify correctly the fraudulent CASHOUT and TRANSFER. At this stage, it is important to underline that the false negatives, which are the most dangerous errors in this domain must be reduced as much as possible. The fact that the model achieve a performance metric of 99% on the training data underlines its potential. This performance highlights the added value of the synergy between KANs for their ability to model complex nonlinear relationships and the robustness of XGBoost.
Compared to previous work of Zeutouo et al., our new hybrid approach demonstrated significant progress in terms of many evaluation criteria that we measured. These results suggest that hybridizing KAN with established boosting algorithms represents a very promising avenue for enhancing the security of financial transactions.
Acknowledgments
I thank the ADPA (Africa Data Protection Awards), and I thank TUSUR, СФУ, and TSU universities for the competitions and conferences that allowed me to present my research to experts.
Conflicts of Interest
None.
Appendix A.
Kaggle code link
References
- Chang, V.; Doan, L.M.T.; Di Stefano, A.; Sun, Z.; Fortino, G. Digital payment fraud detection methods in digital ages and Industry 4.0. Comput. Electr. Eng. 2022, 100. [Google Scholar] [CrossRef]
- Olowu, O.; Adeleye, A.O.; Omokanye, A.O.; Ajayi, A.M.; Adepoju, A.O.; Omole, O.M.; Chianumba, E.C. AI-driven fraud detection in banking: A systematic review of data science approaches to enhancing cybersecurity. GSC Adv. Res. Rev. 2024, 21, 227–237. [Google Scholar] [CrossRef]
- Tsai, W. Deep Learning-Based Financial Fraud Detection with Temporal and Feature-Level Adaptation. J. Comput. Electron. Inf. Manag. 2025, 18, 19–25. [Google Scholar] [CrossRef]
- Emran, A.K.M.; Islam, K.; Nayem, A.I.; Rubel, T.H.; Hasan, S.K. Real-time Payment Fraud Detection Using Graph Neural Intelligence. Adv. Int. J. Multidiscip. Res. 2025, 3. [Google Scholar] [CrossRef]
- Gao, X.; Chen, T.; Zhang, W.; Li, Y.; Sun, X.; Yin, H. Graph Condensation for Open-World Graph Learning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining; ACM: New Yrok, NY, USA, 2024; pp. 851–862. [Google Scholar] [CrossRef]
- Liu, Z. KAN: Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2404.19756. [Google Scholar] [CrossRef] [PubMed]
- Ravid, S.; Amitai, A. Tabular data: Deep learning is not all you need. ScienceDirect 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Edgar, L.R. Synthetic Financial Datasets for Fraud Detection. Kaggle. 2015. Available online: https://www.kaggle.com/datasets/ealaxi/paysim1 (accessed on 30 July 2025).
- Kaggle. Available online: https://www.kaggle.com/code/sergendoumin/fraud-detection-using-kan-xgboost.
- Zeutouo, N.T.G.; Kostyuchenko, E.Y. Fraud Detection using Kolmogorov-Arnold Network. Researchgate 2025. [Google Scholar] [CrossRef]
- Van Vlasselaer, V.; Bravo, C.; Caelen, O.; Eliassi-Rad, T.; Akoglu, L.; Snoeck, M.; Baesens, B. APATE: A novel approach for automated credit card transaction fraud detection using network-based extensions. Decis. Support Syst. 2015, 75, 38–48. [Google Scholar] [CrossRef]
- Kumar, S.; Dutta, M.K.; Singh, A.K. Credit Card Fraud Detection Using XGBoost and Syn-thetic Minority Over-sampling Technique. J. Phys. Conf. Ser. 2021, 1964, 042008. [Google Scholar] [CrossRef]
- Li, Y.; Lin, T.; Wang, J. Financial Fraud Detection via Ensemble Stacking with Textual Senti-ment Analysis. Expert Syst. Appl. 2022, 197. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Y.; Zhou, Z. Deep-Transaction: A Hybrid CNN -XGBoost Framework for Real-Time Payment Fraud Detection. IEEE Trans. Neural Netw. Learn. Syst 2023. [Google Scholar]
- Wang, H.; Li, Q.; Yang, R. AdaFraud: Adaptive Ensemble Learning for Concept-Drift Aware Fraud Detection. ACM SIGKDD, 2024. [Google Scholar] [CrossRef]
- Scikit Learn. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.VotingClassifier.html (accessed on 29 July 2025).
- Mim, M.A.; Majadi, N.; Mazumder, P. A soft voting ensemble learning approach for credit card fraud detection. Heliyon 2024, 10, e25466. [Google Scholar] [CrossRef] [PubMed]
- Yan, W.; Xuelei, S.N. a xgboost risk model via feature selection and bayesian hyper-parameter optimization. arXiv 2019, arXiv:1901.08433. [Google Scholar] [CrossRef]
- Amouri, A.; Al Rahhal, M.M.; Bazi, Y.; Butun, I.; Mahgoub, I. Enhancing Intrusion Detection in IoT Environments: An Advanced Ensemble Approach Using Kolmogorov-Arnold Networks; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Available online: https://imbalanced-learn.org/stable/references/generated/imblearn.metrics.classification_report_imbalanced.html (accessed on 29 July 2025).
- Available online: https://imbalanced-learn.org/stable/references/generated/imblearn.over_sampling.SMOTENC.html (accessed on 19 July 2025).
- Available online: https://github.com/KindXiaoming/pykan/blob/master/tutorials/Example/Example_4_classfication.ipynb (accessed on 20 July 2025).
- Yussif, N.; Takyi, K.; Gyening, R.-M.O.M.; Boadu-Acheampong, S.I. Advanced Mobile Money Fraud Detection Using CNN-BiLSTM and Optimized SGD with Momentum. AJIT-e Online Acad. J. Inf. Technol. 2025, 16, 207–231. [Google Scholar] [CrossRef]
- Yang, L. Kolmogorov–Arnold Networks in Fraud Detection: Bridging the Gap Between Theory and Practice. arXiv 2024, arXiv:2408.10263v2. https://arxiv.org/html/2408.10263v2. [Google Scholar]
Figure 1.
Statistical distribution of the “time” variable by class.
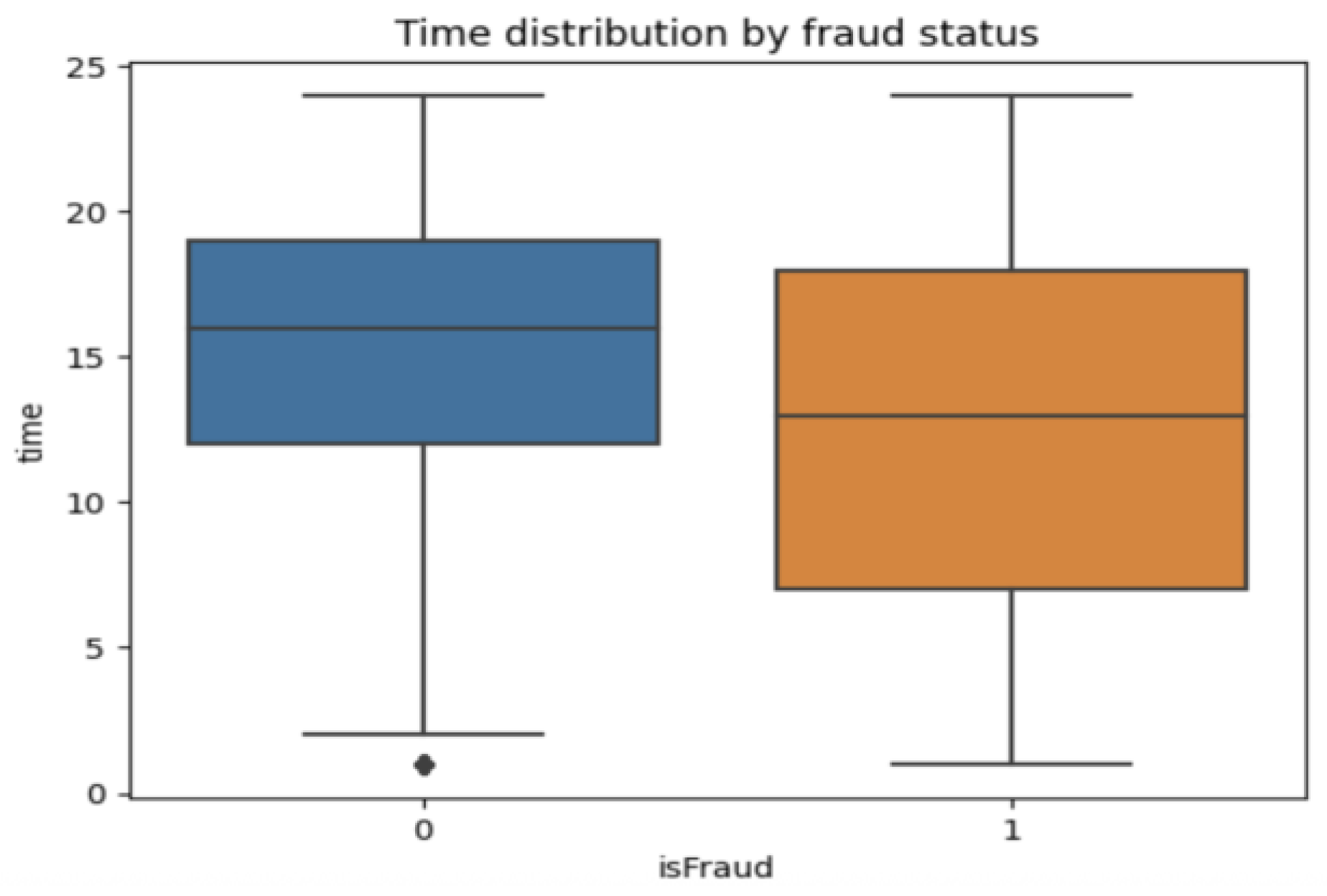
Figure 2.
Dataset size before and after SMOTE SMOTE.
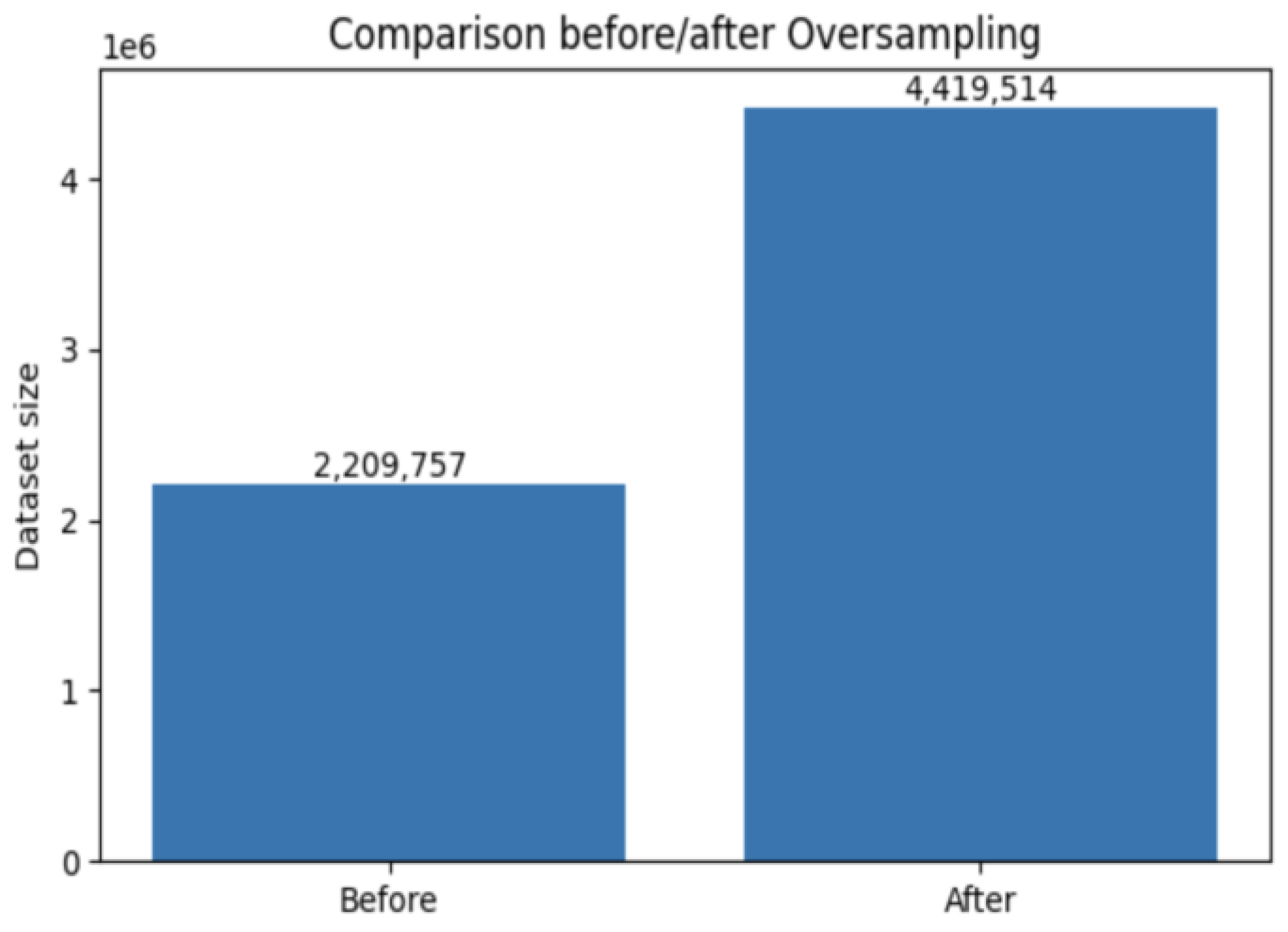
Figure 3.
Confusion matrix of KAN on training data and on test data.
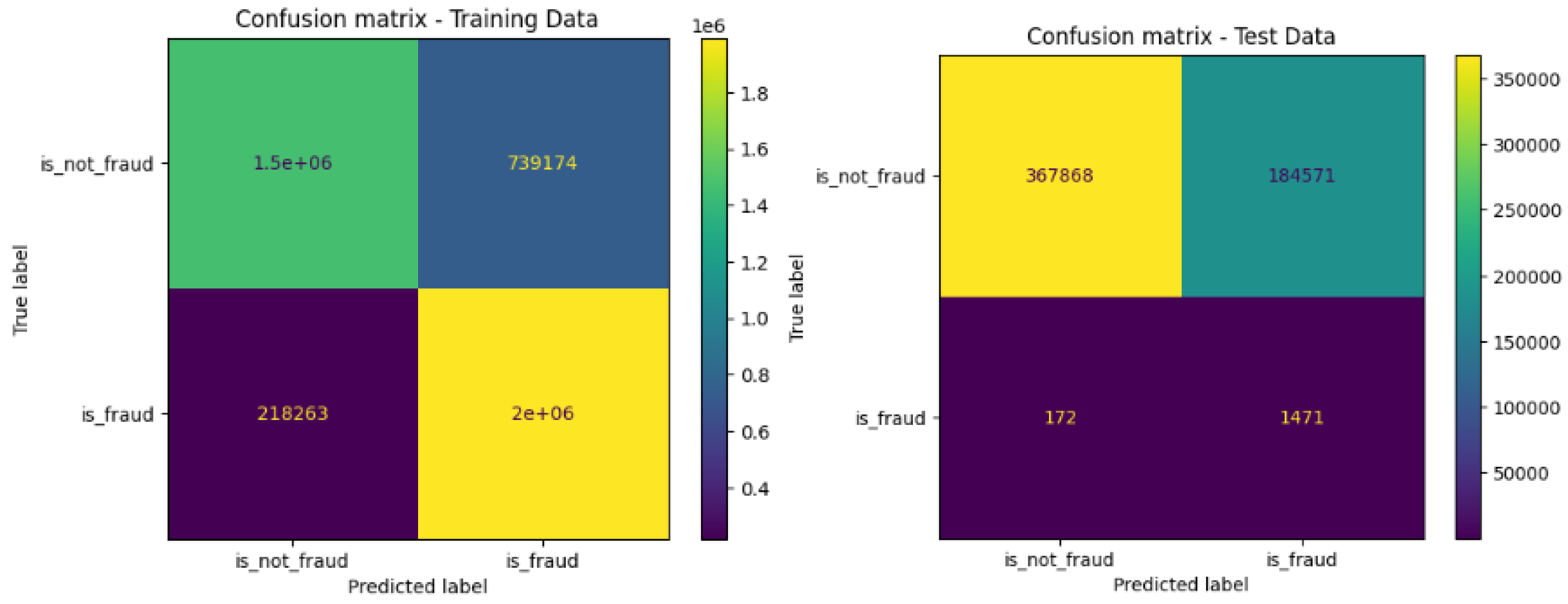
Figure 4.
Proposed KAN-XGBoost model confusion matrix on training data.
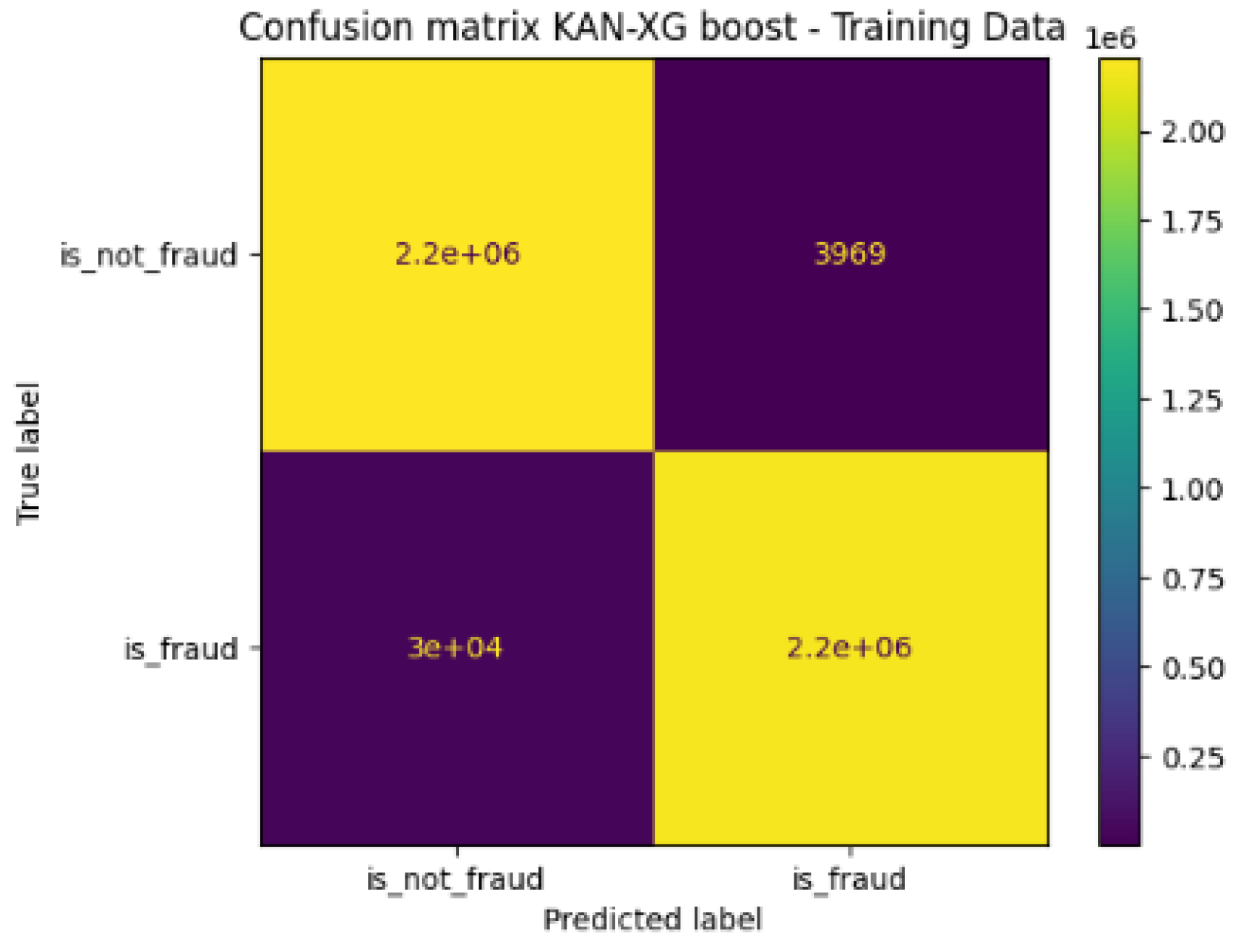
Figure 5.
Confusion matrix of the KAN-XGBoost on the test data.
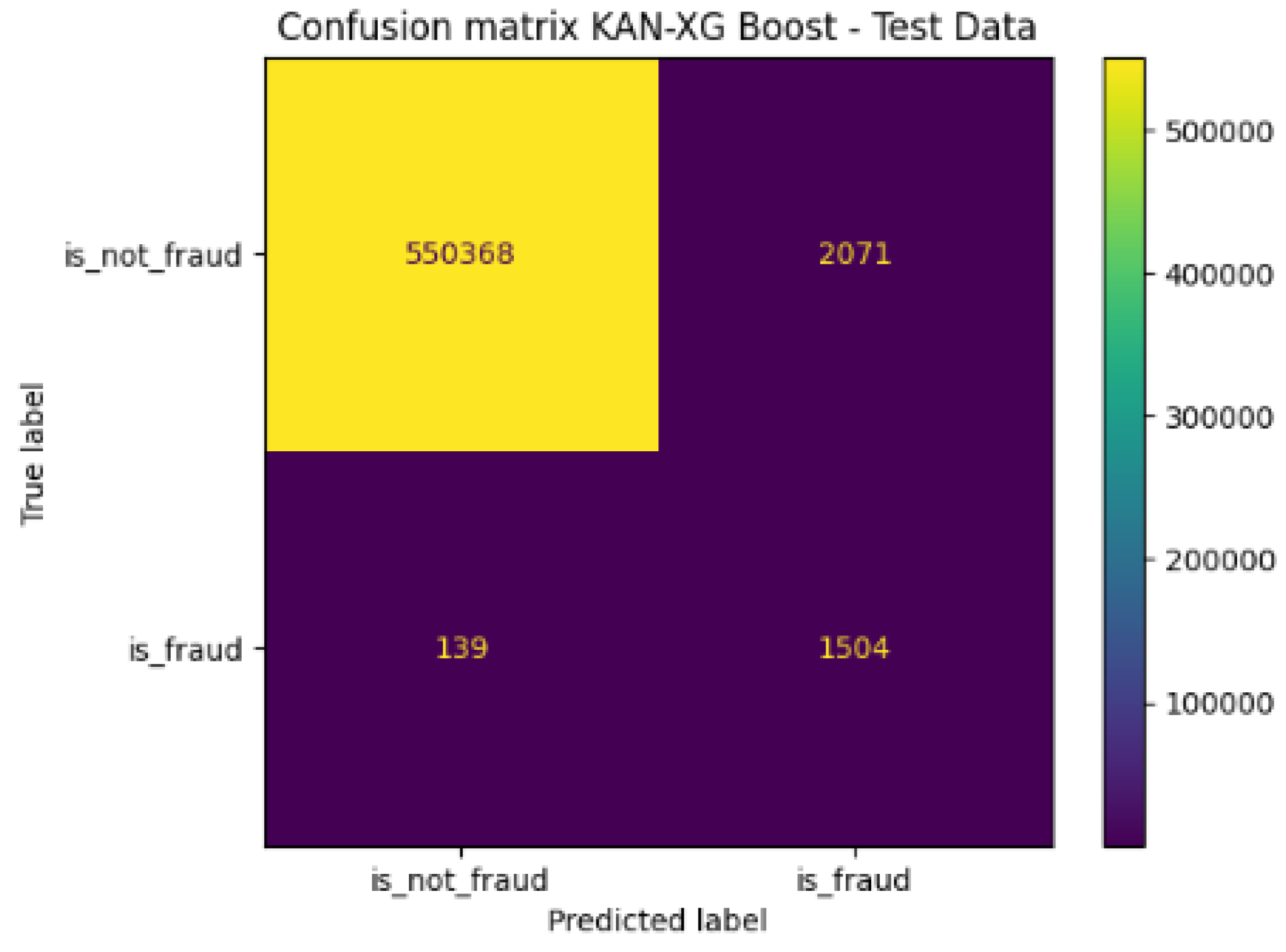
Figure 6.
ROC Curve of KAN and ROC curve of KAN-XGBoost.
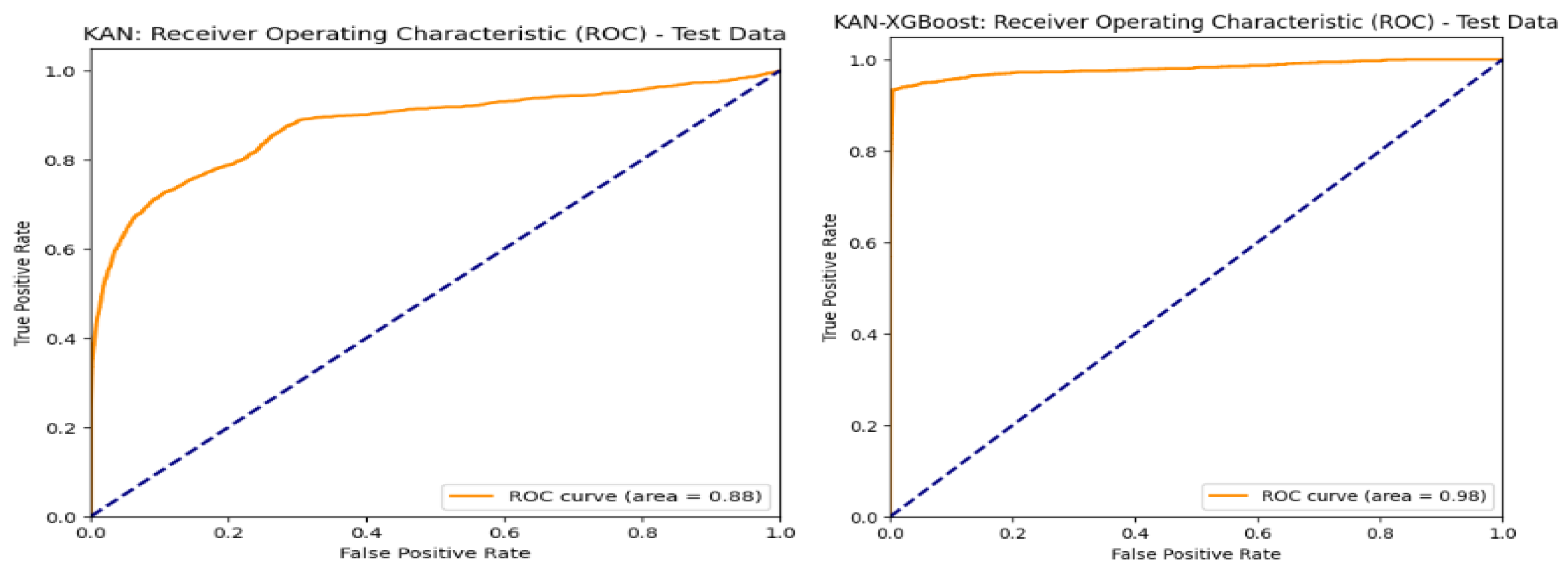
Figure 7.
Performances Summary.
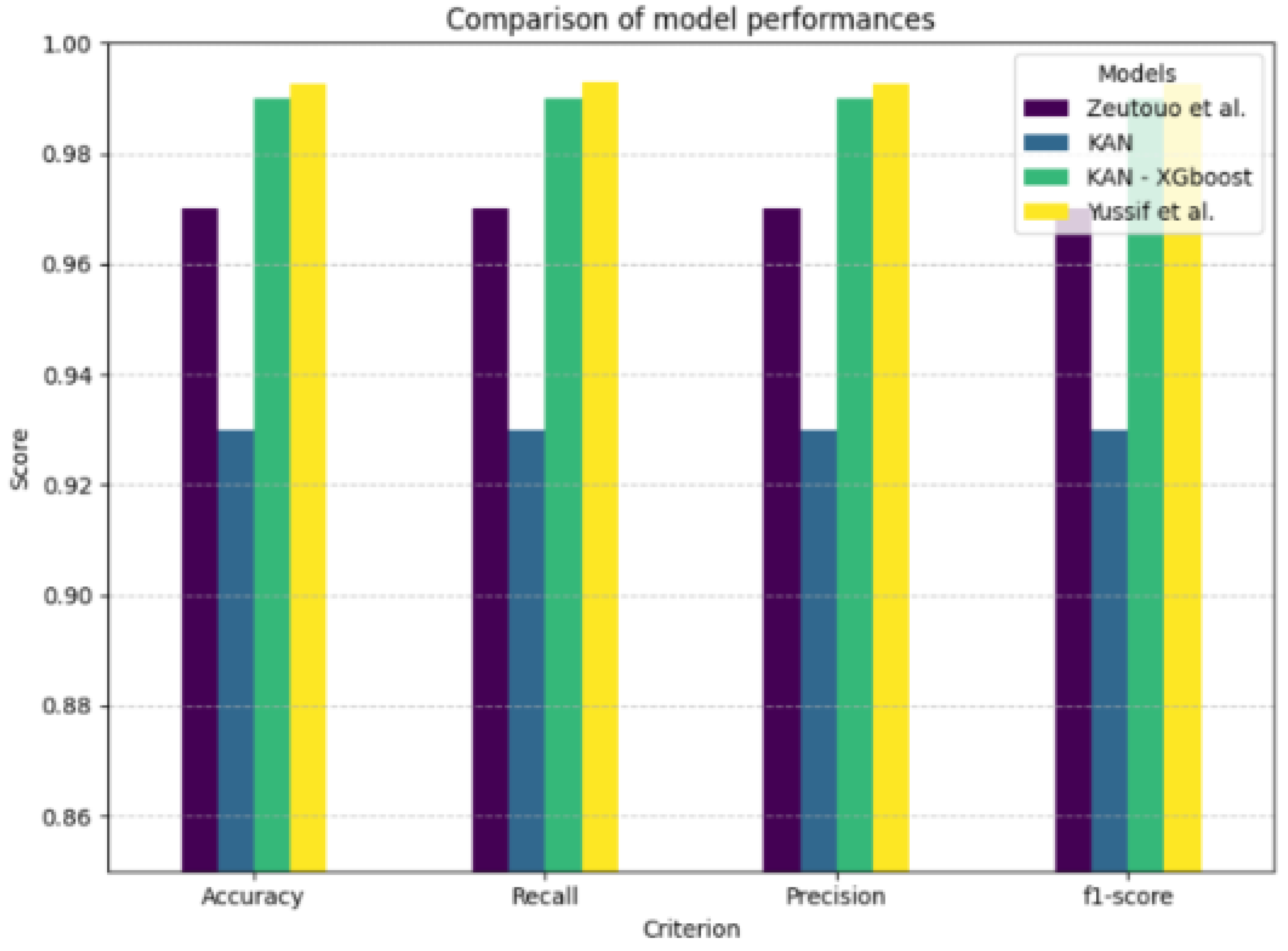
Table 2.
Number of transactions by type of operation before filtering.
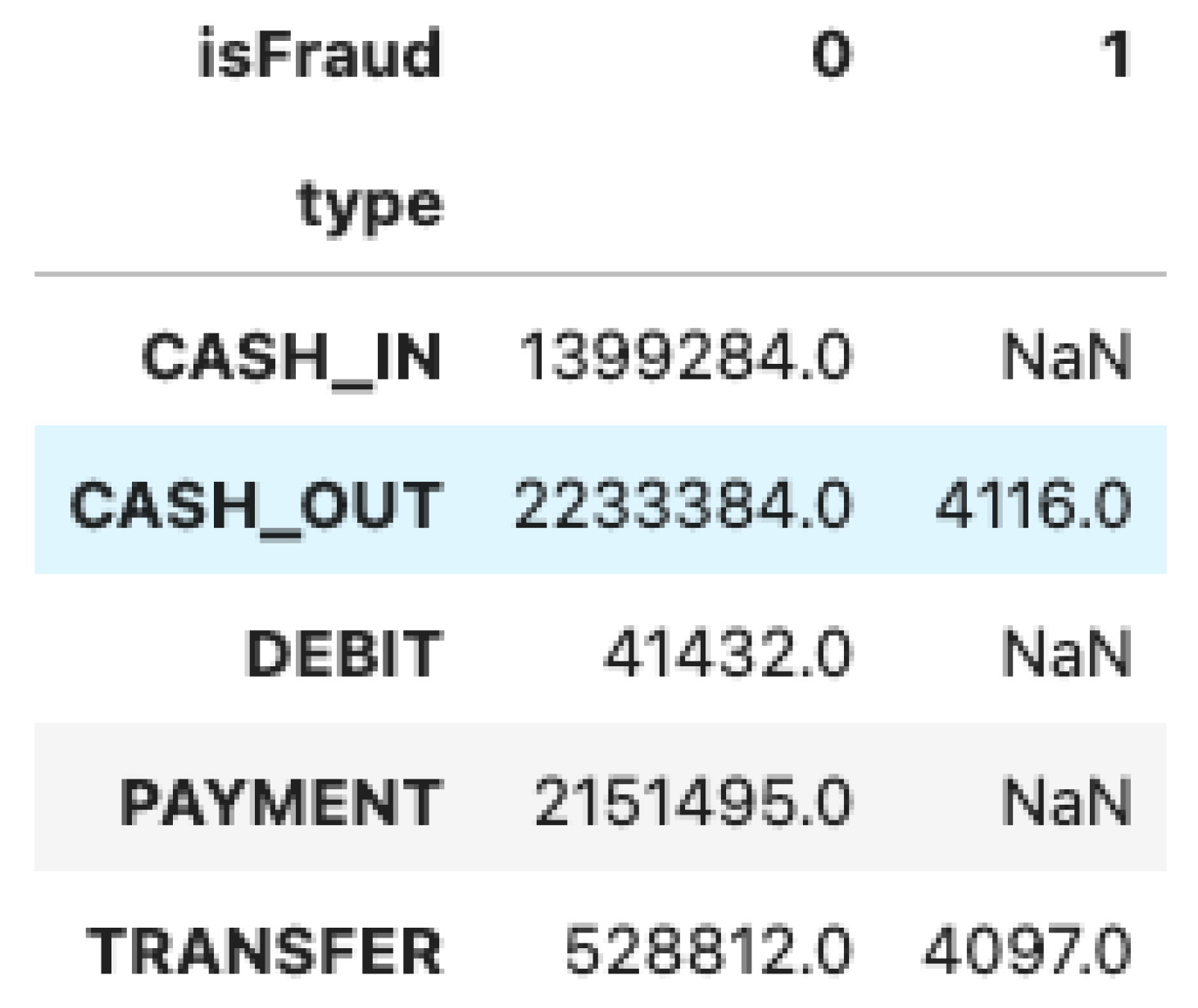
Table 3.
Number of transactions by type of operation after filtering.
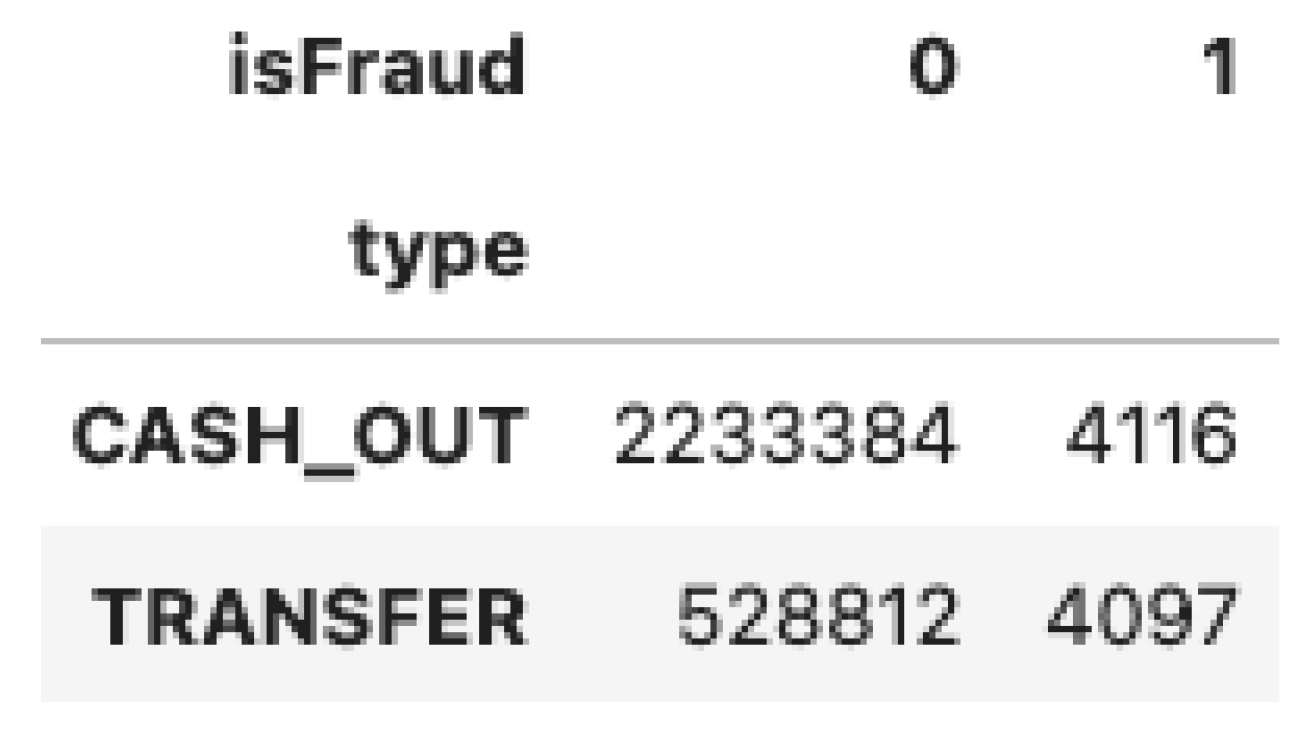
Table 4.
Summary tables of the training set before and after SMOTE.
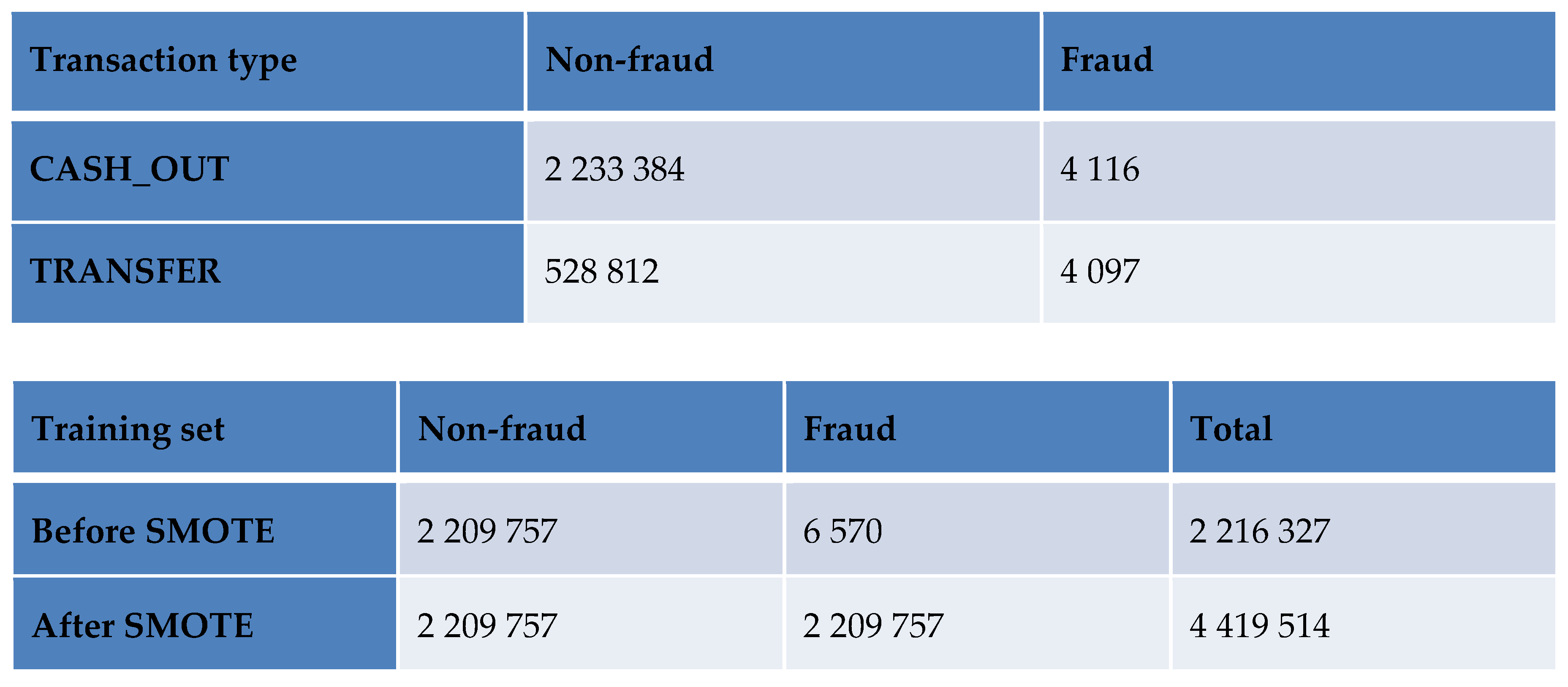
Table 5.
Table of correlations between the variables.
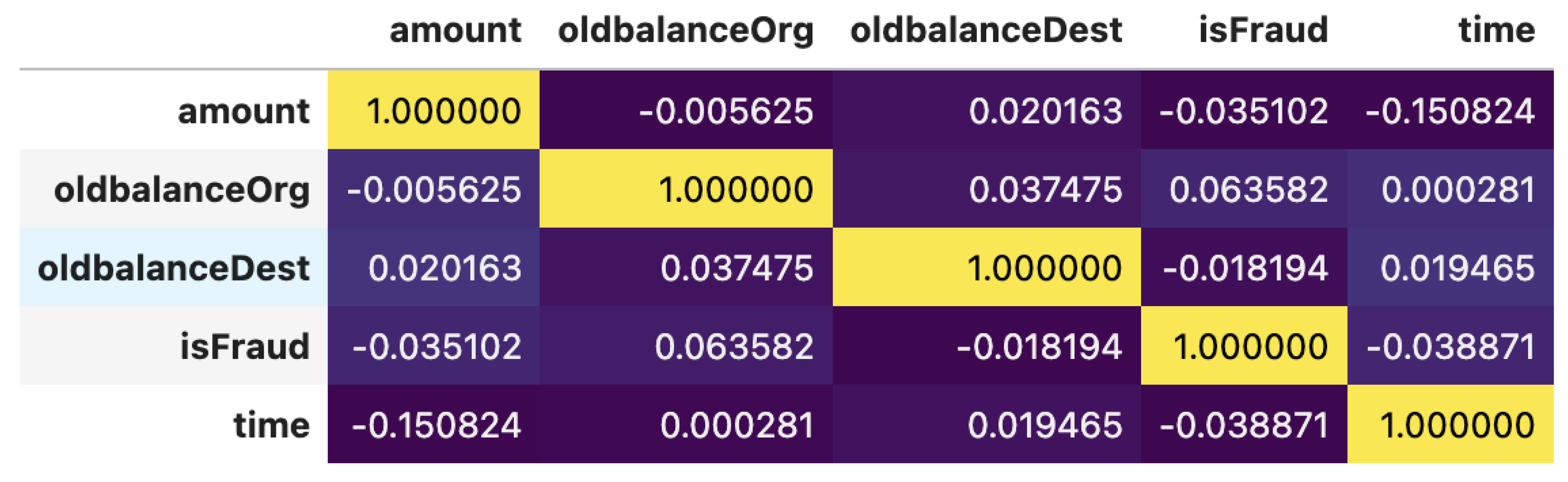
Table 6.
Impact of preprocessing on the KAN model proposed by Zeutouo et al.
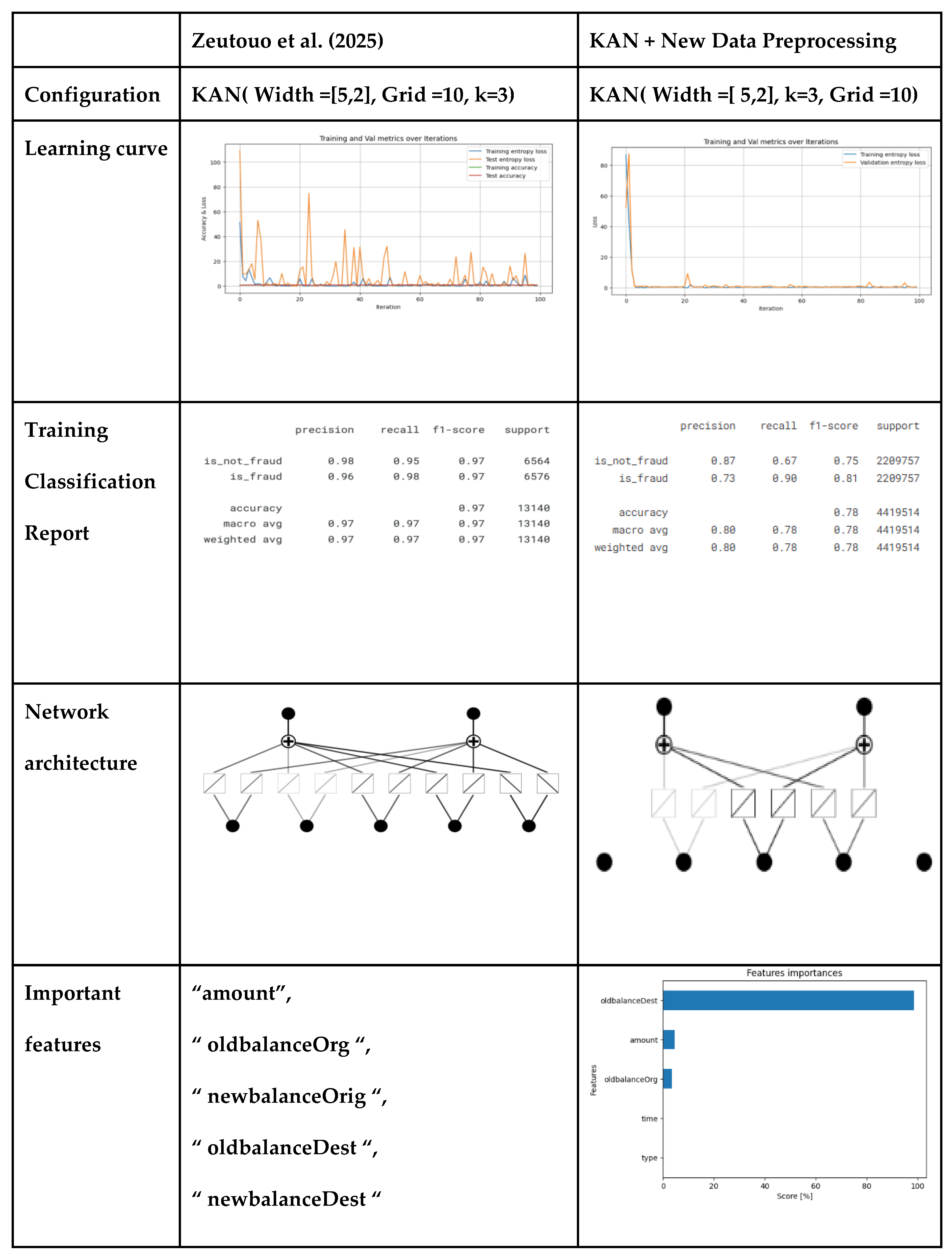
Table 7.
Performance metrics of our proposed ensemble KAN-XGBoost model.
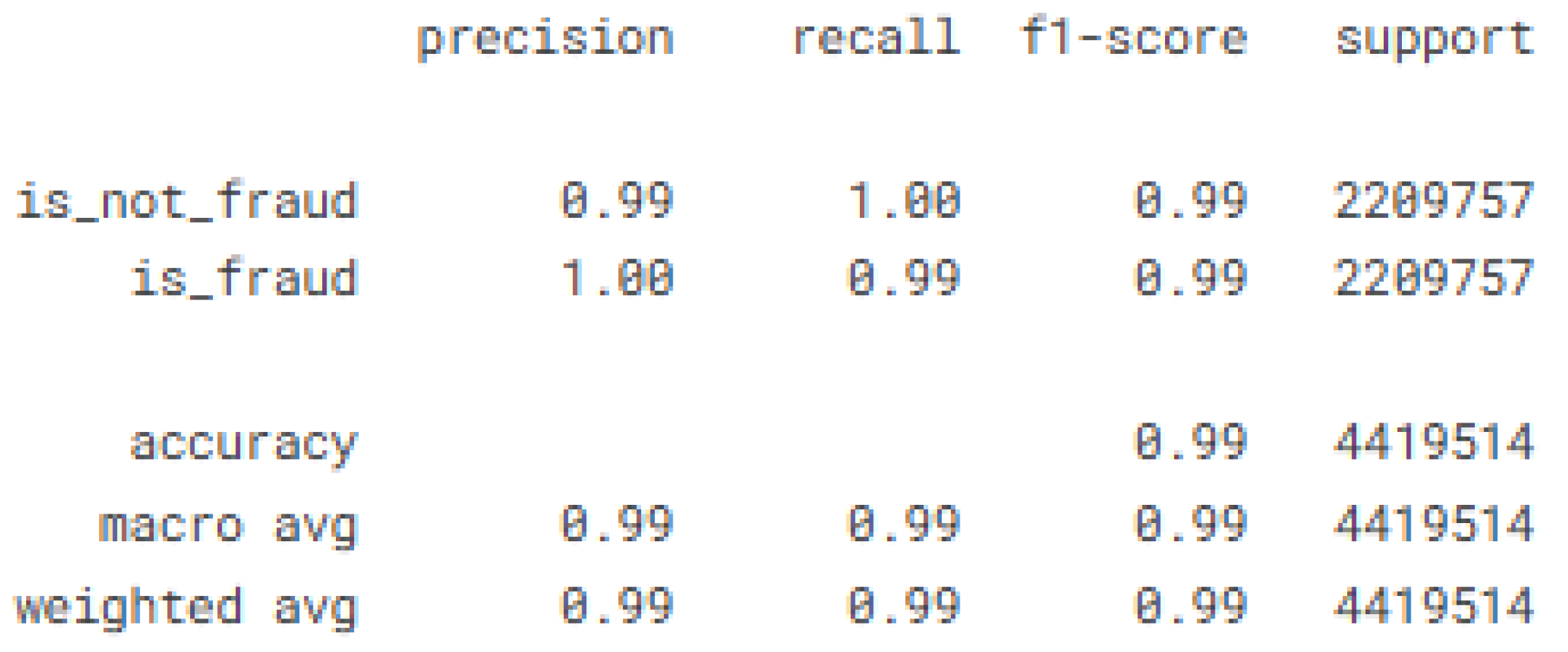
Table 8.
Performance of the proposed KAN-XGBoost model on the test data.
Table 9.
Comparison of models by criterion.
| Criteria | Zeutouo et al. | KAN | KAN-XGboost |
|---|---|---|---|
| Training data size | 13 140 | 4 419 5144 | 4 419 5144 |
| New preprocessing | No | Yes | Yes |
| Accuracy | 0.97 | 0.78 | 0.99 |
| recall | 0.97 | 0.78 | 0.99 |
| precision | 0.97 | 0.80 | 0.99 |
| F1 score | 0.97 | 0.78 | 0.99 |
Table 10.
Obtained AUC values.
| Criteria | KAN | KAN-XGBoost |
|---|---|---|
| AUC | 0.88 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



