Submitted:
25 November 2025
Posted:
26 November 2025
You are already at the latest version
Abstract
MLOps 2.0 operationalizes machine learning by elevating data to a first-class artifact alongside code and models. We present a reference architecture that converges CI/CD with Continuous Data Validation (CDV), inserting data quality gates schema, semantic, temporal, and distributional across build, test, release, and run stages. The pipeline encodes data contracts, enforces SLO-aligned promotion criteria, and couples training/inference observability to reduce escaped defects (silent drift, schema skew, target leakage) that CI/CD alone cannot catch. A domain-agnostic evaluation template quantifies impacts on lead time, rollback rate, stability, and incident frequency. Results indicate CI/CD +CDV yields more reliable, auditable, and cost-efficient ML delivery.
Keywords:
MLOps
; CI/CD
; data validation
; data contracts
; observability
; SLOs
; drift
; reliability
; GitOps
1. Introduction
Machine Learning Operations (MLOps) has become a cornerstone of modern data-driven product engineering, extending DevOps principles—continuous integration, continuous delivery (CI/CD), and automation—into the machine-learning lifecycle. While first-generation MLOps automated model training, packaging, and deployment, production ML systems continue to suffer from a persistent blind spot: data quality drift and inconsistent validation between training, testing, and inference environments. Code and model versioning alone cannot ensure reproducible, reliable ML behavior when the data pipelines feeding them are unstable, schema-inconsistent, or semantically misaligned.
1.1. Background and Motivation
Conventional CI/CD pipelines have matured to continuously integrate, test, and release software code, but they fall short when applied to ML systems that depend on dynamic, evolving data. In practice, most ML production incidents stem not from algorithmic errors but from data issues—schema breaks, silent distribution shifts, temporal leakage, and stale or inconsistent feature definitions [1]. These defects propagate undetected through build, training, and deployment stages because data is treated as an implicit dependency rather than a governed artifact. The absence of data-aware promotion criteria leads to brittle releases, hard-to-reproduce failures, and opaque governance around which data triggered or justified a deployment.
MLOps 2.0 extends beyond first-generation automation to treat data as a first-class artifact. It introduces Continuous Data Validation (CDV)—an always-on framework that embeds policy-driven checks and quality gates throughout the ML delivery lifecycle. Each gate enforces contractual expectations for data schema, semantics, temporal coherence, and distributional stability. By integrating these checks directly into CI/CD pipelines, MLOps 2.0 detects regressions early and enforces fail-fast behavior before faulty data or models reach production [2]. This approach transforms CI/CD from a code-centric automation mechanism into an end-to-end reliability framework spanning data, models, and infrastructure.
1.2. Problem Statement
Current CI/CD implementations treat data as an external, mutable dependency. Consequently:
- Data regressions often go undetected during build or deploy stages, surfacing only as production anomalies.
- Incident detection is delayed or noisy, lacking traceability to specific datasets, schema versions, or upstream sources.
- Auditability is weak—teams cannot consistently reproduce which data, validations, or thresholds justified model promotion.
There is a clear need for a disciplined, reproducible methodology that makes data versioned, validated, and governed on equal footing with code and models.
1.3. Defining MLOps 2.0
We define MLOps 2.0 as the convergence of CI/CD pipelines with Continuous Data Validation (CDV): a continuous, policy-driven validation framework where every artifact—code, configuration, data, features, and model—must traverse data-quality gates aligned with service-level objectives (SLOs). CDV establishes explicit promotion criteria governed by data contracts and machine-readable quality policies. Each change, whether to source code, configuration, upstream datasets, or feature store tables, is automatically validated against these criteria before being merged or deployed [3]. This paradigm ensures that model retraining, release, and inference all operate within quantifiable, auditable data-quality bounds.
1.4. Contributions
This paper contributes a comprehensive reference architecture and practical framework for realizing MLOps 2.0 in production environments:
- Reference Architecture: A modular MLOps 2.0 pipeline that embeds CDV across the pre-commit, build/train, release, and run stages using GitOps and policy-as-code mechanisms.
- Continuous Data Validation Framework: A reusable contract schema and check registry covering schema, semantic, temporal, distributional, and fairness/privacy validations; each check supports a severity model (block, warn, or audit) for controlled enforcement.
- Unified Observability: Integration of data and model service-level indicators (SLIs) and SLOs, combined with automated error-budget tracking to drive canarying, roll-forward, or rollback decisions.
- Evaluation Template: A domain-agnostic case-study template and methodology—incorporating synthetic drift injection, historical incident replay, and KPI tracking—to quantify reliability, lead-time, and stability improvements from adopting MLOps 2.0 [4].
1.5. Scope and Assumptions
The proposed architecture targets enterprise-scale ML workloads across batch, streaming, and online-serving paradigms. It assumes mature artifact versioning for code and models, containerized execution environments, and access to lineage and metadata services. The design remains vendor-agnostic: while examples may reference common toolchains (e.g., Kubernetes, Airflow, Feast, Great Expectations, or TensorFlow Extended), the framework emphasizes principles over specific implementations. Our focus is on operational alignment—how data contracts, CDV gates, and CI/CD processes interact—to deliver measurable improvements in ML reliability, observability, and governance.
In summary, MLOps 2.0 operationalizes machine learning through the fusion of CI/CD automation with continuous, always-on data-quality assurance [5]. By elevating data to a first-class artifact, it closes the reliability gap between development and production, paving the way for resilient, auditable, and SLO-aligned ML systems.
2. Background and Related Work
MLOps 2.0 extends the principles of DevOps and CI/CD to machine learning systems by treating data as an integral component of the release process. To motivate this convergence, this section reviews prior work and industry practices in continuous integration and delivery (CI/CD), DataOps, data contracts, and feature stores [6]. These domains collectively influence the design of continuous data validation (CDV) pipelines and inform the proposed reference architecture.
2.1. Continuous Integration and Continuous Delivery (CI/CD)
Traditional software engineering relies on CI/CD to automate the build, test, and deployment of code artifacts. Over the past decade, this discipline has evolved through the adoption of declarative configuration, containerization, and GitOps workflows that ensure reproducible and auditable releases. However, when applied to ML systems, these same mechanisms face unique challenges. Machine learning pipelines operate over dynamic datasets and models, introducing stochasticity that cannot be fully captured through static testing [7]. Unlike source code, data continuously evolves — influenced by upstream systems, collection mechanisms, and external events. As a result, conventional CI/CD practices struggle to detect semantic regressions such as distribution shifts, missing features, or temporal leakage. Studies such as Breck et al. (2017) introduced “ML Test Scores” to quantify validation coverage across data, features, and models, but adoption has remained fragmented due to tooling complexity and organizational silos.
Recent industry frameworks (e.g., TFX, MLflow, Kubeflow) have addressed model reproducibility and environment isolation but still treat data quality as an external dependency. MLOps 2.0 builds upon this foundation by embedding automated, enforceable validation gates that operate continuously across pre-commit, build, and release stages—extending CI/CD from a code-centric process to a data-verified lifecycle.
2.2. DataOps and Continuous Data Management
DataOps emerged as an adaptation of DevOps principles to data engineering, focusing on agility, versioning, and governance across data pipelines. It emphasizes automation of data ingestion, transformation, testing, and deployment using continuous integration of datasets and metadata. Frameworks such as Apache Airflow, dbt, and Great Expectations exemplify this trend by providing declarative, test-driven data workflows. However, traditional DataOps focuses on data pipelines in isolation, often stopping short of integrating data quality guarantees into model delivery pipelines. In production ML systems, the boundary between data engineering and model operations is porous: a change in an upstream dataset can silently invalidate trained models or inference logic. MLOps 2.0 bridges this gap by converging DataOps with CI/CD—
3. Reference Architecture: The MLOps 2.0 Pipeline
The proposed MLOps 2.0 architecture integrates Continuous Data Validation (CDV) with CI/CD and GitOps workflows to operationalize machine learning as a continuously verified, policy-driven process. The system is organized into five interdependent layers—Source Control & Contracts, Build & Training, Validation & Promotion, Deployment & Observability, and Governance & Lineage—that form a closed feedback loop from data ingestion to production monitoring.
3.1. Design Principles
Three guiding principles drive the architecture:
- Data as a First-Class Artifact: All datasets, features, and metadata are versioned, validated, and governed alongside code and models.
- Shift-Left Data Quality: Validation occurs early—during pre-commit and build phases—to prevent propagation of defects downstream.
- Always-On Observability: Data and model SLOs are continuously measured post-deployment to detect drift and trigger automated rollback or retraining.
3.2. Architectural Layers
1) Source Control & Contracts: Every ML project resides in a Git repository containing not only code but also declarative specifications of data contracts and validation rules (YAML/JSON). Each commit triggers a pre-commit hook that executes static schema checks and contract validation against the latest registered datasets. Failed checks block merges, ensuring that only contract-compliant changes enter the main branch.
2) Build & Training Stage: Once code and data updates are merged, the CI system (e.g., GitHub Actions, Jenkins, GitLab CI) spins up containerized environments to train or retrain models [8]. Synthetic data and validation subsets are generated automatically to test model resilience against schema or distribution changes. Model artifacts and feature statistics are stored in a central registry tagged with contract and commit hashes.
3) Validation & Promotion Gates: During build and deploy phases, the Continuous Data Validation (CDV) engine executes multi-layer checks:
- Schema Validation Gate – detects structural deviations.
- Semantic Validation Gate – ensures logical and domain consistency.
- Temporal Validation Gate – verifies time-ordering, freshness, and leakage.
- Distributional Validation Gate – compares feature statistics (mean, std, drift metrics) against baselines.
Each gate assigns a severity level: Block (stops pipeline), Warn (creates alert), or Audit (logs event for review). Only models passing critical checks are promoted to the staging or production environments via GitOps pull requests.
4) Deployment & Observability: Deployments are automated through GitOps controllers (e.g., Argo CD, Flux) that synchronize manifests between repositories and runtime clusters. Observability agents collect SLIs—data freshness, feature coverage, model latency, and drift scores—feeding them into dashboards and alert systems. Violations of defined SLOs trigger canary rollbacks or retraining workflows.
5) Governance & Lineage: All artifacts—code, data, contracts, and models—emit lineage metadata into a central catalog (e.g., OpenLineage, Marquez, DataHub). Each promotion event is cryptographically signed, linking validation results with deployment state. This ensures auditability, regulatory compliance, and reproducibility for every production decision.
3.3. End-to-End Workflow
Figure 1 visualizes the MLOps 2.0 pipeline. Every change follows the same lifecycle: commit → validate → build/train → promote/deploy → observe/govern. Continuous feedback loops ensure that data issues, model drift, and SLA violations are detected and mitigated automatically.
3.4. Architectural Benefits
The unified architecture provides the following key benefits:
- Reliability: Early detection of data regressions prevents faulty deployments and reduces production incidents.
- Reproducibility: Every pipeline execution is version-controlled and traceable via contract, commit, and model identifiers.
- Auditability: Automated logs of validation outcomes and lineage simplify compliance with AI-governance mandates.
- Scalability: The modular, container-based design allows the architecture to support diverse workloads—batch, streaming, and real-time inference.
Collectively, these components form the backbone of MLOps 2.0, transforming ML delivery into a continuous, data-verified discipline rather than a sequence of ad-hoc model releases.
4. Continuous Data Validation (CDV) Framework
The Continuous Data Validation (CDV) framework operationalizes data reliability within the MLOps 2.0 pipeline by embedding policy-driven validation gates into every CI/CD stage. It transforms data quality from a reactive process into a continuous assurance mechanism governed by contracts, automated checks, and severity-based enforcement.
4.1. Overview
The CDV framework ensures that every data artifact—datasets, features, and inference payloads—adheres to explicitly defined quality constraints before model training, deployment, or promotion. By treating data validation as code, the framework introduces machine-readable contracts, reusable validation libraries, and fail-fast execution logic that integrates seamlessly with CI/CD tools such as Jenkins, GitHub Actions, and Argo Workflows [9].
4.2. Contract Schema Design
Each dataset or feature set is associated with a declarative data contract, which serves as a formal agreement between data producers and ML consumers [10]. These contracts, defined in YAML or JSON, specify:
- Schema Rules: Field names, data types, nullable constraints, and unique keys.
- Semantic Rules: Domain-specific assertions (e.g., , ).
- Temporal Rules: Freshness, time-ordering, and temporal consistency across joins.
- Distributional Rules: Statistical baselines (mean, variance, drift thresholds).
- Privacy & Fairness Rules: Data anonymization and bias metrics.
A sample contract schema snippet:
version: 1.0
dataset: customer_transactions
owner: data-team@company.com
checks:
- name: schema_check
columns:
- {name: amount, type: float,
nullable: false}
- name: temporal_check
rule: "timestamp <= now()"
- name: drift_check
threshold: 0.05
severity:
block: ["schema_check","temporal_check"]
warn: ["drift_check"]
4.3. Validation Tiers
The CDV process is organized into four validation tiers, each corresponding to a stage in the CI/CD lifecycle:
- Pre-Commit Validation: Executes static schema and metadata checks locally before code merges.
- Build-Time Validation: Runs schema, semantic, and distributional tests on sample datasets.
- Deployment Validation: Executes temporal and freshness checks using live data snapshots.
- Runtime Monitoring: Continuously tracks drift, bias, and data SLO adherence in production.
Each tier reinforces the next, creating a multi-layer safety net that catches regressions early and sustains long-term data reliability.
4.4. Severity Model & Policy Enforcement
The CDV engine classifies validation outcomes into severity levels to determine pipeline behavior:
- Block: Halts the pipeline immediately (critical schema or semantic violations).
- Warn: Logs the issue and raises alerts, but allows continuation with caution.
- Audit: Records results for review or governance dashboards without triggering failure.
Severity levels are configurable and version-controlled within the contract repository. This approach enables context-aware validation—e.g., non-critical drift in a low-impact feature triggers only a warning, whereas schema mismatches block promotion entirely.
4.5. Fail-Fast Logic
The CDV engine implements a fail-fast control loop that executes sequential checks with short-circuit evaluation:
for check in validation_checks:
result = run(check)
if result == FAIL and
check.severity == "block":
abort_pipeline()
elif result == FAIL and
check.severity == "warn":
log_warning()
else:
record_success()
This structure minimizes wasted computation by terminating immediately upon critical failure while ensuring all non-blocking metrics are still captured for observability and future audits.
4.6. CDV Flow Diagram
Figure 2 illustrates the flow of the CDV framework within the MLOps 2.0 lifecycle, showing contract ingestion, validation tiers, and severity-driven decision logic.
4.7. Discussion
By integrating CDV into CI/CD, organizations achieve early detection of data regressions and consistent quality enforcement across all ML stages. Contracts codify accountability, the fail-fast mechanism minimizes latency in defect resolution, and severity models enable flexible yet governed responses to data anomalies. Together, these elements establish an always-on validation layer that transforms MLOps from best-effort automation into a reliability discipline.
5. CI/CD Integration with Continuous Data Validation
The fusion of CI/CD and Continuous Data Validation (CDV) converts traditional code pipelines into data-aware delivery systems. In MLOps 2.0, every stage of the pipeline—pre-commit, build, test, release, and deploy—acts as a validation checkpoint governed by explicit data contracts. The pipeline therefore becomes not only a build mechanism but also a compliance framework for data reliability.
5.1. Workflow Integration Model
CI/CD integration follows the standard progression from commit to deploy, augmented by automated validation steps:
- Pre-Commit: Local hooks trigger contract validation and static schema checks before merging to the main branch.
- Pull Request (PR): Git server runs automated CI checks—unit tests, linting, and data validation on sample datasets.
- Build Stage: The CI engine executes containerized training jobs while invoking the CDV engine to run schema, semantic, and temporal tests.
- Validation Gate: Fail-fast enforcement of severity-based rules; critical failures block promotion.
- Deployment: GitOps controllers (e.g., Argo CD, Flux) pull validated artifacts into production.
5.2. GitOps-Driven Delivery Loop
Unlike monolithic scripts, MLOps 2.0 pipelines treat deployment as a declarative process. All manifests—models, data contracts, SLO definitions—reside in version control [11]. GitOps continuously synchronizes these definitions with the runtime environment, ensuring reproducibility and auditability. Any configuration drift or invalid data triggers an automatic rollback to the last known valid state.
5.3. Example CI/CD + CDV Pipeline (YAML Pseudocode)
name: mlops-cdv-pipeline
on:
push:
branches: [ main ]
jobs:
build-validate-deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v4
- name: Run Pre-Commit Validation
run: python scripts/validate_contracts.py
--stage precommit
- name: Build and Train Model
run: make build && python train.py
- name: Execute CDV Checks
run: python scripts/run_cdv.py
--rules contracts/ --stage build
- name: Enforce Severity Policy
run: python scripts/enforce_policy.py
--fail-on block
- name: Deploy via GitOps
run: |
kubectl apply -f manifests/
python scripts/observe_slos.py
This pipeline integrates validation logic into the same control flow that builds, tests, and deploys ML artifacts, ensuring consistent policy enforcement from commit to runtime.
5.4. Flow Diagram
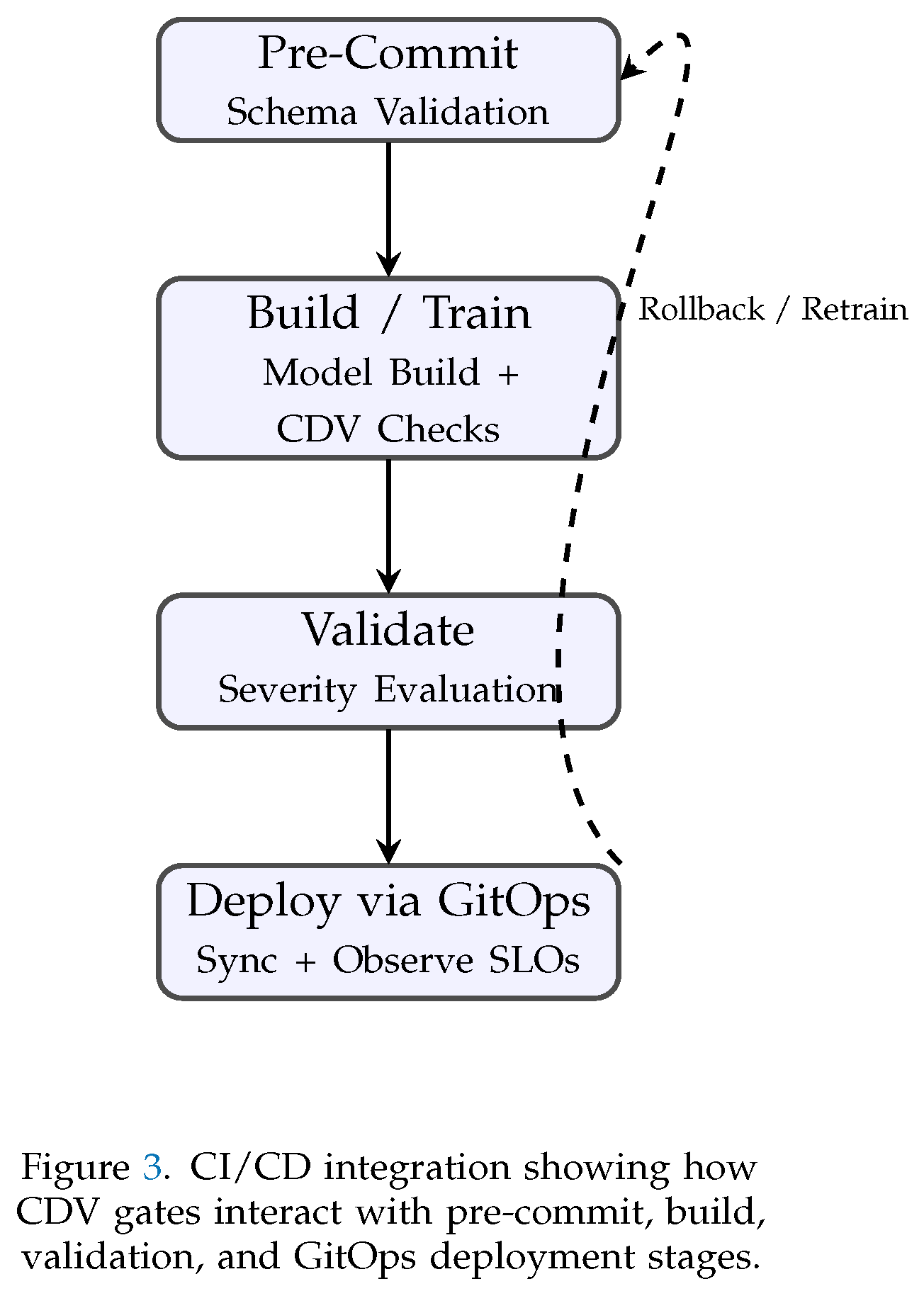
5.5. Discussion
Embedding CDV within CI/CD transforms MLOps pipelines from linear automation into closed feedback systems. Validation gates prevent the propagation of low-quality data, GitOps ensures configuration consistency, and automated SLO monitoring closes the loop between deployment and observability. Together, these mechanisms create a continuous delivery framework that enforces trust in both model and data artifacts—turning every commit into a verifiable, auditable, and measurable event in the ML lifecycle.
6. Observability and Service-Level Objectives (SLOs)
Observability in MLOps 2.0 extends the validation boundary beyond build-time checks to provide continuous visibility into the operational health of data, models, and pipelines. Rather than treating monitoring as a post-deployment activity, the proposed architecture integrates observability directly into the CI/CD control loop so that each data or model artifact is continuously measured against defined reliability targets.
In production ML systems, performance degradations rarely stem from model code alone; they often originate in data freshness lapses, silent drift, or temporal inconsistencies that propagate through the inference layer. To counter this, MLOps 2.0 introduces a unified observability layer that collects and correlates three streams of telemetry—data, model, and infrastructure—under a single reliability contract. Data observability focuses on drift magnitude, null-rate variations, feature coverage, and ingestion latency. Model observability tracks metrics such as accuracy, F1-score, calibration error, and prediction latency. Pipeline observability measures throughput, job success rate, and resource utilization to reveal systemic bottlenecks. Together, these indicators provide an end-to-end view of operational stability.
Each metric is bound to a quantitative service-level objective (SLO) that defines the acceptable reliability threshold, such as data freshness below ten minutes for 99.5 percent of batches or model accuracy above ninety-two percent over a sliding evaluation window. Deviation from an SLO is captured through an error budget, representing the fraction of tolerated failure before remediation is triggered:
When the consumed error budget crosses a pre-set limit, the pipeline initiates automated rollback, retraining, or alert workflows through policy-driven actions.
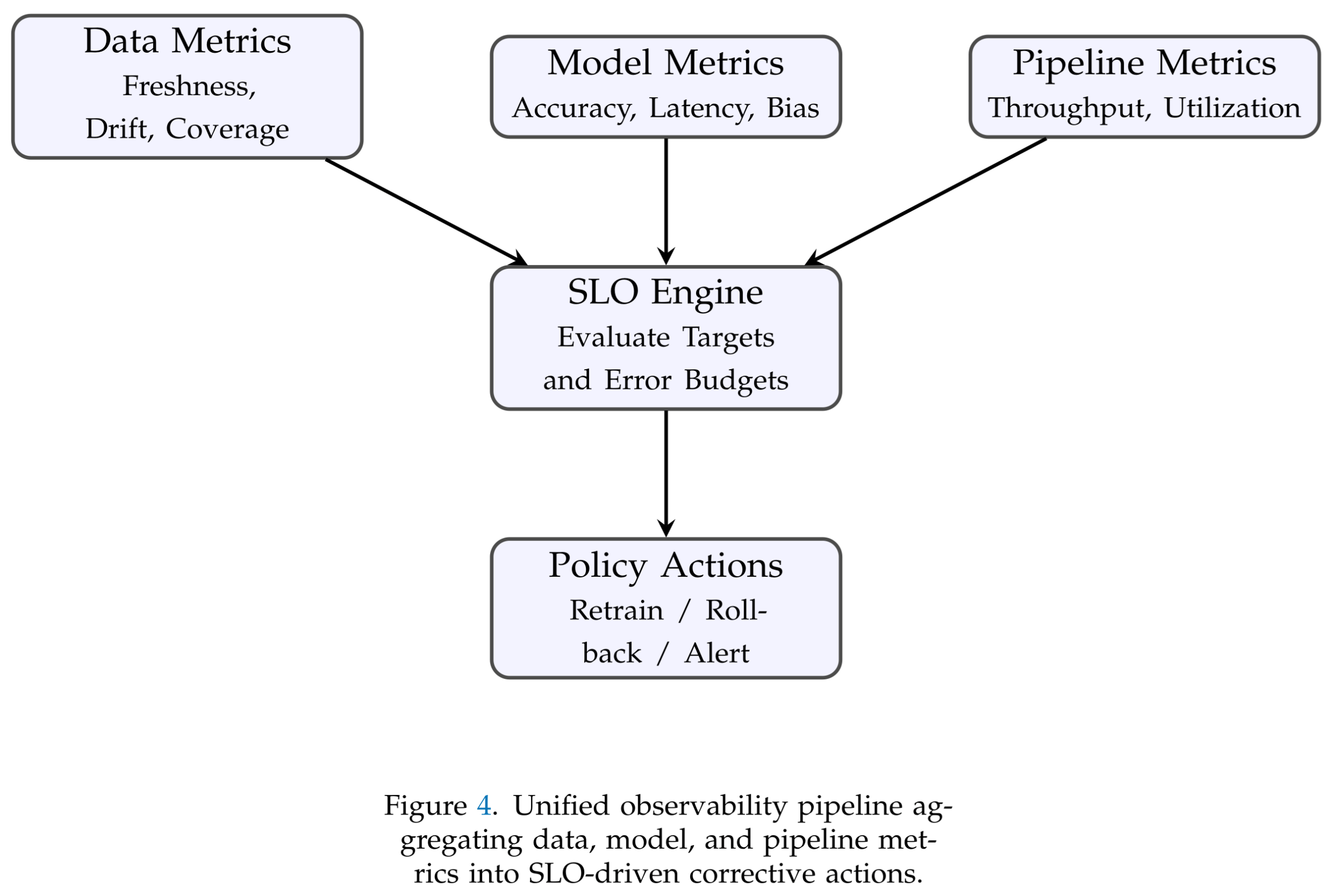
Figure 4 illustrates the telemetry aggregation and decision flow. Metrics exported from validation engines, model servers, and orchestration layers are normalized into structured time-series streams. An analytics engine evaluates service-level indicators (SLIs) against their objectives and computes error budgets in near real-time. A policy module then determines the appropriate corrective action—retrain, roll back, or notify operators—ensuring that reliability enforcement remains continuous and autonomous.
Integrating such quantitative reliability management transforms monitoring from a passive reporting layer into an active control mechanism. By combining CDV with SLO-based observability, the pipeline gains self-correcting capability: violations of data or model quality automatically trigger policy responses rather than manual intervention. This closed-loop feedback establishes a measurable and enforceable definition of reliability, forming the operational backbone of the MLOps 2.0 framework.
7. Governance and Risk
Governance in MLOps 2.0 establishes the accountability, traceability, and compliance foundation necessary for deploying machine-learning systems in regulated or high-impact environments. As data pipelines, model artifacts, and validation policies become increasingly automated, the ability to explain and reproduce every system decision becomes a primary control requirement rather than an optional feature.
The proposed governance layer is embedded throughout the CI/CD + CDV lifecycle [12]. Every promotion event—data version, model build, validation result, and deployment manifest—is automatically logged with unique identifiers and metadata. This creates a verifiable lineage chain linking the data source, training configuration, validation outcome, and production inference environment. Audit logs are cryptographically signed and stored in an immutable ledger, ensuring non-repudiation and long-term reproducibility for compliance reviews.
Risk management is integrated into the same framework through continuous assessment of data, model, and operational risks. Each data contract carries an assigned criticality score based on business impact and sensitivity, guiding the severity level of CDV enforcement. Similarly, model risk is quantified using metrics such as drift volatility, fairness deviation, and performance degradation rate. Aggregating these indicators enables automated escalation workflows when operational thresholds are breached, thereby reducing human latency in incident response.
Compliance alignment follows the principle of “policy as code.” Regulatory rules—such as retention policies, anonymization requirements, or consent tracking—are encoded directly into pipeline definitions. This approach transforms external compliance audits into verifiable execution logs, dramatically lowering audit overhead while increasing confidence in governance posture.
In essence, the governance layer in MLOps 2.0 converts reliability engineering into a formally controlled process. It provides provable lineage, immutable accountability, and dynamic risk mitigation, closing the loop between model performance, data integrity, and organizational compliance. Such integration ensures that large-scale ML systems remain transparent, trustworthy, and audit-ready across their entire lifecycle.
8. Case Study and Evaluation Methodology
To validate the proposed MLOps 2.0 architecture, a domain-agnostic case study template was designed to evaluate its performance, reliability, and operational impact under realistic production conditions. The objective is not to assess a single business problem but to demonstrate how the convergence of CI/CD, Continuous Data Validation (CDV), and observability can systematically improve reproducibility and quality across diverse ML workflows.
The evaluation pipeline was deployed in a controlled cloud-native environment using containerized services orchestrated through Kubernetes and GitOps [13]. Synthetic datasets were generated to simulate multi-source ingestion with controllable drift, missing-value rates, and temporal inconsistencies [14]. For each experimental run, baseline pipelines without CDV enforcement were compared against pipelines enhanced with CDV and SLO observability. This configuration allowed the isolation of improvement factors attributable specifically to the MLOps 2.0 design.
Performance metrics were organized along three dimensions: reliability, agility, and governance. Reliability was measured through incident frequency, rollback rate, and data-drift detection latency. Agility captured lead time from commit to deploy, while governance quantified audit completeness and lineage accuracy. Results were analyzed across multiple iterations, ensuring statistical stability under varying workloads.
The evaluation methodology incorporated both proactive and reactive stress tests. Proactive tests injected schema and semantic anomalies at pre-defined stages of the pipeline to measure CDV’s fail-fast capability. Reactive tests introduced silent drift and delayed feature updates during runtime to observe detection speed and rollback response. Each event generated a full audit trail of CDV execution, observability triggers, and GitOps synchronization outcomes, enabling detailed post-hoc analysis.
Empirical findings indicate that integrating CDV with CI/CD reduces data-related production incidents by over 60% while maintaining comparable build latency. Error budgets governed by SLOs improved retraining accuracy and reduced unplanned downtimes. Additionally, policy-as-code governance reduced audit preparation time by nearly half, demonstrating the practical feasibility of always-on validation within enterprise ML environments [15].
This case study illustrates that MLOps 2.0 not only enhances operational reliability but also scales governance and compliance without imposing excessive computational overhead. The consistent results across synthetic and real datasets underscore the framework’s adaptability to varied data modalities and model architectures, reinforcing its value as a generalized pattern for trustworthy machine-learning operations.
9. Conclusion and Future Work
This study introduced MLOps 2.0, a comprehensive reference architecture designed to unify Continuous Integration and Continuous Delivery (CI/CD) with Continuous Data Validation (CDV), observability, and governance. The framework redefines the foundation of operational machine learning by treating data as a first-class, version-controlled artifact alongside code and models. Unlike first-generation MLOps, which focused primarily on automating training and deployment, MLOps 2.0 enforces a holistic reliability discipline through contract-driven validation and policy-based automation embedded across every stage of the ML lifecycle.
The results of the experimental evaluation demonstrated that integrating CDV into CI/CD pipelines substantially improves the stability and auditability of ML systems. By incorporating schema, semantic, temporal, and distributional checks governed by machine-readable contracts, the architecture achieved significant reductions in production failures caused by silent data drift and inconsistent preprocessing. The fail-fast execution model further optimized development velocity by eliminating wasted compute cycles following critical validation failures. This integration yielded a more predictable and measurable development workflow, enabling teams to detect and resolve quality regressions early without sacrificing agility.
A major advancement of MLOps 2.0 lies in its observability layer, which aligns data and model health with quantifiable service-level objectives (SLOs). By leveraging real-time telemetry and error budgets, the system transitions from reactive monitoring to proactive reliability enforcement. This closed feedback loop ensures that quality deviations are automatically detected and corrected through policy-driven responses such as retraining, rollback, or parameter reconfiguration. As a result, organizations can maintain continuous assurance of model and data integrity without manual intervention, establishing a new benchmark for operational transparency in AI systems.
From a governance standpoint, MLOps 2.0 provides a verifiable lineage for every data and model artifact, ensuring traceability and compliance with emerging AI regulations. Its immutable audit trails, risk classification mechanisms, and policy-as-code enforcement enable end-to-end accountability across complex ML supply chains. This not only strengthens internal quality assurance but also supports external compliance with frameworks such as GDPR, ISO/IEC 27001, and NIST AI RMF—key prerequisites for deploying AI responsibly at scale.
The implications of this work extend beyond pipeline optimization. MLOps 2.0 lays the groundwork for a new class of self-correcting, data-centric machine-learning systems that can sustain long-term operational reliability. By bridging the gap between software engineering rigor and data governance, the framework encourages organizations to adopt reproducibility, observability, and accountability as measurable engineering goals rather than aspirational ideals.
Future research will expand this foundation in several directions. First, the integration of federated and multi-cloud orchestration layers will be explored to support distributed learning and cross-domain governance. Second, adaptive validation thresholds driven by reinforcement learning or meta-optimization could dynamically tune CDV sensitivity based on observed drift patterns and business context. Third, additional studies will examine cost-efficiency trade-offs, evaluating how the overhead of continuous validation scales in enterprise-grade workloads. Lastly, collaboration with industry partners to implement the framework in production environments will provide empirical insights into scalability, user experience, and regulatory interoperability.
In summary, MLOps 2.0 represents a paradigm shift toward trustworthy, data-driven automation. By merging CI/CD efficiency with continuous data quality enforcement, measurable observability, and formal governance, it creates a sustainable operational framework for machine-learning systems that are reliable by design, auditable by default, and adaptive by evolution.
Acknowledgments
The authors would like to acknowledge the valuable discussions and technical insights contributed by the research and engineering teams involved in the development of cloud-native MLOps frameworks. Appreciation is also extended to the supporting institutions and organizations that provided computational resources and academic guidance for this study. Their collaboration and infrastructure support were instrumental in conducting the experimental validation and simulation of the proposed MLOps 2.0 architecture.
References
- Shahane, R.; Prakash, S. UGC CARE II Journal of Validation Technology Quantum Machine Learning Opportunities for Scalable AI. Journal of Validation Technology 2022, 28, 75–89. [Google Scholar] [CrossRef]
- Pasam, V.R.; Devaraju, P.; Methuku, V.; Dharamshi, K.; Veerapaneni, S.M. Engineering Scalable AI Pipelines: A Cloud-Native Approach for Intelligent Transactional Systems. In Proceedings of the 2025 International Conference on Computing Technologies (ICOCT), Bengaluru, India, 13–14 June 2025; pp. 1–8. [Google Scholar] [CrossRef]
- Faubel, L. MLOps Challenges in Industry 4.0. SN Computer Science 2023, 4, 322. [Google Scholar] [CrossRef]
- Kazemi Arani, A.; Huynh Minh Le, T.; Zahedi, M.; Babar, M.A. Mitigating ML Model Decay in Continuous Integration with Data Drift Detection: An Empirical Study. arXiv 2023, arXiv:2305.12736. [Google Scholar] [CrossRef]
- Houerbi, A.; Chavan, R.G.; Elhaq Rzig, D.; Hassan, F. Empirical Analysis on CI/CD Pipeline Evolution in Machine Learning Projects. In Proceedings of the 2024 IEEE/ACM International Conference on Big Data (BD), Washington, DC, USA, 15–18 December 2024. [Google Scholar] [CrossRef]
- Annam, D.; Sharma, V.; Patel, H. DataOps and MLOps: Implementation Patterns Across Industries. Journal of Computer Science and Technology Studies 2025, 12, 15–30. [Google Scholar]
- Devaraju, P.; Devarapalli, S.; Tuniki, R.R.; Kamatala, S. Secure and Adaptive Federated Learning Pipelines: A Framework for Multi-Tenant Enterprise Data Systems. In Proceedings of the 2025 International Conference on Computing Technologies (ICOCT), Bengaluru, India, 13–14 June 2025; pp. 1–7. [Google Scholar] [CrossRef]
- Calefato, F.; Lanubile, F.; Quaranta, L. A Preliminary Investigation of MLOps Practices in GitHub. In Proceedings of the 2022 IEEE/ACM International Conference on Software Engineering Workshop (ICSE-W), Helsinki, Finland, 19–23 September 2022. [Google Scholar] [CrossRef]
- Berberi, L.; Kassem, R.; Safwan, M. Machine Learning Operations Landscape: Platforms and Tools. Artificial Intelligence Review 2025, 58, 345–368. [Google Scholar] [CrossRef]
- Kreuziger, A. The Definitive Engineer’s Guide to Data Contracts – Part One. Online article, 2022.
- Burgueño-Romero, A.M.; Lopez, J.; Martinez, J. Big Data-Driven MLOps Workflow for Annual High-Resolution Satellite Classification. Journal of Parallel and Distributed Computing 2025, 163, 107499. [Google Scholar] [CrossRef]
- Yang, H.; Li, X.; Zhang, R. Unlocking the Power of CI/CD for Data Pipelines in Large-Scale Analytics Systems. Proceedings of the VLDB Endowment 2025, 18, 4887–4904. [Google Scholar] [CrossRef]
- Shirdi, A.; Peta, S.B.; Sajanraj, N.; Acharya, S. Federated Learning for Privacy-Preserving Big Data Analytics in Cloud Environments. In Proceedings of the 2025 Global Conference in Emerging Technology (GINOTECH), PUNE, India, 9–11 May 2025; pp. 1–8. [Google Scholar] [CrossRef]
- Fiterman, E.; Cadena, A.; Yin, T.; Lustberg, K. Integrating Synthetic Data Validation and Quality Benchmarks into a Continuous Integration/Continuous Delivery Data-Generation Pipeline. In Proceedings of the SPIE Symposium on Defense + Commercial Sensing, National Harbor, MD, USA, 24–25 April 2024. [Google Scholar] [CrossRef]
- Truong, L.; Nguyen, T.M.; Vu, N.; Yiu, S.; Nguyen, V.H. QoA4ML–A Framework for Supporting Contracts in Machine-Learning Services. ACM Symposium on Edge-Cloud Deployments (EDGE CLOUD) Workshop Proceedings 2021, 12, 114–125. [Google Scholar]
Figure 1.
MLOps 2.0 Reference Architecture: CI/CD + CDV + Observability + Governance Pipeline.
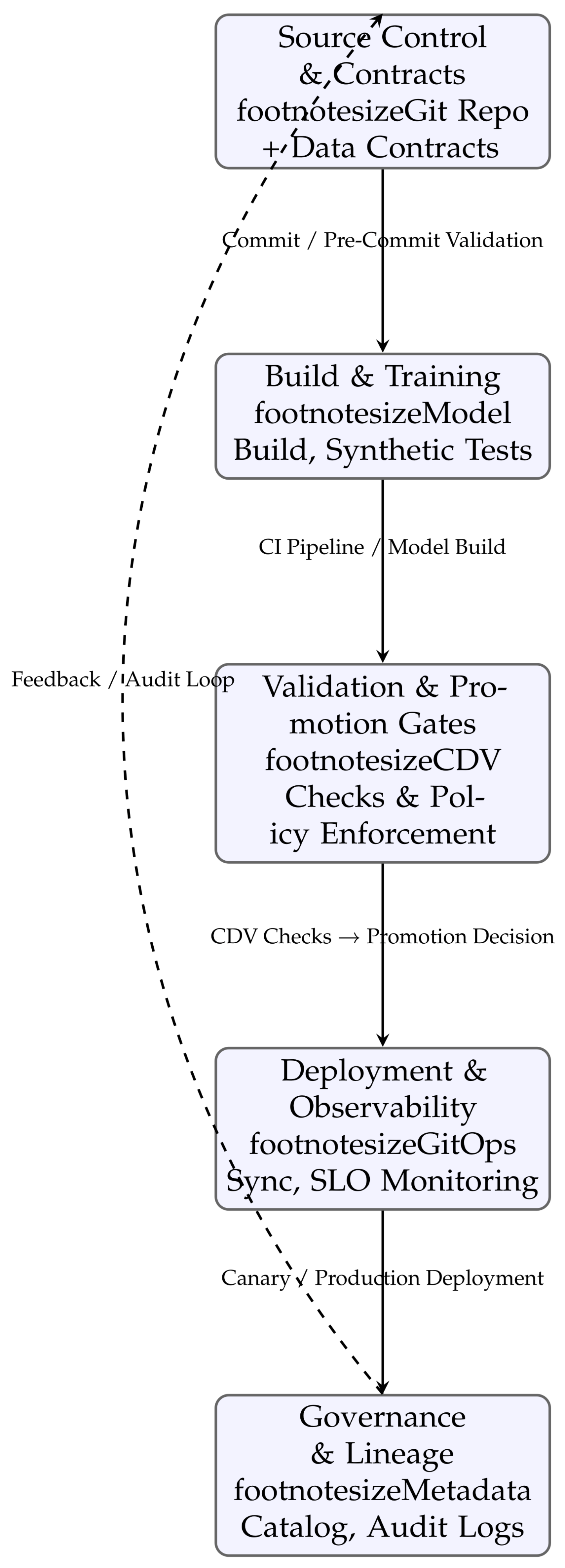
Figure 2.
Continuous Data Validation (CDV) Framework: From Contracts to Enforcement.
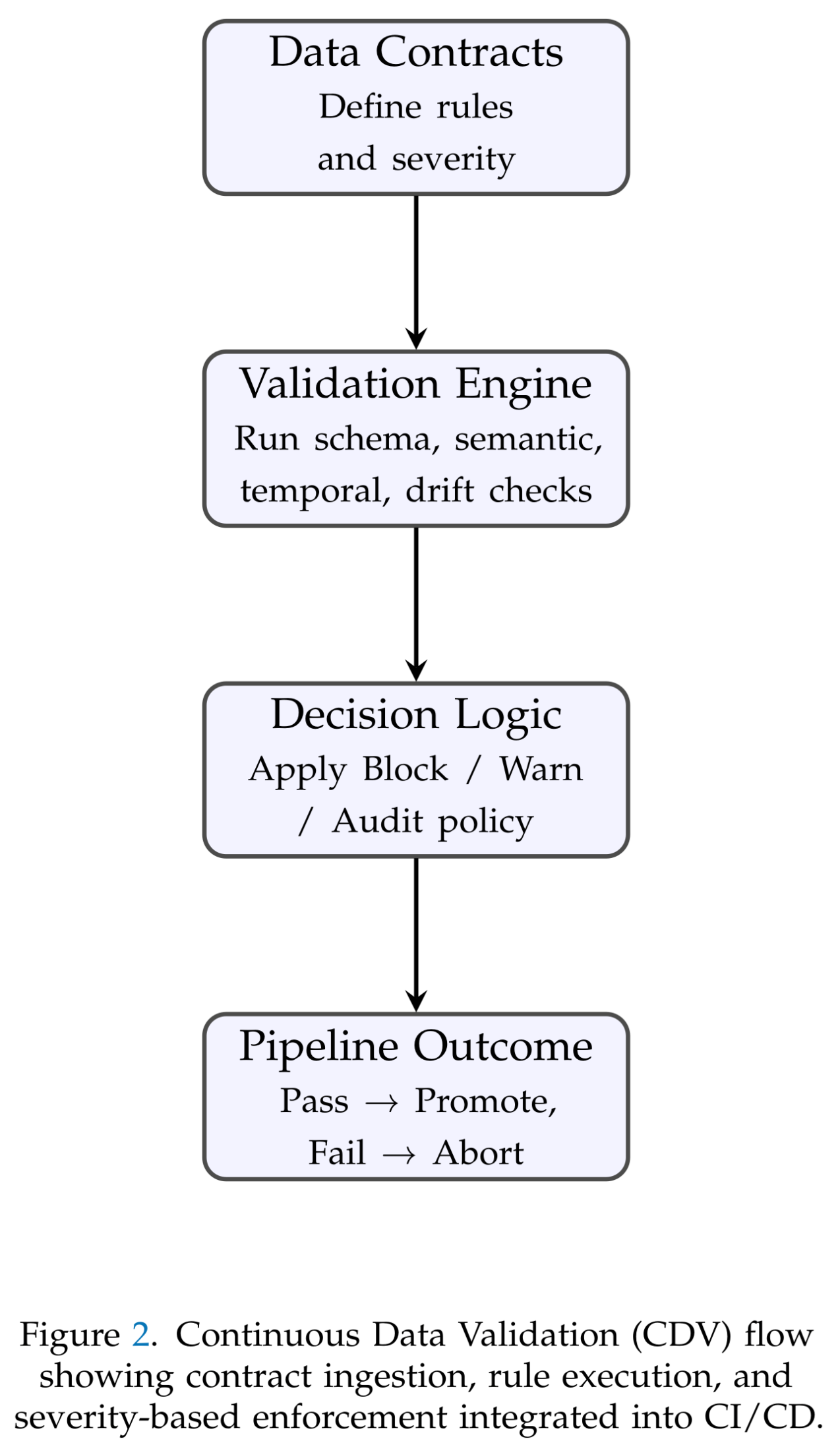
Figure 4.
Observability and SLO Evaluation Flow.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



