
Submitted:
24 November 2025
Posted:
26 November 2025
You are already at the latest version
Abstract
We present a novel framework for hyperspectral satellite image classification that explicitly balances spatial nearness with spectral similarity. The proposed method is trained on closed-set datasets, and it was tested on zero-shot agricultural scenarios that include both class distribution shifts, and presence of novel and absence of known classes. This scenario is reflective of real-world agricultural conditions, where geographic regions, crop types, and seasonal dynamics vary widely and labeled data are scarce and expensive. The input data are projected onto a lower-dimensional spectral manifold, and a pre-trained pixel-wise classifier generates an initial class probability saliency map. A kernel-based spectral-spatial weighting strategy fuses the spatial-spectral features. The proposed approach improves the classification accuracy by 7.22%–15% over spectral-only models on benchmark datasets after iterative convergence. Incorporating the additional unsupervised learning and weak labeling helped surpass several recent state-of-the-art methods. Requiring only 1%–10% labeled training data and at most two tuneable parameters, the framework operates with minimal computational overhead, qualifying it as a data-efficient and scalable learning solution. Recent deep architectures, although exhibiting high closed-set accuracies, often show limited transferability under low-label, open-set or zero-shot agricultural conditions where class distributions shift and novel classes emerge. The rice crop play a pivotal role in global food security but are also a significant contributor to greenhouse gas emissions, especially methane, and extent mapping is very critical. We demonstrate transferability to new domains-including unseen crop class (e.g. , paddy), seasons, and regions (e.g. , Piedmont, Italy)—without re-training. This work presents a novel perspective on hyperspectral classification and domain transferability, suited for sustainable agriculture with limited labels and low-resource domain generalization.
Keywords:
Hyperspectral
; remote sensing
; sustainable agriculture
; spatial nearness
; spectral similarity
; weak supervision
; zero shot learning
; transferability
1. Introduction
Remote sensing has become an ubiquitous tool for monitoring land use, crop distribution, health, and biophysical and biochemical traits [1]. Recently, they are being explored more in the applications of sustainable agricultural production, resource management, adaptation to climate change, and studying greenhouse gas emissions. Farmers, support organizations, or field scientists and personnel often find it difficult to audit or scout fields on a regular basis or might miss out on details during scouting. Temporal monitoring between the pre-sowing and post-harvesting phases, at scale, is essential for timely interventions. Low-altitude flights, UAV-based and satellite-based remote sensing technologies [2,3] address these gaps. Imaging spectrometry for agriculture and forestry has evolved considerably since the launch of Landsat 1 in 1972 [4], culminating in today’s high-resolution UAV-based sensors. Hyperspectral Imaging (HSI) [2,5], with its rich spectral bands, has emerged as a key enabler providing information in both the spatial and spectral dimensions. Using field-collected data and machine learning, it is possible to perform crop discrimination [6], determine biotic and abiotic stresses [7,8], monitor health, nutrients [9], and support the goals of sustainable development [10].
The articles [5,11], provides the recent trends in HSI analysis, while in [12,13], the authors review recent Deep Learning methods. Deep belief [14], residual networks [15] and their recent transformer variants [16], have achieved state-of-the-art accuracies in benchmark datasets. Despite these advancements, hyperspectral remote sensing in agricultural applications is limited by five key challenges:
- the number of spectral components increases the complexity of data processing during preparation, training, and inference [5],
- high correlation between the individual bands and added redundancy [17],
- limited number of benchmark ground truth labeled datasets for monitoring sustainable and regenerative agriculture practices, and
- limited ability of the models to generalize to small plot sizes or new regions or new classes or new context different from training.
Earlier studies extensively addressed spectral redundancy, data dimensionality, and model interpretability. The trade-offs between spatial and spectral features have focused mainly on pan-sharpening [20], super-resolution [21], or enhancement [22]. While attention-based architectures [23,24] can dynamically recalibrate spatial-spectral features through learned weighting mechanisms. Many of them have demonstrated high accuracy in closed-set benchmark datasets [25]. However, they have large parameter spaces and are computationally expensive, focused entirely on obtaining high-accuracy classification maps in selected or localized study regions. In addition, patch-based models (minimum size Ha) do not scale very well for small landholding farm plots ( Ha) with medium resolution satellites ( m). For large scale deployment in practical applications (with full training inference class overlap), trust in the performance of these models is also less due to overfit to the training data/domain. When operating in new regions, environments, and with new crops, they cannot generalize by design. Thus, very few works have addressed the last two challenges related to the limited dataset for small landholding farms with diverse classes and generalizability of models. Notable among these previous work is [26] where the authors use a three-dimensional convolutional neural network or 3D CNN along with an OpenMax layer (with a Weibull distribution) to reject unknown classes. Similarly, in [27], the authors designed a framework to enhance latent spectral and spatial features that can be used to classify the known classes while rejecting the unknown classes–open set classification. Unfortunately, in agriculture applications, new geographies (test region) can have minimal to no overlap between the classes in the training and the test sites or classes. In which case, the classifier will reject all crop classes of interest.
This study presents a novel approach and framework that addresses all of the above five challenges, with a special emphasis on domain generalization (minimal or no overlap with training classes) and low-resource adaptability. We demonstrate transferability and domain generalization for paddy crop extent mapping. Paddy fields play an essential role in global food security, but are also a significant contributor to greenhouse gas (GHG) emissions, especially methane. Methane produced under anaerobic growing conditions typical of flooded rice cultivation accounts for approximately of global anthropogenic methane emissions and approximately of total agricultural GHG emissions. Therefore, accurate remote sensing of the extent of flooded rice cultivation is essential to estimate, monitor, and manage these emissions, thus supporting climate-smart and sustainable rice production systems. This study aims to evaluate whether a weakly supervised minimal parameter spectral-spatial classifier trained on benchmark datasets is transferable to low-label agricultural settings.
1.1. Problem Formulation
Let be the HSI where M and N are the spatial dimensions and D is the number of spectral bands in the image. We define K as the number of distinct classes, with , and by the set of class labels that belong to the set of universal class labels . is transformed into the set of features , where is the total number of pixels. The set of training data pairs, , is randomly chosen from . For our case, we assume that the training examples . The first objective is to build a classifier, s.t. using , and the final class labels with weak labeling are .
1.2. Notation Conventions
We use the following mathematical notation conventions throughout the article:
- Scalars: regular italic (e.g., x, )
- Vectors: bold lowercase (e.g., , )
- Matrices: bold uppercase (e.g., , )
- Sets: calligraphic uppercase (e.g., , )
- Tensors: bold sans-serif (e.g., )
1.3. Contributions
The key contributions of this work are as follows:
- A lightweight framework that introduces a tunable balance between spectral similarity and spatial nearness, with minimal computational overhead.
- An efficient weighting mechanism requiring the tuning of at most two dataset-specific parameters (C, ) while maintaining four fixed parameters (r, , , ) transferable across domains, allowing training with only labeled data. Specifically, only C (SVM regularization) requires dataset-specific tuning, with optionally fine-tuned for improved accuracy as demonstrated in Section 3.3.
- The pixel-based classifier with neighborhood has no patch-based processing, hence applicable to small landholding farm sizes.
- Demonstration of domain generalization capabilities by training on one benchmark dataset (Indian Pines) and successfully inferring on three different datasets viz. the Kennedy Space Center (KSC), Hyperion Botswana and Salinas-A, without retraining.
- Extension to real-world agricultural settings (e.g. ASI PRISMA imagery over Italy), showcasing transferability to unseen crops and regions with minimal supervision.
- Comparative performance approaching state-of-the-art transformer-based models (e.g. MASSFormer with training samples and ours with training samples in Salinas) in terms of accuracy, while requiring fewer parameters.
2. Learning Approach
The proposed learning approach is shown in Figure 1 and has the following main steps:
- Map the analysis-ready data to a lower dimension representation in the space , reducing along the spectral features (either linearly or non-linearly)
- Supervised pixel-wise classification on K classes on the new representation,
- Construct the class probability map based on the pixel-wise classifier and use it as initial seed
- Iterative unsupervised learning using weighted trade-off between spatial nearness and spectral similarity measures,
- An optional ensembling of the different models from random batch of training samples and majority voting can improve reliability,
- Final assignment of the class using weak labeling.
We will discuss the details in the following subsections.
2.1. Class Separability
As the number of spectral bands in the hyperspectral is very high (D), for a spectral classifier such as a SVM, the worst-case computational complexity can be . This is computationally expensive for large features and the correlated bands add redundancy [28]. For class separability and sparsity, the data is orthogonally projected onto a lower-dimensional subspace manifold. After exploring many methods in our experiments and validating their performance with respect to the spectral classifier, the linear PCA [28,29] worked reliably with the least loss of accuracy. This is consistent with previous work [30,31]. KPCA and other nonlinear methods gave poor results when the training sample is small or was computationally more expensive without a significant contribution to the accuracy. The principal components are the Eigen vectors of the covariance matrix of and the amount of “explained variance” in each component is proportional to the Eigen value. So, each hyperspectral pixel is projected onto a lower-dimensional spectral manifold with maximum variance:
where contains the first d eigenvectors of the covariance matrix of . The explained variances are arranged in descending order of value, and the components are chosen so that the cumulative explained variance ratio is higher than a threshold . We fixed the threshold value to be as the cumulative explained-variance plateaued beyond.
2.2. Construction of Initial Classification Probability Map
The initial classification map is obtained from a pixel-wise spectral classifier
with multiclass decision functions, where is identity (linear) or kernel map. For each pixel, we attribute the class probability as
with . The pixel classifier’s probability map, , is used to initialize the subsequent steps. It is possible to add a penalizing term to the probability map depending on the deviation from the true labels . There is much prior literature that compares Random Forest (RF) and Support Vector Machine (SVM) for pixel-wise labeling of the images. Although the overall accuracy (OA) is comparable, SVM classifiers are able to spatially associate pixels with similar signatures better, resulting in less noisy maps [32,33]. In addition, the number of parameters is lower than that of tree-based approaches. Throughout this text, we will use SVM as the pixel-wise classifier, but it can be replaced by RF or CNN-based classifiers with softmax probabilities. We used the SVM algorithm implemented in the ThunderSVM library [34] that has GPU support. The initialization seed (similar to the unary potentials [35,36]) is constructed from the probability map of the pixel classifier.
2.3. The Model
We observed that PCA alone cannot bring about class separability. As an example, in the Indian Pines dataset, the “Corn-notill”, the “Corn-mintil” and “Corn” classes seem to have very similar spectral signatures. This also applied to the classes “Soybean-notill”, “Soybean-mintill”, “Soybean-clean”. Some sustainable agriculture farmers practice ‘zero’ or ‘minimum-tillage’ to reduce mechanical soil interventions. These practices preserve soil structure and beneficial organisms. However, detecting such interventions (or their absence) using single-timestamp imagery is difficult. Interventions may have occurred before sowing, while the acquired image may have been captured much later in time during the vegetative period or at the time of maturity. When the canopy is dense, the signatures from the soil are minimal, and hence the signatures are mostly from the crops. This explains why these classes might have similar signatures when we study the spatial-spectral features.
In order to overcome this, we model the joint distribution of the probabilities of pixels using the nearness with the spatial neighbors and spectral similarity. For each pixel, i, a neighborhood which belongs to the partition of the possible neighborhood partitions of the image. This neighborhood is defined on the output probability map obtained from the spectral classification, and the joint probability distribution is constructed by integrating the spatial nearness and the spectral similarity between the pixels. The following are the definitions of nearness and similarities.
2.3.1. Spatial Nearness Kernel
We assume that the pixels , are spatially close. To quantify this idea, we have the spatial proximity kernel as:
where, is the distance -norm between the reference pixel i and the neighborhood set of pixels . The Gaussian kernel’s parameter, , controls the local spatial connectivity of the pixels. A lower (higher) value of means that the pixels that are closer are only (slightly farther are also) considered spatially similar to the central pixel. This also ensures compatibility of the labels between neighboring pixels. The neighborhood or of radius r is defined as:
2.3.2. Spectral Similarity Kernel
We can assume that the spectrum of the reference and neighborhood pixels is similar if they are of the same class. The spectral similarity is defined as follows:
where, is the spectral feature vector of the reference pixel, is the spectral feature of the neighborhood pixels in , and is the parameter that controls the degree of similarity. Due to the normalization, the parameters of the kernels and are independent of both the spatial and spectral resolutions, respectively.
2.3.3. Boundary Condition Handling
For pixels, i, at the image boundaries where the full neighborhood extends beyond the image extent, we employ mirror padding:
- Symmetric Padding: The input image is padded to by reflecting the values of the pixels at the borders. This ensures that every pixel has a complete neighborhood and is better than truncation.
- Small Memory Overhead: For , padding increases only fractionally the memory footprint () and is negligible for modern hardware.
2.3.4. Attention as Generalized Weighting
In recent transformer architectures, self-attention computes pairwise relationships (attention weights) between spatial tokens/pixels, dynamically weighting their influence based on feature similarity. The kernels described in the previous paragraphs (spatial proximity) and (spectral similarity) play similar roles as attention masks that highlight the relative importance of neighboring pixels based on their spatial proximity and spectral relatedness. Many of the vision transformers (e.g. Swin transformers) incorporate a variant of localized self-attention to the spatial windows, and they locally resemble spatial kernels while the spectral similarity kernel promotes semantic consistency.
2.3.5. Unsupervised Learning
We construct the conditional probability distribution of the final classification map (), given the initial classification map () and the unsupervised learning parametrized by and i.e. . Since the adjacency of pixels in the image is a local phenomenon, it might not be necessary to use the entire initial classification map to obtain the final classification label for a pixel. For the reference pixel i, we compute the conditional probability in the neighborhood . This approach reduces computational cost by not using the predictions from pixels far from the reference pixel [37]. Using the definition of conditional probability,
The numerator term in the above equation is the joint distribution of the initial and final classification maps. Since the denominator term is constant over the neighborhood, the numerator is the only component which decides the conditional probability. In [36], the authors use a mean-field approximation to compute a distribution rather than to compute the exact distribution of Equation (6). To make the computation of the joint probability tractable, we rather assume conditional independence between the neighborhood (given the reference pixel), and we factorize the distribution based on this assumption. This assumption is reasonable because spatial dependencies are the way localized and distant neighbors interact with the reference pixel, and the spectral correlations are captured by the similarity kernel .
For two neighborhood pixel locations j and l in , the conditional independence implies that . The joint probability distribution can be factorized as the following:
where is the potential function between the reference pixel i and the neighborhood pixel , and Z is the partition function given by,
The potential function in Equation (7) can be any positive non-zero functions. Since we are restricted to strictly positive functions, it is convenient to express the potential functions as an exponential:
We assume that is the energy function that is influenced by the unary potentials of the spectral classifier and the neighborhood interactions.
The joint distribution is defined as the product of potentials, and so the total energy is obtained by adding the potentials of the interactions in the spatial and the spectral directions. The potential is defined as:
where the indicator operator is given by,
is the parameter of the energy function and is the probability of the class at neighbor pixel j by the pixel classifier. By combining the spatial and the spectral components together, we can rewrite Equation (10) as:
Dividing the entire equation by and replacing by , Equation (11) could be simplified as follows:
where: ⊙ denotes element-wise multiplication, ∗ denotes convolution, and the trade-off parameter controlling spatial closeness vs. spectral similarity. For simplicity, herein, we refer to as . As described earlier, the total energy is the sum of the potentials as
Equations (12) and (13) are familiarly similar in form to the way that the unary and pairwise potentials are built for the Gibbs’ energy [35]. The difference is that in this case, the output from the spectral classifier interacts with the nearness and similarity kernels non-linearly and is not a spatial-only regularizer. The energy function balances two objectives:
- Spectral term (): Rewards assignments agree with spectrally similar neighbors’ SVM predictions.
- Spatial term (): Encourages spatially coherent labeling while penalizing disagreement with nearby pixels.
- Trade-off parameter (): Controls relative importance. Low trusts the spectral evidence; high enforces spatial smoothness.
is linear in the cost function and can be estimated by minimizing the cost function in . Since the initial classification has good accuracy, we weigh the probability map of the reference pixel with spatial nearness and spectral similarity to reward or penalize the correct and incorrect classification of the initial spectral classifier.
To make a prediction on the reference pixels, we now fix the initial probability map based on the spectral classifier, which implicitly defines the conditional distribution . Then, we take one reference node i at a time and evaluate the total energy for all possible states, keeping all other variables fixed, and set the reference node i to whichever state has the lowest energy. Since the entire inner-loop computation is performed in a small neighborhood, the overall optimization is efficient. After finding the state for a node, we will move to another node and the above steps are repeated. We have a sequence of updates in which every site is visited at least once, and the variables remain unchanged during this time. This inner site-iteration is repeated until the assignment of the class labels is complete for all the sites. The entire methodology is repeated as an outer loop iteration (n) until the total assignment probability of the class labels stabilizes i.e.
Here, or refers to the probabilities of the class at site i at the iteration and is the absolute convergence threshold, which can be very small (say ). Additionally, an early stopping criterion can be enforced, during training, if the improvement between iterations falls below OA for three consecutive iterations, or after a maximum of, say, 50 iterations. Such an iterative approach has been explored in other prior work, such as in the ICM [32]. The inner and outer loop iterations ensure that the local and global connectivity of the pixels are maintained. The iterative algorithm is guaranteed to converge to a local minimum of the energy function (Equation (13)) because the energy is bounded (probabilities ), at each update the energy is reduced or maintained, and the state space is finite (K classes, P pixels). Convergence to the global minimum is not guaranteed, but empirical results show stable solutions across random initializations. The benchmark datasets and a section of the Python code are made available for reproducibility as a Github repository.
2.4. Ensemble Voting
An ensemble voting algorithm helps in reliability, avoid overfit to the training samples and generalizing the model [38]. This can decrease the overall accuracies, but ensures the reliability of the classification results. So, the following optional steps are proposed in addition to the above methodology.
- Step 1: The features are divided into 4 mutually exclusive and collectively exhaustive subsets using random sampling.
- Step 2: The proposed model is built on all the subsets individually and the classification map is obtained for every single model.
- Step 3: The classification maps from Step 2 are stacked and the final classification map is obtained by voting for the majority class.
3. Evaluation
3.1. Benchmark Data for Training and Testing, and Open-Set Data for Inference
We used data from three open-source hyperspectral images, which are the Indian Pines Image, the Salinas Image, and the University of Pavia Image [39]. These are from different sensor resolutions, sizes, and classes. The Indian Pines’ scene was captured by NASA’s AVIRIS sensor over the over the Purdue University Agronomy farm northwest of West Lafayette and the surrounding areas [40] on June 12, 1992. The image has a size with a spatial resolution of and a total of 224 spectral reflectance bands present within the wavelength range to . The scene mainly contains agricultural land, forests, grasslands, and some urban classes. The ground truth is mapped into sixteen mutually exclusive land cover classes. It is conventional practice to reduce the number of spectral bands to 200 by removing the bands covering the regions of water absorption i.e. the bands . Figure 2 shows a randomly selected band (band 3) and the ground truth with class labels.
The Salinas image was captured by NASA’s AVIRIS sensor over the Salinas Valley in California. The image has a size with a spatial resolution of and has 224 spectral reflectance bands. Similarly to the Indian Pines, there are twenty bands that cover the water absorption bands with band numbers . The Salinas ground truth is designated to sixteen classes containing vegetables, bare soils, and vineyard fields. Figure 3 shows a randomly chosen band 101 with ground truth.
The Pavia University scene was acquired as one of the experimental analysis using the ROSIS-03 sensor (or Reflective Optics System Imaging Spectrometer) during a flight campaign over Pavia in northern Italy. The image has 115 spectral bands of size and with a spatial resolution of m per pixel. It is the general norm to keep only 103 channels from the original 115 and discarding the 12 other channels from the raw data. The ground truth contains nine classes as shown in Figure 4 with a randomly chosen band 41.
The test samples are chosen from the same 3 set of images, and hence this is a closed-set with the class representations in the test being fully represented in the training set.
The open-set data is chosen from a study region in Italy, acquired on 25 April 2020, as described in Section 3.6. The PRISMA sensors acquire VNIR and SWIR products, with a 30m spatial-resolution, and a panchromatic camera with a 5m spatial resolution. The hyperspectral camera works in the range of –m with 66 and 173 channels in VNIR and SWIR, respectively. Due to their low SNR, SWIR bands (2392 nm) and (2495 nm) were not considered. We used the L2D HCO product and the SWIR images with the number of bands being 171 and a size of .
3.2. Performance Metrics
The performance of the proposed model is evaluated using three quality indices, which are the overall accuracy (OA), average accuracy (AA), and the Kappa coefficient. The OA is the percentage of correctly classified pixels, the AA is the mean of the percentage of correctly classified pixels for each class, and the Kappa coefficient gives the percentage of correctly classified pixels corrected by the number of agreements that would be expected purely by chance.
In [24], the authors have made a comparison of the different state-of-the-art algorithms and have highlighted that the SVM with the RBF kernel has the least computational time during training. The computational order for our approach is determined by the pixel classifier viz. , whereas for CNN it is for P pixels, L layers and M operations in each layer.
3.3. Analysis of Parameters
The proposed methodology is a mixture of supervised and unsupervised classification because the first stage of the modeling is a supervised spectral classification, and the second stage is an unsupervised approach that uses the spatial nearness and spectral similarity of pixels in the image. The basic objective of the proposed model is to designate each pixel in the image to a class by making use of the least amount of labeled data. So, all pixels in the image are split into two sets, viz. training data and testing data s.t. the training data have samples from each class. The labels of the first set are visible to the model and are used to determine the optimum value of parameters of the classifier, and the testing data is left untouched. The parameters of both classifiers are determined independently and the methodology is as follows.
- Parameter Selection for PCA: We fixed the PCA parameters, viz. the explained ratio, to for all images, and the optimal number of principal components can be automatically calculated from that threshold. The cumulative explained variance ratio curves reached saturation after the first 30 main principal components. However, cross-validation (CV) did not show gains in the accuracies beyond the first 18 principal components.
- Spectral classifier parameter tuning: We used SVM [33] with the RBF kernel as a spectral classifier due to its relatively higher accuracy compared to other classifiers. We observed that spatial adjacency is maintained better by SVM’s pixel-level class label assignment than by using tree-based classifiers. As the number of parameters of the SVM (C and ) is small, these are estimated using an exhaustive grid search algorithm [41,42] within a specified coarse bound using a 5-fold CV. Finer grid search for the parameter is computationally feasible and can be parallelized [41] but at the risk of overfitting to the data.
-
When training, we randomly choose a few pixels from each class label. For training data partition, we deliberately used smaller training fractions than conventional literature splits. This choice simulates real-world data-scarce agricultural conditions and reflects our operational experience. The ground truth collection requires expensive field campaigns with multiple seasonal visits. The minor crops often have minimal representation in the training data, and climate variability causes crop rotation between seasons, necessitating re-labeling. Some authors have estimated that their algorithm gave the best OA when of data was used for training for the Indian Pines, for the Salinas and for the Pavia respectively [43]. In real-world scenarios, ground truth is sparse and expensive. We used smaller training fractions than conventional splits for these benchmark datasets to highlight low-label scenarios. Thus, to reduce efforts in manual ground truth data collection and annotation, our objective towards model building was to use as few training samples as possible or low-resource conditions. Our objective is to demonstrate that the proposed method maintains competitive accuracy even under extreme label scarcity (), whereas deep models typically require much higher data for stable training.Table 1. Training data partition comparison between our study and literature.
Dataset Literature Our Study Rationale Indian Pines Maintained for comparison Salinas 4–10% Sparse-label stress test Pavia Univ Extreme low-resource scenario - Parameter tuning: The parameter r determines the size of the neighborhood around the reference pixel, the parameters and control the degree of spatial nearness and spectral similarity Gaussian kernel, respectively. The parameter , with , specifies the relative importance between the two terms in Equation (11). Because spatial and spectral kernels operate within a radial neighborhood of r, we restrict and to values proportional to r. This is also expected behavior, as the value of the parameter r is linked to spatial resolution. In missions with lower resolution acquisitions, to avoid smoothing, a lower value of r is required. The spatial resolution and the choice of the neighborhood are also closely linked to the type of farm holding size. It is likely that for smaller landholding sizes ( acres or 6400 or Ha), the performance of the method could be affected. The performance of the model is evaluated with respect to the three quality indexes mentioned in Section 3.2 and the results are summarized in Figure 5, Figure 6 and Figure 7.

Table 2 summarizes the optimal parameters required by the algorithm for the analysis in Figure 5, Figure 6 and Figure 7. We found that by fixing the set of parameters to , , , and , for all images, there was a slight loss in the OA but we benefit from not having to fine-tune these parameters in the future. This was also observed in [36] with the smoothness kernel parameter and the weights that did not influence the accuracy of a given dataset. So, the only parameters to estimate are the parameters of the SVM C and to improve accuracies the [44] parameter. We observed that the AA of the algorithm is especially sensitive to C and the degree of dependency is smaller on the other parameters, so we recommend estimating the value of C for each dataset.
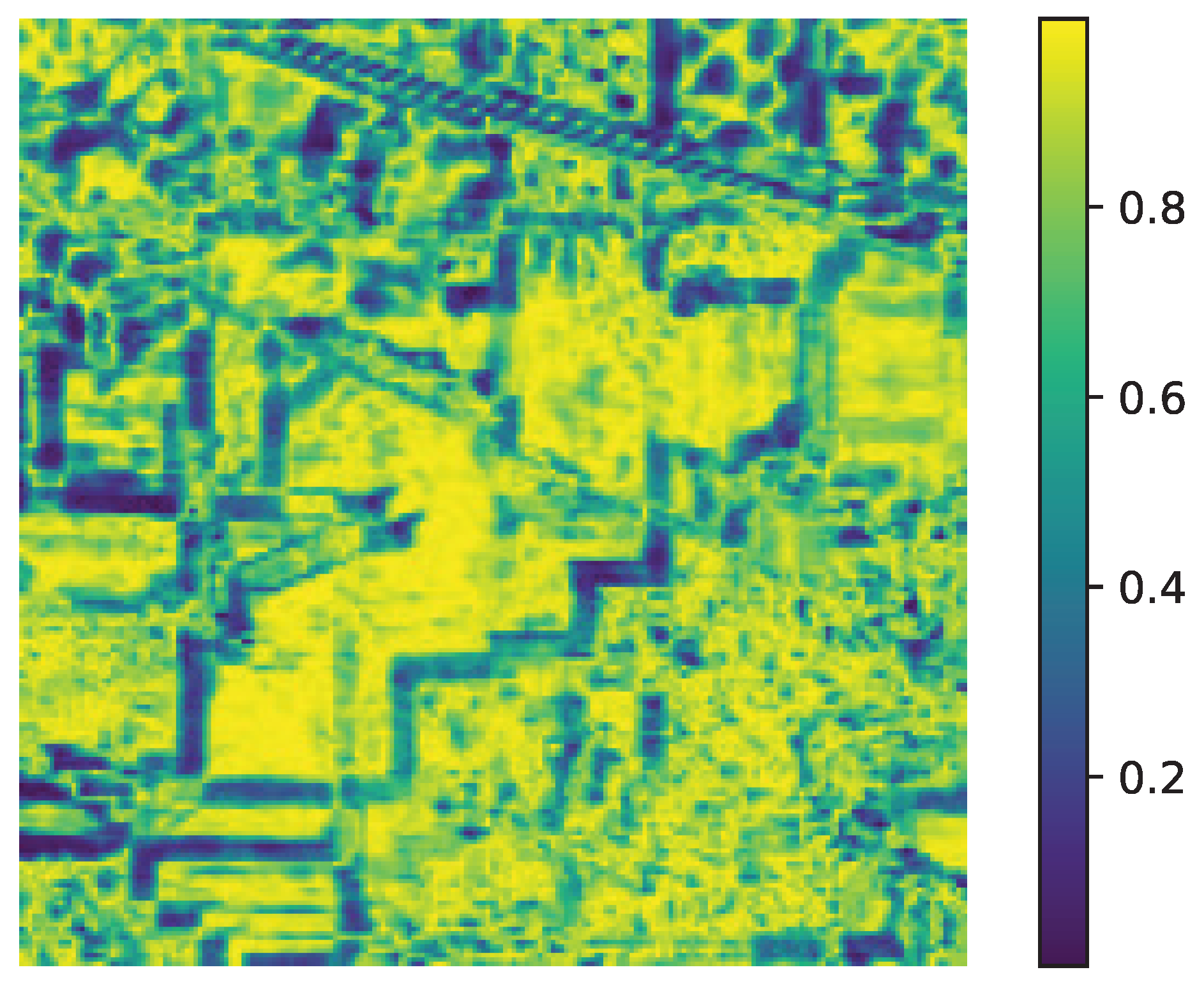
Figure 8.
Spectral similarity map for Indian Pines computed using Equation (5) with . Spectral similarity weights showing high intra-class homogeneity (bright regions) and inter-class heterogeneity (dark regions).
Figure 8.
Spectral similarity map for Indian Pines computed using Equation (5) with . Spectral similarity weights showing high intra-class homogeneity (bright regions) and inter-class heterogeneity (dark regions).
3.4. Classification Results and Model Transferability
The performance of the proposed algorithm is shown, for the three data sets, in Table 3, Table 4 and Table 5 and compared with the other methods. The comparison is made with some closely related hyperspectral classification methods such as Edge Preserving Filter (EPF) [45], Image Fusion and Recursive Filtering (IFRF) [43], Random Multi-Graphs (RMG) [46]. EPF generates pixel-wise classification maps and handles these maps by edge-preserving filtering. Then, the class of each pixel is selected on the basis of the maximum probability. The IFRF combines the spatial and spectral information through image fusion and recursive filtering. IFRF does not directly extract the features of the patches and uses two parameters and to extract the spatial features. RMG is a semi-supervised ensemble learning method based on Random Multi-Graphs.
In Figure 9, Figure 10 and Figure 11, we present the classification results of the EPF, IFRF, and our proposed approach for a single run. Experimental results on this dataset show that the spatial consistency is roughly preserved by all these methods and they all significantly outperform the unary spectral classifier. IFRF and RMG have comparable results and outperform EPF. In some of the previous work above, noisy channels were removed prior to spectral classification. In this work, the only pre-processing steps were the removal of the background pixels that did not have any classification label assigned to them (mixture of classes), and the other step was to normalize the intensities (Min-Max). For the Salinas dataset, feeding the final classification map back as weak labels (replacing the spectral classification map) increased OA to . This exceeds EPF, IFRF, and RMG. We observed the same phenomenon in the Indian Pines, where the accuracy rose to about (from ) with just one refinement iteration. The accuracy increased to for the Indian Pines dataset when the number of training samples was increased. However, the greatest confusion was between the crop classes “Soybean-mintill” and “Corn-notill”. The algorithm is likely to have recognized the corn residue from the previous season as the current season planted soybean due to the minimum tilling agricultural practice.
For Indian Pines, Salinas, and Pavia datasets, several new results have set accuracy benchmarks using CNNs and Transformer architectures, respectively. For example, SSRN [15] reports OA for Indian Pines and for Pavia, trained with and samples, respectively, using Batch Normalization and Dropout. However, training requires 106 minutes and inference seconds on a MSI GT72S laptop with Intel® CoreTM i7 processor up to 64GB memory and the GeForce GTX 980M GPU GB GDDR5. SpectralFormer [16] has demonstrated accuracy with a combined training and inference time of about 20 seconds on a server equipped with an Intel Xeon Silver 4210 -GHz CPU and an NVIDIA GeForce RTX 2080Ti GPU with 11 GB of memory. Our accuracy results are comparable and sometimes better than some of these models. The parameter complexity is very high in some of these recent models, low model interpretability, the transferability and open-set classification is not tested, and requires GPUs for deployment. In addition, in our methodology, the number of parameters to estimate are 2 (C and ). Our algorithm does not require high-performance computations or GPUs, and training and inference take less than 21 seconds for the Indian Pines Dataset, which could be optimized further. We used Intel(R) Xeon(R) CPU GHz and Memory. Hybrid CNN models, 2D and 3D work very well, but seem to be sensitive to the amount of training data and window size. For example, for the Indian Pines dataset, when the training data is less than , for a window size of 25, hybrid approach produce an AA of . When the window size is decreased to 9, the AA drops to .
Our model enables the transfer of all parameters except C, which requires data set-specific tuning. This significantly reduces the dependency on the training data and decreases the training time since only one parameter out of six needs to be optimized for new datasets. To understand the transferability of the model, the model was tested on three additional benchmark datasets with the parameters fixed at , , , , and (see Table 2). The tests were carried out on the AVIRIS Kennedy Space Center dataset and the Hyperion Botswana dataset. For the Salinas-A dataset, the OA and AA were at . Prior studies report that the SVM achieves its best performance for on the Botswana dataset. With this value, the AA and for the spectral classifier were and , and increased with the spectral-spatial classifier to and respectively. However, for the KSC image, the estimated value of C was , and the and OA increased from and to and respectively. By setting the parameter to a low value, the spectral classifier’s decisions alone can be included, and the performance is closer to the spectral classifier.
3.5. Ablation Studies
To evaluate the contribution of each component in the proposed framework, we performed ablation studies by comparing three variants:
- a pixel-wise classifier based on SVM,
- the SVM classifier followed by CRF-based regularization, and
- the full pipeline integrating model transfer, iterative unsupervised learning with refinement and weak labeling.
The goal of the ablation experiments is to disentangle the importance of the individual components and it’s influence on the learning process.
From the ablation studies, it was found that the baseline SVM classifier achieves good separability for certain dominant classes, but suffers from noise and fragmented predictions. Incorporating CRF-based regularization (SVM+CRF) provides spatial consistency and improved accuracies in several classes (e.g., Classes 2, 5, 10, 11, 12), although performance degrades in very small or spectrally ambiguous classes (e.g., Classes 1, 7, 9) leading to an OA of . The complete model takes advantage of weak labeling and iterative unsupervised learning, producing the most balanced performance across classes and significantly higher overall accuracy .
These results confirmed the following:
- Purely pixel-wise classification is insufficient for open-set agricultural scenarios due to high within-class variability and due to minimal/no class overlap with training data.
- Adding spatial regularization using CRF improves the homogeneity of the predictions, but can also decrease the performance if the initial labeling is wrong. Regularization cannot handle unknown classes.
- The full model makes use of both spatial proximity and spectral similarity. So, even if the initial mapping is mislabeled, iteratively it is refined. It is also effective in handling unseen or under-represented classes, demonstrating robustness to domain transfer with limited training labels.
3.6. Testing on New Region and Crop-Zero Shot Conditions
In computer vision, zero shot recognition addresses the challenge of handling test input from classes absent during training (novel classes) or vise versa. Traditional closed-set classifiers assume inherently that the classes present in training are also present in the test set, i.e. . In the case of agricultural applications, this assumption often fails. The crops that must be identified at the test sites are novel and specific to the region of interest i.e. . Multiple crops may grow in a particular region during major and minor seasons, depending on the agroecological zones (see https://gaez.fao.org/). Even when the same set of crops exists in the training and testing sites, we often find that the genetic variety may be different, which might result in the same crop having a different spectral signature for the same phenological stages. In addition, the type of sensor may not be the same as the availability of the same satellite modality, and coverage may not be possible at all study locations. Recently, there has been interest in the development of methods to overcome the limitations of supervised methodologies in a new region or crop by fine-tuning selected collected ground data points [47]. However, it is difficult to collect sample data points across multiple seasons and multiple crops or land use patterns. There are some recent attempts at unsupervised domain adaptation methodologies [48] and transfer learning techniques, but there are no known frameworks for hyperspectral analysis for agricultural applications. All these prior limitations are motivation factors to create the framework explained in Section 2. To assess the generalizability and transferability of our method, we trained on benchmark datasets and evaluated it at a new location, which includes multiple types of land use not seen during training i.e. .
The chosen study area is in the Barengo commune, in the province of Novara, in the Italian Piedmont region, located about 80 kilometers from the city of Turin. The cumulative annual rainfall in this region is about 600mm and the temperatures range between °C.
Rice is an important crop for food security and it is important to map paddy growing regions and monitor them to ensure sustainable production. Paddy crop production is water intensive and is responsible for GHG emissions from Methanogenesis. The mapping of the extent of the rice plot, the quantification of water usage, and emissions can help design sustainable production strategies [49]. We chose the Piedmont region as it is responsible for the production of almost of Italy’s annual total rice production and due to the availability of hyperspectral data from the PRISMA (PRecursore IperSpettrale della Missione Applicativa) [50] (a Hyperspectral/Panchromatic instrument from the ASI-Italian Space Agency). We know that the study area comprises a mixture of land cover classes [51] including croplands (mainly paddy), trees, non-paddy crops, urban/built-up areas, bare soil, and a permanent water body (see Figure 12b). This is very different from the Indian Pines dataset where the crops are primarily Alfalfa, Corn, Oats, Wheat, and Soybean (Figure 2). Satellite acquisition is chosen during the summer rice cropping season. The PRISMA image was acquired on 25 April 2020, coinciding with the transplantation period (early April–late May). While inter-annual variations exist due to climate change, this period remains representative of peak agricultural activity. As mentioned earlier, we used the L2D HCO product and the SWIR images with the number of bands being 171 and a size of . After land preparation and flooding, paddy transplantation begins in early April and continues until the end of May, while all harvesting is complete by mid-October. Currently, there are no known field survey data for the April 2020 acquisition over Piedmont. This PRISMA experiment demonstrates feasibility rather than benchmarking accuracy; multi-sensor cross-validation provides accuracy estimates in the absence of ground truth.
In Figure 13, we show the results of the model trained on the Indian Pines datasets but inferred on the PRISMA dataset specified above. The groups were ‘weakly labeled’ by subject matter experts (human in the loop), based on information from Corine land cover [52], the ESA LULC Map [51], Sentinel-1 rice mask, Sentinel-2 Normalized Difference Vegetation Index (NDVI) values, and street view images.
Transplanted rice cultivation requires standing water, which serves as a spectral signature to identify the regions that grow paddy [53]. In Figure 14, we show the estimated rice growing region identified using the time-series Sentinel-1 VH band, throughout the growing season, as a feature layered on top of the estimated extents of the crop-land (pink color in Figure 12).
Although the paddy mask estimate in Figure 14 is obtained from the temporal data of the entire growing season, it is used as a reference map to validate the results of our classification. In addition to these sources, in the absence of field visit data, we used Street View images to verify selective areas in the regions, as shown in Figure 16.
Figure 15.
Sentinel-2 Normalized Difference Vegetation Index (NDVI) temporal profiles (2020) for validation of PRISMA classification. Each line represents the mean of the pixels in a randomly sampled parcel per class with min-max shaded region. (a) Forest: stable high NDVI (). (b) Urban: consistently low NDVI (). (c) Non-rice crops: single vegetative peak (May). (d) Rice: characteristic pattern showing transplant dip (late April), vegetative peak (July–August), and senescence (September), consistent with regional rice phenology [53].
Figure 15.
Sentinel-2 Normalized Difference Vegetation Index (NDVI) temporal profiles (2020) for validation of PRISMA classification. Each line represents the mean of the pixels in a randomly sampled parcel per class with min-max shaded region. (a) Forest: stable high NDVI (). (b) Urban: consistently low NDVI (). (c) Non-rice crops: single vegetative peak (May). (d) Rice: characteristic pattern showing transplant dip (late April), vegetative peak (July–August), and senescence (September), consistent with regional rice phenology [53].
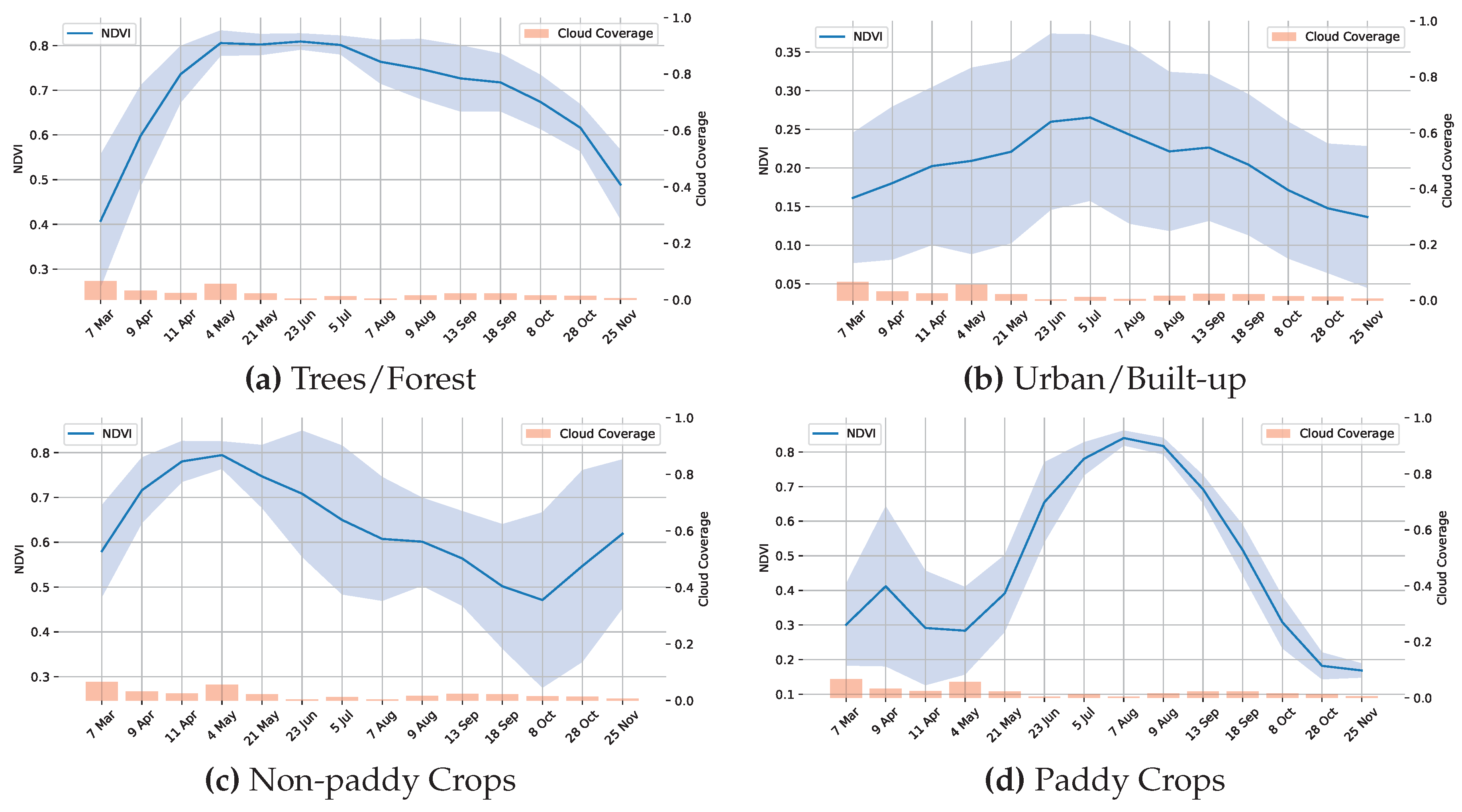
Figure 16.
Sample images are drawn from the different output classes of (a) Built-up area (gray), (b) trees/managed forest (dark green) and (c) flooded paddy plots (light green). The images were acquired along Strada Provinciale 20 by lahniuscollurio, licensed under CC-BY-SA. All the images were acquired in July 2021.
Figure 16.
Sample images are drawn from the different output classes of (a) Built-up area (gray), (b) trees/managed forest (dark green) and (c) flooded paddy plots (light green). The images were acquired along Strada Provinciale 20 by lahniuscollurio, licensed under CC-BY-SA. All the images were acquired in July 2021.

An additional level of verification is by observing the NDVI signatures of each class as shown in Figure 15. We randomly selected a few pixels from each of the following distinct groups: trees, urban/built-up area, non-paddy crops, barren land and flooded rice. Figure 15d shows the Copernicus Sentinel-2 multi-spectral satellite-derived vegetation index (NDVI) plot of randomly sampled pixels from the regions classified as Paddy by our approach. The figure shows that the seedling/transplantation from the nursery to the farm plots occurs around the end of April and at the beginning of May, and the vegetative, reproductive, and ripening stages are also clearly visible. As the year of growth and the availability of the data was in 2020, it is difficult to do the ground truth validation, but we verified that the paddy was growing in these plots in 2023. Farmers have traditionally grown paddy in this region for many seasons and will continue to be the main crop in the region. We also tried the same approach of training a deep learning model with a deep learning model (3D CNN) that uses both spectral and spatial features [54] and then inferred in the Barengo study area, but the model was not transferable and the results were very poor despite the model having a training accuracy of and a validation accuracy of on the Pines dataset (train: test: val split ::).
3.7. Limitations
There are three current limitations of our proposed approach that warrant discussion:
- Spectral Confusion: The model confuses between spectrally similar crops or the same crop with different management practices, and is typical of single temporal snapshot-based analysis. Multi-temporal analysis might resolve this confusion.
- Phenology Sensitivity: The model is sensitive to the phenological stage, and the accuracy is highest during the maturity stage of the crop,
- Validation Constraints: The absence of field campaigns for the PRISMA dataset means that the methodology uses proxy validation through multi-sensor cross-checking rather than actual field campaign data. While we observed that the inter-method agreement was high, having ground-truth field campaigns could also give accuracy statistics.
4. Conclusions and Future Work
We propose a novel lightweight framework for Hyperspectral image-based classification by using a combination of pixel-wise supervised, iterative unsupervised learning methods and weak labeling. The key feature is that the learning method, at least, requires estimation of only one parameter and, for better accuracy, requires a maximum of two parameters and minimal training samples. In the different benchmark images, our method demonstrated improvements in overall accuracy compared to pure spectral classifiers for single-run inference, increasing to after iterative convergence. The method achieved the highest accuracy in the Salinas dataset (), after convergence, and remains comparable to other state-of-the-art models for the Indian Pines dataset (). It is best suited for sustainable agricultural applications and small landholding farm lands where ground truth is very sparse and with many unseen classes. The model is faster to train, and the trained model parameters are transferable across the different datasets while maintaining the accuracies. Our lightweight framework offers a robust baseline for domain transfer in label-sparsity situations, though it might not be a replacement for deep networks where data are abundant, diverse, or in well-annotated settings. Transformer-based models such as the MASSFormer [16] work well in closed-set scenarios with abundant training data. We aim to extend this framework to diverse HSI datasets and datasets from a broader set of satellite missions.
Author Contributions
Conceptualization, P.P.; methodology, P.P. and A.P.; software, P.P.; validation, P.P.; formal analysis, P.P.; investigation, P.P.; resources, P.P.; data curation, P.P. and A.P.; writing—original draft preparation, P.P. and A.P.; writing—review and editing, P.P.; visualization, P.P. and A.P.; supervision, P.P.; project administration, S.S.; funding acquisition, P.P. All authors have read and agreed to the published version of the manuscript.
Data Availability Statement
For reproducibility, all the benchmark data and the code is made available in the github repository.
Acknowledgments
The first author acknowledges the support of UrbanKisaan, and the second and third authors acknowledge the support of the Indian Institute of Technology Madras. The authors further appreciate the financial and research resources provided by UrbanKisaan, which enabled the successful completion of this study. The authors also express their deep appreciation to Mr. Vihari Kanikollu for his substantial contributions during and after the review process, which were instrumental in bringing this document to completion. His insightful discussions on the methodological approach significantly strengthened the study outcomes. Access to the PRISMA dataset was provided by the Agenzia Spaziale Italiana (ASI).
Conflicts of Interest
The authors declare no conflicts of interest.
Notations and Abbreviations
The following notations and abbreviations are used in this manuscript:
| 2D | Two-dimensional |
| 3D | Three-dimensional |
| AA | Average Accuracy |
| AVIRIS | Airborne Visible/Infrared |
| Imaging Spectrometer | |
| HSI | Hyperspectral Image |
| CNN | Convolution Neural Network |
| CV | Cross Validation |
| DL | Deep Learning |
| EPF | Edge Preserving Filter |
| GHG | Green House Gas |
| GPU | Graphics Processing Unit |
| HCO | Co-registered Hypercube |
| ICM | Iterative Conditional Model |
| IFRF | Image Fusion and Recursive Filtering |
| kNN | k-Nearest Neighbors |
| KPCA | Kernel PCA |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| NDVI | Normalized Difference Vegetation Index |
| NIR | Near Infrared |
| OA | Overall Accuracy |
| PCA | Principal Component Analysis |
| PRISMA | Hyperspectral Precursor of the Application Mission |
| RGB | Red-Green-Blue |
| RBF | Radial Basis Function |
| RMG | Random Multi-graph |
| SVM | Support Vector Machine |
| SWIR | Short-Wave Infrared |
| UAV | Unmanned Aerial Vehicle |
| VNIR | Visible and Near-Infrared |
References
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J. Hyperspectral Imaging: A Review on UAV-Based Sensors, Data Processing and Applications for Agriculture and Forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef]
- del Cerro, J.; Cruz Ulloa, C.; Barrientos, A.; de León Rivas, J. Unmanned aerial vehicles in agriculture: A survey. Agronomy 2021, 11, 203. [Google Scholar] [CrossRef]
- Leslie, C.R.; Serbina, L.O.; Miller, H.M. Landsat and agriculture—Case studies on the uses and benefits of Landsat imagery in agricultural monitoring and production. Technical report, US Geological Survey, 2017.
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar]
- Thenkabail, P.S.; Smith, R.B.; Pauw, E.D. Hyperspectral Vegetation Indices and Their Relationships with Agricultural Crop Characteristics. Remote Sens. Environ. 2000, 71, 158–182. [Google Scholar] [CrossRef]
- Apan, A.; Held, A.; Phinn, S.; Markley, J. Detecting sugarcane ‘orange rust’ disease using EO-1 Hyperion hyperspectral imagery. Int. J. Remote Sens. 2004, 25, 489–498. [Google Scholar] [CrossRef]
- Arellano, P.; Tansey, K.; Balzter, H.; Boyd, D.S. Detecting the effects of hydrocarbon pollution in the Amazon forest using hyperspectral satellite images. Environ. Pollut. 2015, 205, 225–239. [Google Scholar] [CrossRef]
- Berger, K.; Verrelst, J.; Féret, J.B.; Wang, Z.; Wocher, M.; Strathmann, M.; Danner, M.; Mauser, W.; Hank, T. Crop nitrogen monitoring: Recent progress and principal developments in the context of imaging spectroscopy missions. Remote Sens. Environ. 2020, 242, 111758. [Google Scholar] [CrossRef]
- Persello, C.; Wegner, J.D.; Hänsch, R.; Tuia, D.; Ghamisi, P.; Koeva, M.; Camps-Valls, G. Deep learning and earth observation to support the sustainable development goals: Current approaches, open challenges, and future opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 172–200. [Google Scholar]
- Khan, M.J.; Khan, H.S.; Yousaf, A.; Khurshid, K.; Abbas, A. Modern Trends in Hyperspectral Image Analysis: A Review. IEEE Access 2018, 6, 14118–14129. [Google Scholar] [CrossRef]
- Signoroni, A.; Savardi, M.; Baronio, A.; Benini, S. Deep Learning Meets Hyperspectral Image Analysis: A Multidisciplinary Review. J. Imaging 2019, 5, 52. [Google Scholar] [CrossRef] [PubMed]
- Audebert, N.; Le Saux, B.; Lefevre, S. Deep Learning for Classification of Hyperspectral Data: A Comparative Review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–Spatial Classification of Hyperspectral Data Based on Deep Belief Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1–12. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, H.; Zheng, Y.; Wu, Z.; Ye, Z.; Zhao, H. MASSFormer: Memory-Augmented Spectral-Spatial Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Guidici, D.; Clark, M. One-Dimensional Convolutional Neural Network Land-Cover Classification of Multi-Seasonal Hyperspectral Imagery in the San Francisco Bay Area, California. Remote Sens. 2017, 9, 629. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLOS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.R. Explaining nonlinear classification decisions with deep Taylor decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]
- Aziz, A.; Bahrudeen, A.; Rahim, A. Spectral Fidelity and Spatial Enhancement: An Assessment and Cascading of Pan-Sharpening Techniques for Satellite Imagery. arXiv 2024, arXiv:2405.18900. [Google Scholar] [CrossRef]
- Alparone, L.; Arienzo, A.; Garzelli, A. Spatial Resolution Enhancement of Satellite Hyperspectral Data via Nested Hypersharpening With Sentinel-2 Multispectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10956–10966. [Google Scholar] [CrossRef]
- Zhu, L.; Wu, J.; Biao, W.; Liao, Y.; Gu, D. SpectralMAE: Spectral Masked Autoencoder for Hyperspectral Remote Sensing Image Reconstruction. Sensors 2023, 23, 3728. [Google Scholar] [CrossRef] [PubMed]
- Meng, Z.; Yan, Q.; Zhao, F.; Liang, M. Hyperspectral Image Classification with Dynamic Spatial-Spectral Attention Network. In Proceedings of the 2023 13th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Athens, Greece, 31 October–2 November 2023; 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Kang, J.; Zhang, Y.; Liu, X.; Cheng, Z. Hyperspectral Image Classification Using Spectral–Spatial Double-Branch Attention Mechanism. Remote Sens. 2024, 16, 193. [Google Scholar] [CrossRef]
- Ahmad, M.; Distefano, S.; Khan, A.M.; Mazzara, M.; Li, C.; Li, H.; Aryal, J.; Ding, Y.; Vivone, G.; Hong, D. A comprehensive survey for Hyperspectral Image Classification: The evolution from conventional to transformers and Mamba models. Neurocomputing 2025, 644, 130428. [Google Scholar] [CrossRef]
- Liu, Y.; Tang, Y.; Zhang, L.; Liu, L.; Song, M.; Gong, K.; Peng, Y.; Hou, J.; Jiang, T. Hyperspectral open set classification with unknown classes rejection towards deep networks. Int. J. Remote Sens. 2020, 41, 6355–6383. [Google Scholar] [CrossRef]
- Yue, J.; Fang, L.; He, M. Spectral-spatial latent reconstruction for open-set hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 5227–5241. [Google Scholar] [CrossRef]
- Datta, A.; Ghosh, S.; Ghosh, A. PCA, Kernel PCA and Dimensionality Reduction in Hyperspectral Images. In Advances in Principal Component Analysis: Research and Development; Naik, G.R., Ed.; Springer: Singapore, 2018; pp. 19–46. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemometrics and Intelligent Laboratory Systems 1987, 2, 37–52, Proceedings of the Multivariate StatisticalWorkshop for Geologists and Geochemists. [Google Scholar] [CrossRef]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear Versus Nonlinear PCA for the Classification of Hyperspectral Data Based on the Extended Morphological Profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef]
- Roy, S.; Krishna, G.; Dubey, S.R.; Chaudhuri, B. HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef]
- Hermes, L.; Frieauff, D.; Puzicha, J.; Buhmann, J.M. Support vector machines for land usage classification in Landsat TM imagery. In Proceedings of the IEEE 1999 International Geoscience and Remote Sensing Symposium. IGARSS’99 (Cat. No.99CH36293), Hamburg, Germany, 28 June–2 July 1999; Volume 1, pp. 348–350. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Wen, Z.; Shi, J.; Li, Q.; He, B.; Chen, J. ThunderSVM: A Fast SVM Library on GPUs and CPUs. Journal of Machine Learning Research 2018, 19, 797–801. [Google Scholar]
- Shotton, J.; Winn, J.M.; Rother, C.; Criminisi, A. TextonBoost for Image Understanding: Multi-Class Object Recognition and Segmentation by Jointly Modeling Texture, Layout, and Context. Int. J. Comput. Vis. 2009, 81, 2–23. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. Advances in Neural Information Processing Systems 2011, 24, 109–117. [Google Scholar]
- Zhang, W.; Li, M. MRF and CRF Based Image Denoising and Segmentation. In Proceedings of the 2014 5th International Conference on Digital Home, Guangzhou, China, 28–30 November 2014; pp. 128–131. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef]
- Wang, S. Hyperspectral Dataset, 2020. [CrossRef]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 Indian Pine Test Site 3, 2015. [CrossRef]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. Technical report, National Taiwan University, 2003.
- Ben-Hur, A.; Weston, J. A user’s guide to support vector machines. Methods Mol. Biol. 2010, 609, 223–239. [Google Scholar]
- Kang, X.; Li, S.; Benediktsson, J.A. Feature Extraction of Hyperspectral Images With Image Fusion and Recursive Filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3742–3752. [Google Scholar] [CrossRef]
- Chapelle, O.; Vapnik, V.; Bousquet, O.; Mukherjee, S. Choosing Multiple Parameters for Support Vector Machines. Mach. Learn. 2002, 46, 131–159. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Spectral-Spatial Hyperspectral Image Classification With Edge-Preserving Filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2666–2677. [Google Scholar] [CrossRef]
- Gao, F.; Wang, Q.; Dong, J.; Xu, Q. Spectral and Spatial Classification of Hyperspectral Images Based on Random Multi-Graphs. Remote Sensing 2018, 10, 1271. [Google Scholar] [CrossRef]
- Hao, P.; Di, L.; Zhang, C.; Guo, L. Transfer Learning for Crop classification with Cropland Data Layer data (CDL) as training samples. Sci. Total Environ. 2020, 733, 138869. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, L.; Zhang, Z.; Tian, F. An unsupervised domain adaptation deep learning method for spatial and temporal transferable crop type mapping using Sentinel-2 imagery. ISPRS J. Photogramm. Remote Sens. 2023, 199, 102–117. [Google Scholar] [CrossRef]
- Qian, H.; Zhu, X.; Huang, S.; Linquist, B.; Kuzyakov, Y.; Wassmann, R.; Minamikawa, K.; Martinez-Eixarch, M.; Yan, X.; Zhou, F.; et al. Greenhouse gas emissions and mitigation in rice agriculture. Nat. Rev. Earth Environ. 2023, 4, 716–732. [Google Scholar] [CrossRef]
- Candela, L.; Formaro, R.; Guarini, R.; Loizzo, R.; Longo, F.; Varacalli, G. The PRISMA mission. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 253–256. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; De Keersmaecker, W.; Souverijns, N.; Brockmann, C.; Quast, R.; Wevers, J.; Grosu, A.; Paccini, A.; Vergnaud, S.; et al. ESA WorldCover 10 m 2020 v100, 2021. [CrossRef]
- Büttner, G. CORINE Land Cover and Land Cover Change Products. In Land Use and Land Cover Mapping in Europe: Practices & Trends; Manakos, I., Braun, M., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 55–74. [Google Scholar] [CrossRef]
- Singha, M.; Dong, J.; Zhang, G.; Xiao, X. High resolution paddy rice maps in cloud-prone Bangladesh and Northeast India using Sentinel-1 data. Sci. Data 2019, 6, 26. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, M.; Khan, A.M.; Mazzara, M.; Distefano, S.; Ali, M.; Sarfraz, M.S. A Fast and Compact 3-D CNN for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
Figure 1.
Framework overview: Training, testing and validation on benchmark hyperspectral images with known class labels and inferring the learned model with fixed parameters to a new test site from PRISMA. Transfer: Trained Model and parameters (no retraining required). Training/testing/validation on the benchmark datasets is represented by red color and the inference on the open-set by blue color.
Figure 1.
Framework overview: Training, testing and validation on benchmark hyperspectral images with known class labels and inferring the learned model with fixed parameters to a new test site from PRISMA. Transfer: Trained Model and parameters (no retraining required). Training/testing/validation on the benchmark datasets is represented by red color and the inference on the open-set by blue color.
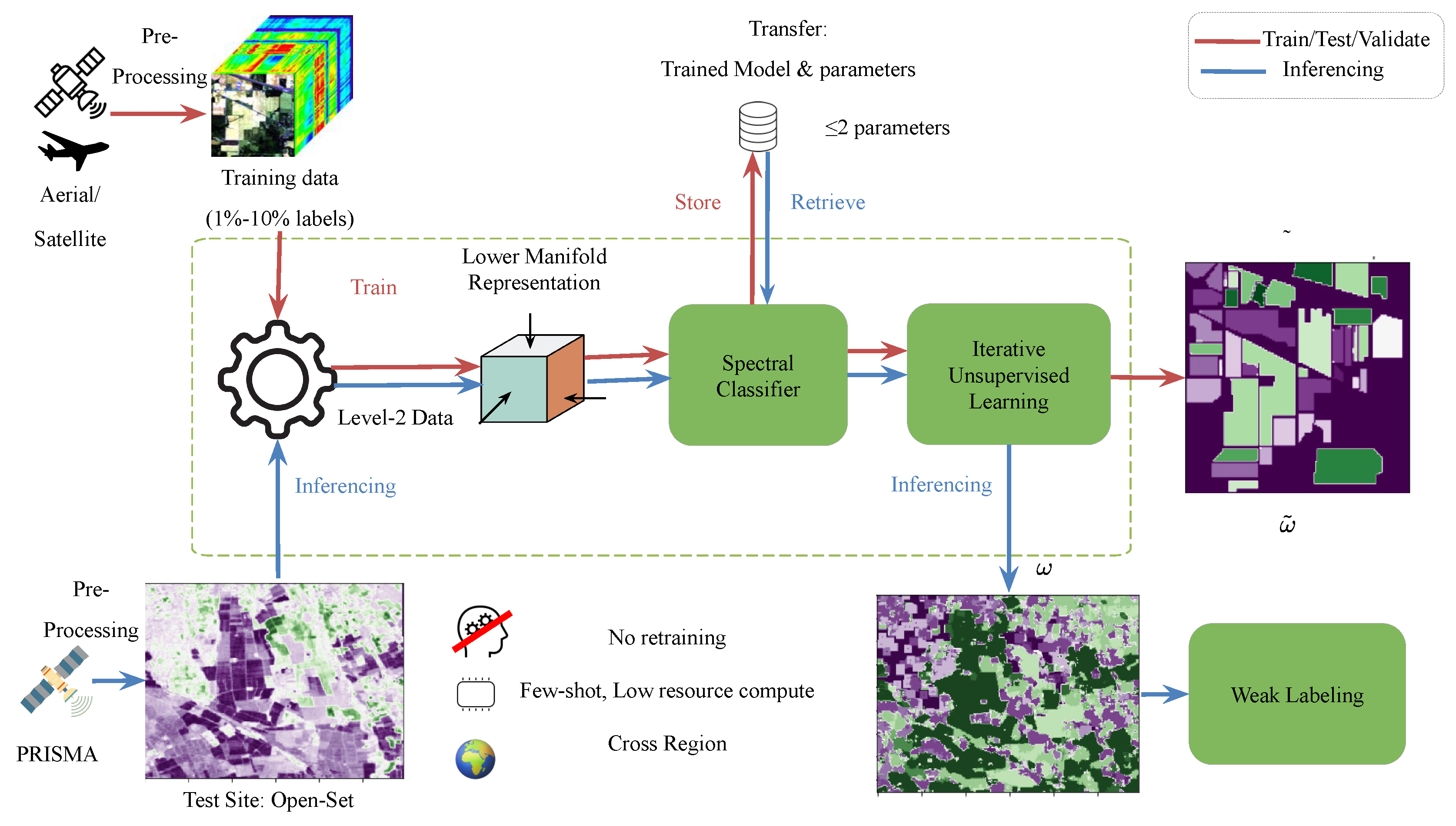
Figure 2.
AVIRIS Indian Pines data set and the corresponding ground truth data: (a) Band 3 (central wavelength nm, FWHM nm, (b) Ground truth with class labels.
Figure 2.
AVIRIS Indian Pines data set and the corresponding ground truth data: (a) Band 3 (central wavelength nm, FWHM nm, (b) Ground truth with class labels.
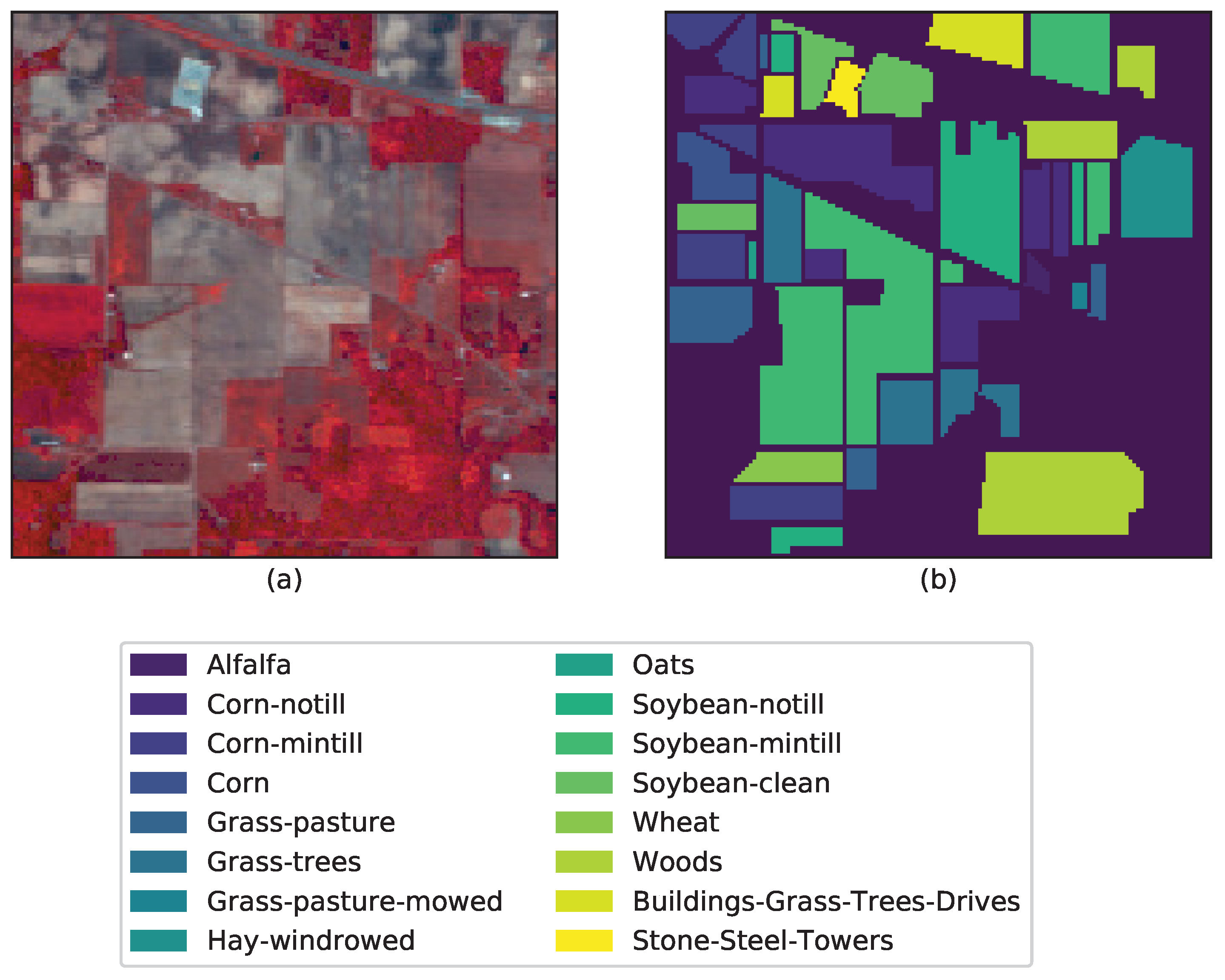
Figure 3.
(a) Band 101, (b) Ground truth of the Salinas image with the respective class labels.
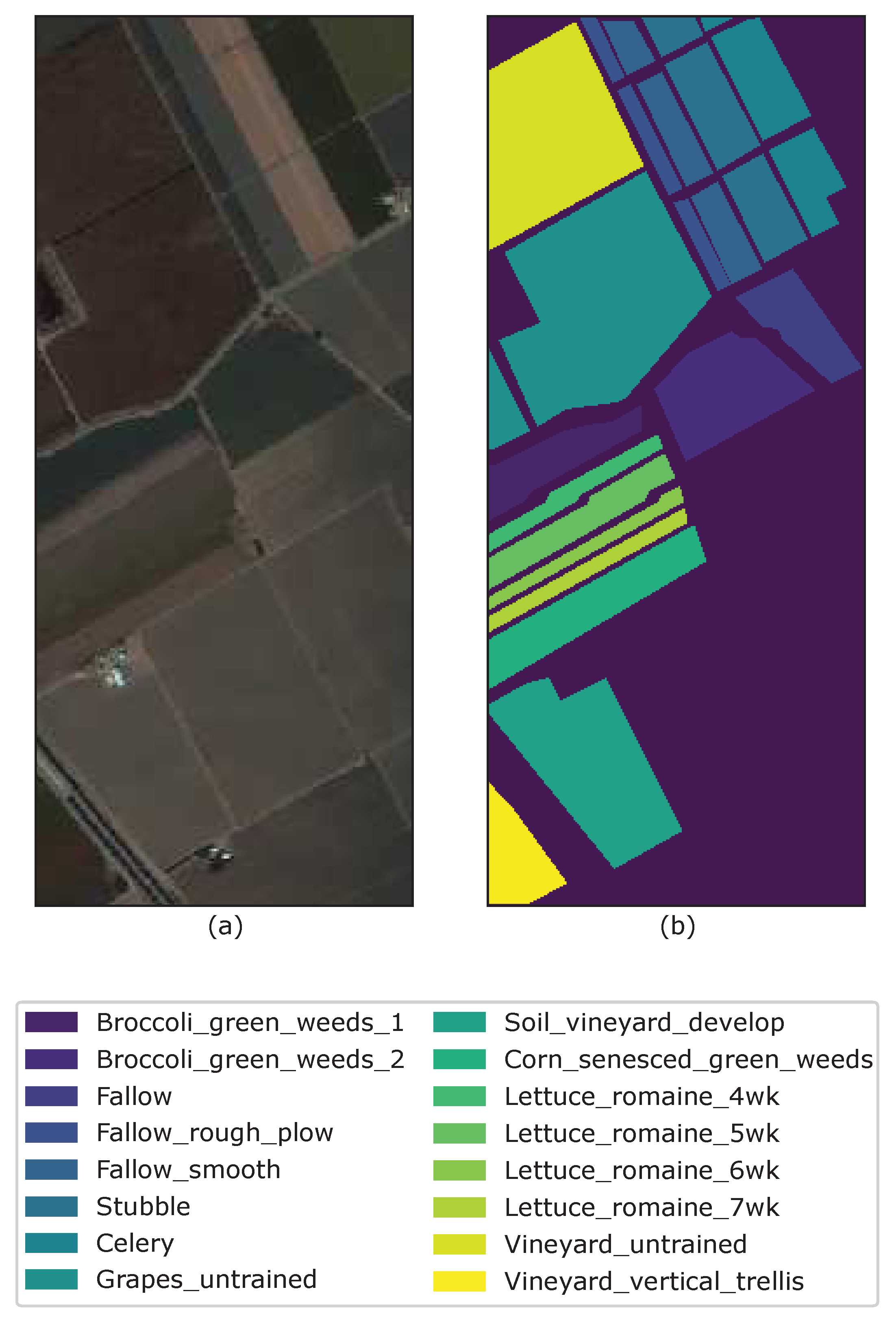
Figure 4.
(a) Band 41 and (b) Ground truth of the Pavia University data with the respective class labels.
Figure 4.
(a) Band 41 and (b) Ground truth of the Pavia University data with the respective class labels.
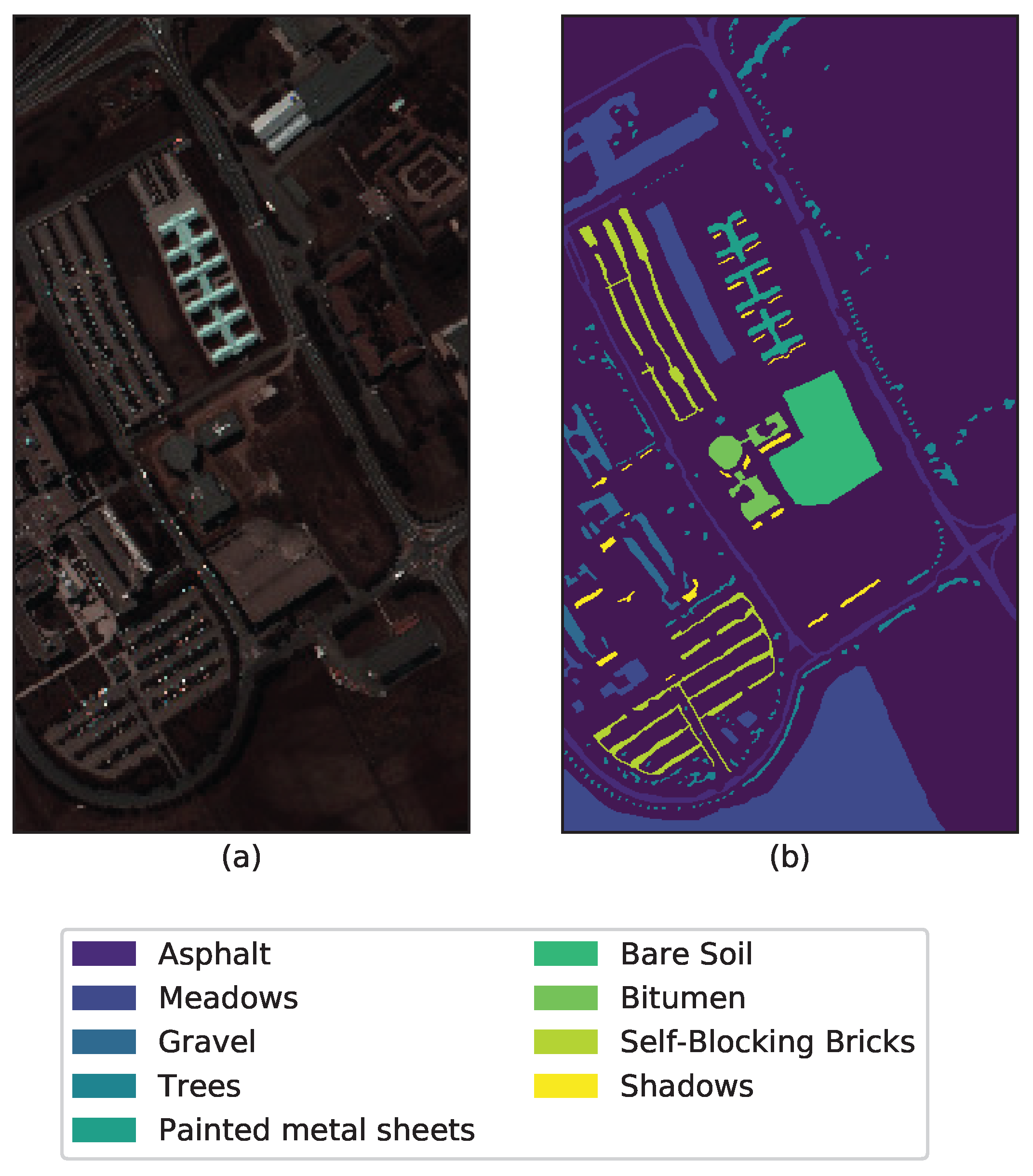
Figure 5.
Analysis of the influence of parameters r and for the Indian Pines Image. The optimal balances spatial consistency with edge preservation. Smaller values () produce noisy classifications; larger values () over-smooth field boundaries.
Figure 5.
Analysis of the influence of parameters r and for the Indian Pines Image. The optimal balances spatial consistency with edge preservation. Smaller values () produce noisy classifications; larger values () over-smooth field boundaries.
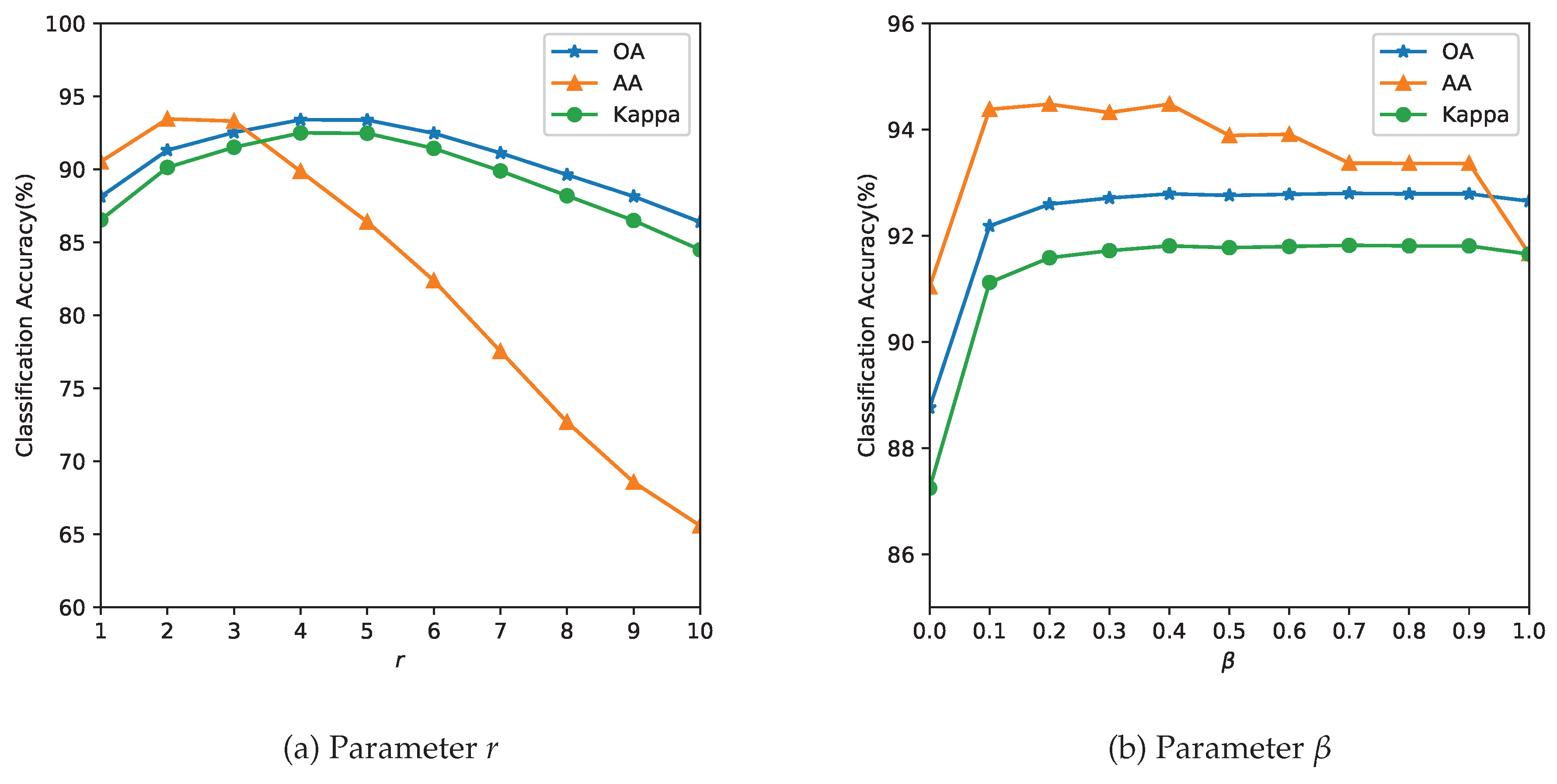
Figure 6.
Analysis of the influence of parameters r and for the Salinas Image.

Figure 7.
Analysis of the influence of parameters r and for the University of Pavia Image.
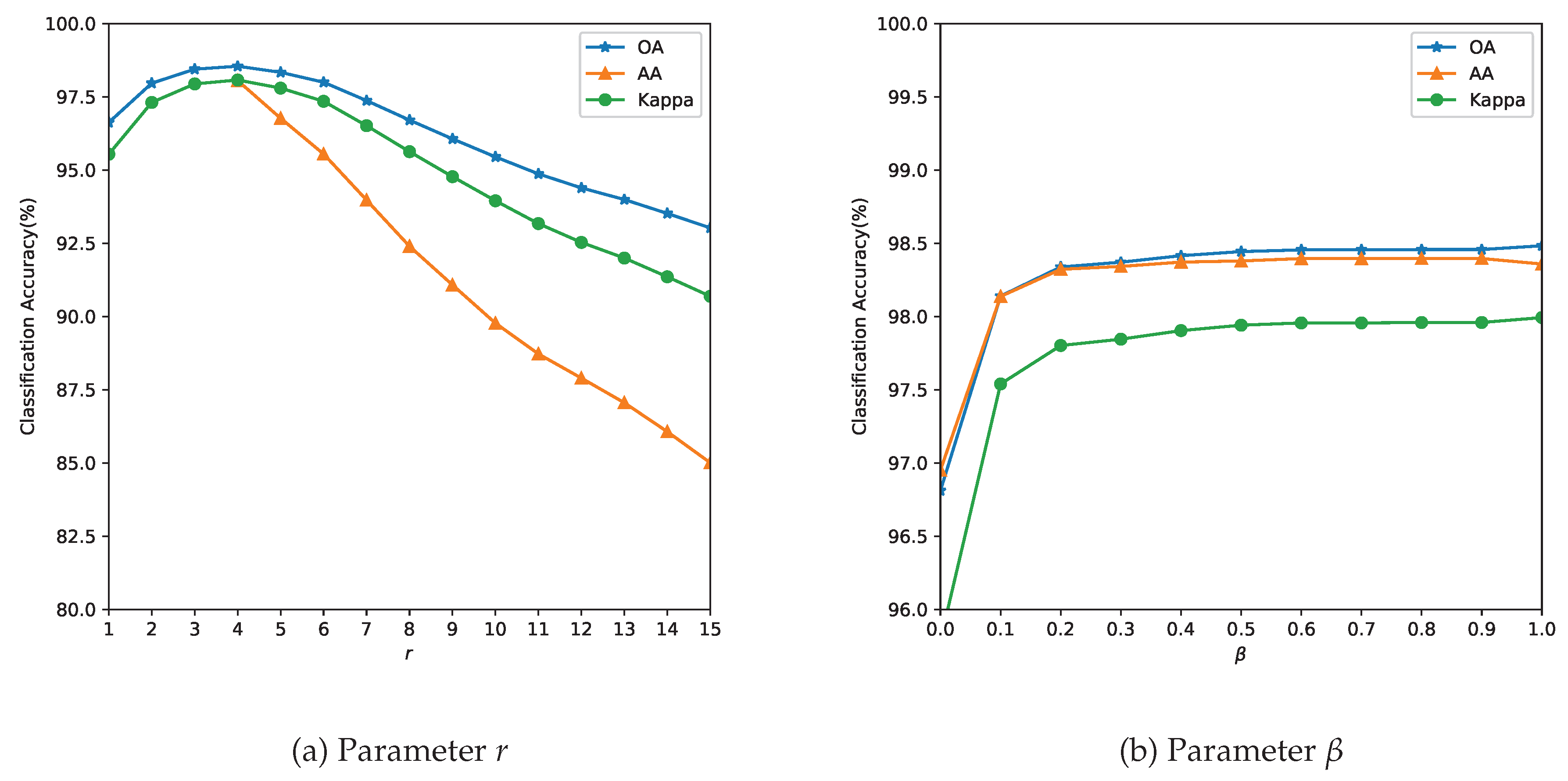
Figure 9.
Classification results by the different methods on the AVIRIS Indian Pines data. (a) Ground Truth map; (b) EPF; (c) IFRF; (d) Proposed Approach.
Figure 9.
Classification results by the different methods on the AVIRIS Indian Pines data. (a) Ground Truth map; (b) EPF; (c) IFRF; (d) Proposed Approach.
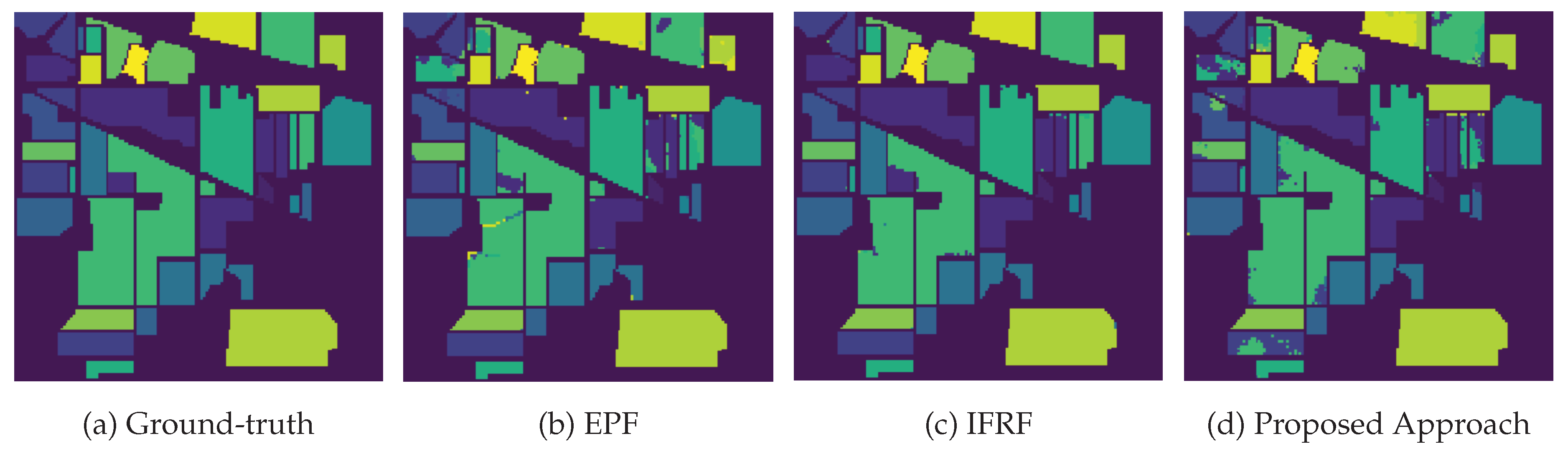
Figure 10.
Classification results by the different methods on the Salinas image. (a) Ground Truth map; (b) EPF; (c) IFRF; (d) Proposed Approach (single run).
Figure 10.
Classification results by the different methods on the Salinas image. (a) Ground Truth map; (b) EPF; (c) IFRF; (d) Proposed Approach (single run).
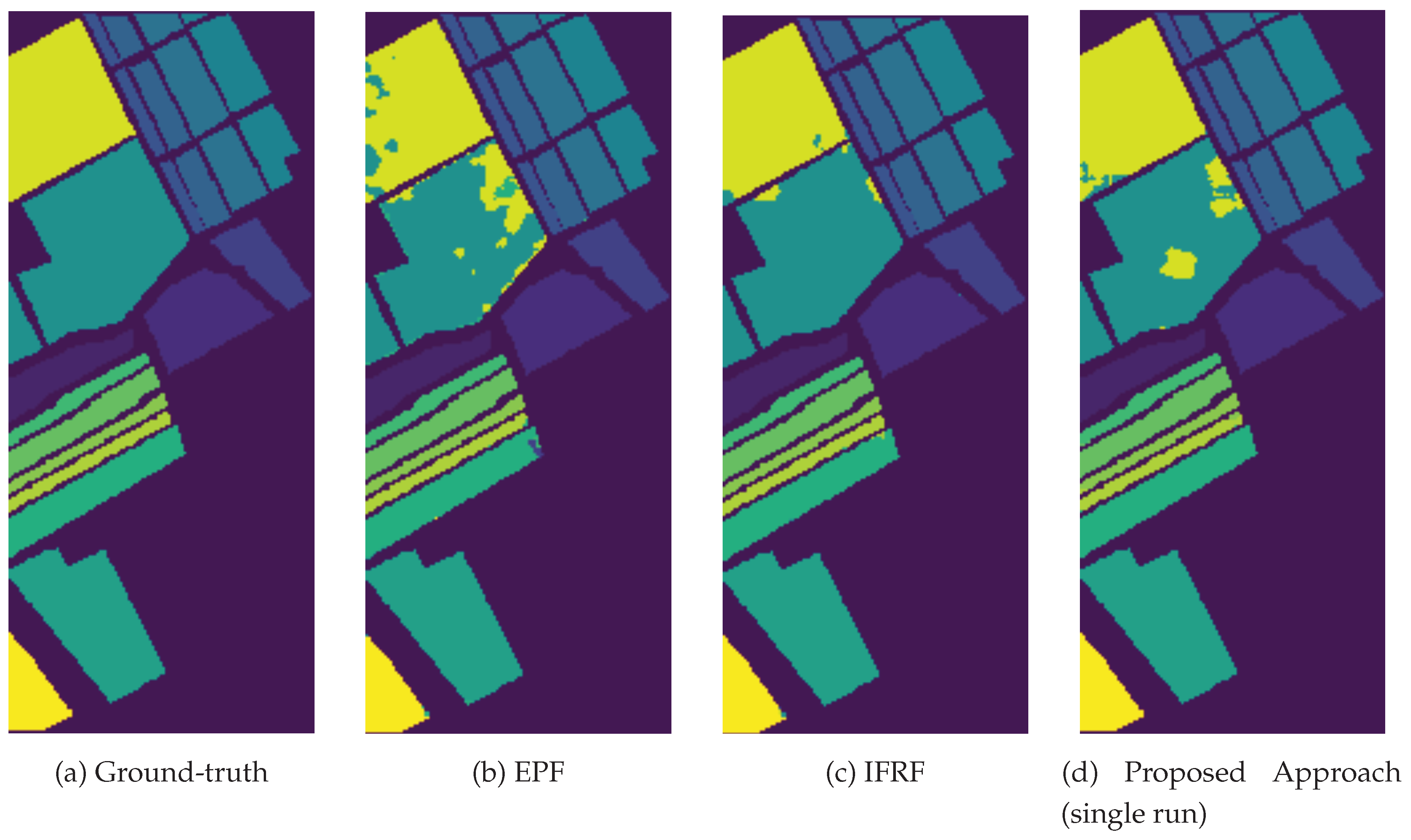
Figure 11.
Classification results by the different methods on the ROSIS–03 Pavia University image. (a) Ground Truth map; (b) EPF; (c) IFRF; (d) Proposed Approach.
Figure 11.
Classification results by the different methods on the ROSIS–03 Pavia University image. (a) Ground Truth map; (b) EPF; (c) IFRF; (d) Proposed Approach.

Figure 12.
Study area. (a) Location map showing Piedmont region and Novara province (80 km from Turin) in Italy. Inset: Novara province with the study region marked in red. (b) ESA WorldCover 2020 land use: cropland (pink), forest (green), grassland (yellow), urban (red), water (blue), bare soil (gray). Coordinate system: EPSG:4326.
Figure 12.
Study area. (a) Location map showing Piedmont region and Novara province (80 km from Turin) in Italy. Inset: Novara province with the study region marked in red. (b) ESA WorldCover 2020 land use: cropland (pink), forest (green), grassland (yellow), urban (red), water (blue), bare soil (gray). Coordinate system: EPSG:4326.
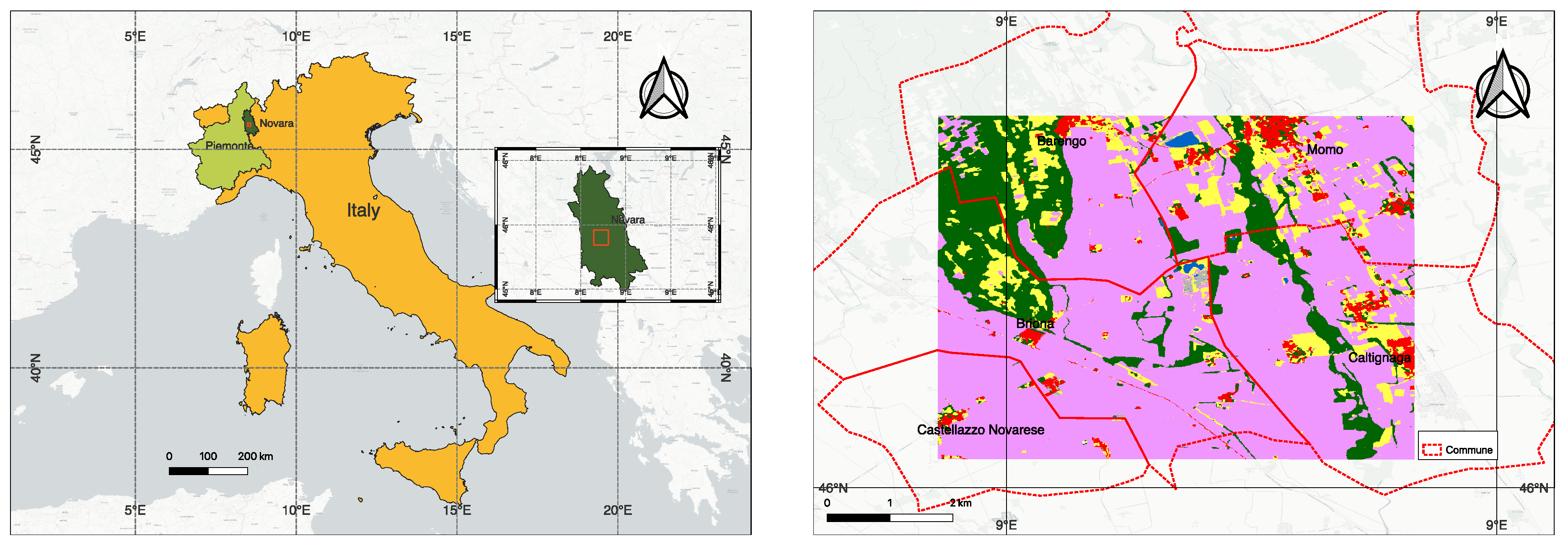
Figure 13.
Output generated by our methodology trained on the Indian Pines dataset and inferred on the PRISMA Hyperspectral dataset at 30m spatial resolution. The groups are relabeled to the known classes of tree (dark green), crops (pink), flooded paddy (light green), barren or sparse vegetation or built-up area (gray). Red outline is the 5 communes (Barengo, Briona, Castellazzo Novarese, Momo, Caltignaga), and the cadastral maps. Weak labels were assigned using multi-source protocol (Section 3.6) ESA WorldCover, Sentinel-1 rice mask, Sentinel-2 Normalized Difference Vegetation Index (NDVI), and Street View validation.
Figure 13.
Output generated by our methodology trained on the Indian Pines dataset and inferred on the PRISMA Hyperspectral dataset at 30m spatial resolution. The groups are relabeled to the known classes of tree (dark green), crops (pink), flooded paddy (light green), barren or sparse vegetation or built-up area (gray). Red outline is the 5 communes (Barengo, Briona, Castellazzo Novarese, Momo, Caltignaga), and the cadastral maps. Weak labels were assigned using multi-source protocol (Section 3.6) ESA WorldCover, Sentinel-1 rice mask, Sentinel-2 Normalized Difference Vegetation Index (NDVI), and Street View validation.
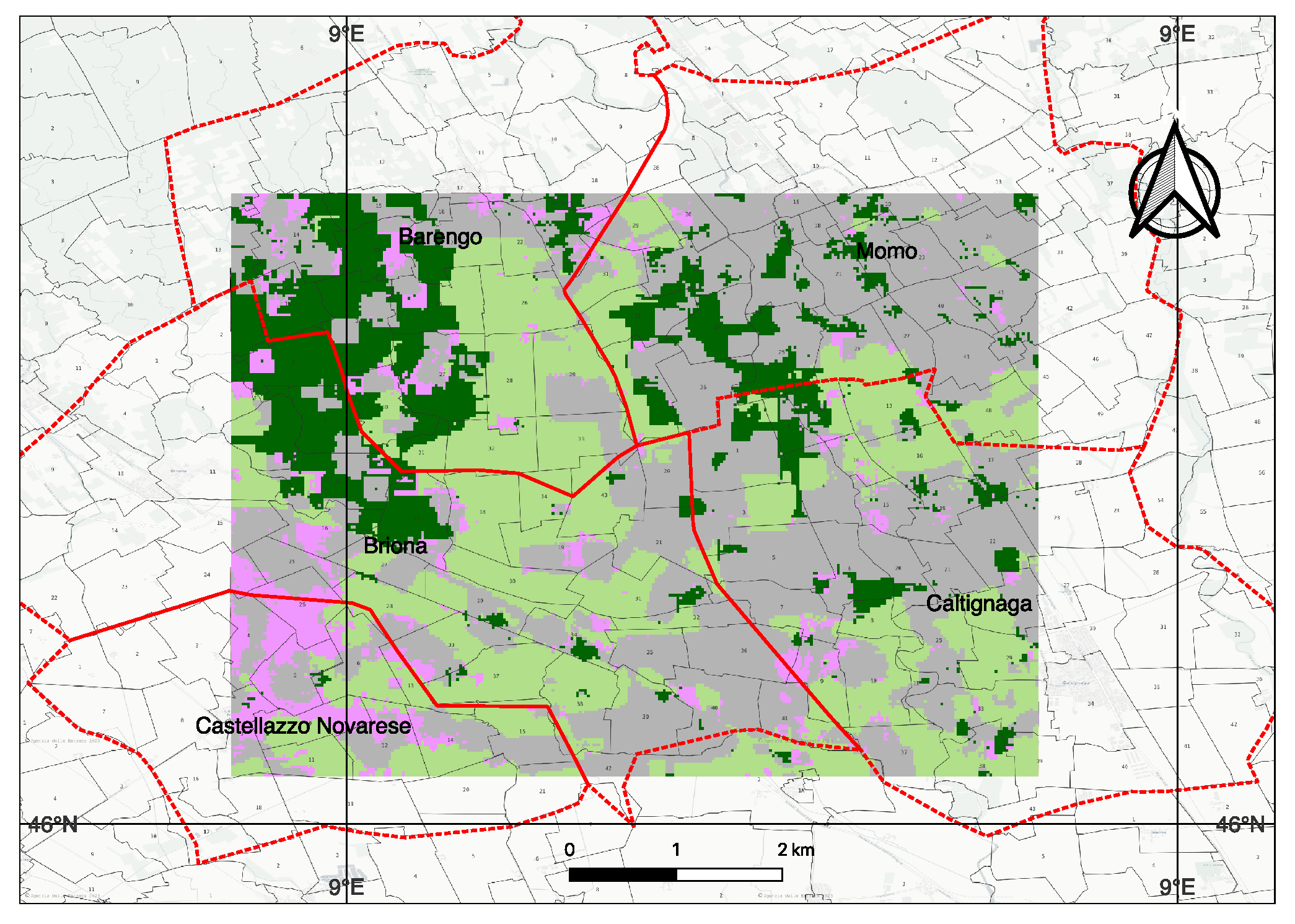
Figure 14.
Paddy growing regions identified in the summer season of 2020 from the time-series (multi-stack) radar backscattering coefficients of Sentinel-1 obtained from April 2020 onward for the study area shown in Figure 12. There is a very good overlap with the output generated by our methodology shown in Figure 13 although it is a comparison with multi time-series stack and single time stack classification outputs.
Figure 14.
Paddy growing regions identified in the summer season of 2020 from the time-series (multi-stack) radar backscattering coefficients of Sentinel-1 obtained from April 2020 onward for the study area shown in Figure 12. There is a very good overlap with the output generated by our methodology shown in Figure 13 although it is a comparison with multi time-series stack and single time stack classification outputs.
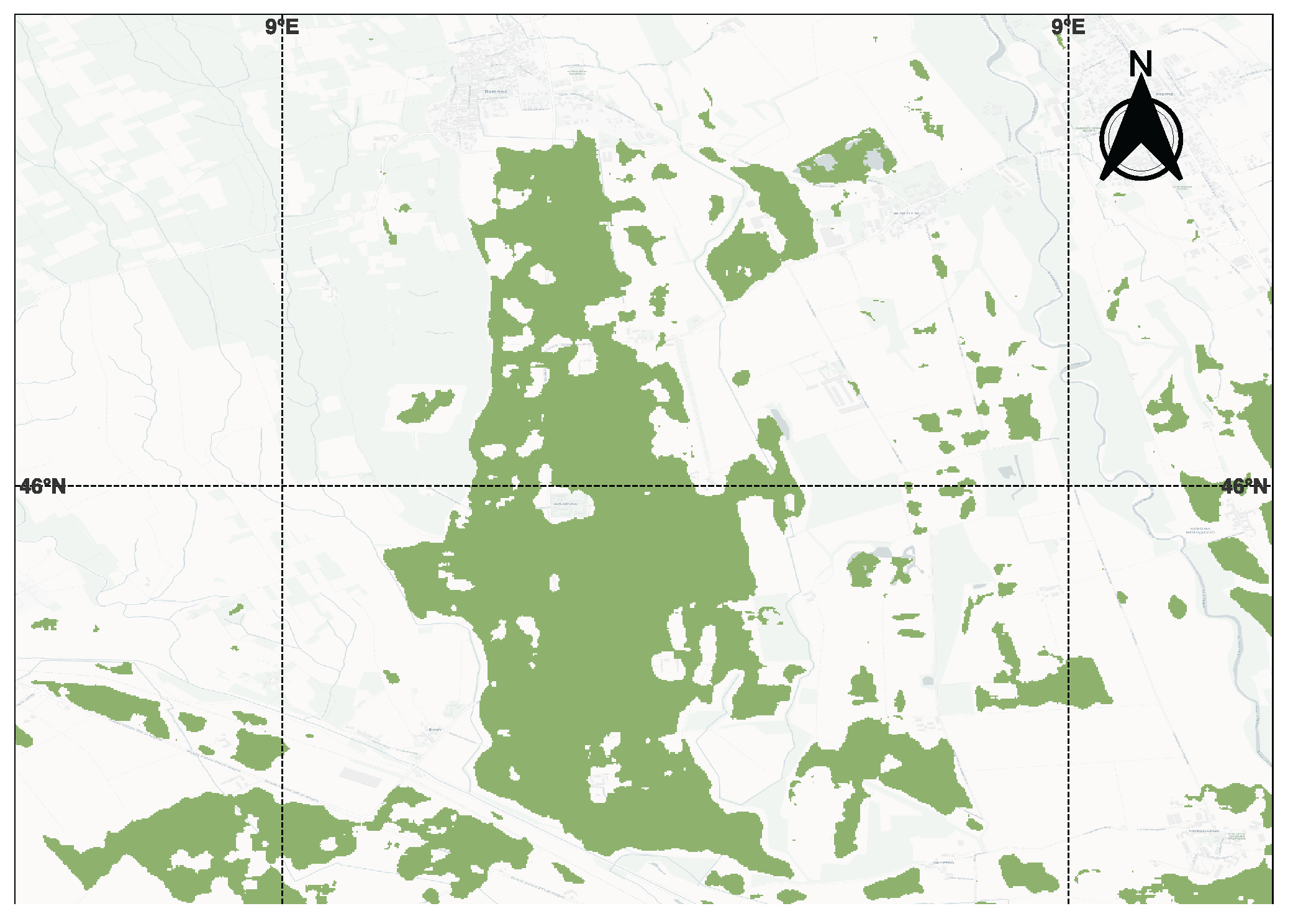
Table 2.
Listing of the estimated parameters required by the joint classifier for each of the benchmark datasets. The Optimal Parameter row shows the fixed transferable parameters used on the open-set (Section 3.4 and Section 3.6). Dataset-specific column show locally-optimized values for C.
Table 2.
Listing of the estimated parameters required by the joint classifier for each of the benchmark datasets. The Optimal Parameter row shows the fixed transferable parameters used on the open-set (Section 3.4 and Section 3.6). Dataset-specific column show locally-optimized values for C.
| Data/Parameters | C | r | ||||
|---|---|---|---|---|---|---|
| Indian Pines | 35 | 8 | 3 | 1 | 1 | |
| Salinas | 43 | 11 | 9 | 4 | 1 | |
| Pavia University | 34 | 7 | 4 | 2 | 2 | |
| Optimal Parameter | Dataset specific | 7 | 4 |
Table 3.
Classification accuracy for the different methods on the Indian Pines dataset.
| Class | Train | Test | SVM | EPF [45] | IFRF [43] | RMG [46] | Proposed (single run) |
|---|---|---|---|---|---|---|---|
| Alfalfa | 20 | 26 | 93.48 | 97.83 | 100.00 | 100.00 | 97.83 |
| Corn-notill | 143 | 1285 | 77.31 | 84.45 | 99.44 | 95.33 | 88.17 |
| Corn-mintill | 83 | 747 | 73.61 | 91.454 | 99.76 | 98.20 | 91.08 |
| Corn | 24 | 213 | 54.85 | 100.00 | 99.58 | 97.86 | 91.14 |
| Grass-pasture | 48 | 435 | 89.71 | 97.10 | 100.00 | 95.17 | 92.96 |
| Grass-trees | 73 | 657 | 96.57 | 99.73 | 100.00 | 98.80 | 100.00 |
| Grass-pasture-mowed | 14 | 14 | 96.43 | 96.43 | 100.00 | 100.00 | 100.00 |
| Hay-windrowed | 48 | 430 | 94.98 | 100.00 | 100.00 | 100.00 | 100.00 |
| Oats | 10 | 10 | 100.00 | 100.00 | 100.00 | 100.00 | 95.00 |
| Soybean-notill | 97 | 875 | 79.22 | 98.35 | 94.69 | 98.24 | 94.03 |
| Soybean-mintill | 217 | 2238 | 70.06 | 93.24 | 98.37 | 98.58 | 88.64 |
| Soybean-clean | 59 | 534 | 65.77 | 97.98 | 99.66 | 98.53 | 95.28 |
| Wheat | 21 | 184 | 98.54 | 99.51 | 99.51 | 100.00 | 100.00 |
| Woods | 119 | 1146 | 96.52 | 97.94 | 99.76 | 100.00 | 100.00 |
| Building-grass-trees-drives | 39 | 347 | 57.25 | 98.96 | 99.74 | 99.74 | 81.09 |
| Stone-steel-towers | 9 | 84 | 79.57 | 100.00 | 100.00 | 98.95 | 97.85 |
| OA (%) | 79.30 | 94.77 | 99.40 | 98.23 | 92.78 | ||
| AA (%) | 82.80 | 97.06 | 99.72 | 98.71 | 94.57 | ||
| Kappa | 76.50 | 94.06 | 99.32 | 97.99 | 91.78 | ||
Table 4.
Classification accuracy of the different methods on the Salinas dataset. The results shown for our approach is for a single run and the OA increases to for our approach when the single run replaces the spectral classification map.
Table 4.
Classification accuracy of the different methods on the Salinas dataset. The results shown for our approach is for a single run and the OA increases to for our approach when the single run replaces the spectral classification map.
| Class | Train | Test | SVM | EPF [45] | IFRF [43] | RMG [46] | Proposed (single run) |
|---|---|---|---|---|---|---|---|
| Broccoli-green-weeds-1 | 67 | 1942 | 99.75 | 100.00 | 100.00 | 100.00 | 100.00 |
| Broccoli-green-weeds-2 | 67 | 3659 | 99.62 | 100.00 | 99.95 | 99.87 | 100.00 |
| Fallow | 67 | 1909 | 96.91 | 100.00 | 100.00 | 99.34 | 100.00 |
| Fallow-rough-plow | 69 | 1325 | 99.71 | 99.93 | 100.00 | 100.00 | 98.85 |
| Fallow-smooth | 67 | 2611 | 96.23 | 99.29 | 99.40 | 98.62 | 99.63 |
| Stubble | 67 | 3892 | 99.82 | 100.00 | 99.82 | 99.77 | 100.00 |
| Celery | 68 | 3511 | 99.72 | 99.92 | 99.83 | 99.66 | 99.86 |
| Grapes-untrained | 69 | 11102 | 63.72 | 84.74 | 98.16 | 98.70 | 91.78 |
| Soil-vineyard-develop | 68 | 6135 | 99.69 | 99.84 | 99.98 | 100.00 | 100.00 |
| Corn-senesced-green-weeds | 68 | 3210 | 91.31 | 96.55 | 99.15 | 98.84 | 99.97 |
| Lettuce-romaine-4wk | 68 | 1000 | 96.72 | 99.72 | 100.00 | 99.81 | 99.16 |
| Lettuce-romaine-5wk | 67 | 1860 | 99.69 | 100.00 | 100.00 | 98.44 | 100.00 |
| Lettuce-romaine-6wk | 67 | 849 | 98.47 | 99.13 | 99.67 | 99.34 | 98.80 |
| Lettuce-romaine-7wk | 67 | 1003 | 94.86 | 98.60 | 99.81 | 99.16 | 97.01 |
| Vineyard-untrained | 70 | 7198 | 72.76 | 93.02 | 98.18 | 96.82 | 96.68 |
| Vineyard-vertical-trellis | 67 | 1740 | 98.67 | 99.23 | 100.00 | 100.00 | 100.00 |
| OA(%) | 87.61 | 95.54 | 99.22 | 99.01 | 97.69 | ||
| AA(%) | 94.23 | 98.12 | 99.56 | 99.27 | 98.86 | ||
| Kappa | 86.25 | 95.05 | 99.13 | 98.89 | 97.43 | ||
Table 5.
Classification accuracy of the different methods on the PaviaU dataset. The results are shown for a single run of our approach and increases to with multiple iterations (in comparison to ).
Table 5.
Classification accuracy of the different methods on the PaviaU dataset. The results are shown for a single run of our approach and increases to with multiple iterations (in comparison to ).
| Class | Train | Test | SVM | EPF [45] | IFRF [43] | RMG [46] | Our Approach (single run) |
|---|---|---|---|---|---|---|---|
| Asphalt | 20 | 26 | 88.36 | 97.19 | 97.21 | 99.76 | 97.48 |
| Meadows | 143 | 1285 | 93.43 | 98.46 | 99.49 | 99.95 | 98.6 |
| Gravel | 83 | 747 | 85.23 | 91.42 | 98.52 | 99.86 | 94.85 |
| Trees | 24 | 213 | 96.15 | 95.50 | 97.42 | 97.75 | 97.29 |
| Painted-metal-sheets | 48 | 435 | 99.55 | 100.00 | 99.63 | 100.00 | 100.00 |
| Bare-soil | 73 | 657 | 92.19 | 100.00 | 99.92 | 100.00 | 99.54 |
| Bitumen | 14 | 14 | 94.66 | 99.92 | 99.40 | 100.00 | 100.00 |
| Self-blocking-bricks | 48 | 430 | 88.27 | 99.00 | 96.66 | 100.00 | 96.99 |
| Shadows | 10 | 10 | 100.00 | 100.00 | 99.47 | 100.00 | 95.46 |
| OA(%) | 92.22 | 98.06 | 98.75 | 99.77 | 98.14 | ||
| AA(%) | 93.08 | 97.94 | 98.64 | 99.70 | 97.81 | ||
| Kappa | 89.79 | 97.44 | 98.34 | 99.70 | 97.55 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



